Maira Uaissova*![]() | Bakhtiyar Zharlykassov
| Bakhtiyar Zharlykassov![]()
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
In present-day conditions of road infrastructure development, ensuring the high quality of asphalt concrete mixes contributes to the durability and reliability of road pavements. This article investigates the application of artificial intelligence techniques to analyze asphalt quality aimed at optimizing production and improving the reliability of road pavements. This study introduces a pioneering approach to asphalt concrete mix quality enhancement using artificial intelligence (AI) techniques, specifically artificial neural networks (ANN) and least-squares support vector machine (LS-SVM). The application of these methods allows for carrying out efficient analysis of data, reflecting asphalt quality, predicting asphalt characteristics, and optimizing production processes. The authors conducted experiments using real asphalt properties, which were used to train and set ANN and LS-SVM models. The obtained results were compared with existing methods of asphalt quality analysis. The conducted analysis confirmed the effectiveness of using ANN and SVM to analyze asphalt quality. This approach provides an opportunity for accurate prediction of asphalt performance characteristics and production process optimization, contributing to the improvement of the durability and reliability of road pavements. The obtained results have practical significance for engineers and specialists in the field of road infrastructure construction and maintenance. The results of the study validate the superiority of AI-driven models in achieving precise and reliable asphalt mix designs, marking a considerable advancement over traditional methods.
AI, ANN, artificial neural network, asphalt quality, least-squares support vector machine, LS-SVM, practical use, prediction
Currently, asphalt is one of the most common materials used for constructing roads and other infrastructure objects. The quality of asphalt directly affects the safety and durability of these objects, and therefore, it is important to possess effective methods to analyze the asphalt quality. In this context, artificial intelligence can provide valuable tools for analyzing asphalt quality [1-3].
One of the advantages of using AI to analyze the quality of asphalt is the ability to use a large amount of data, which allows obtaining more accurate results. Asphalt quality data, including its chemical composition, particle size, density, and other parameters, can be collected from various sources including laboratory and field studies. Using AI allows analyzing this data and identifying relationships between asphalt parameters and asphalt quality [4-6].
Creating a machine learning (ML) technique to analyze asphalt quality is an approach that can be used with AI. For example, neural networks (NNs), decision trees, support vector machines (SVMs), and other ML techniques can be used to train a model based on asphalt quality data [7, 8]. These models can be used to predict the asphalt quality based on its parameters, which can help in determining the optimal parameters for producing a quality asphalt mix.
In the Republic of Kazakhstan, like in many other countries, road pavement quality is an important factor affecting road safety and travel comfort. However, despite significant investment in infrastructure, the quality of asphalt concrete mixes and road pavements in the country often leaves much to be desired. This is due to several challenges, including the underutilization of modern technology and analysis methods in the asphalt production process.
A key problem is the lack of automated control systems to produce asphalt concrete mixes providing more accurate control over the mix quality and production process optimization. AI technology, such as ANN and LS-SVM, which significantly improve the accuracy in determining asphalt quality prediction and optimal production parameters, is not yet widespread in Kazakhstan. Kazakhstan has an underdeveloped scientific base in the application of AI in asphalt production. This limits the opportunities for research and development of new methods and technologies to improve the efficiency of asphalt concrete mix production.
Thus, AI application in asphalt production in Kazakhstan is associated with the necessity to develop automated process control systems for production, implement contemporary analysis methods, and improve the scientific base in this area.
To improve production quality and optimize processes, the following AI-based approaches and methods listed and described below can be used in automated technological control lines of asphalt concrete mix production.
(1) NNs (ANN, CNN) can be used to analyze asphalt quality data and predict optimal parameters for producing quality mix. ANN can be trained based on previously collected asphalt quality data and production parameters, which allows for predicting optimal parameter values based on current data.
(2) The support vector method (SVM) can be used to classify asphalt based on its properties and quality. SVM can help in determining asphalt performance properties, which should be improved to achieve certain quality goals.
(3) Genetic algorithms can be used to optimize production parameters. Genetic algorithms can generate different parameter combinations and evaluate them based on given criteria, such as asphalt quality and production cost.
(4) Natural language processing (NLP) can be used to analyze customer feedback and comments about asphalt quality. NLP can help in identifying common problems and deficiencies associated with asphalt production and suggest solutions to address them.
(5) Clustering methods (K-means clustering) can be used to group asphalt with different properties and quality into categories. This can help in identifying the common characteristics of each category and improve production processes to achieve better product quality.
The combination of different AI-based approaches and techniques can help in achieving optimal asphalt mix quality and improving production processes. The main emphasis is on the use of AI to improve asphalt quality analysis and control and to identify methods to optimize production processes in road construction.
The aim of this article is to investigate and present a new approach for analyzing asphalt quality using AI techniques. The main objective is to develop and validate a methodology involving the application of ANN and LS-SVM to optimize asphalt mix production.
The study aims to address the following research questions:
(1) How can AI techniques, specifically ANN and LS-SVM, be effectively applied to analyze and improve the quality of asphalt concrete mixes?
(2) What are the predictive capabilities of ANN and LS-SVM models in forecasting asphalt performance characteristics and optimizing production parameters?
(3) Can the integration of AI technologies into asphalt mix production lead to significant improvements in the durability and reliability of road pavements, compared to traditional quality analysis methods?
