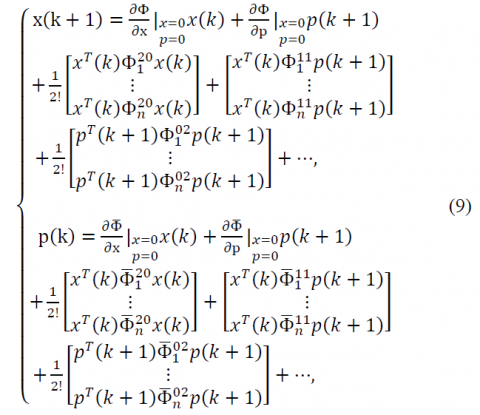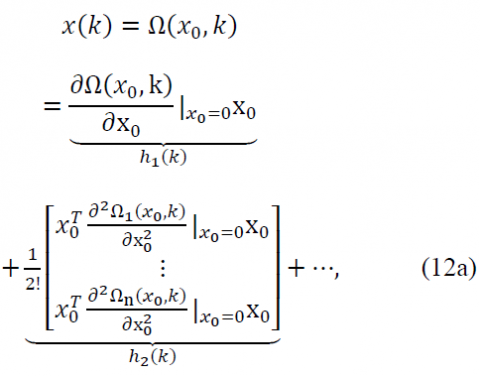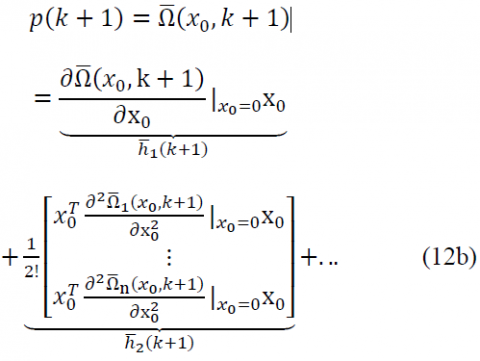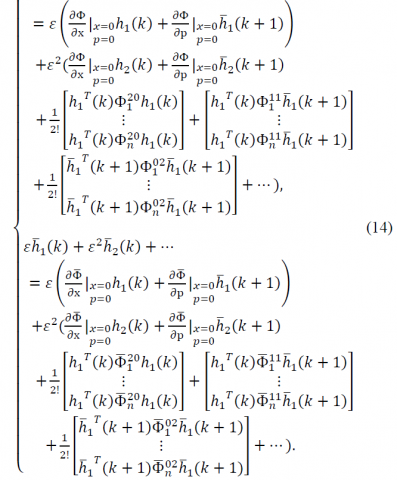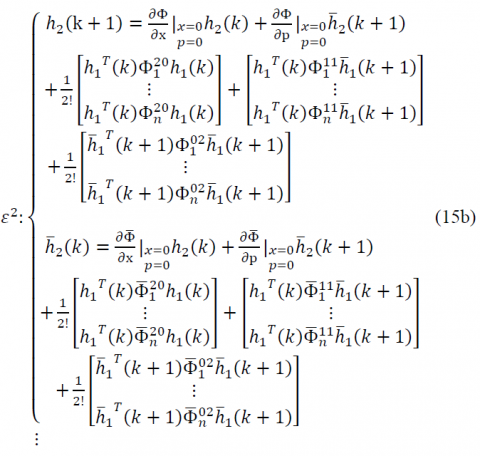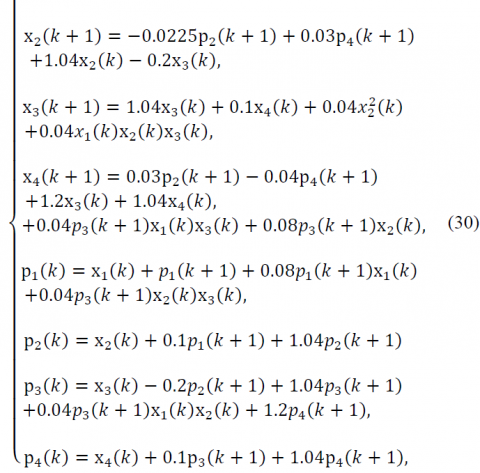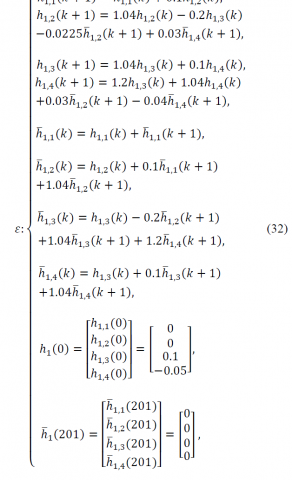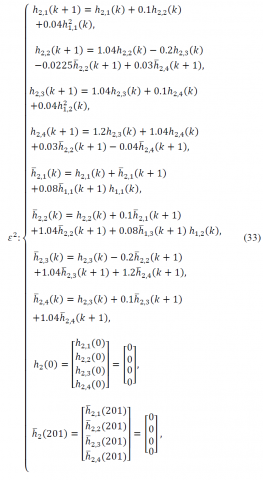Manijeh Hassan Abadi | Asadollah M. Vaziri* | Amin Jajarmi
OPEN ACCESS
This article proposes a new and efficient iterative procedure to solve a class of discrete-time nonlinear optimal control problems. Based on the Pontryagin's maximum principle, the necessary optimality conditions are formulated in the form of a nonlinear discrete boundary value problem (BVP). This problem is then reduced into a sequence of linear discrete BVPs by applying a series expansion approach called the modal series method. Solving the aforementioned sequence by using the techniques of solving linear difference equations, the optimal control law is derived in the form of a uniformly convergent series. In order to demonstrate the efficiency of the proposed method in practice, an iterative algorithm with a fast rate of convergence is provided. In a recursive manner, only a few iterations are needed to find a suboptimal control law with enough accuracy. The effectiveness of this new technique is verified by solving some numerical examples.
boundary value problem, discrete optimal control problem, iterative algorithm, modal series, suboptimal control law
In the theory of optimal control, the nonlinear control problems have attracted a remarkable attention since they have a wide variety of applications in different areas like mechanical engineering, biology, medicine, economy, and robotics [1-4]. Nowadays, due to the improvement of digital computers, the discrete-time optimal control problems (OCPs) have more advantages than the corresponding continuous-time ones [5-9]. Hence, the discrete OCPs with nonlinear terms have importance both from practical and theoretical viewpoints.
Applying the indirect techniques, the discrete nonlinear OCPs are often converted into the Hamilton-Jacobi-Bellman (HJB) equation or a discrete boundary value problem (BVP). Many approaches have been proposed to obtain the approximate solution of the HJB equation such as the adaptive dynamic programming (DP). This technique is classified into several schemes including the heuristic DP [10], dual heuristic DP [11], action-dependent DP, and Q-learning DP [12]. However, the DP policy is not computationally tenable to run and solves the time-varying HJB equations [13]. To overcome this difficulty, a successive approximation approach (SAA) was introduced in Ref. [14]. In this method, a nonlinear discrete BVP is converted into a sequence of non-homogeneous linear time-varying discrete BVPs. The sensitivity approach in Ref. [15] is similar to the SAA except that it uses a sensitivity parameter to provide the approximate solution. In Ref. [16], an inverse optimal control scheme for solving the HJB equation was needed for constructing the control law. In the model predictive control (MPC) or receding horizon control (RHC), an infinite horizon OCP was transformed into a sequence of finite horizon problems, but the stability analysis of the MPC depends on the appropriate designed controller [17]. A discrete-time state-dependent Riccati equation for the discrete nonlinear systems was proposed in Ref. [18]. The main disadvantage of this approach is the time-varying Riccati equation, which causes some difficulties in the practical implementation. The generating function (GF) method gives the optimal solutions according to the GFs, which are obtained numerically as the Taylor series expansion [19]. But this scheme is applicable to the systems close to linear form and it is dependent to the power series convergence, which is difficult to estimate its convergence region [20].
