Priyanka V. Deshmukh*![]() | Aniket K. Shahade
| Aniket K. Shahade![]() | Disha S. Wankhede
| Disha S. Wankhede![]() | Makarand R. Shahade
| Makarand R. Shahade![]() | Nitin N. Sakhare
| Nitin N. Sakhare![]() | Pritam H. Gohatre
| Pritam H. Gohatre![]()
© 2025 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
This study explores the integration of human-machine collaboration (HMC) in natural language processing (NLP) to enhance content creation and decision support. While machines offer scalability and efficiency, the absence of seamless integration with human creativity and domain expertise limits NLP’s full potential. The research outlines a framework that combines automated techniques—such as tokenization, stemming, lemmatization, sentiment analysis, topic modeling, and named entity recognition—with human-guided data curation, annotation, and error correction. The methodology emphasizes user-centered design and empirical evaluation to ensure accuracy, relevance, and usability of NLP outputs. Python-based implementations were used to analyze content performance across platforms, highlighting social media (90% usage) and blogs (78%) as key channels for audience engagement and content delivery. The findings demonstrate that collaborative NLP systems can significantly improve the quality of content generation and support evidence-based decision-making. The study underscores the importance of interdisciplinary approaches and suggests future work focus on applying advanced methods such as deep learning, reinforcement learning, and interactive interfaces to further enrich human-machine synergy in NLP applications.
human-machine collaboration, tokenization, stemming, lemmatization, content creation, natural language processing
Natural language processing (NLP), when enhanced through human-machine collaboration (HMC), offers transformative potential in content creation and decision support. With the help of HMC, NLP can bring significant change to content creation and decision support. Combining creativity and context from people with the efficiency and speed of machines, collaborative NLP systems can make textual tasks both better and faster [1]. NLP enables machines to understand, generate and interpret human language so that they can support many practical applications. Instead of eliminating human work, NLP should help people produce better and deeper results [2].
There are many current challenges that still reduce the success of human-machine teamwork in NLP. The main issue is how well machines and people can communicate [3]. Machines do well with large groups of text and looking for patterns, but they often find it challenging to grasp language meaning, social context and details connected to particular fields which is where humans are usually better [4]. Besides, lots of advanced NLP models are not easy to understand which may reduce trust and usefulness, mainly in situations where decisions matter a lot. Additional issues such as possible biases in the data, privacy challenges and responsibility concerns make it harder to deploy collaborative NLP systems [5].
Therefore, this study works to build systems that combine human and automated processes in NLP. By combining computer science, linguistics and human-centered design, the research tries to develop systems that assist users in creating good content, understanding important information and choosing data-based solutions [6]. As a result, it helps pave the way for human-machine partnership to be central to advancing innovation and performance in NLP areas [7].
Also, many NLP systems currently work by themselves and depend on set pipelines that make it hard to change or include new aspects [8]. When carefully added to each step of NLP, human feedback makes the results more relevant and the models more accurate [9]. Yet, frameworks for humans and machines working together continuously in many real-world cases are not well developed and have not been tested enough [10].
The study presents a way to join both human and machine tools by using automated approaches (such as tokenization, lemmatization and sentiment analysis) and involving people for steps like annotation, validation and adding context [11, 12]. Showing how we use hybrid tools when creating content and making choices, especially in the fields of social media and blogging, we highlight the advantages of these methods [13, 14].
Having this research will allow for better NLP systems now and prepare for even better, transparent and ethical NLP in the future [15]. Reinforcement learning, personalized adjustments and the ability to work with many languages can be included in the future to make NLP more welcoming and efficient [16].
New developments in NLP are having a major impact on working together with machines, mainly for creating content and offering support for making decisions [17, 18]. Using sentiment analysis and machine learning techniques is one-way researchers focus on helping with decisions in specific fields [19, 20]. A similar example is a clinical decision support system that uses aspect-oriented sentiment analysis of reviews to identify insights from patients and use them to tailor individual treatments [21].
Smart construction has studied the use of NLP to reduce human error in fields where safety matters a lot. By using SPAR-H, text mining and a multi-criteria analysis, the researchers designed a plan to minimize tower crane errors and reached a reliability measure as seen in real tower crane operations [22]. This shows that NLP is becoming more useful in making predictions about operational risks and enhancing quick decisions.
ChatGPT and similar large language models now make it possible for computers to interact more naturally with people. They have great potential for making content and developing conversational systems. But research has pointed out issues like bias, misinformation and privacy concerns that make some question whether they should be used [23]. Having LLMs added to Clinical Decision Support Systems (CDSS) in healthcare was shown to increase trust and make them pleasant to use, mainly when such systems acknowledge and confirm the intuition of clinicians instead of replacing it [24].
