Jaime Yoni Anticona-Cueva*![]() | Eduardo Manuel Noriega-Vidal
| Eduardo Manuel Noriega-Vidal![]() | Marco Antonio Cotrina-Teatino
| Marco Antonio Cotrina-Teatino![]() | Marco Solio Marino Arango-Retamozo
| Marco Solio Marino Arango-Retamozo![]()
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
The objective of this study is to evaluate and optimize the costs of unit operations in artisanal underground mining through the application of predictive models based on machine learning. Four models were trained and validated: Multiple Linear Regression (MLR), Random Forest (RF), Decision Tree (DT), and Artificial Neural Networks (ANN), using a dataset that includes operational, geological, and economic variables collected over a three-month period. Among the evaluated models, Decision Trees demonstrated the best performance, achieving a coefficient of determination R² of 0.90, which enabled the identification of optimal cost parameters for critical activities such as drilling and blasting (41.32 US$/tn), shoveling (17.03 US$/tn), hauling (4.13 US$/tn), loading (16.08 US$/tn), ventilation (8.81 US$/tn), and ground support (1.51 US$/tn). Exceeding these costs results in cost overruns in unit operations, negatively impacting the profitability of the company. The results of this study provide an innovative approach to cost optimization in artisanal underground mining, enhancing profitability and contributing to more informed decision-making. The implications of these findings suggest immediate applications and open new opportunities for future research in other mining contexts.
predictive models, Multiple Linear Regression, Decision Tree, Random Forest, machine learning, Artificial Neural Networks, cost-effectiveness
In mining, considered a traditional and conservative industry with respect to innovation, it is at an inflection point due to increasingly complex challenges, such as declining ore grades [1]. These challenges have created an imperative to innovate. The incorporation of mature and emerging technologies into mining and other industries has opened up many opportunities for long-established companies, as well as for knowledge-based start-ups [2, 3]. Profitability in mining is the ability to generate profits by exceeding the costs of extraction, processing, and marketing [4]. This depends on efficient resource extraction, optimization of all operating costs and ore grades [5].
Artisanal mining, a sector that provides income to millions of people in developing countries, faces significant challenges due to its limited operational scale and restricted access to advanced technologies. Unlike large-scale mining operations, artisanal mining is characterized by narrower profit margins and greater vulnerability to fluctuations in operational costs. Optimizing these costs is crucial for the economic survival and sustainability of the sector. However, despite the critical importance of cost optimization, there is a lack of specific technological tools and studies addressing these challenges in the context of artisanal mining. This research aims to fill this gap by applying advanced predictive models, providing artisanal mining operations with precise and adaptable tools to improve their profitability and efficiency.
Each unit operation, from drilling, blasting and processing, represents a significant cost that must be controlled and optimized [6]. The optimization of these costs is important to maintain the company's competitiveness and economic viability [7]. Therefore, constant monitoring and improvement of operating methods are important to ensure that resources are optimally utilized [8].
On the other hand, ore grades some basic theoretical concepts describing the quality of the available quantity of minerals in our earth, The first investigations on the tonnage and grade of metal deposits [9]. However, these metals are not infinite and the average ore grades in the mines have been declining over the last decades [10], companies are therefore faced with greater operational and financial challenges [11], which underscores the need to continually improve operational efficiency and manage resources in a responsible manner [12]. The implementation of predictive models and advanced analytics enables companies to anticipate problems, optimize processes and make decisions [13, 14].
Recent advances in artificial intelligence (AI) and machine learning have demonstrated significant potential for optimizing operational costs across various industries, including mining. Guo et al. [15] developed a highly accurate AI-based model using Artificial Neural Networks (ANN), Random Forests (RF), and Support Vector Machines (SVM) to estimate capital costs in open-pit mining projects, revealing the robustness of AI in cost estimation with an R2 of 0.990. Zhang et al. [16] combined deep neural networks with ant colony optimization to forecast mining project costs, showcasing the effectiveness of hybrid AI approaches. Hennebold et al. [17] explored the application of machine learning for cost prediction in mechanical engineering, emphasizing the need for accurate predictions during the early stages of product development, even with limited data. Additionally, Langenberger et al. [18] applied machine learning techniques, including RF and Gradient Boosting Machines (GBM), to predict high-cost patients in the healthcare sector, demonstrating that tree-based models outperformed other approaches in complex cost prediction tasks. Rafiei and Adeli [19] also successfully applied deep Boltzmann machines and neural networks to improve cost estimation in construction. Despite these advancements, the specific application of these models to the unique challenges of artisanal underground mining remains underexplored. This study addresses this gap by evaluating the effectiveness of multiple predictive models, including ANN and RF, in optimizing the costs of unit operations in artisanal mining. The proposed hypothesis is that these advanced models can significantly enhance profitability by providing accurate cost predictions and optimization strategies tailored to artisanal mining operations.
Mining companies face the important challenge of improving the efficiency and profitability of their mining activities, which implies optimizing the costs associated with unit operations [20, 21]. This process involves the constant quest to maximize productivity and minimize operating expenses, but the individual optimization of these activities does not mean that the entire system is optimized [22], while reducing the risks inherent to mineral extraction and processing [23]. In an increasingly competitive economic environment, mining companies are striving to implement sound and efficient strategies that will enable them to achieve these objectives [24].
According to the study conducted by Cuba Atencio [25]. The company was able to improve the economic benefits through the application of linear programming in the SEPROCAL company. It demonstrated that by applying linear programming it was able to increase the economic benefits achieving a maximum of $241.7 MUS$, which represents an increase of 0.114% with respect to the current benefits without affecting the production level, it was also able to notoriously reduce the operating costs, the total cost went from $11.4 MUS$ to a minimum of $11.2 MUS$, representing a reduction of -1.22%. The application of predictive machine learning models in mining has become a key tool to optimize processes and search for optimal parameters [26], that enable mining companies to collect and analyze large amounts of data in real time, leading to improved operational performance and better decisions [27]. This forecasting capability facilitates the identification of optimization and automation opportunities [28].
In Peru, both large mining companies and small-scale artisanal miners are dedicated on a daily basis to minimizing the costs associated with unit operations and increasing production. This approach not only promotes greater profitability for mining companies, but also ensures a constant production flow, thus contributing to the economic competitiveness of the sector [29]. By adopting smart strategies to forecast profitability, artisanal mining companies can improve their bottom line and ensure sustainable growth.
The manuscript is structured as follows: Section 2 describes the methodology used to develop and evaluate the predictive models. Section 3 presents the results obtained from the application of these models in the context of artisanal mining. Section 4 discusses the implications of the findings for cost optimization and decision making in the mining industry. Finally, Section 5 provides the conclusions and outlines directions for future research.
