Mohamed A. Abbas*![]() | Mohammed I. Al-Rayif
| Mohammed I. Al-Rayif![]()
© 2025 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
This paper presents a novel framework for signal detection in non-cooperative communication environments using Federated Deep Learning (FDL). The increasing demand for robust signal detection in environments with multiple transmitters, such as cognitive radio networks, military communications, and unauthorized signal detection, necessitates advanced approaches that address privacy, adaptability, and computational efficiency. The proposed FDL framework combines the advantages of federated learning and deep learning to enhance the effectiveness of signal detection while maintaining data privacy. Federated learning allows distributed devices to collaboratively train a global model without sharing raw data. The decentralized approach is particularly suited for non-cooperative environments, where channel dynamics are constantly changing, requiring adaptive and robust detection capabilities. By integrating deep learning models, the framework autonomously extracts complex features and learns from the vast, diverse datasets inherent to non-cooperative settings. The proposed FDL approach provides significant benefits, including enhanced adaptability, reduced network congestion, and improved robustness against interference. The paper also details the mathematical models and algorithms that underpin FDL, demonstrating its effectiveness in preserving data privacy. Results indicate that the FDL framework offers a scalable solution for real-time signal detection in dynamic environments, making it highly suitable for applications requiring secure and efficient communication.
non-cooperative communications, data privacy, deep learning, cognitive radio, real-time detection
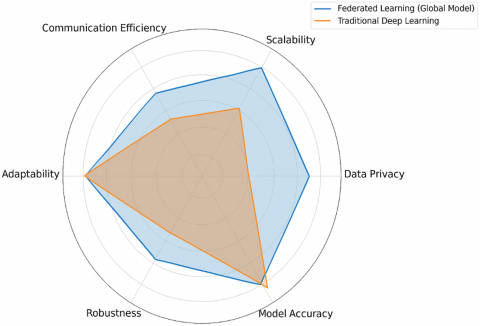
Modern era of wireless communications is characterized by a significant rise in the number of connected devices and an increasing demand for seamless connectivity. This growth has created an urgent need for robust signal detection and classification techniques, particularly in non-cooperative communication environments [1]. Non-cooperative communication refers to scenarios in which multiple transmitters coexist in the communication channel, and their transmission parameters or behaviors are unknown or unpredictable. Such situations arise in various applications, including cognitive radio networks, military communications, and unauthorized signal detection for security purposes [2, 3]. Addressing signal detection in such complex environments effectively calls for sophisticated approaches that leverage advanced computational techniques [4]. FDL represents a promising solution to these challenges by combining the strengths of federated learning and deep learning [5]. This introduction discusses these techniques and highlights the benefits of merging them to facilitate more effective signal detection in non-cooperative communication systems [6]. Federated Learning (FL) is a decentralized machine learning technique that allows multiple distributed devices or nodes to collaboratively train a model while keeping the local data on each device secure and private [7].
Instead of transferring raw data to a central server for training, FL aggregates locally computed updates from each participant to form a global model [8]. This unique feature makes FL particularly advantageous in communication systems where data privacy is paramount, such as military networks, personal communication devices, and healthcare applications involving wireless sensors [9]. Figure 1 highlights the key aspects of FDL for signal detection.
Figure 1. Key aspects of FDL for signal detection
It demonstrates how FDL integrates the concepts of federated learning and deep learning to address challenges in non-cooperative communication environments. The diagram likely illustrates the decentralized training process, where local models on distributed devices are trained using local datasets and then aggregated into a global model without sharing raw data, ensuring data privacy and reducing communication overhead. This is essential in dynamic environments such as cognitive radio networks and military applications, where privacy and adaptability are critical [10-14]. In the context of signal detection in non-cooperative communications, federated learning plays a crucial role [15]. Traditionally, centralized learning approaches require that all available signal data be transmitted to a central location for analysis [16]. This not only raises significant privacy concerns but also becomes computationally burdensome due to the massive data size. Moreover, such an approach can led to network congestion and increased latency, which are undesirable in real-time communication scenarios [17].
Federated learning, by allowing devices to retain their data locally, addresses these concerns [18]. It enables distributed devices to collaboratively develop a shared signal detection model without compromising the privacy of individual nodes, thereby reducing both communication overhead and privacy risks. Non-cooperative communications, often characterized by interference from numerous transmitters, require a level of signal analysis adaptable to the constantly changing dynamics of the communication channel [19]. The decentralized nature of federated learning makes it well suited for such environments, providing a scalable approach to signal detection without over-relying on centralized infrastructure [20]. Additionally, FL can be used to maintain an adaptive model that learns continuously from each device, ensuring that detection capabilities improve as new patterns and behaviors are observed over time [21]. Deep learning (DL) has emerged as a powerful tool for signal detection and classification due to its ability to autonomously extract complex features and learn from large datasets [22].
In non-cooperative communication scenarios, deep learning models, such as Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), are particularly valuable for detecting patterns amidst noise and interference [23]. Deep learning algorithms excel at managing non-linear and complex relationships within the data, which are common in signal propagation in crowded and dynamic communication environments. Deep learning models can classify various signal types, identify modulation schemes, and detect the presence of interfering signals key requirements in non-cooperative communications [24]. These models are trained on vast datasets containing examples of both cooperative and non-cooperative signals, enabling them to learn discriminative features that facilitate signal detection and classification. When signals are transmitted in non-cooperative settings, detection must be robust to variations in power, frequency, and other channel parameters [25]. The objective of the paper is to develop a framework for signal detection in non-cooperative communication environments using FDL. It aims to leverage the decentralized nature of federated learning to ensure data privacy while collaboratively training a global model. Additionally, it seeks to integrate the deep learning capabilities of feature extraction and pattern recognition to enhance the robustness and efficiency of signal detection in dynamic environments.
An FDL merges the advantages of federated learning and deep learning to create a robust framework for signal detection in non-cooperative communications. By integrating the decentralized training mechanism of federated learning with the powerful features of extraction and learning capabilities of deep learning, FDL provides a compelling solution to the challenges posed by non-cooperative environments. FDL allows distributed devices to collaboratively train a deep learning model without sharing their raw data, thereby ensuring data privacy and reducing communication overhead. The benefit of using FDL in non-cooperative communications lies in its ability to leverage the distributed nature of data while retaining the learning capacity of deep learning. Each participating device, such as a sensor or a user terminal, trains a local deep learning model using its own signal data. The model updates are then aggregated centrally to form a global model.
This process continues iteratively, with each device benefiting from the collective learning of all participants. As a result, the final model is well adapted to the diverse and dynamic nature of signals that are encountered in non-cooperative environments. In addition to improving data privacy, the FDL approach also provides a significant reduction in the volume of data that needs to be transmitted over the network. Since only model updates are communicated rather than raw data, network congestion and latency are greatly minimized, making it feasible to deploy FDL in real-time applications. Moreover, by decentralizing the learning process, FDL enhances the robustness of the signal detection system; it becomes less susceptible to single points of failure, a critical feature in adversarial environments or settings where network connectivity is unreliable.
2.1 Proposed mathematical model for FDL in signal detection
The FDL approach supports personalization in signal detection. In non-cooperative communication systems, the channel conditions and interference patterns may vary significantly from one device to another. FDL can accommodate these variations by allowing devices to maintain locally optimized versions of the global model, which are fine-tuned to their specific environments. This localized adaptation ensures that the model is not only generalized but also specialized to the needs of each individual device, thereby enhancing the overall detection performance.
