Manish Gupta![]() | Dharmveer Yadav
| Dharmveer Yadav![]() | Safdar Sardar Khan
| Safdar Sardar Khan![]() | Ashish Kumar Kumawat
| Ashish Kumar Kumawat![]() | Ankita Chourasia
| Ankita Chourasia![]() | Pinky Rane
| Pinky Rane![]() | Anshul Ujlayan*
| Anshul Ujlayan*![]()
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Tomatoes are a noteworthy horticultural crop that has considerable importance in a diverse range of culinary traditions. At now, the primary concern for food security is in the realm of plant diseases. Researchers are actively working towards developing a streamlined approach to detect and diagnose illnesses in their early stages, with the ultimate goal of enhancing the agricultural industry. Currently, computer scientists and engineers are actively engaged in the fast development of a diverse range of tools and methodologies, with a special focus on the field of artificial intelligence. The advancement of cutting-edge machine learning applications for artificial intelligence relies on the establishment of original methods and frameworks. In contrast to the single-layer topologies of more traditional neural network learning methods, "deep learning" makes use of networks with many processing layers. In this research, a DL model is developed to detect & diagnose plant diseases by analyzing healthy & unhealthy plant image samples using deep learning techniques. The dataset contains 43,823 images of plants, including healthy plants and unhealthy plants. For this model implementation, follow some methodology processes like data preprocessing, image segmentation, data balancing, data splitting classification and detection, and assess the model's efficacy. The study uses a Fine-Tuned EfficientNetB7 approach with an impressive Mean Average Accuracy of 99.31%. The proposed technique demonstrates efficacy in early detection and has the potential for further improvement in terms of performance, hence facilitating the development of a real-world automated system for detecting plant diseases in agricultural settings.
plant diseases, image processing, machine learning, deep learning, artificial intelligence
Plants serve an important part in providing sustenance for a global population, therefore serving as a fundamental source of nourishment. When a plant has constant interference with its normal structure, growth, function, or other activities due to a causal cause, it undergoes an aberrant physiological process leading to the development of a disease [1]. Plants have an important role in human existence as they are responsible for a production of food and provide protection from harmful radiation. All terrestrial life depends on plants for food, and they protect the ozone layer, which acts as a UV radiation filter. The tomato plant, which is frequently grown as an edible vegetable, is rich in nutrients. The annual global consumption of tomatoes is thought to be 160 million tons. A tomato is regarded as a practical way for farming households to make money since it is recognized as a significant catalyst in the reduction of poverty [2]. Tomatoes have a significant effect on the agricultural economy because they are one of the most nutrient-dense crops that can be grown. A tomato is a well-liked fruit since it is healthy and has been demonstrated to have preventative properties against a number of diseases. Hepatitis, hypertension, and gingival bleeding are some of these disorders [3]. Due to its widespread use, the demand for tomatoes has noticeably increased. More than 80% of the world's food supply comes from small farms, according to a recent study. Nevertheless, it's crucial to preserve in mind that those farmers face difficult limitations within the form of diseases and pests, which motive a large loss of approximately 50% of their grown vegetation. In the agricultural industry, there is a lot of concern about how diseases and parasitic insects have an effect on tomato growth. As an end result, it's crucial to perform research on diagnosing the illnesses that damage this particular crop. Researchers can create efficient techniques to lessen the harmful effects of those illnesses and pests by means of looking into the several factors that result in the loss in tomato fitness. This study is to evaluate the cutting-edge state of information approximately the detection of illnesses that affect agricultural plants, with a particular emphasis on tomatoes. By a complete literature evaluation, this challenge will develop diagnostic strategies and, in the long term, offer a hand in growing lengthy-term solutions for the agricultural enterprise [4].
There are a number of limitations and challenges that agricultural professionals face when seeking to visually evaluate illnesses in tomato leaves. Since this method relies only on visual belief, it's prone to bias and inaccuracy. Because it works in sure areas however now not others, this approach has restrained use on an international basis. For those running in agriculture, one of the most important demanding situations is the lack of without difficulty communication infrastructure. It is tough to establish a reference to those people due to the fact to the absence of effective conversation channels. Costs are being pushed up even further by means of the truth that agricultural experts want full-size financial assets in order to check vegetation. The problem is made worse for the reason that this technique requires a considerable time funding. Ideas in ML and AI have observed fertile ground thanks to the improvements in cutting-edge computer technology. The improvement of automatic systems for the identity of ailments affecting tomato leaves has been significantly facilitated by way of these ideas. These technologies have the capacity to efficiently monitor massive tomato harvests by utilizing automated procedures [5, 6].
A use of plant protection in an agricultural area has been significantly improved by recent advancements in computer technology. Machine learning (ML) approaches have led to significant advancements across several disciplines, showcasing latest developments and concepts. Diseases on plants were initially identified and diagnosed utilising digital image processing techniques in an early stages of disease detection approaches [7].
Tomatoes are crucial because of their high demand in the food industry and their value in the diet. The benefits to health from these antioxidants are numerous and cannot be overstated. Insects & pests that feed on tomato plants & transmit disease could decrease production of this popular commodity. Farmers that manually treat their tomato plants must be informed of the particular illness they are dealing with. Farmers face a fresh set of difficulties every year as they strive for bountiful harvests. Insect and other pest damage to the production line lowers productivity and diminishes efficiency. For our economy in general and for our farmers in particular, this is a severe problem. Many different insecticides and herbicides are used by farmers to protect their tomato plants toward disease, but the farmers rarely know what the disease is or how to prevent it. Overuse of insecticides and pesticides endangers human health and life. Pesticide use, whether excessive or insufficient, and disease identification errors can all affect crops. When growing tomatoes, it's crucial to correctly identify plant diseases in order to maximize productivity. In contrast, it takes a lot of time & effort to manually diagnose diseases in tomato plants by carefully inspecting them. For assistance on preventing rare ailments, it could be challenging for farmers in remote places to contact experts. A visual examination of plants could produce an incorrect illness diagnosis in the absence of background knowledge. Ineffective preventative measures are therefore put into implementation. A machine can now detect diseased or otherwise damaged tomato plants, determine the cause of the damage, and use that information to better the overall health and output of the crop. After solve these problems, we will introduce a deep learning-based approach that uses the tomatoes picture dataset on GitHub to enhance tomato disease detection and categorization.
