Maher Khalaf Hussein![]() | Lubna Thanoon ALkahla*
| Lubna Thanoon ALkahla*![]() | Asmaa Alqassab
| Asmaa Alqassab![]()
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
In the realm of hyperspectral image (HSI) classification, the selection of appropriate features and spectral-spatial information holds significant importance. Hyperspectral remote sensors offer an abundance of valuable information through numerous spectral bands within each pixel. Therefore, the aim of this research is to show a new approach to the selection of features will help identify and achieve an optimal feature set that improves classification efficiency. As such, this study presents a fresh viewpoint on feature selection for identifying the best subset of features which can improve the efficiency in classification. The research consists of different stages as follows: First stage is featuring extraction using Scale-Invariant Feature Transform (SIFT) and Gray-Level Run Length Matrix (GLRLM) technique then second stage is featuring selection through proposed hybrid between swarms by merging the outputs of two swarm algorithms binary particle swarm optimization (BPSO) and binary gray wolf optimizer (BGWO), it is done through AND Operator. These findings reveal that there is a great improvement in classification accuracy relative to full spectral data exceeding 1% threshold each for the Indian Pines, KSC and Botswana datasets. Remarkable values of 94.47, 93.48 and 81.70 are obtained for the Kappa coefficient, a metric for classification accuracy with regard to Botswana, KSC and Indian Pines datasets respectively. In this sense, these empirical results indicate that the proposed feature selection method outperforms other alternative methodologies discussed in this study.
combinatorial optimization, meta-heuristic algorithm, ant algorithm, bee colony optimization, artificial bee colony
Hyperspectral imaging has garnered significant interest for its capability to deliver comprehensive information about the composition and characteristics of objects within an image. Unlike RGB imaging, hyperspectral imaging captures data in narrow spectral bands allowing for a more comprehensive understanding of the scene, while traditional methods often struggle with high-dimensionality and overfitting in hyperspectral image classification, this study introduces a novel hybrid approach combining BPSO and BGWO, which exploits the strengths of each method to optimize feature selection, improving classification accuracy across various datasets.
In the classification process [1], each pixel in the image is assigned to classes based on its unique spectral signature. This signature represents the reflection or absorption pattern that characterizes each object or material [2]. Hyperspectral image classification has applications, including monitoring, land use mapping, agriculture, and mineral exploration [3]. However, hyperspectral data are complex and high-dimensional since they contain numerous narrow bands that were captured during the scanning process [4]. Addressing this problem, researchers have proposed several methods for feature selection to reduce dimensionality of data while improving classification accuracy [5]. The richness of the measured spectrum, with its high dimensionality, proves valuable for pixel classification, enabling the discrimination of different landscapes within the image scene [6]. However, land cover classification in hyperspectral imaging (HSI) data remains a prominent and challenging topic, primarily due to the “curse of dimensionality.” This challenge stems from the labor-intensive process of obtaining a limited number of ground-truth labeled pixels (training data), which must be appropriately distributed across various classes [7]. The commonly low number of collected ground-truth labels as compared to high spectral bands often leads to an unreliable estimate of classifier parameters hence make it prone to problems of over-fitting or under-fitting; thus, reducing classifier performance [8].
To enhance classification accuracy and efficiency, the remote sensing community has prioritized addressing data redundancy, driving the development of advanced feature selection techniques [9]. In data mining and pattern recognition applications, feature selection is essential, particularly for high-dimensional datasets. In order to develop a model, it entails choosing a subset of independent features [10].
The goals of feature selection encompass faster training of classification models, reduced model complexity, improved accuracy, and minimized overfitting. Thus, feature selection serves as a valuable means of providing prior knowledge of hyperspectral imaging and selecting relevant similarity measures with estimated weights for the classification method [11].
Classification plays a vital role in remote sensing by distinguishing objects within imagery into various classes, facilitating the creation of secondary products for mapping, monitoring, and analyzing land cover and land use changes. In hyperspectral image classification, the main goal is to assign each pixel in the scene to a specific category, a critical step in applications such as identifying land-cover types for Earth monitoring [12].
Over the last two decades, numerous supervised methods have been proposed for hyperspectral image classification. In the initial stages, spectral classifiers relied solely on spectral information, with Support Vector Machine (SVM) classifiers being a typical example. However, SVM's low sensitivity to high dimensionality has driven the development of various SVM-based classifiers tailored to handle the spectral classification of hyperspectral imagery [13]. In light of these challenges and advancements in hyperspectral image processing, our study proposes a novel method that combines feature extraction algorithms, specifically Scale-Invariant Feature Transform (SIFT) and Gray-Level Run Length Matrix (GLRLM), with feature selection algorithms, Binary Particle Swarm Optimization (BPSO), and Binary Grey Wolf Optimizer (BGWO). Our strategy aims to identify the ideal feature set that maximizes classification efficiency.
