Ashoka Kumar Ratha![]() | Nalini Kanta Barpanda
| Nalini Kanta Barpanda![]() | Prabira Kumar Sethy*
| Prabira Kumar Sethy*![]() | Santi Kumari Behera
| Santi Kumari Behera![]()
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
In agricultural applications, the utilization of image processing with machine learning, particularly for fruit classification, has become increasingly prevalent. This study focuses on the automated classification of various Indian mango varieties, employing the deep features of MobileNet-v2 and Shufflenet, integrated with diverse machine learning classifiers. The research is anchored on an extensive dataset, encompassing 15 distinct Indian mango varieties, meticulously collated from various vegetable markets across India. This dataset is accessible at "Sethy, Prabira Kumar; Behera, Santi; Pandey, Chanki (2023), 'Mango Variety', Mendeley Data, V2, doi: 10.17632/tk6d98f87d.2". A comprehensive comparison of various machine learning classifiers highlighted the dominance of the Cubic Support Vector Machine (SVM) when integrated with deep features extracted from MobileNet-v2. This pairing resulted in an outstanding classification accuracy of 99.5% and an Area Under the Curve (AUC) of 1, demonstrating exceptional performance in identifying fruit varieties. The significance of this research lies in its potential to revolutionize fruit classification processes in supermarkets and related sectors. By demonstrating the feasibility of applying advanced computer vision technology for the accurate classification of fruits, this study lays the groundwork for future exploration into the scalability, robustness, and wider applicability of these methods, potentially extending beyond mangoes to other fruit varieties. Such advancements could substantially benefit the agricultural industry, enhancing efficiency in both production and retail sectors.
mango identification, deep learning, convolutional neural network (CNN), computer vision, machine learning, Support Vector Machine (SVM)
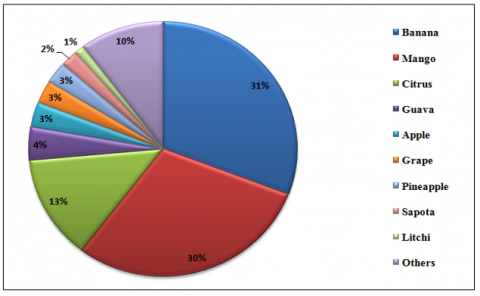
Mangifera indica Linn., a tropical mango known scientifically as Mangifera indica Linn., is renowned for its exceptional flavor and nutritional value and has earned it the moniker "the king of fruits" and numerous health advantages. Popular belief holds that this fruit originated in Myanmar and Northeast India (a region that encompasses Myanmar) approximately 4,000 years ago. Due to the immense number of solitary germs it possesses, it has gradually spread throughout Asia and the rest of the world [1]. Mangoes, whether raw or cooked, are equally delectable. Popular in Indian cuisine, pickles with a sour flavor are made from fresh fruit, whereas mature fruit is consumed uncooked. This fruit is the most consumed after bananas owing to its widespread appeal and high demand [2]. The rate of consumption of various fruits in India is depicted in Figure 1.
India is the leading producer of mangoes, contributing to approximately half of the global total. In 2020–21, the economic value of mango exports from India was 2718.8 million INR, equivalent to 36.23 million USD, with a cumulative value of 21033.58 MT. Mango production is highest in the Indian states of Tamil Nadu, Gujarat, Uttar Pradesh, Andhra Pradesh, Karnataka, and Bihar, among others. Uttar Pradesh was the leading state in terms of mango production, accounting for a substantial 23.47% [3]. In addition to the Philippines, Bangladesh, China, Indonesia, Thailand, Mexico, Pakistan, and Brazil, mangoes are cultivated in other countries [4]. Chachasa, Totapuri, Dasheri, Alphonso, Banganpalli, Kesar, and Langra are among the limited number of commercially cultivated mango varieties in India [5]. To ensure the optimal development of mango trees in India, it is imperative that specific meteorological and environmental criteria be met.
The implementation of machine learning [6], computer vision [7], and image processing [8] has effectively automated fruit supply chain operations, resulting in a significant increase in fruit production over the past few years. Identifying unique fruit varieties within assortments of containers has been the focus of numerous studies, highlighting the need for improved data processing capabilities as well as feature extraction and segmentation stages in ML approaches [9-11].
Different mango grading standards highlight color and size as crucial factors, with skin texture also playing a significant role in accurate classification. Borianne et al. [12] proposed an algorithm focusing on color and size, achieving 94.97% accuracy for mango classification and grading. Similarly, Vyas et al. [13] used a CNN for automatic identification, reaching 99% accuracy for Badami and Totapuri mangoes. Salim et al. [14] introduced an artificial olfactory system for nondestructive ripeness measurement using Harumanis mango, employing an artificial neural network (ANN) for classification.
Momin et al. [15] utilized a faster R-CNN network for mango fruit detection, achieving 90% accuracy but with a lower accuracy of 50% for fruit cultivar identification. In 2012, Zakaria et al. [16] used principal component analysis (PCA) and linear discriminant analysis (LDA) to determine the difference between mango harvests at different weeks by using data from an electric nose and an acoustic sensor. Yimyam et al. [17] used image analysis based on the hue model for mango segmentation.
