Enhanced Improved Proportionate Set-Membership Fast NLMS Using the $\ell_0$ Norm

Lynda Fedlaoui*![]() | Ahmed Benallal
| Ahmed Benallal![]() | Ayoub Tedjani
| Ayoub Tedjani![]() | Mountassar Maamoun
| Mountassar Maamoun![]()
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Authors developed the Improved Proportionate Normalized Least Mean Square algorithm using the $\ell_0$ norm (IPNLMS-L0) to fully leverage the sparsity of impulse responses in echo cancellation scenarios. This algorithm delivered satisfactory outcomes, surpassing the IPNLMS algorithm, especially when addressing sparse impulse responses. However, its utility was limited by its poor performance in non-stationary or dispersive systems and practical constraints associated with evaluating the exponential expression and aligning the parameter β with the impulse response's sparsity. In the initial phase of our research, we aimed to overcome these practical hurdles. To do so, we introduced an approach that employs a sparseness measure grounded in the $\ell_1, \ell_2$, and $\ell_{\infty}$ norms to determine the value of the parameter β. We also applied an approximation method based on a Maclaurin expansion of the exponential term. The integration of these two strategies resulted in the development of an efficient gain control matrix. We seamlessly integrated this matrix into the framework of Improved Set-Membership Fast NLMS (ISMFNLMS). This led to a substantial reduction in computational complexity and an enhanced ability to address non-stationary conditions. Our proposed algorithm, named Enhanced Improved Proportionate Set-Membership Fast NLMS using the $\ell_0$ norm (EIPSMFNLMS-L0), aims to address the challenges of acoustic echo cancellation (AEC) by adeptly handling varying degrees of impulse response sparsity. Simulation results validate that our algorithm, regardless of whether the impulse response is sparse or dispersive, exhibits improved convergence speed, enhanced tracking capability, and achieves lower mean square error (MSE) levels, all while maintaining cost-effective computational performance, outperforming all recent variants of the IPNLMS and ISMFNLMS algorithms.
adaptive filtering, sparse algorithms, system identification, acoustic echo cancellation, Set-Membership Fast NLMS, convergence speed, tracking capability
The aim of this research work is to address the challenging problem of AEC for different sparsity levels of acoustic impulse responses (AIRs) [1]. Sparse system identification is a prevalent issue in various practical applications [1-3]. For instance, in AEC the AIR often exhibits sparsity, where only a small percentage of components have significant magnitudes while the rest are close to zero. The commonly used algorithms, NLMS and Recursive Least Squares (RLS) do not consider the sparse nature of such systems. This led to the development of "proportionate" approaches, resulting in the PNLMS algorithms [2-4]. The idea behind these algorithms is to individually update each coefficient by adjusting the adaptation gain proportionally to the estimated coefficient's magnitude. This prioritizes coefficients with high magnitudes, leading to faster initial convergence and an overall improved convergence rate. Unfortunately, the enhanced performance of the PNLMS algorithms is not sustained throughout the adaptation process. This is because the PNLMS algorithm accelerates the convergence of high-magnitude coefficients at the expense of slowing down the convergence of low-magnitude coefficients. Furthermore, when the Impulse Response (IR) is dispersive, PNLMS performs worse than the NLMS [3-5]. Multiple variations of the PNLMS algorithm have been introduced to enhance the resilience of proportionate algorithms across diverse system types. Among these alternatives, the IPNLMS algorithm [3-5] has emerged as a successful option. It utilizes the $\ell_1$ norm to leverage the sparsity of the IR along with the combination of the NLMS gain and a proportionality rule in the PNLMS. The IPNLMS-L0 algorithm, proposed in studies [6-8], replaces the $\ell_1$ norm with the $\ell_0$ norm in the IPNLMS algorithm. This substitution is based on the recognition of the $\ell_0$ norm as an effective and intuitive mathematical measure of sparseness. The IPNLMS-L0 algorithm introduces a new parameter β for calculating the $\ell_0$ norm and incorporates an exponential term in the gain control matrix equation. It effectively utilizes the sparsity of the IR and performs well, particularly when dealing with sparse IR. However, it has practical limitations [4, 7]. Firstly, choosing an appropriate value for the parameter β is crucial and depends on the sparseness of the IR. Additionally, the exponential term in the gain control matrix equation may pose challenges during real-world implementations.
In addition, recent studies have revealed that algorithms with proportionate characteristics, such as the IPNLMS algorithm, exhibit inadequate performance in numerous sparse systems or when confronted with non-stationary and compressible systems. Specifically, these systems refer to those that do not possess sufficient sparsity [9].
On a different note, while the RLS algorithm and its variants demonstrate a considerably faster convergence rate than the NLMS algorithm, they suffer from high computational complexity. To address this issue, researchers have conducted several experiments to achieve the fast convergence of the RLS algorithm while reducing its computational complexity. The result of these efforts is the development of the FNLMS algorithm [10-13]. When compared to the NLMS algorithm, the FNLMS algorithm exhibits a faster convergence rate and enhanced tracking capability.
The FNLMS algorithm has recently integrated the Set-Membership (SM) approach [14-16]. This integration involves updating the step size based on the estimated output error, resulting in the development of an ISM-FNLMS algorithm.
These enhancements lead to reduced computational update costs and improved tracking capability. However, the algorithm still requires additional consideration for sparseness and an upgrade to incorporate it. In a more recent development, a hybrid sparseness-aware algorithm called Improved Proportionate FNLMS (IPFNLMS) has been created [17]. This algorithm incorporates the gain control matrix of the IPNLMS algorithm into the Kalman-based adaptation gain of the FNLMS algorithm. In comparison to the IPNLMS algorithm, the IPFNLMS algorithm exhibits similar computational costs but demonstrates superior behavior.
The practical limitations of the IPNLMS-L0 algorithm are well-known [4, 7]: the determination of the parameter β and the exponential term evaluation. To address these limitations, the proposed EIPSMFNLMS-L0 algorithm provides a solution by introducing a method that incorporates sparseness measure based on the $\ell_1, \ell_2$, and $\ell_{\infty}$ norms which accurately captures both sparse and dispersive IRs to determine the parameter β and employing an efficient approximation of the exponential term through a Maclaurin expansion. This approach yields to an effective gain control matrix that not only mitigates the shortcomings of the IPNLMS-L0 algorithm but also works effectively and robustly to the variations in the sparseness of the IR. To further reduce the computational complexity of our proposed algorithm and enhance the algorithm's ability to track time-varying changes in the system. we take a step further by integrating our new gain control matrix obtained into the concept of ISMFNLMS. This integration involves incorporating the gain control matrix into the Kalman-based adaptation gain of the FNLMS algorithm and subsequently integrating the SM concept. The resulting EIPSMFNLMS-L0 algorithm achieves a desirable balance between convergence speed, steady-state performance, lower MSE level and robustness to sparse and dispersive AIRs with low-cost complexity, surpassing NLMS, IPNLMS and IPNLMS-L0 and significantly surpasses the recent ISMFNLMS and IPFNLMS algorithms. This study offers comprehensive derivations and explanations of the proposed algorithm, along with the results of numerical simulations. The focus is on comparing the performance of the proposed algorithm with existing algorithms in terms of convergence speed, tracking capability, final mean square error (MSE), and computational complexity. The evaluation covers scenarios involving both sparse and dispersive IRs, as well as stationary and non-stationary signals and systems.
