Venkateswarlu Gavini* | Gurusamy Ramasamy Jothi Lakshmi
© 2022 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Image denoising is an important concept in image processing for improving the image quality. It is difficult to remove noise from images because of the various causes of noise. Imaging noise is made up of many different types of noise, including Gaussian, impulse, salt, pepper, and speckle noise. Increasing emphasis has been paid to Convolution Neural Networks (CNNs) in image denoising. Image denoising has been researched using a variety of CNN approaches. For the evaluation of these methods, various datasets were utilized. Liver Tumor is the leading cause of cancer-related death worldwide. By using Computed Tomography (CT) to detect liver tumor early, millions of patients could be spared from death each year. Denoising a picture means cleaning up an image that has been corrupted by unwanted noise. Due to the fact that noise, edge, and texture are all high frequency components, denoising can be tricky, and the resulting images may be missing some finer features. Applications where recovering the original image content is vital for good performance benefit greatly from image denoising, including image reconstruction, activity recognition, image restoration, segmentation techniques, and image classification. Tumors of this type are difficult to detect and are almost always discovered at an advanced stage, posing a serious threat to the patient's life. As a result, finding a tumour at an early stage is critical. Tumors can be detected non-invasively using medical image processing. There is a pressing need for software that can automatically read, detect, and evaluate CT scans by removing noise from the images. As a result, any system must deal with a bottleneck in liver segmentation and extraction from CT scans. To segment and classify liver CT images after denoising images, a deep CNN technique is proposed in this research. An Image Quality Enhancement model with Image Denoising and Edge based Segmentation (IQE-ID-EbS) is proposed in this research that effectively reduces noise levels in the image and then performs edge based segmentation for feature extraction from the CT images. The proposed model is compared with the traditional models and the results represent that the proposed model performance is better.
liver tumor, CT images, image denoising, image segmentation, convolution neural networks, edge segmentation
The liver is the body's primary organ for digestion, filtering of red blood cells, and the conversion of food into energy, all of which the liver is responsible for. A tumour can arise in the liver if the cells begin to expand out of control [1]. Liver cancer is a disease that affects equally men and women inside a wide range of countries around the world. It is the fourth most prevalent cancer in males and the ninth leading cause of death cancer in women as of 2020 [2]. When diagnosing a tumour in the liver, ultrasonography is the most often utilized modality worldwide. There are exceptions, however, where ultrasonography specialists' knowledge is mostly relied upon to diagnose early-stage liver cancer [3]. Another method is Computed Tomography (CT) that is frequently used for disease detection [4].
For lesion surgical treatment and liver transplants, the ability to segment the liver in medical imaging data is critical. Doctors can use accurate liver segmentation to aid in the diagnosis and treatment of liver conditions [5]. It takes a long time and a lot of work to segment the liver manually. Although automatic liver segmentation techniques have been proposed to lower these costs, the outcome measures of such methods are still limited due to many limitations in CT imaging [6]. An important consideration is that CT images of the liver show a grayscale pattern that is very similar to that of other nearby organs. Secondly, the form and size of a patient's liver varies greatly. In the third place, a variety of CT scanners results in a wide range of CT picture appearances and liver locations [7].
It is imperative that accurate measurements of liver volume be made prior to any major hepatectomy or transplantation procedure [8]. Due to the recent rise in extended hepatectomy, split liver transplantation, and living donor liver transplantation, there is increasing interest in doing liver volumetry [9]. As a first step, complicated surrounding blood vessels and organs can have a negative impact on the segmentation performance [10]. There is also a lot of variation in the morphology of the liver in different portions of the same CT imaging. It is also important to note that liver tissue density is quite similar to that of many other soft tissues in the abdominal cavity [11]. It is also difficult to appropriately segment the liver in medical CT imaging due to low contrast and irregular grey scales. CT liver segmentation has become a serious problem because it can't produce the intended results [12]. Improved diagnosis and treatment of liver diseases, as well as a reduced death risk owing to liver cancer, can be achieved using these techniques. Figure 1 represents the Stages of Liver Tumor.
Figure 1. Stages of liver tumor
One of the hallmarks of liver tumours is their propensity for rapid growth, rapid progression, rapid recurrence, and rapid dissemination throughout the body [13]. There is a pressing need in clinical medicine for an accurate diagnostic approach to detect the lesion region of a liver tumour. Artificial intelligence has improved picture categorization for deep learning during the last few years [14]. In the medical industry, Artificial Intelligence (AI) can have a significant impact on disease detection and therapy [15]. In radiotherapy, the amount of clinical imaging data is increasing. As medical imaging technology advances, CT uses computers as its core and dramatically enhances clinical diagnostic efficacy for a wide range of diseases [16]. CT scans are the most often used tool for detecting liver cancers because of its speed, clarity, and low cost. Liver segmentation is critical to determining vascular disease using computed tomography imaging [17]. Because manual segmentation is prone to inaccuracy and takes a long time, deep learning applications for automated segmentation have grown in relevance.
