OPEN ACCESS
Given a table T with D dimensions, the skycube of T is the union of all skylines obtained by considering each of the subsets of D (subspaces). The number of these skylines is exponential w.r.t D. To make the skycube practically useful, two lines of research have been pursued so far : the first one aims to propose efficient algorithms for computing it and the se-cond one considers either that the skycube is too large to be computed in a reasonable time or it requires too much memory space to be stored. They therefore propose skycube summariza-tion techniques to reduce time and space consumption. Intuitively, previous efforts have been devoted to compute or summarize the following information : "for every tuple t, list the skylines where t belongs to". In this paper, we consider the complementary statement, i.e., "for every tuple t, list the skylines where t does not belong to". This is what we call the negative skycube. Our proposal shows that (i) the negative summary can be obtained much faster than state of the art techniques for positive summaries, (ii) in general, it consumes less space, (iii) skyline queries evaluation using this summary are much faster and (iv) the positive skycube can be obtained much more rapidly than state of the art algorithms.
skyline query, algorithm, subspace, optimization, k-dominant
Tableau 1. Les hôtels
|
Id |
(P)rix |
(D)istance |
(A)ire |
(W)ifi |
|
h1 |
100 |
10 |
20 |
No |
|
h2 |
10 |
100 |
20 |
Yes |
|
h3 |
100 |
10 |
25 |
Yes |
Les requêtes skyline sont un cas particulier de requêtes de préférence dont l’objec- tif est de retrouver un sous-ensemble de tuples qui ne sont pas moins bons que d’autres. Ce résultat s’appelle également Optimum au sens de Pareto. Dans un contexte mul- tidimensionnel, l’utilisateur peut choisir un sous-ensemble d’attributs au regard des- quels les tuples sont comparés. L’ensemble des requêtes skyline est appelé le skycube. En raison du nombre exponentiel de requêtes skyline, la matérialisation du skycube est chronophage et requiert beaucoup d’espace. Pour cette raison, deux directions de recherche ont été suivies depuis lors : d’une part, des algorithmes complexes pour ac- célerer le calcul du skycube ont été proposés, d’autre part, des techniques de compres- sion (réduction de la taille) du skycube ont été définies pour réduire l’espace requis tout en conservant le temps de calcul acceptable. Considérant la réduction de taille, certains algorithmes supposent le skycube comme faisant partie de l’entrée tandis que d’autres présentent des procédures de compression partant de l’ensemble des données brutes.
Le présent travail se base sur l’observation suivante : affirmer qu’un tuple t fait par- tie du skyline nécessite qu’il soit comparé à l’ensemble des autres points. Cependant, la comparaison de t à un autre tuple t′ nous permet de déduire un ensemble de sous- espaces pour lesquels t n’appartient pas au skyline. Partant de là, notre hypothèse de départ est alors que rechercher les sous-espaces au regard desquels t n’appartient pas au skyline peut se faire plus rapidement que le travail complémentaire. Une fois que cet ensemble de sous-espaces est déterminé, retrouver l’ensemble complémentaire est évident.
Sauvegarder pour chaque tuple t, l’ensemble des sous-espaces pour lesquels t n’appartient pas au skyline peut être impossible en pratique en raison de la grande quantité de mémoire qui doit être requise. C’est pourquoi, nous proposons une tech- nique permettant de résumer cette information. L’exemple ci-dessous illustre notre approche.
EXEMPLE 1. — Considérons la liste d’hôtels présentée dans le tableau 1.
Nous avons une préférence pour les hôtels les moins coûteux, les plus près de la mer, présentant les chambres les plus grandes et disposant du Wifi. L’utilisateur a la possibilité de demander le skyline au regard de n’importe laquelle des 24 − 1 requêtes correspondant aux sous-ensembles non vides de l’espace {P, D, A, W}. En comparant les hôtels h2 et h1 , nous déduisons que h2 domine h1 en chacun des sous-espaces subspaces2= {P, W, PW, AP, AW, APW}1 . Cependant, après cette comparaison, nous n’avons aucune information concernant les sous-espaces pour lesquels h1 fait partie du skyline. Pour cela nous avons également besoin de comparer h1 et h3 . Une fois la comparaison effectuée, nous déterminons un nouvel ensemble de sous-espaces dans lesquels h1 est dominé c’est-à-dire subspaces3={A, W, AW, AD, DW, AP, ADP, PW, ADW, APW, DPW, ADPW}. subspaces2 ∪ subspaces3 est l’ensemble des sous-espaces dans lesquels h1 est dominé. Son complémentaire est l’ensemble des sous-espaces pour lesquels h1 fait partie du skyline c’est-à-dire {D, DP}. En pratique, le nombre de sous-espaces associés à un tuple peut être très grand. Nous proposons donc une technique permettant de résumer cet ensemble tout en conservant l’efficacité des requêtes.
Nos contributions peuvent être résumées comme suit : (i) étant donné l’ensemble des sous-espaces au regard desquels un tuple n’appartient pas au skyline, nous pré- sentons une structure de données appelée NSC qui résume le skycube négatif. (ii) Nous proposons une procédure prenant en entrée la table T et retourne le NSC cor- respondant. Enfin, (iii) nous présentons un ensemble de résultats d’expérimentations montrant les avantages et les limites de nos approches par rapport aux algorithmes de l’état de l’art.
Après une brève présentation des travaux se rapportant à cette problématique (sec- tion Travaux relatifs), nous définissons les principaux concepts et notations utilisés tout le long de cet article. Ensuite, nous présentons (section 3) la problématique du résumé du skyline négatif, nous élaborons les algorithmes permettant de résoudre ce problème. Enfin, quelques résultats d’expériences sont présentés (section 4).
1. Nous verrons plus tard qu’il est facile d’obtenir cette information sans avoir à effectuer la comparaison au regard de chacun des sous-espaces
Notations
Soient T (I d, D1 , . . . , Dd ) une table et D = {D1 , . . . , Dd } l’ensemble des dimen- sions de la table T . Chaque sous-ensemble non vide de D est un sous-espace (soit X un sous-ensemble de D). Pour chaque dimension Di , nous supposons établi un ordre total <i au sein de ses valeurs. Soient v, v′ ∈ Di , nous disons que v est préféré à v′ ssi v <i v′. Soient t et t′ deux tuples de la table T , on dit que t est dominé par t′ au regard du sous-espace X , noté t′ ≺X t, ssi t′[Di ] ≤i t[Di ] pour chaque Di ∈ X et il existe Dj ∈ X tel que t′[Dj ] <j t[Dj ]. Le skyline de T au regard du sous-espace X , noté SkyT (X ) ou simplement Sky(X ), est l’ensemble des tuples de T qui ne sont pas dominés au regard de X . Le skycube de T est l’ensemble {Sky(X )|X ∈ 2D et X = ∅}. Par conséquent, le skycube est composé de 2d − 1 skylines. Nous notons n le nombre de tuples appartenant à la table T (la taille de T ).
Le tableau 2 résume les différents notations utilisées tout le long de cet article.
Tableau 2. Notations
|
Notation |
Définition |
|
T , U D X, Y, Z X Y |X | X |Y d Dj n, m t, t′, ti , tj ti [j] t′ ≺X t SkyT (X ) T opmost DOM(t) COMP ARE (t) |
Instances de table (ensemble de tuples) Ensemble des dimensions Sous-ensembles d’attributs (sous-espaces) Mis pour X ∪ Y ; X et Y sont des sous-espaces Nombre d’attributs appartenant à X Paire de sous-espaces X = ∅ et Y Nombre de dimensions (d = |D|) jeme Dimension de T Nombres de tuples Tuples de T Projection du tuple ti sur la je dimension t′ domine t au regard de X Skyline de T au regard de X SkyT (D), Skyline de T au regard de D Sous-espaces dans lesquels t est dominé Ensemble de paires de sous-espaces associés à t |
EXEMPLE 2. — Le tableau 3 sert d’exemple tout le long de cet article. Dans cet exemple, l’utilisateur pourrait demander les meilleurs tuples au regard de chaque combinaison de dimensions {A, B, C, D}. Par exemple, Sky(AB) = {t1 , t2} et Sky(ABC D) = {t2 , t3 , t4 }.
