Sriharsha Vikruthi* | Maruthavanan Archana | Rama Chaithanya Tanguturi
© 2022 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
One of the fundamental functions of traffic monitoring systems is vehicle detection. However, vehicle detection is typically hampered by the shadow problem. Objects are sometimes lost or their shapes are distorted because shadows are misunderstood to be elements of a vehicle. Shadows are a major problem for the current vehicle detecting technology. For video target segmentation, a moving shadow can be easily mistaken for a portion of the object due to their similarity, and the processing speed of classic shadow eradication methods is insufficient for a real-time intelligent transport system. For the purpose of removing shadows, a novel technique is suggested in this research. There are a number of issues that arise as a result of this, including the destruction of objects and the warping of their original shapes. Many algorithms, including deep learning ones, ignore the shadow problem, which contributes to the poor accuracy of vehicle recognition. The shadow problem can reduce the accuracy of vehicle detection, hence traditionally, vehicle detection has been a part of traffic monitoring structures. Vehicle components cast in a shadow may be misidentified, and users may have to deal with the loss of items or the distorting of their shapes. Since the problem could be caused by inaccurate data, the shadow reduction technique is the primary method for improving precision during the vehicle detection procedure. This research presents a method for removing shadows from an image by first identifying the foreground regions using edge data, and then detecting and removing the shadows using prior knowledge based on the image's grayscale data. According to the results of the performance analysis, the suggested method outperforms similar methods in detecting vehicles, hence it will be used in future Intelligent Transportation System deployments.
vehicle detection, foreground region, background region, shadow detection, shadow elimination, edge detection
There are a number of issues plaguing city traffic today, including an increase in the number of cars that must be managed [1]. The vehicle detection is the essential duty for managing the traffic system as many strategies are employed for getting the accuracy [2]. In most cases, increasing speed at the expense of accuracy is acceptable, but the improved detection strategy minimizes this trade-off by identifying and prioritizing the most important vehicles to detect. The shadow is a major concern because it has been misidentified as components of the vehicle, leading to form distortion and object loss, among other problems. The shadow concerns were ignored by many methods, including deep learning methods.
With the help of the edge map concept and the edge detection technique, users can identify the shadow region that has a foreground and background edge [3]. To help with this, a backdrop edge extraction system that uses the vehicle's shadow to pinpoint the generic background area of the separated building is proposed. Grayscale data is identified using the position framework, allowing for the recognition of a dark-colored car among a collection of automobiles [4]. Due to its various benefits, video-processing-based moving vehicle identification has become increasingly popular in recent years within the context of intelligent transportation systems [5]. Standard moving object detection methods, however, are typically impacted by the dynamic background, such as varying illumination, and do not reduce the shadow, which makes further image processing difficult. The vehicle detection and its shadow detection samples are shown in Figure 1.
Figure 1. Vehicle and shadow detection
Recently, video processing-based moving vehicle identification has seen widespread use in the field of intelligent transportation systems [6]. However, there are also a number of issues, such as a moving shadow, a ghost region, and a dynamic background. Using the multi-frame averaging technique [7], a high-quality background image is first obtained; this background image is then used to initialize the background model, drastically decreasing the likelihood of a edge zone being created [8]. When there has been no motion in the last x number of frames, this frame will transition to the background image. To lessen the effect of the constantly changing backdrop on the foreground detection, a conservative updating technique and a foreground point counting method are used. Both civilian and military operations can benefit from vehicle recognition and tracking technologies, especially in areas like highway traffic surveillance, management [9], and urban transportation planning. Roadside vehicle detection processes serve a variety of purposes, including but not limited to vehicle tracking, count, average speed of each vehicle, traffic analysis, and vehicle classification, and can be put into action in a variety of environmental settings [10]. Objects are sometimes lost or their shapes are distorted because shadows are misunderstood to be elements of a vehicle. Erroneous data collection is a major problem, so eliminating shadows is essential for improving vehicle detection accuracy.
