Hidir Selcuk Nogay
© 2021 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Fingerprint pattern recognition is of great importance in forensic examinations and in helping diagnose some diseases. The automatic realization of fingerprint recognition processes can take time due to the feature extraction process in classical machine learning or deep learning methods. In this study, the effective use of deep convolutional neural networks (DCNN) in fingerprint pattern recognition and classification, in which feature extraction takes place automatically, was examined experimentally and comparatively. Five DCNN models have been designed and implemented with a transfer learning approach. Four of these five models are Alexnet, Googlenet, Resnet-18, and Squeezenet pre-trained DCNN models. The fifth model is the DCNN model designed from the ground up. It was concluded that the designed DCNN models can be used effectively in fingerprint recognition and classification, and that fast results can be obtained and generalized with advanced DCNN models.
fingerprint, deep learning, transfer learning, DCNN, pattern recognition
For forensic examiners, fingerprinting is often used as the main element and tool of analysis and comment [1-5]. Because everyone's fingerprints are different and are not alike. Classification and identification processes are performed using the unique features of the fingerprint. Fingerprint identification processes are performed by obtaining the fingerprint, preprocessing the fingerprint images, and identifying the processed fingerprint [6]. The fingerprint is biometric data unique to the person. Due to this feature of fingerprints, it is widely used in the elucidation of forensic cases. A forensic examinator investigates and makes a decision about where a fingerprint or any evidence found at the scene came from or what the source is. The judgments made as a result of such research are subjective judgments [7, 8] and their reliability and validity are dealt with and questioned by the scientific world [9]. Forensic fingerprint examination has been sought by courts as evidence for over a century [10, 11]. In fingerprint analysis, comparing the features of the fingerprint (e.g., a fingerprint found at the crime scene) with the features of a reference fingerprint (e.g., a suspect's fingerprint) is one of the most important steps. Based on the results of this comparison, the examiner assesses whether the fingerprint is the same as the suspect's fingerprint (i.e., reference fingerprint) or was left by someone else. Three levels of information are used to compare fingerprints (Figure 1). Stage 1 is the general pattern, the general view of the fingerprint ridges; Stage 2 refers to the minutiae where the ridges rest or split, and Stage 3 are details such as the structure of the ridges and sweat pores [12]. If examiners prefer to examine by considering all three levels of information separately, then the result of the examination is reported as a diagnostic value as a numerical probability ratio [13]. This reporting approach is a widely used and accepted method [14-16], and it may differ by country [17].
Figure 1. Representation of three stages of basic fingerprint information (inspired by [9])
To use these three information stages effectively, more scientific studies are needed on the first information stage, fingerprint pattern identification. Fingerprint pattern identification or classification is an important first step for forensic examiners. It is an important necessity to use automatic identification and classification methods to obtain high accuracy results regarding pattern recognition from fingerprint data related to a forensic event. Depending on the type of area the fingerprint interacts with, obtaining fingerprints from the scene causes difficulties in some cases. Visualization studies from areas where fingerprints are not possible are supported by technological developments in forensic sciences. It is important to be able to quickly identify the class of fingerprints whose visualization has been completed.
Also, fingerprint pattern recognition or fingerprint pattern classification studies are not only used for forensic examinations. In addition to forensic examinations, fingerprints can be used to help diagnose some diseases such as autism. Many research articles are using the distinguishing feature of data sets consisting of fingerprint images. And also many articles are confirming that there is a correlation between dermatoglyphic features or fingerprint image data and autism or certain diseases [18-20].
Machine learning methods that are effective in pattern recognition can also be used in fingerprint recognition. Deep learning and machine learning methods used in the state of the art are widely used to contribute to the solution of many problems [21]. In this study, the classification of fingerprints using DCNN, which is one of the most popular deep learning methods in recent years, has been examined both comparatively and experimentally.
There are many different methods for automatic fingerprint pattern recognition. The three most basic algorithms used in current methods are correlation-based, minutiae-based, and ridge-based algorithms. Correlation-based techniques require knowing the exact location of the recording point. There are difficulties in extracting details from low-resolution fingerprint images in minutiae-based recognition algorithms. For this reason, it is necessary to preprocess the fingerprints before putting them into the algorithm. In the ridge-based algorithm, as in the detail-based techniques, there is a preprocessing phase to detect the lines correctly in low-resolution images. In these techniques, it is necessary to improve the pattern by normalization of the fingerprint, histogram equalization, binarization, direction map extraction, ridgelines frequency determination, and filtering processes to realize automatic fingerprint pattern recognition. In addition to all this, additional processes such as determining distinctive features or feature extraction are required in the improved fingerprint pattern [22].
Another important problem with existing automatic fingerprint recognition methods is; existing automatic fingerprint pattern recognition systems can be easily deceived by the presentation attack [23] made from silica gel or other low-cost materials [24, 25].