In contemporary times, deep learning has emerged as a prominent subject extensively used in a domains of pattern recognition & classification quandaries. The selection of design choices for deep learning models is contingent upon the creator's identity. However, previous expertise is necessary due to the inherent difficulty in selecting the optimal combination of characteristics. A main aim of this research is to create a reliable method for a categorization of tomato diseases, and other objectives include exploring the numerous aspects that have a major effect on the efficiency of a CNN [8]. Based on the most recent methodology, a use of DL in conjunction with Neural Network architecture yields enhanced classification capabilities and heightened accuracy. This might be attributed to an inherent ability of DL models to autonomously perform many phases of feature extraction [9]. The CNN outperforms more traditional classification methods, making it a popular machine learning method in DNNs [10]. Newer Deep CNN meta-architectures like ResNet, VGGNet, and LeNet have shown remarkable progress. Because these structures were honed to predict tomato leaf disease, they achieved the best classification performance [7].
1.1 Research motivation and contribution
Assisting farmers in accurately identifying and diagnosing diseases in their early stages so they can quickly treat and control these disorders is one of the initiative's key goals. It also strives to raise farmers' knowledge and comprehension of such illnesses, ensuring they are well-informed about possible hazards and preventative actions. The application of deep learning is used as an effective method for identifying and categorizing tomato diseases. Google Colab is used for the comprehensive execution of the experiment, using a dataset including diverse photographs of tomato leaves afflicted by nine distinct ailments, alongside a leaf that is unaffected and deemed healthy. The entire procedure is delineated: Initially, the input photos undergo preprocessing, followed by the segmentation of the intended region from the original images. Additionally, the pictures undergo additional processing using deep learning model. A result indicate that a proposed model has a significant level of efficacy in the identification and categorization of illnesses in tomato leaves, as shown in both a training & test dataset. The primary contribution of the suggested model may be succinctly expressed as:
- In order to prepare a dataset from an open-source repository that includes both healthy and unhealthy (infected) crop image.
- A primary purpose of this study is to create a robust disease classification model for tomatoes, and other objectives include an examination of the various elements that significantly affect a performance of a proposed model.
- According accuracy & precision, a finding of this research is superior than the most recent, modern studies in this sector.
Following is a rest of a paper structure: Our literature review can be found in Section 2. A recommended model are presented and described in Section 3. In Section 4, we provide examples of an outcomes of a suggested methodology and make comparisons to other approaches in the field. Section 5 concludes the study and future work.
Conventional methods for detecting plant diseases often rely on computer vision technology to extract several properties of disease spots, including texture, shape, and color. The identification effectiveness of this approach is poor due to its reliance on a comprehensive specialist knowledge of agricultural diseases. In recent years, a rapid advancement of AI technology has prompted several scholars in the academic community to undertake substantial research endeavors centered on deep learning technology. A primary aim of these efforts has been to enhance a precision of plant disease diagnosis. The predominant methodologies used for the investigation of plant diseases revolve around disease categorization.
In this research, the identification and categorization of tomato leaf diseases have been accomplished by a use of a CNN, a sophisticated DL model [11]. The implementation used the tomato leaf dataset supplied via Kaggle. The dataset includes nine different diseases affecting leaves, as well as a healthy-leaves class. The CNN model under consideration has been instantiated using the Adam and SGD optimizers. From the analysis, it is evident that SGD outperforms Adam in terms of performance as evidenced by the results. The measure used to determine a classification model’s predicted performance outcome is an accuracy & loss metric. From the outcome of the programme, when the SGD optimizer is used it gives high accuracy of 0. 9966 as well as a low loss value of 0. 0044 for the CNN model.
Therefore, the researchers aim at identifying good and ill tomato leaf photos through the two pre-trained CNNs; Inception ResNet V2 & V3 for diagnosing tomato leaf diseases [12]. The two models were trained using 5225 field-recorded photos and an open-source database known as Plant Village. With dropout rates of 5%, 10%, 15%, 20%, 25%, 30%, 40%, and 50%, the models were examined. The best results (99.22% accuracy and a loss of 0.03) were achieved by an Inception ResNet V2 model with a dropout rate of 15%, followed by an Inception V3 model with a dropout rate of 50%. This high percentage of success with the CNNs models suggests that they could be useful in both field & lab settings for diagnosing tomato diseases.
Particularly, we introduced a novel learning model based on VGG architecture for identifying sick and healthy tomato leaves [1]. A 92% success rate can be attributed to the suggested employment. The presented model also has good computational efficiency.
The study introduces a transfer learning approach employing a pre-trained CNN to detect & categorize leaf illnesses in tomato crops [13]. Experiments are conducted on a Plant Village dataset, which consists of 10 various types of tomatoes affected by various diseases and pests, such as Yellow Leaf Curl, Late Blight, Healthy, Septoria Leaf Spot, Target Spot, Mosaic, Mosaic, Leaf Mold, Early Blight, Tomato Bacterial Spot & Virus. A transfer learning method is utilised to fine-tune many pre-trained CNN models. Mo-bileNetV2, InceptionV3, DenseNet169, DenseNet201, VGG-19, DenseNet201, VGG-16, InceptionResNetV2, & Xception are some of a pre-trained CNN models that have been put through their paces. Results revealed that of all the models evaluated, Mobile Net had the greatest overall classification accuracy (96%) in the study.
Tomato plant diseases are identified and classified using a deep CNN model [14]. We utilized the VGG16 DCNN classifier to detect ailments and sick plants in photographs of tomato plants. Our research draws on the Plant Village collection, which contains images of tomato leaves in 10 different categories, some of which feature absolutely healthy plants. The classification accuracy for this dataset is a reasonable 95.5% using a pre-trained VGG16 model & a transfer learning method. Over 99% of tomato plant infections may be detected using this model's top-two accuracy.
So, the main objective of this research was to identify the parameter space that has a substantial effect on the performance of a CNN for illness classification in tomatoes [8]. Employing 22930 tomato leaf photos available in a Plant Village dataset on Kaggle, a basic CNN model was constructed & trained by scratch. A model was used to test various scenarios by adjusting some variables while keeping others constant. The final step was a comparison of the performance metrics for each parameter versus the reference model. In the study, the highest levels of accuracy for prediction (92%), training (94%), and validation (92%), respectively, were achieved.