Computable tomography scans are plagued by the difficulty of selecting a screening region that is much bigger than the actual target area [18]. For clinicians, this is a huge roadblock in the pursuit of timely and correct patient diagnosis and treatment. The effective evaluation of these large-scale pictures is greatly enhanced by the segmentation of the organ to be investigated from the overall computed tomography image [19]. Deep learning technology based Convolution Neural Network (CNN) model has long discussed segmenting organs and tissues from CT scans. Automated segmentation procedures rely more heavily on the algorithm's accuracy and prediction process than in clinical practice [20]. To avoid misleading the end user, the structure to be built should be given as quickly and accurately as feasible. Studying liver segmentation using various data sets, designs and implementation approaches could be a crucial step in furthering our knowledge of the organ's function [21].
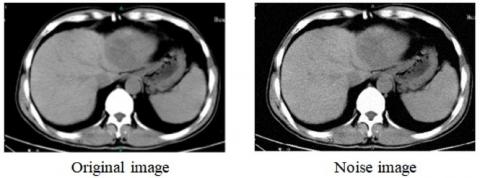
It is possible that the noise and bar aberrations that arise from low-dose computed tomography (CT), which has been shown to lower patients' radiation exposure, could hinder medical diagnosis. CT diagnostic images have failed in practical applications because present methods for directly processing reconstructed images cannot maintain the fine texture structure of the images while simultaneously lowering noise. For precise tumour forecasts, MRI denoising models are in high demand [22]. A Quality Enhancement model with Image Denoising and Edge based Segmentation is proposed in this paper as a solution to this problem. Our solution incorporates image enhancement into the original image, reducing algorithm complexity and increasing denoising efficiency [23]. Each iteration of this process begins with original CT images for processing [24]. The original CT Liver image and denoised image is shown in Figure 2.
Figure 2. CT liver original and denoised image
CNN-based CT scans for organ localization and segmentation resulted in great accuracy and efficiency [25]. A tumour segmentation method with a CNN model for CT image segmentation and denoising model is introduced. Researchers demonstrated a multichannel CNN-based technique that obtained great resilience and accuracy for detecting liver tumour segments [26]. When it comes to liver partitioning procedures, the effectiveness of artificial intelligence-based methods is excellent. For example, the automatic detection methods have demonstrated the promise of utilizing deep learning in clinical practices for more effective medical treatment.
Seo et al. [2] proposed a model that is one of the most critical aspects of radiation therapy for hepatocellular carcinoma that is the division of livers and tumours. The segmentation process is frequently carried out by hand, which makes it time consuming, labour intensive, and prone to variation among and between operators. Automatic liver segmentation and tumour segmentation remain challenging due to the low tissue contrast of the liver compared to neighbouring organs and its malleable shape in CT images, despite different OAR and tumour target delineation techniques that have been developed. Image analysis tasks using the U-Net have recently become more popular and have demonstrated promising results. However, there are three fundamental limitations to traditional U-Net topologies. Skip connections enable for the transfer of poorly educated in feature maps to be repeated in order to enhance learning efficiency, although this often results in blurring of extracted picture features. Characteristics in the experience or association are not integrated with characteristics in the residue path for small object inputs. It also includes additional convolution in order to obtain high level spatial information of small object inputs and high level features of edge information from large object inputs.
Zhang et al. [3] proposed a hepatic diagnostics model for liver tumour segmentation process that is essential. For CT-based liver tumour segmentation, the author provided a new level-set technique incorporating an improved edge indication and an autonomously formed initial curve. To improve the image contrast around the liver and the liver tumour, the CT image pixel intensities were trimmed to lie in a specific range during the preprocessing stage. By first employing two convolution neural network in a coarse-to-fine fashion, the liver was segmented in order to exclude any non-tumor tissues for further tumour segmentation. A 3D patch-based convolutionary network was utilized to fine-tune the liver segmentation and to roughly pinpoint the liver tumour using a 2D slice-based U-net. The segmentation of the tumour was then improved using a brand-new level-set procedure. Unsupervised fuzzy c-means cluster was used to estimate the probability distribution of the liver tumour, which was then used to enhance the edge-detector employed in level-set. The suggested pipeline was tested on two publicly available datasets to verify its effectiveness.
