Ehab Fakhri Hadi*![]() | Mohd Zafri Bin Baharuddin
| Mohd Zafri Bin Baharuddin![]() | Ahmad Wafi Mahmood Zuhdi
| Ahmad Wafi Mahmood Zuhdi![]()
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
The burgeoning demand for effective predictive maintenance in industrial systems necessitates accurate prognostics of equipment's Remaining Useful Life (RUL). In particular, the prediction of RUL plays a crucial role in MOSFET devices for many applications to prevent failures and maintenance schedule optimization. Motivated by the potential requirement for more than what traditional models can provide, this study sought to improve upon these estimates. This research aimed to solve the problem of accurately estimating RUL for MOSFET devices, since these systems are characterized by substantial uncertainties and non-linear processes. To address this issue, we introduced a high-performance prognostic model that promises to take advantage of both the Adaptive Particle Filter (APF) and Gaussian Process Regression (GPR), which is called as PF-GPR method. The model used a genetic algorithm to control when and how many particles were adaptively resampled applying different weighted strategies (mean or median) in response of the stochastic system deterioration. We designed and conducted a series of experiments based on the PF-GPR approach with two objectives: i) to benchmark different systematic resampling schemes; ii) demonstrate that even in case of small number (i.e. FloatTensor section {newString 10}0/75k). Systematic comparisons with standard particle filtering techniques showed the model performed well in tracking RUL as it degraded through wear degrees and estimated prediction errors were obtained. The results showed that the PF-GPR model significantly outperformed traditional methods, in particular their adpative resampling version based on the median. The PF-GPR median approach performed consistently better with respect to true RUL approximation and had the lowest RMSE for all time points. These results highlight the improved strength of prediction power for equipment RULs using our provided approach, thus reinforcing that real-world predictive maintenance applications are possible by said model.
predictive maintenance, Remaining Useful Life (RUL), MOSFET devices, Adaptive Particle Filter (APF), Gaussian Process Regression (GPR), prognostic model, genetic algorithm, resampling strategies
Prognostics--a critical part of predictive maintenance that provides an estimate of the time when system / component failure (e. g., MOSFET) will occur or degrade to a level where appropriate action can be taken [1]. MOSFETs play a key role in electronic device because it acts as switch and amplifier [2]. Health state prediction and lifetime estimation of MOSFETs form the essence to reliability and functionality in an electronic system [3]. The on-state resistance (R_on) of MOSFETs is another parameter that govern efficient operation and typical increases during lifetime owing to the effects like thermal stress, electrical overstress or dielectric breakdown etc. [4]. Tracking the evolution of R_on through time offers useful information about its wear-out modes, which can be further exploited to predict their remaining life (RUL) [5]. R_on degradation path modelling enables the ability to predict when a MOSFET will fail beyond its performance design specifications - in doing so defining end-of-life (EOL) limit [6].
Particle filtering is an estimation approach for a system state that integrates measurements. Of course [7], this is simply a fact that we always deal with in practice since everything we measure occurs over some finite time window. Regarding MOSFET Prognotics, the particles filters could fused with instantaneous measurements of to form a posterior on health state [8]. We use Bayesian sequential estimation for this case. But you are going to have to use a set of particles, or probability distribution over states for your system. The first step that particles pass to fitter is association and the second one updating [9]. The current state estimate is then computed by taking a weighted average of the particles, with weights reflecting the likelihood that each particle currently represents the true unknown state. This is particularly well suited for systems with nonlinear behaviors or non-Gaussian noise, as commonly found in the operational environment of electronic devices [10].
While powerful, particle filters are not perfect. One important problem is that of particle deprivation, where over time the variance in the set decreases drastically. This is an issue in the case where only a handful of particles were weighted heavily and it may produce poor estimate for actual probability distribution [11]. This impoverishment lessens the performance of the filter, since it requires a high diversity in particles to properly achieve an approximation for $p\left(x^t \mid z_1: t\right)$. A reduction in the diversity of particle set causes a breakdown of ability to make future state predictions by the filter, and this is especially significant in prognostics case since accurate estimation involves RUL [12].
In the particle filtering framework, optimization-like strategies are adopted to tackle this problem: some methods have been shown in [13]. These strategies are less drastic and have the target of re-shuffling particles in a manner that is closer to the true posterior distribution (and especially correcting for it after resampling, where impoverishment can be most severe). Optimization is based on the introduction of perturbation to particles, resampling from a larger distribution or by guiding selection and particle movement using algorithms [14].
To resolve the particle impoverishment, meta-heuristic algorithms are crucial [15]. These algorithms are based on nature and have the ability to provide optimal, or near-optimal solutions in difficult search spaces where other methods can fail [16]. The particle filter process can be enhanced by using meta-heuristics, as e.g., genetic algorithms (GA), to guide the particles toward high likelihood regions of the state space [17]. A special class of GAs use selection, crossover and mutation operations on the particle set (due to which it is called PSO+GA), all the above steps are directly evolved by means an EA algorithm for preserving diversity, in escaping from some local maxima where many particles satisfyingly cluster otherwise [18].
The integration of particle filtering with meta-heuristic optimization provides a reliable method for prognosis in electronic components. In this fusion, the prediction of particle filters is improved to predict MOSFET health status and life more accurately [19]. At the point when executed, this makes for a very significant improvement to predictive methods in maintenance which then translates into less down time and longer operational life of equipment-one lead directly back to greater reliability and additional cost savings [19]. Thus, the addition of meta-heuristic algorithms to particle filtering is a major improvement in predictive maintenance and reliability engineering [20].
It was a substantial gap in the prior prognostics literature which motivated the development of this work as an organized framework to undertake MOSFET device failure prognosis comprising statistics-based identification and model learning. Now granted, there are certainly some interesting computational structures that arise that may be very attractive for mining big data streams (like particle filtering), summary functions typically do not show the kind of awareness in their use resource compared to "classic" adaptive techniques. 3D Array Family of seq: adapted to this family. You are in the same external phase as another probe Move too often Classic issue from particles is not solved with a larger version, that will stop exploring probable states very soon due to lack or richness (space too fragmented / population size limit).
These problems are reflected in a lesser degree of particle diversity, hence this has devastating effects on the ability for this filtering process to make any useful predictions. The objective of this paper is to address and bridge that gap through proposing a novel framework, which integrates statistical filtering with model-based learning techniques but also promotes efficiency and robustness in the context of particle filter.
The aim of this article is to enhance the prognostics of MOSFET devices by incorporating a meta-heuristic algorithm—specifically, a genetic algorithm—into the particle filter framework for improved particle classification and resampling. Our objective is to maintain a diverse and representative sample of particles to effectively counteract particle degeneracy. With this innovation, we aim to introduce a more powerful approach to outlier management with the implementation of median-based weight allocation and elimination of the skewing concept perpetuated by traditional mean-based concepts. We also expect the current innovation to significantly increase ISFET prognostics robustness and accuracy, thereby allowing for higher-precision, more trustworthy predictive electronic maintenance. The rest of the article is organized as follows. In section 2, we present the literature survey. Preliminaries are presented in section 3. Section 4 presents experimental results and analysis. Ultimately, in section 5, we present the conclusion and future works.
The development of Particle Filter methodologies has centered on the effort to solve the fundamental challenge of the computational burden, specifically when utilized in nonlinear and non-Gaussian tracking issues. Advances in this sector have prioritized the improvement of PFs in terms of their efficiency and accuracy, allowing them to be used more universally and effectively in several tracking conditions. This saga paper assesses the development of upgraded PF versions that have diminished computational demands while improving state estimation accuracy. The auxiliary particle filter is the central approach, offering a technique for enhancing sample dimensionality to ensure sample diversity. This approach improves not only the Run time Remaining assessment with minor deviations when applied to the Insulated Gate Bipolar Transistor but also eliminates the NDL through its efficient use of a simple slope-based mechanism for critical degradation point identification [21]. Building upon the APF, the regularized auxiliary particle filter (RAPF) emerges as a notable development, incorporating regularization techniques and a rejection/resampling strategy. Therefore, these adaptations enhance the particle distribution, stiffen the resampling stage, resulting in an enhanced filter able to forecast system states more efficiently and more accurately [22].