2.1 The standard IPNLMS algorithm and AEC
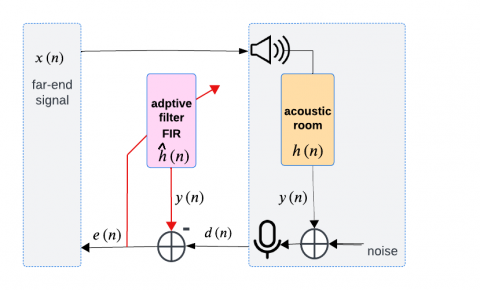
In this section, the IPNLMS algorithm [3] is investigated within the context of an adaptive system designed for AEC. The system configuration is illustrated in Figure 1. Where $x(n)$ is the far-end signal at time index $n$ and $\boldsymbol{x}(n)=$ $\left[\begin{array}{llll}x(n) & x(n-1) & \cdots & x(n-L+1)\end{array}\right]^T$. describes the Ldimensional signal vector and $\boldsymbol{h}(n)=$ $\left[\begin{array}{llll}h(n) & h(n-1) & \cdots & h(n-L+1)\end{array}\right]^T$ indicates the $L-$ dimensional impulse response vector of the unknown time-varying system to be identified. Certainly, as noise is unavoidable in the acoustic environment, noise processing must be considered thus the additive noise b(n) is introduced to the output of the unknown system, and the noisy desired signal d(n) could be expressed as follows:
$d(n)=\boldsymbol{h}^T(n) \boldsymbol{x}(n)+b(n)$ (1)
Figure 1. Adaptive system for AEC
The scalar quantity $y(n)=\boldsymbol{h}^T(n) \boldsymbol{x}(n)$ is the echo signal, where the unknown system $\boldsymbol{h}(n)$ is assumed as a finite impulse response (FIR) model of size $L$. The adaptive filter is noted by the estimated vector $\widehat{\boldsymbol{h}}(n)$.
The a priori error signal $e(n)$, the estimated echo signal $\hat{y}(n)$, and the coefficient update equation of the IPNLMS algorithm are defined as:
$e(n)=d(n)-\hat{y}(n)$ (2)
$\hat{y}(n)=\widehat{\boldsymbol{h}}^T(n-1) \boldsymbol{x}(n)$ (3)
$\widehat{\boldsymbol{h}}(n)=\widehat{\boldsymbol{h}}(n-1)+\mu \frac{\boldsymbol{Q}(n-1) \boldsymbol{x}(n) e(n)}{\boldsymbol{x}^T(n) \boldsymbol{Q}(n-1) \boldsymbol{x}(n)+\delta_{I p}}$ (4)
With
$\boldsymbol{Q}(n-1)=\operatorname{diag}\left\{q_0(n-1) \quad \cdots \quad q_{L-1}(n-1)\right\}$ (5)
The gain diagonal control matrix, denoted as $\boldsymbol{Q}(n-1)$, plays a crucial role in the adaptive filter by adjusting the step size of each coefficient. The μ parameter designates a fixed step-size.
The calculation of the diagonal elements of $\boldsymbol{Q}(n-1)$, follows the procedure outlined in:
$\begin{gathered}q_l(n-1)=\frac{(1-\rho)}{2 L}+\frac{(1+\rho)\left|h_l(n-1)\right|}{2\|\widehat{\boldsymbol{h}}(n-1)\|_1+\delta}, 0 \leq l \leq L-1\end{gathered}$ (6)
where, $\|.\|_1$ is the $\ell_1$ norm, $\delta$ is a small positive number used to avoid division by zero $[1,3]$ and $\rho$ is the control factor that controls the degree of proportionality in IPNLMS, i.e., the behavior of IPNLMS is altered between NLMS and PNLMS according to the value of $\rho$, that is when $\rho=-1$ IPNLMS performs similarly to NLMS and similarly to PNLMS when $\rho$ is close to 1. The best choices for this parameter are: 0, 0.5 and -0.5 [1, 3, 5]. The regularization parameter for the IPNLMS algorithm is:
$\delta_{I P}=\frac{(1-\rho)}{2 L} \delta_{N L M S}$ (7)
2.2 The IPNLMS algorithm built on the $\ell_0$ norm
The IPNLMS algorithm described in the previous section uses the $\ell_1$ norm to exploit the sparseness of the IR for identification problem [3-5]. However, it is worth noting that the $\ell_0$ norm is considered a more suitable mathematical measure of sparseness, as it provides a better reflection of sparseness according to study [6]. Taking the vector $\boldsymbol{z}$ of length $L, z=\left[z_0, z_1, \ldots, z_{L-1}\right]^T \neq 0$, the related function of the $\ell_0$ norm is:
$f(z)= \begin{cases}1, & z \neq 0 \\ 0, & z=0\end{cases}$ (8)
The $\ell_0$ norm of the vector z is expressed as follows:
$\|z\|_0=\sum_{l=0}^{L-1} f\left(z_l\right)$ (9)
Due to the presence of elements in vector z that may be very small but not precisely zero, the function $f(z)$ is not continuous [6-8]. To address this, it is advantageous to approximate the function $f(z)$ with a smooth and continuous function, which is a commonly employed approximation [6].
$\|z\|_0 \approx \sum_{l=0}^{L-1}\left(1-e^{-\beta\left|z_l\right|}\right)$ (10)
The elements of the gain control matrix have been computed using this norm in studies [4, 7], where β is a positive value. The calculation is performed as follows:
$\begin{gathered}q_l(n-1)= \frac{(1-\rho)}{2 L}+\frac{(1+\rho)\left(1-e^{-\beta\left|\widehat{h}_l(n-1)\right|}\right)}{2 \sum_{i=0}^{L-1}\left[1-e^{-\beta\left|\widehat{h}_i(n-1)\right|}\right]+\delta_{I P}}, 0 \leq l \leq L-1\end{gathered}$ (11)
where,
$q_l(n-1)=\frac{\kappa_l(n-1)}{\sum_{i=0}^{L-1} k_i(n-1)}, 0 \leq l \leq L-1$ (12)
The proportionality function $\kappa_l(n-1)$ is evaluated using the following expression:
$\begin{gathered}\kappa_l(n-1)= (1-\rho) \frac{\|\widehat{\boldsymbol{h}}(n-1)\|_0}{L}+(1+\rho)\left(1-e^{-\beta\left|\widehat{h}_l(n-1)\right|}\right), 0 \leq l \leq L-1\end{gathered}$ (13)
3.1 The standard FNLMS algorithm
The FNLMS algorithm, a novel algorithm obtained by simplifying the Fast RLS algorithm, is introduced. This algorithm demonstrates rapid convergence and offers low computational complexity. The adaptation gain for the FNLMS algorithm is given in studies [12, 13] as:
$\boldsymbol{g}(n)=\gamma(n) \tilde{\boldsymbol{c}}(n)$ (14)
where, the likelihood variable is $\gamma(n)$, and the dual Kalman gain is $\tilde{\boldsymbol{c}}(n)$. By completely disregarding the backward and forward predictors and solely utilizing the forward prediction error of the input signal, the evaluation of the dual Kalman gain is conducted. This evaluation process is described in studies [11-13] as follows:
$\left[\begin{array}{c}\tilde{\boldsymbol{c}}(n) \\ c(n)\end{array}\right]=\left[\begin{array}{c}-\frac{\varepsilon(n)}{\lambda \alpha(n-1)+C_0} \\ \tilde{\boldsymbol{c}}(n-1)\end{array}\right]$ (15)
A small positive constant, $C_0$, is employed to prevent division by extremely small values or zero, especially in cases where the input signal remains absent for a prolonged period. The forgetting factor, λ, falls within the range of 0 to 1, while a(n) represents the variance of the forward prediction error.