The mix of NLP with interaction design has made recommendation systems more personalized. For example, when LLMs are used with user-centered design, it makes the service more flexible and helps users feel more satisfied [25]. In terms of Persian conversational QA systems, using LLMs together with keyword extraction greatly increases the quality of the responses, most notably in situations where there is a lot of dialogue [26].
In the context of organizations, OpenAI’s work includes developing generative models like GPT, placing strong importance on ethical AI research to further Artificial General Intelligence (AGI) and avoid biases in its use [26]. Advanced systems that merge human and technological worlds use NLP to help manage complex systems based on what people sense through their senses [27].
Also, NLP-based machine learning and deep learning approaches have greatly changed how neurodegenerative diseases are diagnosed by finding detailed patterns in irregular data, though some concerns about data quality and how the models work still exist [28, 29]. AI with NLP frameworks has been applied to sustainable energy, helping increase both its efficiency and reliability, but researchers identify some technology and social-economic problems [30].
While NLP is advancing, there is little in place for a proper framework that supports people and machines working and learning together for the entire NLP process. This research tries to address this problem with a framework that uses the strength of machine learning and human thinking for better NLP content and support tasks.
Elevating HMC in NLP for enhanced content creation and decision support involves several key steps. Firstly, an in-depth analysis of existing NLP techniques and collaboration frameworks will be conducted to identify gaps and opportunities for improvement. Next, the development of novel algorithms, models, and tools that integrate human expertise and machine capabilities will be undertaken, focusing on enhancing content generation and decision-making processes. Additionally, empirical evaluations, user studies will be conducted effectiveness and usability of the proposed methodologies is based on the real-world scenarios. Throughout the research process, interdisciplinary collaboration between NLP experts, domain specialists, and human-computer interaction researchers will be encouraged to ensure the development of holistic and impactful solutions that address the complex challenges in content creation and decision support domains.
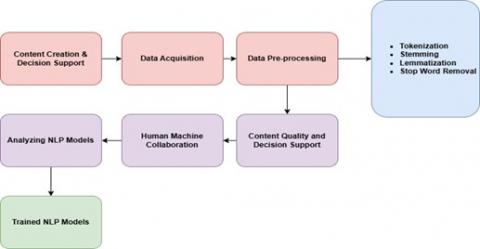
Figure 1 shows the enhanced content creation and decision support, a comprehensive approach is adopted, encompassing data acquisition, preprocessing, HMC, and machine processing. Data acquisition ensures the acquisition of relevant and high-quality datasets, followed by preprocessing steps such as tokenization, stemming, lemmatization, and removal of stop words to refine the data for analysis. The core focus lies in facilitating enhanced content quality and decision support through HMC, where content quality metrics and decision-making support functionalities are defined and integrated into the collaborative framework. Machine processing involves the analysis of NLP models to generate content such as summaries, reports, or creative text formats, leveraging trained natural language processing models to extract insights and create meaningful outputs. This integrated system forges data acquisition into machine processing through a system that combines human expertise and machine intelligence for optimizing decision-making content production systems.
Figure 1. Architectural representation of system
Data Acquisition: Developing an NLP application begins with defining both the task requirements as well as identifying the intended user group during the data acquisition phase. The application needs identification of suitable data sources between text documentation and web data contents and user-generated content that reflects the target audience needs. Data curation requires human involvement by experts to both validate and annotate data during the process because this foundation serves as essential material for training machine learning models.
Data Pre-Processing: The NLP application development process advances to data pre-processing after performing machine-based operations alongside human supervision. Machine processors execute the first stage of data cleanup operations by breaking data into tokens and applying stemming procedures followed by stop word elimination. The data processing becomes more efficient due to this step which prepares the information for analysis. The data accuracy and relevance require human inspection which is essential in combination with automated machine processing at this development stage. The application enables users to access a convenient interface which enables them to review preprocessed data before any further refinement. Users must review and fix tokenization errors and name entity recognition problems and add annotations to essential task data points while assessing data quality and recommending new data sources through the system interface. Basing the NLP application results on human feedback and input allows improvement of data quality and relevance which generates more precise end results.
Tokenization: Network security operations need tokenization as an important data cleaning approach for working with text data such as deep learning models for network security or any NLP applications. These include tokenization, stemming/lemmatization, and stop word removal. Tokenization is the act of breaking down a text into smaller segments or units of meaning, termed tokens, such as words, phrases, or symbols. Most of these steps contribute to dividing the text into chunks that can be further processed. For instance, the sentence: "Intrusion detection is critical to network security. is tokenized to ["Intrusion", "detection", "is", "crucial", "for", "network", "security", "."]. Many NLP libraries such as NLTK, spaCy, Natural Language Toolkit etc. have tokenizers available which help convert the sequence of text into individual tokens (words) for further analysis and modelling tasks.