In machine learning methods, there are time-consuming processes such as feature extraction or determining distinctive features for pattern recognition. Since feature extraction or similar operations are performed automatically in the DCNN method, direct and fast results can be obtained without requiring an extra time-consuming operation, and also DCNN models cannot be easily spoofed by the presentation attack. Fingerprint pattern recognition operations are performed manually in three stages as mentioned before. Fingerprint pattern recognition processes, as mentioned before, are a process that is performed manually in three stages or with time-consuming methods such as classical machine learning methods. Without feature extraction, DCNN's automatic pattern recognition feature can be used for fingerprint recognition and analysis.
To use DCNN effectively for automatic fingerprint classification and to develop more successful DCNN models for this purpose, there is a need for more application and analysis studies based on experimental results on fingerprint classification with existing DCNN models. It is one of the original values of this study that, the pre-trained DCNN models that can classify a thousand categories are reconsidered to classify only eight categories to classify them improving some layers and applying it with a "transfer learning" approach. The other original value is the DCNN model itself, which was designed from scratch to get faster results. This model also allows comparative analysis of conventional DCNN models for fingerprint recognition. The remaining sections of the study after the first section are arranged as follows. In the second chapter, information about obtaining the data set and DCNN architectures are given. In the third section, the numerical and graphical results obtained from the study are presented. The fourth section consists of the conclusion and discussion.
In this section, obtaining the data set for fingerprint pattern classification and the design of DCNN models designed and applied in the study are explained.
In this study, five DCNN models for fingerprint pattern classification were designed and implemented. Four of these five models are classic models, designed and trained to classify more than one million image data into 1000 categories, with successful results (Alexnet, Googlenet, Squeezenet, Resnet18). These models have been reconsidered with the transfer learning approach since our purpose. In all DCNN models applied in this application, the softmax layer and classification layer were changed. The input tensor size of the softmax layer is set to 1x1x8 for each of these five DCNN models, to classify eight types of fingerprint images. In accordance with this layer, the classification layer, which is the last layer after softmax, has also been changed. The other model, the simply designed model (SDM), which was designed from scratch in the study, was applied both to see the effect of the number of layers and other factors in reaching a fast result and to make a comparison by evaluating the accuracy rate. Another reason for using the SDM model is to show the effectiveness of the DCNN method in the study. All DCNN architectures used in the study were performed in a MATLAB environment. This study was conducted with an NVIDIA GeForce GTX 1650, 8055 MB GPU laptop.
2.1 Obtaining the data set
All data used for this experimental study are obtained from the Biometric Ideal Test (BIT) database system (biometrics.idealtest.org/). BIT was formed by a biometrics research team headed by Prof. Tieniu Tan at the Center for Biometrics and Security Research (CBSR), National Laboratory of Pattern Recognition (NLPR), Institute of Automation, Chinese Academy of Sciences (CASIA). All data used for this experimental study are from healthy individuals.
The BIT system is funded by the National Basic Research Program of China (Grant No. 2004CB318110, 2012CB316300), the Natural Science Foundation of China (Grant No. 60736018, 60702024, 61075024, 61135002, 61273272), the Hi-Tech Research and Development Program of China (Grant No.2006AA01Z193, 2007AA01Z162), the International S&T Cooperation Program of China (Grant No. 2010DFB14110) and the National Key Technology R&D Program of China (Grant No. 2012BAK02B01). The BIT system is technically supported by the IAPR (International Association of Pattern Recognition) Technical Committee on Biometrics (IAPR TC4) and ABC (Asian Biometrics Consortium) Committee on Testing and Standards (ACTS).
Fingerprints can be classified into eight categories. The fingerprint data we obtained consists of eight categories as shown in Table 1. A total of 678 fingerprint data were used for this study. Figure 2 shows sample fingerprint image data to be used in the study.
Figure 2. Sample fingerprint image data (2x5)
Table 1. Dataset and patterns of fingerprints
|
Classes |
Patterns |
Number of images |
|
Accidental Whorl |
30 |
|
|
Double Loop |
54 |
|
|
Central Pocket Loop Whorl |
47 |
|
|
Plain Whorl |
208 |
|
|
Plain Arch |
81 |
|
|
Tented Arch |
36 |
|
|
Ulnar Loop |
82 |
|
|
Radial Loop |
140 |
|
|
TOTAL |
|
678 |
2.2 Architecture of the pre-trained DCNN models
2.2.1 Alexnet pre-trained DCNN model
The Alexnet DCNN network is a 25-layer deep neural network first introduced by Krizhevsky et al. [26]. The Alexnet network has 8 layers of deep convolutional layers and is designed to classify 1000 types of images with more than one million image data in the imagenet database [26-28]. The Alexnet model, which was previously trained (pre-trained) and proven to be successful, was used in this study by redesigning the last three layers to perform eight fingerprint classifications in accordance with the purpose of this study, thanks to the transfer learning method. Alexnet DCNN model has been widely used in many scientific fields in recent years to solve many different problems [29-34].
