Tio Dharmawan![]() | Yudha Alif Auliya*
| Yudha Alif Auliya*![]() | Diah Ayu Retnani
| Diah Ayu Retnani![]() | Saiful Bukhori
| Saiful Bukhori![]() | Mohammad Zarkasi
| Mohammad Zarkasi![]() | Imanuel Ataama
| Imanuel Ataama![]()
© 2025 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Waste constitutes a significant environmental challenge globally, including in Indonesia. The manual classification of waste demands considerable time and effort, necessitating the development of technology for automatic classification. The application of deep learning technology for waste classification has advanced swiftly. However, training deep learning models such as DenseNet121 remains a challenge due to the substantial time and computational resources required, particularly with extensive datasets. This study proposes a novel waste classification approach that integrates genetic algorithm (GA)-based hyperparameter optimization with data downsampling and data augmentation to significantly improve computational efficiency without compromising accuracy. To identify the optimal hyperparameter configuration, we tested multiple scenarios involving different image resizing dimensions, as well as augmentation techniques. A refined dataset of 2,748 images curated from CompostNet and TrashNet via duplicate removal, balancing, and quality filtering was used to train and test the model. The proposed approach successfully reduced training time by a factor of four, from 3,099 seconds to 789 seconds. Moreover, GA optimization yielded the best hyperparameter configuration: 896 neurons with a 30% dropout rate in the first layer, and 512 neurons with a 20% dropout rate in the second layer. This configuration improved classification accuracy from 94% to 97%.
genetic algorithm, hyperparameter optimization, DenseNet121, waste classification, data augmentation
Waste constitutes a significant environmental challenge globally, including in Indonesia. In 2023, the documented quantity of waste exceeded 67 million tons annually. The 3R method (Reduce, Reuse, Recycle) can be implemented to minimize waste. Classification of waste types is essential for the implementation of this method. The manual classification of waste is time-consuming and labor-intensive, necessitating the development of technology for automatic classification.
The application of deep learning technology for waste classification has advanced swiftly. The primary challenge in training deep learning models such as DenseNet121 is the considerable duration required for training, particularly when utilizing extensive datasets. The extended training period not only impedes model development but also necessitates substantial computational resources [1].
This study aimed to develop a waste classification system that enhances computational efficiency and accuracy, utilizing DenseNet121, optimized via genetic algorithm (GA), and employing downsampling and augmentation methodologies [2]. This study employs multiple scenarios to identify the optimal combination of hyperparameters for model construction. The hyperparameters to be evaluated are implemented during the resizing, augmentation, and optimization phases. Subsequently, utilizing the optimal hyperparameter combination, the DenseNet121 model will be refined through genetic algorithms to identify the most effective pairs of hyperparameters for neuron count and dropout rate. This study employs a consolidated dataset from CompostNet and TrashNet, comprising a total of 2,748 images.
The use of deep learning technology for waste classification has rapidly developed. One of the widely used methods is the Convolutional Neural Network (CNN), which has proven effective in recognizing patterns in images. The use of transfer learning demonstrates effectiveness in waste classification using the MobileNet model in the CompostNet system. This system is capable of classifying waste into three categories: organic, recyclable, and non-recyclable [3]. Another study conducted a comparative analysis of DenseNet121, ResNet34, MobileNetV2, CompostNet (Version A), and CompostNet (Version B) for waste classification tasks. Among the evaluated models, DenseNet121 demonstrated the highest classification accuracy across various waste categories, including paper, metal, plastic, glass, and compost [4]. However, the main challenge in training deep learning models like DenseNet121 is the relatively long training time, especially when using large datasets. The long training duration not only slows down the model development process but also requires high computational resources. In the context of the research conducted, a solution is needed that can reduce the model training time without sacrificing accuracy.
One of the approaches that can be used to address this issue is by applying downsampling. Downsampling serves to reduce the size of the data processed by the model while retaining important information, thereby accelerating the training process. Additionally, the use of data augmentation techniques such as 25-degree rotation and flipping (horizontal and vertical) can produce more skilled deep neural networks, as the augmentation approach provides variations in the images, allowing the trained model to apply their learning to new images [5], and ensuring that even though the dataset size is reduced, data variation is maintained, so the model's performance does not decline.