$\alpha(n)=\lambda \alpha(n-1)+\varepsilon^2(n)$ (16)
The prediction error $\varepsilon(n)$ in Eq. (15) and Eq. (16) is computed by a first-order prediction model.
$\varepsilon(n)=x(n)-a(n) x(n-1)$ (17)
In scenarios where the input statistics are often unknown or subject to variations over time, the prediction parameter a(n) needs to be determined based on the input signal. To estimate a(n), the following equation is employed:
$a(n)=\frac{r_1(n)}{r_0(n)+C_a}$ (18)
To prevent division by values that are very close to zero, $C_a$ is introduced as a small positive constant. The estimate of the first lag correlation function of $x(n)$ is denoted as $r_1(n)$, while $r_0(n)$ represents the estimate of the power of the input signal. Recursive formulas are used to estimate these two functions, and they are given by:
$r_1(n)=\lambda_a r_1(n-1)+x(n) x(n-1)$ (19)
$r_0(n)=\lambda_a r_0(n-1)+x^2(n)$ (20)
where, $\lambda_a$ is an exponential forgetting factor. The likelihood variable $\gamma(n)$ is recursively defined as [13].
$\gamma(n)=\frac{\gamma(n-1)}{1+\gamma(n-1) o(n)}$ (21)
where,
$o(n)=c(n) x(n-L)+\frac{x(n) \varepsilon(n)}{\lambda \cdot \alpha(n-1)+C_0}$ (22)
In order to have better control over the adaptation gain of the filtering component, a fixed step-size μ has been incorporated. The update equation for this algorithm is defined as:
$\widehat{\boldsymbol{h}}(n)=\widehat{\boldsymbol{h}}(n-1)-\mu \boldsymbol{g}(n) e(n)$ (23)
3.2 The ISMFNLMS algorithm
The SM adaptive filtering presents a new algorithm known as SM-NLMS. Its update equation is similar to that of the NLMS algorithm, but with an "optimal" adaptive step size. This means that the step size assumes a value of zero when the optimization problem described below has been verified, indicating that there is no need for further updates [14-16]. This SM concept was expanded to include the FNLMS algorithm. This extension involved replacing the a priori error with its estimates, which resulted in the development of the ISM-FNLMS algorithm, as described in the study [16]. The objective of this algorithm is to minimize the optimization problem represented by $\|\widehat{\boldsymbol{h}}(n)-\widehat{\boldsymbol{h}}(n-1)\|^2$, while adhering to the constraint that the estimated impulse response vector $\widehat{\boldsymbol{h}}(n)$ belongs to the set $\mathcal{H}(n)$ which is a set comprising all vectors $\widehat{\boldsymbol{h}}(n)$ for which the error is within by a certain upper bound $\omega$. In simpler terms, $\boldsymbol{\mathcal { H }}(n)$ encompasses the vectors whose estimation error is limited by $\omega$. This set can be defined as [14-16]:
$\mathcal{H}(n)=\left\{\widehat{\boldsymbol{h}} \in \mathbb{R}^{L+1}:|d(n)-\widehat{\boldsymbol{h}}(n-1) \boldsymbol{x}(n)| \leq \omega\right\}$ (24)
The achievement of the constraint involves orthogonal projection of the previous estimate $\widehat{\boldsymbol{h}}(n-1)$ onto the closest boundary of the set $\boldsymbol{\mathcal { H }}(\mathrm{n})$. As a result, the ISM-FNLMS algorithm has an updated equation given as follows [14]:
$\widehat{\boldsymbol{h}}(n)=\widehat{\boldsymbol{h}}(n-1)-\mu(n) \boldsymbol{g}(n) e(n)$ (25)
The step-size $\mu(n)$ in Eq. (25) is defined as follows:
$\mu(n)=\left\{\begin{array}{cc}1-\frac{\omega}{\sigma_e(n)} & \text { if }|e(n)|>\omega \\ 0 & \text { otherwise }\end{array}\right.$ (26)
Here, $\omega$ represents the given bound, and $\sigma_e(n)$ is an estimation of the modulus of the error signal. Initially, $\sigma_e(n)$ is set to a value close to the input signal power $\sigma_x$. The parameter $\zeta$ is a forgetting factor, and Eq. (27) defines the update rule for $\sigma_e(n)$ [16]:
$\sigma_e(n)=\zeta \sigma_e(n-1)+(1-\zeta)|e(n)|$ (27)
4.1 Sparseness measure using the $\ell_1, \ell_2$ and $\ell_{\infty}$ norms
Quantifying an estimate of sparseness by considering the $\ell_1$ and $\ell_2$ norms, which specifically characterize the sparse impulse response, can be expressed according to reference [5] using the following expression:
$\hat{\xi}_{12}(n)=\frac{L}{L-\sqrt{L}}\left\{1-\frac{\|\widehat{\boldsymbol{h}}(n-1)\|_1}{\sqrt{L}\|\widehat{\boldsymbol{h}}(n-1)\|_2}\right\}$ (28)
In study [4], an additional measure of sparseness is introduced, which is based on the $\ell_2$ and $\ell_{\infty}$ norms. This measure is designed to reflect dispersive impulse responses. However, since the true impulse response is unknown during the adaptation process, an estimated weight vector $\widehat{\boldsymbol{h}}(n-1)$ is utilized to obtain an estimated version of this measure. The estimated sparseness measure, denoted as $\hat{\xi}_{2 \infty}(n)$, can be calculated using the following equation:
$\hat{\xi}_{2 \infty}(n)=\frac{L}{L-\sqrt{L}}\left\{1-\frac{\|\widehat{\boldsymbol{h}}(n-1)\|_2}{\sqrt{L}\|\widehat{\boldsymbol{h}}(n-1)\|_{\infty}}\right\}$ (29)
where, the $\|\cdot\|_2$ and the $\|\cdot\|_{\infty}$ are the $\ell_2$ and $\ell_{\infty}$ norms respectively. An adequate sparseness measure of both sparse and dispersive IRs may be generated by combining these two measures; an example of this combination is given [4] as:
$\hat{\xi}_{12 \infty}(n)=\frac{\hat{\xi}_{12}(n)+\hat{\xi}_{2 \infty}(n)}{2}$ (30)
This combination allows for a balanced assessment of sparsity, considering the characteristics captured by both the $\hat{\xi}_{12}(n)$ and the $\hat{\xi}_{2 \infty}(n)$ measures.
4.2 Derivation of the proposed algorithm
Two specific practical issues in the IPNLMS-L0 algorithm must be addressed:
Parameter $\beta$ selection: the algorithm's performance heavily relies on the parameter $\beta$ [7], making its selection crucial. Determining the optimal $\beta$ value requires considering multiple factors which can be found in study [6]. A dispersive impulse response necessitates a larger $\beta$ value, while a sparse impulse response requires a smaller $\beta$ value. Therefore, it is essential to develop a feasible method for selecting this parameter.