Tableau 3. Une table de données T
|
Id |
A |
B |
C |
D |
|
t1 |
1 |
1 |
3 |
3 |
|
t2 |
1 |
1 |
2 |
3 |
|
t3 |
2 |
2 |
2 |
2 |
|
t4 |
4 |
2 |
1 |
1 |
|
t5 |
3 |
4 |
5 |
2 |
|
t6 |
5 |
3 |
4 |
2 |
Depuis son introduction à la communauté des chercheurs en bases de données par (Börzsönyi et al., 2001), l’opérateur skyline fait l’objet d’un grand intérêt. Plusieurs al-gorithmes l’implémentant ont été proposés dans la littérature, par exemple (Chomicki et al., 2003 ; Papadias et al., 2005 ; Bartolini et al., 2008). Au regard de nos lectures, BSkyTree (Lee, Hwang, 2010) est considéré comme étant l’algorithme le plus effi- cace pour une exécution séquentielle. Des algorithmes en parallèle ont également été proposés, par exemple (Chester et al., 2015). Certaines propositions considèrent des distributions particulières des données, par exemple, (Morse et al., 2007) proposent un algorithme très efficace dans le cas de dimensions présentant un nombre très faible de valeurs distinctes, tandis que (Shang, Kitsuregawa, 2013) présentent un algorithme ayant de bonnes performances lorsque les données sont anti-corrélées. D’autres tra- vaux considèrent le problème de réduction de la taille du résultat d’une requête sky- line en ne conservant que les tuples satisfaisant certaines contraintes, par exemple, les tuples appartenant à un nombre minimum de skyline de sous-espaces (Chan et al., 2006b) ou en sélectionnant les points skyline qui dominent un nombre maximal d’autres points (Lin et al., 2007).
Les travaux les plus proches du nôtre sont probablement skyline group lattice pré- senté dans (Pei et al., 2005 ; 2006) et le plus récent compressed skycube (CSC) dans (Xia et al., 2012). Ces deux travaux se proposent de résumer le skycube positif. Intui- tivement, le concept de groupe skyline opère comme suit : chaque tuple est associé à un ensemble de paires S1 , S2 où : S1 est le top sous-espace Xt et S2 est un ensemble de bottom sous-espaces Yt1 , . . . , Ytp . Ces sous-espaces sont choisis de telle façon que t ∈ Sky(Z ) pour tout Z ⊆ Xt et il existe Ytj tel que Ytj ⊆ Z . Par exemple, sup- posons que la paire ABC, {A, BC } soit associée au tuple t. Alors nous pouvons déduire par exemple que t ∈ Sky(AB). Le résumé consiste à associer chaque tuple au plus petit nombre possible de paires. Les requêtes skyline des sous-espaces telles que Sky(Z) sont exécutées en parcourant pour chaque tuple, la liste qui lui est as- sociée et en vérifiant q ue Z e st b ien c ompris e ntre u n t op s ous-espace e t u n bottom sous-espace associé à ce dernier.
La technique de compression CSC quant à elle consiste à maintenir pour chaque sous-espace son partial skyline (skyline partiel). Plus précisement, un tuple t est ajouté au skyline partiel de Z ssi (i) t ∈ Sky(Z ) et il n’existe pas Y ⊂ Z tel que t ∈ Sky(Y ). Lorsqu’une requête sur un espace Sky(Z ) est demandée, on procède à l’union de l’en-semble des skyline partiels des sous-espaces Y ⊆ Z et une requête skyline classique est exécutée sur ce résultat intermédiaire. Dans (Xia et al., 2012), il est montré que CSC requiert moins d’espace que skyline group. Cependant, il nc´cessite encore l’exé- cution d’une requête skyline.
Dans (Raïssi et al., 2010), la structure closed skycube a été proposée. L’idée prin- cipale de cette technique est de regrouper les sous-espaces en classe d’équivalence au regard des résultats des requêtes skyline de façon à ne stocker qu’un seul exem- plaire de l’ensemble des tuples. Même si cette solution présente un temps optimal de réponse aux requêtes, la recherche des classes d’équivalence requiert beaucoup de temps. D’autre part, la taille du closed skycube pourrait être égale à celle du skycube dans le cas où tous les skyline sont différents d’un espace à un autre.
Récemment, (Bøgh et al., 2014) a proposé la structure Hashcube pour stocker l’ensemble du skycube. Intuitivement, cette méthode consiste à utiliser des vecteurs de bits pour encoder les sous-espaces pour lesquels les tuples appartiennent au sky- line. Le temps de réponse de cette structure de données est impressionnant, en général il est seulement de 10% plus lent que le temps de réponse idéal. Par contre, il requiert beaucoup de mémoire, sa consommation de mémoire est de 10% la taille du skycube. Puisque la taille du skycube augmente de façon exponentielle avec le nombre de di- mensions, la structure Hashcube sature rapidement la mémoire disponible. Plus im- portant encore, les auteurs ne fournissent pas de procédure pour directement construire cette structure à partir des données. À la place, ils prennent en entrée le skycube, sup- posé construit, et encode celui-ci en la structure de données Hashcube; alors que la construction du skycube est une tâche requérant beaucoup de temps mais aussi de mémoire.
Dans le but de réduire la taille des requêtes skyline, la requête k-dominant skyline a été définie. Un tuple est k-dominé (k > 0) s’il existe un autre tuple et un sous-espace dont la taille est au moins k, dans lequel le premier est dominé par le second. Alors, le k-dominant skyline est l’ensemble de tuples qui ne sont pas k-dominés. Il existe plu- sieurs travaux autour des requêtes k-dominant skyline, certains d’entre-eux (Chan et al., 2006a ; Siddique, Morimoto, 2009 ; 2010 ; Dong et al., 2010 ; Siddique, Morimoto, 2012) présentent des algorithmes pour exécuter cette requête, mais seulement (Dong et al., 2010) présentent une méthode pour optimiser le calcul de plusieurs requêtes. Ces dernière sont obtenues en faisant varier le paramètre k au sein du même espace de référence D. Pour ce faire, ils proposent deux algorithmes calculant le k-dominant skyline cube qui est l’ensemble de tous les k-dominant skyline (k = 1 . . . d). Le pre- mier algorithme, appelé Bottom-Up Algorithm (en abrégé BUA), repose sur le résultat de (k−1)-dominant skyline pour calculer le k-dominant skyline; le second algorithme, appelé Up-Bottom Algorithm (en abrégé UBA), utilise le résultat du (k + 1)-dominant skyline afin de calculer le k-dominant skyline. Aucun des précédents travaux ne four- nit un algorithme optimisant le calcul de toutes les requêtes k-dominant skyline ob- tenues en faisant varier non seulement k mais aussi l’espace de référence. (Siddique, Morimoto, 2012), le plus récent, présente une technique pour calculer le k-dominant skyline reposant sur l’indexation (Domination Power Index). Les auteurs montrent, tout comme (Dong et al., 2010), que leur algorithme est plus efficace que l’algorithme TSA élaboré par (Chan et al., 2006a).
Notre contribution se résume en la proposition d’une structure de données qui, pour chaque tuple t appartenant à la table T , résume l’ensemble des sous-espaces X tels que t n’appartient pas à Sky(X). Ceci est motivé par l’observation suivante : pour un tuple t, alors qu’il est nécessaire de le comparer à tous les autres tuples pour savoir s’il appartient à un skyline Sky(X), le comparer à un seul autre tuple t′ permet déjà de déterminer une partie de l’ensemble des sous-espaces dans lesquels t est dominé, c’est-à-dire, des sous-espaces pour lesquels il n’appartient pas aux skyline respectifs. Nous commençons par présenter quelques définitions préliminaires.
DÉFINITION 3 (Sous-espaces de dominance). — Soit t ∈ T et X ⊆ D. X est un espace de dominance pour t ssi $t \notin S k y(X)$.
DÉFINITION 4 (Skycube Négatif). — Soit t ∈ T et soit DomSubspaces(t) l’en- semble des sous-espaces de dominance de t. Le skycube négatif de T est l’ensemble {DomSubspaces(t) | t ∈ T }.
En d’autres termes, le skycube négatif maintient pour chaque tuple t, les sous- espaces dans lesquels t n’appartient pas à leur skyline respectif.
EXEMPLE 5. — À partir du tableau 3, il est facile de vérifier que DomSubspaces(t1) = {ABC D, ABC, AC D, BC D, AC, BC, C D, C, D}.
Clairement, si le skycube négatif de T est disponible, alors le calcul de tout skyline Sky(X ) est évident : pour chaque tuple t, t ∈ Sky(X ) ssi X ∈ DomSubspaces(t). Donc, le skycube négatif de T apparaît comme le complémentaire de son skycube (positif).
À présent, nous montrons que le skycube négatif peut être calculé plus efficace- ment que la solution naïve consistant à calculer d’abord le skycube positif et ensuite de dériver le kycube négatif. Nous commençons par montrer que la comparaison de t et t′ permet d’obtenir un ensemble de sous-espaces appartenant à DomSubspaces(t).
