Amit Kumar Chandanan![]() | Vandana Roy*
| Vandana Roy*![]() | Vijay Birchha
| Vijay Birchha![]() | Chandrasekaran Raja
| Chandrasekaran Raja![]() | Akshay Varkale
| Akshay Varkale![]() | Musaddak Maher Abdul Zahra
| Musaddak Maher Abdul Zahra![]() | Pankaj Agarwal
| Pankaj Agarwal![]() | Santosh Kumar Vishwakarma
| Santosh Kumar Vishwakarma![]()
© 2025 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
A novel pneumonia detection system integrates Federated Learning (FL) with autoencoders to address data scarcity and privacy concerns commonly faced in medical diagnostics. Traditional pneumonia detection relies on supervised learning methods primarily Convolutional Neural Networks (CNNs) and transfer learning which require large, labelled datasets stored centrally, raising significant ethical and privacy challenges. In contrast, the proposed system leverages FL to enable collaborative model training across multiple medical institutions without sharing sensitive patient data. Autoencoders further enhance the model’s ability to learn effectively from limited labelled data, improving its generalization in real-world clinical settings. Performance evaluations demonstrate that this approach outperforms existing models in detecting pneumonia from chest X-ray images, achieving superior accuracy, precision, recall, and F1-score. Specifically, the model reaches an accuracy of 95.15%, a precision of 95.8%, and a recall of 98.35%, significantly exceeding results from conventional CNN and transfer learning-based methods. The system not only delivers high diagnostic accuracy but also promotes ethical data handling by eliminating the need for centralized data storage. Overall, this solution addresses the critical limitations of traditional diagnostic frameworks and sets the foundation for secure, privacy-preserving, AI-driven clinical tools.
CNN, SVM, LR, RF, ML, DL, AI, FL, DenseNet, MobileNetV2, VIT
Medical automation requires images and data as essential components for healthcare processes along with improved efficiency and accuracy and elevated patient welfare medical facilities use imaging data and process automation systems to enhance their operational efficiency along with their accuracy rate and healthcare delivery level. The examination medical domains require the analysis of images and clinical data for their operations. Achieving a comprehensive Visualizing high-resolution images remains imperative to comprehend both functional and structural aspects of human organs during the process of study. high-resolution photos. Medical images reveal the operational behaviours linked with different medical conditions. with various medical conditions and aids in disease detection. Artificial Intelligence (AI), AI technology specifically Machine Learning (ML) and Deep Learning (DL) demonstrates key importance in medical applications. Medical images benefit healthcare through AI-based evaluation and interpretation which transforms medical practice in multiple aspects. Patient health benefits at substantial levels when diseases are diagnosed early thanks to this technology. These The technology evaluates medical information from diseased patients to generate responses which drive forward medical progress. various medical fields. Multiple important serious health conditions exist throughout the world as reported by the WHO. Worldwide lower respiratory infections occupy position four in the death rankings. Lower respiratory infection known as pneumonia leads to numerous deaths around the world [1].
1.1 Background of pneumonia detection and ML
The respiratory infection pneumonia strikes millions worldwide which creates major mortality and morbidity causing death primarily among elderly people and young children and people with broken immune systems [2]. The three main infectious agents that trigger pneumonia are bacteria, viruses and fungi leading to alveoli swelling and either fluid accumulation or pus formation that blocks normal breathing function. The prompt identification of pneumonia becomes vital because it enables proper medical care and prevents unwanted medical problems. Doctors diagnose pneumonia through clinical signs together with blood tests and radiographic imaging that especially includes chest X-ray results. The process of manual diagnosis of radiologists and clinicians provides long timeframes and proof to human error alongside experience dependency. Medical diagnostics has experienced significant transformation from AI and ML technologies which now enables automatic rapid diagnosis of pneumonia and other diseases effectively.
1.2 Limitations of traditional pneumonia detection approaches
Research-based pneumonia diagnosis depends on radiologic picture evaluation by specialists although multiple factors reduce its diagnostic accuracy [3]. Diverse human interpretive processes result in unreliable results because different radiologists perform varying interpretations of the same image. The process of manual chest X-ray evaluation requires extensive human effort thus delaying patients' potential diagnoses. Limited expert radiologist presence exists in several rural and underdeveloped areas which contributes to health service disparities. Machine learning methods utilize huge batches of properly identified medical images for training purposes which enhances pneumonia detection both in automation and precision. Traditional ML models demand large labelled datasets for operation yet such datasets are hard to acquire because of privacy restrictions combined with limited access to quality medical image annotations.
1.3 Role of DL in pneumonia detection
As a branch of AI, DL is particularly well-suited to medical picture analysis due to its ability to extract intricate patterns from large datasets [4]. The use of CNNs has led to outstanding success in medical image analysis because these networks extract complicated features to produce precise automated disease diagnosis. Multiple research studies applied VGG16 and InceptionV3 and ResNet and DenseNet architecture to detect pneumonia and they reached remarkable accuracy results. Researched models pre-trained on ImageNet databases apply the obtained expertise through transfer learning procedures to enhance medical application performance. Most deep learning models need a centralized database for training which becomes a vital issue when it comes to healthcare data privacy.
1.4 Challenges in medical AI and data privacy concerns
The main struggle in AI-based medical diagnostics involves protecting patient data along with ensuring its safety [5]. Medical imaging databases maintain patient privacy without proper regulation due to their sensitive content. Medical institutions along with hospitals avoid releasing patient data for AI model development because of confidentiality restrictions while facing legal barriers. The scarce quantity of data produces biased models that exhibit inadequate results across diverse medical groups. Supervised learning models need big quantities of labelled datasets but these resources often remain scarce especially in constrained health facilities. An innovative solution needs development to achieve an optimal balance between data protection and model functionality and end-user accessibility.
1.5 Introduction to federated learning and its benefits
AI-based healthcare applications now address their data privacy issues using FL as their leading technology solution. Flies in contrast to traditional deep learning systems as it enables interconnected institutions to conduct joint training while retaining their patient information within separate boundaries [6]. FL employs local training of models in separate healthcare facilities before sending upgrade packages to central servers which aggregate them. Healthcare institutions maintain full patient data privacy through decentralized operations that allow performance improvements from combined model training efforts. FL enables medical institutions to team up and develop complex diagnostic algorithms independently from patient information revealment.
1.6 Autoencoders and unsupervised learning in medical imaging
Extracting features and identifying anomalies are two areas where autoencoders—a kind of neural network—find widespread use due to their unsupervised learning methodology [7]. Autoencoders extract important visual patterns from unprocessed medical image data which leads to their usefulness in diagnosis systems without abundant labelled training examples. The combination of autoencoder technology enables deep learning models to identify pneumonia in small quantities of training images which helps overcome the issue of small labelled datasets. The current proposal improves through integration with autoencoders because this combination supports knowledge sharing between different healthcare centres while protecting individual patient data privacy. A powerful combination which detects pneumonia efficiently while keeping healthcare AI practice ethical.
The diagram demonstrated shows a categorization of pneumonia depending on the agents that cause it. It graphically categorizes pneumonia into three primary forms: bacterial, fungal, and viral in Figure 1. The ellipse on the left, with the caption "Categorization of Pneumonia," is the primary category, with three branches radiating outward. People with weakened immune systems are more likely to get fungal pneumonia, which can be caused by infestations with fungi. In most cases, medications are the first line of defense against infection with bacteria like pneumoniae strains of which can lead to bacteria-related pneumonia. Antibiotics aren't usually the first line of defense against infectious pneumonia, which can be caused by viruses like influenza or respiratory syncytial virus (RSV). This classification aids in determining the most suitable method of diagnosing and treating pneumonia according to its root cause.
