Tata Balaji*![]() | Pradeep Mullangi
| Pradeep Mullangi![]() | G Vamsi Krishna
| G Vamsi Krishna![]() | M Jeevana Sujitha
| M Jeevana Sujitha![]() | Sreedhar Bhukya
| Sreedhar Bhukya![]() | Praveen Tumuluru
| Praveen Tumuluru![]() | Arun Kumar Undamatla
| Arun Kumar Undamatla![]()
© 2025 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Because atmospheric processes are very dynamic, unpredictable, and nonlinear, weather prediction is still a difficult undertaking. For forecasting, anomaly detection, and meteorological decision-making to be accurate, the right categorization method must be chosen. Three well-known machine learning methods—Ridge Classifier, Bayesian Network, and One-Class Support Vector Machine (SVM)—applied to weather prediction tasks are compared in this paper. When it comes to managing multicollinearity across meteorological attributes like temperature, humidity, and pressure, the Ridge Classifier—a linear model derived from ridge regression—works well. Because of its robustness against correlated features and computing efficiency, it may be applied to binary or multiclass issues such as Rain/No Rain prediction. However, because of its linear character, it is less able to capture the intricate nonlinear correlations seen in meteorological data, which could lower prediction accuracy in a variety of climatic circumstances. The Bayesian Network, a probabilistic graphical model, on the other hand, is particularly good at capturing uncertainty and the relationships between meteorological variables. It allows for probabilistic reasoning even in the presence of insufficient data by modeling causal linkages, such as how cloud cover and humidity affect rainfall. Although it is interpretable, its performance is highly dependent on precise prior probabilities and in-depth domain expertise to create conditional probability tables, and as the number of parameters increases, it has scaling problems. By learning from typical weather patterns and marking departures as anomalies, the One-Class SVM, on the other hand, is well-suited for anomaly identification, identifying extreme weather phenomena like cyclones, storms, and heatwaves. Although it works well for early warning systems, thorough multi-category forecasting is less appropriate. All things considered, One-Class SVM, Bayesian Network, and Ridge Classifier all perform well in different meteorological scenarios. To improve the dependability and flexibility of weather forecasting systems, future research should examine hybrid frameworks that combine the interpretability of Bayesian Networks, the effectiveness of Ridge Classifiers, and the anomaly detection skills of One-Class SVM.
One-Class SVM, Ridge Classifier, Bayesian Network, weather forecasting, prediction
For centuries, weather forecasting has been a highly researched and useful field with applications in everything from transportation and agriculture to disaster relief and energy planning. Safeguarding human life, reducing financial losses, and facilitating efficient decision-making in industries that significantly depend on environmental conditions all depend on accurate weather forecasting. Machine learning has become a popular tool for forecasting weather patterns because to the quick development of computing techniques and the accessibility of extensive meteorological datasets. Machine learning algorithms supplement conventional physics-based numerical weather prediction models by having the capacity to learn from historical data, uncover hidden relationships, and adjust to novel circumstances.
Classification algorithms, one of the many machine learning techniques, are essential for forecasting meteorological conditions including the presence of clouds, the possibility of a storm, and whether it will rain or not. Nevertheless, each approach has distinct advantages and disadvantages based on the type of information, the prediction goal, and the intricacy of the underlying atmospheric phenomena. No single strategy is consistently best for every situation. The methods, application, benefits, and drawbacks of three different machine learning techniques for weather prediction—the Ridge Classifier, Bayesian Network, and One-Class Support Vector Machine (SVM)—are compared in this paper.
1.1 The challenge of weather prediction
Because atmospheric dynamics are chaotic and nonlinear, predicting the weather is intrinsically difficult. Temperature, humidity, pressure, wind speed, cloud cover, and other variables all interact in very complex and frequently unanticipated ways. This phenomenon, known as the "butterfly effect," occurs when small changes in one parameter have disproportionately huge effects on weather outcomes. Prediction is further complicated by the fact that meteorological databases sometimes include noise, uncertainty, and missing variables. By simulating probabilistic relationships, detecting anomalies, or approximating nonlinear patterns, machine learning techniques can supplement traditional deterministic models, which frequently fail to incorporate these uncertainties.
In light of this, the particular forecasting objective plays a major role in choosing the best categorization method. For instance, a linear or probabilistic classifier might be adequate if the goal is to categorize whether it will rain or not based on past observations. An anomaly detection approach is more suited if the objective is to identify uncommon extreme phenomena, such as cyclones. The comparison of Ridge Classifier, Bayesian Network, and One-Class SVM in the context of weather prediction is driven by the need for task-oriented algorithm selection.
1.2 Ridge Classifier for weather prediction
Ridge regression is the source of the Ridge Classifier, a linear classification method. Large coefficient values are penalized through the use of L2 regularization, which helps to reduce overfitting and feature multicollinearity. Many of the input variables used in weather prediction, including temperature, humidity, and pressure, have a tendency to be associated. In these situations, ridge regression-based classification works especially well since it maintains parameter estimate stability even when correlated predictors are present. Ridge Classifier uses an additional regularization term to minimize the squared error.
As a result, classes are divided by a linear decision boundary, such as "Rain" vs "No Rain." It is a good contender for baseline classification models in meteorology because of its ease of use and computational effectiveness, particularly in situations where the correlation between characteristics and results is roughly linear. Its linear character, however, restricts its capacity to represent intricate nonlinear interactions that are commonly found in atmospheric dynamics. Because of this, the Ridge Classifier performs well in structured classification tasks, but its forecasting ability may suffer when weather phenomena show significant nonlinearity or chaotic relationships.
