Lin Zhu | Xin Sheng*
© 2022 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
As a modern comprehensive information platform for integrated statistical analysis of express shipments information and for express shipments management decision-making, the express logistics track and trace system needs to use artificial intelligence (AI) technology and image processing technology to automatically extract the text content of express logistics documents. Existing express shipments information identification models usually have problems such as less-than-ideal performance in detecting single characters or small text regions of express logistics documents, high human resource cost for character-level markup, and low speed and accuracy of text recognition. In response, this paper studies the image-processing-based identification method of express logistics information. It presents a recognition process for pre-processing text images of express logistics documents, along with a detailed description of denoising, greyscaling and binarisation methods. While proposing an enhancement strategy for Chinese characters in the section of handwritten Chinese, this paper constructs a model for recognition of express shipping document texts based on bidirectional long-short term memory (LSTM) and attention mechanism. In this way, we fully mined key semantic information of express logistics document texts. The experimental results verify the effectiveness of the constructed model.
image processing, express shipments, text information identification
The production operations and information processing of express logistics have been optimised and adjusted through the trunk network to achieve informationisation of all phases, including basic manual operations, sorting, sealing, dispatching and delivery [1-4]. The "express logistics track and trace system", which supports information-based processing, has been successfully developed and updated to break through the bottleneck of scattered network resources that restricts the development of the express logistics industry, while ensuring the competitive edge of the express logistics network [5-11]. The informationization of express logistics processing phases is urgently needed to expand the quality monitoring function of express logistics management based on the framework of the original express logistics track and trace system. Accordingly, such practice replaces the manual input of express logistics information into the computer, effectively improving the timeliness of express logistics information identification and the quality of the whole real-time track and trace service [12-19]. As a modern comprehensive information platform capable of carrying out integrated statistical analysis of express logistics information and management decisions, it entails artificial intelligence (AI) technology and image processing technology to automatically extract the text content of express logistics documents [20-23].
To effectively improve the text image recognition accuracy of logistics documents, Wu et al. [24] used canny algorithm to process edge detection of text, and k-means algorithm for cluster pixel recognition. This unique combination combined with maximally stable extremal region and optimization of stroke width for image text yields better results in terms of recognition rate, recall, precision, F-score and accuracy. Wang and Zhang [25] offered an enhanced intelligent picture text recognition algorithm based on the intelligent image text recognition method to increase the impact of English image text translation. Texture blocks of adaptable size were used to successfully increase the accuracy and efficiency of restoration due to the varying texture information present in various photos. Tamilselvi et al. [26] was intended to design a novel text recognition using digital images taken from any camera with a set of different pixel densities. A Logical Text Classification Strategy (LTCS) was introduced to perform an effective text recognition process using digital images. Manzoor and Singla [27] presented the development of a computer system that allows the recognition of handwritten text based on image processing techniques, artificial intelligence, artificial neural networks, and pattern recognition for natural and handwritten text recognition systems. In the proposed system the handwritten text is recognized with precision of 0.81 or higher. Zhu et al. [28] developed the recognition network based on transformer (RNBT). The transformer adopted encoder-decoder framework but discarded the RNN unit. The authors also modified the loss function to improve the problem that the encoder-decode framework gets bad recognition performance on images that has longer text length than images in training set.
Existing express shipments information identification models usually have the following problems: (1) less-than-ideal performance in detecting single characters or small text regions of express logistics documents; (2) high human resource cost for character-level markup; (3) low speed and accuracy of text recognition. In response, this paper studies the image-processing-based identification method of express logistics information. Chapter 2 presents a recognition process for pre-processing text images of express logistics documents, along with a detailed description of denoising, greyscaling and binarisation methods. While proposing an enhancement strategy for Chinese characters in the section of handwritten Chinese, this paper constructs a model for recognition of express shipping document texts based on bidirectional long-short term memory (LSTM) and attention mechanism. In this way, we fully mined key semantic information of express logistics document texts. The experimental results verify the effectiveness of the constructed model.