2.1 Data collection
This study is based on a dataset comprising 287 records collected from the operational logs provided by the mining company over a three-month period in an artisanal mining operation in Peru. These records include detailed information on operational costs, operation times, energy consumption, and daily production, among other key indicators. The mining company maintained rigorous and systematic control over these variables, ensuring the quality and consistency of the data used in this analysis (see Table 1).
Table 1. Statistics of the study variables
|
Variables |
Mean |
Std |
Min |
Max |
|
Width (m) |
1.61 |
0.58 |
1.00 |
3.50 |
|
Length (m) |
1.55 |
0.63 |
0.30 |
3.50 |
|
Advance (m) |
0.97 |
0.07 |
0.60 |
1.15 |
|
grain inclination (°) |
53.17 |
15.59 |
30.00 |
70.00 |
|
RMR |
68.37 |
3.70 |
60.00 |
70.00 |
|
Density (tn/m3) |
2.63 |
0.01 |
2.60 |
2.64 |
|
Au grade (oz/tn) |
0.83 |
0.05 |
0.74 |
0.91 |
|
Drilling cost + blasting (US$/tn) |
35.04 |
15.41 |
7.47 |
120.00 |
|
Cleaning cost (US$/tn) |
18.05 |
10.63 |
3.63 |
53.19 |
|
Freight cost (US$/tn) |
15.53 |
0.43 |
15.02 |
16.34 |
|
Carrying cost (US$/tn) |
9.56 |
4.75 |
3.84 |
17.52 |
|
Ventilation cost (US$/tn) |
4.84 |
1.67 |
2.17 |
10.91 |
|
Sustaining cost (US$/tn) |
1.64 |
0.34 |
1.41 |
2.23 |
|
Au price (US$/oz) |
2087.06 |
66.24 |
2007.2 |
2238.4 |
|
Metallurgical recovery |
0.88 |
0.00 |
0.87 |
0.89 |
|
Ore recovery |
0.90 |
0.02 |
0.88 |
0.95 |
|
Profitability (US$) |
7945.2 |
2974.2 |
2076.8 |
18205.8 |
2.2 Data processing and validation
To ensure the integrity and accuracy of the dataset, a thorough data cleaning and validation process was implemented. Outliers were identified using statistical analysis based on standard deviation, with records considered outliers if they fell outside three standard deviations from the mean. Each outlier was reviewed to determine whether it reflected a recording error or natural variability in the process; those values that could not be justified were excluded from the final analysis. Additionally, in cases where missing data were identified, imputation was performed using the mean of the available data to maintain the dataset's integrity without introducing significant biases.
2.3 Data preparation for modeling
After completing data cleaning, the variables were normalized to ensure homogeneity in the scales before being included in the predictive models. This normalization was crucial to ensure that all variables contributed equally to the modeling process without dominating due to differences in measurement units. The final dataset was divided into training and testing subsets, with 5-fold cross-validation applied to assess the robustness and generalization capability of the developed models. This approach involved dividing the dataset into five subsets, where each subset was used as a test set while the remaining subsets were used for training. This methodological approach ensures that the predictive models are accurate and applicable in various contexts within artisanal mining.
2.4 Predictive model Random Forest
Random Forests (RF) are a machine learning method that combines multiple Decision Trees, where each tree is trained using a random sample of the data set and a random subset of features [30]. Each tree in the forest first generates its own prediction based on the data it has seen during training [31]. Then, the predictions of all the trees are combined: in classification problems, the majority vote is used to decide the final class, while in regression problems, the average of the individual predictions is calculated [32].
ˆy=1n∑ni=1Ti(x) (1)
where, ˆy is the final predicted value Ti(x) is the prediction made by the i-th tree for an instance x, n is the number of trees in the forest.
2.5 Predictive model Decision Tree
Decision Trees (DT) are a widely used supervised learning technique for both classification and regression tasks [33]. This non-parametric method builds a model based on decision rules derived directly from the characteristics of the data. The tree structure facilitates interpretation, as each node represents a decision based on a particular feature, and each branch corresponds to the possible outcomes of that decision [34]. As the model moves down the tree, successive decision rules are applied until it reaches a leaf, which provides the final prediction. Eq. (2) shows the prediction for a given region.
ˆyRj=1|Rj|∑i∈Rj(yi−ˆyRj)2 (2)
2.6 Predictive model Multiple Linear Regression
Multiple Linear Regression (MLR) is a fundamental statistical technique for analyzing the relationship between a dependent variable and multiple independent variables [35, 36]. Unlike simple linear regression, which examines a single predictor variable, MLR considers several factors at once, providing a more complete understanding of how they influence the outcome.
y=β0+β1xi1+β2xi2…βpxip+ϵ1 (3)
where,
y: dependent variable
xin: independent variables
βp: coefficients of the independent variables
β0: the ordinate at the origin
ϵ: the residual which is the discrepancy between the observed value and the value estimated by the model.
2.7 Artificial Neural Networks
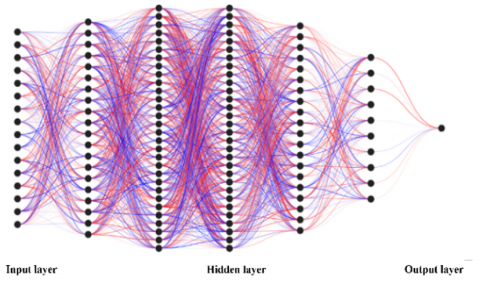
Artificial Neural Networks (ANN) are computational models inspired by the structure of the human brain, capable of learning and recognizing complex patterns in large data sets [37]. The neural network used in this research work has the following structure: an input layer with 16 neurons, followed by dense hidden layers with sizes of 20, 30, 30, 30, 20 and 10 neurons, respectively, and an output layer with 1 neuron. The Adam optimization algorithm was employed with a learning rate of 0.009 and a total of 250 training epochs. The activation function used in the hidden layers is ReLU, while the output layer does not use any activation function (See Figure 1).
input =∑ni=1xiwi+b (4)
where,
b: bias
xi: number of inputs to the neuron
wi: weights
Figure 1. Artificial neural network structure
2.8 Performance metrics
Performance metrics in machine learning are tools for evaluating the accuracy and effectiveness of predictive models [38]. And to see the ability of a model to make accurate predictions and generalize well to new data.
The Mean Squared Error (MSE) measures the average of the squares of the errors, providing an estimate of the variation between predicted and observed values. The Root Mean Square Error (RMSE) is the square root of the MSE. The Mean Absolute Error (MAE) calculates the average of the absolute differences between predictions and observations, highlighting the average magnitude of the errors without considering their direction. The correlation coefficient (R²) indicates the proportion of the variance in the observed data that is explained by the model, with values closer to 1 indicating a better explanatory power of the model [39].