To evaluate the efficacy of our proposed methodology, we employ the Indian Pines dataset, containing hyperspectral images of farmland in Indiana, USA. Comparative analysis with other sophisticated algorithms utilizing GLRLM, SIFT classifiers, and Support Vector Machine (SVM) classifiers demonstrates the superiority of our proposed strategy, yielding notable gains in F1 scores across different categories. To reach this goal, we proposed in this research a new and more reliable technique in the feature selection process that helps in significantly improving the classification of hyperspectral images in various remote sensing and Earth observation applications. The swarm algorithms were hybridized by combining the outputs of two algorithms to improve the binary particle swarm. (BPSO) and Binary Gray Wolf Optimizer (BGWO), which is done through the AND operator, where the results showed a significant improvement in classification accuracy.
Many studies have addressed feature reduction algorithms in hyperspectral imaging because of their high dimensions that affect classification accuracy.one of this study. The classification of hyperspectral images has long been hampered by the 'curse of dimensionality,' where high-dimensional data complicates feature selection. Existing methods often suffer from poor generalization or convergence issues. In this study, we introduce a novel hybrid approach combining Binary Grey Wolf Optimizer (BGWO) and Binary Particle Swarm Optimization (BPSO, which addresses these gaps by exploiting the complementary strengths of both techniques. This hybrid method leads to more effective feature selection, significantly improving classification accuracy across a range of datasets. The study [14] presents a discarding-recovering and co-evolution feature selection strategy for hyperspectral imaging (HSI) datasets to find efficient feature combinations. The suggested method beats EA-based methods including GWO, PSO, GSA, and FA GSA in feature space optimization and speed of search. A few selected qualities give it a prominent OA and satisfactory stability. Performance improves when trustworthy co-evolution interacts with more representative agent information.
Kilickaya et al. [15] suggested hyperspectral image one-class classification method overcomes the high-dimensionality and imbalanced classes of standard machine learning techniques. The proposed approach overcomes HSI data imbalance and dimensionality using S-SVDD. Without band selection or dimensionality reduction, subspace learning approaches translate high-dimensional data to a lower-dimensional feature space suitable for one-class classification. The balanced labels of the LULC classification issue and extensive spectrum information make the suggested technique suitable for HSI data. The pipeline analyzes subspace learning one-class classmates to show its efficacy in addressing the curse of dimensionality and HSI data imbalance. Elmaizi et al. [16] introduce a relevance and synergy maximization (MRMS)-based method for hyperspectral image selection to reduce dimensionality and classify images. Unlike previous filter approaches, the suggested method manages relevance, spectral interaction, and synergy between selected bands. This experiment was tested on three benchmark hyperspectral datasets and found effective and robust. The suggested selection method incorporates geographical metrics and attributes to improve ground truth estimate.
In the study by Wang et al. [17], A novel autoencoder-based feature selection model, leveraging latent representation learning (LRLAFS), is proposed for hyperspectral imaging (HSI) data. The model outperforms others using latent representation learning and an alternate optimization strategy. The model's usefulness is confirmed by three HSI dataset experiments.
Another study by Islam et al. [18] shows that ground cover analysis benefits from hyperspectral imaging (HSI). Classification utilizing the original HSI is difficult because to high correlation, variable information, and processing expenses. Better categorization requires feature extraction (FE) and/or selection (FS). This paper presents an efficient FE technique employing normalized mutual information (NMI)-based band grouping to generate the best features and classify them using kernel support vector machines. The proposed approach enhanced classification performance the most, with 94.93% accuracy for the AVIRIS dataset and 99.026% for the HYDICE dataset.
The study by Zhang and Wang [19] It is observed that the high dimensionality of hyperspectral data and the uniform consideration of all spectral bands pose challenges for CNN-based hyperspectral image classification, despite advancements through deep learning. To address this, this study proposes a spatial proximity feature selection method integrated with a residual spatial-spectral attention network, which incorporates residual spatial attention, spectral attention, and feature selection modules. The network detects land-cover labels and improves classification accuracy better than current methods. Siddiqa et al. [20] present a dimension reduction strategy for high-dimensional hyperspectral image (HSI) classification that reduces feature size and computational time. The normalized cross-cumulative residual entropy (nCCRE) matrix picture replaces the correlation matrix image, decreasing computing cost and enhancing data partitioning. The nCCRE metric improves selected characteristics using minimum redundancy. The proposed strategy outperforms the existing techniques in classification and performance assessments. Extractive subset efficiency on two real HSIs is assessed using the SVM classifier.t-Distributed Stochastic Neighbor Embedding (tSNE) improves hyperspectral image (HSI) display and characterization PCA reduces HSI dimensions, preserves local and global pixel correlations, and produces two-dimensional data. The tSNE enhances visualization and classification [21].
Last but not least, Islam et al. [22] described a modified deep learning model for dimensionality reduction using non-negative matrix factorization (NMF), information-based feature selection, and a 2D wavelet-based CNN, which achieved higher accuracy than traditional procedures.
From previous studies, we observe the success of dimensionality reduction techniques in improving the performance of classifiers on HSI datasets, as well as making them more interpretable. However, determining the most appropriate feature selection algorithm for a given HSI dataset remains an open problem because each method has its advantages and limitations.
