Ekhlas Watan Ghindawi![]()
© 2024 The author. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Image alignment represents a crucial and essential subject in computer vision applications for image analysis. Getting spatial transformation to align a moving image with a reference image is the aim of image alignment. Deep learning techniques, which have been more and more popular recently, provide good outcomes when applied to alignment challenges in addition to many other computer vision problems. In this work, a supervised DL technique has been used in order to estimate the spatial transformation parameter. The spatial transformation model is based on the stiff technique. To convert moving images to a fixed image, rigid transformation parameters are estimated using a supervised convolutional neural network (CNN). The primary contribution of the presented research is to use a model to handle input images with quality degradation to carry out supervised rigid image alignment with the regression model of the CNNs. In the study, many parameters have been examined in an attempt to ascertain the impact of noise in each image and the parameters that yield the optimal outcomes for the problem.
CNN, image alignment, supervised learning, deep learning (DL), image denoising
One of the most noteworthy problems in image processing field is image alignment, or IA. Image alignment is done for a variety of reasons, including getting region of interest images from various perspectives or distances, using various modalities, getting them with various techniques, and getting them at various times. Many industries, including medicine and radiology, defense sector, cartography, remote sensing, and computer vision, use the IA technique. In realm of image processing, image alignment is frequently used for tasks like image-guided operations and illness monitoring and diagnosis [1]. Image alignment algorithms are capable of identifying the connections between images that have different levels of overlap. These algorithms are particularly useful for tasks like video stabilization, summarization, and generating panoramic mosaics [2]. Two photos are used as the alignment process's input. A reference or fixed image is one of input images. We refer to the other image as moving one. The altered image that has been created by applying different transformations, like affine, rigid, or deformable, is represented by moved image. Moving and fixing image pairings into a single coordinate system is the process of image augmentation, or IA. The mapping process aims to align specific features present in both photos. Finding parameters which would result in maximizing similarity between the 2 images is the goal of the image alignment process [2, 3]. As demonstrated in Eq. (1), the image alignment problem may be viewed as optimization problem. Where $\hat{T}$ represents desired spatial transformation, IF stands for reference or fixed image, and IM for moving image in Eq. (1). (IM) is the distorted image produced by applying transformation T on IM. The dissimilarity or the similarity between IF and the warped images (IM) is assessed by function S(). The objerctive of image alignment is finding the transformation T that, given a cost function, maximizes image similarity or reduces image dissimilarity [4].
$\hat{T}=\operatorname{argmi}\left(I_F, T\left(I_M\right)\right)$ (1)
DL networks like CNNs were known as state-of-art in a broad range of applications, especially in the field of computer vision like classification, segmentation, and alignment due to exhibited promising results. When compared to classical methods, DL methods yield better results. Most DL-based models are used in segmentation and classification applications [5, 6]. The alignment challenge differs significantly from the standard classification problem. Finding the image similarity and transformation parameter values (rotation, translation, and scaling) maximizing similarity between fixed and moving images is critical in the image alignment problem. Consequently, it is not possible to directly adapt CNN networks to the alignment issue [7]. Numerous successful research has applied DL techniques on registered image pairs. To evaluate the position and posture of implemented subject during surgery, Miao et al. [8] employed CNN regression. The goal of their CNN model was to forecast 6 inflexible parameters of transformation. The vast majority of realistic ground-truth training material for DL-based image alignment was synthesized by Uzunova et al. [9]. From the available training images, they essentially learned a statistical appearance model, which they then used to synthesis a random number of new images. The study of Eppenhof et al. [10] included employing CNN to record deformable medical computed tomography image pairings. Transformation parameters are learned immediately by their architecture. Utilizing fully convolutional network, some researchers [11] provide an unsupervised learning technique for registering CT image pairings. Their network warps a moving image to a map-fixed image by estimating a dense displacement vector. De Vos et al. [12] used unsupervised learning to train their CNN regressor end-to-end in order to maximize the metrics of similarity between the image pairs. They have used the MNIST data collection and images to test their network. The spatial transform network, which creates the vector of displacement, makes use of the network's output parameters. CNN-based unsupervised stiff image alignment has been proposed by Liu et al. [13]. The network output is the fixed and moved images attributes. Between registered image and fixed image, loss is computed. The stiff motion was represented by ultrasound images. They claimed that compared to traditional procedures, their approach produced faster and more successful results [14]. The key contribution of this work is the innovative, supervised, CNN-based rigid image alignment technique that has been suggested. By experimenting with various parameters, it has been attempted to find the ones that provide the best outcomes for the problem. Furthermore, we examine how the state-of-the-art convolutional network performs in a job of image classification in relation to the quality of images, and we propose a unique architecture to mitigate the consequences. We select common noise forms and JPEG lossy compression, which are immediately recognizable as bad quality in real-world photographs. We utilize the most prevalent noise sources that are observed in actual world—Gaussian—due to the fact that there are other causes which can generate different noise types. Next, in order to improve image alignment performance in the noisy environments, we explore how popular models of NNs perform worse and experiment with the most popular input image pre-processing. We create the neural network model using the most popular input image denoising technique.
