Rajeswari Nakka![]() | Talasila Sri Lakshmi
| Talasila Sri Lakshmi![]() | Donepudi Priyanka
| Donepudi Priyanka![]() | Nallagatla Raghavendra Sai
| Nallagatla Raghavendra Sai![]() | Surapaneni Phani Praveen*
| Surapaneni Phani Praveen*![]() | Uddagiri Sirisha
| Uddagiri Sirisha![]()
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Sentiment analysis (SA) is widely employed across various domains, including government policy directives, corporate customer and staff satisfaction monitoring, political analysis, and public tension monitoring in security structures. However, new difficulties for sentiment analysis algorithms have emerged with the advent of highly unstructured manifestations of emotion in online social media platforms. To address this, we propose an enhanced approach that combines lexicon-based analysis and aspect-based sentiment analysis for tweets. In this study pre-processing step allows us to handle the lack of syntactic and grammatical structure commonly found in social media text. Moreover, acknowledging the multimodal characteristics of social media data, encompassing audio, visuals, and videos, our methodology expands to encompass sentiment analysis of text derived from these diverse modalities. Our approach classifies the content as positive, negative, or neutral, utilizing both the lexicon-based approach and the aspect-based sentiment analysis. By combining these techniques, we aim to capture both general sentiment tendencies and aspect-specific sentiments within the text data. We evaluate the efficacy of our proposed approach using the STS-Gold datasets. Text data achieved the highest sentiment accuracy at 92.83%, followed by audio, image, and video data with accuracies of 91.11%, 87.8%, and 86.67%, respectively by using LAMBDA approach. The results highlight the effectiveness of our approach compared to other state-of-the-art research studies.
aspect based sentiment analysis, multimodal sentiment analysis, lexicon approach, twitter data, natural language models, fusion methods
Throughout Multimodal Sentiment Analysis [1-3] represents a sophisticated strategy involving the systematic extraction and assessment of emotions and sentiments from various sources like text, speech, images, and videos. As technology continues to progress, the amount of data produced on social media platforms and other multimedia outlets has exponentially grown. This surge in data availability brings forth fresh prospects and challenges for comprehending and interpreting the emotions conveyed by users across different types of media content. While conventional sentiment analysis mainly concentrated on textual data, utilizing algorithms and methods to ascertain whether the sentiment expressed in text was positive, negative, or neutral, the surge in multimedia content has necessitated an expansion of sentiment analysis to encompass diverse modalities that capture the intricate and multifaceted nature of human expressions.
Within the realm of multimodal sentiment analysis, Natural Language Processing (NLP) and other artificial intelligence (AI) technologies have a vital role to play in the processing and comprehension of textual content. Textual analysis remains a fundamental aspect, as social media platforms, blogs, and other online sources continue to be a prevalent medium for expressing opinions and emotions. However, the multimodal approach goes beyond text and extends to speech, images, and videos. Audio recordings allow sentiment analysis of spoken language, where the tone, pitch, and rhythm can provide valuable insights into emotions. Image analysis involves understanding visual cues, facial expressions, and gestures to infer sentiments. Video analysis combines both audio and image modalities to capture the dynamics of emotions in real-life scenarios.
Multimodal sentiment analysis [4] faces a key challenge in effectively integrating data from diverse sources and modalities, requiring advanced processing techniques. Robust machine learning models are needed to accurately classify sentiments across various modalities. Applications span industries: in marketing, it gauges customer sentiment; in social media, it tracks public opinions; and in healthcare, it analyzes patient feedback. Despite its growing importance, this field remains complex. Researchers innovate methods to glean deeper insights from multimodal data, enhancing sentiment analysis models. Multimodal sentiment analysis's potential lies in its accuracy, as it considers diverse cues like facial expressions, tone, and body language. Data fusion methods vary, depending on the application's specifics. The ongoing research opens avenues for advancements in this promising field. Text pre-processing techniques in Natural Language Processing (NLP) encompass operations applied to raw textual data for preparation in subsequent analysis and modeling. This step is vital in NLP tasks, enhancing text data quality, minimizing noise, and facilitating comprehension by machine learning algorithms.