Song et al. [6] proposed a Hepatocellular carcinoma and colorectal cancer detection models that originate in the liver and then spread to the liver. This task is difficult because of the tumor's complex background, heterogeneity, and diffuse shape. To date, only the interaction has been successful in segmenting liver tumours into usable segments. The proposed architecture integrates soft and hard that such, as well as long and short skip links, into a single network design. The liver segmentation and tumour segmentation networks are combined into a cascade network to help meet this problem. The liver localization network is proposed to be trained using the joint dice loss function to obtain an accurate 3D liver boundary, and the tumour segmentation network is fine-tuned using the focal transition zone entropy as a loss function to detect more potentially malignant tumours and reduce false positives. Training and evaluation of proposed framework were done on 110 instances from the LiTS dataset, and the results show that the proposed method can achieve faster connection convergence, as well as appropriate semantic segmentation and illustrate that the proposed methodology has a good clinical value in terms of patient care.
Su et al. [8] proposed an Automatic liver and tumour segmentation model that is still a difficult problem to solve, requiring investigation in both 2D and 3D CT volume contexts. Both 2D and 3D contexts can be explored using existing methods, however they only either focused on the 2D environment or only examine the 3D environment including numerous small coordinates. For automatic segmentation of the liver and tumours, these characteristics lead to an insufficient context exploration together. A new full-context convolution neural network is proposed in this paper to fill the gap among 2D and 3D situations. There are many advantages of using a suggested network, such as the ability to use the temporal features along the Z-axis in CT volumes while maintaining the systematically divided in each slice Each slice has its own 2D spatial network and a 3D temporal network for extracting intra-slice features; these are then led by the squeeze-and-excitation layer, which allows 2D contextual and 3D temporal information to flow together.
Naseem et al. [9] proposed a deep convolution networks model that have been frequently used in the segmentation of medical picture datasets. The liver and liver tumour classification in CT images has two issues, despite the fact that these networks are effective for simple object segmentation. Second, convolutional kernels with constant geometry do not match livers and tumours of varying forms and dimensions. Redistributing and strided convolution procedures, on the other hand, can easily result in the loss of geographical context information in images. Deformed encoder-decoder networks liver segmentation methods is proposed to overcome these challenges. Deformable convolution (DefED-Net) is used to improve the channel's ability to learn convolution with adaptive spatial formulating information, and used a layout a ladder-atrous-spatial tower subsystem using multi resolution interpolation rate and relate the subsystem to learn better semantic features than the convolutions spatial hierarchy pooling for CT.
Yan et al. [10] proposed a method for liver template matching that matches surfaces without the use of markers. Preoperative liver pictures produced by CT scans, MRIs, or ultrasounds typically provide surgeons with information on anatomy and the whereabouts of liver tumours and big intrahepatic vessels. Preoperative information is used to identify intraoperative liver tumours or vessels using a laparoscope during minimally invasive surgery. Squeezing or flipping the liver around during surgery is also possible. Because of the risk of severe distortion during these manual procedures, it can be difficult to locate liver tumours or arteries during surgery. A liver tumour can also be difficult to remove without causing damage to major intrahepatic arteries. In this study, the position of intraoperative vasculature or tumours can be determined by using this method. When developing a preliminary biomechanical volume model, the proposed method makes use of CT images, and then applies a brand-new technique for matching surfaces during surgery to figure out how they relate to one another. As a result, the postoperative volume model is distorted by the numerical model in order to align it with the postoperative surface model and reveal intraoperative vascular locations and tumours. To test the suggested approach, an ex vivo porcine liver was used to measure the target registration error.
For decades, image denoising has been explored intensively. A variety of picture filters are mentioned by Dong et al. [12]. Model-based methods using various priors, such as spatial smoothness, non-local patch similarity, sparsity and low-rankness, were later brought to this issue, in either the spatial or transform domain, or a hybrid of the two. There have lately been several studies demonstrating that deep learning models perform better in image denoising than traditional methods. Most present denoising algorithms recreate images by reducing the mean square error (MSE), which is known to be out of sync with human perception quality and frequently tends to overly smooth textures. Even though it is common practise to use picture denoising algorithms as a pre-processing step for noisy visual data prior to high-level visual analysis, their impact on semantic visual information has been less studied by Zhang et al. [16].
Computer vision researchers are increasingly working to bridge the gap between low-level and high-level tasks. Furthermore, the denoising outcomes with richer visual features after getting additional semantic guidance as from high-level tasks, as initially disclosed by Chen et al. [17], are a result of this observation. In Wei et al. [18], a thorough investigation of the interplay between low and high level visual networks was provided. The authors used a joint loss function combining MSE and segmentation loss to tailor the entire pipeline, cascading a fixed pre-trained semantic segmentation structure after a denoising network. Such denoised photos had sharper edges and better textual details, as well as better segmentation and classification accuracy when used for those tasks, according to the scientists.
