Slamet Riyadi*![]() | Febriyanti Azahra Abidin
| Febriyanti Azahra Abidin![]() | Cahya Damarjati
| Cahya Damarjati![]()
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Coronary artery disease (CAD) is a pathological condition that is often fatal and is the main cause of death throughout the world. Early detection of this disease is very important to avoid severe complications such as heart attacks and sudden death. This study employs artificial intelligence, specifically deep learning via Convolutional Neural Networks (CNNs), to enhance CAD detection. While CNN architectures like ResNet50V2 and MobileNetV2 exhibit satisfactory performance individually, they possess distinct strengths and weaknesses. ResNet50V2 requires significant computing resources, hindering its scalability, while MobileNetV2 struggles with extracting complex features from medical images. Therefore, this research aims to combine the EfficientNetV2B0, ResNet50V2, and MobileNetV2 using transfer learning techniques to enhance CAD detection. The methodology involves leveraging pre-trained models and fine-tuning them on a coronary artery disease dataset. Modified models, particularly EfficientNetV2B0 and MobileNetV2, achieve high accuracies of 94% and 86%, respectively, while ResNet50V2 yields 72%. However, combining the models boosts accuracy to 95%, addressing individual model limitations. The concatenated model demonstrates superior predictive capabilities, with more accurate predictions and fewer errors than individual models.
coronary artery disease, transfer learning, Convolution Neural Network (CNN), Concatenation Model, image classification
Coronary artery disease (CAD), also known as coronary atherosclerosis, is a pathological condition in which plaque deposits form in the arteries that supply blood to the heart muscle [1]. The plaque contains fat, calcium, cholesterol, and fibrin, a substance that causes blood clots [2]. Coronary artery disease is the most prevalent type of cardiovascular disease and the primary cause of death globally, responsible for around 17.9 million deaths annually [3]. This condition needs attention because it has a high risk of heart disease [4].
Early detection of coronary artery disease is becoming increasingly important to prevent serious complications such as heart attacks and sudden death. Timely and accurate detection methods can enable effective treatment, can save lives and improve the patient's quality of life. Developing detection methods with artificial intelligence could be crucial in highlighting the significance of early disease detection. Artificial intelligence technology has been extensively utilized across multiple sectors, such as health, agriculture, manufacturing, and education [5]. Deep learning techniques, which are a branch of artificial intelligence, have recently received much attention for solving various challenges, especially in the field of medical imaging [6]. Deep learning techniques are an advanced branch of computer vision that aims to perform a variety of tasks including image detection, recognition, natural language processing, and image analysis [7].
Convolution Neural Network (CNN) is an effective deep learning algorithm for understanding image content, with excellent performance in various tasks including segmentation, classification, detection, and image retrieval [8]. Two CNN architectures, namely ResNet50V2 and MobileNetV2, have been developed for disease detection with quite good detection performance [9, 10]. Both have been used widely in various cases and each has its advantages and disadvantages. ResNet50V2 is capable of training deep networks well [11]. but can suffer from the need for large computing resources. On the other hand, MobileNetV2, which focuses on optimizing memory usage and execution speed [12], has limitations in extracting complex features from medical images.
Other research shows that combining different architectures can lead to more robust performance [13] and representation of complex medical images. The combination of the ResNet50V2 and MobileNetV2 architectures has been carried out to solve the problem of detecting the COVID-19 virus to obtain better performance than the performance of each architecture [14]. This combination uses a transfer learning technique, which is a technique where the training process uses a model that has been previously trained on certain data, which is generally called a pre-trained model. By utilizing transfer learning techniques, the resulting architecture can use knowledge gained from other medical image data, thereby enabling better adaptation to this coronary artery disease dataset. Recent research has demonstrated the ability to transfer learning into medical imaging fields such as chest imaging [15], breast imaging [16], and retina imaging [17].
Although the ResNet50V2 and MobileNetV2 architectures show good performance, they have limitations in terms of the need for large computing resources and obstacles in extracting complex features. To overcome this limitation, this study aims to combine three architectures, namely ResNet50V2, MobileNetV2, and EfficientNetV2B0 to detect coronary artery disease with transfer learning techniques. The EfficientNetV2B0 architecture, which is an evolution of EfficientNetV1, is renowned for its efficiency in the use of computing resources [18]. The new finding from this research is the combination of three CNN architectures using transfer learning in the development of a coronary artery disease detection system. Thus, the combination of the ResNet50V2, MobileNetV2, and EfficientNetV2B0 architectures is expected to overcome the limitations of each model, resulting in a more efficient, responsive, and accurate coronary artery disease detection system.