By focusing on these questions, our research highlights the limitations of conventional techniques and underscores the potential of AI methodologies to revolutionize asphalt quality analysis, providing clearer, more precise, and actionable insights for the construction industry. This distinction not only establishes the novelty of our study but also sets the foundation for future advancements in the field.
The application of AI in asphalt mix production is an actively developing field. Botella et al. [1] investigate ML techniques for estimating bitumen activity in recycled asphalt pavement. Additional research by Liu et al. [2] also uses ML to optimize the asphalt mix design by predicting the effective asphalt content and absorbed asphalt content.
Rahman et al. [3] apply ML techniques to predict metrics related to the performance of asphalt mixes. This study is complemented by Sebaaly et al. [4] who use ANN and genetic algorithms to optimize the design process of asphalt mixtures.
The application of AI in predicting asphalt concrete mix properties is investigated by Androjić and Marović [7] using ANN and MLR models. Mousa et al. [5] apply these models to estimate the optimum asphalt content from aggregate gradation.
Le et al. [6] propose an AI-based model for predicting the dynamic modulus of stone mastic asphalt mix. The work by Karballaeezadeh et al. [9] represents a further development of this field by presenting hybrid prediction models for intelligent road inspection.
The importance of applying AI when building sustainable highway and road systems is highlighted by Arifuzzaman et al. [10]. Hoang [8] presents an AI method for detecting potholes in asphalt pavement using the least-squares method (LSM) and NN.
AI plays an important role in predicting rutting and fatigue parameters in modified asphalt binders as shown by Uwanuakwa et al. [11]. Hosseinzadeh et al. [12] use ML algorithms to predict Marshall asphalt stability.
ANNs have also been used to control the quality of asphalt compaction as shown by the study [13].
Previous research primarily focuses on traditional methods or early-stage AI application, lacking in predictive accuracy and optimization capabilities for asphalt mix design. Studies have shown that reinforcement learning can be effective when solving route optimization problems, resource allocation, and managing infrastructure, such as energy grids and transportation systems.
Reinforcement learning requires a large amount of data for training, which can be challenging in real-world environments. However, modern ML techniques and advances in computer processing power make it possible to solve reinforcement learning problems efficiently, making it increasingly popular in various industries.
Thus, reinforcement learning is a promising area in the field of AI and can be effectively applied to optimize management in various industries.
Two main data analysis methods were used in the present study, ANN and LS-SVM.
The experiment was conducted at the LeaderStroy LLP enterprise (asphalt concrete plant) in Kostanay, Kazakhstan in 2022. This enterprise specializes in the production of asphalt concrete mixes for road construction. As part of the experiment, the physical and mechanical characteristics of asphalt were investigated. Asphalt composition data and performance characteristics were collected and analyzed to determine the asphalt quality. The data were used to train ML models.
Asphalt composition data included information on the type of bitumen used in asphalt production and its concentration. Asphalt characterization data included information on asphalt density, hardness, and wear resistance.
3.1 Study design
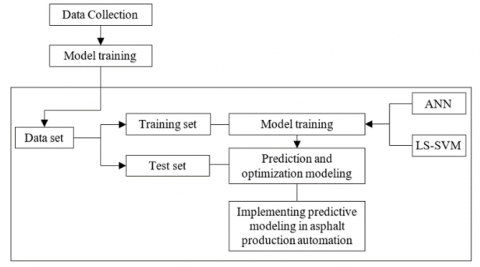
The experimental process consisted of the following steps (Figure 1).
Data collection: data on the composition of asphalt concrete mixes and their physical and mechanical characteristics were collected from LeaderStroy LLP.
Data preprocessing: data preprocessing was performed, including removing outliers, filling in missing values, and scaling.
Model training: the TensorFlow library was used for the ANN-based approach. An NN with multiple layers, including input and output layers, was created. The model was trained based on the preprepared data using the mean square error (MSE) loss function.
The scikit-learn library was used for LS-SVM. The LS-SVM model was created by selecting the optimal hyperparameters, such as kernel type, C parameter, and epsilon parameter.
Testing and analyzing results: to evaluate performance, both models were tested using deferred data. Metrics, such as determination coefficient (R2) and root MSE were used for analysis.
Python programming language programs, as well as TensorFlow and scikit-learn libraries, were used to analyze the data and results. The application of formulas and algorithms for training and testing models was described previously.
ANN: Various ANNs have been used to simulate the relationships between production parameters and asphalt quality, namely, BFGS (Broyden-Fletcher-Goldfarb-Shanno) optimization method for finding the local minimum (or maximum) of a non-smooth multivariate function. This method is based on updating the estimate of the inverse Hessian matrix (second derivative) based on the information of the function gradient. BFGS is an iterative method, which is trying to approximately reconstruct the inverse Hessian matrix to move at each iteration step in the direction opposite to the function gradient.
LS-SVM: LS-SVM has been used to predict asphalt quality based on production parameters. To implement this method, the LS-SVM laboratory (LS-SVM lab) library is used to work with SVM with linear kernel functions and the LSM to minimize the MSE under constraint conditions similar to those used in classical SVM.
Figure 1. Proposed approach of using AI to analyze asphalt quality and determine optimal production parameters
The following model estimation methods were used in the study.
Cross-validation is a method that allows assessing the model performance based on its generalization performance. This method consists of dividing the available data into training and test sets.
The model is trained based on the training set and then is assessed using the test set. This process is repeated several times with different data partitions, and the results are combined to get a better estimate of the model performance.
