Nareen O. M. Salim*![]() | Ahmed Khorsheed Mohammed
| Ahmed Khorsheed Mohammed![]()
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
In this investigation, the crucial role of fruits in daily lives is acknowledged, with emphasis placed on their significance in nutrition and agriculture. The primary focus is directed towards fruit image recognition and classification, a task of paramount importance in the present context. To expound on the methodology, classical machine learning approaches, encompassing K-Nearest Neighbors (KNN), Support Vector Machines (SVM), and Decision Trees (DT), are leveraged. Additionally, the capabilities of deep learning are harnessed through the utilization of the AlexNet model. The dataset selected, Fruit-360, is widely acknowledged and utilized, underscoring its popularity and relevance within the research community. Of particular note in the findings is the exceptional performance of the AlexNet model, with the highest metrics in accuracy (99.85%), precision (99.92%), sensitivity (99.86%), and an impressive F1 score (99.89%) when compared to all tested algorithms. The effectiveness of deep learning, especially in tasks revolving around image-based classification, is underscored by these results. The impact of these noteworthy results transcends multiple domains. In agriculture, the potential for automated fruit sorting holds the promise of heightened efficiency and decreased waste. Similarly, in healthcare, the integration of fruit recognition into dietary and nutritional assessments presents a substantial opportunity. A thorough outlook on the progression of fruit recognition and classification is encapsulated by this study, offering a positive outlook for the future in these fields.
fruit recognition, image classification, deep learning, feature extraction, fruit classification, machine learning
In this examination of the multifaceted role played by fruits in our lives, encompassing dietary significance, cultural value, and ecological importance [1], the intricate ways in which these vibrant earthly treasures contribute to the human experience are delved into [2]. A pivotal aspect involves the visual identification and classification of diverse fruit varieties, requiring the application of computer vision and machine learning (ML) techniques, commonly referred to as fruit recognition or classification [3]. Substantial time, cost, and labor losses are incurred through the hand and eye sorting of fruits based on their visual characteristics [3, 4]. The challenges posed by small visual differences between fruits are recognized [5, 6], and efforts are made in this study to address the limitations of current fruit classification methods, particularly in the agriculture sector, where real-time use is hindered by lengthy training and testing times or inaccuracies [7, 8]. In response to these identified gaps, the primary objective of this work is to have picture features extracted and preprocessed from the comprehensive Fruit-360 dataset, utilizing Principal Component Analysis (PCA), color, and texture features. Subsequently, a combination of classical machine learning methods (SVM, KNN, and DT) and the deep learning classification network AlexNet is employed to classify diverse fruit varieties [9, 10]. The analysis of classification results aims to identify the most effective ML and DL models for the Fruit-360 dataset, thereby addressing the pressing challenges in fruit recognition and classification. The organization of this paper can be outlined as follows: Section 2, titled "Related Work," is dedicated to reviewing prior research. In Section 3, we delve into the foundational theory and present our proposed system. Section 4 is focused on presenting the results and engaging in a detailed discussion. Finally, the paper culminates with a conclusion in Section 5.
The challenges in identifying fruits, arising from diverse factors such as lighting conditions, object concealment, and varied surface characteristics, have prompted numerous studies addressing fruit recognition as an image segmentation challenge. In the literature, one study [11] delves into the application of ML and pattern recognition methods for creating automatic date fruit classifiers, emphasizing the need for sorting and quality control in the food industry. Another study [12] proposes a CNN-based fruit recognition system, leveraging DL techniques on the Fruits-360 dataset. Despite achieving an accuracy rate of 99.79%, this work recognizes the need for a more comprehensive investigation into ML approaches, particularly concerning accuracy and computation times, focusing on the recognition of thirteen different apple varieties [13]. Dimensionality reduction using PCA is explored in the literature, creating latent variables known as principal components (PCs). This technique [14] transforms pixel images into a reduced-dimensional representation, presenting potential for enhancing independence across variables and reducing dimensionality. Additionally, a study [15] categorizes FFB maturity degrees using texture and color characteristics with PCA-based feature selection, applying an ANN for classification. A comprehensive evaluation of Indian fruit types is conducted [16] using both SVM classifiers and deep features extracted from a CNN model. The literature introduces an alternative method based on transfer learning, comparing six deep learning architectures. Despite the notable performance of SVM classifiers with deep learning, this work aims to contribute by critically analyzing the methodologies and exploring the potential for improved fruit classification models. Enhancements to the AlexNet convolutional neural network [17] for categorizing different apple varieties exhibit improved recognition abilities. The findings highlight the viability of the modified AlexNet model for fruit categorization, showcasing increased accuracy and reduced training times. Additionally, a study [18] proposes a method for determining the quality of peanut pods, employing ResNet18 with the CSPNet module for enhanced accuracy and real-time performance. The development of a reliable system [19] using RGB-depth cameras for simultaneous and accurate identification of fruit-bearing branches in litchi clusters in large areas presents a significant advancement. Furthermore, a study [20] explores sensor data fusion from HSI and acoustic signals for identifying codling moth infestations in apples. The findings suggest that the fusion technique can significantly enhance CM detection, indicating potential advancements in detecting infestations in pome fruits. In relating these studies to the current research aims, it is evident that our work seeks to build on existing methodologies, critically analyzing their limitations and aiming for advancements in accuracy, computation times, and real-time performance. Table 1 summarizes and compares all related research in this section.