This section provides a concise summary of recent research on coronary artery disease (CAD) detection using various approaches and Convolutional Neural Network (CNN) model architectures. There is research that proposes a method to detect coronary artery disease (CAD) and its types using Phonocardiogram (PCG) signature analysis, feature fusion, and a two-step classification strategy [19]. They collected PCG data with a low-cost stethoscope and processed it using iterative signal decomposition (EMD). Spectral and statistical features were extracted, and a two-stage classification framework was used to differentiate between healthy cases and CAD cases. The validation results show a high degree of accuracy, with average values of 88.0% for normal, 89.2% for DVCAD, 91.1% for SVCAD, and 85.3% for TVCAD after 10-fold cross-validation.
The use of Convolutional Neural Networks (CNN) such as VGG16, DenseNet121, InceptionV3, and ResNet50 was also used in a study to classify SPECT-MPI images to detect myocardial perfusion abnormalities related to coronary artery disease (CAD) [20]. These models were assessed based on accuracy, precision, recall and F1-score, with the best results achieved by VGG16 and InceptionV3, with the highest accuracy reaching 84.38%. This study shows the potential of using CNN models as a diagnostic aid for physicians in clinical practice to improve the reliability of SPECT-MPI test interpretation and CAD monitoring.
In another study also discussed the importance of using CT angiography to detect coronary artery disease (CAD) and how machine learning (ML) can help improve diagnostic accuracy [21]. This study proposes a new method for detecting CAD with high accuracy and minimal processing time, with emphasis on efficient feature extraction and the use of Convolutional Neural Networks (CNN). Experimental analysis shows that the proposed method is superior in detecting CAD, with prediction accuracies of 99.2% and 98.73% for two different datasets. The results validate that the suggested method can address the difficulties associated with analyzing cardiac CT scans and has the capacity to enhance CAD diagnosis and clinical management. Furthermore, there is research that introduces a novel approach for automatically detecting stenosis in X-ray Coronary Angiography (XCA) pictures. This approach utilizes pre-trained Convolutional Neural Networks (CNN) such as VGG16, ResNet50, and InceptionV3 through transfer learning [22]. This method relies on the utilization of network slicing and fine-tuning techniques. The analysis results show that VGG16, ResNet50, and InceptionV3, which have been pre-trained and adjusted in the initial layers, successfully outperform the reference CNN. Specifically, Inception-v3 provides the best stenosis detection with 95% accuracy, 93% precision, sensitivity, specificity, and F1-score of 98%, 92%, and 95%, respectively. Additionally, class activation maps were applied to identify regions of high interest in stenosis detection.
The combined architecture was also implemented to investigate methods for enhancing the precision of breast cancer classification by employing a dependable framework that utilizes mammography as a scanning technique [23]. Through the development of three different CNN models, namely two with transfer learning and one completely from scratch, this research succeeded in reducing misclassification of lesions in mammography images. By using Bayesian optimization and data augmentation, these models can improve their accuracy. The results of the analysis show that these models can predict disease accurately with an accuracy level of 97.26% in binary cases and 99.13% in multiclassification cases. These findings show a significant improvement compared to previous research, showing an increase in multiclassification accuracy of 16%.
In addition, combined architecture was implemented to detect cases of COVID-19, particularly in response to the significant global mortality rate [24]. Many deaths are caused by delays in disease identification. Therefore, this study aims to detect COVID-19 in chest X-ray images by employing deep learning neural networks, specifically Xception combined with ResNet152V2 and Xception with EfficientNet-B7. The proposed method combines two deep learning networks to detect COVID-19 from X-ray images. The results indicate that the average accuracy for detecting COVID-19 is 62% using Xception combined with EfficientNet-B7 and 60% when Xception is combined with ResNet152V2. However, the proposed combined architecture provides better results with increasing number of epochs and batch size, with an estimated accuracy increase of up to 99.7%.
Researchers have conducted a literature review on disease detection, especially coronary artery disease, and no research has been found that combines the CNN architectures EfficientNetV2B0, ResNet50V2, and MobileNetV2 in this context. Although previous studies have provided valuable insights into this disease, none has specifically investigated the potential of incorporating this CNN architecture for coronary artery disease detection. Consequently, the presence of these gaps emphasizes the requirement for further and innovative investigation into the possible application of combining different CNN architectures in the context of detecting coronary artery disease.
3.1 Dataset
The dataset used to train the model consists of 5,959 image data that includes Coronary Computed Tomography Angiography (CCTA) images from 500 patients, with 18 different views of straightened coronary arteries [25]. Images are categorized into two different groups, namely normal which includes 50% of the image and abnormal which also includes 50% of the image. After that, the images are categorized into three distinct sets, training, validation, and testing. Table 1 presents the proportion of divisions from the dataset used.
