Jie Zhao | Qianjin Feng*
© 2021 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Retinal vessel segmentation plays a significant role in the diagnosis and treatment of ophthalmological diseases. Recent studies have proved that deep learning can effectively segment the retinal vessel structure. However, the existing methods have difficulty in segmenting thin vessels, especially when the original image contains lesions. Based on generative adversarial network (GAN), this paper proposes a deep network with residual module and attention module (Deep Att-ResGAN). The network consists of four identical subnetworks. The output of each subnetwork is imported to the next subnetwork as contextual features that guide the segmentation. Firstly, the problems of the original image, namely, low contrast, uneven illumination, and data insufficiency, were solved through image enhancement and preprocessing. Next, an improved U-Net was adopted to serve as the generator, which stacks the residual and attention modules. These modules optimize the weight of the generator, and enhance the generalizability of the network. Further, the segmentation was refined iteratively by the discriminator, which contributes to the performance of vessel segmentation. Finally, comparative experiments were carried out on two public datasets: Digital Retinal Images for Vessel Extraction (DRIVE) and Structured Analysis of the Retina (STARE). The experimental results show that Deep Att-ResGAN outperformed the equivalent models like U-Net and GAN in most metrics. Our network achieved accuracy of 0.9565 and F1 of 0.829 on DRIVE, and accuracy of 0.9690 and F1 of 0.841 on STARE.
retinal vessel segmentation, generative adversarial networks (GANs), attention module
Retinal vessel segmentation from color fundus images is important to many ophthalmological applications, including diagnosis, treatment, and surgery planning [1, 2]. The morphological and topographical changes of the retinal vessels are closely related to many retinal diseases and systemic diseases, such as hypertension, diabetic retinopathy, glaucoma, and arteriosclerosis [3]. Therefore, the research of retinal vessel segmentation has a significance in medical applications. Because the manual segmentation of retinal vessels is time consuming and demanding for doctors, experts around the world have developed many retinal vessel segmentation algorithms, which fall into the following categories: multiscale approaches, mathematical morphology approaches, matched filtering approaches, model-based approaches, vessel tracking approaches, and pattern recognition approaches [4-6].
The past three decades have witnessed the emergence of multiple excellent fundus segmentation algorithms. For example, Martinez-Perez et al. [7] segmented blood vessels automatically from retinal images through multiscale feature extraction. Zana and Klein [8] combined opening operation, reconstruction, and top-hat transform with curvature evaluation to segment vessel-like patterns. Hoover et al. [9] designed a matched filter response with a dark value representing a strong response, and used threshold probing to segment vessels from retinal images. Based on super-pixels, Zhao et al. [10] developed a chain tracking method to trace retinal vessel skeletons. Lam et al. [11] presented a regularization multi-concavity model, and offered different concavity measures to detect retinal vessels. Dai et al. [12] classified enhanced retinal images as vessels and non-vessels, using Gaussian mixture model (GMM) and gray voting.
In the past few years, deep learning has been increasingly used in image segmentation due to its superiority over traditional methods [5, 13-15]. For retinal vessel segmentation, deep learning can autonomously extract the hierarchical features from the color fundus images, and the parameters of the convolutional layer can be learned through training [14]. Hu et al. [16] integrated the conditional random field (CRF) to convolutional neural networks (CNNs), forming an integrated deep network for retinal vessel segmentation. Yan et al. [17] employed joint segment-level and pixelwise losses in U-Net to segment retinal vessels. Maninis et al. [18] established a unified CNN framework to segment both retinal vessels and optic discs. Uysal and Güraksin [19] designed a CNN to extract retinal vessels by detecting regional vessel slices instead of full-size images. Samuel and Veeramalai [20] improved VGG-16 by using two-vessel extraction layers with added supervision. Sathananthavathi and Indumathi [21] put forward an encoder-enhanced atrous U-Net architecture for retinal vessel segmentation. Lin et al. [22] constructed a multi-path scale network with a high-resolution main path and two low-resolution branches.
The generative adversarial network (GAN) has also attracted much attention, thanks to its ability to create an output as realistic as the gold standard [23]. The conventional GAN consists of a generator and a discriminator. The former generates a new sample from the potential distribution of real samples, while the latter, a binary classifier, tries to judge whether the input sample is real or generated [23]. With the aid of GAN, Son et al. [24, 25] obtained an accurate map of the fundus vessels, and achieved good segmentation results on two public datasets: Digital Retinal Images for Vessel Extraction (DRIVE) and Structured Analysis of the Retina (STARE). Guo et al. [26] combined GAN with dense U-Net for retinal vessel segmentation. Yang et al. [27] constructed a deep convolution GAN with short connection and dense block to separate vessels from fundus images.