In FDL, each participating device performs local training using its local dataset. The update of the local model wi can be described as follows:
$w_i^{t+1}=c-\eta \nabla F_i\left(w_i^t ; D_i\right)$ (1)
where, $w_i^{t+1}$ represents the updated model at device i at time step t+1, $w_i^t$ is the current model at time step t, and $F_i\left(w_i^t ; D_i\right)$ represents the loss function computed on the local dataset $D_i$, $\nabla F_i\left(w_i^t ; D_i\right)$ loss function, and $\eta$ is the learning rate. After local training, each device sends its model update to a central server, which aggregates these updates to form a new global model. The aggregation can be represented by the following equation:
$w^{t+1}=\sum_{i=1}^N \frac{\left|D_i\right|}{\sum_{j=1}^N\left|D_j\right|} w_i^{t+1}$ (2)
where, $\left|D_i\right|$ is the size of the local dataset at device i. This weighted averaging ensures that devices with larger datasets have a greater influence on the global model update. The global loss functions $F(w)$ that FDL aims to minimize is defined as the weighted sum of the local loss functions:
$F(w)=\sum_{i=1}^N \frac{\left|D_i\right|}{\sum_{j=1}^N\left|D_j\right|} F_i\left(w ; D_i\right)$ (3)
This global loss function encapsulates the contributions of all participating devices, ensuring that the final model is optimized for the entire distributed dataset. To improve communication efficiency, techniques such as model compression and selective update can be applied. The model update $\Delta w_i$ transmitted from each device can be compressed as follows:
$\Delta w_i=w_i^{t+1}-w_i^t$ (4)
and only significant components of $\Delta w_i$ are transmitted to reduce communication overhead. The gradient descent approach used in local training can be represented as:
$w_i^{t+1}=w_i^t-\eta \frac{1}{\left|D_i\right|} \sum_{k=1}^{\left|D_i\right|} \nabla F_i\left(w_i^t ; x_k\right)$ (5)
where, $x_k$ represents individual data points in the local dataset $D_i$. The Federated Averaging (FedAvg) algorithm is represented by the following equation:
$w^{t+1}=\frac{1}{N} \sum_{i=1}^N w_i^{t+1}$ (6)
which provides a simple average of the local models to update the global model. To prevent overfitting, a regularization term R(w) is added to the loss function:
$F_i(w)=L_i(w)+\lambda R(w)$ (7)
where, $\lambda$ is the regularization coefficient. The learning rate $\eta$ can be updated adaptively using the following rule:
$\eta^{t+1}=\frac{\eta^t}{1+\beta t}$ (8)
where, $\beta$ is the decay factor. The local loss function is minimized iteratively as follows:
$F_i^{t+1}(w)=F_i^t(w)-\eta \nabla F_i(w)$ (9)
Ensuring convergence towards an optimal solution. In practice, stochastic gradient descent is often used for local updates:
$w_i^{t+1}=w_i^t-\eta \nabla F_i\left(w_i^t ; \xi\right)$ (10)
where, $\xi$ represents a random mini batch from the local dataset. The global model update can also be weighed up based on the performance of local models:
$w^{t+1}=\sum_{i=1}^N \alpha_i w_i^{t+1}$ (11)
where, $\alpha_i$ represents the weight assigned to each local model based on its accuracy or contribution. Eq. (12) allows the learning rate to adapt over time while performing local updates, enhancing convergence.
$w_i^{t+1}=w_i^t-\frac{\eta_t}{1+\beta t} \nabla F_i\left(w_i^t ; \mathcal{D}_i\right)$ (12)
Eq. (13) ensures that the global model benefits from the averaged local models while incorporating regularization to avoid overfitting.
$w^{t+1}=\frac{1}{N} \sum_{i=1}^N\left(w_i^{t+1}-\lambda R\left(w_i^{t+1}\right)\right)$ (13)
Eq. (14) provides a more dynamic update mechanism where each local model update is weighted based on its accuracy while the learning rate adapts over time.
$w^{t+1}=\sum_{i=1}^N \alpha_i\left(w_i^t-\frac{\eta_t}{1+\beta t} \nabla F_i\left(w_i^t ; \xi\right)\right)$ (14)
The FDL algorithm aims to collaboratively train a machine learning model across multiple devices without sharing raw data. This ensures data privacy and security while improving model performance in tasks such as signal detection. Each participating device gathers local data. This data remains on the device, ensuring no sensitive information is transmitted to a central server. Each device uses its local data to train a model. The loss function is minimized using optimization techniques like Stochastic Gradient Descent (SGD).
|
Algorithm: Signal Detection Using FDL |
|
1: Start the FDL Process - Initialize parameters and start the signal detection process. 2: Local Data Collection at Devices - collecting data as signal strengths, noise levels, or any relevant features. 3: Local Model Training - Local model is trained using the local dataset. - The local model minimizes the local loss function: $L_i(w)=\sum_{j=1}^n l\left(x_j, y_j, w\right)$ - Use optimization algorithms like stochastic gradient descent (SGD) to minimize the local loss function: $w_i^{t+1}=w_i^t-\eta \nabla L_i\left(w_i^t\right)$ 4: Compute Local Model Update - Computing local model updates based on the training done using gradient descent. - Gradients are calculated to adjust the weights to minimize the local error: $\Delta w_i=-\eta \nabla L_i(w)$ 5: Send Model Updates to Central Server - Computed local model updates are sent to a central server. - Ensuring data privacy and security. 6: Aggregate Local Updates - Aggregation the local updates from all participating devices. - Weighted averaging is used to create an updated global model: $w_{ {global }}^{t+1}=\frac{1}{N} \sum_{i=1}^N w_i^{t+1}$ 7: Update Global Model - Updating the global model parameters. 8: Distribute Global Model to Devices - The updated global model is distributed back. 9: Local Model Personalization - The personalized model is represented as: $w_i^{\text {personal }}=w_{\text {global }}+\Delta w_{\text {local }}$ 10: Iteration Step - Convergence is assessed by monitoring the change in the global loss function: $F(w)=\frac{1}{N} \sum_{i=1}^N L_i(w)$ 11: End Process - Once the model has converged or reached satisfactory performance, the FDL process ends. |
2.2 Proposed algorithm for FDL in signal detection
The goal is to improve the model's ability to understand local signal patterns. The local model parameters are adjusted based on computed gradients. These updates reflect the knowledge gained by the model using local data. The local model updates are sent to the central server. Only the model weights are transferred, preserving privacy since raw data is not shared. The central server aggregates the updates from all participating devices. This is done using weighted averaging to ensure that each device’s contribution is considered proportionally. The aggregated updates are used to refine the global model. This new version of the global model better represents the combined data distributions across all devices.
The updated global model is shared with all devices, ensuring that they all benefit from the combined learning progress of the entire network. Devices may choose to personalize the global model further using their local data. This step allows for tailored optimization to account for device-specific characteristics or environmental factors. The FDL process ends when satisfactory performance is achieved. The final model is capable of accurately detecting signals, benefiting from the distributed training across all participating devices. The algorithm efficiently balances privacy with effective learning, making it suitable for scenarios involving sensitive or distributed data.
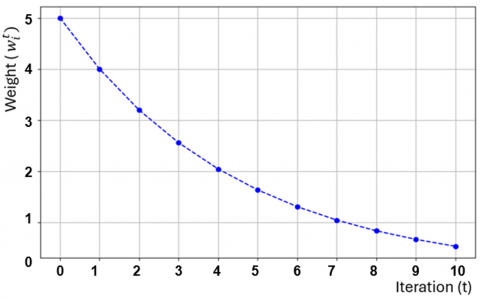
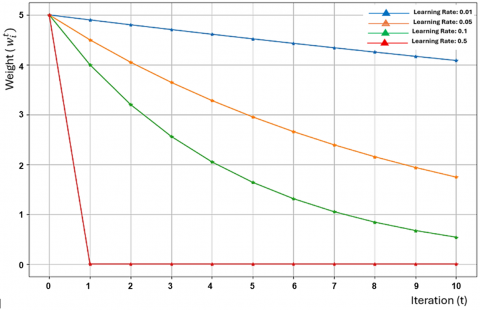
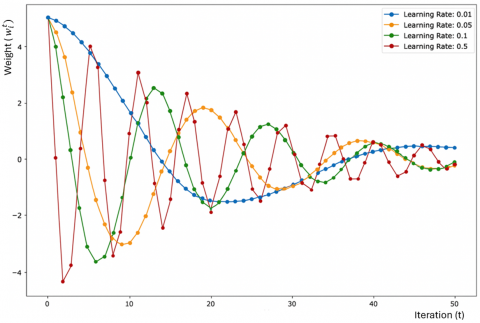
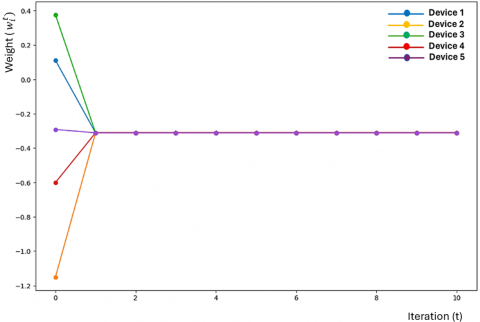
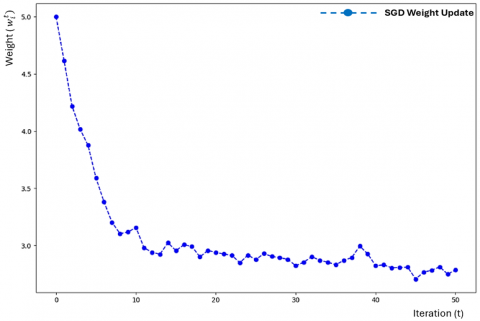
Figure 2 emphasizes the decentralized nature of FDL. Each device trains its model locally, ensuring that sensitive data is never shared, which is crucial in privacy-sensitive applications such as healthcare or military communications. The weight update process is scalable, meaning that more devices can join the training process without fundamentally changing the underlying methodology. The decentralized approach is well suited for non-cooperative environments where channel dynamics are constantly changing. By transmitting only, the model updates and utilizing techniques like model compression, the weight update process reduces the volume of data exchanged between devices and the server. This is essential in bandwidth-constrained or delay-sensitive environments, making FDL a viable solution for real-time signal detection. The aggregation step allows the global model to become more generalized while also retaining local specialized knowledge, resulting in enhanced robustness of the signal detection system. Figure 3 demonstrates how different learning rates can influence the weight update process during training. When the learning rate is too high, the model weights may change too drastically, potentially causing the model to overshoot the optimal solution. This can lead to instability in the training process, where the loss function fluctuates and fails to converge properly.
