Muhamad Azhar Abdilatef Alobaidy*![]() | Zead M. Yosif
| Zead M. Yosif![]() | Mohammed S. Alsoufi
| Mohammed S. Alsoufi![]() | Sayf Al-Ashqar
| Sayf Al-Ashqar![]()
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Face recognition technique has been one of the most important and intriguing fields of detection and observation recently. This is due to the increasing need for real-time, automatic recognition, and surveillance systems, as well as the growing interest in the human visual system's role in face recognition and the design of human-computer interfaces. The most modern methods used for this purpose are dependent on the neural network, especially the deep neural network. Typically, the conventional process of any face recognition system mainly consists of three stages: face detection, feature extraction, and face recognition. An attendance system based on detecting and recognizing the faces of employees or visitors at the University of Mosul in Iraq is presented, the proposed method recognizes the detected faces whether they belong to the university employees or not. The main contribution of this paper is combining intelligent techniques in an important application. By using this method, the faces of both employees and visitors can be detected and recognized immediately in each image. The Viola-Jones method is used for the face detection stage, while the second and third stages are combined due to the use of a deep learning approach. Convolutional Neural Networks (CNNs) as deep intelligent techniques are employed to extract features, followed by training the system with provided samples. This work gets its strength from the deep learning that extracts features using multiple layers in a convolutional manner. A robust image recognition mechanism is utilized to achieve high accuracy in the results, reaching a success rate of 96% across various image samples and scenarios. The proposed model of face recognition is mostly used in real-time applications, as they can be deployed in other universities or organizations.
face, recognition, detection, CNN, viola jones, university employee
The proposed technology enabled the PCs (Personal Computers), besides the other types to understand the visual surrounding world called computer vision. This led to the need for image processing techniques, which are related to performing many processes on images which may include enhancing, denoising, segmentation and other methods. One of the main applications of image processing is face detection, which is used in many applications nowadays. The face recognition technique usually depends on extracting facial features from the detected face.
According to the more sensitive nature of face recognition technology, it is very important to keep in mind that this confidential data must be handled with great care and caution regarding the academic areas that are concerned with students’ belongings and their data regarding methods of impersonating some personalities or attending exams on behalf of other students by exploiting similarities Therefore, many details in the face should be considered in any face recognition to increase safety, reliability and accuracy in identifying characters. The persons, whose photos were posted later on, agreed to use their photos in this study.
Most of the environments and fields have become in touch with the detection and vision techniques, especially when the cameras have to be used. The given data from cameras are used today to detect objects, persons, cars, surveillance systems, traffic monitoring systems, security systems, moving object detections [1, 2], robotic systems [3, 4], and sustainable applications [5]. The real-time systems, which depend on the usage of cameras, are mostly behaved with real video that consists of multi-images displayed in a high frequency. These images have to be captured during their display and listed according to their content. The object or a person is detected inside the captured image according to many processing and operations due to the desired application. The most important part of the person’s detection process is the face; as the face is mostly captured from an image or a video source. Besides, face detection is usually considered as a part of the computer vision field which is known as face detection or recognition. Face detection or face recognition has become popular in recent years with the development of computerized power. This type of detection has a very expanded application range as it includes retrieval systems of a content-based image, biometrics, video processing and photography [6]. People recognition is one of the most important topics in the field of biometric engineering. The face is among the different types of biometrics used for human recognition. This type of biometric, which is ubiquitous, can be acquired in environments as it is unconstrained while providing features that are strongly discriminative for the recognition. For that reason, face recognition has become a very important tool which is used for increasing the capabilities of automatic surveillance video, security systems, and software video analysis, inside thousands of applications in daily life such as entertainment, automatic face tagging in the collections of photos, and smart shopping [7]. In this paper, a proposed method, which gave robust performance and accurate results, especially in real-time applications, is presented. This study adopts a Convolution Neural Network (CNN) as its algorithm can extract the features and classify the objects (faces) in predefined classes. The Haar-like is used in Viola Jones to extract features in face detection. Because of adopting CNN, the convolutions and max pooling techniques are used to get the best face features. Viola-Jones is selected due to its rapid face identification process and is more effective in recognizing potential face areas using Haar-like features. Regions of interest are rapidly narrowed down by this method. After that, CNNs are used for face recognition, taking advantage of their capacity to acquire complex facial traits and attain a high degree of accuracy. The combined method is efficient for real-time applications in a various environmental setting, it strikes a compromise between speed and precision.