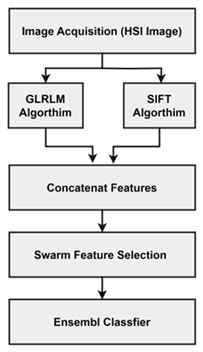
The proposed system, illustrated in Figure 1, consists of three main processes: feature-extraction, feature-selection, and classification. This study evaluates the effectiveness of two feature extraction methods (GLRLM and SIFT) alongside a novel feature selection approach that combines two swarming techniques with a collective classifier to enhance classification accuracy. SIFT identifies key points in images invariant to scale and rotation, making it ideal for robust feature extraction across varying spectral bands. Conversely, GLRLM captures texture features by counting the lengths of consecutive runs of pixels at specific gray levels, providing complementary spatial information for classification. The representation is general for most systems used in categorizing hyperspectral images.
Figure 1. Proposed hyperspectral image classification
For instance, gray-level run length matrix (GLRLM) [23] algorithm is a common method used in computer vision or image analysis for feature extraction while Scale-Invariant Feature Transform (SIFT) [24] also helps achieve this objective. Hyperspectral images (HSI) are classified using these separately as well as in combination [25, 26]. These GLRLM and SIFT are both techniques that can be used for image recognition, where the former is a texture descriptor. By employing both GLRLM and SIFT, different areas of the image will be captured leading to a better representation of the same hence improved classification accuracy. These two algorithms are part of many optimization algorithms used for feature selection in hyperspectral image classification. BPSO on the other hand tries to simulate particles or small organisms moving around, using a simple mathematical model [27]. Conversely, BGWO is an evolutionary algorithm applied to solve mathematical problems [28].
Additionally, this research introduces another model that combines the results obtained from two swarm intelligence algorithms. One dimensional matrix represents sub-features that individual swarms are expected to find using particular algorithms. To ensure only effective features are selected, AND operation is applied between first swarm’s binary vector and second swarm’s vector. The integration between these swarm methods has been indicated by Figure 2 below.
Figure 2. Proposed hybrid swarms’ structure for feature selection
The AND operation between the binary vector of the first swarm (S1) and the vector of the second swarm (S2) is mathematically represented as:
Final_features =s1∩s2 (1)
where, Final features represent the final selected features.
Additionally, BPSO and BGWO have their respective update equations. In BPSO, the position and velocity of each particle are updated as follows [29].
vt+1i=vti⊕( pbest ti⊕xti) (2)
xt+1i=xti+vt+1i (3)
where, pbest_{\boldsymbol{i}}{ }^t is the best position that particle I could have found at time t, x_i^t is the position of particle I at time t, v_i^t is the velocity of particle I at time t, represents the bitwise XOR operation and is also used for the bitwise XOR operation between the particle positions and velocities.
In BGWO, the updated equations for the position of each grey wolf are as follows [30]:
x_i^{t+1}=x_i^t \oplus\left(A \oplus D_i^t\right) (4)
D_i^{t+1}=C \oplus\left(X^{* t} \oplus X_i^{t+1 t}\right) (5)
x_i^{t+1}=clip\left(x_i^{t+1} l b \mathrm{ub}\right) (6)
where, Xi(t) represents the position of the grey wolf i at time t, X^{* t} is the best position found by the grey wolves, A is the coefficient matrix, D_i^t is the distance vector of the grey wolf i at time t, C is a random vector, lb and ub are the lower and upper bounds of the search space.
The hybrid approach aims to enhance the feature selection process in hyperspectral image classification, leading to improved accuracy and performance. By combining the strengths of BPSO and BGWO.
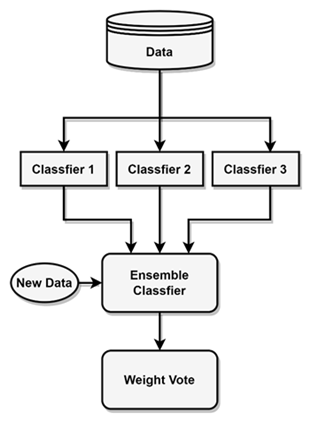
This study employed a combination of different machine learning methods to identify hyperspectral imaging (HSI) data. Specifically, a SVM, KNN algorithm, and Naive Bayes classifiers were utilized, as mentioned in the relevant sources [31-33]. By combining these classifiers, an ensemble classifier was created. A group of classifiers, often referred to as basis classifiers, are built using ensemble methods, which are learning algorithms. Predictions are then made on new data points by taking into account the weighted votes from these classifiers, as shown in Figure 3.