Recently, the attention module is proposed and applied to enable the traditional deep learning network to extract more characteristic tasks and speed up target learning [28]. Attention U-Net has been employed to accurately segment retinal vessels, skin lesions, lung, and pancreas [29-33]. Li et al. [31] designed a connection-sensitive attention U-Net for retinal vessel segmentation. Lv et al. [32] presented an attention-guided U-Net with atrous convolution, which focuses on vessel regions. Chen et al. [33] created the Attentive BConvLSTM U-Net with Redesigned Inception (IBA-U-Net), which integrates the bi-directional convolutional long short-term memory (BConvLSTM) block with the attention block, aiming to segment lungs, skin lesions, and retinal vessels from images.
Despite the progress of the above technologies, retinal vessel segmentation still faces several challenges. Firstly, it is difficult to separate the easily fragmented and often missing small vessels from the background, owing to the diverse morphologies of retinal vessels and the nonuniform illumination in fundus images [5, 6, 13]. Secondly, the segmentation effect is seriously affected by the lesion regions in retinal images. Retinal vessel segmentation becomes very challenging, if the original image contains lesions like diabetic retinopathy, and arteriosclerotic retinopathy. Figure 1 shows three fundus lesion images from DRIVE and STARE datasets. The retinal vessels are not easy to segment, for the vessel structure is obscured by lesions [6, 13]. This calls for a robust and precise retinal vessel segmentation algorithm.
(a) Background diabetic retinopathy; (b) Retinal artery occlusion; (c) Arteriosclerotic retinopathy
Figure 1. Fundus lesion images from DRIVE and STARE datasets
This paper proposes a GAN-based deep network with residual module and attention module (Deep Att-DesGAN). The proposed network, consisting of four identical subnetworks, is deeper than the common GAN. In the network, an improved U-Net serves as the generator, responsible for extracting image features and generating an input image for the discriminator. The generator achieves a good segmentation effect, using the residual module and attention module. Meanwhile, the discriminator iteratively refines the segmentation by gaming. By constantly gaming, the generator and discriminator are optimized constantly. As a result, the generated images become so similar to gold standard images in distribution that they cannot be easily distinguished by the discriminator [24, 25]. The improved U-Net stacks the residual and attention modules, thereby enhancing the generalization ability of the network [29-34]. Specifically, the residual module adjusts the weight of the generator, while the attention module improves the prediction accuracy and reduce the time cost. The flow of our network is illustrated in Figure 2.
Figure 2. Flow of our network
The remainder of this paper is organized as follows: Section 2 proposes the Deep Att-ResGAN, and details the network structure; Section 3 describes the data from DRIVE and STARE datasets, and validates the proposed network with the retinal images; Section 4 summarizes the main findings of the research.
This section details the framework of the Deep Att-ResGAN for retinal vessel segmentation. The network consists of four identical subnetworks [16, 35, 36]. The output of each subnetwork is inputted to the next subnetwork. Each subnetwork contains a generator and a discriminator. Responsible for producing the confused image, the generator relies on the residual module to maintain subnetwork performance, and on the attention module to focus on salient features. The discriminator is responsible for estimating the probability for the segmentation result to be real.
2.1 Image augmentation and preprocessing
The original datasets were expanded through image augmentation, aiming to provide enough training samples. The 20 images in the training set were expanded to 4,800 by flipping and rotation.
Data preprocessing is fundamental to the effect of deep learning. This paper enhances the images through several steps of preprocessing, including contrast limited adaptive histogram equalization (CLAHE), Gamma correction, and normalization [37].
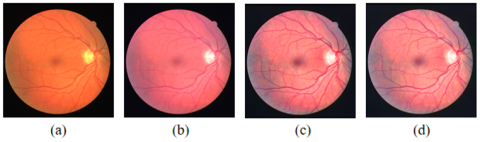
Firstly, the original image was normalized to boost the generalizability of the network [37]. Then, CLAHE was applied to the normalized image to improve the contrast between each vessel and the background, and to highlight the vessel region [9, 38]. Finally, the uneven illumination of the image was suppressed by Gamma correction [37]. Figure 3 illustrates the three steps of preprocessing: global normalization, CLAHE, and Gamma correction.
(a) Original image; (b) Normalized image; (c) Post-CLAHE image; (d) Post-Gamma correction image
Figure 3. Steps of image preprocessing
2.2 Deep Att-ResGAN
The proposed Deep Att-ResGAN consists of four identical Att-ResGANs [31, 32]. As shown in Figure 4, each Att-ResGAN is composed of a generator and a discriminator.
The generator is essentially an improved U-Net, which ensures that the output is as realistic as gold standard. Drawing on the idea of the U-Net, the generator adopts an attention module to further improve the detection accuracy, and employs a residual module to retain some features from the previous network layer [29-34]. Each residual module is followed by a max pooling layer of the size 2×2. During up-sampling, the attention module guides the subnetwork to focus on learning and extracting useful features. In this way, the image features will remain distinctive, despite the deepening of the network.