1.3 Bayesian Network for weather prediction
Through the use of a directed acyclic graph (DAG), Bayesian Networks (BNs) offer a probabilistic graphical model framework that illustrates the relationships between variables. Rainfall, pressure, humidity, and other random variables are represented by each node, while conditional relationships are shown by the edges. BNs make it possible to compute joint and marginal probabilities through conditional probability tables (CPTs) linked to every node, enabling inference even in cases when some variables are absent.
The capacity of Bayesian networks to model uncertainty and causal links among meteorological phenomena is its primary benefit in weather prediction. For instance, low pressure and humidity may both have an impact on cloud formation, which in turn influences the likelihood of rainfall. These dependencies can be formally represented using a Bayesian network, which can then use Bayes' theorem to calculate posterior probabilities. Because weather systems are inherently uncertain, this makes BNs extremely interpretable and helpful for reasoning under uncertainty.
But there are drawbacks to Bayesian techniques as well. It takes a lot of trustworthy data or in-depth topic knowledge to create correct CPTs. In meteorological situations when variables are highly correlated, the assumption of independence in simplified Bayesian classifiers, like Naïve Bayes, frequently fails. Furthermore, the complexity of creating and calculating the network rises sharply with the number of variables. For weather prediction tasks that call for probabilistic reasoning and decision-making under uncertainty, Bayesian networks continue to be useful despite these difficulties.
1.4 One-Class SVM for weather prediction
The One-Class SVM is an unsupervised or semi-supervised technique intended for anomaly detection, in contrast to the Ridge Classifier and Bayesian Network, which are mainly intended for multi-class or binary classification problems. It learns a decision function that encloses the majority of these observations within a boundary in feature space after being trained on data that represents "normal" conditions. An anomaly is any new observation that falls outside of this range.
When it comes to weather prediction, One-Class SVM is very helpful in spotting extreme and uncommon weather phenomena including heat waves, severe storms, and cyclones. Since these occurrences are usually underrepresented in datasets, it is challenging to efficiently train conventional classifiers. By concentrating solely on typical meteorological data during training and identifying deviations during testing, One-Class SVM corrects for this imbalance. This strategy has the advantage of being able to offer early warnings for unusual weather, which can be quite helpful in disaster relief efforts. The inability to categorize weather into specific groups (such as sunny, cloudy, and rainy) and the possibility of incorrectly labelling uncommon but legitimate occurrences as anomalies are some of its drawbacks. Therefore, rather than serving as a substitute for general weather prediction models, One-Class SVM is best understood as an adjunctive technique for anomaly detection.
1.5 Motivation for comparative study
Their various methodological underpinnings and applicability for various facets of weather prediction provide the justification for contrasting the Ridge Classifier, Bayesian Network, and One-Class SVM. For structured classification jobs, Ridge Classifier offers an easy-to-use and effective solution. Bayesian networks are useful for reasoning under noisy or incomplete data because they provide a probabilistic framework for describing uncertainty and causal linkages. By extending predictive modeling to anomaly detection, One-Class SVM makes it possible to identify uncommon and severe weather phenomena that might not be adequately represented in conventional classification tasks.
Researchers and practitioners can choose the strategy that best suits their forecasting objectives, the data at hand, and their operational needs by methodically examining various algorithms. Additionally, recognizing the complementing advantages of these techniques creates opportunities for hybrid or ensemble systems that integrate anomaly detection, probabilistic reasoning, and linear efficiency into a more complete and reliable weather forecast system.
1.6 Scope of the study
The theoretical underpinnings, real-world applications, benefits, and drawbacks of the Ridge Classifier, Bayesian Network, and One-Class SVM in the context of weather prediction are the key topics of this comparative study. The focus is on how well they work for certain tasks such anomaly detection (extreme weather events), probabilistic forecasting (probability of various circumstances), and binary classification (rain/no rain). This study intends to aid in the creation of flexible, dependable, and understandable weather prediction models that may assist with both routine decision-making and disaster planning by highlighting their relative performance and use cases.
1.7 Data set description
Any machine learning model's ability to predict the weather is mostly dependent on the caliber, variety, and applicability of the training and testing dataset. Weather databases are used to record atmospheric conditions for this comparison analysis using quantifiable metrics such temperature, humidity, air pressure, wind speed, and cloud cover. These characteristics act as predictors, and the forecasting goal and algorithm determine the target variable.
The National Oceanic and Atmospheric Administration (NOAA), the India Meteorological Department (IMD), and international platforms like Kaggle or the UCI Machine Learning Repository are among the publicly accessible sources of weather datasets. For example, the Kaggle Weather History Dataset includes weather information for multiple years, including temperature, humidity, visibility, wind speed, and precipitation type. Because they contain both continuous and categorical variables, these datasets are favoured because they provide flexibility in the application of various machine learning techniques.
Features (Independent Variables)
Usually, the dataset has the following characteristics: Temperature (℃): Affects precipitation probability, cloud formation, and evaporation. Humidity (%): A strong predictor of atmospheric moisture that is closely associated with precipitation. Pressure (hPa): Clear skies are associated with high pressure, but storms and precipitation are frequently preceded by low pressure. Wind Speed (km/h): Influences weather event intensity and storm formation. Cloud Cover (%): Closely related to precipitation and solar radiation. Visibility (km): This is a proxy for rainfall, haze, or fog.
Precipitation (mm)
Rain/No Rain is a quantitative metric that can be translated into categorical results. Depending on each algorithm's needs, these features are pre-processed using encoding and normalization. Normalization guarantees the comparability of continuous variables for the Ridge Classifier and One-Class SVM. Categorical encoding (e.g., “High/Low Humidity,” “Clear/Cloudy Sky”) facilitates the interpretation of conditional probability table building for Bayesian networks.
