Satyanarayana Murthy Teki* | Mohan Krishna Varma | Anjana K. Yadav
© 2019 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
The segmentation of medical images on brain tumour faces many challenges. For example, the brain image needs to be divided accurately into non-enhancing tumour, enhancing tumour, tumour core and undamaged area. This paper utilizes four state-of-the-art convolution architectures to perform the segmentation of brain tumour, including the generative adversarial networks (GANs), conditional deep convolution GANs, auto-encoders and u-nets. Based on adversarial networks, the author put forward a novel model for Image segmentation. The model consists of two parts: Auto encoders as generator and Convolution network as discriminator. The proposed model was applied to segment the brain tumour images proposed by Medical Image Computing and Computer-Assisted Interventions Conference (MICCAI), and evaluated by indices like mean accuracy, mean loss and mean intersection over union (IoU). The results show that our model outperformed the traditional algorithms in segmentation effects. The research findings reflect the effectiveness of GANs in segmentation tasks.
image segmentation, brain tumour, deep learning, adversarial network, neural networks
Various medical problems of classification and prediction are effectively being solved by the new deep learning methods. However medical image segmentation is one such area that is not yet being delved into. There are multiple reasons for this, one being unavailability of data for building the model. deep learning requires data for its training phase. In medical image segmentation task getting quality medical scan images and the segmentation images of the parts is a major hindrance to its implementation in deep learning in this sector. MICCAI society has come up with the challenge of brain tumour segmentation using the pre-operative MRI scan images of the patients. The scans of patients are divided into high grade glioma (HGG) and low-grade glioma (LGG). According to ABTA (American Brain Tumor Association) [1, 2], HGGs represent 75 % of all malignant tumors and 25 % of all primary brain tumors. The world health organization [14] (WHO) has categorized HGGs as stage IV brain cancer. We focus on HGG images in this paper. We require to model an algorithm that can understand and efficiently segment the Brain MRIs into the sections of the various gliomas. These include the whole tumour or edema, nong enhancing solid tumour core, the enhancing tumour core and the cystic/necrotic core components. These are visible in the respective MRI scans. The major task here is to perform the image segmentation of these subsections in the 3D brain scan The U-Nets [3, 4] are being used in multiple cases for image segmentation and in case of Medical, Drtion to adversarial networks [5] by Goodfellow for creating images from random noise, many people have tried to experiment with the model and tried to find its various applications in their respective fields. The generator and discriminator are inherent parts of adversarial networks. The generator and the discriminator force each other to improve. The main goal in these models is to bring randomness in the learning data. The generator learns to produce very good fake images while the discriminator learns how to distinguish between the fake images produced by the generator and the real images from the dataset. This model can be used for segmenting medical images. The generator will be a U-Net model that will produce the segmented image and the discriminator will check if the segmented image produced belongs to the actual segmented image data distribution. The major problems we face here are the images. Each patients MRI scans are of high resolution and of size 1.5 GB each in compressed form. These images are not normal JPEG images but are high resolution NIFTI images that require separate processing techniques [6]. The BraTS dataset provided by MICCAI are pre-processed with image normalization and brought to equal sizes of 240x240x155. Thus, each image consists of 155 image channels. Moreover, the T1, T2, T1-gd, T2-FLAIR together help in determining the sub-section segmentation of the brain tumour. Then the 4 images need to be stacked and given as an input to the deep learning model. This makes a 4-dimensional image input that we use to create a 3-dimensional segmentation map output. Also, Glioma Segmentation is difficult due to largely varying intensity in images and the shape of pathology.
The rest of the article has been organized into 9 sections. The related work is discussed in Section 2. The description about the dataset and elaborated methodology are discussed in Section 3 and 4. The proposed work and experimental results are discussed in Section 5 and 6. The results are validated and verified in Section 7.
2.1 Cascaded anisotropic convolution neural networks
Wang et al. [7] proposed a cascaded fully convolutional neural network for medical image segmentation. The network was designed to decompose the single segmentation problems into a sequence of three binary segmentation problems. They initially segmented the whole tumour and using bounding box then segment the tumour core in the second step. The enhancing tumour is separated in third step using the bounding box of tumour core. On the validation set, their network achieved a dice score of 0.7859, 0.905, and 0.838 for Enhancing Tumour, Tumour core and Whole Tumour respectively. Here we needed to do multiple iteration of the network to get the final segmentation image.
