Sentiment Analysis of the Documentary Film Ice Cold on Twitter: A Comparative Study of Machine Learning and Rule-Based Methods

Christine Dewi![]() | Ari Nugraha
| Ari Nugraha![]() | Dalianus Riantama
| Dalianus Riantama![]() | Ahthasham Sajid
| Ahthasham Sajid![]() | Mazliham Mohd Su’ud*
| Mazliham Mohd Su’ud*![]() | Muhammad Mansoor Alam
| Muhammad Mansoor Alam![]()
© 2025 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Sentiment analysis in the film industry represents a significant research area, particularly when applied to specific films or genres. The documentary film Ice Cold: Murder, Coffee, and Jessica Wongso provides a pertinent case study for such analysis. The Support Vector Machine (SVM) is employed to classify the sentiments expressed in reviews, social media posts, and other text data related to the film for sentiment analysis. This study analyzes Twitter sentiment data about the documentary film Ice Cold: Murder, Coffee, and Jessica Wongso by using three classification methods: SVM, Multinomial Naive Bayes (MultinomialNB), and Random Forest. The results indicate that SVM achieved the highest accuracy of 74.62%, followed by Random Forest at 74.43%. The MultinomialNB method yielded a lower accuracy of 62.40%. Additionally, two rule-based methods, Vader and Text Blob, were evaluated. Vader achieved an accuracy of 99.17%, while TextBlob reached 58.16%. These results highlight the performance differences between classification methods and rule-based methods, emphasizing the importance of choosing the appropriate method based on the data characteristics. Overall, SVM demonstrated the most effective method among the machine learning methods evaluated in this study.
sentiment analysis, Ice Cold, Cyanide Coffee, Twitter data, Vader
Sentiment analysis, also known as opinion mining, is a technique used to assess the emotional tone conveyed in a text. It leverages natural language processing (NLP) and machine learning (ML) methods to classify textual data such as positive, negative, or neutral sentiment. This approach is commonly applied to extract subjective information from various sources, including reviews, social media posts, customer feedback, and news articles, to understand public attitudes and perceptions toward specific topics, products, or events. Ultimately, the goal of sentiment analysis is to extract specific insights. Sentiment analysis is employed across various fields for multiple purposes.
For instance, in political analysis, sentiment analysis is utilized to predict election outcomes based on public sentiment toward competing presidential candidates, with proven accuracy in predictions [1]. In social services, a case study using text mining and sentiment analysis methods demonstrated that the Sembako/BPNT program received positive/negative feedback on Twitter, showing positive responses according to accuracy scores and evaluation metrics [2]. In the realm of conservation policy for biodiversity, sentiment analysis on the data used indicated consistency and reliability, suggesting that this dataset can be employed for further research, including topic modeling and related biodiversity policy studies [3]. Moreover, in product feedback analysis, experiments indicated that the Logistic Regression (LR) algorithm was the best classifier with the highest accuracy in detecting unfair reviews, not only in text classification but also in product reviews such as clothing, shoes, jewelry, baby products, and pet supplies [4, 5]. In healthcare services and patient feedback, the analysis results showed that the Health Service Executive (HSE) responds to public feedback desires but needs to improve proactive application engagement and address compatibility issues with older devices, particularly iPhones [6]. In investment analysis of cryptocurrency, the sentiment analysis demonstrated an average accuracy improvement of up to 25%, confirming that Twitter data related to cryptocurrency can be effectively used in developing profitable trading strategies using supervised ML [7]. In social media monitoring analysis, understanding daily emerging public sentiments was achieved. Experiments showed that using multi-class classification with deep learning algorithms provided more accurate results compared to binary approaches. The application of ML and deep learning techniques in classifying sentiments also demonstrated significant advancements [8, 9]. Furthermore, in product research analysis, sentiment analysis was conducted using appreciation theory to explore the sentiments expressed in tweets—particularly those reflecting attitudes, approval, and engagement toward products. The study compared positive and negative sentiments related to two popular smartphone brands in Indonesia: Lumia and Xperia. The findings revealed that Lumia received more positive responses than Xperia, providing valuable insights and strategic considerations for businesses, especially in marketing intelligence, to enhance their understanding of consumer responses to specific products [10]. Lastly, in provider branding review analysis, measuring a provider's brand reputation based on public perception of service quality was tackled by using sentiment analysis of customer feedback on Twitter. With a sample model extracted from the top three mobile providers in Indonesia, this research evaluated various feature extraction schemes, algorithms, and classifications to measure customer satisfaction with 3G, 4G, SMS, voice, and internet services [11, 12]. In the analysis of the IMDB review dataset, the research successfully addressed the challenge of gathering opinions from movie reviews by using neural networks trained on the Stanford movie review database, achieving an impressive final accuracy of 91%. This outcome demonstrates the success and relevance of sentiment analysis in providing comprehensive qualitative and quantitative insights into various aspects of films [13].