Mean square error
MSE=1N∑Ni=1(yi−ˆyi)2 (5)
Root Mean Square Error
RMSE=√1N∑Ni=1(yi−ˆyi)2 (6)
Mean Absolute Error
MAE=1N∑Ni=1|yi−ˆyi| (7)
Correlation coefficient
R2=1−∑Ni=1(yi−ˆyi)2∑Ni=1(yi−yavg)2 (8)
where,
n: the total data
yi: the specifics of the case i
ˆyi: the prediction data for the case of i
yavg: the mean of the observed data.
2.9 Procedure
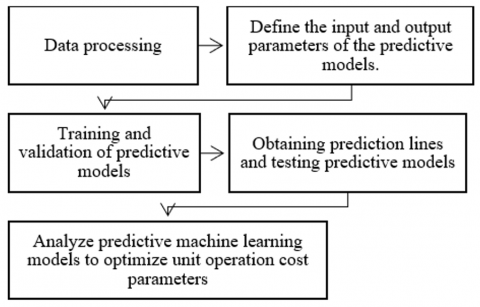
The research procedure is presented in Figure 2. This figure details the steps that will be followed during the research process with the objective of predicting the profitability of an artisanal mining company, as well as identifying the optimal parameters of the unit costs that will allow us to maximize the economic benefit of the companies.
Figure 2. Research flowchart
2.10 Methodology
The methodology used in this study adopted a quantitative approach because it allows us to analyze numerical data in an objective manner and to accurately measure the relationship between the variables of interest [40-43]. Additionally, a specific experimental method was employed, allowing for controlled research conditions and systematic evaluation of the impact of different factors on a company's profitability. To ensure the validity of the results and the robustness of the predictive models, k-fold cross-validation was implemented during the modeling process. This technique ensures that the models are evaluated across different partitions of the dataset, minimizing bias and maximizing the generalization of the results.
3.1 Data processing
To ensure the accuracy and robustness of the predictive models, an exhaustive treatment of outliers was conducted on the initial 287 records collected. Outlier records that could potentially compromise the model's performance were removed, resulting in a final dataset of 252 records. K-fold cross-validation was employed during training to ensure that the models could generalize accurately across different operational scenarios, thereby optimizing costs in artisanal mining operations.
3.2 Define input and output parameters for predictive models
The selection of input and output variables for the predictive models is presented in Table 2. In total, there are 16 input variables and one output variable. In addition, the number available for each of the study variables is shown below.
Table 2. Variable selection
|
Variables |
Cant. |
Tipo |
Input/Output |
|
Width (m) |
252 |
float |
Input |
|
Length (m) |
252 |
float |
Input |
|
Advance (m) |
252 |
float |
Input |
|
Grain inclination (°) |
252 |
integer |
Input |
|
RMR |
252 |
integer |
Input |
|
Density (tn/m3) |
252 |
float |
Input |
|
Au grade (oz/tn) |
252 |
float |
Input |
|
Drilling cost + blasting (US$/tn) |
252 |
float |
Input |
|
Cleaning cost (US$/tn) |
252 |
float |
Input |
|
Freight cost (US$/tn) |
252 |
float |
Input |
|
Carrying cost (US$/tn) |
252 |
float |
Input |
|
Ventilation cost (US$/tn) |
252 |
float |
Input |
|
Sustaining cost (US$/tn) |
252 |
float |
Input |
|
Au price (US$/oz) |
252 |
float |
Input |
|
Metallurgical recovery |
252 |
float |
Input |
|
Ore recovery |
242 |
float |
Input |
|
Profitability (US$) |
252 |
float |
output |
3.3 Training and validation of predictive models
3.3.1 Random Forest (RF)
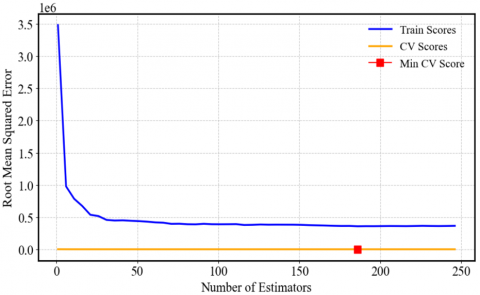
Figure 3 illustrates how the Root Mean Square Error (RMSE) varies with the number of estimators. The blue curve, corresponding to the training set, shows that the RMSE decreases rapidly and then stabilizes around 150 estimators, with a value close to 0.2×106. The yellow curve, representing cross-validation, indicates a nearly constant average RMSE of 0.3×106, suggesting good model generalization. The red point marks the minimum RMSE in cross-validation, which is achieved with approximately 200 estimators, indicating that this number provides an optimal balance between accuracy and generalization.
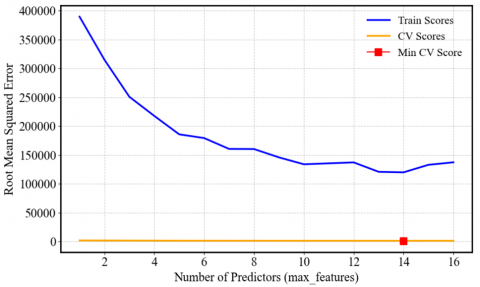
In Figure 4, the RMSE decreases as the number of predictors increases, reaching a minimum of around 150,000 with 14 predictors on the blue training curve. However, adding more predictors beyond this point does not significantly improve the RMSE and could cause overfitting. The yellow cross-validation curve maintains an average RMSE of 50,000, highlighting those 14 predictors is the optimal number, achieving a good balance between accuracy and generalization.
Figure 3. Cross-validation with RMSE to determine the number of estimators
Figure 4. Cross-validation with RMSE to determine the number of predictors
3.3.2 Multiple Linear Regression
The predictive model was trained, validated, and evaluated using Python's Statsmodels library. The process began with data preparation, including the addition of an intercept column to the predictor matrix using the sm.add_constant function. Subsequently, the model was fitted using the sm.OLS() function and trained with the available data.
