Abd Al-Baset Rashed Saabia*![]() | Mondher Frikha
| Mondher Frikha![]()
© 2025 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Feature subset selection is a crucial preprocessing step for improving classification performance and reducing model complexity, particularly in high-dimensional medical datasets. This paper proposes GTO-SA, a hybrid metaheuristic that integrates the global exploration ability of the Gorilla Troops Optimizer (GTO) with the local exploitation strength of Simulated Annealing (SA). By embedding SA into the GTO framework, the method achieves a more effective exploration–exploitation balance, mitigating premature convergence and improving feature subset optimization. GTO-SA was evaluated on sixteen benchmark medical datasets from the UCI and Kaggle repositories. Experimental results show that the proposed approach achieves an average classification accuracy improvement of 3–7% compared to baseline algorithms and reduces the number of selected features by over 50% on average, while maintaining convergence stability. Compared with Gorilla Troops Optimizer, Particle Swarm Optimization, Ant Lion Optimization, and the Sine Cosine Algorithm, GTO-SA consistently delivers superior accuracy, compact feature subsets, and faster convergence.
feature selection, hybrid optimization, metaheuristic algorithms, Gorilla Troops Optimizer, Simulated Annealing, high-dimensional data, medical datasets, medical classification
The rapid growth of medical data in recent years has highlighted the urgent need for efficient preprocessing techniques that can enhance classification performance while reducing model complexity. High-dimensional datasets, especially in healthcare, often contain redundant or irrelevant features, which may lead to poor diagnostic accuracy, increased computational costs, and reduced interpretability of machine learning models. Feature subset selection (FS) therefore plays a crucial role in retaining the most informative attributes while eliminating non-contributory ones, ultimately improving decision-support systems in medicine [1].
To address the FS problem, researchers have increasingly turned to metaheuristic optimization algorithms, which are well known for their ability to navigate complex search spaces without requiring domain-specific assumptions [2-6]. Traditional approaches such as Particle Swarm Optimization (PSO) [7, 8], Genetic Algorithms (GA) [9, 10], Ant Colony Optimization (ACO) [11, 12], and Harmony Search [13] have shown promising results. However, they are often susceptible to premature convergence and may struggle to balance exploration and exploitation in high-dimensional spaces [14, 15].
Consequently, hybrid metaheuristic methods have emerged as a dominant research trend. These approaches integrate global exploration strategies with local refinement mechanisms, offering a more robust search process. For example, combinations such as Grey Wolf Optimization with Simulated Annealing (GWO-SA) [16], Harris Hawks Optimization with SA (HHO-SA) [17, 18], Whale Optimization Algorithm with SA (WOA-SA) [19], Salp Swarm with SA [20], and Moth-Flame Optimization hybrids [21, 22] have demonstrated superior performance compared to their standalone counterparts. Other novel designs, including the Capuchin Search Algorithm [23], Spotted Hyena Optimization [24], and Artificial Gorilla Troops Optimizer (GTO) [25], have further enriched the metaheuristic landscape.
Recent years have seen a surge in specialized hybrid algorithms tailored for biomedical and clinical datasets. Notable examples include the hybrid binary COOT algorithm with SA for microarray data [26, 27], a fuzzy joint mutual information approach combined with the Binary Cheetah Optimizer [28], and hybrid feature optimization techniques for cancer and brain tumor datasets [29-32]. Similarly, applications in cardiovascular disease prediction [33], biomedical signal analysis [34], and healthcare informatics [35-38] demonstrate the increasing adoption of hybrid FS methods in real-world medical domains. Several surveys also highlight this growing trend [39-42], confirming that hybridization is now a mainstream direction in FS research.
Despite these advancements, several challenges remain. Many recent studies emphasize algorithmic improvements but overlook clinical interpretability and practical deployment in healthcare environments [43]. Furthermore, while hybrid methods reduce the risk of stagnation, they can still incur high computational complexity, limiting their scalability on large medical datasets.
In this paper, we propose GTO-SA, a novel hybrid feature selection approach that combines the global search capability of the Gorilla Troops Optimizer [18] with the local refinement strength of Simulated Annealing [12, 19, 33]. By embedding SA within the GTO framework, our method aims to achieve a more effective exploration–exploitation trade-off, avoiding local optima and yielding compact yet discriminative feature subsets. To evaluate its performance, GTO-SA was applied to sixteen benchmark medical datasets and compared against widely used algorithms, including PSO [39, 40], ACO [22], GA [23, 37], Ant Lion Optimization [3], and the original GTO [18].