Exponential term evaluation: implementing the exponential element in Eq. (11) poses challenges in real-world applications. To address this, an efficient approximation is required.
In this section, we present a novel approach to compute the gain control matrix elements that address the aforementioned issues. The main concern, as stated in point (1), is how to determine the value of β based on the sparseness of the impulse response. To address this, we propose incorporating the system sparseness measure $\hat{\xi}_{12 \infty}(n)$ which effectively represents both sparse and dispersive impulse responses, into the calculation of the parameter $\beta$. This association allows for a degree of sparseness to be linked with the optimal value of $\beta$. It is crucial to note that a low value of $\beta$ is required when $\hat{\xi}_{12 \infty}(n)$ is large, indicating a sparse impulse response. Conversely, when $\hat{\xi}_{12 \infty}(n)$ is low, a larger value of $\beta$ is needed for a dispersive impulse response. In both cases of sparseness, an exponential function is preferred to achieve the desired value of $\beta$. However, it is worth mentioning that a linear function yields similar effects. Hence, we have chosen the following expression:
$\beta(n)=\frac{1}{L}\left(1-\psi \hat{\xi}_{12 \infty}(n)\right)$ (31)
A suitable choice for $\psi$ is 0.25. Notably, when $n=0$, both $\ell_2$ and $\ell_{\infty}$ norms in $\hat{\xi}_{12 \infty}(n)$ are zero. To avoid division by zero, $\hat{\xi}_{12 \infty}(n)$ can be calculated and incorporated into Eq. (31) for $n \geq L$ [5]. For $n<L$, we set $\beta(n)=0.5$, which yields satisfactory results for both sparse and dispersive impulse responses.
Regarding point (2), an effective solution involves utilizing the first-order Maclaurin series expansion of the exponential function. We propose the following approximation:
$\begin{aligned} & e^{-\beta(n)\left|\hat{h}_l(n-1)\right|} \approx\left\{\begin{array}{c}1-\beta(n)\left|\hat{h}_l(n-1)\right| \quad i f\left|\hat{h}_l(n-1)\right| \leq \frac{1}{\beta(n)} \\ , \quad 0 \leq l \leq L-1 \\ 0 \quad\quad\quad elsewhere\end{array} \right.\end{aligned}$ (32)
The approximation presented in Eq. (33) limits the values of the estimated coefficient by utilizing the fact that the exponential function is always greater than zero. As an alternative to Eq. (10), the $\ell_0$-norm of the estimated coefficient can be expressed as follows:
$\begin{aligned} & \|\widehat{\boldsymbol{h}}(n-1)\|_0 \approx\left\{\begin{array}{l}\sum_{l=0}^{L-1} \beta(n)\left|\hat{h}_l(n-1)\right| \quad \text { if }\left|\hat{h}_l(n-1)\right| \leq \frac{1}{\beta(n)} \\ \quad\quad\quad, 0 \leq l \leq L-1 \\ L \quad\quad\quad elsewhere\end{array}\right.\end{aligned}$ (33)
In accordance with the principles of both IPNLMS and IPNLMS-L0 algorithms [3, 7], along with the utilization of the new method for selecting $\beta(n)$ and the $\ell_0$-norm approximation outlined in (33), the proportionality function $\kappa_l(n-1)$ can be expressed as:
$\begin{aligned} & \kappa_l(n-1) =\left\{\begin{array}{c}(1-\rho) \frac{\|\widehat{\boldsymbol{h}}(n-1)\|_0}{L}+(1+\rho) \beta(n)\left|\widehat{h}_l(n-1)\right| \\ i f\left|\widehat{h}_l(n-1)\right| \leq \frac{1}{\beta(n)}, \quad 0 \leq l \leq L-1 \\ 2 \quad \quad \quad\quad\quad elsewhere\end{array}\right.\end{aligned}$ (34)
Calculating the $\ell_1$ norm of the proportionality vector k, yields:
$\begin{aligned} & \|\boldsymbol{k}(n-1)\|_1 =\left\{\begin{array}{cc}2\|\widehat{\boldsymbol{h}}(n-1)\|_0 & i f\left|\hat{h}_l(n-1)\right| \leq \frac{1}{\beta(n)} \\ & , 0 \leq l \leq L-1 \\ 2 L & elsewhere \end{array}\right.\end{aligned}$ (35)
The gain control matrix elements can be computed using the new approach by substituting Eq. (34) and Eq. (35) into Eq. (12). The computation of matrix elements is found as follows:
$\begin{aligned} & q_l(n-1) =\left\{\begin{array}{l}\frac{(1-\rho)}{2 L}+\frac{(1+\rho) \beta(n)\left|\widehat{h}_l(n-1)\right|}{2 \beta(n) \sum_{l=0}^{L-1}\left|\widehat{h}_l(n-1)\right|+\delta_{I P}} \\ i f\left|\widehat{h}_l(n-1)\right| \leq \frac{1}{\beta(n)} \quad, 0 \leq l \leq L-1 \\ \frac{1}{L} \quad \text { elsewhere }\end{array}\right.\end{aligned}$ (36)
In the context of changing acoustic environments, the tracking capabilities of IPNLMS-type algorithms have shown limited improvements. Moreover, these algorithms may experience significant performance degradation when dealing with systems that lack sufficient sparseness [9]. Enhancing robustness in such scenarios typically requires additional computational costs. Consequently, there is a demand for a sparseness-aware algorithm that is both low-cost and robust. Inspired by the ISM-FNLMS algorithm described in subsection (3.2), which combines the advantages of the SM concept and the FNLMS algorithm, and exhibits strong tracking capabilities in time-varying environments while reducing computational complexity, we propose a solution. Our approach involves two key steps:
First, we incorporate the previously described novel gain control matrix $\boldsymbol{Q}(n-1)$ with elements given by Eq. (36), into the Kalman-based adaptation gain of the FNLMS algorithm, similar to the approach used in the IPFNLMS algorithm [17]. Next, we introduce the SM concept into the proposed algorithm, akin to the method employed in study [16]. By doing so, we develop the EIPSMFNLMS-L0 algorithm using the $\ell_0$-norm.
These enhancements are achieved through the following two phases:
Phase 01: The insertion and integration of the Kalman-based adaptation gain.