Image alignment classification areas and methods that have been used are briefly explained in this section.
2.1 Classification of techniques for aligning images
There are numerous ways to classify image alignment techniques. Dependent on spatial transformation model, the alignment technique might be either stiff or non-rigid (affine, deformable). Rigid models take scaling, shearing, translation, and other factors into account. Since deformable image alignment determines voxel-to-voxel or pixel-to-pixel for 3D, it is more sophisticated and challenging than rigid image alignment. One could argue that the optimization problem is ill-posed [15-17]. We can see the deformable alignment in Eq. (2). The regularization term is re(T), and the regularization parameter is denoted by $\lambda$.
$\hat{T}=\operatorname{argmi}\left(I_R, T\left(I_M\right)\right)+\lambda \operatorname{reg}(T)$ (2)
2.2 The traditional technique for aligning images
There are four processes involved in conventional image alignment [18-20]. The technique of detecting features is the initial phase. There are two ways to employ features for alignment. The first is intensity-based, while the second involves choosing specific points within the image and aligning them. The matching of features is the second phase. Image transformation, also known as resampling, is the final phase, while transformation model estimation is the third. The moving image is altered in this step based on the transformation parameters. Three crucial elements make up conventional image alignment. These are models of geometric transformation, optimization techniques, and similarity metrics.
2.3 Image alignment using a deep learning technique
DL techniques have lately been effectively applied to image alignment difficulties in addition to classical techniques. The three categories of supervised, unsupervised, and weakly supervised DL-based techniques are as follows. During network training in the supervised model, the "ground truth" values are utilized in order to calculate the loss function. The output image is obtained by applying reverse transformation to the moving image using the parameters of transformation that have been generated at network's output. In the unsupervised method, criteria of similarity have been applied to the inverted image at network's output while calculating error function. "Ground truth" is not employed in this network model [16, 21, 22].
2.4 Denoising methods for image alignment
The issue of a noisy or distorted image data-set has been tackled numerous times in the past. Some researchers [23] tried to alter the neural network model's design by putting a unique image processing module ahead of NN model. For instance, Zhou et al. [24] concentrated on optimizing the NN model to increase its robustness to noise. In order to take into account real-world photos from imprecise image-capturing device, we have concentrated on image preparation techniques, such as image denoising. Our main goal is to show that the earlier methods of image processing also enhance NN model's output. Due to the fact that the most recent NN model has very deep layers, over a 100 layers, and contains numerous filters that have the ability of extracting the various spatial features of an image, typical de-noising filters might not operate on the deep NN. Consequently, we select 3 widely used techniques of de-noising and attach them prior to the NN module. By calculating the similarities between every pixel in the image and a weighted mean of its values, nonlocal filtering [25] leverages redundant information to suppress noise. In the meantime, bilateral filtering [26] substitute intensity value at every pixel in an image with a weighted mean of the intensity values from neighboring pixels to decrease noise and smooth the image while maintaining the edges. Last but not least, a total variation denoising technique [27] minimizes the aberrant signal's overall fluctuation in order to eliminate extraneous information and noise while keeping edges and crucial details intact. This has been based upon the theory that a signal that appears suspicious and has a lot of information could also have high total variation.