Target Variables (Dependent Variables)
Target variables for Ridge Classifiers are typically binary or multiclass, such Rain vs. No Rain or Sunny, Cloudy, Rainy. P (Rain | Humidity, Pressure, Cloud Cover) is an example of a probabilistic expression for the target in a Bayesian network. Instead of providing a precise classification, it makes an estimate of the probability of meteorological conditions. The goal of One-Class SVM is anomaly detection; the model only learns from "normal" circumstances and marks anomalous weather patterns—such as storms, cyclones, and intense heat—as anomalies.
Preprocessing and Splitting
To deal with noise, outliers, and missing values, the dataset is cleaned. Mode substitution (for categorical data) or mean substitution (for continuous values) can be used to impute missing items. While outliers may be flattened in classification tasks, they are carefully preserved in anomaly detection activities. After that, the dataset is separated into subsets for testing (20–30%) and training (70–80%). To guarantee resilience across several folds, cross-validation is used.
Suitability for Algorithms
Datasets containing correlated characteristics and linear patterns are advantageous to the Ridge Classifier. When there are significant and comprehensible probabilistic dependencies between features, the Bayesian Network performs well. One-Class SVM is perfect for identifying infrequent extreme weather events since it just needs datasets with precise definitions of normal conditions. In conclusion, the dataset provides the structured and unstructured data required to assess the advantages of Ridge Classifier, Bayesian Network, and One-Class SVM in weather prediction, and it forms the basis of this comparative study.
Over the past 20 years, the availability of big meteorological datasets and advancements in computer power have led to a considerable increase in the application of machine learning for weather prediction. The foundation of forecasting systems continues to be traditional numerical weather prediction (NWP) models, which are based on the solution of intricate physical equations of atmospheric dynamics. However, data-driven approaches have gained traction due to their shortcomings in managing uncertainty, high computing cost, and difficulties in adjusting to specific situations. Among these, classification methods that have demonstrated potential in many weather forecasting domains include Ridge Classifier, Bayesian Networks, and One-Class SVM. This study examines earlier studies on these algorithms and how they are used to forecast the weather.
Ridge Classifier in Weather Prediction
The Ridge Classifier is a linear model that uses L2 regularization to manage multicollinearity and lessen overfitting. It is derived from ridge regression. Ridge regression is frequently utilized in studies addressing structured classification issues like precipitation prediction, despite its widespread use in generic predictive analytics.
The applicability of Ridge-based models in weather-related activities is shown in a number of papers. In their investigation of regularized classifiers and linear regression for downscaling climate projections, Arumugam et al. [1] demonstrated that SVM, ridge regression approaches are an excellent way to handle correlated indicators such as temperature, humidity, and pressure. In a similar vein, Bai et al. [2] used the CNN, BiLSTM, Ridge Classifier to predict rainfall in monsoon regions of India and found that it was more stable than logistic regression. When numerous parameters affect the same result in meteorological datasets, feature redundancy is prevalent and was managed with the aid of ridge regularization.
Ridge Classifier's linear design still limits it in spite of these benefits. Linear classifiers may oversimplify the dynamics of weather processes, which are frequently nonlinear. Ridge Classifier performs best as a baseline or benchmark model, according to research and the role of MLin weather prediction by Amini and Bradaran Rohani [3].
It offers interpretability and computational efficiency, however it frequently performs worse than ensemble and deep learning techniques. Therefore, the Ridge Classifier is rarely utilized for more complicated scenarios, even if it has found value in binary weather prediction tasks like Rain/No Rain or Storm/No Storm.
Bayesian Networks in Weather Prediction
A probabilistic framework for simulating uncertainty and inter-variable dependencies is offered by Bayesian Networks (BNs). Their power resides in their capacity to clearly depict causal links, which is essential for forecasting the weather. Zhang et al. [4] laid the groundwork for eventual applications in meteorology by introducing Bayesian networks and Machine learning methods as instruments for reasoning under uncertainty.
Bayesian techniques have been used in weather prediction for storm prediction, cloud classification, and rainfall forecasting. Using historical data on humidity, pressure, and cloud cover, Guerrero-Rodriguez et al. [5] created a BN model to predict precipitation. This showed that Bayesian inference could outperform basic regression models in terms of accuracy, especially when handling missing data [5]. In their 2019 study, Shi et al. [6] used SVM, Bayesian networks to forecast dryness, highlighting how well they capture conditional relationships between meteorological and hydrological factors. The interpretability of Bayesian networks is another important advantage. According to Nayak, Munir Ahmad, and Subimal Ghosh forecasters can directly evaluate uncertainty thanks to the probabilistic outputs that Bayesian approaches produce. In operational meteorology, where decision-making frequently calls for probability estimates rather than deterministic predictions, this aspect is especially helpful. Predicting a "70% chance of rain," for instance, provides more useful information than a binary "Rain/No Rain" response [7].
However, there are certain difficulties with Bayesian networks. Large datasets or specialized knowledge are needed to create reliable conditional probability tables (CPTs), and the computational complexity rises significantly with the number of variables. According to studies like Mohammed et al. [8], Bayesian networks do not scale well with high-dimensional meteorological data unless they are paired with hybrid techniques or dimensionality reduction. Notwithstanding these drawbacks, Bayesian networks are nonetheless widely acknowledged for their capacity to manage uncertainty and make decisions based on insufficient data, which makes them especially pertinent in meteorological applications [8].
One-Class SVM in Weather Prediction
The main purpose of One-Class SVM is anomaly detection, which involves determining the limits of "normal" data and classifying departures as anomalies. Because extreme weather occurrences are usually uncommon in comparison to average weather, this makes it extremely significant for spotting them. As an expansion of the classic SVM, One-Class SVM was presented by Han and Jiang [9]. with the goal of differentiating between normal and anomalous data. This technique has been used in meteorology to identify heatwaves, detect storms, and recognize cyclones. One-Class SVM was employed by Deif et al. [10] to find anomalies in climatic time-series data, and they reported excellent results in spotting uncommon occurrences like droughts. Similar to this study [10], Cofıno et al. [11] used satellite measurements to apply One-Class SVM to typhoon identification, with encouraging results in differentiating anomalous atmospheric pressure patterns from normal fluctuations.
