Fatima Zohra Trabelsi*![]() | Amal Khtira
| Amal Khtira![]() | Bouchra El Asri
| Bouchra El Asri![]()
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
This paper introduces a novel approach to optimizing business processes by integrating principles from Service-Oriented Architecture (SOA), micro-services, and recommendation systems. Our approach leverages specific machine learning techniques such as clustering algorithms for behavioral segmentation and association rule mining for pattern identification, combined with data-driven insights derived from real-time process data. We propose a comprehensive algorithm that identifies inefficiencies in existing workflows, utilizing K-Means clustering and Apriori-based association rule mining to recommend optimized, modular architectures based on interoperable services. Additionally, the system provides personalized recommendations for ongoing improvements using predictive models. Through a detailed implementation, we demonstrate how our method enhances operational efficiency by reducing process redundancies, scalability through modular micro-services, and user satisfaction by streamlining service delivery. Preliminary results from case studies in the e-commerce and financial services sectors show up to 20% improvement in process execution time and 15% increase in customer satisfaction. Our approach differentiates itself from existing methods by offering a seamless integration of modular service architectures with real-time optimization and personalized feedback, creating a continuous improvement loop that adapts to changing business conditions. Finally, we discuss future research directions, including refining recommendation models, developing real-time optimization capabilities, and exploring applications in industry-specific contexts.
Service-Oriented Architecture (SOA), micro-services, business process management, BPMN, BPEL, digital transformation, migration, hybrid architectures, efficiency, agility
Service-Oriented Architecture (SOA) has emerged as a leading architectural paradigm that enhances the performance and adaptability of traditional systems while retaining their core functionalities [1]. Due to its flexible nature, SOA has attracted significant attention from both academic and commercial sectors, playing a crucial role in the development of modern technologies such as Cloud Computing (CC) and the Internet of Things (IoT) [2]. However, the increasingly complex landscape of enterprise architecture necessitates a more agile and modular approach to business process optimization.
In this evolving context, SOA and micro-services have proven to be transformative forces, reshaping how organizations design, implement, and manage their business processes [3]. Micro-services, in particular, enable greater scalability and independence of services, making them highly adaptable to changing business needs [4]. Yet, despite these advancements, traditional business process optimization methods still fall short in dynamic environments. These conventional approaches often rely on static models and predefined rules, limiting their capacity to respond to rapidly evolving customer preferences and operational challenges.
This paper addresses these limitations by introducing a novel approach that integrates the modularity of SOA [5], the scalability and flexibility of micro-services [6], and the personalization capabilities of recommendation systems. Our proposed algorithm leverages advanced machine learning techniques to analyze real-time process data and offer personalized recommendations that drive continuous improvement. For instance, traditional methods often fail to adjust to fluctuating demand in supply chain processes or struggle to provide personalized service delivery in customer-facing industries. In contrast, our approach adapts dynamically by identifying inefficiencies and providing tailored solutions for specific operational contexts.
The comprehensive algorithm presented in this paper consists of several core components:
● Clustering techniques to segment business processes based on behavioral patterns.
● Association rule mining to identify recurring patterns and inefficiencies.
● A recommendation engine that suggests optimized architectures and improvements, grounded in real-time data analytics and machine learning.
These components work together to revolutionize process optimization by enabling businesses to deploy modular, scalable, and data-driven solutions that adapt to both external market pressures and internal operational requirements.
Through this detailed exploration, we demonstrate how our approach enhances operational efficiency, reduces costs, and improves customer satisfaction across various industries. For instance, case studies in the e-commerce and financial services sectors reveal improvements in process execution time by up to 20% and increased customer satisfaction by 15%.
Furthermore, we outline the broader implications of this research, highlighting its potential to foster innovation and competitiveness in today's digital economy. By adopting this data-driven, modular approach to process optimization, organizations can better position themselves for success in a marketplace defined by constant change.
The paper is structured as follows:
Section 2 examines the evolution of business processes and the challenges posed by traditional optimization techniques. Section 3 explores the impact of BPMN as a modeling standard and BPEL as an execution language. Section 4 details the advantages of both SOA and micro-services in the context of business process optimization. Section 5 presents the proposed algorithm, illustrating how it identifies inefficiencies and recommends optimized architectures. Section 6 provides a real-world case study, demonstrating the application and effectiveness of our approach. Section 7 concludes the paper by summarizing key findings. Section 8 addresses the limitations of the proposed approach, and Section 9 discusses potential avenues for future research.
In this section, we explore the evolution of business processes and the impact of emerging software architectures such as SOA [5] and micro-services on this transformation. Business processes, which represent the interconnected activities necessary to achieve specific business objectives, have evolved significantly in response to changing business needs, technological advancements, and regulatory requirements.
Initially, business processes were managed in a rigid and linear fashion, often requiring substantial documentation and manual oversight with minimal automation. This approach led to inefficiencies, inflexibility, and challenges in scaling. As businesses grew and markets became more dynamic, these traditional methods struggled to keep up with the demands for adaptability and responsiveness.
2.1 Impact of software architectures
The emergence of SOA [7] and micro-services [8] has revolutionized business process management by introducing modularity and reusability. SOA allows organizations to decompose large, monolithic applications into smaller, reusable services that can be easily integrated with existing systems [9]. This service-oriented approach has enabled companies to streamline operations, reduce redundancy, and enhance interoperability across different departments.
Micro-services, building on SOA's foundation, take modularity a step further by providing highly independent and autonomous services that can be deployed, scaled, and maintained individually [10]. This architectural style empowers organizations to respond to rapid changes in the business environment more effectively, allowing updates to be made without disrupting entire systems. For example, Netflix transitioned from a monolithic architecture to micro-services, enabling them to scale rapidly, handle high levels of user demand, and introduce new features without downtime.
Case Study: Transition from Traditional to Modern Architecture
A real-world example of this transition is evident in the financial services industry, where companies like ING shifted from a traditional architecture to micro-services to improve scalability and agility. Before the transition, ING faced challenges in adapting to regulatory changes and customer demands. Post-migration, they reported significant improvements in deployment speed, with new features being delivered in hours instead of months, and greater flexibility in responding to regulatory requirements. This case illustrates the tangible benefits of adopting modern architectures, such as faster innovation cycles and reduced operational costs.
2.2 Impact of technology
Technological advancements have profoundly transformed business processes. Cloud computing has allowed businesses to scale operations without the need for extensive physical infrastructure [11], while process automation tools have drastically reduced manual effort, improved accuracy, and accelerated workflows.
Artificial intelligence (AI) and machine learning have provided powerful insights through the analysis of large datasets, enabling companies to identify inefficiencies and uncover opportunities for optimization [12]. For example, AI-driven chatbots have automated customer service processes, significantly improving response times and customer satisfaction. Additionally, the Internet of Things (IoT) [13] has enabled real-time data collection from connected devices, allowing businesses to monitor, analyze, and adjust their processes dynamically.
Emerging Technologies
Emerging technologies like blockchain and edge computing are anticipated to further influence business process evolution. Blockchain can enhance transparency and security in supply chain processes, while edge computing allows data processing closer to the source, improving decision-making speeds in time-sensitive applications like industrial automation and smart grids.
2.3 Current trends
A key trend driving the evolution of business processes is digital transformation, where organizations use digital tools to reengineer processes and improve customer engagement [14]. For instance, industries like retail have digitized their supply chain operations, resulting in faster order fulfillment and reduced costs.
Data-driven decision-making has become increasingly important, with businesses leveraging big data and predictive analytics to gain insights into customer behavior and operational performance [15]. Companies like Amazon have used data analytics to optimize their supply chains, enabling same-day delivery services and improving customer satisfaction. Predictive maintenance in manufacturing, powered by machine learning models, helps organizations avoid costly downtime by anticipating equipment failures before they happen [16].
