Mohammad S. Khrisat* | Rushdi. S. Abu Zneit | Hatim Ghazi Zaini | Ziad A. Alqadi
© 2021 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
The fingerprint is used in many vital applications important to humans, which requires searching for an effective way to extract the characteristics of the fingerprint. In this paper we will study some of the most popular methods used to extract fingerprints features. For each method the efficiency, accuracy, flexibility and sensitivity for image rotation will be experimentally tested, measured, analyzed in order to give good recommendations of how and when to use a certain method of features extraction. A detailed comparison analysis between MLBP, K_means, WPT, Minutiae methods will be done using several color images in various rotation modes to insure the stability of image features.
fingerprint, histogram, MLBP, K_means, WPT, minutiae, features, rotation
Fingerprints are prominent bumps in the skin that are adjacent to depressions, and each person has a distinct shape, and it has been proven that the fingerprint cannot be identical and identical in two people in the world even the identical twins that originate from one egg, and these lines leave their impact on everybody that touches it and on the surfaces Particularly smooth. Therefore, fingerprint recognition refers to the mechanism for verifying the compatibility of the two fingerprints of a person, and the fingerprint is one of the types of biometrics used to verify and document identity [1].
People have small bumps on their fingers, which make it easier to catch things. Like every organ of the human body, these protrusions are formed by genetic and environmental factors, which give the genetic code of DNA the basics on which the developing gene must form [2]. But the way to configure it depends on random events. Like the position of the fetus in the womb at a given moment, the concentration and density of the placenta fluid surrounding the fetus, they decide how each bump will form. So, in addition to the countless factors that interfere with a person’s genetic makeup, there are many environmental factors that influence finger formation. The development process is very messy, like the weather that forms clouds, so there can be no duplicate fingerprint twice [3].
Therefore, the fingerprint is a unique personal mark even in identical twins. Although a sneak peek at two fingerprints may turn out to be the same, a professional investigator or advanced program can spot the difference. This is the basic idea for fingerprint analysis in both protection and crime investigation [4].
Fingerprints can be represented by 2D or 3D matrix (gray or color image), and the matrix usually has a big size which make the process of identifying fingerprint very complicated in terms of time, for this reason, it is necessary to search for a way to represent the fingerprint with a group of limited values of small size, so that these values can be used as a classifier or identifier of the fingerprint.
Fingerprint features are a vector of small number of values, and each fingerprint features vector must satisfy the following requirements:
1) It must be unique for each fingerprint.
2) Easy to extract.
3) Must be numeric and easy to use.
4) Must not sensitive to the fingerprint rotation and it must be fixed.
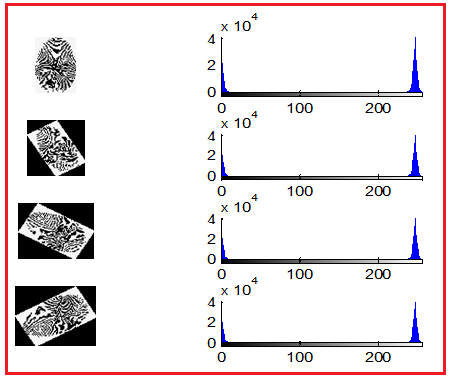
Each fingerprint image can be represented by a histogram, and here we can benefit from an important feature of the image histogram, this feature is represented by the stability of the histogram and not affected by the result of rotating the image and to what degree as shown in Figures 1 and 2 [5].
Figure 1. Fingerprint rotations
Figure 2. Fingerprint’s histograms (histograms are stable)
Multiple methods are used to extract the features of the fingerprint, and these methods vary in their efficiency, flexibility and degree of stability of features, especially after the rotation of the fingerprint. We will address in this item some of the commonly used methods: K_means clustering (K_means), Minutiae, modified local binary pattern (MLBP) and wavelet packet tree decomposition (WPT) methods.
