Nada Abdul Kareem![]()
© 2024 The author. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
The early detection and precise classification of brain tumours are critical in medical imaging, as timely intervention directly impacts the selection of optimal treatment strategies for patients. Accurate tumour segmentation, particularly in brain imaging, plays a vital role in identifying and delineating abnormal tissue regions to support clinical decision-making. Advances in machine learning and deep learning have significantly enhanced the diagnostic accuracy of medical imaging by enabling precise identification and characterization of tumours. In this study, a hybrid framework is proposed for brain tumour segmentation and disease classification, utilizing magnetic resonance imaging (MRI) data. The deep learning model VGG16 was employed to extract high-dimensional features from MRI scans, followed by the application of three machine learning algorithms—Support Vector Classifier (SVC), decision tree, and K-means clustering—for classification tasks. The hybrid approach demonstrated superior performance, with the K-means algorithm achieving the highest segmentation accuracy of 97%. The SVC model achieved an accuracy of 91%, while the decision tree algorithm yielded an accuracy of 89%. This framework offers a robust solution for both tumour segmentation and classification, with potential clinical applications for automating the diagnosis of brain tumours. Notably, the model distinguishes between four tumour types, including three malignant variants, contributing to more effective treatment planning. The integration of deep learning and machine learning techniques within this framework underscores the potential for improving diagnostic efficiency and accuracy in brain tumour analysis.
brain tumour, VGG16, svc, K-mean, decision tree, MRI
Technological advancements in medical imaging, including radiography, MRI, and CT, have significantly impacted disease discovery, diagnosis, and classification. There has been rapid development in the diagnosis and discovery of the classification and classification of brain tumours; tumour segmentation is a significant challenge in medical imaging, particularly in the diagnosis of brain diseases, aiming to accurately and efficiently describe tumour areas, division and classification of brain tumours, through which an accurate diagnosis can be provided to determine the type of tumour and choose the appropriate treatment, whether radiation therapy or drug doses [1, 2]. It also provides an estimate of the development of the disease and the possibility of recovery and helps researchers prepare various studies to understand the different types of tumours to conduct and improve studies. It can also provide various resources for the disease according to the type of tumour [3, 4]. When Artificial Intelligence (AI) methods (machine learning and deep learning) appeared, which helped solve a wide range of problems in computer vision, especially in the field of image and video classification, object recognition, and classification, so many different AI techniques were used to segment brain tumours with very high accuracy [5, 6]. The problem of bullying with brain diseases is still unresolved, which has led researchers to present studies. In this paper, an old model between machine learning and deep learning was presented for segmenting and classifying brain tumours based on the CNN algorithm, through which a set of important characteristics of the tumours were obtained, and then using different machine learning techniques as well as MRI image processing methods [7]. The main problem in image segmentation is the grouping of vectors of similar features of an image. Accurate feature extraction is the basic factor for image verification [8]. This article utilizes MRI scans to categorize and distinguish the initial phases of cancer cells in a two-dimensional brain image. Section 4 describes the suggested approach, Section 5 showcases findings and debates, and Section 6 concludes and presents the software development for the research.
A team of earlier research studies focused on categorizing and dividing brain tumours through creating and implementing various programs based on AI, for instance:
The researchers offered a model primarily based on a sophisticated deep neural network (DNN) to categorise human-mind magnetic resonance photographs as ordinary or pathological [9]. The first degree makes a speciality of preprocessing to decorate photographs with the usage of a statistical method to remove noise, beautify comparison, transform the photograph, and convert the picture to grayscale. This is observed by using a stage of extracting capabilities from the improved mind MRI the usage of a discrete wavelet rework, after which a sophisticated neural community (DNN) is skilled for type. The model completed an accuracy of 95.8%, and the version showed that the processing of natural snap shots plays a vital role in acquiring amazing effects.
The researchers presented a version for classifying brain tumour pix using an AI-based totally approach and the use of deep getting to know algorithms via which the type of brain tumour is determined primarily based on the available dataset, which is classified as malignant or benign [10]. The approach is primarily based on a dataset together with 696 weighted photos for testing functions and an accuracy of 99%. Four become accomplished.