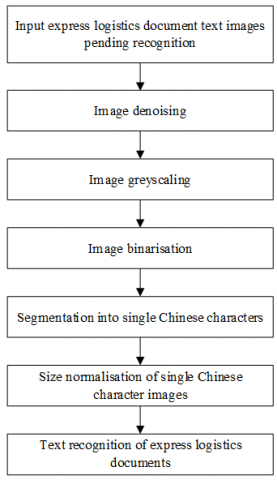
Figure 1 gives a recognition process for pre-processing text images of express logistics documents. Due to environmental reasons, some noise is usually mixed during the acquisition, processing and transmission of express logistics document text images, resulting in blurring and blocked features of express logistics document text images, which makes the text analysis more difficult. In this paper, before carrying out the recognition of such text images, they are denoised based on mean filtering.
Figure 1. A recognition process for pre-processing text images of express logistics documents
Mean filtering assigns a template to the text image pixels of the express logistics documents pending processing. The template covers the neighbouring pixels, replacing each pixel value in an image with the mean value of all pixels within the template. Assuming that the pixel value pending processing is represented by F5 and the processed pixel value by F0, Eq. (1) gives the expression for the coefficients of mean filtering:
${{F}_{0}}=\frac{1}{9}\left[ \begin{matrix} {{F}_{1}} & {{F}_{2}} & {{F}_{3}} \\ {{F}_{4}} & {{F}_{5}} & {{F}_{6}} \\ {{F}_{7}} & {{F}_{8}} & {{F}_{9}} \\\end{matrix} \right]=\frac{1}{9}\sum\limits_{i=1}^{9}{{{F}_{i}}}$ (1)
As the text recognition of handwritten express logistics documents has little to do with the image colour, in order to simplify the pre-processing operation process and reduce the complexity of image processing and analysis, this paper carries out a simple greyscaling, i.e., using the global thresholding method to smooth and refine the image. Assuming that each pixel value in a text image of the express logistics documents is represented by g(c,d), the global threshold is represented by O, and the processed pixel values are represented by h(c,d), then the computational equation is given by:
$h\left( c,d \right)=\left\{ \begin{align} & 255,If\text{ }g\left( c,d \right)>=O \\ & 0,Otherwise \\ \end{align} \right.$ (2)
Since the size of the region for handwritten Chinese characters is unknown in such text images pending recognition, there are differences in the size of different characters generated by direct handwritten Chinese character segmentation. Therefore, this paper normalises the size of the handwritten text region in such text images by discrete function approximation of the greyscale values of all the pixels in the handwritten text region based on interpolating, in order to obtain the pixel values of each coordinate point after the size change of different Chinese character regions. Assume that K represents the length of the original text image in the c-axis direction, K' represents the length of the normalised text image in the c-axis direction, Q represents the length of the original text image in the d-axis direction, and Q' represents the length of the normalised image in the d-axis direction. In terms of the interpolation method, the two points (c', d') and (c, d) before and after image normalisation must satisfy the following equation:
$\left\{\begin{array}{l}\frac{c}{K}=\frac{c^{\prime}}{K^{\prime}} \\ \frac{d}{Q}=\frac{d^{\prime}}{Q^{\prime}}\end{array}\right.$ (3)
The nearest neighbour interpolation of greyscale values rounded to obtain binarised coordinate values does not work very well in many cases for size normalisation of images. Therefore, this paper introduces a bilinear interpolation method, i.e., a calculation based on the pixel values of the four pixel dots surrounding the pixel dot pending processing. Assume that g(i, j) represents the pixel values at (i,j) in the original text image.