Stemming: Stemming is the process of reducing words to their base or root, typically by stripping suffixes. Through normalization, you ensure that different forms of a word are treated as the same thing, allowing for more consistency in text analysis. For instance, reduce "running", "runner", and "ran" to "run". Porter Stemmer and Snowball Stemmer are some of the commonly used stemmers for executing this process and they are available in NLP libraries like NLTK.
Lemmatization: Like stemming, lemmatization reduces words to their base or dictionary form (lemma), however, it takes into account the context and morphological analysis of the words. The outcome of stem analysis creates more precise base forms which should be favored for exact applications. The lemmatization process transforms better into good and running into run. The libraries spaCy and the WordNet Lemmatizer in NLTK provide users with access to tools that transform words into their essential base forms to enhance text analysis accuracy in context.
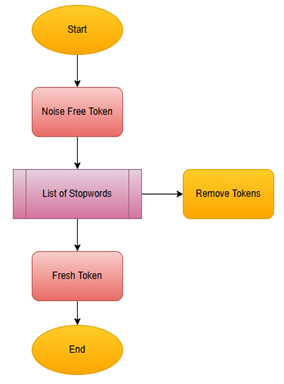
The flow diagram illustrated in Figure 2 illustrates how fresh tokens enter as initial input before the fundamental token list can be generated. The fundamental token list functions as both the starting point for the stemming process as well as the lemmatization step. The Token comparison process in stemming uses WordNet or similar databases to find alternative word forms. A system retrieves Synsets which are collections of synonymous words from each token then substitutes match words with their root forms to condense the text. Tokens move through two different processes during lemmatization because each token receives its dictionary foundation transformation. The stemmed and lemmatized tokens are then outputted as streamlined tokens, marking the end of the process.
Figure 2. Processing flow for stemming and lemmatization
Removal of Stop Words: They are a common word such as and, the and is, that are usually removed from our text data set to focus on the more meaningful words. Stop words, reduce the dimensionality of the text data and remove noise, making the analysis more efficient by focusing on key terms. For example, from the sentence "Intrusion detection is crucial for network security," words like "is" and "for" would be removed, resulting in ["Intrusion", "detection", "crucial", "network", "security"]. Most NLP libraries, such as NLTK, spaCy, and Scikit-learn, provide lists of stop words to facilitate this process.
These initial data-cleaning tasks form the foundation of preprocessing in NLP, ensuring that the text data is structured and standardized for effective analysis and modelling. By tokenizing text, stemming or lemmatizing words, and removing stop words, this study transforms raw text into a format that deep learning models can efficiently process to detect patterns and anomalies in network security contexts.
Figure 3 depicts the flow diagram for the removal of stop words, initiating with the input of fresh tokens. These tokens undergo the process of noise reduction, where a list of stopwords is referenced to identify and remove commonly occurring words that carry little semantic value. Each token is compared against the list of stopwords, and those identified as such are excluded from the analysis, resulting in a noise-free token list. The processed tokens are then outputted, marking the completion of the stop words removal process.
Figure 3. Stop word removal process flow
Enhanced Content Quality and Decision Support: The HMC system requires additional refinement of specific goals following data-preprocessing that accounts for metrics related to content quality and decision support features as well as extra relevant criteria. The system needs to determine fundamental metrics together with necessary functionalities that will support the task requirements. For continuous human-machine interaction a user interface enables users to communicate with the system during the complete NLP procedure. The system uses active learning loops to query users about needed information while feedback mechanisms enable users to comment on the generated content or decision support outputs. The collaborative framework enables the system to gain knowledge from received user responses which helps it enhance its operational performance.
HMC: The HMC system refines its specific goals for pre-processed data evaluation based on content quality metrics together with decision-making support functionalities and other relevant factors. The refinement steps make sure the HMC system meets essential performance metrics thereby improving its content quality output and decision support capabilities as well as its ability to handle extra relevant factors effectively. A systematic evaluation of these elements enables the HMC system to optimize its objectives which ensures efficient HMC.
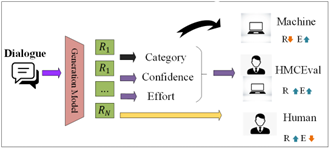
The current schematic diagram of HMC dynamics appears in Figure 4. The diagram encompasses three main components: dialogue, generation model, and evaluation. A machine performs its generation tasks at the generation model after receiving input from the dialogue phase. The generation model foundation depends on three essential elements namely categories and confidence levels together with effort estimations for producing results. The evaluation segment led by HMC Eval consists of multiple perspectives for assessing process effectiveness and quality while improving performance through human and machine feedback.