Table 1. Split dataset
|
Class |
Train |
Valid |
Test |
|
Positive |
1.996 |
50 |
493 |
|
Negative |
2.304 |
50 |
1.066 |
|
Total |
4.300 |
100 |
1.559 |
To increase data diversity and reduce the possibility of overfitting, image augmentation techniques are applied to the training data after image preprocessing. Image preprocessing is done by resizing the image to 224×224 pixels, which is a standard size for many convolutional models such as CNNs. Images are converted to RGB format and normalized to ensure consistency in training. After that, image augmentation techniques are applied, including several transformations. Shear Range is used to apply a shear transformation to an image, emulating changes in perspective and viewing angle. Zoom Range is applied to simulate variations in camera distance by zooming in on the image, while the Horizontal Flip technique is used to flip the image horizontally, increasing viewing angle variations. All these techniques are implemented using to enable the dynamic creation of augmented images during the training process, enriching the training data, and helping the model generalize better.
3.2 Tansfer learning
Transfer learning is a widely used technique for developing deep learning network models for different tasks. In this technique, a model that has been pre-trained on a large data set for a particular task, or what is called a pre-trained layer, is then readjusted, or moved to another task. This process is carried out by leveraging the knowledge the model already has about general features of relevant data, which can then be applied to specific data sets and new tasks. In transfer learning, the first layer of a convolutional network is usually used to learn general features in an image, while the last layer of the network is learned for a specific classification task. Therefore, transfer learning allows models to leverage existing knowledge for new tasks without having to train from scratch. It is then refined to produce a solution that meets the needs of the given task [26].
By utilizing pre-trained layers from a model that has already been trained on the ImageNet dataset, can save the time and resources required to train the model from scratch. ImageNet is an extensive dataset comprising millions of images categorised into numerous classes, making it a widely used benchmark for training and assessing deep learning models in the field of image recognition [27]. This dataset includes a wide variety of objects and concepts, so models trained using this dataset can learn representations of very important and common features from images. These pre-trained layers serve as a robust base that enables the model to rapidly learn from the dataset and adjust the feature representation for the current task. During transfer learning implementation, these pre-trained layers are often frozen. Therefore, the model can maintain existing understanding of general features while changing its representation to meet more specific goals.
3.3 The proposed Concatenation Model based on transfer learning techniques
In developing a combined model for the detection of coronary artery disease, researchers froze the initial blocks of 3 transfer learning models, EfficientNetV2B0, ResNet50V2, and MobileNetV2. Freezing is performed to preserve the relevant basic features of the target dataset, while providing flexibility to adjust more specific features.
After freezing the initial blocks, modifications were made mainly by adding additional layers to each model. The added layers include Conv2D, Maxpooling2D, Flatten, and some Dense layers as seen in Table 2. The addition of these layers aims to enhance the model's capacity to effectively address the challenge of detecting coronary artery disease, by allowing the model to extract more complex or specific features.
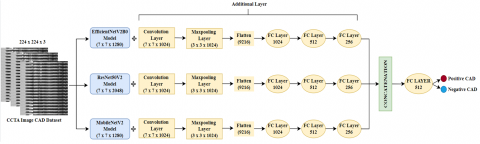
Researchers designed a proposed Concatenation Model for the detection of coronary artery disease with input dimensions of 224×224. This model uses three modified models, with similar input dimensions. The structure of this model is shown in Figure 1 and the detailed parameters for each layer in the architecture are shown in Table 2 to provide a better understanding of our proposed model.
Utilizing a combination of multiple neural network architectures, such as EfficientNetV2B0, ResNet50V2, and MobileNetV2, can enhance the accuracy of classification tasks by leveraging the distinctive capabilities of each model. This approach involves training and merging multiple models to address the same problem. The primary benefit of this approach lies in the fact that the combination of models typically yields superior performance compared to using a single model. This is attributed to the reduction in model variance and the enhancement of generalization. By combining EfficientNetV2B0, ResNet50V2, and MobileNetV2, it can leverage the diverse strengths of EfficientNetV2B0's efficiency, ResNet50V2's deep handling, and MobileNetV2's lightweight architecture. Different architectures learn different feature representations. EfficientNetV2B0 can capture efficient and broad features, ResNet50V2 can capture deep and complex features, and MobileNetV2 can efficiently capture light and essential features. Combining these diverse feature representations can lead to a richer and more comprehensive understanding of the data, thereby improving classification performance. Each model may have different error patterns. By combining them, the final prediction can be more robust because errors from one model can be compensated for by the other, reducing the overall error.