2.2.2 Googlenet pre-trained DCNN model
GoogLeNet is a 144-layer DCNN model developed by researchers at Google. Since parallel modules are used in the GoogleNet network, a significant advantage has been achieved in memory and power usage. In this study, the googlenet pre-trained DCNN model was retrained for fingerprint classification by redesigning the last three layers thanks to the transfer learning approach, in accordance with the purpose of our study. Today, GoogleNet is widely used in different fields [32-34].
2.2.3 Squeezenet pre-trained DCNN model
SqueezeNet was developed in 2016 by researchers at the University of California, Stanford University, and the University of Berkeley, who worked with the DeepScale company. The SqueezeNet DCNN model aims to achieve higher success with a smaller architecture with fewer space-saving parameters [35]. Compared to Alexnet, Alexnet has a parameter of 240 MB, while Squeezenet has only 5 MB of parameters and has a close success and popularity with the success and popularity of AlexNet [36]. For this study, thanks to the transfer learning approach, its architecture was changed. Today, it finds application areas in many scientific studies [37-39].
2.2.4 Resnet18 pre-trained DCNN model
ResNet is an 18-layer DCNN model developed by He and colleagues in 2015 [40]. Its biggest advantage is its very low computational cost. Thanks to transfer learning, the last three layers of eight fingerprint classification have been rearranged. It maintains its popularity as it continues to be used in the solution of many problems in science today [41, 42].
2.2.5 Simple Designed Model (SDM)
In this application, a new DCNN model was designed from scratch to make fingerprint classification faster and compare pre-trained models with the designed model with fewer parameters. Table 2 and Table 3 give information about the layers and internal structure used in the SDM model. While designing the model, input and output tensor sizes for each layer were obtained by using formulas 2 and 3. With the SDM model, by octal classification, the tensor size for the input and output to the softmax layer is arranged as 1x1x8. Figure 3 shows the architecture of the designed model for fingerprint classification. In Figure 3, there are also padding, stride, filter sizes, and filter numbers in each layer. Formula (2) and formula (3) were used to design this model.
Table 2. Structure of the SDM (fist part)
|
Layer Number |
Layer Type |
Input size |
Output size |
|
1 |
Image Input |
224x224 |
224x224 |
|
2 |
Convolution1 |
224x224 |
45x45x32 |
|
3 |
Batch Norm1 |
45x45x32 |
45x45x32 |
|
4 |
ReLu1 |
45x45x32 |
45x45x32 |
|
5 |
Maxpooling1 |
45x45x32 |
22x22x32 |
|
6 |
Convolution2 |
22x22x32 |
11x11x32 |
|
7 |
Batch Norm2 |
11x11x32 |
11x11x32 |
|
8 |
ReLu2 |
11x11x32 |
11x11x32 |
|
9 |
Maxpooling2 |
11x11x32 |
1x1x32 |
|
10 |
Convolution3 |
1x1x32 |
1x1x64 |
|
11 |
Batch Norm3 |
1x1x64 |
1x1x64 |
|
12 |
ReLu3 |
1x1x64 |
1x1x64 |
|
13 |
Fully Connected |
1x1x64 |
1x1x5 |
|
14 |
Softmax |
1x1x8 |
1x1x8 |
|
15 |
Classification Output |
- |
- |
Table 3. Structure of the SDM (second part)
|
Layer Number |
Number of filters |
Filter size |
Stride |
Padding |
|
1 |
- |
- |
- |
- |
|
2 |
32 |
3x3 |
5 |
Same |
|
3 |
- |
- |
- |
- |
|
4 |
- |
- |
- |
- |
|
5 |
- |
5x5 |
2 |
1, 2, 1, 2 |
|
6 |
32 |
5x5 |
2 |
Same |
|
7 |
- |
- |
- |
- |
|
8 |
- |
- |
- |
- |
|
9 |
- |
10x10 |
2 |
0, 0, 0, 0 |
|
10 |
64 |
6x6 |
1 |
Same |
|
11 |
- |
- |
- |
- |
|
12 |
- |
- |
- |
- |
|
13 |
- |
- |
- |
- |
|
14 |
- |
- |
- |
- |
|
15 |
- |
- |
- |
- |
Figure 3. The architecture of the SDM for fingerprints classification
2.3 Training and testing of the DCNN models
For the training and testing process, the limitations of all models were tried to be adjusted equally according to their internal structures. However, as seen in Table 4, all values except "Epoch" and "Learning rate schedule" are set as half of the others for Alexnet. The reason for this difference is that the first designed model is decided on these coefficients. There is no other important reason for these differences. Moreover, this difference does not prevent the models from being compared with each other and does not bring any radical differences as a result of training or testing. During the entire training and testing process, depending on the "cross-entropy", that is, the loss function (4), the training and testing process is carried out trying to bring loss closer to zero. This process is the same for all other DCNN models in the world. The training process aims to reach the highest accuracy rate because the test process is a process that is affected by the training result. The aim here is not only to achieve the highest accuracy but also to get the training and test results fastest. Because achieving rapid results is important for a problem such as a fingerprint classification.