Figure 3. Basic outline of ensemble classifier
|
Pseudo code of Proposed feature selection |
|
# Initialize parameters Initialize BPSO parameters: num_particles, max_iterations, w, c1, c2 Initialize BGWO parameters: num_wolves, max_iterations, A, C, lb, ub # Initialize swarm matrices Initialize S1 with random binary vectors of size num_particles x num_features Initialize S2 with random binary vectors of size num_wolves x num_features # Main loop for BPSO for iteration in range(max_iterations): for particle in S1: Calculate the fitness of the particle using classification accuracy Update best if fitness is better than previous Update velocity using equation (2) Update position using equation (3) # Main loop for BGWO for iteration in range(max_iterations): for wolf in S2: Calculate the fitness of the wolf using classification accuracy Update the best position X^(*t) if fitness is better than previous Update distance vector D_i^t using equation (5) Update position using equation (4) and clip using equation (6) # Perform AND operation between S1 and S2 Final_features = S1 AND S2 # Perform classification using the selected features Train a classifier (e.g., SVM) using Final_features as input # Evaluate classifier performance Test the classifier on validation/testing data and measure accuracy # End |
The suggested method is implemented for testing with Matlab 2021b on a Windows 10 personal computer with a 2.30 GHz CPU and 16.00 GB of RAM.
4.1 Datasets description
For us to evaluate our feature selection and classifier, we considered three different hyperspectral imaging (HSI) datasets in this study, which helped in bringing out the capability of our technique. The Botswana hyperspectral dataset was the first among equals during the analysis. This data was taken from a particular region in Southern Africa and covers a wide spectral range that is very important for capturing the subtle spectral signatures of various land cover classes. The Botswana dataset provides a unique environment on which our methodological efficacy may be tested as well as challenging issues whose solutions require innovative thinking, The Indian Pines dataset is characterized by a diverse range of crop types with a high level of spectral similarity, making it particularly challenging for classification. Additionally, the presence of mixed pixels and noise complicates the analysis. Our method demonstrated significant improvements on this dataset, particularly in reducing the misclassification of spectrally similar classes. Similarly, the Kennedy Space Center (KSC) dataset, which features both natural landscapes and man-made structures, presents a unique challenge due to the variety of spectral signatures. Our approach outperformed existing methods on both datasets, achieving higher accuracy and Kappa coefficients.
Table 1 offers an overview of the Botswana dataset by giving out some of its attributes such as number of bands, spatial dimensions and true labels. This tabulated knowledge has become an anchor of subsequent analyses [34].
On the other hand, Figure 4, vividly captures part of Botswana’s dataset. This visualization illustrates how different discrete land cover categories are defined by the complex spectral variability thus making it apparent how deep and detailed are hyperspectral data contained within the Botswana landscape.
Table 1. The number of labeled samples and types of land cover that are available in Botswana [34]
|
Number of Class |
Name of Class |
No. of Labeled Samples |
|
1 |
Water |
270 |
|
2 |
Hippo grass |
101 |
|
3 |
Floodplain grasses1 |
251 |
|
4 |
Floodplain grasses2 |
215 |
|
5 |
Reeds |
269 |
|
6 |
Riparian |
269 |
|
7 |
Firescar |
259 |
|
8 |
Island interior |
203 |
|
9 |
Acacia woodlands |
314 |
|
10 |
Acacia scrublands |
248 |
|
11 |
Acacia grasslands |
305 |
|
12 |
Short mopane |
181 |
|
13 |
Mixed mopane |
268 |
|
14 |
Exposed soils |
95 |
|
|
Total |
3248 |
Figure 4. Botswana false-color image and ground-truth map [33]
Our investigation was then put on the spotlight by The Kennedy space center (KSC) hyperspectral dataset. This dataset is from one of the most famous space launch sites, which means it contains natural landscapes and man-made structures in close proximity, hence a dynamic and difficult landscape for hyperspectral analysis. We also measured how adaptable it is in this environment using our methodology.
Table 2 systematically outlines the fundamental attributes of the KSC dataset, spanning spectral bands, spatial dimensions, and ground-truth labels. This tabulated compendium serves as a foundational guide for subsequent deliberations.
Figure 5 amplifies our understanding by visually capturing a distinct subset of the KSC dataset. This illustrative glimpse underscores the intricate spectral characteristics inherent in the diverse features peppered across the Kennedy Space Center expanse, unequivocally emphasizing the potency and multifaceted nature of hyperspectral imaging [35].
Last but certainly not least, the Indian Pines hyperspectral dataset, a widely regarded benchmark, enriched our comprehensive analysis. Collected over farmland in Indiana, USA, this dataset presents a captivating yet complex landscape teeming with spectral insights [36, 37]. The Indian Pines dataset served as a rigorous testing ground for meticulously evaluating the efficacy of our proposed methodology.