In the steady state, when considering a stationary input, the adaptation gain for the FNLMS algorithm can be approximated to be comparable to the adaptation gain of the NLMS algorithm [10-13]. It can be expressed as follows:
$\boldsymbol{g}(n) \approx-\frac{\boldsymbol{x}(n)}{V \sigma_x^2} \rightarrow \boldsymbol{x}(n) \approx-V \sigma_x^2 \boldsymbol{g}(n)$ (37)
where,
$V=L\left(1+\frac{\lambda}{(1-\lambda) L}+\frac{C_0}{L \sigma_x^2}\right)$ (38)
where, $\sigma_x^2$ is the power of the input signal. The influence of the input signal power in the adaptation gain can be reduced by choosing $\left[\left(C_0 / L \sigma_x^2\right) \ll 1\right]$. In Eq. (4), by substituting $\boldsymbol{x}(n)$ with $-V \sigma_x^2 \boldsymbol{g}(n)$ we obtain the following expression [17]:
$\begin{aligned} \widehat{\boldsymbol{h}}(n)= & \widehat{\boldsymbol{h}}(n-1) -\frac{\mu}{\left(V \sigma_x^2\right)} \frac{\boldsymbol{Q}(n-1) \boldsymbol{g}(n) e(n)}{\boldsymbol{g}^T(n) \boldsymbol{Q}(n-1) \boldsymbol{g}(n)+\frac{\delta_{I p}}{\left(V \sigma_x^2\right)^2}}\end{aligned}$ (39)
By utilizing the adaptation step-size derived from the approximate mean-square analysis for the NLMS algorithm, specifically, $0<\mu<2$ [18], we ensure the suitability of the step-size in Eq. (39). If $\sigma_x^2 \geq 1 / L$, then $V \sigma_x^2 \geq 1$, since $V>L$ [17, 19, 20]. In such cases, the inequality $0<\left(\mu / V \sigma_x^2\right)<2$ always holds true for $0<\mu<2$. Consequently, the step size in Eq. (39) is substituted with $0<\mu<2$, yielding an update equation form comparable to IPNMLS-type algorithms. Eq. (39) demonstrates the dependency of the regularization parameter on $\sigma_x^2$. As a result, the regularization parameter of the proposed algorithm is simplified and specified as follows:
$\delta_{I P F L}=\frac{(1-\rho)}{2 L} C_0$ (40)
With $C_0$ is the regularization parameter of the FNLMS algorithm.
Phase 02: The derivation of the set-membership version.
The proposed algorithm, just like the ISMFNLMS algorithm, may have its step-size determined by resolving the optimization problem stated in subsection (3.2), in which the a-posteriori error $e_p(n)$ used to form the constraint set $\mathcal{H}(n)$ ought to be equal to $\omega$ [15], as follows:
$e_p(n)=d(n)-\widehat{\boldsymbol{h}}^T(n) \boldsymbol{x}(n)=\omega$ (41)
The a-posteriori error can be rewritten as follows:
$e_p(n)=d(n)-\left(\widehat{\boldsymbol{h}}(n-1)-\mu(n) \frac{\boldsymbol{Q}(n-1) \boldsymbol{g}(n) e(n)}{\boldsymbol{g}^T(n) \boldsymbol{Q}(n-1) \boldsymbol{g}(n)+\delta_{I P F L}}\right) \boldsymbol{x}(n)$ (42)
Using approximation Eq. (37), and under the assumption that the constant $\delta_{I P F L}$ is small, the above equation becomes:
$e_p(n)=e(n)-\mu(n) e(n) V \sigma_x^2$ (43)
Considering that $V \sigma_x^2 \geq 1$, we can conclude that:
$e(n)[1-\mu(n)] \approx \omega$ (44)
Given that estimations are used to replace the magnitude of the error [16], the proposed algorithm adapts the step size $\mu(n)$ according to Eq. (26). Consequently, the update equation for the developed algorithm is expressed as follows:
$\begin{aligned} & \widehat{\boldsymbol{h}}(n) =\widehat{\boldsymbol{h}}(n-1)-\mu(n) \frac{\boldsymbol{Q}(n-1) \boldsymbol{g}(n) e(n)}{\boldsymbol{g}^T(n) \boldsymbol{Q}(n-1) \boldsymbol{g}(n)+\delta_{I P F L}}\end{aligned}$ (45)
The pseudo-code for the proposed algorithm is outlined in Table 1.
Table 1. Pseudo-code for the EIPSMFNLMS-L0 algorithm
|
Initialization |
|
$\begin{aligned} & \rho=-0.5, \lambda_a \approx \zeta, \lambda=1-\frac{1}{L}, \gamma(0)=1, r_1(0)=0, \\ & \alpha(0)=r_0(0)=E_0=1, \psi=0.25, \delta_{I P F L}=\frac{(1-\rho)}{2 L} C_0, \\ & \omega=0.0025, \widehat{h}(0)=\tilde{c}(0)=0_{L \times 1};\end{aligned}$ |
|
For $n=1,2, \ldots$ (iterations) $\boldsymbol{x}(n)=\left[\begin{array}{llll}x(n) & x(n-1) & \cdots & x(n-L+1)\end{array}\right]^T$ Forward Prediction Update $\begin{aligned} & r_1(n)=\lambda_a r_1(n-1)+x(n) x(n-1) \\ & r_0(n)=\lambda_a r_0(n-1)+x^2(n) \\ & a(n)=\frac{r_1(n)}{r_0(n)+C_a} ; \varepsilon(n)=x(n)-a(n) x(n-1) \\ & \alpha(n)=\lambda \alpha(n-1)+\varepsilon^2(n)\end{aligned}$ Update Gain control matrix If $n \geq L$ $\hat{\xi}_{12}(n)=\frac{L}{L-\sqrt{L}}\left\{1-\frac{\|\widehat{\mathbf{h}}(n-1)\|_1}{\sqrt{L}\|\widehat{\mathbf{h}}(n-1)\|_2}\right\}$,$\hat{\xi}_{2 \infty}(n)=\frac{L}{L-\sqrt{L}}\left\{1-\frac{\|\widehat{\mathbf{h}}(n-1)\|_2}{\sqrt{L}\|\widehat{\mathbf{h}}(n-1)\|_{\infty}}\right\}$, $\hat{\xi}_{12 \infty}(n)=\frac{\hat{\xi}_{12}(n)+\hat{\xi}_{2 \infty}(n)}{2}, \beta(n)=\frac{1}{L}\left(1-\psi \hat{\xi}_{12 \infty}(n)\right)$ Else if $\beta(n)=0.5$ End if $q_l(n-1)=\left\{\begin{array}{c}\frac{(1-\rho)}{2 L}+\frac{(1+\rho) \beta(n)\left|\hat{h}_l(n-1)\right|}{2 \beta(n) \sum_{l=0}^{L-1}\left|\hat{h}_l(n-1)\right|+\delta_{I P}} \\ i f\left|\hat{h}_l(n-1)\right| \leq \frac{1}{\beta(n)} \quad, 0 \leq l \leq L-1 \\ \frac{1}{L} \quad \text { elsewhere }\end{array}\right.$ $\boldsymbol{Q}(n-1)=\operatorname{diag}\left\{q_0(n-1) \quad q_1(n-1) \quad \cdots \quad q_{L-1}(n-1)\right\}$ Adaptation Gain (FNLMS-like) $\begin{aligned} & {\left[\begin{array}{l}\tilde{c}(n) \\ c(n)\end{array}\right]=\left[\begin{array}{c}-\frac{\varepsilon(n)}{\lambda \alpha(n-1)+c_0} \\ \tilde{\boldsymbol{c}}(n-1)\end{array}\right], o(n)=c(n) x(n-L)+\frac{x(n) \varepsilon(n)}{\lambda \cdot \alpha(n-1)+C_0^{\prime}},} \\ & \gamma(n)=\frac{\gamma(n-1)}{1+\gamma(n-1) o(n)^2} g(n)=\gamma(n) \tilde{c}(n)\end{aligned}$ |
|
Filtering Part |
|
$e(n)=y(n)-\widehat{\boldsymbol{h}}^T(n-1) \boldsymbol{x}(n)$ Set-Membership part $\begin{aligned} & \sigma_e(n)=\zeta \sigma_e(n-1)+(1-\zeta)|e(n)| \\ & \mu(n)=\left\{\begin{array}{cc}1-\frac{\omega}{\sigma_e(n)} & \text { if }|e(n)|>\omega \\ 0 & \text { otherwise }\end{array}\right.\end{aligned}$ $\widehat{\boldsymbol{h}}(n)=\widehat{\boldsymbol{h}}(n-1)-\mu(n) \frac{\boldsymbol{Q}(n-1) \boldsymbol{g}(n) e(n)}{\boldsymbol{g}^T(n) \boldsymbol{Q}(n-1) \boldsymbol{g}(n)+\delta_{I P F L}}$ End for |
4.3 Computational complexities
Table 2 provides an evaluation of the relative complexity of NLMS, ISMFNLMS, IPNLMS, IPNLMS-L0, IPFNLMS, and EIPSMFNLMS-L0 algorithms in terms of the total number of multiplications (×) per iteration and the corresponding values of the steady-state MSE.