Figure 1. Categorization of Pneumonia
1.7 Moral issues and possible future developments
When it comes to applications of AI for medical purposes, ethical concerns include data protection and privacy, as well as justice. By utilizing FL to safeguard the integrity of information and doing away with the need for centrally managed storage, the suggested model adheres to ethical AI standards [8]. The model is able to decrease biases while attaining great generalizations by operating well on multiple datasets without obtaining data from patients. Improvements in AI diagnostic techniques that combine various learning techniques and provide medical professionals with easier-to-understand models for diagnosing and immediate time diagnostics capability should be the primary goal of future research. This study lends credence to the idea that autonomous pneumonia detection devices may be developed with patients' right to privacy protected while also meeting stringent efficiency and ethical requirements.
Prompt and correct diagnoses is crucial for successful care of pneumonia, which remains a global health concern [9]. Due to their reliance on radiographers, the necessity for qualified analysis of variance, and the privacy concerns associated with data storage in central databases, current methods for diagnosis face three major challenges. There is promise in deep learning algorithms for pneumonia diagnosis, but there is a lack of data and security concerns that might hinder their performance. In order to overcome efficiency constraints, ensure high accuracy, and provide reliable operation, the new model integrates FL systems with automated coders. The model's capacity for cooperative learning makes it feasible to diagnose pneumonia efficiently and securely without sharing patient data, making it a valuable tool for real-world healthcare diagnosis. New research raises hopes for future AI diagnoses and shows the potential for privately owned AI systems in medical.
The diagram visualizes pneumonia symptoms through central grouping as the circular "Pneumonia Symptoms" node which contains the important characteristics in Figure 2. The major pneumonia symptoms affect breathing and cause rapid chest breathing along with disorientation or mental confusion while also leading to excessive sweating and fatigue and discomfort in the stomach or chest area [10]. The symptoms link directly to the central node using arrows to show they represent principal indicators of pneumonia development. Different symptom colours within the diagram create better visibility of their unique consequences on human health while depicting the wide-range symptoms of pneumonia.
Figure 2. Pneumonia symptoms
Pneumonia develops into serious lung infection leading to problems in respiration and body-wide symptoms across the patient [11]. The diagram reproduces two major pneumonia symptoms including breathing problems and chest pain since these occur frequently in patients with pneumonia due to lung inflammatory responses and fluid increases. The combination of fatigue along with excessive sweating and mental confusion indicates that pneumonia creates substantial effects on physical body functioning outside of the respiratory system. Early identification of these symptoms remains essential for medical treatment because pneumonia that goes untreated creates severe complications primarily among fragile groups including young children and elderly patients along with people with weakened immune systems.
The framework of standard autoencoders serves as the focus of the author while they explore the development of the concept. the concept [12]. The different models of autoencoders are classified according to their structural design principles. principles. A comprehensive view emerges about the multiple methods used across the autoencoder field. The paper demonstrates how the usage of autoencoders extends into new technological domains. They can remarkably identify and the system displays two capabilities in image processing by completing object categorization in images (image classification) and achieving human language comprehension (natural language processing). language (natural language processing). While powerful, autoencoders have limitations. The study recognizes the present inadequacies before presenting promising research fronts for future improvements. development.
The framework creates conditions for still stronger autoencoder implementations across different fields. various fields. Single-cell RNA sequencing (scRNA-seq) has transformed our comprehension of cell varieties along with their cellular diversity. and their variations. Researchers find analysing this sophisticated data very difficult when performing COVID-19 studies [13]. The fundamental process requires grouping identical cells under a specific group called clustering. DL The present work brings forward scAAGA which represents a new framework for analysis solutions. suggested by the investigator. A DL algorithm named asymmetric autoencoder constitutes the main component within this model. Table 1 summarizes the review work done in the same field. The scRNA-seq data contains important genetic features that the autoencoder model (asymmetric autoencoder with gene attention) detects automatically. data. The analysis of essential genes during clustering enhances the process of sorting cells that show analogous properties. properties.
Table 1. Overview of related work done in the similar field
|
Methods |
Advantages |
Disadvantages |
|
Convolutional Neural Networks (CNNs) [14] |
Efficient in extracting features and categorization of chest X-rays with elevated precision. |
Needs big labeled datasets; tiny quantities make it overfit. |
|
Support Vector Machine (SVM) [15] |
Functions effectively with limited datasets and elevated-dimensional features spaces. |
Complex structures in medical pictures pose a challenge to performance, which is dependent on selecting features. |
|
Random Forest (RF) Classifier [15] |
Resilient to noise and mitigates overfitting through the utilization of numerous DT. |
Not as good as deep learning models in dealing with highly dimensional picture information. |
|
K-Nearest Neighbours (KNN) [15] |
Straightforward and readily executable for pneumonia categorization. |
Complex to compute with big datasets; susceptible to noise and superfluous features. |
|
Logistic Regression (LR) [16] |
Expeditious and comprehensible for binary categorization of pneumonia instances. |
Weakness in detecting non-linear correlations in picture data. |
|
Transfer Learning (VGG16, ResNet, DenseNet) [17] |
Makes use of pre-trained deep learning algorithms to shorten training time and improve accuracy. |
It is possible that models trained on datasets unrelated to medicine would struggle to identify pneumonia. |
|
Autoencoders for Unsupervised Learning [18] |
Acquires features extraction-friendly effective representations from data without labels. |
Not as accurate as supervised learning methods when it comes to categorization. |
|
Hybrid CNN-RNN Model [18] |
Recorded images of healthcare interdependence in both space and time. |
The real-time implementation is impeded by the high computing cost and the extended training period. |
|
Federated Learning (FL) [19] |
Ensures confidentiality of information by allowing various institutions to train models independently of each other, without exposing any raw data. |
Extremely considerable communication overhead and the possibility of inconsistent models when applied to various datasets. |
|
Deep Reinforcement Learning (DRL) [20] |
Eventually learns the best methods for diagnosing pneumonia. |
Not interpretable in clinical settings; requires substantial expertise. |
|
Ensemble Learning (Combination of CNN, SVM, and Decision Trees) [21] |
Enhances the precision of predictions by the integration of various classifiers. |
More complicated models and more expensive computations. |
|
Gradient Boosting Machines (GBM) [22] |
Good accuracy in predicting outcomes using organized health data. |
For best results, it's necessary to tweak the hyperparameters extensively. |
|
Extreme Gradient Boosting (XGBoost) [23] |
Avoids overfitting and does a good job with data being missing. |
Memory intensive; not designed for use in detecting pneumonia using images. |
|
Recurrent Neural Networks (RNNs) [24] |
Helpful for activities involving sequential diagnostic of pneumonia. |
Has problems with dependencies over the long run and needs a lot of processing power. |
|
Long Short-Term Memory Networks (LSTMs) [25] |
Analyses the course of pneumonia while properly handling temporal interdependence. |
Very costly to compute; training needs massive datasets. |
|
Gated Recurrent Units (GRUs) [26] |
Not dissimilar from LSTMs, but with far better computing efficiency. |
On complicated tasks involving the identification of pneumonia, it performs worse than LSTMs. |
|
Capsule Networks (CapsNet) [27] |
Excels at capturing spatial hierarchies in comparison to conventional CNNs. |
More computing resources are needed due to the high training intricacy. |
|
Graph Neural Networks (GNNs) [28] |
Works well for predicting pneumonia diagnosis connections. |
Not all input data can be accessed in an organized graph format. |
|
Attention-Based Networks [29] |
Highlights important pneumonia characteristics and enhances interpretation. |
More processing power and optimization are needed. |
|
3D CNNs [30] |
Practical for analysing CT images for volumetric pneumonia. |
Intensive computing burden and massive data storage needs. |
|
Self-Supervised Learning [31] |
Minimizes reliance on labelled data for the diagnosis of pneumonia. |
Might not be able to beat completely supervised techniques; needs a lot of pretraining. |
|
Few-Shot Learning (FSL) [32] |
Maintains efficacy with a small number of labelled pneumonia patients. |
Very task-dependent and responsive to tiny changes in training data. |
|
Zero-Shot Learning (ZSL) [32] |
Can detect instances of pneumonia even in the absence of specific training samples. |
Problems with generalizing and understanding complicated patterns in medical images. |
|
Bayesian Neural Networks (BNNs) [33] |
Offers measures of diagnostic ambiguity for pneumonia. |
Difficult in computing terms and challenging to execute on a large scale. |
|
Multi-Modal Learning (Combining X-ray and Clinical Data) [34] |
Allows for better diagnosis of pneumonia by the integration of many data sources. |
Extensive data preparation and integration is necessary. |
|
Radiomics-Based Feature Extraction [35] |
Uses quantitative information extracted from X-ray pictures to identify pneumonia. |
Selecting features necessitates highly specialized domain expertise. |
|
Generative Adversarial Networks (GANs) for Data Augmentation [36] |
Produces artificial pneumonia pictures to improve datasets for training. |
Potential for producing skewed or unrealistic samples. |
|
Wavelet Transform for Feature Extraction [37] |
Improves the identification of pneumonia using features in images analysis. |
Intricate setup that needs specialized understanding. |
|
Optical Flow Analysis [38] |
Examines the patterns of motion in successive X-ray images to detect the development of pneumonia. |
Use is restricted to moving healthcare pictures. |
The investigators tested the method against prevailing techniques when applying it to COVID-19 patient blood cell data. patient blood cell data. The model beat its competitors at every stage to reach notable performance enhancements. in clustering accuracy metrics. The framework uses data augmentation as one of its main features. The technique demonstrates additional strength through data augmentation for the purpose of working with scarce datasets. TDMSAE represents a new method which addresses a significant challenge when attempting to apply ML to fault diagnosis. The method presented by the author provides a solution for handling different machine types. The challenge known as model drift poses itself as a major obstacle. The model shows poor execution on alternative machines even though it was developed for one machine specifically. TDMSAE overcomes this by employing two key modules. Multi-Scale Feature Extraction and Distribution Alignment. The experimental results validate TDMSAE because the model delivers better diagnostic performance compared to traditional techniques. existing methods.