2.1 K_means method
This method is based on grouping the image pixels into groups called clusters, this method is flexible by using the clusters centroids or the within clusters sums as a fingerprint features, the number of features in the features vector depends on the selected number of clusters. This method can use a fingerprint image or the image histogram as an input data set.
This method can be implemented applying the following steps:
Step1: Initialization: Select the number of clusters, the centroid for each cluster and the input data set.
Step2: While the centroids keep changing do the following.
Calculate the absolute value of distance between each point and each cluster centroid.
Depending on the distances calculated values add the point to the closest cluster, and then save the point coordinates.
Update each centroid by the using the average of the points which belong to the cluster.
Here is an example of clustering the following input data set into two clusters:
Tables 1, 2, 3, and 4 show the calculation processes.
From Table 4 we can see that the clusters centroids are: C1=17.1250 and C2=39.3333, the input data set was grouped into two clusters with points:
Cluster 1: 3, 7, 9, 11, 20
Cluster 2: 36, 40, 42
Table 1. Pass 1 C1=6, C2=12
|
Data item(point) |
Distance 1 |
Distance 2 |
Nearest cluster |
New centroids |
|
3 |
3 |
9 |
1 |
C1=6.3333 |
|
7 |
1 |
5 |
1 |
|
|
9 |
3 |
3 |
1 |
|
|
11 |
5 |
1 |
2 |
|
|
20 |
14 |
8 |
2 |
C2=29.8000 |
|
36 |
30 |
24 |
2 |
|
|
40 |
34 |
28 |
2 |
|
|
42 |
36 |
30 |
2 |
Table 2. Pass 2 C1=6.3333, C2= C2=29.8000
|
Data item(point) |
Distance 1 |
Distance 2 |
Nearest cluster |
New centroids |
|
3 |
3.3333 |
26.8000 |
1 |
C1=7.5000 |
|
7 |
0.6667 |
22.8000 |
1 |
|
|
9 |
2.6667 |
20.8000 |
1 |
|
|
11 |
4.6667 |
18.8000 |
1 |
|
|
20 |
13.6667 |
9.8000 |
2 |
C2=34.5000 |
|
36 |
29.6667 |
6.2000 |
2 |
|
|
40 |
33.6667 |
10.2000 |
2 |
|
|
42 |
35.6667 |
12.2000 |
2 |
Table 3. Pass 3 C1=7.5000, C2= C2=34.5000
|
Data item(point) |
Distance 1 |
Distance 2 |
Nearest cluster |
New centroids |
|
3 |
4.5000 |
31.5000 |
1 |
C1=17.1250 |
|
7 |
0.5000 |
27.5000 |
1 |
|
|
9 |
1.5000 |
25.5000 |
1 |
|
|
11 |
3.5000 |
23.5000 |
1 |
|
|
20 |
12.5000 |
14.5000 |
1 |
C2=39.3333 |
|
36 |
28.5000 |
1.5000 |
2 |
|
|
40 |
32.5000 |
5.5000 |
2 |
|
|
42 |
34.5000 |
7.5000 |
2 |
Table 4. Pass 4 C1=17.1250, C2= C2=39.3333
|
Data item(point) |
Distance 1 |
Distance 2 |
Nearest cluster |
New centroids |
|
3 |
14.1250 |
36.3333 |
1 |
C1=17.1250 No changes so stop |
|
7 |
10.1250 |
32.3333 |
1 |
|
|
9 |
8.1250 |
30.3333 |
1 |
|
|
11 |
6.1250 |
28.3333 |
1 |
|
|
20 |
2.8750 |
19.3333 |
1 |
C2=39.3333 No changes so stop |
|
36 |
18.8750 |
3.3333 |
2 |
|
|
40 |
22.8750 |
0.6667 |
2 |
|
|
42 |
24.8750 |
2.6667 |
2 |
2.2 Minutiae method
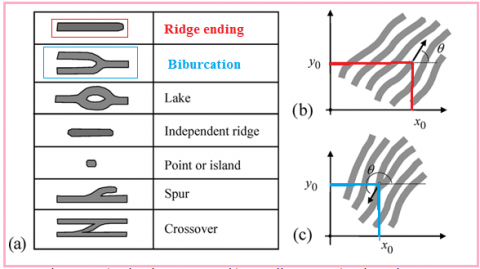
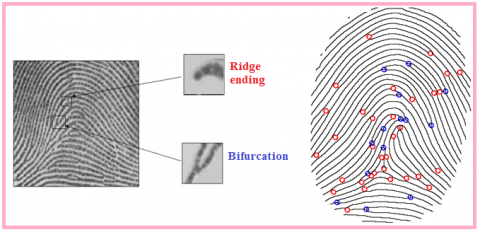
Fingerprint image contains several unique objects each of them is called minutiae as shown in Figures 3 and 4, each of them has its own shape, coordinates and orientation [5].