Assessment metrics include:
- MSE,
- determination coefficient (R2),
- mean absolute error (MAE),
- predictive accuracy (accuracy).
These metrics collectively provide a comprehensive evaluation of the model's predictive performance. MSE and MAE focus on the average error magnitude, which is vital for continuous output predictions. In contrast, R2 and predictive accuracy offer insights into how well the model's predictions match the actual data and its capability to correctly classify or predict outcomes, respectively. Together, they allow allow for assessing how close the values predicted by the model are to the actual values.
Error analysis. Performing error analysis allows understanding in which cases the model gives incorrect predictions and with which data it performs better. Error analysis can be done by visualizing the difference between actual and predicted values or by analyzing the error distribution.
Comparison with other methods. To assess the performance of the models, their results can be compared with those obtained by other existing asphalt quality analysis methods. This allows determining the advantages and disadvantages of ML techniques compared to classical methods and making a grounded decision about the best approach.
The proposed approach uses ANN and LS-SVM methods to analyze asphalt performance properties. Physical and mechanical characterization data are collected, preprocessed, and used to train the models. The ANN model sets the weights of neurons, and the LS-SVM model optimizes the parameters using special kernels. The resulting models are tested using corresponding test data provided with accuracy metrics. The results are compared with each other and with existing analysis methods. This approach allows optimizing production processes and improving the quality of asphalt concrete mixes.
3.2 Technical support
The workstation used included the following processor:
(1) Supermicro computer with Intel Socket 2011 Xeon E5-2690 processor, 128 GB RAM, SDD P400e 200 GB, HDD Seagate SATA3 2 TB, NVIDIA Quadro K5000 graphics card, and two NVIDIA Tesla K20X PCI-E board 6 GB graphics cards.
(2) MacBook Pro 15 Intel Core i7 processor, 16 GB RAM, Radeon Pro 560 512 GB SSD graphics card.
(3) HP laptop processor: 11th generation Intel® Core i3, 8 GB of DDR4 memory, 480 GB of SSD memory.
The selection of the technical environment for our study, featuring high-performance computing systems and advanced graphics processing units (GPUs), was guided by the need for substantial computational power and efficiency. These systems were chosen to effectively handle the demanding computational requirements of training and testing the ANN and LS-SVM models, which are essential for the precise analysis and optimization of asphalt concrete mix quality.
The inclusion of both high-end desktops and portable laptops addresses the need for versatility and mobility in research activities. This allows for a flexible working arrangement, enabling research tasks to be performed efficiently from various locations without compromising on computational capabilities.
However, the reliance on such specific hardware configurations may introduce scalability constraints, potentially limiting the handling of larger datasets or more complex model training scenarios.
To evaluate the effectiveness of using ANN and LS-SVM, an experiment was carried out at an automated process control line for production asphalt concrete mix, where one of the models was used to predict asphalt quality and the other model was used to control the production process.
Data collected from the production line over the past years were used to train both models. The models were tested on independent datasets to evaluate their accuracy and generalization ability.
At the first stage, data on asphalt production parameters and the corresponding asphalt quality were collected. These data could include a variety of parameters, such as types and proportions of asphalt concrete mix components, temperature, heating time, etc. The dataset was divided into a training set, which included 80% of the data, and a validation set, which contained 20% of the data. The first set was used for model building while the second set was reserved to investigate the predictive performance of the models.
A single run of the experiment may not give a reliable indication of the predictive performance of the model due to the problem of randomness in data partitioning. Consequently, the performance of the AI approaches (ANN and LS-SVM) was evaluated using an iterative subsampling process that included 20 runs. In each run, 20% of the dataset was randomly extracted from the testing dataset; the rest of the dataset was used as the training set.
Before the training and prediction phase, the MSE and MAE were also calculated to normalize the entire dataset and evaluate the quality of both models. As can be seen from the Table, the MSE and MAE values for both models were very close, indicating the high accuracy of the models. Data normalization was aimed at avoiding a situation where input variables with large values dominate over variables with small values.
Moreover, the implementation of the two AI models requires specifying several setting parameters. To set these parameters, the original data set was divided into a training set (80%) and a validation set (20%). The model setting parameters corresponding to the best predictive performance based on the validation set were selected as the optimal ones.
Implementation of ANN requires determining the number of neurons in the hidden layer, and the training speed. The number of neurons in the input and output layers was 0.000. The number of neurons in the hidden layer did not exceed 1.5×N. The second setting parameter of ANN was the training speed, whose values could be selected from the set [0.001, 0.01, 0.1, 1]. Other parameters of ANN, including the type of activation function and the number of training epochs, were chosen to be logarithmic-sigmoidal and equal to 3,000, respectively.
In the case of LS-SVM, this AI method requires the appropriate definition of the penalty constant and kernel function parameters. In this study, these two LS-SVM setting parameters were determined using a grid search algorithm.
Analysis of asphalt quality data using ML techniques allows obtaining more accurate information about asphalt composition and characteristics, which can be used to improve asphalt pavement quality. This opens new opportunities to develop more efficient methods for producing and monitoring asphalt quality, which in turn will lead to improved road safety.
The ANN and LS-SVM methods are the ML techniques used in the automated process control line to produce asphalt concrete mixes. Both methods are used to analyze asphalt quality and optimize production parameters.