$g(i+v, j+u)=(1-v)(1-u) f(i, j)+(1+v) u g(i, j+1)+v(1-u) g(i+1, j)+v u g(i+1, j+1)$ (4)
First, in the direction of the c-axis, two pixel dots N1 and N2 of the original text image are interpolated to obtain pixel dot M1, and two pixel dots N3 and N4 are interpolated to obtain pixel dot M2. The formula for interpolation in the c-axis is:
$g\left(M_{1}\right) \approx \frac{c_{2}-c}{c_{2}-c 1} g\left(N_{1}\right)+\frac{c-c_{1}}{c_{2}-c_{1}} g\left(N_{2}\right)$ (5)
$g\left(M_{2}\right) \approx \frac{c_{2}-c}{c_{2}-c_{1}} g\left(N_{3}\right)+\frac{c-c_{1}}{c_{2}-c_{1}} g\left(N_{4}\right)$ (6)
The interpolation of the W pixel dot according to M1 and M2 is then performed on the d-axis by the formula:
$g\left( W \right)\approx \frac{{{d}_{2}}-d}{{{d}_{2}}-{{d}_{1}}}g\left( {{M}_{2}} \right)+\frac{d-{{d}_{1}}}{{{d}_{2}}-{{d}_{1}}}g\left( {{M}_{1}} \right)$ (7)
A conjunction of equations 5, 6 and 7 gives:
$\begin{align} & g\left( W \right)\approx \frac{g\left( {{N}_{3}} \right)}{\left( {{c}_{2}}-{{c}_{1}} \right)\left( {{d}_{2}}-{{d}_{1}} \right)}\left( {{c}_{2}}-c \right)\left( {{d}_{2}}-d \right)+\frac{g\left( {{N}_{4}} \right)}{\left( {{c}_{2}}-{{c}_{1}} \right)\left( {{d}_{2}}-{{d}_{1}} \right)}\left( c-{{c}_{1}} \right)\left( {{d}_{2}}-d \right)+ \\ & \frac{g\left( {{N}_{1}} \right)}{\left( {{c}_{2}}-{{c}_{1}} \right)\left( {{d}_{2}}-{{d}_{1}} \right)}\left( {{c}_{2}}-c \right)\left( d-{{d}_{1}} \right)+\frac{g\left( {{N}_{2}} \right)}{\left( {{c}_{2}}-{{c}_{1}} \right)\left( {{d}_{2}}-{{d}_{1}} \right)}\left( c-{{c}_{1}} \right)\left( d-{{d}_{1}} \right) \\ \end{align}$ (8)
In order to realize the full mining of key semantic information of express logistics document texts, this paper proposes an enhancement strategy of Chinese characters in handwritten text region and constructs an express logistics document text recognition model based on bidirectional LSTM and attention mechanism. Figure 2 gives a schematic diagram of the text recognition process of express logistics documents. The model further enhances the utilisation of key Chinese character information by individually performing repetitive feature extraction of key Chinese characters in handwritten text regions. Meanwhile, to strengthen the feature information that is important for the recognition of Chinese characters in handwritten text regions in the text sequences of the input express logistics documents, the model introduces an attention mechanism that weakens the feature representation of irrelevant information in handwritten text regions. Finally, the image features extracted by the bidirectional LSTM and the attention mechanism are fused in a stitching approach to complete the new feature representation of the express logistics document texts.
The model in this paper is to extract features from key Chinese characters in original express logistics document texts and handwritten text regions respectively. Next is an elaboration on the algorithm process for original express logistics document texts. Assume there is an original express logistics document text sequence. {qc1, qc2, qc3,...,qcm} represents the word vector transformed from the word embedding layer, Fc ={fc1, fc2,...,fcm}represents the feature output of the express logistics document texts obtained by using a bidirectional LSTM network, and Fc$\in$R2yn×m, fc$\in$R2yn. yn represents the dimension of the hidden layer vector of the LSTM network, and m represents the input sequence length of original express logistics document texts. The attention weight pairs of the express logistics document text sequences are then obtained based on the attention mechanism. We calculated the attention scores of each Chinese character using the tanh function as follows:
$F^{c}=\left\{f_{1}^{c}, f_{2}^{c}, \ldots, f_{m}^{c}\right\}$ (9)
${{f}^{c}}=\left[ \overset{\to }{\mathop{{{f}^{c}}}}\,:\overset{\leftarrow }{\mathop{{{f}^{c}}}}\, \right]$ (10)
$u_{i}^{c}=\tanh \left(Q f_{i}^{c}+a\right)$ (11)
The results are then further normalized based on the softmax function to obtain the corresponding weight distribution βci.
$\beta_{i}^{c}=\operatorname{softmax}\left(u_{i}^{c}\right)$ (12)
Assume that fcrepresents the features output from the bidirectional LSTM network. Finally, information weighting is applied to fc based on attention weights to obtain the deep semantic features of express logistics document texts fcb:
$f^{c b}=\sum_{i=1}^{m} \beta_{i}^{c} f_{i}$ (13)
Similarly, the key Chinese character sequences of handwritten text regions are extracted based on the features of the bidirectional LSTM network, and the feature output is obtained by Fp={fp1, fp2,..., fpl}, FpÎR2yn×l. fpÎR2yn represents the length of the key Chinese character sequence, and the dimension of the output vector yn is kept consistent with the output dimension of the original express logistics document text sequence. fpb, which represents the semantic feature of the key Chinese characters in handwritten text regions, can be obtained by information weighting with the attention mechanism. We then spliced and fused the feature representations of the two parts of the express logistics document text sequence to finish constructing new features of the express logistics document texts, denoted as v=[fcb, fpb], v$\in$R4yn. Finally, we finished the recognition of Chinese characters in handwritten text regions for v based on a softmax classifier.