The proposed methods are applied to detect and recognize the employees at the University of Mosul in Iraq.
Biometric systems can use physical characteristics of individuals like fingerprints, iris, and faces, or use other characteristics like speech patterns, walking and signatures [8]. Face recognition is one of the most important biometrics that is used in many fields [9]. In this part, a brief review with some related works is presented and classified into two categories: 1) face detection methods, which are used for face recognition, 2) face recognition methods. In face detection techniques, researchers introduce many different algorithms. Huang et al. [10], introduced the problem of rotation invariant detection with a high accuracy and speed. They developed the structure's tree of WFS for the face detection construction and got a high detection accuracy. Singh et al. [11] addressed a proposed method for many different images’ sizes of the front face having variation in the expressions. They used Morphological Operations and the Sobel Edge Detection, which got a reliable result for the frontal face but they did not take the different situation for face. The paper behaves with the method of Viola-Jones that is related to the problems of detecting faces in images introduced by Egorov et al. [12], which gets a high face detection accuracy in a short time. Geng et al. [13], introduced a method, which is based on a subspace called ISS. A neural network structure that is called ISNN is proposed to realize the ISS to get superior performance. The Model of geometry is usually used to describe the relation of distribution among the points of feature. These features can provide information in face recognition. The experimental results showed that the proposed performance is much better than the other two well-known methods of the face (EBGM, POEM), and had a hard potential to apply the applications that are real [14]. In the study, Arsenovic et al. [15] introduce a new deep-learning method based on images of face recognition. The accuracy overall reached "95.02%" on a relatively small set of data in the original face images of persons in the real-time environments. In this paper, the mentioned methods (Viola-Jones) and (CNN) are considered for detection and recognition purposes which are special face detection applications used to detect and recognize the employees at the University of Mosul.
Face detection, face recognition, and other biometric techniques were improved and developed due to their importance and rapid use in most fields. Many methods were implemented and developed for this purpose. The following are the most used dependent methods in this paper.
One of the most powerful computer vision technologies is face detection and recognition which has become revolutionary and interacted with the surrounding life due to its important applications which are usually dependent on it.
Face detection is used for human face detection in images or videos. Face detection models depend on different techniques that rely on human face features. Face detection has a wide range of applications today. It is not related to detecting human faces only, but it is related to identifying those faces to whom they belong. This is achieved by extracting unique facial features for each face and comparing them with the database of known faces. Face detection simply detects faces while face recognition identifies the face.
3.1 Viola-Jones face detection
Face detection problems were analyzed precisely by using Viola and Jones methods [16]. The Viola and Jones techniques include using the captured images of faces for training. These images are considered to have a size of 24×24 pixels for each. The mentioned method assumes that the relevant features could appear or arise anywhere in each one of the dependent images. Firstly, they excluded and were far from concentrating on the clear “obvious” features. Ears, eyes, mouth, and nose have to be detected as features. Additionally, they usually exclude the colors and skin-tone during the detection, preferring to analyze the faces in terms of intensity characteristics' profile. The Viola-Jones method is based on many steps of processing, which includes the process of obtaining the integral image using cascaded classifiers which are mostly “weak”. This method or technique is called "Haar". Generally, there are three techniques used by the Viola-Jones method [16], these techniques are:
In this method, the obtained classifier has many filters. When the best classifiers are cascaded, the regions "pixels" of the face and the regions of non-face should be separated. The object detection cascaded framework controls face detection. The most important advantage of the proposed idea is that it can detect faces regardless of the illumination condition. The feature extraction operation (Haar filter is used here), which uses the Haar cascaded classifier, is the main part of this step. The Haar features are mostly giving the impression that at least one feature is presented in the dependent image. Each of these features returns a unique value, which is obtained by calculating the difference between the summation of pixels in the white space region, and the summation of pixels in the black space region. In order to decrease the processing time of the features’ face detection, Haar’s features are considered as a rectangular-shaped region. Many of Haar filters (Figure 1) are usually used in face detection, which include the following steps.