A more recent development towards reducing the computational cost is a Particle filter on sequence importance sampling based, using a bank of unscented filters that can generate heavy-tailed proposals efficiently and rigorously incorporate information on the latest observations to achieve substantial performance over conventional PF approaches and other nonlinear filters [23].
This scheme is also suitable for addressing the challenges of multimodal distributions via regularized RBPF, which uses of robust and cluster-based approach called a marginalized particle filter [24]. This innovation improves the accuracy of TPs because it efficiently addresses the complexities of multimodal posterior distributions. Secondly, the fusion of a model-based and data-driven approach to the prediction of the RUL of lithium-ion batteries using AFSA and PF implies the possibility of boosting accuracy significantly. It is possible to achieve the proposed objectives by utilizing optimization algorithms and PF combined in the optimization algorithm. Prior particles are efficiently nudged into high likelihood domains, feeding the distribution richness that damping degeneracy [25]. Lastly, the mutated particle filtering technique is a strategic innovation that enhances the exploration of posterior ones. It refers to a computational approximation of mutation methods and particle selection schemes. The strategy is thus concerned with a complete approximation of probability density functions, serving a computational load issue since particles are more efficiently employed in this version [26]. A better performance in adaptive sampling is presented with the GPF algorithm, where Kullback-Leibler divergence sampling is applied in the accuracy performance named the KLGPF. This model changes partway quickly the size of the particle set when abrupt noise changes are detected a more advanced approach to mandating computational resources [27]. The Self-Adaptive Particle Filter (SAPF) method involves an iterative set of number of particles and the propagation function and effectively and efficiently adjusts to different conditions while maintaining computational performance similar to the classic PF [28]. Meanwhile, in medical imaging, particularly the state-of-the-art task of delineating coronary arteries in 3D computed tomography angiograms, a Bayesian tracking algorithm developed on PFs is accompanied by a new sampling scheme and mean-shift clustering. The result is notable, with the bifurcation detection aspect becoming both quick and accurate, which illustrates how various PF enhancements can be pooled for a single implementation but taken from different application areas [29].
TAN exploration using adaptive PFs, with Fox’s extension based on KLD, not only resolves the computational load issue but also does so dynamically by altering the number of encountered particles. This particular case, particularly when its up-to-date modification of varying bin sizes is considered, suggests that the efforts are still persistent to slow down the growth in computational load of processing the first levels of filtering [30]. In keeping with this trend, a new method has been developed that combines genetic algorithms with PFs to alleviate the problems of particle degeneracy and impoverishment. Exploiting the strengths of GA to push particles towards areas with new high-probability state values, it is possible to reshape the approximated posterior probability density function (PDF) and increase the accuracy of state estimation without compromising particle diversity. By determining the weight threshold for particle classification and running the GA operations to ensure the strength of the mating process based only on them, the posterior PDF approximation has been vastly improved by a factor of four, and the error in expected state estimation has been cut by a factor of over twenty, representing a significant leap forward in enhancing PF methodologies for complex applications [31].
In the study [32], a utilization of resampling at each iteration to minimize sample degeneracy was performed by duplicating high weight particles and removing those with negligible weights. An additional work [33] that is based on regularized PF is while in the study [34], a modified particle filter, i.e., intelligent particle filter (IPF), was proposed where the genetic-operators-based strategy is designed to further improve the particle diversity. Lastly, In the work of [35], an Introduction of a self-evaluation method to monitor the posterior PDF and an adaptive weight adjustment to process low-weight particles were proposed.
A summary table of the existing methods that compares various particle filtering techniques is presented in Table 1.
Table 1. The comparisons of various particle filtering techniques
|
Method |
Description |
Improvement Aimed |
Limitation |
|
SIR-PF [32] |
Utilizes resampling at each iteration to minimize sample degeneracy by duplicating high weight particles and removing those with negligible weights. |
Reduce sample degeneracy |
Leads to sample impoverishment, reducing diversity among particles |
|
Auxiliary PF [21] |
Generates an auxiliary index to guide resampling, aiming to improve particle diversity. |
Enhance particles diversity |
May still suffer from noise and resampling imperfections, leading to a discrete rather than continuous distribution |
|
Unscented PF [23] |
Integrates the unscented Kalman Filter (KF) into the PF process to improve the proposal distribution. |
Improve proposal distribution |
Particle diversity may deteriorate due to noise and the inherent limitations of resampling |
|
Regularized PF [33] Regularized Auxiliary PF [22] Mixture Regulated Rao-Blackwellized PF [24] |
Implement strategies to smooth the posterior density and conduct resampling based on a continuous distribution. |
Improve particle diversity by smoothing posterior density |
High computational cost; reliability issues if posterior PDF cannot accurately represent the high-likelihood region |
|
Intelligent PF [14, 25, 26, 34] |
Employs softcomputing tools (e.g., genetic algorithms, swarm optimization) to track and optimize particle distribution. Includes operations like crossover and mutation. |
Optimize particle distribution and enhance diversity |
Sensitive to noise and parameters setting; high computational costs and implementation challenges in real applications |
|
Adaptive PF [27-30] |
Adjusts the number of particles at each iteration based on various criteria (e.g., Kullback–Leibler divergence, statistical measures) to ensure adequate representation of the posterior PDF space. |
Adjust particle count for better posterior PDF representation |
High computational costs due to determining particle number and multiple resampling; reliability issues with normalized weights for error estimation |
|
The Reference [35] |
Introduces a self-evaluation method to monitor the posterior PDF and an adaptive weight adjustment to process low-weight particles. |
Enhances representation of posterior PDF and enriches diversity without parameter resetting and resampling |
Not handling the lack of measurements during the Remaining Useful Life (RUL) process |
|
Genetic Algorithm-Enhanced Particle Filter (GA-PF) [36] |
GA-PF utilizes genetic algorithms to direct particles towards high-likelihood states and refine the posterior PDF. |
To enhance state estimation accuracy by preventing particle degeneracy and impoverishment |
Requires validation of new offspring weights to ensure replacement leads to improved particle distribution |
The existing literature on prognostics reveals a notable gap: the absence of a comprehensive framework for the prognostication of MOSFET devices that effectively integrates statistical filtering with a trained-based model. Additionally, while particle filtering is a promising approach for such applications, it often lacks efficiency awareness, with key issues like particle degeneracy impeding its efficacy. These issues manifest as a reduced diversity in the particle set, which significantly compromises the predictive power of the filtering process. Our goal in this article is to bridge this gap by presenting an innovative framework that not only merges statistical filtering and model-based training but also addresses the efficiency and robustness of particle filtering. The aim of this article is to enhance the prognostics of MOSFET devices by incorporating a meta-heuristic algorithm—specifically, a genetic algorithm—into the particle filter framework for improved particle classification and resampling. Our objective is to maintain a diverse and representative sample of particles to effectively counteract particle degeneracy. With this innovation, we aim to introduce a more powerful approach to outlier management with the implementation of median-based weight allocation and elimination of the skewing concept perpetuated by traditional mean-based concepts. We also expect the current innovation to significantly increase ISFET prognostics robustness and accuracy, thereby allowing for higher-precision, more trustworthy predictive electronic maintenance.