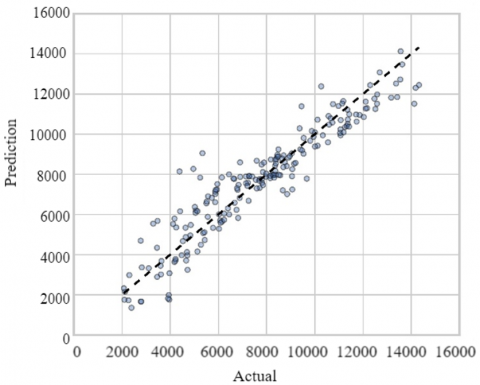
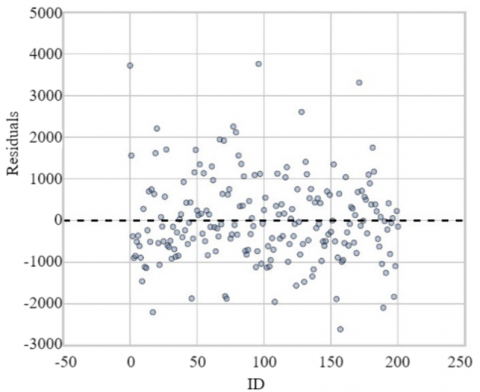
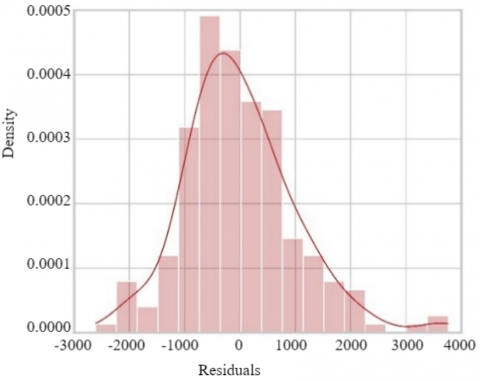
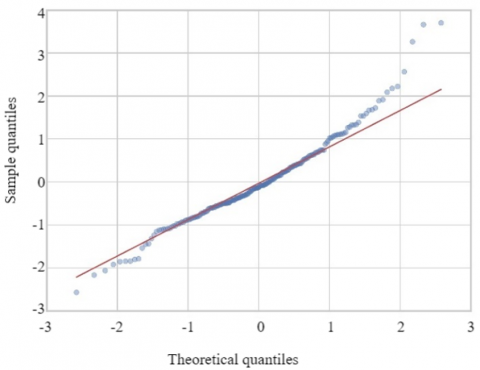
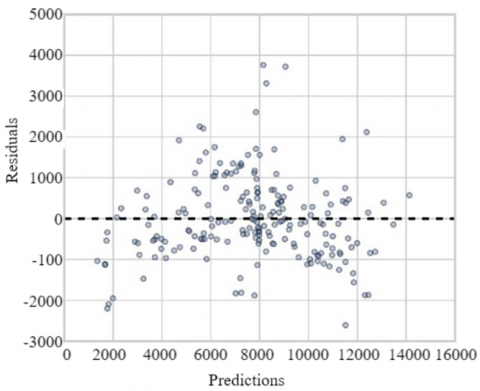
The diagnostic of the model's residuals reveals a good correspondence between the predicted and actual values, as shown in the predicted vs. actual values plot, where the points align closely around the diagonal. The residuals exhibit a random distribution around zero, indicating the absence of significant systematic errors, although some larger residuals suggest the presence of outliers. The residuals' distribution is approximately normal, according to the histogram and Q-Q plot, though there is a slight deviation in the tails, which might indicate minor heteroscedasticity or outliers. Finally, the residuals vs. predictions plot shows no discernible pattern, although there is a slight increase in dispersion for higher predictions, which could suggest mild heteroscedasticity in the model (see Figure 5).
(a) Predicted vs. actual value
(b) Model residuals
(c) Model residuals distribution
(d) Q-Q plot of model residuals
(e) Residuals vs. predictions
Figure 5. Diagnosis of residuals of the predictive Multiple Linear Regression model
3.3.3 Decision Tree
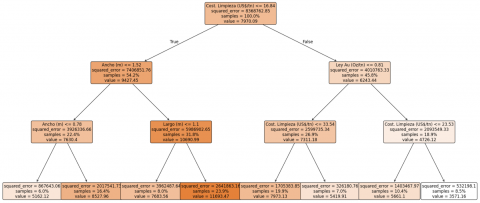
During the initial phase of training and validating the Decision Tree model, a max_depth hyperparameter of 3 was used, as shown in Figure 6. This model resulted in 8 terminal nodes, but the correlation coefficient obtained was relatively low, reaching only 74%. Given this suboptimal performance, a tree pruning process was applied using cross-validation, which determined an optimal ccp_alpha value of 50.53. Subsequently, max_depth was adjusted to 15, significantly increasing the tree's complexity, resulting in 120 terminal nodes and raising the correlation coefficient to 90% with respect to the actual data. This adjustment notably improved the model's predictive ability, reflecting a better balance between the model's complexity and its generalization capacity.
Figure 6. Decision Tree structure
3.3.4 Artificial Neural Networks
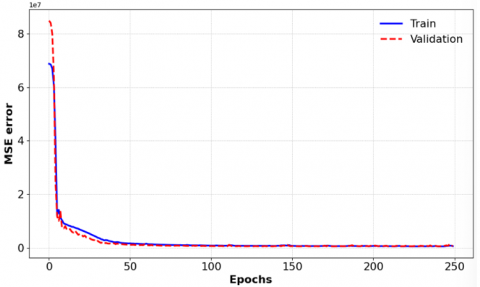
In the training of Artificial Neural Networks, a structure for the model was sought, using 250 epochs, 5 hidden layers, Adam optimization algorithm and a learning rate of 0.009. Applying this structure, a correlation coefficient of 92% was achieved.
Figure 7 shows the development or evolution of the mean square error during training.
Figure 7. Evolution of the mean squared error during training
3.3.5 Performance metrics of predictive models
During the training of Artificial Neural Networks, a structure was employed consisting of 250 epochs, five hidden layers, the Adam optimization algorithm, and a learning rate of 0.009. This configuration allowed the model to achieve a correlation coefficient of 92%, indicating a significant fit. The evolution of the mean squared error (MSE) during the training process showed a rapid initial decrease followed by stabilization, suggesting that the model achieved an adequate balance between accuracy and generalization without overfitting.
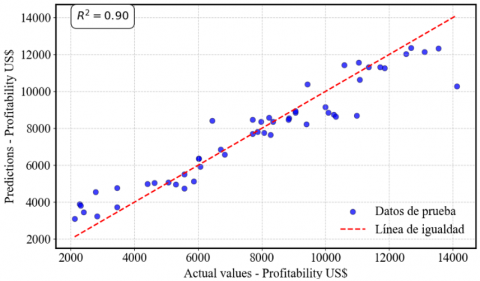
When comparing the Random Forest (RF), Multiple Linear Regression (MLR), Decision Tree (DT), and ANN models, it was observed that the ANN outperformed the others in terms of RMSE, MAE, and MSE. Specifically, the ANN model recorded an RMSE of 934.87 and an MAE of 612.85, which were lower than those of the other models, indicating its superiority in minimizing errors and prediction accuracy. Although the DT model showed a slightly higher coefficient of determination (R²) (0.90), the lower errors associated with the ANN model highlight its capacity to make more precise and reliable predictions.