A model for diagnosing illnesses in plant leaves was created utilizing a Pretrained Deep CNN [15]. A dataset with 10 categories of tomato leaf photos is used to train the Deep CNN model. We uncovered structural patterns that, taken as a whole, boost the model's efficiency. After train a proposed model, a wide variety of training epochs, sample sizes, & omissions were used. Maximum precision has been achieved with the Xception. Exception’s accuracy has improved over time because we've kept extending the training period without resorting to overfitting or sacrificing quality. Moreover, Xception produced a 99.45% accuracy in less computational time.
This initiative describes the use of CNNs, a subclass of DNN, for the detection of maladies in tomato leaves [16]. Before the detection of tomato leaves, the dataset is partitioned as an initial phase. To solve our classification problem, we employ transfer learning by adapting a previously trained model (ResNet-50). To make the ResNet model more accurate and more reflective of the true disease prevalence, data augmentation has been implemented. The ResNet 50 model is trained using a testing dataset, & then its parameters are validated utilizing a testing dataset. There are six major tomato crop diseases that have been identified. Using data augmentation, we four times the amount of the original dataset, and found that the model was 97% accurate.
LeNet employs a slightly modified version of the CNN model for disease detection & identification in tomato leaves [17]. A fundamental goal of this effort is to develop a system for detecting diseases in tomato leaves that is as efficient as modern methods while requiring less computational resources. The input image is classified into the appropriate disease classifications using automatic feature extraction by neural network models. This system's average accuracy ranges from 94% to 95%, proving a NN approach's feasibility even in challenging circumstances.
Common themes in the examined literature include the widespread use of deep learning models, particularly CNNs, for plant disease diagnosis, with a particular emphasis on tomato plants. Publicly available datasets, such as those from Kaggle and Plant Village, are frequently used for training and evaluation. Performance evaluations are constantly based on accuracy and loss metrics. Differences originate from the individual CNN designs used, optimisation methodologies, and the amount of investigation into model parameters and efficiencies. Unlike a few studies that thoroughly look into these troubles, others do now not provide a comprehensive examination, leaving gaps in expertise.
The literature review identifies open demanding situations and knowledge gaps. While some research cross into detail approximately parameter exploration, computing efficiency, and scalability, others do not. Our research intends to close those gaps by very well investigating the outcomes of various factors on version performance, resolving computational efficiency problems, and assessing scalability. The remaining goal is to offer insights that improve the effectiveness and feasibility of deep learning models for detecting plant illnesses, mainly in tomatoes.
Finally, remarkable findings from the literature analysis consist of the sizable use of CNNs for tomato diseases analysis, reliance on publicly to be had datasets, and performance evaluation based on accuracy and loss metrics. Our work stands out by thoroughly investigating model parameters, computational efficiency, and scalability, resulting in a more comprehensive grasp of the complexities involved in plant disease identification. By tackling these issues, we hope to advance the existing state-of-the-art and promote the development of more robust and practical models for real-world application in agriculture.
The following Table 1 provide the related work summary on detection and classification of tomato leaf diseases with deep learning, CNN, pre-trained and transfer learning models.
Table 1. Summary of related work for detection of Leaf Diseases
|
Reference |
Methods |
Datasets |
Results (Accuracy) |
Limitations |
|
[11] |
CNN (Adam & SGD) |
Kaggle-based tomato leaf |
99.66% |
It does not explore other important aspects of model architecture, hyperparameters, or data augmentation techniques that could potentially enhance the model's performance. |
|
[12] |
A pair of Inception-trained CNNs (V3 and ResNet V2) |
PlantVillage |
99.22% |
No detailed analysis of computational efficiency, which is important for real-world deployment. |
|
[1] |
VGG architecture |
Plant dataset |
92% |
The reported accuracy of 92% may not be sufficient for some practical applications, and the study does not discuss potential improvements. |
|
[13] |
Pre-trained CNNs (Various) |
PlantVillage |
96% |
The study does not provide insights into the trade-offs between different pre-trained models used for transfer learning. |
|
[14] |
Transfer learning (VGG16) |
PlantVillage |
95.5% |
No exploration of hyperparameter tuning, which could potentially improve model performance. |
|
[8] |
CNN (parameter exploration) |
PlantVillage |
92% |
Limited analysis of the scalability of the model, making it unclear how the model would perform with larger datasets or more complex tasks. |
|
[15] |
Pretrained CNN (Xception) |
Plant dataset |
99.45% |
No discussion of potential overfitting, which is a common concern when training deep learning models with a large number of epochs. |
|
[16] |
Transfer learning (ResNet-50) |
Plant dataset |
97% |
Lack of information about dataset diversity, which could impact a model's ability to generalize to various disease variations. |
In this section provide the problem statement, proposed methodology with each method that have used for this research development. Also provide the algorithms and flowchart of each proposed algorithm.
3.1 Proposed methodology
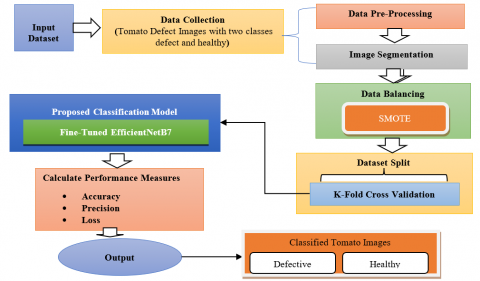
To implement this research, begin by gathering the external tomato defect dataset from GitHub repository. Following the collection of the dataset, preprocessing processes are carried out, including the segmentation of the images and data balancing. After that, classification is performed using the EfficientNetB7 model, which is based on DL. A main goal of this research is to identify & classify tomato-related diseases. This comprehensive method's main objective is to enhance tomato disease detection performance by utilizing the advantages of deep learning and effective network topologies. Figure 1 shows the proposed methodology process with each step, and proposed work phases was described above.
Figure 1. Overview diagram of proposed methodology for detection and classification of tomato leaf diseases
3.1.1 Data collection and preprocessing
For this work used DL classifier for external defects in tomatoes dataset. There are two classes defective and healthy. Total number of images of tomatoes is 43,823 respectively. After collecting the tomatoes images, applied data preprocessing techniques. The preprocessing technique is used to enhance the image data. The raw images that the DL model would need to process are modified or enhanced through image pre-processing before the model is trained. To build an accurate model, it's important to take a close look at both the structure of the underlying network and the input data type. Our dataset underwent extensive pre-processing to ensure that a suggested model was able to extract useful features by an image.