The urgency of using this technique is very clear, especially in the context of developing a waste classification model with DenseNet121 optimized using a GA. With this approach, the training process can be accelerated, allowing more experiments to be conducted in a shorter time and with more efficient use of resources. The final result is expected to maintain high accuracy while also improving efficiency in the waste management process. In order to ensure the quality and consistency of training data, a dataset preparation process was conducted prior to model training. Although the original datasets (TrashNet and CompostNet) contained over 5,000 images in total, a series of preprocessing steps including duplicate removal, class balancing, and image quality filtering resulted in a refined dataset of 2,748 high-quality and representative images. This was essential to avoid class bias, reduce noise, and ensure that the model was trained on clean and balanced data that support better generalization.
Waste classification based on deep learning has been advanced through multiple CNN architectural methodologies. Research on MobileNet demonstrates a comparatively lightweight CNN model for transportation devices that enhances mobile device commuting efficiency. The architecture employs depthwise separable convolution and hardware optimization, rendering it economical for real-time waste classification. This research has been utilized by numerous other scholars to facilitate waste classification with minimal data, while maintaining satisfactory accuracy [6].
DenseNet121 was created for multi-category classification by employing dense connections among dimensions in the convolutional layers, demonstrating superiority in this domain [7]. This model was employed to categorize six types of solid waste in the TrashNet dataset: glass, paper, metal, plastic, food waste, and cardboard [8]. Nonetheless, the limitation of this model lies in its substantial computational resource demands, particularly with extensive datasets [9].
A survey on data imbalance indicates that data augmentation, including image rotation and flipping, is a prevalent data mining technique [10]. his method can enhance accuracy by as much as 12% in the developed model [11]. This approach is pertinent to the waste issue in Indonesia, characterized by an uneven distribution of waste [12]. Conversely, adaptive resampling for downsampling has demonstrated the capacity to diminish identifiable data over time with minimal loss [13]. Scenarios are required in its application to attain optimal results. The significance of scenarios in identifying optimal parameters is rooted in their impact on the model's accuracy and loss outcomes, underscoring that the choice of the appropriate scenario is essential for attaining superior model performance [14]. Adaptive resampling has been implemented in the TACO learning model, demonstrating a potential reduction in training time by up to 40%, albeit with a decline in accuracy exceeding 90% relative to prior performance [15]. This method results in a verbose process regarding the impact of the DenseNet121 model, which is an imbalanced resource [16].
The intricacy of CNN enables the model to discern intricate features; however, it necessitates increased time and computational resources for training and testing. Simultaneously, the application of GA proves to be highly efficacious in addressing diverse optimization and combinatorial challenges [17]. Genetic algorithms operate by employing the principles of natural selection, whereby individuals with superior fitness values possess an increased likelihood of being chosen as solutions in subsequent generations [18]. Evolutionary algorithms have been utilized to optimize learning rates and the number of layers in ResNet-50, yielding a 5% enhancement in accuracy and a 30% decrease in training duration [19]. A separate study demonstrates that DenseNet121, when optimized with a genetic algorithm (GA), enhances accuracy in waste image classification, suggesting that GA is highly effective in improving the performance of CNN models [20]. This technique will provide a foundation for waste classification using this algorithm in comparison to alternative algorithms.
The review indicates that integrating selective augmentation strategies, downsampling, and genetic algorithms with the DenseNet121 model attained a high accuracy level with limited connection resources, while addressing data non-stationarity in the Indonesian waste issue.
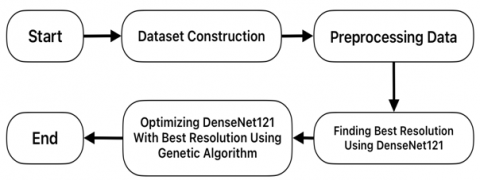
This research is an applied study focused on enhancing the accuracy of the DenseNet121 model for waste classification through GA optimization. The study specifically addresses the challenge of improving training efficiency and reducing computational costs while maintaining high classification accuracy. The research centers on processing waste images using downsampling and augmentation techniques and subsetting dataset, which allows for the optimization of the model’s performance and the reduction of training time. The comprehensive research phases are illustrated in Figure 1.