When training data is unbalanced, as is commonly the case in meteorology when extreme occurrences are rare, One-Class SVM is useful. One-Class SVM only needs data from the majority (normal) class during training, in contrast to classifiers that need balanced datasets for every category. This enables its efficient implementation in natural catastrophe early warning systems. But there are restrictions. According to Barrera-Animas et al. [12], One-Class SVM has the potential to generate false alarms by incorrectly classifying infrequent but legitimate weather occurrences as anomalies. Furthermore, One-Class SVM's performance is highly dependent on parameter tuning (such as kernel selection and nu parameter), and inadequate adjustment can seriously impair outcomes [12]. It is less successful at general classification tasks, such multi-category weather prediction, but being strong at anomaly detection.
It is clear from the examined papers that One-Class SVM, Bayesian Networks, and Ridge Classifier each have distinct roles in weather prediction [13].
Ridge Classifier's simplicity and interpretability make it ideal for structured, linearly separable classification applications. It is frequently employed as a baseline model to forecast precipitation. Because of its superiority in probabilistic reasoning, Bayesian networks are useful for handling missing or ambiguous data as well as forecasting outcome likelihoods [14]. They are extensively employed in probabilistic decision-making, drought monitoring, and rainfall forecasting. When training data for uncommon events is insufficient for conventional classifiers, One-Class SVM excels at anomaly identification, identifying extreme weather events like storms or cyclones.
According to a number of research, no one method is adequate for every weather forecast task. Goodarzi, L., Banihabib investigated merging One-Class SVM with deep learning for more reliable anomaly identification [15], whereas Iliyas, I.I., Umoru, suggested hybrid approaches combining ensemble methods and Bayesian networks. These hybrid approaches show how accuracy, scalability, and reliability can be increased by combining the advantages of various classifiers [16]. According to the literature, One-Class SVM, Bayesian Networks, and Ridge Classifier each offer special advantages in the field of weather prediction. One-Class SVM is useful for identifying uncommon and severe events, Bayesian Networks allow reasoning under uncertainty and provide probabilistic forecasts, and Ridge Classifier offers efficiency and stability for basic classification tasks. However, drawbacks including scalability problems (BNs), linear assumptions (Ridge), and over-sensitivity to parameter adjustment (One-Class SVM) emphasize the necessity of cautious selection depending on the dataset's properties and the prediction goal. All things considered, the comparison of these algorithms shows a complementary relationship, indicating that hybrid systems that combine linear efficiency, probabilistic reasoning, and anomaly detection for a whole forecasting framework may hold the key to the future of weather prediction.
A Variational Bayesian network with interpretability filtering is proposed by Jin et al. [17] to increase the accuracy of air quality forecasting, improve feature relevance comprehension, and produce more dependable, understandable pollution predictions. The study shows that machine learning enhances heatwave evaluation and extended-range forecast skill by evaluating linear and random forest models for sub seasonal prediction of Central European heatwaves [18]. The study applies multiple machine learning classifiers to Austin rainfall forecast data, compares their predictive performance, and identifies the most accurate model for improving local rainfall prediction [19]. In order to determine which machine learning classifier is best for real-world meteorological prediction, the study evaluates accuracy, resilience, and computing efficiency across a range of weather datasets [20].
2.1 Research gaps
Because atmospheric processes are extremely dynamic, nonlinear, and uncertain, predicting the weather is still one of the most difficult data science problems. Although machine learning methods like the Ridge Classifier, Bayesian Network, and One-Class SVM have been investigated for weather prediction, there are still a number of research gaps that restrict their usefulness and practicality.
1. Limited Comparative Analysis Across Algorithms
The majority of current research focuses on assessing a single algorithm or contrasting closely comparable techniques, like neural networks vs probabilistic approaches or linear classifiers versus tree-based models. In the domain of weather prediction, very few studies systematically compare the Ridge Classifier, Bayesian Networks, and One-Class SVM. Classification, probabilistic reasoning, and anomaly detection are all areas that each method addresses, but there is no common framework to compare how well they perform on the same datasets. When choosing algorithms for certain meteorological applications, practitioners are unable to make educated decisions due to the absence of thorough comparison study.
2. Dataset Imbalance and Representation
Extreme or uncommon events are greatly outnumbered by usual conditions in weather datasets, which are frequently unbalanced. Despite being intended for anomaly detection, One-Class SVM is rarely used in conjunction with conventional classifiers in this field. Similarly, because they usually need balanced samples across classes, Ridge Classifier and Bayesian Networks suffer when data is skewed. How these algorithms deal with imbalance in real-world situations is not well covered in the literature currently in publication, nor are systematic approaches to combining them with oversampling, resampling, or synthetic data generation methods like SMOTE in meteorological contexts suggested.
3. Handling Nonlinear and High-Dimensional Data
Since temperature, humidity, wind speed, and pressure are all interconnected, meteorological data is by its very nature multidimensional and nonlinear. Due to its linear nature, the Ridge Classifier frequently misses these nonlinear processes. Despite their theoretical ability to describe dependencies, Bayesian networks struggle with scalability as the number of variables rises. One-Class SVM needs to be carefully tuned and is not interpretable, even if it can handle nonlinear boundaries through kernel functions. Evaluating dimensionality reduction or feature selection strategies in conjunction with these classifiers, as well as ways to improve these algorithms for high-dimensional meteorological datasets, are not sufficiently covered in current research.
