Lukman Anas*![]() | Aghus Sofwan
| Aghus Sofwan![]() | Iwan Setiawan
| Iwan Setiawan![]()
© 2025 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Quantum machine learning (QML) presents a promising computational paradigm for addressing complex data analysis challenges in higher education. This study evaluates the performance of quantum support vector machine (QSVM) compared to classical support vector machine (SVM) in predicting university performance by using scientometric indicators from 5,466 Indonesian universities in the SINTA database. Both models were assessed using standard classification metrics, with QSVM showing modest gains in accuracy (92.3%) and F1-score (91.2%) over SVM (88.7% and 87.2%, respectively), albeit with significantly longer processing time—approximately six times slower. The QSVM was implemented via the Qiskit Aer simulator, and was therefore limited to simulated rather than real quantum hardware. These findings indicate a trade-off between predictive performance and computational efficiency, suggesting that while QSVM offers potential, its latency currently limits practical deployment. Future research should investigate hybrid quantum-classical models, conduct experiments on real quantum devices, and apply explainability techniques to better understand feature contributions. Limitations related to dataset balance and generalizability should also be addressed.
scientometric indicators, quantum machine learning, university performance prediction, quantum machine learning (QML), support vector machine (SVM)
In the contemporary era marked by digital transformation and the Fourth Industrial Revolution, higher education is experiencing mounting pressure to enhance the quality of research and its scientific impact on a global scale [1, 2]. The evaluation of higher education performance has evolved beyond traditional administrative or academic parameters to incorporate scientometric indicators that quantitatively reflect an institution's scientific productivity and impact [3]. Key indicators, such as the number of publications, citation counts, international collaborations, and journal impact factor scores, have become crucial components in assessing the performance of higher education institutions.
As the complexity and volume of scientometric data increase, conventional analysis methods prove to be less efficient and precise in identifying patterns and accurately predicting institutional performance [4, 5]. In practice, machine learning (ML) has been extensively utilized to model and predict the performance of higher education institutions. Numerous studies have demonstrated that algorithms such as random forest, support vector machines (SVMs), k-nearest neighbors (k-NNs), and neural networks can identify significant patterns within academic data. For instance, a study conducted by Noaman et al. [6] introduced an innovative automated model known as the scientists and researchers classification model (SRCM), which is designed to classify, rank, and evaluate the performance of scientists and researchers within a university context utilizing data mining and machine learning techniques. Similarly, research by Sorz et al. [7] emphasizes the role of publication and citation data in mapping the strength of institutional research.
Quantum machine learning (QML) has emerged as a novel approach that integrates quantum computing principles with machine learning techniques. By employing superposition, interference, and entanglement, QML can execute calculations within extremely high-dimensional vector spaces in parallel, thereby theoretically offering advantages in terms of accuracy and computational efficiency over classical methods [8, 9]. Several QML models, such as the quantum support vector machine (QSVM) and variational quantum classifier (VQC), have demonstrated significant potential across various domains, although their application in higher education remains limited.
Several prior studies have devised traditional ML-based approaches within an academic context. For instance, Garg et al. [10] developed an ML model capable of predicting student performance in higher education. Additionally, Balderrama et al. [11] identified the most effective classification algorithm for predicting academic performance, achieving an average accuracy of 94.37%.
Moreover, Hakkal and Lahcen [12] explored the utilization of ensemble learning techniques, such as random forest and XGBoost, to enhance prediction accuracy, demonstrating commendable performance with educational data. Daradkeh et al. [13] proposed a deep learning approach utilizing the CNN method for classifying scientific literature based on scientometric information, attaining an accuracy value of 81%.
Despite the promising outcomes of these methodologies, challenges related to scalability, interpretability, and computational efficiency persist, particularly in handling intricate datasets such as scientometric indicators. Conventional ML models typically lack the capacity to manage datasets characterized by extensive dimensions and non-linear interrelations, which are emblematic of scientometric data encompassing the number of publications, citations, collaboration indices, and institutions' h-indices.
In this context, QML is gaining prominence as a plausible alternative that may address these limitations. By harnessing the principles of superposition and entanglement inherent in quantum mechanics, QML possesses the potential to deliver significant computational advantages in efficiently processing large-scale and complex data [14].
This research endeavors to bridge the gap by evaluating and comparing the performance of QML and classical ML in predicting college performance based on scientometric data.