The modal series method, which was first introduced in Ref. [21], gives a good view of nonlinear systems' dynamical behaviours [22-23]. This method was firstly developed for the analysis of dynamical systems with nonlinear terms [24-26], and recently it was extended for the optimal control and MPC of nonlinear dynamical systems [27-29]. Motivated by the remarkable advantages of the model series method, we aim to extend this technique in this paper to solve a class of discrete nonlinear OCPs. By using the Pontryagin’s maximum principle, the optimality conditions lead to the nonlinear discrete BVP. This problem, using the modal series method, is then transformed into a sequence of linear discrete BVPs, which can be easily solved by the techniques of solving linear difference equations. The optimal solution is also obtained in the form of a uniformly convergent series. An iterative algorithm with low computational effort for finding a suboptimal control law is suggested. Simulation results confirm the effectiveness of the proposed approach.
The rest of this paper is structured as follows. Section 2 explains the problem statement. Section 3 focuses on extending the numerical method. In Sect. 4, an iterative algorithm with a fast convergence rate and low computational effort is introduced to obtain the suboptimal control law. Simulation results are given in Sect. 5 to verify the validity of the new technique. Finally, some conclusions and future works are discussed in the last section.
In this section, we formulate a discrete nonlinear OCP and implement its necessary optimality conditions. To do so, we consider a discrete-time nonlinear system as follows
$\left\{\begin{array}{l}{x(k+1)=f(x(k))+B u(k)+H(x(k)) u(k)} \\ {x(0)=x_{0}}\end{array}\right.$ (1)
where, $x \in R^{n}$ is the state vector and $u \in R^{m}$ is the control variable, $x_{0} \in R^{n}$ is the initial state, f : $\mathbb{R}^{n} \rightarrow \mathbb{R}^{n}$ and H : $\mathbb{R}^{n} \rightarrow \mathbb{R}^{n \times m}$ are, respectively, the analytic vector function and analytic mapping such that f(0)=0, and $B \in \mathbb{R}^{n \times m}$ is a constant matrix. The nonlinear function f can be reformulated by
$f(x(k))=A x(k)+g(x(k))$ (2)
Thus, the system (1) can be rewritten as follows
$\left\{\begin{array}{l}{x(k+1)=A x(k)+g(x(k))+[B+H(x(k))] u(k)} \\ {x(0)=x_{0}}\end{array}\right.$ (3)
The main objective is to minimize the following quadratic performance index (QPI) through finding an optimal control law u*(k) for system (3)
$J=\frac{1}{2} \sum_{k=0}^{N-1}\left[x^{T}(k) Q x(k)+u^{T}(k) R u(k)\right]$ (4)
where, $Q \in \mathbb{R}^{n \times n}$ is a positive semi-definite and $R \in \mathbb{R}^{m \times m}$ is a positive-definite matrix.
The necessary optimality conditions, using the Pontryagin's maximum principle, lead to the nonlinear discrete BVP in the following form
$\left\{\begin{array}{l}{x(\mathrm{k}+1)=\mathrm{Ax}(\mathrm{k})+\mathrm{g}(\mathrm{x}(\mathrm{k}))} \\ {-[B+H(x(k))] R^{-1}[B+H(x(k))]^{T} p(k+1)} \\ {\mathrm{p}(\mathrm{k})=\mathrm{Q} \mathrm{x}(\mathrm{k})+\left[A+\frac{\partial \mathrm{g}(\mathrm{x}(\mathrm{k}))}{\partial \mathrm{x}(\mathrm{k})}+\frac{\partial \mathrm{H}(\mathrm{x}(\mathrm{k}))}{\partial \mathrm{x}(\mathrm{k})}\right]^{T} p(k+1)} \\ {\mathrm{x}(0)=\mathrm{x}_{0}, \mathrm{p}(\mathrm{N})=0, \quad \mathrm{k}=0,1, \ldots, \mathrm{N}-1}\end{array}\right.$ (5)
where, $p \in \mathbb{R}^{n}$ is the co-state vector.
Also, the optimal control law is derived
$\mathrm{u}(\mathrm{k})=-R^{-1}[B+H(x(k))]^{T} p(k+1)$ (6)
Reformulating the problem (5) in a compact form, we provide
$\left\{\begin{array}{l}{x(k+1)=\Phi(\mathrm{x}(\mathrm{k}), \mathrm{p}(\mathrm{k}+1))} \\ {p(k)=\overline{\Phi}(\mathrm{x}(\mathrm{k}), \mathrm{p}(\mathrm{k}+1))} \\ {\mathrm{x}(0)=\mathrm{x}_{0}, \mathrm{p}(\mathrm{N})=0, \quad \mathrm{k}=0,1, \ldots, \mathrm{N}-1}\end{array}\right.$ (7)
where, $\Phi(\mathrm{x}(\mathrm{k}), \mathrm{p}(\mathrm{k}+1))$ and $\overline{\Phi}(\mathrm{x}(\mathrm{k}), \mathrm{p}(\mathrm{k}+1))$ are
$\left\{\begin{array}{c}{\Phi(\mathrm{x}(\mathrm{k}), \mathrm{p}(\mathrm{k}+1))=\mathrm{Ax}(\mathrm{k})+\mathrm{g}(\mathrm{x}(\mathrm{k}))} \\ {-[B+H(x(k))] R^{-1}[B+H(x(k))]^{T} p(k+1)} \\ {\overline{\Phi}(\mathrm{x}(\mathrm{k}), \mathrm{p}(\mathrm{k}+1))=\mathrm{Q} \mathrm{x}(\mathrm{k})+\left[A+\frac{\partial \mathrm{g}(\mathrm{x}(\mathrm{k}))}{\partial \mathrm{x}(\mathrm{k})}+\frac{\partial \mathrm{H}(\mathrm{x}(\mathrm{k}))}{\partial \mathrm{x}(\mathrm{k})}\right]^{T0}}{\times p(k+1)}\end{array}\right.$ (8)
Since f(x(k)) and H(x(k)) are assumed to be analytic, $\Phi : \mathbb{R}^{n \times n} \rightarrow \mathbb{R}^{n}$ and $\overline{\Phi} : \mathbb{R}^{n \times n} \rightarrow \mathbb{R}^{n}$ are nonlinear analytic vector functions.