La définition suivante part de l’idée selon laquelle une seule comparaison pourrait permettre de déterminer un certain nombre d’espaces dans lesquels un tuple est do- miné. Par exemple, si à partir du tableau 3, nous comparons t2 à t5 , nous observons que t2 domine t5 pour chacune des dimensions A, B et C . De ce fait, nous pouvons conjecturer que t5 n’appartient à aucun skyline Sky(X ) tel que X ⊆ ABC . par conséquent, cette unique comparaison nous a permis de déterminer le statut skyline de t5 par rapport aux sept sous-espaces non vides de ABC . Dans la suite, nous formali- sons cette intuition en commençant par définir ce que signifie comparer deux tuples.
DÉFINITION 6. — Soient t, t′ ∈ T . Nous définissons la fonction de comparaison COMP ARE comme suit : COMP ARE (t, t′) = X |Y tel que X est l’ensemble des dimensions Dj telles que t′[Dj ] < t[Dj ] et Y est l’ensemble des dimensions Dk pour lesquelles t et t′ sont égaux2 . Alors, t[Dℓ ] < t′[Dℓ ] pour tout Dℓ ∈ D \ X ∪ Y .
Pour simplifier la notation, nous utilisons COMP ARE (t) pour désigner l’en- semble ∪t′ ∈T {COMP ARE (t, t′)}.
EXEMPLE 7. — Du tableau 3, nous avons COMP ARE (t5 , t6 ) = BC |D parce que t6 [B] < t5 [B] (3 vs. 4), t6 [C ] < t5 [C ] (4 vs. 5) et les deux tuples sont égaux sur la dimension D (2). Nous avons COMP ARE (t6 , t5 ) = A|D .
2. Des paires similaires sont définies dans (Bøgh et al., 2014) mais ne sont pas utilisées de la même façon.
Évidemment, si COMP ARE (t, t′) =$\langle X | Y\rangle$ alors X ∩ Y = ∅.
DÉFINITION 8 (Couverture). — Soit $\langle X | Y\rangle$ une paire d’espaces disjoints et soit Z un espace. On dit que la paire$\langle X | Y\rangle$couvre Z ssi Z ⊆ X Y et Z ∩ X = ∅.
EXEMPLE 9. — p = $\langle A C | B\rangle$ couvre les espaces A, AB, C, AC, BC et ABC . B n’est pas couvert par p car malgré le fait que B ⊆ AC B, on a B ∩ AC = ∅.
La proposition suivante montre que les espaces couverts par la paire obtenue en comparant t à t′ sont précisemment les espaces dans lesquels t′ domine t.
PROPOSITION 10. — Soit t, t′ ∈ T et soit COMP ARE (t, t′) = $\langle X | Y\rangle$ . Alors, d’une part, t′ domine t en chacun des espaces Z couverts par $\langle X | Y\rangle$ , c’est-à-dire, $t \notin S k y(Z)$. D’autre part, t′ ne domine t qu’en ces espaces.
PREUVE 11. — Soit Z un sous-espace couvert par la paire$\langle X | Y\rangle$. Alors, il existe deux sous-espaces disjoints Z1 et Z2 tels que Z1 ∪ Z2 = Z , Z1 ⊆ X , Z2 ⊆ Y et Z1 = ∅. Z1 ⊆ X implique que $t^{\prime} \prec z_{1} t$ et $Z_{2} \subseteq Y$ implique que $t^{\prime}\left[Z_{2}\right]=t\left[Z_{2}\right]$ donc $t^{\prime} \prec z=Z_{1} \cup z_{2} t$.
En fait, COMP ARE (t, t′) est un résumé de l’ensemble des espaces pour lesquels t est dominé par t′. Par conséquent, c’est un résumé d’une partie de l’ensemble des espaces pour lesquels t n’appartient pas aux skyline respectifs.
DÉFINITION 12. — Soit E un ensemble de paires d’espaces. On note COV E R(E) l’ensemble de tous les espaces couverts par au moins une des paires appartenant à E.
EXEMPLE 13. — COV E R({ A|B , AD|∅ }) = {A, AB, D, AD}
DÉFINITION 14. — DOM(t) dénote l’ensemble des espaces Z tels qu’il existe t′ qui domine t au regard de l’espace Z .
En d’autres termes, DOM(t) est l’ensemble de tous les sous-espaces de D pour lesquels t est dominé. Donc 2D \ DOM(t, T ) est l’ensemble des sous-espaces pour lesquels t appartient au skyline.
À ce niveau, il est possible de présenter un algorithme construisant le skycube négatif. Cette structure peut alors être utilisée pour répondre aux requêtes skyline.
L’algorithme 1 montre comment cette structure de données est construite. Son idée principale est simplement de comparer chaque paire de tuples (t, t′) et d’ajou- ter COMP ARE (t, t′) à l’ensemble associé à t.
Dans le cas où COMP ARE (t, t′) est égal à la paire$\langle\mathcal{D} | \emptyset\rangle$ (voir ligne 5), cela signifie que t′ domine t en toutes les dimensions. Par conséquent, t n’appartient à aucun skyline et l’ensemble qui lui est associé peut être réduit à une seule paire.
EXEMPLE 15. — Du tableau 3, la structure de données retournée par BUILDNSC est présentée dans la table 4. Notons que les paires $\langle X | Y\rangle$ pour lesquelles X = ∅ ne sont pas considérées parce qu’elles ne couvrent aucun espace (voir Proposition 10).
Tableau 4. NSC relatif à T
|
T uples |
P aires |
|
t1 |
$\langle C | A B D\rangle,\langle C D | \emptyset\rangle,\langle D | \emptyset\rangle$ |
|
t2 |
$\langle D | C\rangle,\langle C D | \emptyset\rangle,\langle D | \emptyset\rangle$ |
|
t3 |
$\langle A B | \emptyset\rangle,\langle A B | C\rangle,\langle C D | B\rangle$ |
|
t4 |
$\langle A B | \emptyset\rangle,\langle A | B\rangle,\langle A | \emptyset\rangle$ |
|
t5 |
$\langle A B C | \emptyset\rangle,\langle A B C | D\rangle,\langle B C D | \emptyset\rangle,\langle B C | D\rangle$ |
|
t6 |
$\langle A B C | \emptyset\rangle,\langle A B C | D\rangle,\langle A B C D | \emptyset\rangle,\langle A | D\rangle$ |
L’algorithme 2 montre comment la structure de données précédente peut être uti- lisée pour exécuter une requête skyline Sky(Z ). Pour chaque tuple t, il scanne l’en- semble des paires qui lui sont associées. Si une paire couvrant Z est rencontrée, alors t n’appartient pas à Sky(Z ) sinon t est un point skyline de Z .
3.1. Réduction de la taille de NSC
Réduire la taille de NSC (de l’ordre de O(n ∗ min(n, 2d))) permet non seulement de réduire la consommation de mémoire mais en plus d’améliorer le temps de réponse des requêtes skyline. Alors, le problème que nous abordons ici consiste à 1) supprimer les tuples fallacieux, c’est-à-dire ceux qui n’appartiennent à aucun skyline et 2) pour chaque tuple restant, trouver un ensemble minimal de paires couvrant exactement les espaces couverts par COMP ARE (t). Afin de donner une intuition à propos de ce procédé, considérons l’exemple suivant.
EXEMPLE 16. — Supposons D|∅ ∈ COMP ARE (t). Puisque cette paire couvre tous les sous-espaces, nous concluons que t n’appartient à aucun skyline. Donc, t et l’ensemble de paires qui lui est associé peuvent être supprimés de NSC.
EXEMPLE 17. — Soit p = ∅|Y une paire associée à t. Clairement, COV E R(p) = ∅. De ce fait, la paire p peut être retirée sans que cela n’affecte le résultat des requêtes skyline.
EXEMPLE $18 .-$ Soient $p_{1}=\langle A | B C\rangle$ et $ p_{2}=\langle A B | C\rangle$ deux paires as- sociées à $ t .$ COV\mathcal{E} \mathcal { R } $\left(\left\{p_{1}\right\}\right)=\{A, A B, A B C, A C\}$ et $\mathcal{C O V E} \mathcal{R}\left(\left\{\left(p_{2}\right\}\right)=\right.$ $\{A, A B, A B C, A C, B, B C\} .$ En raison de l'inclusion, $p_{1}$ peut être supprimé sans que cela n'affecte le résultat des requêtes skyline.
Le test d’inclusion entre les paires peut être réalisé sans avoir besoin de générer l’ensemble des espaces que celles-ci couvrent. En effet, rappelons que le nombre de sous-espaces couverts est exponentiel avec la taille de la paire, ce qui rend le test d’inclusion coûteux à réaliser.