Figure 3. a) Minutiae types b) Coordinates c) Orientation
Figure 4. Fingerprint structure
Figure 5. CN calculation
Here we will focus on detecting ridge ending and bifurcation minutiae, and here we can use the counts of each of them and the distances as a fingerprint feature.
Each minutia in the fingerprint image can be easily detected depending on the 8 neighbors values and using the calculated classifier crossing number (CN) as shown in Figure 5 [6].
The Euclidean distance for each object points can be calculated using formula (1) (where n is the number of points in each object).
$d(\boldsymbol{p}, \boldsymbol{q})=d(\boldsymbol{q} \cdot \boldsymbol{p})$
$=\sqrt{\left(q_{1}-p_{1}\right)^{2}+\left(q_{2}-p_{2}\right)^{2}+\cdots+\left(q_{n}-p_{n}\right)^{2}}$
$=\sqrt{\sum\left(q_{i}-p_{i}\right)^{2}}$ (1)
This method can be implemented applying the following steps:
Step1: Get the digital image.
Step2: If the digital image is color, then convert it to gray image.
Step3: Convert the gray image to binary.
Step4: Apply morphological thinning to get the image edges.
Step5: For each pixel in the image do the following:
Calculate CN.
Determine the object depending on CN value.
Add 1 to the object count.
Get the pixel coordinates.
Add the coordinates to the points coordinate matrix.
Step6: For each detected object calculate Euclidean distance.
Step7: Use the object counts and distances as a fingerprint features [7].
2.3 Modified local binary pattern method
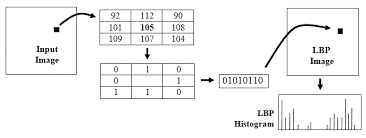
Local binary pattern (LBP) histogram of the fingerprint image is a histogram of an output image after applying LBP operator calculations for each pixel in the input image.
LBP image can be obtained applying the steps shown in Figure 6.
Figure 6. Example of calculating LBP pixel
The introduced MLBP method is based on LBP operator calculation, this method is flexible and we can select the number of features for each fingerprint freely, the following Table 5 shows how to use this method to extract 4-elements features vector for each finger print [8]:
Table 5. MLBP calculation
|
Pixels |
….. |
100 |
120 |
150 |
80 |
170 |
90 |
130 |
….. |
|
|
|
|
|
150<= 170, so b0=1 |
|
|
|
||
|
|
|
|
120 not <=170 so b1=0 |
|
|
||||
|
|
|
|
Binary number=01, decimal =1 So add 1 to count of features vector with index=1 |
|
|
||||
|
|
|
|
|
|
|||||
|
These operations to be repeated for each pixel, at the end we got a vector of for values |
|||||||||
2.4 WPT decomposition method
Wavelet packet tree decomposition can be used to extract features for any fingerprint by reshaping the image matrix into one row matrix, then calculating the approximation and details using formulas 2 and 3 [8]. Here we can control the features vector size by selecting the decomposition level, and taking only the obtained approximation as shown in Figure 7.