The QSVM model was executed in this study using the Qiskit Aer simulator within a classical computing environment. Due to current constraints in quantum hardware accessibility, simulations were employed to approximate quantum behavior. While these simulators may not fully capture hardware-specific noise or real-time quantum constraints, they enable reproducible experimentation and offer initial insights into the theoretical performance of QML compared to classical methods.
While prior studies have explored the application of classical machine learning in higher education analytics, empirical studies that compare quantum and classical approaches using real-world scientometric indicators remain scarce. This research seeks to address this gap by implementing a comparative evaluation of QSVM and classical SVM models using data extracted from Indonesia’s national SINTA database.
The novelty of this study lies in its use of a high-dimensional, nationally representative scientometric dataset processed through a quantum-enhanced kernel method. Methodologically, the integration of Qiskit-based QSVM simulations with classical evaluation metrics represents an innovative approach to educational data analysis. The findings are expected to contribute theoretically by expanding the body of knowledge on QML applications in education, and practically by informing future hybrid AI model development for institutional performance assessment.
This chapter reviews and analyzes a range of relevant literature that provides the foundation for the development of this research. The literature under examination encompasses theories and concepts concerning scientometric-based evaluations of university performance, the application of machine learning (ML) techniques in predicting academic performance, as well as the introduction and implementation of quantum machine learning (QML) across various sectors. The discourse presented in this chapter is systematically organized to elucidate the latest advancements, methodologies employed, and to identify research gaps that underpin the formulation of a QML-based model for predicting college performance.
2.1 Scientometric-based higher education performance evaluation
In the context of digital transformation and the Fourth Industrial Revolution, the assessment of university performance is progressively transitioning from traditional administrative methodologies to approaches grounded in scientometric indicators [15, 16]. Indicators such as the quantity of publications, citation counts, international collaborations, h-index, and journal impact factor are employed to quantitatively evaluate an institution's scientific productivity and influence. The scientometric data not only encapsulate research output but also signify the institution's degree of engagement within global scientific networks [17].
As the volume and complexity of data escalate, rudimentary manual or statistically-based analyses prove to be insufficient. Consequently, there is a growing need for methodologies capable of managing complexity, uncovering latent patterns, and predicting performance with greater accuracy and efficiency.
2.2 Machine learning for academic performance prediction
ML constitutes a branch of artificial intelligence (AI) dedicated to the development of algorithms that enable computers to learn from data and carry out predictions or decision-making processes devoid of explicit programming [18, 19]. Within the realm of higher education, ML is gaining prominence as a method for analysing and forecasting academic performance at the individual level of students, faculty, and the institution collectively [20].
2.3 QML as a new approach
QML has emerged as a groundbreaking approach that integrates the advantages of quantum computing with traditional machine learning algorithms [21]. Leveraging quantum phenomena such as superposition, interference, and entanglement, QML enables parallel computations in high-dimensional Hilbert spaces, potentially offering enhanced model expressiveness and training efficiency compared to classical approaches [22].
One of the most prominent QML implementations is the QSVM, which extends the classical SVM through the use of quantum kernels derived from quantum feature maps. Unlike conventional kernels that project data into fixed non-linear spaces, quantum feature maps encode classical inputs into quantum states using parameterized circuits. In this study, the QSVM model was implemented using the ZZFeatureMap provided by Qiskit, which applied rotation gates and entangling controlled-Z operations to map data into complex quantum states.
To better understand the QML model structure, it is essential to briefly examine three fundamental components of quantum computation: qubits, quantum gates, and quantum measurement.
The quantum bit, or qubit, constitutes the fundamental unit of information in quantum computing, analogous to bits in classical computing systems. Qubits possess the capacity to represent values of 0,1, or both concurrently, leveraging the phenomena of superposition and entanglement inherent in quantum mechanics [9]. Figure 1 illustrates a comparative representation of a classical bit and a quantum bit.
Figure 1. Classical bit vs. quantum bit
Quantum gates are another essential component of quantum computing, functioning similarly to logic gates in classical systems. Nevertheless, quantum gates function according to quantum principles, which provide them with a distinct advantage in executing intricate mathematical operations [23].
Finally, quantum measurement plays a distinct and critical role in quantum computing. Measurement transcends the mere act of reading a value; it also directly influences the ultimate state of a qubit, the fundamental unit of quantum information. In contrast to classical bits, which possess a singular, fixed value, qubits can exist in a state of superposition, embodying the probability of representing either 0 or 1.