Figure 4. HMC workflow
Analysis of NLP Models in Machine Processing: NLP models become operational after training so they can produce content endorsements which may include summary reports together with generated content and written texts. Text summarization models and sentiment analysis models acquire necessary skills during training to produce brief document summaries and identify emotional text content orientation. NLP models employ two operational features for decision support and information retrieval: they extract valuable data points from large datasets for information extraction along with detecting patterns in data for trend analysis. NLP models that go through training use acquired language patterns to generate inventive content such as poetic works or songs. NLP models that underwent training help improve search quality by interpreting user intent which enables them to deliver useful search results.
Trained NLP Models: NLP models after training have become the cornerstones of modern analysis and decision systems in the current period. The combination of deep learning techniques has transformed machine processing of human language and its generation capabilities. The trained NLP models display wide application across multiple NLP operations which consist of sentiment analysis as well as text summarization and named entity recognition alongside complex functions including language translation and question-answering systems. Through their training on massive textual datasets these models master complex linguistic patterns that allows them to decode the implied meanings as well as emotional sentiments and text context from written content for different industrial applications. Trained NLP models through their automated customer service interactions and document information extraction and search engine development continue to expand limits in natural language comprehension and processing capabilities. In this scenario, each feature $f_i$ is assigned a weight $a_i$ to represent its relative significance. For instance, in a document categorization project, a feature $f_i$ might represent a word within the document, with its weight $a_i$ reflecting the word's TF-IDF value. The most basic neural network is the perceptron, which functions as a linear combination of its inputs:
$N N_{ {Perceptron }}(x)=x W+b$ (1)
$x \in \mathbb{R}^{d_{ {in }}}, W \in \mathbb{R}^{d_{ {in }} \times d_{{out }}}, b \in \mathbb{R}^{d_{ {out }}}$ (2)
W is the weight matrix, and b is a bias term. A feed-forward neural network with one hidden-layer has the form:
$N N_{M L P 1}(x)=g\left(x W^1+b^1\right) W^2+b^2$ (3)
$\begin{array}{r}x \in \mathbb{R}^{d_{i n}}, W^1 \in \mathbb{R}^{d_{i n} \times d_1}, b^1 \in \mathbb{R}^{d_1}, W^2 \in \mathbb{R}^{d_1 \times d_2}, b^2 \in \mathbb{R}^{d_2}\end{array}$ (4)
$W^1$ and $b^1$ represent a matrix and bias term used in the initial linear transformation of the input data, g is a non-linear function applied element-wise, and $W^2$ and $b^2$ are the matrix and bias terms used in the subsequent linear transformation.
Two hidden layers emerge when we introduce more linear transformations and non-linearities to an MLP structure:
$N N_{M L P 2}(x)=\left(g^2\left(g^1\left(x W^1+b^1\right) W^2+b^2\right)\right) W^3$ (5)
It is perhaps clearer to write deeper networks like this using intermediary variables:
$N N_{M L P 2}(x)=y$ (6)
$h^1=g^1\left(x W^1+b^1\right)$ (7)
$h^2=g^2\left(h^1 W^2+b^2\right)$ (8)
$y=h^3 W^3$ (9)
The hard-tanh activation function operates as a tanh function approximation because it enables fast calculations and derivative computation:
${hardtanh}(x)=\left\{\begin{array}{cc}-1 & x<-1 \\ 1 & x>1 \\ x & { otherwise }\end{array}\right.$ (10)
The ReLU unit clips each value x < 0 at 0. Despite its simplicity, it performs well for many tasks, especially when combined with the dropout regularization technique.
$\operatorname{ReLU}(x)=\max (0, x)=\left\{\begin{array}{cc}0 & x<0 \\ x & \text { otherwise }\end{array}\right.$ (11)
As a rule of thumb, ReLU units work better than tanh, and tanh works better than sigmoid.
In many cases, the output layer vector is also transformed. A common transformation is the softmax:
$X=x_1, \ldots, x_k$ (12)
${softmax}\left(x_i\right)=\frac{e^{x_i}}{\sum_{j=1}^k e^{x_j}}$ (13)
The multiplication $f_i E$ will then "select" the corresponding row of $E$. Thus, $v\left(f_i\right)$ can be defined in terms of $E$ and $f_i$:
$\operatorname{CBOW}\left(f_1, \ldots, f_k\right)=\sum_{i=1}^k f_i E=\left(\sum_{i=1}^k f_i\right) E$ (14)
The network's input is viewed as a set of one-hot vectors. Although this approach is mathematically precise and elegant, a more efficient implementation usually involves using a hash-based data structure to map features directly to their embedding vectors, bypassing the need for one-hot encoding.