The first step is represented in Haar-like features selection; the selected image is fed to the system as input data (Figure 2). The procedure of this step involved a scan process for all the parts of an image, beginning from the top left pixel (point) to the last point in the right bottom. In this process, and until scanning of the last point, an examining process is applied to ensure that all the face’s features are presented. To detect and select many human faces in images, the scan process has to be repeated many times using Haar features. In this method, the rectangular features are selected and calculated rapidly, due to the integrated image usage. Whenever the mentioned method is applied, four values are expected to be used, these values are used to represent the corners (points of the mentioned rectangle) [12]. Referring to Figure 1, the values at points (a, and b) are given by calculating the summation of all the pixels that are located above and left the points (a, and b).
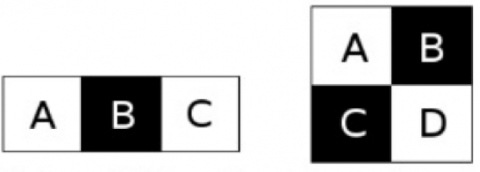
In Figure 2, Haar-like features appear clearly. There is only one region that includes the letter (A) written in black space. Thus, as an equation, it can be written as: f0 (x)=A. In Figure 3, two other examples of filters can be shown.
Figure 1. Haar features
Figure 2. Haar-like features
Figure 3. Haar like filter
The filters shown in Figure 3, are given according to the equations f1(x), and f2(x), where f1(x) = (B – A - C), and f2(x) = (B + C - A*D)". In the Voila Jones algorithm, a window with a 24×24 pixels size has been used as a based window for the purpose of feature evaluation in the given image. Generally, and due to the use of this mentioned window that has dimensions of "1, 60, 000", features cannot be calculated. Thus, the method of the Ada boost is dependent and used as a technique of machine learning to complete the features calculation. Referring to the mentioned case, the Ada Boost machine learning efficiently selected the best features, out of "1, 60,000" features. The Ada boost machine learning is formed as the strongest classifier due to the combination technique which is applied for the linear parts of the weak classifier, which is given as:
$F(x)=\alpha 1 F_1(x)+\alpha 2 F(x)+(2)$
In case the image passes through all of the stages successfully, it can be identified as a person's face. However, it cannot be classified as a person's face when it fails at any one of these mentioned stages. This situation obtains the final description of the algorithm those are used [10, 17]. Viola-jones is a very effective method for face detection, while Haar features are more effective when used by Viola Jones in extracting face features, especially for real-time face detection.
Simple patterns called Haar features are used to represent the changes in intensity between neighbouring areas in a picture; they seem like rectangular pieces of black and white covering particular parts of a face. These designs are intended to draw attention to the common edges, lines, and textural variations seen in facial structures. Two, three, and four rectangle features are a few instances of Haar features for face detection:
The total pixel intensities in the white regions are abstracted from the total pixel intensities in the black regions to compute a Haar feature. This difference yields a numerical number representing the contrast level of the particular facial feature. In face detection, Haar features work well for the following reasons:
The classifiers’ cascade is usually used by the Viola-Jones algorithm to boost efficiency even more; the more complicated features have to be concentrated on possible faces, and to reduce needless computations, simpler features are utilized to eliminate non-face regions rapidly.