3.4 Hyperparameters selection
In this study, we meticulously chose the following hyperparameters based on preliminary experiments and literature review. The Adam optimizer was used with a default learning rate of 0.0001 due to its capacity to achieve a favorable equilibrium between training speed and stability. This enables the model to efficiently converge. A batch size of 16 was selected, determined to be optimal for our dataset and hardware capabilities, providing a balance between memory efficiency and the model's capacity to generalize from the training data. The model was trained for 25 epochs, a number chosen based on early stopping criteria observed during preliminary runs, where it was noted that the model's performance plateaued around this epoch count. The Adam optimizer was selected due to its capacity to dynamically adjust the learning rate during training, resulting in faster convergence and enhanced performance. Finally, a binary cross entropy loss function is used, as it is well suited for binary classification tasks like this case, which aim to differentiate between normal and abnormal coronary artery conditions.
3.5 Performance evaluation
Evaluation metrics are crucial tools for quantifying the effectiveness of classifiers. There are various evaluation metrics that are used to gauge the efficacy of classifier models. One of the fundamental tools used for this purpose is the confusion matrix, a technique widely used in machine learning [28]. The confusion matrix provides a numerical representation of classification accuracy and contains information regarding the actual classes and predictions produced by the classifier. It consists of two dimensions namely actual and predicted class, with each row representing an example of the actual class and each column depicting the predicted class status. In the confusion matrix, the four main metrics used are True Positive (TP), True Negative (TN), False Positive (FP), and False Negative (FN).
Figure 1. Proposed Concatenation Model
Table 2. Details of the proposed Concatenation Model
|
Layer |
Parameters |
Layer |
Parameters |
Layer |
Parameters |
|
Efficientnetv2-b0 |
5,919,312 |
resnet50v2 |
23,564,800 |
mobilenetv2 |
2,257,984 |
|
Conv2D |
1,311,744 |
Conv2D |
2,098,176 |
Conv2D |
1,311,744 |
|
Maxpooling2D |
0 |
Maxpooling2D |
0 |
Maxpooling2D |
0 |
|
Flatten |
0 |
Flatten |
0 |
Flatten |
0 |
|
Dense |
9,438,208 |
Dense |
9,438,208 |
Dense |
9,438,208 |
|
Dense_1 |
524,800 |
Dense_1 |
524,800 |
Dense_1 |
524,800 |
|
Dense_2 |
131,328 |
Dense_2 |
131,328 |
Dense_2 |
131,328 |
|
Concatenate Layer |
Output Shape |
Parameters |
|||
|
Proposed_Model |
768 |
0 |
|||
|
Concatenate_Dense |
1 |
769 |
|||
In this section, the researcher will present the experimental results obtained from this research. Researchers will look at key performance metrics of the proposed model, illustrating experimental findings through graphs and in-depth analysis. The parameters for model training in this study have been carefully determined to ensure optimal performance. The ReLU (Rectified Linear Unit) activation function is used in hidden layers 1 to 3 for all modified models, including in the proposed model. ReLU was chosen for its efficiency in neural networks and its ability to prevent slow training problems. In the output layer, a Sigmoid activation function is selected for all models, generating positive class probabilities in binary classification problems. Optimization was performed using Adam, a commonly used optimizer due to its high convergence speed and adaptability to learning rate. The learning rate chosen was 0.0001, which is within the range commonly used in neural network training. The batch size is set at 16, affecting the speed and stability of model training. The loss function employed is binary cross-entropy, which is appropriate for binary classification problems by measuring the difference between the model's predicted probability distribution and the target probability distribution. Researchers carried out the training process on all the modified trained models and the proposed combined models, namely EfficientNetV2B0, ResNet50V2, and MobileNetV2, using 25 epochs and the same parameter settings.
4.1 Training results and analysis of all modified CNN models based on transfer learning techniques
To illustrate the model training performance, the accuracy graph and loss functions of each modified CNN model will be presented in Figures 2-4.