The segmentation labeling in MRI datasets can be used to help with MRI compressive sensing recovery in a similar way outlined by Choi, J. and Choi, B. [20]. A hybrid picture dehazing and object detection process was analyzed by Hassanzadeh et al. [22]. According to Wang et al. [24], the availability of segmentation information can reduce the over-smoothing effects of CNNs across areas and boost their spatial precision. Directly adaptable to other high-level jobs, this approach can be used in a cascaded fashion. Existing supervised algorithms, particularly for segmentation, require manually labelled segmentations for training purposes. It's difficult to accurately annotate photographs with high resolution when marking pixels by hand, which takes time and increases the risk of human error.
Advantages of Denoising
Disadvantages of Denoising
Liver segmentation is an integral part of both the diagnostic process and the therapy strategy for patients with liver cancer. However, because to the complexity of the liver and the subjectivity of the specialist's knowledge, manual liver segmentation is time-consuming and prone to error [29]. Automation of the segmentation process enabled by computer techniques yields improved efficiency and accuracy [30]. However, automatic liver segmentation is challenging due to the liver's structure, poorly defined borders, and lesions, which all contribute to the liver's overall appearance.
Image quality improvement is used in many different fields to bring back lost features in images that have deteriorated, such as medical imaging, film production, and autonomous vehicles. Deep convolutional neural networks (CNNs) have allowed for rapid improvement in image quality augmentation. However, CNN-based methods are limited in their ability to adapt to different subtasks during network formation. Even worse, they rarely provide adequate context alongside correct spatial representations. A new unified framework for low-light image augmentation, denoising, and image quality enhancement is proposed in this research to address these issues. The edge detection process helps in accurate disease detection and the process is represented in Figure 3.
Ultimately, the goal of image processing is to extract information from images so that computers can detect and analyse the patterns in the images for liver tumor detection. In most cases, image enhancement techniques are employed to bring out previously hidden details or to draw attention to certain parts of an image. One or more aspects of an image are altered during the image enhancement process. Images can be enhanced in a variety of scientific and engineering fields. External noises and environmental disturbances, such as changes in pressure and temperature, can potentially degrade the image quality. Image enhancement is therefore required. Image enhancement has aided in the advancement of research in a wide range of disciplines. There are methods for enhancing images with only a little amount of contrast by extending the histograms over a wide enough dynamic range, as well as multi-scale adaptive equalizations of the histogram. Globally or locally, an image intensity distribution can be changed to an adaptive method. The technique is used to each of the smooth and detail portions of an image to prevent enhancing noises excessively. An Image Quality Enhancement model with Image Denoising and Edge based Segmentation is proposed in this research that effectively reduces noise levels in the image and then performs edge based segmentation for feature extraction from the CT images. The proposed model is explained in the algorithm clearly.
Figure 3. Edge detection in denoised image
Algorithm IQE-ID-EbS
{
Input: Lung CT Image Dataset
Output: Denoised Image
Step-1: The images in the dataset are considered and the image basic features are calculated for improving the quality of the image. The image parameters are calculated as:
$\operatorname{entropy}(E)=-\sum_{i=1}^W P_\delta(i) * \log p_\delta(i)$ (1)
$\operatorname{contrast}(C)=\sum i^2 p_\delta(i)$ (2)
$\operatorname{mean}(M)=\frac{\sum_{i=1}^W P_\delta(i) \sum_{i=1}^W Q_\delta(i)}{\sum_{i=1}^W \operatorname{len}(\text { dataset })}$ (3)
here, P and Q are the pixel coordinates of an image, δ is the intensity value considered for the pixels.
Step-2: The basic features of the image are calculated and the edge based segmentation is performed on the image for partitioning the image into multiple segments that are used for quality enhancement. The segmentation is performed as:
$\operatorname{ImgSeg}(I(P, Q))$ $=\sqrt{\sum_{i=1}^W\left(l-l_m\left(\delta\left[l_p,l_q\right]\right)\right)^T \times I(P+Q)}$ (4)
here, T is the threshold value considered for the segmentation of images so that the feature extraction can be performed.
Step-3: The poor intensity pixels are identified that are considered for enhancement such that the image quality can be enhanced. The dull pixel identification is done as
$D \operatorname{pix} \operatorname{Set}(I(P, Q))=\sum_{i=1} \log \frac{\left(C(x)-\operatorname{Img} g_{\max x}\right)+\min (C)+\left(\operatorname{ImgSeg}(P)-I_{\min }\right)}{\left(\delta_{\max }-\delta_{\min }\right)^2}+\delta\left|H i s t_{\text {ImgSeg }}(P, Q)\right|_T$ (5)
Hist is the histogram function used to calculate the image histogram levels, min and max is the range of intensity values.