The nonlinear discrete BVP (7) cannot be solved analytically except in some simple cases. Hence, we extend the modal series method to transform this problem into a sequence of linear discrete BVPs. For this purpose, first we expand the nonlinear non-polynomial terms of (7) around the operating point (x,p)=(0,0)
where, the coefficients in (9) are written as
$\begin{aligned} \Phi_{i}^{20}=\left.\frac{\partial^{2} \Phi_{i}}{\partial \mathrm{x}^{2}}\right|_{x=0,p=0} & \overline{\Phi}_{i}^{20}=\left.\frac{\partial^{2} \overline{\Phi}_{i}}{\partial x^{2}}\right|_{x=0,p=0} \\ \Phi_{i}^{11}=\left.\frac{\partial^{2} \Phi_{i}}{\partial \mathrm{p} \partial \mathrm{x}}\right|_{x=0,p=0}, & \overline{\Phi}_{i}^{11}=\left.\frac{\partial^{2} \overline{\Phi}_{i}}{\partial \mathrm{p} \partial \mathrm{x}}\right|_{x=0,p=0} \\ \Phi_{i}^{02}=\left.\frac{\partial^{2} \Phi_{i}}{\partial \mathrm{p}^{2}}\right|_{x=0,p=0}, & \overline{\Phi}_{i}^{02}=\left.\frac{\partial^{2} \overline{\Phi}_{i}}{\partial \mathrm{p}^{2}}\right|_{x=0,p=0} \end{aligned}$
and $\Phi_{i}$ and $\overline{\mathbf{\Phi}}_{i}$ the ith components of the vector functions $\Phi$ and $\overline{\mathbf{\Phi}}$ , respectively.
Theorem 1. The solution of the nonlinear discrete BVP (7) can be obtained as
$\left\{\begin{array}{l}{x(\mathrm{k})=\sum_{\mathrm{j}=1}^{\infty} h_{j}(k)} \\ {\mathrm{p}(\mathrm{k}+1)=\sum_{\mathrm{j}=1}^{\infty} \overline{h}_{j}(k+1)}\end{array}\right.$ (10)
where, $h_{j}(k)$ and $\overline{h}_{j}(k+1)$, for $j \geq 1$, are determined from a sequence of a linear discrete BVPs.
Proof. The solution of nonlinear discrete BVP (7) for an arbitrary initial condition x0 can be written as
$\left\{\begin{array}{c}{\mathrm{x}(\mathrm{k})=\Omega\left(x_{0}, k\right)} \\ {\mathrm{p}(\mathrm{k}+1)=\overline{\Omega}\left(x_{0}, k+1\right)}\end{array}\right.$ (11)
Since $\Phi$ and $\overline{\Phi}$ in (7) are analytic, $\Omega : \mathbb{R}^{n} \times \mathbb{R} \rightarrow \mathbb{R}^{n}$ and $\overline{\Omega} : \mathbb{R}^{n} \times \mathbb{R} \rightarrow \mathbb{R}^{n}$ are analytic vector functions with respect to x0 [30]. Therefore, the system (11) is expanded as Maclaurin series with respect to the arbitrary initial condition x0 That is
The vector functions $\Omega$ and $\overline{\Omega}$ have the components $\Omega_{\mathrm{i}}$ and $\overline{\Omega}_{\mathrm{i}}$, respectively. Also, the components of $h_{j}(k)$ and $\overline{h}_{j}(k+1)$ contain a linear combination depending on multiplication of j elements of the vector x0. For instance, $h_{2}(k)$ and $\overline{h}_{2}(k+1)$ contain a linear combination of $x_{0, k} x_{0, l}$ for all $k, l \in\{1, \ldots, n\}$, where $\mathrm{X}_{0, \mathrm{m}}$ is the mth element of x0. In addition, the existence and uniformly convergence of the formulas in (12a) and (12b) are guaranteed since $\Omega$ and $\overline{\Omega}$ are analytic vector functions.
Let $\theta_{1} \subseteq \mathbb{R}^{n}$ and $\theta_{2} \subseteq \mathbb{R}^{n}$ be the subsets of the initial state space and the convergence domains of the Maclaurin series in (12a) and (12b), respectively. Assume that $\Theta=\theta_{1} \cap \theta_{2}$ is not empty and let x(0)= $\varepsilon \mathrm{x}_{0} \in \Theta$ be the initial condition, where $\mathcal{E}$ is an arbitrary parameter. The parameter $\mathcal{E}$ exists since $\Theta$ is assumed to be nonempty. The value of $\mathcal{E}$ does not have any importance and just simplifies the calculations. Therefore, (12a) and (12b) are rewritten with respect to the $\varepsilon \mathrm{x}_{0}$ instead of x0 such that
$\left\{\begin{aligned} \mathrm{x}_{\varepsilon}(\mathrm{k}) &=\Omega\left(\varepsilon x_{0}, k\right)=\varepsilon h_{1}(k)+\varepsilon^{2} h_{2}(k)+\\ &=\sum_{i=1}^{\infty} \varepsilon^{i} h_{i}(k) \\ \mathrm{p}_{\varepsilon}(\mathrm{k}+1) &=\overline{\Omega}\left(\varepsilon x_{0}, k+1\right) \\ &=\varepsilon \overline{h}_{1}(k+1)+\varepsilon^{2} \overline{h}_{2}(k+1)+\cdots \\ &=\sum_{i=1}^{\infty} \varepsilon^{i} \overline{h}_{i}(k+1) \end{aligned}\right.$ (13)
Equation (13) must satisfy (9) since $\varepsilon \mathrm{x}_{0} \in \Theta$. Substituting (13) in (9) and rearranging based on the order of $\mathcal{E}$, we have
The coefficients of the same order of ε on both sides of equation (14) must be equal since (14) must hold for any $\varepsilon \mathrm{x}_{0} \in \Theta$. This procedure leads to the following expressions
$\varepsilon :\left\{\begin{array}{l}{h_{1}(\mathrm{k}+1)=\left.\frac{\partial \Phi}{\partial \mathrm{x}}\right|_{x=0,p=0} h_{1}(k)+\left.\frac{\partial \Phi}{\partial \mathrm{p}}\right|_{x=0,p=0} \overline{h}_{1}(k+1)} \\ {\overline{h}_{1}(k)=\left.\frac{\partial \overline{\Phi}}{\partial \mathrm{x}}\right|_{x=0,p=0} h_{1}(k)+\left.\frac{\partial \overline{\Phi}}{\partial \mathrm{p}}\right|_{x=0,p=0} \overline{h}_{1}(k+1)}\end{array}\right.$ (15a)
and so on (we continue the process with respect to the order of ε). Notice that, the expressions 15(a) and 15(b) are two systems of homogeneous and non-homogeneous linear time-invariant first-order difference equations, respectively. At the first step, assume that $h_{1}(k)$ and $\overline{h}_{1}(k+1)$ have been obtained from (15a) In the second step, $h_{2}(k)$ and $\overline{h}_{2}(k+1)$ can be obtained simply from 15(b) as the non-homogeneous terms of 15(b) are computed from the solution of (15a) Continuing the mentioned process, $h_{i}(k)$ and $\overline{h}_{i}(k+1)$ for $i \geq 2$ can be obtained easily by solving the non-homogeneous linear time-invariant first-order difference equations in the ith step. Within a recursive procedure, the non-homogeneous terms are calculated by the information of previous steps.
Setting k=0 and k=N-1 in (13), the boundary conditions are obtained in the form as below
$\left\{\begin{array}{l}{\varepsilon \mathrm{x}_{0}=x_{\varepsilon}(0)=\Omega\left(\varepsilon x_{0}, 0\right)=\varepsilon h_{1}(0)+\varepsilon^{2} h_{2}(0)+\cdots} \\ {0=\mathrm{p}_{\varepsilon}(N)=\overline{\Omega}\left(\varepsilon x_{0}, N\right)=\varepsilon \overline{h}_{1}(N)+\varepsilon^{2} \overline{h}_{2}(N)+\cdots}\end{array}\right.$ (16)
The coefficients of the same power of $\mathcal{E}$ on both sides of equation (16) must be equal; thus, we have
$\left\{\begin{array}{ll}{h_{1}(0)=\mathrm{x}_{0}, h_{i}(0)=0} \\ {\overline{h}_{1}(N)=0, \quad \overline{h}_{i}(N)=0 \quad \mathrm{i} \geq 2}\end{array}\right.$ (17)
and the proof is complete.