The discriminator is responsible for distinguishing between real and generated samples. If the input is deemed as real, it will be labeled as true; otherwise, it will be labeled as false [24, 25].
The generator and discriminator are trained alternately. Through the continuous optimization of network parameters, the generator can generate more and more realistic new samples, while the discriminator can differentiate between real and generated samples with a growing accuracy. The alternative training will end, when the discriminator can no longer distinguish between real samples and generated samples.
Note: BN and ReLU are short for batch normalization and rectified linear unit, respectively.
Figure 4. Each Att-ResGAN network
2.2.1 Residual module
As shown in Figure 5, the residual module was adopted to avoid vanishing gradients and optimize the network. Each residual block consists of two 3×3 convolutional layers and one 1×1 convolutional layer. The results of these layers are superimposed through residual mapping as the output of the residual block. The two 3×3 convolutional layers are serial connected to produce a deep feature map. The convolutional layers are followed by a BN layer and a ReLU layer. The BN layer reduces parameters and speeds up the training, while ReLU, a nonlinear activation function, lowers the complexity of network computing and maintains the sparsity of training data [39-41].
Figure 5. Two-layer residual block
2.2.2 Attention module
To improve the segmentation effect, an attention module was deployed to focus on the target structure, and readjust the output features of the encoder by computing the attention weight. The attention weight is large in the target area, and small in the background. As shown in Figure 6, the attention module consists of three 1×1 convolutional layers, one 3×3 convolutional layer, one BN layer, two ReLU layers, an up-sampling layer, and a sigmoid activation layer. The attention module learns an attention weight map from the high-level layer. The feature maps of the previous decoder are up-sampled to the resolution of the parallel residual module for attention operation. Finally, the attention weights are multiplied with the current convolutional features, and concatenated into encoder features. The attention module improves the prediction effect and computing efficiency of the proposed network [30-33].
Figure 6. Attention module
2.2.3 Discriminator
The discriminator aims to differentiate between real and generates samples. As shown in Figure 7, our discriminator consists of five convolutional layers and a dense layer. Each convolutional layer contains two strided convolutions, followed by a BN layer and a LeakyReLU layer [42, 43]. Each convolutional layer uses a 3×3 kernel. The parameters of the convolutional layer can be reduced by selecting a small kernel and a deep network structure. The strided convolution and LeakyReLU were selected to replace the traditional max pooling and ReLU, which may cause sparse gradients. The parameter in LeakyReLU was set to 0.2.
Figure 7. Discriminator
This section carries out experiments on DRIVE and STARE datasets, which have 40 and 20 subjects, respectively. The segmentation effect of our network was compared with that of different segmentation algorithms. Our network was implemented under TensorFlow and Keras on a personal computer (PC) with Intel Core™ i9, NVIDIA GeForce GTX 1080Ti graphics processing unit (GPU), and 64G double data rate random-access memory (DDR-RAM) [44, 45].
3.1 Datasets
Our experiments use two public datasets: DRIVE (http://www.isi.uu.nl/Research/Datasets/DRIVE/) and STARE (http://cecas.clemson.edu/~ahoover/stare/) [9, 38]. DRIVE dataset contains 40 fundus images of the resolution 584×565. As the outcomes of Diabetic Retinopathy Screening Program in the Netherlands, these images were captured with a Canon CR5 nonmydriatic 3- charge-coupled device (CCD) camera (field of view: 45°). Twenty of these fundus images were allocated to the training set, and the remaining 20 to the test set. Each image in the dataset has a corresponding hand-labeled image and a mask image [38].
STARE dataset contains 20 fundus images of the resolution 605×700. These images were captured by University of California with a TopCon TRV-50 fundus camera (field of view: 35°). Each fundus image has a corresponding hand-labeled image, which can be used to evaluate the result of retinal vessel segmentation [9]. There is no officially recommended split ratio between training and test sets. Hence, this paper randomly chooses 10 images for training, and uses the other 10 for testing.
3.2 Evaluation metrics
To objectively evaluate the segmentation effect, several general metrics were selected to measure the performance of retinal vessel segmentation: accuracy (Acc), sensitivity (Se), specificity (Sp), F1-score (F1), and the area under the receiver operating characteristic (ROC) curve (AUC) [46]:
$A C C=\frac{T P+T N}{T P+F N+T N+F P}$ (1)
$S e=\frac{T P}{T P+F N}$ (2)
$S p=\frac{T N}{T N+F P}$ (3)
$F 1=\frac{2 \times T P}{2 \times T P+F P+F N}$ (4)
where, TP is true positive (the number of pixels correctly segmented as vessels); TN is true negative (the number of pixels correctly segmented as non-vessels); FP is false positive (the number of pixels incorrectly segmented as vessels); FN is false negative (the number of pixels incorrectly detected as non-vessels) [46, 47]. Table 1 records the discriminations of positive and negative segmentation results.