This work aims to extract spatial transformation parameters between two photos using CNN regression architecture. Figure 1 displays the model's overview. When estimating transformation parameters as an output, CNN regression uses the model's input of fixed and moving images from prepressing stage. Concatenation of the fixed and moving denoising images occurs before the feeding network, after which they are fed as a single image to the alignment network. Since the supervised technique was employed as a learning strategy, ground-truth values were utilized throughout training phase. Two images are processed by the CNN alignment network using a sequence of convolutional and pooling layers. Utilizing the variation in the parameter of transformation that has been generated by the network has been trained by using loss value in conjunction with ground-truth values. The ground-truth value and the model's anticipated output value are the two inputs needed by the loss function.
3.1 Dataset and preprocessing
The Stanford Streaming MAR Dataset has been utilized in order to put the suggested techniques into practice.
The dataset has four categories with 23 distinct objects of interest, each represented by a single film in which the object remains stationary while the camera moves. Every video has 100 frames with a 128×256 resolution. The visuals from the videos in the MAR dataset are shown in Figure 2.
The Figure 3 represents the some samples of fixed and moved images in MAR dataset .Even though it was rarely noticeable, the present CNN produces images with quality loss or noise with decreased accuracy. Historically, noisy images have been processed using image-denoising techniques. Denoising sharpens the edges while reducing fine details and disturbances. This process can be conceptualized as essentially blurring the image and then sharpening its edges. Consequently, the resulting image suppresses noise by emphasizing edges and suppressed features. Denoising techniques have been shown to be a reliable means of suppressing noise, but whether or not they would function well when applied to a deep neural network remains to be seen. Because of this, before grafting the input image onto the neural network, we will first conduct denoising on it. Along with this single-model model, we empirically demonstrate that using the denoising method for training and testing can result in a model that is resistant to certain kinds of noise. We also produced JPEG compression loss because it might potentially be resistant to common quality-distortions.
Have been applied Several rotations between [-20, 20] to original images in order to create synthetic images for the stiff transformation. The fixed image was rotated counterclockwise (positive value of rotation) and clockwise (negative value of rotation) to create synthetic images. The 750 and 250 photos from the MAR data sets are used to train the network.
Figure 1. Proposed model overview
Figure 2. MAR dataset
Figure 3. MAR dataset, fixed and moved images
3.2 Transformation model
The stiff technique served as the study's spatial transformation model. The parameters of the rotation transformations used to make the photos were attempted to be calculated. Mapping every one of the pixels in the image from one position (x1, y1) to the other (x2, y2) is one way to communicate geometric transformations. The rotation amount (θ) is the network's output. Rotation is the process of rotating a point at specific angle (θ) around an (x1, y1) coordinate in the input image to (x2, y2) point in the output image. A transformation matrix is a rotation matrix, as seen in Eq. (3). It is used to turn something in Euclidean space
$\begin{aligned} & x 2 \\ & y 2\end{aligned}=\begin{array}{cc}\cos \theta & -\sin \theta \\ \sin \theta & \cos \theta\end{array} \times \begin{gathered}x 1 \\ y 1\end{gathered}$ (3)
The two-dimensional Cartesian coordinate system's origin is rotated counterclockwise by this matrix at an angle of θ with respect to positive x axis.
3.3 Network archıtecture
The procedures involved in network design contain a few crucial points. The alignment challenge differs significantly from the standard classification problem. Finding the image similarity and transformation parameter values (translation, scaling and rotation) maximizing similarity between fixed and moved images is critical in the image alignment problem. Thus, it is not possible to directly adapt CNN networks-which are regarded as state-of-the-art in the studies of classification and segmentation—to the alignment problem. CNN can be created as regression network for use in IA applications. A continuous numerical value is returned by the single neuron in the last layer of the CNN. The concatenation of the images' moving and fixed positions serves as the network's input, and outputs of spatial parameters θ represent the network. The learning process was guided by ground-truth/target values. Ground-truth values are produced using simulated photos. For the estimation of rigid transformation parameters needed for warping moving to fixed images, a supervised DL network is employed. Loss between the ground-truth labels and projected parameters is estimated next. During the data augmentation phase, a significant quantity of artificial images and ground truth are produced by randomly rotating the original fixed images. There was no similarity metric applied in this study. The network has been trained with the use of loss function rather than image similarity metric. This approach’s drawback is the fact that ground-truth data cannot be gathered. Getting ground-truth data can be done in two ways: the first, using classical alignment algorithms to create it synthetically, and second, using synthetic data. The study employed the second strategy because there weren't enough images.