2.2 Deep hourglass for brain tumour segmentation
Benson et al. [8] proposed a CNN encoder-decoder network based upon the singular hourglass structure. Their network was able to classify the WT, TC and ET in a single pass. Since the validation and training set have high variance in intensity, they normalised the training set such that it was centred on zero with a standard deviation of one. Normalization of data also helped them to reduce the training time and did a significant increase in the accuracy. The encoder contained seven residual bottlenecks and at the end of each max-pooling layer it performed spatial down sampling. Their network achieved an overall dice coefficient of 0.59, 0.82 and 0.63 for ET, TC and WT, respectively.
2.3 3-D U-Net for tumour segmentation
Chen et al. [9] came up with 3 different Convolutional Neural Networks for the 3-D U-Net architecture. Each of the network was trained for each segmentation target with 3- D patches as input. Pre-processing was separately done for each case. Histogram Equalization, and voxel normalization was performed on the patches. The model yielded the dice coefficients of 0.911, 0.9118, and 0.8272 on 30 % of the train-test split data.
2.4 Gated recurrent units for segmentation
Simon et al. [10] propose the solution to tackle the multi-dimensional gated recurrent units that incorporate recurrent neural networks for image segmentation. They performed initial pre-processing of High-Pass filtration and Gaussian-filtration normalizing the intensities of the images. Patches of 80x80x80 voxels is considered for input to model. The model achieved the dice score of 0.8129, 0.9061, and 0.9387.
2.5 Sequential 3-D U-Nets for segmentation
Beers et al. [11] propose sequential 3D U-Net for the segmentation task. They created a pipeline that chained the several unique 3D U-Net. The pipeline was able to pre-learn that the enhancing tumour and non-enhancing tumour are likely to be found in the region of edema and within its proximity. They achieved a greater context for patch based sampling method by predicting down sampled labels and then up sampling them using a separate 3D U-Net. The achieved dice cot efficient of 0.78, 0.67, 0.68 respectively for whole tumour, enhancing and non-enhancing tissue.
2.6 Brain tumour segmentation using an ensemble of 3D U-Nets and overall survival prediction using radiomic features
Some scholars proposed an ensemble of 3D U-Nets with networks of different hyper parameters in order to solve the medical segmentation problem. They modelled 6 networks with different number of encoding and decoding blocks, varied input patch sizes and different weights for calculating the loss. They also developed a linear model for the prediction of survival using the extracted non-imaging and imaging features. They performed bias correction algorithms to the T1, T1Gd, Flair and T2 images. They also performed non-local means denoising in order to further reduce noise after the bias correction. They obtained a dice score of 0.79, 0.909 and 0.836 on the ET, WT and TC, respectively [9, 12, 13].
2.7 Volumetric multimodality neural network for segmentation
Castillo et al. [14] proposed the method of convolution neural network for image segmentation of brain tumour, which was capable of processing volumetric data with multiple MRI modalities all at the same time. This enabled the model to learn from a smaller dataset even with high imbalance. Based on the Deep-Medic, their architecture was organized in three different parallel pathways with its own input resolution and fully connected layers. The average dice coefficient of their model was 0.87 on training dataset and 0.86 on validation set for whole tumour segmentation task.
2.8 Masked V-Net for segmentation
Cata et al. [15] proposed Masked V-Net architecture which was a variation of V-Net for segmentation. Masked V-Net was able to reformulate the residual connections and used ROI masks to constrain the network in order to train on relevant voxels only. The architecture allowed dense training on the problems with a highly skewed class distributions by performing a data sampling on output instead of input. The model achieved a dice score of 0.714, 0.877 and 0.637 on validation set for ET, TC and WT, respectively.
The MICCAI has provided with MRI scanned images of brain tumour and the respective segmentation images. The various tumour parts of the brain need to be segmented into 4 major classes of Edema, Solid core, Cystic core and Enhancing core. The scanned images for input consist of T1, T1ce, T2-FLAIR and T2 [16-17] are shown in Figure 1 to Figure 4. MRI is done using the magnetic resonance property of matter. A uniform external magnetic field magnetizes the protons of the brain tissue. This magnetization is intentionally disturbed by introducing external Radio Frequency (RF). After some time, the nuclei releases RF in order to return back to its original position. These initial RF signals are processed by applying Fourier transformations to them in order to represent them in the form of intensity values of gray pixels and then observed. The time lapse between the successive pulse sequences that are applied on the same slice is Repetition Time (TR). The time difference between delivery of the RF pulse and reception of its echo is Time to Echo (TE). The MRI sequences where short TE and TR times is used are T1-weighted scans. While the MRI sequences where long TE and TR times is used are T2-weighted scans. T2-weighted and Fluid Attenuated Inversion Recovery (FLAIR) are similar with a difference that the TE and TR times in Flair are very long.