Table 1. Discriminations of positive and negative segmentation results
|
Our network Gold standard |
Vessel |
Non-vessel |
|
Vessel |
TP |
FN |
|
Non-vessel |
FP |
TN |
In addition, the AUC is a common measure for the effect of segmentation [46, 47].
3.3 Experimental results
Multiple experiments were conducted to test and evaluate the performance of our network against other advanced approaches.
3.3.1 Segmentation results
Figures 8 and 9 report the segmentation results on DRIVE and STARE datasets, respectively. The images in the two figures were randomly selected from the test results on the two datasets, providing an intuitive display of the effect of our network. From left to right in each image, subgraphs (a) to (d) offer the original images, ground truth, our results, and the comparison between our results and ground truth, respectively; green, red, and blue represent true segmentation results, under segmentation, and over segmentation, respectively.
In Figure 8, the first and third rows display the normal retinal images from DRIVE dataset, which have no sign of diabetic retinopathy. As shown in subgraphs 8 (c) and (d), the retinal vessels segmented by our network are similar to the ground truth, including the main and distal vessels. The second and fourth rows display images with background diabetic retinopathy, i.e., noisy images affected by lesions. Despite the interference of the lesions, our network achieved a good segmentation effect: the problem of vessel fragmentation was solved in the presence of lesion-induced noises.
(a) Original images, (b) Ground truth, (c) Vessel segmentation results, (d) Our results compared vs. ground truth
Figure 8. Vessel segmentation results on DRIVE
(a) Original images, (b) Ground truth, (c) Vessel segmentation results, (d) Our results compared vs. ground truth
Figure 9. Vessel segmentation results on STARE
As shown in Figure 9, the vessel segmentation results of our network are close to the ground truth in subgraph 9(b). In subgraph 9(d), which compares our results with the ground truth, there are very few red and blue areas (under segmentation and over segmentation). Apparently, our network achieved an excellent effect on vessel segmentation. In the second and forth rows, the original images contain many micro-vessels. It can be observed that our network segmented the micro-vessels effectively and coherently.
3.3.2 Comparison with relevant methods
(a) Original images, (b) Ground truth (c) U-Net [15], (d) GAN [24], (e) U-Net + joint losses [17], (f) Our network
Figure 10. Vessel segmentation results of different methods on DRIVE dataset
(a) Original images, (b) Ground truth (c) U-Net [15], (d) GAN [24], (e) U-Net + joint losses [17], (f) Our network
Figure 11. Vessel segmentation results of different methods applied on STARE dataset
(a) Original images, (b) Enlarged patches, (c) Ground truth, (d) U-Net [15], (e) GAN [24], (f) U-Net + joint losses [17], (g) Our network
Figure 12. Enlarged views of the red-boxed patches obtained by different models on DRIVE and STARE datasets
Our network was compared with several advanced methods, such as U-Net, GAN, and U-Net + joint losses [15, 17, 24]. Figures 10 and 11 compare the vessel segmentation results of the different methods on DRIVE and STARE datasets, respectively. It can be inferred that our network could accurately delineate micro-vessels, and keep the vessel structure integrated, despite the low contrast, varied morphologies, and pathological changes of the test images. In the two figures, red boxes indicate that our network outperforms the other methods. For clarify, the area enclosed by each red box was enlarged in Figure 12. From left to right, subgraphs (a)-(g) present the original images, enlarged patches, ground truth, patches obtained by U-Net segmentation [15], patches obtained by GAN segmentation [24], patches obtained by U-Net + joint losses [17], and segmentation results of our network, respectively. It can be observed that the retinal vessels segmented by our network were richer in details, and closer to the ground truth than those obtained by the other methods. Our network, Deep Att-ResGAN, ensures the segmentation precision of micro-vessels, performs well on boundaries, and obtains integrated vessel structures.
Tables 2 and 3 compare the performance metrics of our network with those of many other methods on DRIVE and STARE datasets, respectively. As shown in Table 2, our network achieved the highest accuracy (0.9565) and F1 (0.829) on DRIVE dataset. As shown in Table 3, our network reached the highest accuracy (0.9690) on STARE dataset. Our network also did well in terms of AUC. To sum up, the Deep Att-ResGAN achieves excellent performance on most metrics.
Figures 13 and 14 further compare our network with U-Net, GAN, and U-Net + joint losses on fundus images from DRIVE dataset and STARE dataset, respectively. Our network clearly realized higher accuracy and sensitivity than the other vessel segmentation methods, and the specificity of our network was also relative stable.
