Ida Mulyadi*![]() | Musdalifa Thamrin
| Musdalifa Thamrin![]() | Muhammad Faisal
| Muhammad Faisal![]() | Sry Yunarti
| Sry Yunarti![]() | Saharuddin
| Saharuddin![]() | Asriadi Abd Djalil
| Asriadi Abd Djalil![]() | Satriawaty Mallu
| Satriawaty Mallu![]()
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
The accurate classification of palm sugar varieties is essential for maintaining product quality and ensuring consumer satisfaction within the food industry. This study proposes a hybrid model that integrates feature Hue, Saturation, and Lightness (HSL) colour space, feature Gray-Level Co-occurrence-Matrix (GLCM) texture analysis, and Fuzzy K-Nearest Neighbors (FKNN) algorithms to classify different categories of palm-sugar, including aren texture, coconut texture, and lontar texture varieties. The hybrid approach leverages advanced image processing techniques to extract and analyze critical texture and colour features, achieving a classification accuracy of 98%. The results underscore the potential of this model to enhance operational efficiency, promote product standardization, and support fair market practices in the palm sugar industry. By providing an automated and accurate classification system, this research contributes to both the economic optimization of production processes and the transparency of product quality in the market. Future research related to palm sugar on real-time deployment of the system in industrial environments is essential, with potential integration into automated sorting and packaging systems to further streamline operations.
classification, Fuzzy K-Nearest Neighbors (FKNN), palm sugar, industry, image processing, Hue, Saturation, and Lightness (HSL), Gray-Level Co-occurrence-Matrix (GLCM)
The classification of palm sugar types through image-based analysis is an emerging field that capitalizes on advancements in machine learning and image processing techniques. Accurate classification of palm sugar is essential for both consumer satisfaction and operational efficiency within the food industry. The food industry is under more pressure to guarantee product consistency and quality as the demand for premium raw materials rises due to both consumer preferences and industrial requirements [1]. The global food sweeteners market, expected to surpass $100 billion by the year's end, is experiencing its most rapid growth in the Asia-Pacific region, making the accurate classification palm sugar products more crucial than ever [2].
Recent advances in image-based classification models have demonstrated significant potential across various applications, from biometrics to material science, and can be adapted for palm sugar classification. For example, Zabala-Blanco et al. [3] introduced a weighted extreme learning machine (W-ELM) model that successfully addressed imbalanced data in palm vein images, achieving high classification accuracy without extensive feature extraction. Similarly, convolutional neural networks (CNNs) have been employed for the classification of date palm varieties, yielding impressive accuracy rates and demonstrating the viability of image-based classification in agriculture [4]. These methodologies offer valuable insights and could inspire similar applications in the classification of palm sugar, where challenges such as imbalanced datasets may also arise.
Palm sugar is traditionally divided into three main categories: palm sugar, coconut sugar, and lontar sugar, each distinguished by its unique characteristics. Palm sugar, made from the sap of palm trees, has a dark brown or reddish colour, a soft texture, and a strong sweetness with a caramel-like aroma. Coconut sugar, derived from coconut tree sap, is lighter in colour (light brown or yellowish) and has a harder texture and milder sweetness compared to palm sugar. Meanwhile, lontar sugar, made from the sap of the lontar palm tree, has a dark brown or blackish colour, a coarse texture, and a sweetness with a slight bitterness. These differences play a significant role in their use in traditional dishes, with specific varieties preferred based on taste, aroma, and texture. However, consumer knowledge of these differences is often limited, leading to potential price manipulation in traditional markets.
In the context of palm sugar production, optimizing processes through data-driven approaches is essential for improving efficiency. Ummi et al. focused on multi-objective optimization in the remanufacturing of palm sugar granules, underscoring the need for accurate classification to enhance production efficiency [5]. These optimization techniques, when integrated into hybrid classification models, could streamline the identification of specific palm sugar types for various applications, ensuring a smoother and more efficient production pipeline. Such integration is especially important as palm sugar, a highly sought-after natural sweetener, plays a pivotal role in both culinary and industrial applications.
The mechanical properties of sugar palm composites have been extensively studied, revealing their versatility and potential across several industries. Mohd Izwan et al. [6] explored the mechanical and thermal properties of sugar palm fibre composites, highlighting their suitability for structural applications. Similarly, Nurazzi et al. [7] investigated the mechanical properties of sugar palm yarn composites, demonstrating their potential as alternative materials in various industries. Although this research focuses on material science, these findings are relevant to palm sugar classification, as the physical properties of sugar palm products may influence their classification.
High-quality palm sugar is typically characterized by its consistent colour, smooth texture, and non-clumping properties. One of the most important factors buyers consider when buying palm sugar is staining, yet models specifically addressing the palm-sugar colouration rare in the scientific literature [8]. A non-centrifugal sweetening ingredient made from the sap of different palm trees is called palm sugar, has long been prized for its distinctive taste and flavour, and its classification is becoming increasingly important as demand continues to rise [9].
The development of a hybrid model for palm sugar classification can build on the wealth of research from related fields. By leveraging advanced machine learning techniques, understanding the material properties of sugar palm, and optimizing production processes, this model has the potential to significantly enhance classification accuracy and efficiency. This study employs phased training and testing procedures to construct a model capable of accurately classifying various types of palm sugar and analyzing the resulting data. It makes a notable contribution by addressing a gap in scientific knowledge regarding palm sugar colouration, offering valuable insights that are essential for improving consumer awareness and promoting fair market practices.
The presented methodology, which integrates image analysis techniques for palm sugar classification, is a cutting-edge approach that harnesses advanced technology to meet the evolving needs of the industry. By improving the precision and efficiency of classification, this research paves the way for innovative applications and contributes significantly to the economic viability of palm sugar production and marketing, as illustrated in Figure 1.
Figure 1. Proposed framework
Quantum colour models are necessary for image processing with possible quantum computing hardware in order to record and modify picture colour information [10]. An analysis of every feature of every image texture utilized in the GLCM algorithm was conducted as part of a study on the process for utilizing digital image processing to examine the interior surface of steam pipes. The results showed a significant 92% classification accuracy [11]. Analyzing every feature of every image texture employed in the study on the approach for utilizing digital image processing on the GLCM algorithm to analyze the inside surface of steam pipes produced significantly better classification results in 92% of the cases [12]. The performance of the suggested method is evaluated using data from many road picture datasets under varied illumination circumstances. It detects lane lines with 96% accuracy on a variety of roads. A study using to recognize human walking motion, use the GLCM algorithm from a set of colour photos that have been previously manipulated with contrast stretching, median filters, and resizing techniques [13].