The research uses an organized experimental method to analyse different machine learning and deep learning detection models which detect pneumonia. Publicly available medical imaging datasets from the National Institute of Health (NIH) Chest X-ray collection and relevant repositories constitute a key element of this study because they include both pneumonia cases and normal instances. Several pre-processing operations are performed on the dataset through image resizing along with normalization and contrast enhancement and noise reduction steps which increase the model performance metrics.
The implementation of deep learning models consists of CNNs as well as Transfer Learning models (VGG16, ResNet, DenseNet) and hybrid structures which unite CNNs and RNNs. The training process utilizes GPU hardware alongside the optimal set of parameters for learning rate adjustments, batch size requirements and dropout regularization practices. The performance evaluation process includes the utilization of accuracy alongside sensitivity and specificity and precision and F1-score to conduct model comparisons.
For this research the dataset includes publicly accessible chest X-ray images which primarily originate from three well-established medical repositories which are the NIH Chest X-ray Dataset and RSNA Pneumonia Detection Challenge Dataset together with Stanford CheXpert Dataset. The available datasets include thousands of chest images which have been properly labelled into normal and pneumonia-positive and other lung-related diagnostic categories. A wide range of images from different patient populations makes up the data collection that provides sufficient ground truth information for training purposes.
The dataset requirements for performance improvement include image normalization and subsequent steps of resizing and noise reduction along with contrast enhancement. The prevention of overfitting and model generalization improvement happens through the application of data augmentation techniques such as rotation, flipping and zooming.
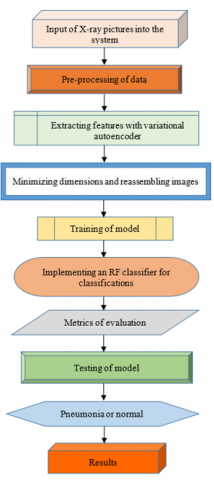
The pneumonia detection program operates through a defined sequence starting with system input of chest X-ray images. The image database functions as the main resource for training and testing purposes because it enables the model to identify patterns which describe pneumonia alongside normal lung conditions in Figure 3. The pre-processing process stands as a critical step because the X-ray imaging data contains diverse sources with inconsistent noise characteristics and resolution values and contrast levels. Standardizing images happens as part of pre-processing data through multiple techniques. Technical experts apply multiple methods to the images during pre-processing including artifact removal through noise reduction along with contrast improvement to present clear lung structures along with normalization to create equal pixel value consistency across all images followed by resizing or cropping to achieve consistent dimensions. Through these steps the model benefits from appropriate high-quality inputs which enhances its accuracy and capability to generalize its predictions.
$R_{n o r m}(a, b)=\frac{R(a, b)-R_n}{R_m-R_n}$ (1)
$ (m, n)=\frac{1}{2 \pi \cdot \sigma^2} f^{-\frac{m^2+n^2}{2 \sigma^2}} $ (2)
$G(J)=\frac{D E K(J)-D E K_n}{(R \times S)-D E K_n} \times 255$ (3)
$Y^{\prime}=Y Z$ (4)
$R(a, b)$ = Originally brightness of pixels at coordinates $(a, b), R_m, R_n$ = Minimal and maximal values of pixels in the picture, $R_{\text {norm }}(a, b)$ = Normalization pixel intensity, $H(m, n)$ = Result of the Gaussian filtering algorithm at pixel $(m, n)$; σ = the average deviation of the Gaussian functional; $m, n$ = The pixel dimensions. $D E K(J)$ = Aggregate distributions relating to intensity of pixels. J, $D E K_n$ = Minimal accumulated distributed value, $R \times S$ = Imaging parameters (height and width), Y = input data matrices, Z = Transforming matrices for minimizing dimensionality, $Y^{\prime}$ = Adapted lower-dimensional information.
The system progresses to feature extraction using a variational autoencoder after completing pre-processing of images. The deep learning variational autoencoder model serves as an unsupervised system that works optimally for both dimension reduction tasks and extracting significant medical image attributes. An encoder component operates within the autoencoder to convert the input image into compressed data in a latent space that emphasizes pneumonia characteristics while reducing unimportant noise. The generated latent space representation creates an essential base for additional process steps so the system prioritizes relevant information in images. Variational autoencoders help the system resolve typical medical image analysis data scarcity problems to create models that perform well with small labelled datasets.
The extracted features move to training stages after the initial extraction process. During the training stage researchers apply processed data into the machine learning model to enable it to recognize patterns that separate pneumonia manifestations from typical lung conditions. A standard practice when using this dataset involves dividing it into training and validation segments for effective deployment to new data samples. The learning approach employs two optimizing methods: gradient descent and back-propagation to reduce classifying mistakes. The optimization performance depends on adjusting parameters including learning rate together with batch size alongside activation functions. Throughout its training process, the model progressively develops superior capabilities to precisely recognize X-ray images.
Figure 3. Phase one of the suggested study's being executed
$w=\mu+\sigma \odot \epsilon$ (5)
$E_{L B}=\frac{1}{2} \sum_{i=1}^e\left(1+\log \left(\sigma_i^2\right)-\mu_i^2-\sigma_i^2\right)$ (6)
$\begin{gathered}K_{Y B F}=F_{p(w \mid y)}[\log q(y \mid w)]- \\ E_{L B}(p(w \mid y) \| q(w))\end{gathered}$ (7)
$z_{r+1}=\sum_{l=1}^L \frac{m_l}{M} z_l$ (8)
$w$ =A latent vector
μ = Mean of the latent area transportation
σ = the standard error of the latent space dispersion
ϵ∼M(0, J) = Random noise
$E_{L B}$ = Kullback-Leibler divergence
$\mu_i^2, \sigma_i^2$ = the average as well as the standard deviation of the latent parameter
i.e. = Dimensions of the latent area
$K_{Y B F}$ = Aggregate loss for Variational Autoencoder
$p(w \mid y)$ = Possibility of rebuilding input y from the latent variable
w. $p(w \mid y)$ = Variational approximations of the probability dispersion
$Z_{r+1}$ = Updates globally modeling weights
$Z_l$ = Localized weights of the model of clients l
$m_l$ = Quantity of information points on client l
M = the overall number of data elements among all clients.