While these foundational components underpin all quantum algorithms, their specific advantage in QSVM lies in constructing a quantum kernel matrix based on the fidelity between quantum states:
K(xi, xj)=∣⟨ψ(xi)∣ψ(xj)⟩}|2 (1)
This formulation allows QSVM to model highly nonlinear relationships between data points. Superposition facilitates the simultaneous encoding of multiple input vectors, while entanglement captures intricate feature correlations that would be challenging to represent in classical space. This capability is particularly valuable in scientometric analysis, where data are high-dimensional and exhibit complex dependencies across features such as citations, publication quartiles, and collaboration indices.
In this study, the QSVM experiments were conducted using the Qiskit Aer simulator rather than real quantum hardware due to current technological limitations. Although simulators do not account for quantum noise or decoherence, they offer a reliable approximation of ideal quantum behavior, facilitating reproducible and scalable experimentation.
2.4 QML algorithm
With the advancement of quantum computing, a variety of QML algorithms have been formulated to tackle a multitude of machine learning challenges, encompassing classification, regression, and optimization. Notable algorithms in this domain include the QSVM, VQC, quantum k-nearest neighbors (QkNNs), quantum Boltzmann machine (QBM), and quantum generative adversarial networks (QGANs). The following paragraphs describe several prominent QML algorithms.
2.4.1 QSVM
QSVM is a quantum adaptation of the SVM algorithm, commonly used for classification tasks [24, 25]. While classical SVMs work by finding the optimal hyperplane that separates two classes of data, QSVM utilizes a quantum kernel, which allows processing data in a higher-dimensional space. This enables the algorithm to identify more complex and effective separations.
2.4.2 VQC
The VQC represents an algorithm that employs parametric quantum circuits to execute classification tasks [26]. VQC optimizes the parameters of the quantum circuit to minimize the loss function, thereby enhancing classification accuracy. This principle bears resemblance to the traditional artificial neural network model, wherein the network parameters are optimized to reduce classification error.
2.4.3 QkNN
QkNN is an adaptation of the k-NNs algorithm tailored for application within a quantum context. In QkNN, the classification process involves identifying the nearest neighbors of the input data within the quantum feature space [27, 28]. The algorithm utilizes quantum distance metrics to compute the distances between data points, thereby facilitating a more efficient neighbor search in comparison to classical methods.
2.4.4 QBM
The QBM represents an implementation of the classical Boltzmann machine within quantum systems. QBM utilizes quantum annealing techniques to identify optimal energy configurations within probabilistic networks [29]. This model is applicable to a variety of domains, including pattern recognition and the modeling of more complex data distributions.
2.4.5 QGANs
QGANs represent an advancement of generative adversarial networks (GAN) within the framework of quantum computing [30, 31]. QGAN comprises two primary constituents: a quantum generator that generates synthetic data and a quantum discriminator that evaluates data veracity. Through the process of adversarial training, both components collaborate to enhance the generator's capacity to produce progressively realistic data.
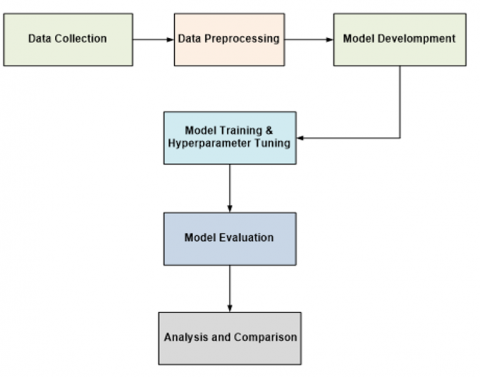
This research employed a comparative quantitative methodology utilizing a case study design. The primary objective was to compare the performance of QML models with classical machine learning models in predicting university performance based on scientometric indicators. Figure 2 illustrates the sequence of research stages undertaken.
Figure 2. Research stages sequence
3.1 Data collection
The data collection phase served as a crucial foundation, as the quality and precision of the data gathered significantly influenced the accuracy and validity of the predictive model, applicable to both classical ML and QML methodologies. The collected data encompassed two primary categories: scientometric data, which included university bibliometric indicators, and university performance data, consisting of institutional performance rankings or scores.
Table 1 presents the types of data and performance indicators that were collected related to the universities.
Table 1. Types of data and higher education performance indicators
|
Scientometric Indicator |
Brief Overview |
|
Number of Publications |
Total articles, conferences, books published |
|
Number of Citations |
Total citations from all publications |
|
H-Index |
Scientific productivity and impact index |
|
Number of Q1-Q4 Articles |
Article distribution by journal quartiles |
|
Field-Weighted Citation Impact (FWCI) |
Ratio of actual citations to expected citations |
Data collection was conducted utilizing the university citation system in Indonesia via SINTA, which is accessible at https://sinta.kemdikbud.go.id/affiliations. This initiative encompassed a total of 5,466 universities. Table 2 presents a sample of the data collection results.