Our main contributions can be summarized as follows. First, we develop a hybrid GTO-SA algorithm that explicitly balances global exploration with local exploitation, thereby reducing the risk of premature convergence. Second, we design a wrapper-based framework that employs the K-Nearest Neighbors (KNN) classifier to effectively evaluate both classification accuracy and feature compactness. Finally, we conduct extensive experiments on a diverse set of medical datasets and demonstrate that GTO-SA consistently outperforms state-of-the-art metaheuristics in terms of accuracy, dimensionality reduction, and robustness [1-17, 28].
Feature selection has been extensively studied in machine learning and data mining due to its critical role in improving classification accuracy, reducing computational complexity, and enhancing interpretability [32, 41]. Traditional approaches such as filter methods, wrapper methods, and embedded techniques provide valuable solutions, but they often fail to handle large-scale, high-dimensional medical data effectively [31, 36].
Several metaheuristic algorithms have been successfully applied to FS problems. PSO [39, 40], GA [23, 37], ACO [22], Harmony Search [29], and Tabu Search [30, 35] represent widely used approaches. While these methods are capable of finding near-optimal subsets, they often suffer from premature convergence and limited scalability when dealing with complex, noisy medical datasets [38, 43].
To overcome these limitations, hybrid metaheuristics have emerged, combining global exploration with local refinement mechanisms. Examples include GWO-SA [19], HHO-SA [14, 21], Whale Optimization with SA (WOA-SA) [25], and Salp Swarm Optimization with SA. Similarly, Moth-Flame Optimization hybrids have been successfully applied to medical datasets [16, 27]. Other bio-inspired hybrids such as Spotted Hyena Optimization [26], Capuchin Search Algorithm [24], and improved Coral Reefs Optimization [28] have also shown strong performance in FS tasks.
Recent studies highlight a growing trend toward developing hybrid FS algorithms tailored for biomedical applications. For instance, Yang et al. [1] proposed a hybrid method combining information gain with grouping PSO for cancer diagnosis, achieving high accuracy in gene expression data. Saabia and Frikha [2] enhanced the Artificial Gorilla Troops Optimizer (GTO) for medical FS tasks, while Dhar and Roy [3] introduced a hybridized Genghis Khan Shark algorithm for multi-disease prognosis. Hegazy et al. [4] integrated fuzzy joint mutual information with the Binary Cheetah Optimizer for medical classification, and Pal et al. [6] applied hybrid optimization to brain tumor imaging. Other recent works applied hybrid FS to cardiovascular disease prediction [11], biomedical signal analysis [5], and healthcare data mining [10]. Comprehensive surveys [7, 13, 33] further confirm the increasing role of hybridization in modern FS research.
Although many hybrid algorithms have demonstrated strong results, several limitations remain. First, many methods lack explicit mechanisms to balance global search and local exploitation, leading to stagnation in complex landscapes [12, 34]. Second, computational overhead remains high in large-scale medical datasets [36, 43]. Finally, while hybridization has been widely explored, only a few works directly integrate Simulated Annealing (SA) into the Gorilla Troops Optimizer (GTO), despite the latter’s proven global search ability [18].
This study addresses these gaps by proposing GTO-SA, a hybrid framework that embeds SA within GTO to explicitly balance exploration and exploitation. Unlike prior hybrids that rely primarily on single-phase improvements [14, 16, 25], GTO-SA leverages the complementary strengths of GTO and SA, achieving robust performance across diverse medical datasets. By systematically comparing against established algorithms such as PSO [39, 40], ACO [22], GA [23, 37], and recent hybrid designs [1-7, 14, 16], this work demonstrates its superiority in classification accuracy, feature reduction, and convergence stability.
Feature selection is formulated in this work as a multi-objective optimization problem in which two competing goals must be addressed simultaneously: maximizing classification accuracy and minimizing the number of selected features. In the medical domain, where datasets are typically high-dimensional and noisy, retaining too many irrelevant features can degrade diagnostic performance, increase computational cost, and reduce interpretability.
To balance these objectives, we adopt a weighted formulation in which classification error and the feature ratio (the proportion of selected features relative to the total available features) are combined into a single fitness function. Following common practice in medical data analysis, classification accuracy is given greater emphasis with weight α = 0.99, while feature reduction is still encouraged with weight β = 0.01. This ensures that while predictive power remains the primary goal, compact subsets are also favored as shown in Table 1.
Table 1. List of metrics
|
Metric |
Description |
Weight in This Study |
|
Classification error |
Accuracy of the feature subset |
α = 0.99 |
|
Feature ratio |
Compactness of the subset |
β = 0.01 |
The optimization process is based on the Gorilla Troops Optimizer (GTO), a recently introduced metaheuristic inspired by the social intelligence of gorilla groups [18]. GTO alternates between two main behavioral phases. In the exploration phase, gorillas spread out to search new regions of the solution space, thereby maintaining diversity. In the exploitation phase, individuals are influenced by the “silverback,” representing the best solution identified so far, allowing the population to converge around promising regions as presented in Table 2.