3.2 CNN deep learning
The deep learning approach is used in both academic and practical application fields, it is usually used in recognition applications such as image recognition and voice recognition [18]. The Convolutional Neural Network (CNN) which is considered a deep learning method, is also used for the same purpose also, it is used for purpose of recognition like finger vine recognition [19], ECG system [20] speech emotion recognition [21], palm-print [22], Therapeutic process [23, 24], and IOT systems [25]. The main difference between traditional machine learning and deep learning is represented in their main work. Deep learning includes internally the feature extraction process, while traditional machine learning does not include the feature extraction process. Thus, it should be performed separately. One of the most popular examples of the learning machine in recent years is based on the approach of deep learning, which is known as a CNN. It can be identified as an innovative technique relatively, used in the area of computing for the purpose of analyzing visual data. Really, the CNN exploitation, which is used for face processing and face recognition is noteworthy. The CNN is used to supervise the techniques of machine learning that can extract “deep” information from the dataset by the rigorous example that is based on the training in a sense. This approach mimics how the human brain undertakes the methods’ types of learning process. The CNN has been successfully applied to the extracted features in images during the recognition of the persons’ faces, image sections' classification, and also segmentation. As shown here, the increase in using CNN in recent years goes alongside the ability of them to learn the complex features using the multi layered nonlinear type of architecture. Originally, the CNN returns to the beginning of 1990 [26]. The predominant skepticism of the gradient descent must always be over the fit. The main argument that is used for, has been a gradient based on the optimization methods, which are led to get the stuck in the local minima. In recent years, these assumptions have usually been overturned, because of the trusted results of CNN that has produced across many research domains. Due to this time, the state-of-the-art learned deep models, which are based on architectures of the CNN, are mostly being used in the visual domains that are computed [27].
A popular variant of Convolutional Neural Networks (CNN) is comparable to the multi-layer perceptron (MLP), and comprises multiple convolution layers followed by sub-sampling (pooling) layers and fully connected (FC) layers at the end. In Figure 4, an example of CNN architecture for image classification is shown. Feature extraction is a crucial procedure, it employs convolutional tools to isolate and identify distinctive characteristics within an image for analysis. The feature extraction network typically consists of numerous pairs of convolutional and pooling layers. The fully connected layer utilizes the output from the convolutional process to determine the image's class based on the previously extracted features. This CNN feature extraction model aims to reduce the dimensionality of the dataset by generating new features that consolidate the information from the initial set of features into a single, comprehensive feature [28].
Figure 4. An example of CNN architecture for image classification
Many applications in different fields, which are considered relatively innovative, were depended on using the CNN technique. In the study [29], CNN is suggested to be used for a project of designing a smart city. In the study [30], CNN is used to design a real-time attendance system; in other hundreds of applications, the CNN is depended and continuing used for the purpose of recognition.
In this paper, the proposed method is advised and utilized for a variety of cases in a MATLAB environment, prior to its implementation with the academic data set; the method is recommended to be employed in attendance applications due to its accuracy and its limited consuming time, which make it suitable to be advocated for usage in real-time application.
As with any research work, the first step is represented in collecting the data set; as mentioned before, the environmental work takes place at the University of Mosul in Iraq, in two construction sites: the central library and the College of Engineering. The faces of many employees are collected to be started with; to do that, a mobile camera is utilized to capture and acquire images of a computer; this process is carried out for both the training and the testing steps. All the experimental works are achieved under MATLAB 2019, depending on the IP camera toolbox (computer side), and the IP application’s camera (mobile side). The MATLAB 2019 environment is selected to perform the system regarding to robustness of the utilized platform for image processing, besides the scientific computing that has a track record of dependability. The image processing toolbox provides pre-built functions for acquiring, manipulating, and analyzing images. Also, the dependent algorithms for face detection and recognition are usually provided by a smooth integration with the computer vision toolbox. It offers simple IP camera connections, video processing, and event triggers; it is important to refer that the IP camera MATLAB toolbox is utilized, and the mobile camera is usually portable and reasonably priced. According to all of these mentioned details, a combination of environments’ work is accomplished between the mobile application and the MATLAB toolbox. To implement the mentioned steps, a simple code is prepared to acquire about 30 samples (images) for each class (person), and then depend on these samples for training and testing purposes. After acquiring the images, different processing techniques have to be applied. The first technique is represented by converting the image to the greys scale, and the second step is represented by filtering the resulting image for the purpose of noise removal. More than one type of filtering process can be used to enhance the image and eliminate the remaining noise; a median filter is mostly used for this purpose due to its suitability and good example for this process.