Table 4. Limitations for the training and validation process
|
|
Alexnet |
Googlenet |
Resnet-18 |
Squezeenet |
SDM |
|
Maximum Epoch |
30 |
30 |
30 |
30 |
30 |
|
Maximum Iteration |
180 |
360 |
360 |
360 |
360 |
|
Iteration per epoch |
6 |
12 |
12 |
12 |
12 |
|
Validation Frequency |
5 |
10 |
10 |
10 |
10 |
|
Initial Learning Rate |
0.001 |
0.003 |
0.003 |
0.003 |
0.003 |
|
Minibatch size |
84 |
45 |
45 |
45 |
45 |
The process of obtaining the output matrix as a result of filtering the input matrix is called convolution. In the convolution process, stride (s) indicates how many columns and how many rows to shift the filter matrix $n_{k} x n_{k}$ (kernel) right and down on the A input matrix (tensor). The row and column size of the input matrix "A" must be greater than "nk" or have to be its multiples. The size of the input matrix “A” are " nA x nA", and after the convolution process, the “A” size matrix turns out to be a “B”-size matrix because of the filtering. 'B' is calculated as follows [43].
$B_{i j}=(A * K)_{i j}=\sum_{f=0}^{n_{K}-1} \sum_{h=0}^{n_{K}-1} A_{i+f, j+h} K_{i+f, j+h}$ (1)
where (1), K indicates the filter, A indicates the input tensor and B indicates the output tensor.
The reduced image size after the convolution process can be enlarged again using the p padding coefficient. Pixels are added to the edges to increase the image size. Added pixels can be filled with zero values. The output matrix b, in which the filling coefficient p is also taken into account, is computed as follows [43].
$n_{B}=\left|\frac{n_{A}+2 p-n_{K}}{s}+1\right|$ (2)
2.3.2 Classification and softmax layer
For the classification process, the cross-entropy loss is calculated in the classification layer. In DCNN models, the classification layer is the last. The softmax function is used to perform multiple classifications and it is the output-unit-activation function that comes after the last fully connected layer. By multiple classifications, the softmax function is expressed as follows:
$y_{r}(x)=\frac{\exp \left(a_{r}(x)\right)}{\sum_{j=1}^{k} \exp \left(a_{j}(x)\right)}$ (3)
where, the softmax function shows the probability distribution of the multiple (octal) classifications.
where, $0 \leq y_{r} \leq 1$ and $\sum_{j=1}^{k} y_{j}=1$ and, $a_{r}$ is the conditional probability of the given r class sample [44].
Table 5. Structural information for all DCNN models
|
|
Alexnet |
Googlenet |
Squeezenet |
Resnet18 |
SDM |
|
Input Image Size |
227x227 |
224x224 |
227x227 |
224x224 |
224x224 |
|
Number of Convolution Layer |
5 |
57 |
26 |
20 |
3 |
|
Number of Pooling |
3 |
14 |
4 |
2 |
2 |
|
Number of Fully Connected |
3 |
1 |
- |
1 |
1 |
|
Number of Dropouts |
2 |
1 |
1 |
- |
- |
|
Number of Normalization |
2 |
2 |
- |
20 |
3 |
|
Number Of Activation Function (ReLu) |
7 |
57 |
26 |
17 |
3 |
|
Total Number of All Layers |
25 |
144 |
68 |
72 |
15 |
|
Rearranged Layers via Transfer Learning |
Classification, Softmax and Last Fully Connected |
Classification, Softmax and Last Fully Connected |
Classification, and Last Convolution |
Classification, Softmax and Last Fully Connected |
- |
2.4 Transfer learning
Transfer learning is a machine learning approach that allows a neural network model, previously designed and trained for a specific purpose, to be used for another purpose by transferring information. In this experimental and comparative study, the last three layers of each of the four pre-trained classic DCNN models were redesigned by a transfer learning approach. The fully connected layers of Alexnet, Googlenet, and Resnet18 pre-trained models are re-edited for classification in eight categories. Since Squeezenet pre-trained DCNN model does not have a fully connected layer, the number of filters in the last convolution layer has been changed to eight. The layers updated according to the transfer learning method and the internal structure of the pre-trained DCNN models are shown in Table 5.
The input image data of all DCNN models have three channels and the rectified linear unit (ReLU) is conducted after each convolution layer. In the pre-trained models with the transfer learning technique applied, the learning rate of the layers before the last three layers is left unchanged. But the learning rate of the next layers (the last three layers) has been slightly increased so that they can quickly adapt to the new situation and be updated quickly. The limitations for training and validation processes are shown in Table 6. For training in the classification layer, input values from the softmax function are assigned to one of the mutually exclusive K classes using the cross-entropy function. The loss function of the network needs to be minimized to complete the training process.
