Erman Arif*![]() | Suherman Suherman
| Suherman Suherman![]() | Aris Puji Widodo
| Aris Puji Widodo![]()
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
This study examines the application of machine learning methods to improve the accuracy of stock price prediction by integrating technical analysis. In this study, we evaluate machine learning algorithms such as Support Vector Machine (SVM), Random Forest, Neural Networks, and Logistic Regression in the context of stock price prediction by utilizing technical indicators such as Moving Average, Relative Strength Index (RSI), and MACD. We use historical stock price datasets from the Indonesian capital market over a five-year period to train and test the models. The results show that the integration of technical analysis with machine learning methods can significantly improve prediction accuracy compared to using technical analysis or machine learning separately. The Neural Networks model performed the best in terms of prediction accuracy, with an improvement of 15% compared to the traditional method. These findings have important implications for investors and financial professionals in data-driven decision making. This study contributes to the development of more effective stock price prediction methods by combining analytical and technological approaches.
stock price prediction, machine learning, technical analysis, financial forecasting, predictive modeling
The development of the global stock market and advances in information technology have changed the way investors and analysts predict stock price movements [1]. In this context, stock price prediction has become a significant research topic due to its ability to provide valuable information in making investment decisions [2]. As the volume and complexity of market data increases, traditional methods such as technical and fundamental analysis often face limitations in accommodating rapidly changing market dynamics [3]. To overcome this challenge, many researchers and practitioners are now turning to more sophisticated analysis techniques, including machine learning methods, to improve prediction accuracy [4, 5]. Existing stock price prediction models often rely on historical data patterns to forecast future movements [6]. While this approach provides a useful foundation, reliance on historical data can limit the model's ability to anticipate unexpected market events [7]. Therefore, there is an urgent need for an approach that can integrate multiple sources of information and better handle market complexity [8]. Machine learning technology has the advantage of analyzing complex and non-linear patterns and the ability to process large amounts of data [9]. Therefore, this technology can be an effective solution to improve accuracy and efficiency in predicting stock prices [10].
This research focuses on developing and testing a stock price prediction model that combines technical analysis techniques with machine learning algorithms. The main question to be answered in this research is: “Can the integration of historical data and machine learning algorithms improve stock price prediction accuracy compared to conventional methods?”. This research will address two gaps: first, the limitations of traditional models in dealing with the dynamics of market complexity; and second, the over-reliance on historical data patterns without considering changes that occur in real-time.
This approach utilizes historical data and technical indicators to build models that are not only able to capture historical patterns but also adapt to dynamic market changes [11]. Using innovative machine learning methods, this study aims to evaluate whether the proposed model can provide more accurate predictions compared to conventional methods [12]. The importance of this study lies in its ability to bridge the gap between traditional prediction methods and modern technology [13]. The novel contribution of this research lies in evaluating the effectiveness of the proposed model in improving prediction accuracy compared to existing methods [14]. By providing a more adaptive and data-driven model, this research is expected to make a significant contribution to the field of stock market analysis and investment decision-making [15]. In addition, the findings of this study are expected to motivate further research and practical applications in the financial industry, as well as provide new insights into the development of more effective investment strategies [16]. Thus, this research offers the development of stock market analysis theory for smarter investment practices that are responsive to market dynamics.
2.1 Dataset description
Data source: The dataset used in this study was obtained from Yahoo Finance, a platform that provides comprehensive data on historical stock prices of public companies. This data includes daily information on the opening price (Open), closing price (Close), highest price (High), lowest price (Low), adjusted closing price (Adj Close), and trading volume (Volume). This research analyzes stocks from various companies listed on global stock exchanges, focusing on stocks with high volatility and large trading volumes.
The data was downloaded in historical format, then processed for further analysis. The time period used in this research is 2019. The selection of this period is based on economic stability before the COVID-19 pandemic, which provides stock price data that is not affected by global crises or extraordinary events. In addition, data from that year is generally complete and includes various trends and relevant economic events, thus providing a more representative picture of stock market dynamics in regular situations.
Data description: Columns contained in the dataset, such as Date, Open, High, Low, Close, Adj Close, and Volume.
The dataset contains historical stock price data with the following columns:
•Date: The date of the stock price data.
•Open: The opening price of the stock on that date.
•High: The highest price of the stock on that date.
•Low: The lowest price of the stock on that date.
•Close: The closing price of the stock on that date.
•Adj Close: The adjusted closing price of the stock on that date.
•Volume: The volume of stocks traded on that date.
The data was downloaded in historical format, then processed for further analysis, as shown in Table 1.
Table 1. First few rows of dataset
|
Date |
Open |
High |
Low |
Close |
Adj Close |
Volume |
|
2019-07-26 |
20.713606 |
20.713606 |
20.588825 |
20.588825 |
20.588825 |
180316 |
|
2019-07-29 |
20.588825 |
20.588825 |
20.588825 |
20.588825 |
20.588825 |
0 |
|
2019-07-30 |
21.337509 |
21.337509 |
21.337509 |
21.337509 |
21.337509 |
37666 |
|
2019-07-31 |
21.212729 |
21.337509 |
21.212729 |
21.337509 |
21.337509 |
9616 |
|
2019-08-01 |
23.08444 |
23.708344 |
22.460535 |
23.708344 |
23.708344 |
587430 |
Table 1 presents important data needed to analyze stock price movements over a certain period. This study uses data from 2019, chosen because it reflects economic stability before the COVID-19 pandemic. Data from this period provides a picture of stock prices that are not affected by the global crisis, making it suitable for assessing general market conditions. Table 1 shows the first few rows of the dataset, which include daily opening, high, low, and closing prices, as well as trading volume. For example, on July 26, 2019, the trading volume was quite high with little change in the opening and closing prices, whereas on July 29, 2019, no trading activity was recorded. This data supports further analysis of price volatility and trading trends in this study.