The implementation was carried out in Python on Intel (R) Core (TM) i7-10750 H 2.60GHz CPU and 16GB RAM using Keras with TensorFlow backend. This study experimented with several factors in an attempt to find the rotation value between image pairings. Table 1 displays the parameter values that were used. The experiment names are shown in Table 1 between T1 and T6. Two distinct values for the learning rate (LR), 0.0001 and 0.00001, were tried using the Adam optimizer. Table 1 displays the various batch size (BS) and epoch number parameters that were used. Two functions have been utilized as loss functions.
Table 1. Training fundimentals
|
|
Epochs |
LR |
BS |
Loss |
W-H |
|
TA1 |
300 |
1, 000E-03 |
40 |
MAE |
256-128 |
|
TA2 |
300 |
1, 000E-04 |
40 |
MAE |
256-128 |
|
TA3 |
200 |
1, 000E-04 |
50 |
MAE |
256-128 |
|
TA4 |
200 |
1, 000E-02 |
20 |
MAE |
256-128 |
|
TA5 |
200 |
1, 000E-02 |
20 |
MSE |
256-128 |
|
TA6 |
200 |
1, 000E-02 |
20 |
MSE |
128-64 |
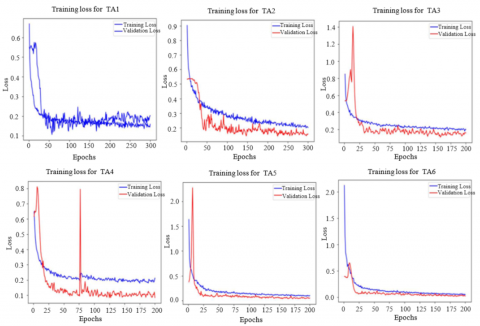
The Mean Squared Error (MSE) and the Mean Absolute Error (MAE) are those. For each of the two fixed and moved images, the input image size was one of two sizes: 128×128×3 and 64×64×3. The concatenation of the moved and fixed image pairs results in the new dimensions being 128×256×3 and 64×128×3, respectively. Figure 4 shows how well the regression models perform.
The parameters that provide the CNN network with the greatest outcomes in estimating the rotation parameter are examined in this study. Several parameters have been explored for this. We have experimented with the apps to find out which parameters work best at lowering the loss value. The loss graphs depicted in Figure 4 display the outcomes of applications from TA1 to TA6. Examining graphs reveals that the altered epoch, LR, and BS values in TA1, TA2, and TA3 applications had nearly identical effects. The loss in the other applications was affected differently in the TA4 application when the BS value of 20 was used. While min loss value has been about 0.20 for the first 3 applications, loss value has been about 0.10 as batch size effect for TA4 application. In TA5 application, the activation function was MSE. It was noted that the application with the MSE loss function produced better outcomes than the first four applications. The input photos' dimensions are altered and supplied to the network in the TA6 application. A shorter training period was obtained by decreasing the image size. After the study, it was found that if input image pair's size has been 64×64 rather than 128×128 then the loss function did not alter significantly. It is possible to argue that using 64×64 input image pair sizes has greater benefits due to the fact that it is crucial to train the model more quickly and with a smaller number of the parameters.