Figure 1. The consumption rate of different fruits in India
Table 1. Summary of mango classification and grading techniques in the literature
|
Author and References |
Methodology Adapted |
Remarks |
|
Borianne et al. (2019) [12] |
Color and size algorithm |
Achieved 94.97% accuracy for mango classification and grading. |
|
Vyas et al. (2014) [13] |
CNN |
Reached 99% accuracy for Badami and Totapuri mango identification. |
|
Salim et al. (2005) [14] |
ANN |
Introduced an artificial olfactory system for nondestructive ripeness measurement using Harumanis mango, achieving classification through ANN. |
|
Momin et al. (2017) [15] |
Faster R-CNN network for mango fruit detection |
Achieved 90% accuracy for mango fruit detection, but lower (50%) accuracy for fruit cultivar identification. |
|
Zakaria et al. (2012) [16] |
PCA and LDA |
Discriminated mango harvest at different weeks using an electric nose and an acoustic sensor. |
|
Yimyam et al. (2005) [17] |
Image analysis based on the hue model |
Used image analysis for mango segmentation based on the hue model. |
|
Zhang and Wu (2012) [18] |
Least-squares support vector machine (LS-SVM) classifier |
Introduced LS-SVM classifier for measuring browning degrees with correct classification accuracies of 85.19% for fractal dimension (FD) and 88.89% for Lab* values. |
|
Razak et al. (2012) [19] |
Fuzzy image cloud clustering |
Applied fuzzy image cloud clustering for the grading of local mango production in Malaysia. |
|
Ke et al. (2022) [20] |
Deep learning - VGG16, Xception |
Achieved satisfactory results for four types of mango cultivars. |
|
Alhawas and Tüfekci (2022) [21] |
Deep learning - MobileNet, ResNet50 |
Emphasized the effectiveness of transfer learning and fine-tuning, reaching perfect testing accuracy, recall, F1 score, and precision of 100%. |
|
Bhole and Kumar (2020) [22] |
Transfer learning-based pretrained SqueezeNet model |
A nondestructive mango sorting and grading system was devised, achieving a classification accuracy of 93.33% for RGB images and 92.27% for thermal images. |
|
Gururaj et al. (2023) [23] |
CNN |
Proposed a system for mango maturity classification, achieving high accuracy for variety recognition (93.23%) and quality grading (95.11%). |
|
Iqbal and Hakim (2022) [24] |
Inception v3 architecture |
A deep learning approach was presented for the automated classification and grading of harvested mangoes, achieving classification accuracy of up to 99.2% and grading accuracy of 96.7%. |
|
Borianne et al. (2023) [25] |
Double-threshold-based classification method |
Focused on improving the performance of Faster R-CNN for fruit cultivar identification. |
|
Wu et al. (2020) [26] |
CNNs (Mask R-CNN, AlexNet, VGGs, ResNets) and self-defined convolutional autoencoder-classifiers |
Proposed a mango grading method using various CNN architectures inspired by multitask learning in classification tasks. |
Zhang and Wu [18] created a LS-SVM classifier that can accurately measure the degree of browning. It achieved 85.19% accuracy for fractal dimension (FD) values and 88.89% accuracy for Lab* values. Razak et al. [19] applied fuzzy image cloud clustering for grading local mango production in Malaysia.
Recent studies, including those of Ke et al. [20] and Alhawas and Tüfekci [21], have focused on deep learning techniques for mango classification. Ke et al. [20] employed VGG16 and Xception and achieved satisfactory results for four types of mango cultivars. Alhawas and Tüfekci [21] emphasized the effectiveness of transfer learning and fine-tuning with MobileNet and ResNet50, which achieved a perfect testing accuracy, recall, F1 score, and precision of 100%.
Bhole and Kumar [22] developed a mango sorting and grading system that ensures minimal damage to the fruit. This system utilizes a pretrained SqueezeNet model through transfer learning, achieving an accuracy of 93.33% for RGB images and 92.27% for thermal images.
Gururaj et al. [23] proposed a system for mango maturity classification using a CNN, achieving high accuracy for variety recognition (93.23%) and quality grading (95.11%). Iqbal and Hakim [24] introduced a deep learning method for the automatic classification and grading of harvested mangoes. They achieved a classification accuracy of up to 99.2% and a grading accuracy of 96.7% by employing the Inception v3 architecture.
Borianne et al. [25] introduced a classification method based on double thresholds for identifying fruit cultivars, with a focus on enhancing the performance of Faster R-CNN. Wu et al. [26] suggested a way to grade mangoes using convolutional neural networks, such as Mask R-CNN, AlexNet, VGGs, ResNets, and self-defined convolutional autoencoder-classifiers, which are influenced by learning to do more than one thing at once in regard to classification tasks. A summary of mango classification and grading techniques in the literature is provided in Table 1.
This study delves into the automatic classification of Indian mango varieties. The aim is to harness the power of computer vision, specifically by leveraging deep features extracted from MobileNet-v2 and ShuffleNet. This study further explored the effectiveness of different machine learning classifiers in accurately distinguishing between diverse mango cultivars.
Through the utilization of advanced methodologies, our aim is to narrow the gap between traditional manual classification approaches and the potential of emerging technologies. Our objectives center around enhancing the classification accuracy, investigating the resilience of the proposed methodology, and determining the most appropriate machine learning classifier for this purpose.
This study not only advances technology in agricultural practices but also fulfills practical requirements in the commercial sector, particularly for supermarkets managing diverse fruit selections. The findings of this research can improve the efficiency and accuracy of classifying mango varieties, establishing a groundwork for broader applications in fruit categorization and beyond.
2.1 Data collection and preprocessing
We considered utilizing a portion of the existing data by mining databases such as Fruits 360. Based on our assessment of publicly available datasets, we determined that to implement this approach for quality prediction use in the Indian context, it is necessary to collect new data from the beginning. The proposed methodology is evaluated in Figure 2 by utilizing a dataset comprising images of fifteen unique mango cultivars procured from various vegetable markets in India. The dataset in question was disclosed to the public in the Mendeley Data, V2, doi: 10.17632/tk6d98f87d.2 article "Mango Variety" by Sethy, Prabira Kumar, BEHERA, SANTI, and Pandey, Chanki (2023).