Figure 7. WPT decomposition
$A_{j+1, i}=\frac{e v e n_{j, i}+o d d_{j, i}}{2}$ (2)
$D_{j+1, i}=\frac{e v e n_{j, i}+o d d_{j, i}}{2}$ (3)
Table 6 shows an example of how to calculate approximations and details:
Table 6. Approximations and details calculation example
|
|
3 |
7 |
9 |
11 |
20 |
36 |
40 |
42 |
|
Level 1 |
Approximation |
Detail |
||||||
|
5 |
10 |
28 |
41 |
-2 |
-1 |
-9 |
-1 |
|
|
Level 2 |
Approximation |
Detail |
Approximation |
Detail |
||||
|
7.5 |
34.5 |
-2.5 |
-6.5 |
-1.5 |
-5 |
-0.5 |
-4 |
|
|
Level 3 |
Approximation |
Detail |
Approximation |
Detail |
Approximation |
Detail |
Approximation |
Detail |
|
21 |
-13.5 |
-4.5 |
2 |
-3.25 |
1.75 |
-2.25 |
1.75 |
|
3.1 K_means clustering implementation
The main disadvantage of this method is that it requires high extraction time especially for images with big sizes, this will reduce the efficiency of this method, and Table 7 shows the results of K-means clustering using images with big sizes [9].
To overcome the previous mentioned disadvantage we can use the fingerprint image histogram as an input data set for clustering, Table 8 shows the obtained results for the selected 10 fingerprints images.
From Table 8 we can see the following facts:
-K_means is efficient by providing an average extraction time of 0.07 seconds.
The obtained features for each fingerprint image are unique.
-K_means method is flexible in selecting the features vector size, which equal the number of cluster.
-K_means methods can give us an alternative feature by selecting the within clusters sums as a features.
-K_means method is not sensitive to the fingerprint rotation; they keep the same without any changes even if the image was rotated as shown in Table 9.
(Rotation degrees were selected as an example; here we can select any rotation degree).
3.2 MLBP implementation
MLBP method of features extraction is efficient for images with various sizes; Table 10 shows the obtained experimental results using images with various sizes.
The same images were rotated 45 degrees, Table 11 shows the obtained results.
Table 7. K_means extraction time for big images (4 clusters)
|
Image number |
Size(byte) |
Centroids(features) |
Extraction time(seconds) |
|||
|
F1 |
5140800 |
26.2997 |
77.3687 |
130.4123 |
197.0929 |
31.735000 |
|
F2 |
6119256 |
63.9469 |
110.3634 |
148.1826 |
228.5058 |
35.637000 |
|
F3 |
150849 |
24.7795 |
88.6582 |
162.6748 |
230.7880 |
2.310000 |
|
Extraction time rapidly increases when the image size increases. |
||||||
Table 8. Fingerprint images features (K_means clustering)
|
Fingerprint # |
Size (byte) |
Features(centroids) |
Extraction time (seconds) |
|||
|
Cluster 1 |
Cluster 2 |
Cluster 3 |
Cluster 4 |
|||
|
1 |
231000 |
350 |
7150 |
74180 |
261000 |
0.072000 |
|
2 |
3935100 |
900 |
11900 |
55600 |
1021700 |
0.083000 |
|
3 |
98256 |
170 |
3240 |
24610 |
102680 |
0.068000 |
|
4 |
151050 |
72 |
477 |
16624 |
56269 |
0.069000 |
|
5 |
151122 |
81 |