Table 2. Sample of higher education performance data collection
|
University |
Publication |
Citation |
H-Index |
Quartile Articles |
FWCI |
Output |
|||
|
Q1 |
Q2 |
Q3 |
Q4 |
||||||
|
A |
15000 |
300000 |
120 |
8000 |
3000 |
1000 |
2000 |
1.5 |
High |
|
B |
5000 |
70000 |
70 |
1500 |
500 |
2000 |
1000 |
1.1 |
Medium |
|
C |
2000 |
15000 |
40 |
500 |
300 |
150 |
1050 |
0.8 |
Low |
3.2 Data preprocessing
Following data collection from SINTA, the subsequent phase involved data preprocessing. This procedure aimed to guarantee that the data in the development of ML and QML models were clean, consistent, and suitable for further analysis.
The first step was data cleaning, which included handling missing values by conducting a comprehensive review of incomplete or absent entries, particularly for indicators such as the number of publications, citations, H-index, quartile articles (Q1-Q4), and FWCI. Missing values were addressed using mean imputation for each respective indicator. Outlier detection and correction followed, targeting unreasonable values such as negative publication counts or extreme FWCI scores. These outliers were identified using the interquartile range (IQR) method and were either corrected or removed based on relevance. Additionally, consistency checks were performed to ensure that the aggregate number of articles across quartiles (Q1 + Q2 + Q3 + Q4) did not exceed the total number of publications.
The next step was data transformation. All numerical variables—including publication counts, citation numbers, H-index, article quartiles, and FWCI—were normalized using the min-max scaling method to fit within the range [0, 1]. This normalization was intended to mitigate the influence of a singular feature on the prediction model. Min-max normalization was chosen for its ability to preserve the original data distribution while scaling to a uniform range, which is particularly beneficial for algorithms, such as SVM and QSVM, that rely on distance-based calculations or kernel evaluations. Without normalization, features with larger magnitudes, such as citation counts, could disproportionately affect decision boundaries, thereby reducing prediction accuracy and generalizability. Furthermore, the [0, 1] range aligns with quantum encoding constraints when using feature maps like ZZFeatureMap, which assume bounded input values for efficient quantum circuit parameterization. To enhance the representation of publication quality, feature engineering was applied by computing the ratio of article distribution per quartile relative to the total number of publications. In addition, college and university names were numerically encoded (e.g., A = 0, B = 1, C = 2) to ensure compatibility with ML and QML models.
Following transformation, data integration was performed by merging scientometric data and university performance data into a consolidated tabular dataset. Each row in the dataset represents a single higher education institution, while each column corresponds to a processed performance feature or indicator. Finally, the dataset was split into two subsets: 80% for training and 20% for testing. This partitioning enabled the models to be trained effectively and evaluated for predictive performance.
3.3 Model development
In the model development stage, the process involved the construction, training, and evaluation of a predictive model intended to ascertain university performance based on scientometric indicators. The primary objective of this phase was to identify the optimal model, utilizing both classical and quantum methodologies, that yields the most precise predictions.
Selected models were categorized into two groups: the QML model and the classical ML model. In this research, the QML model employed was QSVM, which was adapted to function with data that had undergone normalization and processing. QSVM was anticipated to effectively manage the intricate relationships between scientometric indicators and university performance, thereby producing more accurate and efficient predictive outcomes. Conversely, the classical ML approach adopted the SVM model. This model was chosen due to its demonstrated capacity to predict performance based on both numerical and categorical data and its advantages in proficiently addressing a variety of prediction challenges. Both methodologies underwent training and evaluation to ascertain the most effective model for predicting university performance based on scientometric indicators. The QSVM model was implemented using the Qiskit Machine Learning library (version 0.8.3), utilizing the AerSimulator backend with statevector configuration. Classical SVM was implemented using the Scikit-learn library (version X.X), employing the radial basis function (RBF) kernel with γ = 0.1 and regularization parameter C = 1.0. The same hyperparameters were maintained across experiments to ensure a fair comparison.
3.4 Model training and hyperparameter tuning
Following model selection, the training phase was conducted using the training data, which comprised 80% of the entire dataset. At this stage, the model learned to map the relationship between the input features (scientometric indicators) and the output labels (university performance).