Corollary 1. The optimal trajectory and control law are determined by
$\left\{\begin{array}{l}{x^{*}(\mathrm{k})=\sum_{\mathrm{i}=1}^{\infty} h_{i}(k)} \\ {u^{*}(\mathrm{k})=-R^{-1}\left[B+H\left(\sum_{\mathrm{i}=1}^{\infty} h_{i}(k)\right)\right]^{T} \sum_{\mathrm{i}=1}^{\infty} \overline{h}_{i}(k+1)}\end{array}\right.$ (18)
where, $h_{i}(k)$ and $\overline{h}_{i}(k+1)$ for $i \geq 1$ are obtained by solving the recursive sequence of (15a) and (15b).
According to the Corollary 1, the proposed method just requires solving a sequence of linear time-invariant discrete BVPs, while the other approximation methods such as the SAA and sensitivity approach need to solve a sequence of linear time-varying problems [14-15]. Thus, the proposed approach takes the memory space and calculating time less than the other approximation techniques.
The uniform convergence of the solution in (18) is proved by the next theorem.
Theorem 2. Define the state, co-state, and control sequences as follows
$\left\{\begin{array}{l}{x^{(l)}(k) \triangleq \sum_{i=1}^{1} h_{i}(k)} \\ {p^{(l)}(k+1) \triangleq \sum_{i=1}^{1} \overline{h}_{i}(k+1)} \\ {u^{(l)}(k) \triangleq-R^{-1}\left[B+H\left(x^{(l)}(k)\right)\right]^{T} p^{(l)}(k+1)}\end{array}\right.$ (19)
Then, the above-mentioned sequences converge uniformly to $x^{*}(\mathrm{k}), p^{*}(\mathrm{k}+1)$ and $u^{*}(\mathrm{k})$ respectively.
Proof. As can be interpreted from the proof of Theorem 1, the expansions $\sum_{i=1}^{\infty} h_{i}(k)$ and $\sum_{i=1}^{\infty} \overline{h}_{i}(k+1)$ converge uniformly to the exact solution of the problem (7). This means
$\left\{\begin{array}{l}{x(k) \triangleq \lim _{l \rightarrow \infty} \sum_{i=1}^{1} h_{i}(k) \Leftrightarrow x^{(l)}(k) \stackrel{\text { uniformly }}{\longrightarrow} x(k)} \\ {p(k+1) \triangleq \lim _{l \rightarrow \infty} \sum_{j=1}^{1} \overline{h}_{i}(k+1)} \\ {\Leftrightarrow p^{(l)}(k+1) \stackrel{\text {uniformly}}{\longrightarrow} p(k+1)}\end{array}\right.$ (20)
Moreover, the control sequence depends on the state and co-state vector sequences through an analytic mapping and a linear operator, respectively. Thus, the control sequence converges uniformly to the optimal control law, i.e.,
$u^{*}(\mathrm{k})=-R^{-1}\left[B+H\left(\sum_{\mathrm{i}=1}^{\infty} h_{i}(k)\right)\right]^{T} \sum_{\mathrm{i}=1}^{\infty} \overline{h}_{i}(k+1)$
$=-R^{-1}\left[B+H\left(\lim _{l \rightarrow \infty} \sum_{i=1}^{1} h_{i}(k)\right)\right]^{T} \lim _{l \rightarrow \infty} \sum_{j=1}^{1} \overline{h}_{i}(k+1)$ (21)
$=\lim _{l \rightarrow \infty}\left\{-R^{-1}\left[B+H\left(\sum_{i=1}^{1} h_{i}(k)\right)\right]^{T} \sum_{j=1}^{1} \overline{h}_{i}(k+1)\right\}$
$\begin{aligned}=\lim _{l \rightarrow \infty}\left\{-R^{-1}[ \right.&\left.\left.B+H\left(x^{(l)}(k)\right)\right]^{T} p^{(l)}(k+1)\right\} \\ &=\lim _{l \rightarrow \infty} u^{l}(\mathrm{k}) \end{aligned}$
Now, the proof is complete.
Remark 1. Assume that the solution of discrete nonlinear OCP (3) and (4) with the initial condition $\mathrm{x}_{0} \in \Theta$ is available as in (18). Then, it is not necessary to repeat the recursive process to find the solution for any other initial condition $\varepsilon \mathrm{x}_{0}$, as long as $\varepsilon \mathrm{x}_{0} \in \Theta$. For this problem, the optimal trajectory and control law can be obtained from
$\left\{\begin{array}{c}{x^{*}(\mathrm{k})=\sum_{\mathrm{i}=1}^{\infty} \varepsilon^{i} h_{i}(k)} \\ {u^{*}(\mathrm{k})=-R^{-1}\left[B+H\left(\sum_{\mathrm{i}=1}^{\infty} \varepsilon^{i} h_{i}(k)\right)\right]^{T} \sum_{\mathrm{i}=1}^{\infty} \varepsilon^{i} \overline{h}_{i}(k+1)}\end{array}\right.$ (22)
This section deals with the result of previous section to be applicable for practical purposes. In the following, we present a suboptimal control law and an iterative algorithm. The optimal trajectory and control in (18), including the infinite series, are almost impossible to obtain. Substituting $\infty$ with a finite positive number M, the approximation solutions are attained by the Mth-order suboptimal trajectory and control law
$\left\{\begin{array}{l}{\mathrm{x}_{M}(\mathrm{k})=\sum_{\mathrm{j}=1}^{\mathrm{M}} h_{i}(k)} \\ {\mathrm{u}_{M}(\mathrm{k})=-R^{-1}\left[B+H\left(\sum_{\mathrm{i}=1}^{\mathrm{M}} h_{i}(k)\right)\right]^{T} \sum_{\mathrm{i}=1}^{\mathrm{M}} \overline{h}_{i}(k+1)}\end{array}\right.$ (23)
In practical applications, the integer M is determined by a concrete control precision. Furthermore, the QPI can be calculated by
$J_{M}=\frac{1}{2} \sum_{k=0}^{N-1}\left[x_{M}^{T}(k) Q x_{M}(k)+u_{M}^{T}(k) R u_{M}(k)\right]$ (24)
The Mth-order suboptimal control is accurate enough if the following condition holds for a given positive constant $\gamma>0$
$\left|\frac{J_{M}-J_{M-1}}{J_{M}}\right|<\gamma$ (25)
The values of the QPI and the Mth-order suboptimal control law will be very close to the $J^{*}$ and $u^{*}(k)$, respectively, if the error bound is chosen small enough.
In order to obtain $J_{M}$ and $u_{M}(k)$ the following iterative algorithm is presented.
4.1 Iterative algorithm
We summarize the algorithmic steps as below:
The above algorithm, based on Theorem 2, has a fast rate of convergence. Thus, only a small number of iterations are needed to get a desirable accuracy, which decreases the size of computations effectively.
In this section, the proposed iterative algorithm is applied to solve two numerical examples for showing the validity and the effectiveness of the proposed method.