Regarding the images and signal processing fields, the median filter is mostly relied on as a very useful tool, especially when it is used for the purpose of noise reduction; it is considered one of the best options for face detection. median filter is generally not influenced in contrast to the linear filters by salt-and-pepper noise, and maintaining the edge. Compared to averaging filters, non-linear operation preserves edges and details better. On the other side, the computational efficiency outperforms the complicated filters due to their simple sorting mechanism [31].
The following Figure 5, shows the main steps of this paperwork system (training phase), in order to detect faces inside the captured images, and after the completion of the images’ preparation steps, the Viola Jones is applied then to seek faces in all image parts. Whenever more than one face has appeared in an image, the system will detect them, return the IDs, and the location of each appeared face; the following Figures 6 and 7 show different individual faces detected in different images. This approach showed a success face detection for different face situations.
Figure 5. Block diagram
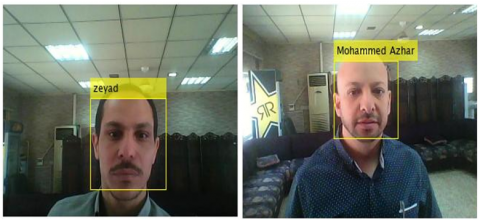
Figure 6. Single face detection (I)
Figure 7. Single face detection (II)
In Figure 8, multi-faces images are introduced to demonstrate the efficacy of the employed method in detecting multiple faces within each image. Usually, any method is susceptible to encountering a problem; in this paper, the proposed detection method suffered from a non-recognition problem, when low illumination is considered to be happening in the scene; this problem mostly led to a failure in face detection in the corresponding image, Figure 9. Another drawback happens when the face is rotating at more than 20 degrees; in this case, the detection algorithm will miss the face, and the result then will lead to be appeared as it is clear (no faces have to be detected) as shown in Figure 10.
Figure 8. Multi face detection
Figure 9. Illumination bad effect in face detection
Figure 10. Face detection for rotated face
After the completion of the face detection process, the recognition process has to be carried out; the detected images that contain one face have to be a part of the training phase data set. In each depended image, the face has to be cropped, and then the cropped part must be resized to become ready for the processing phase, which is held on by the Convolutional Neural Network (CNN). The CNN image size should be equal to 227*277 in pixels; the image must resize to be compatible with this used type of neural network. Deep learning algorithms typically aim to acquire a range of representations by employing a multi-layered hierarchy. Whenever the system is provided with tons of information, it has to understand and respond to the output coming signals in useful ways. A CNN, which has a convolutional layer, has a number of filters that do the convolutional operation. The CNN then classifies the entered data set according to a number of classes that have been entered in a special folder containing the data set; each of these classes has to be labelled. In this paper, eight persons were dependent, according to that, eight classes are considered. In Table 1, the eight (8) selected classes with their details (Names, employees or not, position, and their faces), in which the work is achieved to recognize them from many persons or visitors at the university site (Central Library and Mechatronics Engineering Department as examples). Each class contains ten images (10) for each person (employee). As the most used deep neural network method, CNN was utilized to separate the data set into two groups: the training and the testing groups. The first group includes (70%) of images that contain the faces of university employees; this group is used for the training process (phase). The second group which includes (30%) of the images and includes faces of university employees, is used for the testing phase. The second group, which has (30%), is on validating the system; this is because the CNN is considered a supervised network; therefore, it is important to make the validation set to update the weights of the network.