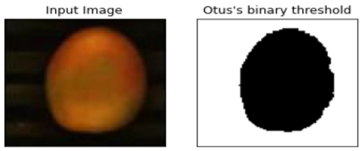
Image Segmentation: After digital images have been pre-processed, a next step is image segmentation, a division of the image into individual parts. Thresholding methods were used to do the segmentation.
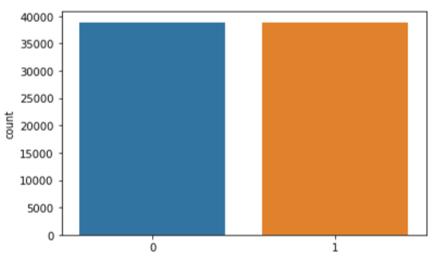
Data Balancing Techniques: This study uses SMOTE data balancing technique. The SMOTE is another resampling technique used to redress imbalanced datasets; it does so by generating artificial samples from the minority group in an effort to increase a number of minority class samples. Synthetic generation of new samples was modified to avoid overfitting by departing from the multiplication approach [18, 19].
3.1.2 Data splitting
After the data has been cleaned and prepared, we split it utilizing a K-fold cross validation process, with a fold 5. This process is defined below in detail:
K-Fold cross validation: K-fold cross-validation is widely used in DL to create accurate prediction models. After each iteration of the K-fold cross-validation approach, the training set is based on the previous K folds, while the validation set is based on the most recent fold. Every iteration consists of two steps: model training on a training set & evaluation on a validation set. Each iteration's performance is typically measured and recorded. The Performance measures are often aggregated after a certain number of iterations, K, when evaluating models. The goal of this aggregation procedure is to give a full evaluation of a model's efficacy. Measuring performance after each round and averaging the results provides this information.
3.1.3 Classification
This phase classifies the information and appears at the numerical characteristics of the image's attributes. For training and classification, it uses a fine-tuned EfficientNetB7 DL-primarily based model for tomato diseases. Below is an intensive description of this model:
Fine-tuned EfficientNetB7: In the field of computer vision, this approach may be very effective and high-performing. A modern iteration of the EfficientNet architecture has gone through good sized optimisation to demonstrate first rate overall performance in certain datasets or applications. The advantages of transfer learning are made apparent when a stable knowledge base is constructed using ImageNet, a large and varied dataset. This sets the degree for the implementation of transfer learning. The manner of fine-tuning involves editing the version as a way to higher meet the unique requirements of the target task, which leads to extra flexibility and advanced performance. The refined EfficientNetB7 model has shown exquisite performance in dealing with various visual recognition issues, together with image classification. The architecture of proposed model shows in Figure 2. Through the usage of the efficacy of its underlying framework, this model consists of certain optimisations to enhance its common overall performance. As an end result, this method gives an adaptable and robust way to cope with a number of visible identification challenges, producing first rate precision and effectiveness [20, 21].
Rationale for using EfficientNetB7: Because of its effectiveness and better consequences in computer vision test, EfficientNetB7 turned into selected for this research. It is a famous design that has shown remarkable performance in a whole lot of application and datasets. Its effectiveness is particularly crucial for diagnosing tomato illnesses because it has to examine a whole lot of images speedy and precisely. Using the ImageNet dataset, EfficientNetB7 builds a strong know-how base primarily based on TL. The quality-tuning approach modifies the model to suit the specific desires of the goal undertaking, subsequently growing its performance and adaptableness. The model has shown useful in quite a number of visible identification problems, giving it a feasible alternative for recognising and diagnosing tomato-associated illness.
Key innovations and advantages of approach: To improve tomato disease diagnostics, the proposed technique consists of some of primary advancements and novel capabilities. The utilization of the EfficientNetB7 version, with its properly-documented performance and wonderful overall performance in computer vision packages, is a game-changing breakthrough. Through the application of transfer learning from the ImageNet dataset, the model profits a stable knowledge foundation that makes it greater adaptable to the intricacies of tomato sickness versions. After the fine-tuning method, the EfficientNetB7 architecture is further customised to the precise desires of tomato ailment detection, resulting in progressed universal overall performance and versatility. Efficient use of the SMOTE statistics balancing technique is a key component of this method, because it guarantees that the model can handle with samples from both majority and minority classes and corrects dataset imbalances. This enhances the approach for detecting tomato diseases, which is vital for practical agricultural uses. These trends set up the proposed technique as a comprehensive and beneficial device, bringing a super leap forward in automated plant disease detection.
Comparison with existing methods: The suggested EfficientNetB7 model will be quantitatively compared to various approaches that have been thoroughly described in the literature research using metrics like as precision, accuracy, recall, and F1 score. To prove that the model can accurately distinguish between healthy and defective tomatoes, they will utilize these criteria for classification. The goal of developing EfficientNetB7 was to create a system that could handle more tomato disease variations with more computational economy and better accuracy than previous methods.
Figure 2. Architecture of EfficientNetB7 [22]
The findings from the experiment are executed on an HP workstation with 32GB of RAM, a 1TB hard drive, the Windows 10 OS, a 24GB Nvidia GPU, & an Intel Core i7 processor. Utilising this hardware, we employed the Python programming language and Jupyter Notebook along with various Python utilities such as Keras, TensorFlow, NumPy, pandas, Sklearn, and matplotlib, and so on. For this research endeavour, a Github tomatoes image dataset was divided into train & test sets. For a classification and identification of tomato images using deep learning. The subsequent section provides implemented model evaluation and data analysis findings.
4.1 Dataset description
The dataset we described is related to classifying external defects in tomatoes (https://github.com/ArthurZC23/Deep-learning-classifier-for-external-defects-in-tomatoes), it is available on GitHub. It consists of two classes: "defective" and "healthy," with a total of 43,823 images. The dataset is further splitted into training, testing, & validation sets for each class, with different quantities of images for each split. Here's a breakdown of the dataset:
Defective Class:
Train Set: 2,479 images
Test Set: 1,240 images
Validation Set: 1,240 images
Healthy Class:
Train Set: 19,422 images
Test Set: 9,721 images
Validation Set: 9,721 images
In summary, this dataset contains images of tomatoes categorized into "defective" and "healthy" classes, with a total of 43,823 images. The images are further splitted into training, testing, & validation subsets for both classes, with varying quantities of images in each subset. The deep learning models for fault classification in tomatoes may be trained and evaluated using these datasets.
