Qinzhe Liu* | Bingbing Tong | Dongliang Li | Yan Lu | Yuhong Fu | Lei Chen | Kuangyi Zhao
© 2020 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
In the integrated energy system, the smart and safe electricity consumption requires complex computation and faces high safety risk. To solve the problem, this paper designs a smart and safe electricity consumption model for integrated energy system based on electric big data. Firstly, an aggregate return index was designed based on clustering degree and dispersion degree to automatically optimize the number of classes, and facilitate the k-means clustering (KMC). Next, the optimization criterion for the behavior features of smart and safe electricity consumption was proposed, in which the effectiveness and correlations of the features are measured by the amount of mutual information and the degree of correlation, respectively. After that, the authors put forward a feature optimization strategy for smart and safe electricity consumption behaviors. By this strategy, effective and independent features were selected to form a simplified feature set for the clustering of smart and safe electricity consumption behaviors. On this basis, a smart and safe electricity consumption model was presented for integrated energy system. The effectiveness of our model was confirmed through example analysis.
smart and safe electricity consumption, electric big data, clustering analysis, feature selection, k-means clustering (KMC)
In recent years, many smart electricity meters have been put into use, together with their supporting monitoring devices. As a result, a variety of electric big data have been collected in time. With a great potential of application, electric big data is an important type of big data, which introduce the concepts, techniques, and methods of big data in the power sector. Originating in all links of power generation (e.g. power generation, transmission, transformation, distribution, consumption, and dispatching), electric big data can be considered as a set of visualized data involving multiple companies, disciplines, and businesses.
With the grid access of renewable energy, flexible use of active loads, and interconnection between regional grids, the power system has evolved into a typical largescale dynamic system with ultrahigh dimensions. Further, the power system is increasingly coupled with the gas system and thermal system, creating an electricity-centered integrated energy system. To effectively control such a complex system, it is necessary to apply big data technology in the integrated energy system, capture physical states with smart sensors, create data-driven simulation models, and combine assisted decision-making with operation control [1]. These measures help to enhance the operating safety, reform the service model, and innovate energy utilization of the integrated energy system, pushing forward the energy revolution.
Many scholars at home and abroad have analyzed the behaviors of electricity users. For example, Hu et al. [2] improved the k-means clustering (KMC) to expound the electricity consumption of users. Based on cloud computing platform, Shuai et al. [3] realized clustering analysis of electricity consumption behaviors under the framework of distributed program, using a smart user collection system. Zhou et al. [4] explored the statistical law of electricity consumption behaviors in response to changes in electricity price, and established a time-of-use (TOU) electricity pricing model based on the game between grid company and users. Li et al. [5] analyzed the factors affecting residential electricity consumption, and carried out fuzzy comprehensive evaluation (FCE) of the demand-side response capacities for users with different concepts, incomes, and information preferences. Wang et al. [6] constructed a user response model under peak-valley electricity prices, estimated the parameters of the model, and proposed a real-time update process for the model that adapts to the peak-valley TOU electricity price. Inspired by big data technology, Asl et al. [7] predicted the parallel load based on random forest (RF) algorithm. Wang et al. [8] put forward several application scenarios based on electricity consumption behaviors, such as decision support to electricity pricing, preparation of demand plan, and formulation of energy efficiency scheme. None of the above studies on electricity consumption behaviors have mentioned how to analyze and select the features of such behaviors. The behavior feature sets were utilized without data analysis or optimization. The effectiveness of these sets remains to be verified, against the target user samples [9-15].
This paper presents an analysis approach for electricity consumption based on electric big data. Based on clustering degree and dispersion degree, an aggregate return index was designed to automatically optimize the number of classes, laying the basis of the KMC [16-19]. After that, the effectiveness and correlations of power consumption behaviors were evaluated, and used to formulate a feature optimization strategy, which reduces the computing load of optimizing the feature set through quantification of the relevant indices. Finally, the feature optimization strategy was applied to obtain a suitable feature set from the extracted user samples, and complete the analysis on electricity consumption behaviors.