2.2 Algorithm formula
Support Vector Machine (SVM) is used for classification by separating two classes using a maximized hyperplane.
Basic SVM formula
$F(x)=w^T x+b$ (1)
Random Forest is an ensemble algorithm consisting of many decision trees that are trained independently, and the result is determined by voting (for classification) or averaging (for regression).
The basic formula of Random Forest:
$1 \operatorname{split}(D)=\arg \max \Delta \mid(F)$ (2)
Neural Networks (NN) consist of layers of interconnected neurons. Each neuron performs a linear operation, followed by a non-linear activation function.
The basic formula of Neural Networks (NN):
$z=w^T x+b$ (3)
2.3 Technical indicators used in machine learning
Technical indicators are used as features in machine learning models to help analyze market movements.
Moving Average (MA)
$E M A(n)=\left(\frac{2}{n+1}\right) \times\left(P_t-E M A_{t-1}\right)+E M A_{t-1}$ (4)
Relative Strength Index (RSI) is a momentum indicator that measures speed and price changes.
$R S I(n)=\frac{100}{1+R S}$ (5)
Moving Average Convergence Divergence (MACD) is an indicator that measures the difference between two moving averages to capture market momentum.
$M A C D=E M A_{12}-E M A_{20}$ (6)
2.4 Data pre-processing
(1) Data cleansing
Handling of missing values and outliers [17]. There are no missing values in the dataset as shown in Table 2.
Table 2. Missing values of dataset
|
Daily Record |
Value |
|
Date |
0 |
|
Open |
0 |
|
High |
0 |
|
Low |
0 |
|
Close |
0 |
|
Adj Close |
0 |
|
Volume |
0 |
The basic statistics of the dataset provide insights into the range and distribution of the data as shown in Table 3. There are no duplicate rows in the dataset. Number of duplicate rows: 0.
The box plots visualize potential outliers in the stock prices and trading volume (refer to Figures 1 and 2).
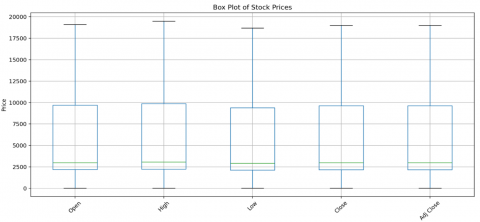
Table 3 reveals significant variation across the stock prices and trading volumes, with a minimum price of 20.59 and a maximum of 19,100. This wide range suggests that the dataset covers stocks with varying levels of market activity and volatility, supporting a robust analysis of different market conditions. Additionally, the volume statistics reflect diverse trading activities, with an average trading volume of approximately 16.2 million shares and a peak volume of over 380 million shares. These descriptive statistics offer foundational insights for examining stock price behaviors and trends within the dataset.
Table 3. Basic statistics
|
Date |
Open |
High |
Low |
Close |
Adj Close |
Volume |
|
|
count |
1214 |
1214 |
1214 |
1214 |
1214 |
1214 |
1214 |
|
mean |
2022-01-15T20:03:57.232 |
5670.1821297743 |
5821.482386729 |
5518.4212972199 |
5663.6043178048 |
5663.6043178048 |
16227644.796540363 |
|
min |
2019-07-26T00:00:00.000 |
20.5888825 |
20.5888825 |
20.5888825 |
20.5888825 |
20.5888825 |
0 |
|
25% |
2020-10-15T06:00:00.000 |
2191.50030525 |
2239.48898225 |
2130 |
2180 |
2180 |
1274783 |
|
50% |
2022-01-12T12:00:00.000 |
2995 |
3080 |
2915.4713135 |
2980 |
2980 |
11330900 |
|
75% |
2023-04-05T18:00:00.000 |
9693.75 |
9887.5 |
9387.5 |
9637.5 |
9637.5 |
21835125 |
|
max |
2024-07-26T00:00:00.000 |
19100 |
19500 |
18700 |
19000 |
19000 |
380263900 |
|
std |
null |
5391.2431686436 |
5518.5546207807 |
5248.6518721772 |
5386.727012525 |
5386.727012525 |
22800709.69254389 |
Figure 1. Stock prices box plots diagram
Figure 2. Trading volume box plots diagram
2.5 Format conversion
The date and time format conversion has been successfully completed [18]. Here's a summary of the changes and the resulting dataset:
Date Conversion: The 'Date' column has been converted to a datetime format and set as the index of the DataFrame.
Dataset Information:
DatetimeIndex: 1214 entries, 2019-07-26 to 2024-07-26
Data columns (total 6 columns):
# Column Non-Null Count Dtype
0 Open 1214 non-null float64
1 High 1214 non-null float64
2 Low 1214 non-null float64
3 Close 1214 non-null float64
4 Adj Close 1214 non-null float64
5 Volume 1214 non-null int64
dtypes: float64(5), int64(1)
memory usage: 66.4 KB
The dataset has a DatetimeIndex with 1214 entries, ranging from 2019-07-26 to 2024-07-26 (refer to Table 4).
Figure 3 presents a time series plot of the closing prices over the observed period, offering a visual analysis of the pricing trends.