4.2 Visualization results
The following Figures 3-7 shows the dataset Visualisation with input images and thresholds image, also Figure 4 shows the count plot of data distribution and Figure 7 provide the balanced dataset graph with SMOTE.
Figure 3. Preprocessed image of tomatoes
Figure 4. Before data balanced images of tomatoes
Figure 5. Pie chart of unbalanced dataset distribution
Figure 6. After data balanced images of tomatoes
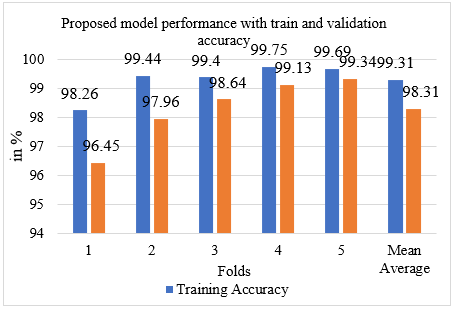
Figure 7. Bar graph of train and validation accuracy performance with each running folds
Figure 5 shows the pie chart of unbalanced data distribution with healthy and defective data. Healthy class contain 88.69% of data and defective class contain 11.31% dataset.
4.3 Performance evaluations
Parameters for plant disease detection using a deep learning system that draws from a publicly accessible, freely downloadable tomato dataset are evaluated. The models with the smallest validation loss were selected for further testing, and these were put to work classifying test set samples. Classification results from several models can be viewed and compared using a confusion matrix.
The values for each class in a multiclass confusion matrix are as follows:
True Positive (TP): When a model produces accurate predictions for the Positive Class, that's a true positive.
True Negative (TN): Any time a model incorrectly forecast a Negative Class; it is said to have produced a False Negative.
False Positive (FP): Incorrectly predicting a Positive Class is an example of a False Positive.
False Negative (FN): Any time a model incorrectly predicts a Negative Class, it is said to have produced a False Negative.
Additionally, calculate standard metrics that gauge the effectiveness of picture categorization per class using the numbers from the matrix to determine which model for each neural network is the best one.
The suggested study uses a variety of assessment criteria, including accuracy and precision.
Accuracy: The simplest indicator to use for evaluating performance is accuracy, which is just a ratio of correctly forecasted observations to all observations. If we are really cautious, we could believe that our model is the best. When a data set is symmetrical and the positive, negative, and false positives are about equal, accuracy is a useful statistic. Consequently, additional factors need be included in order to assess the model's performance [23].
Accuracy=TN+TPFP+TN+FN+TP (1)
Precision: A categorization model's precision is a gauge of how well it performs in testing. Informally, accuracy is a measure of how well our model predicts the future. When photos are accurately categorized, it is stated mathematically as a percentage of all the images that were expected to belong to a certain class (1):
Precision=TPTP+FP (2)
The diagnostic precision of a binary classification test is quantified by its accuracy at either making a diagnosis or dismissing a diagnosis. Class accuracy is determined by dividing the number of correct classifications by the total of numbers of false positives and false negatives. To calculate recall, subtract a number of TP from the total number of FN & divide the result by a total number of items in the positive class [24, 25].
F1-score: To illustrate the harmonic mean of recall and accuracy, this score will be used. The F1 score is a formula that averages the weights of the recall and accuracy ratings. 1 is the best value for F1, while 0 is the worst. We may calculate the F1 score by using the following formula.
F−measure=2× Recall × Precision Recall + Precision (3)
AUC-ROC: The acronym "AUC" refers to the "Area under the ROC Curve." In other words, AUC is a measure of the total area under the ROC curve in two dimensions, from 0 to 1. AUC is useful since it provides a single metric to evaluate performance at each and all classification cutoffs.
4.4 Classification results of proposed model
The following Table 2 provide the proposed model performance with train and validation accuracy based on epochs.
Table 2. Training and validation accuracy with number of folds
|
Fold |
Training Accuracy |
Validation Accuracy |
|
1 |
0.9826 |
0.9645 |
|
2 |
0.9944 |
0.9796 |
|
3 |
0.9940 |
0.9864 |
|
4 |
0.9975 |
0.9913 |
|
5 |
0.9969 |
0.9934 |
|
Mean Average |
99.31% |
98.31% |
This section offers a summary of the research results that were acquired by training and evaluating a performance of tomato disease detection & classification models utilizing the proposed deep learning framework.
Figure 7 shows the train and validation accuracy performance with five number of folds with average mean value. Proposed system obtains 99.31% training accuracy and validation accuracy of 98.31% while initial folds 1 model get only 98.26% train performance and 96.45% of validation performance.
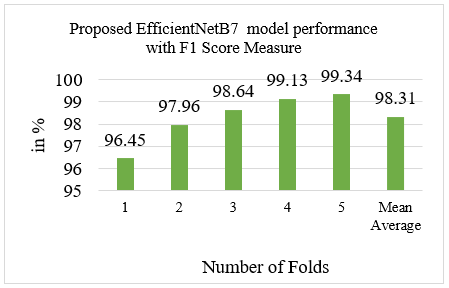
Figure 8 shows the proposed EfficientNetB7 performance on F1-Score measure with five number of folds with average mean value. Table 3 shows that proposed system obtains 98.31% F1-Score while initial folds 1 model get only 96.45% that continuously increase on 5th fold with 99.34% F1-score.
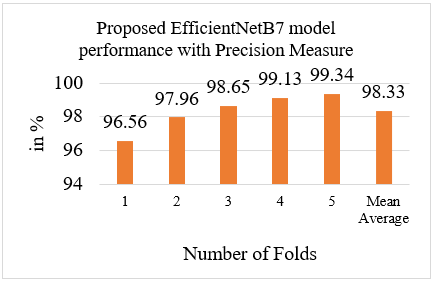
Figure 9 shows the proposed EfficientNetB7 performance on precision measure with five number of folds with average mean value. Proposed system obtains 98.33% of precision while initial folds 1 model get only 96.56% that continuously increase on 5th fold with 99.34% precision.