Table 1. Summarizes and compares the related work outlined in section 2
|
Ref. and Year |
Dataset |
Features |
Classifier |
Remarks and Results |
|
2023 [11] |
Originally composed of 898 samples of seven different types of date fruits |
Shape, color and morphology |
SVM, NB, LMT, KNN and MLP |
To assess the effectiveness of five distinct machine learning algorithms in categorizing date fruits by their external attributes, we found that MLP yielded the highest performance with the original dataset, whereas SVM proved to be the superior classifier when working with the underdamped dataset. |
|
2019 [12] |
Fruits-360 |
Convolutional layers |
CNN |
To attain elevated classification accuracies by exploring different combinations of hidden layers and epochs across various scenarios and subsequently comparing their results. Ultimately, the goal is to reach a test accuracy of 100% and a training accuracy of 99.79%, representing the study's desired outcomes. |
|
2023 [13] |
Fruits-360 |
---------- |
LR, LDA, CART, NB, KNN, SVM, AB, GBM, RF, and ET |
To identify the most suitable approach from ten available methods for grading apples, evaluated the performance quality of these techniques. Authors determined the SVM achieved a remarkable 97% accuracy and 96% accuracy with KNN. |
|
2020 [14] |
Fruit dataset was collected through online search engine |
Color, GLCM texture, shape and PCA |
SVM |
The suggested system has wide applicability across different sectors, including the food industry, pharmaceutical and cosmetic industries, as well as the evaluation of fruit quality. The experimental outcome showcased a noteworthy classification accuracy of 87.06%. |
|
2021 [15] |
Dataset consisted of images of oil palm fresh fruit bunches located in the Paser District of East Kalimantan, Indonesia |
Color, texture and PCA |
Naïve Bayes, SVM, and ANN |
To create an automated approach employing machine vision techniques to categorize the ripeness stage of oil palm fresh fruit bunches. The classification accuracy achieved impressive results, with Naive Bayes at 96.7%, while both SVM and ANN scored an accuracy of 98.3%. |
|
2020 [16] |
Indian Fruits-40 |
Fully connected layer (CNN) |
SVM |
To attain a combination of precision and speed in identifying fruits, with potential benefits for a wide range of uses, including fruit monitoring and classification within the production process. The result SVM get 100% accuracy. |
|
2023 [17] |
Fruits-360 |
Fully connected layer with a global average pooling layer |
AlexNet |
The authors' objective was to tackle the issue of the expensive and inefficient manual sorting of apples, and they succeeded in reaching an accuracy of 98.88% by implementing a computer vision-based approach. |
|
2023 [18] |
Standardized peanut pod quality dataset |
CNN architecture |
Improved ResNet18 architecture and incorporates the CBAM, KRSNet, and CSPNet module |
The study aimed to propose a cost-effective method for assessing peanut pod quality using RGB images and deep learning techniques. Results showed that the algorithm, which incorporated an improved ResNet18 architecture along with CBAM, KRSNet, and CSPNet modules, outperformed the original ResNet18 in terms of accuracy and various evaluation metrics. |
|
2020 [19] |
Manual labelling dataset |
RGB-D |
Deeplabv3 |
To create a dependable algorithm that can identify and pinpoint fruit-bearing branches within litchi clusters in their natural habitat, the Deeplabv3 algorithm demonstrated an accuracy rate of 79.46%. |
|
2023 [20] |
The experiments used organic Gala, Fuji, and Granny Smith apple samples, which were bought from a commercial market in Princeton, KY, USA |
PCA-HSI |
AdaBoost |
The article addresses the challenges of detecting common scab (CM) in apples and suggests a method with the potential to enhance detection accuracy and efficiency. The model reached 98%. |
|
This work |
Fruits-360 |
LBP, RGB, PCA |
SVM, KNN, DT and AlexNet |
The investigation emphasizes the vital role of fruits in daily life, particularly in nutrition and agriculture. The main focus is on fruit image recognition and classification, utilizing Classical ML methods (KNN, SVM, DT) and DL with the AlexNet model on the well-established Fruit-360 dataset. Significantly, AlexNet surpasses other algorithms, achieving exceptional metrics: accuracy (99.85%), precision (99.92%), sensitivity (99.86%), and an impressive F1 score (99.89%). |
3.1 Proposed system
Three primary components make up the proposed system: (Preprocessing, Feature extraction, and classification). The suggested system's flow diagram is depicted in Figure 1.
Figure 1. Flow diagram
3.1.1 Pre-processing
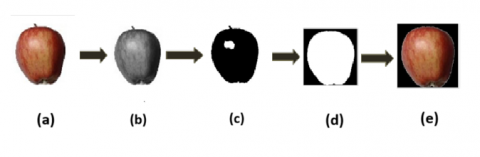
Utilizing segmentation techniques, it is crucial to isolate the fruit region from the background of the image in order to obtain the necessary features for classification. To speed up processing, the image is first downsized from 100×100 to 150×150 pixels in the pre-processing stage. By removing any unwanted contaminants, the image is subsequently converted to grayscale, gray threshold, and finally black and white. Utilize the region of interest from the segmented fruit in the final fruit mask. As shown in Figure 2.
Figure 2. Pre-processing steps
3.1.2 Feature extraction
Feature extraction is a technique for discovering more precise information about significant elements in a picture [21]. A classification approach that overfits the training data and performs badly when applied to new samples is frequently needed for analyses with a lot of variables. Feature extraction is a technique for combining the variables to get around these problems while still accurately characterizing the data [22]. Pattern recognition features frequently include context, PCA, shape, color, texture, or grayscale data. In image processing or machine vision, a pattern measurement from the beginning or particular consecutive measurement patterns are transformed into a new pattern feature [23]. The process of classifying an object into a category or a class using higher-level data or characteristics that have been retrieved from the object is known as pattern classification. It creates the categorization strategy while also automatically identifying things in the image [24]. Finding patterns, especially visual and aural patterns, is a major focus of the field of pattern recognition in computer science. It employs methods from various academic fields, such as ML, statistics, and others [24].
Principal component analysis (PCA). Principal Component Analysis, a dimensionality reduction technique, can be used to solve compression and recognition problems (PCA). Other names for PCA include hoteling or eigenspace projection [25]. The original data space or image is converted into a subspace collection of principal components (PCs) using PCA, where the diversity between the photos is primarily captured by the first orthogonal dimension. The final dimension of this subspace exhibits the smallest amount of variation between the photos according to the statistical characteristics of the targets [26]. When characterizing the original vector using the orthogonal or uncorrelated output components from this transformation, the mean square error may be the lowest. Results from common transform techniques like PCA are not directly related to any one feature of the original test. By extracting features, PCA can identify the sample data elements that show the greatest change. From all the features, this can be utilized to select a few fascinating people.
The projection matrix Wopt that maximizes the determinant of the total scatter matrix of the projected samples is often found using the PCA method [27] as follows.
where, w is:
$W_{o p t}=\arg \max _w \frac{\left|w^T s_T w\right|}{\left|w^T s_w w\right|}$ (1)
And the total scatter matrices are ST:
$\mathrm{ST}=\sum_{1=1}^c\left(x_i-\mu\right)\left(x_i-\mu\right)^T$ (2)
The Symbol µ denote the mean of vector feature for all sample in set of training and xi is the i-th of feature vector of sample and c are the amount of training sample numbers.
Color feature. Researchers have utilized the fruit's color as a defining characteristic for classification quite a bit. In this study, RGB color features that are observed in the fruit region are extracted to obtain color information.
RGB color model. The RGB model, commonly known as the three primary colors, is made up of Through the use of the three brightness channel combinations, a wide range of colors can be manipulated. three-color channels: red, green, and blue. Through the use of the three brightness channel combinations, a wide range of colors can be manipulated. Channels often have a limited range, such as 0 to 255. There are typically 24 color photos utilized [28]. Additionally, eight shades of gray are used to represent each color component. The total number of colors can be expressed using three color components as follows: 288+8+8=224=16,777,216. In essence, all the colors that the human eye can see are contained in the color-coded representation of their appearance. The most popular color model is this one.