The counting based vehicle detection technique [11] has been implemented as initially extracted and segregated into a remote region and generates a segmentation procedure for enhancing the vehicle detection process. For the purpose of real-time traffic analysis, the trajectories of vehicles are determined so that counts of various types of vehicles can be obtained. SVM based classification algorithm has been used to automatically detect automobiles, analyse vehicle speeds, and monitor lane usage; all of these tasks are related to computer vision. The optimal flow technique [12] has been constructed to detect the shadow detection with HSV color space for marking the position and performing segmentation and finally performs the vehicle detection. The composite feature has been used to identify the bottom shadow by maintaining a threshold for discovering the target vehicle, the ROI function has the region features. The monocular vision related methodology has been utilized for vehicle distance calculation; the vehicle detection is achieved by effective multi-feature fusion method for enhancing the robustness and accuracy. The shadow detection and elimination of vehicles general process is shown in Figure 2.
Figure 2. Shadow detection and removal general process
The current state of vision-based vehicle object recognition can be broken down into two distinct categories: simpler machine vision techniques and more advanced deep learning techniques. In conventional machine vision systems, the vehicle's motion is used to isolate it from the static background. Background subtraction, continuous video frame difference [13], and optical flow are the three main subcategories into which this technique can be broken down [14]. The variance is determined by comparing the pixel values in two or three successive video frames using the video frame difference method. Moreover, the threshold differentiates the background from the foreground region that is in motion [15]. To further detect the vehicle's halt, this technique can be used to dampen background noise. Background information is utilised to create the background model when the background in the video is static. To segment the moving object [16], images from each frame are compared to the backdrop model. Optical flow is used to identify the video's dynamic regions [17].
The proposed technique is developed to provide the solution of shadow identification and the enhanced vehicle detection technique has been proposed to eliminate the shadow detection and accurate vehicle detection [18]. The proposed method mitigates traffic safety concerns about vehicle detection by taking into account the impact of shadows. We solved the problem of inaccurate vehicle detection and made great strides toward improving detection rates. When collecting foreground details from a given frame, the background edge extraction framework is utilised to identify and classify edges as either foreground or background. The front shadows were removed and the grayscale data was combined with existing knowledge [19]. The position framework's edge detection keeps track of where the cars' shadows fall and uses that information in conjunction with established facts to evaluate the after image [20]. The results of the tests show that the proposed method effectively gets rid of shadows and improves the accuracy of vehicle detection.
With the help of the edge map concept and the edge detection technique, we can identify the shadow region that has a foreground and background edge. To help with this, we built a backdrop edge extraction system that uses the vehicle's shadow to pinpoint the generic background region of the separated building. In order to distinguish a dark-colored car from a collection of vehicles, the position framework is utilized to recognize grayscale data.
The section 1 discuss about the vehicle detection and shadow detection and the process of detection is discussed clearly. The section 2 discuss about the literature survey and the section 3 explains the proposed model and section 4 represents the results and comparisons and section 5 concludes the thesis.
Shadow detection and elimination using discrete wavelet transform (DWT) was proposed by Lu et al. [1]. Because of its multi-resolution capability, DWT divides images into four distinct bands. Combining DWT with HSV (Hue, Saturation, Value) is central to the proposed approach. The Relative standard deviation, which is both more relevant and consistent than the standard deviation, has replaced the standard deviation as the new threshold value. In other words, the threshold can be determined mechanically, without the need for supervised learning or human intervention. The Wavelet Coefficient is the only variable in this method. For the videos, the proposed method is evaluated and analysed [2]. In addition, the procedure is well-suited to low-light environments and produces high-quality results regardless of whether they are conducted outside or indoors [3].
Arinaldi et al. [4] proposed an automatic shadow detection approach based on Near-Infrared (NIR) data. The technique takes advantage of the Near-infrared sensitivity of camera sensors. High quality bitwise shadow mask is generated from the input of both visible and NIR images. As a result, their algorithm performs best with raw photos (Raw images). In contrast to a segmentation-based approach, such as that of Sun et al. [5], and a pixel-based approach, such as that of Chen et al. [6], their proposed method yields computationally quick and accurate results and can perform well under complex illumination situations. The system works well overall, but it has a few weak spots: if an object has a lower reflectance in the NIR than in the visible picture, it may be incorrectly recognised as shadow, and if it has a greater reflectivity in the NIR than in the visible image, shadow may be overlooked [7]. The technique they describe is more adaptable, sturdy, and produces satisfactory results in both indoor and outdoor settings [8]. Considering that it could be expanded to include moving backgrounds in the future.