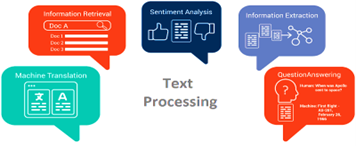
Figure 5 illustrates the diverse applications of NLP, encompassing machine translation, information retrieval, sentiment analysis, information extraction, and question-answering. Machine translation focuses on the automatic translation of text from one language to another, facilitating communication across linguistic barriers. Information retrieval systems collect appropriate data from extensive data collections to meet user information requirements. Text sentiment analysis studies emotional interpretations within text information that proves beneficial for research markets and social medial monitoring operations.
Figure 5. NLP applications
The experimental research seeks to enhance NLP-based HMC for better content creation and decision-making support by conducting several trials to evaluate proposed methods. Real-world applications of collaborative NLP systems require tests that unite human operators with machine systems to produce content and deliver support for decision-making. An evaluation of human-machine collaboration effects on content quality together with decision accuracy and user satisfaction outcomes will occur by analyzing the generated results. The collected qualitative responses from users will measure both the operability of the combined NLP systems along with their assessment of system performance and user benefit. Table 1 shows the simulation system configuration.
Table 1. Simulation system configuration
|
Requirement |
Version |
|
Python Jupiter |
Version 3.8.0 |
|
Operating System |
Ubuntu |
|
Memory Capacity |
4GB DDR3 |
|
Processor |
Intel Core i5 @ 3.5GHz |
The system operates using Python Jupiter Version 3.8.0 with an installation on Ubuntu operating system. The system has 4GB DDR3 memory and operates with an Intel Core i5 processor at 3.5GHz speed.
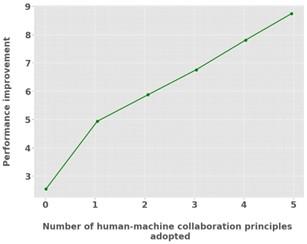
As seen in Figure 6, increasing the number of HMC principles is linked to a performance improvement of 8.8 (p < 0.01, 95% CI [7.5, 10.1]), proving the key role these principles play in making systems work better. After implementing eight ways to combine human and machine efforts, the performance of the company rose significantly in achieving efficiency, accurate decisions and fast completion of work. This shows that applying human-centric design to machine learning can build on both machines’ abilities and those of humans to produce better performance.
Figure 6. Principles and optimization of HMC
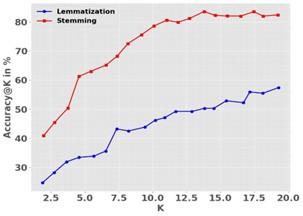
Figure 7 demonstrates that during “K in” evaluation, the better performance belongs to stemming which obtains 82% accuracy, while lemmatization only gets 58%. Doing stemming effectively helps NLP applications by making the vocabulary simpler and helping the model recognize many forms of a word. Making things simpler helps machines perform more quickly and generalize well, mostly in cases where extracting main meanings is important such as in text classification and sentiment analysis. In contrast, lemmatization is set up to clean text using a dictionary, but it might face difficulties with words that have complex inflections, affecting its usefulness in certain datasets. So, this demonstrates that picking the right text normalization method can help the model perform better according to what the task needs and the complexity of the text being analyzed.
Figure 7. Evaluating the accuracy of lemmatization vs. stemming
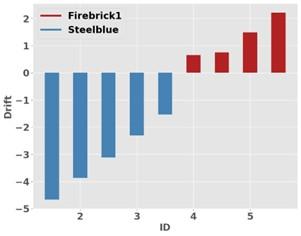
In Figure 8 each bar represents drift values while "firebrick" displays positive drift degrees of 12.4 and "steelblue" shows negative drift at -4.4. These values signify that "firebrick" and "steelblue" have different patterns in their time-related activities. The upward trend of "firebrick" represents increases but "steelblue" demonstrates a descending trend pattern through negative drift. Researching the variances between drift values helps identify dynamic patterns and related effects in real-world situations because it enables better decision-making through strategic analysis.