LEMME $19 .-$ Soient $p_{1}=\left\langle X_{1} | Y_{1}\right\rangle$ et $ p_{2}=\left\langle X_{2} | Y_{2}\right\rangle .$ Alors $\mathcal{C O V E \mathcal { R }}\left(\left\{p_{1}\right\}\right) \subseteq$ $\mathcal{C O V E R}\left(\left\{p_{2}\right\}\right)$ ssi $(i) X_{1} Y_{1} \subseteq X_{2} Y_{2}$ et (ii) $X_{1} \subseteq X_{2}$
PREUVE $20 .-$ Si $X_{1} Y_{1} \nsubseteq X_{2} Y_{2}$ alors $p_{2}$ ne peut pas couvrir l'espace $X_{1} Y_{1}$ tandis que $p_{1}$ le couvre. Supposons à présent que la condition (i) est satisfaite mais pas la condition (ii). Alors, il existe une dimension $D_{j} \in X_{1} \backslash X_{2} .$ La paire $p_{1}$ couvre le sous-espace $Z=D_{j}$ alors que ce n'est pas le cas pour $p_{2} .$ Donc la condition (ii) est nécessaire. Ce qui conclut la preuve.
L’égalité suivante est immédiate :
$\mathcal{D} \mathcal{O} \mathcal{M}(t, T)=\mathcal{C} \mathcal{O} \mathcal{V} \mathcal{E} \mathcal{R}\left(\bigcup_{t^{\prime} \in T} \mathcal{C} \mathcal{M} \mathcal{P} \mathcal{A} \mathcal{R} \mathcal{E}\left(t, t^{\prime}\right)\right)$
Ainsi, matérialiser l’ensemble des paires $\bigcup_{t^{\prime} \in T} \mathcal{C O M P A R E}\left(t, t^{\prime}\right)$ pour chaque tuple t nous permet de savoir si t appartient au skyline relatif à n’importe quel sous-espace Z ∈ 2D.
L’inconvénient de matérialiser l’ensemble $\bigcup_{t^{\prime} \in T} \mathcal{C O M P A R E}\left(t, t^{\prime}\right)$ est le fait qu’il pourrait contenir de la redondance. Dans la section suivante, nous montrons comment réduire le nombre de paires tout en conservant les propriétés.
3.1.1. Approches pour la réduction de la taille de NSC
Le problème de compression de NSC consiste à trouver, pour chaque tuple t, un ensemble P de taille minimale tel que COV E R(P ) = COV E R(COMP ARE (t)).
Nous abordons ce problème selon deux approches :
– Nous considérons en entrée l’ensemble des paires associées à t et essayons de trouver un sous-ensemble minimal de COMP ARE (t).
– Nous considérons en entrée les espaces dans lesquels t est dominé et détermi- nons un ensemble minimal de paires couvrant ces espaces.
Du point de vue résumé, la solution de la seconde approche est naturellement préfé- rable puisqu’elle est de plus petite taille. Notons cependant que l’entrée de la première approche est de taille plus petite que celle de la seconde : les paires contre les espaces couverts par ces paires.
Notre problème pourrait être formalisé comme suit : étant donné un tuple t et l’ensemble de paires qui lui est associé COMP ARE (t), comment déterminer un ensemble minimal de paires E∗ tel que COV E R(E∗) = COV E R(COMP ARE (t))?
Ce problème peut également être reformulé de deux manières :
(i) le problème sous contrainte de ressource : E∗ ⊆ COMP ARE (t);
(ii) le problème sans contrainte : E∗ n’est pas forcement un sous-ensemble de
COMP ARE (t).
La section suivante (section 3.1.2) aborde le problème sous-contrainte d’inclusion
(3.1.1) tandis que la section 3.1.3 aborde le problème sans cette contrainte (3.1.1).
3.1.2. Minimisation de COMP ARE (t)
Soit E un ensemble de paires, l’objectif de cette partie est de trouver un autre ensemble de paires E∗ ⊂ E dont la cardinalité (nombre de paires) est la plus petite possible et tel que COV E R(E∗) = COV E R(E)
EXEMPLE 21. — Soit p1 = AB|C , p2 = BC |A et p3 = AC |∅ trois paires associées au tuple t. Il est facile d’observer qu’il n’y a pas d’inclusion entre les en- sembles d’espaces couverts par ces paires. Mais, la paire p3 peut être retirée. En effet, COV E R(p3 ) = {A, AC, C }. A et AC sont couverts par p1 tandis que C est couvert par p2 . Donc, la paire p3 est redondante.
Nous avons COV E R(E∗ = {P3 }) = COV E R(E), donc matérialiser E∗ est moins coûteux que de matérialiser E pour deux raisons :
– E∗ requiert moins d’espace que E;
– requêter E∗ (vérifier qu’un espace Z est couvert) est plus rapide que requêter E.
Le problème abordé dans cette section peut alors être formalisé comme suit :
|
Le problème RSP : Étant donné un tuple t et l’en- semble de paires qui lui est associé COMP ARE (t). Ré- duire la taille de l’ensemble de paires COMP ARE (t) (RSP) revient à trouver un sous-ensemble de paires E ⊆ COMP ARE (t) de taille minimale tel que COV E R(E) = COV E R(COMP ARE (t)). |
Le théorème suivant établit la difficulté du problème RSP.
THÉORÈME 22. — RSP est NP-Difficile.
PREUVE 23. — (esquisse) Évidemment, ce problème de minimisation est NP. La preuve qu’il est NP-Difficile est basée sur la réduction à partir du problème de l’en- semble minimal couvrant (minimal set cover, MSC). Étant donnée une instance de problème MSC, nous construisons une table T de tuples distincts t dans laquelle le nombre de dimensions d est égal au nombre d’éléments devant être couverts dans MSC et où le nombre de tuples n est égal au nombre initial d’ensembles dans MSC.
Nous établissons une correspondance entre E et les ensembles de MSC et mon- trons que toute solution de MSC est une solution de RSP.
Soit s = {s1 , s2 , . . . , sn } l’ensemble d’ensembles d’éléments, entrée de l’instance du problème MSC. Soit t = (1, 1, . . . , 1) un tuple ayant d valeurs. Pour chaque en- semble sj∈ MSC, nous ajoutons à T un tuple t′ tel que t′[i] = 0 ssi i ∈ sj sinon t′[i] = 1. Par conséquent, COMP ARE (t, t′) = X |Y ssi ∃s ∈ MSC tel que X = s.
Par exemple, soit s = {s1 = {1, 2}; s2 = {2, 3}; s3 = {1, 3}} l’instance de MSC. Le nombre d’éléments à couvrir est d = 3 et le nombre d’ensembles n = 3. Alors, nous obtenons la table T ayant n + 1 = 4 tuples (incluant t) et 3 dimensions. Ceci est illustré par le tableau suivant.
|
Id |
1 |
2 |
3 |
|
t |
1 |
1 |
1 |
|
t1 |
0 |
0 |
1 |
|
t2 |
1 |
0 |
0 |
|
t3 |
0 |
1 |
0 |
Il y a une correspondance entre les si ∈ s et les pi = C ompare(t, ti ). Par exemple, Compare(t, t1 ) =$\langle 12 | 3\rangle$ correspond à s1 = {1, 2}. De ce fait, il peut être prouvé qu’un ensemble si appartient à la solution de l’instance de MSC ssi sa paire corres- pondante appartient à la solution du problème RSP.
Dans (Chvatal, 1979), un algorithme glouton approximatif en temps polynomial a été proposé pour résoudre le problème MSC. Cet algorithme choisit à chaque étape l’ensemble couvrant le plus grand nombre d’éléments non encore couverts par les ensembles précédemment choisis. L’adaptation de cet algorithme pour résoudre le problème RSP est évidente et présentée à travers l’algorithme 3. Il s’agit dans notre cas de choisir, à chaque itération la paire couvrant le plus grand nombre d’espaces non encore couverts par les paires déjà choisies.
L’algorithme 4 montre comment créer une liste réduite de paires associées à un tuple. Cet algorithme appelle la fonction ApproxMPC qui est une adaptation de la proposition de (Chvatal, 1979) au problème RSP.
EXEMPLE 24. — Le résultat de la minimisation du tableau 4 utilisant l’algorithme 4 est présenté dans le tableau 5. Notons que le nombre de paires est passé de 20 à 8.