Senan et al. [11] developed a brain tumour segmentation methodology based on a hybrid approach combining artificial neural networks with the fuzzy K-means algorithm, using a fixed set of MRI scans. The process was divided into several stages, including pre-processing, feature extraction, identification, classification, and segmentation. Grey-Level Co-occurrence Matrix (GLCM) features were extracted during the feature extraction phase, and the method was evaluated using the BRATS dataset, achieving an accuracy of 94%.
The article explores techniques in mind tumour segmentation, such as deep gaining knowledge of traditional machine mastering [12]. Ensemble strategies are used to enhance accuracy by using combining version predictions. Freely accessible datasets are examined for creating and evaluating hybrid models. To address generalization and robustness issues, diverse datasets are emphasized. Hybrid approaches are compared to traditional methods in the literature. Recent developments in combining deep learning and machine learning for brain tumour identification are detailed. This study underscores the significance of hybrid methods in enhancing segmentation precision and efficiency for improved patient care.
The study utilized transfer learning with EfficientNets to classify brain tumours into glioma, meningioma, and pituitary tumour categories [13]. Five pre-trained models from EfficientNets were fine-tuned using the CE-MRI Figshare dataset. The method involved a two-level process of optimizing the pre-educated model, first priming it with weights from ImageNet, then adding layers for tumour classification. Testing confirmed the stepped-forward EfficientNets outperformed other pre-trained fashions, with statistics augmentation also enhancing accuracy. Grad-CAM visualization was employed to analyze attention maps for tumour localization in brain images. The results demonstrated significant performance improvements using EfficientNetB2 as the baseline model, achieving 99.06% accuracy, 98.73% precision, 99.13% recall, and 98.79% F1-score.
The researchers provided a method based totally on a hybrid DCNN and an progressed LuNet class algorithm for detecting and classifying brain tumours as glioma or meningioma [14]. The approach entails preprocessing the usage of LOG filter out, segmentation the usage of FCM-GMM, and VGG16 characteristic extraction to generate thirteen type features. The proposed method seeks to improve the overall performance of the classifier, as LuNet classifiers are cost-effective and easy to apply for novices. The simulated outcomes show an accuracy price of 99.7%, outperforming conventional algorithms inclusive of SVM, choice tree, and Resnet-50. The hybrid method demonstrates advanced performance as compared to existing techniques for detecting and classifying mind tumours.
This item reviews the theoretical aspects used in the design and implementation of the proposed model, with a brief explanation of the most important methods, which are based on machine learning and deep learning.
3.1 Machine learning-based technique
AI uses algorithms and statistical models to enable computers to learn from data, identify patterns, and make predictions or decisions based on these patterns.
Machine learning can potentially improve the accuracy and speed of brain cancer diagnosis, reduce the need for invasive procedures, and personalize treatment for individual patients. However, developing machine learning models for brain cancer classification requires large, high-quality datasets and rigorous validation to ensure their reliability and accuracy.
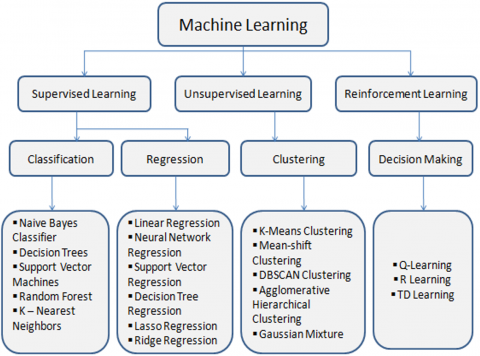
Many different machine learning approaches include supervised, unsupervised, semi-supervised, and reinforcement learning. These approaches can be used for various applications, including image and speech recognition, natural language processing, and predictive analytics. Figure 1 shows the machine-learning algorithms [15].
Figure 1. The machine learning algorithms [15]
3.1.1 Support Vector Machine (SVM)
SVM is a powerful machine learning technique used in classification, regression, and outlier detection in various domains such as text, image, spam, handwriting recognition, and gene expression analysis. It has been used in the classification process of brain diseases, where the algorithm is used to deal with high-dimensional data and non-linear relationships and focuses on separating hyperplanes between target features. The algorithm is supervised and used in classification to identify the best hyperplane in an N-dimensional space to separate data points into different classes.