Figure 1. Research stage
3.1 Dataset construction
This study utilizes a combined dataset from two publicly available sources: TrashNet and CompostNet, resulting in a total of 2,748 images spanning seven waste categories. Given the class imbalance-where some categories were underrepresented-data augmentation was applied specifically to the minority classes to increase their representation without requiring additional data collection.
3.2 Preprocessing data
To enhance the diversity of the dataset and improve the model's ability to generalize, several data augmentation techniques were applied. These included rotation by 25 degrees to simulate varying image orientations, horizontal and vertical flipping to generate mirrored counterparts, and shearing transformations to introduce slight geometric distortions. These augmentations were particularly beneficial for enhancing the representation of minority classes and encouraging the model to learn more robust and discriminative features. Furthermore, all images were resized to three different input dimensions-224×224, 256×256, and 300×300-to evaluate the impact of input resolution on model performance. The dataset was subsequently divided into training and testing subsets, with a 75:25 split. This partitioning ensured that the model was evaluated on previously unseen data, providing a reliable measure of its generalization capability.
3.3 Model architecture and initial configuration
The DenseNet121 model was selected for this study due to its compact and efficient architecture, which facilitates improved gradient flow and promotes feature reuse through densely connected layers [1]. To enhance learning efficiency and convergence speed, transfer learning was applied using pre-trained weights from ImageNet. The base architecture was extended with a fully connected (FC) layer consisting of one dense layer with 1024 neurons, followed by an output layer of 7 neurons corresponding to the waste categories.
3.4 Training setup
All training procedures were conducted using a batch size of 16 and a total of 60 epochs, the value used is based on the best result from [4]. The experiments utilized two optimization algorithms: Adam, with a learning rate of 5.13×10⁻³, and Adadelta, with a learning rate of 0.1 and a decay rate of 0.001. These configurations were consistently applied across all experimental phases to ensure comparability and reproducibility.
Phase I: Input resolution exploration
The first phase focused on identifying the most appropriate input image resolution that offers a balance between classification performance and computational cost. Input images were resized to several dimensions, including 512×384, 300×400, and 224×224. To further explore efficiency, a dataset subsetting strategy was applied, in which only 50% of the original samples were used for certain configurations-namely, 50% of the 512×384 and 50% of the 300×400 datasets-while preserving class distribution. Each resolution and subset combination were evaluated using both the Adam and Adadelta optimizers, with the FC configuration kept fixed as previously described.
Phase II: Fully connected layer optimization using a genetic algorithm
In the second phase, the structure of the fully connected layers was optimized using a GA. This phase focused on tuning two key hyperparameters: the number of neurons and the dropout rate in two consecutive dense layers. The search space for each layer included neuron counts ranging from 128 to 1024 in steps of 128, and dropout rates from 0% to 50%. The optimization focus is used to mitigate the risk of model overfitting [1]. Each candidate solution was encoded as a chromosome in the genetic population. The GA was configured with a population size of 10, evolved over 4 generations, and employed crossover and mutation probabilities of 85% and 30%, respectively. The F1-score was used as the fitness function to guide selection and reproduction, as it provides a balanced metric for evaluating model precision and recall in the presence of class imbalance.
3.5 Optimizer comparison protocol
To compare the impact of different optimization strategies, both Adam and Adadelta were applied across all resolution and architectural configurations. Adam was selected for its adaptive learning rate and momentum-based updates, which facilitate faster convergence. Adadelta was included for its dynamic learning rate mechanism and capability to handle sparse gradients efficiently. This comparison aimed to evaluate each optimizer's effectiveness in diverse training conditions without altering other hyperparameters.
4.1 Dataset collection
The researchers are currently in the process of data collection, utilizing two publicly available datasets: TrashNet and CompostNet. TrashNet contains 2,527 images distributed across six waste categories: cardboard, glass, paper, metal, plastic, and trash. CompostNet, on the other hand, includes 2,678 images classified into seven categories: cardboard, compost, glass, paper, metal, plastic, and trash.