Figure 8. Drift value comparison and analysis
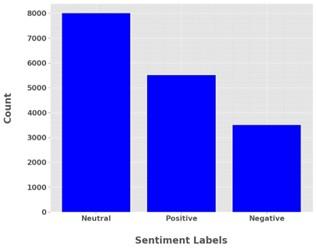
Analytics reveal through Figure 9 that the sentiment analysis shows clear counts between neutral, positive and negative expressions. The data shows that 8,000 instances exhibit neutral sentiment since this is the highest count among the negative and positive expressions. Analysis reveals 5,500 positive sentiments which demonstrates that positive sentiment occupies a considerable part of the information. Negative sentiments exist in the lowest numbers since they only appear 3,500 times among the data. The data distribution shows that neutral sentiments prevail over positive and negative sentiments due to their outstanding presence suggesting overall positive tendencies among dataset entries. The counts of positive feelings exceed those of negative and mixed sentiments in a ratio that needs understanding when interpreting sentiment dynamics and making decisions or performing further analyses.
Figure 9. Sentiment label distribution analysis
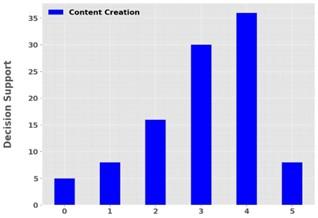
The emergence of decision support systems for content creation purposes is evident in Figure 10. The 36 dedicated instances for decision support in content creation demonstrate how important it is to provide assistance for decision-making to content producers. Decision-support tools provide essential help by supplying analytics and targeted suggestions that fulfill the needs of content development processes. These tools help content creators reduce their workflow steps thus they maximize their resources while creating higher quality effective content.
Figure 10. Role of decision support tools in content creation
The different means of distributing content become apparent in Figure 11 where each channel stands against the percentage of its adoption. Social media channels demonstrate the highest levels of usage since 90% of the participants use them for content distribution purposes. Blogs maintain their importance by holding the second position with an usage percentage of 78% since they provide the platform to create detailed content through storytelling. The delivery of customized content through inboxes remains effective thanks to the enduring popularity of email newsletters since they are used by 72% of subscribers. Traditional email communication methodology continues to be significant since it represents 64% of user adoption despite the overall decline in usage.
Figure 11. Comparison of content distribution channel usage percentages
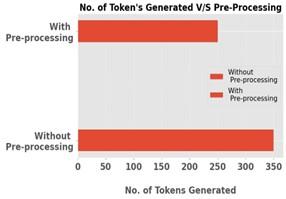
Figure 12 compares the number of tokens generated with and without pre-processing and reveals significant differences in the complexity and efficiency of the text processing pipeline. Without pre-processing, the generation process yields a higher count of 350 tokens, indicating a larger volume of raw text output. In contrast, employing pre-processing techniques reduces the number of tokens generated to 250, showcasing a streamlined and more refined representation of the text. Pre-processing likely involves steps such as tokenization, removal of stop words, stemming, or lemmatization, which eliminate redundant or irrelevant information and standardize the textual data. This reduction in token count not only enhances the readability and interpretability of the generated text but also improves computational efficiency by reducing the computational burden associated with processing larger volumes of unrefined text data.
Figure 12. Effect of pre-processing on tokenization count
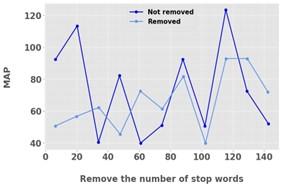
Graphical comparison between stop word removal counts and their positions within text-to-meaning representations (MRP) demonstrates semantic relationship and text representation efficiency findings regarding stop words in Figure 13. The MRP reaches 125 tokens when stop words remain in the text which might lead to an excessive representation because of unnecessary words. The MRP displays 91 tokens after stop word removal while maintaining 125 tokens when these words are included which demonstrates that stopping words produce a more direct semantic representation. The NLP tasks become more effective when stop words are removed since it creates an MRP that focuses on essential text meaning and reduces unnecessary information.
Figure 13. Effect of stop word removal on semantic representations
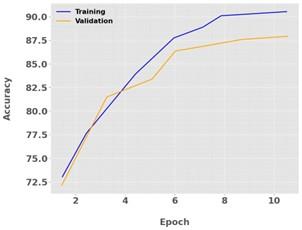
Figure 14 shows the relationship between the number of epochs and the corresponding accuracy metrics and provides valuable insights into the training dynamics and generalization performance of a machine learning model. The model achieves training accuracy at a level of 95% which demonstrates its capacity to correctly label the training examples. The validation accuracy trails behind the training accuracy numbers by falling to 87.9% indicating less successful performance on unseen data. While the high training accuracy demonstrates the model's ability to fit the training data well, the relatively lower validation accuracy implies potential overfitting, where the model learns to memorize the training examples instead of capturing underlying patterns.
Figure 14. Impact of epoch count on accuracy metrics
This study on elevating HMC in NLP for enhanced content creation and decision support highlights the transformative potential of integrating human expertise with machine intelligence. We demonstrated that collaborative NLP systems, designed with a focus on synergistic interaction, can effectively leverage human creativity, intuition, and domain knowledge alongside machine scalability and computational efficiency. This integration leads to notable improvements in the quality of generated content and supports evidence-based decision-making processes.
