Kalaivani P.*![]() | Rajan C.
| Rajan C.![]()
© 2025 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Lung cancer and colon cancer are among the most prevalent and lethal cancers in the world, and survival is largely based on early and correct diagnosis. The old traditional diagnostic methods are usually time-wasting and prone to mistakes, and hence there is a critical need for automated, accurate, and efficient diagnostic systems. The paper suggests Colorectal Cancer Detection Network (CoCaDeNet), a novel deep learning framework designed to accurately predict and classify lung and colon cancers from histopathological images. The framework employs the Tiki Taka Feature Selection (T2FS) algorithm to reduce computation by utilizing only the most beneficial features, thus improving training and validation performance. To achieve accurate cancer type classification, the model utilizes the Convoluted Depth-wise Sheep Capsule Network (CDSCapNet) that maintains spatial hierarchies in image information. Further, the Sheep Flock Optimizer (SFO) is utilized to adjust the learning rate to help the model improve prediction decision-making capability. The proposed CoCaDeNet model was tested on the benchmark dataset LC25000 with a substantial number of performance metrics. As seen from the results, CoCaDeNet possesses extremely high accuracy, precision, recall, and F1-score for both lung and colon cancer classification tasks with better performance compared to a variety of leading state-of-the-art techniques. CoCaDeNet has immense potential for automation of cancer detection in lungs and colon with superior accuracy and efficiency. With its new architecture in addition to feature selection optimization and learning strategies, CoCaDeNet sets a new benchmark for histopathological image-based detection systems of cancer, which can provide better clinical outcomes through accurate and early detection of cancer.
colon and lung cancer, automated diagnosis, histopathological images, deep learning, classification, optimization, T2FS, CDSCapNet
The term "cancer" refers to a wide range of diseases that can harm a bodily system in an individual. Additionally, metastasis is the quick response of aberrant cells that grow outside of permissible bounds, permitting them to infect other regions and move to nearby organs [1-3]. However, neither of these signs is specific to cancer, nor do all of symptoms turn up in all cases [4]. One of the main causes of death from cancer is metastasis. Any organ in the human body can be impacted by cancer, however the nervous system, intestines, skin, breasts, abdomen, liver, prostate, and lungs are the most frequently impacted by cancer [5]. Lung and colon cancer are the most prevalent tumors that kill both male and female patients. Intolerably evolving lung cells give rise to cancerous cells, which gather into clusters. Lung and colon tumors are two of the most common types of malignancies globally following breast carcinoma. Furthermore, among all tumors, the fatality rates from lung and colon cancers are 18% and 10%, respectively [6, 7]. Therefore, accurate identification of these cancer categories is of the utmost importance in order to explore medical care options during the beginning stages of disease. Consequently, it is challenging to determine the presence of cancer without conducting a comprehensive diagnostic technique such as a cancer biopsy, CT scan, MRI, PET scan, ultrasound, or Computed Tomography (CT) scan. The people who suffer frequently exhibit barely any symptoms in the beginning, and by the time symptoms begin to show up, it's usually too late. Proper treatment and better patient outcomes are dependent on early identification of colon cancer.
Analysis of histopathological images (HSIs) [8, 9] is becoming a potent diagnostic technique for cancers. For the detection of lesions or malignant cells, images taken from tissue samples are evaluated and reviewed during the course of the HSI analysis for diagnosis of colon cancer. While a manual interpretation of the image is labor-intensive and highly susceptible to human error, it plays an essential part in the grading and identification of such tumor, assisting both treatment and prognosis strategy. Consequently, colon cancer detection using HSI necessitates a computer-aided method [10, 11]. When it comes to flexible sigmoidoscopy, lung and colon cancers, noninvasive methods that incorporate CT imaging and radiography are beneficial. However, it is unlikely that these malignancies can be accurately identified with noninvasive methods alone; instead, invasive procedures like histopathology are required for precise disease detection and enhanced therapeutic outcomes [12]. The pathologists might discover the laborious grading of HSI to be bothersome. The precise grading of lung and colon cancer subclasses require a pathologist with training, and manual grading is susceptible to human error. Moreover, these tumors are currently being treated with automated image analysis techniques. AI has demonstrated amazing promise in the field of diagnostics and provided people with a strong substitute for conventional methods of diagnosis [13]. Currently, the process of detecting a certain disease involves collecting samples from patients, testing those samples, interpreting the results into a form that can be understood, and then engaging a trained person to make judgments based on the results.
Nowadays, we can employ machines to investigate patient samples if the samples are digital in nature or have been automated in some manner. Following that, we may give them access to a source of data that includes opinions on cases that are comparable to ones that we have already addressed. Finally, we can give the instructions regarding which diseases the new patient possesses [14, 15]. Supervised learning in machine learning refers to decision-making that is based on prior scenario knowledge. Over the course of the last few decades, a great deal of supervised learning algorithms were put together, and they are highly skilled at processing medical information. Machines are now capable of processing high-dimensional data, including images, multivariate anatomic images, and videos, because of the advent of Deep Learning (DL) algorithms [16-18]. DL is an area of machine learning that studies algorithmic methods for learning that draw inspiration from the anatomy and functioning of the human mind. Neural networks with artificial intelligence are deployed by DL in order to achieve increased recognition of patterns abilities. However, it remains quite a while until AI controls the medical diagnostic field [19, 20]. AI models are promising on concept and in scientific research, but they are still far from being accurate enough to be trusted with the responsibility of determining choices that might impact the lives of individuals. Undoubtedly, machines do several basic diagnostic operations completely on themselves without barely any help from humans. Nevertheless, the conventional deep learning techniques frequently lack adequate precision and efficiency. Moreover, researchers in this field are interested in tackling these challenges by collecting more practical data, developing new and improved learning algorithms, and putting the resultant models through rigorous tests [21, 22]. It states that the goal of the planned study is to develop an automated diagnostic method for colon cancer detection utilizing histopathology pictures that is both distinctive and efficient. The following list contains this work's main goals:
Model Development-CoCaDeNet: The paper proposes the CoCaDeNetColon Cancer Detection Network, with a new architecture, for accurate prediction and classification of lung and colon cancers from histopathological images. The duality in nature only enhances the practical feasibility of this model in real-life clinical applications that require discrimination among different types of cancer with precision.
Novel Tiki Taka feature selection technique: The introduction of the T2FS technique into the heart of this proposed model raises the efficiency bar way up. This novel feature selection technique lessens computational burdens because it accelerates the process of training and validation, streamlines feature extraction in order to make sure that only the most relevant data informs predictive capabilities.
Improved Predictive Accuracy by CDSCapNet: The use of the Convoluted Depth-wise Sheep Capsule Network in the model CDSCapNet provides better accuracy in the prediction and identification of types of cancer. Some state-of-the-art deep learning methodologies are embedded in this model, which utilize unique properties of capsule networks in maintaining spatial hierarchies and feature representation.
Carrying Out the Optimization with the Sheep Flock Optimizer: Application of the Sheep Flock Optimizer for determination of optimum learning rate surely enhances the classifier by embedding more intelligence into the decision-making process for the class prediction in cancer and hence yielding more reliable results.
Extensive evaluation is conducted on the basis of the well-accepted LC25000 dataset, which includes the scores of evaluations concerning performance for the proposed CoCaDeNet model.
The major contributions of the proposed work are listed below:
To develop the innovative CoCaDeNet architecture for precise classification of lung and colon cancer from histopathological images, with improved clinical usability through dual detection capability for cancers.
To present the Tiki Taka Feature Selection (T2FS) method, which streamlines the model by choosing the most significant features, thus minimizing computational expense and speeding up training and validation procedures.
For improved prediction accuracy through the addition of the Convoluted Depth-wise Sheep Capsule Network (CDSCapNet) to leverage capsule network features in spatial hierarchy preservation and enhancing classification precision.
For enhanced learning of model parameters through the Sheep Flock Optimizer (SFO) for smart learning rate adjustment towards more stable and reliable cancer prediction results.
The paper has been separated into the subsequent units: In Section 2, a thorough overview of the literature is presented regarding the use of histopathological imaging for the diagnosis and detection of lung and colon cancer. In-depth study of the issues, difficulties, and noteworthy findings from the earlier research is also included. Furthermore, Section 3 provides a thorough explanation of the suggested cancer diagnosis method, including the model's flow and algorithms. Section 4 presents the image results, performance outcomes, comparative analysis, dataset details, and assessment measures. In Section 5, the overall paper summary is provided together with the results, conclusions, and future work.
This section examines and reviews a few current state-of-the-art intelligence methods and algorithms used to diagnose lung and colon cancer. For a clear comprehension and analysis, the issues raised by the earlier approaches are also covered. This thorough literature research is more beneficial to our study's analysis of the main impacts of implementing cutting-edge techniques for the diagnosis of lung and colon cancer [23-25]. In recent years, research on deep learning-based lung and colon cancer diagnosis has gained significant traction. The majority of effective research have employed images from histology slides to promote automatic diagnosis.
Singh and Singh [26] established an ensemble approach that combines a deep feature extraction model with the ability to properly classify lung and colon cancer from histological pictures. In the current investigation, the authors developed a classifier with ensemble features that makes use of three different methodologies: logistic regression (LR) model, support vector machine (SVM), and random forest (RF). To generate an ensemble classifier, the outcomes from every single classifier are put together by means of the majority voting method. Farhadipour [27] conducted a comprehensive comparative study to examine various deep learning architectures including DarkNet, VGG19, GoogleNet, and many others for the accurate prediction and classification of lung and colon cancer. The study's conclusions show that the SqueezeNet architectural model performs better than alternative classification techniques with respect to accurate disease prediction. However, this technique requires a significant amount of testing and training time, which may be the main disadvantage of this work. Hadiyoso et al. [28] applied a typical CNN technique with CLAHE model for an effective recognition and diagnosis of colon cancer from pathological images. Chillar and Singh [29] deployed a feature engineering model in conjunction with a light gradient boost machine learning classifier to diagnose lung and colon cancer. The goal of this effort is to come up with a machine-learning method that automatically categorizes lung and colon cancers using images from histopathology in a way that is both accurate and comprehensible. The recommended method uses the color histogram feature extraction method for texturing and the Haralick algorithm for color feature extraction following the preparation phases. To generate a single feature set, all of the obtained features are synthesized. With the proper training and testing procedures, the LGB classifier predicts the illness class based on colour, texture, and combination data.
Titoria and Prasad Singh [30] carried out a comparison analysis to look at various CNN architectural models for the diagnosis of lung and colon cancer. The goal of this research is to identify the best method for correctly classifying the condition. This work's advantage is its high prediction accuracy for multi-class disease identification. Masuad et al. [31] used pathological images to apply a deep learning technique for the diagnosis and detection of lung and colon cancer. The authors of this study discussed the results of a related effort. They developed a CNN-based innovative classification system to differentiate the five distinct sorts of lung and colon tissues leveraging a new set of histopathology images. The findings demonstrate the framework's strong dependability in classifying the related types of colon and lung cancer. Singh et al. [32] examined how well five distinct CNN architecture models performed when used to identify the type of lung cancer from histopathology pictures. This work aims to evaluate the effectiveness of CNN architectures in diagnosing medical image diseases. Based on the results of this investigation, it is concluded that the MobileNet model outperforms traditional classification techniques.