Figure 4. Regression model performance
A supervised rigid alignment approach using CNN for MR images has been proposed in this research. An input image denoising technique has been given in the study, and it attempts to find parameters that provide the optimal outcomes for the issue by experimenting with a range of values. From the military sector to the medical profession, image alignment is used in numerous fields. This crucial stage is employed in numerous applications, including image fusion, multi-sensor image analysis, and stereo. In numerous other domains, including visual odometry, stereo vision, object tracking, estimating holography, and image mosaicking, it is also employed as an alignment step. The problem of image alignment, which is used in a broad range of different contexts and for a variety of purposes, currently lacks a gold standard. Even with all of the work that has been done, academics are continuously working on this issue and developing new solutions.We currently use an NN model and a separate pre-processing tool for image alignment. Thus, we plan to define further preprocessing modules and create architecture with end-to-end learning structures in the future. In this study, we have employed the well-known de-noising technique as a pre-processing module to highlight edges and outlines as well as a way to accentuate particular features. Better outcomes are anticipated if we have success in creating a bespoke pre-processing module.
[1] Chen, X., Diaz-Pinto, A., Ravikumar, N., Frangi, A.F. (2021). Deep learning in medical image registration. Progress in Biomedical Engineering, 3(1): 012003. https://doi.org/10.1088/2516-1091/abd37c
[2] Ghindawi, E.W., Abdulateef, S.A. (2023). Novel extraction and tracking method used in multiplelevel for computer vision. Indonesian Journal of Electrical Engineering and Computer Science, 31(2): 1061-1069. https://doi.org/10.11591/ijeecs.v31.i2.pp1061-1069
[3] Ghindawi, E.W., Abdulateef, S.A., Kadhim, L.M. (2021). Proposed image forgery detection method using important features matching technique. Journal of Engineering Science and Technology, 16(2): 1525-1538.
[4] Mikaeili, M., Bilge, H.Ş. (2020). Estimating rotation angle and transformation matrix between consecutive ultrasound images using deep learning. In 2020 Medical Technologies Congress, Antalya, Turkey, pp. 1-4. https://doi.org/10.1109/TIPTEKNO50054.2020.9299237
[5] Dodge, S., Karam, L. (2016). Understanding how image quality affects deep neural networks. In 2016 Eighth International Conference on Quality of Multimedia Experience (QoMEX), Lisbon, Portugal, pp. 1-6. https://doi.org/10.1109/QoMEX.2016.7498955
[6] da Costa, G.B.P., Contato, W.A., Nazare, T.S., Neto, J.E., Ponti, M. (2016). An empirical study on the effects of different types of noise in image classification tasks. arXiv preprint arXiv:1609.02781. https://doi.org/10.48550/arXiv.1609.02781
[7] Zheng, S., Song, Y., Leung, T., Goodfellow, I. (2016). Improving the robustness of deep neural networks via stability training. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, pp. 4480-4488. https://doi.org/10.1109/CVPR.2016.485
[8] Miao, S., Wang, Z.J., Zheng, Y., Liao, R. (2016). Real-time 2D/3D registration via CNN regression. In 2016 IEEE 13th International Symposium on Biomedical Imaging (ISBI), Prague, Czech Republic, pp. 1430-1434. https://doi.org/10.1109/ISBI.2016.7493536
[9] Uzunova, H., Wilms, M., Handels, H., Ehrhardt, J. (2017). Training CNNs for image registration from few samples with model-based data augmentation. In Medical Image Computing and Computer Assisted Intervention-MICCAI 2017: 20th International Conference, Quebec City, QC, Canada, pp. 223-231. https://doi.org/10.1007/978-3-319-66182-7_26
[10] Eppenhof, K.A., Lafarge, M.W., Moeskops, P., Veta, M., Pluim, J.P. (2018). Deformable image registration using convolutional neural networks. Medical Imaging 2018: Image Processing, 10574: 192-197. https://doi.org/10.1117/12.2292443
[11] ableASISs-Open access series of imaging studies. https://docs.oasis-open.org/odata/odata/v4.01/odata-v4.01-part1-protocol.html.