Tableau 5. Liste des paires synthétisant les ensembles de dominance
|
Tuples |
Listes des paires associées |
|
t1 t2 t3 t4 t5 t6 |
$\langle C | A B D\rangle,\langle C D | \emptyset\rangle$ $\langle C D | \emptyset\rangle$ $\langle A B | C\rangle,\langle C D | B\rangle$ $\langle A B | \emptyset\rangle$ $\langle A B C | D\rangle$ $\langle A B C D | \emptyset\rangle$ |
3.1.3. Minimisation sans contrainte d’inclusion
Il est important de préciser que la solution exacte du problème RSP ne présente pas la garantie d’être le plus petit ensemble de paires codant l’ensemble des espaces dans lesquels t est dominé. Son idée maîtresse est juste de retirer les paires redon- dantes. Une autre manière d’aborder ce problème de minimisation est de considérer l’ensemble U des espaces couverts par l’ensemble des paires P associées au tuple t et d’essayer de dériver un ensemble minimal de paires Q qui couvre U . Notons que Q n’est pas forcement inclus dans P . Nous illustrons la différence entre les deux ap- proches à travers l’exemple suivant.
EXEMPLE 25. — Soit P = { AB|C , BC |A } l’ensemble des paires associées à t. P est minimal dans ce sens qu’il est imposible d’en retirer une paire quelconque tout en couvrant l’ensemble des espaces couverts par P . Notons cependant que Q = { ABC |∅ } couvre exactement les mêmes espaces que P et est de taille plus petite.
|
Le problème MSP : Étant donnés un tuple t et l’en- semble qui lui est associé DOM(t) qui représente l’en- semble des espaces dans lesquels t est dominé. Le pro- blème MSP consiste à trouver un ensemble minimal de paires E tel que COV E R(E) = DOM(t). |
La difficulté que nous rencontrons à résoudre ce problème tient du fait que le sky- line n’est pas monotone, c’est-à-dire$Y \subseteq X \not=S k y(Y) \subseteq S k y(X)$. La consé- quence de cette propriété dans notre travail peut être présentée comme suit : soit X ∈ DOM(t). On pourrait être tenté de coder cette information par la paire $\langle X | \emptyset\rangle$. Cependant, cette paire couvre tous les sous-espaces de X alors qu’il est possible qu’il existe un sous-espace Y ⊆ X tel que t ∈ Sky(Y ). Dans la suite, nous mettons en exergue quelques propriétés nous permettant d’accomplir notre tâche consistant à ré-sumer cette information.
LEMME $26 .-$ Soit $t \in | T$ et soient $X, Y$ deux espaces. Si $t \notin S k y_{T}(X Y)$ et $t \in\operatorname{Sky}_{T}(X)$ alors $t \notin \operatorname{Sky}_{T}(Y)$
PREUVE 27 (par l'absurde). $-$ Supposons que $t \underbrace{t \in S k y_{T}(X)}_{(1)}, \underbrace{t \in S k y_{T}(Y)}_{(2)}$ et $\underbrace{t \notin S k y_{T}(X Y)}_{(3)}$
De $(1)$ et $(3),$ il existe $u \in S k y_{T}(X)$ tel que $\underbrace{u[X]=| t[X]}_{(4)}$ et $\underbrace{u \prec Y}_{(5)}$
De $(2)$ et $(3),$ il existe $v \in S k y_{T}(Y)$ tel que $\underbrace{v[Y]=t[Y]}_{(6)}$ et $\underbrace{v \prec x t}_{(7)}$
Nous obtenons une contradiction entre (1) et (7) car t est dominé au regard de X et t appartient au skyline de X. Nous obtenons également une contradiction entre (2) et (5) car t est dominé au regard de Y et t appartient au skyline de Y .
Ceci implique que, si $X \in \mathcal{D} \mathcal{O} \mathcal{M}(t)$ alors il existe au plus un fils $X_{1}$ de $X^{3}$ tel que $X_{1} \notin \mathcal{D} \mathcal{O} \mathcal{M}(t) .$
Ce résultat peut être expliqué par le fait que pour tous $X_{1}, X_{2},$ deux sous-espaces distincts tels que $\left|X_{1}\right|=\left|X_{2}\right|=|X|-1,$ nous avons $X_{1} \cup X_{2}=X .$ En appliquant la proposition $26,$ si $t \notin S k y_{T}(X)$ et $t \in S k y_{T}\left(X_{1}\right)$ alors $t \notin S k y_{T}\left(X_{2}\right) ;$ alors il existe au plus un fils $X_{1}$ de $X$ tel que $t \in S k y_{T}\left(X_{1}\right) .$
En allant plus loin, nous pouvons généraliser en établissant le résultat suivant. Intuitivement, il déclare qu'il existe au plus un plus grand sous-espace $Z$ de $X$ tel que $t \in S k y(Z)$ tandis que $t \notin S k y(X) .$ Formellement, Proposition $28 .-$ soit $X \in \mathcal{D O M}(t) .$ Alors l'ensemble $\underset{Z \subset X, Z \notin \mathcal{D} \mathcal{O} \mathcal{M}(t)}{\operatorname{Argmax}}|Z|$
contient au plus un element.
Ceci signifie que si $t \notin$ Sky $(X)$ alors il existe au plus un sous-espace $Z \subset X$ de taille maximale (en nombre d'attributs) tel que $t$ appartient au skyline de $Z .$
PREUVE $29 .-$ Supposons qu'il existe deux sous-espaces $X_{1}$ et $X_{2}$ de taille maxi- male tels que $X_{1} \notin \mathcal{D} \mathcal{M}(t)$ et $X_{2} \notin \mathcal{D} \mathcal{O} \mathcal{M}(t)$ alors $X_{1} \cup X_{2} \notin \mathcal{D} \mathcal{M}(t)$ $\text { (voir Proposition } 26) .$ De plus, puisque $X_{1} \cup X_{2} \subseteq X$ et $X_{1} \neq X_{2}$ alors $\left|X_{1} \cup X_{2}\right|>\max \left(\left|X_{1}\right|,\left|X_{2}\right|\right) .$ Il $\mathrm{y}$ a une contradiction car soit $X_{1} \cup X_{2}=X$ $\text { (mais } X \in \mathcal{D} \mathcal{O} \mathcal{M}(t)),$ soit $X_{1}$ et $X_{2}$ n'appartiennent pas à a la solution de (i).
De la proposition précédente, nous pouvons déduire le résultat suivant qui intui- tivement montre que si $Y$ est le plus grand sous-espace de $X$ tel que $t \notin$ Sky $(X)$ et $t \in S k y(Y)$ alors chaque $Z \subseteq X$ tel que $t \in S k y(Z)$ est nécessairement un sous-espace de $Y .$ Formellement, PROPOSITION $30 .-$ Soit $X \in \mathcal{D} \mathcal{O M}(t),$ Soit $Y=\underset{Z \subset X, Z \notin \mathcal{D} \mathcal{O} \mathcal{M}(t)}{\operatorname{Argmax}}|Z|$ alors $\forall Z \subset$ $X$ tel que $Z \notin \mathcal{D O M}(t)$ nous obtenons $Z \subseteq Y$
3. $X_{1}$ est un fils de $X$ ssi $X_{1} \subset X$ et $\left|X_{1}\right|=|X|-1$
PREUVE 31 (par l'absurde). - Soit $W \subset X$ tel que $X \notin \mathcal{D O M}(t)$ et $W \nsubseteq Y$ alors $W \cup Y \subseteq X$ et $W \cup Y \notin \mathcal{D O M}(t)$ (car $W$ et $Y$ n'appartiennent pas à $\mathcal{D O M}(t),$ voir Proposition 26), alors il y a une contradiction car $|W \cup Y|>|Y|$ $Y \neq \operatorname{Argmax}_{Z \subset X, Z \notin \mathcal{D} \mathcal{O} \mathcal{M}(t)}|Z| .$
Intuitivement, ce résultat établit que chaque sous-espace de $X \in \mathcal{D} \mathcal{M}(t)$ qui $\text { n' appartient pas à } \mathcal{D} \mathcal{O} \mathcal{M}(t) \text { est inclus dans un autre espace (noté } Y)$ pour lequel $t$ appartient au skyline. Alors, chaque sous-espace appartenant à $2^{X} \backslash 2^{Y}$ appartient à $\mathcal{D O M}(t),$ de ce fait, $\langle X \backslash Y | Y\rangle$ est la paire couvrant à la fois $X$ et le maximum de sous-espaces de $X$ inclus dans $\mathcal{D} \mathcal{O} \mathcal{M}(t) .$
La propriété précédente peut être exploitée pour résoudre le probleme MSP comme suit: soit $X \in \mathcal{D} \mathcal{O} \mathcal{M}(t) .$ Alors $X$ correspond à la paire $\langle X \backslash Y | Y\rangle$ telle que $Y$ est le plus grand sous-espace de $X$ tel que $t \in S k y(Y) .$ Si chaque $X \in \mathcal{D} \mathcal{O} \mathcal{M}(t)$ est remplacé comme décrit précédemment, alors nous obtenons un ensemble de paires dont la minimisation consiste simplement à supprimer les paires $p_{i}$ telles qu'il existe une paire $p_{j}$ qui la couvre. Cette procédure est décrite dans l'algorithme $5 .$
(1) nous montrons tout d'abord que OutputSet couvre tous les espaces apparte- nant à $\mathcal{D} \mathcal{O} \mathcal{M}(t)$ ; et ne couvre que ceux-ci (double inclusion).