The main contributions of this research are as follows: (1) The use of data from the Twitter platform containing opinions related to the documentary film, along with corresponding positive or negative sentiment labels. (2) The objective of this experimental study is to compare various models to identify which has the highest accuracy and generalization. (3) This research employs various classification methods, including unsupervised learning techniques such as Vader and TextBlob, as well as supervised learning methods like Multinomial Naive Bayes (MultinomialNB), Support Vector Machine (SVM), and Random Forest. Different approaches are employed, including a count vectorizer, Term Frequency-Inverse Document Frequency (TF-IDF) vectorizer, minimum and maximum word count thresholds, and maximum feature limits. Additionally, this study adopts word embedding techniques and bidirectional Long Short-Term Memory (LSTM), with baseline LSTM models, Word2Vec embeddings, and GloVe embeddings.
2.1 Sentiment analysis, Random Forest, MultinomialNB, and SVM
Sentiment analysis (SA) is a technique within NLP used to assess the sentiment or opinion contained in a text. This process involves evaluating text to determine whether it conveys a positive, negative, or neutral sentiment. Sentiment analysis has various applications, such as measuring customer feedback, tracking sentiment on social media, and reviewing product evaluations [14]. Various methods, including MultinomialNB, SVM, and Random Forest, have been utilized to analyze data from platforms like Twitter. Sentiment analysis has significantly evolved over the years, thanks to dictionary-based algorithms and ML, contributing to increased accuracy. Prior knowledge and contextual understanding are also crucial, especially with the advent of deep learning algorithms in SA, to effectively capture the polarity of opinions [15].
Random Forest is a widely used ML technique in sentiment analysis, known for combining the strengths of multiple decision trees to enhance classification accuracy. It operates by constructing numerous decision trees during the training phase, with each tree built from a randomly selected subset of the training data. Each tree makes a prediction, and the final decision is determined by a majority vote from all trees. In the context of sentiment analysis, Random Forest classifies text based on positive, negative, or neutral sentiment. The analysis process begins with text data preprocessing, involving data cleaning, tokenization, stemming, and converting text into numerical representations such as TF-IDF or word embeddings. Subsequently, the training data is partitioned to generate multiple decision trees using bootstrapping techniques. At each node, a random subset of features is considered to identify the optimal split, typically based on metrics such as Gini Impurity or Information Gain. The final output of Random Forest is the majority voting result from all decision trees, ensuring more robust and accurate predictions.
MultinomialNB is a classification algorithm based on Bayes' theorem, commonly used in sentiment analysis and NLP. It is particularly effective for text classification tasks where input data is represented as word frequency vectors. The "naive" assumption underlying this method is that each feature (word) in the dataset is independent, though this assumption can be considered unrealistic in some cases. Nevertheless, MultinomialNB has the advantage of simplicity, making it easy to implement and computationally efficient. In the context of sentiment analysis, MultinomialNB works by estimating the distribution of word frequencies in a document and using this information to classify the text into specific sentiment categories. The model learning process involves estimating the probability of each word occurrence in a particular sentiment category [16]. The strength of this method lies in its ability to work well with large and complex text datasets and its capability to manage high-dimensional feature classification problems. Literature studies have shown the application of MultinomialNB in various contexts, including comparing its performance with other classification methods in sentiment analysis tasks. As part of the landscape of text classification algorithms, MultinomialNB continues to be a subject of research and development to enhance its precision and robustness in practical applications. The MultinomialNB model can be formulated as shown in Eq. (1) [17].