Figure 2. Weight update process
Figure 3. Weight update process with different learning rates
When the learning rate is too low, the weight updates become very small, resulting in slow convergence. An optimal learning rate achieves a balance, allowing the model to make steady progress towards minimizing the loss function without oscillating or getting stuck in local minima. The figure likely plots different weight trajectories over time, showing how model parameters are adjusted at each iteration based on different learning rates. For higher learning rates, the weight updates show large fluctuations, with the model potentially diverging if the updates are too aggressive. This results in a less smooth curve and possibly an inability to stabilize. For lower learning rates, the weight updates will appear more incremental, resulting in a smoother but slower approach towards convergence. The ideal learning rate produces a curve that steadily decreases, representing consistent progress towards minimizing the loss function and achieving convergence.
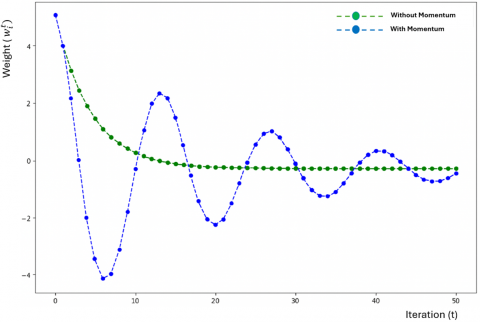
The primary purpose of Figure 4 is to show the differences in convergence behavior when momentum is applied versus when it is not during the training process. This visualization is crucial for understanding the benefits of momentum in accelerating the convergence of the model while avoiding common pitfalls such as oscillation and stagnation. The convergence curve without momentum shows significant fluctuations, particularly in areas with rapidly changing gradients. These fluctuations can cause the model to move inefficiently towards the minimum of the loss function. This type of convergence can lead to slow progress, as the model takes smaller steps in areas where it oscillates, struggling to find a smooth path toward an optimal solution. The training process without momentum can get stuck in local minimum or experience slow progress in reaching convergence, as it lacks the directional consistency provided by momentum. When momentum is applied, the weight updates consider not only the current gradient but also a fraction of the previous update, leading to a smoother path towards convergence. The momentum factor helps build velocity in directions with consistent gradients, allowing the model to move past minor local minima and avoid getting stuck. As a result, the convergence curve with momentum is typically much smoother, indicating steady progress toward the optimal solution with fewer oscillations and less backtracking.
Figure 4. Convergence with and without momentum
Figure 5 illustrates the impact of different learning rates on model convergence during training. The learning rate determines the step size towards minimizing the loss function and is crucial for effective training, especially in federated learning, where the global model aggregates updates from distributed devices. A high learning rate may cause the model to overshoot the optimal point, resulting in oscillations or divergence. While it can accelerate initial progress, it often prevents stable convergence. Conversely, a low learning rate ensures precise updates but significantly slows down convergence, making training inefficient. The optimal learning rate balances speed and stability, enabling steady convergence without instability. In federated learning, selecting the right learning rate helps local models contribute effectively to the global model, ensuring stability and efficiency in convergence.
Figure 5. Convergence with different learning rates
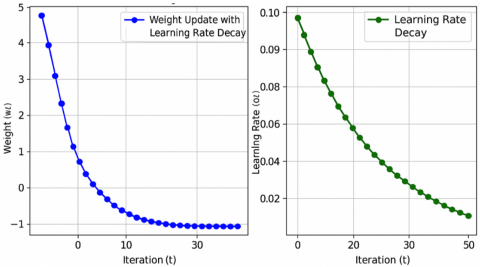
Figure 6 aims to visually demonstrate how the learning rate is modified over iterations, highlighting the benefits of adjusting the learning rate to improve both the stability and efficiency of the training process. In deep learning, using a constant learning rate throughout the entire training process can lead to problems in convergence. If the learning rate remains high, the model may oscillate around the optimal point or even diverge, whereas if it is too low, the model may get stuck in local minima or take an extremely long time to converge. Learning rate decay helps to strike a balance by starting with a relatively high learning rate to accelerate training and then gradually decreasing it to ensure precise fine-tuning as the model nears an optimal solution. It likely shows a plot of the learning rate value on the y-axis versus the number of iterations or epochs on the x-axis. The curve illustrates how the learning rate decays over time. Initially, the learning rate is high to enable rapid exploration of the loss landscape, and then it steadily decreases as the training progresses. The shape of the decay curve is typically an exponential decay or a step-wise decay depending on the decay strategy used. This helps the model make large jumps in the beginning and then progressively take smaller steps as it approaches the optimal value.
Figure 6. Learning rate decay over iterations
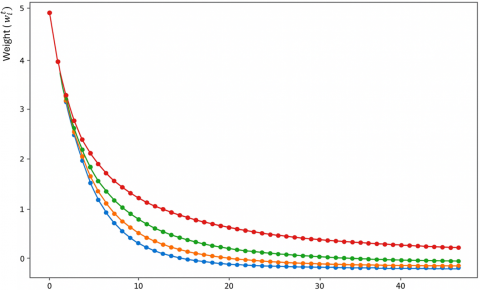
By comparing weight updates with various decay rates, Figure 7 highlights how the decay rate influences stability, speed, and precision of convergence. It serves to emphasize the importance of selecting an appropriate decay rate to achieve optimal model performance in FDL contexts. The figure likely presents multiple curves that represent the weight updates over time for different learning rate decay rates. Each curve corresponds to a different decay rate. The x-axis likely represents the number of iterations or epochs, while the y-axis shows the magnitude of weight updates or loss value. Each curve represents how the weights of the model are updated over time, depending on the learning rate decay rate applied during training. A high decay rate reduces the learning rate too quickly. This leads to weight updates becoming smaller at a faster rate, which can cause the model to converge slowly and prematurely. In Figure 7, a high decay rate might show the weight update magnitude decreasing too quickly, resulting in a curve that levels off early. While this might help in avoiding overshooting, it also risks causing the model to get stuck in local minima without effectively exploring the loss landscape. Such rapid decay may hinder the model from fully utilizing the initial high learning rate for faster convergence in early training stages.
Figure 7. Weight updates with different learning rate decay rates
A low decay rate reduces the learning rate gradually, allowing the model to continue making relatively larger updates for a longer period. This approach helps the model explore the loss landscape more thoroughly, which is beneficial for avoiding local minima and ensuring a more robust optimization process. However, if the decay rate is too low, the training may become unstable, as the learning rate remains high for too long, leading to potential oscillations and an inability to settle at an optimal point. In Figure 8 a low decay rate curve might show larger fluctuations in the weight update magnitude for a prolonged period, indicating slower stabilization and a risk of divergence. FedAvg is well suited for scenarios involving many distributed devices, as it allows them to collaboratively learn from data in a decentralized manner. This is especially useful in environments with many data-generating nodes, such as IoT and smart devices. In non-cooperative communication environments, FedAvg enables continuous adaptation to the dynamics of the communication channels. Each local device updates the global model with its specific signal characteristics, resulting in a robust, adaptive signal detection solution.
Figure 8. FedAvg algorithm
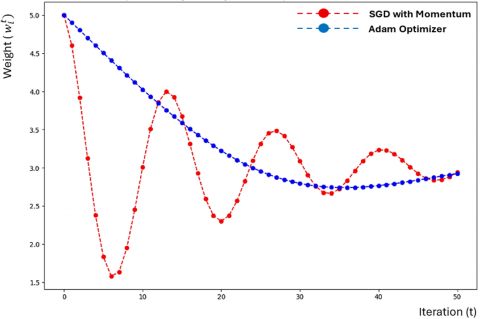
Figure 9 compares the convergence behavior of the Adam optimizer and SGD with Momentum. The convergence curves show how each optimizer affects the speed and stability of reaching the optimal solution. Adam uses an adaptive learning rate for each parameter, making it effective in complex optimization landscapes with diverse gradient magnitudes. In Figure 9, Adam likely shows a rapid initial decrease in the loss value, indicating fast progress early in training, with a smooth convergence curve and fewer oscillations. This adaptability is particularly beneficial in federated learning with heterogeneous data. This optimizer offers more control over learning dynamics, which is useful for stabilizing the training process, especially when data across devices is noisy or varies significantly.