Table 3. Training and validation accuracy with number of folds
|
Fold |
F1 Score |
Precision |
ROC AUC |
|
1 |
96.45 |
96.56 |
96.44 |
|
2 |
97.96 |
97.96 |
97.96 |
|
3 |
98.64 |
98.65 |
98.64 |
|
4 |
99.13 |
99.13 |
99.13 |
|
5 |
99.34 |
99.34 |
99.34 |
|
Mean Average |
98.31 |
98.33 |
98.31 |
Figure 8. Bar graph of F1-score performance with each running folds
Figure 9. Bar graph of precision performance with each running folds
Figure 10 shows the proposed EfficientNetB7 performance on ROC-AUC measure with five number of folds with average mean value. Proposed system obtains 98.31% of ROC-AUC while initial folds 1 model get only 96.56% that continuously increase on 5th fold with 99.34% ROC-AUC.
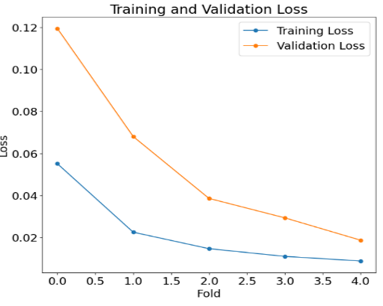
Figure 11 depicting a training & validation loss of a proposed model. An x-axis of a picture represents the range of fold from 0 to 4, while a y-axis displays a loss value of both a train & test k-fold cross validation model. The provided graph exhibits a line graph format, with two distinct lines representing train loss and validation loss, respectively. The line representing a train loss is shown in a color blue, whereas the line representing the validation loss is depicted in the color orange. The graph illustrates a downward trend in the loss function over the course of time for a training dataset. A suggested model demonstrates a reduction in loss, as seen by a validation dataset loss of 0.0194 and a training dataset loss of 0.0101, respectively.
Figure 10. Bar graph of ROC-AUC performance with each running folds
Figure 11. Train and validation loss graph using proposed EfficientNetB7 model
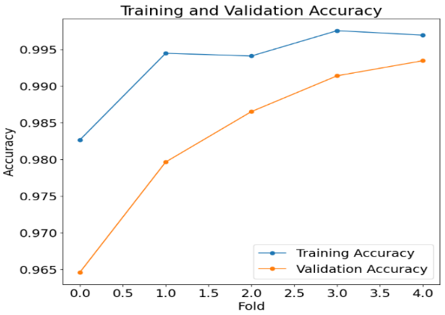
Figure 12. Training and validation accuracy graph using proposed EfficientNetB7 model
Figure 12 illustrates a training & validation accuracy graph of a proposed model. Accuracy scores for a train and test along a y-axis of an image, while an x-axis indicates a range of fold from 0 to 4. The provided graph exhibits a line graph format, with two distinct lines representing train accuracy & validation accuracy, respectively. A line representing an accuracy of the training data is shown in blue, while the line representing an accuracy of a validation data is depicted in orange. A proposed model is more accurate than a modern method, with a validation dataset accuracy of 98.31% a training accuracy of 99.31%, respectively.
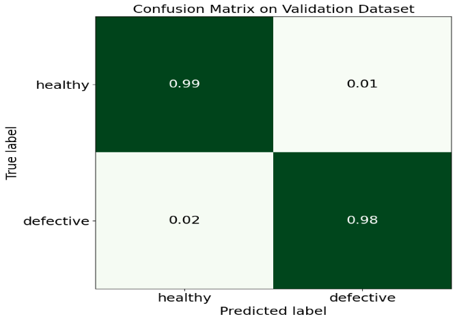
Figure 13. Confusion matrix of validation dataset using proposed EfficientNetB7 model
Figure 14. Confusion matrix of training dataset using proposed EfficientNetB7 model
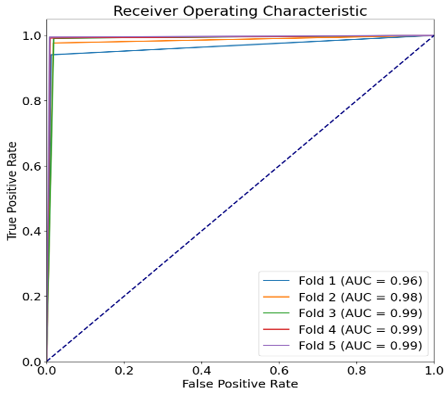
Figure 15. Roc curve of EfficientNetB7 model with each fold
Figure 13 displays a validation confusion matrix of an efficient B7 model with two tomato image classes: healthy and defective. The matrix is a square with four quadrants. An x-axis displays a forecasted class & a y-axis shows a true class. The numbers on the matrix's right side represent a total number of photos in each class. A number of healthy photos correctly categorized as healthy (0.99) is represented by a top left quadrant. A few of healthy photos were wrongly identified as faulty in the top right quadrant (0.01). The number of defective photos that were wrongly categorized as healthy (0.02) is represented in the bottom left quadrant. The bottom right quadrant represents the number of defective images that were correctly classified as defective (0.098), respectively.
Figure 14 displays a training confusion matrix of an efficient B7 model with two tomato image classes: healthy and defective. Proposed model obtains true predicted tomato images 100% and defective images only 10%, respectively.
Figure 15 displays a ROC curve for multiple classes with five folds. In figure x-axis represent a false positive rate and y-axis displays a true positive rate. ROC-AUC calculate with five folds using the tomato disease images. Model obtain 96% and 98% ROC_AUC on fold 1 and 2 while fold 3 to 5 model obtain 99% ROC_AUC.
Table 4. Comparative analysis of proposed and base models
|
Parameters |
Base Model |
Fine-Tuned EfficientNetB7 |
|
Training loss |
0.0978 |
0.0101 |
|
Validation loss |
0.1195 |
0.0194 |
|
Training accuracy |
0.9697 |
0.9931 |
|
Validation accuracy |
0.9642 |
0.9831 |
|
Average precision |
0.85 |
0.9833 |
Figure 16. Comparison graph between base and proposed model train and validation accuracy
Figure 17. Comparison graph between base and proposed model train and validation loss
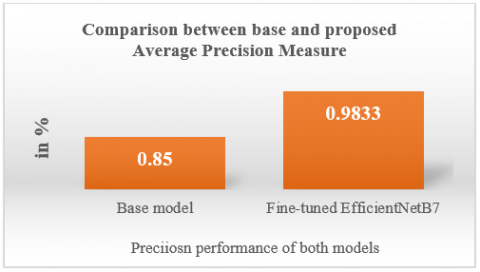
Figure 18. Comparison graph between base and proposed model with average precision measure
Table 4 and Figures 16-18 show a comparative analysis of a outcomes of proposed and base model with train and validation accuracy/loss and precision measures. Several crucial parameters were assessed in order to compare a performance of a base model & an EfficientNetB7 model. The training loss for the base model was 0.0978, while the training loss for the optimized EfficientNetB7 was substantially lower at 0.0101. This suggests that the refined model obtained a significantly better fit with the training data. When evaluating validation loss, a similar pattern was observed. The validation loss for the base model was 0.1195, whereas the validation loss for EfficientNetB7 was 0.0194. The fine-tuned model outperformed the original model, demonstrating its superior ability to generalize to data not previously observed. The base model also demonstrated a considerable improvement in accuracy metrics. Training accuracy for a baseline model was 0.9697, whereas that for EfficientNetB7 was 0.9931. In addition, while the validation accuracy of a baseline model was 0.9642, a validation accuracy of an improved model, after tuning, was 0.9831, which is better. The metric Average Precision, which is frequently crucial in classification tasks, also saw a significant improvement in the refined model. The base model had an Average Precision of 0.85, while the fine-tuned EfficientNetB7 achieved an Average Precision of 0.9833, which is a significant improvement. This greater value indicates that the fine-tuned model was especially accurate when classifying positive instances.