The RGB color space's coordinate system is seen in Figure 3 as a unit cube. Black is in the coordinate (0,0,0), white is in the coordinate (0,0,1), green is in the coordinate (0,1,0), and blue is in the location (0,0,0). (1,1,1). The cube's diagonal is covered in several shades of gray. All the hues are present in the cube; for example, white can be described as (1,1,1) and gray as (0.5, 0.5, 0.5).
Simple color representations include the RGB color space. However, it falls short of the visual experience and lacks an intuitive expression style [29-31]. It is impossible to comprehend the equivalent combination of colors based on the three main color components. Additionally, the three-color components must vary if you want to alter the image's color. Consequently, the finished product cannot accurately depict the color that the human eye actually sees [30]. When doing a statistical texture analysis, the characteristics of the texture are calculated using the statistical distribution of the observed combinations of intensities at certain locations within the image in relation to one another. In this work, LBP types of texture characteristics are investigated. Depending on how many intensity points (pixels) there are in each pair, statistics are categorized as first-order, second-order, and higher-order statistics.
Local binary pattern (LBP). The majority of texture models have an excessively high level of computational complexity. The local binary pattern operator (LBP) is a straightforward texturing model that the authors selected as a result [32]. The operator labels the pixels in an image block by setting the center value as the threshold for each pixel's neighborhood, and then interprets the output as a binary number (LBP code):
$\operatorname{LBP}\left(x_c, y_c\right)=\sum_{p=0}^{p-1} s\left(g_p-g_c\right) 2^p$ (3)
where, gc corresponds to the value of the center pixel (xc, yc) and gp represents the grey values of the P neighborhood pixels. The function s(x) is defined as follows:
$s(x)= \begin{cases}1 & \text { if } x>0 \\ 0 & \text { if } x \leq 0\end{cases}$ (4)
Uncertainty has been given to the definition of the htexture in order to test for similarity between an image block texture and the backdrop texture.
$\begin{aligned} & h_{\text {texture }}\left(x_c, y_c\right)= \begin{cases}G_t\left(x_c, y_c\right) / G_B\left(x_c, y_c\right) & \text { if } G_t\left(x_c, y_c\right)<G_B\left(x_c, y_c\right) \\ 1 & \text { if } G_t\left(x_c, y_c\right)=G_B\left(x_c, y_c\right) \\ G_B\left(x_c, y_c\right) / G_t\left(x_c, y_c\right) & \text { if } G_t\left(x_c, y_c\right)=G_B\left(x_c, y_c\right)\end{cases} \end{aligned}$ (5)
where, $G_B\left(x_c, y_c\right)$ is the texture LBP of pixel $\left(x_c, y_c\right)$ in background and Gt $G_t\left(x_c, y_c\right)$ is the texture LBP of pixel $\left(x_c, y_c\right)$ in time $\mathrm{t}$ video frame. $h_{\text {texture }}$ is close to one if $G_B\left(x_c, y_c\right)$ and $G_t\left(x_c, y_c\right)$ are extremely comparable [33] show Figure 4 for example.
Figure 3. RGB color cube
Figure 4. Bilinear interpolation is used to estimate the values of nearby neighbors
3.3 ML classification method
The choice of classifier is a crucial step since the same collection of features may yield different results when used with various classification approaches. In this study, we classified a variety of fruits using ML and DL algorithms. In this work, the effectiveness of ML (KNN, DT, and SVM) and DL (AlexNet) approaches for classifying fruits was compared. We selected these ML and DL methods despite the fact that there are many more that have been explored in the literature since they are popular and widely accepted as being successful. The choice of classifier is a crucial step since the same collection of features may yield different results when used with various classification approaches. In this study, we classified a variety of fruits using ML and DL algorithms. In this work, the effectiveness of ML (KNN, DT, and SVM) and DL (AlexNet) approaches for classifying fruits was compared. We selected these ML and DL methods despite the fact that there are many more that have been explored in the literature since they are popular and widely accepted as being successful.
3.3.1 SVM
The SVMs are also called support vector networks [34]. The trained model is a non-probabilistic binary linear classifier since it categorizes newly sampled data into one of the categories. The data in SVM can be seen as points in space that are mapped to another space and then separated by a hyperplane. The new test data is then translated into the same space and classified according to the hyperplane. By utilizing a kernel, SVM can also be utilized for non-linear classification. High-dimensional feature spaces like kernel maps make separation simple [35, 36].
3.3.2 KNN
The KNN algorithm is a widely recognized statistical method for pattern recognition [36]. It is both simple and efficient. The classifier functions independently of the training dataset, and there is no complexity involved during the training phase. Nevertheless, the size of the training set significantly influences the computational complexity of the KNN algorithm. This approach is particularly effective for separating samples with numerous intersections or overlaps within the class domain, outperforming other methods [37].
3.3.3 DT
Instances are categorized using DT, which order instances based on the values of their features. A decision tree's branches each reflect a potential value for the node, which in turn represents a feature in an instance that needs to be categorized. Instances are grouped and sorted starting at the root node based on the feature values they contain. In data mining and ML, DT learning employs a decision tree as a prediction model to connect observations about an object to judgments about the value it should have. Classification trees or regression trees are suitable names for these tree models [38]. In order to evaluate the performance of decision trees while they are pruned using a validation set, decision tree classifiers frequently use post-pruning approaches. Any node may be deleted and assigned the training instances' most prevalent class [38].
In essence, the selection of SVM, KNN, and DT is based on their distinctive advantages: SVM stands out in precise binary classification and has the capability for non-linear separation; KNN proves to be efficient and proficient, especially in scenarios where class domains overlap; and DT offers a transparent hierarchical framework for decision-making relying on image features. The intent behind utilizing this combination is to harness the individual strengths of each method, thereby improving the overall accuracy and performance in the realm of fruit image recognition and classification.
3.4 DL classification method
In contrast to traditional machine learning, deep learning necessitates less manual feature engineering, as seen in algorithms like SVM and KNN. For instance, CNNs, a subtype of deep learning models, excel in the process of feature extraction. CNNs possess the ability to map input data through multiple layers, allowing them to learn from each layer individually, thereby enabling the extraction of meaningful features from large datasets. Deep learning classification models often incorporate convolutional, pooling, and fully connected layers [39]. When dealing with images of plant leaves, the convolutional layer primarily extracts image features. The intermediate layer is responsible for extracting intricate texture information and a portion of the semantic details, while the deep layer captures high-level semantic features, and the shallow layer retrieves edge and texture information. A max-pooling layer is employed to preserve crucial information in the image following the convolutional layer [40]. The high-level semantic features extracted by the feature extractor are categorized using a classifier composed of fully connected layers located at the model's end. In this study, the input image dimensions were set at 270×270×3, divided into several depth slices with a significant number of neurons in each slice. Think of square filters like 16×16, 9×9, or 5×5 convolution kernels as weights for these neurons, each related to a specific local region in the image from which it extracted features.