The data were collected from an automated process control line at an asphalt concrete mix production facility. Historical data from the production line were utilized to train the AI models, namely ANN and LS-SVM. This training involved using the data to predict asphalt quality and control the production process effectively.
ANN is an ML technique that simulates the human brain using NNs. ANN is used to analyze asphalt quality data that is collected during production. ANN is trained on a dataset that is used to determine the relationships between input and output data. ANN can predict asphalt quality based on the available data allowing operators to quickly and accurately determine production parameters.
LS-SVM is an ML technique, used to solve regression and classification problems. It is based on SVM but uses LSM to solve the optimization problem. LS-SVM is used to optimize production parameters, such as temperature and mixing time to achieve optimum asphalt quality.
The ANN and LS-SVM operation process in the automated process control line to produce asphalt concrete mixes consists of the following stages:
·Data acquisition: asphalt quality data are collected during production.
·Model training: the dataset is used to train ANN and LS-SVM.
·Parameter prediction: based on the available data, ANN predicts the asphalt quality and LS-SVM optimizes the production parameters.
·Parameter adjustment: the automated process control line to produce asphalt concrete mixes adjusts production parameters based on predicted data and optimized parameters.
·Monitoring: the automated process control line to produce asphalt concrete mixes monitors the production process and asphalt quality data to allow operators to respond quickly to any deviations from required parameters. For example, if the asphalt quality does not meet established standards, the automated system can automatically adjust production parameters to achieve the required quality.
Data processing: using ANN and LS-SVM, the automated system can process asphalt quality and other production data to determine the optimal parameters for producing high-quality asphalt mixes.
Production management: based on data resulting from monitoring and data processing, the automated system can manage the production process to optimize asphalt quality and minimize raw material and energy losses.
Quality control: the automated process control line to produce asphalt concrete mixes also includes a quality control system, which can automatically check the asphalt quality at various production stages to ensure that the product meets established standards.
By leveraging advanced sensors, real-time data analysis, and automated adjustments, the system ensures that each batch of asphalt concrete mix is consistent with the last, adhering to the precise specifications required for infrastructure projects. This not only enhances the durability and performance of roads and highways but also contributes to safer and more reliable transportation networks. Furthermore, the ability to monitor and adjust the production process in real time significantly reduces waste, improves efficiency, and minimizes environmental impact, demonstrating a forward-thinking approach to sustainable construction practices.
The mathematical model of the automated process control line to produce asphalt concrete mixes is trained on a set of previously obtained data and based on these data predicts asphalt quality and optimizes production parameters to maximize quality. Operators can monitor the production process using the data provided to the automated process control line to produce asphalt concrete mixes and make decisions based on the model predictions.
The model is implemented using an NN, trained on a large amount of asphalt production data, as well as asphalt quality data, resulting from laboratory testing. An NN represents a deep learning model, consisting of many layers of neurons connected by weighted links.
Input data to the model may include parameters, such as temperature, moisture, mixing time, number of components used, etc. Based on this data, the model predicts the quality of the produced asphalt mix.
Deep learning techniques, such as the backpropagation algorithm (or backward propagation of errors), are used to train an NN. During the training process, the model is adjusted to the available data and set to the optimal values of weights and biases.
Moreover, the model can be augmented with SVM or other ML algorithms to improve the accuracy of predictions.
Thus, the mathematical model of an automated process control line to produce asphalt concrete mixes using AI allows for increasing the efficiency of asphalt production, improving the quality of manufactured product, and reducing production costs.
The end result of the automated process control line to produce asphalt concrete mixes can be represented as a matrix (Table 1), where each row corresponds to a certain batch of mix produced, while columns show mix characteristics, such as temperature, density, viscosity, etc.
Table 1. Asphalt mix production data matrix
|
Batch |
Temperature (℃) |
Viscosity (Pa*s) |
Density (kg/m3) |
Dosage of Stone Materials (kg) |
|
1 |
150 |
0.1 |
2,400 |
1,000 |
|
2 |
155 |
0.15 |
2,450 |
1,100 |
|
3 |
158 |
0.12 |
2,500 |
1,200 |
|
4 |
152 |
0.09 |
2,380 |
1,050 |
|
5 |
149 |
0.11 |
2,420 |
1,000 |
Various ML techniques, such as ANN and LS-SVM, are used to process the data and build the mathematical model.
ANN uses NNs to process and analyze data. NNs consist of many interconnected nodes called neurons, which accept input data and process them to produce output data [14-17]. ANN can be trained based on the available data to create a mathematical model, which can be used to predict the performance characteristics of the asphalt concrete mix.
LS-SVM uses SVM to build the mathematical model. SVM consists of finding a hyperplane, which separates data by classes to the utmost. In the case of asphalt mix quality analysis, LS-SVM can be trained based on the available data to create a mathematical model that can be used to predict mix performance characteristics.
Both ANN and LS-SVM models are used in the automated process control line to produce asphalt concrete mixes to predict asphalt quality characteristics based on data incoming in the real-time production process.
The mathematical model of ANN is based on ANNs, which are multilayer structures consisting of interconnected neurons. ANN uses data on previously received asphalt quality characteristics and other production parameters to train the NN for creating predictions. The formula for the direct propagation of the input signal through the NN layers is as follows [18]:
$a^{(l)}=f\left(z^{(l)}\right)=f\left(w^{(l)} a^{(l-1)}+b^{(l)}\right)$ (1)
where, l is the layer number, a(l) is the activation vector of l layer, z(l) is the weighted input signal of l layer, w(l) is the matrix of weights between l–1 layers, b(l) is the displacement vector of l layer, and f is the activation function. A backpropagation algorithm is used to update the weights, which minimizes the loss function and adjusts the weights of the NN to achieve the best prediction.