Figure 1. T1 MRI scan image
Figure 2. T1ce MRI scan image
Figure 3. T1-Flair MRI scan image
Figure 4. T2 MRI scan image
The whole tumour can be seen in the T2-FLAIR scan and the tumour core is visible in the T2 scan. The various segments are respectively coloured in different colours for better human understanding. The tumour sub regions are coloured as follows: edema in yellow, solid core (non-enhancing) in red, the necrotic or the cystic core in green and the enhancing core in blue. The remaining part of the brain is unaffected with tumour as shown in Figure 5.
The visualisation of images is done using the python nibaT bel neuroimaging library [6] and due to color mapping exact codes are not visible. The final labels of different glioma sub-regions provided are: 1 for Necrotic and cystic core region, 3 for Non-enhancing Tumour, 2 for peri-tumoural Edema, 4 for Enhancing Tumour and 0 for everything else. All the scanned images are provided in nifti format. The dataset consists of MRI scans of High Grade Glioma for 210 patients and MRI scans of Low Grade Glioma for 75 patients. The HGG are patients with higher risk of death and bigger tumour size. Each patient data thus consists of 5 images that include the native T1, the post-contrast T1- weighted ie T1gd, T2 weighted, T2-FLAIR volumes and the ground truth segmented image. Every scan image is of size 240x240x155, that is of 155 image channels.
Figure 5. MRI segmentation-map image of tumor sub regions
This work utilizes four state-of-the-art Convolution architectures, the Generative Adversarial Networks, Conditional Deep Convolution GANs, Auto-encoders and U-Nets to perform the segmentation of brain tumor. The following section gives a brief outline of the four architectures.
4.1 Review of GANs
Generated Adversarial [5] Networks had huge success since they were introduced by Ian Goodfellow and the co-authors [16]. They belong to the category of generative models and can produce new data. The beauty of model lies in its learning. Rather than learning the pattern of data they learn data distribution of individual classes. Statistically speaking, GANs try to learn the distribution or n-dimensional vector space to which a particular data belongs to. So GANs can create data similar to our own data, be it audio, video or text.
GANs [5] consist of two network parts namely Generator and the Discriminator. The Generator is capable of creating data. This means given a certain label, it tries to generate its features. The Adversarial part is called the Discriminator. When given the features it tries to predict if the features belong to our data or not.
It evaluates the data for their authenticity. Similar to the game of cop and counterfeiter, where the counterfeiter is learning to generate fake money while the cop is learning to detect the fake money. The generator tries to thus fool the discriminator with its data and discriminator becomes good in discriminating the real and fake data. In the end the generator is able to generate data very similar to the actual data and discriminator is unable to decide if it is fake. The Generator G takes noise as input and generates new data while the discriminator D decides if each of the data sample belongs to the population of training set or not.
min maxV(D;G) = E x(log(D(x)))+E(log(1−D(G(z)))) (1)
Above given is the loss function for the vanilla GAN model [16].
4.2 Conditional deep convolution GAN
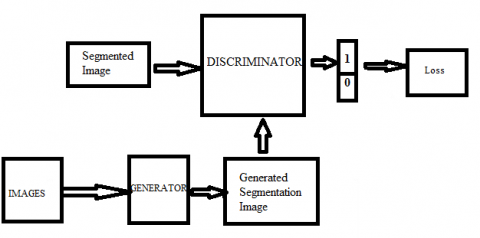
The problem GAN was that there was no control over the modes of data being generated. So Mirza et al. came up with a solution that extended GANs to conditional [7, 18] GAN [19-20] where the generator and the discriminator are given some information such as class of variable. In case of image segmentation, we are feeding the base image and trying to generate segmentation images from it. Thus we are giving a condition to our generator. Conditional GANs are designed to restrict their vector space, to that of training images and their segmentation maps. Below is the Architecture of our GAN model as shown in Figure 6.