The derivation of the Variational Autoencoder (VAE) loss function is based on maximizing the Evidence Lower Bound (ELBO), which balances reconstruction accuracy and regularization. It includes the expected log-likelihood of the data and the Kullback–Leibler divergence between the approximate and true posterior distributions. The reparameterization trick allows gradient flow through stochastic nodes. During training, parameter settings such as a learning rate of 0.001 and a batch size of 32 are used to ensure stable convergence and effective gradient updates, optimizing both the encoder and decoder networks for accurate X-ray image reconstruction and classification.
After finishing training the system puts into practice its RF classifier for the classification process. RF classification functions as an ensemble learning system which builds several decision trees which subsequently merge their prediction results into strong prognostic forecasts. The model renders excellent performance in medical image classification because it effectively handles complicated data relationships that are non-linear in nature. An ensemble of DT in the RF classifier makes the model more resilient to overfitting thus ensuring better generalization for unknown X-ray images.
The classification process depends on learned features from the variational autoencoder as the predictor decides between pneumonia diagnoses and normal pulmonary conditions. The evaluation phase begins after classification because system performance metrics are computed to assess model effectiveness. The system utilizes precision along with recall and F1-score and accuracy to measure its performance. The precise performance and recall evaluation methods show how effectively a model succeeds at identifying pneumonia cases in predicted instances and demonstrates its ability to properly detect existing pneumonia cases. The performance metrics combine precision and recall results into the F1-score and measure overall accuracy through correctly identified cases. Successful implementation of high-performance models depends on achieving high scores on all metrics which guarantees reliable outcomes in actual clinical practice.
The training process is guided by the gradient-based optimization of a regularized objective function. The model's parameters are updated iteratively using:
$z_{r+1}=z_r-\eta \nabla K\left(z_r\right)$ (9)
where, η is the learning rate, and ∇K(zᵣ) denotes the gradient of the loss function K with respect to the current parameter zᵣ. This standard gradient descent update rule minimizes the objective function iteratively.
To compute class probabilities, we use a softmax-like formulation:
$Q(x=i \mid y)=\frac{f^{z_i} y+c_i}{\sum_{l=1}^L f^{z_l} y+c_l}$ (10)
This represents the probability distribution over output classes, where f is the activation function, and zᵢ, cᵢ are learned parameters.
The loss function for classification is given by the cross-entropy:
$K=-\sum_{j=1}^M x_i \log \left(\widehat{x}_J\right)$ (11)
which penalizes deviation between true labels xⱼ and predicted probabilities x̂ⱼ.
In variational models, momentum-based updates are also considered. For the first-order momentum:
$n_v=\beta_1 n_{v-1}+\left(1-\beta_1\right) h_v$ (12)
and for second-order moment tracking:
$w_v=\beta z_{v-1}+(1-\beta) h_v^2$ (13)
These help smooth parameter updates and stabilize training, especially in autoencoder structures.
Entropy-based regularization is used to enhance feature diversity:
$H(E)=1-\sum_{j=1}^r q_j^2$ (14)
which measures uncertainty in the output space. A more diversified feature space leads to better generalization.
Feature relevance (FR) is evaluated as:
$F R=G(E)-\sum_{j=1}^n \frac{\left|E_j\right|}{|E|} G\left(E_j\right)$ (15)
where, G(E) is the entropy of the entire feature space and G(Eⱼ) is the entropy within feature subset Eⱼ.
Entropy G(F) for feature selection is defined as:
$G(F)=-\sum_{j=1}^e r_j \log _2 r_j$ (16)
emphasizing the distributional spread of features in decision-making.
Model output aggregation in federated learning is given by:
$z=\frac{1}{M} \sum_{j=1}^M e_j(y)$ (17)
where, eⱼ(y) is the output of the model for client j and M is the number of clients.
Regularization is crucial for controlling model complexity:
$K=K_o+\lambda\|z\|^2$ (18)
$K=K_o+\lambda \sum\left|z_j\right|$ (19)
$K=K_o+\lambda \sum z_j^2$ (20)
These forms correspond to L2, L1, and ridge regularization respectively, penalizing large weights to prevent overfitting.
λ: Regularity strength, $\|z\|^2$ : L2 norms of the weights, $\sum\left|z_j\right|$ : Sum of the absolute amounts of objects, $\sum z_j^2$ : Sum of squaring weighted.
The model architecture incorporates multiple computational stages, where each component enhances different aspects of learning, optimization, and generalization.
The convolution operation is fundamental for feature extraction and is mathematically represented as:
$P(m, n)=\sum_r \sum_s J(m+r, n+s) L(r, s)$ (21)
Here, J is the input image, and L is the convolutional kernel. The output P(m,n) represents the response at location (m,n) by sliding the kernel over the input image.
Activation is performed using a ReLU function:
$d(t)=\max (0, t)$ (22)
This introduces non-linearity and suppresses negative values, ensuring sparse activation and improved convergence in deep networks.
Pooling, used for downsampling, is expressed as:
$R(m, n)=\max _{r, s} P(m+r, n+s)$ (23)
This max-pooling operation reduces spatial dimensions and retains the most prominent features within a region.
To enforce margin-based learning and penalize misclassifications, a hinge loss variant is used:
$T=\sum_{j=1}^M \max \left(0,1-z_j \widehat{Z_{\jmath}}\right)$ (24)
This ensures that predictions ẑⱼ remain close to the true label zⱼ, particularly in binary classification tasks.
Feature similarity is measured using cosine similarity:
$\cos (\theta)=\frac{z_1 \cdot z_2}{\left\|z_1\right\| x\left\|z_2\right\|}$ (25)
This captures the angular similarity between latent vectors, useful in clustering and embedding-based tasks.
The learning rate is dynamically adjusted during training using:
$\eta_v=\eta_0 f^{-\lambda v}$ (26)
where, η₀ is the initial learning rate, λ is the decay constant, and v is the epoch or iteration count. This decays the learning rate progressively to refine convergence.
Gradient descent with iteration control is applied as:
$z_{l, v+1}=z_{l, v}-\eta \nabla K_l\left(z_{l, v}\right)$ (27)
This updates local parameters zₗ on client l by descending the gradient of the local loss Kₗ.
Federated optimization employs a regularized update to align client and global models:
$U\left(z_l\right)=U_l\left(z_l\right)+\frac{\mu}{2}\left\|z_l-z\right\|^2$ (28)
This penalizes deviation from the global model z, controlled by regularization factor μ.
Model variance across clients is tracked by:
$w b s(Y)=\frac{1}{M} \sum_{j=1}^M\left(z_j-\bar{z}\right)^2$ (29)
This represents between-client variance and is critical in non-iid federated learning settings to detect model drift.
Finally, confidence intervals for statistical evaluation are computed using:
$D J=\bar{y} \pm W \frac{\sigma}{\sqrt{M}}$ (30)
where, ȳ is the sample mean, σ is the standard deviation, M is the number of samples, and W is the critical value from the appropriate statistical distribution (e.g., t or z). This quantifies the uncertainty in performance metrics.
Figure 4. Procedures for training in the context of FL (2nd Phase)
The model evaluation leads to testing which proves its ability to classify X-ray images which have not been observed before is shown in Figure 4. Successful model generalization assessment requires this testing phase. The trained classifier applies diagnosing tests to an exclusive dataset which did not take part in training or validation processes. The testing phase ensures that the model acquires useful learning instead of memorized patterns which let it correctly identify pneumonia versus standard instances during practical use. Other performance upgrades including extra model training and parameter modifications should be conducted when needed to enhance operational efficiency.
Federated Learning (FL) protects data privacy by keeping raw data local and sharing only model updates. To prevent parameter leakage or gradient inversion attacks, techniques like differential privacy add noise to updates, obscuring individual data contributions. Secure aggregation further enhances security by encrypting updates so the server sees only aggregated results. These methods collectively ensure strong defenses against adversarial threats while maintaining data confidentiality in decentralized training environments.