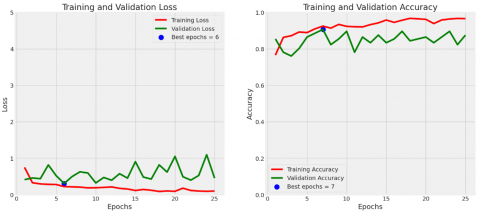
Figure 2. Accuracy and loss curves of modified pre-trained EfficientNetV2B0 model
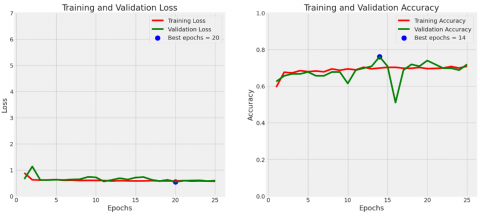
Figure 3. Accuracy and loss curves of modified pre-trained ResNet50V2 model
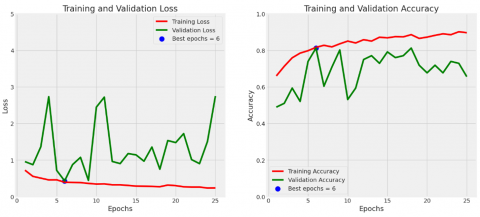
Figure 4. Accuracy and loss curves of modified pre-trained MobileNetV2 model
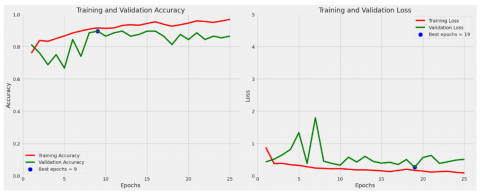
Figure 5. Accuracy and loss curves for the proposed Concatenation Model
Table 3. Model performance evaluation
|
Model |
Class |
Precision |
Specificity |
Recall |
F1-Score |
Accuracy |
|
EfficientNetV2B0 Model |
Negative |
95% |
95% |
95% |
95% |
94% |
|
Positive |
90% |
90% |
90% |
90% |
||
|
ResNet50V2 Model |
Negative |
89% |
67% |
67% |
77% |
72% |
|
Positive |
54% |
83% |
83% |
65% |
||
|
MobileNetV2 Model |
Negative |
83% |
99% |
99% |
90% |
86% |
|
Positive |
97% |
56% |
56% |
71% |
||
|
Proposed Model |
Negative |
96% |
96% |
96% |
96% |
95% |
|
Positive |
91% |
92% |
92% |
91% |
From the training process that has been carried out, the modified EfficientNetV2B0 model shows extraordinary performance, managing to achieve an impressive accuracy of 94%. This high accuracy shows the model's ability to recognize and learn complex patterns in the dataset. With a total of 17,325,649 parameters, consisting of 17,206,737 trainable parameters and 118,912 non-trainable parameters, this model shows its capacity to utilize parameters efficiently for accurate classification. The success of the EfficientNetV2B0 model highlights the suitability of this architecture for tasks requiring high precision and sensitivity to complex features.
In contrast to the EfficientNetV2B0 model, the modified ResNet50V2 model shows lower accuracy of 72% during training. Even though it has many parameters, namely 35,757,569, consisting of 35,486,209 trainable parameters and 271,360 non-trainable parameters, this model performs quite well on CAD datasets. The modified MobileNetV2 model showed good performance, achieving an accuracy of 86% during training. Even though it has a smaller number of parameters, namely 13,664,321, consisting of 13,625,601 trainable parameters and 38,720 non-trainable parameters, this model shows efficient classification capabilities. This shows that the MobileNetV2 architecture, with its lightweight design and efficient parameter utilization, can effectively learn and generalize from datasets. The relatively high accuracy of this model confirms its suitability where high computational efficiency and performance are desired.
4.2 Training results and analysis of the proposed Concatenation Model
The results and analysis of the combined model show that the proposed architecture, which combines the modified EfficientNetV2B0, ResNet50 V2, and MobileNetV2 models, has a total of 66,747,537 parameters. Of this number, 66,323,153 parameters are trainable, while 424,384 other parameters are non-trainable. This model succeeded in achieving an accuracy level of 95%, showing better performance in predicting classification on a dataset used with input images of the same size, namely 224×224. This illustrates the effectiveness of the combined model in utilizing the strengths and advantages of each model. used, thus producing more accurate and reliable prediction results.
Figure 5 shows the accuracy and loss curves of the combined model combining EfficientNetV2B0, ResNet50 V2, and the modified MobileNetV2. This curve visually represents the performance of the combined model during the training process, with accuracy and loss values displayed for each epoch on the training and validation data.
4.3 Test results of all modified CNN models and proposed Concatenation Model
Testing was carried out using a confusion matrix to visually represent the model's performance in data classification. From the test results, in the EfficientNetV2B0 model, there were 1,016 accurate predictions for the negative class and 443 for the positive class, with 50 incorrect predictions for each class. ResNet50V2 shows 719 correct predictions for the negative class and 408 for the positive class, and 347 and 85 incorrect predictions, respectively. MobileNetV2 produced 1,057 accurate predictions for the negative class and 278 for the positive class, with 9 and 215 incorrect predictions, respectively. The combined model produced 1,023 correct predictions for the negative class and 452 for the positive class, with 43 and 41 incorrect predictions, respectively.