The LS-SVM mathematical model is based on SVM, which uses a training data set to construct a hyperplane separating different data classes. LS-SVM is an extension of SVM, which uses regularization to reduce noise and improve the generalization performance of the model. LS-SVM minimizes the error function based on the training data set, which is as follows [19, 20]:
$\min _{\mathrm{w}, \mathrm{b}, \xi} \frac{1}{2} w^T w+C \sum_{\mathrm{i}=1}^{\mathrm{n}} \xi_{\mathrm{i}}$ (2)
where, w is the weight vector, b is the bias, ξ is the error, C is the regularization parameter, and n is the amount of training data.
ANN uses multiple processing of data through several hidden layers, which allows accounting for the complicated relationships between different factors and improving the prediction accuracy. The formula for calculating the NN output in the case of multilayer architecture is as follows:
$y_k=f\left(\sum_{j=1}^{N_h} w_{k j}^{(2)} f\left(\sum_{i=1}^{N i n} w_{j i}^{(1)} x_i+w_{j 0}^{(1)}\right)+w_{k 0}^{(2)}\right)$ (3)
where, $y_k$ is the output signal of the $k$-th neuron, $N_h$ is the number of neurons in the hidden layer, $w_{k j}^{(2)}$ is the weight of the synapse between the $j$-th neuron of the hidden layer and the $k$-th neuron of the output layer, $f$ is the activation function, $N_{i n}$ is the number of inputs, $w_{j i}^{(1)}$ is the weight of the synapses between the $i$-th input and the $j$-th neuron of the hidden layer, $w_{j 0}^{(1)}$ is the bias of the $j$-th neuron of the hidden layer, $w_{k 0}^{(2)}$ is the bias of the $k$-th neuron of the output layer.
On the other hand, LS-SVM uses SVM, which is a special case of NNs and can be implemented as a single-layer NN without hidden layers. The formula for calculating the LS-SVM output is as follows:
$y_k=\sum_{i=1}^n \alpha_i y_i K\left(x_i, x_k\right)+b$ (4)
where, yk is the output signal; n is the number of training examples; αi is the weight assigned to the i-th training example; yi is the target value of the i-th training example; K(xi, xk) is the kernel, which defines the function mapping of the input data into a higher-dimensional space, where classification or regression is easier to perform. Typically, Gaussian or polynomial kernels are used for this purpose.
To train ANN and LS-SVM, it is necessary to have a training data set, which consists of the input parameters of the asphalt mix production process and corresponding values of the asphalt quality, which is target variable.
Once the models are trained based on the training dataset, they can be used to predict the asphalt quality based on the current input parameters of the production process. The prediction results can be displayed on the operator's screen or sent to the process control system to adjust the production parameters automatically.
A kernel function is used to transform the data into a higher-dimensional space, where the data become linearly separable. The following kernel functions are commonly used:
·Linear kernel: K(x, y)=x * y
·Polynomial kernel: K(x, y)=gamma*x*y+coef0)degree
·Radial basis kernel (RBF): K(x, y)=exp (-gamma*||x-y||2)
Here gamma, coef0, and degree are parameters, which can be adjusted for optimal model performance.
Table 2. Comparison between ANN and LS-SVM
|
Method |
Advantages |
Disadvantages |
|
ANN |
Ability to process a large amount of data, to train based on multiple tasks simultaneously, flexibility in changing the model structure |
Slow training speed, unclear interpretation of results |
|
LS-SVM |
Fast operation, fewer number of parameters, ability to build a model with a small amount of training data |
Need for careful setting of kernel parameters, sensitivity to outliers |
In general, the choice between ANN and LS-SVM depends on the specific task and the requirements to performance and interpretability of the results (Table 2). The following optimization algorithm is used to build the LS-SVM model, subject to conditions:
yi-(wTφ(xi)+b)≤ϵ+ξi
(wTφ(xi)+b)-yi≤ϵ+ξi
ξi≥0, i=1, …, n
where, w and b are the model parameters, φ(xi) is the attribute vector, ξi are non-negative variables, ϵ is the allowable error, C is the regularization factor, and p is the degree of softness, which determines how heavily unimplemented constraints are weighted.
Both models, ANN and LS-SVM, can be used to predict asphalt quality, based on data obtained in the course of production. Using these models allows automating the quality control process and optimizing production processes, resulting in improved quality and resource savings.
The coefficients in these models can be determined using optimization techniques, such as the LSM or the gradient descent method. In the LSM for LS-SVM, it is necessary to find the solution of the system of equations:
$K \alpha=y$ (5)
where, K is the kernel function matrix, α is the coefficient vector, and y is the target value vector.
To train ANN, one can use the backpropagation algorithm. In this method, the network weights are updated by gradient descent method using the formula:
$w_{i, j}=w_{i, j}-\alpha \frac{\partial L}{\partial w_{i, j}}$ (6)
where, wi,j is the weight between the i-th input node and the j-th hidden node, α is the training speed, and L is the loss function, defining the difference between the network output and the target values.