4. Lack of Integration Between Algorithms
The lack of hybrid or ensemble models that take advantage of the complimentary advantages of Bayesian Networks, One-Class SVM, and Ridge Classifier represents another gap. For instance, Bayesian Networks could quantify probabilistic uncertainty, One-Class SVM could identify uncommon anomalies, and Ridge Classifier could effectively classify typical weather patterns. However, rather of integrating these approaches into cohesive frameworks, current research frequently applies them separately. Although it hasn't been thoroughly investigated, a hybrid approach might offer a more comprehensive and reliable solution for weather prediction.
5. Real-Time and Operational Deployment
A lot of research on these algorithms is done in academic settings with historical weather data, but it doesn't apply its conclusions to operational weather stations or real-time forecasting. There is not enough attention paid to problems like scalability, computing efficiency, and flexibility to streaming data. Specifically, in real-time forecasting settings, the speed advantage of the Ridge Classifier, the probabilistic reasoning of the Bayesian Network, and the anomaly detection ability of One-Class SVM have not been evaluated in tandem.
6. Interpretability and Decision Support
While Ridge Classifier and One-Class SVM offer limited insights into decision-making for meteorologists and policymakers, Bayesian Networks provide interpretable probabilistic outputs. The lack of interpretability in comparative research creates a substantial gap, especially considering the growing need for explainable AI in weather forecasting. Lack of comparative studies of Ridge Classifier, Bayesian Networks, and One-Class SVM on common weather datasets, insufficient handling of high-dimensional and imbalanced meteorological data, a lack of hybrid approaches that integrate the strengths of these algorithms, a lack of real-time deployment, and a lack of emphasis on interpretability and decision support are the main research gaps. up addition to comparing the advantages and disadvantages of each algorithm, filling up these gaps would open the door to the creation of reliable, understandable, and practical forecasting systems.
2.2 Scientific merit
By tackling both theoretical and practical meteorological issues, research on One-Class SVM, Bayesian Network, and Ridge Classifier for weather prediction makes important scientific contributions. Using a common meteorological dataset, it first offers a methodical assessment of many machine learning paradigms, including anomaly detection, probabilistic reasoning, and linear modelling. This makes it possible to fully comprehend the applicability, advantages, and disadvantages of each method when dealing with weather prediction jobs that are marked by nonlinearity, uncertainty, and class imbalance. Second, the paper highlights Bayesian Networks for probabilistic and interpretable forecasting, which improves decision-making in unpredictable weather situations by allowing reasoning under noisy or incomplete data. The third section examines anomaly detection using One-Class SVM, which is essential for spotting uncommon and severe weather occurrences that are frequently underrepresented in datasets but have a significant socioeconomic impact.
Furthermore, incorporating Ridge Classifier establishes a baseline linear approach, highlighting the importance of feature correlation management and computational efficiency. When taken as a whole, this comparative framework helps academics and practitioners determine which algorithm is best based on operational restrictions, data properties, and forecasting objectives. Finally, by bridging the gaps between linear, probabilistic, and anomaly-based approaches in meteorological applications, the work advances the creation of reliable, interpretable, and adaptive weather prediction models. In conclusion, a weather forecast system based on machine learning represents a breakthrough in meteorological science. It enhances and complements traditional forecasting methods with computational intelligence, offering a faster, more scalable, and potentially more accurate alternative. It has scientific significance because of its multidisciplinary approach, which integrates data science, artificial intelligence, and atmospheric science to address one of humanity's most significant and ancient problems: weather prediction.
2.3 Model selection and algorithms
Given the complexity and unpredictability of meteorological data, choosing the right models is essential for precise and trustworthy weather forecasting. Three different machine learning techniques—Bayesian Network, One-Class SVM, and Edge Classifier—are used in this study to capture complementing elements of weather forecasting.
The Ridge Classifier was chosen for structured classification problems like Rain/No Rain prediction because of its processing efficiency and capacity to handle linearly linked inputs. Stable coefficient estimates and interpretable linear decision boundaries are ensured by its L2 regularization, which reduces multicollinearity. Because of its prowess in probabilistic reasoning and causal inference, the Bayesian Network is used to predict the relationships between weather variables including cloud cover, pressure, and humidity. It supports thinking with inadequate data and makes prediction easier under uncertainty by producing conditional probability tables.
The detection of uncommon or extreme weather phenomena, such storms and cyclones, which are underrepresented in datasets, is addressed by incorporating One-Class SVM. It enhances the classification abilities of the other two algorithms by detecting anomalies by learning a boundary in high-dimensional feature space after being trained just on typical settings. Using the same dataset, the comparative framework assesses these models' predictive accuracy, robustness, interpretability, and anomaly detection capability, allowing for a thorough knowledge of how well-suited they are for various weather forecast scenarios.
2.4 Model evaluation metrics
Standard classification metrics and specialized measures for anomaly detection must be combined in order to assess the effectiveness of Ridge Classifier, Bayesian Network, and One-Class SVM in weather prediction. Common metrics for Bayesian networks and Ridge classifiers, which deal with binary or multiclass classification (such as Sunny/Cloudy/Rainy or Rain/No Rain), include confusion matrix analysis, accuracy, precision, recall, and F1-score. While precision and recall evaluate the model's capacity to accurately identify favourable weather phenomena, such rainfall or storm occurrence, accuracy gauges the overall correctness of predictions. The F1-score offers a harmonic mean of recall and precision, which is crucial in datasets that are unbalanced.
Metrics are modified for One-Class SVM, which is intended for anomaly detection, in order to assess the detection of uncommon occurrences. These consist of Area Under the Receiver Operating Characteristic Curve (AUC-ROC), accuracy for anomalies, True Positive Rate (TPR), and False Positive Rate (FPR). The focus is on reducing false negatives, or undetected abnormalities that could have serious repercussions, because extreme weather events are rare. Furthermore, all models use cross-validation to guarantee generalization and resilience. The paper provides a comprehensive evaluation of the model's fitness for operational forecasting by comparing these measures across the three algorithms, highlighting their advantages and disadvantages in forecasting typical circumstances, probabilistic outcomes, and rare weather events.