Example 1. The model of an F-8 fighter aircraft was proposed at the first time in [31-33]. The discrete nonlinear OCP of the F-8 fighter aircraft is given by
$\mathbf{J}(\mathbf{k})=\frac{1}{2} \sum_{\mathbf{k}=\mathbf{0}}^{1599}\left[\mathbf{x}_{\mathbf{1}}^{2}(\mathbf{k})+\mathbf{x}_{2}^{2}(\mathbf{k})+\mathbf{x}_{3}^{2}(\mathbf{k})+\mathbf{5} \mathbf{u}^{2}(\mathbf{k})\right]$
$A=\left[\begin{array}{ccc}{0.9965} & {0} & {0.005} \\ {-0.0001} & {1} & {0.005} \\ {-0.021} & {0} & {0.9980}\end{array}\right]$
$g(x)=\left[\begin{array}{c}{0.0023 x_{1}^{2}-0.0005 x_{1} x_{3}+0.0192 x_{1}^{3}} \\ {-0.0001 x_{2}^{2}-0.005 x_{1}^{2} x_{3}^{2}} \\ {-0.0024 x_{1}^{2}-0.018 x_{1}^{3}+0.00005 x_{1}^{2} x_{3}^{2}}\end{array}\right]$ (26)
$H(x)=\left[\begin{array}{c}{0.0014 x_{1}^{2}+0.00008 x_{2}^{2}} \\ {0.00008 x_{2}^{2}} \\ {0.0313 x_{2}^{2}}\end{array}\right]$
$B=\left[\begin{array}{l}{-0.0013} \\ {-0.0003} \\ {-0.1047}\end{array}\right], \quad x(0)=\left[\begin{array}{c}{\frac{5 \pi}{36}} \\ {0} \\ {0}\end{array}\right]$
Table 1. Simulation results at different iterations for Example1
|
i (Iterations) |
$\boldsymbol{J}_{\boldsymbol{i}}$ |
$\left|\frac{\boldsymbol{J}_{\boldsymbol{i}}-\boldsymbol{J}_{\boldsymbol{i}-\mathbf{1}}}{\boldsymbol{J}_{\boldsymbol{i}}}\right|$ |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
12.9017 18.0879 22.0233 24.8668 26.2316 27.2317 28.4959 28.7099 28.7168 28.7126 28.7126 28.7126 |
- 0.2867 0.1786 0.1143 0.0520 0.0367 0.0269 0.0178 0.0074 0.00005 0.00003 0.0000001 |
|
Method |
i |
QPI |
error |
|
Modal series method |
12 |
28.7126 |
$0.1 \times 10^{-6}$ |
|
Sensitivity approach |
20 |
28.7765 |
0.0063 |
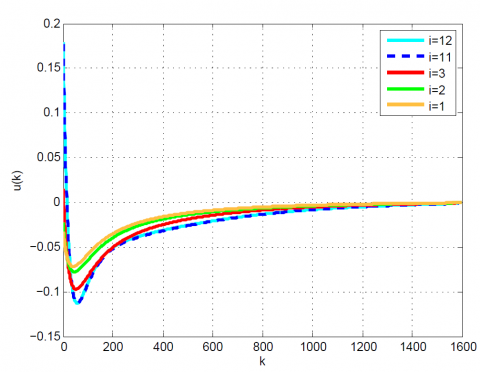
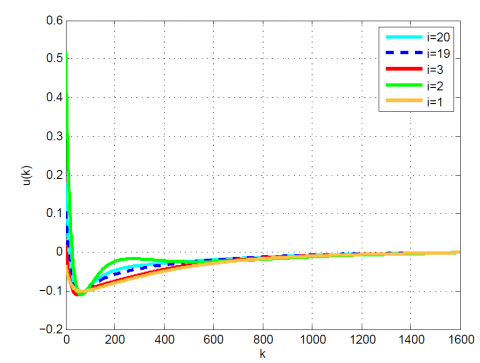
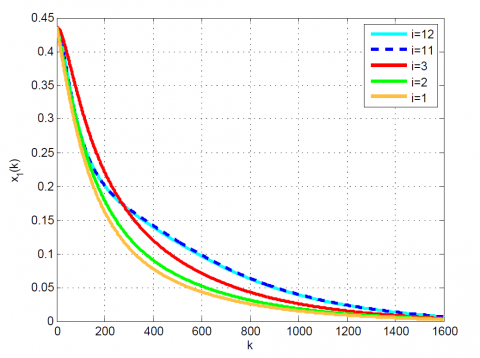
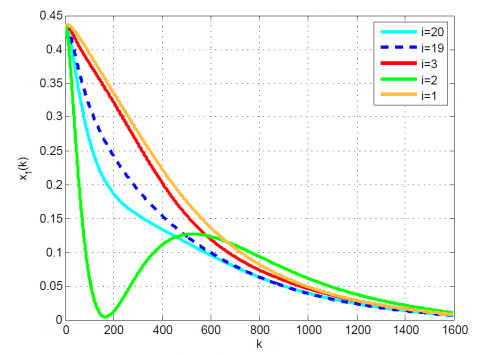
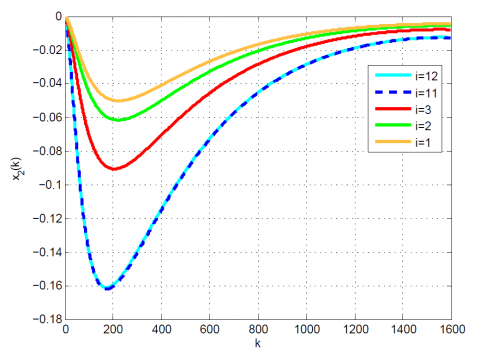
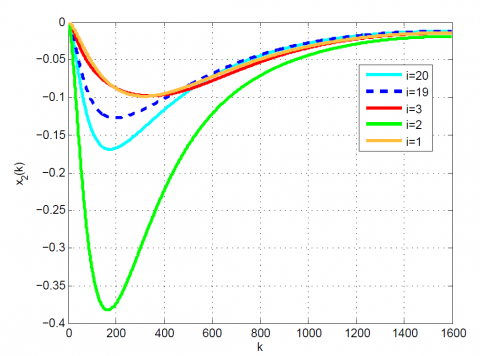
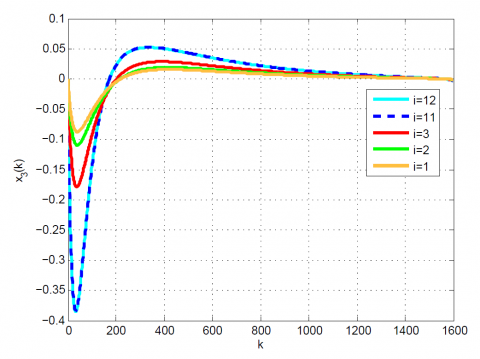
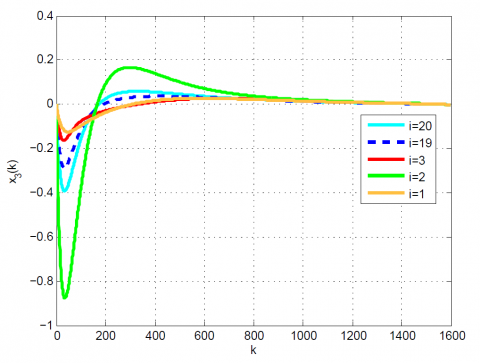
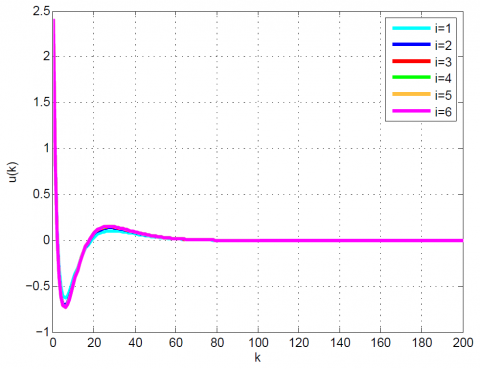
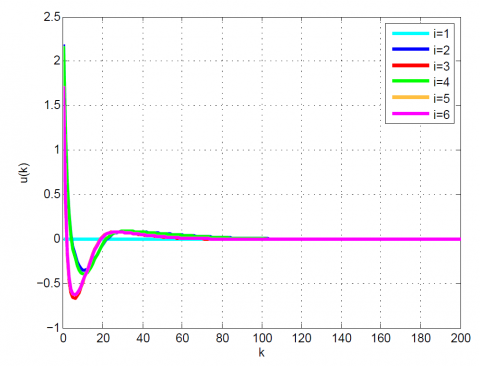
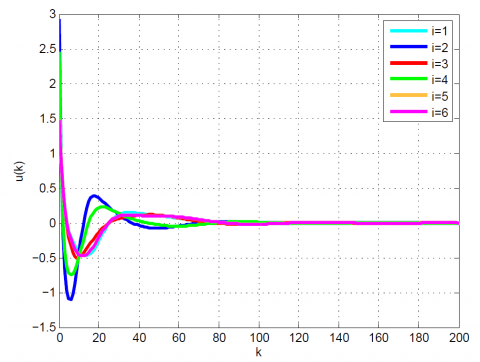
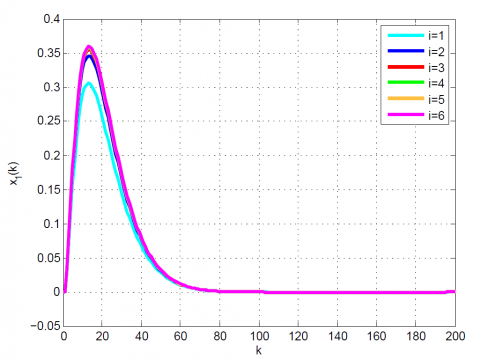
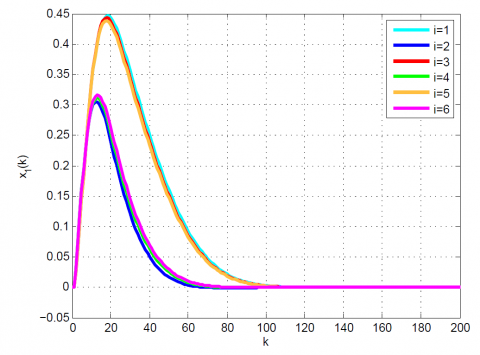