Based on the confusion matrix, the combined model was shown to outperform the separate models in terms of accuracy and error reduction, resulting in more precise predictions. This improvement is seen in the increased accuracy of forecasts and the decreased number of errors. Table 3 presents the performance assessment of several models used for the categorization job. The assessed models consist of EfficientNetV2B0, ResNet50V2, MobileNetV2, and a novel model that combines these architectures. The table presents a comparison of important performance measures, including Precision, Specificity, Recall, F1-Score, and Accuracy, for both the negative and positive classes. These metrics provide a thorough summary of the efficacy of each model in accurately recognizing both groups. The combined model regularly outperformed the separate models in all criteria, demonstrating its greater capacity to handle the categorization job.
EfficientNetV2B0 demonstrated strong performance across all metrics, with precision, specificity, recall, and F1-score of 95% for the negative class and 90% for the positive class, respectively, resulting in an overall accuracy of 94%. Most likely, the efficient scaling method of this model contributes to balanced performance and good feature representation. ResNet50V2 shows poor performance in the negative class with recall and specificity of only 67%, and precision of 89%, resulting in an F1-score of 77%. For the positive class, precision reached 54%, specificity and recall each 83%, with an F1-score of 65%, and overall accuracy of 72%. This indicates difficulty in detecting negative samples, which may be caused by overfitting or a model architecture that is not suitable for this task without further optimization. MobileNetV2 shows significant imbalance between classes. In the negative class, precision is 83%, specificity and recall are 99% each, with an F1-score of 90%. However, in the positive class, precision reached 97%, specificity and recall were only 56%, resulting in an F1-score of 71%, and overall accuracy of 86%. This imbalance suggests a possible bias towards negative samples. The proposed combined model shows the best performance with precision, specificity, recall, and F1-score of 96% for the negative class, and 91%-92% for the positive class, respectively, as well as an overall accuracy of 95%. This shows that the ensemble approach effectively leverages the strengths of each model, resulting in balanced and superior performance.
EfficientNetV2B0 leverages combined scaling to balance network depth, width, and resolution, resulting in good overall performance. ResNet50V2 with deep residual learning helps in training very deep networks but may suffer if not optimized for this specific task. MobileNetV2 is designed for mobile devices with depth-separable convolution, efficiently reducing parameters but may not capture complex features such as deeper networks. The combined model leverages the strengths of the above architectures to create an ensemble that excels in feature extraction and representation. Optimization strategies for EfficientNetV2B0 may involve techniques such as learning rate heating and decay, dropouts, and batch normalization. ResNet50V2 may require special adjustments to the dataset to avoid overfitting and balance class performance. MobileNetV2 may require optimization techniques to balance high specificity and recall in the negative class and improve performance in the positive class. Likelihood combined models use voting or weighted averaging mechanisms to combine predictions, increasing robustness and generalizability. Error analysis shows that EfficientNetV2B0 has a low error rate, ResNet50V2 has a high error rate especially in the negative class, MobileNetV2 shows the need for class rebalancing during training, and the combined model successfully reduces errors with the ensemble approach.
Images can be detected best when they have clear features and high contrast. Such coronary angiography images showing large plaques or obvious obstruction tend to be identified accurately by the model. This is due to the model's ability to recognize and analyze the complex details of the image. The combination of different architectures allows the model to better handle different aspects of the image, improving detection accuracy. Conversely, images that fail to be detected often have low quality, such as weak contrast, noise, or artifacts that obscure important details of the image. Images with small plaques or poorly defined lesions can be challenging because the features may not be prominent enough or may be distorted. The model may struggle in this case if one of the architectures cannot deal with noise or has difficulty distinguishing less obvious features.
Table 3 shows that although each model has its own strengths and weaknesses, the proposed concatenated model effectively combines these strengths to achieve superior performance. The proposed model shows great potential for clinical applications such as early detection and screening, clinical decision support, as well as continuous monitoring via wearable devices and telemedicine services. In routine health check-ups, this model can detect CAD early, especially in high-risk populations. High accuracy and specificity enable the model to be used in mobile health applications for early assessment of CAD in remote areas. As a decision support tool, this model can assist clinicians in patient evaluation and provide second opinions, increasing diagnostic accuracy. Integration of the model into wearable devices enables real-time monitoring of heart health, providing early warning of abnormal conditions. In telemedicine, this model supports remote diagnosis and monitoring, improving access to care. However, challenges remain, including the varying quality and variability of clinical data, as well as the need for appropriate data pre-processing to maintain accuracy. This concatenated model produced balanced precision, recall, specificity, and F1 scores across both classes, as well as the highest overall accuracy. This concatenated model also has high specificity, showing its ability to identify the negative class effectively, while still maintaining a good level of sensitivity in classifying the positive class.