$P(p \mid n) \propto P(p) \prod_{1 \leq k \leq n d} P\left(t_k \mid p\right)$ (1)
where, P(tk|p) is the probability of the occurrence of text document (tk), n is the number of documents, and p is the polarity. Subsequently, the polarity or similarity of documents is calculated using the formulation presented in Eq. (2).
$P\left(t_k \mid p\right)=\frac{\operatorname{count}\left(t_k \mid p\right)+1}{\operatorname{count}\left(t_p\right)+|V|}$ (2)
where, (tk|p) is the number of times tk appears in text documents with polarity p, and (tp) refers to the number of tokens appearing in news articles with polarity p.
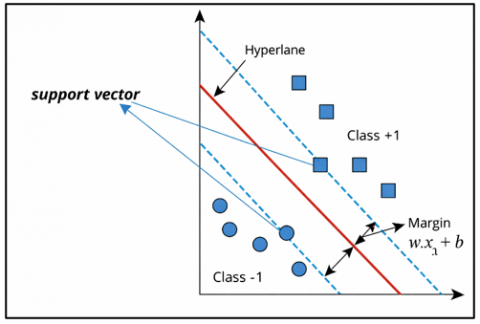
SVM is a classification algorithm that has gained significant popularity across various applications, including sentiment analysis in NLP. The basic principle of SVM is to find the best hyperplane that separates two classes of data with the maximum margin [18]. SVM can manage cases where the decision boundary between classes is non-linear, thanks to the concept of kernel mapping, which allows for modeling more complex relationships between data features. The main advantages of SVM include strong generalization capability and effectiveness in high-dimensional spaces, making them a popular choice for text analysis involving large feature sets. In the context of sentiment analysis, SVM is commonly used to classify text into positive, negative, or neutral sentiment categories. Literature studies highlight the success of SVM in handling complex issues such as text classification with non-linear relationships and high feature dimensions [19]. However, the use of SVM requires careful parameter tuning, including the selection of kernels and the parameter C, which controls the trade-off between classification error penalty and the margin of the hyperplane. Further research is focused on optimizing SVM parameters to enhance their performance in specific sentiment analysis tasks. With its continually evolving capabilities, SVM remains a strong choice in text classification modeling and sentiment analysis, as stated in Figure 1 in reference [20].
Figure 1. SVM structure for classifying two classes (+1 and 1) based on the hyperplane line [21]
2.2 Documentary film Ice Cold: Murder, Coffee, and Jessica Wongso
The release of the documentary film Ice Cold: Murder, Coffee, and Jessica Wongso (Ice Cold) on Netflix triggered significant changes in public sentiment on Twitter. The documentary discusses the murder case of Wayan Mirna Salihin, who died from cyanide-laced coffee, with Jessica Wongso as the primary suspect. Before the film's release, Twitter conversations about the case were relatively neutral, focusing on the facts of the case and legal developments. After the release, sentiment on Twitter changed dramatically.
The analysis of Twitter data in this study reveals a sharp increase in both conversation volume and emotional intensity following the documentary's release. Many users expressed strong emotions, including anger, disbelief, and suspicion toward the legal process. The documentary appears to have stirred public interest and raised new questions about justice and transparency in the case. Twitter users shared their views on the case's errors or truths, and discussions became more heated and polarized. Factors influencing this sentiment shift may include the engaging narrative of the documentary, which led viewers to question case details. Additionally, the availability of social media platforms like Twitter enabled users to quickly share their opinions and engage in discussions, thereby accelerating the change in sentiment. The documentary became a hot topic on Twitter, sparking widespread debate and discussion.
2.3 Twitter
Twitter is a social media platform that enables users to share and engage with others through short messages, known as 'tweets.' Each tweet is limited to 280 characters and may contain text, images, videos, links, and hashtags (#) to facilitate content categorization and discovery. On Twitter, users can follow their chosen accounts, post tweets, like, comment on, and retweet others' content. The platform has become a hub for real-time information sharing, making it a popular source of news, opinions, and the latest updates on various topics. With its broad audience, Twitter remains a relevant and widely used social networking platform [22].