(a) nous commençons par montrer que $\mathcal{C O V E R}(p) \subseteq \mathcal{D O M}(t), \forall p \in$ OutputSet. Soit $\langle W | T\rangle$ une paire appartenant à OutputSet, Test (par construction) le plus grand sous-espace de $W T$ qui n'appartient pO\mathcal{M} ( t ) . ~ A l o r s ~ $T$ inclut tout $\text { sous-espace de } W T \text { n'appartenant pas à } \mathcal{D} \mathcal{O} \mathcal{M}(t) \text { (voir Proposition } 30),$ alors $2^{W T}$ $2^{T}=\mathcal{C} \mathcal{O} \mathcal{V} \mathcal{E} \mathcal{R}(\langle W | T\rangle) \subseteq \mathcal{D} \mathcal{O} \mathcal{M}(t)$
(b) nous avons montré que pour chaque espace Z appartenant à DOM(t) il existe une paire de OutputSet qui couvre Z . Chaque itération (voir cinquième ligne) de l’algorithme ajoute à OutputSet une paire qui couvre un espace de DOM(t), non encore couvert par les paires ajoutées précédemment. Et l’algorithme a dans le pire cas une complexité en temps de O(m2) où m est la taille de l’entrée. Alors, l’algorithme s’arrête après un temps fini, lorsque tous les espaces appartenant à DOM(t) sont couverts par au moins une paire de OutputSet
(2) Ensuite, montrons que OutputSet est de taille minimale. Supposons que lp soit une liste de paires couvrant exactement les espaces de DOM(t). Nous allons montrer qu’il existe une fonction injective f allant de OutputSet vers lp ce qui reviendrait à dire que la taille de OutputSet est plus petite (ou égale à) la taille de tout lp. Pour f , nous choisissons la fonction qui associe à chaque paire $\langle X | Y\rangle$∈ OutputSet la paire $\langle x | y\rangle \in l p$ telle que $\langle x | y\rangle$ couvre $X Y(\text { s'il y a plusieurs paires satisfaisant cette }$ condition, alors nous choisissons la plus petite dans l'ordre lexicographique).
(a) Montrons que la fonction $f$ est definie pour toute paire $\langle X | Y\rangle \in$ Outputset, $\forall\langle X | Y\rangle \in$ Output Set, l'espace $X Y$ appartient à $\mathcal{D} \mathcal{O} \mathcal{M}(t)$ donc il existe au moins une paire $p \in l p$ telle que $p$ couvre $X Y .$
(b) Montrons enfin que la fonction $f$ est injective; en d'autres termes, ceci est équivalent à montrer que pour tous $\left\langle X_{1} | Y_{1}\right\rangle$ et $\left\langle X_{2} | Y_{2}\right\rangle$ , deux paires appartenant à OutputSet, il n'existe pas de paire $\langle x | y\rangle \in$ lp couvrant à la fois $ X_{1} Y_{1}$ et $X_{2} Y_{2}$ . Par l'absurde, supposons qu'il existe une telle paire $\langle x | y\rangle \in l p ;$ alors $\underbrace{X_{1} Y_{1} \subseteq x y}_{\text {(1) }}$ (1) et $\underbrace{X_{1} Y_{1} \cap x \neq \emptyset}_{(2)}$ aussi bien que $\underbrace{X_{2} Y_{2} \subseteq x y}_{(3)}$ et $\underbrace{X_{2} Y_{2} \cap x \neq \emptyset}_{(4)}(1)$ et $(3)$ impliquent que $X_{1} Y_{1} \cup X_{2} Y_{2} \subseteq x y$ et $(2)$ et $(4)$ impliquent que $\left(X_{1} Y_{1} \cup X_{2} Y_{2}\right) \cap x y \neq \emptyset$ alors $X_{1} Y_{1} \cup$ $X_{2} Y_{2} \in \mathcal{D} \mathcal{O} \mathcal{M}(t) .$ Donc, il existe aussi une paire $\langle X | Y\rangle \in$ OutputSet couvrant $ X_{1} Y_{1} \cup X_{2} Y_{2}$ ce qui implique que $X \cap\left(X_{1} Y_{1} \cup X_{2} Y_{2}\right) \in \emptyset$ , en d'autres termes $X_{1} Y_{1} Y_{1} \neq \emptyset$ ou $X \cap X_{2} Y_{2} \neq \emptyset$ . Donc, $\langle X | Y\rangle$ couve $\left\langle X_{1} | Y_{1}\right\rangle$ ou $\left\langle X_{2} | Y_{2}\right\rangle$ ce qui est absurde car, par construction de l'algorithme, 5 ne peut pas ajouter à Output Set $\left.\text { la paire }\left\langle X_{1} | Y_{1}\right\rangle\left(\text { resp. }\left\langle X_{1} | Y_{1}\right\rangle\right) \text { si l'espace } X_{1} Y_{1} \text { (resp. } X_{2} Y_{2}\right)$ est déja couvert par une autre paire ajoutée $(\langle X | Y\rangle) .$
3.1.4. Comparer les tuples au Topmost suffit
Dans cette partie, nous montrons que pour construire notre structure de données, il suffit de comparer les tuples à ceux appartenant au em topmost skyline c'est-à dire $S k y(\mathcal{D}),$ au lieu de les comparer à l'ensemble des tuples de la table $T .$ Ceci est particulièrent intéressant lorsque la taille du topmost skyline est petite par rapport à $n$ .
THEOREME $34 .-$ Soit $E=\bigcup_{t^{\prime} \in S \text {ky}(\mathcal{D})} c \mathcal{M} \mathcal{P} \mathcal{A} \mathcal{E} \mathcal{E}\left(t, t^{\prime}\right)$ Alors $\mathcal{C O V E R}(E)=\mathcal{C O V E R}(\mathcal{C O M P A R E}(t))$ PREUVE $35 .-$ On sait que $\mathcal{C O M P A R E}(t)=\bigcup_{t^{\prime} \in T o p m o s t} \mathcal{C O M P A R E}\left(t, t^{\prime}\right) \cup \bigcup_{t^{\prime} \notin \text {Topmost}} \mathcal{C O M P A R E}\left(t, t^{\prime}\right)$ or $\quad \bigcup \quad \mathcal{C O M P A R E}\left(t, t^{\prime}\right)=E .$ En raison de la distributivité de l'opérateur $\mathcal{C} \mathcal{O} \mathcal{V} \mathcal{E} \mathcal{R}$ sur l'union nous pouvons écrire $\mathcal{C O V E R}(\mathcal{C O M P A R E}(t))=\mathcal{C O V E R}(E) \cup \mathcal{C O V E R}\left(\bigcup_{t^{\prime} \notin \text {Topmost}} \mathcal{C O M P A R E}\left(t, t^{\prime}\right)\right)$
Il suffit alors de prouver que$\operatorname{cov} \varepsilon \mathcal{R}\left(\underset{t^{\prime} \notin \text {Topmost}}{\bigcup} \operatorname{cod} \mathcal{P} \mathcal{A} \mathcal{R} \mathcal{E}\left(t, t^{\prime}\right)\right) \subset \operatorname{coveR}(E)$
En d'autres termes, on pourrait juste montrer que pour tout $t^{\prime} \notin$ Topmost,$\operatorname{cov} \varepsilon \mathcal{R}\left(\mathcal{C} \mathcal{O} \mathcal{M P} \mathcal{A} \mathcal{E} \mathcal{E}\left(t, t^{\prime}\right)\right) \subseteq \mathcal{C} \mathcal{O} \mathcal{V} \mathcal{E} \mathcal{R}(E)$
Soit $t^{\prime}$ un tuple de $T$ tel que $t^{\prime} \notin$ Topmost. par définition du skyline, il existe un tuple $u \in$ Topmost tel que $u$ domine $t^{\prime},$ c'est-à-dire, $u \prec \rho t^{\prime} .$ Soit $\left\langle X_{1} | Y_{1}\right\rangle=$ $\mathcal{C} \mathcal{O} \mathcal{M P} \mathcal{A} \mathcal{R} \mathcal{E}(t, u)$ et $\left\langle X_{2} | Y_{2}\right\rangle=\mathcal{C} \mathcal{O} \mathcal{M} \mathcal{P} \mathcal{A} \mathcal{R}\left(t, t^{\prime}\right) .$ Pour chaque sous-espace $Z$ couvert par $\left\langle X_{2} | Y_{2}\right\rangle,$ nous avons $(i) t^{\prime} \prec z$ t. De plus, $u \prec \mathcal{D} t^{\prime}$ implique que $(i i)$ $u \preceq z t^{\prime}(\operatorname{car} Z \subseteq \mathcal{D}) .$
De $(i)$ et (ii) on a $u \prec z t ;$ donc $Z$ est couvert par $\left\langle X_{1} | Y_{1}\right\rangle .$ Tout espace couvert par $\left\langle X_{2} | Y_{2}\right\rangle$ est aussi couvert par $\left\langle X_{1} | Y_{1}\right\rangle$
Par conséquent, pour tout $t^{\prime} \notin$ Topmost, la paire $\mathcal{C} \mathcal{M P} \mathcal{A} \mathcal{R} \mathcal{E}\left(t, t^{\prime}\right)$ est redon- dante dans la liste de paires associées au tuple $t .$
Tableau 6. Données réelles
|
Données |
d |
n |
|
NBA MBL IPUMS |
17 18 10 |
20493 92797 75836 |
EXEMPLE 36. — De notre exemple précédent, puisque le topmost skyline est consti- tué des tuples t2 , t3 et t4 , les tuples seront uniquement comparés à ceux-ci. Par exemple, la liste de paires associée au tuple t1 est { C |ABD , C D|∅ } dont la taille est 2 en considérant le T opmost au lieu d’un ensemble de 3 paires si on avait comparé t1 à l’ensemble des tuples.