This section presents the developed methodology of the article. It consists of adaptive genetic algorithm-based particle filter which is presented in sub-section 3.1. Next, the problem formulation is presented in sub-section 3.2. Afterwards, the mathematical model is presented in sub-section 3.3. Subsequently, the architecture is presented in sub-section 3.4. Finally, in sub-section 3.5. The enhanced adaptive-based particle (EAPF) is presented.
3.1 Adaptive genetic algorithm-based particle filter (AGA-PF)
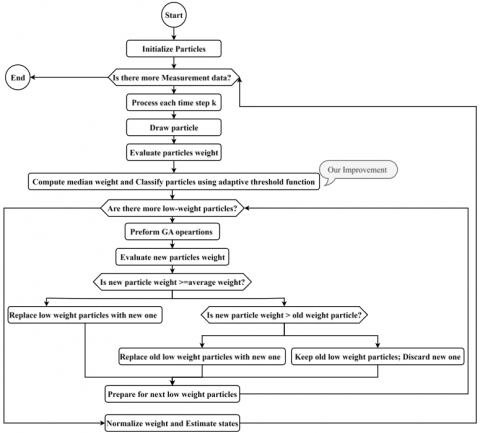
Another related problem in particle filters is degeneracy and impoverishment in which after resampling several iterations, one or very few particles may end up having most if not all the necessary weight. This state of degeneracy means that the diversity of the particle group is greatly reduced leading to a poor representation of the real posterior distribution. Impoverishment, on the other hand, is when the particles are forced to get closer to a small limited number of states leading to reduced effective sample size which is critical in ensuring the filter can model multiple hypotheses. The new algorithm in Figure 1 [36] addresses the above problems by reintroducing adaptive genetic algorithm operations using the Particle Filter framework. The adaptive idea behind this system is to change the rule of operation based on the current state of the particles. Below is a high-level characterization, of how the algorithm works. The algorithm begins by initializing a combination of particles from a before distribution, to represent the case space of the system being estimated. For each time step, particles are propagated according to the dynamic model and their weights are evaluated based on how well they predict the current observations. Particles are then classified into two sets based on their weights: a low-weight set (which are at risk of contributing to degeneracy) and a high-weight set. Genetic algorithm operations, specifically crossover and mutation, are adaptively applied to the low-weight particles. The decision to apply crossover or mutation is based on a comparison with the effective sample size (ESS) threshold. The crossover operation combines features from a pair of particles, one with low weight and another with high weight, hoping to introduce beneficial traits from the high-weight particles into the low-weight population. Mutation introduces random changes to a low-weight particle, guided by the variance of the state evolution noise, aiming to explore new regions of the state space. After the GA operations, new weights are evaluated. If the new particle's weight is greater than the average, it replaces its low-weight parent in the high-weight set, increasing the diversity of the high-weight particles. If the new weight is not better than the average but still improves on the original low-weight particle, it replaces the parent. Otherwise, the new particle is discarded, and the original particle is retained. This cycle repeats for each low-weight particle. The process aims to enhance the diversity of particles and prevent the filter from collapsing to a small number of states. By adaptively applying GA principles, the algorithm seeks to mitigate degeneracy and impoverishment, leading to more robust state estimation.
For more elaboration, about the genetic operations a flowchart that depicts an adaptive genetic algorithm-based approach for enhancing particle filter performance by addressing particle degeneracy and impoverishment is presented in Figure 1 and we present the pseudocode in Algorithm 1.
The algorithm begins by initializing a set of particles $x_0^i$, which are drawn from the initial distribution $p\left(x_0\right)$ for $i=\{1, \ldots, N\}$. This step establishes the initial state of the particles based on the prior knowledge of the system. The time step $k$ is initialized to 1, setting up the starting point for the iterative process that follows. At each time step $k$, particles $x_k^i$ are updated by drawing from the transition distribution $p\left(x_k \mid x_{k-1}^i\right)$ for $i=\{1, \ldots, N\}$.
Figure 1. Adaptive genetic algorithm-based approach for enhancing particle filter performance by addressing particle degeneracy and impoverishment
Algorithm 1. Genetic algorithm-based adaptive resampling
|
Require: Initial particle set $\left\{x_0^i\right\}_{i=1}^N$, with weights $\left\{w_0^i\right\}_{i=1}^N$, Ensure: Updated particle set $\left\{x_0^i\right\}_{i=1}^N$, with normalized weights $\left\{w_0^i\right\}_{i=1}^N$, Start 1: Initialize particles: $x_0^i \sim p\left(x_0\right)$ for $i=\{1, \ldots, N\}$ 2: Set time step k = 1 3: while measurement data available do 4: Draw particles: $x_0^i \sim p\left(x_k \mid x_{k-1}^i\right)$, for $i=\{1, \ldots, N\}$ 5: Evaluate weights: $w_k^i=p\left(y_k \mid x_k^i\right)$ 6: Classify particles: 7: for $i=1$ to N do 8: if $w_k^i<w_k^{{avg }}$ then 9: $x_k^i \in C_k^L$ 10: else 11: $x_k^i \in C_k^H$ 12: end if 13: end for 14: Set $l=1$ 15: while $l<N_k^L$ do 16: Select $x_{k L}^l \in C_k^L$ 17: Draw h from $\left\{1, \ldots, N_k^H\right\}$ 18: Select $x_{k H}^l \in C_k^H$ 19: Generate offspring $x_{k o}^l$: 20: $u \sim U(0,1)$ 21: if $u \leq \frac{E S S_k}{N}$ then 22: Crossover: $x_{k O}^l=\alpha_k^l x_{k L}^l+\left(1-\alpha_k^l\right) x_{k H}^h$ 23: where $\alpha_k^l \sim U(0,1)$ 24: else 25: Mutation: $x_{k O}^l \sim N\left(x_{k H}^h, \sigma_u^2 I_{d_x}\right)$ 26: end if 27: Evaluate weight: $w_{k O}^l=p\left(y_k \mid x_{k O}^l\right)$ 28: Verify and replace: 29: if $w_{k O}^l \geq w_k^{a v g}$ then 30: Replace $x_{k L}^l$ with $x_{k O}^l$ 31: else 32: if $w_{k O}^l>w_{k L}^l$ then 33: Replace $x_{k L}^l$ with $x_{k O}^l$ 34: else 35: Discard $x_{k O}^l$ 36: end if 37: end if 38: Increment 39: end while 40: Normalize weights: $\left\{w_k^i\right\}_{i=1}^N$ 41: Increment time step $k$ 42: end while End |
This step propagates the particles according to the system's dynamics, incorporating the information from the previous time step. The weights $w_k^i$ of the particles are then evaluated using the likelihood function $p\left(y_k \mid x_k^i\right)$. This assesses how well each particle represents the observed data at the current time step. Particles are classified into two categories based on their weights.
Particles with weights $w_k^i$ less than the average weight $w_k^{ {avg }}$ are classified as low-weight particles $\left(C_k^L\right)$, and those with weights greater than or equal to the average weight $w_k^{ {avg }}$ are classified as high-weight particles $\left(C_k^H\right)$. This classification helps identify particles that need improvement through genetic operations. The genetic operations begin with the initialization of the counter $l$ to 1. For each low-weight particle $x_{k L}^l$ in $C_k^L$, a high-weight particle $x_{k H}^h$ is selected from $C_k^H$, where $h$ is randomly drawn from $\left\{1, \ldots, N_k^H\right\}$. An offspring particle $x_{k o}^l$ is then generated using either crossover or mutation, depending on a random variable $u$ drawn from a uniform distribution $u(0,1)$. The offspring particle $x_{k O}^l$ is generated using the formula:
GA operation: $\left\{\begin{array}{l}\text { Crossover (Step 5.1), if } u \leq \frac{E S S_k}{N} \\ \text { Mutation (Step 5.2), if } u>\frac{E S S_k}{N}\end{array}\right.$ (1)
where, $u \sim v(0,1)$.