A strategy for building a three-shadow model was developed by Tai et al. [9]. The method eliminates the shadowing effect of the moving foreground by incorporating three features that are inherently robust to changes in illumination: Color Information, Peripheral Increment Sign Correlation (PISC), and Edge Information. The results are then improved by region-based analysis. The proposed solution is an improvement over in two cases: For better accuracy in the end product, the proposed method uses the HSV colour model instead of the YUV colour model, and streamlines the procedure. The parameters of the initial shadow model and automatic shadow detection should be the focus of their future study. It is claimed that the shadow model can be built without a clear reference image or prior knowledge of the final product.
For shadow identification from a single image, Lu et al. [10] suggested a Fuzzy split and merge solution with a fuzzy predicate. When it comes to fuzzy predicates, the ANFIS is the one who does the training (Adaptive Neuro-Fuzzy Inference System). The image is poorly represented in the tree form, thus the method begins with a top-down technique to segment it into four homogeneous quad tree blocks. Next, it employs a bottom-up strategy to combine the nearby homogeneous region by use of a fuzzy predicate [11]. According to the results of the analysis, the proposed strategy outperforms the alternatives [12].
The statistical discriminant model for CCTV monitoring was proposed by Redmon et al. [13]. To discriminate between static and dynamic shadows, the model first extracts features for classification, then uses statistical learning techniques like Partial Least Square (PLS) and Logistic Discriminant (LD), and lastly applies post processing to further refine the results. Their algorithm can automatically adjust to different indoor and outdoor conditions and requires only a small collection of labelled samples to detect moving shadows in the dark. The need for labelled samples can be reduced with the inclusion of semi-supervised learning to the model, which is something that should be worked on in the future.
A lot of works have been used for object detection from the video sequences, particularly in the traffic field. The intersection based vehicle detection data has been attained through the improved results while the moving vehicles in the already identified lane as it didn’t detect the vehicles in multiple lanes in the particular time period [14]. The contour growing technique [15] has been implemented to demonstrate the vehicle and the model is used to identify the vehicle location with the tracking process. The deep learning model has produced the considerable progress in the field of computer vision as the Convolutional Neural Networks and R-CNN plays the vital role for the improvement. Several techniques have been required the enhanced hardware and processing speed to increase the performance of the vehicle detection process as didn’t rely on the real-time requirements.
As a result of the failing shadow detection technique, even the most sophisticated algorithms, such as YOLO [16], SSD [17], would experience a decrease in detection accuracy. Color and geometry related techniques are generally utilised to eradicate the shadows. Using vectors, we can convert the RGB colour space into pixel space, illustrating the brightness and contrast through the chrominance process, and also establishing the backdrop framework enabled HSV colour space for recognising the shadow and brightness features [18]. For the purpose of developing the vehicle detection [19], the integration method has been constructed utilising the RGB related HSV colour space. The location and the length has been changed while executing in outdoor circumstances, so the Reference shadow model is utilised for recognising the shadows from the remaining frames in the video sequences.
In recent years, the advanced deep learning techniques like deep neural networks and neuro-fuzzy have been implemented for recognising the shadow from the input photos. Constructing the sophisticated backdrop model is necessary for offering answers to a number of difficult problems occurring in real time. The threshold settings for eliminating the shadows have been used according to numerous light intensity related concerns and can be implemented independently. Since it is difficult to show a connection between the characteristics of an object and its illuminating environment, the area sharing those characteristics and the colour of its shadow have been eliminated. The proposed technique should be created for eradicating the shadow from the objects according to the geometric data which needs the vehicle forms and also it needs to be satisfied the real-time Transportation system requirements.
In every video frame, an object extraction technique has been implemented according to the edge data and the entire process is demonstrated in Figure 3. The edge detection is used to identify the foreground regions, shadow area and the background edge extraction framework which needs for extracting the background edge of the specific region and finally extracting the foreground region using the edge map concept. The shadow problem is solved using the position framework for identifying the shadows and utilize the prior knowledge for analyzing the related cast shadows from the video frame sequences.