3.1.2 K-means
The study assumes a pre-defined clustering number, K, and assigns group points. K-means clustering is optimal when data is properly separated but unsuitable when points overlap. It establishes a strong correlation between the data points. The K-means clustering algorithm does not offer explicit insights into the quality of the clusters. Different initial cluster centroid assignments might lead to different clusters. Moreover, the K-means method is susceptible to noise. It is possible that it got stuck in local minima.
Clustering is a method for dividing a population or set of data points into smaller groups. The goal is to make the data points within each group more similar while still being unique. Clustering is sorting things into categories according to their similarities or differences.
An unsupervised learning approach called K-means will be utilized. The number of groups or clusters we wish to classify our stuff into is represented by the letter 'K' in the method's name. Using a random number generator to initialize k cluster centroids, the computer sorts objects into k similarity groups based on Euclidean distance. We assign each item to the closest mean and update the mean's coordinates, which are the averages of the items. The process involves iterating through clusters, where mean points represent average values of objects grouped within them, initializing means with random objects or data set values [16].
3.1.3 Decision tree and decision table
Decision tree is a popular machine learning algorithm, with ID3 being a top-down approach. C4.5 and Behave DT approaches have been used to generate decision trees with a tree-like structure. These algorithms produce judgment rules that can forecast the result for test scenarios that have not been encountered before. These algorithms offer superior precision and enhanced interpretation. The decision Tree algorithm is capable of handling both continuous and discrete data. A decision table is a visual representation of intricate decision rules presented in a tabular format with rows and columns.
3.2 Deep learning-based methods
Deep learning is a machine learning and AI approach that mimics how individuals learn [17].
Hierarchical learning is a method where each layer builds upon the previous one, introducing the concept of hierarchical architecture [18]. Deep learning is a crucial aspect of data science and is beneficial for data scientists who need to analyze and comprehend large amounts of data. Figure 2 shows the deep learning structure.
Deep learning simplifies data processing by creating feature sets independently, eliminating human interaction, and relying on neural networks like the human brain for accuracy [19].
Let’s discuss layers’ types:
Input layer – The input layer has input features, which is a dataset known to us.
Hidden layer – Hidden layer, just like we need to train the brain through hidden neurons.
Output layer – value that we want to classify [20].
Below is a quick overview of the deep learning algorithms that were used to extract the features used as inputs to the machine learning-based classification system.
3.2.1 Basic usages of deep learning
Deep learning is used to solve a diversity of issues in computer vision applications, including object recognition, object detection, segmentation, text classification, image classification, image caption, speech recognition, generative models, manufacturing, biometrics recognition systems, similarity learning, gaming, and many more [21].
Figure 2. Deep neural network [18]
3.2.2 Convolutional Neural Network (CNN)
CNN is a deep learning model designed for structured grid-like inputs like photographs. It employs convolutional, pooling, and fully connected layers for tasks like image classification and object recognition.
3.2.3 VGG-16
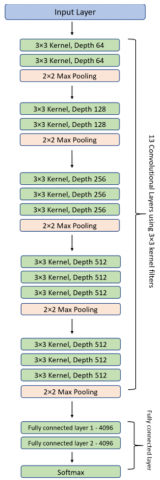
The VGG-16 model, a 16-layer CNN architecture developed by the University of Oxford's Visual Geometry Group, is known for its simplicity, effectiveness, and proficiency in computer vision tasks. The VGG-16 deep learning model employs a stack of convolutional layers and max-pooling layers, enabling complex hierarchical representations of visual data despite its simplicity, resulting in reliable predictions [22].
The precise structure of the VGG-16 networks shown in Figure 3 is as follows:
Figure 3. VGG-16 model architecture [22]
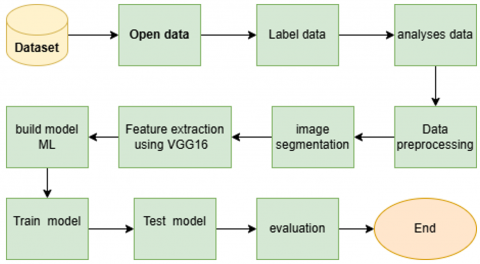
This item deals with the proposed research methodology for classifying brain diseases. It reviews the general framework of the model and describes the proposed method, which is based on machine learning and deep learning. The VGG16 algorithm is utilized for feature extraction, and the extracted features are subsequently fed into three machine learning algorithms to analyze MRI images and classify them as brain tumours. Figure 4 shows the general structure of the proposed model.