The superiority of the ANN model is attributed to its ability to capture complex relationships between variables, something that simpler models like MLR cannot achieve as effectively. The standout performance of the ANN, as reflected in key metrics such as RMSE and MAE, demonstrates its suitability for optimizing costs in artisanal mining operations, making it the most robust option for this type of analysis.
The Decision Tree (DT) model stands out in this study due to its higher coefficient of determination (R²), indicating a greater ability to explain the variability in operational costs of artisanal mining operations. This precision allows for more effective identification of areas where costs can be optimized, providing a robust tool to improve operational efficiency. By applying the DT model, companies can make data-driven decisions to reduce cost overruns, which is crucial in a sector where margins are often tight.
The Decision Tree not only excels in accuracy but also in ease of interpretation and scalability. This model is highly applicable to operations of any size, from small-scale mining to large industrial projects. Its ability to break down complex decisions into clear rules facilitates its implementation in various mining contexts, allowing companies to quickly adjust their strategies and continuously improve efficiency.
3.4 Obtaining prediction lines and testing predictive models
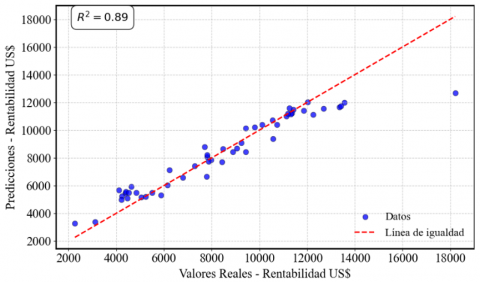
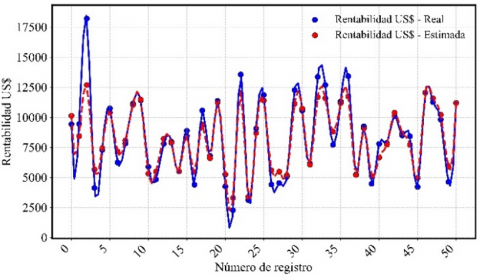
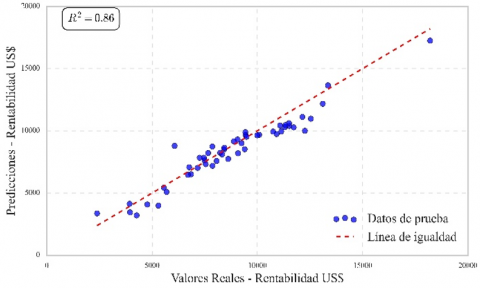
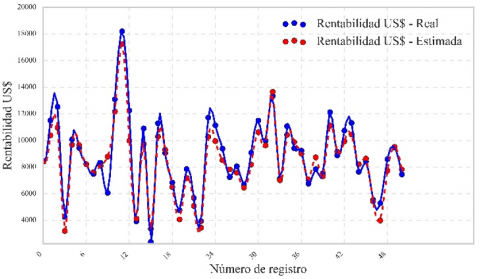
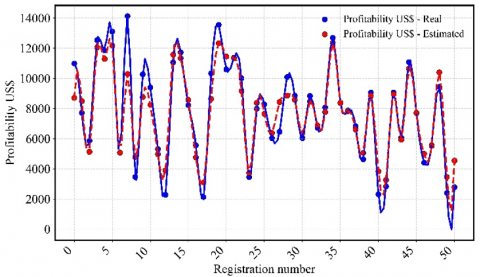
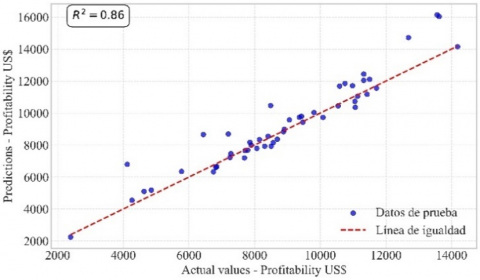
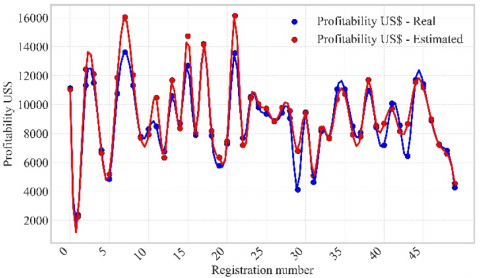
Figure 8 shows the prediction line of the Random Forest model, which achieved a correlation coefficient of 0.89, indicating a solid fit. This correlation is validated in Figure 9, where the actual and estimated profitability are graphically compared, showing a close alignment between the two. Figure 10 presents the prediction line of the Multiple Linear Regression model, which achieved a correlation coefficient of 0.91. Figure 11 confirms this relationship, showing a high concordance between actual and estimated profitability, reflecting the model’s effectiveness in capturing data variability. Figure 12 illustrates the prediction line of the Decision Tree model, with a correlation coefficient of 0.90. This correlation is verified in Figure 13, where a strong correspondence between actual and estimated profitability values is observed, highlighting its predictive capability. Figure 14 presents the prediction line of the Artificial Neural Networks model, which achieved the highest correlation coefficient of 0.92. This relationship is corroborated in Figure 15, where the comparison between actual and estimated profitability shows a superior fit, positioning neural networks as the most accurate and robust model among those evaluated, with the lowest Root Mean Square Error (RMSE) (Table 3).
Table 3. Performance metrics of predictive models
|
Model |
RF |
MLR |
DT |
ANN |
|
RMSE |
1089.47 |
1068.39 |
1027.53 |
934.87 |
|
MAE |
649.71 |
865.34 |
743.10 |
612.85 |
|
MSE |
1186955.32 |
1141457.2 |
1055821.35 |
873982.99 |
|
R2 |
0.89 |
0.86 |
0.90 |
0.86 |
Figure 8. Line of predictions Random Forest model
Figure 9. Actual US$ profitability vs estimated US$ Profitability - Random Forest Model
Figure 10. Line of predictions Multiple Linear Regression model
Figure 11. Actual US$ profitability vs. estimated US$ Profitability Multiple Linear Regression
Figure 12. Line of prediction Decision Tree model
Figure 13. Actual US$ profitability vs. estimated US$ profitability Decision Tree model
Figure 14. Line of predictions Artificial Neural Networks
Figure 15. Actual US$ profitability vs. estimated US$ profitability Artificial Neural Networks
The Random Forest model highlights drilling, blasting, hauling, and ventilation as the main cost drivers in artisanal mining operations. These variables are critical because they represent the activities with the greatest impact on operational costs. The high importance assigned to these variables suggests that optimization efforts should focus on these areas, as any improvement in the efficiency of these processes can lead to significant reductions in total costs. This not only validates the traditional focus on these areas but also prioritizes these operations as key targets for intervention and resource optimization.