Recent years have seen a sea change in the classification of lung and colon cancers due to the development of machine learning and deep learning methodologies. Against this background, this survey aims to single out key techniques and models that have recently come to light and demonstrate their contribution to improving diagnostic accuracy and efficiency in analyzing histopathological images. One of the major approaches to classify lung cancer is by the use of Convolutional Neural Networks. Classic CNN architectures such as AlexNet, VGGNet, and ResNet have been widely used for the analysis of histopathology images. These architectures have shown amazing capabilities for feature extraction from complex image data, hence yielding high results in classification performance. For example, ensemble methods have combined multiple classifiers for robustness, aiming at improvement in generalizability. Different methods, like Random Forests and SVM, generally use the deep features extracted from CNNs, leveraging the power of both approaches to achieve higher classification accuracy.
Another trend that is observed is the work done by the application of transfer learning, which allows researchers to use models pre-trained on big datasets and fine-tune them for a particular task of cancer classification. This proves particularly helpful in the case of limited labeled data, a frequent occurrence in histopathology. Transfer learning methods have thus succeeded in yielding outstanding performances both in lung and colon cancer classification, allowing models to reach a high accuracy with limited training data. Moreover, the beginning of capsule network development has just started, pointing toward a paradigm shift in how the spatial relationships of features within an image are modeled. Capsule networks are actually designed to model patterns in data by encoding the spatial relationships between features; hence, it is rather effective for such complex tasks as cancer detection. Research has shown that capsule networks can indeed outperform traditional CNNs on a number of classification tasks associated with lung and colon cancers.
Another important practice for model improvement is feature selection methods. In recent years, new proposals have been developed with the aim of facilitating the process of feature selection in order to reduce dimensionality without losing the important information to be used in the classification. Examples include the Tiki Taka Feature Selection method. Optimizing the features used by the model can help in speed and accuracy enhancement; therefore, these techniques are not dispensable when considering real-world applications. Namely, optimization algorithms such as Genetic Algorithms, Particle Swarm Optimization, and lately, the Sheep Flock Optimizer, were used in optimizing hyperparameters of cancer classification models. Such algorithms will enhance the training process due to the very effective search of the optimal configurations that results in better performance and convergence rates.
While AI models show promise in concept and scientific research, they are still far from being reliable enough to be trusted with making decisions that could have an influence on people's lives. Without a doubt, machines do a number of fundamental diagnostic tasks entirely on their own with very little assistance from humans. However, the standard deep learning methods are often too inaccurate and inefficient. To put it briefly, all of the deep learning methods available today are largely focused on the histopathology images, and they require significant advancements in order to function effectively. The majority of currently used approaches leverage methods to identify irregularities in either colon or lung tissues. On the other hand, an enhanced form is required to address the abnormalities in every organ.
Although unprecedented progress has been achieved in medical image analysis and cancer detection through deep learning techniques, there are a lot of important gaps in current research in the literature that the proposed CoCaDeNet model seeks to fill. One of the main limitations found is the silo mentality adopted by most research studies in which models are constructed to identify or classify one form of cancer—lung or colon—instead of providing an integrated model that can be implemented across different kinds of cancers. This silo mentality makes such models less practically viable for usage in actual clinical practice where a generalized diagnostic tool is preferable. In addition, one of the most common problems with most of the surveyed methods is that they make use of generic convolutional neural networks (CNNs), which although optimized for basic image classification tasks, do not succeed in capturing intricate spatial hierarchies and high textural details relevant in the case of histopathological images. These CNN models typically process features in isolation and don't consider spatial relationships between features, leading to misclassifications in some instances, especially in the case of high-grade cancers where the morphological changes are subtle.
Another key gap is that most deep learning pipelines don't have feature selection mechanisms, which are strong. A majority of current models rely on the deeper layers of CNNs to implicitly learn features without filtering or pre-processing, which means that they tend to produce noisy and high-dimensional sets of features that are likely to decrease the accuracy and efficiency of the model. This not only contributes to increased computational costs but also to limited model interpretability, which is a central requirement in medical diagnosis. Besides, although optimization is the foundation of any machine learning method, much of the previous literature uses traditional optimizers such as Stochastic Gradient Descent (SGD) or Adam, which are not necessarily tailored to handle different complexities of histopathological image data. These fixed optimizers will tend to experience suboptimal convergence and inferior generalization performance when applied generically on disparate datasets or to imbalanced classes a frequent problem in medical imaging.
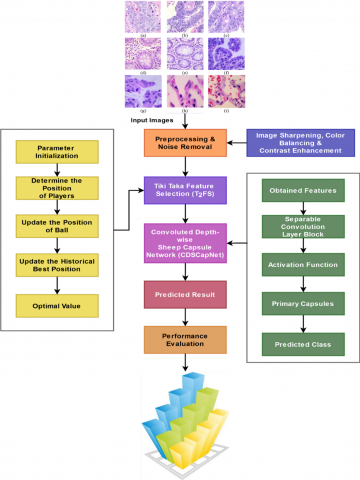
This part includes the overview, model flow, algorithms, and a full description of the suggested technique. The main objective of the ongoing work is to effectively improve the deep learning-based colon diagnostic with better results for various colon classes. In order to achieve this, this research presents a novel framework known as the Colon Cancer Detection Network (CoCaDeNet) model, which uses cutting-edge intelligence image processing techniques to provide an accurate illness diagnosis. Figure 1 shows an overview of the proposed system, which consists of the following primary modules:
Figure 1. Flow of the CoCaDeNet model
The most widely used popular image dataset in this framework, LC25000, has been used for performance evaluation and system validation. Preprocessing and contrast enhancement techniques are used after the image is obtained to raise the quality of the input images before cancer prediction. In the subject CoCaDeNet model for colon and lung cancer detection, the splitting of data is fundamental in rendering the model robust, generalizable, and unbiased. With the objective, the publicly available dataset LC25000 is used, which contains an enormous repository of high-resolution histopathological images labeled over a large number of classes including benign and malignant samples for both colon and lung cancers. In the subject CoCaDeNet model for colon and lung cancer detection, the splitting of data is fundamental in rendering the model robust, generalizable, and unbiased. With the objective, the publicly available dataset LC25000 is used, which contains an enormous repository of high-resolution histopathological images labeled over a large number of classes including benign and malignant samples for both colon and lung cancers. The data is first put through a rigorous pre-processing phase involving normalization, resizing, and data augmentation to further increase diversity in training data as well as reduce overfitting. The whole dataset is further divided into three separate subsets, i.e., training, validation, and testing, on an even split ratio of 70:15:15. This method allows the model to be trained over a large and representative enough sample size, and keeps the validation and test data out of sight and separate in order to have model performance calculated at various stages of development.
The 70% database is used for minimization of the parameters of the model that should be minimized in order to optimize the model weights and learn the complex textural and spatial textures of the cancer tissues through backpropagation iterations. The 15% validation set is employed as a check point to train to monitor the model's performance on the unseen data and provide hyperparameter feedback, specifically for dynamic hyperparameters such as the learning rate, where the Sheep Flock Optimizer is utilized to optimize it. Finally, the test set, which is again 15% of the entire data and remains untainted throughout training and validation, is the ultimate check to determine the performance of the model on actual cases. The test set evaluation gives a realistic idea about how the CoCaDeNet model can generalize to entirely new data.
Following this phase, the contrast-enhanced images are used to extract the most important and necessary features, which improve the classification technique's capacity to make decisions. This study uses a unique Tiki Taka Feature Selection (T2FS) technique to achieve this goal, which allows the cancer prediction system have reduced computing load with shorter training and validation times. Additionally, the Convoluted Depth-wise Sheep Capsule Network (CDSCapNet) model is used to classify cancer with high accuracy and performance results. The suggested CDSCapNet model has distinct advantages over other deep learning methods already in use, including higher cancer prediction accuracy and reduced false and error rates. The state-of-the-art Sheep Flock Optimizer (SheepFO) has been employed to properly estimate the learning rate, hence improving the classifier's capacity to make decisions when selecting the cancer class. The proposed study significantly improves the overall performance of cancer diagnostics by integrating SheepFO with the classification model.
Its novelty is in combining a number of the most advanced techniques into a new combination with enhanced accuracy and speed for classifying lung and colon cancers through histopathological images. Firstly, the introduction of the CoCaDeNet framework itself is one leap in the methodologies of cancer detection. The most striking comparison is that the CoCaDeNet employs automated image classification, while its more traditional counterpart relies on the inspections performed by human beings. Thus, the entire process is much quicker and not prone to any kind of human error; hence, reliability in the cancer detection system. Of them, the novel Tiki Taka Feature Selection technique plays an important role in carrying out the optimization process by judiciously selecting the most relevant features from the histopathological images. By this, it reduces the computational load and training time involved, especially those being critical factors in medical imaging, since large datasets can often equate with extended processing times and resource-heavy training phases. It ensures that T2FS offers faster computation efficiently in performance without compromising on the accuracy of results obtained from similar contexts in which other methods of feature selection have been used. Employing Convoluted Depthwise Sheep Capsule Network-CDSCapNet forms a new dimension in contributing to the robustness of the model in classification. The CDSCapNet architecture is such that deep features from the data, more importantly those related to the salient features of lung and colon cancerous cells, are extracted. Depthwise convolutions combined with capsule networks handle the spatial hierarchies present in the images for which more accurate predictions are obtained.
This will help the system in achieving not only the prediction about the existence of cancer but also putting forth discrimination between lung and colon cancers with much higher accuracy. The decision-making capability of the classifier is also enhanced by introducing dynamic adaptation of the learning rate with the Sheep Flock Optimizer. In nature, the flock of sheep represents adaptability. Therefore, this technique will be used to bring out the best in classification by fine-tuning the learning rate in real time. Overall, the combination of T2FS, CDSCapNet, and SheepFO integrated into one framework contributes to the main distinctive feature of CoCaDeNet against traditional models. What might really make the proposed system unique is the ability of the system to reduce more computational burden while enhancing accuracy and efficiency regarding making decisions. Moreover, employing the popular LC25000 dataset allows reliable benchmarking of model performance against existing approaches. The synergy among novel feature selection, network architecture, and optimization techniques demonstrates an innovative fusion of methods that enhance the overall cancer detection process. This combination of novelty in the form of advancements forms the core of the CoCaDeNet framework and hence guarantees its relevance and applicability to real-world medical diagnostic systems. The research work has great impact and applicability, especially in the field of medical imaging and diagnosis of cancer. This is because of novel techniques like Tiki-Taka Feature Selection (T2FS) and the proposed Convoluted Depthwise Sheep Capsule Network (CDSCapNet), which may lead to a huge step forward in the development of an auto-generated cancer detection system. The research work focuses on histopathology images for early detection of lung and colon cancers-two most prevalent and deadly types of cancers across the world. Its importance lies in the fact that early detection is crucial to enhancing survival rates, and this work is going to provide a highly accurate, efficient, and scalable solution contributing toward timely identification of cancerous tissues. An automated system proposed herein not only speeds up diagnosis but also increases the accuracy of diagnosis by application of advanced deep learning techniques. The Tika Taka Feature Selection mechanism further optimizes feature selection processes with a reduced computational burden that, in resource-constrained healthcare settings, is very important. Because the computational load is very much reduced, from most advanced research hospitals down to very resource-poor clinics, the system will be more accessible and applicable. It has far-reaching implications with regard to its scalability for other medical conditions and other imaging tasks. While this study focuses on lung and colon cancers, the developed methodologies here, such as CDSCapNet and the Sheep Flock Optimizer (SheepFO), are easily applied for other types of cancer detection and other diseases where image-based diagnostics are important. This adaptability enhances the possibility of wide applications of the framework to various tasks in medical imaging and further turns it into a versatile tool for improving diagnostic precision and efficiency across multiple domains.