Figure 2. Schematic diagram of the text recognition process for express logistics documents
Figure 3. Architecture of text recognition model for express logistics documents
The text recognition model for express logistics documents based on bidirectional LSTM and attention mechanism consists of five layers: input processing layer, semantic feature extraction layer of document text, attention mechanism layer, semantic feature fusion layer of document text, and Chinese character classification layer of handwritten text region. Figure 3 gives the architecture of the text recognition model for express logistics documents.
For an express logistics document text containing m words C={c1, c2, c3,..., cm}, the word embedding layer maps each word ci in the original express logistics document text to a word vector qci based on a real number representation, and the key Chinese characters in handwritten text regions contain l words P={p1, p2, p3,..., pl}. Similarly, each of these words pj is mapped to a word vector qpj. Q$\in$Ry×|u| denotes the completed word vector matrix obtained after the word embedding layer processing, where the dimension of word vector is denoted by y and the dimension of lexicon is denoted by |u|. Then the original express logistics document text is processed through the word embedding layer as a matrix C$\in$Ry×m constructed from qci. Each word pj in the key Chinese characters in handwritten text regions is also processed as a matrix PÎRy×l constructed from qpj, and qci and qcj can be obtained through the word vector matrix Q.
The original express logistics document text sequences are mapped through the word embedding layer as word vectors with shallow semantic information C={qc1,qc2,qc3...,qcm}, and the key Chinese character sequence of handwritten text regions is mapped as P={qp1,qp2,qp3...,qpl}. Suppose fcb represents the semantic features obtained after model processing, and fpb represents the corresponding document text features after feature extraction and feature enhancement. Satisfying fcb$\in$Ryn and fpb$\in$Ryn, fcb and fpb are spliced and fused to form a semantic feature representation matrix N satisfying N=[fcb:fpb], N$\in$R2×yn.
To further enhance the semantic information utilisation of original express logistics document text with key Chinese character information in handwritten text regions, this paper uses a self-attention mechanism to achieve feature fusion at the semantic level of express logistics document text. Below is a detailed description of how the attention weights are calculated based on the self-attention mechanism.
fcb and fpb are obtained based on the semantic feature extraction layer, and the output of both is collapsed into a matrix N=[fcb:fpb], N$\in$R2×yn. In the computational framework of the self-attentive mechanism, the query Q=NT, the keyword K=N and the value V=N. Firstly, the relevance of each vector in the K and Q matrixes is quantified by a multilayer perceptron g. The computational result is represented by ARij.
$A R_{i j}=g\left(K_{i}, Q_{j}\right)$ (14)
Next, the correlation matrix constructed by ARij was normalized using the softmax function to obtain the attention weight matrix AR:
$A R=\operatorname{Softmax}\left(\tanh \left(Q^{r} N^{O}+a^{r}\right)\right.$ (15)
The fused semantic feature representation matrix N' can be obtained based on the AR dot product weighting operation on N, represented by N'=[n1:n2], and the feature fusion process is represented by the following equation:
$N^{\prime}=A T \otimes N$ (16)
Suppose the parameters to be trained are denoted by Qp and a, and the dimensions of AR, Q, a are denoted by AR$\in$R2×2, N$\in$R2×yn, Qr$\in$R2×yn, yr$\in$R2×2 respectively. By splicing the vectors n1 and n2 in N', we can obtain the semantic feature n in the form of vectors for the text of express logistics documents, which can be expressed as n = [n, n2], n$\in$R4yn.
In the semantic feature fusion layer of document texts, the model fuses and stitches the features of fcb and fpb through a self-attentive mechanism to form a feature representation n of the express logistics document text, which can be used as the Chinese character classification features in the handwritten text region pending processing in the classification layer. Assuming that the string generation function is represented by Π, we have
$n=\Pi\left[n_{1}, n_{2}\right]$ (17)
The final recognition of the Chinese characters in handwritten text regions is done by the softmax classifier, as shown in equation 18.