En plus du gain d’espace dû à la réduction du nombre de comparaisons pour chaque tuple, cette optimisation rend l’algorithme glouton utilisé pour résoudre le problème RSP plus rapide en raison de la réduction de la taille de l’entrée.
Dans le but de comparer notre proposition aux algorithmes de l’état de l’art, nous avons implémenté nos solutions aussi bien que CSC (Xia et al., 2012). Nous avons utilisé les implémentations de BSkyTree (Lee, Hwang, 2010), Hashcube (Bøgh et al., 2014) et QSkyCube (Lee, Hwang, 2014) fournies par leurs auteurs respectifs. Tous les programmes ont été écrits en C++. Nous avons utilisé une machine équipée de deux processeurs hexa-core et 24 Go sous Linux. Dans cette section, nous dénotons par NSC la structure skycube négatif réduite à l’aide de l’algorithme approximatif répondant au problème RSP et nous notons NSC* la structure utilisant la solution du problème MSP. Clairement, NSC* devrait être de plus petite taille que NSC.
Pour les expérimentations, nous utilisons des données synthétiques obtenues sui- vant le procédé décrit par (Börzsönyi et al., 2001). Nous utilisons également un en- semble de données réelles régulièrement exploitées au sein de la communauté skyline. Nous considérons trois critères de comparaison : le temps de construction, la quantité de mémoire requise et le temps des requêtes. En ce qui concerne le dernier critère et pour éviter tout biais, nous considérons le temps nécessaire pour exécuter l’ensemble des 2d − 1 requêtes skyline.
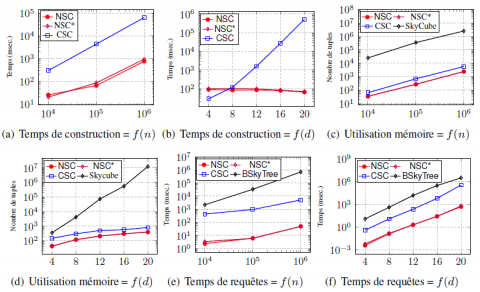
4.1. Données réelles
Ces données sont décrites dans le tableau 6. Les résultats obtenus présentés dans la figure 1 montrent que NSC surpasse CSC pour tous les critères : NSC est 100 fois plus rapide pour la construction de la structure. En ce qui concerne l’utilisation de la mémoire NSC ne requiert pas plus d’espace mémoire que CSC, par exemple,
Figure 1. Données réelles
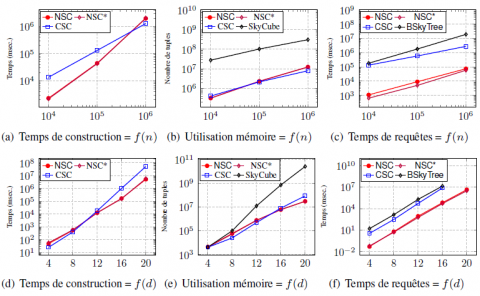
Figure 2. Données synthétiques corrélées (k = 100)
pour les données IPUMS, les deux algorithmes demandent presque la même quantité de mémoire, ce qui représente environ 10% de la mémoire requise par le skycube. Ce qui donne une première idée sur le taux de compression en fonction du nombre de dimensions : d = 10 pour IPUMS contre respectivement 17 et 18 pour NBA et MBL.
Nous constatons, au regard du temps de réponse, que pour un grand nombre de dimensions (NBA and MBL), CSC a de pires performances que BSkyTree, une so- lution ne faisant aucun pré-calcul. Notons que la même observation avec des données synthétiques a été soulignée dans (Bøgh et al., 2014). Il est important de préciser que
Figure 3. Données synthétiques indépendantes
Figure 4. Construction du Skycube: NSC vs QSkyCube
NSC et NSC* ont des comportement similaires quel que soit le critère retenu. Leurs courbes respectives sont presque toujours confondues.
4.2. Données synthétiques
Nous générons trois types de données synthétiques : corrélées, indépendantes et anti-corrélées suivant l’outil fournit par (Börzsönyi et al., 2001). Pour chacun d’eux, nous comparons NSC et NSC* à CSC en faisant varier le nombre de tuples n dans l’ensemble {104 , 105 , 106 } et en maintenant le nombre dimensions d égal à 14. Nous faisons ensuite varier le nombre de dimensions d dans l’ensemble {4, 8, 12, 16}, tout en conservant le nombre de tuples n égal à 105 .
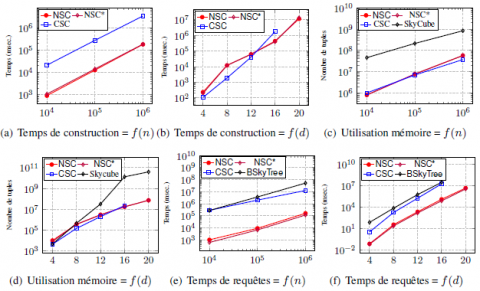
Pour les données corrélées (figure 2), nous observons que lorsque d augmente, NSC surpasse largement CSC au regard des temps de construction et de requêtes (voir figures 2b et 2f). Au regard de n, les deux méthodes semblent atteindre des temps de construction et de requêtes presque linéaires (voir figures 2a et 2e). En termes d’utili- sation de la mémoire, les deux algorithmes sont comparables même si NSC est légè- rement plus petit. les résultats obtenus avec les données indépendantes sont présentés dans la figure 3. Les mêmes remarques tiennent pour les données indépendantes (fi- gure 3) et les données anti-corrélées (figure 5). Cependant, il est important de préciser que lorsque n = 106 et d = 20 (figure 5b), CSC n’avait pas terminé la construction de la structure de données après 36 heures tandis que NSC a été construite en environ 3 heures. À partir de la structure de données construite, les 220 − 1 requêtes ont été exécutées en environ une heure. CSC pourrait alors être plus rapidement construite à partir du skycube obtenu de cette façon qu’en utilisant la version originale de l’algo- rithme fournie dans (Xia et al., 2012). Ceci revient à dire que, utiliser un algorithme naïf pour construire CSC en construisant en premier le skycube et ensuite en déter- minant pour chaque tuple les plus petits espaces pour lesquels ils appartiennent au skyline est plus rapide que l’algorithme complexe et inefficace proposé.
Il est cependant intéressant de remarquer que, pour de petites valeurs de d (figures 3e et 5d, d = 4), non seulement CSC requiert moins d’espace mémoire que NSC mais c’est aussi le cas pour l’ensemble du skycube. En d’autres termes, le nombre de skylines auxquels les tuples n’appartiennent pas est plus élevé que le nombre de skylines auxquels les tuples appartiennent. Par ailleurs, nous remarquons que CSC a presque la même taille que le skycube. Ceci signifie que dans de telles situations (d petit), il n’est pas recommandé d’utiliser NSC et encore moins CSC : le skycube entier est la meilleure option.