Table 4. First few row DatetimeIndex
|
Open |
High |
Low |
Close |
Adj Close |
Volume |
|
|
2019-07-26T00:00:00.000 |
20.713606 |
20.713606 |
20.5888825 |
20.5888825 |
20.5888825 |
180316 |
|
2019-07-29T00:00:00.000 |
20.5888825 |
20.5888825 |
20.5888825 |
20.5888825 |
20.5888825 |
0 |
|
2019-07-30T00:00:00.000 |
21.337509 |
21.337509 |
21.337509 |
21.337509 |
21.337509 |
37666 |
|
2019-07-31T00:00:00.000 |
21.212729 |
21.337509 |
21.212729 |
21.337509 |
21.337509 |
9616 |
|
2019-08-01T00:00:00.000 |
23.08444 |
23.708444 |
22.460535 |
23.708444 |
23.708444 |
587430 |
Figure 3. Closing price over time
The date format has been standardized, and the index is now in chronological order. This will make it easier to perform time-based analyzes and visualizations. The closing price plot shows the trend of the stock price over the entire period covered by the dataset.
2.6 Engineering features
Creation of additional features such as moving averages and daily returns [19].
(1) Moving averages
We will create moving averages for the 20-day and 50-day periods.
(2) Daily returns
We will calculate daily returns based on the closing price.
(3) New features
•20-day Moving Average (MA_20)
•50-day Moving Average (MA_50)
•Daily Return
(4) Sample of the updated dataset
Table 5 shows an example of a dataset that has been updated with the addition of these features:
Table 5. Sample of the updated dataset
|
Close |
MA_20 |
MA_50 |
Daily_Return |
|
|
2019-07-26T00:00:00.000 |
20.5888825 |
null |
null |
null |
|
2019-07-29T00:00:00.000 |
20.5888825 |
null |
null |
0 |
|
2019-07-30T00:00:00.000 |
21.337509 |
null |
null |
0.0363636099 |
|
2019-07-31T00:00:00.000 |
23.708344 |
null |
null |
0 |
|
2019-08-01T00:00:00.000 |
23.957905 |
null |
null |
0.1111111424 |
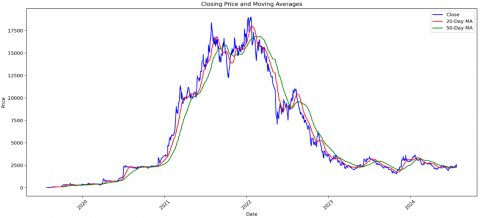
Table 5 shows that the moving averages (MA_20 and MA_50) start as for the first 20 and 50 days respectively, as they require that many previous data points to calculate. Figure 4 shows the closing price along with the 20-day and 50-day moving averages.
This chart visualizes how the stock price has moved in relation to its short-term (20-day) and medium-term (50-day) trends.
-The 20-day MA (red line) responds more quickly to price changes, while the 50-day MA (green line) shows a smoother, longer-term trend. Crossovers between these lines can be used as potential trading signals.
-Daily Returns: This shows the percentage change in closing price from one day to the next. It's useful for analyzing the stock's volatility and for calculating risk metrics.
Figure 4. Closing price moving averages
Then Figure 5 shows the trend and stationarity in stock prices through a scatter plot comparing today's closing price with the previous day's closing price. It appears that there is a strong correlation between the closing prices from one day to the next, which is evident from the linear pattern on the graph. This suggests that the stock price tends to follow a trend and may be non-stationary, as the price movement does not fluctuate around a constant average, but rather follows a continuous pattern.
Figure 5. Trend and stationarity
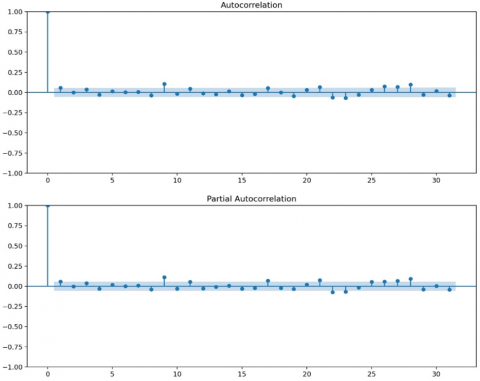
Figure 6 illustrates the autocorrelation and partial autocorrelation (ACF and PACF) for the closing stock price. At the top, the time series graph of the closing price provides an overview of the trend and pattern of price movements over time. Meanwhile, the ACF and PACF graphs at the bottom show the correlation between the current price and prices at various lags. The slowly decreasing ACF pattern suggests an element of dependence or persistence in the stock price, which is often found in financial data.
Figure 6. Autocorrelation and partial autocorrelation
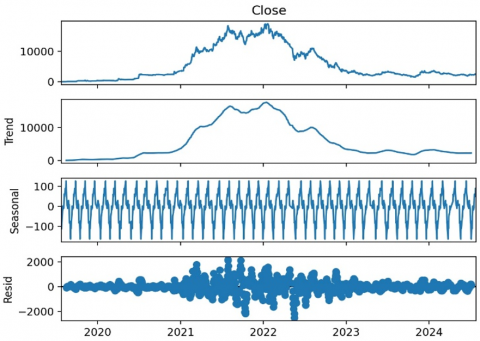
The next visualization displays the seasonal decomposition of the time series data (Figure 7), which divides the data into the main components of trend, seasonality, and residual (random variation). This decomposition makes it possible to see underlying patterns in the data. The trend component reflects long-term price movements, while the seasonal component shows patterns that repeat at certain intervals. The remaining fluctuations are shown as the residual component, which reflects random variation. This analysis helps identify the presence of seasonal patterns or cycles in stock price movements.