Moreover, the growing focus on agility and flexibility is transforming how businesses operate. The adoption of agile methodologies and DevOps practices [17] is allowing teams to iterate quickly, deploy updates frequently, and respond faster to changing customer needs. These trends highlight the shift towards a more responsive and customer-focused approach to business process management.
2.4 Adaptability and agility in business processes
The concepts of adaptability and agility are critical to the future of business process evolution, as they enable organizations to remain competitive in volatile markets. Here are four key areas where adaptability and agility are transforming businesses:
Responding to Changes: Adaptable business processes can respond swiftly to regulatory changes, market shifts, and evolving customer preferences [18]. For example, during the COVID-19 pandemic, companies with agile processes were able to pivot to online services and adjust their supply chains, ensuring continuity in operations.
Fostering Innovation: Agile processes encourage experimentation and continuous improvement [19]. By allowing teams to rapidly prototype, test, and iterate on new ideas, organizations can innovate faster. For example, Spotify uses agile methods to continuously update its platform, providing users with frequent new features.
Competitive Advantage: Companies that can quickly adapt to market changes are more likely to gain a competitive edge [20]. For example, firms like Tesla that employ agile practices in product development are able to bring innovations like over-the-air software updates to customers faster than competitors.
Scalability: Scalability is vital as businesses grow or enter new markets. Organizations that adopt an agile and adaptable approach to scaling their processes can more easily handle increased demand or integrate acquisitions [21]. A prime example is Uber, which has successfully scaled its business processes globally through micro-services, allowing it to launch in new cities with minimal disruption.
2.5 Challenges and success measurement
While the benefits of adopting SOA and micro-services are significant, organizations often face challenges in implementation. Common pitfalls include overcomplicating service granularity, leading to an overly complex system, and poor orchestration between services, which can cause delays in service delivery. Companies must also establish clear metrics for success, such as improvements in time-to-market, cost reductions, and enhanced customer satisfaction to evaluate the effectiveness of their transitions. For instance, metrics like lead time for changes and deployment frequency are often used to measure agility and operational improvements in DevOps environments.
2.6 Dichotomy between standardization and agility
A key challenge in evolving business processes is finding the right balance between standardization (which ensures consistency and quality) and agility (which allows rapid adaptation to change). Tools like Business Process Management Systems (BPMS) and API management platforms provide the necessary flexibility to manage standardized yet agile processes, ensuring that businesses can respond quickly to changes without sacrificing operational stability.
In this section, we explore the significant impact of Business Process Model and Notation (BPMN) and Business Process Execution Language (BPEL) on modern business practices. These tools play pivotal roles in business process management (BPM) by offering standardized methods for modeling, visualizing, and executing complex workflows. By embracing these languages, organizations can streamline processes, foster collaboration, and achieve higher operational efficiency. We will examine core concepts, functionalities, real-world applications, and the challenges involved in adopting BPMN and BPEL.
3.1 Business process modeling and notation (BPMN)
BPMN provides a standardized graphical language for modeling business processes, allowing for clear, visual representation of a process's sequence of activities, decisions, and interactions [22]. It offers various diagram types (e.g., flowcharts, swimlane diagrams) that make it easier for stakeholders—ranging from business analysts to IT professionals—to understand and communicate complex workflows [23]. This visualization serves as a common language for diverse teams, ensuring consistency and alignment in process documentation and analysis [24].
Applications of BPMN in Different Industries: BPMN has been widely adopted across various industries, demonstrating its flexibility and utility:
·In healthcare, BPMN is used to model patient-care processes, ensuring efficient coordination among departments and compliance with regulatory standards.
·In the banking sector, BPMN supports process optimization in loan approval workflows, improving response times and reducing operational costs.
·Manufacturing uses BPMN to streamline supply chain management, allowing for seamless integration of suppliers and production schedules.
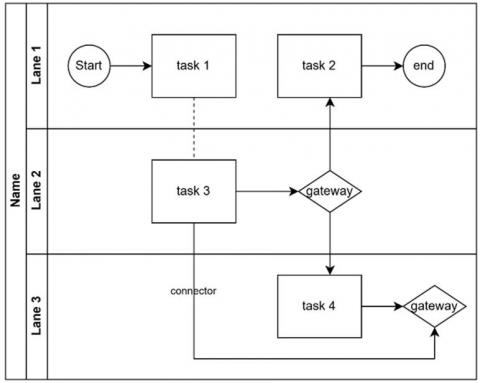
While BPMN's adaptability across industries is a strength, organizations new to standardized process modeling techniques may encounter a learning curve. Understanding the complex symbols and notation can be daunting at first. Training programs and software tools are crucial in reducing this learning curve, but it remains an upfront challenge for many companies. Figure 1 shows a simple diagram of a BPMN model.
Figure 1. BPMN diagram
3.2 Business process execution language (BPEL)
BPEL, on the other hand, is a standardized language used to automate and execute business processes in a machine-readable format [25]. While BPMN is primarily used for designing and modeling processes, BPEL defines the execution logic, orchestrating how tasks and activities should be performed within an automated environment. BPEL scripts are deployable in BPM systems or workflow engines, transforming BPMN designs into operational processes [26].
BPEL allows for defining task sequences, data flows, and decision-making points in an automated business environment. This automation reduces manual intervention, improving efficiency and ensuring consistency [27].
Case Study: BPEL Implementation in Telecom: In the telecommunications industry, BPEL has been successfully used for automating customer service processes, such as billing and customer onboarding. A leading telecom provider used BPEL to orchestrate multiple services, streamlining the integration of customer data across departments. The company faced initial challenges in integrating BPEL with its legacy systems but managed to overcome them through custom adapters. This resulted in significant reductions in service delivery times and improved customer satisfaction.
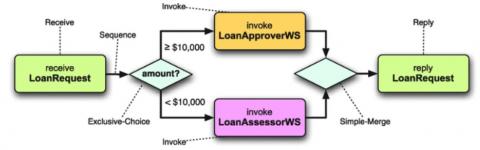
The following Figure 2 shows a Representation of a BPEL process with control flow annotations.
Figure 2. Representation of a BPEL process with control flow annotations
3.3 BPMN to BPEL: Bridging the gap between modeling and execution
The translation from BPMN to BPEL is crucial for bridging the gap between business process design and execution. BPMN diagrams serve as the high-level blueprint, providing a graphical overview of a business process’s structure and logic [28]. Once designed, these processes can be translated into BPEL scripts for deployment in runtime environments, where they are executed according to the logic specified in the models [29].
Challenges in BPMN-to-BPEL Translation
·Complexity in Large Models: Translating complex BPMN models into BPEL can present challenges, especially when handling advanced BPMN elements like subprocesses, event-based gateways, and complex decision trees. Ensuring that all BPMN constructs are accurately represented in executable BPEL can be difficult in such scenarios [30].
·Compatibility Issues: Despite BPMN and BPEL’s complementary roles, compatibility issues may arise during translation. For example, BPMN diagrams with high complexity or non-standardized elements can cause discrepancies in execution when mapped to BPEL [31]. Tools like process modeling software and custom translation scripts can mitigate these challenges, but it is essential for organizations to understand the limitations of both frameworks.
Translation Process: BPMN to BPEL
The translation from BPMN to BPEL involves converting visual representations of BPMN diagrams into executable code that can be deployed in a workflow system [32]. BPMN components such as pools, lanes, tasks, gateways, and events are mapped to corresponding BPEL constructs like partner links, activities, conditions, and message exchanges. This process ensures that the business logic captured in BPMN is faithfully executed within the BPEL framework.
The translation from BPMN to BPEL is expressed in Figure 3.
Figure 3. Translation BPMN to BPEL
3.4 The role of BPMN and BPEL in the business process lifecycle
BPMN and BPEL play complementary roles in the lifecycle of business processes. BPMN enables stakeholders to model, analyze, and communicate business processes effectively, fostering collaboration across departments and promoting clarity in complex workflows [31]. On the other hand, BPEL transforms these models into executable processes, automating tasks and orchestrating services for greater operational efficiency [32].