$d=Q s+a$ (18)
Assume that the number of categories to be classified is denoted by X, Q$\in$RX×y, d$\in$RX, and the dimensionality of the semantic feature vector is denoted by y. Equation 19 gives the corresponding category probability distribution.
$e_{x}=\frac{\exp \left(d^{x}\right)}{\sum_{x=1}^{x}\left(d^{x}\right)}$ (19)
Figure 4 shows the effect of pre-processing the text of an original express waybill. It can be seen that after denoising, greyscaling and binarisation, the text image of the original waybill presents a much better clarity, and the contrast between the handwritten text and the background region has also improved.
Figure 5 shows the effect of different word embedding methods on the performance of the models for the text recognition of express logistics documents, specifically the Neural Network Language Model (NNLM) model (1), C&W model (2), Continuous Bag of Words (CBOW) model (3), and Skip-gram model (4).
According to Figure 5, using the four word vector models as the word embedding layer of the express logistics document text recognition model will have a great impact on the model's recognition of the semantic information of the express logistics document text. Using the Skip-gram model to initialise the express logistics document text sequence can result in an accuracy of over 80% for the express logistics document text recognition of the constructed model, while the recognition accuracy of other word embedding methods is significantly lower. Therefore, this paper uses the Skip-gram model to initialise the text sequences of express logistics documents.
Figure 4. Pre-processing effect of text images of an express waybill
Figure 5. Effect of different word embedding methods on the model
Figure 6. Example of a generated handwritten text region
Figure 6 shows the detection of handwritten text regions by the optimally trained model, with the handwritten text regions marked by the green boxes. According to figure 6, the model's handwritten Chinese text detection is already quite satisfactory and can detect almost all of the handwritten Chinese text regions, with good detection results as well for the smaller numeric regions.
The model in this paper is compared with five popular text recognition models, namely CRNN, Rosetta, STAR-Net, RARE and SRN. Three metrics, Precision, Recall and H-mean, were chosen to evaluate the performance advantages and disadvantages of the above models on the text image set of express logistics documents. Table 1 shows the performance of different models for handwritten text region recognition. According to the table, the overall performance of the model constructed in this paper is the highest, achieving a high level of text detection for express logistics documents. Thanks to the introduction of bidirectional LSTM and attention mechanism, the model in this paper has a higher accuracy, recall and H-mean value compared to the five other models.
Table 1. Performance of different models for handwritten text region recognition
|
Sequence number of experimental model |
Precision |
Recall |
H-mean |
|
1 |
0.8142 |
0.7159 |
0.7418 |
|
2 |
0.8629 |
0.8251 |
0.8263 |
|
3 |
0.8025 |
0.8316 |
0.8825 |
|
4 |
0.9596 |
0.9582 |
0.9152 |
|
5 |
0.9171 |
0.9417 |
0.9645 |
|
Model in this paper |
0.9514 |
0.9624 |
0.9271 |
(1)
(2)
Figure 7. Results comparison of loss values for different models
Figure 8. Results comparison of recognition accuracy of different models
According to the predetermined experimental design of effectiveness comparison with the introduction of bidirectional LSTM and attention mechanism, the loss values and accuracy rates of the three models that completed the training before and after the introduction were counted and summarized over 350 training cycles. Figure 7 gives the results comparison of loss values of different models: (1) shows the change in loss values of the models over 350 training cycles; (2) shows the change in loss value of the model from 100 to 350 training cycles. Reference model 1 is the model before the introduction of bidirectional LSTM, and reference model 3 is the model before the introduction of attention mechanism. According to Figure 7, the convergence speed and loss value oscillation of the model constructed in this paper are more satisfactory. Figure 8 gives the results comparison of the recognition accuracy of different models. According to the figure, the recognition accuracy is significantly higher than that of the model before the introduction of the bidirectional LSTM and attention mechanism.