Table 2. Computational complexities
|
Algorithm |
Multiplication |
Steady-State MSE (dB) |
||
|
|
Sparse |
Dispersive |
Sparse |
Dispersive |
|
NLMS |
2L |
-48.32 |
-39.27 |
|
|
ISMFNLMS |
L+0.17L |
L+0.26L |
-50 |
-39.37 |
|
IPNLMS |
5L |
-48.60 |
-39.01 |
|
|
IPNLMS-L0 |
5L |
-48.53 |
-39.22 |
|
|
IPFNLMS |
6L |
-48.77 |
-39.40 |
|
|
EIPSMFNLMS-L0 |
4L+0.75L |
4L+0.93L |
-50 |
-39.21 |
The proposed algorithm exhibits a computational complexity of approximately 7L when the SM concept is not employed. This breakdown consists of 2L for the update control matrix, L for the FNLMS gain, L for the error component, and 3L for the filtering part. However, by incorporating the SM concept, the computational complexity is significantly reduced. This reduction is achieved by setting the step-size to zero once the optimization problem within the SM is verified, eliminating the need for additional updates.
In the case of the ISM-FNLMS algorithm, the computational complexity is determined by L multiplications for the filter error, with an additional percentage of L for the adaptation part. For the EIPSMFNLMS-L0 algorithm, the complexity is 4L plus a percentage of 3L. This percentage is obtained by dividing the number of times the adaptive filter is updated by the total number of iterations.
The nature of the system being identified (sparse or dispersive) has a notable impact on the computational complexity's performance. Furthermore, as mentioned in study [16], the magnitude of the error-bound threshold, which is influenced by noise levels, affects the computational complexity. In this paper, the error-bound threshold remains constant at 0.0025 for signal $y(n)$ to noise $b(n)$ ratio (SNR) equals to 50dB, allowing us to focus solely on the impact of system sparseness.
The proposed algorithm achieves a significant reduction in computational complexity compared to previous algorithms. This decrease in complexity does not only preserves performance but also enhances it. It is worth noting that the proposed algorithm effectively eliminates the exponential computational complexity associated with the IPNLMS-L0 algorithm.
Our study involved a comprehensive performance evaluation of the proposed EIPFSMNLMS-L0 algorithm in comparison to several other algorithms, including ISMFNLMS, IPNLMS, IPNLMS-L0, IPFNLMS, and classical NLMS algorithms.
5.1 Experimental setup
The schematic diagram in Figure 1 was employed to investigate an AEC application. We conducted simulations under various operating conditions. These conditions encompassed the use of two distinct correlated stationary input signals, namely USA Standards Institute (USASI) depicted in Figure 2 (a) which is a zero-mean correlated noise, featuring a spectral dynamic range of 29dB, and auto-regressive (AR20) which is a simulated by AR stationary process of order 20 with a spectral dynamic range of 42dB shown in Figure 2 (b), as well as a speech input signal, displayed in Figure 2 (c), is a real non-stationary signal characterized by a spectral dynamic range of 46dB. All signals used in this simulation are sampled at a rate of 16 kHz.
Additionally, we considered different impulse responses with different levels of sparseness which were synthetically generated using the method described in previous studies [5, 17] to generate output signal given in Figures 3-5. These synthetic IRs are subsequently named SIRs.
5.1.1 Time-varying SIRs generation
The time-varying scenarios were generated by multiplying the SIRs by an artificial gain depicted in Figure 6. This gain variation was applied between 60000 and 80000 samples for USASI noise and in the interval 90000 to 110000 samples for the AR20 input noise. It is important to note that the artificial gain was only applied to the SIRs corresponding to stationary input signals.
5.1.2 Generation of desired output signals
The time-varying SIRs were convolved with the three input signals. We used three sets of two pairs and one triad of SIRs, each set of equal length consisting of sparse and dispersive SIRs. The first pair, shown in Figures 3 (a) and 3 (b), was used in conjunction with the USASI input signal and length L=256. The second pair, shown in Figures 4 (c) and 4 (d), with a length of L=512, was used with the AR (20) input signal. Finally, the third triplet, shown in Figures 5 (e), 5 (f) and 5 (g), with a length of L=1024, was used with the speech input signal. To include the noise component to the desired signal $d(n)$, we added a white Gaussian noise $b(n)$ with an SNR of 50 dB or 30 dB to the echo signal $y(n)$.
Figure 2. The used input signals
Figure 3. Two types of SIRs with L=256: (a) $\hat{\xi}_{12}(n)=0.8296$, (b) $\hat{\xi}_{12}(n)=0.3028$
5.2 Performance metric
The Mean-Square Error value (MSE) is the performance metric employed in all our simulations. The MSE is expressed in decibels (dB) and is calculated as follows:
$M S E(d B)=10 \log _{10}\left(<e^2(n)>\right)$ (46)
where, < .> indicates time averages over blocks of 1024 samples for USASI noise and SPEECH signals, and 2048 samples for AR (20).
Figure 4. Two types of SIRs with L=512: (c) $\hat{\xi}_{12}(n)=0.8637,(d) \hat{\xi}_{12}(n)=0.4080$
Figure 5. Three types of SIRs with L=1024: (e) $\hat{\xi}_{12}(n)=0.8789$, (f) $\hat{\xi}_{12}(n)=0.6506,(\mathrm{~g}) \hat{\xi}_{12}(n)=0.4552$
Figure 6. Artificial gain for tracking capability tests
5.3 Selection of simulation parameters
Regarding the algorithm parameters, we selected a common step-size of $\mu=0.5$ for all algorithms to achieve a roughly consistent steady-state MSE value. The remaining parameters were chosen to provide good performance with a trade-off between convergence, tracking ability, and the minimum steady-state MSE value.
For the ISMFNLMS, IPFNLMS, and EIPSMFNLMS-L0 algorithms, two forgetting factors were employed. The first one $\lambda_a$ is used to track changes in the statistics of the input signal [9-13] and it is evaluated over a rectangular window of 35 ms (equivalent to a 560 -sample window) $\lambda_a \approx \zeta \approx 1-$ $1 / 560=0.9982$. The second forgetting factor $\lambda$ captures variations in the unknown system and is determined by $\lambda=$ $1-1 / L$. We considered three different lengths of impulse response (L=256, 512 and 1024).
The regularization constants $C_0$ and $C_a$ were initially set to values comparable to the input signal power and were subsequently modified to achieve equivalent steady-state MSE levels for ISMFNLMS, IPFNLMS, and EIPSMFNLMS-L0 algorithms. The constant $E_0$ is utilized during initialization and set to $E_0=1$. The initial value of $\sigma_e(0)$, is set to $\sigma_x / 100$ at an SNR of 50 dB or $\sigma_x / 10$ when the SNR is 30 dB.