After generating the offspring, its weight $w_{k O}^l$ is evaluated using the likelihood function $p\left(y_k \mid x_{k O}^l\right)$. This evaluation assesses the offspring's performance in representing the observed data.
The offspring's weight is then verified against the average weight. If the offspring's weight $w_{k O}^l$ is greater than or equal to the average weight $w_k^{ {avg }}$, the offspring replaces the low-weight parent particle $x_{k L}^l$. If the offspring's weight is less than the average weight, a further check is performed to see if $w_{k O}^l$ is greater than the low-weight parent particle's weight $w_{k L}^l$. If so, the offspring replaces the parent; otherwise, the offspring is discarded, and the parent is retained.
After processing all low-weight particles, the weights of all particles are normalized to ensure they sum to one. This step prepares the particle set for the next time step. The entire process repeats for the next time step, continuing until there are no more available measurement data. This iterative approach allows the algorithm to continuously adapt and refine the particle set, thereby improving state estimation over time.
3.2 Problem formulation
Given a prediction framework for Remaining Useful Life (RUL) of MOSFET devices utilizing Particle Filter-Gaussian Process Regression (PF-GPR), our objective is to enhance the PF-GPR model by introducing an Adaptive Particle Filter (APF) mechanism. This enhancement aims to modify the resampled particles based on an Adaptive Genetic Algorithm (AGA) approach, thereby addressing the critical issues of degeneracy and impoverishment that are prevalent in standard particle filter applications. The core problem is formulated as follows: we seek to accurately forecast the on-state resistance $\left(R_{D S-o n}(t)\right)$ of MOSFET devices until the point of failure, utilizing a dataset that encapsulates the behavior of $R_{D S-o n}(t)$ from the start of observation $t_0$ to a predetermined prediction moment $t_p$. The goal is to minimize the prognostic error, which is defined as the absolute difference between the inverse function of the actual on-state resistance at failure time $\left(R_{D S-o n}^{-1}\left(t_f\right)\right)$ and the inverse function of the predicted on-state resistance at the estimated failure time $\left(R_{D S-o n}^{-1}\left(\hat{t}_f\right)\right)$:
Error $_{\text {prognostic }}=\left|R_{D S-o n}^{-1}\left(\hat{t}_f\right)-R_{D S-o n}^{-1}\left(t_f\right)\right|$ (2)
The introduction of the APF component into the PF-GPR framework is designed to dynamically adjust the genetic operations (crossover and mutation) applied to the particles, particularly focusing on those with low weights that are at risk of contributing to the filter's degeneracy and impoverishment. By leveraging the median weight as a robust threshold for classifying particles into low and high-weight sets, and by adaptively applying genetic algorithm techniques based or the state of the particle set, the APF aims to enhance the diversity of the particle set and improve the accuracy of state estimation. This adaptive approach ensures that the PF-GPR model not only maintains its capacity for accurate RUL prediction of MOSFET devices but also significantly improves its resilience against the limitations that traditionally hamper particle filter performance. By addressing these challenges, the enhanced PF-GPR framework (incorporating APF) promises more reliable and robust future forecasting of $R_{D S-o n}(t)$, leading to improved predictive maintenance strategies for MOSFET devices.
3.3 Mathematical model
Sequential parameter state estimation in prognostic systems, such as those designed for predicting the RUL of MOSFET devices, necessitates two critical functions: the state evolution function $f_t(\cdot)$ and the measurement function $g_t(\cdot)$, which are defined as follows:
$\begin{aligned} & x_t=f_t\left(x_t-1, u_t\right) \\ & y_t=g_t\left(x_t, v_t\right)\end{aligned}$ (3)
Here, $x_t$ and $y_t$ represent the parameter state vector and the measurement vector at time step $t$, respectively. The vector $u_t$ denotes the noise (or random values) introduced during the state evolution from time step $t-1$ to $t$, and $v_t$ denotes the noise present during data measurement at time step $t$. Although true parameter states cannot be exactly determined, the full posterior Probability Density Function (PDF) of the state at time step $t$ can be recursively calculated using Bayes' rule as follows:
$p\left(X_t \mid Y_t\right)=\frac{p\left(X_t-1 \mid Y_t-1\right) p\left(y_t \mid x_t\right) p\left(x_t \mid X_t-1\right)}{p\left(y_t \mid Y_t-1\right)}$ (4)
In this equation, $X_t=\left\{x_1, x_2, \ldots, x_t\right\}$ and $Y_t=\left\{y_1, y_2, \ldots, y_t\right\}$ are sets that contain all state vectors and all measurements up to the discrete time step $t$. The densities $p\left(y_t \mid x_t\right), p\left(x_t \mid X_t-1\right)$, and $p\left(y_t \mid Y_{t-1}\right)$ represent the likelihood function, the state evolution distribution, and a normalizing constant, respectively.
To address the issue of degeneracy and impoverishment in Particle Filters (PFs)-where a few or even one particle may end up with the majority of the weight after several iterations of resampling, leading to a poor representation of the posterior distribution-an adaptive genetic algorithm Based Particle Filter (AGA-PF) is extended from the study [36] and integrated within our framework. The AGA-PF introduces adaptive genetic algorithm (GA) operations within the PF framework, aiming to maintain diversity among the particles and prevent the filter from collapsing to a small number of states. This is achieved through the use of adaptive crossover and mutation operations based on the particles' weights, effectively exploring new regions of the state space and enhancing the filter's performance. The classical weights of the particles at time, $\mathrm{w}_t^i$, are re-adjusted to generate. The likelihood of the state of each particle relative to the observation with an expectation at this point; each particle is subsequently resampled on the basis of their calculated weights. Formally, the process of weight update and resampling maybe defined as follows:
$\mathrm{w}_t^i \propto \frac{p\left(X_t^i \mid Y t\right)}{q\left(X_t^i \mid Y t\right)}$ (5)
where, $\mathrm{w}_t^i$ denote the weight of the th particle out of particles at time $t$, $\widetilde{\mathrm{w}}_t^i$ is the normalized th particle weight such that $\sum_{i=1}^N w_t^i=1$, $\delta(\cdot)$ is the Dirac delta function; and $q\left(X_t \mid Y_t\right)$ is the importance density for drawing particles $X_t^i$. By optimizing the particle filtering process through the generation of more controlling parameters via AGA-PF extension and connecting it with our prosystem of MOSFET, our system aims to improve RUL’s predictive precision for MOSFET devices and assure the sturdy state estimation even under the under the challenge of parameter degeneracy and impoverishment.
By improving the particle filtering process through extending AGA-PF approach to include more controlling parameters and integrating it with our prognostic system of MOSFET, our system purposes to enhance the predictive accuracy of the RUL for MOSFET devices, ensuring robust state estimation even under the challenge of parameter degeneracy and impoverishment.
3.4 Architecture
The diagram depicted in Figure 2 illustrates the architecture of the proposed advanced predictive maintenance framework. This framework is developed with the explicit aim to improve the accuracy of the RUL prediction for MOSFET devices. Specifically, the core of the developed architecture is the integration of adaptive particle filter, hereinafter referred to as APF, with Gaussian Process Regression to form an Enhanced PF-GPR model. This novel statistical technique allows finding solutions to three existing PF problems, including degeneracy, collapse, and sample impoverishment, as a result greatly enhancing the prognostic capabilities. The process initiated by the collection of “Measurement Data $R_{D S-\text { on }}(t)$”, which is multiple MOSFET devices’ switch’s on-state resistance over time. It is then put through “Data Preprocessing,” where it is normalized, and relevant features are extracted in creating a more relevant and easier-to-analyze feature set. Preprocessed data is input in the EAPF, being at the heart of the enriched model. In EAPF, particles are initiated, and low and high-weight sets are distinguished by a mean/median weight threshold chosen for its sensitivity to the outlier. Genetic operations – crossover and mutation – are adaptively applied to low-weight particles, allowing for a spectrum of particles. The enriched particle set from APF is utilized by the "Gaussian Process Regression (GPR)" module. Here, the model is trained, and predictions regarding $R_{D S-\text { on }}(t)$ are made, forecasting the device's condition up until the point of failure. The final step in the framework is the "Prognostic Error Calculation", where the inverse function of predicted and actual on-state resistance at the estimated failure time is computed to determine the prognostic error. This measure of error provides critical feedback, allowing for the continuous refinement of the APF process, thereby enhancing the overall prediction accuracy of the PF-GPR model.