Table 6. Limitations for the training and validation process
|
Maximum epoch |
30 |
|
Maximum iteration |
300 |
|
Iteration per epoch |
30 |
|
Validation Frequency |
10 Iteration |
|
Initial learning rate |
0.001 |
|
Mini batch size |
75 |
|
Learning rate schedule |
Constant |
Loss $=-\sum_{i=1}^{N} \sum_{j=1}^{K} t_{i j} \ln y_{i j}$ (4)
where, N indicates the number of samples, K indicates the number of classes and tij shows the sample i in the j class, and yij shows the output for sample j class i [44].
The results obtained are shown in Table 7 for all models. In Table 7, it is noteworthy that the results of each model are quite different from each other. The most successful test results belong to Googlenet with an accuracy rate of about 83%. The most unsuccessful is the Squeezenet, which has a 30% accuracy rate.
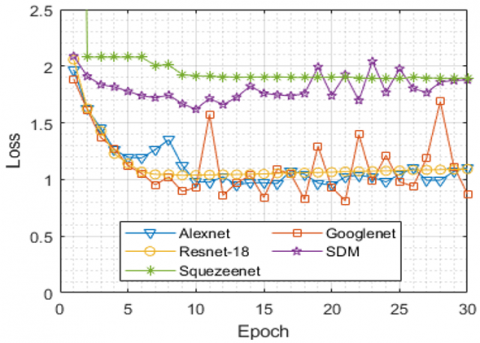
Figure 4. Validation accuracy graphs for all models with fingerprint dataset
Figure 5. Validation loss graphs for all models with fingerprint dataset
Table 7. Accuracy and loss results for the fingerprints classification with the DCNN models
|
|
Training |
Validation |
Time Elapsed (hh:mm:ss) |
|||
|
DCNN Models |
Accuracy (%) |
Loss |
Accuracy (%) |
Loss |
Num. Corrects |
|
|
Alexnet |
98.81 |
0.0358 |
74.81 |
1.1033 |
101 |
00:10:19 |
|
Googlenet |
100.00 |
0.0146 |
82.96 |
0.8721 |
112 |
00:14:02 |
|
Resnet18 |
100.00 |
0.0037 |
65.19 |
1.0918 |
89 |
00:35:26 |
|
Squeezenet |
31.11 |
1.8878 |
30.37 |
1.8966 |
41 |
00:05:10 |
|
SDM |
95.56 |
0.1461 |
50.37 |
1.9018 |
68 |
00:01:01 |
Table 8. Confusion matrixes for fingerprints classifications models
|
|
|
Predicted class |
||||||||
|
Accidental Whorl |
Central Pocket Loop |
Double Loop |
Plain Arch |
Plain Whorl |
Radial Loop |
Tented Arch |
Ulnar Loop |
|||
|
Alexnet |
True class |
Accidental Whorl |
|
|
1 |
|
1 |
2 |
|
2 |
|
Googlenet |
6 |
|
|
|
|
|
|
|
||
|
Resnet-18 |
3 |
|
1 |
|
1 |
|
|
1 |
||
|
Squeezenet |
|
|
|
|
6 |
|
|
|
||
|
SDM |
|
1 |
1 |
1 |
1 |
|
|
2 |
||
|
Alexnet |
Central Pocket Loop |
|
4 |
|
|
2 |
2 |
|
1 |
|
|
Googlenet |
2 |
3 |
|
|
4 |
|
|
|
||
|
Resnet-18 |
1 |
2 |
|
|
3 |
2 |
|
1 |
||
|
Squeezenet |
|
|
|
|
9 |
|
|
|
||
|
SDM |
|
|
|
3 |
4 |
1 |
|
1 |
||
|
Alexnet |
Double Loop |
|
|
7 |
|
4 |
|
|
|
|
|
Googlenet |
|
|
10 |
|
|
1 |
|
|
||
|
Resnet-18 |
|
|
6 |
|
1 |
4 |
|
|
||
|
Squeezenet |
|
|
|
|
10 |
1 |
|
|
||
|
SDM |
|
|
5 |
|
|
3 |
|
3 |
||
|
Alexnet |
Plain Arch |
|
|
|
12 |
|
|
2 |
2 |
|
|
Googlenet |
|
1 |
|
13 |
|
1 |
|
1 |
||
|
Resnet-18 |
|
1 |
|
9 |
|
1 |
3 |
2 |
||
|
Squeezenet |
|
|
|
|
16 |
|
|
|
||
|
SDM |
|
1 |
|
10 |
3 |
|
|
2 |
||
|
Alexnet |
Plain Whorl |
|
|
3 |
|
38 |
|
|
1 |
|
|
Googlenet |
|
|
3 |
|
38 |
1 |
|
|
||
|
Resnet-18 |
|
|
2 |
|
36 |
3 |
1 |
|
||
|
Squeezenet |
|
|
|
|
41 |
1 |
|
|
||
|
SDM |
|
2 |
5 |
3 |
25 |
2 |
|
5 |
||
|
Alexnet |
Radial Loop |
|
1 |
|
|
|
23 |
|
4 |
|
|
Googlenet |
|
|
3 |
|
|
23 |
|
2 |
||
|
Resnet-18 |
|
2 |
2 |
1 |
1 |
19 |
|
3 |
||
|
Squeezenet |
|
|
|
|
28 |
|
|
|
||
|
SDM |
|
1 |
|
1 |
5 |
18 |
|
3 |
||
|
Alexnet |
Tented Arch |
|
|
|
2 |
|
1 |
4 |
|
|
|
Googlenet |
|
|
|
|
|
|
7 |
|
||
|
Resnet-18 |
|
|
|
1 |
|
3 |
3 |
|
||
|
Squeezenet |
|
|
|
|
6 |
1 |
|
|
||
|
SDM |
|
|
|
3 |
|
3 |
|
1 |
||
|
Alexnet |
Ulnar Loop |
|
|
|
2 |
|
1 |
|
13 |
|
|
Googlenet |
1 |
|
1 |
1 |
1 |
|
|
12 |
||
|
Resnet-18 |
|
|
|
1 |
1 |
3 |
|
11 |
||
|
Squeezenet |
|
|
|
|
16 |
|
|
|
||
|
SDM |
|
|
1 |
1 |
3 |
1 |
|
10 |
||