Figure 6. GAN
Furthermore, the generator and discriminator can be any neural network based on the use case and choice. Since we are dealing with images, and convolution layers seem to work very well with them, we choose convolution layers as a part of our generator and discriminator. Hence the name conditional deep convolution generative adversarial networks. Although we need to understand that we are using a further enhancement to CDCGANs and try to exploit both U-Nets as well as conditional GAN thus creating U-Net based adversarial networks.
L(G;D)=E(log(D(x; y)))+E(log(1−D(x; G(x; z)))) (2)
The updated loss for conditional GANs is given above [12]. We can see how the condition is forced on the model by introducing differentiating between the segmentation map and generator output.
4.3 Review of auto encoders
Auto encoders [19] when introduced were deeply tried on various use cases for image enhancement, image regeneration, data denoising and dimensionality reduction. The Auto encoder consists of an encoder and a decoder unit. They work by compressing the given input into a smaller feature vector representation and then trying to reconstruct the output similar to the original representation. The encoder compresses the input while the decoder aims to reconstruct the input from this latent space representation. An important attribute of the auto encoder network design is the bottleneck. During the down sampling if the encoder compresses the input to a very small size, then it becomes very difficult for the decoder network to reconstruct the input back. If the bottleneck is not small enough, then the model simply learns each value in the input during the convolution layers. It is thus of very high importance of how much we compress our input by encoder in order to decompress it back by the decoder. The major problem faced by Auto encoders is that during the encoding phase the images are compressed. Compression leads to loss of information. Unless not trained on a large data it becomes very difficult for the decoder to construct the original image back. This in our case would be the segmentation image as shown in Figure 7.
Figure 7. Auto-encoder
4.4 Review of U-net
The problem faced by the Auto encoders is its loss of information during compression phase. If we could somehow find a way to retain some of the feature information and pass it to the network during the encoding phase it will become very easy for the model to regenerate the original image. This is exactly what the U-net tries to do [3]. The encoder is similar to that of Auto-encoders where image passes through multiple convolution networks and is down-sampled. The second part of the network consists of up-sampling and concatenation of similar level features followed by regular convolution operations. Thus during up-sampling we are concatenating the higher resolution features from the down part of encoder with the up-sampled features in order to learn better representation of data. These connections between the encoder and decoder are termed as skip connections.
We propose a novel method for Image segmentation using adversarial networks. Adversarial networks are being used in the various fields of Image generation and so on. The Adversarial network has a generator and discriminator part. The generator consists of a U-Net. While the Discriminator consists of convolution networks. The MRI scans of brain consist of T1, T2, T1ce, T2-Flair [16]. These four images individually show the various parts of the tumours.
The images consist of 155 slices and all the four scans are important for proper segmentation of tumor. Thus we prepare dataset by combining each slice of the four scans as single image. Here the first slice of T1, T2, T1ce and T2- Flair are stacked to form one image which should be used to predict the first slice of segmented image. In this way for one patient scan we pre-process image such that, nth slice of each of four scans are stacked to form an image of dimension 4 x 240 x 240. This is done for all the 155 slices. Thus the final input dimension for one image becomes 155 x 4 x 240 x 240. This forms a single tensor input.
Since our images become five dimensional that is four dimensional image and one dimension of batch size, we use Convolution 3D instead of Convolution 2D here. The generator takes input of four MRI scans and tries to generate the segmentation map of the brain that will contain the subsections of the tumour.
The discriminator will alternatively learn to find the difference between the fake segmentation images produced by the generator and the actual segmentation maps. After the generator is trained enough such that the discriminator is unable to confidently distinguish between the segmentation maps produced by the generator and the actual segmentation map, the generator part of the network can be taken and used for the Image segmentation process.
5.1 Pre-processing
A large variation in the intensity was observed in the data, so we performed normalization of images to mean centered around zero and standard deviation of one.
z=(x − µ)/sigma (3)
Also training of the network was done on batches of images of size 3 each and these images were further normalised using the above mean to stabilize the training for each batch.
5.2 Network architecture
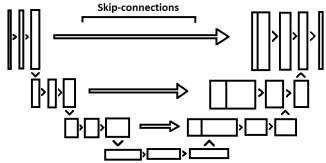
The model consists of a pipeline of generator and discriminator networks as shown in Figure 8. The generator is a U-Net network that has an encoder and decoder network with skip connections. The down sampling occurs in the encoder and the up sampling occurs in the decoder network. The features from same level of encoder is passed to the decoder output during upl sampling.