Previous studies using the same dataset and ResNet architecture achieved a positive predictive value of 90.48% and a negative predictive value of 95.6% [29]. In comparison, the proposed combined model achieves a positive predictive value of 91% and a negative predictive value of 96%, demonstrating a slight improvement in both metrics. This further underscores the effectiveness of the combined approach in enhancing prediction accuracy.
From this study, it can be concluded that the modified models, especially the EfficientNetV2B0 and MobileNetV2 models, have exceptional performance in classifying coronary artery disease from coronary angiography images. With accuracies of 94% and 86% respectively, these models can be relied upon to aid in the diagnosis of coronary artery disease. Even though ResNet50V2 has lower accuracy compared to EfficientNetV2B0 and MobileNetV2, this model still makes a significant contribution to the classification process with an accuracy of 72%. In some cases, combination with other models can improve overall system performance. Combining the EfficientNetV2B0, ResNet50V2, and MobileNetV2 models significantly improves accuracy to 95%, indicating that the combined model approach allows different models to complement each other and overcome the weaknesses of each individual model. The combined model successfully produced more accurate predictions, with more correct predictions and fewer incorrect predictions compared to the individually modified models. This shows how model integration can improve performance in coronary artery disease classification. Overall, this work shows that modified CNN models and combined model techniques have significant potential in aiding the diagnosis of coronary artery disease through the analysis of coronary angiography pictures. With good performance and adequate balance of evaluation metrics, these models can be valuable tools for medical practitioners in the detection and treatment of coronary artery disease. As a next step, it is recommended to conduct further research that focuses on external validation of the models developed using larger and more representative datasets. This step will help ensure the generalizability of the results and the reliability of the model over a diverse set of clinical cases.
The authors would like to acknowledge Universitas Muhammadiyah Yogyakarta for the financial support on this research and publication.
[1] Shreya, D., Zamora, D.I., Patel, G.S., Grossmann, I., Rodriguez, K., Soni, M., Joshi, P.K., Patel, S.C., Sange, I. (2021). Coronary artery calcium score-a reliable indicator of coronary artery disease? Cureus, 13(12). https://doi.org/10.7759%2Fcureus.20149
[2] Prajapati, R., Patel, P., Upadhyay, U., Professor, A. (2021). A review on coronary artery disease. World Journal of Pharmaceutical Research, 10(13): 775-790. https://doi.org/10.20959/wjpr202113-22133
[3] World Health Organization. (2021). Cardiovascular Disease. https://www.who.int/Health-Topics/Cardiovascular-Diseases.
[4] Tohirova, J., Shernazarov, F. (2022). Atherosclerosis: causes, symptoms, diagnosis, treatment and prevention. Science and Innovation, 1(D5): 7-15. https://doi.org/10.5281/zenodo.6988810
[5] Mutasa, S., Sun, S., Ha, R. (2021). Understanding artificial intelligence based radiology studies: CNN architecture. Clinical Imaging, 80: 72-76. https://doi.org/10.1016/j.clinimag.2021.06.033
[6] Kim, M., Yun, J., Cho, Y., Shin, K., Jang, R., Bae, H.J., Kim, N. (2019). Deep learning in medical imaging. Neurospine, 16(4): 657-668. https://doi.org/10.14245/ns.1938396.198
[7] Haq, A.U., Li, J.P., Khan, I., Agbley, B.L.Y., Ahmad, S., Uddin, M.I., Zhou, W., Khan, S., Alam, I. (2022). DEBCM: Deep learning-based enhanced breast invasive ductal carcinoma classification model in IoMT healthcare systems. IEEE Journal of Biomedical and Health Informatics, 28(3): 1207-1217. https://doi.org/10.1109/JBHI.2022.3228577
[8] Liu, X., Deng, Z., Yang, Y. (2019). Recent progress in semantic image segmentation. Artificial Intelligence Review, 52: 1089-1106. https://doi.org/10.1007/s10462-018-9641-3
[9] Haruna, U., Ali, R., Man, M. (2023). A new modification CNN using VGG19 and ResNet50V2 for classification of COVID-19 from X-ray radiograph images. Indonesian Journal of Electrical Engineering and Computer Science, 31(1): 369-377. https://doi.org/10.11591/ijeecs.v31.i1.pp369-377
[10] Indraswari, R., Rokhana, R., Herulambang, W. (2022). Melanoma image classification based on MobileNetV2 network. Procedia Computer Science, 197: 198-207. https://doi.org/10.1016/j.procs.2021.12.132