The pipeline finishes by using the model to classify each X-ray input which results in an assessment between pneumonia and normal diagnoses in Figure 4. Users who interact with the system can view the diagnostic results depending on whether they are a radiologist or doctor or part of a hospital automation process. The diagnosis and treatment decisions of medical professionals receive assistance from the produced output. The model uses federated learning together with variational autoencoders to uphold privacy standards and flexible operation thus making it appropriate for healthcare use despite limited access to labelled data and strict patient confidentiality requirements.
This approach trains a machine learning algorithm using dispersed datasets. In this context, "Server" refers to the server, "Clients" denotes a compilation of clients, and V represents the total amount of rounds the model undergoes during training. In each loop, the subsequent actions are executed:
|
Algorithm 1: FL (client, server, V) |
|
# The server allocates the design to the clients. 1. In the starting iteration, the centralized server establishes the global models N0 with arbitrary values for variables. # Client Selection 2. In each cycle v=1…V, the centralized server picks a subset of l nodes among the pool P containing n data points and transmits the most recent model Nv-1 to these k nodes. # Every user trained the algorithm with its local data. 3. Every jth node, whose j ϵ l, directly trained the model Nv-1 on its respective data Ej for a specified period of epochs and transmits the modified model Hi t to the centralized server. # The server modifies the variables of the globally model. 4. A centralized server consolidates the local modifications using an aggregating technique with an aggregated rate η to formulate a novel global framework Nv. |
Users can rely on this system for reliable pneumonia detection because it combines privacy-enhancing protocols with deep learning features and ensemble methodology. The utilization of federated learning enables healthcare institutions to work together for model development without disclosing confidential patient information thus solving key privacy issues in medical Artificial Intelligence. Automated autoencoder models boost the model's functionality for handling low-data scenarios which secures efficient pneumonia diagnosis in resource-limited environments. The system demonstrates an accurate and efficient and privacy-aware method for pneumonia diagnosis of chest X-ray images through its well-organized input-to-results framework.
A federated learning system based on pneumonia detection of X-ray images appears in the given diagram. The system describes how to process data next to pre-processing before training and aggregation steps before evaluation and classification. X-ray images enter the system to function as-initial-source-data before mirrored to pneumonia detection purposes. The medical images originating from different medical institutions or datasets require pre-processing treatment for quality enhancement and noise elimination and dimension normalization. The pre-processing step includes pixel value re-scaling as well as the application of noise reduction via Gaussian filters combined with contrast enhancement through histogram equalization and uniform image cropping. VAE processes images after pre-processing to extract important features from each sample. The VAE engages in reducing the image dimensions yet conserving vital data points which streamlines training operations.
The system advances to perform limited model training after finishing feature extraction. Model training occurs at distributed client nodes through the implementation of federated learning instead of occurring on a centralized server. The client nodes only have access to restricted dataset portions to maintain absolute privacy for each member. Database owners must then be chosen from amongst the clients to take part in the federated training phase. The server receives updated model parameters through client selection without access to the actual databases following modification of the variables. This ensures privacy-preserving model updates. Model parameters are transmitted to the server for each training session after clients complete their training process. The X-ray images remain decentralized while the server performs aggregation of these updates without being able to view the actual image data.
The system conducts data aggregation through FedAvg processing at server level by combining all uploaded variables from different clients. United under FedAvg (Federated Averaging) the server creates a global model update by taking weighted averages from received model parameters. The aggregated model goes through several refinement steps after aggregation which normally consist of three rounds for this scenario. Through repeated training processes the accuracy of the model can improve while its ability to generalize different client data sets is enhanced. The evaluation process for the model occurs after both model training and aggregation completion using performance metrics. The evaluation metrics determine the performance of federated learning by calculating classification accuracy combined with precision and recall and F1-score measurements. The trained model receives testing data that has not been part of its previous training process to verify its operational capacity.
The model performs classifications of new X-ray images by determining whether they show signs of pneumonia or remain normal. The model generates classification results by applying patterns which it acquired during the training period. A system detects and categorizes images which present pneumonia-related abnormalities in their structure. The system’s final delivery provides a diagnosis by interpreting the model’s predicted results. The framework protects healthcare regulations by keeping X-ray pictures on local servers together with the transfer of shared model parameters instead of sharing image-based data. A system that implements federated learning with VAEs provides security solutions and efficiency improvement in medical image classification for practical healthcare applications.
The proposed model introduces computational complexity primarily through communication overhead in Federated Learning (FL), as multiple client-server interactions are needed during training rounds. This increases latency and bandwidth usage, especially with large model updates. Additionally, autoencoders require significant training resources, including high memory and GPU support, particularly when handling high-resolution X-ray images. However, these challenges can be mitigated using model compression, client-side optimization, and adaptive communication techniques. Despite higher hardware demands, the model’s decentralized nature offers scalability and preserves privacy, making it a worthwhile trade-off in healthcare applications.
Our innovative method which integrates FL systems with autoencoders successfully demonstrates its competencies in pneumonia detection according to the conducted strict evaluation process. Tests indicate that autoencoders with FL for pneumonia detection produce outcomes that match those of traditional models. This accomplishment holds major importance because it solves major difficulties that occur across the field. The approach works well despite dealing with restricted labelled information as well as data protection requirements. By leveraging unsupervised learning, the autoencoder framework produces excellent outcomes even when limited labelled data exists, which is a frequent problem during implementation. in healthcare AI. This healthcare solution creates new options to be used in numerous healthcare locations, delivering limited datasets. labelled data is often limited. The incorporation of FL allows healthcare organizations to cooperate during distributed training on separate dataset locations. residing at various healthcare institutions.
The joint effort negates the necessity for centralization of data. A distributed data storage system represents an essential measure for always maintaining healthcare patient privacy. By training on Private data from multiple sources can be analysed by the model without compromising patient security, which allows it to reach potentially higher performance levels. greater robustness and generalizability. The presented method brings a radical approach to pneumonia detection research. addresses critical needs in healthcare AI. The framework enables partnership among different entities while safeguarding personal information and promoting efficient model development systems. The solution develops models efficiently with the combination of Federated Learning and unsupervised learning systems. The new method enables progress in AI-based medical diagnosis tools through its innovative approach. while prioritizing ethical data practices.
8.1 Precision
It quantifies the proportion of accurately predicted positive cases among all expected positives.
8.2 Recall
It quantifies the number of true positive cases accurately detected.
8.3 F1-score
It maximizes both recall and precision. Beneficial in cases when the cost of inaccurate positive and negative results is high.
8.4 Accuracy
It quantifies the overall number of correct forecasts. It is beneficial for balancing datasets, however deceptive in unbalanced datasets.
8.5 Specificity
Evaluates the model's efficacy in identifying normal (non-pneumonia) instances. Increased specificity results in a reduction of false positives.
8.6 ROC-AUC (Receiver operating characteristic -area under the curve)
It assesses the model's overall capacity to differentiate between pneumonia and normal patients. Elevated values signify superior discriminating capability.
8.7 Training time (sec)
The duration required to train the algorithm on the dataset. Accelerated training is advantageous, particularly for extensive datasets.
8.8 Inference time (ms)
The duration required for the model to analyse and categorize each X-ray picture. Reduced values signify expedited estimation, which is crucial for applications that operate rapidly.