Figure 8. U-Net architecture
The encoder of U-Net has four layers of Convolution3D, Batch-Normalisation and Leaky Relu. The encoder takes an input of images of size 155 x 4 x 240 x 240. The output of encoder network is a feature of dimension 155 x 1 x 15 x 15. The decoder network of U-Net again contains four layers of convolution Transpose 3D and Leaky Relu. The features transferred from encoder are appended in each up-sampling layer. The output is then passed through a sigmoid layer. The output generated by the decoder is of size 155 x 1 x 240 x 240 which is the output of the generator network. The Discriminator contains four layers of Convolution3D, Batch Normalization 3D and Leaky Relu and a last layer is of Convolution 3D and sigmoid. Often it is observed that GANs tend to collapse during training. Batch Normalization here helps in stabilizing the training in GAN.
6.1 Experiment setup
The images are of size 1.5 GB each. So keeping a larger batch size leads to insufficient CUDA memory. We can crop images to smaller size but that will create another problem of deciding the part where the tumour is and having consistent parts in the four MRI images. So we decide to rather keep a smaller batch size of size 5 images. The Generator and discriminator were made to learn at different learning rates in the start. Initially the learning rate of generator was 0.0005 and discriminator was 0.00005. The generator was trained at a faster learning rate as compared to the discriminator. After few epochs the generator and discriminator were made to learn in alternating fashion where the generator was trained for 10 epochs with discriminator training freezed. Then the discriminator was trained for 10 epochs with generator training freezed. After few rounds in this alternation fashion, both the generator and discriminator were again set to train simultaneously at same learning rate. This enabled both the generator and discriminator to learn efficiently without letting the model collapse or over fit.
Our network was implemented in Python in Pytorch framework and trained in Linux 16.0 environment with one NVIDIA TITAN GPU with 8 GB of memory and 12 CPU with 120 GB memory.
6.2 Problems in training GANs
There are cases when the GAN model is unable to converge. The model parameters tend to oscillate and never become stable. Also there is high possibility of the discriminator becoming too good at its task. Thus no matter what generator produces, the discriminator discards it as being fake. The generator is never able to learn and generator loss keeps increasing. The generator model collapses and produces limited data. Moreover unbalance between the generator and discriminator can cause model to become over fit. Thus the model is unable to generalise and learn the data distribution.
6.3 Results
We generate segmented images from the MRI scanned Images. The loss predicted generally can be misleading in case of segmentation. The reason behind that when the accuracy is calculated for two images, pixel by pixel distance is calculated and considered. Since the major region of our images is background, majority of pixels may match bringing a high accuracy even if the actual segmentation pixels don’t match. So we use another evaluation metric ie. IoU which is calculated as below.
$I O U=\frac{G(z) / Y}{G(z)ΓT}$ (4)
Intersection over union is thus the appropriate metric for calculating our model performance. The model took 15 minutes for one epoch and was trained for 700 epochs. The Intersection over Union score was calculated for the test dataset was shown in Table 1 and clearly it is shown in Figure 9.
Table 1. Model result
|
Model |
Mean Accuracy |
Mean Loss |
Mean IoU |
|
U-Net Adversarial Net |
0.94 |
0.0007 |
0.89 |
|
Traditional Algorithm |
0.5 |
1.94 |
0.88 |
Figure 9. U-net result
The model was taking 67 ms for segmentation of an input image. Furthermore the model was able to clearly find the region of tumor core and whole tumor. The smaller regions of cystic or necrotic components were missed on certain images. Also certain regions of enhancing tumor were also missed and were labelled as a part of whole tumor. Although there were no cases where tumor regions were mislabeled as non tumor region.
Recently introduced GANs have provided a different way to learn the representations of training data without their extensive annotation. This research aimed to explore the GAN in the field of medical Image segmentation and improve the accuracy over other deep learning based segmentation techniques. Specifically we proposed the architecture of auto encoding adversarial networks and training strategy to GAN so that the model turns out to be stable. The proposed model consists of two networks: Auto encoders as generator and Convolution network as discriminator. MICCAI BraTS challenge Brain tumour segmentation images were used as dataset for training and evaluating the performance of the network. The experimental results confirm that GANs can be used for segmentation tasks and achieved better results.
We would like to thank MICCAI for conducting the BraTS challenge and providing its dataset. I like to thank Madanapalle Institute of Technology and science for experimental wok in Research Laboratory.