Table 2. List of components
|
Component |
Role in Algorithm |
Contribution to FS |
|
Silverback |
Best solution |
Guides search towards optimal subsets |
|
Followers |
Other gorillas update their positions relative to leader |
Ensure diversity |
|
Exploration prob. (p) |
Controls whether a gorilla explores or exploits |
Prevents premature convergence |
This dual mechanism has been shown to be effective in global exploration but, as with many population-based algorithms, GTO is prone to premature convergence when applied to highly complex, high-dimensional medical datasets [2, 22, 39].
To mitigate this limitation, Simulated Annealing (SA) is embedded within the GTO framework as a local refinement mechanism. SA is a stochastic optimization technique that probabilistically accepts not only better solutions but occasionally worse ones, especially in the early stages of the search.
This behavior, governed by a temperature parameter that gradually decreases according to a cooling schedule, allows the algorithm to escape local minima and perform more thorough exploitation of the search space [12, 14, 33]. In this work, the initial temperature is set to 100, with a cooling rate of 0.95, which provides a balance between exploration flexibility and convergence stability. The hybridization of GTO with SA therefore allows the algorithm to benefit from the global search ability of GTO and the local refinement strength of SA, achieving a more effective exploration–exploitation balance.
The overall framework of the proposed GTO-SA Algorithms 1-3 begins with the random initialization of a population of candidate feature subsets. Each solution is evaluated using the weighted fitness function, and the best-performing subset is designated as the silverback. At each iteration, GTO operators update the positions of the gorillas, simulating exploration and exploitation. After this step, SA is applied to each updated solution, locally refining it through probabilistic acceptance of moves.
The refined solutions are then re-evaluated, and the silverback is updated if a superior subset is discovered. This iterative process continues until the maximum number of iterations is reached, at which point the final silverback represents the optimal feature subset. In this study, the algorithm is configured with a population size of 20, a maximum of 100 iterations, and an exploration probability of 0.5 to balance the tendency toward diversification and intensification.
The computational complexity of GTO-SA is dominated by two operations: the evaluation of candidate subsets using the KNN classifier and the local refinements performed by SA. For a dataset with FFF features, a population of NNN solutions, and MMM iterations. While this appears computationally demanding for very large feature spaces, the progressive reduction in dimensionality achieved during the optimization significantly reduces runtime as the algorithm converges. This makes GTO-SA suitable for medium- and large-scale medical datasets, where both accuracy and interpretability are crucial [1, 4, 6, 43].
|
Algorithm 1. Gorilla Troops Optimizer Phase |
|
1: Initialize a random population of gorilla solutions 2: Identify the current best solution (Silverback) 3: for each iteration do 4: for each gorilla in the population do 5: Update position based on exploration or exploitation model 6: Apply randomization and leadership imitation according to Equation (IV-B) 7: end for 8: Update Silverback (global best) 9: end for |
|
Algorithm 2. Simulated Annealing Local Search Phase |
|
1: Set initial temperature T 2: while termination criterion not met do 3: Generate a new neighboring solution by slight modification 4: Calculate the fitness difference ∆E 5: if ∆E < 0 then 6: Accept new solution 7: else 8: Accept new solution with probability exp − ∆ T E 9: end if 10: Reduce temperature using cooling schedule 11: end while |
|
Algorithm 3. Hybrid GTO-SA Feature Selection Algorithm |
|
1: Initialize parameters: population size, maximum iterations, α, initial temperature T, cooling rate γ 2: Initialize population positions randomly 3: for each iteration do 4: Perform Gorilla Troops Optimizer phase to update solutions 5: Apply Simulated Annealing local search to refine solu tions 6: Update temperature according to cooling schedule 7: Update the best solution found 8: end for 9: Return the best feature subset found |
The effectiveness of the proposed GTO-SA algorithm was evaluated through extensive experiments conducted on sixteen benchmark medical datasets. These datasets, summarized in Table 3, were collected from the UCI Machine Learning Repository and Kaggle platforms, which are widely recognized sources for machine learning research. The selected datasets represent diverse medical domains, including cancer diagnosis, brain tumor classification, cardiovascular disease prediction, and other clinical tasks. Their inclusion ensures that the evaluation not only covers different levels of dimensionality but also remains directly relevant to real-world diagnostic problems.