Table 2. The number of land-cover classifications and labeled samples that are available in the KSC dataset [35]
|
Number of Class |
Name of Class |
No. of Labeled Samples |
|
1 |
Scrub |
761 |
|
2 |
Willow swamp |
243 |
|
3 |
Cabbage palm hammock |
256 |
|
4 |
Cabbage palm/Oak hammock |
252 |
|
5 |
Slash pine |
161 |
|
6 |
Oak/Broadleaaf hammock |
229 |
|
7 |
Hardwood swamp |
105 |
|
8 |
Graminoid marsh |
431 |
|
9 |
Spartina marsh |
520 |
|
10 |
Cattaial marsh |
404 |
|
11 |
Salt marsh |
419 |
|
12 |
Mudflats |
503 |
|
13 |
Water |
27 |
|
|
Total |
5211 |
Figure 5. KSC dataset false-color image and ground-truth map [35]
Table 3. The number of land-cover classifications and tagged samples that are available in the Indian Pines dataset [37]
|
Number of Class |
Name of Class |
No. of Labeled Samples |
|
1 |
Alfalfa |
46 |
|
2 |
Corn-no-till |
1428 |
|
3 |
Corn-min |
830 |
|
4 |
Corn |
237 |
|
5 |
Grass/Pasture |
483 |
|
6 |
Grass/Trees |
730 |
|
7 |
Grass/Pasture-mowed |
28 |
|
8 |
Way-windrowed |
478 |
|
9 |
Oats |
20 |
|
10 |
Soybeans-no-till |
972 |
|
11 |
Soybeans-min |
2455 |
|
12 |
Soybean-clean |
593 |
|
13 |
Wheat |
205 |
|
14 |
Woods |
1265 |
|
15 |
Bldg.-Grass-Tree-Drives |
386 |
|
16 |
Stone-steel towers |
93 |
|
|
Total |
10249 |
Table 3 delivers a concise summation of the Indian Pines dataset's key attributes, encompassing spectral bands, spatial dimensions [37], and ground-truth labels. This tabular scaffolding sets the stage for our subsequent exploration.
Figure 6 takes us deeper, visually capturing a distinct slice of the Indian Pines dataset. This visual elucidation underscores the intricate spectral differentiations intrinsic to varied land cover categories, amplifying our appreciation for the depth and intricacy of hyperspectral data harbored within the Indian Pines dataset.
Collectively, the comprehensive evaluation across these three distinct hyperspectral datasets-Botswana, KSC, and Indian Pines - firmly underscores the robustness and versatility of our proposed methodology across an eclectic array of landscapes and scenarios.
4.2 Experiments for widely used methods of feature selection
This section employs commonly utilized feature selection procedures, including CMIM, mRMR, JMI methods, and Relief algorithms, to assess the efficiency of the suggested method. Tables 4-6 present the Kappa coefficient and classification accuracy results for three hyperspectral imaging (HSI) datasets, employing various widely employed feature selection techniques. The tables present overall classification accuracy (OA) and Kappa coefficient for each category, obtained through the utilization of various feature selection strategies, The results demonstrate the superior performance of the hybrid approach, particularly in high-dimensional datasets like Indian Pines and KSC. The combination of BPSO and BGWO ensured that both global exploration and local exploitation were optimized, leading to a more accurate selection of features. This resulted in higher classification accuracy compared to other feature selection methods, especially in the presence of noise and spectral overlap. The AND operation between the swarms further ensured that only the most relevant features were retained, significantly reducing the dimensionality of the dataset without sacrificing classification performance.
According to the information found in Tables 4-6, the proposed feature selection method showed better classification accuracy than full spectrum use. The Botswana dataset as well as Indian Pines and KSC datasets has it at more than 1%. Moreover, the results revealed that the Botswana, KSC, and Indian Pines data sets have Kappa coefficients above 94.47, 93.48, and 81.70 respectively meaning that higher classification accuracy of the proposed technique gave better results as compared to other methods stated in this paper.
Table 4. Kappa and overall classification accuracy for the Botswana dataset
|
Class Number |
Full Spectral |
mRMR |
CMIM |
JMI |
Relief |
Proposed |
|
1 |
95.31 |
97.35 |
96.77 |
94.87 |
97.35 |
97.50 |
|
2 |
91.87 |
87.76 |
87.76 |
88.21 |
85.47 |
90.95 |
|
3 |
90.13 |
91.87 |
87.09 |
86.22 |
93.17 |
91.43 |
|
4 |
81.14 |
42.85 |
70.60 |
54.74 |
42.85 |
83.82 |
|
5 |
65.83 |
16.86 |
38.93 |
35.48 |
20.31 |
61.69 |
|
6 |
67.02 |
57.31 |
52.94 |
46.63 |
51.97 |
65.56 |
|
7 |
86.11 |
90.36 |
88.23 |
90.36 |
88.23 |