It can be easily understood that how many correct predictions or how many false predictions are made from which fingerprint category, by looking at the confusion matrices covering each model in Table 8. For example, Googlenet correctly predicted six of the "Accidental whorl" category of a fingerprint. Another example, the method that estimates the number of the "Plain Whorl" fingerprint category as the most accurate, is very surprisingly Squeezenet with 41.
It can easily be seen graphically from the accuracy and loss curves that the estimation results of the models are very different from each other, in Figures 4 and Figure 5 respectively. The results given in Table 7 are visually concreted in Figure 4 and Figure 5.
Fingerprint pattern recognition is the first and most important of the three levels of knowledge used for forensic examiners in forensic cases. In cases where the fingerprint pattern image is not clear, it can be very difficult to reach precise results by fingerprint pattern recognition and matching with other patterns. For this purpose, the need for automatic pattern diagnosis and deep learning methods formed the motivation of this study. In this study, the usability of the DCNN method in order to classify and recognize eight fingerprint patterns in the literature was experimentally and comparatively investigated and examined. Four classical pre-trained DCNN models were applied by reorganizing the last three layers, benefiting from the transfer learning approach. In addition, considering the desire to get faster results, a DCNN model that occupies less space (with fewer parameters), consists of fewer layers, and has a simpler internal structure was designed from scratch and this new DCNN model was named "simply designed model" (SDM). A five-fold cross-validation method was used for the reliability of the test results.
According to the results, an accuracy rate of approximately 83% was achieved by using the Googlenet pre-trained DCNN model. However, the training time of the Googlenet was about 14 minutes. On the other hand, 75% accuracy could be achieved in about 10 minutes with Alexnet. Although SDM was very simple and fast of all, it was not successful enough in terms of accuracy. It has been proved that Squeezenet pre-trained DCNN model and similar DCNN models are not very suitable for such classifications. There may be two reasons why the results are not high enough (> 95% etc.). First of all, it is very difficult to obtain very high classification accuracy rates with deep learning methods in such studies with a large classification category (multiple classifications) due to the nature of the work. Second, some fingerprint images may not be clear in the data set used. In order not to affect the comments, the data obtained from the database were used as-is instead of removing the unclear images. Also, unequal numbers of data categories can negatively affect classification accuracy. As a result, DCNN methods for fingerprint pattern recognition turned out to be quite suitable for automatic detection systems and more advanced systems. More advanced automatic detection systems that can assist in forensic investigations can be designed and implemented, especially with proven classical DCNN models such as Alexnet and Googlenet. Another important result obtained from this study is that DCNN models can be generalized and used in fingerprint classification and recognition problems related to forensic examination or diagnosis of diseases, and in forensic and health systems.
This project was funded by the Scientific Research Projects Coordination Unit of Kayseri University. Project ID: 1025.