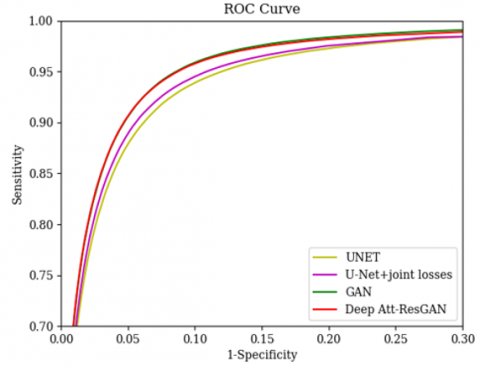
We also evaluate the models by using the ROC curves on the DRIVE and STARE datasets, which is shown in Figure 15 and Figure 16 [48]. Figure 15 shows that Deep Att-ResGAN ranks second in AUC on the DRIVE data set, and Figure 16 indicates that Deep Att-ResGAN improves the AUC by at least 0.2% on the STARE dataset. It can be seen from the ROC curves that our proposed method has a smaller blood vessel segmentation error.
Table 2. Performance comparison of multiple vessel segmentation methods on DRIVE dataset
|
Methods |
Year |
Acc |
Se |
Sp |
F1 |
AUC |
|
U-Net [15] |
2015 |
0.9531 |
0.7537 |
0.9820 |
- |
0.9755 |
|
GAN [24] |
2017 |
0.9560 |
0.8300 |
0.9744 |
0.829 |
0.9803 |
|
U-Net + joint losses [17] |
2018 |
0.9544 |
0.7668 |
0.9818 |
- |
0.9767 |
|
RetinaGAN [25] |
2019 |
0.9552 |
0.8469 |
0.9713 |
0.8275 |
0.9810 |
|
Guo [26] |
2020 |
0.9542 |
0.8283 |
0.9726 |
0.8215 |
0.9772 |
|
SUD-GAN [27] |
2020 |
0.9560 |
0.8340 |
0.9820 |
- |
0.9786 |
|
AAU-Net [32] |
2020 |
0.9558 |
0.7941 |
0.9798 |
- |
0.9847 |
|
Uysal [19] |
2021 |
0.9527 |
0.7778 |
0.9784 |
- |
- |
|
MPS-Net [22] |
2021 |
0.9563 |
0.8361 |
0.9740 |
0.8287 |
0.9805 |
|
IBA-U-Net [33] |
2021 |
0.9550 |
0.7858 |
0.9832 |
0.8214 |
0.9878 |
|
Our network |
2021 |
0.9565 |
0.8314 |
0.9757 |
0.829 |
0.9795 |
Note: SUD-GAN and AAU-Net are short for deep convolution adversarial network combined with short connection and dense block, and asymmetric attention up sampling network, respectively. The same below.
Table 3. Performance comparison of multiple vessel segmentation methods on STARE dataset
|
Methods |
Year |
Acc |
Se |
Sp |
F1 |
AUC |
|
U-Net [15] |
2015 |
0.9639 |
0.8270 |
0.9842 |
- |
0.9779 |
|
GAN [24] |
2017 |
0.9657 |
0.8350 |
0.9812 |
0.834 |
0.9838 |
|
U-Net+joint losses [17] |
2018 |
0.9612 |
0.7581 |
0.9846 |
- |
0.9801 |
|
RetinaGAN [25] |
2019 |
0.9667 |
0.8169 |
0.9845 |
0.8378 |
0.9873 |
|
SUD-GAN [27] |
2020 |
0.9663 |
0.8334 |
0.9897 |
- |
0.9734 |
|
AAU-Net [32] |
2020 |
0.9640 |
0.7598 |
0.9878 |
- |
0.9824 |
|
Uysal [19] |
2021 |
0.9589 |
0.7558 |
0.9811 |
- |
- |
|
MPS-Net [22] |
2021 |
0.9689 |
0.8566 |
0.9819 |
0.8491 |
0.9873 |
|
Our network |
2021 |
0.9690 |
0.8378 |
0.9838 |
0.841 |
0.9858 |
Figure 13. Comparisons of our network, U-Net, GAN, and U-Net + joint losses on the test images 1-20 from DRIVE dataset
Figure 14. Comparison of our network, U-Net, GAN, and U-Net + joint losses on test images 1-10 from STARE dataset
Figure 15. ROC curves of different methods on DRIVE dataset
Figure 16. ROC curves of different methods on STARE dataset
The automatic and precise segmentation of retinal vessel images help doctors diagnose diseases quickly, and facilitate many practical applications. However, the traditional methods cannot segment low-contrast micro-vessels and vessels in lesion areas, or achieve a high segmentation accuracy/sensitivity. This paper proposes a novel network named Deep Att-ResGAN to segment the vessels in fundus images. Specifically, the U-Net architecture was extended into a generator with an attention module and a residual module. The residual network, which is sensitive to the change of eigenvalues, can retain the feature information of different granularities accurately, while the attention module helps the network focus on the target vessel structure. In addition, four identical subnetworks of GAN were arranged to reduce the segmentation error. The output of each GAN was imported to the next GAN. Our network can extract vessel areas excellently, especially the micro-vessels and vessels in lesion areas, which are generally difficult to detect.