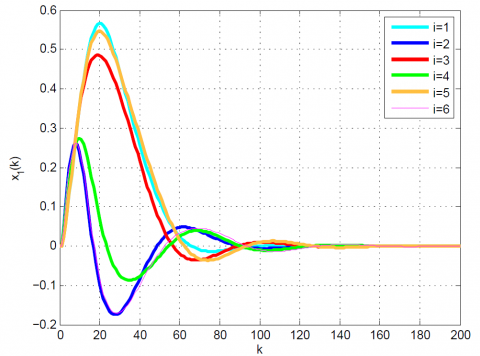
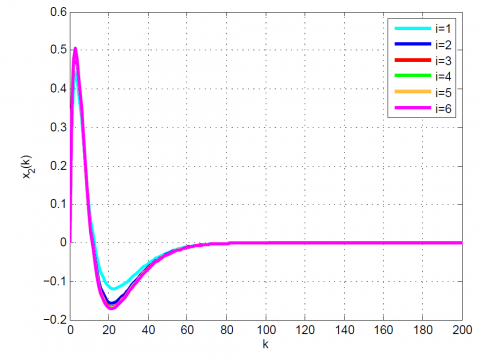
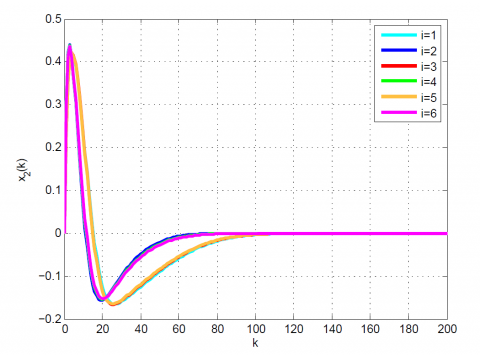
After 12 iterations, the convergence is achieved since $\left|\frac{J_{12}-J_{11}}{J_{12}}\right|=0.1 \times 10^{-6}<0.2 \times 10^{-6}$. Moreover, $u_{12}(k)$ and x12(k) are obtained from (23). The results up to 12th iteration are summarized in Table 1. Also, some comparative results between the modal series method and the sensitivity approach are shown in Table 2 and Figures 1-4. As can be seen, the modal series method has a faster rate of convergence than the sensitivity approach and converges uniformly to the optimal solution. In addition, in contrast with the sensitivity approach, the presented method converges uniformly after a few iterations.
(a) Control variable
(b) Control variable
Figure 1. Comparative results for Example 1 between the (a) modal series method and (b) sensitivity approach for u(k)
(a) $x_{1}(k)$ of state vector
(b) $x_{1}(k)$ of state vector
Figure 2. Comparative results for Example 1 between the (a) modal series method and (b) sensitivity approach for $x_{1}(k)$
(a) $x_{2}(k)$ of state vector
(b) $x_{2}(k)$ of state vector
Figure 3. Comparative results for Example 1 between the (a) modal series method and (b) sensitivity approach for $x_{2}(k)$
(a) $x_{3}(k)$ of state vector
(b) $x_{3}(k)$ of state vector
Figure 4. Comparative results for Example 1 between the (a) modal series method and (b) sensitivity approach for $x_{3}(k)$
Example 2. Making further research to test validity the proposed method, the fourth-order nonlinear discrete-time system in [15] is considered with more computational complexity than the previous example
According to the Pontryagin's maximum principle, the following discrete nonlinear system of equations should be solved
and the optimal control law is described by
$u^{*}(\mathrm{k})=-0.15 p_{2}(k+1)+0.2 p_{4}(k+1)$ (31)
Applying the proposed algorithm with the error bound
$\gamma=0.002$, the following sequence of linear discrete BVPs should be solvedand so on (we continue the process with respect to the order of ε). Simulation results at different iterations are listed in Table 3.