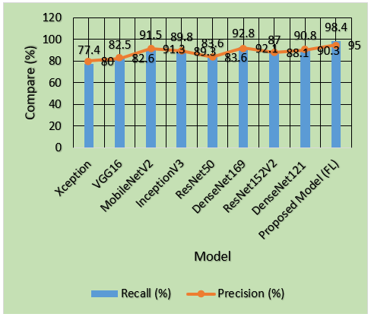
Table 2. Analysing and comparing model effectiveness using recall and precision
|
Model |
Recall (%) |
Precision (%) |
|
Xception |
77.4 |
80.0 |
|
VGG16 |
82.5 |
82.6 |
|
MobileNetV2 |
91.5 |
91.3 |
|
InceptionV3 |
89.8 |
89.3 |
|
ResNet50 |
83.6 |
83.6 |
|
DenseNet169 |
92.8 |
92.1 |
|
ResNet152V2 |
87.0 |
88.1 |
|
DenseNet121 |
90.8 |
90.3 |
|
Proposed Model (FL) |
98.4 |
95.0 |
The analysis examines different deep learning models by comparing their recall alongside their precision in the provided Table 2 and Figure 5. The proposed FL model stands out from all existing models because it demonstrates the best performance in both recall (98.4%) and precision (95.0%) allowing it to detect positive cases with enhanced accuracy. Both DenseNet169 and MobileNetV2 show robust performance levels with 92.8% recall and 92.1% precision and 91.5% recall and 91.3% precision, respectively. The Xception along with ResNet50, exhibit limited success rates in pattern recognition compared to newer network architectures, with respective recall results of 77.4% and 83.6% and precision values of 80.0% and 83.6%. Mature decision-makers should select the proposed model (FL) as their primary option due to its optimal performance-evaluation balance between recall and precision.
Figure 5. Comparative analysis of various models according to recall and precision
Table 3. Comparative analysis of various models utilizing f1-score and accuracy metrics
|
Model |
F1-Score (%) |
Accuracy (%) |
|
Xception |
78.7 |
77.9 |
|
VGG16 |
81.2 |
82.5 |
|
MobileNetV2 |
91.3 |
91.0 |
|
InceptionV3 |
89.2 |
89.3 |
|
ResNet50 |
83.6 |
83.6 |
|
DenseNet169 |
91.0 |
92.4 |
|
ResNet152V2 |
87.1 |
87.4 |
|
DenseNet121 |
90.1 |
90.2 |
|
Proposed Model (FL) |
96.7 |
95.3 |
Figure 6. Evaluating model effectiveness using F1-Score and accuracy
Several deep learning models receive evaluation based on their F1-score and accuracy metrics through this Table 3 and Figure 6. This proposed model (FL) delivers maximum F1-score results (96.7%) together with accuracy of 95.3% indicating it maintains outstanding accuracy combined with precision and recall performance. The classification abilities of MobileNetV2 and DenseNet169 are confirmed through their respective test results which show 91.3% F1-score and 91.0% accuracy. InceptionV3 released 89.2% F1-score coupled with 89.3% accuracy while DenseNet121 delivered 90.1% F1-score at 90.2% accuracy for reliable results. Xception together with ResNet50 demonstrate reduced performance through their F1-score of 78.7% and accuracy of 77.9% while also showing 83.6% F1-score and accuracy. This indicates Xception and ResNet50 may lack the effectiveness of newer architecture forms. According to the results the FL model achieved the best accuracy level among all tested models because of its robust balance.
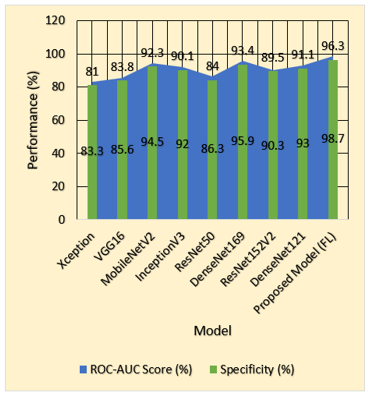
Table 4. Evaluation of various models with respect to specificity and ROC-AUC scores
|
Model |
Specificity (%) |
ROC-AUC Score (%) |
|
Xception |
81.0 |
83.3 |
|
VGG16 |
83.8 |
85.6 |
|
MobileNetV2 |
92.3 |
94.5 |
|
InceptionV3 |
90.1 |
92.0 |
|
ResNet50 |
84.0 |
86.3 |
|
DenseNet169 |
93.4 |
95.9 |
|
ResNet152V2 |
89.5 |
90.3 |
|
DenseNet121 |
91.1 |
93.0 |
|
Proposed Model (FL) |
96.3 |
98.7 |
Figure 7. Comparing of specificity and ROC-AUC scores across various models
A comparison between different deep learning models regarding specificity and ROC-AUC score findings exist in the Table 4 and Figure 7. The proposed model (FL) achieves the best combination of specificity (96.3%) and ROC-AUC score (98.7%) which demonstrates its great capability to differentiate between negative and positive outcomes with excellent overall performance. The deep learning models DenseNet169 and MobileNetV2 demonstrate strong discrimination capabilities between classes with 93.4% specificity and 95.9% ROC-AUC and 92.3% specificity and 94.5% ROC-AUC respectively. The performance levels of InceptionV3 and DenseNet121 maintain reliability through their 90.1% specificity and 92.0% ROC-AUC scores alongside 91.1% specificity and 93.0% ROC-AUC scores respectively. The performance of Xception (81.0% specificity, 83.3% ROC-AUC) is the least effective among the assessed models while VGG16 (83.8% specificity, 85.6% ROC-AUC) together with ResNet50 (84.0% specificity, 86.3% ROC-AUC) demonstrate moderate success. FL presents strong evidence of being the best model since it demonstrates higher accuracy rates in distinguishing between positive and negative cases than all alternative models in the study.
Table 5. Evaluation of training times across various models
|
Model |
Training Time (s) |
|
Xception |
2300 |
|
VGG16 |
1900 |
|
MobileNetV2 |
1400 |
|
InceptionV3 |
2000 |
|
ResNet50 |
1800 |
|
DenseNet169 |
1500 |
|
ResNet152V2 |
2200 |
|
DenseNet121 |
1600 |
|
Proposed Model (FL) |
1300 |
Figure 8. Analysis of various models' training times
The Table 5 compares the training times of various deep learning models. MobileNetV2 demonstrates the fastest education duration at 1400 seconds which gives it the label of most efficient computational model. The training speeds for DenseNet169 reach 1500 seconds and for DenseNet121 amount to 1600 seconds as measured by the dataset. VGG16 (1900s) and InceptionV3 (2000s) need training durations that exist between speedy and elaborate execution. From all models ResNet50 (1800s) showed somewhat faster training performance than other models yet ResNet152V2 (2200s) and Xception (2300s) needed the most time for training operations because they require extensive computational resources. Training MobileNetV2 and DenseNet models occurs faster compared to Xception and ResNet152V2 models which need prolonged convergence time as shown in Figure 8.
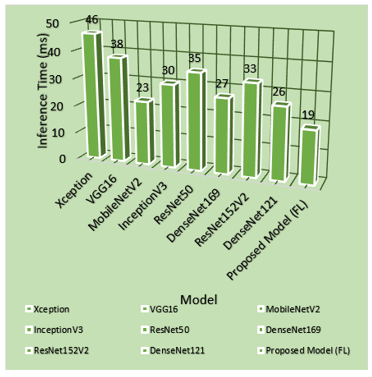
Table 6. Evaluation of various models’ inference times
|
Model |
Inference Time (ms) |
|
Xception |
46 |
|
VGG16 |
38 |
|
MobileNetV2 |
23 |
|
InceptionV3 |
30 |
|
ResNet50 |
35 |
|
DenseNet169 |
27 |
|
ResNet152V2 |
33 |
|
DenseNet121 |
26 |
|
Proposed Model (FL) |
19 |
Figure 9. Comparing the inference times of various models
Table 7. Evaluation of the proposed method with different FL and AE models
|
Model |
Accuracy (%) |
Precision (%) |
Recall (%) |
F1-Score (%) |
|
Proposed FL + Autoencoder |
95.15 |
95.8 |
98.35 |
96.9 |
|
FL + CNN |
91.2 |
90.4 |
93.1 |
91.7 |
|
FL + Transfer Learning |
92.6 |
92.1 |
94.3 |
93.2 |
|
Standalone Autoencoder |
89.7 |
88.5 |
91.2 |
89.8 |
|
Centralized CNN |
90.8 |
90.2 |
92.5 |
91.3 |
The presented table shows the time needed for deep learning models to make inferences. The proposed model (FL) delivers the shortest inference duration of 19 milliseconds thus making it the most efficient solution. MobileNetV2 runs inference at a speed of 23ms because of its compact design. DenseNet121 takes 26 milliseconds to perform tasks while DenseNet169 requires 27 milliseconds during the process as depicted in Figure 9 and Table 6. The inference times for InceptionV3 (30 ms) and ResNet152V2 (33 ms) along with ResNet50 (35 ms) fall in between while VGG16 (38 ms) and Xception (46 ms) need more time due to their complex computational structure. The proposed model together with MobileNetV2 represents the most effective configuration for real-time applications because they deliver the best inference efficiency.