The platform also provides an application programming interface (API) that allows developers and researchers to access Twitter data legally and securely. The API requires four authentication keys: consumer key, consumer secret, access token, and access secret, which help secure access to data such as tweets, profiles, and other sensitive information. The API has become a crucial tool for researchers looking to analyze Twitter data for various purposes, including sentiment analysis and studies on public opinion [23].
3.1 Research stages
This section outlines the overall structure of the research. The dataset was collected through Twitter data mining and subsequently imported for analysis. During the preprocessing stage, the data was cleaned by removing duplicate words, non-letter characters, and irrelevant elements. Additionally, the text was normalized to ensure consistency across the dataset. This study utilized word embedding to represent words in a low-dimensional space, typically as real-valued vectors. This technique allows words with similar meanings to be grouped closer together, while words with different meanings are spaced further apart. The Term Frequency-Inverse Document Frequency (TFIDF) model was used for feature selection and extraction, converting text documents into TFIDF feature matrices [24].
Text cleaning and preprocessing are crucial stages in NLP tasks like sentiment analysis [17]. This stage transforms raw text into a clean and consistent format, enabling more efficient processing by ML algorithms. Common text cleaning and preprocessing techniques include converting text to lowercase, tokenization, which breaks text into individual words, and removing punctuation, special characters, and numbers that typically do not affect sentiment analysis. However, in specific contexts like product reviews, it may be necessary to retain some numbers and special characters. In the word embedding process, words are transformed into numerical representations through mapping with hidden layers in artificial neural networks. This transformation reduces dimensionality by bringing words with similar meanings closer together in the vector space. The analysis is then conducted using several predefined methods, and the methodology concludes with the results of the processing from the selected methods, providing a comparison between the methods [25].
Figure 2 illustrates the comparison of sentiment classification in this study. The experimental process was conducted to explore various libraries for data labeling, namely TextBlob and Vader Sentiment. TextBlob is a Python library used for processing textual data and determining sentiment polarity, whereas Vader (Valence Aware Dictionary and sentiment Reasoner) is a lexicon and rule-based sentiment analysis tool specifically designed for social media text. Additionally, this research explores various feature selection and extraction methods, such as TF-IDF Vectorizer and Count Vectorizer [25-27]. These methods were then integrated with the implementation of various algorithms such as Random Forest, MultinomialNB, and SVM, to evaluate their effectiveness in sentiment classification. The comparison of sentiment classification can be seen in Figure 3.

Figure 2. Research stages

Figure 3. Sentiment classification comparison
3.2 Dataset
The dataset used in this study was collected through crawling Twitter data using specific keywords relevant to the research context. The initial extraction resulted in a total of 6000 data entries. Subsequently, this dataset underwent a preprocessing phase, including cleaning and refinement processes. This effectively reduced the dataset to a more manageable size, resulting in a filtered set of 2000 entries. The preprocessing steps involved removing unnecessary information, special characters, and noise. In addition, tokenization and case folding were applied to enhance the uniformity of the text data. Our dataset can be accessed through this link: https://github.com/ChristineDewi/Sentiment-Analysis-Ice-Cold-Murder-Coffee-and-Jessica-Wongso.
Following the preprocessing phase, the dataset was further refined to eliminate any outliers or inconsistencies, resulting in a final set of 2,000 instances. This curated dataset served as the foundation for training and evaluating the sentiment analysis models. The training set containing 2000 instances enabled a robust evaluation of model performance. The use of a refined and preprocessed dataset is a crucial step to ensure the accuracy and reliability of the sentiment analysis models developed in this study. An example of the Twitter data crawling results can be seen in Table 1.