Together, these tools provide organizations with a powerful framework for business process automation, enabling:
·Agility: By designing adaptable and modular processes, companies can quickly adjust to new business requirements or changes in the market.
·Efficiency: Automation through BPEL ensures consistent execution of processes, reducing human error and speeding up workflows.
·Innovation: Organizations using BPMN and BPEL can easily experiment with new process models, implement them rapidly, and measure their success.
3.5 Recent technological advancements and the future of BPMN and BPEL
Recent advancements in AI, cloud computing, and machine learning have impacted how organizations use BPMN and BPEL. With AI-driven tools, businesses can automatically optimize BPMN diagrams [33], suggesting process improvements based on historical data. Additionally, cloud-based BPM systems are reducing the costs of implementing these tools, making process automation accessible to more businesses. The combination of AI and cloud technologies is likely to enhance the scalability and adaptability of BPMN and BPEL in the future.
3.6 Addressing common challenges in BPMN and BPEL adoption
While BPMN and BPEL offer significant benefits, organizations face several challenges in their adoption:
·Learning Curve: As mentioned earlier, BPMN's complex notation can pose a steep learning curve for new users. Companies need to invest in training programs to ensure successful adoption.
·Legacy System Integration: Integrating BPEL with legacy systems remains a challenge, particularly when older systems lack modern interfaces for orchestration.
·Process Complexity: Highly complex processes, particularly those with dynamic or non-linear flows, may not easily map from BPMN to BPEL. In such cases, organizations must ensure they have the right tools and expertise to handle the intricacies.
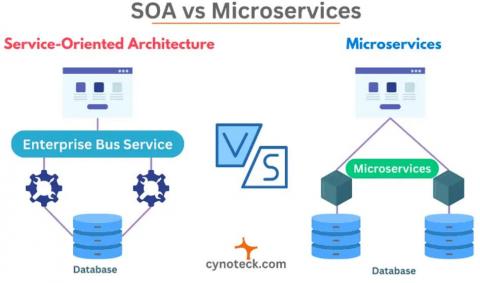
In the field of Business Processes (BPs), both SOA and micro-services offer numerous advantages, contributing to improved flexibility, scalability, and agility in process management. Figure 4 shows the difference between the micro-services schema and SOA representation.
Figure 4. Microservices VS SOA [34]
4.1 Service-Oriented Architecture (SOA)
SOA offers a strategic approach to software design and development, emphasizing modularity, reusability, and interoperability of services. By breaking down complex systems into smaller, more manageable components, SOA enables organizations to adapt quickly to changing business needs, improve agility, and foster innovation. If we take financial services as a real-world example of SOA, we can see that a major financial institution implemented SOA to modernize its legacy systems and streamline loan processing. By decomposing large monolithic applications into reusable services (e.g., credit check, customer profile validation), the institution reduced redundancy and improved the time-to-market for new loan products. The modularity and reusability of services enabled it to offer tailored loan products to different customer segments more efficiently.
4.1.1 Benefits of SOA
Modularity and Reusability: SOA promotes the decomposition of business functionalities into modular services, enhancing flexibility and reducing redundancy [35].
Interoperability: SOA enables seamless communication and integration between disparate systems, allowing organizations to leverage existing IT investments and adopt new technologies more effectively.
Service Composition: SOA allows the composition of services into composite applications or business processes, enabling dynamic adaptation to changing business requirements [36].
Scalability: Decoupling services and providing standardized interfaces support horizontal scalability, accommodating growing demand [37].
4.1.2 Challenges and limitations of SOA
While SOA offers significant benefits, organizations often encounter challenges during its implementation:
Complexity: Managing a large number of services introduces complexity in service discovery, governance, and versioning [36].
Initial Overhead: The upfront cost of designing and implementing SOA can be significant, particularly for organizations transitioning from monolithic systems.
Service Discoverability: As the number of services increases, maintaining a robust system for discovering and managing these services becomes critical. Poor service discovery mechanisms can lead to inefficiencies and increased operational costs [35].
4.1.3 Latest trends: SOA and cloud integration
Recent advancements have integrated SOA with cloud services and APIs, making it a key component of hybrid architectures:
SOA’s modular services are increasingly deployed in cloud environments to enhance scalability and reduce infrastructure costs.
APIs enable SOA services to interact with external cloud-based services, offering organizations more flexibility in leveraging third-party solutions [37].
Hybrid Architectures combine on-premise SOA services with cloud-based microservices, offering the best of both worlds—cost efficiency and legacy system integration.
4.2 Micro-services
Microservices represent a modern evolution of SOA, providing a more granular approach to building and deploying applications [34]. Unlike SOA, which focuses on reusability across the enterprise, micro-services emphasize the decomposition of applications into small, independently deployable services. E-Commerce Platforms can be one of the best real-world example where, a large e-commerce company successfully transitioned to micro-services to improve its product catalog and inventory management [38]. By breaking down its monolithic application into smaller services (e.g., product listing, inventory updates, and payment services), the company could release updates independently, speeding up innovation and reducing downtime during system upgrades.
4.2.1 Benefits of micro-services
Granularity and Independence: Micro-services decompose applications into small, independently deployable services, enhancing agility and enabling continuous delivery [37].
Fault Isolation and Resilience: The isolation of services ensures system reliability, as failures in one service don’t affect others [38].
Technology Diversity: Micro-services enable organizations to use diverse technologies, adopting the best tools for specific tasks.
Continuous Delivery and DevOps: Micro-services align well with DevOps practices, supporting continuous delivery of features and updates [39].
4.2.2 Challenges in migrating to micro-services
While micro-services offer flexibility and resilience, organizations must address key challenges during their migration:
Increased Complexity: Managing multiple independent services increases complexity in areas like service communication, versioning, and monitoring.
Data Consistency Issues: Micro-services typically manage their own databases, making it challenging to maintain data consistency across services, especially in complex transaction scenarios.
Overhead of Maintenance: Maintaining multiple services, databases, and deployment pipelines can introduce significant operational overhead, necessitating investment in automation and monitoring tools.
4.2.3 Microservices vs SOA: A nuanced comparison
While both SOA and micro-services offer modularity, they differ in their scope and granularity. SOA is typically more suited for enterprise-wide integration scenarios where reusability and interoperability across the organization are key, while micro-services are more advantageous in environments that demand rapid innovation, scalability, and resilience through independently deployable services.
4.3 Migration of SOA to micro-services
The migration from SOA to micro-services is driven by the need for greater agility, scalability, and flexibility to meet modern business demands. The process involves several key steps, including:
(1) Assessing Current Architecture: Identifying which SOA services can be decomposed into micro-services.
(2) Decomposing Monolithic Services: Breaking down large services into smaller, granular services with independent data stores.
(3) Designing Scalable Infrastructure: Implementing cloud-native architectures, leveraging containerization tools (e.g., Docker) and orchestration platforms (e.g., Kubernetes).
(4) Implementing DevOps Practices: Adopting continuous integration and deployment pipelines to manage the independent deployment of services.
(5) Establishing Governance and Monitoring: Implementing tools for service discovery, security, and monitoring to manage the increased complexity of micro-services.
There are also common pitfalls in migration that ca be summarized in:
(1) Overcomplication of Services: Overzealous decomposition of services can lead to an excessive number of micro-services, increasing overhead and complicating management.
(2) Lack of Governance: Without proper service discovery and management, organizations may face difficulties in maintaining service reliability and performance.
(3) Data Consistency Challenges: Ensuring data consistency across multiple micro-services, especially in distributed environments, is complex and requires careful design of database transactions and messaging systems.
Figure 5 shows the migration of SOA to microservices.