Thus, using AI-based mathematical models in the automated process control line to produce asphalt concrete mixes allows conducting automatic analysis of asphalt quality data and optimizing the production process, which contributes to improved product quality, as well as time and resources savings.
The experiment has shown that both ANN and LS-SVM models have demonstrated high accuracy in predicting asphalt quality and controlling the production process. However, depending on the specific target and available data, one model may be more effective than the other.
It has been also found that the automated process control line to produce asphalt concrete mixes using ANN and LS-SVM models can significantly improve production efficiency and quality, as well as reduce scrap and waste.
Thus, using AI models, such as ANN and LS-SVM, in the automated process control line to produce asphalt concrete mixes can significantly improve the production process and product quality.
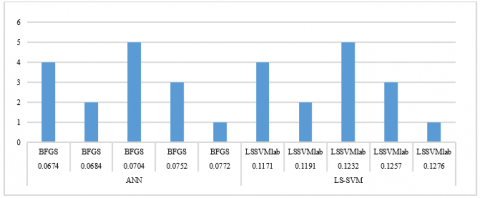
As reflected by Figure 2, the ANN model has shown higher accuracy than LS-SVM, with slightly shorter training time. However, LS-SVM has shown good results when using small amount of data. This model can be useful when fast model training on small samples is required.
Figure 2. Model quality scores
In general, the experimental results have shown that both the ANN and LS-SVM models can be used for asphalt mix production control, and both models have demonstrated good results when used in the automated process control line to produce asphalt concrete mixes.
Table 3 shows the training and testing results of the ANN and LS-SVM models on 80% training sample and 20% validation sample. As can be seen from the table, both models show high accuracy in training and testing, as well as low error. Both models have very close determination coefficient (R2) on both training and validation samples.
Thus, the experimental results have shown that both ANN and LS-SVM can be effectively used in the automated process control line to produce asphalt concrete mixes. Both models have demonstrated high accuracy and low error, which allows operators to respond quickly to changes in the production process and control the quality of asphalt.
Table 3. Experimental results
|
Test Number |
Model Type |
Training Algorithm |
MSE |
R2 |
r |
RE |
RV |
|
1 |
ANN |
BFGS |
0.0032 |
0.9954 |
0.9977 |
0.0772 |
1.0291 |
|
1 |
LS-SVM |
LSSVMlab |
0.0053 |
0.9863 |
0.9931 |
0.1276 |
0.6769 |
|
2 |
ANN |
BFGS |
0.0028 |
0.9963 |
0.9981 |
0.0684 |
1.0128 |
|
2 |
LS-SVM |
LSSVMlab |
0.0049 |
0.9892 |
0.9946 |
0.1191 |
0.7542 |
|
3 |
ANN |
BFGS |
0.0031 |
0.9956 |
0.9978 |
0.0752 |
1.0443 |
|
3 |
LS-SVM |
LSSVMlab |
0.0052 |
0.9867 |
0.9933 |
0.1257 |
0.7123 |
|
4 |
ANN |
BFGS |
0.0027 |
0.9964 |
0.9981 |
0.0674 |
1.0234 |
|
4 |
LS-SVM |
LSSVMlab |
0.0048 |
0.9896 |
0.9948 |
0.1171 |
0.7719 |
|
5 |
ANN |
BFGS |
0.0029 |
0.9961 |
0.9979 |
0.0704 |
1.0117 |
|
5 |
LS-SVM |
LSSVMlab |
0.0050 |
0.9886 |
0.9941 |
0.1232 |
0.7208 |
Table 3 shows the experimental results obtained using both ANN and LS-SVM models, and different learning algorithms. As a result, the MSE, determination coefficient (R2), correlation coefficient (r), and relative error (RE) were obtained.
As is seen from Table 3, both models performed well, however, the ANN model, when using the BFGS algorithm, has demonstrated slightly better results than the LS-SVM model when using the LSSVMlab algorithm.
The superior performance of ANN over LS-SVM may be attributed to ANN's ability to better capture complex nonlinear relationships within the asphalt quality data. This could be due to ANN's flexible network architecture, which allows for a more nuanced understanding of the intricate patterns present in the data, compared to LS-SVM's linear approach.
The determination coefficient (R2) and the correlation coefficient (r) further validate the ANN model's robustness, with higher values demonstrating a stronger correlation between predicted and actual data. This suggests that the ANN model is more adept at capturing the complex relationships within the asphalt production parameters, leading to more reliable optimization strategies for mix production.
Relative error (RE) provides additional context on the variability of the model's predictions, with lower values indicating more consistent performance. The ANN model's lower RE, as compared to the LS-SVM model, underscores its potential in consistently predicting asphalt quality across varied production scenarios.
The conducted study showed that using ML techniques allows more accurately determining asphalt quality and optimal parameters for asphalt production compared to conventional analysis methods.
The following results were obtained in the conducted research:
·A mathematical model of the automated process control line to produce asphalt concrete mixes using two AI-based ML techniques, ANN and SVM with linear kernel (LS-SVM), was developed and implemented.
·The quality of asphalt produced using the model-based quality control technique was investigated. The results showed that using the automated process control line to produce asphalt concrete mixes significantly improved the quality of produced asphalt.
·Data collected over several months of production line operation were used to train the model. These data were divided into training and validation samples, and the optimal model parameters were derived from the training sample.
·Using ANN and LS-SVM allowed achieving high accuracy in predicting asphalt quality.