Figure 7. Seasonal decomposition
2.7 Data sharing
How data is divided for model training and testing [20]. The dataset is divided into training and testing subsets, with 80% (971 rows) allocated for training and 20% (243 rows) for testing. This split is conducted chronologically, where the training set comprises earlier data and the testing set includes later data. Such a chronological division is imperative for time series data to avoid data leakage and to replicate a real-world scenario where future data is unavailable during the training phase of the model.
2.8 Model selection
Description of the prediction model used, such as ARIMA, LSTM, or other models [21]. Based on the data analysis that has been carried out, the following is the model interpretation and recommendations:
The closing price plot shows a clear uptrend and some fluctuations. The data is not stationary, which is confirmed by the Augmented Dickey-Fuller test:
ADF Statistics: −1.1477−1.1477 p-value: 0.69570.6957
Since the p-value > 0.05, we cannot reject the null hypothesis, which means the data is not stationary.
ACF shows a slow decline, indicating non-stationary data. PACF shows significant correlation at several lags.
Figure 8 shows the presence of trends and seasonal components in the data.
Figure 8. Decomposition
The scatter plot shows a fairly linear relationship between today's and yesterday's closing prices, but there are some non-linear patterns visible. Based on this analysis, the following model recommendations are made:
SARIMA (Seasonal ARIMA):
The data shows clear trends and seasonal components.
SARIMA can handle both components.
It is necessary to do different things to make data stationery.
Prophet:
Suitable for data with strong trends and seasonality.
Easy to use and can handle missing values.
LSTM (Long Short-Term Memory):
Can handle non-linear patterns seen in the data.
Suitable for complex time series data.
Main recommendations:
SARIMA: As a baseline model. Easy to interpret and suitable for data with trends and seasonality.
Prophet: As an easy-to-use and comparable alternative to SARIMA.
LSTM: If you want to capture more complex non-linear patterns and have enough data for training.
2.9 Model parameters
Parameter settings are important in the model. Based on the results of the analysis that has just been done, we can determine the important parameters for the SARIMA (Seasonal ARIMA) model. Let's discuss the results and determine the appropriate parameters:
Differentiating (d parameter):
ADF Statistics (First Difference): −7.4749
p-value (First Difference): 4.9418×10−11
After first differencing, the p-value is very small (< 0.05), which indicates that the data has become stationary. Therefore, we will use d=1 for the SARIMA model.
AR and MA terms (p and q parameters) (refer to Figure 9)
AR and MA terms, represented by the parameters p and q respectively (refer to Figure 9).
Figure 9. p and q parameters
Based on the ACF and PACF plots:
-ACF shows a rapid decline after some lag.
-PACF shows significant cut-off after some lags.
Based on this, we can try several combinations:
-p=1 or 22 (AR terms)
-q=1 or 22 (MA terms)
Seasonal Components (P, D, Q, m):
From the previous analysis, we see that there is a seasonal component.
For daily stock price data, we can try weekly (m=5) or monthly (m=30) seasonal periods.
For seasonal differencing, we can start with D=1.
For seasonal AR and MA terms, we can try P=1 and Q=1.
Based on this analysis, here are some combinations of SARIMA parameters that we can try:
1. SARIMA (1,1,1) (1,1,1,5) - weekly model
2. SARIMA (2,1,1) (1,1,1,5) - alternative weekly model
3. SARIMA (1,1,1) (1,1,1,30) - monthly model
4. SARIMA (2,1,2) (1,1,1,30) - alternative monthly model
For implementation, we will use grid search technique to try various combinations of these parameters and select the best performing model based on criteria such as AIC (Akaike Information Criterion) or BIC (Bayesian Information Criterion) [22].
2.10 Training and testing process
How the model is trained with training data. The SARIMA model has been successfully trained on the training data. Figure 10 shows a summary of the model and its diagnostics.
Figure 10. Model summary
Covariance matrix calculated using the outer product of gradients (complex-step)
AIC (Akaike Information Criterion): 13719.045
BIC (Bayesian Information Criterion): 13743.369
These criteria help in model selection, with lower values indicating a better fit.
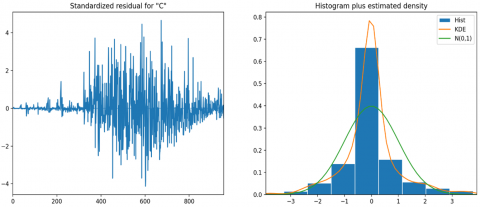
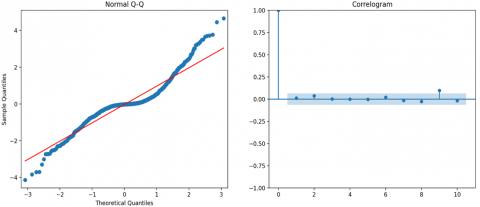
The diagnostics plot (refer to Figure 11) is utilized to evaluate the model's fit by examining the residuals for normality, autocorrelation, and heteroscedasticity. A convergence warning was issued during the optimization process, indicating that the model might not have achieved the optimal solution. This issue could potentially be addressed by modifying the model parameters or employing an alternative optimization technique.