621 |
19845 |
57190 |
0.108000 |
|
6 |
532500 |
270 |
5080 |
70520 |
193540 |
0.091000 |
|
7 |
2104050 |
570 |
23670 |
223320 |
872240 |
0.074000 |
|
8 |
151200 |
97 |
419 |
14280 |
56355 |
0.071000 |
|
9 |
151050 |
69 |
577 |
7057 |
56337 |
0.068000 |
|
10 |
150897 |
79 |
702 |
20531 |
54726 |
0.081000 |
|
Average |
765620 |
|
|
|
|
0.0785 |
Table 9. Features for fingerprint 1 and various rotated versions
|
Fingerprint |
Size (byte) |
Features(centroids) |
Extraction time (seconds) |
|||
|
Cluster 1 |
Cluster 2 |
Cluster 3 |
Cluster 4 |
|||
|
1 |
231000 |
350 |
7150 |
74180 |
261000 |
0.072000 |
|
Rotated 25 degrees |
231000 |
350 |
7150 |
74180 |
261000 |
0.072000 |
|
3 Rotated 60 degrees |
231000 |
350 |
7150 |
74180 |
261000 |
0.072000 |
|
Rotated 135 degrees |
231000 |
350 |
7150 |
74180 |
261000 |
0.072000 |
Table 10. MLBP results (images with various sizes)
|
F1 |
5140800 |
1748515 |
690226 |
667124 |
2034931 |
0.1940 |
|
F2 |
6119256 |
1566343 |
1027114 |
969247 |
2556548 |
0.2380 |
|
F3 |
150849 |
57977 |
23237 |
20181 |
49450 |
0.0060 |
|
Extraction time is significantly small for various image sizes. |
||||||
Table 11. MLBP features for rotated images
|
Image number |
Size(byte) |
Centroids(features) |
Extraction time(seconds) |
|||
|
F1 |
5140800 |
1748515 |
690226 |
667124 |
2034931 |
0.1940 |
|
F1 rotated 45 degrees |
5140800 |
1792257 |
671778 |
635231 |
7605693 |
0.1940 |
|
F2 |
6119256 |
1566343 |
1027114 |
969247 |
2556548 |
0.2380 |
|
F2 rotated 45 degrees |
6119256 |
1467454 |
1097850 |
1061771 |
9264908 |
0.2380 |
|
F3 |
150849 |
57977 |
23237 |
20181 |
49450 |
0.0060 |
|
F3 rotated 45 degrees |
150849 |
55753 |
25958 |
20693 |
254667 |
0.0060 |
|
Extraction time is significantly small for various image sizes. |
||||||
Table 12. Fingerprint MLBP features
|
Fingerprint # |
Size (byte) |
Features |
Extraction time (seconds) |
|||
|
1 |
231000 |
65 |
50 |
59 |
78 |
0.0350 |
|
2 |
3935100 |
78 |
36 |
41 |
97 |
0.0330 |
|
3 |
98256 |
78 |
43 |
49 |
82 |
0.0230 |
|
4 |
151050 |
66 |
47 |
53 |
86 |
0.0240 |
|
5 |
151122 |
70 |
49 |
50 |
83 |
0.0230 |
|
6 |
532500 |
68 |
48 |
41 |
95 |
0.0240 |
|
7 |
2104050 |
84 |
39 |
41 |
88 |
0.0300 |
|
8 |
151200 |
60 |
50 |
53 |
89 |
0.0240 |
|
9 |
151050 |
66 |
53 |
55 |
78 |
0.0220 |
|
10 |
150897 |
61 |
40 |
37 |
114 |
0.0240 |
|
Average |
765620 |
|
|
|
|
0.0262 |
From Table 11 we can see that MLBP method is very sensitive to image rotations, and to overcome this disadvantage we can use the image histogram to find the fingerprints features, Table 12 shows the results for the selected 10 fingerprint images.
From Table 10 we can raise the following facts related to MLBP method:
-The method is efficient by providing a small average time of features extraction.
-The obtained features for each fingerprint image are unique.
-Using histogram will reduce the extraction time and will keep the features without any changes even if the image was rotated.