Figure 4. Proposed model architecture
Below is a detailed explanation of the entities of the general framework above, with a review of its partial stages.
4.1 Dataset
For this research, a dataset was used that combines the three datasets (com.figshare, Sartaj data set, Br35h). The size of the images in this dataset is different, as the images were changed to the required size after processing and removing the extra margins.
In this paragraph, the dataset that was used as input for the proposed framework is described. The total number of images is 7023, MRI images of four categories as follows:
The data collected was mixed to ensure randomness, which is crucial for unbiased training of the machine learning model used in the proposed model. The first step in preparing the data is the basic one for subsequent analysis: pre-treatment and typical training stages. Figure 5 shows samples of the data set used.
Figure 5. Samples from a data set
4.1.1 Image details
4.1.2 Acquisition protocols
The specific acquisition protocols for each dataset may differ based on the equipment and research objectives from each source. However, by combining data from various sources, a more robust and generalized dataset is created that captures the variability present across different MRI protocols and equipment.
4.1.3 Rationale for combining three datasets
Combining the Figshare, SARTAJ, and Br35H datasets into a single, comprehensive dataset enhances the model’s ability to generalize across different variations in imaging, patient demographics, and acquisition protocols. Here's why this approach was chosen:
(1) Dataset Enrichment: Each dataset individually might have limitations, such as a small number of samples restricted to a particular tumour type or modality. Combining three datasets expands the variety of images, thus providing richer, more diverse data to train a model. This also helps prevent overfitting to the specific characteristics of one dataset.
(2) Balanced Representation of Tumour and No Tumour Classes:
(3) Improved Generalization: By combining datasets from different sources, the dataset captures variability in MRI acquisition protocols, machine settings, and patient demographics. This helps develop models that are more robust and generalizable across different real-world scenarios, MRI machines, and healthcare settings.
(4) Increase in Class Balance: Some of the individual datasets may have an imbalance between tumour types (e.g., more images of gliomas than meningiomas). Combining multiple datasets helps balance the class distribution, ensuring that machine learning models do not become biased towards overrepresented tumour types.
(5) Improved Model Precision: When it comes to scientific imaging tasks, having larger and more diverse datasets typically results in more accurate models. Through merging two sets of data, there is a boost in overall size and scope, leading to enhanced training for machine learning models and improved accuracy in categorization.
4.1.4 Applications and use cases
The combined dataset has several potential applications:
4.2 Analysis data
This section analyzed data and MRI images in a preliminary manner to understand the distribution of brain disease data. This step is necessary to obtain an insight into the data and ensure balanced representation across the different categories.
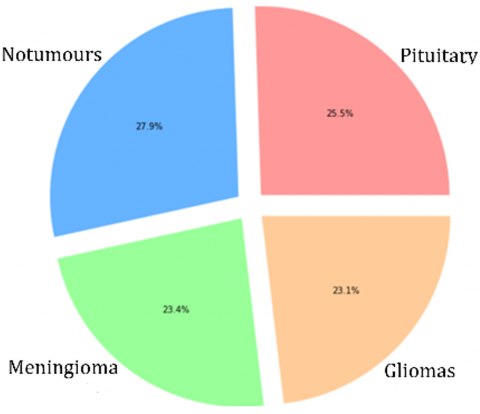
Figure 6 shows a percentage based on a type of tumour, which provides a clear overview of the data set composition used. Using distinct colours and percentile annotations helps identify any differences in a data set and is vital for training a model in machine learning. Figure 7 represents the frequency polygon for each type of brain tumour in a data set. Figure 8 illustrates the percentage of data division for training and testing before performing the processing process, because the data set used in the proposed model is divided from the source. 81.3% for training and 18.7% for testing.
Figure 6. Percentage of each type of tumour
Figure 7. Distribution of types of brain tumours
Figure 8. Split test and training data
4.3 Data preprocessing
Preprocessing the image data is a critical step in enhancing the quality and variability of the dataset. We employed several image augmentation techniques to ensure the model receives diverse input, which is crucial for robust learning and generalization.