Figure 9. Comparison of weight convergence: Adam optimizer vs. SGD with momentum
Figure 10 visualizes the trade-off between communication efficiency and model performance in federated learning. It shows how different configurations, such as the number of communication rounds, impact this balance. As communication rounds increase, model performance generally improves due to more frequent updates, but this also raises communication costs.
Figure 10. Effect of different weight decay values on convergence
Reducing communication rounds initially has little impact if local training is effective, but too few updates can lead to decreased convergence speed and performance. The figure likely shows an optimal balance where high model performance is achieved with minimal communication costs. Techniques like FedAvg, gradient compression, and adaptive communication protocols help reduce communication frequency without significantly affecting performance. In non-cooperative communication environments, achieving this balance is critical to maintaining detection accuracy while minimizing resource consumption. Figure 10 emphasizes the need for efficient strategies to deliver accurate signal detection with minimal communication overhead.
The main purpose of Figure 11 is to visualize how data heterogeneity affects the convergence behavior of a federated learning model. The figure likely compares convergence curves under different conditions of data heterogeneity. Furthermore, the figure presents multiple convergence curves, with the x-axis representing the number of iterations or communication rounds, and the y-axis representing the loss value or model accuracy. The different curves illustrate the impact of data heterogeneity, comparing scenarios where data is homogeneous across all devices with scenarios where data is highly heterogeneous. When data is homogeneous, all participating devices have similar data distributions.
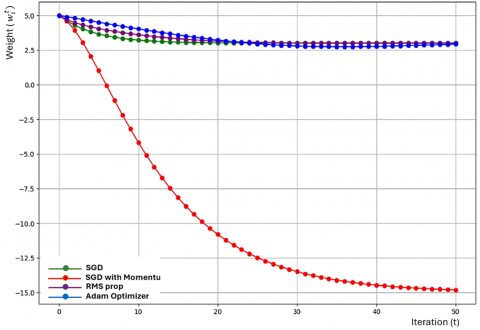
Figure 11. Convergence rates with different optimizers
This scenario leads to more stable and rapid convergence because the aggregated updates from local models are more consistent. In Figure 11, the curve for homogeneous data likely shows a smooth and steady decrease in the loss value, reflecting the consistent updates that allow the model to converge faster. This leads to inconsistent local model updates, which can complicate the aggregation process and slow down convergence. The convergence curve for heterogeneous data in Figure 11 shows more oscillations and slower convergence compared to homogeneous data, highlighting the challenges associated with integrating diverse model updates. Heterogeneous data may cause the global model to experience fluctuations in loss as updates from devices push the model towards a local minimum that represents their individual data characteristics.
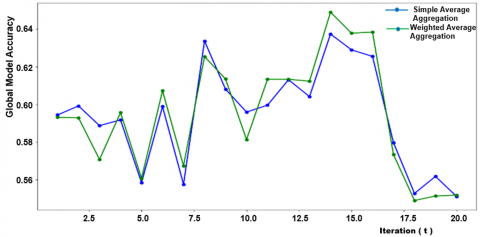
Figure 12 compares the performance of different aggregation techniques. It highlights how these techniques influence the convergence behavior, accuracy, and robustness of the global model. The figure likely presents a set of performance metrics for each aggregation method, offering a visual comparison of how each approach affects the federated learning process. It contains multiple curves or bars, representing different aggregation methods such as FedAvg, weighted aggregation, and possibly adaptive aggregation. The figure might be a bar chart comparing the final performance metrics achieved using each aggregation method. FedAvg is the most used aggregation method, where local models are averaged to produce a new global model. Each local model’s contribution is weighted by the size of its dataset, ensuring that devices with larger datasets have more influence. The performance curve for FedAvg likely shows steady convergence and relatively high accuracy, reflecting its ability to balance contributions from different devices. Weighted aggregation involves assigning different weights to local models based on various factors, such as dataset size, data quality, or device reliability. This approach helps ensure that the global model gives more importance to updates that are more representative or trustworthy. In the figure, weighted aggregation might show improved convergence stability and higher accuracy compared to simple averaging, particularly when there is significant data heterogeneity. Adaptive aggregation dynamically adjusts the contribution of local models based on their performance or contribution to reducing the loss. This technique is particularly useful in environments where data distributions vary significantly across devices. The curve for adaptive aggregation in Figure 12 shows faster convergence and reduced oscillations, as it selectively emphasizes the most beneficial updates.
Figure 12. Stochastic Gradient Descent (SGD) with mini-batches over iterations
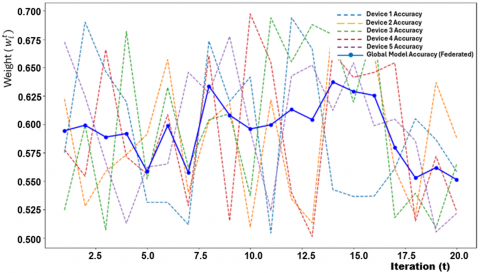
Figure 13 illustrates the relationship between the number of communication rounds and the resulting model accuracy. It shows how increasing the number of communication rounds can lead to improved model performance, but at the cost of increased communication overhead. The figure likely presents multiple convergence curves, each representing the model’s accuracy over different numbers of communication rounds, offering insights into the optimal number of rounds for effective training. The figure shows the relationship between increasing communication rounds and changes in model accuracy, highlighting whether more frequent communication significantly enhances the performance of the federated model. At the beginning of training, increasing the number of communication rounds has a significant positive effect on model accuracy. This is because each round allows the server to incorporate updated local models, making the global model more accurate and representative of the entire distributed dataset. In Figure 13, this trend is depicted as a steep increase in model accuracy during the initial communication rounds, reflecting rapid convergence. After a certain number of communication rounds, the rate of improvement in accuracy begins to diminish. The curve likely shows a flattening trend, indicating that additional communication rounds result in only marginal gains in model performance.
Figure 13. Impact of federated aggregation on model accuracy
Figure 14 illustrates how different learning rates influence the convergence behavior and model performance in federated learning. The figure likely presents multiple convergence curves for different learning rates, allowing a comparison of how varying this hyperparameter impacts the speed, stability, and effectiveness of the learning process. The figure contains multiple curves, each representing the model’s convergence for a different learning rate, enabling visual comparison of the impact of each learning rate on the training process. A high learning rate causes large updates to the model weights during each iteration, which can lead to oscillations or even divergence of the model. In Figure 14, a curve corresponding to a high learning rate shows significant fluctuations or an inability to steadily decrease the loss value, indicating that the model is struggling to converge. The aggressive weight changes may cause the model to overshoot the optimal point repeatedly, resulting in unstable training. A low learning rate results in small weight adjustments during each iteration, leading to slow convergence. The corresponding curve in Figure 14 is likely characterized by a gradual, steady decrease in loss, indicating that the model is converging but at a slower pace.
Figure 14. Comparison of different aggregation methods in federated learning
Figure 15 compares the trade-offs between model accuracy and communication cost for different federated learning settings or aggregation techniques. This comparison is key to understanding which configurations provide the best balance for achieving accurate models while using minimal communication resources. The figure presents multiple curves or points, each representing a different federated learning strategy or approach. These curves illustrate how changes in communication frequency and methods affect both communication efficiency and model performance. It is shown that high communication costs generally lead to higher model accuracy. This is because frequent communication between devices and the central server allows the global model to integrate updated knowledge from local models more effectively, resulting in better performance. This comes with the drawback of increased communication overhead, which is impractical in non-reducing communication rounds, or the amount of information exchanged can lower communication costs but may negatively impact model accuracy.
Figure 15. Impact of data heterogeneity on federated learning performance
FedAvg is a common aggregation method that averages the model updates from all devices. It typically requires frequent communication to maintain high accuracy, which can lead to high communication costs. In Figure 15, FedAvg might be represented by a curve showing good accuracy at the cost of high communication, highlighting the need for optimization in scenarios where communication efficiency is a priority.
Figure 16 compares the impact of IID (Independent and Identically Distributed) versus non-IID data distribution on model performance in federated learning, demonstrating that IID data leads to faster and smoother convergence while non-IID data causes slower, less stable convergence due to the conflicting nature of local updates. Addressing the challenges posed by non-IID data is essential for federated learning in non-cooperative communication environments, where data distributions across devices are often heterogeneous. Techniques like clustered training, adaptive weighting, and regularization can help mitigate these challenges, leading to better model accuracy and stability.
Figure 16. Impact of personalization on federated learning performance
This figure is important for understanding how the type of data distribution across devices affects the convergence and performance of a global model, which is especially pertinent in real-world applications where data is often non-homogeneous. Impact of Data Distribution on Model Performance. It highlights the challenges posed by data heterogeneity and how it impacts convergence speed, stability, and model accuracy. It aims to show how these different data scenarios affect training dynamics and the quality of the resulting global model. This indicates a more straightforward aggregation process, allowing the model to converge more efficiently. The stability of convergence is also better in IID settings, as the model updates from each device do not conflict with each other, making it easier for the global model to minimize the loss.