[1] Kassin, S.M., Dror, I.E., Kukucka, J. (2013). The forensic confirmation bias: Problems, perspectives, and proposed solutions. Journal of Applied Research in Memory and Cognition, 2(1): 42-52. https://doi.org/10.1016/j.jarmac.2013.01.001
[2] Dror, I.E., Cole, S.A. (2010). The vision in “blind” justice: Expert perception, judgment, and visual cognition in forensic pattern recognition. Psychonomic Bulletin & Review, 17(2): 161-167. https://doi.org/10.3758/pbr.17.2.161
[3] Tangen, J.M., Thompson, M.B., McCarthy, D.J. (2011). Identifying fingerprint expertise. Psychological Science, 22(8): 995-997. https://doi.org/10.1177/0956797611414729
[4] Haber, L., Haber, R.N. (2007). Scientific validation of fingerprint evidence under Daubert. Law, Probability and Risk, 7(2): 87-109. https://doi.org/10.1093/lpr/mgm020
[5] Stoel, R.D., Kerkhoff, W., Mattijssen, E.J.A.T., Berger, C.E.H. (2016). Building the research culture in the forensic sciences: Announcement of a double blind testing program. Science & Justice, 56(3): 155-156. https://doi.org/10.1016/j.scijus.2016.04.003
[6] Yang, X., Hu, Q., Li, S. (2020). Recognition and classification of damaged fingerprint based on deep learning fuzzy theory. Journal of Intelligent Fuzzy Systems, 38(4): 3529-3537. https://doi.org/10.3233/JIFS-179575
[7] Dror, I.E., Hampikian, G. (2011). Subjectivity and bias in forensic DNA mixture interpretation. Science & Justice, 51(4): 204-208. https://doi.org/10.1016/j.scijus.2011.08.004
[8] Saks, M.J., Kidd, R.F. (1980). Human information processing and adjudication: Trial by heuristics. Law & Society Review, 15(1): 123. https://doi.org/10.2307/3053225
[9] Mattijssen, E.J.A.T., Witteman, C.L.M., Berger, C.E.H., Stoel, R.D. (2020). Assessing the frequency of general fingerprint patterns by fingerprint examiners and novices. Forensic Science International, 313: 110347. https://doi.org/10.1016/j.forsciint.2020.110347
[10] Francis Galton, F.R.S. (1893). Finger prints. American Anthropologist, 6(3): 341-342. https://doi.org/10.1525/aa.1893.6.3.02a00120
[11] None. (1905). Identification by finger prints. The Lancet, 165(4263): 1280-1281. https://doi.org/10.1016/S0140-6736(01)38462-3
[12] Langenburg, G. (2013). The consideration of fingerprint probabilities in the courtroom. Australian Journal of Forensic Sciences, 45(3): 296-304. https://doi.org/10.1080/00450618.2013.784360
[13] Aitken, C., Taroni, F. (2004). Statistics and the Evaluation of Evidence for Forensic Scientists (2nd ed.). Wiley.
[14] Biedermann, A., Garbolino, P., Taroni, F. (2013). The subjectivist interpretation of probability and the problem of individualisation in forensic science. Science & Justice, 53(2): 192-200. https://doi.org/10.1016/j.scijus.2013.01.003
[15] Buckleton, J.S., Triggs, C.M., Champod, C. (2006). An extended likelihood ratio framework for interpreting evidence. Science & Justice, 46(2): 69-78. https://doi.org/10.1016/s1355-0306(06)71577-5
[16] Biedermann, A. (2015). The role of the subjectivist position in the probabilization of forensic science. Journal of Forensic Science and Medicine, 1(2): 140. https://doi.org/10.4103/2349-5014.169569
[17] Martire, K.A., Kemp, R.I., Watkins, I., Sayle, M.A., Newell, B.R. (2013). The expression and interpretation of uncertain forensic science evidence: Verbal equivalence, evidence strength, and the weak evidence effect. Law and Human Behavior, 37(3): 197-207. https://doi.org/10.1037/lhb0000027
[18] Stosljevic, M., Adamovic, M. (2013). Dermatoglyphic characteristics of digito-palmar complex in autistic boys in Serbia. Vojnosanitetski Pregled, 70(4): 386-390. https://doi.org/10.2298/vsp1304386s
[19] Hartin, P.J., Barry, R.J. (1979). A comparative dermatoglyphic study of autistic, retarded, and normal children. Journal of Autism and Developmental Disorders, 9(3): 233-246. https://doi.org/10.1007/bf01531738
[20] Mustafa, R., Afroze, A., Sobnom, S., Hossain, A.A.M., Ahmed, M.S., Haque, A.Q.M.A. (2019). Comparative dermatoglyphic study between schizophrenic patients and healthy controls. KYAMC Journal, 10(2): 66-72. https://doi.org/10.3329/kyamcj.v10i2.42781
[21] Bone, D., Goodwin, M.S., Black, M.P., Lee, C.C., Audhkhasi, K., Narayanan, S. (2014). Applying Machine learning to facilitate autism diagnostics: Pitfalls and promises. Journal of Autism and Developmental Disorders, 45(5): 1121-1136. https://doi.org/10.1007/s10803-014-2268-6
[22] Jiang, W., Ma, J. (2021). Fingerprint feature data matching algorithm based on distributed computing. Journal of Ambient Intelligence and Humanized Computing, pp. 1-10. https://doi.org/10.1007/s12652-020-02811-4
[23] Goicoechea-Telleria, I., Fernandez-Saavedra, B., Sanchez-Reillo, R. (2016). An evaluation of presentation attack detection of fingerprint biometric systems applying ISO/IEC 30107-3. In International Biometric Performance Testing Conference.