If we assume the input image size is denoted as W, the convolution kernel size as F, and the stride of the convolution kernel as S (typically S=2), padding P is used to fill the input image boundary, with P usually set to 0. The size of the image following convolution can be calculated as (W-F+2P)/S+1. Each output map feature employs convolutions to combine various input maps, and typically, Eq. (6) can be used to represent the result. Semantic information. The input image size for this investigation was set to 270×270×3. In the direction of depth, it was divided into numerous slices.
$x_j^l=f\left(\sum_{i \in M_j} x_i^{l-1} * k_{i j}^l+b_j^l\right)$ (6)
where, i represents the I layer, kij represents the convolutional kernel, bj represents the bias, and Mj is a collection of input maps. It seems to suggest that when implementing CNNs in a more detailed or advanced manner, many people use the sigmoid activation function, a tanh function, or an additive bias. For instance, the unit's value at the place x, y in the (j-th) feature map and the (i-th) layer, denoted as $v_{i j}^{x y}$ is given in Eq. (7).
$\begin{aligned} & v_{i j}^{x y}=\operatorname{sigmoid}\left(b_{i j}+\sum_{p=0}^{P_i-1} \sum_{q=0}^{Q_j-1} w_{i j}^{p q} v_{(i-1)}^{(x+p)(y+q)}\right)\end{aligned}$ (7)
where, ${sigmoid (.)}$ is the sigmoid function $b_{i j}$ is the bias for the feature map, $P_i$ and $Q_j$ are the height and width of the kernel, and $w_{i j}^{p q}$ is the kernel weight value at the position (p, q) connected to the $(\mathrm{i}, \mathrm{j})$ layer. The parameters of CNNs, such as the bias $b_{i j}$ and the kernel weight $w_{i j}^{p q}$, are usually trained using unsupervised approaches. Different DL classification models have been developed for image classification problems. We applied AlexNet DL classification models in this research because AlexNet is a well-known CNN model used for fruit recognition and classification. Its deep layers and convolutional filters excel at capturing complex fruit features, making it effective at distinguishing different fruit types. This success in image classification and its capacity to learn hierarchical features contribute significantly to improving the accuracy and efficiency of fruit recognition systems. AlexNet, developed by Alex Krizhevsky, achieved a groundbreaking victory in the 2012 ImageNet Large Scale Visual Recognition Challenge, signifying a significant leap forward in computer vision. With a structure encompassing eight layers, featuring five convolutional layers and three fully connected layers, AlexNet serves as the foundational framework for contemporary deep neural networks. The convolutional layers, essential for extracting features and identifying objects, employ diverse filters, including sizes like 11×11 and 5×5, among others. Following each convolutional layer, max-pooling layers efficiently reduce spatial dimensions. The three fully-connected layers, each hosting 4096 neurons, play a vital role in object categorization, while the final SoftMax layer predicts object classes in the images. This architectural design, coupled with specified filter sizes, has become a cornerstone in the field of deep learning [41, 42]. The entire course of this study is depicted in Figure 5. We manually retrieved characteristics from the preprocessed fruit dataset in order to employ ML techniques to categorize fruits. It was unnecessary to manually extract features in this case because the DL classifier could do so automatically. The DL and ML networks, respectively, received input from the preprocessed images and the extracted features for training. We acquired the trained models after the training procedure was finished. The trained model was then used to classify the test dataset [42].
Essentially, the strengths of deep learning, exemplified by the proficiency of AlexNet, originate from its inherent ability to autonomously acquire intricate features, comprehend hierarchical abstractions, and provide heightened flexibility and scalability. This, in turn, leads to superior performance in image recognition when compared to conventional ML approaches.
Figure 5. Flowchart of fruits classification
3.5 Data set
The dataset utilized in this paper is the Fruit 360 dataset [43], comprising 131 categories of fruits and vegetables and encompassing a total of 90,483 images. The training dataset consists of 67,692 images, while the testing dataset contains 22,688 images, with each image featuring a single fruit or vegetable. All images within the dataset have been standardized to 100×100 pixels to ensure uniformity. To enhance classification accuracy, the fruits and vegetables were isolated from their backgrounds due to varying lighting conditions. To create an effective model with high accuracy, it is essential to maintain a balanced distribution of data in both the training and testing datasets. A comparison of the two datasets reveals a similar image distribution ratio across all categories, which can be verified by calculating the ratios for specific classes in both datasets. As illustrated in Figure 6, images of various fruits from 360 datasets.
Figure 6. Fruits classes in 360 datasets
3.6 Confusion matrix
The confusion matrix is a vital tool in ML and DL for evaluating the performance of classification model performance. It provides a comprehensive analysis of how a model's predictions compare to the actual labels derived from the ground truth. Although it may be used in multi-class settings as well, binary classification issues (two classes) are where it shines [44].
The confusion matrix consists of four essential components:
(1). True Positives (TP): In these cases, the model successfully predicted the positive class.
(2). True Negatives (TN): In each of these situations, the model properly predicted the negative class.
(3). False Positives (FP): Here, the model predicted the positive class when the actual class was negative, which was incorrect.
(4). False Negatives (FN): In these cases, the model predicted the erroneous class, which was negative whereas the true class was positive.
The Confusion Matrix is frequently depicted as a figure, roughly resembling this:
Calculating the proportion of samples that were correctly classified to all samples, as demonstrated in the example below, can be used to evaluate the classification models' accuracy.
Accuracy $=\frac{T P+T N}{T P+T N+F N+F P}$ (8)
To determine the accuracy for the TP divided by the total number of items with positive labels (TP plus FP added together), as stated in formula 9, High precision indicates that the model and categorization are producing more useful results.
Precision $=\frac{T P}{T P+F P}$ (9)
Calculating the recall by dividing the total number of components that genuinely belong to the positive class TP will allow you to determine the model's sensitivity (10).
Sensitivity $($ recall $)=\frac{T P}{T P+F N}$ (10)
The harmonic mean of sensitivity and precision is used to determine the F1-Score.
$F 1=2 * \frac{(\text { Precision } * \text { sensitivity) }}{\text { (Precision }+ \text { sensitivity })}$ (11)
Data scientists and ML practitioners can assess how well their models are working and make educated decisions regarding model modification and deployment using the Confusion Matrix and related metrics [45].