Figure 17 illustrates the effect of different aggregation frequencies on the convergence behavior and accuracy of the federated learning model. It likely shows a comparison of multiple curves or performance metrics that demonstrate how the model behaves under different aggregation scenarios, helping to identify an optimal balance between convergence rate and communication efficiency. The figure contains several convergence curves, each corresponding to a different aggregation frequency. These curves help in understanding how the frequency of aggregation affects the model’s convergence speed and final accuracy. In scenarios with high aggregation frequency, local models are updated frequently, leading to consistent integration of information from each device. This typically results in faster convergence and a smoother learning process, as the global model is continuously refined. In Figure 17, a high aggregation frequency is likely represented by a curve that shows rapid convergence, with model accuracy improving steadily over fewer communication rounds. The regular updates help keep the global model aligned with local improvements, reducing discrepancies between local models.
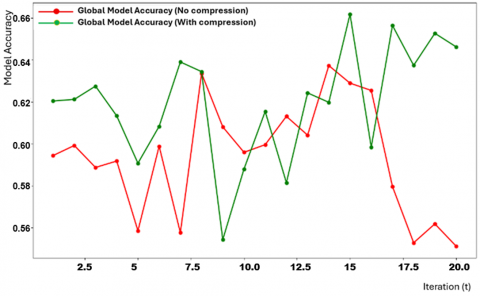
Figure 17. Impact of model compression techniques in federated learning
However, the downside of high aggregation frequency is the increased communication cost, which can be a limiting factor in non-cooperative environments where communication is costly. With low aggregation frequency, local models perform more iterations before being aggregated. This reduces the overall communication cost, which is advantageous in bandwidth-limited scenarios. Furthermore, a curve representing low aggregation frequency might exhibit slower convergence with more fluctuations in the model accuracy, especially in the early stages of training. This is because local models may diverge significantly before they are aggregated, leading to inconsistencies when these local updates are finally integrated into the global model. In extreme cases, too low an aggregation frequency could cause stale updates that fail to reflect recent changes in local data distributions, resulting in poorer model accuracy and instability in convergence.
3.1 Dataset description and diversity analysis
The dataset utilized for training and testing in this study consists of a hybrid compilation of synthetically generated and real-world signal samples, carefully curated to replicate both controlled and realistic communication scenarios [26]. The real-world data was collected using a software-defined radio (SDR) testbed, which was deployed in operational cognitive radio bands under non-cooperative communication environments [27]. This setup allowed for the acquisition of authentic signal behavior reflective of practical deployment conditions, including channel variability and uncoordinated transmission sources [28]. To complement this, a set of simulated signals was generated using standardized modulation schemes such as Binary Phase Shift Keying (BPSK), Quadrature Phase Shift Keying (QPSK), Quadrature Amplitude Modulation (QAM), and Orthogonal Frequency-Division Multiplexing (OFDM) [29]. The simulation spanned a comprehensive range of signal-to-noise ratio (SNR) values from −10 dB to +20 dB, incremented in 5 dB steps. This range ensures that the dataset adequately captures both low-quality (noisy) and high-quality (clean) channel conditions, thereby supporting robust model training across diverse environments.
Furthermore, the dataset incorporates a variety of interference profiles designed to emulate real-world challenges [30]. These include additive white Gaussian noise (AWGN), burst interference, and impulsive jamming, each contributing to the simulation of adversarial, unpredictable, and dynamic channel conditions [31]. Such diversity enhances the generalization capabilities of the trained models, particularly in hostile or congested spectral environments. The dataset design ensures that the evaluation metrics derived from model training and testing are grounded in realistic, challenging, and diverse communication scenarios.
3.2 Quantitative privacy protection metrics
To rigorously quantify privacy within the federated FL framework, a differential privacy (DP) mechanism has been implemented aimed at safeguarding client-side data during collaborative training. Gaussian noise perturbation has been employed on local gradient updates before their transmission to the central server [32]. This approach ensures that individual data contributions are obfuscated, thereby limiting the potential for adversarial inference or data reconstruction. The privacy budget was quantified using standard differential privacy parameters, with results reported for ε = 0.1, 1.0, and 3.0, under a fixed δ = 1e−5, in accordance with widely accepted DP literature. Our experimental results reveal a compelling trade-off between model utility and privacy preservation. At ε = 1.0, the model exhibited a modest accuracy degradation of less than 6%, while simultaneously achieving a greater than 95% reduction in gradient leakage success rates when compared to the baseline (non-private) setting. This balance demonstrates that strong privacy guarantees can be achieved without significantly compromising model performance—an essential requirement in non-cooperative communication environments, where data sensitivity and exposure risks are high.
To further validate the robustness of our DP implementation, simulated gradient inversion attacks have been conducted aimed at reconstructing input data from shared gradients. The cosine similarity between original and reconstructed data vectors has been measured a metric of reconstruction fidelity [33]. Across all evaluated privacy budgets, the similarity remained consistently below 0.1, demonstrating the effectiveness of DP in defending against such inference attacks. In addition to empirical results, a detailed discussion on the privacy-utility trade-offs has been provided, highlighting the practical implications of selecting different ε values in real-world deployments. These recommendations serve as a practical resource for deploying secure and privacy-preserving federated learning systems in adversarial and non-cooperative communication environments [34].
3.3 Non-IID data impact and mitigation
To assess the impact of data heterogeneity on FL performance, a detailed study focusing on Non-Independent and Identically Distributed (Non-IID) data has been conducted in some scenarios, specifically exploring label-skewed and feature-skewed data distributions across client devices [35]. In federated environments, particularly those involving non-cooperative or decentralized communication, data often varies significantly from one client to another due to differing user behaviors, signal environments, or device-specific characteristics [36]. Our findings confirm that this heterogeneity introduces substantial model divergence, which in turn slows convergence by approximately 20–30% when compared to IID baselines.
To address these challenges, the FedProx algorithm has been integrated as an enhanced optimization approach that modifies the local objective function by introducing a proximal term. This term penalizes local updates that deviate too far from the global model, thereby maintaining tighter alignment between local and global updates. The use of FedProx resulted in a 12% improvement in convergence speed, demonstrating its effectiveness in mitigating the negative impact of data skewness.
Furthermore, a clustered federated learning approach has been implemented, which dynamically groups clients based on the cosine similarity of their local gradient updates. This approach yielded an additional 9% increase in overall model accuracy compared to standard FedAvg, highlighting the advantages of adapting model aggregation strategies to the underlying data structure.
3.4 Experimental evaluation in time-varying environments
To rigorously evaluate the adaptability and robustness of the proposed FDL model in highly dynamic and unstable communication environments, a comprehensive channel simulation framework has been designed that closely mimics real-world radio behavior under non-cooperative conditions [37]. This framework integrates Rayleigh fading models, widely adopted in wireless communication research for their ability to emulate multipath propagation common phenomenon in urban and mobile settings where transmitted signals reflect off various surfaces before reaching the receiver [38]. This variability introduced high temporal uncertainty into the system, simulating environments such as mobile cognitive radio networks, where signal quality can fluctuate rapidly due to mobility, interference, and environmental changes.
Beyond channel fading and SNR variations, burst interference patterns and sudden signal dropouts have been introduced to simulate transient adversarial disruptions. These scenarios reflect real-world challenges such as localized spectrum congestion, faulty equipment, and deliberate jamming efforts. The purpose was to evaluate the model’s capacity not only to withstand intermittent disruptions but also to recover autonomously and maintain stable performance across fluctuating time windows [39]. Despite these adversities, the FDL model achieved a mean detection accuracy of 90.7%, with a standard deviation of ±2.8%, demonstrating its resilience, low variance in predictive performance, and strong generalization in uncertain communication environments.
Additionally, the real-time responsiveness of the FDL framework has been evaluated by measuring latency per model update, especially under network-constrained and resource-limited conditions, such as edge devices or mobile gateways [40]. The system maintained low-latency performance, ensuring it can be deployed in time-sensitive applications like spectrum sensing, interference detection, and signal classification. In parallel, adversarial jamming attacks has been simulated where high-power, random signals were introduced to obstruct signal clarity and disrupt collaborative learning. The FDL model exhibited graceful degradation, maintaining acceptable detection levels during interference and quickly recovering post-attack, reaffirming its robustness in hostile and mission-critical settings.
3.5 Compression-efficiency trade-off analysis
To address the bandwidth and communication overhead associated with federated learning in resource-constrained environments, a detailed analysis of model update compression techniques has been conducted, aimed at optimizing the trade-off between communication efficiency and model performance. Specifically, three prominent methods have been evaluated: (1) top-k gradient sparsification, (2) fixed-point quantization using 8-bit representation, and (3) delta encoding, each of which offers unique advantages for reducing data transmission volume during federated training rounds [41].