Images were taken using a smartphone camera under natural daylight conditions without shading. A mobile phone holder was used to maintain a distance of 35-40 cm from the fruit during image capture. To enhance image quality and minimize visual distractions, a white background was used to ensure clutter-free images. Furthermore, the presence of daylight was taken into account, and efforts were made to avoid direct light on the object during image capture.
Furthermore, the use of a white background provides a clear contrast between the mangoes and the background, facilitating easier segmentation. The horizontal and vertical application of Sobel filters is a common technique for edge detection in image processing.
Figure 2. Varieties of Indian mango fruits were used during the experimental setup
Table 2. Data samples used for executing the experiments
|
Sl. No. |
Mango Variety |
No. of Images |
|
1 |
Alphonso |
203 |
|
2 |
Ambika |
100 |
|
3 |
Amrapali |
150 |
|
4 |
Banganpalli |
100 |
|
5 |
Chausa |
100 |
|
6 |
Dasheri |
100 |
|
7 |
Himsagar |
150 |
|
8 |
Kesar |
100 |
|
9 |
Langra |
100 |
|
10 |
Malgova |
150 |
|
11 |
Mallika |
200 |
|
12 |
Neelam |
100 |
|
13 |
Raspuri |
100 |
|
14 |
Totapuri |
100 |
|
15 |
Vanraj |
100 |
The Sobel filter (horizontal) is effective at identifying horizontal edges in images by capturing features such as the contours and boundaries of mangoes. Similarly, the Sobel filter (vertical) is employed to detect vertical edges, contributing to a comprehensive understanding of the spatial structure of the mangoes in the images. By combining information from both horizontal and vertical edge detection, the segmentation process becomes more robust, capturing the intricate details of the mango shapes.
In this study, a total of 1853 samples were used to perform the experiments, with the number of images varying depending on the class of mangoes, as shown in Table 2.
2.2 Model building
The procedure for developing a model comprises two distinct phases. Initially, we implemented two transfer learning-based pretrained CNN models, MobileNet-v2 and ShuffleNet. Using the architecture detailed below, these models were executed. During the second phase, a classification method based on machine learning was suggested as a means of differentiating mango fruit classes. These models have demonstrated cutting-edge performance across a range of model capacities when executing a variety of tasks and benchmarks. In regard to feature extraction for the purpose of object identification and segmentation, they exhibit remarkable efficiency. Figures 3 and 4 illustrate the architectural design of two hybrid small CNN models utilized for the recognition of mango fruit.
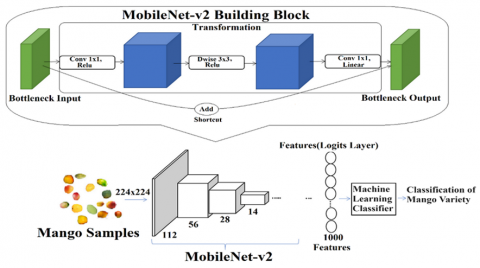
2.2.1 MobileNet-v2 model
MobileNet-v1, a convolutional framework that reduces the size and expense of networks, is well suited for implementation on low-cost or mobile devices. This feature enhances the accessibility and user friendliness of deep network classification and image processing on mobile devices. The MobileNet-v2 model, which is an enhancement of the MobileNet-v1 model, resolved issues pertaining to nonlinearities in the model's narrow layers and its foundational building blocks [27]. MobileNet v2 exhibits two additional features that contribute to its enhancement in comparison to its antecedent. One is that bottlenecks may form in a sequential process spanning multiple levels; the other is that shortcuts can be implemented to bypass these bottlenecks. The operational concept [28] of the MobileNet-v2 model, which symbolizes this situation, is illustrated in Figure 3. The MobileNet-v2 model saves time and resources in comparison to models that incorporate hardware components, such as mobile devices, due to its reduced parameter count. The filters and combination stages in MobileNet v2 are subdivided based on depth (dw). The input for each layer of this model is provided by a deep convolution filter with a resolution of 1 × 1. Two clusters of inputs are generated by employing depth-separable convolutional filters. This impacts both the pricing and efficiency of the model. Through the fusion of characteristics obtained via filtration, a novel stratum is formed during amalgamation procedures. The architecture of the MobileNet-v2 model incorporates the batch norm and ReLU linearity [29]. The group norm model engenders a tranquillizing effect. This approach has the potential to foster and facilitate a rapid rate of learning. The ReLU activation function ensures the nonlinearity of the model [30]. MobileNet-v2 accepts inputs measuring 224 by 224 pixels. Within the final model layer, the SVM function is implemented as a classifier. The process of filter rotation across the input image is executed by the convolutional layers located at the model's input. Attributes are incorporated into the activation maps produced by this process. Additionally, the input is shrunk by the pooling layer of this method prior to being forwarded to the subsequent layer [31, 32].
Figure 3. MobileNet-v2 with machine learning classifier
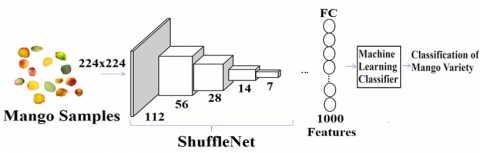
Figure 4. ShuffleNet with a machine learning classifier
A number of machine learning classifiers were employed to categorize the data in this study, which utilized a MATLAB-built pretrained model known as MobileNet-v2 [33]. The model concurrently processes numerous inputs during the mini-batch stage; the value selected at this juncture is intrinsically linked to the hardware performance. A mini-batch size of 64 was employed in the course of our investigation.
We assessed the efficacy of the CNN models in the identification of mango fruit using MATLAB 2020a. The efficacy of the CNN models was assessed using seven confusion matrix metrics, namely, accuracy, PPV, TPR, FDR, FNR, AUC, and F1 score. A Dell Inspiron 15 laptop equipped with NVIDIA GeForce graphics and a Core i5 5th Generation processor was utilized to execute each program.