The classical machine learning model, SVM, was implemented using the Scikit-learn library with a radial basis function (RBF) kernel. The hyperparameters were set to default values (C = 1.0, gamma = 0.1), based on prior empirical studies and preliminary experimentation.
QSVM was implemented using the Qiskit Machine Learning library, employing a ZZFeatureMap and the AerSimulator backend. The quantum kernel was constructed using fidelity-based measurements of quantum states. Parameter values were selected following standard configurations used in quantum classification tasks, in the absence of formal hyperparameter tuning methods such as grid search.
Both models were trained independently on the same dataset and evaluated on the 20% test split to ensure fair performance comparison.
3.5 Model evaluation
After training, assessing model performance utilizing test data was performed. Evaluation was conducted employing pertinent metrics, which included accuracy, precision, recall, F1-score, Cohen’s Kappa, confusion matrix analysis.
Accuracy quantified the ratio of accurate predictions relative to the total predictions generated by the model. Precision, Recall, and F1-Score offered a comprehensive assessment to evaluate the equilibrium between true positive and false positive predictions. Cohen’s Kappa was used to assess inter-rater agreement beyond chance, providing a robust metric for evaluating the consistency of classifications across the High, Medium, and Low university performance categories. The confusion matrix provided insight into the types of errors that the model exhibited, such as incorrect predictions between high and low ranked universities. The use of a confusion matrix further enabled the identification of misclassification patterns between categories, enhancing interpretability.
3.6 Analysis and comparison
A critical phase in model evaluation involved analyzing and comparing the performance of two or more trained models. The primary objective was to assess the efficacy of each model according to specific evaluation metrics and to compare the results obtained between each model.
This study aimed to develop and compare predictive models of university performance based on scientometric indicators, with the goal of identifying the most accurate and effective model for academic performance evaluation. Based on the analysis and comparison results, this research provides recommendations on the optimal model for predicting university performance.
The following section presents the findings of a comparative experiment conducted between QML utilizing the QSVM model and classical ML employing the SVM model for predicting university performance. The analysis incorporates various scientometric indicators used to assess university performance, including the number of publications, citations, H-index, articles within journal quartiles, and citation impact factor (FWCI).
Tables 3 and 4 illustrate the evaluation metrics for both models, including accuracy, precision, recall, F1-score, and processing time. The outcomes of university performance prediction are classified into three categories: High, Medium, and Low, determined by the accuracy achieved by each model. Each column in the tables offers comprehensive information that facilitates an efficacy comparison between the two methodologies in predicting university performance.
Table 3. Sample data of QSVM model performance evaluation results
|
University |
Publications |
Citations |
Quartile Articles (Q1, Q2, Q3, Q4) |
FWCI |
True Label |
Predicted Label |
Error Type |
|
A |
15,000 |
300,000 |
8000, 3000, 1000, 2000 |
1.5 |
High |
High |
Correct |
|
B |
5,000 |
70,000 |
1500, 500, 2000, 1000 |
1.1 |
Medium |
Medium |
Correct |
|
C |
2,000 |
15,000 |
500, 300, 150, 1050 |
0.8 |
Medium |
Low |
False Negative |
|
D |
18,000 |
500,000 |
10000, 5000, 3000, 5000 |
1.8 |
High |
High |
Correct |
|
E |
8,000 |
120,000 |
6000, 2000, 1500, 1000 |
1.2 |
Medium |
Medium |
Correct |
Table 4. Sample data of SVM model performance evaluation results
|
University |
Publications |
Citations |
Quartile Articles (Q1, Q2, Q3, Q4) |
FWCI |
True Label |
Predicted Label |
Error Type |
|
A |
15,000 |
300,000 |
8000, 3000, 1000, 2000 |
1.5 |
High |
High |
Correct |
|
B |
5,000 |
70,000 |
1500, 500, 2000, 1000 |
1.1 |
Medium |
High |
False Positive |
|
C |
2,000 |
15,000 |
500, 300, 150, 1050 |
0.8 |
Medium |
Medium |
Correct |
|
D |
18,000 |
500,000 |
10000, 5000, 3000, 5000 |
1.8 |
High |
High |
Correct |
|
E |
8,000 |
120,000 |
6000, 2000, 1500, 1000 |
1.2 |
Medium |
Medium |
Correct |
In this experiment, the QSVM model was implemented using the ZZFeatureMap provided by Qiskit, which transforms input features into quantum states through parameterized Z-rotations and entangling controlled-Z (CZ) gates. This feature map projects classical data into a high-dimensional Hilbert space, enabling the quantum kernel to extract non-linear correlations that are often not linearly separable in classical spaces. The quantum kernel matrix was constructed based on fidelity measures between quantum states, providing a fundamentally different representation of data relationships. Although the simulation was conducted on the Qiskit Aer simulator, it provided a reliable approximation for evaluating the theoretical performance of QML models like QSVM in practical scenarios.