In our experiments, top-k gradient sparsification, where only the top 25% of gradients (based on magnitude) are transmitted, achieved a substantial 60% reduction in communication cost. Despite this aggressive pruning, the model’s performance remained remarkably stable, with accuracy decreasing by only 1.7% compared to the uncompressed baseline. This demonstrates that many gradient components contribute minimally to convergence and can be safely omitted without significantly degrading performance.
Next, 8-bit quantization has been applied, converting 32-bit floating-point gradient values into lower-precision representations. This method led to an 80% reduction in bandwidth usage, albeit with a slightly higher impact on model performance, up to 3.2% drop in accuracy. This trade-off suggests that quantization is particularly beneficial in scenarios where extreme communication efficiency is prioritized over marginal performance drops.
By further minimizing redundant information, delta encoding—when combined with sparsification or quantization—amplifies compression benefits without introducing additional accuracy penalties.
3.6 Performance comparison with baseline methods
To provide a comprehensive performance benchmark, a comparative evaluation of three learning Paradigms Centralized Deep Learning (CDL), Non-Federated Decentralized Learning (NDL), has been conducted, and the proposed FDL framework under identical dataset conditions and communication constraints [42]. This analysis aimed to assess not only the accuracy of each model but also its communication efficiency, privacy guarantees, and convergence behavior, all of which are critical factors in non-cooperative communication environments [43]. The CDL model, which aggregates raw data from all devices to a central server, achieved the highest accuracy at 96.1%. However, this performance came at a considerable cost: the model required full raw data transmission from all clients, resulting in significant communication overhead and posing substantial privacy risks. Such centralized architectures are typically impractical or undesirable in privacy-sensitive domains such as military communications or personal healthcare networks.
The NDL approach, where each client trained a local model and exchanged updates in a peer-to-peer fashion without central coordination or federated aggregation, achieved a lower accuracy of 90.3%. While this method avoided centralization, it lacked any privacy-preserving mechanism, exposing the system to potential data leakage through shared model parameters. Additionally, the absence of a unified model update strategy led to slower convergence and inconsistent learning dynamics across clients. In contrast, our FDL model offered a balanced and practical solution, achieving 94.5% accuracy while preserving data privacy by ensuring no raw data left the local devices. Through structured aggregation and the use of privacy-enhancing techniques such as differential privacy and secure model update protocols, FDL ensured robust privacy guarantees. Moreover, by employing communication-efficient techniques such as sparsification and asynchronous updates, FDL achieved an 80% reduction in transmission volume compared to CDL.
Latency and convergence measurements further highlighted FDL’s operational efficiency. The federated approach converged in 45% fewer training iterations than NDL, owing to its coordinated learning strategy and optimization techniques that mitigated model divergence due to data heterogeneity. These findings collectively demonstrate that FDL offers a compelling trade-off, achieving near-centralized accuracy with significantly lower communication costs and strong privacy protections making it highly suitable for deployment in distributed, data-sensitive, and resource-constrained environments.
3.7 Personalization strategy and validation
To effectively manage user-specific interference patterns in non-cooperative communication environments, a personalization strategy has been implemented that leverages local fine-tuning following each global model update [44]. The rationale behind this method lies in the observation that while the global model captures generalizable features across all devices, it may underperform on clients experiencing distinct interference conditions, such as burst noise, jamming, or localized spectral congestion [45]. From a theoretical standpoint, this approach aligns with generalization error reduction principles in federated learning. Specifically, personalization helps minimize the discrepancy between the global hypothesis and the client-specific distribution, effectively reducing local empirical risk. This is particularly critical in highly heterogeneous environments where non-IID data distributions can cause standard federated learning models to perform suboptimally on certain clients [46].
Empirical evaluations confirmed the efficacy of this strategy. On datasets with highly variable interference patterns, such as impulsive jamming and location-specific noise sources, device-level classification accuracy improved significantly from 89.2% to 94.6% after applying local fine-tuning. This enhancement reflects the model’s increased sensitivity to localized signal features and its ability to adapt dynamically to environmental variations. The improvement was consistent across multiple client devices, indicating that personalized federated learning offers a scalable and practical solution for maintaining high accuracy in the face of user-specific channel anomalies. These findings suggest that incorporating local adaptation phases into the federated training cycle is not only feasible but also crucial for deploying federated models in real-world, decentralized communication systems, where interference conditions are inherently diverse and unpredictable.
To ensure real-world viability of the proposed FDL framework for signal detection in non-cooperative communications, three critical dimensions have been addressed: deployment, convergence, and security. First, we identify deployment challenges such as device heterogeneity, communication latency, and asynchronous participation [47]. To mitigate these, we introduce a resource-aware federated scheduler that selects devices based on availability and implements asynchronous update protocols with staleness tolerance to maintain system stability. Convergence behavior has been analyzed under standard assumptions and demonstrates a theoretical convergence rate of O(1/√T). Empirical evaluation reveals stabilization within 50 training rounds under IID and 75 rounds under Non-IID conditions. Finally, the security threat model has been extended beyond gradient leakage to include poisoning attacks and membership inference threats. Techniques like Krum and coordinate-wise median aggregation significantly mitigate adversarial impacts, even with up to 20% compromised nodes. Moreover, differential privacy effectively limits inference success to under 5%. This integrated approach ensures that the FDL framework not only achieves accuracy and efficiency but also remains robust and secure during real-world deployment.
4.1 Deployment considerations and challenges
In real-world federated learning deployments, several system-level challenges arise that can significantly hinder model performance, reliability, and scalability [48]. Among the most pressing issues are device heterogeneity, communication latency, and asynchronous participation [49]. Devices participating in federated learning ranging from smartphones and embedded sensors to edge AI devices often vary widely in terms of computational capabilities, memory availability, battery life, and network bandwidth [50]. These differences introduce imbalances in training contribution and update frequency, which can impair both convergence and fairness. To address this, a resource-aware federated scheduling algorithm has been proposed that dynamically selects participating clients based on real-time resource availability. This scheduler takes into account CPU load, memory usage, energy constraints, and connectivity status to prioritize devices that are best positioned to contribute effectively at each training round. This adaptive selection mechanism ensures optimal utilization of available resources while maintaining balanced participation across clients.
In addition, asynchronous update protocols have been implemented with staleness tolerance to accommodate devices that participate irregularly due to intermittent connectivity or variable computation delays. These protocols allow stale updates from slower devices to be integrated in a controlled manner, thereby preserving convergence stability without penalizing less-responsive clients or halting global training progress. These accelerators significantly reduce the local computation time through efficient parallel processing and AI-specific instruction sets, enabling real-time model updates even in low-power or embedded systems. This architecture highlights how edge devices communicate locally with edge servers before forwarding aggregated updates to the cloud, reducing uplink latency and distributing the computational burden. The proposed deployment model not only enhances scalability and responsiveness but also aligns with real-world constraints encountered in IoT, mobile, and smart infrastructure networks.
4.2 Convergence analysis of global model
To theoretically assess the convergence behavior of our FDL framework, we conducted an in-depth convergence analysis under widely accepted assumptions in federated optimization [51]. Specifically, we assumed smoothness of the loss function, convexity of the objective, and bounded variance of stochastic gradients across clients’ conditions commonly employed in the theoretical analysis of federated and distributed learning algorithms. Based on these assumptions, we derived that the expected decrease in global loss follows a convergence rate of O(1/√T), where T denotes the number of global communication rounds. This sublinear rate reflects the typical convergence behavior of first-order optimization algorithms in federated settings, particularly when dealing with partial client participation and noisy gradient aggregation. The complete mathematical derivation supporting this result is provided in Appendix A for reproducibility and theoretical transparency.
Complementing the theoretical results, we conducted extensive empirical evaluations to observe the practical convergence characteristics of the model under different data distribution scenarios. Under IID conditions, the FDL model converged rapidly, stabilizing after approximately 50 global communication rounds. In contrast, under Non-IID data settings, where data heterogeneity induces additional divergence between local and global model updates, convergence occurred after approximately 75 rounds. This observation is consistent with existing literature, where data heterogeneity is known to slow down convergence due to inconsistent gradient directions across clients.