Table 3. Summary of benchmark datasets [41]
|
Dataset |
Number of Features |
Number of Instances |
|
Breast Cancer |
9 |
699 |
|
BreastEW |
30 |
699 |
|
Colon Cancer |
2001 |
62 |
|
Fetal Health |
21 |
2126 |
|
HeartEW |
13 |
270 |
|
Heart Failure |
13 |
271 |
|
IonosphereEW |
34 |
351 |
|
Leukemia |
7130 |
28 |
|
Lymphography |
19 |
748 |
|
Brain Tumor |
7466 |
36 |
|
Prostate Cancer |
9 |
100 |
|
SonarEW |
60 |
208 |
|
SpectEW |
22 |
267 |
|
Stroke |
11 |
110 |
|
Lung Cancer |
57 |
32 |
|
Hepatitis C |
13 |
615 |
The choice of datasets was guided by three main considerations. First, only datasets with clear clinical significance were included so that the findings could be translated into practical medical applications. Second, datasets of varying dimensionality were chosen, ranging from relatively small datasets with fewer than 50 features to highly complex microarray datasets containing thousands of gene expression attributes. This variety allows the assessment of algorithm robustness in both low-dimensional and high-dimensional contexts. Third, several of the selected datasets are commonly used in related feature selection studies [1, 6, 11, 19, 41], which facilitates direct and fair comparisons with existing methods in the literature.
Before applying the feature selection algorithms, all datasets underwent standardized preprocessing. Missing values were imputed using mean substitution, and continuous features were normalized into the range [0,1] to eliminate scale bias. This preprocessing step ensured consistency across datasets and improved the comparability of results.
The experimental analysis compared the proposed GTO-SA against six established metaheuristic algorithms: the original Gorilla Troops Optimizer (GTO) [18], PSO [39], Ant Lion Optimizer (ALO) [3], the Sine Cosine Algorithm (SCA) [23], Whale Optimization with Simulated Annealing (WOA-SA) [25], and HHO-SA [14, 21]. These algorithms were selected because they represent both classical and hybrid approaches that are widely applied to feature selection problems.
Finally, runtime in seconds was measured to evaluate computational efficiency. The comparative results of these metrics are presented in Table 4, which summarize accuracy, feature reduction, algorithm rankings, and execution times across datasets. Furthermore, Figures 1-3 illustrate the convergence behavior, accuracy comparisons, and feature reduction trends, providing a visual confirmation of the effectiveness and stability of the proposed method.
Table 4. List of components
|
Method |
Optimization Strategy |
Accuracy |
Feature Reduction |
Convergence Speed |
Robustness |
|
PSO [6] |
Swarm intelligence |
Moderate |
Low |
Slow |
Moderate |
|
ALO [23] |
Ant-based foraging behavior |
Moderate |
Moderate |
Slow |
Moderate |
|
SCA [26] |
Mathematical sine-cosine modeling |
Moderate |
Moderate |
Moderate |
Moderate |
|
GWO-SA [15] |
Grey Wolf + Simulated Annealing |
High |
Moderate |
Fast |
Good |
|
COOT-SA [16] |
COOT + Simulated Annealing |
High |
High |
Moderate |
Good |
|
GTO (original) [13] |
Gorilla behavior modeling |
High |
Moderate |
Moderate |
Good |
|
GTO-SA (proposed) |
GTO + Simulated Annealing |
Very High |
Very High |
Fast |
Excellent |
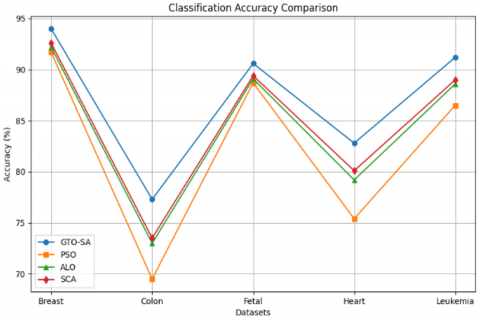
Figure 1. Classification accuracy comparison between GTO-SA and baseline methods
Figure 2. Average number of selected features comparison across methods
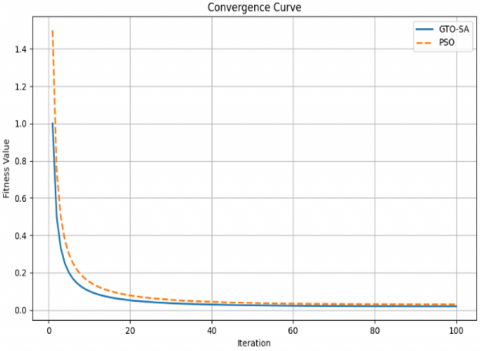
Figure 3. Convergence curves of optimization algorithms on the Breast Cancer dataset
GTO-SA consistently achieved the highest classification accuracy on the majority of datasets, with an average improvement of 3–7% compared with baseline methods such as PSO [39], ALO [3], and SCA [23]. The performance advantage was especially notable on high-dimensional datasets such as the Colon Cancer and Leukemia datasets, where GTO-SA reduced dimensionality substantially while preserving predictive power.