2.2.2 ShuffleNet model
To optimize learning for small networks, the model is fine-tuned utilizing channel shuffling. The model incorporates a variety of convolutional layers, such as group, depthwise, channel shuffling, pooling, and FC layers, into its network architecture. To generate activation maps, the convolutional layer applies a filter with a reduced volume to the input volume. This term is used to characterize the process of generating "activation maps" using features derived from input data. A 3 × 3 pixel filter was chosen for this investigation because the typical resolution is 3 × 5 or 5 × 5.
Data in the form of 224 × 224 pixels may be input into the ShuffleNet framework. A number of classifiers based on machine learning are employed to classify features within the deepest layer of the model. Additionally, two additional critical variables of the ShuffleNet architecture are employed in this study: a learning rate of 0.001 and a mini-batch size of 64. Additional justifications for employing the ShuffleNet model in this inquiry include its exceptional performance in identifying fruit images, its seamless integration with mobile devices, and its comparatively reduced parameter count in comparison to nearly all alternative pretrained CNN models.
2.3 Tuning of hyperparameters
These factors significantly affect the training process and its optimization, which has an impact on the CNN structure. Given that the optimal hyperparameter values vary based on the specific task and dataset, manual adjustment is necessary to attain the desired results. There is no universal set of hyperparameters that guarantees success across all scenarios. Our best outcomes were achieved with a learning rate of 0.001 and a batch size of 64. The learning rate, which can be anywhere from 0 to 1, is a very important hyperparameter that controls how much the model changes when the weights are changed based on the classification test loss. The classification test loss is computed by averaging the squared differences between the actual and predicted values. Our model has a high degree of accuracy in classifying with low test loss due to a learning rate of 0.001. This shows that the model needs more training epochs to obtain the best results because smaller weight changes are needed each time. The training time is measured in minutes and seconds, with a batch size of 64 chosen to mitigate the impact of larger batch sizes. The optimum number of epochs was determined to be 50, where an epoch indicates how many times the neural network is trained on a complete set of data. To optimize the accuracy and training speed of the suggested model, a momentum of 0.5 was set.
The performance of the MobileNet-v2 (Table 3) and ShuffleNet (Table 4) models was evaluated based on metrics such as accuracy, AUC (i.e., area under the curve), PPV (i.e., positive predictive value), TPR (i.e., true positive rate), FDR (i.e., false discovery rate) and FNR (i.e., false negative rate) calculated using the following equations:
Accuracy $=\frac{\mathrm{TP}+\mathrm{TN}}{\mathrm{TP}+\mathrm{TN}+\mathrm{FP}+\mathrm{FN}}$ (1)
PPV or Precision $=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FP}}$ (2)
$T P R$ or Recall $=\frac{T P}{T P+F N}$ (3)
$\mathrm{FDR}=\frac{\mathrm{FP}}{\mathrm{TP}+\mathrm{FP}} \quad$ or 1-PPV (4)
$\mathrm{FNR}=\frac{\mathrm{FN}}{\mathrm{TP}+\mathrm{FN}} \quad$ or $1-\mathrm{TPR}$ (5)
$\mathrm{AUC}=$ Area under curve (6)
F1 Score $=2 \cdot \frac{\text { precison } \times \text { recall }}{\text { precision }+ \text { recall }}$ (7)
where, TP is true positive, TN is true negative, FP is false positive, and FN is false negative.
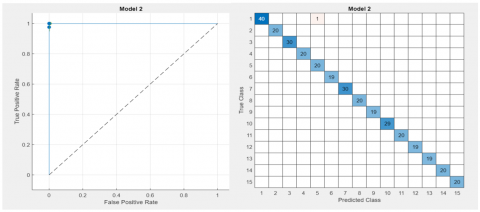
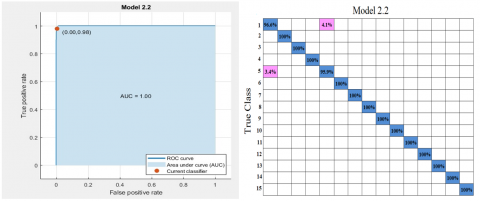
To evaluate the classification performance of two lightweight CNN models, namely, MobileNet-v2 and ShuffleNet, we employed deep features extracted from these models. The underlying principles and machine learning classifications were assessed utilizing both models. We evaluated twenty-two distinct classifiers for the deep features. As shown in Table 3, the Cubic SVM outperformed all other classifier paradigms and models evaluated with the MobileNet-v2 CNN model, achieving an accuracy of 99.5% and an area under the curve (AUC) of 1. The cubic SVM, which was employed as a classifier and paradigm in the ShuffleNet CNN model, demonstrated an AUC of 1 and an impressive accuracy of 99.4%, as presented in Table 4. The findings indicate that MobileNet-v2 exhibits superior performance in classifying Indian mangoes compared to the pretrained CNNs, with cubic SVM emerging as the superior classifier. The outcomes of MobileNet-v2 with SVM and ShuffleNet with SVM, expressed as the AUC and confusion matrix, are illustrated in Figures 5 and 6, respectively. The proposed model is highly suitable for incorporation into low-cost devices due to its underpinning in a lightweight CNN model. Furthermore, the F1 score serves as the principal metric for maintaining the trade-off between recall and precision, which is similarly elevated in the case of the cubic SVM. In this case, it is critical to have affirmative instances—specifically, authentic mango varieties—for fraud detection, for instance, and a high recall (TPR) is even more important to ensure that all relevant occurrences are identified. When cubic SVM is utilized, the TPR or recall is one hundred percent.