4.3. Comparaison à Hashcube
Dans cette partie, nous comparons NSC à la structure de données Hashcube pro- posée dans (Bøgh et al., 2014). Nous avons utilisé l’implémentation de Hashcube fournie par les auteurs 4 . Il est important de préciser que l’implémentation de Hash- cube a besoin que l’ensemble du skycube soit calculé puisque c’est ce dernier qu’elle prend en entrée. De ce fait, nous ne pouvons pas considérer le temps de construction. Avec les données NBA, NSC garde en mémoire 13259 tuples tandis que Hashcube stocke 541316. D’autre part, répondre à l’ensemble des 217 − 1 requêtes requiert 30 millisecondes à Hashcube contre 2.1 secondes pour NSC.
Dans le but d’éprouver la structure de données Hashcube, nous avons généré un jeu de données synthétiques présentant des dimensions indépendantes. Ce jeu de don-
4. Pour les besoins de comparaison, les auteurs ont également implémenté la technique CSC. Nous ne l’avons pas utilisée parce qu’elle était plus lente que la notre.
Figure 5. Anticorrelated Synthetic Data (k = 100)
nées contient 107 tuples et 16 dimensions. Son skycube requiert de stocker 20 ∗ 109 tuples. Nous avons essayé de construire la structure de donnée Hashcube correspon- dante mais les 24Go de mémoire disponibles n’ont pas été suffisants pour la conser- ver. Pour le même jeu de données, NSC utilise moins de 12Go pour stocker environ 4.5∗107 tuples. Par conséquent, lorsque le skycube est trop grand, ce qui arrive lorsque le nombre de dimensions est élevé, Hashcube ne peut pas être entièrement chargé en mémoire. Ce que nous pouvons tirer de cette expérimentation est que : on pourrait choisir Hashcube lorsque le nombre de dimensions est relativement petit. Dans de telles situations, il est préférable d’entièrement matérialiser le skycube, sinon NSC doit alors être choisi.
4.4. Construction du skycube
Dans cette section, nous comparons notre contribution à QSkyCube (Lee, Hwang, 2014) récemment proposé pour le calcul du skycube complet. La figure 4 montre cer- tains résultats que nous avons obtenus. Nous avons généré des données synthétiques indépendantes fixant le nombre de tuples n à 105 et faisant varier le nombre de dimen- sions d dans l’ensemble {4, 8, 12, 16}. Il est important de souligner le fait que pour NSC, nous avons reporté le temps d’exécution total, c’est-à-dire le temps de construc- tion de la structure et celui de l’exécution des 2d − 1 requêtes. Comme cela peut être observé, lorsque d augmente, c’est-à-dire d > 8, NSC devient plus rapide. Il est in- téressant de noter que lorsque d atteint 16, QSkyCube a été arrêté car ayant saturé toute la mémoire disponible. Cette expérimentation montre que 1) notre proposition est compétitive pour le calcul du skycube (particulièrement) lorsque d devient grand, et 2) notre proposition peut être considérée comme la première étape pour construire Hashcube puisque ce dernier requiert que le skycube soit entièrement construit.
Nous avons présenté la structure skycube négatif et fourni les algorithmes permet- tant de la réduire. L’idée maîtresse de cette structure est de stocker pour chaque tuple un résumé de l’ensemble des sous-espaces pour lesquels il n’appartient pas au sky- line. Ceci est en contradiction avec les anciens travaux où l’objectif était de résumer l’ensemble des sous-espaces pour lesquels le tuple appartient au skyline. Nos expéri- mentations ont montré que NSC est particulièrement efficace en termes de temps de construction, d’utilisation de la mémoire et de temps de réponse. Dans les précédents travaux, soit les algorithmes demandaient beaucoup de temps pour la construction, soit la structure de données produite était trop grande pour tenir en mémoire. Nos ex- périmentations montrent également que cette structure est plus rapide pour construire le skycube que les algorithmes de l’état de l’art spécialement conçus dans cet objectif.
Une autre propriété intéressante est sa faculté à pouvoir répondre efficacement à une autre forme de requête qui est la requête k-dominant skyline. Dans les travaux futurs, nous prévoyons de proposer une solution à la maintenance incrémentale de la structure NSC. Cette possibilité est le principal avantage de la structure Compres- sed Skycube (CSC) bien qu’elle souffre, comme nous l’avons vu, de l’inefficacité de l’exécution des requêtes. Nous envisageons également d’adapter notre structure à la représentation binaire Hashcube. Ceci aura pour effet de réduire encore plus nos temps de réponse aux requêtes.
Nous remercions les rapporteurs anonymes ainsi que l’éditeur pour leurs sugges-tions qui nous ont permis de bien améliorer la présentation de ce travail. Ce tra-vail a été partiellement réalisé dans le cadre des projets PETASKY et SPEED DATA financés respectivement par l’initiative MASTODONS du CNRS et le Programme d’investissements d’avenir (PIA).
Bartolini I., Ciaccia P., Patella M. (2008). Efficient sort-based skyline evaluation. ACM Trans. Database Syst., vol. 33, no 4.
Bøgh K. S., Chester S., Sidlauskas D., Assent I. (2014). Hashcube: A data structure for space and query efficient skycube compression. In Proceedings of CIKM conference.
Börzsönyi S., Kossmann D., Stocker K. (2001). The skyline operator. In Proc. of ICDE conf. Chan C. Y., Jagadish H. V., Tan K., Tung A. K. H., Zhang Z. (2006a). Finding k-dominant skylines in high dimensional space. In Proceedings of SIGMOD international conference.
Chan C. Y., Jagadish H. V., Tan K., Tung A. K. H., Zhang Z. (2006b). On high dimensional skylines. In Proceedings of EDBT conference.
Chester S., Sidlauskas D., Assent I., Bøgh K. S. (2015). Scalable parallelization of skyline computation for multi-core processors. In Proceedings of ICDE conference.
Chomicki J., Godfrey P., Gryz J., Liang D. (2003). Skyline with presorting. In Proc. of ICDE conference.
Chvatal V. (1979). A Greedy Heuristic for the Set-Covering Problem. Mathematics of Operations Research, vol. 4, no 3, p. 233–235. Consulté sur http://dx.doi.org/10.2307/3689577
Dong L., Cui X., Wang Z., Cheng S. (2010). Finding k-dominant skyline cube based on sharing-strategy. In Proceedings of FSKD conference.
Lee J., Hwang S. won. (2010). BSkyTree: scalable skyline computation using a balanced pivot selection. In Proc. of EDBT conf.
Lee J., Hwang S. won. (2014). Toward efficient multidimensional subspace skyline computation. VLDB Journal, vol. 23, no 1, p. 129-145.
Lin X., Yuan Y., Zhang Q., Zhang Y. (2007). Selecting stars: The k most representative skyline operator. In Proceedings of ICDE conference.
Morse M. D., Patel J. M., Jagadish H. V. (2007). Efficient skyline computation over lowcardinality domains. In Proceedings of VLDB conf.
Papadias D., Tao Y., Fu G., Seeger B. (2005). Progressive skyline computation in database systems. ACM Trans. Database Syst., vol. 30, no 1.
Pei J., JinW., Ester M., Tao Y. (2005). Catching the best views of skyline: A semantic approach based on decisive subspaces. In Proc. of VLDB conf.
Pei J., Yuan Y., Lin X., Jin W., Ester M., Liu Q. et al. (2006). Towards multidimensional subspace skyline analysis. ACM TODS, vol. 31, no 4, p. 1335-1381.
Raïssi C., Pei J., Kister T. (2010). Computing closed skycubes. Proc. of VLDB conf.
Shang H., Kitsuregawa M. (2013). Skyline operator on anti-correlated distributions. PVLDB, vol. 6, no 9, p. 649–660.
Siddique A., Morimoto Y. (2009). K-dominant skyline computation by using sort-filtering method. In Proceedings of PAKDD conference.
Siddique A., Morimoto Y. (2010). k-dominant and extended k-dominant skyline computation by using statistics. International Journal on Computer Science and Engineering, no 5, p. 1934.
Siddique A., Morimoto Y. (2012). Efficient k-dominant skyline computation for high dimensional space with domination power index. Journal of Computers, vol. 7, no 3, p. 608 -615.
Xia T., Zhang D., Fang Z., Chen C. X., Wang J. (2012). Online subspace skyline query processing using the compressed skycube. ACM TODS, vol. 37, no 2.