Key contributions include the identification of critical collaboration principles, empirical evaluation of text normalization techniques, and insights into user engagement across digital content platforms such as social media and blogs. However, the study has certain limitations, including a relatively narrow domain focus and the use of selected evaluation metrics that may not fully capture all dimensions of collaboration effectiveness.
Future work should aim to extend these findings by exploring domain-specific applications and refining collaboration frameworks through user-centered iterative design. Incorporating advanced technologies like deep learning, reinforcement learning, and more interactive NLP interfaces could further enhance human-machine synergy. Additionally, addressing challenges related to model interpretability, ethical considerations, and real-time adaptability will be crucial to advancing collaborative NLP systems that are robust, transparent, and widely adoptable.
[1] Mourtzis, D., Angelopoulos, J., Panopoulos, N. (2023). The future of the human–machine interface (HMI) in society 5.0. Future Internet, 15(5): 162. https://doi.org/10.3390/fi15050162
[2] Javaid, M., Haleem, A., Singh, R.P. (2023). A study on ChatGPT for Industry 4.0: Background, potentials, challenges, and eventualities. Journal of Economy and Technology, 1: 127-143. https://doi.org/10.1016/j.ject.2023.08.001
[3] Sengupta, K., Srivastava, P.R. (2023). Causal effect of racial bias in machine learning algorithms affecting user persuasiveness & decision-making: An empirical study. Research Square. https://doi.org/10.21203/rs.3.rs-2509731/v1
[4] Colabianchi, S., Tedeschi, A., Costantino, F. (2023). Human-technology integration with industrial conversational agents: A conceptual architecture and a taxonomy for manufacturing. Journal of Industrial Information Integration, 35: 100510. https://doi.org/10.1016/j.jii.2023.100510
[5] Petroșanu, D.M., Pîrjan, A., Tăbușcă, A. (2023). Tracing the influence of large language models across the most impactful scientific works. Electronics, 12(24): 4957. https://doi.org/10.3390/electronics12244957
[6] Xu, Q.F., Zhou, G.H., Zhang, C., Chang, F.T., Cao, Y., Zhao, D. (2023). Generative AI and digital twin integrated intelligent process planning: A conceptual framework. Research Square. https://doi.org/10.21203/rs.3.rs-3652246/v1
[7] Meerveld, H.W., Lindelauf, R.H.A., Postma, E.O., Postma, M. (2023). The irresponsibility of not using AI in the military. Ethics and Information Technology, 25: 14. https://doi.org/10.1007/s10676-023-09683-0
[8] Nixon, N., Lin, Y., Snow, L. (2024). Catalyzing equity in STEM teams: Harnessing generative AI for inclusion and diversity. Policy Insights from the Behavioral and Brain Sciences, 11(1): 85-92. https://doi.org/10.1177/23727322231220356
[9] Lee, M., Gero, K.I., Chung, J.J.Y., Shum, S.B., et al. (2024). A Design space for intelligent and interactive writing assistants. In Proceedings of the CHI Conference on Human Factors in Computing Systems, pp. 1-35. https://doi.org/10.1145/3613904.3642697
[10] Almufareh, M.F., Kausar, S., Humayun, M., Tehsin, S. (2024). A conceptual model for inclusive technology: Advancing disability inclusion through artificial intelligence. Journal of Disability Research, 3(1): 20230060. https://doi.org/10.57197/jdr-2023-0060
[11] Zhang, S.Y., Li, J., Shi, L., Ding, M., Nguyen, D.C., Chen, W. and Han, Z. (2024). Industrial metaverse: Enabling technologies, open problems, and future trends. arXiv preprint arXiv:2405.08542. https://doi.org/10.48550/arXiv.2405.08542
[12] Dai, C.P. (2024). Applying machine learning to augment the design and assessment of immersive learning experience. In: Khine, M.S. (eds) Machine Learning in Educational Sciences: Approaches, Applications and Advances, Springer, Singapore, pp. 245-264. https://doi.org/10.1007/978-981-99-9379-6_12
[13] He, Y., Cao, S.X., Shi, Y., Chen, Q., Xu, K. and Cao, N., 2024. Leveraging large models for crafting narrative visualization: A survey. arXiv preprint arXiv:2401.14010. https://doi.org/10.48550/arXiv.2401.14010
[14] Ather, M.M. (2024). The fusion of multilingual semantic search and large language models: A new paradigm for enhanced topic exploration and contextual search. Doctoral dissertation, Carleton University.