Table 1. Detected faces details
|
No. |
Name |
Employee/ Not Employee |
Position |
Face |
|
1 |
Muhamad |
Employee |
Mechatronics Department |
|
|
2 |
Zeyad |
Employee |
Mechatronics Department |
|
|
3 |
Saeed |
Employee |
Mechatronics Department |
|
|
4 |
Abdullah |
Employee |
Mechatronics Department |
|
|
5 |
Sayf |
Employee |
Central Library |
|
|
6 |
Stranger |
Not Employee |
Visitor |
|
|
7 |
Dhafar |
Employee |
Central Library |
|
|
8 |
Stranger |
Not Employee |
Visitor |
The accuracy that was gotten from the training set is about 96%. As shown in Figure 11, the depended system includes about 100 epochs, but it is fixed at epoch 50. Therefor there is no need for extra training, because no changes are happened, in addition to the reduction in the training consuming time.
To ensure that, this work is properly needs to use test for the system. The system is tested using 80 images (ten images for each class), and the system performs all steps in the training stage. The following Figure 12 shows the test steps of the work.
The testing system of this work consists of ten images for each person (employee). Whenever the image is delivered to the system, the faces should be detected, even when more than one face appears in the image. After that, each face has to be classified into one of the considered classes (8 class) that are trained in this system. One of the crucial challenges of this work is that even if the detected face is not related to the classes of this system, the detected face has to be enrolled in a special class for strangers. In the following Figure 13, the system is successful in classifying faces into corresponded classes.
Figure 11. Deep learning-training phase
Figure 12. Test phase block diagram
Figure 13. Single face recognition
Figure 14. Classes accuracy
The resulting accuracy of the test stage showed that more than 96% of the detected faces were classified successfully, while less than 4% of them were detected as faces but failed to be classified according to their classes. Figure 14 includes some of the proposed system results. The accuracy of each lass is utilized as a part of the graph that is shown in Figure 14.
The system is examined and succeeded in being used in real-time, in more than one situation, even in a cluttered environment as it is shown in Figure 15. Finally, the system succeeded in classifying multi-face in the image.
Figure 15. Real time face recognition
Face recognition systems find extensive applications in the field of biometric technology. In this paper’s approach, the Viola-Jones method is employed for face detection known for its robustness and real-time performance. However, it does have limitations and struggles with face detection of faces at certain angles, particularly when the face is rotated by approximately 20 degrees. To address this limitation, we leverage Convolutional Neural Networks (CNN) for face classification. This approach yields impressive results, with the test stage achieving an accuracy rate of approximately 96%. In some cases, around (3-4%) of the input images may fail to be correctly classified. The proposed system demonstrates robustness in real-time face recognition, whether dealing with single or multiple faces. Nevertheless, variations in illumination levels negatively affect both the detection and recognition phases, occasionally leading to misclassifications. Although the suggested method demonstrated resilience, further researchers could investigate the use of deep learning for both face detection and recognition which is also used to overcome the problem of rotating images.
The authors express their gratitude to the staffs of the college of engineering, as well as the staff of the central library /university of Mosul for their invaluable assistant and support.