The calculation of regularization parameters differs among the algorithms. The IPFNLMS and EIPSMFNLMS-L0 algorithms utilize Eq. (40), whereas the NLMS algorithm uses $\delta_{N L M S} \approx \sigma_x^2$. In the case of the IPNLMS-L0 algorithm, the value of $\beta$ is adjusted based on the type of input signal 0.5 for stationary inputs, 50 for sparse IRs and 500 for dispersive IRs with a speech input signal. For IPNLMS-L0, a specific value of $\rho=0.5$ is assigned. On the other hand, for IPNLMS, IPFNLMS, and EIPNLMS-L0, $\rho$ is consistently set to -0.5.
Table 3 summarizes the length of the SIRs utilized for each input signal and the associated forgetting factors for each length.
Table 3. Signals, synthetic impulse response lengths, and forgetting factors
|
Parameters Input Signal |
$\lambda=1-\frac{1}{L}$ |
L |
|
USASI |
0.9961 |
256 |
|
AR (20) |
0.9980 |
512 |
|
SPEECH |
0.9990 |
1024 |
5.4 Results and discussions
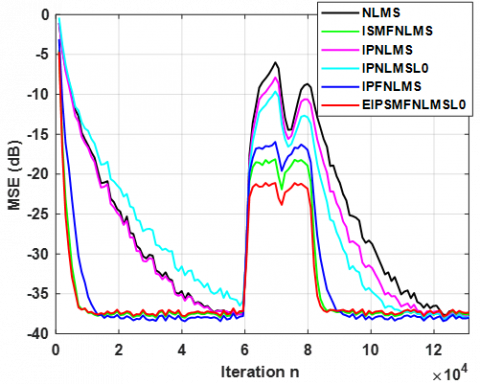
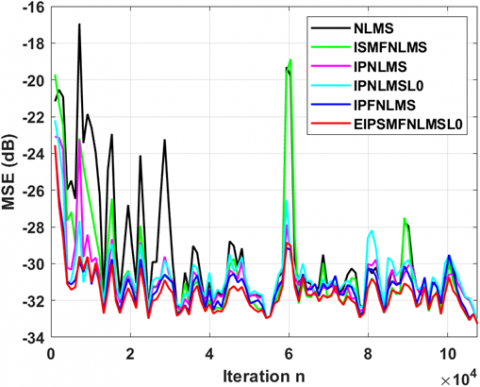
We began the performance comparisons using the USASI input with the first pair of time-varying SIRs (for both sparse and dispersive cases) of length L=256, as illustrated in Figure 7 for sparse case and Figure 8 for dispersive case. The results reveal that IPNLMS-L0 outperforms IPNLMS in handling sparse IRs but suffers from slower convergence and reduced tracking as sparseness decreases. While ISMFNLMS shows improvement for dispersive IRs, all algorithms fall behind our proposed algorithm EIPSMFNLMS-L0, which excels in faster convergence, superior tracking and lower error for sparse and dispersive cases with a lower computational complexity, surpassing even the recently introduced IPFNLMS algorithm.
In the case of the AR (20) input signal convoluted with the time-varying second pair of SIRs of L=512, the proposed algorithm demonstrates superior overall performance in situations with sparse IRs, as shown in Figure 9. It achieves the fastest convergence speed and the strongest tracking capability compared to the NLMS, IPNLMS, IPNLMS-L0, ISMFNLMS and IPFNLMS algorithms. Concerning dispersive SIRs, shown in Figure 10, the EIPSMFNLMS-L0 algorithm exhibits a fastest convergence speed approximately equivalent to that of the ISMFNLMS algorithm. However, it surpasses the other algorithms in terms of convergence speed, tracking ability, and final MSE.
Figure 7. Performance comparison under time-varying- in sparse $\hat{\xi}_{12}(n)=0.8296$ SIRs of length $L=256$. Using USASI noise Input signal. $C_0=C_a=1.2, \omega=0.0025$ and SNR=50dB
Figure 8. Performance comparison under time varying-time in dispersive $\hat{\xi}_{12}(n)=0.3028$ SIRs of length $L=256$. Using USASI noise Input signal. $C_0=C_a=1.2, \omega=0.0025$ and SNR=50dB
Figure 9. Performance comparison under time varying- in sparse $\hat{\xi}_{12}(n)=0.8637$ SIRs of length $L=512$. Using AR20 noise input signal. $C_0=C_a=1.8, \omega=0.0025$ and SNR=50dB
Figure 10. Performance comparison under time varying- in dispersive$\hat{\xi}_{12}(n)=0.4080$ SIRs of length $L=512$. Using AR (20) noise Input signal. $C_0=C_a=1.8, \omega=0.0025$ and SNR=50dB
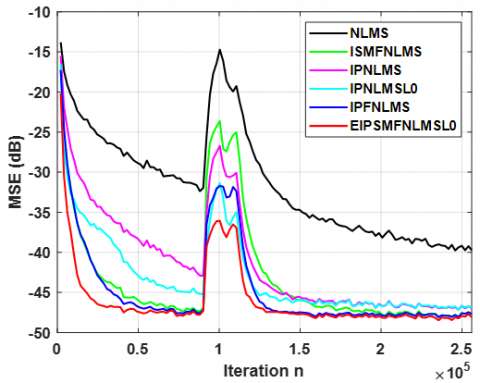
Figure 11. Performance comparison in sparse$\hat{\xi}_{12}(n)=0.6539$ SIRs of length $L=1024$. Using SPEECH Input signal. $C_0=C_a=1.2, \omega=0.0025$ and SNR=50dB
Figure 12. Performance comparison in dispersive $\hat{\xi}_{12}(n)=0.4552$ synthetic AIRs of length $L=1024$. Using SPEECH Input signal. $C_0=C_a=1.2, \omega=0.0025$ and SNR=50dB
The comparison with speech input signals and the third pair of SIRs of length L = 1024, with signal-to-noise ratio SNR = 50 dB. Figures 11 and 12 show the results obtained for these cases, as it can be seen that these tests demonstrate the superior performance of the proposed algorithm in both sparse and dispersive systems, reinforcing its effectiveness compared to other algorithms.
Figure 13 shows an additional experiment in a rather difficult situation with non-stationary speech input convolved with a large SIR with L=1024 points and very sparse $\hat{\xi}_{12}(n)=0.8789$ with an SNR of 30 dB. This last experiment confirms the superiority of the proposed algorithm compared to other algorithms.
Based on these simulations, it is clear that our proposed algorithm outperforms all algorithms used in this study in terms of MSE, convergence speed and tracking capability, at a reduced computational cost.
Figure 13. Performance comparison in very sparse $\hat{\xi}_{12}(n)=0.8789$ SIRs of length $L=1024$. Using SPEECH Input signal. $C_0=C_a=1.2, \omega=0.015$ and SNR=30dB
We successfully addressed the practical limitations of the IPNLMS-L0 algorithm by introducing a novel method for calculating the gain control matrix elements. This innovative approach not only improves resilience to changes in sparsity but also eliminates the need for costly exponential calculations in practice.
By integrating this gain control matrix into the Improved Set-Membership Fast NLMS framework, we achieved a reduction in computational costs and improved tracking performance, enhancing the algorithm's overall cost-effectiveness.