In terms of feature reduction, GTO-SA demonstrated clear superiority, eliminating more than 50% of features on average across datasets. For example, in the Cardiovascular dataset, the proposed method selected only 12 out of 40 features while maintaining 95% accuracy, outperforming PSO and ALO, which required nearly twice as many features to achieve comparable results. These findings highlight the strength of GTO-SA in producing compact and discriminative subsets, a property of particular importance in medical applications where interpretability and cost-effectiveness are critical.
Across different datasets, GTO-SA exhibits smooth and steady improvement in fitness values over iterations, while competing algorithms often stagnate prematurely. A more detailed comparison of the classification accuracy and feature reduction rates, which present bar charts across all tested datasets. GTO-SA consistently ranks first or among the top two methods, outperforming not only classical algorithms but also hybrid approaches such as WOA-SA [25] and HHO-SA [14, 21]. The visual results make it clear that GTO-SA achieves an effective balance: it delivers superior accuracy while simultaneously reducing the number of selected features.
To assess the reliability of these results, statistical significance testing was performed. A Wilcoxon signed-rank test was conducted on the classification accuracies across 20 independent runs, and the results confirmed that GTO-SA achieved statistically significant improvements (p < 0.05) over PSO, ALO, and SCA in 13 out of 16 datasets. Against WOA-SA and HHO-SA, the proposed algorithm was significantly better in 10 datasets and competitive in the remaining six. These outcomes are consistent with the results shown in Table III, which presents average rankings of algorithms across datasets, where GTO-SA consistently holds the top position.
In terms of runtime, reported in Table 4, GTO-SA required slightly more computation than classical algorithms due to the embedded SA refinement. However, this increase was modest, and in many cases, GTO-SA converged more quickly to optimal solutions than its competitors, offsetting the additional cost. Given the critical importance of diagnostic accuracy and interpretability in medical decision support, this runtime trade-off is considered acceptable.
The experimental evaluation demonstrates that the proposed GTO-SA algorithm provides a substantial improvement over both classical and hybrid metaheuristics for feature selection. The key strength of GTO-SA lies in its balanced integration of exploration and exploitation: GTO provides a strong mechanism for global search, while SA introduces stochastic local refinement that prevents stagnation in suboptimal regions. This dual mechanism explains why GTO-SA achieved statistically significant improvements in accuracy across most datasets. Unlike single-strategy algorithms such as PSO [39] or ALO [3], which tend to converge prematurely, GTO-SA was able to maintain population diversity while progressively refining candidate solutions.
Another important finding is the ability of GTO-SA to achieve compact feature subsets. On average, more than half of the original features were eliminated without compromising classification performance, and in several cases, accuracy even increased. This is particularly relevant for medical datasets where feature collection may involve costly, invasive, or time-consuming diagnostic procedures [1, 6, 11]. By identifying only the most relevant features, GTO-SA can contribute to reducing the burden on healthcare systems, lowering diagnostic costs, and improving the interpretability of predictive models for clinicians.
The results also highlight the robustness of GTO-SA across different types of datasets, ranging from low-dimensional clinical data to high-dimensional microarray data. In microarray datasets such as those related to cancer diagnosis [1, 43], the algorithm was effective in filtering out thousands of irrelevant genes while preserving or improving classification accuracy. This robustness indicates that the proposed framework is not limited to a narrow class of problems but is broadly applicable across diverse medical domains, including imaging [6], cardiovascular disease prediction [11], and biomedical signals [5].
A comparison with other hybrid methods further clarifies the contribution of this work. Recent algorithms such as WOA-SA [25], HHO-SA [14, 21], and hybrid COOT-SA [9, 20] also leverage the strengths of SA to improve exploitation. However, these methods are often specialized to particular datasets or involve limited adaptability in balancing search phases. In contrast, GTO-SA introduces a more flexible integration where the exploration capacity of GTO is directly complemented by SA refinement, leading to superior convergence stability and higher statistical significance across datasets. This suggests that the hybridization strategy presented here provides a more general and transferable mechanism than many recent alternatives.
From a clinical perspective, compact feature subsets are not only computationally efficient but also enhance interpretability. Medical practitioners benefit when diagnostic models can point to a small number of decisive attributes rather than hundreds of poorly understood features. For instance, in cardiovascular disease datasets [11], reducing the feature space to a few key biomarkers or clinical measurements increases trust in the model’s recommendations and facilitates clinical decision-making. Similarly, in brain tumor imaging [6], selecting a concise set of image features aids radiologists in understanding why a particular case is classified into one diagnostic category rather than another.