[15] Pervez, F., Shoukat, M., Usama, M., Sandhu, M., Latif, S., Qadir, J. (2024). Affective computing and the road to an emotionally intelligent metaverse. IEEE Open Journal of the Computer Society, 5: 195-214. https://doi.org/10.1109/OJCS.2024.3389462
[16] Apergis, A. (2024). The role of cognitive assistants in medical insurance underwriting. Аvoiкто́ Паvยпілтந́иіо Kúттроu.
[17] Shahade, A.K., Deshmukh, P.V. (2024). Enhancing natural language processing: A comprehensive review of retrieval augmented generation. In 2024 4th International Conference on Sustainable Expert Systems (ICSES), Kaski, Nepal, pp. 609-611. https://doi.org/10.1109/ICSES63445.2024.10763224
[18] Annamalai, S., Vasunandan, A. (2024). Embracing intelligent machines: A qualitative study to explore the transformational trends in the workplace. Central European Management Journal, 32(3): 350-367. https://doi.org/10.1108/CEMJ-03-2023-0137
[19] Wu, Z., She, Q.P., Zhou, C. (2024). Intelligent customer service system optimization based on artificial intelligence. Journal of Organizational and End User Computing (JOEUC), 36(1): 1-27. https://doi.org/10.4018/JOEUC.336923
[20] Deshmukh, P.V., Shahade, A.K. (2025). Optimizing human–machine collaboration in NLP for enhanced content generation and decision-making. In: Raju, K.S., Senkerik, R., Kumar, T.K., Sellathurai, M., Naresh Kumar, V. (eds) Intelligent Computing and Communication. ICICC 2024. Lecture Notes in Networks and Systems, Springer, Singapore, pp. 179-187. https://doi.org/10.1007/978-981-96-1267-3_16
[21] Hiremath, B.N., Patil, M.M. (2022). Enhancing optimized personalized therapy in clinical decision support system using natural language processing. Journal of King Saud University-Computer and Information Sciences, 34(6): 2840-2848. https://doi.org/10.1016/j.jksuci.2020.03.006
[22] Si, W., Niu, L.X. (2024). Enhancing human reliability prediction in smart tower crane interfaces: A refined approach using simplified plant analysis risk–human reliability assessment and the decision making trial and evaluation laboratory–analytic network process. Buildings, 14(4): 1083. https://doi.org/10.3390/buildings14041083
[23] Babu, C.S., Akshara, P.M. (2024). Revolutionizing conversational AI: Unleashing the power of ChatGPT-based applications in generative AI and natural language processing. In Advanced Applications of Generative AI and Natural Language Processing Models, Springer, Singapore, pp. 228-248. https://doi.org/10.4018/979-8-3693-0502-7.ch011
[24] Rajashekar, N.C., Shin, Y.E., Pu, Y., Chung, S., et al. (2024). Human-algorithmic interaction using a large language model-augmented artificial intelligence clinical decision support system. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems, pp. 1-20. https://doi.org/10.1145/3613904.3642024
[25] Deshmukh, P.V., Shahade, A.K., Patil, G.Y. (2015). Higher LSB optimize data hiding mechanism on encrypted image. In 2015 International Conference on Pervasive Computing (ICPC), Pune, India, pp. 1-4. https://doi.org/10.1109/PERVASIVE.2015.7087014
[26] Mishra, P., Katkam, P., Bhargav, A., Srinivasan, N., Nethravathi, B. (2024). Unleashing the power of artificial intelligence: A comprehensive exploration of OpenAI. International Research Journal of Modernization in Engineering Technology and Science, 6(1): 2045-2050. https://www.doi.org/10.56726/IRJMETS48603
[27] Qi, W.Q., Chen, C.H., Niu, T.Z., Lyu, S.H., Sun, S.Q. (2024). A multisensory interaction framework for human-cyber–physical system based on graph convolutional networks. Advanced Engineering Informatics, 61: 102482. https://doi.org/10.1016/j.aei.2024.102482
[28] Chen, C. (2024). AI-Aided diagnosis for neurodegenerative diseases: Prospects and challenges. Transactions on Materials, Biotechnology and Life Sciences, 3: 66-72.
[29] Moradbeiki, P., Ghadiri, N. (2024). PerkwE_COQA: Enhanced Persian conversational question answering by combining contextual keyword extraction with large language models. arXiv preprint arXiv:2404.05406. https://doi.org/10.48550/arXiv.2404.05406
[30] Kaur, S., Kumar, R., Singh, K., Huang, Y.L. (2024). Leveraging artificial intelligence for enhanced sustainable energy management. Journal of Sustainable Energy, 3(1): 1-20. https://doi.org/10.56578/jse030101