The Decision Tree provides clear rules that closely align with existing operational practices in mining. For example, decisions on how to adjust ventilation or when to clean equipment are not only reflected in the data but are also recognized as essential operational practices for maintaining efficiency and safety in underground mining. This model translates these practices into quantifiable rules, facilitating more structured, data-driven decision-making, which is crucial for improving daily operations and reducing operational costs in mining.
The model's findings have direct implications for the management and optimization of mining operations. Identifying and prioritizing critical cost areas allows mining companies to focus their resources on the aspects that most affect profitability. Moreover, by translating operational knowledge into practical rules, the Decision Tree helps managers implement data-driven improvements, which can increase the efficiency and competitiveness of mining operations. These results not only offer a predictive outlook but also provide a practical guide for optimizing operations and maximizing economic benefits.
3.5 Analyze predictive machine learning models to optimize the cost parameters of unit operations
This section examines the optimization of unit operation costs to improve profitability in artisanal mining companies. The predictive models trained in the previous chapter, such as Random Forest, Multiple Linear Regression, Decision Tree, and Artificial Neural Networks, were employed to identify the optimal operating cost parameters. After training these models, the Particle Swarm Optimization (PSO) algorithm was applied, allowing the models to be fine-tuned and the best cost parameters for unit operations to be determined.
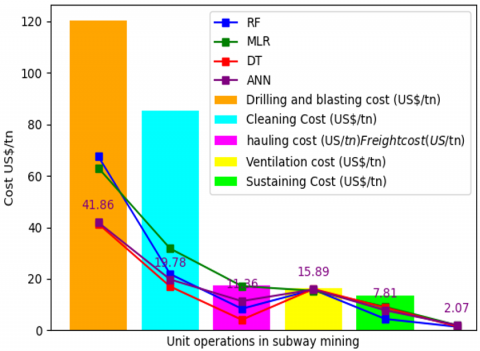
The results showed that Artificial Neural Networks (ANN) stood out among the evaluated models, achieving the lowest Root Mean Square Error (RMSE) and the highest correlation coefficient, with an R2 of 0.92. The optimal parameters obtained are presented in Table 4, where it is observed that, for example, the optimal cost for Drilling and Blasting was 41.86 US$/ton in the ANN model, compared to 67.43 US$/ton in Random Forest, 63.01 US$/ton in Multiple Linear Regression, and 41.32 US$/ton in Decision Tree. Similarly, the optimal cost for Cleaning was optimized to 19.78 US$/ton in the ANN model, which was notably lower than the 31.77 US$/ton estimated by Multiple Linear Regression.
These results are graphically presented in Figure 16, where the bars indicate the maximum cost recorded during the study months. The optimization of unit operation costs not only maximizes economic profitability in mining companies but also facilitates strategic decision-making by providing more accurate cost parameters that are adjusted to operational reality.
Table 4. Optimal parameters of the cost of unit operations
|
Cost of Unit Operations |
Unidad |
RF |
MLR |
DT |
ANN |
|
Drilling + Blasting |
US$/tn |
67.43 |
63.01 |
41.32 |
41.86 |
|
Cleaning |
US$/tn |
21.87 |
31.77 |
17.03 |
19.78 |
|
Freight |
US$/tn |
8.40 |
17.19 |
4.13 |
11.36 |
|
Carrying |
US$/tn |
15.8 |
15.38 |
16.08 |
15.89 |
|
Ventilation |
US$/tn |
4.44 |
9.17 |
8.81 |
7.81 |
|
Sustaining |
US$/tn |
1.41 |
2.00 |
1.51 |
2.07 |
Figure 16. Optimal cost parameters for unit operations
3.6 Practical application and considerations for implementation
The implementation of predictive models such as Decision Trees (DT) and Artificial Neural Networks (ANN) in real mining operations offers significant potential for improving operational efficiency and reducing costs. However, the transition from a theoretical framework to practical application presents challenges that require careful planning.
Potential Obstacles: A major challenge in implementing these models is resistance to change, which is common in the mining industry, as it tends to be conservative in adopting new technologies. The perceived complexity of machine learning models and the lack of familiarity with them may limit initial adoption. Additionally, integrating these models into existing operational systems can be complex, requiring considerable investment in terms of time and resources for effective implementation.
Technological Requirements: The adoption of these models demands advanced technological infrastructure. It is essential to have robust systems for data collection and storage, large-scale data processing capabilities, and software platforms that allow real-time execution and monitoring of the models. Furthermore, it is crucial to train personnel to manage these technologies and use the results in operational decision-making. Specialized training in data analysis and the handling of advanced technologies will be key to overcoming initial barriers and maximizing the benefits of these models.
Economic Impact: The economic impact of implementing predictive models in mining operations can be significant. In the short term, the costs associated with acquiring technology, integrating systems, and training personnel may be substantial. However, the long-term benefits, such as cost optimization, improved decision-making, and enhanced operational efficiency, have the potential to far outweigh the initial investments. Companies that successfully implement and scale these models will be better positioned to face the challenges of a competitive global mining market, gaining a significant and sustained economic advantage.
4.1 Key findings, implications, and contributions
When training, evaluating and testing the predictive machine learning models to determine the profitability of an operating well, it was observed that the Decision Tree model obtained a coefficient of determination of 0.90, with an RMSE of 1027.53, followed by the artificial neural network model with an RMSE of 717.99, a coefficient of determination of 0.86. The Random Forest model obtained a coefficient of determination of 0.89, with an RMSE of 1089.47. Finally, the Multiple Linear Regression model obtained an R2 of 0.86 with an RMSE of 1068.39.
It was possible to find the optimal parameters of the costs associated to the unitary operations of an artisanal mining company through the optimization algorithm PSO (Particle Swarm), the DT showed a higher R2 and therefore found its optimal parameters in the operating costs (US$/tn); It was obtained in drilling and blasting of 41.32, shovel cleaning of 17.03, hauling 4.13, loading 16.08, ventilation 8.81, and support 1.51 where exceeding these costs generates a cost overrun in unit operations; These parameters will allow us to adjust to the optimal costs generated by the predictive models, which will help us to make informed decisions before the profitability of the mining company is compromised.