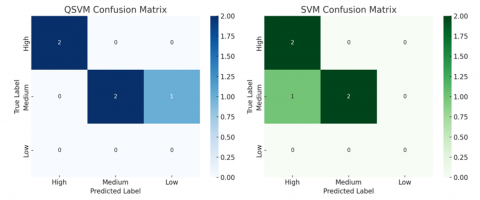
Based on the comparative evaluation presented in Tables 3 and 4, both the QSVM and classical SVM models achieved identical accuracy levels of 80% across the five sample universities. However, a closer inspection reveals notable qualitative differences in the type and implications of prediction errors produced by each model.
The QSVM model correctly classified four out of five universities, with one misclassification observed in University C, where the true performance label was "Medium" but was incorrectly predicted as "Low." This type of error is categorized as a False Negative, indicating the model's conservative tendency in classifying borderline cases. Such conservatism may reflect QSVM's stronger sensitivity to underperforming scientometric indicators such as lower citation counts, reduced publication volume, and a modest FWCI of 0.8. Notably, universities with high publication output and strong citation metrics, such as Universities A and D, were accurately predicted as “High” performers, suggesting that QSVM effectively leverages complex data patterns to support correct classification.
Conversely, the SVM model also correctly classified four out of five universities but committed a False Positive in the case of University B. Here, the model predicted "High" performance despite the true label being "Medium." This over-classification likely results from the model’s emphasis on publication and citation counts, while underweighting more nuanced indicators like FWCI, which in this case was a moderate 1.1. Unlike QSVM, SVM appears more prone to optimistic bias, assigning higher performance levels in cases where high-volume metrics exist, even if qualitative impact indicators are not as strong.
These findings indicate that, while QSVM and SVM exhibit comparable accuracy on a per-university basis, QSVM offers a more cautious and precise classification strategy, particularly in scenarios where data patterns are complex and subtle. This behavior aligns with the theoretical strengths of quantum computing, which enables better modeling of entangled features and non-linear data distributions. On the other hand, SVM provides a faster and computationally lighter alternative, albeit with a tendency to overpredict performance when faced with ambiguous inputs.
In application contexts where minimizing false positives is critical, such as resource allocation or performance-based funding in higher education, the conservative nature of QSVM may offer strategic advantages. However, for exploratory or large-scale deployments constrained by processing time and hardware availability, the classical SVM remains a viable and effective choice.
These distinctions reinforce the importance of aligning model selection not only with accuracy metrics but also with the nature of classification errors and their real-world consequences. Furthermore, future work should incorporate formal statistical tests—such as McNemar’s test or bootstrapped confidence intervals—to establish the robustness of these observed differences and ensure reliable interpretation in policy and academic decision-making.
Figure 3 shows the comparative confusion matrices of QSVM and SVM models.
Figure 3. Confusion matrices of QSVM and SVM models
This study presents a comparative evaluation between QSVM and classical SVM for predicting university performance based on scientometric indicators. While the QSVM model implemented via quantum simulation demonstrated modest improvements in accuracy and F1-score compared to its classical counterpart, these gains were offset by significantly higher latency and computational demands. It is important to emphasize that the current results are derived from a simulated environment (Qiskit Aer simulator) and do not reflect the constraints or potential benefits of actual quantum hardware deployment. Given these limitations, the claims regarding QML’s superiority should be interpreted cautiously.
Future research should address several directions to strengthen the applicability and robustness of QML in educational analytics:
(1) development and evaluation of hybrid quantum-classical models that optimize both performance and resource efficiency;
(2) implementation and benchmarking of QSVM on real quantum processors to assess hardware feasibility and reliability;
(3) incorporation of explainability frameworks, such as SHAP or LIME adapted for quantum models, to identify the relative contribution of scientometric features, including FWCI, H-Index, and quartile distributions.