The research paper introduces several notable contributions to the field. Firstly, it presents the development of a dedicated Text Extraction Model designed specifically for tweets, enhancing the extraction process. Secondly, the paper introduces a Multi-modal Text Retrieval Model that effectively retrieves and manages multimedia objects, ensuring a comprehensive approach. Lastly, the research integrates both Lexicon-Based and Aspect-Based Approaches to perform sentiment analysis, combining the strengths of these methods for more accurate and insightful results. These contributions collectively enhance the understanding and analysis of textual and multimedia data in various contexts.
The Lexicon-based approach [5] is a widely used and straightforward technique in Natural Language Processing (NLP) for sentiment analysis. It relies on existing lexicons or dictionaries that associate words with sentiment scores, such as positive, negative, or neutral. The core concept of this approach involves assigning sentiment scores to individual words within a given text and then combining these scores to determine the overall sentiment of the text.
Aspect-based Sentiment Analysis [6, 7] (ABSA) is an advanced technique in Natural Language Processing (NLP) that goes beyond traditional sentiment analysis by focusing on specific aspects or components of a given text, such as product features, services, or entities. Unlike the Lexicon-based approach, ABSA provides a more detailed and fine-grained analysis of sentiments, enabling a deeper understanding of opinions and attitudes towards different aspects within the text.
Fusion of Lexicon and Aspect based sentiment Analysis: The advantage of combining Lexicon-based and Aspect-based Sentiment Analysis approaches lies in their complementary strengths, which can lead to more accurate and informative sentiment analysis results. By leveraging both methods together, the overall sentiment analysis process becomes more robust and effective. The contributions of the research paper can be summarized as follows:
(1) Development of a Text Extraction Model for Tweets.
(2) Multi-modal Text Retrieval Model for Multimedia Objects.
(3) Fusion of Lexicon-Based and Aspect-Based Approaches to perform sentiment analysis.
In this section, we present a review of existing works on sentiment analysis (SA) that utilize the lexicon approach and aspect based Sentiment Analysis.
Vu and Le [8] introduced a lexicon-based pre-processing approach that incorporated sentiment dictionaries, yielding effective results through the integration of popular sentiment analysis methods. Notably, their technique enhanced performance by filtering opinion-oriented words during data pre-processing. Abirami and Gayathri [9] surveyed contemporary sentiment analysis methods, discussing diverse approaches, challenges, and strategies to overcome them.
To combat issues with ambiguity and non-standard datasets, Pamungkas and Putri [10] proposed a lexicon-based sentiment analysis method for Indonesian opinion data. In the study by Agarwal and Toshniwal [11], clustering, emotion extraction, and knowledge discovery were introduced as new methods for doing sentiment analysis on tweets from cricket fans using a lexicon-based methodology. Fan reactions were connected to player output. Features, approaches, domains, and difficulties in bringing SA to social media are all covered by Alessia et al. [12] in assessment of sentiment analysis methods. In order to improve sentiment classification accuracy and strength detection, Mudinas et al. [13] presented a hybrid sentiment analysis system that merged lexicon-based and learning-based approaches. Dedeepya et al. [14] presented a two-part, lexicon-based approach to entity-level sentiment analysis for Twitter feeds; the first portion identifies opinionated tweets and assigns polarities to classify things; the second part improves recall by using these given polarities.
In order to better capture emotions in online videos, Poria et al. [15] presented a multimodal sentiment analysis framework that uses a combination of audio, visual, and textual modalities. Using feature and decision-level approaches, we are able to integrate affective information across modes, with 80% accuracy on YouTube datasets. In the study by Ahmad et al. [16], we find a comprehensive review of hybrid tools for sentiment analysis, with an emphasis on their features and precision. Problems associated with text noise were investigated by focusing on tweets' textual content and ignoring any accompanying media.