Step-4: The image quality enhancement is performed by adding the intensity values to the dull pixels and the overall pixel normalization is performed. The image quality enhancement is performed as:
$\operatorname{EPixSet}(I(P, Q))_W=\sum_{i=1}^W \mid \operatorname{DpixSet}(i)+\beta_{\max }^i+\frac{1}{\sum_{j=1}^c\left(\frac{\left\|M(i)-P_i\right\|}{\left\|M(i)-Q_i\right\|}\right)^T} \mid+\min (\delta)$ (6)
where, β is the dull pixels in the image and M is the gray levels in the image.
Step-5: The image denoising is performed to remove the noise in the CT images so that the quality enhancement is done for extracting the features that are useful for tumor detection. Each of the dense blocks in CNN is considered that has four dense modules, which are separated by three transitional layers in the architecture. There is a bottleneck 1×1 convolution layer and a 3×3 convolution layer in each dense Module. As the network gets more complex, Transition blocks are added between each Dense Block in order to reduce the number of feature maps that are generated for image denoising. The image denoising is performed as:
DenoiseImg $(\operatorname{EPixSet}(P, Q))=\exp \left(\frac{\left(\text { EPixSet }_{\text {img }}(\delta)-\text { DpixSet }_{\text {img }}(\delta)\right)^T}{\left(\frac{\delta+\beta^2}{\text { sizeof }(\text { EPixSet })}\right) * i}\right)+\frac{\max (\delta(\text { EPizSet }(P, Q)))}{\max (\beta(\text { EPixSet }(P, Q)))}$ (7)
Step-6: The denoised image is further used for feature extraction for liver tumor detection.
}
Data inconsistencies may emerge during noise reduction in the projection domain, even if statistical law can be fully utilised by the projection domain denoising algorithm. Noise and artefacts can be introduced into reconstructed images easily, making it impossible to get desired results with classic single image denoising methods. The CT image denoising approach based on deep learning can considerably reduce the noise and remove the stripe artefacts from CT images. Image denoising algorithms based on MSE or weighted MSE, on the other hand, are prone to a loss of image detail because of upsampling and downsampling links in the network structure. Additional instability was observed during training for the complicated network model, which is difficult to converge. The proposed model is implemented in python and executed in Google Colab platform. The proposed model considers liver CT images from the dataset link https://www.kaggle.com/datasets/andrewmvd/liver-tumor-segmentation.
There are several image processing libraries available in Python, like as OpenCV is a widely-used image processing library that has found widespread use in domains such as real-time computer vision, 2D and 3D feature toolkits, facial and gesture recognition, human-computer interaction, mobile robots, object identification, and many more. Image manipulation and processing can be performed with the help of the Numpy and Scipy libraries. Sckikit Offers a plethora of algorithms for the processing of images. The Python Imaging Library (PIL) allows you to do things like produce thumbnails, resize, rotate, and convert between file formats, among other things, with existing images.
Image degradation, such as noise and blurring of fine details, is a common problem in CT Images. Image denoising can be used to reduce the amount of noise in CT scans. An image denoising goal is to minimize the noise while preserving crucial features like edges, corners and textures. A new technique for denoising CT images with edge preservation based on a locally adaptive pixel set is presented in this research. The proposed scheme's visual quality is found to be superior than several standard current approaches when compared to those ways already in use. The results were accurate and efficient in showing tumour fragments in faulty liver pictures. Through the encoding and decoding of little information from segments, CNNs gave effective results in the detection of even small tumours. Pixel-by-pixel analysis formed the basis of the investigation. The proposed Image Quality Enhancement model with Image Denoising and Edge based Segmentation (IQE-ID-EbS) is compared with the traditional stacked dense denoising–segmentation network for under sampled tomograms and knowledge transfer using synthetic tomograms (Stacked-DenseUSeg) model.
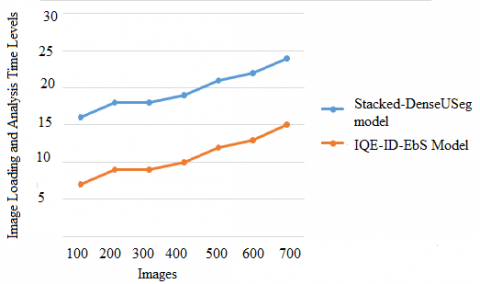
Computer vision algorithms rely heavily on datasets to mimic these cognitive capacities in liver segmentation and edge detection. Digital images are used by developers to train and assess their algorithms in computer vision datasets, which are curated sets. The images are loaded from the datasets and then the images are analyzed to perform segmentation, edge detection and then denoising. The image loading and analysis time levels are shown in Figure 4.