The objective of imbalanced data classification is to classify intricate data that exhibit a significantly disparate distribution concerning the quantity of data samples within each class [14]. The significance of classification tasks in the advancement and evolution of pattern recognition, data mining, and machine learning in fields has led to a significant focus on research linked to these tasks [15]. To address pest identification jobs with effective data, a study assesses crop pest photos and filters highly informative data [16]. Predicting lupus nephritis classes is one area in which FKNN has demonstrated efficacy in a number of medical domains [17], detecting Coronavirus Disease 2019 [18], and predicting atopic dermatitis [19], It demonstrates how FKNN performs better at pattern recognition than KNN [20], in which results accurate rate is 91.3%. Prior studies have classified and identified machine surface textures utilizing the GLCM extraction feature using image processing and machine learning [21].
According to earlier studies on image classification and extraction methods, hybrid HSL, GLCM, and FKNN have not been used in any research. This study suggests using the HSL-GLCM-FKNN hybrid technique to classify different forms of palm sugar in order to address the challenge of recognizing them. Through picture identification, details about different varieties of palm sugar such as aren palm, coconut palm, and lontar palm may be gathered. These details can then be used as a guide to determine the right price. A gap in previous research that motivated a hybrid approach (HSL-GLCM-FKNN) for palm sugar classification. Previous research did not combine the power of the colour model (HSL) and texture features (GLCM): this gap is the main reason the proposed approach as a solution addresses the limitations of previous work.
The following are the study's main goals: Firstly, investigate if image-based analysis can be used to classify palm sugar types. Secondly, assess the suggested model's performance and contrast it with other classification techniques. Finally, to show how the hybrid model may be implemented in real-world industry by a software.
Methodology describes the approach used in research to give an idea of how the research was conducted and what data was collected. Overall, to classify palm sugar into category Aren, Coconut, and Lontara using hybrid HSL, GLCM, and FKNN as follows:
Preprocessing
Images undergo resizing, denoising, and conversion into HSL and grayscale formats to facilitate feature extraction.
Feature extraction
HSL features: Color features such as Hue, Saturation, and Lightness are extracted to capture the distinct color profiles of different types of palm sugar.
GLCM features: Texture features (e.g., contrast, correlation, energy) are extracted using GLCM to analyze the texture patterns of the sugars.
Classification using FKNN
A composite feature vector combining HSL and GLCM features is used to train the FKNN model.
The FKNN model assigns fuzzy membership values to each image, determining the likelihood of it belonging to one of the categories: Aren, Coconut, or Lontara.
The implementation of these stages is further explained in the subsequent chapter.
3.1 Palm sugar
Palm sugar, distinguished by its solid composition and hues that vary from reddish-brown to deep brown, typically comes in unique semicircular blocks. These blocks are often shaped with the aid of coconut shells or bamboo, reflecting the traditional methods employed in its production. Sugar and carbs are the same chemically, in which Generally speaking, sugar refers to small-sized carbohydrates with a sweet taste and the capacity to dissolve [22]. According to this study, there are three types of palm sugar as research sample, as shown in Figure 2.
Figure 2 shows many types of palm sugar, including type aren, which is reddish-brown in colour and has a clean, dry texture, lontar which is light brown in colour, has a rough surface and a dry texture, then it is composed of cocos nucifera or coconut. Coconut type has dark brown features and a taut structure and texture.
Figure 2. Category of palm-sugar
3.2 HSL feature
The HSL Feature lightness is defined as a colour brightness value or a value of a component ranging from white to black. A color's brightness is greatly reduced or it darkens when the lightness value is 0. In the meantime, the colour's brightness level becomes extremely brilliant or white if the lightness value is 1. The RGB to HSL colour conversion algorithm is expressed in Eqs. (1)-(3) [23]:
$\mathrm{H}=\arctan 2\left(\mathrm{~B}^{\prime}, \mathrm{R}^{\prime}\right)^*\left(\frac{180}{\pi}\right)$ (1)
$\mathrm{L}=\frac{\left(\max \left(\mathrm{B}^{\prime}, \mathrm{R}^{\prime}, \mathrm{B}^{\prime}\right)+\min (\mathrm{R}, \mathrm{G}, \mathrm{B})\right)}{2 * 100 \%}$ (2)
$\mathrm{S}=\frac{\left(\left(\max \left(\mathrm{B}^{\prime}, \mathrm{R}^{\prime}, \mathrm{B}^{\prime}\right)-\min (\mathrm{R}, \mathrm{G}, \mathrm{B})\right)\right)}{(1-|\mathrm{L} * 2-1|) * 100 \%}$ (3)
The determination of saturation values determines each immutability function, and lightness consists of 0 until 1. Meanwhile, the Hue value consists of 0 to 360.
3.3 GLCM feature
GLCM feature is ideal for analysis techniques when involves quantitative information on image textures [24]. This method's basic assumption is that a texture will show a looping of grayscale pairings or combinations of levels. The co-currency matrix expression is Pdⁱ (i, j) [25]. There are eight possible directions to locate a neighboring pixel when there is a "d" distance between them. Texture features from an image can be employed in the co-currency matrix to distinguish between images belonging to various classes [26].
The process of extracting features from a digital image using the GLCM neighborliness angle involves [27]. The working contrast, which is determined by using Eq. (4): is the moment of inertia (or how widely apart pieces spread) on the picture matrix:
$\sum_i \sum_j[i-j]^2 \cdot p(i, j)$ (4)
Moreover, the identity of correlation is employed to quantify the linear dependence among the image's greyish-level values, which are computed using Eq. (5).
$\sum_i \sum_j \frac{(i-\mu i)(j-\mu j) p(i, j)}{\sigma i \sigma j}$ (5)
Additionally, the feature of energy is used to represent an image uniformity measure that is computed using Eq. (6).
$\sum_{i_{i j}} p(i, j)^2$ (6)
Lastly, the consistency of the matrices of concurrency fluctuations in the image of observation [28], given in Eq. (7).