Table 1. Example results of Twitter data crawling
|
No. |
Tweets |
Sentiment |
|
1 |
After watching the documentary Ice Cold, I realized one statement was true because my professor said that people tend to perceive an evil psychologist as a beautiful figure. |
Positive |
|
2 |
After watching the documentary Ice Cold, it feels saddening to think about the law in a cruel country where money is no longer in control, but rather a frightening power. |
Negative |
|
3 |
At least by watching the documentary Ice Cold, you can feel its impact even if you haven't followed the case in detail. |
Neutral |
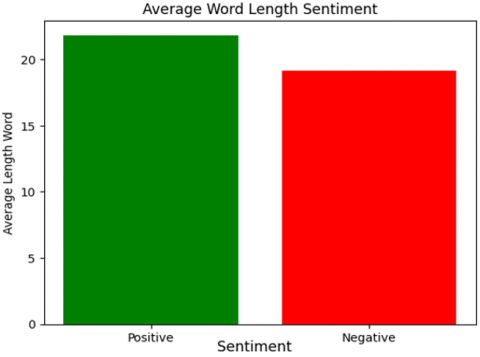
Figure 4(a) illustrates the average word count in reviews: positive reviews contain an average of 21.83 words, negative reviews 19.16 words, and neutral reviews 11.98 words. Figure 4(b) depicts the distribution of word counts across the entire dataset. The data reveals that the average word count for positive reviews is 21.83, for negative reviews is 19.16, and for neutral reviews is 11.98. It is worth noting that, on average, positive reviews use slightly shorter words than negative reviews.
A balanced class distribution in the dataset is essential for maintaining the reliability of performance metrics. When the dataset is heavily skewed towards positive or negative reviews, accuracy metrics can be misleading, providing limited insights. This is because when one class dominates, predicting the most frequently occurring class becomes inherently easier, as shown in Figure 4.


(a)


(b)
Figure 4. Visualization of the dataset with (a) average word length in reviews, (b) word count in reviews
Figure 4 provides an overview of the dataset, illustrating three main aspects: (a) average word length in reviews, (b) word count in reviews. The performance results for each classification method are presented in Table 2. Initial results for sentiment score classification by Vader on this data are quite promising [28, 29]. Sentiment categorization achieved an accuracy of 99.17% from the reviews used in the analysis. However, the effectiveness of Vader varies between positive and negative evaluations. The accuracy rate for classifying positive reviews is 99.18%.
Table 2. Performance results of unsupervised sentiment classification
|
Metrics |
MultinomialNB |
Random Forest |
|
Accuracy |
0.6240 |
0.7443 |
|
Sensitivity |
0.6621 |
0.7568 |
|
Specificity |
0.6242 |
0.7448 |
|
Precision |
0.6240 |
0.7568 |
|
F1 |
0.5912 |
0.7468 |
|
Roc_Auc |
0.8440 |
0.8966 |
In the context of sentiment analysis experiments, three primary classification methods were tested [18]: SVM, MultinomialNB, and Random Forest, as shown in Table 3. The test results indicate that SVM achieved the highest performance with an accuracy of 74.62%. This demonstrates that SVM effectively built a model for sentiment classification on the dataset used. Random Forest closely followed with an accuracy of 74.43%, highlighting its ability to handle model complexity and deliver strong classification results. However, MultinomialNB showed a lower accuracy of 62.40%, though it still significantly contributed to sentiment analysis.
Table 3. Performance results of supervised sentiment classification
|
Metrics |
SVM |
MultinomialNB |
Random Forest |
|
Accuracy |
0.7462 |
0.6240 |
0.7443 |
|
Sensitivity |
0.7462 |
0.6621 |
0.7568 |
|
Specificity |
0.7462 |
0.6242 |
0.7448 |
|
Precision |
0.7462 |
0.6240 |
0.7568 |
|
F1 |
0.7447 |
0.5912 |
0.7468 |
|
Roc_Auc |
0.8929 |
0.8440 |
0.8966 |
In addition to these three classification methods, two rule-based sentiment analysis methods were also assessed: Vader and TextBlob. Vader, which is based on sentiment rule analysis, demonstrated a very high accuracy of 99.17%. This underscores its efficiency for certain datasets and its capability to deliver outstanding sentiment analysis performance. On the other hand, TextBlob, a rule-based sentiment analysis method, recorded a lower accuracy of 58.16%. Nevertheless, it still provided useful insights compared to classification-based methods. These test results illustrate the performance differences between classification methods and rule-based sentiment analysis methods, emphasizing that method selection depends on the specific needs and characteristics of the dataset used [16].