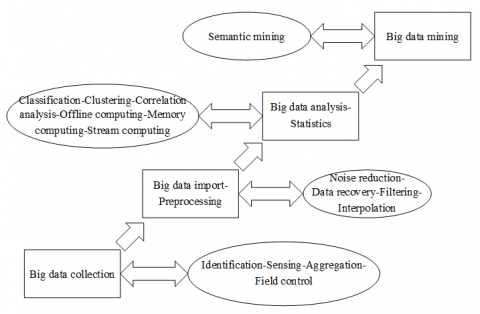
The collection, analysis and application of electric big data require complex technologies, such as big data collection, big data import/preprocessing, big data statistics/analysis, and big data mining.
2.1 Big data collection
The collection of big data is impossible without the technologies of the Internet and the Internet of things (IoT). The main technologies include identification, sensing, and aggregation.
Identification can be performed through radio frequency identification (RFID), barcode, quick response (QR) code, and biometric identification technologies (iris, fingerprint, and voice).
Sensing is often achieved with embedded sensors, which form a sensor network. The sensor network can collect the various indices and data that affect or reflect the operation state of the grid.
Aggregation is an effective way to realize local processing, while reducing the consumption of communication bandwidth. Once aggregated, the big data can be processed locally to remove redundant information, increase the user capacity of the network, and improve the efficiency of bandwidth utilization.
2.2 Big data import/preprocessing
Before analysis, the collected big data must be imported to the memory or database. During the import, the format and standard of the data should be unified, and the unstructured data should go through storage and modelling.
After the import, the big data need to be preprocessed. It is inevitable for the collected data to contain noises or incorrect items, under the effects of the physical environment, weather, and the aging or malfunction of the monitoring devices. Moreover, some items may be erroneous, omitted, or lost, if the communication environment is harsh. To solve the defects, the relevant data should be denoised, and the lost items be restored. The preprocessing is also called data cleaning.
2.3 Big data statistics/analysis
Big data statistics and analysis involve such technologies as classification, clustering, and correlation analysis. By the time features, the technologies can be divided into offline computing, batch computing, memory computing, and stream computing.
The big data can be classified by the following algorithms: nearest neighbor algorithm, support vector machine (SVM), boosted trees, Bayesian classifier, neural network, and RF algorithm. To improve the classification performance, the classification algorithms are often combined with the fuzzy theory.
Clustering can be understood as unsupervised classification. The most popular clustering algorithm is the KMC.
Correlation analysis, the primary strategy for big data analysis, mainly mines the correlations between objects based on support and confidence. The basic algorithms for correlation analysis include Apriori algorithm and frequent pattern (FP) growth algorithm.
2.4 Big data mining
The results of big data analysis should go through data mining. Taking data as the center of processing, the big data analysis often outputs results that are difficult to comprehend and not in line with the research purpose. In the worst-case scenario, the results might be useless and even contradictory. To realize data mining, human intervention is needed to filter and purify the results, and transform them into semantic forms that can be understood by human. In light of the features of big data, Mahout implemented data mining algorithms through parallel computing, which greatly reduces the calculation delay.
Figure 1. The procedure of big data analysis
3.1 Patterns of electricity consumption behaviors
The patterns of electricity consumption behaviors need to be identified from high-dimensional data, which are noisy, intricately correlated, and time varying. The traditional model-driven method only tackles the single dimensional relationship between electricity price and electricity consumption. However, the methods and psychology of electricity consumption have diversified over the years. Facing the complex new situation, the model-driven method is no longer suitable. Fortunately, the data-driven method can take account of multi-dimensional factors across multiple fields.
The patterns of electricity consumption behaviors are often recognized by clustering algorithms. Based on selected features and weights, a clustering algorithm performs similarity search of samples, and classifies them according to features. The classification could be very meticulous, depending on the information on electricity consumption.
The commonly used clustering algorithms are fuzzy C-means clustering, KMC, SVM, and competitive learning. Among them, the KMC is an unsupervised learning algorithm, capable of classifying large datasets in a rapid and efficient manner. Therefore, the KMC was selected to identify the patterns of electricity consumption behaviors.