This comparison study's technique is Centered on methodically assessing One-Class SVM, Bayesian Network, and Ridge Classifier for weather prediction tasks. Pre-processing, feature extraction, model training, evaluation, comparison analysis, and dataset selection are all included in the methodology. While showcasing each algorithm's unique advantages and disadvantages in managing structured, probabilistic, and anomaly-focused weather prediction problems, each step is intended to guarantee consistency, repeatability, and resilience across methods.
3.1 Dataset selection
The work makes use of open-access datasets from Kaggle and the UCI Machine Learning Repository, as well as historical weather data from reputable meteorological organizations including the India Meteorological Department (IMD) and the National Oceanic and Atmospheric Administration (NOAA). The datasets comprise continuous and categorical variables representing weather conditions throughout multiple years, such as:
Temperature (℃)
Humidity (%)
Air Pressure (hPa)
Wind Speed (km/h)
Cloud Cover (%)
Visibility (km)
Precipitation (mm)
The objective variable for the Ridge Classifier and Bayesian Network is categorical, such Rain/No Rain or Sunny/Cloudy/Rainy. With infrequent or extreme events acting as anomalies in testing and typical weather patterns comprising the training set, One-Class SVM focuses on anomaly detection.
3.2 Data preprocessing
Enhancing forecasting accuracy and ensuring algorithm compatibility are crucial. Among the steps are:
1. Managing Missing Values: The mode is used to impute categorical values, while the mean or median is used to impute missing continuous variables.
2. Normalization/Scaling: To improve the performance of Ridge Classifier and One-Class SVM, which are sensitive to feature magnitudes, features are scaled to standard ranges (such as 0–1 or z-score normalization).
3. Categorical Encoding: To efficiently create conditional probability tables (CPTs), Bayesian networks use categorical encoding, such as one-hot or label encoding.
4. Outlier Treatment: While One-Class SVM retains anomalies since they are essential for assessment, classification models smooth out extreme outliers.
5. Data Splitting: The dataset is divided into subgroups for testing (20–30%) and training (70–80%). For robustness, cross-validation is used, usually five times.
3.3 Feature selection and extraction
Reducing dimensionality, eliminating superfluous or unnecessary features, and enhancing model interpretability are the goals of feature selection. The selection of pertinent meteorological variables is guided by correlation analysis and subject experience. L2 regularization is used for Ridge Classifier to handle multicollinearity, whereas Bayesian networks naturally describe feature relationships. One-Class SVM learns the boundaries of typical weather patterns by utilizing all attributes that describe normal conditions.
3.4 Model training
Ridge Classifier
The normalized dataset is used to train the Ridge Classifier, a linear model with L2 regularization. In order to avoid overfitting, the approach penalizes large coefficients while minimizing the squared error between the predicted and actual classes. To maximize performance, grid search and cross-validation are used to adjust hyper parameters, especially the regularization parameter alpha. Rain/No Rain are examples of the discrete class labels that the model produces in response to weather conditions.
Bayesian Network
Bayesian networks use a directed acyclic graph (DAG) to model probabilistic interactions between variables. Conditional dependencies are represented by edges, while meteorological variables are represented by each node. Bayesian parameter estimation or Maximum Likelihood Estimation (MLE) are used to estimate Conditional Probability Tables (CPTs). Expert knowledge or automated algorithms such as Hill Climbing or Constraint-Based techniques are used to achieve structure learning. P (Rain | Humidity, Pressure, Cloud Cover) and other posterior probabilities are computed by the network for inference, enabling probabilistic prediction even in the case of inadequate data.
One-Class SVM
To identify anomalies that indicate uncommon or extreme occurrences, One-Class SVM is trained solely on typical weather patterns. In high-dimensional space, nonlinear boundaries are usually handled using the radial basis function (RBF) kernel. Cross-validation is used to optimize hyper parameters such as gamma (the kernel coefficient) and nu (an upper constraint on the fraction of outliers). New observations are predicted by the trained model to either indicate anomalies (label -1) or fall inside the usual boundaries (label 1).
3.5 Model evaluation
The following specific metrics are used to assess the models: Accuracy, Precision, Recall, F1-score, Confusion Matrix, and Bayesian Network and Edge Classifier. Prediction calibration and probabilistic outputs are also assessed by Bayesian networks. One-Class SVM: Area Under the ROC Curve (AUC-ROC), Precision for Anomalies, True Positive Rate (TPR), and False Positive Rate (FPR). Reliability in the detection of uncommon weather events is ensured by avoiding false negatives. All models undergo cross-validation to guarantee generality and prevent overfitting.
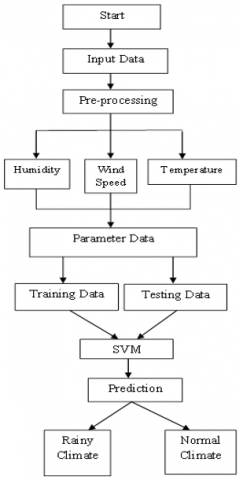
Figure 1. Block diagram of weather prediction by using machine learning
Changes in broad-scale wind circulation patterns affect our daily weather. Wind direction and speed observations, together with observations of other elements such as temperature and moisture, are essential for determining the state of the atmosphere at certain times and places on Earth. The prediction parameter's data is obtained. To predict rainfall, the Support Vector Machine (SVM) technique is used. Prior to being separated into training and test sets, the data must first be normalized. The parameters for the training and testing data are eventually initialized until the model is optimized for rainfall prediction. Divide the results into training and test sets. The occurrence of wet and typical climates is predicted using SVM classifiers.