Figure 4. Image loading and analysis time levels
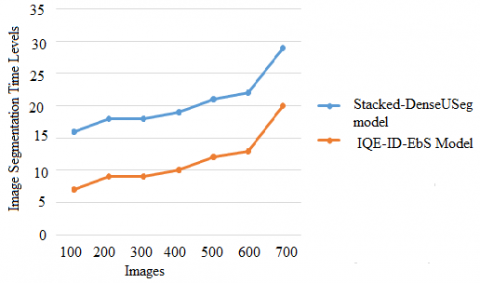
Effective segments are those that are easy to put together with their own image pieces, but complex with other sections of the image. If users are looking for a non-parametric approach to segmentation, users don't need to define or model image segments in advance. The segmentation process divides the image into multiple portions making the liver tumor detection accurate. The image segmentation time levels of the proposed and traditional models are shown in Figure 5.
Among the many metrics utilised in evaluating an image's quality, the peak signal-to-noise ratio (PSNR) and the structural similarity index (SSIM) stand out as particularly popular choices. Table 1 represents the PSNR and SSIM ranges.
Table 1. PSNR and SSIM values
|
Model |
PSNR |
SSIM |
|
Proposed IQE-ID-EbS Model |
34.23 |
0.8 |
|
Stacked Dense Useg Model |
28.11 |
0.5 |
Figure 5. Image segmentation time levels
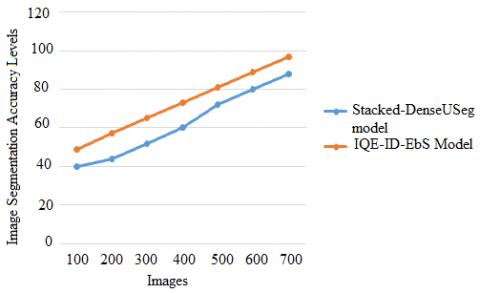
Segmenting a digital image into several parts, or image regions or image objects, is an important technique in computer vision and image processing. An image's representation can be simplified by segmentation, which aims to make it more intelligible and easier to understand. In general, image segmentation is employed for the purpose of identifying objects and image boundaries. Image segmentation, on the other hand, is the technique of assigning a label to each pixel in an image, so that images with the same label have similar properties. Figure 6 represents the image segmentation accuracy levels.
Figure 6. Image segmentation accuracy levels
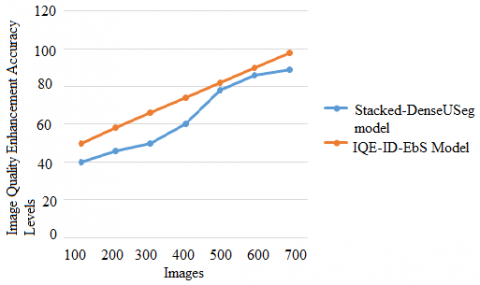
To improve the quality of digital images for presentation or additional study, image augmentation is required. The practice of increasing the quality and information content of raw data before it is processed is known as image enhancement. Some common methods include image quality, spatial filtering, and density slicing. Improve the readability or interpretation of information in a picture for human viewers by applying image enhancement techniques. Image enhancement can also be used to give better input for other automatic imaging approaches. The image quality enhancement accuracy levels are shown in Figure 7.
Figure 7. Image quality enhancement accuracy levels
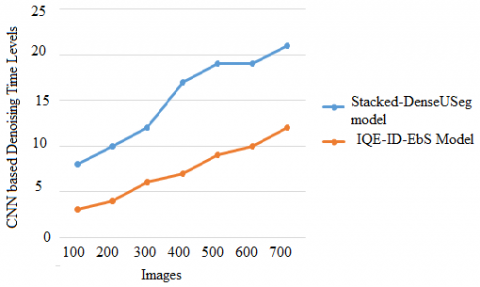
An image denoising technique aims to reduce noise while preserving important details. Wavelet-based approaches are particularly relevant in this situation. The performance of convolution neural networks is affected by noise in images. In the preprocessing step, noisy images are generally recovered, which improves the CNN classification performance. The CNN based Denoising Time Levels of the proposed and traditional models are shown in Figure 8.
Figure 8. CNN based denoising time levels
Table 2. CNN based denoising accuracy levels
|
Images considered |
CNN based denoising accuracy levels |
|
|
Proposed |
Exisitng |
|
|
100 |
59 |
43 |
|
200 |
64 |
50 |
|
300 |
70 |
60 |
|
400 |
79 |
70 |
|
500 |
82 |
73 |
|
600 |
90 |
79 |
|
700 |
98 |
89 |
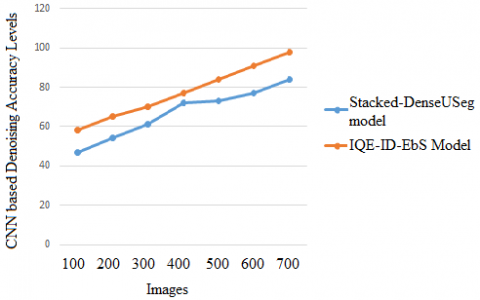
Obtaining the underlying image content is critical for excellent performance in a variety of applications, including image reconstruction, activity recognition, image registration, and image segmentation and classification. Denoising an image is the method by which unwanted noise from it is removed. Various intrinsic or extrinsic circumstances can have a significant impact on visual noise, making it difficult to eliminate completely. A key challenge in the field of computer vision and image processing is the topic of image denoising that need to be applied on images for accurate lesion detection. Table 2 and Figure 9 depicts the CNN based Denoising Accuracy Levels of the traditional and proposed models.