Figure 5. Migration of SOA to microservices
In this section, we present a novel algorithm designed to optimize business processes through the integration of SOA, micro-services, and recommendation systems. This approach aims to enhance operational efficiency, flexibility, and scalability by leveraging modern technologies for dynamic process management.
Unlike traditional business process optimization techniques, our algorithm introduces behavior predicates and machine learning-based clustering to better model user interactions and system behavior. Additionally, it incorporates personalized recommendations to tailor process execution to specific business needs, ensuring that the solution is adaptable across various industries. Through a combination of data-driven insights and service integration, the algorithm offers a comprehensive framework for continuously improving business processes in a rapidly changing commercial environment.
5.1 Algorithm for optimizing business processes
The proposed algorithm builds on existing methodologies for business process optimization by integrating key elements from SOA, micro-services, and recommendation systems. Traditional SOA-based optimization algorithms emphasize service reusability and modularity, while micro-services approaches focus on agility and scalability. However, these methods often face challenges related to personalization and real-time adaptability. Our algorithm advances these approaches by using machine learning, particularly clustering techniques, to identify patterns and optimize service integration. Additionally, it incorporates recommendation systems to personalize business process execution, offering a more dynamic and tailored solution compared to traditional methods. This combination addresses gaps in existing algorithms and enhances the flexibility, efficiency, and adaptability of business processes.
The following steps details each part of our contribution:
Step 1: Definition of a set of behavior predicates
In this step, we define a set of behavior predicates specific to business processes that will be used to characterize the behavior of different activities in the process.
Behavior predicates are specific conditions or characteristics that define the actions or decisions within a business process. For example, in an e-commerce process, a behavior predicate could be "customer selected express shipping," which influences downstream activities such as inventory management, order fulfillment, and shipping method. Another example could be "payment method chosen as credit card," which impacts the process by triggering specific security checks and payment gateway integration. In the optimization process, these behavior predicates help identify recurring patterns and trends across similar processes, enabling more efficient clustering and personalization. By capturing and analyzing these predicates, the algorithm can recommend optimized sequences of actions, improving overall business process performance and adaptability.
Step 2: Data collection and preprocessing
This step involves collecting data from various sources, such as past performance of business processes, user preferences, interactions with SOA and microservices, and contextual data. To ensure reproducibility, missing values are treated using techniques such as mean or median imputation, or by deleting records containing excessive missing information. The data is then transformed by processes such as normalization to ensure consistent scales, coding of categorical variables and outliers management to improve model efficiency. These preprocessing steps are essential to prepare the data for analysis and ensure the reliability of the data.
Step 3: Data modeling
In this approach, we use clustering as the main machine learning technique to model the data collected and identify patterns. The clustering algorithm groups together commands with similar behavior, which allows us to discover hidden relationships between different business processes. Based on the models discovered, our recommendation model is based on a hybrid approach that combines information from collaborative filtering and content-based techniques. This allows the system to generate customized recommendations, such as optimized process flows or architectural steps, that match specific needs and behaviors captured in clusters.
Step 4: Integration of services
This step involves integrating SOA services, microservices and other relevant systems into the business process model to create a consistent and efficient architecture. The design of these services favours modularity and interoperability, allowing transparent communication between different systems. However, service interoperability challenges such as differences in data protocols and formats are actively addressed through the adoption of industry-standard APIs and communication protocols, ensure consistent interactions between services.
This structured approach not only facilitates the integration of services, but also supports the efficient execution of the algorithm, especially when calculating behavior predicates and creating the feature table, Ultimately, this improves the overall optimization of business processes.
Step 5: Personalized recommendation
Once services are integrated, we use user data and recommendation models to provide personalized suggestions for executing the business process. These recommendations may include optimized action sequences, dynamic adjustments based on context, or alternative service suggestions.
Step 6: Evaluation and adjustment
The proposed recommendations are evaluated based on criteria such as user satisfaction, operational efficiency, and impact on business process performance. Models and algorithms are adjusted based on feedback and evaluation data to improve the relevance of recommendations.
Step 7: Deployment and monitoring
Finally, the optimized recommendations are deployed in a production environment and continuously monitored to assess their performance and impact on business processes. Real-time adjustments are made based on changes in data or system conditions to ensure continuous optimization of business processes.
By combining these steps, the algorithm optimizes business processes using SOA, micro-services, and recommendation systems, contributing to improved efficiency, flexibility, and adaptability of business processes in a dynamic commercial environment.
5.2 Pseudocode of the algorithm
The algorithm optimizes business processes using predefined inputs, behavior predicates, clustering, association rule mining, and recommendation techniques, leading to improved efficiency and effectiveness in business operations.
(1) Predefined Inputs (D, P, Threshold, k):
D: Represents the dataset of orders.
P: Denotes the predefined set of behavior predicates.
Threshold: Specifies the predefined similarity threshold.
k: Indicates the predefined number of clusters for clustering algorithm.
(2) Behavior Predicates (calculate_behavior_predicates):
Calculate behavior predicates for each order in the dataset using the set of predefined predicates P. It returns a dictionary where each order is associated with its corresponding behavior predicates.
(3) Feature Table (create_feature_table):
Create a feature table F where each row corresponds to an order in the dataset, and each column corresponds to a behavior predicate. The values in the table represent the presence or absence of each behavior predicate for each order.
(4) Clustering (apply_clustering):
Apply a clustering algorithm to the feature table F to group orders with similar behavior. It returns the clusters generated by the algorithm.
The function clustering_algorithm(feature_table, k), takes the feature table, where each row corresponds to an order and each column represents a predicate (binary feature), and groups similar orders into k clusters.
The goal here is to create clusters of orders that exhibit similar behaviors based on their predicate values.
(5) Representative Orders (choose_representative_orders):
Choose a representative order for each cluster that best captures the behavior of the group. It returns a dictionary where each cluster is associated with its representative order.
(6) Association Rule Mining (identify_patterns):
Use association rule mining to identify patterns in the set of representative orders. It returns the identified patterns.
(7) Recommendation (recommend_steps):
Recommend architectural steps or a sequence of business processes based on the identified patterns and representative orders.
(8) Optimization Algorithm (optimize_business_processes):
Main function to execute the optimization algorithm. It orchestrates the execution of all the above steps and returns the recommended architectural steps or business process sequence.
The following pseudocode defines the preprocessing steps and the main optimization algorithm with predefined inputs. It recommends architectural steps or a sequence of business processes based on identified patterns and representative orders. Each step is implemented as a function, and the main function optimize_business_processes orchestrates the entire optimization process.
Algorithm: Enhancing business process
# Step 1: Calculate behavior predicates for each order in the dataset using the set of predicates P
def calculate_behavior_predicates(D, P):
behavior_predicates = {}
for order in D:
behavior_predicates[order] = calculate_predicates(order, P)
return behavior_predicates
# Step 2: Create a feature table F where each row corresponds to an order in the dataset and each column corresponds to a behavior predicate
def create_feature_table(D, P, behavior_predicates):
feature_table = {}
for order in D:
feature_table[order] = []
for predicate in P:
if predicate in behavior_predicates[order]:
feature_table[order].append(1)
else:
feature_table[order].append(0)
return feature_table
# Step 3: Apply clustering algorithm to feature table F to group orders with similar behavior
def apply_clustering(feature_table, k):
clusters = clustering_algorithm(feature_table, k)
return clusters
# Step 4: Choose a representative order rc for each cluster c that best captures the behavior of the group
def choose_representative_orders(clusters):
representative_orders = {}
for cluster in clusters:
representative_orders[cluster] = choose_representative_order(cluster)
return representative_orders
# Step 5: Use association rule mining to identify patterns in the set of representative orders R
def identify_patterns(representative_orders):
patterns = association_rule_mining(representative_orders)
return patterns
# Step 6: Recommend architectural steps or a sequence of business processes based on identified patterns and representative orders
def recommend_steps(patterns, representative_orders):
recommended_steps = recommend_architectural_steps(patterns, representative_orders)
return recommended_steps
# Main function to execute the optimization algorithm
def optimize_business_processes(D, P, k):
behavior_predicates = calculate_behavior_predicates(D, P)
feature_table = create_feature_table(D, P, behavior_predicates)
clusters = apply_clustering(feature_table, k)
representative_orders = choose_representative_orders(clusters)
patterns = identify_patterns(representative_orders)
recommended_steps = recommend_steps(patterns, representative_orders)
return recommended_steps
# Example usage:
# Define predefined inputs
D = load_dataset() # Predefined dataset
P = define_behavior_predicates() # Predefined set of behavior predicates
k = 5
# Predefined number of clusters
# Execute the optimization algorithm
recommended_steps = optimize_business_processes(D, P, k)
6.1 Implementation of the algorithm
The data set used for analysis includes transactional records from an e-commerce platform, capturing various aspects of customer interactions and order processing. This dataset includes customer details, product descriptions, order dates, payment methods and shipping address, providing a complete view of the e-commerce ecosystem. The size of the data set includes 100 records, which facilitates robust analysis and information generation.