Technologies for accurately identifying and locating vehicles, as well as maintaining a safe buffer zone between them, have emerged as the primary focus of research into intelligent transportation systems. One of the most critical aspects of vehicle safety also happens to be one of the most relevant topics of study: vehicle detection and recognition. Malignant traffic accidents, including as rear-end collisions, can be efficiently avoided with real-time vehicle detection and recognition. Due to issues with poor contrast, excessive noise, and blurred edges in infrared images, this paper focuses primarily on preprocessing those images in a different colour space before applying a threshold segmentation technique and infrared image restoration to separate the foreground vehicle from the background. The majority of the information about in an object in an image is contained in its edges.
Figure 3. Edge detection process
The proposed technique is utilized for positioning the foreground regions with shadows and vehicles. The background edge extraction framework is used for extracting the generic background region of the specific frame and obtaining the foreground regions. The shadow issue has been solved using the position framework for locating the vehicle shadow and utilizes the prior data for identifying the related shadow casts. Initially, the background edge extraction framework is extracting the both edges and identifying the edge map. The Sobel operator is used for detecting the edges from the edge map δi and the logical AND operation of the similar frames of the edge map for identifying Bgi using Eq. (1).
$B g_i=\delta_i A N D \delta_{i+1} A N D \delta_{i+2} A N D \delta_{i+3} A N D \delta_{i+4}$ (1)
Noise, the backdrop edge of linked frames, and the AND logical operation on those frames should all be taken into account before the algorithm proceeds with erasing the object’s edges. The entire process is repeated while the shaking frame is identified, the logical OR operation on the related frames Bgi, Bgi+1, Bgi+2, …,… to discover the background edge map (BE) is computed in Eq. (2).
$B E=\delta_i \text { OR } \delta_{i+1} \mathrm{OR}_{i+2} \mathrm{OR}_{i+3} \mathrm{OR} \delta_{i+4}$ (2)
The background edge of the particular frame is perfectly extracted and enhance the proposed technique which has been performed with XOR operation from the Bg for discovering the extraction framework (ExBE). The squared (3x3) component A is used for extracting the frame in Eq. (3).
$E x_{B E}=B E X O R A$ (3)
The logical AND operation on δj and the extraction framework ExBE is used to discover the edge map in more accurately in Eq. (4).
$B E_j=E x_{B E} A N D \delta_j$ (4)
The logical XOR operation is used to identify the edge map in accurately of the specific frame BEj for generating the foreground edge map FEj in Eq. (5).
$F E_i=\delta_i X O R B E_j$ (5)
The morphological operations are performed to discover the foreground edge map for eliminating the noise and the edge detection technique has been maintained through the background elimination process as the little noise points are available. The shadows may be visible while the objects partially occlude from the sources of the light. A shadow may be the self-shadow as the objects are not illuminated from the light and the cast shadow is the projected object. The cast shadow has been identified through the simple differentiations from the background as it is useful for the object. The shadow region has been differentiated from the grayscale data; the color image has been converted into the shadow detection and eliminating through the proposed technique. The grayscale image has the data to differentiate the vehicle area to the shadow area. The shadow has been reflected to the object that reflects the vehicle side, the vehicle area normally contains the most complex texture framework compared to the shadow area. It normally has the texture framework; the edge is clearly visible and easily identified from the background region.
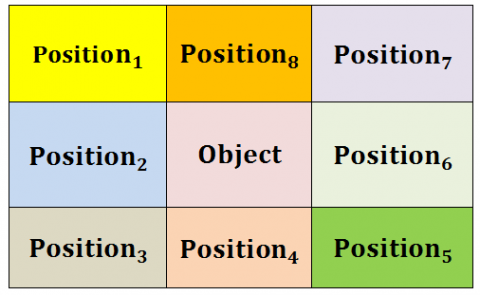
In every video frame, the foreground areas are extracted as the shadows and vehicles according to the proposed technique. The grayscale and edge data is used for detecting the shadows for the vehicle; the shadow region is very easy for detecting the vehicle and maintains the position related relationship within the cast shadow and the vehicle through the prior knowledge and the position parameter. The grayscale data is used for detecting the dark colored vehicle and several vehicles were coming in, the proposed technique is used to monitor the location where the vehicle shadows are available and the relative location within the cast shadow has remained unchanged for the long time. The object area in the boundary box centre position has 8 regions surrounded and marked with number in Figure 4.