It is important to note that not all unit operations can be optimized in the same way. For example, in the case of maintenance cost for underground mining companies, personnel safety must not be compromised for the sake of cost reduction. Safety is a priority that cannot be sacrificed in the optimization process.
4.2 Study limitations and directions for future research
This study presents certain limitations, primarily the restriction of analysis to a three-month period, which may not fully capture seasonal variability or long-term operational changes. Additionally, the focus on a specific artisanal mining operation may limit the generalization of the results to other mining contexts. These limitations suggest that the findings should be interpreted with caution when applied to different types of operations or over broader time scales.
Future research should consider extending the data collection period to a year or more to better capture operational and seasonal variations and apply and validate these models in different types of mining operations, such as open-pit mining or in various geographical regions, to evaluate their applicability and robustness in other contexts. Furthermore, adapting these predictive models for integration into automated mining operations by combining technologies such as the Internet of Things (IoT) and artificial intelligence could create smart mining platforms that optimize both costs and operational safety. This comprehensive approach would not only improve the accuracy and applicability of the models in cost optimization but also contribute to the efficiency and sustainability of mining operations, accelerating innovation and the adoption of more advanced practices in the industry.
|
n |
total data |
|
yi |
specifics of the case i |
|
ˆyi |
prediction data for the case of i |
|
yavg |
mean of the observed data |
|
y |
dependent variable |
|
xin |
independent variables |
|
b |
bias |
|
xi |
number of inputs to the neuron |
|
wi |
pesos |
|
Greek symbols |
|
|
βp |
coefficients of the independent variables |
|
β0 |
the ordinate at the origin |
|
ϵ |
the residual which is the discrepancy between the observed value and the value estimated by the model |
[1] Calzada Olvera, B. (2022). Innovation in mining: what are the challenges and opportunities along the value chain for Latin American suppliers? Mineral Economics, 35(1): 35-51. https://doi.org/10.1007/s13563-021-00251-w
[2] Ediriweera, A., Wiewiora, A. (2021). Barriers and enablers of technology adoption in the mining industry. Resources Policy, 73: 102188. https://doi.org/10.1016/j.resourpol.2021.102188
[3] Perifanis, N.A., Kitsios, F. (2023). Investigating the influence of artificial intelligence on business value in the digital era of strategy: A literature review. Information, 14(2): 85. https://doi.org/10.3390/info14020085
[4] Bikubanya, D.L., Radley, B. (2022). Productivity and profitability: Investigating the economic impact of gold mining mechanisation in Kamituga, DR Congo. The Extractive Industries and Society, 12: 101162. https://doi.org/10.1016/j.exis.2022.101162
[5] Curry, J.A., Ismay, M. J., Jameson, G.J. (2014). Mine operating costs and the potential impacts of energy and grinding. Minerals Engineering, 56: 70-80. https://doi.org/10.1016/j.mineng.2013.10.020
[6] Abbaspour, H., Drebenstedt, C., Badroddin, M., Maghaminik, A. (2018). Optimized design of drilling and blasting operations in open pit mines under technical and economic uncertainties by system dynamic modelling. International Journal of Mining Science and Technology, 28(6): 839-848. https://doi.org/10.1016/j.ijmst.2018.06.009
[7] Botín, J.A., Vergara, M.A. (2015). A cost management model for economic sustainability and continuous improvement of mining operations. Resources Policy, 46: 212-218. https://doi.org/10.1016/j.resourpol.2015.10.004
[8] Fourie, H. (2016). Improvement in the overall efficiency of mining equipment: A case study. Journal of the Southern African Institute of Mining and Metallurgy, 116(3): 275-281. https://doi.org/10.17159/2411-9717/2016/v116n3a9
[9] Rötzer, N., Schmidt, M. (2018). Decreasing metal ore grades—Is the fear of resource depletion justified? Resources, 7(4): 88. https://doi.org/10.3390/resources7040088
[10] Magdalena, R., Valero, A., Calvo, G. (2023). Limit of recovery: how future evolution of ore grades could influence energy consumption and prices for nickel, cobalt, and PGMs. Minerals Engineering, 200: 108150. https://doi.org/10.1016/j.mineng.2023.108150
[11] Teichmann, F., Boticiu, S., Sergi, B.S. (2023). RegTech–Potential benefits and challenges for businesses. Technology in Society, 72: 102150. https://doi.org/10.1016/j.techsoc.2022.102150
[12] Xiong, Y., Guo, H., Nor, D.D.M.M., Song, A., Dai, L. (2023). Mineral resources depletion, environmental degradation, and exploitation of natural resources: COVID-19 aftereffects. Resources Policy, 85: 103907. https://doi.org/10.1016/j.resourpol.2023.103907
[13] Aldoseri, A., Al-Khalifa, K.N., Hamouda, A.M. (2023). Re-thinking data strategy and integration for artificial intelligence: Concepts, opportunities, and challenges. Applied Sciences, 13(12): 7082. https://doi.org/10.3390/app13127082
[14] Attaran, M., Attaran, S. (2019). Opportunities and challenges of implementing predictive analytics for competitive advantage. Applying Business Intelligence Initiatives in Healthcare and Organizational Settings, 2: 64-90. https://doi.org/10.4018/978-1-5225-5718-0.ch004
[15] Guo, H., Nguyen, H., Vu, D.A., Bui, X.N. (2021). Forecasting mining capital cost for open-pit mining projects based on artificial neural network approach. Resources Policy, 74: 101474. https://doi.org/10.1016/j.resourpol.2019.101474
[16] Zhang, H., Nguyen, H., Bui, X, Nguyen, T., Bui, T., Nguyen, N., Anh, D., Mahesh, V., Moayedi, H. (2020). Developing a novel artificial intelligence model to estimate the capital cost of mining projects using deep neural network-based ant colony optimization algorithm. Resources Policy, 66: 101604. https://doi.org/10.1016/j.resourpol.2020.101604
[17] Hennebold, C., Klopfer, K., Lettenbauer, P., Huber, M. (2022). Machine learning based cost prediction for product development in mechanical engineering. Procedia CIRP, 107: 264-269. https://doi.org/10.1016/j.procir.2022.04.043
[18] Langenberger, B., Schulte, T., Groene, O. (2023). The application of machine learning to predict high-cost patients: A performance comparison of different models using healthcare claims data. PLOS ONE, 18(1): e0279540. https://doi.org/10.1371/journal.pone.0279540
[19] Rafiei, M.H., Adeli, H. (2018). Novel machine-learning model for estimating construction costs considering economic variables and indexes. Journal of Construction Engineering and Management, 144(12): 04018106. https://doi.org/10.1061/(ASCE)CO.1943-7862.0001570
[20] Neingo, P.N., Tholana, T. (2016). Trends in productivity in the South African gold mining industry. Journal of the Southern African Institute of Mining and Metallurgy, 116(3): 283-290. https://doi.org/10.17159/24119717/2016/v116n3a10
[21] Botín, J.A., Vergara, M.A. (2015). A cost management model for economic sustainability and continuous improvement of mining operations. Resources Policy, 46: 212-218. https://doi.org/10.1016/j.resourpol.2015.10.004
[22] Ozdemir, B., Kumral, M. (2019). A system-wide approach to minimize the operational cost of bench production in open-cast mining operations. International Journal of Coal Science & Technology, 6(1): 84-94. https://doi.org/10.1007/s40789-018-0234-1
[23] Nwaila, G.T., Frimmel, H.E., Zhang, S.E., Bourdeau, J.E., Tolmay, L.C., Durrheim, R.J., Ghorbani, Y. (2022). The minerals industry in the era of digital transition: An energy-efficient and environmentally conscious approach. Resources Policy, 78: 102851. https://doi.org/10.1016/j.resourpol.2022.102851
[24] Mancini, L., Sala, S. (2018). Social impact assessment in the mining sector: Review and comparison of indicators frameworks. Resources Policy, 57: 98-111. https://doi.org/10.1016/j.resourpol.2018.02.002
[25] Cuba Atencio, M.J. (2023). Optimización del ciclo de minado para incrementar los beneficios económicos aplicando programación lineal en la empresa SEPROCAL SAC. http://repositorio.undac.edu.pe/handle/undac/3622.