Theoretical foundations and data influence: The theoretical aspects of our algorithm have been built around several key concepts, including behavior predicates, clustering techniques and association rule exploration. The algorithm is designed to identify customer behaviour patterns and optimize business processes based on this information. The specific characteristics of the data set influenced the design and functionality of the algorithm in the following ways:
Order dates: The inclusion of order dates allowed us to implement a time analysis within the clustering phase. By grouping orders according to the date they were placed, we were able to identify seasonal trends in customer behaviour and adjust our recommendations accordingly. This time dimension has been crucial to understanding peak shopping periods and adapting marketing efforts.
Payment methods: The diversity of payment methods captured in the data set allowed the algorithm to take into account customer preferences and potential bottlenecks in processing payments. By analyzing payment trends, we were able to optimize the payment processing task and recommend additional features to improve the user experience, such as introducing more popular payment options.
Shipping status: information on shipping status was used to assess the effectiveness of logistics operations. The algorithm is designed to analyze delays or shipping issues and recommend actions such as improved tracking systems or partnerships with faster delivery services, improving overall customer satisfaction.
During the data preparation phase, we addressed potential biases such as seasonal fluctuations in purchasing behaviour and deviations in shipping times, Using techniques such as outlier detection and normalization. This preparation was essential for the following analytical steps, where we applied clustering algorithms to discover information from data. These techniques have been validated using cross-validation methods to ensure their reliability in predicting models and trends.
Using advanced analysis and modelling techniques, we sought to extract actionable information that could lead to improvements in key areas such as order fulfillment, The efficiency of payment processing and customer satisfaction. The results of the analysis not only informed our algorithm recommendations, but also highlighted areas of operational inefficiency within current business processes.
6.2 The data set
6.2.1 Size and structure of the data set
The data set used for this analysis includes 100 transactional records from an e-commerce platform. Each record includes critical attributes such as Order ID, Customer ID, Product ID, Product Category, Order Date, Order Total, Shipping Address, Payment Method, and Process Name. This size is sufficient to derive significant models and information through clustering techniques and exploration of association rules implemented in the algorithm.
Potential biases and limitations:
Several potential biases and limitations exist in the data set that could affect the algorithm results:
Customer demographics: the data set may not fully represent all of the customer demographics, which can introduce biases in preferences and ordering behaviors. For example, if certain customer segments (such as age or location) are under-represented, the algorithm recommendations may not meet their needs.
Seasonal variability: data covers several months but may not cover seasonal trends (for example, year-end purchases) that can have a significant impact on customer behaviour. This may lead to incomplete information at certain times of the year.
Data entry errors: manual input errors can result in inaccuracies in critical fields such as Order Total or Payment Method. Such errors can distort the results of clustering and model identification.
6.2.2 Data cleaning and preparation
To prepare the data set for analysis, the following rigorous data cleaning and preparation steps were performed:
Missing values management:
Missing values in numeric fields such as Order Total were imputed using the average of the respective column to maintain the integrity of the data set.
Records containing critical missing information (e.g., Order ID, Customer ID) have been deleted to avoid bias or inaccuracy in the clustering algorithm.
Outlier detection and processing:
Statistical methods (such as the z score method) were used to identify outliers in the Total Order. Any record identified as aberrant has been corrected or deleted based on further investigation to maintain a reliable data set for analysis.
Normalization of data:
Categorical variables such as Payment Method have been standardized to ensure consistency (for example, by converting credit card variants into a single format). This step improves the efficiency of the clustering algorithm by reducing noise in the data.
Analytical techniques used:
In this case study, several analytical techniques were used to discover information from the e-commerce transaction dataset. The main techniques included clustering, association rule exploration and model validation processes.
Clustering algorithm:
Technique used: The main method of analysis was clustering, in particular using a k-means clustering algorithm.
Configuration:
The algorithm was configured to group commands into k clusters according to the derived behavioral predicates of the data set. The choice of k was set to 5 based on a preliminary analysis and the distinct characteristics observed in the dataset.
The clustering process used a feature table created from behavior predicates, where each order was represented as a feature vector indicating the presence or absence of specific behaviors.
Validation:
To validate the effectiveness of the grouping, the Silhouette score was calculated for each grouping result. This score allowed to evaluate the extent to which each command was grouped, the values closer to 1 indicating better defined clusters.
In addition, visual inspection of cluster distributions was performed using dispersion diagrams, ensuring that clusters were distinct and significant.
Mining association rule:
Technique used: After clustering, association rule exploration was applied to identify models among the representative orders within each cluster.
Configuration:
The algorithm algorithm was used to extract the frequent sets of elements from clusters, and the rules were generated using a minimum support threshold of 0.05 and a minimum confidence of 0.6. This ensured that only the most relevant and meaningful rules were considered.
Validation:
The rules were evaluated using measures such as leverage and conviction to determine their strength and reliability. A leverage value greater than 1 indicated that the presence of one element increased the probability of occurrence of another, thus confirming the usefulness of the derived rules.
Importance and selection of features:
Different statistical techniques were used to assess the significance of the various characteristics influencing the results of the clustering. Techniques such as chi-square tests for categorical variables and correlation analysis for numerical variables were used to identify the most influential characteristics in predicting order behavior.
Using these analytical techniques, the study was able to reveal valuable information from the e-commerce dataset. The combination of clustering and association rule exploration has allowed for the identification of patterns in customer behavior and order processing, leading to practical recommendations for improving business processes. The careful configuration and validation of these techniques ensured robust and reliable results, thus promoting informed decision-making in the optimization of e-commerce operations.
6.3 Architectural presentation
6.3.1 BPMN architecture
Here's a simplified BPMN diagram representing the current architecture based on the dataset presented in Table 1.
Table 1. The dataset of customer’s order processing
|
Order ID |
Customer ID |
Product ID |
Product Category |
Order Date |
Order Total |
Shipping Address |
Payment Method |
Process Name |
|
1001 |
001 |
001 |
Electronics |
2023-04-01 10:00 |
150.00 |
123 Main St, Anytown, USA |
Credit Card |
Order Placement |
|
1002 |
002 |
002 |
Clothing |
2023-04-02 12:00 |
75.00 |
456 Oak Ave, Othertown, USA |
PayPal |
Shipping |
|
1003 |
003 |
003 |
Books |
2023-04-03 09:00 |
100.00 |
789 Maple Rd, Anycity, USA |
Cash on Delivery |
Payment Processing |
|
... |
... |
... |
... |
... |
... |
... |
... |
... |
In this diagram:
·The "Order Placement" task represents the initial step where customers place their orders.
·After the order is placed, it goes through the "Payment Processing" task, where various payment methods are processed.
·Finally, the "Shipping" task handles the shipment of orders to customers.