This paper studies the image-processing-based identification method of express logistics information. It presents a recognition process for pre-processing text images of express logistics documents, along with a detailed description of denoising, greyscaling and binarisation methods. While proposing an enhancement strategy for Chinese characters in the section of handwritten Chinese, this paper constructs a model for recognition of express shipping document texts based on bidirectional long-short term memory (LSTM) and attention mechanism. In this way, we fully mined key semantic information of express logistics document texts. The experimental results show the effectiveness of the constructed model in this paper on pre-processing original express logistics document texts. This paper presents the impact of different word embedding methods on the model’s performance of the text recognition of express logistics documents. The Skip-gram model is chosen to initialise the text sequence of express logistics documents. The paper shows the effect of the trained-to-optimal model on the detection of handwritten Chinese text regions. We saw that the model delivers moderately satisfactory results in the detection of handwritten Chinese texts. The results comparison of the loss values and recognition accuracy of different models are given to verify the effectiveness of the constructed model.
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research is supported by the Key Research Project of universities in Guangdong Province: Research on express package recycling under the guidance of green logistics (Grant No.: 2018GWQNCX117), "Qinglan Project" of Jiangsu Province.
[1] Watanabe, H., Saito, K., Miyazaki, S., Okada, T., Fukuyama, H., Kato, T., Taniguchi, K. (2021). Proof of authenticity of logistics information with passive RFID tags and blockchain. In 2021 International Conference on Electronic Communications, Internet of Things and Big Data (ICEIB), pp. 213-216. https://doi.org/10.1109/ICEIB53692.2021.9686409
[2] Gackstetter, D., Moshrefzadeh, M., Machl, T., Kolbe, T.H. (2021). Smart rural areas data infrastructure (SRADI)–an information logistics framework for digital agriculture based on open standards. GIL-Jahrestagung, Informations-und Kommunikationstechnologie in kritischen Zeiten. Lecture Notes in Informatics (LNI), Proceedings-Series of the Gesellschaft fur Informatik (GI), P-309: 109-114.
[3] Wijewickrama, M.K.C.S., Chileshe, N., Rameezdeen, R., Ochoa, J.J. (2021). Information sharing in reverse logistics supply chain of demolition waste: A systematic literature review. Journal of Cleaner Production, 280: 124359. https://doi.org/10.1016/j.jclepro.2020.124359
[4] Wan, C. (2022). Modern intelligent logistics management paradigm based on management information system model. In 2022 International Seminar on Computer Science and Engineering Technology (SCSET), 155-158. https://doi.org/10.1109/SCSET55041.2022.00045
[5] Yan, H. (2022). Optimization of regional logistics distribution information network platform. Security and Communication Networks. https://doi.org/10.1155/2022/6729247
[6] Rahman, M.L., Putra, E.F.S., Sensuse, D.I., Suryono, R.R. (2021). A review of e-logistics model from consumer satisfaction and information technology perspective. In 2021 2nd International Conference on ICT for Rural Development (IC-ICTRuDev), 1-6. https://doi.org/10.1109/IC-ICTRuDev50538.2021.9656509
[7] Yachai, K., Kongboon, R., Gheewala, S.H., Sampattagul, S. (2021). Carbon footprint adaptation on green supply chain and logistics of papaya in Yasothon Province using geographic information system. Journal of Cleaner Production, 281: 125214. https://doi.org/10.1016/j.jclepro.2020.125214
[8] Ding, Y., Jain, N. (2022). Research on logistics management information system of electronic commerce based on computer information technology. In The International Conference on Cyber Security Intelligence and Analytics, 123: 569-576. https://doi.org/10.1007/978-3-030-96908-0_71
[9] Zhong, J., Yin, J., Huang, L. (2022). Implementation of logistics information system based on data mining and high-performance model. In 2022 International Conference on Electronics and Renewable Systems (ICEARS), 1692-1696. https://doi.org/10.1109/ICEARS53579.2022.9752037
[10] Wu, Z., Yang, K., Xue, H., Zuo, J., Li, S. (2022). Major barriers to information sharing in reverse logistics of construction and demolition waste. Journal of Cleaner Production, 350: 131331. https://doi.org/10.1016/j.jclepro.2022.131331
[11] Chen, Q., Han, J., Li, J., Chen, L., Li, S. (2021). A privacy-preserving logistics information system with traceability. In International Symposium on Cyberspace Safety and Security, 13172: 145-163. https://doi.org/10.1007/978-3-030-94029-4_11
[12] Demirova, S. (2021). Development and scope of information logistics under the influence of external and internal factors. In 2021 IV International Conference on High Technology for Sustainable Development (HiTech), 1-5. https://doi.org/10.1109/HiTech53072.2021.9614229
[13] Kitsios, F., Kamariotou, M., Madas, M.A., Fouskas, K., Manthou, V. (2019). Information systems strategy in SMEs: critical factors of strategic planning in logistics. Kybernetes, 49(4): 1197-1212. https://doi.org/10.1108/K-10-2018-0546
[14] Kifokeris, D., Koch, C. (2020). A conceptual digital business model for construction logistics consultants, featuring a sociomaterial blockchain solution for integrated economic, material and information flows. J. Inf. Technol. Constr., 25(29): 500-521. https://doi.org/10.36680/j.itcon.2020.029
[15] Liu, P., Li, Y. (2020). Multiattribute decision method for comprehensive logistics distribution center location selection based on 2-dimensional linguistic information. Information Sciences, 538: 209-244. https://doi.org/10.1016/j.ins.2020.05.131
[16] Zhou, H. (2022). Application of RFID information technology in logistics warehouse management. In 2022 IEEE Asia-Pacific Conference on Image Processing, Electronics and Computers (IPEC), pp. 1215-1217.