[26] Chimunhu, P., Topal, E., Ajak, A.D., Asad, W. (2022). A review of machine learning applications for underground mine planning and scheduling. Resources Policy, 77: 102693. https://doi.org/10.1016/j.resourpol.2022.102693
[27] Bendaouia, A., Qassimi, S., Boussetta, A., Benzakour, I., Amar, O., Hasidi, O. (2024). Artificial intelligence for enhanced flotation monitoring in the mining industry: A ConvLSTM-based approach. Computers & Chemical Engineering, 180: 108476. https://doi.org/10.1016/j.compchemeng.2023.108476
[28] Sjödin, D., Parida, V., Kohtamäki, M. (2023). Artificial intelligence enabling circular business model innovation in digital servitization: Conceptualizing dynamic capabilities, AI capacities, business models and effects. Technological Forecasting and Social Change, 197: 122903. https://doi.org/10.1016/j.techfore.2023.122903
[29] Lazarenko, Y., Garafonova, O., Marhasova, V., Grigashkina, S. (2021). The determinants of strategic innovation-driven competitiveness of mining companies. E3S Web of Conferences, 303: 01061. https://doi.org/10.1051/e3sconf/202130301061
[30] Breiman, L. (2001). Random Forests. Machine Learning, 45: 5-32. https://doi.org/10.1023/A:1010933404324
[31] Liu, Y., Wang, Y., Zhang, J. (2012). New machine learning algorithm: Random Forest. In Information Computing and Applications: Third International Conference, ICICA 2012, Chengde, China, pp. 246-252. https://doi.org/10.1007/978-3-642-34062-8_32
[32] Khan, A.A., Chaudhari, O., Chandra, R. (2023). A review of ensemble learning and data augmentation models for class imbalanced problems: Combination, implementation and evaluation. Expert Systems with Applications, 122778. https://doi.org/10.1016/j.eswa.2023.122778
[33] Matzavela, V., Alepis, E. (2021). Decision Tree learning through a predictive model for student academic performance in intelligent m-learning environments. Computers and Education: Artificial Intelligence, 2: 100035. https://doi.org/10.1016/j.caeai.2021.100035
[34] Song, Y.Y., Ying, L.U. (2015). Decision Tree methods: Applications for classification and prediction. Shanghai Archives of Psychiatry, 27(2): 130. https://doi.org/10.11919/j.issn.1002-0829.215044
[35] Holmes, W.H., Rinaman, W.C., Holmes, W.H., Rinaman, W.C. (2014). Multiple linear regression. Statistical Literacy for Clinical Practitioners, 367-396. https://doi.org/10.1007/978-3-319-12550-3_14
[36] Smalheiser, N.R. (2017). Chapter 13 - Correlation and other concepts you should know. In Data Literacy, pp. 169-185. https://doi.org/10.1016/B978-0-12-811306-6.00013-0
[37] Kalogirou, S. (2013). Neural network modeling of energy systems. In Reference Module in Earth Systems and Environmental Sciences. https://doi.org/10.1016/B978-0-12-409548-9.01563-3
[38] Plevris, V., Solorzano, G., Bakas, N.P., Ben Seghier, M. E.A. (2022). Investigation of performance metrics in regression analysis and machine learning-based prediction models. In 8th European Congress on Computational Methods in Applied Sciences and Engineering (ECCOMAS Congress 2022). European Community on Computational Methods in Applied Sciences. https://doi.org/10.23967/eccomas.2022.155
[39] Zhan, S., Chong, A. (2021). Data requirements and performance evaluation of model predictive control in buildings: A modeling perspective. Renewable and Sustainable Energy Reviews, 142: 110835. https://doi.org/10.1016/j.rser.2021.110835
[40] Solomon, P., Draine, J. (2010). An overview of quantitative research methods. In the Handbook of Social Work Methods, pp. 26-32. https://doi.org/10.47191/ijmra/v6-i8-52
[41] Tazay, A.F., Hazza, G.A.W., Zerkaoui, S., Alghamdi, S.A. (2022). Optimal design and techno-economic analysis of a hybrid solar-wind power resource: A case study at Al Baha University, KSA. International Journal of Energy Production and Management, 7(1): 13-34. https://doi.org/10.2495/EQ-V7-N1-13-34
[42] Zhu, J.H., Munjal, R., Sivaram, A., Paul, Santhiyapillai R.S., Tian, J., Jolivet, G. (2022). Flow regime detection using gamma-ray-based multiphase flowmeter: A machine learning approach. International Journal of Computational Methods and Experimental Measurements, 10(1): 26-37. https://doi.org/10.2495/CMEM-V10-N1-26-37
[43] Storcz, T., Kistelegdi, I., Horváth, K.R., Ercsey, Z. (2022). Applicability of multivariate linear regression in building energy demand estimation. Mathematical Modelling of Engineering Problems, 9(6): 1451-1458. https://doi.org/10.18280/mmep.090602