In constructing the final dataset, the two sources were carefully merged, taking into account the potential presence of duplicate or visually identical images across both datasets. After the necessary filtering and de-duplication process, a refined dataset of 2,748 unique images was obtained, covering seven waste categories: cardboard, compost, glass, paper, metal, plastic, and trash. This curated dataset served as the foundation for the subsequent model training and evaluation tasks.
To address class imbalance during dataset preparation, special attention was given to categories with a limited number of images-namely, the trash and compost classes, which initially contained 174 and 184 images, respectively. To enhance the representation of these minority classes, data augmentation techniques were applied. As a result, the total number of images in the dataset increased to 3,106.
Figure 2 illustrates examples of the augmented images for each class, showcasing the visual diversity introduced to support more effective model training and generalization.
Figure 2. Augmentation results for each class in the dataset
4.2 Baseline evaluation with varying input resolutions and optimizers
The primary objective of this study was to identify the optimal model configuration that effectively balances classification performance and training time. Experiment 1 was defined as the reference configuration, using an input resolution of 512×384 and the Adam optimizer with a learning rate of 5.13e-3. This setup achieved an accuracy of 94%and required 3099 seconds of training time, which provided a baseline for comparison in subsequent experiments.
To evaluate the impact of varying image resolution and optimizer settings on model performance, several experiments were conducted. Experiment 2, which utilized a 300×400 resolution and the Adam optimizer, achieved the highest accuracy (96%) among all the configurations tested, with a reduced training time of 2002 seconds. While this configuration provided the best performance in terms of accuracy and computational efficiency, it did not provide the most optimal balance when considering the goal of minimizing training time.
Other configurations were also tested to evaluate their trade-offs. Experiment 3, which used 50% of the 512×384 resolution with the Adam optimizer, achieved 91% accuracy and reduced training time to 825 seconds. This experiment demonstrated that reducing image resolution led to faster training times, but at the cost of decreased classification accuracy. Similarly, Experiment 4, which used 50% of the 300×400 resolution and the Adam optimizer, attained 90% accuracy and 578 seconds of training time, providing the fastest training time, though the accuracy was further reduced.
Experiment 5, using 224×224 resolution with the Adam optimizer, achieved 95% accuracy and 831 seconds of training time, offering a reasonable balance between classification performance and computational cost. Despite achieving high accuracy, however, the configuration still required relatively high training time when compared to Experiment 2.
Furthermore, the Adadelta optimizer was tested in Experiments 6 through 10. The results showed that although Adadelta led to minor reductions in training time in some configurations, it did not outperform the Adam optimizer in terms of accuracy. For instance, Experiment 6, using 512×384 resolution with the Adadelta optimizer, achieved 93% accuracy and 3126 seconds of training time, while Experiment 7 with 300×400 resolution and Adadelta achieved 91% accuracy and 1982 seconds of training time. Despite some advantages in training time, these configurations yielded lower accuracy compared to those using the Adam optimizer (Table 1).
After thoroughly analyzing the results of all the experiments, Experiment 8 emerged as the optimal configuration. In Experiment 8, 50% of 512×384 resolution was used in conjunction with the Adadelta optimizer (lr=0.1, decay=0.001), achieving 95% accuracy and 789 seconds of training time. This configuration stood out due to its ability to significantly reduce training time by utilizing only half of the dataset while maintaining a high accuracy. The decision to use 50% of 512×384 resolution resulted in a marked reduction in the amount of computational resources required, but without a notable loss in performance. Furthermore, the relatively efficient Adadelta optimizer contributed to a further reduction in training time.