Figure 10. Comparison of the proposed method with different FL and AE models
Figure 10 and Table 7 suggests that the proposed pneumonia detection model, which combines Federated Learning (FL) with autoencoders, demonstrates significant improvements over existing methods in both performance and privacy preservation. Comparative experiments show that it achieves 95.15% accuracy, 95.8% precision, 98.35% recall, and a 96.9% F1-score surpassing FL-CNN, FL with transfer learning, standalone autoencoders, and centralized CNN models. Unlike conventional approaches that require centralized data and large labeled datasets, the proposed system ensures patient privacy by keeping data decentralized and enhances learning efficiency from limited samples through autoencoders. These results validate the model’s potential as a secure, accurate, and ethical solution for clinical pneumonia diagnosis.
This method stands apart from traditional CNNs and centralized deep learning models by integrating Federated Learning (FL) with autoencoders, enabling decentralized training across medical institutions without sharing raw patient data. Unlike centralized models that require large labeled datasets and compromise privacy, this approach preserves data confidentiality by keeping data local. The inclusion of autoencoders enhances its capability to learn from limited labeled samples, addressing a major limitation in conventional methods. By combining privacy-preserving distributed training with efficient small-sample learning, the model not only improves diagnostic accuracy but also aligns with ethical and legal standards in real-world healthcare settings.
To improve healthcare picture evaluation, this work focuses on integrating sophisticated methods of DL with privacy-preserving procedures. It uses FL to facilitate cross-institutional collaboration on training while also addressing the pressing problem of data privacy. By utilizing a decentralized method, we can keep sensitive health information locally while yet taking use of community learning. The research also delves into how unsupervised learning approaches might help with little labelled data, making models more adaptable and resilient in real-world situations. The goal of implementing multiple model methods for optimization is to improve the overall efficacy of the model, decrease inference time, and increase computational effectiveness. Additionally, the study highlights how important it is to have effective and reliable ways of communicating in federated learning in order to keep data intact and reduce security threats. In addition, it emphasizes the advantages of sophisticated structures in meeting privacy requirements while boosting the reliability of health care diagnoses. The development of excellent durability models that do not compromise respect for information is made possible by the combination of privacy-preserving approaches with deep learning. This adds to the expanding area of AI-driven medical services. This study lays the groundwork for more research into privacy-aware machine learning, which will allow us to investigate more flexible, effective, and reliable applications of AI in areas like healthcare diagnosis.
Improved safeguarding privacy DL algorithms for medical image analysis that can scale efficiently will be the subject of future research. One important step is to improve FL methods so they can process bigger datasets with fewer interactions overhead and strong protection from malicious assaults. If we want to lower computing costs without sacrificing accuracy, we'll look at better model compressing and quantized methods. To further increase the approach's adaptability to various medical uses, self-supervised learning approaches may be used to enhance performance of models in low-data circumstances.
In future work, we plan to collaborate with medical institutions to obtain real-world clinical data for testing and validation. This will allow us to evaluate the proposed model's effectiveness in actual healthcare settings, ensuring practical applicability. Such real data testing will strengthen the model's credibility, confirm its robustness across diverse patient populations, and further validate its privacy-preserving capabilities in real-time medical environments.
[1] Kashyap, A., Raghuvanshi, J. (2020). A preliminary study on exploring the critical success factors for developing COVID-19 preventive strategy with an economy centric approach. Management Research: Journal of the Iberoamerican Academy of Management, 18(4): 357-377. https://doi.org/10.1108/mrjiam-06-2020-1046
[2] Aouthu, S., Suman, S.K., Anuradha, S., Sanapala, R.K., Geetha, A. (2025). Automated diagnosis of acute cerebral ischemic stroke lesions using capsule graph neural networks from diffusion-weighted MRI scans. Journal of Electrical Engineering & Technology, 20: 2631-2650. https://doi.org/10.1007/s42835-024-02120-2
[3] Chauhan, G., Chauhan, V. (2019). A phase-wise approach to implement lean manufacturing. International Journal of Lean Six Sigma, 10(1): 106-122. https://doi.org/10.1108/ijlss-09-2017-0110
[4] Bhagyalakshmi, L., Suman, S.K., Sujeethadevi, T. (2020). Joint routing and resource allocation for cluster based isolated nodes in cognitive radio wireless sensor networks. Wireless Personal Communications, 114: 3477-3488. https://doi.org/10.1007/s11277-020-07543-4
[5] Srivastava, P.K., Kumar, S., Tiwari, A., Goyal, D., Mamodiya, U. (2023). Internet of thing uses in materialistic ameliorate farming through AI. AIP Conference Proceedings, 2782(1): 020133. https://doi.org/10.1063/5.0154574
[6] Malik, N. (2018). Authentic leadership–an antecedent for contextual performance of Indian nurses. Personnel Review, 47(6): 1244-1260. https://doi.org/10.1108/pr-07-2016-0168
[7] Raja, C., Santhosh Krishna, B.V., Loganathan, B., Kumar Suman, S., Bhagyalakshmi, L., Alrashoud, M., Giri, J., Sathish, T. (2024). A wavelet CNN with appropriate feed-allocation and PSO optimized activations for diabetic retinopathy grading. Automatika, 65(4): 1593-1605. https://doi.org/10.1080/00051144.2024.2409552
[8] Kala, S., Nandan, H., Sharma, P. (2022). Shadow and weak gravitational lensing of a rotating regular black hole in a non-minimally coupled Einstein-Yang-Mills theory in the presence of plasma. The European Physical Journal Plus, 137(4): 1-18. https://doi.org/10.1140/epjp/s13360-022-02634-6
[9] Roy, V. (2022). Breast cancer classification with multi-fusion technique and correlation analysis. Fusion: Practice & Applications, 9(2): 48-61. https://doi.org/10.54216/FPA.090204
[10] Sood, K., Dev, M., Singh, K., Singh, Y., Barak, D. (2022). Identification of asymmetric DDoS attacks at layer 7 with idle hyperlink. ECS Transactions, 107(1): 2171. https://doi.org/10.1149/10701.2171ecst
[11] Shrivastava, Y., Shrivastava, P.K., Nandan, D. (2022). Signal processing algorithms like ensemble empirical mode decomposition and statistical analysis-based tool chatter severity prediction. Traitement du Signal, 39(4): 1221-1227. https://doi.org/10.18280/ts.390414
[12] Roy, V., Roy, L., Ahluwalia, R., Khambra, G., Ramesh, M., Rajasekhar, K. (2023). An advance implementation of machine learning techniques for the prediction of cervical cancer. In 2023 IEEE International Conference on ICT in Business Industry & Government (ICTBIG), Indore, India, pp. 1-5. https://doi.org/10.1109/ICTBIG59752.2023.10456347
[13] Prabhu, C., Venkateswara Gandhi, R., Jain, A.K., Lalka, V.S., Thottempudi, S.G., Rao, P.P. (2020). A Novel Approach to Extend KM Models with Object Knowledge Model (OKM) and Kafka for Big Data and Semantic Web with Greater Semantics. In Complex, Intelligent, and Software Intensive Systems, 993: 544-554. https://doi.org/10.1007/978-3-030-22354-0_48