Our network was compared with several advanced methods on DRIVE and STARE datasets. The comparison shows that our network can effectively segment the structure of retinal vessels and preserve the details, laying a good basis for clinical diagnosis. The accuracy and F1 of our network reached 0.9565 and 0.829 on DRIVE, and 0.9690 and 0.841 on STARE, respectively. In general, our network realized better performance than existing methods on most metrics.
The future work will test our network on more clinical data to further improve the network performance, and realize the detection of microaneurysms and other types of fundus lesions. Our network will also be extended to the segmentation of the optic disc and other structures [49, 50], and continuously improved to facilitate the diagnosis of ophthalmological diseases.
This work was supported by National Natural Science Foundation of China (Grant No.: 81974275), Medical Scientific Research Foundation of Guangdong Province (Grant No.: B2021253), and University Innovation and Enhancement Project, Guangdong Pharmaceutical University.
[1] Fraz, M.M., Remagnino, P., Hoppe, A., Uyyanonvara, B., Rudnicka, A.R., Owen, C.G., Barman, S.A. (2012). Blood vessel segmentation methodologies in retinal images – A survey. Computer Methods & Programs in Biomedicine, 108(1): 407-433. http://doi.org/10.1016/j.cmpb.2012.03.009
[2] Dasgupta, A., Singh, S. (2017). A fully convolutional neural network based structured prediction approach towards the retinal vessel segmentation. In 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI), Melbourne, Australia, pp. 248-251. http://doi.org/10.1109/ISBI.2017.7950512
[3] Vijayakumari, V., Suriyanarayanan, N. (2012). Survey on the detection methods of blood vessel in retinal images. European Journal of Scientific Research, 68(1): 83-92.
[4] Singh, N., Kaur, L. (2015). A survey on blood vessel segmentation methods in retinal images. In 2015 International Conference on Electronic Design, Computer Networks & Automated Verification (EDCAV), Shillong, India, pp. 23-28. http://doi.org/10.1109/EDCAV.2015.7060532
[5] Moccia, S., De Momi, E., El Hadji, S., Mattos, L.S. (2018). Blood vessel segmentation algorithms-Review of methods, datasets and evaluation metrics. Computer Methods and Programs in Biomedicine, 158: 71-91. https://doi.org/10.1016/j.cmpb.2018.02.001
[6] Srinidhi, C.L., Aparna, P., Rajan, J. (2017). Recent advancements in retinal vessel segmentation. Journal of Medical Systems, 41(4): 1-22.
[7] Martinez-Perez, M.E., Hughes, A.D., Thom, S.A., Bharath, A.A., Parker, K.H. (2007). Segmentation of blood vessels from red-free and fluorescein retinal images. Medical Image Analysis, 11(1): 47-61. http://doi.org/10.1016/j.media.2006.11.004
[8] Zana, F., Klein, J.C. (2001). Segmentation of vessel-like patterns using mathematical morphology and curvature evaluation. IEEE Transactions on Image Processing, 10(7): 1010-1019. http://doi.org/10.1109/83.931095
[9] Hoover, A.D., Kouznetsova, V., Goldbaum, M. (2002). Locating blood vessels in retinal images by piecewise threshold probing of a matched filter response. IEEE Transactions on Medical Imaging, 19(3): 203-210. http://doi.org/10.1109/42.845178
[10] Zhao, J., Yang, J., Ai, D., Song, H., Jiang, Y., Huang, Y., Zhang, L., Wang, Y. (2018). Automatic retinal vessel segmentation using multi-scale superpixel chain tracking. Digital Signal Process, 81: 26-42. http://doi.org/10.1016/j.dsp.2018.06.006
[11] Lam, B., Gao, Y., Liew, W.C. (2010). General retinal vessel segmentation using regularization-based multi-concavity modeling. IEEE Transactions on Medical Imaging, 29(7): 1369-1381. http://doi.org/10.1109/TMI.2010.2043259
[12] Dai, P., Luo, H., Sheng, H., Zhao, Y., Li, L., Jing, W., Zhao, Y., Suzuki, K. (2015). A new approach to segment both main and peripheral retinal vessels based on gray-voting and gaussian mixture model. Plos One, 10(6): e0127748. http://doi.org/10.1371/journal.pone.0127748
[13] Almotiri, J., Elleithy, K., Elleithy, A. (2018). Retinal vessels segmentation techniques and algorithms: A survey. Applied Sciences, 8: 155. http://doi.org/10.3390/app8020155