Across a diverse range of operational scenarios, our proposed EIPSMFNLMS-L0 algorithm consistently showcases superior performance compared to recent alternatives IPFNLMS, IPNLMS-L0 and ISM-FNLMS algorithms, particularly when addressing varying impulse response sparsity and non-stationary conditions. The proposed algorithm consistently achieves the lowest error, fastest convergence rate, most robust tracking performance, and minimal computational complexity for both sparse and dispersive IRs.
The simulation results clearly indicate the effectiveness of the proposed algorithm in meeting the challenges of an AEC with different levels of sparseness.
|
AEC |
Acoustic Echo Cancellation |
|
AIR |
Acoustic Impulse Response |
|
NLMS |
Normalized Least Mean Square |
|
RLS |
Recursive Least Square |
|
PNLMS |
Proportionate Normalized Least Mean Square |
|
IPNLMS |
Improved Proportionate Normalized Least Mean Square |
|
IPNLMS-L0 |
Improved Proportionate Normalized Least Mean Square using on the $\ell_0$ norm |
|
FNLMS |
Fast Normalized Least Mean Square |
|
SM |
Set Membership |
|
ISMFNLMS |
Improved Set Membership Fast Normalized Least Mean Square |
|
EIPSMFNL |
Enhanced Improved Proportionate Set Membership Fast Normalized Least |
|
MS-L0 |
Mean Square built on the $\ell_0$ norm |
|
MSE |
Mean Square Error |
|
IPFNLMS |
Improved Proportionate Fast Normalized Least Mean Square |
|
USASI |
USA Standards Institute |
|
AR (20) |
Auto Regressive Process of order 20 |
|
SNR |
Signal to Noise Ratio |
|
Greek symbols |
|
|
μ |
step size |
|
ρ |
control factor |
|
δ |
regularization parameter |
|
β |
parameter related to the sparsity of the impulse response |
|
γ(n) |
likelihood variable |
|
ε(n) |
prediction error |
|
α(n) |
variance of the forward error |
|
λ |
forgetting factor |
|
$\lambda_a$ |
forgetting factor |
|
$\hat{\xi}_{12 \infty}(n)$ |
sparseness measure built on the $\ell_1, \ell_2$, and $\ell_{\infty}$ norms |
|
ω |
bound on the error |
|
$\sigma_e(n)$ |
estimation of the modulus of the error |
[1] Huang, Y., Benesty, J., Chen, J. (2006). Acoustic MIMO signal processing. Springer Science & Business Media. https://doi.org/10.1007/978-3-540-37631-6
[2] Duttweiler, D.L. (2000). Proportionate normalized least-mean-squares adaptation in echo cancelers. IEEE Transactions on Speech and Audio Processing, 8(5): 508-518. https://doi.org/10.1109/89.861368
[3] Benesty, J., Gay, S.L. (2002). An improved PNLMS algorithm. In 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing, Orlando, FL, USA, pp. II-1881-II-1884. https://doi.org/10.1109/ICASSP.2002.5744994
[4] Paleologu, C., Benesty, J., Ciochina, S. (2010). Sparse adaptive filters for echo cancellation. Synthesis Lectures on Speech and Audio Processing, 6(1): 124. https://doi.org/10.2200/S00289ED1V01Y201006SAP006
[5] Khong, A.W., Naylor, P.A. (2006). Efficient use of sparse adaptive filters. In 2006 Fortieth Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, pp. 1375-1379. https://doi.org/10.1109/ACSSC.2006.354982
[6] Gu, Y., Jin, J., Mei, S. (2009). $\ell_0$ norm constraint LMS algorithm for sparse system identification. IEEE Signal Processing Letters, 16(9): 774-777. https://doi.org/10.1109/LSP.2009.2024736
[7] Paleologu, C., Benesty, J., Ciochină, S. (2010). An improved proportionate NLMS algorithm based on the l 0 norm. In 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, pp. 309-312. https://doi.org/10.1109/ICASSP.2010.5495903
[8] Xin, H., Yingmin, W., Feiyun, W., Aiping, H. (2020). An improved proportionate normalized LMS based on the L0 norm for underwater acoustic channel estimation. In 2020 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Macau, China, pp. 1-5. https://doi.org/10.1109/ICSPCC50002.2020.9259509
[9] Lima, M.V., Chaves, G.S., Ferreira, T.N., Diniz, P.S. (2021). Do proportionate algorithms exploit sparsity? arXiv preprint arXiv:2108.06846. https://doi.org/10.48550/arXiv.2108.06846
[10] Benallal, A., Benkrid, A. (2007). A simplified FTF-type algorithm for adaptive filtering. Signal Processing, 87(5): 904-917. https://doi.org/10.1016/j.sigpro.2006.08.013
[11] Arezki, M., Benallal, A., Meyrueis, P., Berkani, D. (2010). A new algorithm with low complexity for adaptive filtering. Engineering Letters, 18(3): 205. https://doi.org/10.1016/j.sigpro.2006.08.013
[12] Benallal, A., Arezki, M. (2014). A fast convergence normalized least‐mean‐square type algorithm for adaptive filtering. International Journal of Adaptive Control and Signal Processing, 28(10): 1073-1080. https://doi.org/10.1002/acs.2423
[13] Arezki, M., Namane, A., Benallal, A. (2017). Performance analysis of the fast-NLMS type algorithm. In Proceedings of the World Congress on Engineering (Vol. 1).
[14] Gollamudi, S., Nagaraj, S., Kapoor, S., Huang, Y.F. (1998). Set-membership filtering and a set-membership normalized LMS algorithm with an adaptive step size. IEEE Signal Processing Letters, 5(5): 111-114. https://doi.org/10.1109/97.668945
[15] Jin, Z., Li, Y., Wang, Y. (2017). An enhanced set-membership PNLMS algorithm with a correntropy induced metric constraint for acoustic channel estimation. Entropy, 19(6): 281. https://doi.org/10.3390/e19060281
[16] Hassani, I., Arezki, M., Benallal, A. (2020). A novel set membership fast NLMS algorithm for acoustic echo cancellation. Applied Acoustics, 163: 107210. https://doi.org/10.1016/j.apacoust.2020.107210
[17] Tedjani, A., Benallal, A. (2020). A novel cost-effective sparsity-aware algorithm with Kalman-based gain for the identification of long acoustic impulse responses. Signal, Image and Video Processing, 14(8): 1679-1687. https://doi.org/10.1007/s11760-020-01715-2
[18] Slock, D.T. (1993). On the convergence behavior of the LMS and the normalized LMS algorithms. IEEE Transactions on Signal Processing, 41(9): 2811-2825. https://doi.org/10.1109/78.236504
[19] Fedlaoui, L., Benallal, A., Maamoun, M. (2023). A novel modified improved propotionnate fast NLMS algorithm for acoustic echo cancellation. In 2023 2nd International Conference on Electronics, Energy and Measurement (IC2EM), Medea, Algeria, pp. 1-6. https://doi.org/10.1109/IC2EM59347.2023.10419617
[20] Fedlaoui, L., Benallal, A., Maamoun, M. (2024). A proportionate fast NLMS with competent individual activation factors. In 2024 8th International Conference on Image and Signal Processing and their Applications (ISPA), Biskra, Algeria, pp. 1-6. https://doi.org/10.1109/ISPA59904.2024.10536743