The preprocessing function augment_image performs the following transformations on each image:
4.4 Image segmentation
We carried out a custom photo preprocessing function and picture segmentation to enhance the capabilities of the brain tumour MRI pictures. This preprocessing step aims to enhance the first-class and clarity of the images, making it easier for the device-gaining knowledge of the model to discover and classify tumours appropriately. Here is a detailed clarification of the image segmentation:
The image segmentation feature applies a series of differences to the enter pix:
Thresholding: Initially, the image is converted into a binary image through the use of a thresholding method. More precisely, it utilizes a binary threshold to assign pixel values below 100 to 0, and values above 200 to 250. This stage assists in dividing the image into sections, emphasizing the areas of interest (possible tumours) by making them distinguishable from the background.
Morphological Closing: The characteristic applies a morphological closing operation to refine the binary image. This operation makes use of a kernel (a small matrix) to shut holes in the foreground objects. In this situation, a kernel of size 2×2 is used. The closing operation enables taking away small black spots and joining disjointed white areas in the binary image, improving the detected features' structural integrity.
4.5 Feature extraction using VGG16
Why VGG16 has been selected for feature extraction
VGG16 is one of the most commonly used pre-trained CNN for feature extraction in computer vision tasks like medical image analysis, including brain tumour detection. Here’s why VGG16 was selected over other popular architectures like ResNet or Inception:
1. Simplicity and Proven Effectiveness
2. Transfer Learning
3. Depth and Representation Power
4. Feature Localization
Comparison with other architectures (ResNet, Inception).
1. ResNet (Residual Networks)
Architecture: ResNet introduces the concept of residual connections or skip connections, which solve the vanishing gradient problem, enabling deeper networks (e.g., ResNet-50, ResNet-101).
Strength: ResNet models are significantly deeper than VGG16 (e.g., ResNet-50 has 50 layers). They excel in extracting highly abstract, deep-level features due to their depth and residual connections.
Pros: Better at avoiding the vanishing gradient problem in very deep networks, leading to improved performance on more complex tasks.
Efficient training due to residual learning.
Cons: While ResNet’s depth makes it powerful, it can also increase complexity and computational cost.
In some cases, such depth may not provide additional value for medical imaging tasks, where finer details and local features are more critical than extremely deep feature representations.
Comparison to VGG16: ResNet tends to perform better on large-scale datasets but may not always offer significant improvements in specialized tasks like brain MRI classification compared to VGG16.
The additional depth may not be necessary for tasks with a smaller number of classes, especially when using transfer learning with moderate-sized medical datasets.
2. Inception (GoogLeNet/InceptionV3)
Architecture: Inception uses a more complex structure called Inception modules, which apply multiple convolutional filters of different sizes (1x1, 3x3, 5x5) in parallel and then concatenate the results.
Strength: Inception is designed to capture multi-scale features by using filters of different sizes, which helps the model understand both local and global features simultaneously.
Pros: Efficiently captures features across multiple scales, which could be useful in medical images where features like tumour size can vary.
More computationally efficient than VGG16, as it avoids redundancy in convolution operations.
Cons: The architecture of Inception is more complicated, making it tougher to interpret or regulate for precise use cases.
Training and high-quality tuning inception may be more difficult because of its sophisticated layout.
Comparison to VGG16: Inception is great at capturing features of different scales, but VGG16's simplicity makes it more convenient for smaller tasks like brain MRI classification, focusing on local features like tumour boundaries and textures.
For unique medical imaging duties, the computational efficiency of Inception might not be a huge advantage in comparison to the easy yet powerful layout of VGG16.
Why VGG16 over ResNet or Inception for brain MRI feature extraction?
Interpretability: In medical imaging, fashions like VGG16 are easier to interpret and troubleshoot. Understanding which convolutional layers make a contribution to tumour class can be important in a healthcare setting wherein explainability is vital.
Efficiency: VGG16 offers excellent stability between intensity and computational performance. It is less complicated than ResNet and Inception, making it less complicated to first-rate-track and adapt to unique datasets like brain MRIs.
Proven Track Record: VGG16 has been appreciably utilized in clinical imaging research and has shown constant results in extracting features from medical scans, making it a reliable preference.
Specialized Feature Detection: Given that mind MRI pictures frequently require precise localization of tumours, VGG16's small filter sizes (3x3) are surprisingly effective in shooting the pleasant-grained information and spatial structure inside medical photos.