$\sum_i \sum_j \frac{p(i, j)}{1+[i-j]^2}$ (7)
3.4 FKNN
In order to predict utilizing membership degree values in each class, test data is assigned class membership values in FKNN classification approach, which blends fuzzy techniques with the KNN classifier. A well-liked supervised machine learning technique for multiclass classification and regression using features from several datasets is FKNN [29]. The stages of calculating FKNN in calculates Fuzzy initialization using Eq. (8) as follows [30]:
$\left\{\begin{array}{c}0.51+\left(\frac{n_j}{k}\right) * 0.49, \text { if } j=i \\ \left(\frac{n_j}{k}\right) * 0.49, \text { if } \neq i\end{array}\right.$ (8)
where, uij is the class membership value on vector j, nj is the number of members of class j, K is the number of nearest neighbours, and j is the target class.
a. Calculate the Euclidean distance.
b. Calculate the degree of membership of new data against each class using Eq. (9).
$u_i(x)=\frac{\sum_{j=1}^K u_{i j}\left(1 /\left\|x-u_i\right\| \frac{2}{m-1}\right.}{\sum_{j=1}^K\left(1 /\left\|x-u_i\right\| \frac{2}{m-1}\right.}$ (9)
Choose the class using Eq. (10).
$y^{\prime}=\operatorname{ArgMax}_{j=1}^C\left(u\left(x_i, x_i\right)\right)$ (10)
This section describes how to use hybrid HSL, GCLM, and Fuzzy KNN, where each step is correlated until the process functions as a whole. There are multiple subsections that feature discussion pertaining to this study.
4.1 Pre - processing
Figure 3. Cropping of image [31]
The training model supports the process of identifying and classifying an object, thus eliminating the need for human supervision [32], thereby improving effectiveness across a range of applications for processing images of palm sugar. The objective of the pre-processing technique is to convert the dataset into appropriate machine learning inputs [33]. Pre-processing in this study consists of cropping, scaling, and colour conversion of each image, with a 1:1 comparison of each image.
Figure 3 shows how palm sugar photos are cropped in the appropriate portions for analysis to create training process datasets.
4.2 Scaling and segmentation
The practice of breaking down an image into its component parts or extracting certain information from it using predetermined parameters like colour, orientation, or scale is known as image decomposition. This makes it easier to analyze different aspects of the image [34]. The input image for this study was reduced from its original size of 6000 by 4000 pixels to 256 × 256 pixels.
Figure 4. Segmentation category of palm sugar [31]
Since image segmentation divides an image's pixel count into segments that are filled with pixels on an object, it is crucial for many computer vision applications [35]. The initial stage of pattern recognition is segmentation, after which the properties of the divided objects can be utilized to identify patterns or carry out tasks of classification. Improved image quality makes it simpler to recognize and comprehend objects, as demonstrated by the segmentation findings in Figure 4.
4.3 Grayscale mode
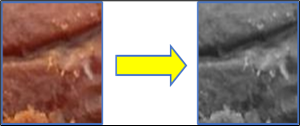
The removal of colour information from grayscale photographs allows for a clearer focus on texture and brightness details, facilitating a more focused analytical procedure on specific components [36]. As seen in Figure 5, scaling was done in this study to alter an image's resolution, size, and horizontal and vertical dimensions. RGB images were converted to grayscale to create an image matrix.
Figure 5. Conversion image form RGB to grayscale [31]
Figure 6 illustrates how the grayscale mode drastically reduces complexity when compared to RGB images because it only needs one colour channel per pixel.
Figure 6. Category of palm sugar in grayscale mode [31]
After converting the RGB values to Grayscale, the HSL values are calculated as follows:
Given R = 176, G = 111, and B = 77
Grayscale value is determined using the formula:
Grayscale = 0.296R + 0.312G + 0.113B
Substituting the values gives:
Grayscale = 0.296(176) + 0.312(111) + 0.113(77) = 52.096 + 34.632 + 8.701 = 95.429
Next, the RGB values are normalized as:
R = 176 / 255 = 0.69, G=111/255= 0.43, B = 77 / 255 = 0.30
Using the normalized values, the Hue (H) is calculated with the formula:
H = arctan2(B, R) *(180/π)
Substituting the values:
H = arctan2(0.30, 0.69) × (180/π) = 27.37°
The Lightness (L) is calculated as:
L = (max(R, G, B) + min(R, G, B)) / 2
Substituting the maximum and minimum values:
L = (0.69 + 0.30) / 2 = 0.49
The Saturation (S) is computed using the formula:
S = (max (R, G, B) - min (R, G, B)) / (1 - |2L - 1|) × 100%
Substituting the known values:
S = (0.690 - 0.302) / (1 - |2(0.496) - 1|) × 100% = 39.11%
Finally, the Lightness value is confirmed as:
L = (0.690 + 0.302) / 2 × 100% = 49.6%
Based on these calculations (as shown in Figure 5): the RGB values of 176, 111, and 77 correspond to HSL values of 27.37°, 39.11%, and 49.6%, respectively.
4.4 Extraction
The HSL and GLCM techniques are used in this study's feature extraction. This image extraction method's purported advantage is its capacity to improve accuracy by depending on pixel values or histograms [37]. Following the pre-processing step, features be extracted from the image inputs. Entropy, energy, homogeneity, and contrast are the four GLCM extraction features that are calculated from each image by first creating a co-occurrence matrix. The angles that are used for each angle are 0o, 45o, 90o, and 135o. Using language descriptions of RGB colour images as a guide, this study suggests a colour-correcting process. The basic principle is to adjust the Hue - Saturation channels to match the colours present in the colour image, without modifying the RGB. Reducing the quantity of objects in the Hue channel is the aim of the rectification stage, which aims to enhance processing speed and efficiency, as presented in Table 1.
Eqs. (4) and (5) are utilized to determine the accumulation contras value and accumulation correlation value of the GLCM data obtained from Table 1, Eq. (6) for accumulation Energy value, and Eq. (7) for accumulation of homogeneity value.
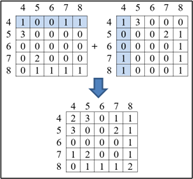
The process of finding the matrix value of 00 in GCLM is given as an example as follows: The way to calculate a 0-degree matrix is to check the neighbouring values left and right in each row of the matrix. As seen in Figure 7, in the first row, (8.7): (7.5): and (5.4) are neighbours. After determining all the neighbours from left to right on the row, look at the number of occurrences in each neighbouring value.