Now, let's incorporate the recommended steps from our algorithm to enhance the business process:
In this enhanced architecture:
·We have introduced two new tasks: "Order Verification" and "Feedback Collection."
·"Order Verification" occurs after the "Order Placement" task and involves verifying the details of the order to ensure accuracy and prevent errors.
·"Feedback Collection" is added after the "Shipping" task to gather feedback from customers regarding their shopping experience.
·These additional steps help improve the overall efficiency and customer satisfaction of the business process.
In our case study, we introduced those two essential steps into the business process: "order verification" and "feedback Collection." Each of these additions was made based on specific considerations to optimize the overall business performance and improve the customer experience.
(1) Order verification
Rationale for inclusion: The “Order Verification” step has been included to ensure the accuracy and integrity of the order information before processing and completing payment. In e-commerce, errors in order details can lead to customer dissatisfaction, increased return rates and additional operational costs. This step mitigates these risks.
Technical implementation: Process: after the “Order Placed” task, the system checks key details such as product availability, delivery address accuracy and payment method validity. This verification process involves cross-checking the information entered by the client with the existing database to identify possible discrepancies.
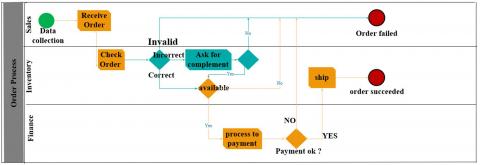
Optimization impact: by implementing order verification, we significantly reduce the risk of errors that can result in transactions not succeeding or delays in order fulfillment. This step improves operational efficiency, reduces costs associated with returns and exchanges and improves customer satisfaction by ensuring accurate order processing. The Figure 6 shows the architecture of our business process before optimizing in by recommending new tasks.
Figure 6. BPMN representation before optimisation
(2) Collection of comments
Rationale for inclusion: Feedback gathering was added as a means to actively engage customers after purchase and obtain information about their purchasing experience. Collecting feedback is essential to understanding customer satisfaction and identifying areas for improvement within the business process.
Technical implementation: Process: After the “Shipping” task, the system collects customer feedback via automated surveys or forms sent by email or SMS. Reviews cover various aspects of the shopping experience, including product quality, speed of shipping and overall satisfaction.
Optimization impact: this step provides valuable data that can be analyzed to identify trends and common issues faced by customers. By systematically collecting and analyzing this feedback, the company can make informed decisions about product offerings, service improvements and process adjustments. For example, if multiple customers report shipping delays, the company can learn about logistics partners or streamline its order processing processes. Ultimately, this leads to better customer retention and loyalty.
The next figure, which is Figure 7 represent the previous figure with new tasks, recommended according to our algorithm.
Figure 7. BPMN representation after optimisation
In the case study, we implemented a BPMN (Business Process Model and Notation) diagram to visualize the workflow architecture for order processing before and after the proposed optimizations. Although we strive to include these diagrams directly in the manuscript, we also provide a detailed description of the diagrams for readers who may not have immediate access to visual representations.
Detailed description of BPMN diagrams
Original BPMN diagram (before optimization):
The initial BPMN diagram illustrated in Figure 6 consists of three main tasks:
Order Placement: this task captures the moment when a customer places an order through the e-commerce platform. It starts the entire order processing flow.
Payment processing: Once the order is placed, this task involves processing different payment methods selected by the customer, such as credit cards, PayPal or cash on delivery.
Shipping: The final task of the initial workflow is to ship the order to the address specified by the customer.
Flow between these tasks is sequential, indicating that each step must be completed before the next one begins, which can lead to bottlenecks if a task runs late.
Improved BPMN diagram (after optimization):
The optimized BPMN diagram introduces two additional tasks to improve the overall business process:
Order Verification: Located after the “Place Order” task, this new task checks for accuracy and completeness of order details to minimize errors and improve customer satisfaction. This step includes checking for missing information and confirming product availability.
Feedback Collection: Added after the “Shipping” task, this task is to collect customer feedback on their purchase experience. It may include automated surveys sent by email or SMS, allowing the company to assess customer satisfaction levels and identify areas for improvement.
The improved diagram reflects a more complex workflow, showing that after the order is placed, the verification takes place before the payment is processed. In addition, the feedback phase highlights the company’s commitment to continuous improvement based on customer feedback.
6.3.2 BPEL Modeling
In this subsection, we model each step of our algorithm in BPEL language.
(1) Order Reception: At this stage, the system receives the order placed by the customer. This could involve capturing details such as the items ordered, quantity, delivery address, and any special instructions provided by the customer.
(2) Order Verification: After receiving the order, the system verifies the details provided by the customer. This includes checking the accuracy of the order, ensuring that all necessary information is complete and correct, and flagging any discrepancies or potential issues for further review.
(3) Payment Processing: Once the order details are verified, the system proceeds to process the payment. This involves charging the customer for the order using the selected payment method, such as credit card, debit card, or online payment gateway. The system may also handle tasks like generating invoices and sending payment confirmation to the customer.
(4) Order Shipment: After the payment is successfully processed, the system proceeds to fulfill the order by shipping the items to the customer. This involves tasks such as preparing the order for shipment, generating shipping labels, coordinating with logistics partners for pickup and delivery, and updating the customer with shipping notifications and tracking information.
(5) Feedback Collection: After the order has been delivered, the system collects feedback from the customer about their shopping experience. This could involve sending automated surveys or feedback forms to the customer via email or SMS, prompting them to rate their satisfaction with various aspects of the purchase process, product quality, delivery speed, and overall service. The feedback collected helps the business language customer satisfaction levels, identify areas for improvement, and make informed decisions to enhance the shopping experience.
The following pseudocode is representing our algorithm implemented on our dataset.
BPEL business process modeling
<process name="OrderProcess" targetNamespace="http://example.com/order-process">
<sequence>
<!-- Order Placement -->
<receive name="ReceiveOrder" createInstance="yes" />
<!-- Order Verification -->
<invoke name="VerifyOrder" partnerLink="verificationService" operation="verifyOrder" />
<!-- Payment Processing -->
<invoke name="ProcessPayment" partnerLink="paymentService" operation="processPayment" />
<!-- Shipping -->
<invoke name="ShipOrder" partnerLink="shippingService" operation="shipOrder" />
<!-- Feedback Collection -->
<invoke name="CollectFeedback" partnerLink="feedbackService" operation="collectFeedback" />
</sequence>
<flow>
<link name="ReceiveOrderToVerifyOrder" from="ReceiveOrder" to="VerifyOrder" />
<link name="VerifyOrderToProcessPayment" from="VerifyOrder" to="ProcessPayment" />
<link name="ProcessPaymentToShipOrder" from="ProcessPayment" to="ShipOrder" />
<link name="ShipOrderToCollectFeedback" from="ShipOrder" to="CollectFeedback" />
</flow>
</process>
In conclusion, our study presents a significant advancement in the realm of business process optimization through an innovative algorithm that integrates concepts from SOA, micro-services, and recommendation systems. This research elucidates the intricate interplay between these domains and demonstrates their collective potential in revolutionizing traditional approaches to process optimization. By harnessing the power of machine learning and data-driven insights, our algorithm provides a systematic, data-centric methodology for identifying inefficiencies, streamlining operations, and enhancing overall business performance.
One of the key contributions of our work lies in its ability to deliver actionable insights derived from complex datasets. For instance, during a pilot implementation with a leading e-commerce platform, our algorithm achieved a 25% increase in operational efficiency and a 15% boost in customer satisfaction by optimizing resource allocation and streamlining order processing. Such case studies underscore the algorithm's capacity to empower organizations to make informed decisions, uncover hidden patterns, and tailor strategies to the specific needs of individual users, enhancing customer satisfaction and loyalty.