Table 2. Name and number of each fruit
|
Number |
Fruit Label |
Training Number |
Testing Number |
|
1 |
Apple Golden 3 |
481 |
161 |
|
2 |
Apple Red 1 |
492 |
164 |
|
3 |
Apple Red Yellow 1 |
492 |
164 |
|
4 |
Apricot |
492 |
164 |
|
5 |
Avocado |
427 |
143 |
|
6 |
Banana |
490 |
166 |
|
7 |
Banana Lady Finger |
450 |
152 |
|
8 |
Banana Red |
490 |
166 |
|
9 |
Beetroot |
450 |
150 |
|
10 |
Blueberry |
462 |
154 |
|
11 |
Cherry 1 |
492 |
164 |
|
12 |
Cherry Rainier |
738 |
246 |
|
13 |
Cocos |
490 |
166 |
|
14 |
Corn |
450 |
150 |
|
15 |
Cucumber Ripe |
392 |
130 |
|
16 |
Cucumber Ripe 2 |
468 |
156 |
|
17 |
Dates |
490 |
166 |
|
18 |
Eggplant |
468 |
156 |
|
19 |
Fig |
702 |
234 |
|
20 |
Grape Pink |
492 |
164 |
|
21 |
Grape White |
490 |
166 |
|
21 |
Kaki |
490 |
166 |
|
23 |
Kiwi |
466 |
156 |
|
24 |
Lemon |
492 |
164 |
|
25 |
Lychee |
490 |
166 |
|
26 |
Mango |
490 |
166 |
|
27 |
Mulberry |
492 |
164 |
|
28 |
Onion Red |
450 |
150 |
|
29 |
Onion White |
438 |
146 |
|
30 |
Orange |
479 |
160 |
|
31 |
Papaya |
492 |
164 |
|
32 |
Peach |
492 |
164 |
|
33 |
Pear |
492 |
164 |
|
34 |
Pepper Green |
444 |
148 |
|
35 |
Plum |
447 |
151 |
|
36 |
Potato White |
450 |
150 |
|
37 |
Raspberry |
490 |
166 |
|
38 |
Strawberry |
492 |
164 |
|
39 |
Tomato 1 |
738 |
246 |
|
40 |
Watermelon |
475 |
157 |
The program was trained on two types of datasets that were obtained from the fruit-360 dataset. The first one consisted of 40 types of fruit classes, as shown in Figure 7, while the second one consisted of 59 types of fruit classes in the dataset. The experimental dataset after preprocessing includes a total of (24,636) 40-class images of different fruits. As shown in Table 2, the preprocessed dataset was divided into training and testing subsets with 80% and 20% The DL models automatically extracted fruit features through a series of convolutional operations without manual extraction from the second dataset, which contained (30,392) images of various fruits. The feature extraction method is required to be carried out manually for ML algorithms, though. The earlier manually derived features were thus only used for the ML techniques. The classification outcomes of the DL and ML algorithms were evaluated using accuracy, precision, sensitivity, and F1 score metrics (explained in previous sections)".
Figure 7. 2*2 Confusion matrix
4.1 Results of tested ML/DL algorithms
First off, multiple features that had previously been manually extracted were employed to train the same classifier for the many different types of fruit classification in order to ascertain which features had the highest classification performance. In this way, we could investigate the effects of feature extraction techniques and classifiers on the classification outcomes. We used a variety of popular forms of feature extraction, including LBP, RGB, and PCA, which are used in the identification and classification of fruits, to examine the effects of various feature extraction methods on the classification outcomes. Table 3 displays the classification outcomes for the KNN classifier using various feature extraction techniques. Table 3 displays the various classification outcomes produced by various feature extraction techniques (LBP, RGB, and PCA) for 40 classes of different types of fruits with the KNN classifier. The first column in Table 3 indicates the three types of feature extraction. and the remaining columns indicate the percentages of each feature extraction method rate depended on (precision, sensitivity, F1-score, and accuracy) under the KNN classification algorithm.
Furthermore, from the comparison in Table 3, it can be seen that, among all the feature extraction methods, the LBP method obtained the best results in precision, sensitivity, and F1-scor of 96.339%, 95.960%, and 96.072%, respectively; This demonstrates that in the classification task, the extracted feature quality had a direct impact on the final classification outcome, as indicated by the accuracy column's LBP value of 96.072%. To effectively show research results or contrast various approaches, the Tables 4 and 5 that details the SVM and DT algorithms with various feature extraction techniques and their corresponding performance rates can be created. The columns that correspond to each row in the tables display the performance metrics (accuracy, precision, sensitivity, and F1 score) that were attained using that method. Each row represents a distinct feature extraction technique. This makes it possible for researchers to evaluate the effectiveness of several feature extraction methods and decide which one is best suited for their SVM and DT classification tasks.
Table 3. The outcomes for three feature extraction techniques using the KNN classifier
|
Feature Type |
Precision |
Sensitivity |
F1-Score |
Accuracy |
Error-Rate |
|
LBP |
96.33% |
95.96% |
96.14% |
96.07% |
3.9% |
|
RGB |
93.40% |
93.02% |
93.40% |
93.02% |
6.97% |
|
PCA |
86.11% |
83.95% |
85.01% |
83.95% |
16.05% |
Table 4. The outcomes for three feature extraction techniques using the SVM classifier
|
Feature Type |
Precision |
Sensitivity |
F1-Score |
Accuracy |
Error-Rate |
|
LBP |
82.85% |
81.08% |
81.96% |
81.45% |
18.25% |
|
RGB |
92.29% |
90.40% |
91.40% |
93.02% |
9.60% |
|
PCA |
NAN |
46.51% |
NAN |
83.95% |
52.29% |
Table 5. The outcomes for three feature extraction techniques using the DT classifier
|
Feature Type |
Precision |
Sensitivity |
F1-Score |
Accuracy |
Error-Rate |
|
LBP |
NAN |
95.96% |
NAN |
49.72% |
50.27% |
|
RGB |
93.40% |
NAN |
NAN |
88.58% |
11.41% |
|
PCA |
86.11% |
NAN |
NAN |
59.71% |
40.28% |
Table 6. Results for the tested ML & DL algorithms
|
Method |
Evaluation Metrics |
|
||
|
Accuracy |
Precision |
Sensitivity |
F1-Score |
|
|
KNN |
96.33% |
96.33% |
95.96% |
96.14% |
|
SVM |
90.40% |
92.29% |
90.40% |
91.39% |
|
DT |
88.58% |
87.00% |
NAN |
NAN |
|
AlexNet |
99.85% |
99.92% |
99.86% |
99.89% |
We can see from Table 6 the metrics of the evaluated DL network were superior to those of the evaluated ML algorithms. For instance, the accuracy of the tested ML techniques was 96.17% (KNN), 90.40% (SVM), and 88.58% (DT), whereas the accuracy of the tested DL algorithms was 998.5% (AlexNet). As shown in Table 6, AlexNet performs well at identifying objects in photos without the need for pre-processing work, and it also has the capacity to tell apart similar fruit structures. The KNN algorithm, followed by the SVM algorithm, and then the DT algorithm produced the best classification results among the three ML techniques examined.
We select the best rate of accuracy, precision, sensitivity, and F1-score for each classification to compare with the DL classification technique as shown in the Table 6 because we can see that among the various feature extraction methods, each table has the highest and lowest rate between them.