[14] Litjens, G., Kooi, T., Ehteshami Bejnordi, B., Setio, A., Ciompi, F., Ghafoorian, M., van der Laak, J., Ginneken, B., Sánchez, C. (2017). A survey on deep learning in medical image analysis. Medical Image Analysis, 42: 60-88. http://doi.org/10.1016/j.media.2017.07.005
[15] Ronneberger, O., Fischer, P., Brox, T. (2015). U-Net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention(MICCAI), Munich, Germany, 234-241. http://dio.org/10.1007/978-3-319-24574-4_28
[16] Hu, K., Zhang, Z., Niu, X., Zhang, Y., Cao, C., Xiao, F., Gao, X. (2018). Retinal vessel segmentation of color fundus images using multiscale convolutional neural network with an improved cross-entropy loss function. Neurocomputing, 309: 179-191. http://doi.org/10.1016/j.neucom.2018.05.011
[17] Yan, J., Yang, X., Cheng, K. (2018). Joint segment-level and pixel-wise losses for deep learning based retinal vessel segmentation. IEEE Transactions on Biomedical Engineering, 65(9): 1912-1923. http://doi.org/10.1109/TBME.2018.2828137
[18] Maninis, K.K., Pont-Tuset, J., Arbeláez, P., Van Gool, L. (2016). Deep retinal image understanding. In Medical Image Computing and Computer-Assisted Intervention(MICCAI), Lecture Notes in Computer Science, Berlin, Germany, 9901. http://doi.org/10.1007/978-3-319-46723-8_17
[19] Uysal, E., Güraksin, G.E. (2021). Computer-aided retinal vessel segmentation in retinal images:convolutional neural networks. Multimedia Tools and Applications, 80: 3505-3528. http://doi.org/10.1007/s11042-020-09372-w
[20] Samuel, P.M., Veeramalai, T. (2021). VSSC Net: vessel specific skip chain convolutional network for blood vessel segmentation. Computer Methods and Programs in Biomedicine, 198: 105769. http://doi.org/10.1016/j.cmpb.2020.105769
[21] Sathananthavathi, V., Indumathi, G. (2021). Encoder enhanced atrous (EEA) unet architecture for retinal blood vessel segmentation. Cognitive Systems Research, 67(4): 84-95. http://doi.org/10.1016/j.cogsys.2021.01.003
[22] Lin, Z., Huang, J., Chen, Y., Zhang, X., Zhao, W., Li, Y., Lu, L., Zhan, M., Jiang, X., Liang, X. (2021). A high resolution representation network with multi-path scale for retinal vessel segmentation. Computer Methods and Programs in Biomedicine, 208: 106206. https://doi.org/10.1016/j.cmpb.2021.106206
[23] Goodfellow, I.J., Pouget-Abadie, J., Mirza, M., Bing, X., Bengio, Y. (2014). Generative adversarial networks. Advances in Neural Information Processing Systems, 3: 2672-2680. https://doi.org/10.1145/3422622
[24] Son, J., Park, S.J., Jung, K.H. (2017). Retinal vessel segmentation in fundoscopic images with generative adversarial networks. Computer Vision and Pattern Recognition.
[25] Son, J., Park, S.J., Jung, K.H. (2019). Towards accurate segmentation of retinal vessels and the optic disc in fundoscopic images with generative adversarial networks. Journal of Digital Imaging, 32: 499-512. http://doi.org/10.1007/s10278-018-0126-3
[26] Guo, X., Chen, C., Lu, Y., Meng, K., Xiao, R. (2020). Retinal vessel segmentation combined with generative adversarial networks and dense U-Net. IEEE Access, 8: 194551-194560. http://doi.org/10.1109/access.2020.3033273
[27] Yang, T., Wu, T., Li, L., Zhu, C. (2020). SUD-GAN: Deep convolution generative adversarial network combined with short connection and dense block for retinal vessel segmentation. Journal of Digital Imaging, 33: 946-957. http://doi.org/10.1007/s10278-020-00339-9
[28] Bahdanau, D., Cho, K., Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. Computation and Language.
[29] Oktay, O., Schlemper, J., Folgoc, L.L., Lee, M., Heinrich, M., Misawa, K., Mori, K., Mcdonagh, S., Hammerla, N.Y., Kainz, B., Glocher, B, Rueckert, D. (2018). Attention U-Net: Learning where to look for the pancreas. Computer Vision and Pattern Recognition.
[30] Wei, Z., Song, H., Chen, L., Li, Q., Han, G. (2019). Attention-Based DenseUnet network with adversarial training for skin lesion segmentation. IEEE Access, 7: 136616-136629. http://doi.org/10.1109/access.2019.2940794
[31] Li, R.R., Li, M.M., Li, J.C., Zhou, Y.T. (2019). Connection sensitive attention U-NET for accurate retinal vessel segmentation. Computer Vision and Pattern Recognition.