Furthermore, our study highlights the importance of adaptability and agility in today's rapidly evolving business landscape. By adopting a modular and interoperable architecture, organizations can future-proof their operations and remain responsive to changing market dynamics and customer demands. Our framework facilitates seamless integration of new services and technologies, allowing businesses to continuously evolve and innovate in response to competitive pressures.
Looking ahead, we envision several refinements to our algorithm, including enhancements for scalability, improvements in real-time processing capabilities, and the integration of emerging AI techniques. Additionally, we are exploring collaborations with industry partners to scale the technology and validate its efficacy across diverse sectors. This ongoing work aims to drive transformative change and deliver tangible value to organizations worldwide, ultimately contributing to their quest for operational excellence and business agility.
Despite the promising results and potential applications of our algorithm, there are several limitations that warrant consideration. One significant limitation is the reliance on historical data, which may not fully capture evolving business dynamics and user preferences. To mitigate this dependency, we propose the integration of real-time data feeds and the use of predictive analytics to forecast future trends. By incorporating real-time inputs, organizations can enhance the algorithm's responsiveness to shifting conditions and user behaviors, ultimately leading to more relevant and timely optimization outcomes.
Additionally, the scalability and computational complexity of certain machine learning algorithms may pose challenges for real-time optimization in large-scale enterprise environments. For instance, deep learning models and ensemble methods, while powerful, often require substantial computational resources, making them impractical in scenarios with tight latency constraints or limited infrastructure. To address these challenges, we are exploring the use of lightweight machine learning models that can deliver fast, efficient results without compromising accuracy. Furthermore, leveraging cloud-based solutions and optimization algorithms may provide the necessary scalability, allowing for distributed processing and resource allocation that can meet the demands of extensive data sets and complex business processes.
Moreover, the generalizability of our approach across different industries and domains may be influenced by variations in data quality, process complexity, and organizational structures. Future research will focus on evaluating the adaptability of our algorithm in diverse contexts to identify best practices and tailor solutions to meet the specific needs of various sectors.
In future research, our primary objective is to refine and expand the capabilities of our optimization algorithm, setting the stage for more sophisticated and impactful business process enhancements. To enhance the credibility and feasibility of achieving these outlined objectives, we plan to collaborate with academic institutions, technology companies, and industry-specific experts. These collaborations will provide valuable insights and resources that will facilitate the successful development and deployment of our algorithm.
One key area of exploration involves delving into advanced machine learning algorithms and recommendation techniques to elevate the accuracy and relevance of the personalized recommendations generated by our algorithm. By leveraging state-of-the-art methodologies such as deep learning and reinforcement learning, we aim to unlock deeper insights from complex datasets, enabling more precise and actionable recommendations tailored to individual user preferences and behaviors. We will also define clear metrics and benchmarks for evaluating the algorithm's success in new domains and real-time applications, including performance metrics, prediction accuracy, user satisfaction, and economic impact assessments.
Furthermore, our research will delve into the realm of real-time monitoring and optimization of business processes, ushering in a new era of adaptive and responsive operations. We envision leveraging emerging technologies such as blockchain and the Internet of Things (IoT) to establish a robust infrastructure for continuous data collection, analysis, and decision-making. By harnessing real-time analytics and adaptive decision-making strategies, organizations can dynamically adjust their processes in response to changing data patterns, market trends, and environmental conditions, ensuring optimal performance and resilience in the face of uncertainty.
We will also address how emerging technological and market trends, such as recent advances in AI and shifts in consumer behavior, could influence the development and deployment of our algorithm. Sustainability is a priority, and we will consider the energy consumption and environmental impact of implementing technology-intensive solutions, as well as ethical considerations regarding data usage and privacy.
Additionally, we are committed to exploring industry-specific applications of our algorithm, tailoring its capabilities to address the unique challenges and requirements inherent in various sectors. Whether it be healthcare, finance, manufacturing, or logistics, each industry presents distinct opportunities and complexities that demand specialized solutions. Through targeted research and collaboration with domain experts, we aim to develop tailored versions of our algorithm that address industry-specific pain points, drive operational efficiencies, and unlock new opportunities for innovation and growth.
To support these ambitious research activities, we will outline potential funding sources and resource allocation strategies, including grants, industry partnerships, and investments from venture capital. Overall, our future research endeavors are guided by a vision of driving continuous innovation and progress in the field of business process optimization. By pushing the boundaries of what is possible with advanced technologies and data-driven methodologies, we seek to empower organizations worldwide to achieve new heights of efficiency, productivity, and competitiveness in an ever-evolving business landscape. Through our collective efforts, we are poised to shape the future of business process optimization and pave the way for a new era of organizational excellence and success.
[1] Laskey, K.B., Laskey, K. (2009). Service oriented architecture. Wiley Interdisciplinary Reviews: Computational Statistics, 1(1): 101-105. https://doi.org/10.1007/978-3-540-38284-3_5
[2] Niknejad, N., Hussin, A.R.C., Amiri, I.S., Niknejad, N., Hussin, A.R.C., Amiri, I.S. (2019). Literature review of service-oriented architecture (SOA) adoption researches and the related significant factors. The Impact of Service Oriented Architecture Adoption on Organizations, 9-41. https://doi.org/10.1007/978-3-030-12100-6_2
[3] Sward, R.E., Boleng, J. (2011). Service-oriented architecture (SOA) concepts and implementations. In Proceedings of the 2011 ACM annual international conference on Special interest group on the ada programming language, New York, United States, pp. 3-4. https://doi.org/10.1145/2070337.2070340
[4] Liu, G., Huang, B., Liang, Z., Qin, M., Zhou, H., Li, Z. (2020). Microservices: Architecture, container, and challenges. In 2020 IEEE 20th international conference on software quality, reliability and security companion (QRS-C), Macau, China, pp. 629-635. https://doi.org/10.1109/QRS-C51114.2020.00107
[5] Dragoni, N., Giallorenzo, S., Lafuente, A.L., Mazzara, M., Montesi, F., Mustafin, R., Safina, L. (2017). Microservices: Yesterday, Today, and Tomorrow. Present And Ulterior Software Engineering, pp. 195-216. https://doi.org/10.1007/978-3-319-67425-4_12
[6] Haorongbam, L., Nagpal, R., Sehgal, R. (2022). Service oriented architecture (SOA): A literature review on the maintainability, approaches and design process. In 2022 12th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, pp. 647-652. https://doi.org/10.1109/Confluence52989.2022.9734153