Table 1. Scenario test results on the DenseNet121 model
|
Experiment |
Resize |
Optimizer |
Accuracy (%) |
Time (s) |
|
1 [4] |
512×384 |
Adam (lr=5.13e-3) |
94 |
3099 |
|
2 |
300×400 |
Adam (lr=5.13e-3) |
96 |
2002 |
|
3 |
50% of (512×384) |
Adam (lr=5.13e-3) |
91 |
825 |
|
4 |
50% of (300×400) |
Adam (lr=5.13e-3) |
90 |
578 |
|
5 |
224×224 |
Adam (lr=5.13e-3) |
95 |
831 |
|
6 |
512×384 |
Adadelta (lr=0.1, decay=0.001) |
93 |
3126 |
|
7 |
300×400 |
Adadelta (lr=0.1, decay=0.001) |
91 |
1982 |
|
8 |
50% of (512×384) |
Adadelta (lr=0.1, decay=0.001) |
95 |
789 |
|
9 |
50% of (300×400) |
Adadelta (lr=0.1, decay=0.001) |
91 |
543 |
|
10 |
224×224 |
Adadelta (lr=0.1, decay=0.001) |
92 |
848 |
Table 2. Optimal chromosome in each generation of CNN and its performance
|
Model |
Generation |
Accuracy (%) |
Training Time Per Chromosome (s) |
Hyperparameter Values |
|||
|
Layer 1 |
Layer 2 |
||||||
|
Number of Neurons |
DropOut Rate |
Number of Neurons |
DropOut Rate |
||||
|
Original DenseNet121 |
- |
94 |
3099 |
- |
- |
- |
- |
|
Optimized DenseNet121 |
1 |
92 |
752 |
512 |
0 |
128 |
0 |
|
2 |
92 |
752 |
512 |
0 |
128 |
0 |
|
|
3 |
95 |
812 |
640 |
0 |
128 |
0 |
|
|
4 |
97 |
789 |
896 |
30 |
512 |
20 |
|
Although Experiment 2 with 300×400 resolution and the Adam optimizer produced slightly higher accuracy (96%), Experiment 8 was preferred for its superior balance between performance, reduced training time, and efficient use of dataset size. The performance and time efficiency achieved in Experiment 8 suggest that it is the most suitable configuration for real-world applications, where both model effectiveness and computational resources are important considerations.
In conclusion, Experiment 8 proved to be the most optimal configuration, providing 95% accuracy while significantly reducing training time to 789 seconds. This configuration not only leveraged a reduced dataset size but also optimized the balance between performance and training efficiency, making it the best configuration for the task at hand. Table 2 displays the chromosomes exhibiting optimal performance in each generation of the CNN.
4.3 Hyperparameter optimization using a genetic algorithm
To evaluate the effectiveness of the GA in optimizing the DenseNet121 model, several generations of chromosome configurations were assessed. The baseline model, referred to as the "Original DenseNet121," utilized a fixed FC layer configuration with default settings and achieved an accuracy of 94% on the test set, with a training time of 3099 seconds. This served as the reference point for further comparative analysis.
The optimization phase using GA was conducted across four generations, with each chromosome representing a distinct configuration of hyperparameters-specifically, the number of neurons and dropout rates in two fully connected layers. The GA was designed to identify configurations that balance classification accuracy and training efficiency.
In Generation 1 and Generation 2, identical chromosome configurations (Layer 1: 512 neurons, 0% dropout; Layer 2: 128 neurons, 0% dropout) were evaluated, both yielding 92% accuracy and a significantly reduced training time of 752 seconds per chromosome. These configurations already showcased the potential of GA in reducing computational time while maintaining competitive accuracy.
Generation 3 presented a configuration with increased neurons in Layer 1 (640 neurons) while keeping Layer 2 unchanged. This modification resulted in a 95% accuracy and a slight increase in training time to 812 seconds, indicating a performance gain without a substantial computational cost.
The most effective configuration emerged in Generation 4, which demonstrated the highest classification accuracy of 97%-a 3% improvement over the original model. This configuration involved a deeper and more regularized network: 896 neurons with 30% dropout in Layer 1 and 512 neurons with 20% dropout in Layer 2. The associated training time was 789 seconds, substantially lower than that of the baseline model. This outcome illustrates that strategic tuning of FC layers using GA not only enhances model performance but also significantly reduces training time.
These findings highlight the efficacy of combining evolutionary algorithms like GA with deep learning models for hyperparameter optimization. The approach successfully discovered a configuration that surpassed the performance of the original architecture, both in terms of accuracy and efficiency. The optimized model demonstrates strong potential for deployment in real-world waste classification scenarios, where high performance and limited computational resources are often critical factors.