Figure 4. Position framework
After completing the shadow detection process, the position framework is assigned to compute the foreground region. The vehicle region has been identified with the object region which is surrounded by the shadow casts; the threshold value is used to mark the object whenever the value of total pixels is larger than the threshold value. Hence the location of the shadow cast has been identified with the vehicle and the shadow region shape.
Algorithm – Shadow detection and elimination technique for Vehicle Detection
Step 1: The vehicles can be classified into the dark colored and light colored vehicles.
Step 2: The color judgment of the vehicle is based on the amount of largest pixels in grayscale pixels.
Step 3: The darkest regions are selected from the foreground area for the identified shadow region; it is demonstrated as the boundary area within the shadow and the vehicle.
Step 4: The foreground gray value is computed using Eq. (6).
$F G(k)=\frac{1}{\sum_{g(x, y)=0}^{255} 1} \sum_{g(i, j)=k} 1$ (6)
where, g(x, y) is the gray value for the location (x, y), the total amount of pixels in gray value is k to the total pixels in the video frames.
Step 5: The pixel ratio value is computed in Eq. (7).
$\rho(s)=\sum_{k=0}^s F G(k)$ (7)
where, s is the threshold value, if ρ(s)<0.1 is called as the identified shadow region.
Step 6: The Sobel operator is used for performing the edge detection as the identified texture and edge data from the foreground regions through the edge map process.
Step 7: The complex texture has been used to identified the empty elements in the edge map, the empty elements are identified as the shadow region.
Step 8: The identified shadow regions are computed in Step 4 and the marked region in Step 5.
Step 9: If there is no overlapped area after the process, the shadow region is very tiny and it can be ignored, otherwise go to Step 2 for further processing.
Step 10: The shadow region is estimated and identified the vehicle region, the location is updated.
Step 11: If the shape and location is not identified, the estimated shadow is the vehicle area so eliminate the mark.
Step 12: Repeat Step 9 until the identified region is matched with the prior knowledge.
The experiments are performed from the UA-DETRAC [15] dataset as the shadow elimination and vehicle detection strategy has been varied from single to multiple vehicles and compared the proposed technique with the related methodologies of YOLO [8] and SSD [9]. The UA-DETRAC benchmark is a difficult test of multi-object recognition and tracking in the real environment. The dataset consists of 24 separate video clips shot with a Canon EOS 550D camera over the course of 10 hours and taken in Beijing and Tianjin, China. Each movie has a resolution of 960 by 540 pixels and is captured at 25 frames per second (fps). The UA-DETRAC dataset contains over 140,000 frames and 8250 manually annotated cars, for a grand total of 1.21 million labelled bounding boxes of objects. Using the evaluation measures described on this site, we also conduct benchmark testing on state-of-the-art systems for object detection and multi-object tracking. The entire video sequences are captured by permanent cameras at several locations. The functionality of shadow detection of a light colored vehicle has the edge map and producing the edge map. The light colored vehicles can be easily segregated from the shadow, the experiments are conducted the entire detects of the shadow region and the location is updated with the shape, prior knowledge. While detecting the dark colored vehicle, the boundary within the shadow and the boundary have been varied. The expected shadow region consists of the un-illuminated region as the specific texture and edge features have been produced the shadow detection without any specific errors and the parameters are illustrated in Table 1.
Table 1. Parameters
|
Parameter |
Values |
|
Processor |
Intel i7-7700 HQ |
|
Software |
python 3.7 |
|
Open source |
OpenCV 4.5.1 |
|
Graphics |
Titan X Pascal |
|
Dataset |
UA-DETRAC |
|
Video sequences |
42 |
|
Identified vehicles |
684883 |
|
Video frames |
57234 |
The histogram is used to identify the type of vehicles as the light colored or dark colored and also the shadow region. The illuminated areas of gray values are more than 100 and the darkest part is 20 with the highlighted areas are around 200. The shadow region has the gray value of 100 that may vary according to the location as the boundary region within the shadow and the object is normally the darkest area while the gray values within 20 to 40. The gray values have the values within 20 to 105; the result in Figure 5 demonstrates that the weather is very good.