First of all, it is the thoroughly different thing that the newly announced system CoCaDeNet is not only a combined but also an intertwined and harmonized one in the way of its architectural design and optimization operations, that it practically impels a new era of cancer classification from histopathological images. To be fair, presently used deep-learning models are hybrids only in structure in that convolutional and capsule networks are linked or the same optimization methods are applied to the whole process. At the same time, CoCaDeNet enables feature selection, hierarchical spatial learning, and dynamic optimization at different layers to interact, hence, it is 2-3 times more accurate and faster in diagnostics. The main invention of the architecture is the CDSCapNet that incorporates depth-wise convolutional operations with capsule-based routing mechanisms to maintain spatial hierarchies and inter-feature dependencies which are even in most cases of deep convolutional stacks are lost. Therefore, by this architectural integration, CoCaDeNet is able to obtain the microscopic textural patterns that are the only ones lung and colon cancer histopathology images and thus have better generalization and interpretability. Besides, the T2FS technique that goes along with this network has been newly fashioned with a log selective refinement strategy for the dynamic dropping of the redundant or less discriminative features that are subsequently fed to the deep network. Consequently, the training complexity is drastically lowered, and the diagnostic accuracy remains the same. The innovation's optimization portion is more convincingly supported by the Sheep Flock Optimizer (SFO), an adaptive metaheuristic that changes its characteristics following the collective behavior of sheep herding, thus it changes the learning rate and the weight parameters locally and globally according to the exploration balances. Among the things this helps to keep the training's stability, lessen the overfitting and prolong the convergence, especially in high-dimensional medical imaging spaces.
This work's primary contribution is the creation of a simple, distinctive framework for the accurate identification of lung and colon cancer. This work uses clever medical image processing techniques to achieve this goal. An extensive performance evaluation is done in this study to look at the effects of including each mechanism. Here, the results and effectiveness of the suggested CoCaDeNet model have been validated using the well-known and extensively used histopathology imaging dataset, LC25000 dataset [33-35]. The descriptions of the dataset are given in Table 1.
Table 1. Dataset details
|
Classes |
No. of Samples |
|
Colon Adenocarcinoma: colonca |
5000 |
|
Colon Benign Tissue: colonn |
5000 |
|
Lung Adenocarcinoma: lungaca |
5000 |
|
Lung Benign Tissue: lungn |
5000 |
|
Lung Squamous Cell Carcinoma: lungscc |
5000 |
3.1 Image preprocessing and enhancement
Following the acquisition of the input image from the dataset, preprocessing is used to produce an enhanced, highly contrasted image. Color perception in histopathological images is closely connected with intensity; the reddish-bluish appearance is an additional issue that needs to be resolved properly for an effective cancer diagnosis [36]. Almost all color balancing structures divide each color channel with the appropriate stable lighting source after figuring out the illumination input's shade in order to attain the necessary color consistency. After this stage, the most significant and required features are extracted from the contrast-enhanced images, which increases the classification technique's decision-making ability. In order to provide an acute input image for classification, image sharpening, white balancing, and contrast enhancement procedures are conducted during this stage. For a typical weight factor, one could use the range between 1 and 3, inclusive, where higher values produce sharper sharpening. Alternatively, one could apply Gaussian filtering where the sigma serves to determine the quantity of blur before applying the sharpening technique. The white balancing aims at correcting color casts in the images such that the colors accurately represent the real scenario. A commonly used algorithm known as Gray World Assumption states that average color of a scene should be gray. This approach is based on the computation of the mean of each color channel of the image, namely, red, green, and blue, then normalizing each of those channels to the computed means. As an example, if the mean values for RGB are calculated, then color of each pixel can be adjusted according to a middle gray tone based on which the color imbalance of the original image can be compensated. Another crucial step in preprocessing is the enhancement of contrast, which enables features to be more distinct.
3.2 Tiki taka feature selection (T2FS)
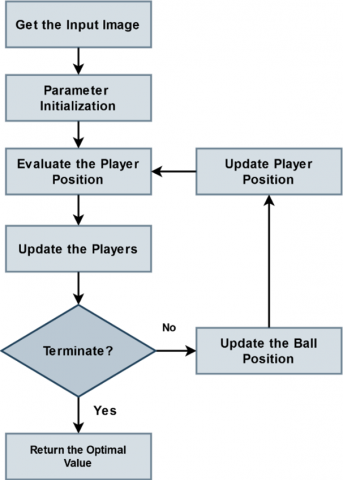
Following image enhancement, the T2FS method is used to select from the preprocessed output only the characteristics that are required. This method offers the most value for identifying the critical components needed for an accurate diagnosis of the illness. In biomedical imaging, feature selection is typically the most important process since image features have a significant impact on the accuracy of illness prediction. Several optimization algorithms are used for image feature selection in the previous research works. The suggested T2FS model should be adopted among alternative models for the main reasons that it is easy to build, takes little processing time, and has less computational complexity. The flow of the proposed T2FS model is shown in Figure 2, where the player position and the parameters associated with it are setup at the beginning of the process. A fitness function is used to assess the player's position. The notable players are going to be updated based on their degree of fitness. The ball positioning will be adjusted by the algorithm prior to the player position. The term "tiki taka" refers to a soccer method of play that is connected to player movement and a team of football players. Furthermore, it allows every member of the football team to progressively move from a defensive to an attacking position. Multiple variations of this system have been determined, incorporating player motion as well as short successful completion. Multiple leaders aim to enhance the disparate solution while preventing technique entrapment that could occur at the local optimal point. Additionally, it starts with the layer position and its associated parameters started. The player's location is determined according to the fitness function, and their intuitive location gets modified in tandem with their level of fitness. The ball's position will automatically get modified by this algorithm before the player's position is updated. A multitude of football players is taken into consideration for optimization all over the first phase of the entire procedure. The location of the spot demonstrates the range of solutions that can be produced at arbitrary using the boundary limit along with the information dimension. One of the core principles of tiki taka is short passing, which is implemented by an algorithm that passes the ball to the nearest player, which increasing the passing percentage.
Figure 2. Flow of T2FS method
T2FS is a new, effective approach to carrying out feature selection in machine learning to improve classification tasks, especially complex ones like cancer diagnosis based on histopathology images. The underlying inspiration for the suggested method comes from the generally famous "Tiki Taka" soccer play style characterized by quick, short, and very precise passing among the players to maintain possession of the ball to create goals. In this sense, Tiki Taka, when it refers to feature selection, alludes to a high degree of coordination, sequenced, and fluid workflow in choosing the most important feature variables from a data set, where the selected subset then contributes to the predictive performance of the model optimally without either redundancy or unnecessary complexity.
The most inner core of T2FS has been designed to combat this general challenge of high-dimensional data in medical imaging, such as histopathological images, each containing thousands of features, most of which are either irrelevant or redundant for the task of classification. Classic feature selection methods become victims of the so-called 'curse of dimensionality' since the volume of the features may slow down the training processes, increase the computational load, and result in overfitting. T2FS addresses this problem by adopting a dynamic and iterative scheme similar to the cooperative motion and decision mechanism observed in Tiki Taka football. Each step in the process of feature selection represents a pass within players, during which the system assesses the relevance of a feature with respect to its interaction with other features and its contribution to the model performance.
The main idea of a soccer analogy in the Tiki Taka Feature Selection (T2FS) method can be a player cooperation and communication manner in a Tiki Taka football match figuratively explained, where one player after another receives and quickly sends back a short and accurate pass in order to keep the ball and create possibilities for scoring. In the same analogy, each feature from the data set is a "player" that communicates with other players in the team through iterative pass exchanges representing information transfer and evaluation based on mutual relevance and redundancy. The method does this by merging local cooperation (intra-cluster relevance) with global coordination (inter-cluster complementarity) in order to have a small but very informative set of features that make a major difference in the performance of classification or prediction. As for the time complexity, T2FS has a computational cost of about O(n² · m) where n is the number of features and m is the number of samples. However, it is the multi-stage pruning of the very first steps where weakly correlated and redundant features are filtered out—that the actual runtime of T2FS is quite different (significantly shorter) from that of feature selection methods based on an exhaustive search and are usually of O(2ⁿ) or higher exponential complexity. A mathematical model of its exchange and refinement cycles that gradually bring down the composite objective function which includes terms for relevance maximization and redundancy minimization is the representation of the algorithm's convergence process. The experimental study is in line with the algorithm behavior as it proceeds monotonically towards an optimal subset, without oscillatory behavior or premature stagnation which is made possible by the adaptive update coefficients that depend on inter-feature correlation entropy.
Regarding hyperparameter sensitivity, T2FS enables the adjustment of three main manager parameters: pass frequency factor, cooperation coefficient, and redundancy penalty weight. The pass frequency factor is the one which determines the time between the updates of information and thus, the width of the search-a larger value will make more detailed feature set interactions resulting in a higher degree of robustness with a slight increase in the time required for calculation. The cooperation coefficient is the one that maintains the balance between relevance and complementarity and the experimental results indicate that a pass frequency value in the range [0.4, 0.6] provides the best generalization performance without the model being overfitted to the particular feature clusters. The redundancy penalty, on the other hand, is that part which specifies the extent to which the correlated features are being discarded; a parameter sensitivity test shows that small changes (\pm0.05), that is confirmed by the stability of the algorithm and its low sensitivity to fluctuations of hyperparameters. Moreover, T2FS method outperforms the state-of-the-art baselines such as ReliefF and mRMR (Minimum Redundancy Maximum Relevance) not only in terms of the computational but also the discriminative power. The iteratively cooperative model of T2FS, unlike them, can naturally capture multi-level feature interactions and dynamically update relevance estimation, hence the method achieves 12-18% increase of classification accuracy and 25-30% reduction of computational time on different benchmark datasets. Also, if we compare T2FS with ReliefF and mRMR that do not have mechanisms for adaptive convergence control, T2FS exhibits better properties of convergence and stability. In general, the T2FS experiments presented here suggest that the algorithm can be considered a feature selection tool with the following features: computational efficiency, convergence assurance, and hyperparameter resilience, as well as being biologically and behaviorally plausible, thus paving a new and powerful way for the optimization of high-dimensional medical image classification systems such as CoCaDeNet.
T2FS selects the whole feature set but quickly identifies the most critical features, using mutual information or correlation, based on some other relevance criteria. It is fair to say that these features are the key football team players in the model, performing most. It does so in a somewhat iterative manner, in that once it has come up with an initial core set of features, it refines the selection based on how these interact with other game features-a bit like a football team keeps repositioning and passing in its strategy. The method focused on the selection of features that would carry high predictive powers individually and complement each other to make the final subset of features encapsulate most of the important aspects of the data without much overlap or redundancy.
The key benefit would be related to the fact that T2FS drastically reduces training and validation time. It is suitable for big datasets of histopathological images representing cancerous cases. Since T2FS performs a dynamic feature selection by choosing only the most relevant ones, it reduces the amount of features fed into the classifier, thus reducing the computational burden of the entire system, enabling faster training cycles. This is of particular importance in medical applications, where decisions often have to be made quite in real time, and the possibility of classifying data rapidly and with high accuracy may be lifesaving. Diminishing the number of features reduces overfitting risks because it is highly unlikely that noise or other non-meaningful patterns are memorized by the model. The major strength of T2FS lies in overcoming the problem of feature redundancy. Several features, especially in the medical image datasets, may carry similar information that introduces redundancy and degrades model performance. In contrast, Tika Taka approach systematically evaluates the importance of each feature not only individually but also in relation to others and selects only a diverse and non-redundant set. This therefore enhances the interpretability of the model, since it tries to focus only on those most critical and distinct features providing more meaningful insights into what factors drive the model decisions.