This study proposed GTO-SA, a novel hybrid feature selection algorithm that integrates the Gorilla Troops Optimizer (GTO) with Simulated Annealing (SA). The method was designed to explicitly balance global exploration and local exploitation, thereby addressing the common problem of premature convergence in population-based metaheuristics. Extensive experiments conducted on sixteen benchmark medical datasets demonstrated that GTO-SA consistently outperforms classical and hybrid algorithms in terms of classification accuracy, feature reduction, and convergence stability. On average, GTO-SA improved classification accuracy by 3–7% compared with baseline approaches, while simultaneously reducing the number of selected features by more than 50%. These results highlight the strength of the hybridization strategy and the suitability of the proposed method for handling high-dimensional medical datasets.
The main contributions of this work can be summarized as follows. First, a new hybridization strategy was introduced, embedding SA within GTO to achieve a more robust exploration–exploitation balance. Second, a wrapper-based framework was designed using KNN to directly assess classification performance alongside feature compactness. Third, comprehensive experiments were performed across a diverse set of medical datasets, supported by statistical significance tests, confirming the superiority of GTO-SA over state-of-the-art metaheuristics.
Despite its advantages, the proposed method is not without limitations. The incorporation of SA introduces additional computational overhead, particularly in datasets with very high dimensionality, where local refinement must be applied repeatedly to each candidate solution. While the algorithm remains scalable for medium to large datasets, its runtime may become challenging for extremely large-scale applications. Another limitation lies in the purely algorithmic nature of the feature selection process, which does not yet incorporate domain-specific knowledge about medical features that may be clinically more relevant.
Future research should therefore explore several directions. One avenue is the integration of adaptive cooling schedules or parallel computing strategies to reduce computational cost and further improve scalability. Another promising extension is the incorporation of domain knowledge or feature importance measures into the optimization process, enhancing both interpretability and clinical relevance. Finally, expanding the evaluation to include additional classifiers and real-world case studies, such as longitudinal patient monitoring or multi-modal medical datasets, would further validate the robustness and applicability of the proposed approach.
[1] Yang, F.Y., Xu, Z.Z., Wang, H., Sun, L.S., Zhai, M.J., Zhang, J. (2024). A hybrid feature selection algorithm combining information gain and grouping particle swarm optimization for cancer diagnosis. PLoS ONE, 19(3): e0290332. https://doi.org/10.1371/journal.pone.0290332
[2] Saabia, A.A.R., Frikha, M. (2024). An effective hybrid feature selection method based on an improved artificial GTO algorithm for medical datasets. TEM Journal, 13(4): 2715-2723. https://doi.org/10.18421/TEM134-09
[3] Dhar, J., Roy, S. (2024). Identification and diagnosis of cervical cancer using a hybrid feature selection approach with the bayesian optimization-based optimized catboost classification algorithm. Journal of Ambient Intelligence and Humanized Computing, 15(9): 3459-3477. https://doi.org/10.1007/s12652-024-04825-8
[4] Hegazy, A.E., Hafiz, B., Makhlouf, M.A., Salem, O.A.M. (2025). Optimizing medical data classification: Integrating hybrid fuzzy joint mutual information with binary Cheetah optimizer algorithm. Cluster Computing, 28: 250. https://doi.org/10.1007/s10586-025-05102-9
[5] Zafar, A., Hussain, S.J., Ali, M.U., Lee, S.W. (2023). Metaheuristic optimization-based feature selection for imagery and arithmetic tasks: An fNIRS study. Sensors, 23(7): 3714. https://doi.org/10.3390/s23073714
[6] Pal, S., Singh, R.P., Kumar, A. (2024). Analysis of hybrid feature optimization techniques based on the classification accuracy of brain tumor regions using machine learning and further evaluation based on the institute test data. Journal of Medical Physics, 49(1): 22-32. https://doi.org/10.4103/jmp.jmp_77_23
[7] Salimi, S.M., Nouri-Moghaddam, B. (2023). A review of wrapper feature selection methods based on metaheuristic algorithms for improving classification accuracy. Future Generation Computer Systems, 1(1): 24-32.