Hence, the cubic SVM under the MobileNet-v2 CNN model performed well in terms of validation. To cross-check the reliability, the model is executed with test data. The cubic SVM model integrated with the MobileNet-v2 CNN architecture underwent fine-tuning across various hyperparameter values to achieve optimal accuracy. The dataset was partitioned into training (70%), validation (20%), and testing (10%) sets. After 50 epochs and with a batch size of 64, the model attained a validation accuracy of 99.5% and an AUC value of 1.
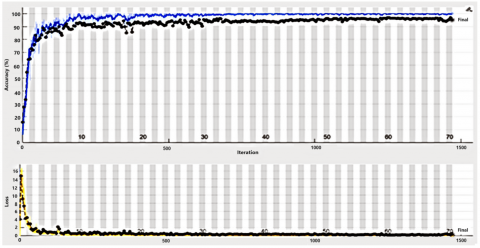
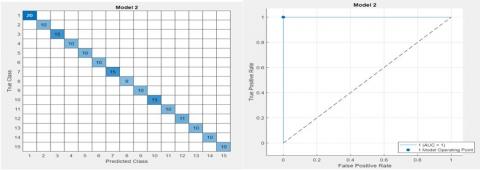
Furthermore, the test accuracy is 100%, and the AUC is 1 with a test loss of 0.25. Increasing the number of epochs from 50 to 70 and the batch size from 16 to 64 led to a notable increase in test accuracy, increasing it from 97% to 100%. This adjustment demonstrated a significant impact on reducing the loss from 0.25 to 0.15 while considerably boosting accuracy. However, extending the number of epochs from 70 to 100 while maintaining a batch size of 64 resulted in a decrease in test accuracy to 98.5% and an increase in test loss to 0.18. This trend indicated the onset of overfitting with prolonged epochs. Consequently, the decision was made not to exceed 70 epochs to mitigate overfitting issues. Through thorough testing of various hyperparameter values, the optimal configuration of 70 epochs with a batch size of 64 yielded the best outcomes, achieving 100% test accuracy and a test loss of 0.12. Figure 7 illustrates the highest test accuracy and minimum loss achieved per mango cultivar class at 70 epochs with a batch size of 64 for mango cultivar classification. Again, the confusion matrix and AUC in the test data of the cubic SVM under the MobileNet-v2 CNN model are illustrated in Figure 8. One of the paramount insights gleaned from our inquiry is the subsequent disclosure of a recently generated dataset to the public. The impact of training two lightweight CNN models, MobileNet-v2 and ShuffleNet, to extract deep features on mango variety categorization is evaluated.