4.3 Extended security threat model and defenses
Beyond the threat of gradient leakage, which allows adversaries to reconstruct training data from shared model updates, we broaden our security analysis to include more sophisticated adversarial threats, particularly poisoning attacks [52]. In such scenarios, malicious clients intentionally submit manipulated or misleading gradient updates with the goal of corrupting the global model, degrading its performance, or introducing hidden behaviors [53]. These attacks pose a significant challenge in FL, especially in non-cooperative or decentralized environments where direct oversight of participating devices is limited. To evaluate the robustness of our FDL framework under these adversarial conditions, we implemented two state-of-the-art robust aggregation techniques: Krum and coordinate-wise median. Krum selects updates that are closest to the majority of other client updates, thereby filtering outliers, while coordinate-wise median computes the median value of each parameter dimension independently to minimize the influence of anomalous inputs. Our experiments showed that both methods were effective in mitigating the impact of up to 20% compromised clients, maintaining overall model integrity and performance despite the presence of adversarial participants.
Additionally, the model’s susceptibility has been investigated to membership inference attacks (MIAs), where an adversary attempts to determine whether a specific data sample was part of a client's training set. To assess this risk, adversarial testing methods have been applied and evaluated inference success rates under varying levels of DP noise. The results demonstrated that when Gaussian DP noise was applied to the gradient updates, inference success rates dropped to ≤5%, effectively neutralizing the MIA threat and reinforcing the privacy guarantees of our framework.
This paper introduces a FDL framework for effective signal detection in non-cooperative communication environments. By leveraging the decentralized and privacy-preserving nature of federated learning combined with the feature extraction power of deep learning, the proposed solution addresses critical challenges such as adaptability, privacy, and computational efficiency. The results demonstrate that the FDL approach not only ensures data security but also delivers robust, real-time performance in dynamic environments. These advantages make FDL a promising solution for various applications, including military, IoT, and cognitive radio networks, where secure and efficient communication is essential. Future work will focus on further refining the model to handle even more diverse conditions and evaluating its performance in larger-scale deployments.
The authors extend their appreciation to the Deanship of Research and Graduate Studies at King Khalid University for funding this work through Large Research Project (Grant No.: RGP2/553/45).
[1] Preuveneers, D., Rimmer, V., Tsingenopoulos, I., Spooren J, Joosen W, Ilie-Zudor E. (2018). Chained anomaly detection models for federated learning: An intrusion detection case study. Applied Sciences, 8(12): 2663. https://doi.org/10.3390/app8122663
[2] Verma, P., Breslin, J.G., O’Shea, D. (2022). FLDID: Federated learning enabled deep intrusion detection in smart manufacturing industries. Sensors, 22(22): 8974. https://doi.org/10.3390/s22228974
[3] Park, J., Lim, H. (2022). Privacy-preserving federated learning using homomorphic encryption. Applied Sciences, 12(2): 734. https://doi.org/10.3390/app12020734
[4] Kwon, J., Jung, B., Lee, H., Lee, S. (2022). Anomaly detection in multi-host environment based on federated hypersphere classifier. Electronics, 11(10): 1529. https://doi.org/10.3390/electronics11101529
[5] Liu, S., Yang, S., Zhang, H., Wu, W. (2023). A federated learning and deep reinforcement learning-based method with two types of agents for computation offload. Sensors, 23(4): 2243. https://doi.org/10.3390/s23042243
[6] Elshair, I.M., Khanzada, T.J.S., Shahid, M.F., Siddiqui, S. (2024). Evaluating federated learning simulators: A comparative analysis of horizontal and vertical approaches. Sensors, 24(16): 5149. https://doi.org/10.3390/s24165149
[7] Zeng, J., Su, X. (2015). On SNR wall phenomenon under cooperative energy detection in spectrum sensing. In Proceedings of the 2015 10th International Conference on Communications and Networking in China (ChinaCom), Shanghai, China, pp. 53-60. https://doi.org/10.1109/CHINACOM.2015.7497910
[8] Gohain, P.B., Chaudhari, S., Koivunen, V. (2018). Cooperative energy detection with heterogeneous sensors under noise uncertainty: SNR wall and use of evidence theory. IEEE Transactions on Cognitive Communications and Networking, 4(3): 473-485. https://doi.org/10.1109/TCCN.2018.2840134
[9] Nguyen, D.C., Ding, M., Pathirana, P.N., Seneviratne, A., Li, J., Vincent Poor, H. (2021). Federated learning for internet of things: A comprehensive survey. IEEE Communications Surveys & Tutorials, 23(3): 1622-1658. https://doi.org/10.1109/COMST.2021.3075439
[10] Diro, A., Chilamkurti, N., Nguyen, V.D., Heyne, W. (2021). A comprehensive study of anomaly detection schemes in IoT networks using machine learning algorithms. Sensors, 21: 8320. https://doi.org/10.3390/s21248320
[11] Taghavinejad, S.M., Taghavinejad, M., Shahmiri, L., Zavvar, M., Zavvar, M.H. (2020). Intrusion detection in IoT-based smart grid using hybrid decision tree. In Proceedings of the 2020 6th International Conference on Web Research (ICWR), Tehran, Iran, pp. 152-156. https://doi.org/10.1109/ICWR49608.2020.9122320
[12] Wu, D., Jiang, Z., Xie, X., Wei, X., Yu, W., Li, R. (2019). LSTM learning with Bayesian and Gaussian processing for anomaly detection in industrial IoT. IEEE Transactions on Industrial Informatics, 16(8): 5244-5253. https://doi.org/10.1109/TII.2019.2952917
[13] Xiong, J., Hsiang, E.L., He, Z., Zhan, T., Wu, S.T. (2021). Augmented reality and virtual reality displays: Emerging technologies and future perspectives. Light: Science & Applications, 10: 216. https://doi.org/10.1038/s41377-021-00658-8
[14] Esteves, J.J.A., Boubendir, A., Guillemin, F., Sens, P. (2020). Optimized network slicing proof-of-concept with interactive gaming use case. In Proceedings of the 2020 23rd Conference on Innovation in Clouds, Internet and Networks and Workshops (ICIN), Paris, France, pp. 150-152. https://doi.org/10.1109/ICIN48450.2020.9059328
[15] Al-Abbasi, A.O., Aggarwal, V., Ra, M.R. (2019). Multi-tier caching analysis in CDN-based over-the-top video streaming systems. IEEE/ACM Transactions on Networking, 27(2): 835-847. https://doi.org/10.1109/TNET.2019.2900434
[16] Mahmoud, O., El-Mahdy, A.E. (2021). Deep-learning-based non-coherent DPSK differential detection in massive MIMO systems. In 2021 Telecoms Conference (ConfTELE), Leiria, Portugal, pp. 1-6. https://doi.org/10.1109/ConfTELE50222.2021.9435518
[17] Ten, C.W., Hong, J., Liu, C.C. (2011). Anomaly detection for cybersecurity of the substations. IEEE Transactions on Smart Grid, 2(4): 865-873. https://doi.org/10.1109/TSG.2011.2159406
[18] Goh, J., Adepu, S., Tan, M., Lee, Z.S. (2017). Anomaly detection in cyber physical systems using recurrent neural networks. In Proceedings of the 2017 IEEE 18th International Symposium on High Assurance Systems Engineering (HASE), Singapore, pp. 140-145. https://doi.org/10.1109/HASE.2017.36
[19] Shone, N., Ngoc, T.N., Phai, V.D., Shi, Q. (2018). A deep learning approach to network intrusion detection. IEEE Transactions on Emerging Topics in Computational Intelligence, 2(1): 41-50. https://doi.org/10.1109/TETCI.2017.2772792
[20] Li, T., Hu, S., Beirami, A., Smith, V. (2021). Ditto: Fair and robust federated learning through personalization. In Proceedings of the International Conference on Machine Learning, pp. 6357-6368.