To determine the number of classes k, a clustering effectiveness index was constructed to evaluate the clustering quality and optimize the number of classes. This strategy is simple and independent of sample distribution, eliminating the need for manual setting of threshold. Specifically, an error decrement coefficient was designed based on the sum of squared error (SSE), and combined with the contour coefficient into an aggregate return index. The aggregate return index reflects the clustering degree and dispersion degree of the clusters, and automatically optimizes the number of classes k.
First, the SSE ISSE can be defined as:
$I_{\mathrm{SSE}}(k)=\sum_{i=1}^{k} \sum_{x \in C_{i}}\left|x-m_{i}\right|^{2}$ (1)
where, Ci is the i-th class; x a sample in Ci; mi is the centroid of Ci, i.e. the mean f all samples.
If k increases below the optimal number of classes, the clustering degree will grow, and the decrement of the SSE will surge; If k increases above the optimal number of classes, the clustering degree will plunge, and the decrement of the SSE will shrink quickly.
To quantify the aggregate return, the error decrement coefficient βSSE can be defined as:
$\beta_{\mathrm{SSE}}=\frac{I_{\mathrm{SSE}}(k-1)-I_{\mathrm{SSE}}(k)}{I_{\mathrm{SSE}}(k)-I_{\mathrm{SSE}}(k-1)}$ (2)
If sample xi is allocated to cluster A, then its contour coefficient ISC can be described as:
$I_{\mathrm{SC}}\left(x_{i}\right)=\frac{b\left(x_{i}\right)-a\left(x_{i}\right)}{\max \left(a\left(x_{i}\right)-b\left(x_{i}\right)\right)}$ (3)
where, a(xi) is the mean Euclidean distance between sample xi and other samples in cluster A. Let D(xi, b) be the mean Euclidean distance between sample xi and other samples in cluster B. Then, $b\left(x_{i}\right)=\min _{B \neq A}\left\{D\left(x_{i}, b\right)\right\}$ is the minimum mean distance between sample xi and other clusters.
The mean contour coefficient ISC of the sample set is the average of the contour coefficients of all samples:
$I_{\overline{S C}}=\frac{1}{n} \sum_{x_{i} \in C} I_{S C}\left(x_{i}\right)$ (4)
where, C is the sample set; n is the total number of samples.
The error decrement coefficient reflects the intra-cluster clustering degree, while the mean contour coefficient reflects the inter-cluster dispersion degree. The two coefficients can be fused into the aggregate return index IRe:
$I_{\mathrm{Re}}=\beta_{\mathrm{SSE}}+I_{\overline{S C}}$ (5)
For a given maximum number of classes kmax, multiple clustering can be performed with each integer within [2, kmax] as the number of classes. The clustering results are the best, when the aggregate return index reaches the maximum. In this way, the number of classes k can be optimized automatically with the aggregate return index.
Using the optimal k value, the KMC was carried out on the samples, producing the class label of each user.
3.2 Features of electricity consumption behaviors
The features of electricity consumption have significant impacts on the identification methods and results of electricity consumption patterns. Reasonable features must be selected to assist with the pattern recognition and user classification. To select suitable and effective features of electricity consumption, this paper fully considers the effectiveness of electrical consumption features and the correlations between these features, and evaluates the effectiveness with mutual information.
To begin with, the set of all features was taken as the initial candidate feature set Z, which contains n features z. The subset of optional features is denoted as Y. Then, the mutual information I(z,c) between electricity consumption feature z and user class c was defined as the amount of information about user class c under the known feature z, that is, the decrement of the uncertainty of user class c after knowing feature z. The greater the I(z,c), the more effective the feature z.
Next, the entropies of feature z and user class c were estimated by the probability density function P. The information entropy H(z) of feature z and that H(c) of user class c can be respectively obtained by:
$H(z)=-\sum_{z} p(z) \log _{2} p(z)$ (6)
$H(c)=-\sum_{c} p(c) \log _{2} p(c)$ (7)
The joint information entropy H(z,c) of feature z and user class c was introduced to measure the uncertainty of feature z and user class c:
$H(z, c)=-\iint p(z, c) \log _{2} p(z, c) d z d c$ (8)
Thus, the mutual information I(z,c) can be obtained as:
$I(z, c)=H(z)+H(c)-H(z, c)$ (9)
Moreover, the degree of correlation was adopted to measure the correlation between every two electricity consumption features. The degree of correlation ρzy of feature z with feature y in the subset of optional features Y falls in the interval of [-1, 1]. Hence, the two features are more correlated, as the absolute value of ρzy approaches 1, and less correlated, as the latter approaches 0. If the subset of optional features is empty, the ρzy value is 0 by default. The value of ρzy can be calculated by:
$\rho_{z y}=\frac{\operatorname{cov}(z, y)}{\sigma_{z} \sigma_{y}}$ (10)
where, cov(z, y) is the covariance between feature z and feature y in the subset of optional features Y; σz and σy are the standard deviations of z and y, respectively.