3.3 WPT decomposition implementation
Fingerprint images usually have different sizes, so it is difficult to determine the levels of decomposition to get the needed size of features vector, to overcome this disadvantage we can use the fingerprint image histogram, the selected fingerprints were processed using this method and Table 13 shows the experimental results:
Table 13. Fingerprint WPT features
|
Fingerprint # |
Size (byte) |
Features |
Extraction time (seconds) |
|||
|
1 |
231000 |
8410 |
1889 |
1895 |
16682 |
0.0990 |
|
2 |
3935100 |
3795 |
345 |
279 |
11978 |
0.1290 |
|
3 |
98256 |
34114 |
8060 |
7861 |
72785 |
0.1000 |
|
4 |
151050 |
15543 |
4580 |
4735 |
38080 |
0.0990 |
|
5 |
151122 |
1181.8 |
431 |
527.8 |
4156.3 |
0.1130 |
|
6 |
532500 |
6125 |
1102 |
1196 |
13765 |
0.1710 |
|
7 |
2104050 |
29086 |
2119 |
2192 |
54272 |
0.1000 |
|
8 |
151200 |
13630 |
6221 |
7494 |
35655 |
0.0980 |
|
9 |
151050 |
1544.6 |
386.1 |
449.5 |
3913.5 |
0.1010 |
|
10 |
150897 |
264.9 |
1405.9 |
482.4 |
4175.0 |
0.1060 |
|
Average |
765620 |
|
|
|
|
0.1116 |
Table 14. Minutiae features
|
Fingerprint # |
Size (byte) |
Features |
Extraction time (seconds) |
|||
|
Ridge ending |
Bifurcation |
DR |
DB |
|||
|
1 |
231000 |
655 |
2444 |
500.6755 |
451.5496 |
0.4500 |
|
2 |
3935100 |
69 |
2379 |
461.7359 |
992.3719 |
2.2630 |
|
3 |
98256 |
39 |
1149 |
240.4683 |
301.0814 |
0.1640 |
|
4 |
151050 |
6 |
375 |
188.7326 |
101.8332 |
0.0980 |
|
5 |
151122 |
15 |
229 |
31.3847 |
193.7524 |
0.0900 |
|
6 |
532500 |
37 |
512 |
367.7839 |
298.4024 |
0.3000 |
|
7 |
2104050 |
48 |
2853 |
966.6276 |
844.4104 |
1.2210 |
|
8 |
151200 |
2 |
53 |
106.4519 |
238.8326 |
0.1040 |
|
9 |
151050 |
7 |
368 |
223.8928 |
101.8332 |
0.0900 |
|
10 |
150897 |
14 |
138 |
94.8103 |
236.1779 |
0.1120 |
|
Average |
765620 |
|
|
|
|
0.4892 |
From Table 13 we can raise the following facts related to WPT decomposition method:
-The method is efficient by providing a small average time of features extraction 9 with average time =0.11 seconds).
-The obtained features for each fingerprint image are unique.
-Using histogram will reduce the extraction time and will keep the features without any changes even if the image was rotated.
-The method is flexible of determining the features vector size by selecting the necessary level of approximation.
3.4 Minutiae method of features extraction
Here we select the ending ridges and bifurcations and used the counts of ridge points, the counts of bifurcation, the Euclidean distances for both ridge ending and bifurcation objects, Table 14 shows the obtained experimental results, and from this table we can raise the following facts related to minutiae:
-The method is efficient by providing a small average time of features extraction 9 with average time =0.48 seconds).
-The obtained features for each fingerprint image are unique.
-Using histogram will destroy the minutiae objects.
-Rotating the fingerprint will produce different features, so we have to keep more than one version for each fingerprint associated with the same person.
-The method is flexible of determining the features vector size by selecting the necessary number of objects depending on CN value.
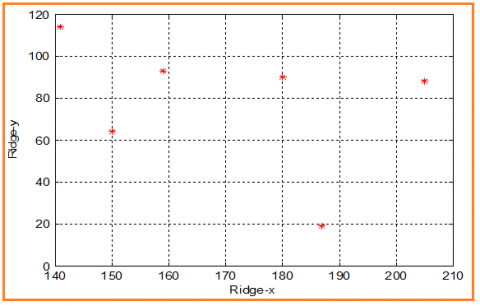
Table 15 shows the ridge ending coordinates for fingerprint 4, while Figures 8 and 9 show the plot of these points.