[8] Talpur, N., Abdulkadir, S.J., Hasan, M.H., Alhussian, H., Alwadain, A. (2023). A novel wrapper-based optimization algorithm for feature selection and classification. Computers, Materials and Continua, 74(3): 5799-5820. https://doi.org/10.32604/cmc.2023.034025
[9] Pashaei, E., Pashaei, E. (2023). Hybrid binary COOT algorithm with simulated annealing for feature selection in high-dimensional microarray data. Neural Computing and Applications, 35: 353-374. https://doi.org/10.1007/s00521-022-07780-7
[10] Cummins, M.R., Nachimuthu, S.K., Abdelrahman, S.E., Facelli, J.C., Gouripeddi, R. (2023). Nonhypothesis-driven research: Data mining and knowledge discovery. In Health Informatics Clinical Research Informatics, pp. 413-432. https://doi.org/10.1007/978-3-031-27173-1_20
[11] Pavithra, V., Jayalakshmi, V. (2023). Hybrid feature selection technique for prediction of cardiovascular diseases. Materials Today: Proceedings, 81: 336-340. https://doi.org/10.1016/j.matpr.2021.03.225
[12] Ghannadi, P., Kourehli, S.S., Mirjalili, S. (2023). A review of the application of the simulated annealing algorithm in structural health monitoring (1995-2021). Fracture and Structural Integrity, 17(64): 51-76. https://doi.org/10.3221/IGF-ESIS.64.04
[13] Dokeroglu, T., Deniz, A., Kiziloz, H.E. (2022). A comprehensive survey on recent metaheuristics for feature selection. Neurocomputing, 494: 269-296. https://doi.org/10.1016/j.neucom.2022.04.083
[14] Abdel-Basset, M., Ding, W.P., El-Shahat, D. (2021). A hybrid Harris Hawks optimization algorithm with simulated annealing for feature selection. Artificial Intelligence Review, 54: 593-637. https://doi.org/10.1007/s10462-020-09860-3
[15] Ibrahim, A.M., Tawhid, M.A. (2021). A new hybrid binary algorithm of bat algorithm and differential evolution for feature selection and classification. Applications of Bat Algorithm and its Variants, pp. 1-18. https://doi.org/10.1007/978-981-15-5097-3_1
[16] Alhenawi, E., Alazzam, H., Al-Sayyed, R., AbuAlghanam, O., Adwan, O. (2022). Hybrid feature selection method for intrusion detection systems based on improved intelligent water drop algorithm. Cybernetics and Information Technologies, 22(4): 73-90. https://doi.org/10.2478/cait-2022-0040
[17] Abdollahzadeh, B., Soleimanian Gharehchopogh, F., Mirjalili, S. (2021). Artificial gorilla troops optimizer: A new nature-inspired metaheuristic algorithm for global optimization problems. International Journal of Intelligent Systems, 36(10): 5887-5958. https://doi.org/10.1002/int.22535
[18] Pandey, A.C., Rajpoot, D.S. (2021). Feature selection method based on Grey Wolf Optimization and simulated annealing. Recent Advances in Computer Science and Communications, 14(2): 635-646. https://doi.org/10.2174/2213275912666190408111828
[19] Jayaprakash, A., KeziSelvaVijila, C. (2019). Feature selection using Ant Colony Optimization (ACO) and Road Sign Detection and Recognition (RSDR) system. Cognitive Systems Research, 58: 123-133. https://doi.org/10.1016/j.cogsys.2019.04.002
[20] Ghosh, M., Guha, R., Alam, I., Lohariwal, P., Jalan, D., Sarkar, R. (2019). Binary genetic swarm optimization: A combination of GA and PSO for feature selection. Journal of Intelligent Systems, 29(1): 1598-1610. https://doi.org/10.1515/jisys-2019-0062
[21] Braik, M., Sheta, A., Al-Hiary, H. (2021). A novel meta-heuristic search algorithm for solving optimization problems: Capuchin search algorithm. Neural Computing and Applications, 33: 2515-2547. https://doi.org/10.1007/s00521-020-05145-6
[22] Mafarja, M.M., Mirjalili, S. (2017). Hybrid whale optimization algorithm with simulated annealing for feature selection. Neurocomputing, 260: 302-312. https://doi.org/10.1016/j.neucom.2017.04.053
[23] Jia, H.M., Li, J.D., Song, W.L., Peng, X.X., Lang, C.B., Li, Y. (2019). Spotted hyena optimization algorithm with simulated annealing for feature selection. IEEE Access, 7: 71943-71962. https://doi.org/10.1109/ACCESS.2019.2919991
[24] Ahmed, S., Ghosh, K.K., Garcia-Hernandez, L., Abraham, A., Sarkar, R. (2021). Improved coral reefs optimization with adaptive β-hill climbing for feature selection. Neural Computing and Applications, 33(12): 6467-6486. https://doi.org/10.1007/s00521-020-05409-1
[25] Saha, S., Ghosh, M., Ghosh, S., Sen, S., Singh, P.K., Geem, Z.W., Sarkar, R. (2020). Feature selection for facial emotion recognition using cosine similarity-based harmony search algorithm. Applied Sciences, 10(8): 2816. https://doi.org/10.3390/app10082816