Through the above analysis, each electricity consumption feature z can be evaluated by:
$J(z)=I^{\prime}(z, c) \prod_{y}\left(1-\left|\rho_{z y}\right|\right)$ (11)
where, $J(z) \in[0,1]$ is the evaluated value of electricity consumption feature z; I'(z, c) is the normalized mutual information between feature z and user class c.
The evaluation function for the subset of optional features Y can be established as:
$J(Y)=\sum_{y} J(y)$ (12)
where, J(y) is the evaluation function for each feature in Y.
The greater the value of J(z), the more effective the corresponding feature is to the analysis of electricity consumption behavior. Therefore, the J(Y) is the sum of the evaluated values of all the features in the subset Y.
3.3 Feature optimization strategy for electricity consumption behaviors
Figure 2 explains our feature optimization strategy for electricity consumption behaviors. Firstly, a certain number of samples were selected from all the users, and all the features were extracted from the selected samples. Next, the sample features were evaluated by the established criterion. The features were selected one by one through forward heuristic search: starting with an empty set, each search chooses the feature with the highest evaluated value from the current subset of optional features, and relocates it into the set of selected features until the latter set meets the performance requirements. That is, the selected feature y must satisfy:
$y=\arg \max \{J(z)\}$ (13)
Considering both computing efficiency and selection effect, this strategy can achieve a good screening effect with a small computing load. The termination condition (the information of the remaining features is far lower than their redundancy) was defined as follows:
$D=\frac{\max \{J(z)\}}{J(Y)} \leq T$ (14)
where, D is the ratio of the evaluated value of the optimal optional feature to that of the subset of optional features. If the D value is smaller than the preset threshold T=0.1, the feature optimization will be terminated. The termination condition is highly effective and easy to calculate, without needing to preset the number of features. The feature optimization process is summarized as follows:
The initial candidate feature set Z is taken as the input, and the subset of optional features Y is empty. First, the evaluated value of each feature z in set Z is calculated by formula (11). Next, the optimal features are selected by formula (13) as the optional features, and relocated from set Z to subset Y. After that, the subset Y is evaluated by formula (14). If the termination condition is satisfied, the subset Y will be outputted; otherwise, the above steps are repeated until the termination condition is satisfied.
The optimal features corresponding to the electricity users can be extracted from the subset Y and subject to clustering analysis. Then, the electricity consumption behaviors of each class of users can be analyzed separately.
Figure 2. The feature optimization strategy for electricity consumption behaviors
To verify the effectiveness of our feature optimization strategy, the daily electricity data of 550 users were selected from a grid. From the common features of electricity consumption, six features were selected and compiled into a feature set: daily electricity consumption, daily maximum load, mean daily load, daily peak-to-valley difference, valley power coefficient, and the percentage of electricity consumption in normal periods. The selected features are denoted as 1-6 in turn.
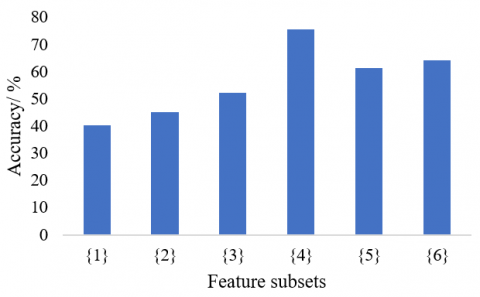
The KMC algorithm was employed for clustering analysis. For comparison, the original user classes were obtained from the original load curves before feature extraction. Then, each iterative feature selection of our feature optimization strategy was analyzed in details. Table 1 and Figure 3 provide the information about the first feature selection process.