Figure 2. The architecture of an enhanced PF-GPR model with adaptive particle filter for improved RUL prediction of MOSFET devices
3.5 Enhanced adaptive based particle (EAPF)
EAPF uses the average weight as a criterion to classify particles into low-weight and high-weight sets in a particle filter could be influenced by outliers, which might not accurately reflect the typical distribution of particle weights. In situations with significant weight disparities among particles, the mean can be skewed by extremely high or low weights, which do not represent the majority of the particle set. This skewing can lead to a misclassification of particles and, consequently, poor performance of the filter, as it may fail to effectively focus computational resources on the most promising regions of the state space. Replacing the average with the median weight can mitigate this issue as the median is more robust to outliers. The median, by definition, is the middle value of a dataset when ordered from the lowest to the highest value, or the average of the two middle values when the dataset has an even number of observations. Therefore, it is unaffected by extremely large or small values and can provide a better central tendency measure for weight distribution. The mean weighting strategy calculates the average weight of all particles at a given time step. This average weight is used as a benchmark to classify particles and guide the genetic operations.
$w_k^{\mathrm{avg}}=\frac{1}{N} \sum_{i=1}^N w_k^i$ (6)
where, $N$ is the total number of particles.
$x_k^i \in \begin{cases}C_k^L, & \text { if } w_k^i<w_k^{\text {avg }} \\ C_k^H, & \text { if } w_k^i \geq w_k^{\text {avg }}\end{cases}$ (7)
This classification helps identify particles that need improvement through genetic operations. The median weighting strategy uses the median of the particle weights as a reference to classify particles. The median provides a more robust measure in the presence of outliers, ensuring that the classification is not unduly influenced by extreme values.
$w_k^{\text {med }}=\operatorname{median}\left(\left\{w_k^i\right\}\right)$ (8)
$x_k^i \in \begin{cases}C_k^L, & \text { if } w_k^i<w_k^{\text {med }} \\ C_{k^{\prime}}^H, & \text { if } w_k^i \geq w_k^{\text {med }}\end{cases}$ (9)
This method makes sure that particles are chosen in a balanced way for genetic operations, helping to maintain diversity within the particle set. A flowchart of Enhanced Adaptive based particle (EAPF) is presented in Figure 3.
Figure 3. The enhanced adaptive particle filter algorithm utilizing median weight threshold and adaptive threshold function for particle classification and state estimation
4.1 Experimental design
The data collection and preprocessing methodology for the predictive maintenance model followed a structured approach to ensure the data accurately represented operational conditions while eliminating unnecessary noise. The process began with data sampling. Given the large volume and relative consistency of transient state data for drain-source voltage, gate signal voltage, and drain currents, a sampling strategy was implemented to refine the dataset, focusing on transient data relevant to the predictive model's requirements. Next, transient data extraction was performed, concentrating on File 36 Run 1. Key parameters ($V_{D S}, I_D$, and $V_G$) were extracted to compute resistance during the transient state, reflecting actual MOSFET operational conditions. Resistance calculation followed, using the Eq. (10):
$R_{D S}=V_{D S} / I_D$ (10)
This equation was applied to derive resistance values indicative of various device operational states. State determination involved distinguishing between ON and OFF states based on average gate signal voltages. Values above this average were classified as ON, while those below were considered OFF. This classification allowed for the calculation of on-state resistance values, denoted as $R_{D S o n}$. Finally, temperature normalization was performed to account for the temperature dependence of resistance. Using flange temperature readings from steady state files, resistance calculations were standardized across different temperatures.
The main data transformations involved sampling transient data and calculating temperature-normalized resistance. Due to discrepancies between transient and steady state data, only transient data was used, with further sampling to reduce data volume.
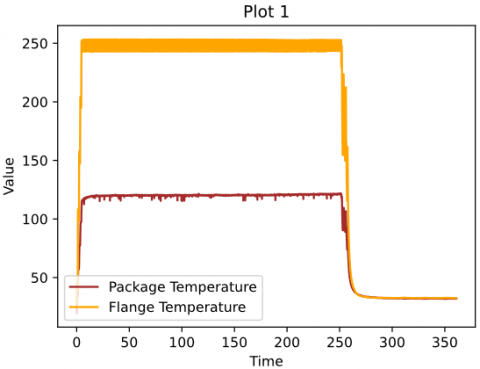
Figure 4 illustrates gate control, drain source voltage, and drain current signals during a transient phase at the beginning and end of the device's lifecycle. The sampling process involved reading file 36 run 1, extracting Transient State file data ($V_{D S}, I_D$, and $V_G$), and calculating resistance using Eq. (10). The clear separation of ON and OFF states allowed for the computation of average values for both states. Resistance values during the ON state were designated as $R_{D S o n}$. Temperature normalization was crucial due to the temperature dependence of resistance. The process involved characterizing resistance changes over time at different degradation stages, using flange temperature readings from steady state files.
(a)
(b)
Figure 4. Gate control, drain-source voltage, and drain current signals during a transient phase at both the start and end of its operational life [37]
Figures 5 and 6 demonstrate the evolution of package and flange temperatures before and after normalization for one experiment. The final resistance was determined by normalizing resistance values obtained from a regression model describing temperature-resistance relationships.
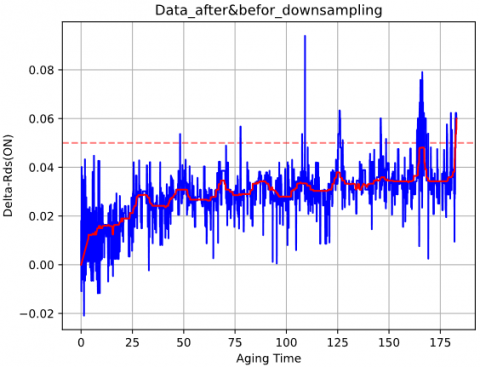
Figure 7 depicts this process. The MOSFET was considered failed when the normalized $R_{D S o n}$ reached 0.05, serving as the failure threshold in the predictive maintenance model.
(a)
(b)
Figure 5. Flange and package temperatures for different time instants, before and after the normalization process [37]
Figure 6. Change of resistance with flange temperature [37]
Figure 7. $\Delta R_{\text {DSon }}(\mathrm{t})$ after normalization with respect to temperature [37]
In our experimental design, we meticulously tailored the parameters listed in Table 2 to optimize our predictive maintenance model. This model is centered around the prediction of Remaining Useful Life (RUL) for MOSFET devices by harmonizing Particle Filter (PF) and Gaussian Process Regression (GPR) methodologies. The above parameters are set throughout the two experiments to ensure comparability and enhance the model’s verification.