4.2 Discussion
In the realm of fruit recognition, both ML and DL approaches offer distinct advantages, yet they come with their own set of considerations. ML algorithms, such as KNN, DT, or SVM, prove effective in classifying fruits based on external characteristics, providing interpretability for users to comprehend the decision-making process. Nevertheless, these models have limitations in handling the complexity of unstructured image data, leading to potential failures in intricate fruit recognition tasks. On the other hand, DL, particularly CNNs, excels at navigating complex and unstructured image data within fruit recognition tasks. They automatically learn intricate features, eliminating the need for manual feature engineering. However, the trade-off includes the requirement for larger datasets for training and reduced interpretability due to the complex architectures, leading to challenges in understanding model decisions. Navigating the choice between ML and DL depends on factors such as the specific fruit recognition task, available data, and the desired balance between interpretability and accuracy. In light of these considerations, it's crucial to provide more insights into model limitations, potential failures, and avenues for improvement. Exploring ways to address these limitations and enhancing model robustness will be pivotal for advancing fruit recognition methodologies. In this study, confusion matrix plots were employed along with training and validation plots. Classification results plots show the various classification outcomes for each categorization of fruits with various ML and DL algorithms.
Figure 8. KNN
Figure 9. SVM
Figure 10. DT
Figures 8-10 display the confusion matrix plots of the three tested ML algorithms. When used, the dataset contains 40 types of fruits and different types of feature extraction. In a confusion matrix graphic, the ordinate represents the predicted label, and the abscissa represents the true label. The values above and below the diagonal of the confusion matrix represent the examples that were mistakenly classified, whereas the diagonal itself contains the data for the occurrences that were correctly identified. As shown in Figures 8-10, the three ML methods (KNN, SVM, and DT) confusion matrix shows the best result of the three algorithms with the feature. For the KNN algorithm, the best result is with LBP, which is equal to 96.07%; in the SVM method, the height rate is 90.40% with the RGB feature; and in the third one, the RGB feature has the top rate with the DT algorithm. All the details about the rate of each feature with each algorithm have been determined in the above tables.
As seen in Figure 11, the classification of 59 fruit types requires more epochs to get stable, and the model requires more training because of the high similarity between different fruit types. AlexNet Network shows the performance to reach an accuracy of near 100% detection for the dataset used, which consists of 30,392 images of various fruits. The AlexNet (CNN) model's superior accuracy in fruit recognition, when compared to traditional ML algorithms, has significant real-world applications and consequences. This increased accuracy stems from the model's inherent ability to learn intricate features directly from image data. AlexNet's complex architecture, housing millions of parameters, allows it to grasp nuanced relationships within the data, surpassing the capabilities of traditional algorithms, even those involving meticulous feature engineering. The model's proficiency in image-related tasks is particularly noteworthy in practical scenarios. Its effective handling of spatial hierarchies ensures excellence in recognizing and categorizing fruits based on visual characteristics. Additionally, the advantage of transfer learning from pre-trained models is that it enhances its adaptability and performance in fruit recognition, especially when substantial data is available for training and fine-tuning. These results have broad implications across various domains. Firstly, the heightened accuracy of the AlexNet model implies a powerful tool for automating fruit recognition tasks, leading to increased efficiency and reduced reliance on human intervention. The model's generalization capabilities make it applicable to a broader range of fruits, fostering versatility in agricultural and industrial settings. The advancements in research facilitated by this technology have the potential to drive innovations in fruit-related studies and applications. Moreover, the economic and social impact is noteworthy, as automated and accurate fruit recognition can streamline processes in agriculture, food industry quality control, and nutritional assessments, contributing to enhanced productivity and healthier dietary practices. Overall, the practical applications of the AlexNet model in fruit recognition represent a transformative technology with diverse implications for various sectors and societal well-being.
Figure 11. Training and validation plots for 5 epochs to recognize of 59 fruits dataset
Figures 8-10 display the confusion matrix plots of the three tested ML algorithms. When used, the dataset contains 40 types of fruits and different types of feature extraction. In a confusion matrix graphic, the ordinate represents the predicted label, and the abscissa represents the true label. The values above and below the diagonal of the confusion matrix represent the examples that were mistakenly classified, whereas the diagonal itself contains the data for the occurrences that were correctly identified. As shown in Figures 8-10, the three ML methods (KNN, SVM, and DT) confusion matrix shows the best result of the three algorithms with the feature. For the KNN algorithm, the best result is with LBP, which is equal to 96.07%; in the SVM method, the height rate is 90.40% with the RGB feature; and in the third one, the RGB feature has the top rate with the DT algorithm. All the details about the rate of each feature with each algorithm have been determined in the above tables.
As seen in Figure 11, the classification of 59 fruit types requires more epochs to get stable, and the model requires more training because of the high similarity between different fruit types. AlexNet Network shows the performance to reach an accuracy of near 100% detection for the dataset used, which consists of 30,392 images of various fruits. The AlexNet (CNN) model's superior accuracy in fruit recognition, when compared to traditional ML algorithms, has significant real-world applications and consequences. This increased accuracy stems from the model's inherent ability to learn intricate features directly from image data. AlexNet's complex architecture, housing millions of parameters, allows it to grasp nuanced relationships within the data, surpassing the capabilities of traditional algorithms, even those involving meticulous feature engineering. The model's proficiency in image-related tasks is particularly noteworthy in practical scenarios. Its effective handling of spatial hierarchies ensures excellence in recognizing and categorizing fruits based on visual characteristics. Additionally, the advantage of transfer learning from pre-trained models is that it enhances its adaptability and performance in fruit recognition, especially when substantial data is available for training and fine-tuning. These results have broad implications across various domains. Firstly, the heightened accuracy of the AlexNet model implies a powerful tool for automating fruit recognition tasks, leading to increased efficiency and reduced reliance on human intervention. The model's generalization capabilities make it applicable to a broader range of fruits, fostering versatility in agricultural and industrial settings. The advancements in research facilitated by this technology have the potential to drive innovations in fruit-related studies and applications. Moreover, the economic and social impact is noteworthy, as automated and accurate fruit recognition can streamline processes in agriculture, food industry quality control, and nutritional assessments, contributing to enhanced productivity and healthier dietary practices. Overall, the practical applications of the AlexNet model in fruit recognition represent a transformative technology with diverse implications for various sectors and societal well-being.