As shown in Table 1, daily peak-to-valley difference (feature 4) achieved the highest evaluated value by our feature optimization strategy. Figure 3 shows that the classification accuracy was 75.6%, using daily peak-to-valley difference, which was far higher than the accuracy obtained using any other feature. Therefore, the evaluated value of a feature can basically reflect the classification accuracy using that feature.
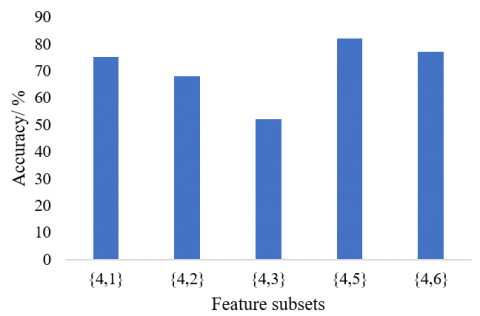
Figure 4. The clustering accuracy of each feature subset in the second feature selection
Table 2 and Figure 4 provide the information about the second feature selection process. Note that the daily peak-to-valley difference was not analyzed, because it had been chosen in the first selection.
As shown in Table 2, daily electricity consumption (feature 1) had the highest evaluated value. Figure 4 shows that the classification accuracy using the subset of feature 1 was far higher than the accuracy obtained using any other feature. Therefore, the value of each feature evaluated by our strategy can accurately reflect the classification accuracy using the subset of that feature.
Table 1. The evaluated value of each feature in the first feature selection
|
Feature |
Daily electricity consumption |
Daily maximum load |
Mean daily load |
Daily peak-to-valley difference |
Valley power coefficient |
Percentage of electricity consumption in normal periods |
|
Feature number |
1 |
2 |
3 |
4 |
5 |
6 |
|
Evaluated value |
0 |
0.365 |
0.322 |
1 |
0.481 |
0.641 |
Table 2. The evaluated value of each feature in the second feature selection
|
Feature |
Daily electricity consumption |
Daily maximum load |
Mean daily load |
Daily peak-to-valley difference |
Valley power coefficient |
Percentage of electricity consumption in normal periods |
|
Feature number |
1 |
2 |
3 |
4 |
5 |
6 |
|
Evaluated value |
0.322 |
0.125 |
0 |
/ |
0.233 |
0.254 |
Based on electric big data, this paper puts forward an analysis method for electricity consumption behaviors. Firstly, the KMC algorithm was improved to eliminate the need for manual setting of the k value. The aggregate return index was designed as the criterion for k value selection, such that the k value can be optimized automatically. Next, the effectiveness of electricity consumption behaviors was quantified based on the amount of feature information, and a feature optimization strategy for electricity consumption behaviors was developed in view of mutual information and correlation coefficient. The proposed strategy improves the reliability and effectiveness of the analysis on electricity consumption behaviors, and promotes the mining of valuable information from electric big data, providing useful information for the formulation of relevant policies and services.