87.17 |
|
8 |
98.42 |
89.92 |
94.04 |
86.57 |
86.31 |
98.16 |
|
9 |
96.94 |
83.91 |
90.53 |
87.54 |
78.14 |
96.51 |
|
10 |
97.15 |
90.56 |
98.25 |
94.13 |
79.57 |
98.53 |
|
11 |
98.61 |
98.08 |
98.88 |
96.76 |
98.08 |
98.88 |
|
12 |
96.14 |
95.48 |
89.52 |
90.40 |
97.47 |
99.23 |
|
13 |
98 |
100 |
100 |
100 |
100 |
100 |
|
14 |
93.96 |
87.65 |
90.21 |
87.46 |
85.90 |
94.45 |
|
OA (%) |
89.76 |
80.71 |
84.55 |
81.38 |
78.92 |
90.28 |
|
Kappa |
93.67 |
82.45 |
89.96 |
90.65 |
91.20 |
94.47 |
Table 5. Kappa and overall classification accuracy for the KSC dataset
|
Class Number |
Full Spectral |
mRMR |
CMIM |
JMI |
Relief |
Proposed |
|
1 |
94.31 |
96.35 |
95.77 |
93.87 |
96.35 |
96.5 |
|
2 |
90.87 |
86.76 |
86.76 |
87.21 |
84.47 |
89.95 |
|
3 |
89.13 |
90.87 |
86.09 |
85.22 |
92.17 |
90.43 |
|
4 |
84.14 |
41.85 |
69.6 |
53.74 |
41.85 |
82.82 |
|
5 |
64.83 |
15.86 |
37.93 |
34.48 |
19.31 |
60.69 |
|
6 |
66.02 |
56.31 |
51.94 |
45.63 |
50.97 |
64.56 |
|
7 |
85.11 |
89.36 |
87.23 |
89.36 |
87.23 |
86.17 |
|
8 |
97.42 |
88.92 |
93.04 |
85.57 |
85.31 |
97.16 |
|
9 |
95.94 |
82.91 |
89.53 |
86.54 |
77.14 |
95.51 |
|
10 |
96.15 |
89.56 |
97.25 |
93.13 |
78.57 |
97.53 |
|
11 |
97.61 |
97.08 |
97.88 |
95.76 |
97.08 |
97.88 |
|
12 |
95.14 |
94.48 |
88.52 |
89.4 |
96.47 |
98.23 |
|
13 |
99.88 |
100 |
100 |
99.88 |
100 |
100 |
|
14 |
92.96 |
86.65 |
89.21 |
86.46 |
84.9 |
93.45 |
|
OA (%) |
92.16 |
85.12 |
87.98 |
8490 |
83.17 |
92.7 1 |
|
Kappa |
92.70 |
80.6 |
88.21 |
88.84 |
89.65 |
93.48 |
Table 6. Kappa and overall classification accuracy for the Indian Pines dataset
|
Class Number |
Full Spectral |
mRMR |
CMIM |
JMI |
Relief |
Proposed |
|
1 |
29.27 |
0 |
97.6 |
31.71 |
17.07 |
58.54 |
|
2 |
83.42 |
60.7 |
44.36 |
69.88 |
69.18 |
83.74 |
|
3 |
72.02 |
56.22 |
30.66 |
99.1 |
29.72 |
69.75 |
|
4 |
71.83 |
51.17 |
20.19 |
31.46 |
30.99 |
70.89 |
|
5 |
91.49 |
19.54 |
84.6 |
75.4 |
83.91 |
91.03 |
|
6 |
96.5 |
91.78 |
94.37 |
93 |
91.7 |
97.72 |
|
7 |
68 |
40 |
0 |
40 |
0 |
68 |
|
8 |
98.84 |
96.98 |
96.05 |
97.44 |
99.07 |
99.53 |
|
9 |
55.56 |
0 |
0 |
55.6 |
16.67 |
55.56 |
|
10 |
78.17 |
53.26 |
17.26 |
34 |
52.69 |
80 |
|
11 |
85.6 |
75.1 |
89.54 |
88.37 |
81.08 |
86.33 |
|
12 |
85.96 |
37.45 |
19.29 |
14.04 |
38.95 |
89.89 |
|
13 |
94.57 |
90.76 |
92.93 |
90.22 |
77.17 |
95.11 |
|
14 |
97.19 |
97.36 |
97.36 |
97.19 |
96.84 |
97.72 |
|
OA (%) |
52.16 |
14.99 |
37.18 |
35.73 |
40.63 |
60.23 |
|
Kappa |
79.17 |
55.02 |
56.02 |
65.53 |
56.07 |
81.70 |
Figure 6. Indian Pines dataset false-color image and ground truth map [36]
A novel approach to hyperspectral image (HSI) classification feature selection that enhances classification efficiency is presented in this study. The researchers have used SIFT and GLRLM techniques for feature extraction and then a hybrid approach was proposed which combined the outputs of two swarm algorithms, BPSO and BGWO, through AND Operator on both scales. According to Indian Pines, KSC, and Botswana datasets, classification results were improved significantly as compared to full spectral data and have consistently raised above 1% threshold. For Botswana, KSC and Indian Pines datasets respectively, The Kappa coefficient as a measure of classification precision achieves outstanding values of 94.47, 93.48, and 81.70. These empirical results prove the usefulness of the proposed feature selection method over other methods tested within this study.
In summary, the hybrid swarm approach combining BPSO and BGWO proved to be a highly effective method for feature selection in hyperspectral image classification. By leveraging the strengths of both algorithms, the method not only improved classification accuracy but also demonstrated robustness across various datasets. This approach holds potential for wide applications in fields such as environmental monitoring, where accurate land cover classification is crucial, and precision agriculture, where early crop health detection can lead to more sustainable farming practices.
We extend our sincere gratitude to the managing editor and anonymous reviewers for their invaluable feedback and suggestions, which significantly enhanced the quality of this contribution. Additionally, we are profoundly thankful to Dr. Fawziya Mahmood Ramo and Prof. Manar Younis Kashmola for their encouragement and recommendation to submit our research to this esteemed journal.