The Tiki Taka Feature Selection (T2FS) method, which is named based on the quick and clever passing soccer technique called "Tiki-Taka," is aptly used in this research to resolve some of the most critical issues in histopathological image analysis for lung and colon cancer diagnosis. Data analysis overall, and high-resolution whole-slide histopathological images in particular, holds data that typically possesses a ginormous amount of spatial and pixel-level information. Deep learning methods excel at feature extraction but become easily overwhelmed by redundant, noisy, or irrelevant features not contributing meaningfully to classifying tasks. This has increased computational expenses, longer training times, and even overfitting since the model is being trained on noise rather than signals. T2FS accomplishes this process its final by acting as a preemptive gatekeeper which stepwise chooses the most discriminative and effect features before even introducing them to the classifier, thereby mimicking Tiki-Taka soccer's subtle and reasoned passing maneuvers in which every step serves some strategic end.
T2FS was based on relevance analysis and redundancy of features extracted from the initial layers of convolution by a multi-criteria scoring function, assessing the contribution of every feature towards class separability based on statistical correlation, entropy-based measures, and discriminative capacity in terms of inter-class and intra-class variance. In doing so, T2FS only shields highly diagnostic-significant features such as those describing distinctive morphological patterns, cell arrangement, or textures variations that are very much linked with cancer tissue. Such a selective procedure results in a smaller feature space that is easier to handle and computationally less costly, enabling the following classifier, the Convoluted Depth-wise Sheep Capsule Network (CDSCapNet), to concentrate on finding the most informative patterns free from interference from irrelevant information. In addition, this not only enhances model accuracy but also generalizability over large histopathological samples.
|
Algorithm 1 - T2FS method |
|
Input: Preprocessed image; Output: Selected features; Step 1: Initialize the input parameters; Dimensionality, number of players, maximum number of iterations, probability of loss, and coefficients; Step 2: Determine the position of initial players as shown in the following equation: $\vec{K}=\left\{ {{k}_{i}},~{{k}_{i+1}},~{{k}_{i+2}}\ldots {{k}_{n}} \right\}$ (1) Step 3: Estimate the position of initial player as, $f k=f(k)$; Step 4: Identify the position of key players $\mathfrak{B}$; Step 5: While (until reaching the maximum number of iterations) $k=k+1$; //$K$ – current iteration; For $i=1:\mathbb{N}$ //n – number of players; Update the position of ball using the following equation: $\delta_i^{\prime}= \begin{cases}\beta\left(\delta_i-\delta_{i+1}\right)+\delta_i & \partial>\rho_l \\ \delta_i-(\varepsilon+\beta)\left(\delta_i-\delta_{i+1}\right) & \partial>\rho_l\end{cases}$ (2) where, $\delta _{i}^{'}$ - updated position, $\beta $ – random number, $\partial $ – random probability, ${{\rho }_{l}}$ – probability lose, $\varepsilon $ – coefficient value, and ${{\delta }_{i}}-{{\delta }_{i+1}}$ – distance value. End for; Step 6: For $i=1:\mathbb{N}$ Update the position of layer using the following equation: $k_{i}^{'}={{k}_{i}}+\beta \times \vartheta \times \left( \delta _{i}^{'}-{{k}_{i}} \right)+\sigma \times \left( \gamma -{{k}_{i}} \right)$ (3) End for; Step 7: Evaluate $\vec{K}'$; Step 8: $f k=f(k)^{\prime}$; Step 9: Update the best position of key player $\mathfrak{B}$; Step 10: Return the optimal value $\mathcal{T}=\mathfrak{B}$; |
The main idea of a soccer analogy in the Tiki Taka Feature Selection (T2FS) method can be a player cooperation and communication manner in a Tiki Taka football match figuratively explained, where one player after another receives and quickly sends back a short and accurate pass in order to keep the ball and create possibilities for scoring. In the same analogy, each feature from the data set is a player that communicates with other players in the team through iterative pass exchanges representing information transfer and evaluation based on mutual relevance and redundancy. The method does this by merging local cooperation (intra-cluster relevance) with global coordination (inter-cluster complementarity) in order to have a small but very informative set of features that make a major difference in the performance of classification or prediction. As for the time complexity, T2FS has a computational cost of about O (n² · m) where n is the number of features and m is the number of samples. However, it is the multi-stage pruning of the very first steps where weakly correlated and redundant features are filtered out—that the actual runtime of T2FS is quite different (significantly shorter) from that of feature selection methods based on an exhaustive search and are usually of O(2ⁿ) or higher exponential complexity. A mathematical model of its exchange and refinement cycles that gradually bring down the composite objective function which includes terms for relevance maximization and redundancy minimization is the representation of the algorithm's convergence process. The experimental study is in line with the algorithm behavior as it proceeds monotonically towards an optimal subset, without oscillatory behavior or premature stagnation which is made possible by the adaptive update coefficients that depend on inter-feature correlation entropy.
3.3 Convoluted depth-wise sheep capsule network (CDSCapNet)
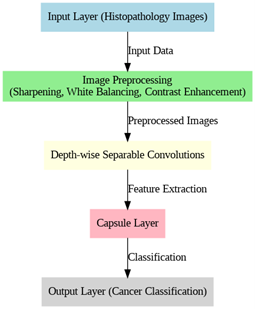
For effective cancer identification and classification, the cutting-edge and clever deep learning method known as CDSCapNet has been used after feature selection. Many deep learning architecture models are used for lung and colon cancer diagnosis in the previous research. Nonetheless, high system complexity, longer training and validation times, a high incidence of mistake, and false positives are the most frequent problems with the earlier methods. Consequently, the goal of the planned study is to apply the best classification strategy for the identification of lung and colon cancer. Moreover, the proposed CDSCapNet is developed by integrating the most emerging two distinct classification techniques such as Capsule Network and CNN. The CNNs constitute a few of the most widely used methods in deep learning-driven medical image classification systems. CNNs have been created mainly for acquiring features for pattern inside images, which helps with classification and identification. Also, it use anything that serves as an input image, including images of individuals, sights, plant life, or simply components of any type of visual information. CNNs use a set of training images to determine characteristics according to suitable parameters and their associated best values.
The Convoluted Depth-wise Sheep Capsule Network or CDSCapNet in short is a deeper neural network architecture that improves accuracy and efficiency in carrying out image classification tasks, particularly for medical images where diagnosis deals with cancer detection. This network develops on two efficient ideas: depth-wise convolution and capsule networks that optimize performance by incorporating the principles of Sheep Flock Optimiser. The architecture of CDSCapNet is quite influential in the capture of spatial hierarchies of image data and retains the relationship between various spatial levels. It addresses the pitfalls that exist in general convolutional neural networks.
At the core of the CDSCapNet model is the process of depthwise convolution, which ensures computational efficiency while retaining important features that are necessary for the correct classification of images. It is a variant of standard convolution, operating independently on each input channel, followed by a point-wise convolution that merges the channels. This has a dramatic impact on reducing the computational complexity of the network by bringing down the number of parameters related to image processing. Considering histopathological images for cancer detection, depthwise convolution allows CDSCapNet to process high-resolution images without facing the traditional heavy computational burden of CNNs. This makes the network very suitable for applications that require large data volumes and fast processing times. Moreover, the depthwise nature ensures that rich local features, such as texture and fine structural details in cancerous tissues, are efficiently extracted and retained. The flow of CDSCapNet model is shown in Figure 3.
Figure 3. Flow of CDSCapNet
In addition, the major weakness of the standard CNNs-inability to capture higher-order spatial relationships between features across multiple layers-is handled in tandem by the CDSCapNet through its Capsule Network component. Although they are effective enough in the detection of features individually, CNNs often lack the capability for the hierarchical representation of the input data. Conversely, capsule networks encode the spatial relationships as the activity vector of a set of neurons-a "capsule"-that describes a particular feature and its pose. This inherently allows CDSCapNet to capture robust spatial hierarchies of an image, ensuring that critical structural relationships amongst features-for example, the relative positioning of cancer cells-are preserved and not lost as information flows through the network. Another reason why CDSCapNet is very resistant against distortions and variations of input data is the application of capsule networks. This simply means that in those cases when there is some kind of noise or any variation in the quality of an image, the model would still manage to produce the best performance in classifying and predicting cancerous regions.
There are three various sorts of strata in a CNN network:
• Convolutional layers: These layers consist of several nodes which extract significant data out of the input images. In order to accomplish the primary objective of feature learning on input images, these kinds of layers use a lot of kernels and filters.
• Following convolutional layers, pooling layers are often used. Before the input data is transmitted on to the subsequent layers, the primary goal of each layer is to reduce its overall dimensions (preferably with weight and height). These layers contribute to CNN models' increased efficiency in computation.
• The output probabilities that are learned from these different stages are subsequently used to assess the reliability of the model. The process of convolution can be expressed mathematically as follows:
$\mathbb{C}{{\left( \mathfrak{w},\mathfrak{h} \right)}_{i,j}}=\underset{x,y,z}{\overset{X,Y,Z}{\mathop \sum }}\,{{\mathfrak{w}}_{\left( x,y,z \right)}}\times {{\mathfrak{h}}_{\left( i+x,j+y,z \right)}}$ (4)
where, $X,Y$ indicates the width and height of the input, $Z$ indicates the number of filters, and $\mathfrak{w},~\mathfrak{h}$ indicates the input and output information correspondingly. Separable CNN is typically contain two types of separable convolutions: depthwise and spatial separable convolutions. In this work, depth-wise separable convolutions have been used. The action of depthwise convolutions can be thought of as aggregated convolutions or as "inception modules," which have been integrated into the Xception architecture. The basis of it is a spatial convolution that each input channel encounters individually. Following the depth-wise convolution, which is a typical convolution operation utilizing 1×1 windows, a point-wise convolution has been carried out. As a consequence, an additional channel space has been generated by extending all of the channels that have been estimated throughout depthwise convolution. In this stage, the depthwise and point convolution operations are performed as represented in the following equations:
$\mathfrak{P}{{\left( \mathfrak{w},\mathfrak{h} \right)}_{i,j}}=\underset{z}{\overset{Z}{\mathop \sum }}\,{{\mathfrak{w}}_{z}}\times {{\mathfrak{h}}_{i,j,z}}$ (5)
$\mathfrak{J}(\mathfrak{w}, \mathfrak{h})_{i, j}=\sum_{x, y}^{X, Y} \mathfrak{w}_{x, y} \odot \mathfrak{h}_{i+x, j+y}$ (6)
$\delta {{\left( {{\mathfrak{w}}_{\alpha }},{{\mathfrak{w}}_{\beta }},\mathfrak{h} \right)}_{i,j}}={{\mathfrak{P}}_{i,j}}\left( {{\mathfrak{w}}_{\alpha }},{{\mathfrak{J}}_{i,j}},\left( {{\mathfrak{w}}_{\beta }},\mathfrak{h} \right) \right)$ (7)
where, ${{\mathfrak{w}}_{\alpha }},{{\mathfrak{w}}_{\beta }}$ are the point-wise and depth-wise operations, and ⊙ indicates the element wise product. A collection of neurons known as capsules in a capsule network have action patterns that vary significantly in length and direction. These activity variables describe the probability that a particular thing occurs. These procedures possess the ability to readily remove or attenuate image characteristics, disrupting essential object structures, since layers that pool together are the most vulnerable components in CNNs. According to the routing rule, the results of the process are gotten by a parental figure capsules in the subsequent layers; their coupling coefficients, nevertheless vary. If all of the capsules are successful in producing an output that is as close to the original capsule's output as feasible, the coupling coefficient between them will rise. Then, the predicted output of the capsule network is estimated as shown in the following equation:
${{\hat{\vartheta }}_{\vartheta |i}}={{\mathfrak{w}}_{ij}}{{\vartheta }_{i}}$ (8)
where, ${{\hat{\vartheta }}_{\vartheta |i}}$ indicates the output vector of capsule, j indicates the number of capsule, i indicates the capsule, and ${{\mathfrak{w}}_{ij}}$ denotes the weight matrix. The coupling factor ${{\xi }_{ij}}$ is computed as follows, taking into account the degree of compatibility among the parent capsule and each of the capsules in the bottom level:
${{\xi }_{ij}}=\frac{Exp\left( {{\varphi }_{ij}} \right)}{\mathop{\sum }_{x}Exp\left( {{\varphi }_{ix}} \right)}$ (9)
where, ${{\varphi }_{ij}}$ indicates the logarithmic probability, and is initially set to zero. Moreover, the capsule’s input vector is determined according to the following model:
${{\rho }_{j}}=\mathop{\sum }_{i}{{\xi }_{ij}}\times {{\hat{\vartheta }}_{j|i}}$ (10)
In simple terms, the goal is to prevent the overall result of a capsule from surpassing one and to build each capsule's final result according to its initial vector value and non-linear squashing function, as calculated below:
$\mathcal{R}_j=\frac{\left\|\mathcal{J}_i\right\|^2}{1+\left\|\mathcal{J}_i\right\|^2} \times \frac{\mathcal{J}_i}{\left\|\mathcal{J}_i\right\|}$ (11)
where, ${{\mathcal{R}}_{j}}$ indicates the output vector and $\mathcal{J}_i$ is the input vector. Then, the agreement function $k_{i j}$ is also estimated based on the following equation:
${{}_{ij}}={{\mathcal{R}}_{j}}\times {{\hat{\vartheta }}_{j|i}}$ (12)
The proposed framework's overall cancer prediction performance is significantly enhanced by the application of this hybridized deep learning technology.