[1] Yu, H.J., Dai, H.L., Tian, G.D. (2020). Big-data-based power battery recycling for new energy vehicles: Information sharing platform and intelligent transportation optimization. IEEE Access, 8: 99605-99623. https://doi.org/10.1109/ACCESS.2020.2998178
[2] Hu, J.Y., Zhu, E.G., Du, X.G., Du, S.W. (2014). Application status and development trend of power consumption information collection system. Automation of Electric Power Systems, 38(2): 131-135. https://doi.org/10.7500/AEPS20130617005
[3] Shuai, C.Y., Yang, H.C., Ouyang, X. (2019). Analysis and identification of power blackout-sensitive users by using big data in the energy system. IEEE Access, 7: 19488-19501. https://doi.org/10.1109/ACCESS.2018.2886551
[4] Zhou, Z.Y., Xiong, F., Huang, B.Y. (2017). Game-theoretical energy management for energy internet with big data-based renewable power forecasting. IEEE Access, 5: 5731-5746. https://doi.org/10.1109/ACCESS.2017.2658952
[5] Li, Z.K., Guo, W.Y. (2020). Optimal operation of integrated energy system considering user interaction. Electric Power Systems Research, 187: 106505. https://doi.org/ 10.1016/j.epsr.2020.106505
[6] Wang, Y., Chen, Q., Hong, T., Kang, C. (2018). Review of smart meter data analytics: Applications, methodologies, and challenges. IEEE Transactions on Smart Grid, 10(3): 3125-3148. https://doi.org/10.1109/TSG.2018.2818167
[7] Asl, D.K., Seifi, A.R., Rastegar, M. (2020). Optimal energy flow in integrated energy distribution systems considering unbalanced operation of power distribution systems. International Journal of Electrical Power & Energy Systems, 121: 106132. https://doi.org/10.1016/j.ijepes.2020.106132
[8] Wang, Y., Chen, Q., Kang, C., Xia, Q. (2016). Clustering of electricity consumption behavior dynamics toward big data applications. IEEE Transactions on Smart Grid, 7(5): 2437-2447. https://doi.org/10.1109/TSG.2016.2548565
[9] Zhang, B., Hu, W.H., Li, J.H. (2020). Dynamic energy conversion and management strategy for an integrated electricity and natural gas system with renewable energy: Deep reinforcement learning approach. Energy Conversion and Management, 220: 113063. https://doi.org/10.1016/j.enconman.2020.113063
[10] Zhou, K.L., Yang, S.L., Ding, S., Luo, H. (2014). On cluster validation. Systems Engineering-Theory & Practice, 34(9): 2417-2431. https://doi.org/10.12011/1000-6788(2014)9-2417
[11] Su, H., Zio, E., Zhang, J.J. (2020). A systematic method for the analysis of energy supply reliability in complex Integrated Energy Systems considering uncertainties of renewable energies, demands and operations. Journal of Cleaner Production, 267: 122117. https://doi.org/10.1016/j.jclepro.2020.122117
[12] Sun, Y., Cui, C., Lu, J., Hao, J., Liu, X. (2017). Non-intrusive load monitoring method based on delta feature extraction and fuzzy clustering. Automation of Electric Power Systems, 41(4): 86-91. https://doi.org/10.7500/AEPS20160504016
[13] Zhao, Z., Lee, W.C., Shin, Y., Song, K.B. (2013). An optimal power scheduling method for demand response in home energy management system. IEEE Transactions on Smart Grid, 4(3): 1391-1400. https://doi.org/10.1109/TSG.2013.2251018
[14] Qu, Z., Chen, G. (2015). Big data compression processing and verification based on Hive for smart substation. Journal of Modern Power Systems and Clean Energy, 3(3): 440-446. https://doi.org/10.1007/s40565-015-0144-9
[15] Zhao, P.F., Gu, C.H., Huo, D. (2020). Coordinated risk mitigation strategy for integrated energy systems under cyber-attacks. IEEE Transactions on Power Systems, 35(5): 4014-4025. https://doi.org/10.1109/TPWRS.2020.2986455
[16] Zhang, C.C., Zhang, H.Y., Luo, J.C., He, F. (2018). Massive data analysis of power utilization based on improved K-means algorithm and cloud computing. Journal of Computer Applications, 38(1): 159-164. https://doi.org/10.11772/j.issn.1001-9081.2017071660
[17] Alonso, A.M., Nogales, F.J., Ruiz, C. (2020). Hierarchical clustering for smart meter electricity loads based on quantile autocovariances. IEEE Transactions on Smart Grid, 11(5): 4522-4530. https://doi.org/10.1109/TSG.2020.2991316
[18] Hu, W., Hu, Y.W., Yao, W.H., Lu, W.Q., Li, H.H., Lv, Z.W. (2019). A blockchain-based smart contract trading mechanism for energy power supply and demand network. Advances in Production Engineering & Management, 14(3): 284-296. https://doi.org/10.14743/apem2019.3.328
[19] Hu, W., Yao, W.H., Hu, Y.W., Li, H.H. (2019). Collaborative optimization of distributed scheduling based on blockchain consensus mechanism considering battery-swap stations of electric vehicles. IEEE Access, 7(9): 137959-137967. https://doi.org/10.1109/ACCESS.2019.2941516