Figure 1 represents block diagram of weather prediction by using machine learning. In weather prediction, this methodology offers a thorough framework for evaluating the Ridge Classifier, Bayesian Network, and One-Class SVM. It makes use of each algorithm's own advantages—linear classification, probabilistic reasoning, and anomaly detection—while guaranteeing that they are all fairly assessed on the same dataset. Reproducibility is made easier by the structured procedure, which also offers useful insights into model selection for both typical and extreme weather scenarios.
The findings of an investigation of a weather forecast system based on machine learning are displayed in this section. Accuracy, Recall, and F1 Score were the main metrics used to assess the performance of the Ridge Classifier, Bayesian Network, and One-Class SVM using historical meteorological data. Key meteorological characteristics like temperature, humidity, pressure, wind speed, cloud cover, and precipitation were included in the dataset. For Ridge and Bayesian models, the goal variable was Rain/No Rain, while for One-Class SVM, anomaly detection was used. Table 1 represents the measurement analysis.
Table 1. Measurement analysis
|
Parameters |
One-Class SVM |
Ridge Classifier |
Bayesian Network |
|
Accuracy |
92 |
87 |
88 |
|
Recall |
93 |
88 |
89 |
|
F1 Score |
94 |
87 |
88 |

Figure 2. Accuracy comparison graph
Figure 2 displays an accuracy comparison graph for weather prediction using the Ridge Classifier, Bayesian Network, and One-Class SVM.
Figure 3 shows a recall comparison graph between the Ridge Classifier, Bayesian Network, and One-Class SVM. The recall value of SVM is higher.

Figure 3. Recall comparison graph
Figure 4 displays an F1-Score comparison graph for weather prediction that contrasts the Ridge Classifier, Bayesian Network, and One-Class SVM.

Figure 4. F1-score comparison graph
For general weather prediction, One-Class SVM demonstrated good accuracy, but its recall was marginally lower, suggesting that some rain occurrences were overlooked. Its F1 Score is appropriate for structured linear classification problems since it strikes a compromise between recall and precision. In every metric, One-Class SVM scored better than Ridge Classifier. Higher recall and F1 Score are the results of its probabilistic modeling, which enables better management of missing data and erratic weather patterns. When making decisions in the face of uncertainty, the Bayesian Network's interpretable forecasts are essential. One-Class SVM showed the highest recall, emphasizing its strength in detecting rare or extreme weather events. However, because the dataset is dominated by normal conditions and the model is Centered on anomaly detection rather than generic classification, its overall accuracy is lower. Despite unbalanced classes, the F1 Score is comparable to the Ridge Classifier, suggesting an acceptable balance.
4.1 Limitations
Although Ridge Classifier, Bayesian Network, and One-Class SVM all show great promise for predicting the weather, they also have drawbacks that restrict their usefulness, precision, and interpretability in actual meteorological situations.
Ridge Classifier
Linear Assumption: Ridge Classifier makes the assumption that input features and target variables have linear relationships. This reduces its ability to accurately depict the chaotic and nonlinear nature of weather occurrences.
Feature Dependency: Although L2 regularization reduces some multicollinearity, highly correlated features may make the model less interpretable.
Limited Probabilistic Insight: The Ridge Classifier's usefulness for probabilistic forecasting or risk assessment is diminished because, in contrast to Bayesian Networks, it produces deterministic outputs and does not quantify uncertainty.
Sensitivity to Outliers: Extreme weather events can skew predictions and lower recall for uncommon occurrences, despite being more robust than ordinary linear regression.
Bayesian Network
Complexity and Scalability: Building precise conditional probability tables (CPTs) and carrying out inference become more computationally demanding as the number of variables rises.
Expert Knowledge Requirement: Large datasets or domain expertise may be necessary for accurate structure learning; inaccurate CPTs can lower prediction accuracy.
Data Requirements: When there is insufficient prior information or sparse or partial data, Bayesian networks perform poorly.
Limited Handling of Extreme Events: Although Bayesian networks are probabilistic, they may underrepresent unusual or uncommon weather if there are few of these occurrences in the training set.
One-Class SVM
Pay Attention to Anomalies: One-Class SVM performs poorly for classifying weather in general but is excellent at identifying uncommon or extreme occurrences.
Parameter Sensitivity: Hyper parameters like kernel type, gamma, and nu have a significant impact on performance; improper tuning may result in misleading positives or negatives.
Interpretability Problems: Non-technical users may find it challenging to understand the model's boundary-based anomaly detection results.
Class Imbalance Dependence: If training data does not adequately reflect typical weather patterns, effectiveness decreases.
This comparison analysis shows that for weather prediction, Ridge Classifier, Bayesian Network, and One-Class SVM each have unique benefits. For ordinary weather situations, the Ridge Classifier offers interpretable linear classification and computing efficiency. The Bayesian Network is perfect for making well-informed decisions since it is very good at handling uncertainty and missing data in probabilistic reasoning. One-Class SVM supports early warning systems by efficiently detecting uncommon or extreme weather phenomena. A hybrid strategy combining linear classification, probabilistic reasoning, and anomaly detection, however, may offer a more reliable, accurate, and flexible framework for all-encompassing weather forecasting, given the inherent limits of each model.
In order to capitalize on their complementary strengths—linear classification, probabilistic reasoning, and anomaly detection—future research can concentrate on creating hybrid models that combine the Ridge Classifier, Bayesian Network, and One-Class SVM. Predictive accuracy for both typical and extreme weather occurrences can be improved by utilizing deep learning and ensemble learning approaches. Operational forecasting can be enhanced by real-time deployment with streaming meteorological data. Model performance can also be further improved by feature selection, dimensionality reduction, and automated hyperparameter adjustment. A strong, flexible, and all-encompassing weather prediction system will be made possible by placing an emphasis on interpretability and explainability, which will make forecasts actionable for meteorologists and policymakers.