Table 1. Colouring the palm sugar in RGB, Hue, Saturation, and Lightness [31]
|
Category |
RBG |
Hue |
Saturation |
Lightness |
|
PS-Aren |
||||
|
PS-Lontar |
||||
|
PS-Coconut |
Figure 7. The matrix search for 00
Based on Figure 7, the value of the transpose matrix is determined, and each row in the table of 00 matrix results is converted into a column until the last row, as in Figure 8.
Next, the intensity value obtained is determined by adding the initial matrix's value to the transformation matrix's value, as shown in Figure 9.
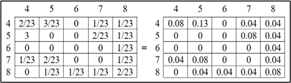
Based on the figure, it is known that the number of 0 degrees has a total value of 24. Next, a search for the value of the co-occupancy matrix or normalization of 0 degrees is carried out by dividing each 00 intuition value by the total value. Overall, the result of the calculation is shown in Table 2.
The full 300-image training image dataset as well as the 12 testing images were extracted by GLCM. Contras, Correlation, Energy, and Homogeneity are the features that are employed. The properties of the training images are extracted and the results are kept in a database for identification and classification.
Figure 8. Determination of 00 intensity value
Figure 9. Results of the calculation of the value of the co-occupancy matrix
Table 2. Value of extraction palm sugar [33]
|
Type |
Contras |
Correlation |
Energy |
Homogeneity |
|||||||||||||
|
0o |
45o |
90o |
135o |
0o |
45o |
90o |
135o |
0o |
45o |
90o |
135o |
0o |
45o |
90o |
135o |
||
|
Aren |
3.25 |
5.72 |
7.16 |
6.58 |
-0.07 |
-0.01 |
-0.09 |
-0.01 |
0.05 |
0.08 |
0.10 |
0.09 |
0.35 |
0.32 |
0.14 |
0.32 |
|
|
Coconut |
3.20 |
6.41 |
7.37 |
6.41 |
-0.09 |
-0.09 |
-0.09 |
-0.01 |
0.01 |
0.09 |
0.42 |
0.08 |
0.28 |
0.28 |
0.14 |
0.28 |
|
|
Lontar |
3.40 |
5.79 |
6.75 |
6.88 |
-0.07 |
-0.02 |
-0.08 |
-0.01 |
0.04 |
0.08 |
0.26 |
0.08 |
0.32 |
0.30 |
0.13 |
0.30 |
|
4.5 Classification
K-Nearest Neighbour (K-NN) approaches are valued in traditional data mining for their simplicity and ease of use in classification tasks [38]. The GLCM approach is utilized in this study's image classification process to get feature values. The FKNN method is then used to compare these feature values with the values of the test and training data in order to use them in the classification process. Machine learning algorithms excel in feature extraction, automatically identifying relevant information more efficiently [39]. One of the most well-known and successful supervised classification techniques among the many machine-learning methodologies is the FKNN classifier [40]. To determine the weight of the training sample, training is conducted [41], The classification of palm sugar varieties is another use for it. Since a substantial amount of training data must be used, FKNN has the known advantage of being a more robust algorithm with high success rates [42]. As shown in Table 3, the training outcome database includes the training sample weights generated by FKNN using the palm sugar type model during the training stage.
Using the FKNN approach and Eq. (8), all data in Table 3 are used as training data to classify the palm sugar type. Table 4 then shows the results of the Euclidean distance calculation.
Table 3. Data of training
|
Id |
Feature of HSL |
Feature of GLCM |
Class |
|||||
|
FH |
FS |
FL |
F-Contrast |
F-Correlation |
F-Energy |
F-Homogeneity |
||
|
1 |
13 |
41 |
40 |
68.46 |
0.90 |
0.06 |
0.25 |
Lontar |
|
2 |
14 |
64 |
31 |
70.37 |
0.90 |
0.06 |
0.25 |
Aren |
|
3 |
97 |
36 |
37 |
125.59 |
0.90 |
0.04 |
0.21 |
lontar |
|
4 |
24 |
54 |
40 |
162.27 |
0.79 |
0.06 |
0.21 |
Coconut |
|
5 |
23 |
41 |
43 |
358.25 |
0.63 |
0.03 |
0.14 |
Coconut |
|
6 |
20 |
35 |
54 |
54.19 |
0.88 |
0.01 |
0.28 |
Aren |
|
7 |
21 |
71 |
31 |
48.79 |
0.96 |
0.07 |
0.29 |
Aren |
|
8 |
84 |
22 |
50 |
126.14 |
0.90 |
0.04 |
0.22 |
Lontar |
|
9 |
22 |
70 |
33 |
90.53 |
0.88 |
0.04 |
0.24 |
Lontar |
|
10 |
12 |
53 |
33 |
35.57 |
0.99 |
0.02 |
0.52 |
Aren |
|
11 |
10 |
50 |
25 |
81.96 |
0.81 |
0.07 |
0.22 |
Aren |
|
12 |
21 |
57 |
31 |
202.01 |
0.80 |
0.03 |
0.18 |
Lontar |
|
13 |
14 |
48 |
37 |
57.68 |
0.96 |
0.05 |
0.27 |
??? |
Table 4. The Euclidean value calculation
|
ID |
Euclidean-Distance Calculation |
Class |
|
1 |
$=\sqrt{(68.46-57.68)^2+(0.90-0.96)^2+(0.06-0.05)^2+(0.25-0.27)^2}=10.78$ |
Lontar |
|
2 |
$=\sqrt{(70.37-57.68)^2+(0.90-0.96)^2+(0.06-0.05)^2+(0.25-0.27)^2}=12.97$ |
Aren |
|
3 |
$=\sqrt{(125.59-57.68)^2+(0.90-0.96)^2+(0.04-0.05)^2+(0.21-0.27)^2}=67.91$ |
Lontar |
|
4 |
$=\sqrt{(162.27-57.68)^2+(0.79-0.96)^2+(0.06-0.05)^2+(0.21-0.27)^2}=104.59$ |
Coconut |
|
5 |
$=\sqrt{(358.25-57.68)^2+(0.63-0.96)^2+(0.03-0.05)^2+(0.25-0.27)^2}=300.57$ |
Coconut |
|
6 |
$=\sqrt{(54.19-57.68)^2+(0.88-0.96)^2+(0.01-0.05)^2+(0.28-0.27)^2}=3.61$ |
Aren |
|
7 |
$=\sqrt{(48.79-57.68)^2+(0.96-0.96)^2+(0.06-0.05)^2+(0.29-0.27)^2}=4.68$ |
Aren |
|
8 |
$=\sqrt{(126.14-57.68)^2+(0.90-0.96)^2+(0.04-0.05)^2+(0.22-0.27)^2}=8.88$ |
Lontar |
|
9 |
$=\sqrt{(90.53-57.68)^2+(0.88-0.96)^2+(0.05-0.05)^2+(0.24-0.27)^2}=32.85$ |
Lontar |
|
10 |
$=\sqrt{(35.57-57.68)^2+(0.99-0.96)^2+(0.02-0.05)^2+(0.52-0.27)^2}=22.10$ |
Aren |
|
11 |
$=\sqrt{(81.96-57.68)^2+(0.81-0.96)^2+(0.07-0.05)^2+(0.22-0.27)^2}=24.28$ |
Aren |
|
12 |
$=\sqrt{(202.01-57.68)^2+(0.80-0.96)^2+(0.03-0.05)^2+(0.18-0.27)^2}=144.33$ |
Lontar |
Table 5. Result of Euclidean distance
|
K-Fold |
ID (S) |
Average Distance |
Min Distance |
Max Distance |
|
3 |
6, 8 |
6.25 |
3.61 |
8.88 |
|
5 |
1 |
10.78 |
10.78 |
10.78 |
|
7 |
2 |
12.97 |
12.97 |
12.97 |
|
9 |
10, 11 |
23.19 |
22.10 |
24.28 |
|
10 |
9, 3, 4, 12 |
87.42 |
32.85 |
144.33 |
The input values will undergo an ascending sorting process based on a pre-defined “k” value. Subsequently, the old value will be subtracted starting from the smallest value in comparison to the new input value. Following this reduction process, the K-Nearest Neighbours algorithm will be employed to identify neighbouring values that play a pivotal role in determining the classification.