The performance of the optimized DenseNet121 model, configured using the genetic algorithm, is further validated through the confusion matrix presented in Figure 3. This matrix illustrates the classification outcomes across seven waste categories: Cardboard, Compost, Glass, Metal, Paper, Plastic, and Trash. The model demonstrates high classification accuracy across all classes, with accuracy values ranging from 95% to 99%. Specifically, the Cardboard and Compost classes achieved the highest accuracy of 99%, with only one misclassified instance in each class. Similarly, the Metal class reached 98% accuracy, indicating reliable performance with very few errors. The Paper and Plastic classes attained 97% and 96% accuracy, respectively, with a small number of instances misclassified as other categories. Although the Glass class showed a slightly lower accuracy of 95%, most of the misclassifications were concentrated in visually similar categories, such as Plastic and Metal. The Trash class, which typically poses greater classification challenges due to its diverse visual features, still achieved a commendable 96% accuracy.
The overall distribution in the confusion matrix reveals that the optimized model effectively distinguishes between waste classes, even in the presence of inter-class visual similarities. The few misclassifications observed are within a reasonable range and suggest a robust model performance. These results confirm that the best-performing model configuration-consisting of 896 neurons with a 30% dropout rate in the first fully connected layer and 512 neurons with a 20% dropout in the second layer-was successful in learning discriminative features across all categories. The outcome also underscores the effectiveness of the genetic algorithm in optimizing the model’s hyperparameters, leading to improved accuracy and reduced training time. This enhanced model performance makes it suitable for real-world waste classification applications, particularly in scenarios requiring a balance between computational efficiency and high predictive accuracy.
Figure 3. Confusion matrix for DenseNet121 model on test set
Waste management in Indonesia has become an increasingly complex challenge due to the continual rise in waste volume. Deep learning offers a promising avenue to support more efficient and scalable waste classification systems. This study proposed an optimized DenseNet121 architecture enhanced through a two-phase strategy: image preprocessing techniques and GA-based hyperparameter tuning.
In the first phase, data augmentation and downsampling were employed not only to improve dataset diversity and model generalization but also to reduce the computational cost. By resizing images to lower resolutions and subsetting the dataset, training time was significantly decreased without a substantial loss in accuracy. Specifically, this approach reduced the model's training time by a factor of four—from 3099 seconds to 789 seconds.
In the second phase, the GA effectively identified the optimal configuration of the fully connected layers. The best-performing configuration consisted of 896 neurons with a 30% dropout rate in the first dense layer and 512 neurons with a 20% dropout rate in the second. This optimization led to an increase in classification accuracy from 94% to 97%, demonstrating the GA's ability to enhance model performance while maintaining computational efficiency.
Future work should focus on expanding the dataset to include a broader range of waste types collected from diverse regions, which would improve the model’s generalizability. Moreover, deploying the optimized model on edge computing devices could enable real-time classification in operational waste management systems, further increasing practical applicability and environmental impact.
This research was supported by the Research Group Grant Program under Universitas Jember, with additional support from the Institute for Research and Community Service (LP2M) Universitas Jember. We sincerely appreciate the facilities and resources provided, which have significantly contributed to the success of this study. We also extend our gratitude to all members of the SMART for their collaboration and valuable contributions. Lastly, we would like to thank all parties involved for their insightful discussions and continuous support throughout this research.