[1] Abdilatef, M.A. (2014). Moving object detection in industrial line application. (Doctoral dissertation). ResearchGate. http://doi.org/10.13140/RG.2.2.32398.05448
[2] Abdilatef, M.A. (2016). A comparison between moving object detection methods including a novel algorithm used for industrial line application. International Journal of Computer Applications, 152(1): 20-28. http://doi.org/10.5120/ijca2016911753
[3] Yosif, Z.M., Mahmood, B.S., Al-khayyt, S.Z. (2021). Assessment and review of the reactive mobile robot navigation. Al-Rafidain Engineering Journal (AREJ), 26(2): 340-355. https://doi.org/10.33899/rengj.2021.129484.1082
[4] Alobaidy, M.A.A., Saeed, S.Z. (2023). A comparative study of multi-layer perceptron and Jordan recurrent neural networks for signals classification in a robotic system. Journal Européen des Systèmes Automatisés, 56(4): 547-551. https://doi.org/10.18280/jesa.560404
[5] Anaz, A., Kadhim, N., Sadoon, O., Alwan, G., Adhab, M. (2023). Sustainable utilization of machine-vision-technique-based algorithm in objective evaluation of confocal microscope images. Sustainability, 15(4): 3726. https://doi.org/10.3390/su15043726
[6] Özdil, A., Özbilen, M.M. (2014). A survey on comparison of face recognition algorithms. In 2014 IEEE 8th International Conference on Application of Information and Communication Technologies (AICT), IEEE, pp. 1-3. https://doi.org/10.1109/ICAICT.2014.7035956
[7] Wang, M., Deng, W. (2021). Deep face recognition: A survey. Neurocomputing, 429: 215-244. https://doi.org/10.1016/j.neucom.2020.10.081
[8] Taskiran, M., Kahraman, N., Erdem, C.E. (2020). Face recognition: Past, present and future (a review). Digital Signal Processing, 106: 102809. https://doi.org/10.1016/j.dsp.2020.102809
[9] Singh, G., Goel, A.K. (2020). Face detection and recognition system using digital image processing. In 2020 2nd International Conference on Innovative Mechanisms for Industry Applications (ICIMIA), IEEE, pp. 348-352. https://doi.org/10.1109/ICIMIA48430.2020.9074838
[10] Huang, C., Ai, H., Li, Y., Lao, S. (2007). High-performance rotation invariant Multiview face detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 29(4): 671-686. https://doi.org/10.1109/TPAMI.2007.1011
[11] Singh, A., Singh, M., Singh, B. (2016). Face detection and eyes extraction using Sobel edge detection and morphological operations. In 2016 Conference on Advances in Signal Processing (CASP), IEEE, pp. 295-300. https://doi.org/10.1109/CASP.2016.7746183
[12] Egorov, A.D., Divitskii, D.U., Dolgih, A.A., Mazurenko, G.A. (2018). Some cases of optimization face detection methods on image (Using the Viola-Jones method as an example). In 2018 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus), Moscow and St. Petersburg, Russia, pp. 1075-1078. https://doi.org/10.1109/EIConRus.2018.8317276
[13] Geng, X., Zhou, Z.H., Smith-Miles, K. (2008). Individual stable space: An approach to face recognition under uncontrolled conditions. IEEE Transactions on Neural Networks, 19(8): 1354-1368. https://doi.org/10.1109/TNN.2008.2000275
[14] Huang, Y.S., Chen, S.Y. (2015). A geometrical-model-based face recognition. In 2015 IEEE International Conference on Image Processing (ICIP), IEEE, pp. 3106-3110. https://doi.org/10.1109/ICIP.2015.7351375
[15] Arsenovic, M., Sladojevic, S., Anderla, A., Stefanovic, D. (2017). Face Time Deep learning, based face recognition attendance system. In 2017 IEEE 15th International Symposium on Intelligent Systems and Informatics (SISY), pp. 000053-000058. https://doi.org/10.1109/SISY.2017.8080587
[16] Nehru, M., Padmavathi, S. (2017). Illumination invariant face detection using viola jones algorithm. In 2017 4th International Conference on Advanced Computing and Communication Systems (ICACCS), IEEE, pp. 1-4. https://doi.org/10.1109/ICACCS.2017.8014571