Figure 5. Twitter data for positive and negative classes
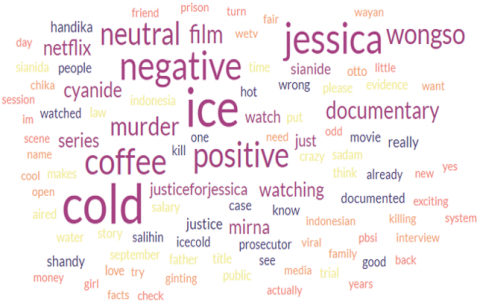
As shown in Figure 5, there is an average difference of 2.67 words. This highlights the importance of maintaining a balanced dataset to ensure the reliability of performance metrics. When the dataset is heavily imbalanced—dominated by either positive or negative reviews—accuracy alone may become misleading, as models can achieve high accuracy simply by predicting the majority class due to its numerical dominance. Figure 5 illustrates the positive and negative words. As shown in Figure 6, words like "viral," "wrong," "prison," "killing," and "justice" are part of the word cloud for positive text. This study uses WordCloud [30-32], where the WordCloud function is used with parameters (width=1000, height=500, max_words=100, min_font_size=5). The word cloud for positive words, with interpolation set to 'bilinear,' is presented in this experiment. In Figure 6, an example word cloud for negative words is also provided. Words like "war," "satire," "turn," "fail," and "exist," along with other negative terms, are depicted in the cloud. This experiment involves a maximum of 100 words, with the negative word cloud using interpolation set to 'bilinear.'
Figure 6. Word cloud from Ice Cold using Vader
This sentiment analysis experiment evaluated three main classifiers: SVM, MultinomialNB, and Random Forest. The test results indicated that SVM performed the best, achieving the highest accuracy of 74.62%. This demonstrates the success of SVM in building an effective sentiment classification model for the dataset used. Random Forest closely followed with an accuracy of 74.43%, showcasing its ability to handle model complexity and provide robust classification results. On the other hand, MultinomialNB showed a lower accuracy of 62.40%, but still contributed significantly to the sentiment analysis.
In addition to the classification methods, two rule-based sentiment analysis approaches—Vader and TextBlob—were also evaluated. Vader, which utilizes a lexicon and rule-based approach, achieved an impressive accuracy of 99.17%, demonstrating its effectiveness on the given dataset and its strong capability in performing sentiment analysis. Conversely, TextBlob, another rule-based sentiment analysis method, showed a lower accuracy of 58.16%. Despite its lower accuracy compared to the classification methods, TextBlob still provided valuable insights. These test results confirm the performance differences between classification methods and rule-based sentiment analysis approaches, emphasizing that the choice of method highly depends on the specific needs and characteristics of the dataset used. Additionally, it is noteworthy that in this study, SVM emerged as the most effective method among those tested.
Christine Dewi: Investigation, Data curation, Writing – review & editing, Validation, Writing – original draft, Formal analysis, Conceptualization. Ari Nugraha: Methodology, Data curation, Writing – original draft, Writing – review & editing, Conceptualization. Dalianus Riantama: Writing – original draft, Methodology, Data curation, Resources, Software, Investigation. Ahthasham Sajid: Software, Visualization, Methodology, Formal analysis, Writing – original draft, Investigation. Mazliham MohD Su’ud: Visualization, Data curation, Writing – review & editing, Software, Writing –original draft, Investigation, Methodology. Muhammad Mansoor Alam: Visualization, Data curation, Writing – review& editing, Software, Writing – original draft, Investigation, Methodology.
This research was supported by the Faculty of Computing and Informatics, Multimedia University, Cyberjaya, Malaysia, and the Vice-Rector for Research, Innovation, and Entrepreneurship at Satya Wacana Christian University.
[1] Budiharto, W., Meiliana, M. (2018). Prediction and analysis of Indonesia presidential election from Twitter using sentiment analysis. Journal of Big Data, 5(1): 1-10. https://doi.org/10.1186/s40537-018-0164-1
[2] Noor, M., Gata, W., Risnandar, R., Fakhrudin, F., Novitarani, A. (2022). Optimization of sentiment analysis of program Sembako (BPNT) based on Twitter. Journal of Applied Engineering and Technological Science, 4(1): 223-234.