Figure 5. Histogram for gray values
The precision and recall are the specific indicators for measuring the vehicle detection performance. The precision is measured using the correctly predicted results from the entire prediction results and the recall is measured as the correctly predicted results from the total amount of vehicles. The location accuracy has been finalized using the mean IoU which specifies the overlap within the ground truth into the prediction boxes. The highest IoU score demonstrates the proposed technique could detect more vehicles than other related techniques in real-time environment. Figure 6 demonstrates the performance evaluation for the parameters of precision, recall and average IoU and the result demonstrates that the proposed technique is performed well compared to the related techniques.
Figure 6. Performance analysis for various parameters
The processing speed of the proposed technique is improved than the related techniques which maintain the reduced missed detection rate. The threshold value is utilized to provide the output score and to minimize the unwanted candidate box which is also used for detecting more number of vehicles and increase the recall rate. The occlusion within the objects couldn’t useful for detecting the vehicles as the largest threshold will cause the repeated detections and the inclusion of the shadow detection will enhance the detection accuracy and the speed comparison is illustrated in Figure 7.
The proposed technique is framed for predicting the coordinates with the boundary box and completes the detection through shadow detection and elimination technique, it is also used to identify the tiny objects in real-time environment. The multi-scale detection technique is involved to produce the improved accuracy of vehicle detection. The experimental result proved that the proposed technique has enhanced performance for vehicle detection compared to the related techniques which is demonstrated in Figure 8.
Figure 7. Frames per second
Figure 8. Vehicle detection rate
The observations from the Experimental results can be found that the occlusion and tiny regions are the primary reasons for detection failure for the related techniques and the detection result is accurate and stable for the proposed technique. The pixel value modification from the remaining images into the frame sequence is same as the specific images. The efficiency of the proposed technique has been verified as the vehicle detection process to frame by frame on the UA-DETRAC dataset. The shadow plays a vital role which produces the prediction as inaccurately for the related techniques which are not stable for vehicle detection demonstrated in Figure 9.
Figure 9. Comparison of vehicle detection
The monitoring of traffic is a crucial use case for video-based supervision systems. Researchers have been working on Vision-Based ITS, transportation planning, and traffic engineering applications for quite some time now in order to extract useful and accurate traffic data for traffic image classification and traffic flow control, such as vehicle status, vehicle path, vehicle tracking, vehicle stream, object classification, traffic density, traffic velocity, traffic lane changes, licence plate recognition, etc. In order to recognise vehicles in a complicated scene, it is necessary to first remove the shadow cast by them and then to classify them. Shadow reduction is an essential stage in the process of detecting moving automobiles in real-world traffic film. When something obscures the sun from a moving car, the outside becomes shadowed and needs to be reclaimed. This type of shadow, called a "dynamic shadow," moves in response to live things. Therefore, the segmented region of a moving vehicle is usually larger than the actual region, and the regions of two or more separated moving vehicles become stuck together, leading to errors. Simple yet effective, the proposed Shadow detection and removal approach for Vehicle Detection has the potential to offer workable answers to real-world issues. In addition to accurate vehicle detection, the proposed technique offers a low false-positive detection rate. As shown by a comparison to a real-time traffic monitoring system, the proposed strategy is superior. The suggested technology maintains high accuracy and superior vehicle detection in a time-efficient manner, making it applicable to use in high-volume, real-world traffic areas. Several different types of intelligent transportation systems could benefit from the proposed strategy.