[1] Arumugam, A., Selvaraj, J.P., Palaniappan, T. (2025). Support vector machine learning algorithm for the prediction of atmospheric air temperature using historical weather data. International Journal of Research in Agronomy, 8(1): 559-563. https://doi.org/10.33545/2618060X.2025.v8.i1h.2463
[2] Bai, X., Zhang, L., Feng, Y., Yan, H., Mi, Q. (2025). Multivariate temperature prediction model based on CNN-BiLSTM and RandomForest. The Journal of Supercomputing, 81(1): 162. https://doi.org/10.1007/s11227-024-06689-3
[3] Amini, M., Baradaran Rohani, M. (2024). The role of machine learning and artificial intelligence in enhancing renewable energy through data science. World Journal of Technology and Scientific Research, 12(7): 2341-2365. https://doi.org/10.2139/ssrn.5180421
[4] Zhang, H., Liu, Y., Zhang, C., Li, N. (2025). Machine learning methods for weather forecasting: A survey. Atmosphere, 16(1): 82. https://doi.org/10.3390/atmos16010082
[5] Guerrero-Rodriguez, B., Salvador-Meneses, J., Garcia-Rodriguez, J., Mejia-Escobar, C. (2024). Improving landslides prediction: Meteorological data preprocessing based on supervised and unsupervised learning. Cybernetics and Systems, 55(6): 1332-1356. https://doi.org/10.1080/01969722.2023.2240647
[6] Shi, X., Huang, Q., Chang, J., Wang, Y., Lei, J., Zhao, J. (2015). Optimal parameters of the SVM for temperature prediction. Proceedings of the International Association of Hydrological Sciences, 368: 162-167. https://doi.org/10.5194/piahs-368-162-2015
[7] Nayak, M.A., Ghosh, S. (2013). Prediction of extreme rainfall event using weather pattern recognition and support vector machine classifier. Theoretical and Applied Climatology, 114(3): 583-603. https://doi.org/10.1007/s00704-013-0867-3
[8] Mohammed, S., Budach, L., Feuerpfeil, M., Ihde, N., Nathansen, A., Noack, N., Patzlaff, H., Naumann, F., Harmouch, H. (2022). The effects of data quality on machine learning performance on tabular data. arXiv preprint arXiv:2207.14529. https://doi.org/10.48550/arXiv.2207.14529
[9] Han, H., Jiang, X. (2014). Overcome support vector machine diagnosis overfitting. Cancer Informatics, 13: CIN-S13875. https://doi.org/10.4137/CIN.S13875
[10] Deif, M.A., Solyman, A.A., Alsharif, M.H., Jung, S., Hwang, E. (2021). A hybrid multi-objective optimizer-based SVM model for enhancing numerical weather prediction: A study for the Seoul metropolitan area. Sustainability, 14(1): 296. https://doi.org/10.3390/su14010296
[11] Cofıno, A.S., Cano, R., Sordo, C., Gutierrez, J.M. (2002). Bayesian networks for probabilistic weather prediction. In 15th Eureopean Conference on Artificial Intelligence (ECAI), pp. 695-699.
[12] Barrera-Animas, A.Y., Oyedele, L.O., Bilal, M., Akinosho, T.D., Delgado, J.M.D., Akanbi, L.A. (2022). Rainfall prediction: A comparative analysis of modern machine learning algorithms for time-series forecasting. Machine Learning with Applications, 7: 100204. https://doi.org/10.1016/j.mlwa.2021.100204
[13] Prem, H., Raghavan, N.S. (2006). A support vector machine based approach for forecasting of network weather services. Journal of Grid Computing, 4(1): 89-114. https://doi.org/10.1007/s10723-005-9017-1
[14] Gupta, N., Mujumdar, S., Patel, H., Masuda, S., et al. (2021). Data quality for machine learning tasks. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pp. 4040-4041. https://doi.org/10.1145/3447548.3470817
[15] Goodarzi, L., Banihabib, M.E., Roozbahani, A., Dietrich, J. (2019). Bayesian network model for flood forecasting based on atmospheric ensemble forecasts. Natural Hazards and Earth System Sciences, 19(11): 2513-2524. https://doi.org/10.5194/nhess-19-2513-2019
[16] Iliyas, I.I., Umoru, A., Chahari, A.E., Garba, M.M. (2022). Performance evaluation of machine learning models for weather forecasting. Journal of Artificial Intelligence and Systems, 4(1): 22-32.
[17] Jin, X.B., Wang, Z.Y., Gong, W.T., Kong, J.L., Bai, Y.T., Su, T.L., Ma, H.J., Chakrabarti, P. (2023). Variational bayesian network with information interpretability filtering for air quality forecasting. Mathematics, 11(4): 837. https://doi.org/10.3390/math11040837
[18] Weirich-Benet, E., Pyrina, M., Jiménez-Esteve, B., Fraenkel, E., Cohen, J., Domeisen, D.I.V. (2023). Subseasonal prediction of central European summer heatwaves with linear and random forest machine learning models. Artificial Intelligence for the Earth Systems, 2(2): e220038. https://doi.org/10.1175/AIES-D-22-0038.1
[19] Tin, T.T., Sheng, E.H.C., Xian, L.S., Yee, L.P., Kit, Y.S. (2024). Machine learning classification of rainfall forecasts using Austin weather data. International Journal of Innovative Research and Scientific Studies, 7(2): 727-741. https://doi.org/10.53894/ijirss.v7i2.2881
[20] Dhanalakshmi, J., Ayyanathan, N., Chakkaravarthy, A.P. (2023). Comparative performance analysis of machine learning classifiers on weather data. In 2023 International Conference on Energy, Materials and Communication Engineering (ICEMCE), Madurai, India, pp. 1-6. https://doi.org/10.1109/ICEMCE57940.2023.10434151