[3] Uliniansyah, M.T., Budi, I., Nurfadhilah, E., Afra, D.I.N., et al. (2024). Twitter dataset on public sentiments towards biodiversity policy in Indonesia. Data in Brief, 52: 109890. https://doi.org/10.1016/j.dib.2023.109890
[4] Elmurngi, E.I., Gherbi, A. (2018). Unfair reviews detection on Amazon reviews using sentiment analysis with supervised learning techniques. Journal of Computer Science, 14(5): 714-726. https://doi.org/10.3844/jcssp.2018.714.726
[5] Warsito, B., Prahutama, A. (2020). Sentiment analysis on Tokopedia product online reviews using random forest method. E3S Web of Conferences, 202: 16006. https://doi.org/10.1051/e3sconf/202020216006
[6] Rekanar, K., O’Keeffe, I.R., Buckley, S., Abbas, M., et al. (2022). Sentiment analysis of user feedback on the HSE’s COVID-19 contact tracing app. Irish Journal of Medical Science, 191(1): 103-112. https://doi.org/10.1007/s11845-021-02529-y
[7] Colianni, S., Rosales, S., Signorotti, M. (2015). Algorithmic trading of cryptocurrency based on Twitter sentiment analysis. CS229 Project, 1(5): 1-4.
[8] Bahrawi, N. (2019). Sentiment analysis using random forest algorithm-online social media based. Journal of Information Technology and Its Utilization, 2(2): 29-33. https://doi.org/10.30818/jitu.2.2.2695
[9] Babu, N.V., Kanaga, E.G.M. (2022). Sentiment analysis in social media data for depression detection using artificial intelligence: A review. SN Computer Science, 3(1): 74. https://doi.org/10.1007/s42979-021-00958-1
[10] Alamsyah, A., Rahmah, W., Irawan, H. (2015). Sentiment analysis based on appraisal theory for marketing intelligence in Indonesia's mobile phone market. Journal of Theoretical and Applied Information Technology, 82(2): 335.
[11] Vidya, N.A., Fanany, M.I., Budi, I. (2015). Twitter sentiment to analyze net brand reputation of mobile phone providers. Procedia Computer Science, 72: 519-526. https://doi.org/10.1016/j.procs.2015.12.159
[12] Tineges, R., Triayudi, A., Sholihati, I.D. (2020). Sentiment analysis of IndiHome services based on Twitter using the support vector machine (SVM) classification method. Jurnal Media Informatika Budidarma, 4(3): 650. https://doi.org/10.30865/mib.v4i3.2181
[13] Shaukat, Z., Zulfiqar, A.A., Xiao, C., Azeem, M., Mahmood, T. (2020). Sentiment analysis on IMDB using lexicon and neural networks. SN Applied Sciences, 2(2): 148. https://doi.org/10.1007/s42452-019-1926-x
[14] Tan, K.L., Lee, C.P., Lim, K.M. (2023). A survey of sentiment analysis: Approaches, datasets, and future research. Applied Sciences, 13(7): 4550. https://doi.org/10.3390/app13074550
[15] Bahary, A.F., Sibaroni, Y., Mubarok, M.S. (2019). Sentiment analysis of student responses related to information system services using Multinomial Naïve Bayes (Case study: Telkom University). Journal of Physics: Conference Series, 1192(1): 012046. https://doi.org/10.1088/1742-6596/1192/1/012046
[16] Zulfikar, W.B., Atmadja, A.R., Pratama, S.F. (2023). Sentiment analysis on social media against public policy using Multinomial Naive Bayes. Scientific Journal of Informatics, 10(1): 25-34. https://doi.org/10.15294/sji.v10i1.39952
[17] Hidayah, N., Sahibu, S. (2021). Multinomial naïve bayes algorithm for sentiment classification of public opinion on government COVID-19 handling using Twitter data. Jurnal Rekayasa Sistem dan Teknologi Informasi, 5(4): 820-826. https://doi.org/10.29207/resti.v5i4.3146
[18] Ramasamy, L.K., Kadry, S., Lim, S. (2021). Selection of optimal hyper-parameter values of support vector machine for sentiment analysis tasks using nature-inspired optimization methods. Bulletin of Electrical Engineering and Informatics, 10(1): 290-298. https://doi.org/10.11591/eei.v10i1.2098
[19] Darwis, D., Pratiwi, E.S., Pasaribu, A.F.O. (2020). Application of the SVM algorithm for sentiment analysis on Twitter data of the Corruption Eradication Commission of the Republic of Indonesia. Jurnal Ilmiah Edutic: Pendidikan dan Informatika, 7(1): 1-11. https://doi.org/10.21107/edutic
[20] Reynaldhi, M.A.R., Sibaroni, Y. (2021). Sentiment analysis of movie reviews on Twitter using hybrid SVM, naïve Bayes, and decision tree classification methods. Proceedings of Engineering, 8(5).