Table 2. Experimental design parameters
|
Parameter |
Description |
Experiment 1 |
Experiment 2 |
|
Resampling Method |
Technique for resampling particles |
Systematic Resampling |
Systematic Resampling |
|
Number of Particles |
Number of particles used in the filter |
1000 |
1000 |
|
Process Noise |
Mean and Standard deviation of process noise |
Mean: 0.0004 Std Dev: 0.011 |
Mean: 0.0004 Std Dev: 0.0115 |
|
Measurement Noise |
Mean and Standard deviation of measurement noise |
Mean: 0 Std Dev: 0.02 |
Mean: 0 Std Dev: 0.02 |
In addition, they validate the model’s robustness across different contexts. Feature Resampling, another type of resampling, is included as Resampling method applied to the two Experiments. Instead, as important mitigator of resampling, Systematic Resampling is deployed to minimize particle degeneration, ensuring a correct distribution of particles.
Therefore, diversity is preserved, which is pivotal to the accuracy of state estimation. The number of particles is set at 1000, in both experimental studies. The fixed number of particles factor achieves a trade-off between increased computational efficiency and enhanced representation of the state space, which permits the accurate identification of system response and enhances the capacity to predict RUL accurately.
The process noise is defined with a mean of 0.0004, which allows for the incorporation of subtle variability at system evolution. Although in Experiment 1, the standard deviation is 0.011, in Experiment 2, it is adjusted insignificantly to 0.0115.
This slight variation is implemented to determine how PF is sensitive to the alterations in process noise and assess whether the assumed model is reliable when process noise varies in a marginally drastic manner. In both experiments, the measurement noise is the same and does not exhibit a mean and a standard deviation of 0 and 0.02, correspondently.
Such an adjustment enables disentangling the influence of process noise changes on the RUL prediction accuracy from the effects of measurement noise. Thus, one can clearly determine how the process noise parameters affect the prognostic precision.
The above carefully chosen parameters form the backbone of our experimental setup and play a crucial role in moving the predictive maintenance domain forward. Indeed, since we have maintained the same parameters during testing, we hope to present a consistently dependable methodology in foreseeing the decline in equipment states, ensuring that the industrial systems are efficiently and proactively managed.
4.2 Experimental results and analysis
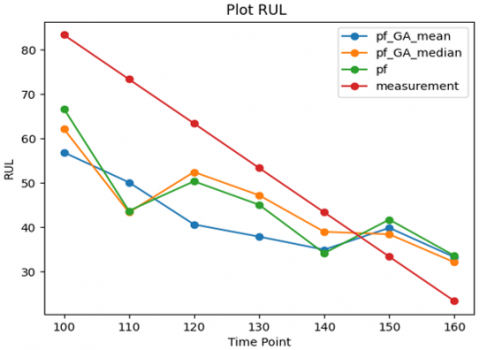
As shown in Figure 8, the curve represented as ‘measurement’ is the actual RUL data; hence, it is the exact data the models are supposed to follow for the RUL.
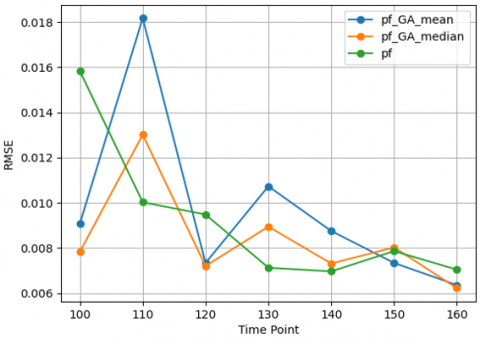
Figure 8. Remaining Useful Life (RUL) predictions over time based on Particle Filter with Genetic Algorithm with mean and median and a classic Particle Filter model using the root on-state drain-source resistance RMSE with its actual measurement – Experiment 1
For each time point that falls under the curve, any model that predicts the RUL accurately operates on the data point of assessment. If the predictions of a model are fit well under the curve, then the model is more accurate. For our method, the ‘PF-GA-median’ aligns more accurately under the ‘measurement’ data point at all the time points.
This concludes that the RUL prediction is more accurate; fitting under the curve explained with. The mean is averaged and is generally affected by the highest weight, which offers a median weight a robust resampling threshold, and the largest weight affects the lowest weight.
This phenomenon helps maintain a representative set of particles PF-GA-mean, which uses the mean weight to resample, diverges the most from the measurement curve, especially after 130 minutes. This implies that mean weight is not as effective in preserving predictive accuracy in the long term when particle weights are heavily variance. Finally, the PF curve demonstrates the most divergence from the measurement curve.
This shows that pre-evolutions Particle Filter methods, without genetic algorithms, are least effective at predicting RUL accurately.
To sum up, based on the results, it is possible to conclude that the adaptive particle filter with median-type weight performs better than the Particle Filter with mean weights and the default Particle Filter model.
It can be assumed from the results that the adaptive approach and median-based resample are efficient instruments for improving the accuracy in RUL prediction in predictive maintenance.
Figure 9. RMSE comparison of on-state drain-source resistance $(-o n)$ forecasts using standard Particle Filter (PF) and Particle Filter with Genetic Algorithm using mean (PF-GA-mean and median (PF-GA-median) resampling methods. Experiment 2
Figure 9 presents Root Mean Square Error values for the PF-GA RDS-on (mouser Case: 2019) forecasts at various lead times. Mean and median PF-GA algorithms are compared to PF. In all time frames mean and median PF-GA cases have lower RMSE than PF, so it is safe to conclude that they are more accurate in predicting the RDS-on. In other words, the resampling based on the median statistics retains more diversity in the particle set, which maintains the state estimator’s accuracy over time. PF-GA-mean demonstrates higher variability in its RMSE, especially notable at the 100-minute mark where a peak suggests a significant divergence from the actual RDS-on values. This could indicate that mean-based resampling might be less resilient to the influence of outlier particles, which can adversely affect the predictive accuracy. Standard PF shows a general decline in RMSE as time progresses, yet it does not achieve the lower error levels of PF-GA-median. This suggests that while standard PF may improve with additional data, it lacks the adaptive characteristics that help PF-GA-median maintain higher accuracy throughout the prediction period. Overall, the lower RMSE associated with PF-GA-median signifies its superior performance in forecasting RDS-on, a crucial precursor variable for determining RUL. Its ability to deliver consistent and reliable predictions highlights the potential of adaptive median-based resamplir strategies in enhancing prognostic models for predictive maintenance applications.
Similarly, for second experiment Figure 10 presents the RUL predictions at various time points. The 'measurement' curve, representing the ground truth, is the reference against which the other models are compared. The 'pf_GA_mean' and 'pf_GA_median' curves, representing the Particle Filter with Genetic Algorithm using mean and median weights respectively, along with the standard Particle Filter ('pf'), show varying degrees of accuracy in tracking the 'measurement' curve. The 'pf_GA_median' appears to track the ground truth more closely than the 'pf_GA_mean', indicating a better performance. This suggests that the median resampling method provides a more robust performance, potentially due to its resilience to the effects of outlier weights. The standard 'pf' algorithm follows, demonstrating reasonable accuracy but with more deviation from the ground truth than 'pf_GA_median'. Figure 11 showcases the RMSE for each predictive method across the same time points. Consistent with the RUL predictions, 'pf_GA_median' maintains a lower RMSE throughout, corroborating its higher accuracy and stability in prediction. The 'pf_GA_mean' shows higher RMSE values, especially at the 110-minute mark, where it peaks significantly, indicating a momentary decline in predictive accuracy. Notably, all models converge towards similar RMSE values towards the end of the observed period, suggesting that as the failure event approaches, the models' predictions become more aligned, possibly due to accumulating more data that informs the prediction algorithms.
The results from the two graphs—focusing on Remaining Useful Life (RUL) predictions and the corresponding Root Mean Square Error (RMSE) values—offer valuable insights into the performance of different particle filter-based prognostic approaches for MOSFET devices. In Experiment 2, we witness the comparative efficacy of the Particle Filter with Genetic Algorithm using both mean and median weights (PF-GA-mean and PF-GA-median) against the standard Particle Filter (PF).