Table 3. Performance of the MobileNet-v2 classifier for parameter evaluation
|
Sl. No. |
|
Classifier |
Accuracy (In %) |
AUC |
TPR (In %) |
FNR (In %) |
PPV (In %) |
FDR (In %) |
F1 Score (%) |
|
1 |
Tree |
Fine Tree |
87.3 |
0.99 |
100.00 |
0.00 |
86.50 |
13.50 |
92.761 |
|
Medium Tree |
59.6 |
0.96 |
100.00 |
0.00 |
63.58 |
36.42 |
77.73 |
||
|
Coarse Tree |
29.6 |
0.92 |
22.32 |
23.85 |
25.67 |
20.99 |
23.87 |
||
|
2 |
Naïve Bayes |
Gaussian Naïve Bayes |
96.7 |
0.97 |
100.00 |
0.00 |
97.06 |
2.94 |
98.50 |
|
Kernel Naïve Bayes |
98.5 |
0.99 |
100.00 |
0.00 |
98.90 |
1.09 |
99.44 |
||
|
3 |
SVM |
Linear SVM |
99.3 |
1.00 |
100.00 |
0.00 |
99.43 |
0.56 |
99.71 |
|
Quadratic SVM |
99.4 |
1.00 |
100.00 |
0.00 |
99.53 |
0.46 |
99.76 |
||
|
Cubic SVM** |
99.5 |
1.00 |
100.00 |
0.00 |
99.67 |
0.46 |
99.83 |
||
|
Fine Gaussian SVM |
62.7 |
0.99 |
57.80 |
42.20 |
94.52 |
5.47 |
71.73 |
||
|
Medium Gaussian SVM |
99.3 |
1.00 |
100.00 |
0.00 |
99.43 |
0.56 |
99.71 |
||
|
Coarse Gaussian SVM |
98.7 |
1.00 |
100.00 |
0.00 |
99.24 |
0.76 |
99.61 |
||
|
4 |
KNN |
Fine KNN |
99.4 |
0.99 |
100.00 |
0.00 |
99.53 |
0.46 |
99.76 |
|
Medium KNN |
99.0 |
1.00 |
100.00 |
0.00 |
99.23 |
0.77 |
99.61 |
||
|
Coarse KNN |
74.4 |
1.00 |
74.52 |
26.20 |
83.74 |
16.25 |
78.86 |
||
|
Cosine KNN |
98.9 |
1.00 |
100.00 |
0.00 |
99.06 |
0.94 |
99.52 |
||
|
Cubic KNN |
99.0 |
1.00 |
100.00 |
0.00 |
99.20 |
0.80 |
99.59 |
||
|
Weighted KNN |
99.1 |
1.00 |
100.00 |
0.00 |
99.26 |
0.73 |
99.62 |
||
|
5 |
Ensemble |
Boosted Trees |
94.9 |
1.00 |
100.00 |
0.00 |
94.85 |
5.14 |
97.35 |
|
Bagged Trees |
98.9 |
1.00 |
100.00 |
0.00 |
99.00 |
1.00 |
99.49 |
||
|
Subspace Discriminant |
99.4 |
1.00 |
100.00 |
0.00 |
99.50 |
0.50 |
99.74 |
||
|
Subspace KNN |
99.3 |
0.99 |
100.00 |
0.00 |
99.50 |
0.50 |
99.74 |
||
|
RUSBoosted Trees |
74.1 |
0.97 |
74.14 |
25.85 |
77.33 |
22.66 |
75.706 |
**The best results are indicated in bold.
Table 4. The ShuffleNet classifier performance for the evaluation of parameters
|
Sl. No. |
|
Classifier |
Accuracy (In %) |
AUC |
TPR (In %) |
FNR (In %) |
PPV (In %) |
FDR (In %) |
F1 Score (%) |
|
1 |
Tree |
Fine Tree |
89.7 |
0.96 |
100.00 |
0.00 |
89.62 |
10.37 |
94.52 |
|
Medium Tree |
56.4 |
0.92 |
72.18 |
27.12 |
75.67 |
24.32 |
73.88 |
||
|
Coarse Tree |
34.1 |
0.93 |
20.41 |
19.08 |
23.84 |
16.16 |
21.99 |
||
|
2 |
Naïve Bayes |
Gaussian Naïve Bayes |
96.6 |
0.97 |
100.00 |
0.00 |
97.02 |
2.97 |
98.48 |
|
Kernel Naïve Bayes |
98.1 |
0.98 |
100.00 |
0.00 |
98.44 |
1.56 |
99.21 |
||
|
3 |
SVM |
Linear SVM |
99.1 |
1.00 |
100.00 |
0.00 |
99.36 |
0.63 |
99.67 |
|
Quadratic SVM |
99.4 |
1.00 |
100.00 |
0.00 |
99.46 |
0.53 |
99.72 |
||
|
Cubic SVM** |
99.4 |
1.00 |
100.00 |
0.00 |
99.50 |
0.50 |
99.74 |
||
|
Fine Gaussian SVM |
59.1 |
0.98 |
53.55 |
46.44 |
94.26 |
5.73 |
68.29 |
||
|
Medium Gaussian SVM |
99.3 |
1.00 |
100.00 |
0.00 |
99.36 |
0.63 |
99.67 |
||
|
Coarse Gaussian SVM |
98.2 |
1.00 |
100.00 |
0.00 |
98.83 |
1.16 |
99.41 |
||
|
4 |
KNN |
Fine KNN |
99.4 |
0.99 |
100.00 |
0.00 |
99.50 |
0.50 |
99.74 |
|
Medium KNN |
99.0 |
1.00 |
100.00 |
0.00 |
99.23 |
0.77 |
99.61 |
||
|
Coarse KNN |
78.1 |
1.00 |
82.34 |
15.28 |
85.70 |
12.96 |
83.98 |
||
|
Cosine KNN |
99.1 |
1.00 |
100.00 |
0.00 |
99.24 |
0.69 |
99.61 |
||
|
Cubic KNN |
99.0 |
1.00 |
100.00 |
0.00 |
99.23 |
0.77 |
99.61 |
||
|
Weighted KNN |
99.1 |
1.00 |
100.00 |
0.00 |
12.70 |
0.63 |
22.53 |
||
|
5 |
Ensemble |
Boosted Trees |
94.9 |
0.99 |
100.00 |
0.00 |
95.04 |
4.95 |
97.45 |
|
Bagged Trees |
98.4 |
1.00 |
100.00 |
0.00 |
98.56 |
1.43 |
99.27 |
||
|
Subspace Discriminant |
99.5 |
0.99 |
100.00 |
0.00 |
99.60 |
0.40 |
99.79 |
||
|
Subspace KNN |
99.3 |
0.99 |
100.00 |
0.00 |
99.53 |
0.53 |
99.76 |
||
|
RUSBoosted Trees |
77.0 |
0.96 |
78.52 |
21.47 |
79.43 |
19.36 |
78.97 |
**The best results are indicated in bold.
Figure 5. AUC and confusion matrix for the Cubic SVM under the MobileNet-v2 CNN model for validation
Figure 6. AUC and confusion matrix for the cubic SVM under the ShuffleNet CNN model for validation
Figure 7. Accuracy with loss at 70 epochs with 64 batch sizes
Figure 8. Confusion matrix with AUC of Cubic SVM under the MobileNet-v2 CNN model for mango kind classification
Table 5. Comparison of the proposed methodology with other state-of-the-art methods
|
Authors & References |
No. of Variety of Mango |
Methodology Adopted |
Remarks |
|
Ke et al. (2022) [20] |
4 |
VGG16 and xception |
N/A |
|
Alhawas and Tüfekci (2022) [21] |
8 |
Resnet-50 |
Acc., recall, prec. and F1 Score 100% |
|
Win (2019) [34] |
5 |
Image Processing(IP) |
Acc. Range (90-100) % |
|
Behera et al. (2019) [35] |
10 |
Image processing (IP) |
Acc. 90% |
|
Proposed Method |
15 |
MobileNet-v2 with SVM |
Acc. 99.5% |
We further assess the machine learning classifications in conjunction with their underlying paradigms by utilizing the deep features of MobileNet-v2 and ShuffleNet. CubicSVM outperformed the other 22 classifiers evaluated in this study, specifically for the deep feature of MobileNet-v2 and ShuffleNet, in terms of performance (99.5% accuracy, 1 area under the curve). By utilizing a lightweight CNN model, the proposed model can be effortlessly deployed on low-end devices.
In addition, the model is compared with the current state-of-the-art models, as shown in Table 5.