Final justification:
VGG16 was chosen for its simplicity, strong transfer learning performance, and ability to extract hierarchical features. While ResNet and Inception have advantages in complex tasks, VGG16's interpretability, success in medical imaging, and lower complexity make it ideal for brain tumour classification with MRI images.
In our framework, we utilized the VGG16 model for feature extraction from brain tumour MRI images using deep learning techniques. This crucial step in our machine learning pipeline harnesses the model's powerful capabilities trained on the ImageNet dataset.
4.5.1 Loading the VGG16 model
We employed the VGG16 version, which is a convolutional neural network pre-educated at the ImageNet dataset. This model is widely identified for its effectiveness in function extraction due to its deep structure and widespread education on numerous photographs. The version was loaded with pre-educated weights, and the pinnacle layers were excluded to cognizance on the convolutional base for feature extraction.
4.5.2 Extracting features
We handed the preprocessed photographs through the VGG16 model to extract excessive-degree features. These capabilities, generated from the convolutional layers, seize intricate patterns and representations inside the images that benefit category tasks.
4.6 Build model machine learning
After the function extraction technique using the VGG16 algorithm, 58,889,256 capabilities were received for the information set used for magnetic resonance snap shots. These features are considered inputs to the proposed machine learning model, which consists of three algorithms (SVC, decision-tree, K-means). The appropriate classification, tumour classification, and types were obtained.
This item reviews the results of implementing the proposed model, which was examined using an MRI data set, where an MRI scan of previously collected and processed brain tumours is performed. Pre-processing of MRI images is crucial to improving the image's visual effect before processing it. The images are usually collected from a data set with poor quality and noise that must be filtered out.
5.1 Preprocessing results
Figure 9 shows a sample of the data after the initial processing process, where the noise was removed and brightness, contrast, sharpness and normalization were performed.
Figure 9. Images after processing
5.2 Images segmentation results
Figure 10 shows a sample of the data set after performing the segmentation process using the techniques mentioned in Paragraph (5). Unimportant areas were neglected.
Figure 10. Segmentation process
5.3 Feature extraction results
Figure 11 represents samples of the features that were extracted from MRI images after using the vGG16 algorithm.
Figure 11. Samples of the features
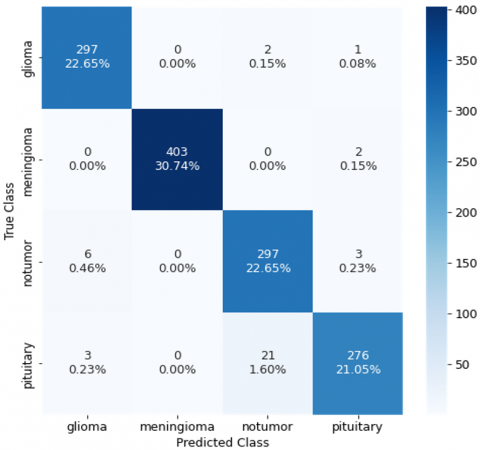
This section reviews the implementation results based on combined machine learning and deep learning techniques for three algorithms (SVC, K-mean, and CNN). The results include the above (robot classification, convolution matrix) for each algorithm used as their value below in the Tables 1-3 and Figures 12-14.
Figure 12. SVC convolution matrix
Figure 13. Decision tree convolution matrix
Figure 14. K-mean classification report
Table 4 suggests the overall performance of a model detecting brain tumors (Glioma, Meningioma, Pituitary) and no tumors. The version plays best in detecting "No Tumor" cases, with excessive accuracy across all metrics. The "Pituitary" tumor is the hardest to predict, displaying the bottom rankings. Overall, the model demonstrates sturdy accuracy, especially in precision and segmentation satisfactory.