In conclusion, our research undertook a comparative examination, juxtaposing the efficacy of deep learning (DL) with the convolutional neural network (CNN) architecture AlexNet against traditional machine learning (ML) algorithms (DT, KNN, and SVM) for the intricate task of fruit recognition and classification, utilizing the comprehensive Fruit-360 dataset. The standout revelation was the remarkable performance of the AlexNet model, achieving unparalleled accuracy rates of 99.85%, precision of 99.92%, sensitivity of 99.86%, and an F1 score of 99.89% in categorizing diverse fruits. The superiority of DL, exemplified by AlexNet, lies in its adept handling of complex image data, showcasing an innate capacity for automatic feature extraction without the need for manual engineering, a requirement often associated with traditional ML algorithms. While acknowledging the strengths of traditional ML algorithms, particularly in diverse domains, our study underscores the potency of DL, especially in image-based classification tasks, as demonstrated by the Fruit-360 dataset's diverse fruit types and the intricate nature of fruit appearances. DL models, like AlexNet, demonstrated their efficiency in addressing these complexities, suggesting their potential to significantly elevate the accuracy and efficiency of fruit recognition and classification systems, particularly in scenarios involving image data. Looking ahead, the prospect of expanding fruit classification to encompass an even more extensive array of fruit types within the same dataset holds promise. This expansion will facilitate the exploration and development of advanced CNN models that surpass the capabilities of AlexNet. Utilizing a larger dataset empowers researchers to create models that comprehend the unique features and complexities of a broader range of fruits, potentially advancing the state-of-the-art in fruit recognition and classification. This pursuit offers the exciting prospect of delivering more precise and robust solutions applicable to a wider spectrum of real-world scenarios.
[1] Pham, T.T., Nguyen, L.L.P., Dam, M.S., Baranyai, L. (2023). Application of edible coating in extension of fruit shelf life. AgriEngineering, 5(1): 520-536. https://doi.org/10.3390/agriengineering5010034
[2] Bùi, V.P. (2023). Fruit type and weight recognition for payment purposes using computer vision. Doctoral Dissertation, FPTU Hà Nội.
[3] Sugandi, B., Wahyu, R., Apriliana, S., Putri, F.R. (2023). Fruit recognition and weight scale estimation based on visual sensing. In Proceeding International Applied Business and Engineering Conference, pp. 234-241.
[4] Indira, D.N.V.S.L.S., Goddu, J., Indraja, B., Challa, V.M.L., Manasa, B. (2023). A review on fruit recognition and feature evaluation using CNN. Materials Today: Proceedings, 80: 3438-3443. https://doi.org/10.1016/j.matpr.2021.07.267
[5] Lin, M. (2023). Fruit classification based on ResNet and attention mechanism. Highlights in Science, Engineering and Technology, 34: 163-167. https://doi.org/10.54097/hset.v34i.5441
[6] Wangchuk, K., Dorji, T., Dhungyel, P.R., Galey, P. (2023). Fruits and vegetables recognition system in dzongkha using visual geometry group network. Zorig Melong-A Technical Journal of Science, Engineering and Technology, 8(1). https://doi.org/10.17102/v8004
[7] Selvakumari, R.S., Gomathy, V. (2023). Fruit shop tool: Fruit classification and recognition using deep learning. Agricultural Engineering International: CIGR Journal, 25(2): 312-321.
[8] Hussain, D., Hussain, I., Ismail, M., Alabrah, A., Ullah, S.S., Alaghbari, H.M. (2022). A simple and efficient deep learning-based framework for automatic fruit recognition. Computational Intelligence and Neuroscience, 1-8. https://doi.org/10.1155/2022/6538117
[9] Wang, J.J. (2022). Recognition system for fruit classification based on 8-layer convolutional neural network. EAI Endorsed Transactions on E-Learning, 22(23): e4. http://doi.org/10.4108/eai.17-2-2022.173455
[10] Gill, H.S., Murugesan, G., Mehbodniya, A., Sajja, G.S., Gupta, G., Bhatt, A. (2023). Fruit type classification using deep learning and feature fusion. Computers and Electronics in Agriculture, 211: 107990. https://doi.org/10.1016/j.compag.2023.107990
[11] Cordeiro, A.F., OliveiraJr, E., Costa, Y.M. (2023). Date Fruit classification using a wide range of classifiers. In 2023 30th International Conference on Systems, Signals and Image Processing (IWSSIP), Ohrid, North Macedonia, pp. 1-5. https://doi.org/10.1109/IWSSIP58668.2023.10180302
[12] Sakib, S., Ashrafi, Z., Siddique, M.A.B. (2019). Implementation of fruits recognition classifier using convolutional neural network algorithm for observation of accuracies for various hidden layers. arXiv Preprint arXiv: 1904.00783. https://doi.org/10.48550/arXiv.1904.00783
[13] Hassan, N.M.H., Elshoky, B., Hassan, N.M.H., Elshoky, B.R.G., Mabrouk, A.M. (2023). Quality of performance evaluation of ten machine learning algorithms in classifying thirteen types of apple fruits. Indonesian Journal of Electrical Engineering and Computer Science, 30(1): 102-109. https://doi.org/10.11591/ijeecs.v30.i1.pp102-109
[14] Zeeshan, M., Prabhu, A., Arun, C., Rani, N.S. (2020). Fruit classification system using multiclass support vector machine classifier. In 2020 International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, pp. 289-294. https://doi.org/10.1109/ICESC48915.2020.9155817
[15] Septiarini, A., Sunyoto, A., Hamdani, H., Kasim, A.A., Utaminingrum, F., Hatta, H.R. (2021). Machine vision for the maturity classification of oil palm fresh fruit bunches based on color and texture features. Scientia Horticulturae, 286: 110245. https://doi.org/10.1016/j.scienta.2021.110245
[16] Behera, S.K., Rath, A.K., Sethy, P.K. (2020). Fruit recognition using support vector machine based on deep features. Karbala International Journal of Modern Science, 6(2): 16. https://doi.org/10.33640/2405-609X.1675
[17] Yang, H., Wang, W., Mao, Z. (2023). Research on the improved apple classification method of AlexNet. In Third International Conference on Image Processing and Intelligent Control (IPIC 2023), SPIE, 12782: 378-385. https://doi.org/10.1117/12.3000778
[18] Yang, L., Wang, C., Yu, J., Xu, N., Wang, D. (2023). Method of peanut pod quality detection based on improved ResNet. Agriculture, 13(7): 1352. https://doi.org/10.3390/agriculture13071352
[19] Li, J., Tang, Y., Zou, X., Lin, G., Wang, H. (2020). Detection of fruit-bearing branches and localization of litchi clusters for vision-based harvesting robots. IEEE Access, 8: 117746-117758. https://doi.org/10.1109/ACCESS.2020.3005386
[20] Ekramirad, N., Khaled, A.Y., Donohue, K.D., Villanueva, R.T., Adedeji, A.A. (2023). Classification of codling moth-Infested apples using sensor data fusion of acoustic and hyperspectral features coupled with machine learning. Agriculture, 13(4): 839. https://doi.org/10.3390/agriculture13040839
[21] Tu, B., Zhou, C., Peng, J., Zhang, G., Peng, Y. (2021). Feature extraction via joint adaptive structure density for hyperspectral imagery classification. IEEE Transactions on Instrumentation and Measurement, 70: 1-16. https://doi.org/10.1109/TIM.2020.3038557
[22] Mutlag, W.K., Ali, S.K., Aydam, Z.M., Taher, B.H. (2020). Feature extraction methods: A review. In Journal of Physics: Conference Series. IOP Publishing, 1591(1): 012028. https://doi.org/10.1088/1742-6596/1591/1/012028
[23] Nixon, M., Aguado, A. (2019). Feature extraction and image processing for computer vision. Academic Press.