·The developed model can be used to optimize the production of asphalt concrete mixes, which allows reducing the production time and improving the quality of the produced asphalt.
·The results obtained can be used by manufacturing companies engaged in the production of asphalt concrete mixes to improve product quality and increase production efficiency.
·The conducted study showed the scientific novelty of using SVM with linear kernel (LS-SVM) in the automated process control line to produce asphalt concrete mixes.
Comparing the obtained results with other recent research, several significant aspects were revealed. Botella et al. [1] investigate application of ML techniques to estimate binder activity in reclaimed asphalt crumb. Their results also confirm the benefits of ML techniques in analyzing asphalt materials.
Liu et al. [2] also examine asphalt mixture optimization by predicting the effective asphalt content and absorbed asphalt content using ML techniques. The results of the present study support their findings on the significance of using ML techniques in the asphalt mix design process.
Thus, the results of the present study showed that ML techniques can be effectively used to analyze the quality of asphalt and improve the quality of asphalt pavement. This opens new opportunities for improving road infrastructure and safety.
The proposed approach includes the following main stages:
(1) Data collection: this stage involves collecting data on asphalt mix production, including information on mix composition, production parameters, material quality, and other relevant variables. Various data sources can be used for this purpose, including laboratory tests, sensors, and production monitoring systems.
(2) Data preprocessing: this stage involves preprocessing and scrubbing of the collected data. This may include removing outliers, filling in missing values, normalizing the data, and converting variables into a format convenient to process.
(3) Model selection and training: this stage involves selecting and training an ML technique used to analyze the data and predict the quality parameters of asphalt concrete mixtures. Different models can be used, such as ANN, LS-SVM, or genetic algorithms. The model is trained based on the preliminary prepared data. The model is adjusted based on the known relationships between the input data and the target quality parameters.
(4) Model validation and testing: this stage involves assessment of model performance using selected validation data. The model outcomes are compared with known target quality parameters to analyze accuracy, efficiency, and stability of the model.
(5) Integration into an automated process line: at this stage, the model is integrated into the automated process control line to produce asphalt concrete mixes. The model can be used to make real-time decisions, manage and optimize production processes, and provide recommendations and predictions to operators.
The overall structure of the proposed approach includes the data acquisition, data preprocessing, model selection and training, model validation and testing, and model integration into process control line. This provides a comprehensive approach to analyzing data and optimizing production processes for quality results.
Analyzing asphalt quality data using ML techniques allowed us identifying hidden patterns in the data which were not detected using statistical methods. This allowed determining the effect of each parameter on asphalt quality more accurately and highlighting the most significant factors.
Determining the optimal parameters for producing quality asphalt mixes also showed that ML techniques can produce more accurate results than traditional optimization methods, such as least-squares.
Comparing the obtained results with existing methods for analyzing asphalt quality showed that ML techniques can produce more accurate results, especially when analyzing big data. Moreover, using ML techniques can significantly reduce the time needed for analysis and improve the accuracy of the results.
However, using ML techniques requires a large amount of data and skilled specialists to process data and interpret the results. Models need to be carefully validated and tested to avoid errors and flaws in the outcomes.
As for the practical implementations, the adoption of LS-SVM technology can streamline production processes, allowing for real-time adjustments that cater to varying environmental conditions and material properties. This level of adaptability ensures that the final product not only meets but exceeds quality standards, potentially extending the lifespan of road infrastructure and reducing the need for frequent repairs.
The quality evaluation of asphalt was conducted in the present research article using ML techniques. Different analysis methods, evaluation of their accuracy, and determination of the optimal parameters for producing a quality asphalt mix were discussed.
The research results showed that using ML techniques to analyze the quality of asphalt can significantly improve the production process and provide a higher quality product. The results of the study can be used to optimize the asphalt production process and develop new methods of quality control and decision making in road repair planning.
Thus, the application of ML techniques to analyze asphalt quality is a promising research area in road construction and maintenance, which can contribute to the quality of asphalt, increasing its service life and improving road safety.
Our results of the study showed that ML techniques can serve an effective tool for analyzing asphalt quality and optimizing the production of asphalt mixes.
The results of the present study are just the first step in developing new approaches and methods for analyzing asphalt quality and thus require further development and improvement. They can be a useful starting point for further research in this area.
Future studies could delve into the integration of additional machine learning models, such as deep learning and reinforcement learning, to compare their efficacy against ANN and LS-SVM in this context. Investigating the scalability of these ML techniques in larger, more diverse datasets would provide insights into their adaptability and performance in varying environmental conditions and material compositions.