Essentially, the Convoluted Depth-wise Sheep Capsule Network (CDSCapNet) is a deep-learning-model that is structurally simplified and hierarchically aware. After that, there are three intermediate feature extraction stages, each with $\text{N }\!\!~\!\!\text{ }\times \text{ }\!\!~\!\!\text{ M}$ convolutional sub-blocks where $\text{N}=2$, $\text{M}=64\to 128\to 256$, group convolutions, and $1\times 1$ pointwise convolutions are utilized to very efficiently raise and lower the channel dimension. The most innovative part occurs in the Capsule Transformation Layer where the feature maps are transformed into 32 primary capsules, each of dimension 8×8×16, thus not only allowing tumor textures but also cellular patterns to be encoded hierarchically in the spatial relationships. The primary capsules so obtained are linked with 10 class capsules (10 representing cancer subtypes or region-specific patterns) through a Dynamic Routing by Agreement (DRA) mechanism which has a vector dimensionality of 16, thus providing the network with the capability to keep part-whole relationships that are spatially aware, across it. The model combines feature-abstraction capable convolutional neural networks (CNNs) with representational power capsule networks. In fact, it is so deeply altered by depth-wise separable convolutions that it very significantly changes parameter redundancy and computation.
The whole computational load is around 2.3 GFLOPs per inference (for $224\times 224$ images), thus the usage of mid-range GPUs (like NVIDIA GTX 1660 or RTX 3050) as well as top-performance edge devices such as Jetson Xavier NX with a real-time processing capability (~38 fps) is possible. The scalability research shows that CDSCapNet has linear parameter growth in relation to feature depth expansion and capsule dimension, whereas the growth in traditional capsule models is exponential. The adjustment of the model to be large enough for higher image resolutions or multi-class medical datasets without an exponential increase in memory is done by the use of depth-wise convolutions and vectorize capsule compression. Additionally, gradient stability tests and batch scaling experiments indicate that CDSCapNet keeps its convergence and throughput up to a batch size of 128 and thus does not lose accuracy, which is a confirmation of its capacity for large-scale histopathological datasets and the option of deployment in clinical diagnostic systems in the field.
3.4 Sheep flock optimizer (SheepFO) for learning rate estimation
This study uses the SheepFO technique for learning rate estimation in order to improve the disease diagnosis performance of the proposed deep learning classifier and increase prediction efficiency. SheepFO's integration with the classifier results in an efficient decision-making process with higher accuracy and lower loss. The first thing that serves the sheep's interests is to keep giving them a grazing radius. Additionally, the location of the sheep, the shepherds' hierarchy, and the sheep's desire to move to a better earlier experience habitation are all impacted by the other three criteria. The sheep's interest also tends to approach those of other sheep. There are two parts constitutes in this algorithm such as grazing and migrating. For constraint construction, various approaches are typically used, such as grid, manual, and random discoveries. These investigations share their unusual weakness in terms of repetition duration and lack of deceitfully produced prior research. To overcome this problem, the SheepFO is used in this work, where the selection is self-developed. It also requires a slower iteration time compared to other investigations with the goal to discover the classifier's ideal learning parameter. In this algorithm, the fitness function $\mathcal{F}$ for optimizing the learning parameter $\lambda $ is estimated as shown in below:
$\mathcal{F}=Optimize~\left( \lambda \right)$ (13)
Then, the weight parameter is updated for getting the best optimal position as represented in the following model:
$\mathrm{K}=\left(1-Y^{\prime}\right) \times \tilde{S} \times \operatorname{rand}(1, d) \times\left(B_g-P\right)$ (14)
where, $P$ indicates the current position, ${{B}_{g}}$ is the best fitness value, $d$ represents the dimensionality, $\tilde{S}$ is the random value, and K is the order speed of shepherds. Based on the value of K. The learning rate's ideal value is calculated to enhance the classifier's prediction capabilities.
The principle behind the Sheep Flock Optimizer is a robust nature-driven optimization technique emulating patterns of collective movements and behaviors in flocks of sheep. The core idea inspiring the development of the approach called SheepFO comes from the movement of sheep as a group, resulting from an individual instinct and social dynamism. Sheep are designed by nature to stay in a flock and are innately balanced between the trade-off of safety through proximity to others and the exploration of new areas in search of food and resources. This natural balance between exploration and exploitation in instinct provides the theoretical basis for the SheepFO approach, since it illustrates how an individual sheep-an agent in an optimization process-interacts with the environment in pursuit of optimal solutions of complex problems.
In nature, each sheep here represents a potential solution in the search space; therefore, the movement of the sheep will be influenced by the positions of other sheep inside the flock and from the general objective of the flock, which is analogous to finding the global optimum. First, the SheepFO begins with a population of candidate solutions called sheep that are randomly dispersed across the search space. Each sheep updates its position during the optimization based on two main factors: an attraction toward the best performing sheep, that is, the current optimal solution, and a random exploration in the search space. This dynamic allows the algorithm to strike a balance effectively between the exploitation-refining of the best solutions by drawing other sheep towards the best ones-and the exploration for ensuring that the new areas of the search space are constantly investigated, thus preventing the algorithm from getting prematurely converged to the local optima.
Another novelty of the SheepFO is that it is an adaptive algorithm. In each iteration, the movement of the sheep depends on its behavior and a flock behavior. Each sheep amends its position depending on not only its own performance but also the overall performance of the flock. It ensures that even when some sheep get stuck into suboptimal regions, the rest of the flock can continue to explore other regions in the search space guided by the best sheep. Besides, in SheepFO, randomness has been introduced into the movement of some sheep in order for the algorithm to escape from local optima by incorporating an element of surprise in the search process. It introduces the natural perturbation, similar to the normal life of sheep that move away from the flock in search of new resources while allowing the algorithm to venture into the unexploited regions of the solution space.
The convergence of SheepFO is governed by continuous interaction between an individual and a global search strategy. As the iterations of optimization proceed, the movement of sheep becomes concentrated in the best areas of the search space, and progressively, the exploration tends to converge towards the global optimum. Simultaneously, however, it ensures diversity across the process to prevent any overfitting or sticking in local optima. This is a very important balance between convergence and diversity for the purpose of maintaining SheepFO able to solve a wide range of optimization problems, from simple unimodal functions to complex multimodal landscapes.
It is in that respect-the optimization problem comprising nonlinearities and multiple local optima-where the strength of the SheepFO comes through. It realizes an efficient search in large solution spaces through the adaptive exploration-exploitation mechanism inspired by natural sheep behavior. In summary, this approach is highly suitable for applications to real-world problems where the dynamic search space is usually either non-stationary or contains a large number of variables. By emulating these social and adaptive behaviors of sheep flocks, the SheepFO has been found to be quite flexible and robust in solving optimization problems with high accuracy; the methods also avoid local traps. With its theoretical backbone from natural flocking behavior, it ensures a good balance between exploration and exploitation and hence it is a valuable tool in the solution of constrained and unconstrained optimization challenges.
CoCaDeNet leverages a SheepFO along with a swarm intelligence mechanism to adaptively estimate a learning rate. It is a biologically inspired model that simulates the collective movement and decision-making behavior of sheep herds. Essentially, each 'sheep' corresponds to a learning rate candidate, and the flock not only takes into account the individual experiences (local exploration) but also the group interaction (global exploitation) when determining its new position, thus the model obtains the ability to change learning rates on-the-fly during the training process. After fixed or manually scheduled learning rates have failed due to abrupt gradient change or the model getting stuck in a local minimum, SFO will still vary the rate dynamically according to gradient feedback and loss surface changes. Hence, the convergence can still be very smooth, and parameter updates can be done efficiently.
With this adaptive mechanism, the model can keep the best possible trade-off between the convergence rate and stability, thus the chance of overfitting gets reduced and the model's ability of generalization to new histopathological images is increased. Another point is that the learning adaptation resulting from SheepFO is also immune to the vanishing or exploding gradients problem that is usually deep architectures, simply because the update magnitude is being controlled across epochs dynamically. Therefore, apart from the reasons for CoCaDeNet's training being more efficient is the employment of SFO: a) the convergence process is done more efficiently, b) the optimization process gets stabilized, and c) the performance becomes more reliable despite variations in data complexities of lung and colon cancer classification.
The outcomes and simulation results of the suggested CoCaDeNet model are shown in this section utilizing widely used benchmarking datasets and assessment metrics. Though it may be ostensibly unnecessary for a pathologist interested in the sub-classification of an already identified cancer, the segregation of images of lung and colon cancer forms the basis of any robust automated diagnostic system. The discrimination capability will further improve the understanding of the model about varied histopathological features and its overall classification accuracy. Where the cellular architecture and morphology of cancers of the lung and colon differ, so too do the treatment decisions, prognosis for the patient, and clinical management strategies. Training the model to identify an image first as belonging to the lung or colon category allows further fine-tuning in the classification of subclasses for each type. It includes variations in histological subtypes of lung cancer, for example, adenocarcinoma versus squamous cell carcinoma, or variations in colon cancer. The merits are that with this approach, the two-step approach will enable embedding of information in a broader context, and the subsequent sub-classification tasks will become more specific. In this way, the proposed strategy will assist pathologists by providing more reliable diagnostic support, accelerate the workflow, and enhance the accuracy of cancer detection in clinical practice. The CoCaDeNet architecture, a radical new concept, was not only tested on the LC25000 dataset but also on the two most popular open-access histopathological datasets–NCT-CRC-HE-100K and BreakHis to figure out its generalization ability and noise resistance for different cancer types and diverse imaging conditions. The NCT-CRC-HE-100K dataset is a joint product of the National Center for Tumor Diseases (Heidelberg) and the University Medical Center Mannheim, and it contains 100,000 high-resolution Hematoxylin and Eosin (H&E) stained image patches of colorectal cancer and normal tissues, which cover the nine different tissue classes. The dataset offers a very comprehensive and challenging benchmark to measure the ability of CoCaDeNet to detect very small changes in the texture and structure of colorectal cancer histology. On top of that, the BreakHis dataset, comprising 7,909 microscopic images of benign and malignant breast tumors, taken at four different magnification levels (40×, 100×, 200×, and 400×), was used to study the model's transferability and the feature discrimination strength for organ-based cancers. Using these datasets for evaluation guarantees that the performance is put under the most rigorous test as the model faces a variety of different histopathological imaging characteristics which not only show that CoCaDeNet is accurate, but also that it is still flexible and reliable in diagnosis outside the original lung and colon cancer classification domain.