The next step is to apply the FKNN method to overcome the data uncertainty problem by allowing each data point to have a membership level in multiple classes instead of just one firm class. As shown in the example, the value of K = 3. In the data set, it is determined that there are 3 classes, namely aren, lontar, and coconut. Then, the K (3) value consists of the membership value of palm (3.62): lontar (10.78; 8.88): and coconut has no members, as presented in Table 5.
The next, set the value m=1 to each class member and assign the value m=0 to non-members of the class. The calculation of FKNN using Eq. (9) is written as follows:
Aren $=\frac{\frac{1}{3.62^2}+\frac{0}{10.8^2}+\frac{0}{8.887^2}}{\frac{1}{3.62^2}+\frac{1}{10.8^2}+\frac{1}{8.887^2}}=\frac{0.00857}{0.097536}=0.087899$
Lontar $=\frac{\frac{0}{3.62^2}+\frac{1}{10.8^2}+\frac{1}{8.887^2}}{\frac{1}{3.62^2}+\frac{1}{10.8^2}+\frac{1}{8.887^2}}=\frac{0.088963}{0.097536}=0.912100$
Finally, choose the class with the most significant membership value using Eq. (10) to obtain a value of 0.912100 in the Lontar class. The calculation of the K value (3,5,7,9,10) is shown in Table 6.
Table 6. Result of FKNN
|
No. |
K-Fold |
FKNN |
Class |
|
1 |
3 |
0.91 |
Lontar |
|
2 |
5 |
0.79 |
Aren |
|
3 |
7 |
0.80 |
Aren |
|
4 |
9 |
0.80 |
Aren |
|
5 |
10 |
0.71 |
Aren |
Limitations were identified in the methods used, including FKNN being heavily influenced by the size and quality of training data, potential overfitting with small or poorly labelled datasets, the impact of variations in lighting and sample preparation on feature extraction accuracy, and the possibility that HSL and GLCM may not capture all necessary visual characteristics for precise classification.
The testing of expert needs was done using respondents dispersed throughout multiple villages in South Sulawesi, Indonesia, utilizing the hybrid technique that has been developed. It is well established that a complex confusion matrix is essential for assessing classification performance [43, 44]. In order to assess the classification accuracy of the findings generated from the hybrid HSL, GLCM, and FKNN techniques, this study analyzed a number of palm sugar photos with varying image characteristics. Table 7 shows testing data from respondents.
Using the confusion matrix method, a recommended validation findings using data of actual was conducted based on the data in Table 7 [45, 46]:
Precision=TP/(TP+FP) (11)
Recall=TP/(TP+FN) (12)
Table 7. Result of the testing data [33]
|
Palm Sugar Category |
PS. Aren |
PS. Coconut |
PS. Lontar |
Total |
|
PS. Aren |
105 |
1 |
1 |
107 |
|
PS. Coconut |
1 |
92 |
0 |
93 |
|
PS. Lontar |
1 |
1 |
98 |
100 |
|
Total |
300 |
|||
Table 8. Confusion matrix calculation result
|
Indicator |
Palm Sugar Category |
||
|
Aren |
Coconut |
Lontar |
|
|
T P |
105 |
92 |
98 |
|
F P |
2 |
1 |
2 |
|
F N |
2 |
2 |
1 |
|
Precision Eq. (9) |
26.25 |
30.66 |
32.66 |
|
Recall Eq. (10) |
0.98 |
0.97 |
0.98 |
|
F1 Score Eq. (11) |
1.89 |
1.89 |
1.92 |
|
Accurate Eq. (12) |
0.98 |
||
F1 - Score $=\frac{2(\text { Precision } \times \text { Recall })}{(\text { Precision }+ \text { Recall })}$ (13)
Accurate=(TP)/(TP+FP+FN) (14)
According to Table 8, the study findings perform good in terms of data classification, with an accuracy value of 0.98. Because the "K" subsets are chosen as data based on analyst comparison using the KNN and FKNN algorithm, testing of accuracy level is performed using K-Fold cross-validation, as illustrated in Figure 10. The subset is divided into many iterations.
Eight tests employing 300 test data using KNN and FKNN are reported, with the good accuracy of 0.98 on k-fold 239 and the poor accuracy of 0.72 on k-fold 151. These results suggest that the model constructed is of good quality. The FKNN is often better than KNN and CNN because it can handle ambiguous data, weigh neighbours based on proximity, have smooth decision boundaries, handle outliers, and provide interpretability with fuzzy membership values. Its resilience to noise, adaptability to complex patterns, and effectiveness in handling class imbalance make it a superior method for classification in many real-world datasets. Applying the identical approach and methodology to obtain the accuracy value, a comparative analysis is performed between the outcomes of prior relevant research cases and the suggested technique. The comparison of the results is given in Table 9.