The work relies on certain hardware configurations and assumes dataset representativeness, which are limits despite noteworthy achievements. The model outperforms a baseline model in terms of accuracy, F1-score, precision, and ROC-AUC, as shown by a number of evaluation metrics and visualisations. Nevertheless, the extent to which findings can be applied to various agricultural situations depends on the quality and characteristics of the dataset. It is important to thoroughly examine the study's assumptions on data stationarity over time, the study's resilience in dynamic disease landscapes, and any biases in the preprocessing methods. When compared to a baseline model, the suggested model stands out as a significant improvement in automated tomato disease diagnosis, thanks to the fine-tuning and utilization of the EfficientNetB7 architecture.
The findings shown with the evaluation of parameters demonstrate the notable efficacy of the proposed model in accurately classifying image of healthy and defective tomatoes. The proposed approach has outcomes in a notable improvement in a performance of a model. Based on the data displays in Table 1. A training & validation loss for the base model were 0.0978 and 0.1195, respectively. Its accuracy in both training & validation is 0.9697 & 0.9642, respectively. An Average Precision score for the base model was 0.85. The suggested EfficientNetB7 model has a training loss of 0.0101 & a validation loss of 0.0194, with an enhanced EfficientNetB7 model performing better. Training accuracy was 0.9931, while validation accuracy was 0.9831, both improvements over previous models. It is notable that the proposed model also showed a significantly higher Average Precision score of 0.9833, It demonstrating that the proposed model has greater accuracy and efficiency. The aforementioned findings provide it a helpful resource for quality assurance and disease identification within the agriculture sector.
The obtained results are consistent with the research's original objectives and contributions. The primary goal was to enhance contamination detection in tomatoes with the use of deep learning, maximum especially the EfficientNetB7 model. The model outperforms a baseline model according to accuracy, precision, and total performance, as proven by way of the testing findings. The proposed approach substantially improves automated tomato disease detection by means of ditching the constraints of previous strategies and using the EfficientNetB7 architecture. The practical implementation of the model in real-world agricultural situations is highlighted with the aid of the findings, which indicate sizeable accuracy and resilience. The study's effect extends past theoretical developments; it gives a practical solution that may decorate agricultural practices, crop management strategies, and, in the long run, useful resource efforts to make certain food protection on a worldwide scale.
There are a variety of practical makes use for the proposed EfficientNetB7 tomato disease detection version, especially in the agricultural field. Through automatic and accurate tomato disease diagnosis, farmers can also get early insights into plant health that can allow focused treatment and decrease crop losses. This technology has the ability to essentially adjust the way ailments are handled with the aid of permitting prompt responses to rising risks and inspiring using sustainable agricultural practices. The model is a helpful tool for optimising aid allocation, decreasing pesticide usage, and elevating typical crop yield due to its excessive accuracy and reliability. By imparting a low-cost and realistic means of tracking and diagnosing plant sicknesses, this has a look at promotes precision agriculture. Farmers, agribusinesses, and the worldwide meals security initiative all gain from it as well.
This makes it viable to decide the freshness of food via looking at outside characteristics like color, shape, texture, and size, in addition to inner factors consisting of size, coloration, and chemical and organic modifications in the food that can be quickly detected the use of a lot of sensors. This permits for the assessment of food freshness based on each exterior attribute, consisting of colour, texture, and size, and interior elements, together with size, color, and chemical and biological alterations in the meals that may be directly identified through a number of sensors. One ability street for improvement is the creation of a web-based application that is able to supplying the results derived from the procedure of analyzing food products. It is anticipated that in destiny endeavors, there might be an expansion of the scope of studies to consist of a huger dataset, together with a wider variety of categories bearing on fruits and vegetables. A proposition has been put up to augment the inclusion of additional models for the purpose of evaluating their precision in relation to current models, using the same dataset. Further enhancements may be made to the grading and classification system to include additional elements that enable the identification of disease kinds and/or the textural structure of fruits. These are all potential areas for future exploration and development. The future improvement of the tomato image classification model should prioritize the expansion of the dataset, use of sophisticated neural network designs, incorporation of real-time processing capabilities, development of user-friendly interfaces, continuous model maintenance, and enhancement of interpretability. These actions have the potential to improve a model's performance & augment its applicability and influence inside the agriculture sector.