[12] De Vos, B.D., Berendsen, F.F., Viergever, M.A., Staring, M., Išgum, I. (2017). End-to-end unsupervised deformable image registration with a convolutional neural network. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: Third International Workshop, DLMIA 2017, and 7th International Workshop, ML-CDS 2017, Held in Conjunction with MICCAI 2017, Québec City, QC, Canada, pp. 204-212. https://doi.org/10.1007/978-3-319-67558-9_24
[13] Liu, H.L., Chi, Y.L., Mao, J.W., Wu, X.X., Liu, Z.Q., Xu, Y.Y., Xu, G.B., Huang, W.M. (2021). End to end unsupervised rigid medical image registration by using convolutional neural networks. In 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Mexico, pp. 4064-4067. https://doi.org/10.1109/EMBC46164.2021.9630351
[14] Ciregan, D., Meier, U., Schmidhuber, J. (2012). Multi-column deep neural networks for image classification. In 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, pp. 3642-3649. https://doi.org/10.1109/CVPR.2012.6248110
[15] Cao, X., Fan, J., Dong, P., Ahmad, S., Yap, P.T., Shen, D. (2020). Image registration using machine and deep learning. In Handbook of Medical Image Computing and Computer Assisted Intervention, pp. 319-342. https://doi.org/10.1016/B978-0-12-816176-0.00019-3
[16] Shelhamer, E., Long, J., Darrell, T. (2016). Fully convolutional networks for semantic segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(4): 640-651. https://doi.org/10.1109/TPAMI.2016.2572683
[17] Girshick, R., Donahue, J., Darrell, T., Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. In 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, pp. 580-587. https://doi.org/10.1109/CVPR.2014.81
[18] Nag, S. (2017). Image registration techniques: A survey. arXiv preprint arXiv:1712.07540. https://doi.org/10.48550/arXiv.1712.07540
[19] Kausch, L., Thomas, S., Kunze, H., Privalov, M., Vetter, S., Franke, J., Mahnken, A.H., Maier-Hein, L., Maier-Hein, K. (2020). Toward automatic C-arm positioning for standard projections in orthopedic surgery. International Journal of Computer Assisted Radiology and Surgery, 15: 1095-1105. https://doi.org/10.1007/s11548-020-02204-0
[20] Liao, H., Lin, W. A., Zhang, J., Zhang, J., Luo, J., Zhou, S.K. (2019). Multiview 2D/3D rigid registration via a point-of-interest network for tracking and triangulation. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, pp. 12630-12639. https://doi.org/10.1109/CVPR.2019.01292
[21] Maes, F., Collignon, A., Vandermeulen, D., Marchal, G., Suetens, P. (1997). Multimodality image registration by maximization of mutual information. IEEE transactions on Medical Imaging, 16(2): 187-198. https://doi.org/10.1109/42.563664
[22] Miao, S., Wang, Z.J., Liao, R. (2016). A CNN regression approach for real-time 2D/3D registration. IEEE Transactions on Medical Imaging, 35(5): 1352-1363. https://doi.org/10.1109/TMI.2016.2521800
[23] Diamond, S., Sitzmann, V., Julca-Aguilar, F., Boyd, S., Wetzstein, G., Heide, F. (2021). Dirty pixels: Towards end-to-end image processing and perception. ACM Transactions on Graphics (TOG), 40(3): 23. https://doi.org/10.1145/3446918
[24] Zhou, Y., Song, S., Cheung, N.M. (2017). On classification of distorted images with deep convolutional neural networks. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, pp. 1213-1217. https://doi.org/10.1109/ICASSP.2017.7952349
[25] Buades, A., Coll, B., Morel, J.M. (2005). A non-local algorithm for image denoising. In 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05), San Diego, CA, USA, pp. 60-65. https://doi.org/10.1109/CVPR.2005.38
[26] Tomasi, C., Manduchi, R. (1998). Bilateral filtering for gray and color images. In Sixth International Conference on Computer Vision (IEEE Cat. No.98CH36271), Bombay, India, pp. 839-846. https://doi.org/10.1109/ICCV.1998.710815
[27] Chambolle, A. (2004). An algorithm for total variation minimization and applications. Journal of Mathematical Imaging and Vision, 20: 89-97. https://doi.org/10.1023/B:JMIV.0000011325.36760.1e