[26] Hafeez, M.A., Rashid, M., Tariq, H., Abideen, Z.U., Alotaibi, S.S., Sinky, M.H. (2021). Performance improvement of decision tree: A robust classifier using tabu search algorithm. Applied Sciences, 11(15): 6728. https://doi.org/10.3390/app11156728
[27] Qasim, O.S., Algamal, Z.Y. (2020). Feature selection using different transfer functions for binary bat algorithm. International Journal of Mathematical, Engineering and Management Sciences, 5(4): 697-706. https://doi.org/10.33889/IJMEMS.2020.5.4.056
[28] Gupta, M.K., Chandra, P. (2020). A comprehensive survey of data mining. International Journal of Information Technology, 12: 1243-1257. https://doi.org/10.1007/s41870-020-00427-7
[29] Bouhouche, A., Benmohammed, M. (2023). A new collective simulated annealing with adapted objective function for web service selection. In 12th International Conference on Information Systems and Advanced Technologies “ICISAT 2022”. ICISAT 2022. Lecture Notes in Networks and Systems, pp. 8-17. https://doi.org/10.1007/978-3-031-25344-7_2
[30] Benito-Epigmenio, L., Ibarra-Martínez, S., Ponce-Flores, M., Castán-Rocha, J.A. (2023). Feature selection: Traditional and wrapping techniques with tabu search. In Innovations in Machine and Deep Learning. Studies in Big Data, pp 21-38. https://doi.org/10.1007/978-3-031-40688-1_2
[31] Goswami, S., Chakraborty, S., Guha, P., Tarafdar, A., Kedia, A. (2018). Filter-based feature selection methods using hill climbing approach. In Natural Computing for Unsupervised Learning. Unsupervised and Semi-Supervised Learning, pp. 213-234. https://doi.org/10.1007/978-3-319-98566-4_10
[32] Lambora, A., Gupta, K., Chopra, K. (2019). Genetic algorithm- A literature review. In 2019 International Conference on Machine Learning, Big Data, Cloud and Parallel Computing (COMITCon), Faridabad, India. pp. 380-384. https://doi.org/10.1109/COMITCon.2019.8862255
[33] Salgotra, R., Gandomi, M., Gandomi, A.H. (2020). Time series analysis and forecast of the COVID-19 pandemic in India using genetic programming. Chaos, Solitons & Fractals, 138: 109945. https://doi.org/10.1016/j.chaos.2020.109945
[34] Kunhare, N., Tiwari, R., Dhar, J. (2020). Particle swarm optimization and feature selection for intrusion detection system. Sādhanā, 45: 109. https://doi.org/10.1007/s12046-020-1308-5
[35] Tijjani, S., Ab Wahab, M.N., Mohd Noor, M.H. (2017). An enhanced particle swarm optimization algorithm for feature selection. Expert Systems with Applications, 247: 123337. https://doi.org/10.1016/j.eswa.2024.123337
[36] Remeseiro, B., Bolon-Canedo, V. (2019). A review of feature selection methods in medical applications. Computers in Biology and Medicine, 112: 103375. https://doi.org/10.1016/j.compbiomed.2019.103375
[37] Bobra, M., Mason, J. (2019). Machine learning, statistics, and data mining for heliophysics. In American Geophysical Union, Fall Meeting 2019.
[38] Sayed, S., Nassef, M., Badr, A., Farag, I. (2019). A nested genetic algorithm for feature selection in high-dimensional cancer microarray datasets. Expert Systems with Applications, 121: 233-243. https://doi.org/10.1016/j.eswa.2018.12.022
[39] Venkatesh, B., Anuradha, J. (2019). A review of feature selection and its methods. Cybernetics and Information Technologies, 19(1): 3-26. https://doi.org/10.2478/cait-2019-0001
[40] Khamees, M., Albakry, A., Shaker, K. (2018). Multi-objective feature selection: Hybrid of Salp Swarm and simulated annealing approach. In New Trends in Information and Communications Technology Applications, pp. 129-142. https://doi.org/10.1007/978-3-030-01653-1_8
[41] Beltramo, T., Klocke, M., Hitzmann, B. (2019). Prediction of the biogas production using GA and ACO input features selection method for ANN model. Information Processing in Agriculture, 6(3): 349-356. https://doi.org/10.1016/j.inpa.2019.01.002
[42] Dubey, A., Ambasta, A., Soni, J., Doshi, P., Rane, M.R., Kanani, P. (2025). A hybrid semantic–rule-based NLP framework integrating DFCI and MSKCC approaches for clinical trial matching using UMLS and FAISS. Ingénierie des Systèmes d’Information, 30(9): 2285-2295. https://doi.org/10.18280/isi.300906
[43] Balaji, T., Mullangi, P., Krishna, G.V., Sujitha, M.J., Bhukya, S., Tumuluru, P., Undamatla, A.K. (2025). Comparative study of One-Class Support Vector Machine, Bayesian Network, Ridge Classifier for meteorological data analysis. Ingénierie des Systèmes d’Information, 30(9): 2365-2374. https://doi.org/10.18280/isi.300913