[11] Sarwinda, D., Paradisa, R.H., Bustamam, A., Anggia, P. (2021). Deep learning in image classification using residual network (ResNet) variants for detection of colorectal cancer. Procedia Computer Science, 179: 423-431. https://doi.org/10.1016/j.procs.2021.01.025
[12] Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., Chen, L.C. (2018). Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4510-4520. https://doi.org/10.48550/arXiv.1801.04381
[13] Saad, W., Shalaby, W.A., Shokair, M., El-Samie, F.A., Dessouky, M., Abdellatef, E. (2022). COVID-19 classification using deep feature concatenation technique. Journal of Ambient Intelligence and Humanized Computing 13(4): 2025-2043. https://doi.org/10.1007/s12652-021-02967-7
[14] El Gannour, O., Hamida, S., Cherradi, B., Al-Sarem, M., Raihani, A., Saeed, F., Hadwan, M. (2021). Concatenation of pre-trained convolutional neural networks for enhanced COVID-19 screening using transfer learning technique. Electronics, 11(1): 103. https://doi.org/10.3390/electronics11010103
[15] Yadav, S.S., Jadhav, S.M. (2019). Deep convolutional neural network based medical image classification for disease diagnosis. Journal of Big data, 6(1): 1-18. https://doi.org/10.1186/s40537-019-0276-2
[16] Shen, L., Margolies, L.R., Rothstein, J.H., Fluder, E., McBride, R., Sieh, W. (2019). Deep learning to improve breast cancer detection on screening mammography. Scientific Reports, 9(1): 12495. https://doi.org/10.1038/s41598-019-48995-4
[17] Chakravarthy, A.D., Abeyrathna, D., Subramaniam, M., Chundi, P., Halim, M.S., Hasanreisoglu, M., Sepah, Y.J., Nguyen, Q.D. (2019). An approach towards automatic detection of toxoplasmosis using fundus images. In 2019 IEEE 19th International Conference on Bioinformatics and Bioengineering (BIBE), Athens, Greece, pp. 710-717. https://doi.org/10.1109/bibe.2019.00134
[18] Tan, M., Le, Q. (2021). Efficientnetv2: Smaller models and faster training. In International conference on machine learning, pp. 10096-10106. https://doi.org/10.48550/arXiv.2104.00298
[19] Khan, M.U., Aziz, S., Iqtidar, K., Zaher, G.F., Alghamdi, S., Gull, M.A (2022). A two-stage classification model integrating feature fusion for coronary artery disease detection and classification. Multimedia Tools and Applications, 81(10): 13661-13690. https://doi.org/10.1007/s11042-021-10805-3
[20] Magboo, V.P.C., Magboo, M.S.A. (2023). Diagnosis of coronary artery disease from myocardial perfusion imaging using convolutional neural networks. Procedia Computer Science, 218: 810-817. https://doi.org/10.1016/j.procs.2023.01.061
[21] Alothman, A.F., Sait, A.R.W., Alhussain, T.A. (2022). Detecting Coronary artery disease from computed tomography images using a deep learning technique. Diagnostics, 12(9): 2073. https://doi.org/10.3390/diagnostics12092073
[22] Ovalle-Magallanes, E., Avina-Cervantes, J.G., Cruz-Aceves, I., Ruiz-Pinales, J. (2020). Transfer learning for stenosis detection in X-ray coronary angiography. Mathematics, 8(9): 1510. https://doi.org/10.3390/math8091510
[23] Alshayeji, M.H., Al-Buloushi, J. (2023). Breast cancer classification using concatenated triple Convolutional Neural Networks model. Big Data and Cognitive Computing, 7(3): 142. https://doi.org/10.3390/bdcc7030142
[24] SV, T.P., Jeyasingh, A. (2022). Detection of COVID-19 from chest X-ray images using concatenated deep learning neural networks. International Journal of Current Research and Review, 14(03): 53-59. https://doi.org/10.31782/ijcrr.2022.14310
[25] Demirer, M., Gupta, V., Bigelow, M., Erdal, B., Prevedello, L., White, R. (2019). Image dataset for a CNN algorithm development to detect coronary atherosclerosis in coronary CT angiography. Mendeley Data, 1. https://doi.org/10.17632/fk6rys63h9.1
[26] Maqsood, M., Nazir, F., Khan, U., Aadil, F., Jamal, H., Mehmood, I., Song, O.Y. (2019). Transfer learning assisted classification and detection of Alzheimer’s disease stages using 3D MRI scans. Sensors, 19(11): 2645. https://doi.org/10.3390/s19112645
[27] Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L. (2009). Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, Miami, FL, USA, pp. 248-255. https://doi.org/10.1109/CVPR.2009.5206848
[28] Chicco, D., Jurman, G. (2020). The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC genomics, 21: 1-13. https://doi.org/10.1186/s12864-019-6413-7
[29] Laidi, A., Ammar, M. (2023). Investigating explainable AI for enhanced atherosclerosis detection and decision transparency. In National Conference on Artificial Intelligence and its Applications, Tlemcen, Algeria, pp. 69-74.