Figure 10. The comparison of the Remaining Useful Life (RUL) predictions using Particle Filter with Genetic Algorithm mean (PF-GA-mean), median (PF-GA-median), standard Particle Filter (PF), and actual measurements over time – Experiment 2
Figure 11. RMSE comparison of on-state drain-source resistance $(-o n)$ forecasts using standard Particle Filter (PF) and Particle Filter with Genetic Algorithm using mean (PF-GA-mean and median (PF-GA-median) resampling methods. Experiment 2
The RUL predictions indicate that the PF-GA-median maintains a closer approximation to the actual measurements throughout the experiment. This is indicative of its superior capability in capturing the degradation pattern of the MOSFET devices, likely due to the robustness of median weighting in handling outliers and maintaining particle diversity. On the other hand, the PF-GA-mean shows larger deviations from the measurement curve, which suggests that the mean weighting is more susceptible to being skewed by extreme values, resulting in less accurate predictions.
The RMSE graph provides a quantitative backing to these observations. It is evident from the consistently lower RMSE values that the PF-GA-median achieves greater predictive accuracy over time. The lower RMSE signifies that the median-based approach more effectively minimizes prediction errors, aligning with the known resilience of median values to extreme variations in datasets. Conversely, the peaks in the RMSE graph for PF-GA-mean highlight specific time points where the model's predictions were less reliable.
The results of the paired t-test for the RMSE values are as follows: For the first graph, the t-statistic is 1.642 and the p-value is 0.152. For the second graph, the t-statistic is 2.763 and the p-value is 0.033. For the first graph, the p-value (0.152) is greater than 0.05, indicating that the difference between the mean and median RMSE values is not statistically significant. For the second graph, the p-value (0.033) is less than 0.05, indicating that there is a statistically significant difference between the mean and median RMSE values, suggesting the superiority of the median RMSE over the mean RMSE.
The standard PF's performance, while outpaced by the median approach, does show the ability to track the actual RUL values reasonably well, though with less precision as indicated by its RMSE. Its performance may be further improved with enhancements like those introduced in the PF-GA-median method.
4.3 Discussion and comparison with traditional methods
Given this, the PF-GPR method aims to be robust against noise and uncertainties in sensor measurements. Several important features and mechanisms realized enable this robustness:
The PF-GPR approach exhibits enhanced robustness as compared to conventional particle filtering methods due its several merits:
We addressed the crucial problem of predicting Remaining Useful Life (RUL) for Metal-Oxide-Semiconductor Field-Effect Transistor (MOSFET) devices, which is extremely important in the field predictive maintenance. In this work, to enhance the prediction accuracy of RUL predictions, we inspired with Particle filter and proposed a new model called Adaptive Particle Filter-Gaussian Process Regression (PF-GPR) that incorporates advance resampling scheme for enhancing common issues in particle filtering.
We have developed a genetically adapted particle filter based on mean and median weighting schemes; respectively designated as particle/genetic algorithm (PF-GA)-mean and PF-GA-median. The experimental methodology was designed systematically to resample a large number of particles in order to effectively represent the state space, simultaneously forcing incorporation realistic process and measurement noise parameters.
Quantitative results were informative and showed PF-GA-median pro- vided a better accuracy in estimating Actual Remaining Useful Life than both the other two filters, namely PFGAg-mean based filter, standard Particle Filter. The findings confirmed that median-based resampling method could remarkably enhance RUL prediction performance in terms of precision.
These results have significant implications for predictive maintenance in the industrial setting. Our PF-GPR model, particularly the hybridized models and ensemble methods with finally-predicted output (PF-GA-median) may provide a more accurate forecasting of failures in MOSFET devices. For a certain class of components, this advance could result in maintenance schedules that are more optimal, less downtime and significant cost change for any industry weighed down by the dependency on these parts.
Overall, the main contributions of our study to PHM can be summarized as follows.
Our study was based on a single dataset for MOSFET devices, which is the main limitation of this work; it reduced our obtainable insights to those operational conditions covered in that dataset. Nonetheless, the findings were robust enough to inform precise directions of work in future.
Different directions for future work appear likely, though.
Our PF-GPR model, especially the PF-GA-median version achieves a great improvement in terms of MOSFET prognostics. It can help for better and more economical predictive maintenance strategies in the industrial context which require accurate estimates of RUL. We hope that as we further refine and develop this method, it will continue to result in new ways of increasing the reliability/lifetime of important electronic components for other industries.
We extend our gratitude to University Tenaga Nasional for their invaluable support throughout the completion of this work.
|
RDSon |
on-state resistance |
|
$\mathrm{t}_{\mathrm{f}}$ |
the moment of failure |
|
$\mathrm{E}_{\mathrm{p}}$ |
prognostic error |
|
$w_k^{\text {med }}$ |
median weight calculation |
|
$C_k^L$ |
low-weight particles |
|
$C_k^H$ |
high-weight particles |
|
$w_k^{\text {avg }}$ |
the average weight |
|
$\mathrm{VS}_{\mathrm{G}}$ |
gate signal voltage |
|
$\mathrm{R}_{\mathrm{DS}-\mathrm{on}}(\mathrm{t})$ |
drain and source |
|
$\mathrm{t}_{\mathrm{p}}$ |
prediction moment |
|
$R_{D S-o n}^{-1}\left(t_f\right)$ |
denotes the inverse function of on-state resistance at the moment of failure |
[1] Zhao, S., Peng, Y., Yang, F., Ugur, E., Akin, B., Wang, H. (2021). Health state estimation and remaining useful life prediction of power devices subject to noisy and aperiodic condition monitoring. IEEE Transactions on Instrumentation and Measurement, 70: 1-16. https://doi.org/10.1109/TIM.2021.3054429
[2] Chen, J., Du, X., Luo, Q., Zhang, X., Sun, P., Zhou, L. (2020). A review of switching oscillations of wide bandgap semiconductor devices. IEEE Transactions on Power Electronics, 35(12): 13182-13199. https://doi.org/10.1109/TPEL.2020.2995778
[3] Dusmez, S., Duran, H., Akin, B. (2016). Remaining useful lifetime estimation for thermally stressed power MOSFETs based on on-state resistance variation. IEEE Transactions on Industry Applications, 52(3): 2554-2563. https://doi.org/10.1109/TIA.2016.2518127
[4] Stella, F., Pellegrino, G., Armando, E. (2018). Coordinated on-line junction temperature estimation and prognostic of SiC power modules. In 2018 IEEE Energy Conversion Congress and Exposition (ECCE), Portland, OR, USA, pp. 1907-1913. https://doi.org/10.1109/ECCE.2018.8557850
[5] Ragab, M., Chen, Z., Wu, M., Foo, C.S., Kwoh, C.K., Yan, R., Li, X. (2020). Contrastive adversarial domain adaptation for machine remaining useful life prediction. IEEE Transactions on Industrial Informatics, 17(8): 5239-5249. https://doi.org/10.1109/TII.2020.3032690