As can be seen, the suggested algorithm converges after 6 iterations, i.e., $\left|\frac{J_{6}-J_{5}}{J_{6}}\right|=0.0019<0.002$
Thus, the suboptimal control law is in the form
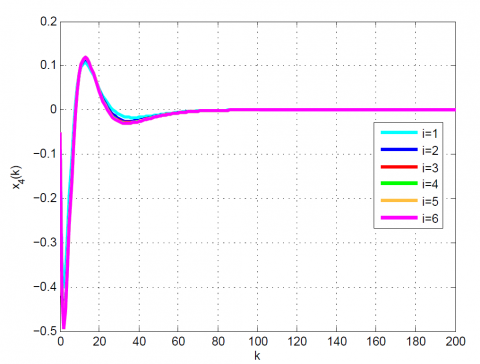
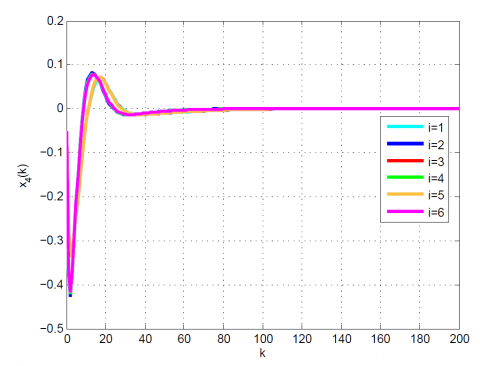
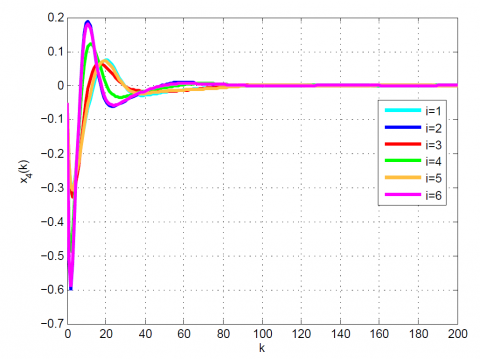
In order to compare with the other existing methods, we show the simulation results in Table 3, 4 and Figures 5-9. Unlike the SAA and sensitivity approach, the suggested method uniformly converges to the optimal solution. Moreover, the obtained results show the simplicity, efficiency, and high accuracy of the suggested technique.
As it is turned out, the modal series method is very straightforward and reduces the computational complexity effectively.
(a) Control variable
(b) Control variable
(c) Control variable
Figure 5. Comparative results for Example 2 between the (a) modal series method, (b) SAA, and (c) sensitivity approach for u(k)
(a) x1(k) of state vector
(b) x1(k) of state vector
(c) x1(k) of state vector
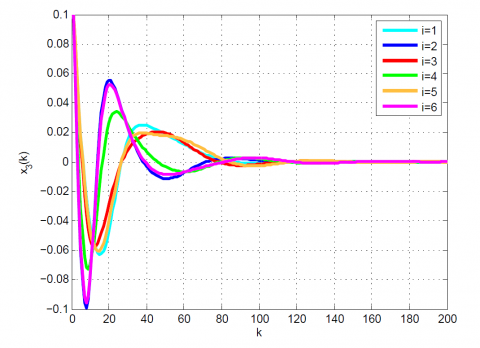
Figure 6. Comparative results for Example 2 between the (a) modal series method, (b) SAA, and (c) sensitivity approach for x1(k)
(a) x2(k) of state vector
(b) x2(k) of state vector
(c) x2(k) of state vector
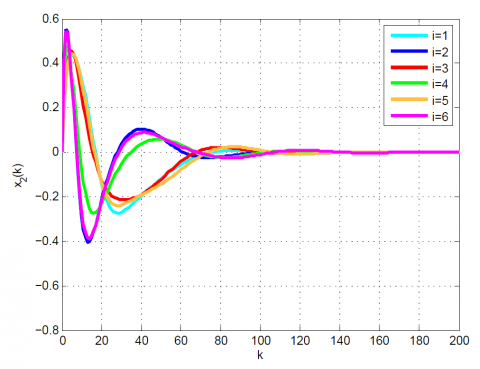
Figure 7. Comparative results for Example 2 between the (a) modal series method, (b) SAA, and (c) sensitivity approach for x2(k)
(a) x3(k) of state vector
(b) x3(k) of state vector
(c) x3(k) of state vector
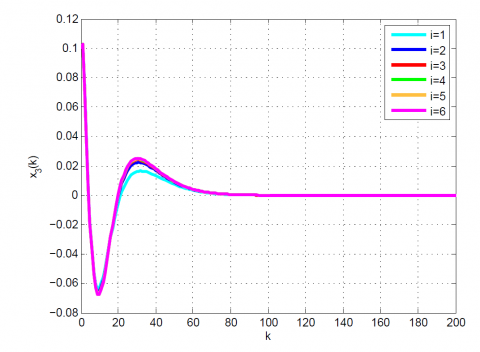
Figure 8. Comparative results for Example 2 between the (a) modal series method, (b) SAA, and (c) sensitivity approach for x3(k)
(a) x4(k) of state vector
(b) x4(k) of state vector
(c) x4(k) of state vector
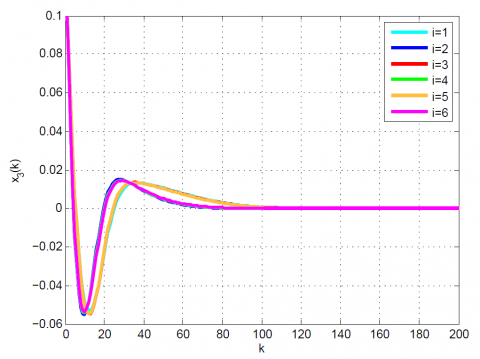
Figure 9. Comparative results for Example 2 between the (a) modal series method, (b) SAA, and (c) sensitivity approach for x4(k)
Table 3. Simulation results at 6 iterations for Example 2
|
i (Iterations) |
$J_{i}$ |
$\left|\frac{\boldsymbol{J}_{\boldsymbol{i}}-\boldsymbol{J}_{\boldsymbol{i}-1}}{\boldsymbol{J}_{\boldsymbol{i}}}\right|$ |
|
1 2 3 4 5 6 |
5.5554 7.1735 7.5985 7.7250 7.7672 7.7820 |
- 0.2256 0.0559 0.0164 0.0054 0.0019 |
|
Method |
i |
QPI |
Error |
|
Modal series method |
6 |
7.7820 |
0.0019 |
|
SAA |
6 |
7.6626 |
0.3447 |
|
Sensitivity approach |
5 |
7.4765 |
0.0034 |
In this article, a new practical technique was introduced for solving a class of discrete nonlinear OCPs. Contrary to other approximation methods such as SAA and sensitivity approach, the proposed scheme avoids solving linear time-varying BVPs and just deals with a sequence of linear time-invariant discrete BVPs. Hence, only the techniques of solving linear difference equations are employed in this scheme. Also, the obtained solution was uniformly convergent to the optimal solution and the suggested technique had a fast rate of convergence. Therefore, the computational complexity of presented method is lower than other approximation techniques.
Future works can be focused on the large-scale problems and extending the method to more general form of discrete nonlinear OCPs.