This research's contribution is to make use of technology's capacity to differentiate between different kinds of palm sugar quality, which can lead to the development of automated systems to be used in the community or in the introducing and categorizing of palm sugar in the market. Significance The hybrid approach makes it easier to identify different types of palm sugar by incorporating texture features (GLCM), colour representation (HSL), and FKNN classification algorithms. This expands the potential for the development of automated systems that can accurately and efficiently distinguish between several kinds of palm sugar for the food business that relies on image processing.
Figure 10. Result of k-fold validation
Table 9. The outcome of comparing the accuracy of pertinent algorithms
|
Research Topic |
Methods |
Accuracy |
|
Farmland Images Classification [47] |
HSV and PCA |
87.36% |
|
Driver Assistance Automatic in Lane Detection [12] |
Gradient Threshold and Hue-Lightness-Saturation |
96% |
|
Human Walking Activity Recognition [13] |
GLCM and LSTM |
96% |
|
Analysis of Textural [11] |
Gray Level Co-occurrence Matri |
92% |
|
Machined Surfaces Classification [21] |
ML techniques applied to GLCM |
91.30%. |
|
Palm Sugar Classification |
HSL, GLCM, and FKNN |
98.30% |
4.6 Implementation of methodology
This section describes the results of applying the proposed methodology to software. In the initial stage, the sugar image data is entered into the system to be set as training data, as the results are displayed in Figure 11.
Figure 11 shows the amount of data to be used for training a classification model, likely a machine learning or computer vision model, that distinguishes between different types of brown sugar based on colour and texture characteristics. The extracted HSL and GLCM features are fed into the model, which then learns to classify future samples accurately. Furthermore, it is done testing used testing data, as presented in Figure 12.
After all the data is entered, the next process is to conduct a test that is carried out by identifying images to find out the sugar category, where in this process it is done on a mobile-based application, as the results are shown in Figure 13.
Figure 11. List of training data by software
Figure 12. List of testing data by software
Figure 13. Identification category of palm sugar in mobile application
The integration of HSL, GLCM, and FKNN algorithms in the hybrid methodology presents significant potential for industrial applications, particularly in the field of palm sugar quality control. This system offers the capability to automate classification processes, ensuring consistent quality and accuracy in product labelling, thus reducing human error and enhancing operational efficiency in manufacturing environments. Additionally, in the domain of supply chain management, the classification system can optimize inventory control and processing by facilitating the efficient use of raw materials, leading to reductions in waste and improvements in overall productivity. Within the food and beverage industry, the system guarantees ingredient consistency, a critical factor for maintaining product quality, while providing transparency to consumers through the accurate classification of palm sugar types. Furthermore, this methodology can contribute to precision agriculture, where it can assist farmers by linking sugar classification to geographic and environmental conditions, potentially improving crop yields and enhancing the traceability of products throughout the supply chain.
Future research directions offer several opportunities for improving the hybrid methodology. A key area of investigation is the exploration of additional GLCM features, such as contrast, entropy, and correlation, which may enhance the accuracy and robustness of classification models. Similarly, further tuning of HSL parameters could optimize feature extraction from images under varying environmental conditions, such as changes in lighting. The FKNN algorithm also warrants deeper investigation, particularly through the application of cross-validation techniques to determine the optimal K-value. Additionally, the use of adaptive K-values based on local data densities may yield improved classification performance in different dataset contexts. Beyond these algorithmic enhancements, integrating multi-modal data, such as spectral or chemical information, with image-based features could lead to further gains in classification accuracy and generalization. The incorporation of deep learning techniques, such as convolutional neural networks (CNNs), could also be explored, particularly in hybrid models combining FKNN with CNNs to achieve more sophisticated feature extraction and classification. Finally, research on real-time deployment of the system in industrial environments is essential, with potential integration into automated sorting and packaging systems to further streamline operations.
[1] de Matos Paz, J.E., Dantas, A.M., de Sousa Fernandes, D.D., Pontes, M.J.C. (2024). Classification of sugar using digital imaging and pattern recognition techniques. Journal of Food Composition and Analysis, 125: 105796. https://doi.org/10.1016/j.jfca.2023.105796
[2] Upadhyaya, A., Sonawane, S.K. (2023). Palmyrah palm and its products (neera, jaggery and candy)—A review on chemistry and technology. Applied Food Research, 3(1): 100256. https://doi.org/10.1016/j.afres.2022.100256
[3] Zabala-Blanco, D., Hernández-García, R., Barrientos, R.J. (2023). SoftVein-WELM: A weighted extreme learning machine model for soft biometrics on palm vein images. Electronics, 12(17): 3608. https://doi.org/10.3390/electronics12173608
[4] Safran, M., Alrajhi, W., Alfarhood, S. (2024). DPXception: A lightweight CNN for image-based date palm species classification. Frontiers in Plant Science, 14: 1281724. https://doi.org/10.3389/fpls.2023.1281724