[21] Dewi, D.D., Qisthi, N., Sobariah Lestari, S.S., Putri, S., Hidayah, Z. (2023). Comparison of neural network and support vector machine methods in classifying diabetes disease diagnosis. Cerdika: Jurnal Ilmiah Indonesia, 3(9): 828-839. https://doi.org/10.59141/cerdika.v3i09.662
[22] Adwan, O., Al-Tawil, M., Huneiti, A., Shahin, R., Zayed, A.A., Al-Dibsi, R. (2020). Twitter sentiment analysis approaches: A survey. International Journal of Emerging Technologies in Learning, 15(15): 79-93. https://doi.org/10.3991/ijet.v15i15.14467
[23] Sahayak, V., Shete, V., Pathan, A. (2015). Sentiment analysis on Twitter data. International Journal of Innovative Research in Advanced Engineering, 2(1): 178-183.
[24] Joachims, T. (1996). A probabilistic analysis of the Rocchio algorithm with TFIDF for text categorization (No. CMUCS96118).
[25] Jiang, Z., Gao, B., He, Y., Han, Y., Doyle, P., Zhu, Q. (2021). Text classification using novel term weighting scheme-based improved TFIDF for internet media reports. Mathematical Problems in Engineering, 2021(1): 6619088. https://doi.org/10.1155/2021/6619088
[26] Alita, D., Isnain, A.R. (2020). Sarcasm detection in the sentiment analysis process using the random forest classifier. Jurnal Komputasi, 8(2): 50-58. https://doi.org/10.23960/komputasi.v8i2.2615
[27] Bonta, V., Kumaresh, N., Janardhan, N. (2019). A comprehensive study on lexicon based approaches for sentiment analysis. Asian Journal of Computer Science and Technology, 8(S2): 1-6. https://doi.org/10.51983/ajcst-2019.8.S2.2037
[28] Vohra, A., Garg, R. (2023). Deep learning based sentiment analysis of public perception of working from home through tweets. Journal of Intelligent Information Systems, 60(1): 255-274. https://doi.org/10.1007/s10844-022-00736-2
[29] Jewel, D., Kelemen, R.E., Huang, R.L., Zhu, Z., et al. (2023). Virus-assisted directed evolution of enhanced suppressor tRNAs in mammalian cells. Nature Methods, 20(1): 95-103. https://doi.org/10.1038/s41592-022-01706-w
[30] Ajik, E.D., Suleiman, A.B., Ibrahim, M. (2023). Enhancing user experience through sentiment analysis for katsina state transport agency: A textblob approach. Fudma Journal of Sciences, 7(6): 117-122. https://doi.org/10.33003/fjs-2023-0706-2057
[31] Puvvula, D., Rodda, S. (2024). Enhancing decision making through aspect based sentiment analysis using deep learning models. Mathematical Modelling of Engineering Problems, 11(10): 2849-2858. https://doi.org/10.18280/mmep.111028
[32] Muhajir, M., Rosadi, D., Danardono. (2024). Integrating Decision Tree and BIRCH clustering algorithms of BERTopic for analyzing public sentiment on Dirtyvote movie. Mathematical Modelling of Engineering Problems, 11(12): 3391-3401. https://doi.org/10.18280/mmep.111217