[1] Lu, H., Zhang, Y., Li, Y., Jiang, C., Abbas, H. (2020). User-oriented virtual mobile network resource management for vehicle communications. IEEE Transactions on Intelligent Transportation Systems, 22(6): 3521-3532. https://doi.org/10.1109/TITS.2020.2991766
[2] Lu, H., Li, Y., Mu, S., Wang, D., Kim, H., Serikawa, S. (2017). Motor anomaly detection for unmanned aerial vehicles using reinforcement learning. IEEE Internet of Things Journal, 5(4): 2315-2322. https://doi.org/10.1109/JIOT.2017.2737479
[3] Song, H., Liang, H., Li, H., Dai, Z., Yun, X. (2019). Vision-based vehicle detection and counting system using deep learning in highway scenes. European Transport Research Review, 11(1): 1-16. https://doi.org/10.1186/s12544-019-0390-4
[4] Arinaldi, A., Pradana, J.A., Gurusinga, A.A. (2018). Detection and classification of vehicles for traffic video analytics. Procedia Computer Science, 144: 259-268. https://doi.org/10.1016/j.procs.2018.10.527
[5] Sun, W., Sun, M., Zhang, X., Li, M. (2020). Moving vehicle detection and tracking based on optical flow method and immune particle filter under complex transportation environments. Complexity, 2020: 1-15. https://doi.org/10.1155/2020/3805320
[6] Chen, X., Chen, H., Xu, H. (2020). Vehicle detection based on multifeature extraction and recognition adopting RBF neural network on ADAS system. Complexity, 2020: 1-11. https://doi.org/10.1155/2020/8842297
[7] Rezaei, M., Terauchi, M., Klette, R. (2015). Robust vehicle detection and distance estimation under challenging lighting conditions. IEEE Transactions on Intelligent Transportation Systems, 16(5): 2723-2743. https://doi.org/10.1109/TITS.2015.2421482
[8] Chen, Z., Lu, H., Tian, S., Qiu, J., Kamiya, T., Serikawa, S., Xu, L. (2020). Construction of a hierarchical feature enhancement network and its application in fault recognition. IEEE Transactions on Industrial Informatics, 17(7): 4827-4836. https://doi.org/10.1109/TII.2020.3021688
[9] Tai, J.C., Tseng, S.T., Lin, C.P., Song, K.T. (2004). Real-time image tracking for automatic traffic monitoring and enforcement applications. Image and Vision Computing, 22(6): 485-501. https://doi.org/10.1016/j.imavis.2003.12.001
[10] Lu, H., Yang, R., Deng, Z., Zhang, Y., Gao, G., Lan, R. (2021). Chinese image captioning via fuzzy attention-based DenseNet-BiLSTM. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), 17(1s): 1-18. https://doi.org/10.1145/3422668
[11] LeCun, Y., Bottou, L., Bengio, Y., Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11): 2278-2324. https://doi.org/10.1109/5.726791
[12] Girshick, R., Donahue, J., Darrell, T., Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 580-587.
[13] Redmon, J., Divvala, S., Girshick, R., Farhadi, A. (2016). You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 779-788.
[14] Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.Y., Berg, A.C. (2016). SSD: Single shot multibox detector, European Conf. Computer Vision, Berlin, 21-37.
[15] Hamid, R.M., Agrawal, R.K. (2018). Shadow detection and removal from moving object using neuro-fuzzy. Int J Res Eng Appl Manag, 3(10): 18-21.
[16] Kar, A., Deb, K. (2015). Moving cast shadow detection and removal from Video based on HSV color space. In 2015 International Conference on Electrical Engineering and Information Communication Technology (ICEEICT), pp. 1-6. https://doi.org/10.1109/ICEEICT.2015.7307443
[17] Brunel, S.M.J., Li, Y., Liu, X. (2017). Removing shadows from video. Int J Mach Learn Comput, 7(6):232–237.
[18] John, B.S., Hari, S., Rajam, A. (2018). An effective approach to shadow removal and skin segmentation using deep neural networks. Int J Innov Res Sci Technol, 4(12): 35-37.
[19] Wang, P., Wang, D., Zhang, X., Li, X., Peng, T., Lu, H., Tian, X. (2020). Numerical and experimental study on the maneuverability of an active propeller control based wave glider. Applied Ocean Research, 104: 102369.
[20] Wen, L., Du, D., Cai, Z., Lei, Z., Chang, M.C., Qi, H., Lyu, S. (2020). UA-DETRAC: A new benchmark and protocol for multi-object detection and tracking. Computer Vision and Image Understanding, 193: 102907.