[5] Ummi, N., Noor, E., Romli, M. (2022). Multi-objective optimization model for determining palm sugar granules production in remanufacturing process using NSGA-II. IOP Conference Series: Earth and Environmental Science, 1063(1): 012020. https://doi.org/10.1088/1755-1315/1063/1/012020
[6] Mohd Izwan, S., Sapuan, S.M., Zuhri, M.Y.M., Mohamed, A.R. (2021). Thermal stability and dynamic mechanical analysis of benzoylation treated sugar palm/kenaf fiber reinforced polypropylene hybrid composites. Polymers, 13(17): 2961. https://doi.org/10.3390/polym13172961
[7] Nurazzi, NM., Khalina, A., Sapuan, S.M., Ilyas, R.A. (2019). Mechanical properties of sugar palm yarn/woven glass fiber reinforced unsaturated polyester composites: Effect of fiber loadings and alkaline treatment. Polimery, 64(10): 665-675. https://doi.org/10.14314/polimery.2019.10.3
[8] Alves, V., dos Santos, J.M., Pinto, E., Ferreira, IM., Lima, V.A., Felsner, M.L. (2024). Digital image processing combined with machine learning: A new strategy for brown sugar classification. Microchemical Journal, 196: 109604. https://doi.org/10.1016/j.microc.2023.109604
[9] Liu, J., Wan, P., Zhao, W., Xie, C., Wang, Q., Chen, D.W. (2022). Investigation on taste-active compounds profile of brown sugar and changes during lime water and heating processing by NMR and e-tongue. LWT, 165: 113702. https://doi.org/10.1016/j.lwt.2022.113702
[10] Yan, F., Li, N., Hirota, K. (2021). QHSL: A quantum Hue, Saturation, and Lightness color model. Information Sciences, 577: 196-213. https://doi.org/10.1016/j.ins.2021.06.077
[11] Fajardo, J.I., Paltán, C.A., López, L.M., Carrasquero, E.J. (2022). Textural analysis by means of a gray level co-occurrence matrix method. Case: Corrosion in steam piping systems. Materials Today: Proceedings, 49: 149-154. https://doi.org/10.1016/j.matpr.2021.07.493
[12] Al Noman, M.A., Zhai, L., Almukhtar, F.H., et al. (2023). A computer vision-based lane detection technique using gradient threshold and hue-lightness-saturation value for an autonomous vehicle. International Journal of Electrical and Computer Engineering, 13(1): 347. https://doi.org/10.11591/ijece.v13i1.pp347-357
[13] Anbalagan, E., Anbhazhagan, S.M. (2023). Deep learning model using ensemble based approach for walking activity recognition and gait event prediction with grey level co-occurrence matrix. Expert Systems with Applications, 227: 120337. https://doi.org/10.1016/j.eswa.2023.120337
[14] Zeraatkar, S., Afsari, F. (2021). Interval–valued fuzzy and intuitionistic fuzzy–KNN for imbalanced data classification. Expert Systems with Applications, 184: 115510. https://doi.org/10.1016/j.eswa.2021.115510
[15] Ma, Y., Huang, R., Yan, M., Li, G., Wang, T. (2022). Attention-based local mean k-nearest centroid neighbor classifier. Expert Systems with Applications, 201: 117159. https://doi.org/10.1016/j.eswa.2022.117159
[16] Li, Y., Ercisli, S. (2023). Data-efficient crop pest recognition based on KNN distance entropy. Sustainable Computing: Informatics and Systems, 38: 100860. https://doi.org/10.1016/j.suscom.2023.100860
[17] Wu, S.B., Mao, P., Li, R.Z., Cai, Z.N., Heidari, A.A., Xia, J.F., Chen, H.L., Mafarja, M., Turabieh, H., Chen, X.W. (2021). Evolving Fuzzy K-Nearest Neighbors using an enhanced sine cosine algorithm: Case study of lupus nephritis. Computers in Biology and Medicine, 135: 104582. https://doi.org/10.1016/j.compbiomed.2021.104582
[18] Ye, H., Wu, P.L., Zhu, T.R., Xiao, Z.X., Zhang, X., Zheng, L., Zheng, R.W., Sun, Y.J., Zhou, W.L., Fu, Q.L., Ye, X.X., Chen, A., Zhang, S., Heidari, A.A., Wang, M.J., Zhu, J.D., Chen, H.L., Li, J.F. (2021). Diagnosing coronavirus disease 2019 (COVID-19): Efficient Harris Hawks-inspired fuzzy K-nearest neighbor prediction methods. IEEE Access, 9: 17787-17802. https://doi.org/10.1109/ACCESS.2021.3052835
[19] Li, Y., Zhao, D., Xu, Z., Heidari, A.A., Chen, H.L., Jiang, X.Y., Liu, Z.F., Wang, M.M., Zhou, Q.Y., Xu, S.L. (2023). bSRWPSO-FKNN: A boosted PSO with fuzzy K-nearest neighbor classifier for predicting atopic dermatitis disease. Frontiers in Neuroinformatics, 16: 1063048. https://doi.org/10.3389/fninf.2022.1063048
[20] Zhang, Q., Sheng, J., Zhang, Q., Wang, L., Yang, Z., Xin, Y. (2023). Enhanced Harris hawks optimization-based fuzzy k-nearest neighbor algorithm for diagnosis of Alzheimer's disease. Computers in Biology and Medicine, 165: 107392. https://doi.org/10.1016/j.compbiomed.2023.107392
[21] Prasad, G., Vijay, G.S., Kamath, R. (2022). Comparative study on classification of machined surfaces using ML techniques applied to GLCM based image features. Materials Today: Proceedings, 62: 1440-1445. https://doi.org/10.1016/j.matpr.2022.01.285
[22] Mohammed, A.A.B.A., Hasan, Z., Omran, A.A.B., Elfaghi, A.M., Ali, Y.H., Akeel, N.A.A., Ilyas, R.A., Sapuan, S.M. (2023). Effect of sugar palm fibers on the properties of blended wheat starch/polyvinyl alcohol (PVA)-based biocomposite films. Journal of Materials Research and Technology, 24: 1043-1055. https://doi.org/10.1016/j.jmrt.2023.02.027
[23] Qiu, D., Liang, H., Wang, Z., Tong, Y., Wan, S. (2022). Hybrid-supervised-learning-based automatic image segmentation for water leakage in subway tunnels. Applied Sciences, 12(22): 11799. https://doi.org/10.3390/app122211799
[24] Sferrazza, P. (2023). Grey level co-occurrence matrix and learning algorithms to quantify and classify use-wear on experimental flint tools. Journal of Archaeological Science: Reports, 48: 103869. https://doi.org/10.1016/j.jasrep.2023.103869
[25] Daneshvari, M.H., Nourmohammadi, E., Ameri, M., Mojaradi, B. (2023). Efficient LBP-GLCM texture analysis for asphalt pavement raveling detection using eXtreme Gradient Boost. Construction and Building Materials, 401: 132731. https://doi.org/10.1016/j.conbuildmat.2023.132731
[26] Zhang, S., Wu, J.R., Shi, E., Yu, S.G., Gao, Y.F., Li, L.H.C., Kuo, L.R., Pomeroy, M.J., Liang, Z.J. (2023). MM-GLCM-CNN: A multi-scale and multi-level based GLCM-CNN for polyp classification. Computerized Medical Imaging and Graphics, 108: 102257. https://doi.org/10.1016/j.compmedimag.2023.102257