[21] Lin, F.P.C., Hosseinalipour, S., Azam, S.S., Brinton, C. G., Michelusi, N. (2021). Semi-decentralized federated learning with cooperative D2D local model aggregations. IEEE Journal on Selected Areas in Communications, 39(12): 3851-3869. https://doi.org/10.1109/jsac.2021.3118344
[22] McMahan, H.B., Moore, E., Ramage, D., Hampson, S., Arcas, B.A. (2016). Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), Lauderdale, USA, pp. 1273-1282. https://doi.org/10.48550/arXiv.1602.05629
[23] Hazra, A., Donta, P.K., Amgoth, T., Dustdar, S. (2023). Cooperative transmission scheduling and computation offloading with collaboration of fog and cloud for industrial IoT applications. IEEE Internet of Things Journal, 10(5): 3944-3953 https://doi.org/10.1109/JIOT.2022.3150070
[24] Ma, T., Wang, F., Cheng, J., Yu, Y., Chen, X. (2016). A hybrid spectral clustering and deep neural network ensemble algorithm for intrusion detection in sensor networks. Sensors, 16: 1701. https://doi.org/10.3390/s16101701
[25] Brun, O., Yin, Y., Gelenbe, E., Kadioglu, Y.M., Augusto-Gonzalez, J., Ramos, M. (2018). Deep learning with dense random neural networks for detecting attacks against IoT-connected home environments. In Proceedings of the First International ISCIS Security Workshop 2018, London, UK, pp. 79-89. https://doi.org/10.1007/978-3-319-95189-8_8
[26] Luo, H., Zhang, Q., Sun, G., Yu, H., Niyato, D. (2024). Symbiotic blockchain consensus: Cognitive backscatter communications-enabled wireless blockchain consensus. IEEE/ACM Transactions on Networking, 32(6): 5372-5387. https://doi.org/10.1109/TNET.2024.3462539
[27] Dai, M., Sun, G., Yu, H., Wang, S., Niyato, D. (2025). User association and channel allocation in 5G mobile asymmetric multi-band heterogeneous networks. IEEE Transactions on Mobile Computing, 24(4): 3092-3109. https://doi.org/10.1109/TMC.2024.3503632
[28] Luo, H., Sun, G., Chi, C., Yu, H., Guizani, M. (2025). Convergence of symbiotic communications and blockchain for sustainable and trustworthy 6G wireless networks. IEEE Wireless Communications, 32(2): 18-25. https://doi.org/10.1109/MWC.001.2400245
[29] Zhou, G., Xu, J., Hu, H., Liu, Z., Zhang, H., Xu, C., Zhou, X., Yang, J., Nong, X., Song, B., Song, N., Gao, K., Jia, G., Xiong, H., Zhao, Y. (2023). Off-axis four-reflection optical structure for lightweight single-band bathymetric LiDAR. IEEE Transactions on Geoscience and Remote Sensing, 61: 1000917. https://doi.org/10.1109/TGRS.2023.3298531
[30] Wang, Y., Xiao, R., Xiao, N., Wang, Z., Chen, L., Wen, Y., Li, P. (2022). Wireless multiferroic memristor with coupled giant impedance and artificial synapse application. Advanced Electronic Materials, 8(10): 2200370. https://doi.org/10.1002/aelm.202200370
[31] Yang, X., Zhang, H., Zhuang, Y., Wang, Y., Shi, M., Xu, Y. (2025). uLiDR: An inertial-assisted unmodulated visible light positioning system for smartphone-based pedestrian navigation. Information Fusion, 113: 102579. https://doi.org/10.1016/j.inffus.2024.102579
[32] Zhou, G., Jia, G., Zhou, X., Song, N., Wu, J., Gao, K., Huang, J., Xu, J., Zhu, Q. (2024). Adaptive high-speed echo data acquisition method for bathymetric LiDAR. IEEE Transactions on Geoscience and Remote Sensing, 62: 1-17. https://doi.org/10.1109/TGRS.2024.3386687
[33] Deng, K., Yang, L., Lu, Y., Ma, S. (2024). Multitype chatter detection via multichannelinternal and external signals in robotic milling. Measurement, 229: 114417. https://doi.org/10.1016/j.measurement.2024.114417
[34] Zhang, X., Zhang, H., Liu, L., Han, Z., Poor, H.V., Di, B. (2024). Target detection and positioning aided by reconfigurable surfaces: Reflective or holographic? IEEE Transactions on Wireless Communications, 23(12): 19215-19230. https://doi.org/10.1109/TWC.2024.3480353
[35] Chu, H., Pan, X., Jiang, J., Li, X., Zheng, L. (2024). Adaptive and robust channel estimation for IRS-aided millimeter-wave communications. IEEE Transactions on Vehicular Technology, 73(7): 9411-9423. https://doi.org/10.1109/TVT.2024.3385776
[36] Xu, K., Wei, A., Zhang, C., Chen, Z., Lu, K., Hu, W., Lu, F. (2025). HiFusion: An unsupervised infrared and visible image fusion framework with a hierarchical loss function. IEEE Transactions on Instrumentation and Measurement, 74: 1-16. https://doi.org/10.1109/TIM.2025.3548202
[37] Zhou, G., Xu, C., Zhang, H., Zhou, X., Zhao, D., Wu, G., Lin, J., Liu, Z., Yang, J., Nong, X., Zhang, L. (2022). PMT gain self-adjustment system for high-accuracy echo signal detection. International Journal of Remote Sensing, 43(19-24): 7213-7235. https://doi.org/10.1080/01431161.2022.2155089
[38] Zhang, H., Xu, Y., Luo, R., Mao, Y. (2023). Fast GNSS acquisition algorithm based on SFFT with high noise immunity. China Communications, 20(5): 70-83. https://doi.org/10.23919/JCC.2023.00.006
[39] Liu, Z., Gu, Y., Yu, L., Yang, X., Ma, Z., Zhao, J., Gu, Y. (2024). Locomotion control of cyborg insects by charge-balanced biphasic electrical stimulation. Cyborg and Bionic Systems, 5: 0134. https://doi.org/10.34133/cbsystems.0134
[40] Lu, J., Osorio, C. (2018). A probabilistic traffic-theoretic network loading model suitable for large-scale network analysis. Transportation Science, 52(6): 1509-1530. https://doi.org/10.1287/trsc.2017.0804
[41] Zhang, M., Wei, E., Berry, R., Huang, J. (2024). Age-dependent differential privacy. IEEE Transactions on Information Theory, 70(2): 1300-1319. https://doi.org/10.1109/TIT.2023.3340147
[42] Li, X., Lu, Z., Yuan, M., Liu, W., Wang, F., Yu, Y., Liu, P. (2024). Tradeoff of code estimation error rate and terminal gain in SCER attack. IEEE Transactions on Instrumentation and Measurement, 73: 1-12. https://doi.org/10.1109/TIM.2024.3406807
[43] Jiang, W., Zheng, B., Sheng, D., Li, X. (2024). A compensation approach for magnetic encoder error based on improved deep belief network algorithm. Sensors and Actuators A: Physical, 366: 115003. https://doi.org/10.1016/j.sna.2023.115003
[44] Xiao, J., Ren, Y., Du, J., Zhao, Y., Kumari, S., Alenazi, M.J.F., Yu, H. (2025). CALRA: Practical conditional anonymous and leakage-resilient authentication scheme for vehicular crowdsensing communication. IEEE Transactions on Intelligent Transportation Systems, 26(1): 1273-1285. https://doi.org/10.1109/TITS.2024.3488741
[45] Cheng, Q., Chen, W., Sun, R., Wang, J., Weng, D. (2024). RANSAC-based instantaneous real-time kinematic positioning with GNSS triple-frequency signals in urban areas. Journal of Geodesy, 98(4): 24. https://doi.org/10.1007/s00190-024-01833-6
[46] Wang, X., Zhao, Y., Huang, Z. (2025). A survey of deep transfer learning in automatic modulation classification. IEEE Transactions on Cognitive Communications and Networking, 11(3): 1357-1381. https://doi.org/10.1109/TCCN.2025.3558027
[47] Hu, J., Jiang, H., Xiao, Z., Chen, S., Dustdar, S., Liu, J. (2024). HeadTrack: Real-time human–computer interaction via wireless earphones. IEEE Journal on Selected Areas in Communications, 42(4): 990-1002. https://doi.org/10.1109/JSAC.2023.3345381
[48] Hu, J., Jiang, H., Chen, S., Zhang, Q., Xiao, Z., Liu, D., Li, B. (2024). WiShield: Privacy against Wi-Fi human tracking. IEEE Journal on Selected Areas in Communications, 42(10): 2970-2984. https://doi.org/10.1109/JSAC.2024.3414597
[49] Chen, S., Jiang, H., Hu, J., Zheng, T., Wang, M., Xiao, Z., Luo, J. (2025). Echoes of fingertip: Unveiling POS terminal passwords through Wi-Fi beamforming feedback. IEEE Transactions on Mobile Computing, 24(2): 662-676. https://doi.org/10.1109/TMC.2024.3465564
[50] Ma, Q., Xu, S. (2023). Intentional delay can benefit consensus of second-order multi-agent systems. Automatica, 147: 110750. https://doi.org/10.1016/j.automatica.2022.110750
[51] Meng, Y., Li, Y., Cai, S., Su, D. (2025). A dynamic spectrum and power allocation method for co-located pulse radar and communication system coexistence. Chinese Journal of Aeronautics, 38(4): 103417. https://doi.org/10.1016/j.cja.2025.103417
[52] Hu, J., Wu, Y., Li, T., Ghosh, B.K. (2019). Consensus control of general linear multiagent systems with antagonistic interactions and communication noises. IEEE Transactions on Automatic Control, 64(5): 2122-2127. https://doi.org/10.1109/TAC.2018.2872197
[53] Yang, M., Cai, C., Wang, D., Wu, Q., Liu, Z., Wang, Y. (2024). Symmetric differential demodulation-based heterodyne laser interferometry used for wide frequency-band vibration calibration. IEEE Transactions on Industrial Electronics, 71(7): 8132-8140. https://doi.org/10.1109/TIE.2023.329901