[17] Alyushin, M.V., Alyushin, V.M., Kolobashkina, L.V. (2018). Optimization of the data representation integrated form in the viola-jones algorithm for a person’s face search. Procedia Computer Science, 123: 18-23. https://doi.org/10.1016/j.procs.2018.01.004
[18] Wu, D., Zheng, S.J., Zhang, X.P., Yuan, C.A., Cheng, F., Zhao, Y., Lin, Y.J., Zhao, Z.Q., Jiang, Y.L., Huang, D.S. (2019). Deep learning-based methods for person re-identification: A comprehensive review. Neurocomputing, 337: 354-371. https://doi.org/10.1016/j.neucom.2019.01.079
[19] Zhao, D., Ma, H., Yang, Z., Li, J., Tian, W. (2020). Finger vein recognition based on lightweight CNN combining center loss and dynamic regularization. Infrared Physics & Technology, 105: 103221. https://doi.org/10.1016/j.infrared.2020.103221
[20] Li, Y., Pang, Y., Wang, K., Li, X. (2020). Toward improving ECG biometric identification using cascaded convolutional neural networks. Neurocomputing, 391: 83-95. https://doi.org/10.1016/j.neucom.2020.01.019
[21] Qayyum, A.B.A., Arefeen, A., Shahnaz, C. (2019). Convolutional neural network (CNN) based speech-emotion recognition. In 2019 IEEE International Conference on Signal Processing, Information, Communication & Systems (SPICSCON), pp. 122-125. https://doi.org/10.1109/SPICSCON48833.2019.9065172
[22] Alobaidy, M.A.A., Yosif, Z.M., Alkababchi, A.M. (2023). Age-Dependent palm print recognition using convolutional neural network. Revue d'Intelligence Artificielle, 37(3): 795-800. https://doi.org/10.18280/ria.3700328
[23] Anaz, A., Skubic, M., Bridgeman, J., Brogan, D.M. (2018). Classification of therapeutic hand poses using convolutional neural networks. In 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), pp. 3874-3877. https://doi.org/10.1109/EMBC.2018.8513260
[24] Abdullah, N.Y., Al-Kazzaz, S.A.A. (2023). Evaluation of physiotherapy exercise by motion capturing based on artificial intelligence: A review. Al-Rafidain Engineering Journal (AREJ), 28(2): 237-251. https://doi.org/10.33899/rengj.2023.138562.1235
[25] Qaddoori, S.L., Ali, Q.I. (2023). An efficient security model for industrial internet of things (IIoT) system based on machine learning principles. Al-Rafidain Engineering Journal (AREJ), 28(1): 329-340. https://doi.org/10.33899/rengj.2022.134932.1191
[26] Elmahmudi, A., Ugail, H. (2018). Experiments on deep face recognition using partial faces. In 2018 International Conference on Cyberworlds (CW), IEEE, pp. 357-362. https://doi.org/10.1109/CW.2018.00071
[27] Pranav, K.B., Manikandan, J. (2020). Design and evaluation of a real-time face recognition system using convolutional neural networks. Procedia Computer Science, 171: 1651-1659. https://doi.org/10.1016/j.procs.2020.04.177
[28] Alzubaidi, L., Zhang, J., Humaidi, A.J., Al-Dujaili, A., Duan, Y., Al-Shamma, O., Santamaría, J., Fadhel, M.A., Al-Amidie, M., Farhan, L. (2021). Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. Journal of Big Data, 8: 1-74. https://doi.org/10.1186/s40537-021-00444-8
[29] Praveen, G.B., Dakala, J. (2020). Face recognition: Challenges and issues in smart city/environments. In 2020 International Conference on COMmunication Systems & NETworkS (COMSNETS), IEEE, pp. 791-793. https://doi.org/10.1109/COMSNETS48256.2020.9027290
[30] Winarno, E., Al Amin, I.H., Februariyanti, H., Adi, P.W., Hadikurniawati, W., Anwar, M.T. (2019). Attendance system based on face recognition system using CNN-PCA method and real-time camera. In 2019 International Seminar on Research of Information Technology and Intelligent Systems (ISRITI), IEEE, pp. 301-304. https://doi.org/10.1109/ISRITI48646.2019.9034596
[31] Gonzalez, R.C., Woods, R.E. (2008). Digital Image Processing (3rd ed.). Prentice Hall.