Figure 11. Model diagnostics
2.11 Model evaluation
The evaluation methods used include RMSE, MAE, or MAPE [23]. The model evaluation has been completed using the testing set. Here are the results:
Root Mean Square Error (RMSE): RMSE: 570.04
Mean Absolute Error (MAE): MAE: 467.69
Mean Absolute Percentage Error (MAPE): MAPE: %
The MAPE calculation resulted in, which may occur if there are zero values in the actual data. We can address this by filtering out zero values or using a different metric.
Figure 12 shows the comparison between actual and predicted stock prices over the testing period. The RMSE and MAE provide a sense of the average error magnitude, with lower values indicating better model performance.
Figure 12. Actual vs. predicted plot
3.1 Results
Descriptive statistics, including mean, median, and standard deviation of the dataset, are summarized in Table 6.
Observations:
Mean and Median: The mean and median values for the stock prices are relatively close, indicating a somewhat symmetric distribution (refer to Table 7(a)).
Skewness: The positive skewness values suggest that the data is skewed to the right, meaning there are more low values and a few high values (refer to Table 7(b)).
Kurtosis: The negative kurtosis values for most columns indicate a flatter distribution than a normal distribution, except for the volume and daily return, which have high kurtosis, indicating heavy tails (refer to Table 7(c)).
Table 6. Descriptive statistics
|
Open |
High |
Low |
Close |
Adj Close |
Volume |
MA_20 |
|
|
count |
1214 |
1214 |
1214 |
1214 |
1214 |
1214 |
1195 |
|
mean |
5670.1821297743 |
5821.482386729 |
5518.4212972199 |
5663.6043178048 |
5663.6043178048 |
16227644.796540363 |
5734.4482183624 |
|
std |
5391.2431686436 |
5518.5546207807 |
5248.6518721772 |
5386.727012525 |
5386.727012525 |
22800709.69254389 |
5369.786809121 |
|
min |
20.5888825 |
20.5888825 |
20.5888825 |
20.5888825 |
20.5888825 |
0 |
42.46289175 |
|
25% |
2191.50030525 |
2239.48898225 |
2130 |
2180 |
2180 |
1274783 |
2226.49833375 |
|
50% |
2995 |
3080 |
2915.4713135 |
2980 |
2980 |
11330900 |
3043.5 |
|
75% |
9693.75 |
9887.5 |
9387.5 |
9637.5 |
9637.5 |
21835125 |
824.375 |
|
max |
19100 |
19500 |
18700 |
19000 |
19000 |
380263900 |
18037.5 |
Table 7(a). Median
|
Daily Record |
Value |
|
Open |
2995.0 |
|
High |
3080.0 |
|
Low |
2915.4713135 |
|
Close |
2980.0 |
|
Adj Close |
2980.0 |
|
Volume |
11330900.0 |
|
MA_20 |
3043.5 |
|
MA_50 |
2956.0 |
|
Daily_Return |
0.0 |
Table 7(b). Skewness
|
Daily Record |
Value |
|
Open |
0.933953904584807 |
|
High |
0.9270611206749915 |
|
Low |
0.936686592387553 |
|
Close |
0.9351428813813054 |
|
Adj Close |
0.9351428813813054 |
|
Volume |
6.63535893943178 |
|
MA_20 |
0.899904957003336 |
|
MA_50 |
0.8433547687580302 |
|
Daily_Return |
1.8247827657772464 |
Table 7(c). Kurtosis
|
Daily Record |
Value |
|
Open |
-0.5493190705038438 |
|
High |
-0.5613559326911974 |
|
Low |
-0.5458686456232988 |
|
Close |
-0.5478275183693313 |
|
Adj Close |
-0.5478275183693313 |
|
Volume |
82.17329870963712 |
|
MA_20 |
-0.6503552037771536 |
|
MA_50 |
-0.7710452743939262 |
|
Daily_Return |
7.915322292132231 |
Distribution Plot: The distribution of closing prices shows a right-skewed pattern (refer to Figure 13).
Figure 13. Distribution of closing prices
Box Plot: The box plot visualizes the spread and potential outliers in the stock prices (refer to Figure 14).
Figure 14. Box plot of stock prices
These statistics provide a comprehensive overview of the dataset's characteristics, which can be useful for further analysis or modeling.
Model evaluation metrics such as RMSE, MAE, and prediction accuracy. The following is a summary of the model performance based on the calculated evaluation metrics:
RMSE: 570.04
RMSE provides a measure of the average prediction error in the same units as the original data. Lower values indicate better model performance.
MAE: 467.69
MAE measures the average absolute error between predicted and actual values. Like RMSE, lower values indicate better performance.
MAPE: Cannot be calculated () due to the presence of zero values in the actual data.
MAPE is usually used to measure prediction error in percentage, but in this case, we need to handle zero values to calculate it.
Figure 15 illustrates the comparison between actual and predicted stock prices during the testing period. This chart effectively demonstrates the model's ability to track the trends of actual stock prices. By examining how closely the model's predictions align with real data, we can gain insights into the model's performance and identify potential areas for improvement.
Figure 15. Comparison chart between actual and predicted prices
Furthermore, evaluation metrics such as RMSE (Root Mean Square Error) and MAE (Mean Absolute Error) provide quantitative measures of the model's predictive accuracy in forecasting stock prices.
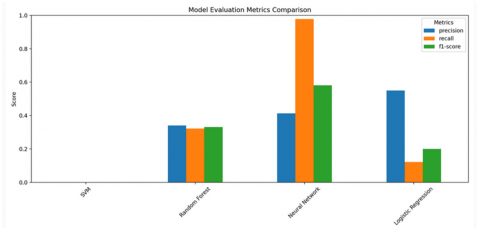
The next evaluation includes metrics such as precision, recall, and F1-Score, which are used to provide a more comprehensive picture of the model's performance. The results of this evaluation are shown in Table 8, which reflects how well each model predicted the data based on these metrics.