[6] Pugalenthi, K., Park, H., Raghavan, N. (2019). Prognosis of power MOSFET resistance degradation trend using artificial neural network approach. Microelectronics Reliability, 100-101: 113467. https://doi.org/10.1016/j.microrel.2019.113467
[7] Xie, H., Gu, T., Tao, X., Ye, H., Lu, J. (2015). A reliability-augmented particle filter for magnetic fingerprinting based indoor localization on smartphone. IEEE Transactions on Mobile Computing, 15(8): 1877-1892. https://doi.org/10.1109/TMC.2015.2480064
[8] Ni, Z., Lyu, X., Yadav, O.P., Singh, B.N., Zheng, S., Cao, D. (2019). Overview of real-time lifetime prediction and extension for SiC power converters. IEEE Transactions on Power Electronics, 35(8): 7765-7794. https://doi.org/10.1109/TPEL.2019.2962503
[9] Zhao, T., Nehorai, A. (2007). Distributed sequential Bayesian estimation of a diffusive source in wireless sensor networks. IEEE Transactions on Signal Processing, 55(4): 1511-1524. https://doi.org/10.1109/TSP.2006.889975
[10] Li, T., Bolic, M., Djuric, P.M. (2015). Resampling methods for particle filtering: Classification, implementation, and strategies. IEEE Signal Processing Magazine, 32(3), 70-86. https://doi.org/10.1109/MSP.2014.2330626
[11] Elfring, J., Torta, E., Van De Molengraft, R. (2021). Particle filters: A hands-on tutorial. Sensors, 21(2): 438. https://doi.org/10.3390/s21020438
[12] Khorshidi, A., Shahri, A.M. (2016). GA-inspired particle filter for mitigating severe sample impoverishment. In 2016 4th International Conference on Control, Instrumentation, and Automation (ICCIA), Qazvin, Iran, pp. 377-382. https://doi.org/10.1109/ICCIAutom.2016.7483192
[13] Li, T., Sun, S., Sattar, T.P., Corchado, J.M. (2014). Fight sample degeneracy and impoverishment in particle filters: A review of intelligent approaches. Expert Systems with Applications, 41(8): 3944-3954. https://doi.org/10.1016/j.eswa.2013.12.031
[14] Yin, S., Zhu, X. (2015). Intelligent particle filter and its application to fault detection of nonlinear system. IEEE Transactions on Industrial Electronics, 62(6): 3852-3861. https://doi.org/10.1109/TIE.2015.2399396
[15] Zhou, N., Liu, Q., Yang, Y., Wu, D., Gao, G., Lei, S., Yang, S. (2023). An indoor positioning algorithm based on particle filter and neighbor-guided particle optimization for wireless sensor networks. IEEE Transactions on Instrumentation and Measurement, 73: 1-16. https://doi.org/10.1109/TIM.2023.3329158
[16] Salcedo-Sanz, S. (2016). Modern meta-heuristics based on nonlinear physics processes: A review of models and design procedures. Physics Reports, 655: 1-70. https://doi.org/10.1016/j.physrep.2016.08.001
[17] Garg, H. (2016). A hybrid PSO-GA algorithm for constrained optimization problems. Applied Mathematics and Computation, 274: 292-305. https://doi.org/10.1016/j.amc.2015.11.001
[18] Viana, M.S., Morandin Junior, O., Contreras, R.C. (2020). A modified genetic algorithm with local search strategies and multi-crossover operator for job shop scheduling problem. Sensors, 20(18): 5440. https://doi.org/10.3390/s20185440
[19] Pugalenthi, K., Park, H., Hussain, S., Raghavan, N. (2021). Hybrid particle filter trained neural network for prognosis of lithium-ion batteries. IEEE Access, 9: 135132-135143. https://doi.org/10.1109/ACCESS.2021.3116264
[20] Sardari, F., Moghaddam, M.E. (2017). A hybrid occlusion free object tracking method using particle filter and modified galaxy based search meta-heuristic algorithm. Applied Soft Computing, 50: 280-299. https://doi.org/10.1016/j.asoc.2016.11.028
[21] Bingul, Z. (2007). Adaptive genetic algorithms applied to dynamic multiobjective problems. Applied Soft Computing, 7(3): 791-799. https://doi.org/10.1016/j.asoc.2006.03.001
[22] Liu, J., Wang, W., Ma, F. (2011). A regularized auxiliary particle filtering approach for system state estimation and battery life prediction. Smart Materials and Structures, 20(7): 075021. https://doi.org/10.1088/0964-1726/20/7/075021
[23] Van Der Merwe, R., Doucet, A., De Freitas, N., Wan, E. (2000). The unscented particle filter. Advances in Neural Information Processing Systems, 13: 584-590.
[24] Murangira, A., Musso, C., Dahia, K. (2016). A mixture regularized rao-blackwellized particle filter for terrain positioning. IEEE Transactions on Aerospace and Electronic Systems, 52(4): 1967-1985. https://doi.org/10.1109/TAES.2016.150089
[25] Tian, Y., Lu, C., Wang, Z., Tao, L. (2014). Artificial fish swarm algorithm-based particle filter for Li-ion battery life prediction. Mathematical Problems in Engineering, 2014(1): 564894. https://doi.org/10.1155/2014/564894
[26] Li, D.Z., Wang, W., Ismail, F. (2014). A mutated particle filter technique for system state estimation and battery life prediction. IEEE Transactions on Instrumentation and Measurement, 63(8): 2034-2043. https://doi.org/10.1109/TIM.2014.2303534
[27] Fox, D. (2001). KLD-sampling: Adaptive particle filters. Advances in Neural Information Processing Systems, 1-8. https://proceedings.neurips.cc/paper_files/paper/2001/file/c5b2cebf15b205503560c4e8e6d1ea78-Paper.pdf
[28] Soto, A. (2005). Self adaptive particle filter. In International Joint Conference on Artificial Intelligence, pp. 1398-1406.
[29] Lesage, D., Angelini, E.D., Funka-Lea, G., Bloch, I. (2016). Adaptive particle filtering for coronary artery segmentation from 3D CT angiograms. Computer Vision and Image Understanding, 151: 29-46. https://doi.org/10.1016/j.cviu.2015.11.009
[30] Zhou, T., Peng, D., Xu, C., Zhang, W., Shen, J. (2018). Adaptive particle filter based on Kullback-Leibler distance for underwater terrain aided navigation with multi-beam sonar. IET Radar, Sonar & Navigation, 12(4): 433-441. https://doi.org/10.1049/iet-rsn.2017.0239
[31] Varde, P.V., Pecht, M.G. (2018). Physics-of-failure approach for electronics. In Risk-Based Engineering. Springer Series in Reliability Engineering, pp. 417-445. https://doi.org/10.1007/978-981-13-0090-5_12
[32] Li, Z., Zheng, Z., Outbib, R. (2018). A prognostic methodology for power MOSFETs under thermal stress using echo state network and particle filter. Microelectronics Reliability, 88-90: 350-354. https://doi.org/10.1016/j.microrel.2018.07.137
[33] Musso, C., Oudjane, N., Le Gland, F. (2001). Improving regularised particle filters. In Sequential Monte Carlo Methods in Practice, New York, pp. 247-271. https://doi.org/10.1007/978-1-4757-3437-9_12
[34] Gebraeel, N., Lei, Y., Li, N., Si, X., Zio, E. (2023). Prognostics and remaining useful life prediction of machinery: Advances, opportunities and challenges. Journal of Dynamics, Monitoring and Diagnostics, 2(1): 1-12. https://doi.org/10.37965/jdmd.2023.148
[35] Singh, A., Anurag, A., Anand, S. (2016). Evaluation of Vce at inflection point for monitoring bond wire degradation in discrete packaged IGBTs. IEEE Transactions on Power Electronics, 32(4): 2481-2484. https://doi.org/10.1109/TPEL.2016.2621757
[36] Kuptametee, C., Michalopoulou, Z.H., Aunsri, N. (2023). Adaptive genetic algorithm-based particle herding scheme for mitigating particle impoverishment. Measurement, 214: 112785. https://doi.org/10.1016/j.measurement.2023.112785
[37] Hadi, E.F., Baharuddin, M.Z.B., Zuhdi, A.W.M., Ghadir, G.K., Al-Tmimi, H.M., Mustafa, M.A. (2024). Enhancing remaining useful life predictions in predictive maintenance of MOSFETs: The efficacy of integrated particle filter-gaussian process regression models. International Journal of Safety & Security Engineering, 14(2): 647-669. https://doi.org/10.18280/ijsse.140230