[27] Gapsari, F., Darmadi, D.B., Setyarini, P.H., Wijaya, H., Madurani, K.A., Juliano, H., Sulaiman, A.M., Hidayatullah, S., Tanji, A., Hermawan, H. (2023). Analysis of corrosion inhibition of Kleinhovia hospita plant extract aided by quantification of hydrogen evolution using a GLCM/SVM method. International Journal of Hydrogen Energy, 48(41): 15392-15405. https://doi.org/10.1016/j.ijhydene.2023.01.067
[28] Gao, S. (2021). Gray level co-occurrence matrix and extreme learning machine for Alzheimer's disease diagnosis. International Journal of Cognitive Computing in Engineering, 2: 116-129. https://doi.org/10.1016/j.ijcce.2021.08.002
[29] Adhikary, S., Banerjee, S. (2023). Introduction to distributed nearest hash: On further optimizing cloud based distributed knn variant. Procedia Computer Science, 218: 1571-1580. https://doi.org/10.1016/j.procs.2023.01.135
[30] Vommi, A.M., Battula, T.K. (2023). A hybrid filter-wrapper feature selection using Fuzzy KNN based on Bonferroni mean for medical datasets classification: A COVID-19 case study. Expert Systems with Applications, 218: 119612. https://doi.org/10.1016/j.eswa.2023.119612
[31] Jumarlis, M., Mulyadi, I., Mirfan, I., Mardiah, M.F., Anisa, H. (2024). A hybrid hue saturation lightness, gray level co-occurrence matrix, and k-nearest neighbour for palm-sugar classification. IAES International Journal of Artificial Intelligence, 13(3): 2934-2954. https://doi.org/10.11591/ijai.v13.i3.pp2934-2945
[32] Cui, Y., Yang, G., Zhou, Y., Zhao, C., Pan, Y., Sun, Q., Gu, X. (2023). AGTML: A novel approach to land cover classification by integrating automatic generation of training samples and machine learning algorithms on Google Earth Engine. Ecological Indicators, 154: 110904. https://doi.org/10.1016/j.ecolind.2023.110904
[33] Hayashi, T., Cimr, D., Fujita, H., Cimler, R. (2023). Image entropy equalization: A novel preprocessing technique for image recognition tasks. Information Sciences, 647: 119539. https://doi.org/10.1016/j.ins.2023.119539
[34] Xu, G., Xu, X., Wang, X. (2023). Generalized multi-scale image decomposition for new tone manipulation. Digital Signal Processing, 135: 103945. https://doi.org/10.1016/j.dsp.2023.103945
[35] Hoang, C.M., Kang, B. (2024). Pixel-level clustering network for unsupervised image segmentation. Engineering Applications of Artificial Intelligence, 127: 107327. https://doi.org/10.1016/j.engappai.2023.107327
[36] Hagara, M., Stojanović, R., Bagala, T., Kubinec, P., Ondráček, O. (2020). Grayscale image formats for edge detection and for its FPGA implementation. Microprocessors and Microsystems, 75: 103056. https://doi.org/10.1016/j.micpro.2020.103056
[37] Abujayyab, S.K., Almajalid, R., Wazirali, R., Ahmad, R., Taşoğlu, E., Karas, I.R., Hijazi, I. (2023). Integrating object-based and pixel-based segmentation for building footprint extraction from satellite images. Journal of King Saud University-Computer and Information Sciences, 35(10): 101802. https://doi.org/10.1016/j.jksuci.2023.101802
[38] Oğur, N.B., Kotan, M., Balta, D., Yavuz, B.Ç., Oğur, Y.S., Yuvacı, H.U., Yazıcı, E. (2023). Detection of depression and anxiety in the perinatal period using Marine Predators Algorithm and kNN. Computers in Biology and Medicine, 161: 107003. https://doi.org/10.1016/j.compbiomed.2023.107003
[39] Ibraheem, M.K.I., Dvorkovich, A.V., Al-khafaji, I.M.A. (2024). A comprehensive literature review on image and video compression: Trends, algorithms, and techniques. Ingénierie des Systèmes d’Information, 29(3): 863-876. https://doi.org/10.18280/isi.290307
[40] Mohamed, T.M. (2018). Pulsar selection using fuzzy knn classifier. Future Computing and Informatics Journal, 3(1): 1-6. https://doi.org/10.1016/j.fcij.2017.11.001
[41] Faisal, M., Rahman, T.K.A. (2023). Determining rural development priorities using a hybrid clustering approach: A case study of South Sulawesi, Indonesia. International Journal of Advanced Technology and Engineering Exploration, 10(103): 696-719. https://doi.org/10.19101/IJATEE.2023.10101215
[42] Rachmawanto, E.H., Anarqi, G.R., Sari, C.A. (2018). Handwriting recognition using eccentricity and metric feature extraction based on k-nearest neighbors. In 2018 International Seminar on Application for Technology of Information and Communication, Semarang, Indonesia, pp. 411-416. https://doi.org/10.1109/ISEMANTIC.2018.8549804
[43] Hendricks, M.D., Meyer, M.A., Gharaibeh, N.G., Van Zandt, S., Masterson, J., Jr, J.T.C., Horney, J.A., Berke, P. (2018). The development of a participatory assessment technique for infrastructure: Neighborhood-level monitoring towards sustainable infrastructure systems. Sustainable Cities and Society, 38: 265-274. https://doi.org/10.1016/j.scs.2017.12.039
[44] Faisal, M., Abd Rahman, T.K., Mulyadi, I., Aryasa, K., Thamrin, M. (2024). A novelty decision-making based on hybrid indexing, clustering, and classification methodologies: An application to map the relevant experts against the rural problem. Decision Making: Applications in Management and Engineering, 7(2): 132-171. https://doi.org/10.31181/dmame7220241023
[45] Faisal, M., Chaudhury, S., Sankaran, K.S., Raghavendra, S., Chitra, R.J., Eswaran, M., Boddu, R. (2022). Faster R-CNN algorithm for detection of plastic garbage in the ocean: A case for turtle preservation. Mathematical Problems in Engineering, 2022(1): 3639222. https://doi.org/10.1155/2022/3639222
[46] Setiaji, P., Adi, K., Surarso, B. (2024). Development of classification method for determining chicken egg quality using GLCM-CNN method. Ingénierie des Systèmes d’Information, 29(2): 397-407. https://doi.org/10.18280/isi.290201
[47] Miao, R.H., Tang, J.L., Chen, X.Q. (2015). Classification of farmland images based on color features. Journal of Visual Communication and Image Representation, 29: 138-146. https://doi.org/10.1016/j.jvcir.2015.02.011