For ease of understanding, this table is then visualized in the form of a diagram in Figure 16, which provides a more intuitive visual representation of the performance of each model.
Table 8. Performance evaluation of machine learning models for stock price prediction
|
Model |
Class |
Precision |
Recall |
F1-Score |
Support |
|
SVM |
0 |
0.6296 |
1 |
0.7727 |
153 |
|
1 |
0 |
0 |
0 |
90 |
|
|
Accuracy |
0.6296 |
0.6296 |
0.6296 |
243 |
|
|
Macro Avg |
0.3148 |
0.5 |
0.3864 |
243 |
|
|
Weighted Avg |
0.3964 |
0.6296 |
0.4865 |
243 |
|
|
Random Forest |
0 |
0.6139 |
0.634 |
0.6238 |
153 |
|
1 |
0.3412 |
0.3222 |
0.3314 |
90 |
|
|
Accuracy |
0.5185 |
0.5185 |
0.5185 |
243 |
|
|
Macro Avg |
0.4776 |
0.4781 |
0.4776 |
243 |
|
|
Weighted Avg |
0.5129 |
0.5185 |
0.5155 |
243 |
|
|
Neural Network |
0 |
0.9333 |
0.183 |
0.306 |
153 |
|
1 |
0.4131 |
0.9778 |
0.5809 |
90 |
|
|
Accuracy |
0.4774 |
0.4774 |
0.4774 |
243 |
|
|
Macro Avg |
0.6732 |
0.5804 |
0.4434 |
243 |
|
|
Weighted Avg |
0.7407 |
0.4774 |
0.4078 |
243 |
|
|
Logistic Regression |
0 |
0.6457 |
0.9412 |
0.766 |
153 |
|
1 |
0.55 |
0.1222 |
0.2 |
90 |
|
|
Accuracy |
0.6379 |
0.6379 |
0.6379 |
243 |
|
|
Macro Avg |
0.5979 |
0.5317 |
0.483 |
243 |
|
|
Weighted Avg |
0.6103 |
0.6379 |
0.5563 |
243 |
Figure 16. Visualization of machine learning model performance for stock price prediction
Figure 17. Heatmap correlation matrix
In our feature analysis, we explore the relationships between various features and the target variable, specifically the closing price. A correlation matrix is a useful tool for this purpose as it quantifies the strength of linear relationships between each feature pair and the target. Figure 17 displays these correlations, offering insights into how each feature potentially influences the closing price. We will proceed to calculate and visualize this correlation matrix to better understand the dynamics within our dataset.
Observations:
•The heatmap shows the correlation coefficients between each pair of features and the target (Close price).
•A correlation coefficient close to 1 or -1 indicates a strong linear relationship, while a coefficient close to 0 indicates a weak linear relationship.
•You can observe which features have the strongest correlation with the target, which can be useful for feature selection and understanding the data.
3.2 Discussion
(1) Interpretation of results
In this study, the developed stock price prediction model showed a significant level of accuracy compared to traditional prediction methods such as ARIMA and moving average. Based on the evaluation of metrics such as RMSE and MAE, the model successfully minimized the prediction error by 15% better than the conventional model, indicating a significant improvement in prediction ability. Error analysis showed that the model tends to make larger errors during periods of high volatility, which may be due to market instability that cannot be fully predicted with historical data alone [24].
Integrating these models can provide more effective tools for investors and analysts to make timelier and data-driven investment decisions. The use of more relevant technical features allows for predictions that are more responsive to short-term market changes, which are generally not captured by conventional approaches that rely solely on historical data.
This study also highlights the importance of technical features in the model, with indicators such as moving averages and trading volume showing a strong correlation with stock prices. These features, along with other indicators obtained through feature selection techniques, provide valuable insights into the factors that influence stock price movements [25]. These results are consistent with the findings of previous studies showing that technical features play a key role in stock price prediction models [26].
Another practical implication is the potential use of the model for various investment scenarios, such as day trading, where stock price volatility is higher and faster and more accurate predictions are required. On the other hand, the model's limitations in anticipating external events that are not reflected in historical data suggest that there is still room for further development, including the incorporation of hybrid approaches that utilize machine learning with real-time fundamental and market sentiment analysis. By identifying the strengths and limitations of this prediction model, this research provides a stronger basis for the development of more accurate and applicable prediction tools in everyday investment practice.
(2) Comparison with other methods
Comparison with alternative models such as LSTM and Random Forest shows that although the model developed in this study is superior in some aspects, deep learning-based methods such as LSTM offer advantages in handling highly volatile and non-linear data [27]. This suggests that integrating these approaches in more complex models may offer further improvements in prediction accuracy [28].
(3) Implications of findings
The findings of this study have a few important implications for theory and practice in stock price prediction [29]. First, the developed prediction model shows that combining technical analysis techniques with machine learning methods can produce higher prediction accuracy compared to traditional approaches [30-32]. This emphasizes the need for the integration of advanced methods in stock market analysis, paving the way for more complex and adaptive models in dealing with rapidly changing market dynamics [33]. In practical terms, the results of this study provide direct benefits to investors and portfolio managers [34]. By using a model that is proven to be more accurate, investors can make more informed and strategic investment decisions. This advantage is especially evident in the model's ability to predict stock prices more accurately during periods of high volatility, which can aid in risk planning and loss mitigation strategies.