Figure 8. Ridge ending for fingerprint 4
Figure 9. Plot of ridge ending for fingerprint 4
Table 15. Ridge ending for image 4
|
Ending ridge points coordinates |
|
|
Ridge_x |
Ridge_y |
|
187 |
19 |
|
150 |
64 |
|
205 |
88 |
|
180 |
90 |
|
159 |
93 |
|
141 |
114 |
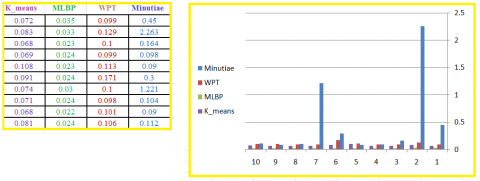
For efficiency comparisons we took the extraction time for each method as shown in Figure 10 (Minutiae has the worst efficiency, while MLBP has the best):
Figure 10. Time comparisons
All the studied methods are not sensitive to image rotation except minutiae method, because taking the histogram will destroy the objects structures within the fingerprint, and this show in Table 16:
Table 16. Various methods features
|
Fingerprint |
K_means |
MLBP |
WPT |
Minutiae |
|
1 |
350 |
65 |
8410 |
655 |
|
7150 |
50 |
1889 |
2444 |
|
|
74180 |
59 |
1895 |
500.6755 |
|
|
261000 |
78 |
16682 |
451.5496 |
|
|
1 rotated 35 degree |
350 |
65 |
8410 |
594 |
|
7150 |
50 |
1889 |
2266 |
|
|
74180 |
59 |
1895 |
220.6354 |
|
|
261000 |
78 |
16682 |
239.0063 |
|
|
No changes |
No changes |
No changes |
Changed |
The way that section titles and other headings are displayed in these instructions, is meant to be followed in your paper.
Various methods for fingerprint features extraction were introduced, implemented and analyzed. Experimental results showed that using histogram will improve the efficiency of K-means, MLBP, and WPT method. K_means method features are stable even if we rotate the fingerprint image. Using image histogram in MLBP and WPT methods will fix the features and will keep them without changes even if we rotate the image. Using Histogram in minutiae method is not recommended because it destroys the fingerprint structure.
It is mandatory to have conclusions in your paper. This section should include the main conclusions of the research and a comprehensible explanation of their significance and relevance. The limitations of the work and future research directions may also be mentioned. Please do not make another abstract.
[1] Hemanth, J., Balas, V.E. (2018). Biologically Rationalized Computing Techniques for Image Processing Applications. Springer. p. 116. https://doi.org/10.1007/978-3-319-61316-1
[2] Becker, R.F., Dutelle, A.W. (2018). Criminal Investigation. Jones & Bartlett Learning. p. 133.
[3] Leyden, J. (2017). Fingerprinting of UK school kid's cause's outcry archived, The Register August 10, 2017.
[4] Bleay, S., Sears, V., Downham, R. (2017). Fingerprint Source Book. second edition.
[5] Alqadi, Z., Aqel, M. El Emary, I.M.M. (2006). Fingerprint matching algorithm based on ridge path map. European Journal of Scientific Research, 15(3): 344-351.
[6] Moustafa, A.A., Alqadi, Z.A. (2009). A practical approach of selecting the edge detector parameters to achieve a good edge map of the gray image. Journal of Computer Science, 5(5): 355-362. https://doi.org/10.3844/jcssp.2009.355.362
[7] Al-Dwairi, M.O., Alqadi, Z.A., Abujazar, A.A., Zneit, R.A. (2010). Optimized true-color image processing. World Applied Sciences Journal, 8(10): 1175-1182.
[8] Zahran, B., Al-Azzeh, J., Ziad, A., Al Zoghoul, M., Khawatreh, S. (2018). A modified LBP method to extract features from color images. Journal of Theoretical and Applied Information Technology, 96(10): 3014-3024.
[9] Zneit, R.A., Khrisat, M.S., Khawatreh, S.A., Alqadi, Z. (2020). Two ways to improve WPT decomposition used for image features extraction. European Journal of Scientific Research, 157(2): 195-205.