The primary objective of the study was to assess the performance of two CNN architectures, MobileNet-v2 and ShuffleNet, in the context of mango fruit detection and identification. In this specific experiment, fifteen distinct varieties of genuine Indian mango fruits were taken into account. On the basis of the deep characteristics extracted from two lightweight CNN models, a variety of Indian mangoes are categorized. Upon comparing the performance of both models, it was determined that the Cubic SVM classifier for the MobileNet-v2 CNN model in the transfer learning approach is superior. It achieves an AUC of 1 and an accuracy rate of 99.5% in the identification of mangoes. The Mobilenet-v2 model exhibits superior performance in supermarket mango detection and categorization compared to the other hybrid small CNN models. As a consequence of this study demonstrating the viability of employing image processing technologies to identify and classify produce, agricultural practices may be positively impacted. Furthermore, this research provides a foundation for subsequent investigations that will employ this approach to a diverse array of fruit varieties, extending beyond mangoes.
Additionally, a larger dataset would likely aid in addressing potential biases that may arise from a limited sample size, leading to a more robust and reliable model. Regular updates to the dataset, incorporating new mango varieties as they emerge, would further ensure the model's adaptability to the evolving landscape of mango cultivars.
Our objective for the future is to enhance the diversity of mango fruits, thereby facilitating farmers in accurately identifying the specific classification or category to which a given mango fruit belongs. This will successfully help individuals acquire fruits of higher grade from the market. In the future, researchers can create a mobile application that is simple to navigate and that will present a comprehensive range of classification outcomes for various fruits and vegetables. This study may lead to the development of tools compatible with low-end equipment for practical applications, especially in agricultural contexts where resources may be restricted. Building lightweight, user-friendly apps or software that efficiently runs on low-cost smartphones or tablets could be part of this integration. These apps could be useful for farmers since they could help them identify and categorize mango varieties in the field, which would inform their farming and harvesting decisions.
Self-generated datasets are publicly accessible and available for use in “sethy, prabira Kumar; BEHERA, SANTI; Pandey, Chanki (2023), “Mango Variety”, Mendeley Data, V2, doi: 10.17632/tk6d98f87d.2”.
[1] Owino, W.O., Ambuko, J.L. (2021). Mango fruit processing: Options for small-scale processors in developing countries. Agriculture, 11(11): 1105. https://doi.org/10.3390/agriculture11111105
[2] Wardhan, H., Das, S., Gulati, A. (2022). Banana and mango value chains. In: Gulati, A., Ganguly, K., Wardhan, H. (eds) Agricultural Value Chains in India. India Studies in Business and Economics. Springer, Singapore. https://doi.org/10.1007/978-981-33-4268-2_4
[3] APEDA (Agricultural and Processed Food Products Export Development Authority). (2022). Mango. Ministry of Commerce and Industry, Government of India. https://apeda.gov.in/apedawebsite/contact_us/contact_ us.htm, accessed on May 2022.
[4] Agilandeeswari, L., Prabukumar, M., Goel, S. (2017). Automatic grading system for mangoes using multiclass SVM classifier. International Journal of Pure and Applied Mathematics, 116(23): 515-523.
[5] Government of India. (2013). Postharvest profile of mango. Government of India, Ministry of Agriculture, Department of Agriculture and Cooperation. Faridabad, India. https://agmarknet.gov.in/Others/preface-mango.pdf, accessed on May 2022.
[6] Femling, F., Olsson, A., Alonso-Fernandez, F. (2018). Fruit and vegetable identification using machine learning for retail applications. In 2018 14th International Conference on Signal-Image Technology & internet-Based Systems (SITIS), Las Palmas de Gran Canaria, Spain, pp. 9-15. https://doi.org/10.1109/SITIS.2018.00013
[7] Zhang, Y., Wang, S., Ji, G., Phillips, P. (2014). Fruit classification using computer vision and feedforward neural network. Journal of Food Engineering, 143: 167-177. https://doi.org/10.1016/j.jfoodeng.2014.07.001
[8] Dubey, S.R., Jalal, A.S. (2015). Application of image processing in fruit and vegetable analysis: A review. Journal of Intelligent Systems, 24(4): 405-424. https://doi.org/10.1515/jisys-2014-0079
[9] Lino, A.C.L., Sanches, J., Fabbro, I.M.D. (2008). Image processing techniques for lemons and tomatoes classification. Bragantia, 67(3): 785-789. https://doi.org/10.1590/S0006-87052008000300029
[10] Hossain, M.S., Al-Hammadi, M., Muhammad, G. (2018). Automatic fruit classification using deep learning for industrial applications. IEEE Transactions on Industrial Informatics, 15(2): 1027-1034. https://doi.org/10.1109/TII.2018.2875149
[11] Chen, L., Yuan, Y. (2019). Agricultural disease image dataset for disease identification based on machine learning. In: Li, J., Meng, X., Zhang, Y., Cui, W., Du, Z. (eds) Big Scientific Data Management. BigSDM 2018. Lecture Notes in Computer Science(), vol 11473. Springer, Cham. https://doi.org/10.1007/978-3-030-28061-1_26
[12] Borianne, P., Borne, F., Sarron, J., Faye, É. (2019). Deep Mangoes: From fruit detection to cultivar identification in color images of mango trees. arXiv preprint arXiv:1909.10939. https://doi.org/10.48550/arXiv.1909.10939
[13] Vyas, A.M., Talati, B., Naik, S. (2014). Quality inspection and classification of mangoes using color and size features. International Journal of Computer Applications, 98(1): 1-5. https://doi.org/10.5120/17144-7161
[14] Salim, S.N.M., Shakaff, A.Y.M., Ahmad, M.N., Adom, A.H. (2005). A feasibility study of using an electronic nose as a fruit ripeness measuring instrument. In 1st International Workshop on Artificial Life and Robotics, pp. 7-11.