[1] Li, Z., Zhu, Q., Wang, Y., Zhang, Z., Zhou, X., Lin, A., Fan, J. (2020). Feature extraction method based on spectral dimensional edge preservation filtering for hyperspectral image classification. International Journal of Remote Sensing, 41(1): 90-113. https://doi.org/10.1080/01431161.2019.1635723
[2] Shang, X., Song, M., Yu, C. (2019). Hyperspectral image classification with background. In IGARSS 2019 - 2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, pp. 2714-2717. https://doi.org/10.1109/IGARSS.2019.8898520
[3] Chen, W., Ouyang, S., Yang, J., Li, X., Zhou, G., Wang, L. (2022). JAGAN: A framework for complex land cover classification using Gaofen-5 AHSI images. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 15: 1591-1603. https://doi.org/10.1109/JSTARS.2022.3144339
[4] Lone, Z.A., Pais, A.R. (2022). Object detection in hyperspectral images. Digital Signal Processing, 131: 508-512. https://doi.org/10.1016/J.DSP.2022.103752
[5] Zebari, R., Abdulazeez, A., Zeebaree, D., Zebari, D., Saeed, J. (2020). A comprehensive review of dimensionality reduction techniques for feature selection and feature extraction. Journal of Applied Science and Technology Trends, 1(2): 56-70. https://doi.org/10.38094/jastt1224
[6] Appice, A., Malerba, D. (2019). Segmentation-aided classification of hyperspectral data using spatial dependency of spectral bands. ISPRS Journal of Photogrammetry and Remote Sensing, 147: 215-231. https://doi.org/10.1016/j.isprsjprs.2018.11.023
[7] He, L., Li, J., Liu, C., Li, S. (2018). Recent advances on spectral-spatial hyperspectral image classification: An overview and new guidelines. IEEE Transactions on Geoscience and Remote Sensing, 56(3): 1579-1597. https://doi.org/10.1109/TGRS.2017.2765364
[8] Islam, M.T., Islam, MR., Uddin, M.P., Ulhaq, A. (2023). A deep learning-based hyperspectral object classification approach via imbalanced training samples handling. Remote Sensing, 15(14): 3532. https://doi.org/10.3390/rs15143532
[9] Lv, C., Zhang, Y., Wang, J., Huang, L., Wang, S., Sun, W. (2022). A classification feature optimization method for remote sensing imagery based on fisher score and mRMR. Applied Sciences, 12(17): 8845. https://doi.org/10.3390/app12178845
[10] Yu, R., Wang, K., Li, M., Hu, S., Zeng, J., Shao, H. (2021). Three-dimensional convolutional neural network model for early detection of pine wilt disease using UAV-based hyperspectral images. Remote Sensing, 13(20): 4065. https://doi.org/10.3390/rs13204065
[11] Zhang, J. (2022). A hybrid clustering method with a filter feature selection for hyperspectral image classification. Journal of Imaging, 8(7): 180. https://doi.org/10.3390/jimaging8070180
[12] Gao, Y., Zhang, X., Chen, X., Zhang, Y., Zhang, W., Wu, H. (2022). Fusion classification of HSI and MSI using a spatial-spectral vision transformer for wetland biodiversity estimation. Remote Sensing, 14(4): 850. https://doi.org/10.3390/rs14040850
[13] He, X., Chen, Y., Lin, Z. (2021). Spatial-spectral transformer for hyperspectral image classification. Remote Sensing, 13(3): 498. https://doi.org/10.3390/rs13030498
[14] Liao, B., Li, Y., Liu, W., Gao, X., Wang, M. (2023). Discarding–recovering and co-evolution mechanisms based evolutionary algorithm for hyperspectral feature selection. Remote Sensing, 15(15): 3788. https://doi.org/10.3390/rs15153788
[15] Kilickaya, S., Ahishali, M., Sohrab, F., Ince, T., Gabbouj, M. (2023). Hyperspectral image analysis with subspace learning-based one-class classification. arXiv preprint. https://arxiv.org/pdf/2304.09730.
[16] Elmaizi, A., Sarhrouni, E., Hammouch, A., Chafik, N. (2022). Hyperspectral images classification and dimensionality reduction using spectral interaction and SVM classifier. arXiv preprint. https://arxiv.org/pdf/2210.15546.pdf.