[1] Mao, W.L., Chen, W.C., Wang, C.T., Lin, Y.H. (2021). Recycling waste classification using optimized convolutional neural network. Resources, Conservation and Recycling, 164: 105132. https://doi.org/10.1016/j.resconrec.2020.105132
[2] Czekała, W., Drozdowski, J., Łabiak, P. (2023). Modern technologies for waste management: A review. Applied Sciences, 13(15): 8847. https://doi.org/10.3390/app13158847
[3] Frost, S., Tor, B., Agrawal, R., Forbes, A.G. (2019). CompostNet: An image classifier for meal waste. In 2019 IEEE Global Humanitarian Technology Conference (GHTC), Seattle, WA, USA, pp. 1-4. https://doi.org/10.1109/GHTC46095.2019.9033130
[4] Srivatsan, K., Dhiman, S., Jain, A. (2021). Waste classification using transfer learning with convolutional neural networks. IOP Conference Series: Earth and Environmental Science, 775(1): 012010. https://doi.org/10.1088/1755-1315/775/1/012010
[5] Hak, L.A.A., Ali, W.A., Saba, S.J. (2024). Facial expression recognition using data augmentation and transfer learning. Ingénierie des Systèmes d'Information, 29(3): 1219-1225. https://doi.org/10.18280/isi.290338
[6] Howard, A.G. (2017). Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv Preprint, arXiv: 1704.04861. http://arxiv.org/abs/1704.04861
[7] Huang, G., Liu, Z., Van Der Maaten, L., Weinberger, K.Q. (2017). Densely connected convolutional networks. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, pp. 2261-2269. https://doi.org/10.1109/CVPR.2017.243
[8] Bouman, K.L., Johnson, M.D., Zoran, D., Fish, V.L., Doeleman, S.S., Freeman, W.T. (2016). Computational imaging for VLBI image reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, pp. 913-922. https://doi.org/10.1109/CVPR.2016.105
[9] Shorten, C., Khoshgoftaar, T.M. (2019). A survey on image data augmentation for deep learning. Journal of Big Data, 6(1): 1-48. https://doi.org/10.1186/s40537-019-0197-0
[10] Wong, S.C., Gatt, A., Stamatescu, V., McDonnell, M.D. (2016). Understanding data augmentation for classification: When to warp? In 2016 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Gold Coast, QLD, Australia, pp. 1-6. https://doi.org/10.1109/DICTA.2016.7797091
[11] Ghosh, K., Bellinger, C., Corizzo, R., Branco, P., Krawczyk, B., Japkowicz, N. (2024). The class imbalance problem in deep learning. Machine Learning, 113(7): 4845-4901. https://doi.org/10.1007/s10994-022-06268-8
[12] James, G., Witten, D., Hastie, T., Tibshirani, R., Taylor, J. (2023). Statistical learning. In an Introduction to Statistical Learning: With Applications in Python, pp. 15-67. Cham: Springer International Publishing.
[13] Single, S., Iranmanesh, S., Raad, R. (2023). Realwaste: A novel real-life data set for landfill waste classification using deep learning. Information, 14(12): 633. https://doi.org/10.3390/info14120633
[14] Auliya, Y.A., Fadah, I., Baihaqi, Y., Awwaliyah, I.N. (2024). Green bean classification: Fully convolutional neural network with Adam optimization. Mathematical Modelling of Engineering Problems, 11(6): 1641-1648. https://doi.org/10.18280/mmep.110626
[15] Wang, J., Perez, L. (2017). The effectiveness of data augmentation in image classification using deep learning. arXiv Preprint, arXiv: 1712.04621. https://doi.org/10.48550/arXiv.1712.04621
[16] Dhiya‘Ulhaq, I.Z., Hidayat, M.A., Dharmawan, T. (2024). Classification of coffee fruit maturity level based on multispectral image using naïve bayes method. Jurnal Ilmu Komputer dan Informasi, 17(2): 121-126. https://doi.org/10.21609/jiki.v17i2.1181
[17] Rodríguez-Molina, A., Villarreal-Cervantes, M.G., Mezura-Montes, E., Aldape-Pérez, M. (2019). Adaptive controller tuning method based on online multiobjective optimization: A case study of the four-bar mechanism. IEEE Transactions on Cybernetics, 51(3): 1272-1285. https://doi.org/10.1109/TCYB.2019.2903491
[18] Amiresmaeili, V., Jahantigh, H. (2017). Optimization of integrated management to use surface water and groundwater resources by using imperialist competitive algorithm and genetic algorithm (Tehran Plain). Civil Engineering Journal, 3(11): 1068-1083. http://doi.org/10.28991/cej-030938
[19] Fadah, I., Elliyana, A., Auliya, Y.A., Baihaqi, Y., Haidar, M., Sefira, D.M. (2022). A hybrid genetic-variable neighborhood algorithm for optimization of rice seed distribution cost. Mathematical Modelling of Engineering Problems, 9(1): 36-42. https://doi.org/10.18280/mmep.090105
[20] Real, E., Aggarwal, A., Huang, Y., Le, Q.V. (2019). Regularized evolution for image classifier architecture search. Proceedings of the AAAI Conference on Artificial Intelligence, 33(1): 4780-4789. https://doi.org/10.1609/aaai.v33i01.33014780