[1] Balakrishna, N., Sunitha, G., Karthik, A., Madhavi, K.R., Avanija, J. (2022). Tomato leaf disease detection using deep learning: A CNN approach. In 2022 International Conference on Data Science, Agents and Artificial Intelligence (ICDSAAI), Chennai, India. https://doi.org/10.1109/ICDSAAI55433.2022.10028922
[2] Wang, R., Lammers, M., Tikunov, Y., Bovy, A.G., Angenent, G.C., de Maagd, R.A. (2020). The RIN, NOR and CNR spontaneous mutations inhibit tomato fruit ripening in additive and epistatic manners. Plant Science, 294(762): 110436. https://doi.org/10.1016/j.plantsci.2020.110436
[3] Schreinemachers, P., Simmons, E.B., Wopereis, M.C.S. (2018). Tapping the economic and nutritional power of vegetables. Global Food Security, 16: 36-45. https://doi.org/10.1016/j.gfs.2017.09.005
[4] Trivedi, N.K., Gautam, V., Anand, A., Aljahdali, H.M., Villar, S.G., Anand, D., Goyal, N., Kadry, S. (2021). Early detection and classification of tomato leaf disease using high-performance deep neural network. Sensors, 21(23): 7987. http://doi.org/10.3390/s21237987
[5] Salih, T.A., Ali, A.J., Ahmed, M.N. (2020). Deep learning convolution neural network to detect and classify tomato plant leaf diseases. Open Access Library Journal, 7(5). https://doi.org/10.4236/oalib.1106296
[6] Zhang, Y., Song, C., Zhang, D. (2020). Deep learning-based object detection improvement for tomato disease. IEEE Access, 8: 56607–56614. https://doi.org/10.1109/ACCESS.2020.2982456
[7] David, H.E., Ramalakshmi, K., Gunasekaran, H., Venkatesan, R. (2021). Literature review of disease detection in tomato leaf using deep learning techniques. In 2021 7th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, pp. 274-278. https://doi.org/10.1109/ICACCS51430.2021.9441714
[8] Gunarathna, M.M., Rathnayaka, R.M.K.T. (2020). Experimental determination of CNN hyper-parameters for tomato disease detection using leaf images. In 2020 2nd International Conference on Advancements in Computing (ICAC), Malabe, Sri Lanka, pp. 464-469. https://doi.org/10.1109/ICAC51239.2020.9357284
[9] Sladojevic, S., Arsenovic, M., Anderla, A., Culibrk, D., Stefanovic, D. (2016). Deep neural networks-based recognition of plant diseases by leaf image classification. Computational Intelligence and Neuroscience, 2016(6): 1-11. https://doi.org/10.1155/2016/3289801
[10] Fuentes, A., Yoon, S., Kim, S.C., Park, D.S. (2017). A robust deep-learning-based detector for real-time tomato plant diseases and pests recognition. Sensors, 17(9): 2022. https://doi.org/10.3390/s17092022
[11] Saini, A., Guleria, K., Sharma, S. (2023). Tomato leaf disease classification using convolutional neural network model. In 2023 Second International Conference on Electrical, Electronics, Information and Communication Technologies (ICEEICT), Trichirappalli, India, pp. 1-6. https://doi.org/10.1109/ICEEICT56924.2023.10157203
[12] Saeed, A., Abdel-Aziz, A.A, Mossad, A., Abdelhamid, M.A., Alkhaled, A.Y., Mayhoub, M. (2023). Smart detection of tomato leaf diseases using transfer learning-based convolutional neural networks. Agriculture, 13(1): 139. https://doi.org/10.3390/agriculture13010139
[13] Pradhan, P. Kumar, B. (2022). Automatic detection of tomato diseases using fine-tuned pre-trained deep learning models. In 2022 3rd International Conference for Emerging Technology (INCET), Belgaum, India. https://doi.org/10.1109/INCET54531.2022.9825376
[14] Habiba, S.U., Islam, M.K. (2021). Tomato plant diseases classification using deep learning-based classifier from leaves images. In 2021 International Conference on Information and Communication Technology for Sustainable Development (ICICT4SD), Dhaka, Bangladesh, pp. 82-86. https://doi.org/10.1109/ICICT4SD50815.2021.9396883
[15] Anandhakrishnan, T., Jaisakthi, S.M. (2020). Identification of tomato leaf disease detection using pretrained deep convolutional neural network models. Scalable Computing: Practice and Experience, 21(4): 625-635. https://doi.org/10.12694/scpe.v21i4.1780
[16] Nithish, E.K., Kaushik, M., Prakash, P., Ajay, R., Veni, S. (2020). Tomato leaf disease detection using convolutional neural network with data augmentation. In 2020 5th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, pp. 1125-1132. https://doi.org/10.1109/ICCES48766.2020.9138030
[17] Tm, P., Pranathi, A., Saiashritha, K., Chittaragi, N.B., Koolagudi, S.G. (2018). Tomato leaf disease detection using convolutional neural networks. In 2018 11th International Conference on Contemporary Computing (IC3), Noida, India, pp. 1-5. https://doi.org/10.1109/IC3.2018.8530532
[18] Joloudari, J.H., Marefat, A., Nematollahi, M.A., Oyelere, S.S., Hussain, S. (2023). Effective class-imbalance learning based on SMOTE and convolutional neural networks. Applied Science, 13(6): 4006. https://doi.org/10.3390/app13064006
[19] Rajpoot, V., Dubey, R., Mannepalli, P.K., Kalyani, P., Maheshwari, S., Dixit, A., Saxena, A. (2022). Mango plant disease detection system using hybrid BBHE and CNN approach. Traitement du Signal, 39(3): 1071-1078. https://doi.org/10.18280/ts.390334
[20] Tan, M., Le, Q.V. (2019). EfficientNet: Rethinking model scaling for convolutional neural networks. International Conference on Machine Learning. https://doi.org/10.48550/arXiv.1905.11946--20
[21] Lessmann, S., Baesens, B., Seow, H.V., Thomas, L.C. (2015). Benchmarking state-of-the-art classification algorithms for credit scoring: An update of research. European Journal of Operational Research, 247(1): 124-136. https://doi.org/10.1016/j.ejor.2015.05.030 --21
[22] Ebenuwa, S.H., Sharif, M.S., Alazab, M., Al-Nemrat, A. (2019). Variance ranking attributes selection techniques for binary classification problem in imbalance data. IEEE Access, 7: 24649-24666. https://doi.org/10.1109/ACCESS.2019.2899578--22
[23] Yousaf, K., Nawaz, T., Habib, A. (2024). Using two-stream EfficientNet-BiLSTM network for multiclass classification of disturbing YouTube videos. Multimedia Tools and Applications, 12: 36519-36546. https://doi.org/10.1007/s11042-023-15774-3
[24] Stein, R.M. (2007). Benchmarking default prediction models: Pitfalls and remedies in model validation. The Journal of Risk Model Validation, 1(1): 77-113. https://doi.org/10.21314/JRMV.2007.002---24
[25] Rajpoot, V., Dubey, R., Khan, S.S., Maheshwari, S., Dixit, A., Deo, A., Doohan N.V. (2022). Orchard boumans algorithm and MRF approach based on full threshold segmentation for dental X-Ray images. Traitement du Signal, 39(2): 737-744. https://doi.org/10.18280/ts.390239