[1] Botella, R., Lo Presti, D., Vasconcelos, K., Bernatowicz, K., Martínez, A.H., Miró, R., Specht, L., Mercado, E.A., Pires, G.M., Pasquini, E., Ogbo, C., Preti, F., Pasetto, M., del Barco Carrión, A.J., Roberto, A., Orešković, M., Kuna, K.K., Guduru, G., Martin, A.E., Carter, A., Giancontieri, G., Abed, A., Dave, E., Tebaldi, G. (2022). Machine learning techniques to estimate the degree of binder activity of reclaimed asphalt pavement. Materials and Structures, 55: 112. https://doi.org/10.1617/s11527-022-01933-9
[2] Liu, J., Liu, F., Zheng, C., Zhou, D., Wang, L. (2022). Optimizing asphalt mix design through predicting effective asphalt content and absorbed asphalt content using machine learning. Construction and Building Materials, 325: 126607. https://doi.org/10.1016/j.conbuildmat.2022.126607
[3] Rahman, S., Bhasin, A., Smit, A. (2021). Exploring the use of machine learning to predict metrics related to asphalt mixture performance. Construction and Building Materials, 295: 123585. https://doi.org/10.1016/j.conbuildmat.2021.123585
[4] Sebaaly, H., Varma, S., Maina, J.W. (2018). Optimizing asphalt mix design process using artificial neural network and genetic algorithm. Construction and Building Materials, 168: 660-670. https://doi.org/10.1016/j.conbuildmat.2018.02.118
[5] Mousa, K.M, Abdelwahab, H.T, Hozayen, H.A. (2018). Models for estimating optimum asphalt content from aggregate gradation. Proceedings of the Institution of Civil Engineers Construction Materials, 174(2): 69-74. https://doi.org/10.1680/jcoma.18.00035
[6] Le, T.H., Nguyen, H.L., Pham, B.T., Nguyen, M.H., Pham, C.T., Nguyen, N.L., Le, T.T., Ly, H.B. (2020). Artificial intelligence-based model for the prediction of dynamic modulus of stone mastic asphalt. Applied Sciences, 10(15): 5242. https://doi.org/10.3390/app10155242
[7] Androjić, I., Marović, I. (2017). Development of artificial neural network and multiple linear regression models in the prediction process of the hot mix asphalt properties. Canadian Journal of Civil Engineering, 44(12): 994-1004. https://doi.org/10.1139/cjce-2017-0300
[8] Hoang, N.D. (2018). An artificial intelligence method for asphalt pavement pothole detection using least squares support vector machine and neural network with steerable filter-based feature extraction. Advances in Civil Engineering, 2018: 7419058. https://doi.org/10.1155/2018/7419058
[9] Karballaeezadeh, N., Zaremotekhases, F., Shamshirband, S., Mosavi, A., Nabipour, N., Csiba, P., Várkonyi-Kóczy, A.R. (2020). Intelligent road inspection with advanced machine learning; Hybrid prediction models for smart mobility and transportation maintenance systems. Energies, 13(7): 1718. https://doi.org/10.3390/en13071718
[10] Arifuzzaman, M., Aniq Gul, M., Khan, K., Hossain, S.M.Z. (2021). Application of artificial intelligence for sustainable highway and road system. Symmetry, 13(1): 60. https://doi.org/10.3390/sym13010060
[11] Uwanuakwa, I.D., Ali, S.I.A., Hasan, M.R.M., Akpinar, P., Sani, A., Shariff, K.A. (2020). Artificial intelligence prediction of rutting and fatigue parameters in modified asphalt binders. Applied Sciences, 10(21): 7764. https://doi.org/10.3390/app10217764
[12] Hosseinzadeh, H., Hasani, A., Arman, S., Hejazi, A. (2022). Predicting Marshall asphalt stability using supervised machine learning algorithms, support vector machine and random forest. Journal of Transportation Research, 20(3): 249-262. https://doi.org/10.22034/tri.2022.322772.2998
[13] Beainy, F., Commuri, S., Zaman, M. (2010). Asphalt compaction quality control using artificial neural network. In 49th IEEE Conference on Decision and Control (CDC), Atlanta, GA, USA, pp. 4643-4648. https://doi.org/10.1109/CDC.2010.5717127
[14] Kaseko, M.S., Ritchie, S.G. (1993). A neural network-based methodology for pavement crack detection and classification. Transportation Research Part C: Emerging Technologies, 1(4): 275-291. https://doi.org/10.1016/0968-090X(93)90002-W
[15] Chumakova, E.V., Korneev, D.G., Chernova, T.A., Gasparian, M.S., Ponomarev, A.A. (2023). Comparison of the application of FNN and LSTM based on the use of modules of artificial neural networks in generating an individual knowledge testing trajectory. Journal Européen des Systèmes Automatisés, 56(2): 213-220. https://doi.org/10.18280/jesa.560205
[16] Chumakova, E.V., Chernova, T.A., Belyaeva, Y.A., Korneev, D.G., Gasparian, M.S. (2022). Use of neural networks in the adaptive testing system. International Journal of Advanced Computer Science and Applications, 13(5): 20-27. http://doi.org/10.14569/IJACSA.2022.0130504
[17] Chumakova, E.V., Korneev, D.G., Gasparian, M.S., Ponomarev, A.A., Makhov, I.S. (2023). Building a neural network to assess the level of operational risks of a credit institution. Journal of Theoretical and Applied Information Technology, 101(11): 4205-4213.
[18] Tran, T.H., Hoang, N.D. (2016). Predicting colonization growth of algae on mortar surface with artificial neural network. Journal of Computing in Civil Engineering, 30(6): 04016030. https://doi.org/10.1061/(ASCE)CP.1943-5487.0000599
[19] Sun, W., Ye, M. (2015). Short-term load forecasting based on wavelet transform and least squares support vector machine optimized by fruit fly optimization algorithm. Journal of Electrical and Computer Engineering, 2015: 862185. http://doi.org/10.1155/2015/862185
[20] Chen, Z.B. (2014). Research on application of regression least squares support vector machine on performance prediction of hydraulic excavator. Journal of Control Science and Engineering, 2014: 686130. https://doi.org/10.1155/2014/686130