[32] Lv, Y., Ma, H., Li, J., Liu, S. (2020). Attention guided U-Net with atrous convolution for accurate retinal vessels segmentation. IEEE Access, 8: 32826-32839. http://doi.org/10.1109/ACCESS.2020.2974027
[33] Chen, S., Zou, Y., Liu, P.X. (2021). Iba-u-net: Attentive BConvLSTM U-net with redesigned inception for medical image segmentation. Computers in Biology and Medicine, 135: 104551. http://doi.org/https://doi.org/10.1016/j.compbiomed.2021.104551
[34] Diakogiannis, F.I., Waldner, F., Caccetta, P., Wu, C. (2020). ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS Journal of Photogrammetry and Remote Sensing, 162: 94-114. http://doi.org/10.1016/j.isprsjprs.2020.01.013
[35] Guo, Y., Budak, Ü., Şengür, A. (2018). A novel retinal vessel detection approach based on multiple deep convolution neural networks. Computer Methods and Programs in Biomedicine, 167: 43-48. http://doi.org/10.1016/j.cmpb.2018.10.021
[36] Kang, E., Koo, H.J., Yang, D.H., Seo, J.B., Ye, J.C. (2019). Cycle-consistent adversarial denoising network for multiphase coronary CT angiography. Medical Physics, 46(2): 550-562. http://doi.org/10.1002/mp.13284
[37] Jin, Q., Meng, Z., Tuan, D.P., Chen, Q., Wei, L., Su, R. (2019). DUNet: A deformable network for retinal vessel segmentation. Knowledge-Based Systems, 178(15): 149-162. http://doi.org/10.1016/j.knosys.2019.04.025
[38] Staal, J., Abramoff, M.D., Niemeijer, M., Viergever, M.A., van Ginneken, B. (2004). Ridge-based vessel segmentation in color images of the retina. IEEE Transactions on Medical Imaging, 23(4): 501-509. http://doi.org/10.1109/tmi.2004.825627
[39] He, K., Zhang, X., Ren, S., Sun, J. (2016). Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), pp. 770-778. http://doi.org/10.1109/CVPR.2016.90
[40] Ibtehaz, N., Rahman, M.S. (2020). MultiResUNet: Rethinking the U-Net architecture for multimodal biomedical image segmentation. Neural Networks, 121: 74-87. http://doi.org/10.1016/j.neunet.2019.08.025
[41] Alom, M.Z., Hasan, M., Yakopcic, C., Taha, T.M., Asari, V.K. (2018). Recurrent Residual Convolutional Neural Network based on U-Net (R2U-Net) for Medical Image Segmentation. J. of Medical Imaging, 6(1): 014006. https://doi.org/10.1117/1.JMI.6.1.014006
[42] Mirza, M., Osindero, S. (2014). Conditional generative adversarial nets. Machine Learning.
[43] Radford, A., Metz, L., Chintala, S. (2015). Unsupervised representation learning with deep convolutional generative adversarial networks. Machine Learning.
[44] Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., Zheng, X. (2016). Tensorflow: Large-scale machine learning on heterogeneous distributed systems. Distributed, Parallel, and Cluster Computing.
[45] Chollet, F. (2015). Keras: Deep Learning for humans. https://github.com/keras-team/keras.
[46] Geetharamani, R., Balasubramanian, L. (2016). Retinal blood vessel segmentation employing image processing and data mining techniques for computerized retinal image analysis. Biocybernetics and Biomedical Engineering, 36(1): 102-118. http://doi.org/10.1016/j.bbe.2015.06.004
[47] Imani, E., Javidi, M., Pourreza, H.R. (2015). Improvement of retinal blood vessel detection using morphological component analysis. Computer Methods and Programs in Biomedicine, 118(3): 263-279. http://doi.org/10.1016/j.cmpb.2015.01.004
[48] Javidi, M., Pourreza, H.R., Harati, A. (2017). Vessel segmentation and microaneurysm detection using discriminative dictionary learning and sparse representation. Computer Methods and Programs in Biomedicine, 139: 93-108. http://doi.org/10.1016/j.cmpb.2016.10.015
[49] Singh, N.P., Singh, V.P. (2020). Efficient segmentation and registration of retinal image using gumble probability distribution and brisk feature. Traitement du Signal, 37(5): 855-864. https://doi.org/10.18280/ts.370519
[50] Luo, Z.L., Jia, Y.B., He, J.Z. (2019). An optic disc segmentation method based on active contour tracking. Traitement du Signal, 36(3): 265-271. https://doi.org/10.18280/ts.360310