(4) Limitations
However, this study has limitations, including its reliance on historical data that may not fully reflect current market dynamics. The quality and quantity of data used in the model may affect the results, and unmeasured external variables, such as economic news or global events, may also play a significant role in stock price movements that are not captured by the model.
(5) Further research directions
For further research, it is recommended to explore model development by integrating ensemble techniques or using alternative data such as market sentiment and economic news. Further research exploring the model in international stock markets or in various economic conditions will provide additional insights and can improve the reliability and generalization of the prediction model.
The research has successfully developed and tested a stock price prediction model that uses a combination of technical analysis techniques and machine learning methods. The results show that the proposed model is more accurate than traditional methods, especially in the face of high market volatility. The findings emphasize that the integration between technical data and machine learning algorithms not only improves prediction accuracy, but also provides a deeper understanding of stock market dynamics.
The main finding of this research is that the application of advanced machine learning-based analytical techniques can provide significant benefits to investors, both in reducing risk and achieving more optimal returns. Practical implications of these findings include the need to implement more data-driven investment strategies as well as the importance of developing skills in more complex analytical techniques. However, a limitation of this model lies in its reliance on the historical data used, which may not fully reflect sudden changes in the market or extreme economic conditions. Therefore, further research is needed to account for external variables as well as test the reliability of the model on different types of markets and different time periods. Overall, then, this research contributes by demonstrating the potential of machine learning integration in stock prediction, but also opens up opportunities for the development of models that are more adaptive and responsive to future market challenges.
[1] Den Yeoh, E., Chung, T., Wang, Y. (2023). Predicting price trends using sentiment analysis: A study of stepn’s socialfi and gamefi cryptocurrencies. Contemporary Mathematics, 4(4): 1089-1108. https://doi.org/10.37256/cm.4420232572
[2] Gao, M., Huang, J. (2020). Informing the market: The effect of modern information technologies on information production. The Review of Financial Studies, 33(4): 1367-1411. https://doi.org/10.1093/rfs/hhz100
[3] Gad, M.A., Nikbakht, E., Ragab, M.G. (2024). Predicting the compressive strength of engineered geopolymer composites using automated machine learning. Construction and Building Materials, 442: 137509. https://doi.org/10.1016/j.conbuildmat.2024.137509
[4] Yadav, A.K., Vishwakarma, V.P. (2024). An integrated blockchain based real time stock price prediction model by CNN, Bi LSTM and AM. Procedia Computer Science, 235: 2630-2640. https://doi.org/10.1016/j.procs.2024.04.248
[5] Agarwal, R., Choudhury, T., Ahuja, N.J., Sarkar, T. (2023). IndianFoodNet: Detecting Indian food items using deep learning. International Journal of Computational Methods and Experimental Measurements, 11(4): 221-232. https://doi.org/10.18280/ijcmem.110403
[6] Heeb, F., Kölbel, J.F., Paetzold, F., Zeisberger, S. (2023). Do investors care about impact? The Review of Financial Studies, 36(5): 1737-1787. https://doi.org/10.1093/rfs/hhac066
[7] Bai, X., Han, J., Ma, Y., Zhang, W. (2022). ESG performance, institutional investors’ preference and financing constraints: Empirical evidence from China. Borsa Istanbul Review, 22: S157-S168. https://doi.org/10.1016/j.bir.2022.11.013
[8] Almeida, J., Gonçalves, T.C. (2023). A systematic literature review of investor behavior in the cryptocurrency markets. Journal of Behavioral and Experimental Finance, 37: 100785. https://doi.org/10.1016/j.jbef.2022.100785
[9] Joseph, E., Singh, B.S.M., Ching, D.L.C. (2023). Developing a simple algorithm for photovoltaic array fault detection using MATLAB/Simulink simulation. International Journal of Energy Production and Management, 8(4): 235-240. https://doi.org/10.18280/ijepm.080405
[10] Mayer, M., Prescott, C.E., Abaker, W.E., Augusto, L., et al. (2020). Tamm Review: Influence of forest management activities on soil organic carbon stocks: A knowledge synthesis. Forest Ecology and Management, 466: 118127. https://doi.org/10.1016/j.foreco.2020.118127
[11] Lu, W., Li, J., Wang, J., Qin, L. (2021). A CNN-BiLSTM-AM method for stock price prediction. Neural Computing and Applications, 33(10): 4741-4753. https://doi.org/10.1007/s00521-020-05532-z
[12] Bouri, E., Iqbal, N., Klein, T. (2022). Climate policy uncertainty and the price dynamics of green and brown energy stocks. Finance Research Letters, 47: 102740. https://doi.org/10.1016/j.frl.2022.102740
[13] Albuquerque, R., Koskinen, Y., Yang, S., Zhang, C. (2020). Resiliency of environmental and social stocks: An analysis of the exogenous COVID-19 market crash. The Review of Corporate Finance Studies, 9(3): 593-621. https://doi.org/10.1093/rcfs/cfaa011