[14] Prajapati, Y.N., Sharma, M. (2023). Designing AI to predict Covid-19 outcomes by gender. In 2023 International Conference on Data Science, Agents & Artificial Intelligence (ICDSAAI), Chennai, India, pp. 1-7. https://doi.org/10.1109/icdsaai59313.2023.10452565
[15] Vishwakarma, S.K., Sharma, P.C., Raja, R., Roy, V., Tomar, S. (2020). An effective cascaded approach for EEG artifacts elimination. International Journal of Pharmaceutical Research, 12(4): 4822. https://doi.org/10.31838/ijpr/2020.12.04.653
[16] Prajapati, Y.N., Sharma, M. (2024). Novel machine learning algorithms for predicting COVID-19 clinical outcomes with gender analysis. In: Garg, D., Rodrigues, J.J.P.C., Gupta, S.K., Cheng, X., Sarao, P., Patel, G.S. (eds) Advanced Computing. IACC 2023. Communications in Computer and Information Science, vol 2054. Springer, Cham. https://doi.org/10.1007/978-3-031-56703-2_24
[17] Khan, J.A., Rathore, R.S., Abulreesh, H.H., Al‐thubiani, A.S., Khan, S. Ahmad, I. (2018). Diversity of antibiotic‐resistant Shiga toxin‐producing Escherichia coli serogroups in foodstuffs of animal origin in northern India. Journal of Food Safety, 38(6): e12566. https://doi.org/10.1111/jfs.12566
[18] Gupta, H., Sharma, C. (2022). Face mask detection using transfer learning and OpenCV in live videos. In 2022 International Conference on Fourth Industrial Revolution Based Technology and Practices (ICFIRTP), Uttarakhand, India, pp. 115-119. https://doi.org/10.1109/icfirtp56122.2022.10059441
[19] Roy, V. (2024). A context-aware Internet of Things (IoT) founded approach to scheming an operative priority-based scheduling algorithms. Journal of Cybersecurity & Information Management, 13(1): 28-35. https://doi.org/10.54216/JCIM.130103
[20] Singh, V.P., Bansal, R., Singh, R. (2022). Big-data analytics. Advances in Data Science and Analytics: Concepts and Paradigms, pp. 275-291. https://doi.org/10.1002/9781119792826.ch12
[21] Suman, S.K., Porselvi, S., Bhagyalakshmi, L., Kumar, D. (2014). Game theoretical approach for improving throughput capacity in wireless ad hoc networks. In 2014 International Conference on Recent Trends in Information Technology, Chennai, India, pp. 1-6. https://doi.org/10.1109/ICRTIT.2014.6996152
[22] Kashyap, R., Roy, V., Patil, P.D., Manhar, A., Roy, L. (2023). Deep learning's role in advancing gastroenterology and digestive health. In 2023 IEEE International Conference on ICT in Business Industry & Government (ICTBIG), Indore, India, pp. 1-6. https://doi.org/10.1109/ICTBIG59752.2023.10455988
[23] Saini, A., Kumari, A., Kumar, S. (2022). A proposed method of machine learning based framework for software product line testing. In 2022 International Conference on Fourth Industrial Revolution Based Technology and Practices (ICFIRTP), Uttarakhand, India, pp. 10-13. https://doi.org/10.1109/icfirtp56122.2022.10059409
[24] Gupta, H., Sharma, C., Arya, S., Joshi, K. (2022). A machine learning framework for detection of fake news. In: Singh, R., Balas, V.E., Kar, A.K., Gehlot, A., Shamshirband, S. (eds) Business Data Analytics. ICBDA 2022. Communications in Computer and Information Science, vol 1742. Springer, Cham. https://doi.org/10.1007/978-3-031-23647-1_6
[25] Jain, H., Mahadev, M. (2022). An analysis of SMS spam detection using machine learning model. In 2022 Fifth International Conference on Computational Intelligence and Communication Technologies (CCICT), Sonepat, India, pp. 151-156. https://doi.org/10.1109/ccict56684.2022.00038
[26] Shrivastava, Y., Neha, E., Singh, B., Shrivastava, P.K., Murthy, K.V.S.R., Nandan, D. (2022). Analysis of regenerative raw signals using variational mode decomposition. Traitement du Signal, 39(1): 299-304. https://doi.org/10.18280/ts.390131
[27] Gupta, H., Imran, J., Sharma, C. (2023). Flu-Net: two-stream deep heterogeneous network to detect flu like symptoms from videos using grey wolf optimization algorithm. Journal of Ambient Intelligence and Humanized Computing, 14(6): 7733-7745. https://doi.org/10.1007/s12652-023-04585-x
[28] Khan, J.A., Abulreesh, H.H., Kumar, R., Samreen, Ahmad, I. (2019). Antibiotic Resistance in Campylobacter jejuni: Mechanism, Status, and Public Health Significance. In Antibacterial Drug Discovery to Combat MDR, pp. 95-114. https://doi.org/10.1007/978-981-13-9871-1_4
[29] Sharma, C., Singh, M.P., Chaudhary, S. (2021). Cost analysis of solar-wind based hybrid renewable energy system. In: Komanapalli, V.L.N., Sivakumaran, N., Hampannavar, S. (eds) Advances in Automation, Signal Processing, Instrumentation, and Control. i-CASIC 2020. Lecture Notes in Electrical Engineering, vol 700. Springer, Singapore. https://doi.org/10.1007/978-981-15-8221-9_256
[30] Choubey, S.B., Choubey, A., Nandan, D., Mahajan, A. (2021). Polycystic ovarian syndrome detection by using two-stage image denoising. Traitement du Signal, 38(4): 1217-1227. https://doi.org/10.18280/ts.380433
[31] Tyagi, H., Kumar, V., Kumar, G. (2022). A review paper on real-time video analysis in dense environment for surveillance system. In 2022 International Conference on Fourth Industrial Revolution Based Technology and Practices (ICFIRTP), Uttarakhand, India, pp. 171-183. https://doi.org/10.1109/icfirtp56122.2022.10059434
[32] Kumar, A., Kumar, V., Saini, A., Kumari, A., Kumar, V. (2022). Classification of minority attacks using machine learning. In 2022 International Conference on Fourth Industrial Revolution Based Technology and Practices (ICFIRTP), Uttarakhand, India, pp. 101-105. https://doi.org/10.1109/icfirtp56122.2022.10059437
[33] Kannan, M., Kumar, M., Saini, S., Sharma, V. (2022). AHP-WASPAS approach for choice of non-conventional manufacturing process. In 2022 International Conference on Fourth Industrial Revolution Based Technology and Practices (ICFIRTP), Uttarakhand, India, pp. 297-302. https://doi.org/10.1109/icfirtp56122.2022.10059423
[34] Nandan, D., Kanungo, J., Mahajan, A. (2024). An error-efficient Gaussian filter for image processing by using the expanded operand decomposition logarithm multiplication. Journal of Ambient Intelligence and Humanized Computing, 15: 1045-1052. https://doi.org/10.1007/s12652-018-0933-x
[35] Rathi, V., Singh, G., Kumar, P., Chaudhary, M., Singh, P., Mishra, M. (2022). Legality of worldwide cannabis use and associated economic benefits. In: Belwal, T., Belwal, N.C. (eds) Revolutionizing the Potential of Hemp and Its Products in Changing the Global Economy. Springer, Cham. https://doi.org/10.1007/978-3-031-05144-9_3
[36] Prajapati, Y.N., Sharma, M., Azam, F., Biradar, A. (2024). Enhancing COVID-19 diagnosis and severity evaluation through machine learning algorithms applied to CT images. Multidisciplinary Science Journal, 6(11): 2024207-2024207. https://doi.org/10.31893/multiscience.2024207
[37] Vashishtha, A.K., Sharma, M., Sharma, A. (2022). Mechanism incorporating secure mutual validation and key spreading organization in intelligent transport system. In 2022 International Conference on Fourth Industrial Revolution Based Technology and Practices (ICFIRTP), Uttarakhand, India, pp. 219-225. https://doi.org/10.1109/icfirtp56122.2022.10059443
[38] Sharma, S., Tomar, P., Sharma, P. (2022). Emotional recognition through facial expression using support vector machine. In 2022 International Conference on Fourth Industrial Revolution Based Technology and Practices (ICFIRTP), Uttarakhand, India, pp. 248-253. https://doi.org/10.1109/icfirtp56122.2022.10063209