Additionally, the study’s reliance on a relatively small and imbalanced dataset limits generalizability. Expanding the dataset, ensuring class balance, and validating models across different institutional contexts are essential steps toward building more generalizable and equitable quantum machine learning frameworks in the higher education domain.
|
B |
dimensionless heat source length |
|
CP |
specific heat, J. kg-1. K-1 |
|
g |
gravitational acceleration, m.s-2 |
|
k |
thermal conductivity, W.m-1. K-1 |
|
Nu |
local Nusselt number along the heat source |
|
Greek Symbols |
|
|
$\alpha$ |
thermal diffusivity, m2. s-1 |
|
$\beta$ |
thermal expansion coefficient, K-1 |
|
$\phi$ |
solid volume fraction |
|
Ɵ |
dimensionless temperature |
|
µ |
dynamic viscosity, kg. m-1.s-1 |
|
Subscripts |
|
|
p |
nanoparticle |
|
f |
fluid (pure water) |
|
nf |
nanofluid |
[1] Akour, M., Alenezi, M. (2022). Higher education future in the era of digital transformation. Education Sciences, 12(11): 784. https://doi.org/10.3390/educsci12110784
[2] Shenkoya, T., Kim, E. (2023). Digital transformation of the fourth industrial revolution and its impact on open knowledge. Sustainability, 15(3): 2473. https://doi.org/10.3390/su15032473
[3] Akbash, K.S., Pasichnyk, N.O., Rizhniak, R.Y. (2021). Analysis of key factors of influence on scientometric indicators of higher educational institutions of Ukraine. International Journal of Educational Development, 81: 102330. https://doi.org/10.1016/j.ijedudev.2020.102330
[4] Janavi, E., Abdi, S. (2024). Faculty members' performance appraisal system: A bibliometric analysis of the scientific literature. International Journal of Information Science and Management, 22(3): 63-83. https://doi.org/10.22034/ijism.2024.2013962.1281
[5] El-Ouahi, J. (2024). Scientometric rules as a guide to transform science systems in the Middle East and North Africa. Scientometrics, 129(2): 869-888. https://doi.org/10.1007/s11192-023-04916-x
[6] Noaman, A.Y., Gad-Elrab, A.A.A., Baabdullah, A.M. (2024). Towards Scientists and Researchers Classification Model (SRCM)-based machine learning and data mining methods: An ISM-MICMAC approach. Journal of Innovation and Knowledge, 9(3): 100516. https://doi.org/10.1016/j.jik.2024.100516
[7] Sorz, J., Glänzel, W., Ulrych, U., Gumpenberger, C., Gorraiz, J. (2020). Research strengths identified by esteem and bibliometric indicators: A case study at the University of Vienna. Scientometrics, 125(2): 1095-1116. https://doi.org/10.1007/s11192-020-03672-6
[8] Rani, S., Desai, C., Ambilwade, R.P. (2024). Quantum machine learning: Leveraging quantum computing for enhanced learning algorithms. International Journal of Forensic Medicine and Research, 6(5): 1-15. https://doi.org/10.36948/ijfmr.2024.v06i05.27450
[9] Zaman, K., Marchisio, A., Hanif, M.A., Shafique, M. (2023). A survey on quantum machine learning: Current trends, challenges, opportunities, and the road ahead. arXiv preprint arXiv:2310.10315. http://arxiv.org/abs/2310.10315
[10] Garg, A., Lilhore, U.K., Ghosh, P., Prasad, D., Simaiya, S. (2021). Machine learning-based model for prediction of student's performance in higher education. In 2021 8th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, pp. 162-168. https://doi.org/10.1109/SPIN52536.2021.9565999
[11] Balderrama, L.T., Lima, D.A. (2023). Insights into factors influencing academic success: An application of classification models in higher education. Artificial Intelligence Applications, 2(3): 247-256. https://doi.org/10.47852/bonviewaia32021465
[12] Hakkal, S., Lahcen, A.A. (2024). XGBoost to enhance learner performance prediction. Computers and Education: Artificial Intelligence, 7: 100254. https://doi.org/10.1016/j.caeai.2024.100254
[13] Daradkeh, M., Abualigah, L., Atalla, S., Mansoor, W. (2022). Scientometric analysis and classification of research using convolutional neural networks: A case study in data science and analytics. Electronics, 11(13): 2066. https://doi.org/10.3390/electronics11132066
[14] Belagali, R.G., Belagali, R. (2024). Exploring the potential of quantum machine learning for enhanced data processing. International Journal of Research and Analytical Reviews, 9(4): 316-322. https://ijnrd.org/papers/IJNRD2404266.pdf.