[1] Croicu, A.M. (2019). An optimal control model to reduce and eradicate anthrax disease in herbivorous animals. Bulletin of Mathematical Biology, 81(1): 235-255. https://doi.org/10.1007/s11538-018-0525-0
[2] Liu, S. (2018). Study on modeling simulation and optimal control method for the transmission risk of the Ebola virus. Simulation, 95(3): 195-208. https://doi.org/10.1177%2F0037549718757652
[3] Garcia-Torres, F., Bordons, C., Ridao, M.A. (2019). Optimal economic schedule for a network of microgrids with hybrid energy storage system using distributed model predictive control. IEEE Transactions on Industrial Electronics, 66(3): 1919-1929. https://doi.org/10.1109/tie.2018.2826476
[4] Tomi´c, M., Jovanovi´c, K., Chevallereau, C., Potkonjak, V., Rodi´c, A. (2018). Toward optimal mapping of human dual-arm motion to humanoid motion for tasks involving contact with the environment. International Journal of Advanced Robotic Systems, 15(1): 1729881418757377. https://doi.org/10.1177/1729881418757377
[5] Feng, Y., Han, F., Yu, X. (2016). Reply to “Comments on ’Chattering free full-order sliding-mode control’[Automatica 50 (2014)1310-1314]”. Automatica, 72: 255-256. https://doi.org/10.1016/j.automatica.2016.04.036
[6] Flamm, B., Eichler, A., Warrington, J., Lygeros, J. (2018). Dual dynamic programming for nonlinear control problems over long horizons. 2018 European Control Conference (ECC), Limassol, Cyprus, pp. 471-476. https://doi.org/10.23919/ecc.2018.8550104
[7] Wei, Q., Li, B., Song, R. (2018). Discrete-time stable generalized self-learning optimal control with approximation errors. IEEE Transactions on Neural Networks and Learning Systems, 29(4): 1226-1238. https://doi.org/10.1109/tnnls.2017.2661865
[8] Grüne, L., Pirkelmann, S., Stieler, M. (2018). Strict dissipativity implies turnpike behavior for time-varying discrete time optimal control problems. Control Systems and Mathematical Methods in Economics, 687: 195-218. https://doi.org/10.1007/978-3-319-75169-6_10
[9] Rosolia, U., Borrelli, F. (2018). Learning model predictive control for iterative tasks. a data-driven control framework. IEEE Transactions on Automatic Control, 63(7): 1883-1896. https://doi.org/10.1109/tac.2017.2753460
[10] Mu, C., Wang, D., He, H. (2017). Data-driven finite-horizon approximate optimal control for discrete-time nonlinear systems using iterative HDP approach. IEEE Transactions on Cybernetics, 48(10): 2948-2961. https://doi.org/10.1109/tcyb.2017.2752845
[11] Song, R., Xiao, W., Sun, C. (2014). A new self-learning optimal control laws for a class of discrete-time nonlinear systems based on ESN architecture. Science China Information Sciences, 57(6): 1-10. https://doi.org/10.1007/s11432-013-4954-y
[12] Li, J., Chai, T., Lewis, F.L., Ding, Z., Jiang, Y. (2019). Off-policy interleaved Q-learning: Optimal control for affine nonlinear discrete-time systems. IEEE Transactions on Neural Networks and Learning Systems, 30(5): 1308-1320. https://doi.org/10.1109/tnnls.2018.2861945
[13] Wei, Q., Liu, D. (2015). A novel policy iteration based deterministic Q-learning for discrete-time nonlinear systems. Science China Information Sciences, 58(12): 1-15. https://doi.org/10.1007/s11432-015-5462-z
[14] Tang, G.Y., Wang, H.H. (2005). Successive approximation approach of optimal control for nonlinear discrete-time systems. International Journal of Systems Science, 36(3): 153-161. https://doi.org/10.1080/00207720512331338076
[15] Tang, G.Y., Xie, N., Liu, P. (2005). Sensitivity approach to optimal control for affine nonlinear discrete-time systems. Asian Journal of Control, 7(4): 448-454. https://doi.org/10.1111/j.1934-6093.2005.tb00408.x
[16] Molloy, T.L., Ford, J.J., Perez, T. (2018). Finite-horizon inverse optimal control for discrete-time nonlinear systems. Automatica, 87: 442-446. https://doi.org/10.1016/j.automatica.2017.09.023
[17] Kohler, J., Muller, M.A., Allgower, F. (2019). Nonlinear reference tracking: An economic model predictive control perspective. IEEE Transactions on Automatic Control, 64(1): 254-269. https://doi.org/10.1109/tac.2018.2800789
[18] Kishida, M. (2018). Event-triggered control for discrete-time nonlinear systems using state-dependent Riccati equation. 2018 European Control Conference (ECC), Limassol, Cyprus, pp. 1499-1504. https://doi.org/10.23919/ecc.2018.8550427
[19] Chen, D., Fujimoto, K., Suzuki, T. (2016). Discrete-time nonlinear optimal control via generating functions. IEICE Transactions on Fundamentals of Electronics, Communications and Computer Sciences, 99(11): 2037-2048. https://doi.org/10.1587/transfun.e99.a.2037
[20] Chen, D. (2016). Optimal control of continuous and discrete time systems via generating functions. Ph.D. dissertation. Nagoya University, Nagoya, Japan.
[21] Pariz, N. (2001). Analysis of nonlinear system behavior: The case of stressed power systems. Ph.D. dissertation. Department of Electrical Engineering, Ferdowsi University of Mashhad, Mashhad, Iran.
[22] Soltani, S., Pariz, N., Ghazi, R. (2009). Extending the perturbation technique to the modal representation of nonlinear systems. Electric Power Systems Research, 79(8): 1209-1215. https://doi.org/10.1016/j.epsr.2009.02.011
[23] Khatibi, M., Shanechi, H.M. (2011). Using modal series to analyze the transient response of oscillators. International Journal of Circuit Theory and Applications, 39(2): 127-134. https://doi.org/10.1002/cta.621
[24] Pariz, N., Shanechi, H.M., Vaahedi, E. (2003). Explaining and validating stressed power systems behavior using modal series. IEEE Transactions on Power Systems, 18(2): 778-785. https://doi.org/10.1109/tpwrs.2003.811307
[25] Shanechi, H.M., Pariz, N., Vaahedi, E. (2003). General nonlinear modal representation of large scale power systems. IEEE Transactions on Power Systems, 18(3): 1103-1109. https://doi.org/10.1109/tpwrs.2003.814883
[26] Khatibi, M., Shanechi, H.M. (2015). Using a modified modal series to analyse weakly nonlinear circuits. International Journal of Electronics, 102(9): 1457-1474. https://doi.org/10.1080/00207217.2014.982212
[27] Jajarmi, A., Pariz, N., Effati, S., Kamyad, A.V. (2012). Infinite horizon optimal control for nonlinear interconnected largescale dynamical systems with an application to optimal attitude control. Asian Journal of Control, 14(5): 1239-1250. https://doi.org/10.1002/asjc.452
[28] Sajjadi, S.S., Pariz, N., Karimpour, A., Jajarmi, A. (2014). An off-line NMPC strategy for continuous-time nonlinear systems using an extended modal series method. Nonlinear Dynamics, 78(4): 2651-2674. https://doi.org/10.1007/s11071-014-1616-6
[29] Jajarmi, A., Baleanu, D. (2018). Optimal control of nonlinear dynamical systems based on a new parallel eigenvalue decomposition approach. Optimal Control Applications and Methods, 39(2): 1071-1083. https://doi.org/10.1002/oca.2397
[30] Agarwal, R.P. (2000). Difference Equations and Inequalities: Theory, Methods, and Applications. CRC Press. https://doi.org/10.1201/9781420027020
[31] Garrard, W.L., Jordan, J.M. (1977). Design of nonlinear automatic flight control systems. Automatica, 13(5): 497-505. https://doi.org/10.1016/0005-1098(77)90070-x
[32] Banks, S.P., Mhana, K. (1992). Optimal control and stabilization for nonlinear systems. IMA Journal of Mathematical Control and Information, 9(2): 179-196. https://doi.org/10.1093/imamci/9.2.179
[33] Rehbock, V., Teo, K., Jennings, L. (1996). Optimal and suboptimal feedback controls for a class of nonlinear systems. Computers & Mathematics with Applications, 31(6): 71-86. https://doi.org/10.1016/0898-1221(96)00007-7