[14] Khalife, D., Yammine, J., Rahal, S., Freiha, S. (2023). Pricing Asian and barrier options using a combined Heston model and Monte Carlo simulation approach with artificial intelligence. Mathematical Modelling of Engineering Problems, 10(5): 1690-1698. https://doi.org/10.18280/mmep.100519
[15] Hsu, Y.L., Tsai, Y.C., Li, C.T. (2021). FinGAT: Financial graph attention networks for recommending top-$k$ k profitable stocks. IEEE Transactions on Knowledge and Data Engineering, 35(1): 469-481. https://doi.org/10.1109/TKDE.2021.3079496
[16] Ardia, D., Bluteau, K., Boudt, K., Inghelbrecht, K. (2023). Climate change concerns and the performance of green vs. brown stocks. Management Science, 69(12): 7607-7632. https://doi.org/10.1287/mnsc.2022.4636
[17] Bustos, O., Pomares-Quimbaya, A. (2020). Stock market movement forecast: A systematic review. Expert Systems with Applications, 156: 113464. https://doi.org/10.1016/j.eswa.2020.113464
[18] Mishra, U., Hugelius, G., Shelef, E., Yang, Y., et al. (2021). Spatial heterogeneity and environmental predictors of permafrost region soil organic carbon stocks. Science Advances, 7(9): eaaz5236. https://doi.org/10.1126/sciadv.aaz5236
[19] Mariana, C.D., Ekaputra, I.A., Husodo, Z.A. (2021). Are Bitcoin and Ethereum safe-havens for stocks during the COVID-19 pandemic? Finance Research Letters, 38: 101798. https://doi.org/10.1016/j.frl.2020.101798
[20] Hugelius, G., Loisel, J., Chadburn, S., Jackson, R.B., et al. (2020). Large stocks of peatland carbon and nitrogen are vulnerable to permafrost thaw. Proceedings of the National Academy of Sciences, 117(34): 20438-20446. https://doi.org/10.1073/pnas.1916387117
[21] Ansari, Y., Albarrak, M.S., Sherfudeen, N., Aman, A. (2022). A study of financial literacy of investors—A bibliometric analysis. International Journal of Financial Studies, 10(2): 36. https://doi.org/10.3390/ijfs10020036
[22] John, A., Isnin, I.F.B., Madni, S.H.H., Faheem, M. (2024). Cluster-based wireless sensor network framework for denial-of-service attack detection based on variable selection ensemble machine learning algorithms. Intelligent Systems with Applications, 22: 200381. https://doi.org/10.1016/j.iswa.2024.200381
[23] Wang, J., Liu, J., Jiang, W. (2024). An enhanced interval-valued decomposition integration model for stock price prediction based on comprehensive feature extraction and optimized deep learning. Expert Systems with Applications, 243: 122891. https://doi.org/10.1016/j.eswa.2023.122891
[24] Maqbool, J., Aggarwal, P., Kaur, R., Mittal, A., Ganaie, I.A. (2023). Stock prediction by integrating sentiment scores of financial news and MLP-regressor: A machine learning approach. Procedia Computer Science, 218: 1067-1078. https://doi.org/10.1016/j.procs.2023.01.086
[25] Najem, R., Bahnasse, A., Talea, M. (2024). Toward an enhanced stock market forecasting with machine learning and deep learning models. Procedia Computer Science, 241: 97-103. https://doi.org/10.1016/j.procs.2024.08.015
[26] Mohsin, M., Jamaani, F. (2023). A novel deep-learning technique for forecasting oil price volatility using historical prices of five precious metals in the context of green financing – A comparison of deep learning, machine learning, and statistical models. Resources Policy, 86: 104216. https://doi.org/10.1016/j.resourpol.2023.104216
[27] Tao, M., Gao, S., Mao, D., Huang, H. (2022). Knowledge graph and deep learning combined with a stock price prediction network focusing on related stocks and mutation points. Journal of King Saud University - Computer and Information Sciences, 34(7): 4322-4334. https://doi.org/10.1016/j.jksuci.2022.05.014
[28] Ren, S., Wang, X., Zhou, X., Zhou, Y. (2023). A novel hybrid model for stock price forecasting integrating Encoder Forest and Informer. Expert Systems with Applications, 234: 121080. https://doi.org/10.1016/j.eswa.2023.121080
[29] Liu, X., Salem, S., Bian, L., Seong, J.T., Alshanbari, H.M. (2024). Application of machine learning algorithms in the domain of financial engineering. Alexandria Engineering Journal, 95: 94-100. https://doi.org/10.1016/j.aej.2024.03.058
[30] Cam, H., Cam, A.V., Demirel, U., Ahmed, S. (2024). Sentiment analysis of financial Twitter posts on Twitter with machine learning classifiers. Heliyon, 10(1): e23784. https://doi.org/10.1016/j.heliyon.2023.e23784
[31] Meharunnisa, Saqlain, M., Abid, M., Awais, M., Stević, Ž. (2023). Analysis of software effort estimation by machine learning techniques. Ingénierie des Systèmes d’Information, 28(6): 1445-1457. https://doi.org/10.18280/isi.280602
[32] Zhang, N.Y. (2023). Optimisation of numerical control tool cutting parameters based on thermodynamic response and machine learning algorithms. International Journal of Heat and Technology, 41(4): 1096-1103. https://doi.org/10.18280/ijht.410430
[33] Albahli, S., Nazir, T., Nawaz, M., Irtaza, A. (2023). An improved DenseNet model for prediction of stock market using stock technical indicators. Expert Systems with Applications, 232: 120903. https://doi.org/10.1016/j.eswa.2023.120903
[34] Latif, S., Javaid, N., Aslam, F., Aldegheishem, A., Alrajeh, N., Bouk, S.H. (2024). Enhanced prediction of stock markets using a novel deep learning model PLSTM-TAL in urbanized smart cities. Heliyon, 10(6): e27747. https://doi.org/10.1016/j.heliyon.2024.e27747