Table 1. SVC classification report
|
|
Precision |
Recall |
F1-Score |
Support |
|
Pituitary |
0.92 |
0.98 |
0.95 |
300 |
|
Notumor |
0.94 |
0.99 |
0.97 |
405 |
|
Meningioma |
0.84 |
0.78 |
0.81 |
306 |
|
Glioma |
0.90 |
0.85 |
0.87 |
300 |
|
Accuracy |
|
|
0.91 |
1311 |
|
Macro avg |
0.90 |
0.90 |
0.90 |
1311 |
|
Weighted avg |
0.90 |
0.91 |
0.90 |
1311 |
Table 2. Decision tree classification report
|
|
Precision |
Recall |
F1-Score |
Support |
|
Pituitary |
0.86 |
0.96 |
0.91 |
300 |
|
Notumor |
0.97 |
0.99 |
0.98 |
405 |
|
Meningioma |
0.83 |
0.79 |
0.81 |
306 |
|
Glioma |
0.86 |
0.78 |
0.82 |
300 |
|
Accuracy |
|
|
0.89 |
1311 |
|
Macro avg |
0.88 |
0.88 |
0.88 |
1311 |
|
Weighted avg |
0.89 |
0.89 |
0.89 |
1311 |
Table 3. K-mean classification report
|
|
Precision |
Recall |
F1-Score |
Support |
|
Pituitary |
0.97 |
0.99 |
0.98 |
300 |
|
Notumor |
1.00 |
1.00 |
1.00 |
405 |
|
Meningioma |
0.93 |
0.97 |
0.95 |
306 |
|
Glioma |
0.98 |
0.92 |
0.95 |
300 |
|
Accuracy |
|
|
0.97 |
1311 |
|
Macro avg |
0.97 |
0.97 |
0.97 |
1311 |
|
Weighted avg |
0.97 |
0.97 |
0.97 |
1311 |
Table 4. The metrics used to evaluate the final results of the proposed model based on the following metrics
|
Metric |
Glioma |
Meningioma |
Pituitary |
No Tumor |
Average |
|
Dice Score |
0.87 |
0.89 |
0.85 |
0.95 |
0.89 |
|
Jaccard Index (IoU) |
0.78 |
0.81 |
0.75 |
0.90 |
0.81 |
|
Hausdorff Distance |
4.5 mm |
5.1 mm |
6.2 mm |
2.0 mm |
4.45 mm |
|
Precision |
0.88 |
0.91 |
0.86 |
0.97 |
0.91 |
|
Recall |
0.85 |
0.87 |
0.82 |
0.93 |
0.87 |
|
F1-Score |
0.86 |
0.89 |
0.84 |
0.95 |
0.88 |
One of the most common diseases is brain tumours due to the proliferation of abnormal or portable cells and their rapid spread. Therefore, early tumour detection determines its type, malignant or benign. It is considered one of the very necessary matters. This is the distinction between normal and abnormal tumours and the classification of normal tumours into different types. This study built a hybrid model between machine and deep learning to detect, identify, and segment brain tumours on MRI images. The model relies on algorithms (VGG16, SVC, K-means, decision tree). The advantage of using it in the model is extracting, identifying and classifying the types of tumours between normal and abnormal and those classified into 3 types. Accuracy was obtained. K-means algorithm with 97% accuracy, then the SVC algorithm with 91% accuracy, and then the decision tree algorithm with 89% accuracy.
[1] Zhao, L., Jia, K. (2016). Multiscale CNNs for brain tumor segmentation and diagnosis. Computational and Mathematical Methods in Medicine, 2016(1): 8356294. https://doi.org/10.1155/2016/8356294
[2] Saddique, M., Kazmi, J.H., Qureshi, K. (2014). A hybrid approach of using symmetry technique for brain tumor segmentation. Computational and Mathematical Methods in Medicine, 2014(1): 712783. https://doi.org/10.1155/2014/712783
[3] Varuna Shree, N., Kumar, T.N.R. (2018). Identification and classification of brain tumor MRI images with feature extraction using DWT and probabilistic neural network. Brain Informatics, 5(1): 23-30. https://doi.org/10.1007/s40708-017-0075-5
[4] Sajjad, M., Khan, S., Muhammad, K., Wu, W., Ullah, A., Baik, S.W. (2019). Multi-grade brain tumor classification using deep CNN with extensive data augmentation. Journal of Computational Science, 30: 174-182. https://doi.org/10.1016/j.jocs.2018.12.003
[5] Rehman, A., Naz, S., Razzak, M.I., Akram, F., Imran, M. (2020). A deep learning-based framework for automatic brain tumors classification using transfer learning. Circuits, Systems, and Signal Processing, 39(2): 757-775. https://doi.org/10.1007/s00034-019-01246-3