[1] Louis, D.N. (2007). The WHO classification of tumours of the central nervous system. Acta Neuropathologica, 114(2): 97-109. https://doi.org/10.1007/s00401-016-1545-1
[2] Association, A.B.T. (2019). Brain tumor statistics. https://www.abta.org/about-brain-tumors/brain-tumor-education
[3] Ronneberger, O., Fischer, P., Brox, T. (2015). U-Net: convolutional networks for biomedical image segmentation. Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, pp. 234-241. https://doi.org/10.1007/978-3-319-24574-4_28
[4] Zhu, J.Y., Park, T., Isola, P., Efros, A.A. (2017). Unpaired image-to-image translation using cycle-consistent adversarial networks. 2017 IEEE International Conference on Computer Vision (ICCV), pp. 5967-5976. https://doi.org/10.1109/ICCV.2017.244
[5] Hui, J. (2018). GAN ways to improve GAN performance. https://towardsdatascience.com/gan-ways-to-improve-gan-performance-acf37f9f59b, accessed on 20 Nov. 2018.
[6] Nibabel for NeuroImaging in Python. (2018). https://nipy.org/nibabel, accessed on 25 Jan. 2019.
[7] Wang, G., Li, W., Ourselin, S., Tom. V. (2017). Automatic brain tumour segmentation using cascaded anisotropic convolution neural nets works. Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries, pp. 178-190. https://doi.org/10.1007/978-3-319-75238-9_1
[8] Benson, E., Pound, M.P., French, A.P., Jackson, A.S., Pridmore, T.P. (2018). Deep hourglass for brain tumour segmentation. Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries, pp. 419-428. https://doi.org/10.1007/978-3-030-11726-9_37
[9] Chen, W., Liu, B., Peng, S., Sun, J., Qiao, X. (2019). S3D-UNet: Separable 3D U-Net for brain tumor segmentation. Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injurie, pp. 358-368. https://doi.org/10.1007/978-3-030-11726-9_32
[10] Simon, A., Simon, P., Cattin, P. (2017). Multi-dimensional gated recurrent units for the segmentation of biomedical 3D-Data. Deep Learning and Data Labeling for Medical Applications, pp. 142-151. https://doi.org/10.1007/978-3-319-46976-8_15
[11] Beers, A., Chang, K., Brown, J., Sartor, E., Mammen, C.P., Gerstner, E., Rosen, B., Kalpathy-Cramer, J. (2018). Sequential 3D U-Nets for biologically-informed brain tumor segmentation. Computer Science-Computer Vision and Pattern Recognition, arXiv:1709.02967.
[12] Feng, X., Tustison, N., Meye, C. (2018). Brain tumour segmentation using an ensemble of 3D U-Nets and overall survival prediction using radiomic features. Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries, pp. 279-288. https://doi.org/10.1007/978-3-030-11726-9_25
[13] Nie, D., Zhang, H., Adeli, E., Liu, L., Shen, D. (2016). 3D deep learning for multi-modal imaging guided survival time prediction of brain tumor patients. Medical Image Computing and Computer-Assisted Intervention – MICCAI 2016, pp. 212-220. https://doi.org/10.1007/978-3-319-46723-8_25
[14] Castillo, L.S., Daza, L.A., Rivera, L.C. Arbalez, P. (2017). Volumetric multimodality neural network for brain tumor segmentation. 13th International Conference on Medical Information Processing and Analysis, 10572: 34-41. https://doi.org/10.1117/12.2285942
[15] Catà, M., Casamitjana, A., Sánchez, I, Combalia, M., Vilaplana, V. (2017). Masked VNet: An approach to brain tumour segmentation. In Multimodal Brain Tumor Segmentation Benchmark, Brain-lesion Workshop, MICCAI 2017.
[16] Goodfellow, J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y. (2014). Generative adversarial nets. NIPS'14 Proceedings of the 27th International Conference on Neural Information Processing Systems, 2: 2672-2680.
[17] Priston, D.C. (2006). Magnetic resonance imaging (MRI) of the brain and spine: Basics. https://case.edu/med/neurology/NR/NRHome.htm
[18] Mirza, M., Osindero, S. (2014). Conditional generative adversarial nets. Computer Science-Machine Learning, arXiv:1411.1784.
[19] Jordanm, J. (2018). Introduction to auto encoders. https://www.jeremyjordan.me/autoencoders, accessed on 20 Nov. 2018.
[20] Mirzaa, M., Osindero, S. (2014). Conditional adversarial networks. Computer Science-Machine Learning, arXiv:1411.1784.