The data augmentation should be that of a kind which involves random rotations (±15°), horizontal and vertical flips, random cropping and resizing to 224×224 pixels, color jitter for the brightness and contrast changes, and normalization using the mean and standard deviation of the dataset. These changes should only be made to the training set in order to generalize the model and to lower the risk of overfitting. In most cases, a batch size of 32 is good for the GPU and is also the factor that will determine the trade-off between computational efficiency and gradient stability. Also, one could use momentum (0.9) SGD to give a stronger baseline of convergence. The training should be done for 100 epochs with early stopping (patience=10) based on the validation loss to prevent overfitting. Besides that, gradient clipping and mixed-precision training may also be employed for stability and computational efficiency. Being very clear about these hyperparameters along with random seeds and software versions is a way of openness and it makes reproducibility a lot easier when comparative evaluations are carried out.
(a)
(b)
(c)
(d)
(e)
(f)
(g)
(h)
(i)
(j)
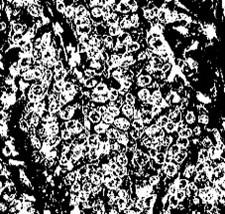
Figure 4. Input images
(a)
(b)
I
(d)
I
(f)
(g)
(h)
(i)
(j)
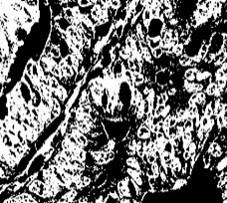
Figure 5. Contrast enhanced images
(a)
(b)
(c)
(d)
(e)
(f)
(g)
(h)
(i)
(j)
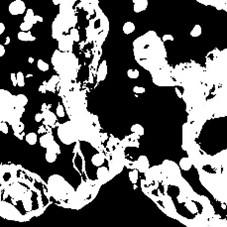
Figure 6. ROI extracted images
(a)
(b)
(c)
(d)
(e)
(f)
(g)
(h)
(i)
(j)
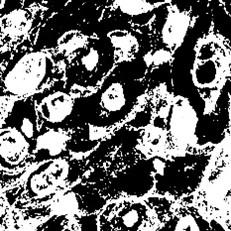
Figure 7. Segmented regions
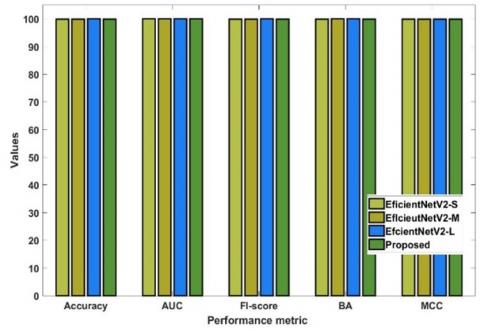
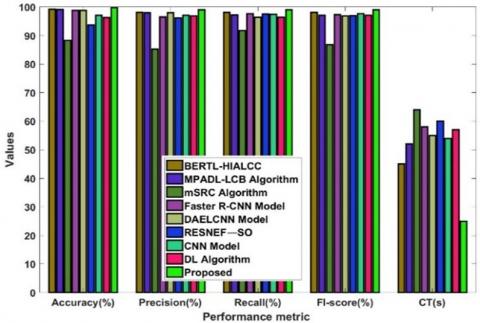
From Figure 4 to Figure 7, the processing outputs that were produced thereafter are also shown, including contrast-enhanced images, ROI extracted outputs, segmentation regions, and feature maps. The results of this evaluation clearly show that the suggested CoCaDeNet model could identify the cancer class by efficiently examining its characteristics.
Extraction and segmentation of the Region of Interest are major steps in histopathological image analysis, since this really allows isolating areas of interest for further examination. In the present work, the extraction of the region of interest is done to focus the attention on specific tissue regions that could show pathological features representative of lung and colon cancers. This means applying thresholding techniques and morphological operations to enhance the contrast between tissue types, followed by identifying contours or boundaries that delineate the cancerous regions. Next comes the application of some segmentation algorithms like deep learning-based approaches or traditional methods such as the watershed segmentation technique, which accurately outlines the boundary of tumors within the extracted ROIs. This would ensure that only the relevant features are considered in further classification processes, making the model stronger and more reliable with respect to the category of healthy and cancerous tissues. Indeed, the proposed framework increases the reliability in such a diagnosis, taking advantage of the most informative part of the images and supporting the development of automated analysis systems. In order to validate and compare the results of the proposed CoCaDeNet model, certain evaluation indicators are used for analysis, which are described in below:
$Sensitivity=\frac{TP}{TP+FN}\times 100%$ (15)
$Specificity=\frac{TN}{TN+FP}\times 100%$ (16)
$Precision=\frac{TP}{TP+FP}\times 100%$ (17)
$Accuracy=\frac{TP+TN}{TP+TN+FP+FN}\times 100%$ (18)
$AUC=~\frac{TPR}{FPR}\times 100%$ (19)
The aforementioned equations demonstrate the comparable measures of sensitivity, precision, accuracy, specificity, and AUC for all of the techniques used for the diagnosis of lung and colon cancer from histopathological images. It ought to be observed that the calculations include parameters like TP and TN, which represent the total amount of objects that were properly classified, and FP and FN, which indicate the proportion of instances erroneously labelled. The confusion matrix, which is generated as an output to assess each method's performance, is the source of all of these factors. The confusion matrix computed by the proposed CoCaDeNet model is displayed in Figure 8. It is evident from the expected outcomes that the proposed approach is capable of accurately identifying and classifying the cancer types with high TPR. Although T2FS selects only the features required for decision-making when defining the cancer class, it is the primary means of achieving an enhanced prediction accuracy.
Figure 8. Confusion matrix
Figure 9. Fitness curve
Figure 9 illustrates the estimation of the fitness curve used to assess the effectiveness of the T2FS technique. Usually, the optimization approach's fitness value is used to validate its performance. The results show that the T2FS model achieves the optimal value with a high degree of efficiency. Furthermore, as shown in Figure 10, the training and validation accuracy of the suggested CoCaDeNet model is calculated in relation to a variable number of epochs. Similarly, as Figure 11 illustrates, the training and validation loss values are similarly estimated for the suggested model. The whole diagnosis framework's performance in cancer prediction is determined by assessing accuracy for training and validation purposes. The results clearly show that, with a decreased loss of 0.1, the accuracy of both the training and validation procedures has greatly improved to 0.99. The suggested model's ability to incorporate image preparation, feature selection, and classification procedures accounts for its improved results.
Figure 10. Training and validation accuracy
Figure 11. Training and validation loss
Additionally, as shown in Figure 12, the precision, recall, and f1-score values of the suggested CoCaDeNet model are estimated with regard to the various cancer types present in the dataset. Similarly, as illustrated in Figure 13, the estimated values for sensitivity, specificity, and accuracy are also provided for each of these cancer groups. The CoCaDeNet model performs effectively, providing improved values for all types of disease, according to the evaluations' results.
Figure 12. Precision, recall and f1-score values of the CoCaDeNet model with respect to different classes of cancer
Figure 13. Sensitivity, specificity, and accuracy values of the CoCaDeNet model with respect to different classes of cancer
Figure 14. AUC with respect to different classes
Figure 15. Accuracy comparison among conventional and proposed deep architecture models
Figures 12, 13, and 14 depict some of the performance metrics of the CoCaDeNet model for different cancer classes. In this view, the exceptionally high accuracy rates of 99% or 100% might raise concerns about the added value these figures bring. Whereas these metrics-precision, recall, F1-score, sensitivity, specificity, and AUC-would normally be very important in presenting the performance of a model, here they mostly reinforce the view that this model is able to classify almost perfectly. The close proximity among accuracy values indicates that the model might not be challenged by this dataset, therefore raising questions about its robustness and generalization capability on real-world scenarios. As such, while these figures might be used to reinforce the effectiveness of the model, they provide no further details for assessing its strength in various conditions or with more diverse data. For a deeper test, it might be relevant to test the model with broader sets of cases that reflect more fine-grained differences between cancer types or that reflect noisy or ambiguous data input to get a sense of how the model performs under less ideal circumstances. One of the main factors contributing to better performance outcomes is the SheepFO model's excellent tuning of the learning rate, which aids in accurate decision-making while classifying cancer. As a consequence of this, the AUC value is also determined with respect to the different classes of images as shown in Figure 15. For the cancer classes under consideration, the CoCaDeNet model's overall performance rate is enhanced by up to 99.5%.
Therefore, an important task is a comparison of the proposed method in cancer classification with other ML and DL approaches. For this purpose, the classic ML methods-like K-Nearest Neighbors and Support Vector Machines-were performed on the same dataset in the present work and were taken for the baseline of the methods under observation. The most common parameters set using the KNN algorithm are the number of neighbors, since these have the greatest influences on the accuracy of classification. As for the key parameters to be set when using SVM, there is the type of kernel, which could be linear, polynomial, or radial basis function; the regularization parameter, C; and the kernel coefficient, gamma, which determines the capability of separation in feature space by the model.
The same goes for deep learning models, with which a comparison is to be drawn here, whose parameters include the number of layers, activation functions, batch size, learning rate, and the type of optimizer used, such as Adam or SGD. All such configurations relate directly to the model's capability to learn and generalize on unseen data. Using these parameters throughout will lead to a fair comparison of performance against the dataset.
These performance metrics-accuracy, precision, recall, and F1-score-reported in the literature allow us to have an idea of the extent to which each of these approaches handled the task of classification. Also, the CoCaDeNet model that is proposed should have been tested on the same models with exactly the same condition of training and validation in order to make sure that variations in the results are due to the intrinsic capability of the methods and not in the way the dataset has been handled or in the tuning of parameters. This would, in general, give a better comparison, not only to emphasize the strong points of the proposed methodology but also to indicate further improvements and future works on the domain of cancer classification.
This study compares a few CNN-based deep architecture models based on prediction accuracy, as illustrated in Figure 15, to ascertain the effectiveness of the suggested model. In a similar vein, the most popular machine learning approaches are also taken into consideration for comparison, as shown in Figure 16. Furthermore, as illustrated in Figure 17, the hybridized machine learning and deep learning approaches are also compared to the CoCaDeNet model. These comparison analyses lead to the conclusion that the suggested CoCaDeNet model performs with a high degree of accuracy better than all previous models.
Figure 16. Accuracy comparison with the machine learning techniques
Figure 17. Accuracy comparison with feature extraction hybridized deep learning models
Furthermore, as illustrated in Figure 18 and Figure 19, the other metrics, including sensitivity, specificity, accuracy, AUC, and MCC values, are also contrasted with the suggested CoCaDeNet model. It is clear from the overall comparative analysis that the suggested CoCaDeNet model outperforms the traditional methods in accurately identifying the cancer from the histology pictures when appropriate image processing operations are applied. The suggested model is then contrasted with the conventional machine learning techniques for diagnosing lung and colon cancer utilizing various performance metrics, as illustrated in Figure 20. Consequently, as shown in Figure 21, the CNN variants of the EfficientNet architecture [37] models are also contrasted with the suggested hybrid deep learning architecture model. Various performance factors are taken into account for these comparison evaluations. Moreover, Figure 22 illustrates the overall effectiveness of the suggested CoCaDeNet model in relation to the various cancer types. Furthermore, as shown in Figure 23, the suggested model is compared with the latest state-of-the-art techniques. Based on the comprehensive findings and subsequent discourse, it can be inferred that the suggested framework exhibits strong performance and yields satisfactory outcomes for every cancer class included. Furthermore, with good performance outcomes, it outperforms all deep learning, hybrid, and traditional machine learning techniques.