[6] Wang, Y., Zu, C., Hu, G., Luo, Y., Ma, Z., He, K., Wu, X., Zhou, J. (2018). Automatic tumor segmentation with deep convolutional neural networks for radiotherapy applications. Neural Processing Letters, 48: 1323-1334. https://doi.org/10.1007/s11063-017-9759-3
[7] Jégou, S., Drozdzal, M., Vazquez, D., Romero, A., Bengio, Y. (2017). The one hundred layers tiramisu: Fully convolutional densenets for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pp. 11-19. https://doi.org/10.1109/CVPRW.2017.156
[8] Tufail, A.B., Ullah, I., Khan, W.U., Asif, M., Ahmad, I., Ma, Y.K., Khan, R., Kalimullah, Ali, M.S. (2021). Diagnosis of diabetic retinopathy through retinal fundus images and 3D convolutional neural networks with limited number of samples. Wireless Communications and Mobile Computing, 2021(1): 6013448. https://doi.org/10.1155/2021/6013448
[9] Ullah, Z., Farooq, M.U., Lee, S.H., An, D. (2020). A hybrid image enhancement based brain MRI images classification technique. Medical Hypotheses, 143: 109922. https://doi.org/10.1016/j.mehy.2020.109922
[10] Mehrotra, R., Ansari, M.A., Agrawal, R., Anand, R.S. (2020). A transfer learning approach for AI-based classification of brain tumors. Machine Learning with Applications, 2: 100003. https://doi.org/10.1016/j.mlwa.2020.100003
[11] Senan, E.M., Jadhav, M.E., Rassem, T.H., Aljaloud, A.S., Mohammed, B.A., Al-Mekhlafi, Z.G. (2022). Early diagnosis of brain tumour MRI images using hybrid techniques between deep and machine learning. Computational and Mathematical Methods in Medicine, 2022(1): 8330833. https://doi.org/10.1155/2022/8330833
[12] Sajjanar, R., Dixit, U.D., Vagga, V.K. (2024). Advancements in hybrid approaches for brain tumor segmentation in MRI: A comprehensive review of machine learning and deep learning techniques. Multimedia Tools and Applications, 83(10): 30505-30539. https://doi.org/10.1007/s11042-023-16654-6
[13] Babu Vimala, B., Srinivasan, S., Mathivanan, S.K., Mahalakshmi, Jayagopal, P., Dalu, G.T. (2023). Detection and classification of brain tumor using hybrid deep learning models. Scientific Reports, 13(1): 23029. https://doi.org/10.1038/s41598-023-50505-6
[14] Balamurugan, T., Gnanamanoharan, E. (2023). Brain tumor segmentation and classification using hybrid deep CNN with LuNetClassifier. Neural Computing and Applications, 35(6): 4739-4753. https://doi.org/10.1007/s00521-022-07934-7
[15] Estivill-Castro, V. (2002). Why so many clustering algorithms: A position paper. ACM SIGKDD Explorations Newsletter, 4(1): 65-75. https://doi.org/10.1145/568574.568575
[16] Macqueen, J. (1967). Some methods for classification and analysis of multivariate observations. In Proceedings of 5-th Berkeley Symposium on Mathematical Statistics and Probability, 1: 281-297.
[17] Yuan, C., Yang, H. (2019). Research on K-value selection method of K-means clustering algorithm. Multidisciplinary Scientific Journal, 2(2): 226-235. https://doi.org/10.3390/j2020016
[18] Hastie, T., Tibshirani, R., Friedman, J.H., Friedman, J.H. (2009). The elements of statistical learning: Data mining, inference, and prediction. In the Elements of Statistical Learning. New York: Springer, 2: 1-758.
[19] Forgy, E.W. (1965). Cluster analysis of multivariate data: Efficiency versus interpretability of classifications. Biometrics, 21: 768-769.
[20] Lloyd, S. (1982). Least squares quantization in PCM. IEEE Transactions on Information Theory, 28(2): 129-137.
[21] Sarker, I.H., Colman, A., Han, J. (2019). Recencyminer: Mining recency-based personalized behavior from contextual smartphone data. Journal of Big Data, 6(1): 1-21. https://doi.org/10.1186/s40537-019-0211-6
[22] Chuku, A.J., Godspower, N.O. (2019). Structural analysis of wing in ground craft rotor blade using carbon compounds. International Journal of Research Publications, 39(2).