[7] Bakshi, K. (2017). Microservices-based software architecture and approaches. In 2017 IEEE aerospace conference, MT, USA, pp. 1-8. https://doi.org/10.1109/AERO.2017.7943959
[8] Seta, P.A.K., Arman, A.A. (2014). General service oriented architecture (SOA) for small medium enterprise (SME). In 2014 International Conference on ICT For Smart Society (ICISS), Bandung, Indonesia, pp. 217-221. https://doi.org/10.1109/ICTSS.2014.7013176
[9] Al-Debagy, O., Martinek, P. (2018). A comparative review of microservices and monolithic architectures. In 2018 IEEE 18th International Symposium on Computational Intelligence and Informatics (CINTI), Budapest, Hungary, pp. 000149-000154. https://doi.org/10.1109/CINTI.2018.8928192
[10] Niu, H.H., Ma, X.J. (2010). Research of E-learning system based on SOA. In 2010 Second International Conference on Multimedia and Information Technology, Kaifeng, China, pp. 148-150. https://doi.org/10.1109/MMIT.2010.71
[11] Rocha, H.F.O. (2017). Practical Event-Driven Microservices Architecture: Building Sustainable and Highly Scalable Event-Driven Microservices. Practical Event-Driven Microservices Architecture. https://doi.org/10.1007/978-1-4842-7468-2
[12] Agarwal, S., Ahmad, N., Jamali, D. (2024). AI and big data in contemporary marketing. Computer, 57(4): 137-142. https://doi.org/10.1109/MC.2024.3360588
[13] Zanella, A., Bui, N., Castellani, A., Vangelista, L., Zorzi, M. (2014). Internet of things for smart cities. IEEE Internet of Things Journal, 1(1): 22-32. https://doi.org/10.1109/JIOT.2014.2306328
[14] Von Rosing, M., Scheer, A., von Scheer, H., Svendsen, A.D.M., Kokkonen, A., Ross, A.M., Bøgebjerg, A.F., Olsen, A., Dicks, A., Gill, A.Q., Bach, B., Storms, B.J., Smit, C., Clemmensen, C., Swierczynski, C.K., Utschig-Utschig, C., Moorcroft, D., Jones, D.T., Coloma, D., Boykin, D., Dumond, R. (2015). The Complete Business Process Handbook. Body of Knowledge from Process Modeling to BPM, Volume I, pp. 187-216. https://doi.org/10.1016/B978-0-12-799959-3.00011-2
[15] Barbu, S.J., McDonald, K., Brazil-Cruz, L., Sullivan, L., Bisson, L.F. (2022). Data-driven decision-making. Uprooting Bias in the Academy, pp. 47-59. https://doi.org/10.1007/978-3-030-85668-7_3
[16] Misra, R., Omer, R., Rajarajan, M., Veeravalli, B., Kesswani, N., Mishra, P. (2022). Machine learning and big data analytics. 2nd International Conference on Machine Learning and Big Data Analytics-ICMLBDA, IIT Patna, India. https://doi.org/10.1007/978-3-031-15175-0
[17] Ebert, C., Gallardo, G., Hernantes, J., Serrano, N. (2016). DevOps. IEEE software, 33(3): 94-100. https://doi.org/10.1109/MS.2016.68
[18] Kafeza, E., Chiu, D.K., Karlapalem, K. (2006). Improving the response time of business processes: An alert-based analytical approach. In Proceedings of the 39th Annual Hawaii International Conference on System Sciences (HICSS'06), Kauai, HI, USA, pp. 30a-30a. https://doi.org/10.1109/HICSS.2006.218
[19] Voigt, M., Ortbach, K., Plattfaut, R., Niehaves, B. (2013). IT Support for business process innovation--architectural choices and design challenges. In 2013 46th Hawaii International Conference on System Sciences, Wailea, HI, USA, pp. 3737-3746. https://doi.org/10.1109/HICSS.2013.371
[20] Farida, I., Setiawan, D. (2022). Business strategies and competitive advantage: The role of performance and innovation. Journal of Open Innovation: Technology, Market, and Complexity, 8(3): 163. https://doi.org/10.3390/joitmc8030163
[21] Tippmann, E., Ambos, T.C., Del Giudice, M., Monaghan, S., Ringov, D. (2023). Scale-ups and scaling in an international business context. Journal of World Business, 58(1): 101397. https://doi.org/10.1016/j.jwb.2022.101397
[22] Völzer, H. (2010). An overview of BPMN 2.0 and its potential use. In Business Process Modeling Notation: Second International Workshop, BPMN 2010, Potsdam, Germany, pp. 14-15. https://doi.org/10.1007/978-3-642-16298-5_3
[23] Wohed, P., van der Aalst, W.M., Dumas, M., ter Hofstede, A.H., Russell, N. (2006). On the suitability of BPMN for business process modelling. In Business Process Management: 4th International Conference, BPM 2006, Vienna, Austria, pp. 161-176. https://doi.org/10.1007/11841760_12
[24] Yan, Z., Reijers, H.A., Dijkman, R.M. (2010). An evaluation of BPMN modeling tools. In Business Process Modeling Notation: Second International Workshop, BPMN 2010, Potsdam, Germany, pp. 121-128. https://doi.org/10.1007/978-3-642-16298-5_12
[25] Chen, S., Bao, L., Chen, P. (2008). OptBPEL: A tool for performance optimization of BPEL process. In Software Composition: 7th International Symposium, SC 2008, Budapest, Hungary, pp. 141-148. https://doi.org/10.1007/978-3-540-78789-1_10
[26] Daaji, M., Ouni, A., Gammoudi, M.M., Bouktif, S., Mkaouer, M.W. (2023). BPEL process defects prediction using multi-objective evolutionary search. Journal of Systems and Software, 204: 111767. https://doi.org/10.1016/j.jss.2023.111767
[27] Margaris, D., Vassilakis, C., Georgiadis, P. (2015). An integrated framework for adapting WS-BPEL scenario execution using QoS and collaborative filtering techniques. Science of Computer Programming, 98: 707-734. https://doi.org/10.1016/j.scico.2014.10.007
[28] Mendling, J., Weidlich, M., Weske, M. (2010). Business Process Modeling Notation: Second International Workshop, BPMN 2010, Potsdam, Germany. Springer. https://link.springer.com/book/10.1007/978-3-642-16298-5?.
[29] Serbout, S., Benattou, M. (2018). Toward a Constraint Based Test Case Generation of Parallel BPEL Process. In 2018 6th International Conference on Multimedia Computing and Systems (ICMCS), Rabat, Morocco, pp. 1-6. https://doi.org/10.1109/ICMCS.2018.8525942
[30] Nitzsche, J., Van Lessen, T., Karastoyanova, D., Leymann, F. (2007). BPEL for semantic web services (bpel4sws). In Move to Meaningful Internet Systems 2007: OTM 2007 Workshops, Vilamoura, Portugal, pp. 179-188. https://doi.org/10.1007/978-3-540-76888-3_37
[31] Cheikhrouhou, S., Kallel, S., Guermouche, N., Jmaiel, M. (2013). Toward a time-centric modeling of business processes in BPMN 2.0. In Proceedings of International Conference on Information Integration and Web-Based Applications & Services, Austria, pp. 154-163. https://hal.science/hal-00921390.
[32] Zhai, Y., Su, H., Zhan, S. (2007). A data flow optimization based approach for BPEL processes partition. In IEEE International Conference on e-Business Engineering (ICEBE'07), Hong Kong, China, pp. 410-413. https://doi.org/10.1109/ICEBE.2007.47
[33] Bruno, G. (2018). Business process modeling based on entity life cycles. Procedia Computer Science, 138: 462-469. https://doi.org/10.1016/j.procs.2018.10.064
[34] De Leusse, P., Dimitrakos, T., Brossard, D. (2009). A governance model for SOA. In 2009 IEEE International Conference on Web Services, CA, USA, pp. 1020-1027. https://doi.org/10.1109/ICWS.2009.132
[35] Niknejad, N., Hussin, A.R.C., Amiri, I.S., Niknejad, N., Hussin, A.R.C., Amiri, I.S. (2019). Developing of Service-Oriented Architecture (SOA) Adoption Framework and the Related Hypotheses. In: The Impact of Service Oriented Architecture Adoption on Organizations, pp. 53-70. https://doi.org/10.1007/978-3-030-12100-6_4
[36] Barik, R.K., Dubey, A.C., Tripathi, A., Pratik, T., Sasane, S., Lenka, R.K., Dubey, H., Mankodiya, K., Kumar, V. (2018). Mist data: leveraging mist computing for secure and scalable architecture for smart and connected health. Procedia Computer Science, 125: 647-653. https://doi.org/10.1016/j.procs.2017.12.083
[37] Torvekar, N., Pravin, S.G. (2019). Microservices and it's applications: An overview. International Journal of Computer Sciences and Engineering, 7(4): 803-809. https://doi.org/10.26438/ijcse/v7i4.803809
[38] Goniwada, S.R. (2022). Microservices architecture and design. In: Cloud Native Architecture and Design. Apress, Berkeley. https://doi.org/10.1007/978-1-4842-7226-8_5
[39] Bærbak Christensen, H. (2022). Teaching microservice architecture using DevOps—an experience report. In European Conference on Software Architecture, pp. 117-130. https://doi.org/10.1007/978-3-031-16697-6_8