[17] Wang, X., Wang, Z., Zhang, Y., Jiang, X., Cai, Z. (2022). Latent representation learning based autoencoder for unsupervised feature selection in hyperspectral imagery. Multimedia Tools and Applications, 81(9): 12061-12075. https://doi.org/10.1007/s11042-020-10474-8
[18] Islam, M.R., Ahmed, B., Hossain, M.A., Uddin, M.P. (2023). Mutual information-driven feature reduction for hyperspectral image classification. Sensors, 23(2): 657. https://doi.org/10.3390/s23020657
[19] Zhang, X., Wang, Z. (2023). Spatial proximity feature selection with residual spatial-spectral attention network for hyperspectral image classification. IEEE Access, 11: 23268-23281. https://doi.org/10.1109/ACCESS.2023.3253627
[20] Siddiqa, A., Islam, R., Afjal, M.I. (2022). Spectral segmentation based dimension reduction for hyperspectral image classification. Journal of Spatial Science, 1-20. https://doi.org/10.1080/14498596.2022.2074902
[21] Hossain, M.M., Hossain, M.A., Miah, A.S.M., Okuyama, Y., Tomioka, Y., Shin, J. (2023). Stochastic neighbor embedding feature-based hyperspectral image classification using 3D convolutional neural network. Electronics, 12(9): 2082. https://doi.org/10.3390/electronics12092082
[22] Islam, M.T., Kumar, M., Islam, M.R., Sohrawordi, M. (2022). Subgrouping-based NMF with imbalanced class handling for hyperspectral image classification. In Proceedings of the 2022 25th International Conference on Computer and Information Technology (ICCIT), Cox's Bazar, Bangladesh, pp. 739-744. https://doi.org/10.1109/ICCIT57492.2022.10055177
[23] Adel, B., Andreica, A., Camelia, C. (2021). Towards feature selection for digital mammogram classification. Procedia Computer Science, 192: 632-641. https://doi.org/10.1016/j.procs.2021.08.065
[24] Hicham, B., Ahmed, C., Abdelali, L. (2022). Face recognition method combining SVM machine learning and scale invariant feature transform. E3S Web of Conferences, 351: 01033. https://doi.org/10.1051/e3sconf/202235101033
[25] Xu, H., Ren, J., Lin, J., Mao, S., Xu, Z., Chen, Z., Zhao, J., Wu, Y., Xu, N., Wang, P. (2023). The impact of high-quality data on the assessment results of visible/near-infrared hyperspectral imaging and development direction in the food fields: A review. Journal of Food Measurement and Characterization, 17(3): 2988-3004. https://doi.org/10.1007/s11694-023-01822-x
[26] Ma, T., Xing, Y., Gong, D., Lin, Z., Li, Y., Jiang, J., He, S. (2022). A deep learning-based hyperspectral keypoint representation method and its application for 3D reconstruction. IEEE Access, 10: 85266-85277. https://doi.org/10.1109/access.2022.3197183
[27] Alkahla, L.T., Alneamy, J.S. (2021). Face identification in a video file based on hybrid intelligence technique-review. Journal of Physics: Conference Series, 1818(1): 012041. https://doi.org/10.1088/1742-6596/1818/1/012041
[28] Medjahed, S.A., Ouali, M. (2019). Spectral band selection using binary gray wolf optimizer and signal to noise ratio measure. In Lecture Notes in Networks and Systems, 64: 75-89. https://doi.org/10.1007/978-3-030-05481-6_6
[29] Zhu, J., Liu, J., Chen, Y., Xue, X., Sun, S. (2023). Binary restructuring particle swarm optimization and its application. Biomimetics, 8(2): 266. https://doi.org/10.3390/biomimetics8020266
[30] Too, J., Abdullah, A., Mohd Saad, N., Mohd Ali, N., Tee, W. (2018). A new competitive binary grey wolf optimizer to solve the feature selection problem in EMG signals classification. Computers, 7(4): 58. https://doi.org/10.3390/computers7040058
[31] Arifin, M., Widowati, W., Farikhin, F. (2023). Optimization of hyperparameters in machine learning for enhancing predictions of student academic performance. Ingénierie des Systèmes d’Information, 28(3): 575-582. https://doi.org/10.18280/isi.280305
[32] Cunningham, P., Delany, S.J. (2021). k-Nearest neighbor classifiers-A tutorial. ACM Computing Surveys, 54(6): 1-25. https://doi.org/10.1145/3459665
[33] Hashmix, A., Nafis, M.T., Naaz, S., Nandan, D., Hussain, I. (2023). Predictive modelling of glycated hemoglobin levels using machine learning regressors. Ingénierie des Systèmes d’Information, 28(6): 1505-1513. https://doi.org/10.18280/isi.280607
[34] Paul, A., Chaki, N. (2020). Supervised data-driven approach for hyperspectral band selection using quantization. Geocarto International, 37(8): 2312-2322. https://doi.org/10.1080/10106049.2020.1822929
[35] Zhu, K., Chen, Y., Ghamisi, P., Jia, X., Benediktsson, J.A. (2019). Deep convolutional capsule network for hyperspectral image spectral and spectral-spatial classification. Remote Sensing, 11(3): 223. https://doi.org/10.3390/rs11030223
[36] Huang, H., Chen, M., Duan, Y. (2019). Dimensionality reduction of hyperspectral image using spatial-spectral regularized sparse hypergraph embedding. Remote Sensing, 11(9): 1039. https://doi.org/10.3390/rs11091039
[37] Li, C., Chen, Y., Li, L., Li, W., Zhang, B. (2018). Hyperspectral remote sensing image classification based on maximum overlap pooling convolutional neural network. Sensors, 18(10): 3587. https://doi.org/10.3390/s18103587