[24] Liu, F., Liu, G., Wang, X. (2019). High-accurate and robust fingerprint anti-spoofing system using optical coherence tomography. Expert Systems with Applications, 130: 31-44. https://doi.org/10.1016/j.eswa.2019.03.053
[25] Sousedik, C., Busch, C. (2014). Presentation attack detection methods for fingerprint recognition systems: A survey. IET Biometrics, 3(4): 219-233.
[26] Krizhevsky, A., Sutskever, I., Hinton, G.E. (2017). ImageNet classification with deep convolutional neural networks. Communications of the ACM, 60(6): 84-90. https://doi.org/10.1145/3065386
[27] ImageNet. (2012). Imagenet. http://www.image-net.org, accessed on January 10, 2020.
[28] Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A.C., Li, F.F. (2015). ImageNet large scale visual recognition challenge. International Journal of Computer Vision, 115(3): 211-252. https://doi.org/10.1007/s11263-015-0816-y
[29] Daas, S., Yahi, A., Bakir, T., Sedhane, M., Boughazi, M., Bourennane, E. (2020). Multimodal biometric recognition systems using deep learning based on the finger vein and finger knuckle print fusion. IET Image Process., 14: 3859-3868. https://doi.org/10.1049/iet-ipr.2020.0491
[30] Rim, B., Kim, J., Hong, M. (2020). Fingerprint classification using deep learning approach. Multimedia Tools and Applications, pp. 1-17. https://doi.org/10.1007/s11042-020-09314-6
[31] Toosi, A., Cumani, S., Bottino, A. (2019) Assessing transfer learning on convolutional neural networks for patch-based fingerprint liveness detection. Studies in Computational Intelligence, pp. 263-279. https://doi.org/10.1007/978-3-030-16469-0_14
[32] Raja, K.B., Raghavendra, R., Venkatesh, S., Gomez-Barrero, M., Rathgeb, C., Busch, C. (2019). A study of hand-crafted and naturally learned features for fingerprint presentation attack detection. In Handbook of Biometric Anti-Spoofing, pp. 33-48. https://doi.org/10.1007/978-3-319-92627-8_2
[33] Zhang, X., Pan, W., Bontozoglou, C., Chirikhina, E., Chen, D., Xiao, P. (2020). Skin capacitive imaging analysis using deep learning GoogLeNet. In Science and Information Conference, pp. 395-404. https://doi.org/10.1007/978-3-030-52246-9_29
[34] Li, Y., Wang, H., Dang, L. M., Sadeghi-Niaraki, A., Moon, H. (2020). Crop pest recognition in natural scenes using convolutional neural networks. Computers and Electronics in Agriculture, 169: 105174. https://doi.org/10.1016/j.compag.2019.105174
[35] Abhinav, G. (2018). Deep Learning Reading Group: SqueezeNet. KDnuggets.
[36] Iandola, F.N., Han, S., Moskewicz, M.W., Ashraf, K., Dally, W.J., Keutzer, K. (2016). SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size. arXiv preprint arXiv:1602.07360
[37] Zeng, J., Chen, Y., Qin, C., Wang, F., Gan, J., Zhai, Y., Zhu, B. (2019). A novel method for finger vein recognition. In Chinese Conference on Biometric Recognition, pp. 46-54. https://doi.org/10.1007/978-3-030-31456-9_6
[38] Jung, H., Koo, K., Yang, H. (2019). Measurement-based power optimization technique for OpenCV on heterogeneous multicore processor. Symmetry, 11(12): 1488. https://doi.org/10.3390/sym11121488
[39] Zhang, W., He, X., Li, W., Zhang, Z., Luo, Y., Su, L., Wang, P. (2020). An integrated ship segmentation method based on discriminator and extractor. Image and Vision Computing, 93: 103824. https://doi.org/10.1016/j.imavis.2019.11.002
[40] He, K., Zhang, X., Ren, S., Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770-778. https://doi.org/10.1109/CVPR.2016.90
[41] Tuncer, T., Ertam, F., Dogan, S., Aydemir, E., Pławiak, P.ł. (2020). Ensemble residual network-based gender and activity recognition method with signals. The Journal of Supercomputing, 76(3): 2119-2138. https://doi.org/10.1007/s11227-020-03205-1
[42] Yu, X., Wang, S.H. (2019). Abnormality diagnosis in mammograms by transfer learning based on ResNet18. Fundamenta Informaticae, 168(2-4): 219-230. https://doi.org/10.3233/fi-2019-1829
[43] Michelucci, U. (2019). Advanced Applied Deep Learning: Convolutional Neural Networks and Object Detection. Apress, Berkeley, CA. https://doi.org/10.1007/978-1-4842-4976-5
[44] Bishop, C.M. (2016). Pattern Recognition and Machine Learning (Information Science and Statistics) (Softcover reprint of the original 1st ed. 2006 ed.).