Figure 9. CNN based denoising accuracy levels
The field of image denoising has been actively studied for decades. The classic methods discuss numerous picture filters. Later, model-based approaches in the spatial domain, the transform domain, or a combination of the two, with a variety of priors like regional smoothness, non-local patch similarity, sparsity, and low-rankness, were used to the problem. Recently, multiple research have shown that deep learning models outperform conventional approaches in picture denoising and segmentation. Most present denoising algorithms recreate images by reducing the mean square error (MSE), which is well-known to be out of sync with human perception quality and frequently tends to overly smooth textures. The existing approaches of directly processing reconstructed images cannot reduce image noise while keeping image structural details due to the difficulties of modeling statistical variables in the image domain. This research provides a CT image denoising approach based on image segmentation and by enhancing the Image quality for liver tumor detection. This research proposed a Image Quality Enhancement model with Image Denoising and Edge based Segmentation model that initially applies denoising and then detects the edges of the CT images and performs CNN based segmentation and then enhances the image quality for accurate feature extraction for liver tumor detection. The proposed model can be extended using the multi level image enhancement and denoising model with novel filters for complete noise removal and accurate segmentation.
[1] Bellos, D., Basham, M., Pridmore, T., French, A.P. (2021). A stacked dense denoising–segmentation network for undersampled tomograms and knowledge transfer using synthetic tomograms. Machine Vision and Applications, 32(3): 1-22. https://doi.org/10.1007/s00138-021-01196-4
[2] Seo, H., Huang, C., Bassenne, M., Xiao, R., Xing, L. (2019). Modified U-Net (mU-Net) with incorporation of object-dependent high level features for improved liver and liver-tumor segmentation in CT images. IEEE Transactions on Medical Imaging, 39(5): 1316-1325. https://doi.org/10.1109/TMI.2019.2948320
[3] Zhang, Y., Jiang, B., Wu, J., Ji, D., Liu, Y., Chen, Y., Wu, E., Tang, X. (2020). Deep learning initialized and gradient enhanced level-set based segmentation for liver tumor from CT images. IEEE Access, 8: 76056-76068. https://doi.org/10.1109/ACCESS.2020.2988647
[4] Gavini, V., Jothi, L.G.R., Rahman, M.Z.U. (2021). An efficient machine learning methodology for liver computerized tomography image analysis. International Journal of Engineering Trends and Technology, 69(7): 80-85. https://doi.org/10.14445/22315381/IJETT-V69I7P212
[5] Gavini, V., Lakshmi, G.J., Rahman, M.Z.U. (2006). A robust CT scan application for prior stage liver disorder prediction with googlenet deeplearning technique. ARPN Journal of Engineering and Applied Sciences, 16(18): 1850-1857.
[6] Song, L., Wang, H., Wang, Z.J. (2021). Bridging the gap between 2D and 3D contexts in CT volume for liver and tumor segmentation. IEEE Journal of Biomedical and Health Informatics, 25(9): 3450-3459. https://doi.org/10.1109/JBHI.2021.3075752
[7] Lei, T., Wang, R., Zhang, Y., Wan, Y., Liu, C., Nandi, A.K. (2021). DefED-Net: Deformable encoder-decoder network for liver and liver tumor segmentation. IEEE Transactions on Radiation and Plasma Medical Sciences, 6(1): 68-78. https://doi.org/10.1109/TRPMS.2021.3059780
[8] Su, S.T., Ho, M.C., Yen, J.Y., Chen, Y.Y. (2020). Featured surface matching method for liver image registration. IEEE Access, 8: 59723-59731. https://doi.org/10.1109/ACCESS.2020.2983325
[9] Naseem, R., Khan, Z.A., Satpute, N., Beghdadi, A., Cheikh, F.A., Olivares, J. (2021). Cross-modality guided contrast enhancement for improved liver tumor image segmentation. IEEE Access, 9: 118154-118167. https://doi.org/10.1109/ACCESS.2021.3107473