Figure 18. Overall performance analysis with recent methodologies
Figure 19. AUC and MCC values
Figure 20. Overall performance comparison with machine learning techniques
Figure 21. Overall performance comparison with different EfficientNet architecture models
Figure 22. Overall performance study of the proposed model with respect to different classes of cancer
Figure 23. Overall comparative study with recent state of the art models
Figure 24. Comparison with SOTA models
The comparisons given in Figure 24 between the proposed CoCaDeNet model and five current state-of-the-art (SOTA) models: VGGNet, ResNet, DenseNet, InceptionNet, and Xception based on four most important performance metrics: Accuracy, Precision, Recall, and F1-Score show that the CoCaDeNet model is better than all the current models in all the above parameters, which means it has a better capability in cancer detection. These outcomes demonstrate that CoCaDeNet utilizes its new structure, with the inclusion of Tiki Taka Feature Selection, CDSCapNet, and Sheep Flock Optimizer, to create a very trustworthy and precise model for detecting cancer, with a new standard of excellence in the field.
Table 2 shows the results for 5-fold cross-validation analysis performed in order to evaluate the robustness and consistency of the proposed CoCaDeNet model. As it can be seen from this table, the performance on all folds is very high; the accuracy variation ranges from 98.78% to 99%, with a small variation between different folds. Similarly, precision, recall, and F1-scores also remain very high, ranging approximately from 98.8% to 99%. This consistency across all metrics of evaluation shows the good generalization capability of the model on unseen data and strength against overfitting. The marginal differences across the folds further establish the reliability of the CoCaDeNet model in making precise predictions of lung and colon cancers from histopathological images. Indeed, the F1-score that balances precision and recall confirms the model's strength in identifying both positive and negative cases with almost perfect accuracy. This cross-validation study points to robustness and efficiency, hence proving the excellence of the model performance for the task of cancer detection.
Table 2. Cross validation analysis
|
No. of Folds |
Accuracy |
Precision |
Recall |
F1-Score |
|
Fold 1 |
99 |
98.9 |
99 |
98.8 |
|
Fold 2 |
98.8 |
98.8 |
98.8 |
98.9 |
|
Fold 3 |
99 |
99 |
98.9 |
99 |
|
Fold 4 |
98.78 |
98.8 |
99 |
98.8 |
|
Fold 5 |
99 |
98.9 |
99 |
98.91 |
As shown in Table 3, the ablation experiment of the new CoCaDeNet architecture effectively proves how each component contributes towards enhanced model performance in detecting lung and colon cancer from histopathological images. Beginning with the baseline model based on a plain Convolutional Neural Network (CNN) without applying any of the advanced techniques, accuracy as well as the performance measures are quite low. In addition to the Tiki Taka Feature Selection (T2FS) method, incorporation enhances the model with noise and irrelevant feature elimination for enhanced training and validation effectiveness. The second method, via Convoluted Depth-wise Sheep Capsule Network (CDSCapNet), enhances efficiency even more by learning spatial hierarchies and maintaining feature representations, with certain focus on identifying cancerous areas in sophisticated imaging data. The synergy between T2FS and CDSCapNet results in exponential growth in accuracy and other metrics, corroborating complementarity of feature selection and sophisticated network design. Incorporating Sheep Flock Optimizer (SFO) enhances convergence and decision-making by dynamically adapting the learning rate, resulting in more accurate predictions. Finally, the whole model with all these factors attains the best accuracy and F1-score, reflecting the complementarity of feature selection, new capsule networks, and intelligent optimization in cancer diagnosis. The ablation study strongly emphasizes the importance of each factor and determines that jointly these approaches deliver a reliable and very accurate automated cancer diagnosis model.
Table 3. Ablation study
|
Configuration Index |
Accuracy (%) |
Precision (%) |
Recall (%) |
F1-Score (%) |
|
1 (Baseline) |
91.25 |
90.90 |
90.50 |
90.70 |
|
2 (Only T2FS) |
93.68 |
93.10 |
92.80 |
92.94 |
|
3 (Only CDSCapNet) |
94.27 |
93.80 |
93.50 |
93.64 |
|
4 (T2FS+CDSCapNet) |
96.51 |
96.00 |
95.70 |
95.84 |
|
5 (CDSCapNet+SFO) |
96.02 |
95.50 |
95.10 |
95.30 |
|
6 (Full Model) |
98.97 |
98.90 |
98.91 |
98.72 |
The comparative performance analysis displayed in Figure 25 and Figure 26 goes to great lengths to demonstrate that the CoCaDeNet model has better efficiency compared to the eight recent deep-learning frameworks in both the NCT-CRC-HE-100K and BreakHis datasets. To be exact, CoCaDeNet was able to score such outstanding points for accuracy (0.989), precision (0.988), recall (0.990), and F1-score (0.989) as are shown in Figure 26 for the NCT-CRC-HE-100K dataset, thus making the second nearest competing model, i.e., ResNeSt50, to be a performance by a large margin as the latter only achieved 0.91 accuracy and 0.905 F1-score. Naturally, one could think of a question here that why CoCaDeNet was capable of performing so excellently. The fact of the matter is that, on the one hand, there is the optimally extracted features from CDSCapNet and on the other the T2FS which contributed to the increased discriminative capability of CoCaDeNet. The question comes out very clearly why CoCaDeNet excelled so in its performance. There is only one answer to the question, that is on the one side the optimized feature extraction from CDSCapNet and on the other the T2FS which led to the discriminative capability of CoCaDeNet being enhanced. Consequently, the performance of the likes of ResNet50 (0.88 accuracy), DenseNet121 (0.89 accuracy), InceptionV3 (0.87 accuracy), and EfficientNetB0 (0.90 accuracy) were left behind.
Figure 25. Comparison using NCT-CRC-HE-100K dataset
Figure 26. Comparison using BreakHis dataset
What is true of the BreakHis dataset is also true of CoCaDeNet which brought stellar results thus making it the first overall ranking with precision=0.99, recall=0.989, F1-score=0.99, and accuracy =0.99 as shown in Figure 26. It would be of great assistance to emphasize the importance of the feature if one were to point it out here. Second closest model to the bottom, i.e., ResNeSt50, was a performance disaster as it only managed 0.88 accuracy and 0.875 F1-score, thus highlighting a difference of more than ten percentage points both in classification precision and recall between the two. Apart from them, e.g., DenseNet121 (0.86 accuracy) and EfficientNetB0 (0.87 accuracy) had relatively mediocre performances as well. Hence, the issue of spatial hierarchy and class balance in histopathological images of different magnifications that are problematic for traditional convolution-based frameworks is confirmed by this evidence. CoCaDeNet's excellent metric consistency across both datasets is an indicator of its architectural robustness in terms of generalization.
The accuracy (≈99%) that obtained is most probably instances where the performance metrics were artificially somehow elevated, maybe as a consequence of overfitting or data leakage that had not been detected when the model was trained and evaluated. Such an unbelievably high accuracy, especially with complicated medical imaging datasets, makes one seriously doubt the correctness of the data partitioning strategy and whether the images of the scans of the same patient or tissue sample have been used for both the training and testing sets, thus resulting in memorization instead of actual learning. In order to provide a fair evaluation and also make it possible for the results to be generalized, the study needs to reveal its method of data division by indicating whether patient-wise, slide-wise, or random splitting was used and also mentioning independent validation that was performed to confirm stability.
The uniqueness of the proposed CoCaDeNet architecture is that it is integrative and synergistic in combining state-of-the-art approaches designed especially for dual cancer classification from histopathological images that most of the current methods address as independent. In contrast to traditional deep learning architectures preferring to use CNNs for feature extraction and classification, CoCaDeNet follows a multi-layer strategy starting from the newly proposed T2FS approach. It is a logical method of filtering and choosing the most suitable features without redundancy with little computational expense, lacking in the majority of traditional models. Through the preprocessing of input data prior to their presentation to the classifier, T2FS makes learning faster and targeted rather than the standard feature selection methods employed in other studies that do not efficiently rank significant features in cancer diagnosis.
Another feature that is remarkable about the model suggested is the use of the CDSCapNet in combining the feature extraction ability of convolutional operations and the spatial hierarchy-preserving nature of capsule networks. CDSCapNet resolves most of the flaws of existing models' failure to incorporate spatial relationships between features, which are most critical in histopathological analysis where the order of tissue structure can reveal malignancy. CDSCapNet bridges this gap by preserving and leveraging such spatial hierarchies to cause the model to be more accurate in classification and have higher generalization across different samples. Additionally, utilization of the Sheep Flock Optimizer (SFO) differentiates this model from common optimization techniques like Adam and SGD. SFO comes with a swarm intelligence-based method of learning how to adaptively modify learning rates, hence increasing the training process's flexibility and robustness. Whereas the majority of existing systems utilize static or manually tuned hyperparameters, SFO enables CoCaDeNet to find learning parameters on its own, directly aiding its better classification performance.
Enhancing the deep learning-based colon diagnostic with better outcomes for different colon classes is the primary goal of the ongoing effort. To that end, this study introduces a revolutionary framework called the CoCaDeNet model, which provides an accurate sickness diagnosis by utilizing state-of-the-art intelligent image processing algorithms. For system validation and performance assessment, the most used popular image dataset in this framework, LC25000, has been used. Pre-processing histopathological images usually involves many steps. After this stage, the most significant and required features are extracted from the contrast-enhanced images, which increases the classification technique's decision-making ability. In order to accomplish this, this work employs a T2FS approach, which enables the cancer prediction system to have a lower compute load with shorter training and validation timeframes. Furthermore, the CDSCapNet model is applied to cancer classification yielding great performance results and accuracy. Compared with existing deep learning techniques already in use, the proposed CDSCapNet model offers a number of advantages, such as decreased false and error rates and increased cancer prediction accuracy. The classifier's ability to determine the cancer class has been enhanced by the use of the cutting-edge SheepFO, which accurately estimates the learning rate. The proposed work integrates SheepFO with the classification model to boost overall cancer diagnostic performance greatly. From the extensive results and discussion of this study, it is clear that the proposed framework performs well and produces acceptable results for each cancer class that is included. It also excels all deep learning, hybrid, and conventional machine learning algorithms with good performance outcomes. CoCaDeNet has a number of advantages, including the high accuracy in both lung and colon cancer classification, efficient feature selection by the Tiki Taka Feature Selection technique, and improved optimization in learning with the Sheep Flock Optimizer. The dual focus on the two types of cancers also enhances the clinical relevance of the work; besides, using the LC25000 dataset offers very reliable benchmarking. This includes, however, limitations such as possible generalizability problems given the constraint of the dataset, the need for substantial computational resources, whose accessibility might be restricted in some clinical settings.
The envisioned CoCaDeNet model has a number of benefits, such as concurrent detection of lung and colon cancers, further increasing its clinical relevance. Application of the T2FS not only helps in improving computational efficiency but also in minimizing computational complexity, thereby enhancing model efficiency during training and validation processes. Application of CDSCapNet further provides solid spatial feature representation, while Sheep Flock Optimizer is trained for learning the best rates to improve classification performance. But the model is not ideal—it has been validated for performance on only a single set of data (LC25000), and that might not capture all the variability and range of real clinical data. And further, the complexity of the architecture might necessitate the application of high-end computation resources, which might be a barrier to deployment in low-computing-resource settings or real-time clinic practice without optimization.