[15] Momin, M.A., Rahman, M.T., Sultana, M.S., Igathinathane, C., Ziauddin, A.T.M., Grift, T.E. (2017). Geometry-based mass grading of mango fruits using image processing. Information Processing in Agriculture, 4(2): 150-160. https://doi.org/10.1016/j.inpa.2017.03.003
[16] Zakaria, A., Shakaff, A.Y.M., Masnan, M.J., Saad, F.S.A., Adom, A.H., Ahmad, M.N., Jaafar, M.N., Abdullah, A.H., Kamarudin, L.M. (2012). Improved maturity and ripeness classifications of Magnifera Indica cv. Harumanis mangoes through sensor fusion of an electronic nose and acoustic sensor. Sensors, 12(5): 6023-6048. https://doi.org/10.3390/s120506023
[17] Yimyam, P., Chalidabhongse, T., Sirisomboon, P., Boonmung, S. (2005). Physical properties analysis of mango using computer vision. In International Conference on CAS. IEEE: Goyang, Republic of Korea, pp: 746-750.
[18] Zhang, Y., Wu, L. (2012). Classification of fruits using computer vision and a multiclass support vector machine. Sensors, 12(9): 12489-12505. https://doi.org/10.3390/s120912489
[19] Razak, T.R.B., Othman, M.B., Abu Bakar, M.N., bt Ahmad, K.A., Mansor, A.R. (2012). Mango grading by using fuzzy image analysis. In International Conference on Agricultural, Environment and Biological Sciences (ICAEBS'2012). Phuket, Thailand, pp. 18-22.
[20] Ke, C., Weng, N.T., Yang, Y., Yang, Z.M., Sumari, P., Abualigah, L., Kamel, S., Ahmadi, M., Al-Qaness, M.A., Forestiero, A., Alsoud, A.R. (2022). Mango varieties classification-based optimization with transfer learning and deep learning approaches. In: Abualigah, L. (eds) Classification Applications with Deep Learning and Machine Learning Technologies. Studies in Computational Intelligence, vol 1071. Springer, Cham. https://doi.org/10.1007/978-3-031-17576-3_3
[21] Alhawas, N., Tüfekci, Z. (2022). The effectiveness of transfer learning and fine-tuning approach for automated mango variety classification. Avrupa Bilim ve Teknoloji Dergisi, (34): 344-353. https://doi.org/10.31590/ejosat.1082217
[22] Bhole, V., Kumar, A. (2020). Mango quality grading using deep learning technique: Perspectives from agriculture and food industry. In Proceedings of the 21st Annual Conference on Information Technology Education, pp. 180-186. https://doi.org/10.1145/3368308.3415370
[23] Gururaj, N., Vinod, V., Vijayakumar, K. (2023). Deep grading of mangoes using convolutional neural network and computer vision. Multimedia Tools and Applications, 82(25): 39525-39550. https://doi.org/10.1007/s11042-021-11616-2
[24] Iqbal, H.M.R., Hakim, A. (2022). Classification and grading of harvested mangoes using convolutional neural network. International Journal of Fruit Science, 22(1): 95-109. https://doi.org/10.1080/15538362.2021.2023069
[25] Borianne, P., Sarron, J., Borne, F., Faye, E. (2023). Deep mango cultivars: Cultivar detection by classification method with maximum misidentification rate estimation. Precision Agriculture, 24(4): 1619-1637. https://doi.org/10.1007/s11119-023-10012-0
[26] Wu, S.L., Tung, H.Y., Hsu, Y.L. (2020). Deep learning for automatic quality grading of mangoes: Methods and insights. In 2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, pp. 446-453. https://doi.org/10.1109/ICMLA51294.2020.00076
[27] Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., Chen, L.C. (2018). Mobilenetv2: Inverted residuals and linear bottlenecks. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, pp. 4510-4520. https://doi.org/10.1109/cvpr.2018.00474
[28] Google AI Blog: MobileNetV2: The next generation of on-device computer vision networks n.d. https://ai.googleblog.com/2018/04/mobilenetv2-next-generation-of-on.html, accessed on January 8, 2023.
[29] Howard, A.G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., Andreetto, M., Adam, H. (2017). Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861. https://doi.org/10.48550/arXiv.1704.04861
[30] Chen, G., Chen, P., Shi, Y., Hsieh, C.Y., Liao, B., Zhang, S. (2019). Rethinking the usage of batch normalization and dropout in the training of deep neural networks. arXiv preprint arXiv:1905.05928. https://doi.org/10.48550/arXiv.1905.05928
[31] Toğaçar, M., Özkurt, K.B., Ergen, B., Cömert, Z. (2020). BreastNet: A novel convolutional neural network model through histopathological images for the diagnosis of breast cancer. Physica A: Statistical Mechanics and its Applications, 545: 123592. https://doi.org/10.1016/j.physa.2019.123592
[32] Toğaçar, M., Ergen, B., Cömert, Z. (2020). Application of breast cancer diagnosis based on a combination of convolutional neural networks, ridge regression and linear discriminant analysis using invasive breast cancer images processed with autoencoders. Medical Hypotheses, 135: 109503. https://doi.org/10.1016/j.mehy.2019.109503
[33] Pretrained MobileNet-v2 convolutional neural network MATLAB software MathWorks (2018) https://www. mathworks.com/help/deeplearning/ref/mobilenetv2.html.accessed January 9, 2023.
[34] Win, O. (2019). Classification of mango fruit varieties using naïve Bayes algorithm. International Journal of Trend in Scientific Research and Development (IJTSRD), 3(5): 1475-1478. https://doi.org/10.31142/ijtsrd26677
[35] Behera, S.K., Sangita, S., Rath, A.K., Sethy, P.K. (2019). Automatic classification of mango using statistical feature and SVM. In: Biswas, U., Banerjee, A., Pal, S., Biswas, A., Sarkar, D., Haldar, S. (eds) Advances in Computer, Communication and Control. Lecture Notes in Networks and Systems, vol 41. Springer, Singapore. https://doi.org/10.1007/978-981-13-3122-0_47