[10] Yan, K., Cai, J., Zheng, Y., Harrison, A.P., Jin, D., Tang, Y., Tang, Y., Huang, L., Xiao, J., Lu, L. (2020). Learning from multiple datasets with heterogeneous and partial labels for universal lesion detection in CT. IEEE Transactions on Medical Imaging, 40(10): 2759-2770. https://doi.org/10.1109/TMI.2020.3047598
[11] Dong, X., Zhou, Y., Wang, L., Peng, J., Lou, Y., Fan, Y. (2020). Liver cancer detection using hybridized fully convolutional neural network based on deep learning framework. IEEE Access, 8: 129889-129898. https://doi.org/10.1109/ACCESS.2020.3006362
[12] Dong, W., Wang, H., Wu, F., Shi, G., Li, X. (2019). Deep spatial–spectral representation learning for hyperspectral image denoising. IEEE Transactions on Computational Imaging, 5(4): 635-648. https://doi.org/10.1109/TCI.2019.2911881
[13] Shi, Q., Tang, X., Yang, T., Liu, R., Zhang, L. (2021). Hyperspectral image denoising using a 3-D attention denoising network. IEEE Transactions on Geoscience and Remote Sensing, 59(12): 10348-10363. https://doi.org/10.1109/TGRS.2020.3045273
[14] Cheng, W., Lu, J., Zhu, X., Hong, J., Liu, X., Li, M., Li, P. (2019). Dilated residual learning with skip connections for real-time denoising of laser speckle imaging of blood flow in a log-transformed domain. IEEE Transactions on Medical Imaging, 39(5): 1582-1593. https://doi.org/10.1109/TMI.2019.2953626
[15] Jung, C., Han, Q., Zhou, K., Xu, Y. (2021). Multispectral Fusion of RGB and NIR Images Using Weighted Least Squares and Convolution Neural Networks. IEEE Open Journal of Signal Processing, 2: 559-570. https://doi.org/10.1109/OJSP.2021.3122074
[16] Zhang, Y., Lin, H., Li, Y., Ma, H. (2019). A patch based denoising method using deep convolutional neural network for seismic image. IEEE Access, 7: 156883-156894. https://doi.org/10.1109/ACCESS.2019.2949774
[17] Chen, S., Eldar, Y.C., Zhao, L. (2021). Graph unrolling networks: Interpretable neural networks for graph signal denoising. IEEE Transactions on Signal Processing, 69: 3699-3713. https://doi.org/10.1109/TSP.2021.3087905
[18] Wei, K., Fu, Y., Huang, H. (2020). 3-D quasi-recurrent neural network for hyperspectral image denoising. IEEE Transactions on Neural Networks and Learning Systems, 32(1): 363-375. https://doi.org/10.1109/TNNLS.2020.2978756
[19] Zhou, Z., Siddiquee, M.M.R., Tajbakhsh, N., Liang, J. (2019). Unet++: Redesigning skip connections to exploit multiscale features in image segmentation. IEEE Transactions on Medical Imaging, 39(6): 1856-1867. https://doi.org/10.1109/TMI.2019.2959609
[20] Choi, J., Choi, B. (2021). Highly contrast image correction for dim boundary separation of image semantic segmentation. IEEE Access, 9: 64142-64152. https://doi.org/10.1109/ACCESS.2021.3075084
[21] Chen, R., Zhang, F.L., Rhee, T. (2020). Edge-aware convolution for RGB-D image segmentation. In 2020 35th International Conference on Image and Vision Computing New Zealand (IVCNZ), pp. 1-6. https://doi.org/10.1109/IVCNZ51579.2020.9290608
[22] Hassanzadeh, T., Hamey, L.G., Ho-Shon, K. (2019). Convolutional neural networks for prostate magnetic resonance image segmentation. IEEE Access, 7: 36748-36760. https://doi.org/10.1109/ACCESS.2019.2903284
[23] Yaniv, O., Portnoy, O., Talmon, A., Kiryati, N., Konen, E., Mayer, A. (2020). V-net light-parameter-efficient 3-d convolutional neural network for prostate mri segmentation. In 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), pp. 442-445. https://doi.org/10.1109/ISBI45749.2020.9098643
[24] Wang, Y., Song, X., Chen, K. (2021). Channel and space attention neural network for image denoising. IEEE Signal Processing Letters, 28: 424-428. https://doi.org/10.1109/LSP.2021.3057544
[25] Bera, S., Biswas, P.K. (2021). Noise conscious training of non local neural network powered by self attentive spectral normalized Markovian patch GAN for low dose CT denoising. IEEE Transactions on Medical Imaging, 40(12): 3663-3673. https://doi.org/10.1109/TMI.2021.3094525
[26] Gao, J., Yu, Z., Nie, K., Xu, J. (2020). A real noise elimination method for CMOS image sensor based on three-channel convolution neural network. IEEE Sensors Journal, 20(19): 11549-11555. https://doi.org/10.1109/JSEN.2020.2997955