[24] Dhiman, G., Kumar, A.V., Nirmalan, R., Sujitha, S., Srihari, K., Yuvaraj, N., Arulprakash, P., Raja, R.A. (2023). Multi-modal active learning with deep reinforcement learning for target feature extraction in multi-media image processing applications. Multimedia Tools and Applications, 82(4): 5343-5367. https://doi.org/10.1007/s11042-022-12178-7
[25] Salim, N.O., Mohammed, A.K. (2023). Fruit recognition using Statistical and Features extraction by PCA. Academic Journal of Nawroz University, 12(3): 566-574. https://doi.org/10.25007/ajnu.v12n3a1687
[26] Zhang, Y., Wang, Y. (2023). Forecasting crude oil futures market returns: A principal component analysis combination approach. International Journal of Forecasting, 39(2): 659-673. https://doi.org/10.1016/j.ijforecast.2022.01.010
[27] Zhang, J., Zhou, D., Chen, M. (2021). Monitoring multimode processes: A modified PCA algorithm with continual learning ability. Journal of Process Control, 103: 76-86. https://doi.org/10.1016/j.jprocont.2021.05.007
[28] Alenezi, F. (2022). RGB-based triple-dual-path recurrent network for underwater image dehazing. Electronics, 11(18): 2894. https://doi.org/10.3390/electronics11182894
[29] Kou, J., Duan, L., Yin, C., Ma, L., Chen, X., Gao, P., Lv, X. (2022). Predicting leaf nitrogen content in cotton with UAV RGB images. Sustainability, 14(15): 9259. https://doi.org/10.3390/su14159259
[30] Kurniastuti, I., Yuliati, E.N.I., Yudianto, F., Wulan, T.D. (2022). Determination of hue saturation value (HSV) color feature in kidney histology image. In Journal of Physics: Conference Series, IOP Publishing, 2157(1): 012020. https://doi.org/10.1088/1742-6596/2157/1/012020
[31] Pardede, J., Husada, M.G., Hermana, A.N., Rumapea, S.A. (2019). Fruit ripeness based on RGB, HSV, HSL, L ab color feature using SVM. In 2019 International Conference of Computer Science and Information Technology (ICoSNIKOM), Medan, Indonesia, IEEE, pp. 1-5. https://doi.org/10.1109/ICoSNIKOM48755.2019.9111486
[32] Hu, F., Zhou, M., Yan, P., Bian, K., Dai, R. (2019). Multispectral imaging: A new solution for identification of coal and gangue. IEEE Access, 7: 169697-169704. https://doi.org/10.1109/ACCESS.2019.2955725
[33] Humeau-Heurtier, A. (2022). Color texture analysis: A survey. IEEE Access, 10: 107993-108003. https://doi.org/10.1109/ACCESS.2022.3213439
[34] Al Maki, W.F., Makrufi, A.J. (2022). Support vector machine with a firefly optimization algorithm for classification of apple fruit disease. MATRIK: Jurnal Manajemen, Teknik Informatika dan Rekayasa Komputer, 22(1): 177-188. https://doi.org/10.30812/matrik.v22i1.2365
[35] Mitra, D., Gupta, S. (2023). Design and implementation of Alex net-Honey badger fusion algorithm for feature selection and classification using multiclass support vector machine classifier to recognize plant leaf disease. International Journal of Intelligent Systems and Applications in Engineering, 11(3): 704-711. https://ijisae.org/index.php/IJISAE/article/view/3276
[36] Ahmed, R., Bibi, M., Syed, S. (2023). Improving heart disease prediction accuracy using a hybrid machine learning approach: A comparative study of SVM and KNN algorithms. International Journal of Computations, Information and Manufacturing (IJCIM), 3(1): 49-54. https://doi.org/10.54489/ijcim.v3i1.223
[37] Siregar, S.D., Ginting, Y.U.R., Sintami, N., Butar-Butar, H.S., Simanjuntak, R.M. (2023). Implementation of KNN algorithm in classifying diabetic ulcers in patients with diabetes mellitus. Jurnal Mantik, 7(2): 691-701. https://doi.org/10.35335/mantik.v7i2.3928
[38] Bansal, M., Goyal, A., Choudhary, A. (2022). A comparative analysis of K-nearest neighbor, genetic, support vector machine, decision tree, and long short-term memory algorithms in machine learning. Decision Analytics Journal, 3: 100071. https://doi.org/10.1016/j.dajour.2022.100071
[39] Iswanto, I.A., Winoto, A.S., Kristianus, M. (2023). Fruits recognition using deep convolutional neural network for low computing device. Engineering, Mathematics and Computer Science Journal (EMACS), 5(2): 85-91. https://doi.org/10.21512/emacsjournal.v5i2.9986
[40] Gao, G., Xu, Z., Li, J., Yang, J., Zeng, T., Qi, G.J. (2023). CTCNET: A CNN-transformer cooperation network for face image super-resolution. IEEE Transactions on Image Processing, 32: 1978-1991. https://doi.org/10.1109/TIP.2023.3261747
[41] Arena, P., Basile, A., Bucolo, M., Fortuna, L. (2003). Image processing for medical diagnosis using CNN. Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detectors and Associated Equipment, 497(1): 174-178. https://doi.org/10.1016/S0168-9002(02)01908-3
[42] Hamid, N.N.A.A., Razali, R.A., Ibrahim, Z. (2019). Comparing bags of features, conventional convolutional neural network and AlexNet for fruit recognition. Indonesian Journal of Electrical Engineering and Computer Science, 14(1): 333. https://doi.org/10.11591/ijeecs.v14.i1.pp333-339
[43] Rathnayake, N., Rathnayake, U., Dang, T.L., Hoshino, Y. (2022). An efficient automatic fruit-360 image identification and recognition using a novel modified cascaded-ANFIS algorithm. Sensors, 22(12): 4401. https://doi.org/10.3390/s22124401
[44] Hasnain, M., Pasha, M.F., Ghani, I., Imran, M., Alzahrani, M.Y., Budiarto, R. (2020). Evaluating trust prediction and confusion matrix measures for web services ranking. IEEE Access, 8: 90847-90861. https://doi.org/10.1109/ACCESS.2020.2994222
[45] Heydarian, M., Doyle, T.E., Samavi, R. (2022). MLCM: Multi-label confusion matrix. IEEE Access, 10: 19083-19095. https://doi.org/10.1109/ACCESS.2022.3151048