[15] Chen, J. (2023). A scientometric analysis of information technology in sustainable higher education: Knowledge structure and frontier trends. Discover Sustainability, 4(1): 48. https://doi.org/10.1007/s43621-023-00148-4
[16] Nurmandi, A., Younus, M., Lawelai, H., Suardi, W. (2025). Scientometric analysis of digital transformation maturity in research and development. Society, 13(1): 223-240. https://doi.org/10.33019/society.v13i1.800
[17] Gomis, M.K.S., Oladinrin, O.T., Saini, M., Pathirage, C., Arif, M. (2023). A scientometric analysis of global scientific literature on learning resources in higher education. Heliyon, 9(4): e15438. https://doi.org/10.1016/j.heliyon.2023.e15438
[18] Ohia, D., Daniel, C. (2024). Advancements and challenges in machine learning and artificial intelligence: Shaping the future of technology. https://www.researchgate.net/publication/377150546_Advancements_and_Challenges_in_Machine_Learning_and_Artificial_Intelligence_Shaping_the_Future_of_Technology.
[19] Soori, M., Arezoo, B., Dastres, R. (2023). Artificial intelligence, machine learning and deep learning in advanced robotics, a review. Cognitive Robotics, 3: 54-70. https://doi.org/10.1016/j.cogr.2023.04.001
[20] Ali, J.A., Muse, A.H., Abdi, M.K., Ali, T.A., Muse, Y.H., Cumar, M.A. (2025). Machine learning-driven analysis of academic performance determinants: Geographic, socio-demographic, and subject-specific influences in Somaliland's 2022-2023 national primary examinations. International Journal of Educational Research Open, 8: 100426. https://doi.org/10.1016/j.ijedro.2024.100426
[21] Mehendale, P. (2023). Quantum machine learning: The next frontier in AI. Journal of Scientific and Engineering Research, 10(1): 104-108. https://doi.org/10.5281/zenodo.13753380
[22] Li, L., Zhang, X., Cui, Z., Xu, W., Xu, X., Wang, J., Shu, R. (2025). An overview of quantum machine learning research in China. Applied Sciences, 15(5): 2555. https://doi.org/10.3390/app15052555
[23] Cui, R., Lyu, Z. (2023). Analysis of quantum gates in quantum circuits. Theoretical and Natural Science, 10(1): 1-8. https://doi.org/10.54254/2753-8818/10/20230301
[24] Suzuki, T., Hasebe, T., Miyazaki, T. (2024). Quantum support vector machines for classification and regression on a trapped-ion quantum computer. Quantum Machine Intelligence, 6(1): 1-14. https://doi.org/10.1007/s42484-024-00165-0
[25] Kumar, K.K., Nutakki, M., Koduru, S., Mandava, S. (2024). Quantum support vector machine for forecasting house energy consumption: A comparative study with deep learning models. Journal of Cloud Computing, 13(1): 69. https://doi.org/10.1186/s13677-024-00669-x
[26] Maheshwari, D., Sierra-Sosa, D., Garcia-Zapirain, B. (2022). Variational quantum classifier for binary classification: Real vs. Synthetic dataset. IEEE Access, 10: 3705-3715. https://doi.org/10.1109/ACCESS.2021.3139323
[27] Maldonado-Romo, A., Montiel-Pérez, J.Y., Onofre, V., Maldonado-Romo, J., Sossa-Azuela, J.H. (2024). Quantum K-nearest neighbors: Utilizing QRAM and SWAP-test techniques for enhanced performance. Mathematics, 12(12): 1872. https://doi.org/10.3390/math12121872
[28] Muntazhar, A.Z.A., Sulistyaningrum, D.R., Subiono. (2023). Quantum k-nearest neighbors for object recognition. In International Conference on Mathematics: Pure, Applied and Computation, Singapore: Springer Nature, pp. 135-147. https://doi.org/10.1007/978-981-97-2136-8_11
[29] Amin, M.H., Andriyash, E., Rolfe, J., Kulchytskyy, B., Melko, R. (2018). Quantum Boltzmann machine. Physical Review X, 8(2): 021050. https://doi.org/10.1103/PhysRevX.8.021050
[30] Pajuhanfard, M., Kiani, R., Sheng, V.S. (2024). Survey of quantum generative adversarial networks (QGAN) to generate images. Mathematics, 12(23): 3852. https://doi.org/10.3390/math12233852
[31] Assouel, A., Jacquier, A., Kondratyev, A. (2022). A quantum generative adversarial network for distributions. Quantum Machine Intelligence, 4(2): 28. https://doi.org/10.1007/s42484-022-00083-z