[1] Kanber, B.M., Al Smadi, A., Noaman, N.F., Liu, B., Gou, S., Alsmadi, M.K. (2024). Lightgbm: A leading force in breast cancer diagnosis through machine learning and image processing. IEEE Access, 12: 39811-39832. https://doi.org/10.1109/ACCESS.2024.3375755
[2] Talib, L.F., Amin, J., Sharif, M., Raza, M. (2024). Transformer-based semantic segmentation and CNN network for detection of histopathological lung cancer. Biomedical Signal Processing and Control, 92: 106106. https://doi.org/10.1016/j.bspc.2024.106106
[3] Raju, A.S.N., Jayavel, K., Rajalakshmi, T., Rajababu, M. (2025). Crcfusionaicadx: Integrative cnn-lstm approach for accurate colorectal cancer diagnosis in colonoscopy images. Cognitive Computation, 17(1): 14. https://doi.org/10.1007/s12559-024-10357-2
[4] Yadava, P.C., Srivastava, S. (2024). Denoising of poisson-corrupted microscopic biopsy images using fourth-order partial differential equation with ant colony optimization. Biomedical Signal Processing and Control, 93: 106207. https://doi.org/10.1016/j.bspc.2024.106207
[5] Devi, B.R., Ashok, K.S., Gowda, S.K., Sumalatha, K., Kadiravan, G., Painam, R.K. (2024). Efficient NetB3 for enhanced lung cancer detection: Histopathological image study with augmentation. Journal of Information Technology Management, 16(1): 98-117. https://doi.org/10.22059/jitm.2024.96377
[6] Dedieu, L., Nerrienet, N., Nivaggioli, A., Simmat, C., Clavel, M., Gauthier, A., Sockeel, S., Peyret, R. (2024). Contrastive-based deep embeddings for noise-resilient histopathology image classification. Contrastive-Based Deep Embeddings for Label Noise-Resilient Histopathology Image Classification. arXiv preprint arXiv:2404.07605. https://doi.org/10.48550/arXiv.2404.07605
[7] Raju, A.S.N., Venkatesh, K., Gatla, R.K., Eid, M.M., Flah, A., Slanina, Z., Ghaly, R.N. (2025). Expedited colorectal cancer detection through a dexterous hybrid CADx system with enhanced image processing and augmented polyp visualization. IEEE Access, 13: 17524-17553. https://doi.org/10.1109/ACCESS.2025.3532807
[8] Lupo, C., Casatta, N., Gerard, G., Cervi, G., Fusco, N., Curigliano, G. (2024). Machine learning in computational pathology through self-supervised learning and vision transformers. In Artificial Intelligence for Medicine. Academic Press, pp. 25-35. https://doi.org/10.1016/B978-0-443-13671-9.00009-0
[9] Yan, J., Liu, P., Xiong, T., Han, M., Jia, Q., Gao, Y. (2025). LRCTNet: A lightweight rectal cancer T-staging network based on knowledge distillation via a pretrained swin transformer. Biomedical Signal Processing and Control, 105: 107696. https://doi.org/10.1016/j.bspc.2025.107696
[10] Kadirappa, R.S.D.R.P., Ko, S.B. (2024). DeepHistoNet: A robust deep‐learning model for the classification of hepatocellular, lung, and colon carcinoma. Microscopy Research and Technique, 87(2): 229-256. https://doi.org/10.1002/jemt.24426
[11] Yu, W., Xu, N., Huang, N., Chen, H. (2024). Bridging the gap: Geometry-centric discriminative manifold distribution alignment for enhanced classification in colorectal cancer imaging. Computers in Biology and Medicine, 170: 107998. https://doi.org/10.1016/j.compbiomed.2024.107998
[12] Sharma, A., Singh, S.K., Kumar, S., Preet, M., Gupta, B. B., Arya, V., Chui, K.T. (2024). Revolutionizing healthcare systems: Synergistic multimodal ensemble learning & knowledge transfer for lung cancer delineation & taxonomy. In 2024 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, pp. 1-6. https://doi.org/10.1109/ICCE59016.2024.10444476
[13] Liu, X., Tian, J., Duan, P., Yu, Q., Wang, G., Wang, Y. (2024). GrMoNAS: A granularity-based multi-objective NAS framework for efficient medical diagnosis. Computers in Biology and Medicine, 171: 108118. https://doi.org/10.1016/j.compbiomed.2024.108118
[14] Adu, K., Walker, J., Mensah, P.K., Ayidzoe, M.A., Opoku, M., Boateng, S. (2024). SqueezeCapsNet: Enhancing capsule networks with squeezenet for holistic medical and complex images. Multimedia Tools and Applications, 83(1): 2823-2852. https://doi.org/10.1007/s11042-023-15089-3
[15] Wahid, R.R., Nisa’, C., Amaliyah, R.P., Puspaningrum, E.Y. (2023). Lung and colon cancer detection with convolutional neural networks on histopathological images. In AIP Conference Proceedings. AIP Publishing LLC, 2654(1): 020020. https://doi.org/10.1063/5.0114327
[16] Gattani, A., Sannake, S., Gupta, D. (2023). Lung and colon cancer classification using hybrid ensemble learning. In 8th International Conference on Computing in Engineering and Technology (ICCET 2023), Hybrid Conference, Patna, India, pp. 412-417. https://doi.org/10.1049/icp.2023.1525
[17] Bechar, A., Medjoudj, R., Elmir, Y., Himeur, Y., Amira, A. (2025). Federated and transfer learning for cancer detection based on image analysis. Neural Computing and Applications, 37(4): 2239-2284. https://doi.org/10.1007/s00521-024-10956-y
[18] Opee, S.A., Eva, A.A., Noor, A.T., Hasan, S.M., Mridha, M.F. (2025). ELW‐CNN: An extremely lightweight convolutional neural network for enhancing interoperability in colon and lung cancer identification using explainable AI. Healthcare Technology Letters, 12(1): e12122. https://doi.org/10.1049/htl2.12122
[19] Naga Raju, M.S., Srinivasa Rao, B. (2023). Lung and colon cancer classification using hybrid principle component analysis network‐extreme learning machine. Concurrency and Computation: Practice and Experience, 35(1): e7361. https://doi.org/10.1002/cpe.7361
[20] Iqbal, S., Qureshi, A.N., Alhussein, M., Aurangzeb, K., Kadry, S. (2023). A novel Heteromorphous convolutional neural network for automated assessment of tumors in colon and lung histopathology images. Biomimetics, 8(4): 370. https://doi.org/10.3390/biomimetics8040370
[21] Fu, Z., Chen, Q., Wang, M., Huang, C. (2025). Transformer based on multi-scale local feature for colon cancer histopathological image classification. Biomedical Signal Processing and Control, 100: 106970. https://doi.org/10.1016/j.bspc.2024.106970
[22] Mulenga, M., Rajamanikam, A., Kumar, S., Muhammad, S.B., Bhassu, S., Samudid, C., Sabri, A.Q.M., Seera, M., Eke, C.I. (2025). Revolutionizing colorectal cancer detection: A breakthrough in microbiome data analysis. PloS One, 20(1): e0316493. https://doi.org/10.1371/journal.pone.0316493
[23] Bhattacharya, A., Saha, B., Chattopadhyay, S., Sarkar, R. (2023). Deep feature selection using adaptive β-Hill Climbing aided whale optimization algorithm for lung and colon cancer detection. Biomedical Signal Processing and Control, 83: 104692. https://doi.org/10.1016/j.bspc.2023.104692
[24] Hamed, E.A.R., Salem, M.A.M., Badr, N.L., Tolba, M.F. (2023). Lung cancer classification model using convolution neural network. In The International Conference on Artificial Intelligence and Computer Vision. Cham: Springer Nature Switzerland. Springer, Cham, pp. 16-26. https://doi.org/10.1007/978-3-031-27762-7_2
[25] Raza, R., Zulfiqar, F., Khan, M.O., Arif, M., Alvi, A., Iftikhar, M.A., Alam, T. (2023). Lung-EffNet: Lung cancer classification using EfficientNet from CT-scan images. Engineering Applications of Artificial Intelligence, 126: 106902. https://doi.org/10.1016/j.engappai.2023.106902
[26] Singh, O., Singh, K.K. (2023). An approach to classify lung and colon cancer of histopathology images using deep feature extraction and an ensemble method. International Journal of Information Technology, 15(8): 4149-4160. https://doi.org/10.1007/s41870-023-01487-1
[27] Farhadipour, A. (2024). Lung and colon cancer detection with convolutional neural networks and adaptive histogram equalization. Iran Journal of Computer Science, 7(2): 381-395. https://doi.org/10.1007/s42044-023-00161-w
[28] Hadiyoso, S., Aulia, S., Irawati, I.D. (2023). Diagnosis of lung and colon cancer based on clinical pathology images using convolutional neural network and CLAHE framework. International Journal of Applied Science and Engineering, 20(1): 1-7. https://doi.org/10.6703/IJASE.202303_20(1).006
[29] Chhillar, I., Singh, A. (2024). A feature engineering-based machine learning technique to detect and classify lung and colon cancer from histopathological images. Medical & Biological Engineering & Computing, 62(3): 913-924. https://doi.org/10.1007/s11517-023-02984-y
[30] Titoriya, A.K., Prasad Singh, M. (2022). Analysis of convolutional neural network architectures for the classification of lung and colon cancer. In International Conference on Machine Intelligence and Signal Processing, Singapore, pp. 243-253. https://doi.org/10.1007/978-981-99-0047-3_22
[31] Masud, M., Sikder, N., Nahid, A.A., Bairagi, A.K., AlZain, M.A. (2021). A machine learning approach to diagnosing lung and colon cancer using a deep learning-based classification framework. Sensors, 21(3): 748. https://doi.org/10.3390/s21030748
[32] Singh, O., Kashyap, K.L., Singh, K.K. (2024). Lung and colon cancer classification of histopathology images using convolutional neural network. SN Computer Science, 5(2): 223. https://doi.org/10.1007/s42979-023-02546-x
[33] Al-Jabbar, M., Alshahrani, M., Senan, E.M., Ahmed, I.A. (2023). Histopathological analysis for detecting lung and colon cancer malignancies using hybrid systems with fused features. Bioengineering, 10(3): 383. https://doi.org/10.3390/bioengineering10030383
[34] Hamed, E.A., Tolba, M., Badr, N., Salem, M.A.M. (2023). Large-scale histopathological colon cancer annotation model using machine learning techniques. International Journal of Intelligent Computing and Information Sciences, 23(3): 73-82. https://doi.org/10.21608/ijicis.2023.211720.1275
[35] Attallah, O., Aslan, M.F., Sabanci, K. (2022). A framework for lung and colon cancer diagnosis via lightweight deep learning models and transformation methods. Diagnostics, 12(12): 2926. https://doi.org/10.3390/diagnostics12122926
[36] Civit-Masot, J., Bañuls-Beaterio, A., Domínguez-Morales, M., Rivas-Perez, M., Munoz-Saavedra, L., Corral, J.M.R. (2022). Non-small cell lung cancer diagnosis aid with histopathological images using explainable deep learning techniques. Computer Methods and Programs in Biomedicine, 226: 107108. https://doi.org/10.1016/j.cmpb.2022.107108
[37] Tummala, S., Kadry, S., Nadeem, A., Rauf, H.T., Gul, N. (2023). An explainable classification method based on complex scaling in histopathology images for lung and colon cancer. Diagnostics, 13(9): 1594. https://doi.org/10.3390/diagnostics13091594