[17] Starostka-Patyk, M. (2021). The use of information systems to support the management of reverse logistics processes. Procedia Computer Science, 192: 2586-2595. https://doi.org/10.1016/j.procs.2021.09.028
[18] Liu, X. (2021). Application of network security in logistics information management platform. In International Conference on Machine Learning and Big Data Analytics for IoT Security and Privacy, 98: 590-598. https://doi.org/10.1007/978-3-030-89511-2_76
[19] Chen, K.J., Zhang, J.H., Lan, Y.X., Chen, P. (2022). E-commerce logistics provider selection based on multi-criteria decision-making approach with uncertain information. International Journal of Industrial and Systems Engineering, 40(1): 104-125.
[20] Wang, L.F., Huang, F., Zhu, G.H. (2021). Design of cold chain logistics information real time tracking system based on wireless RFID technology. In International Conference on Advanced Hybrid Information Processing, 440-453. https://doi.org/10.1007/978-3-030-94551-0_35
[21] Shen, L., Yang, Q., Hou, Y., Lin, J. (2022). Research on information sharing incentive mechanism of China's port cold chain logistics enterprises based on blockchain. Ocean & Coastal Management, 225: 106229. https://doi.org/10.1016/j.ocecoaman.2022.106229
[22] Vakhovych, I., Kryvovyazyuk, I., Kovalchuk, N., Kaminska, I., Volynchuk, Y., Kulyk, Y. (2021). Application of information technologies for risk management of logistics systems. In 2021 62nd International Scientific Conference on Information Technology and Management Science of Riga Technical University (ITMS), 1-6. https://doi.org/10.1109/ITMS52826.2021.9615297
[23] Li, Q., Wu, G. (2021). ERP system in the logistics information management system of supply chain enterprises. Mobile Information Systems. https://doi.org/10.1155/2021/7423717
[24] Wu, F., Zhu, C., Xu, J., Bhatt, M.W., Sharma, A. (2022). Research on image text recognition based on canny edge detection algorithm and k-means algorithm. International Journal of System Assurance Engineering and Management, 13(1): 72-80. https://doi.org/10.1007/s13198-021-01262-0
[25] Wang, H.J., Zhang, L. (2022). Computational application on English translation system based on intelligent image text recognition. Security and Communication Networks, 2022. https://doi.org/10.1155/2022/7793574
[26] Tamilselvi, M., Ramkumar, G., Anitha, G., Nirmala, P., Ramesh, S. (2022). A novel text recognition scheme using classification assisted digital image processing strategy. In 2022 International Conference on Advances in Computing, Communication and Applied Informatics (ACCAI), 1-6. https://doi.org/10.1109/ACCAI53970.2022.9752542
[27] Manzoor, S.I., Singla, J. (2021). A novel system for image text recognition and classification using deep learning. In 2021 International Conference on Computing Sciences (ICCS), 61-64. https://doi.org/10.1109/ICCS54944.2021.00020
[28] Zhu, Y.W., Wang, S.L., Huang, Z., Chen, K., Lin, X., Zhang, Q.H. (2019). Attention-based text recognition in image. Proceedings-2019 IEEE 4th International Conference on Data Science in Cyberspace, pp. 278-283.