Jurek et al. [17] suggested a novel lexicon-based sentiment analysis method for Twitter. It goes beyond simple categorization by including sentiment normalisation and evidence-based combination functions in order to arrive at sentiment intensity. The system's effectiveness was demonstrated by examining tweets about the English Defence League and the ensuing levels of disruption. Nigam and Yadav [18] used R to do lexicon-based sentiment analysis. Sentiment analysis of a small sample of tweets using simple criteria was the subject of their research.
Taboada et al. [19] suggested a lexicon-based technique to extracting sentiment from texts through the use of a word-based algorithm. Maynard et al. [20] presented an approach to polarity and strength in sentiment analysis that makes use of a vocabulary. The approach gives the terms in the employed dictionaries a semantic bias. In order to implement sentiment analysis, they developed a semantically oriented word dictionary by computing the semantic orientation of words and assuring consistency and dependability.
In the study by Kaur and Kautish [3], the authors examine multimodal sentiment analysis methods, classifying literature and identifying developments. Arava et al. [21] conducted sentiment analysis on reviews of films, paying special attention to subjective phrases. A multimodal SA technique to rating tweets' expressiveness was proposed by Kumar and Garg [22]. Using a viable algorithm based on Twitter data, Marrapu et al. [23] anticipated the outcomes of the UK election. Ahmed et al. [24, 25] found that expressed sentiments from social media can predict election outcomes with a fair degree of accuracy, employing a volumetric and SA approach to election prediction.
By merging both lexicon-based and aspect-based methodologies, in this paper we maximize the advantages of each technique, resulting in a more precise and insightful sentiment analysis of multimedia content. While the lexicon-based method identifies overall sentiment patterns, the aspect-based approach enables a nuanced examination of sentiments concerning particular aspects or themes within the content. This fusion enhances sentiment analysis accuracy and facilitates a deeper comprehension of the sentiments conveyed in multimedia data.
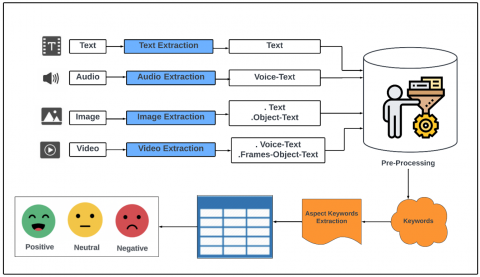
The Based on the proposed framework, the process flow Algorithm 1 and Figure 1 illustrates how to find sentiments using both an aspect-based and lexicon-based approaches. Lexicon and Aspect based Multimodal Data Analysis (LAMBDA approach):
Algorithm 1: Aspect-Based Sentiment Analysis (SA-ABSA)
Data: Text, Aspect Keywords, Aspect Sentiment Lexicon
Result: Aspect Sentiment Scores (Pos, Neg, Neu)
(1). Start
(2). Extract aspect keywords from text.
(3). Initialize aspect sentiment counters: Pos, Neg, Neu.
(4). For each aspect keyword:
a. Check if aspect keyword is in text.
b. If aspect keyword found:
i. Extract sentiment from lexicon.
ii. If sentiment is positive, increment Pos counter.
iii. If sentiment is negative, increment Neg counter.
iv. If sentiment is neutral, increment Neu counter.
(5). End aspect loop.
(6). Return aspect sentiment scores (Pos, Neg, Neu).
(7). Stop.
The algorithm 1 is based on aspect-based-sentiment-analysis (ABSA). It involves identifying aspect keywords in the pre-processed text, checking their presence, extracting sentiment from an aspect sentiment lexicon, and incrementing sentiment counters for each aspect. The algorithm outputs sentiment scores (positive, negative, neutral) for each aspect analyzed.
By combining both the lexicon-based and aspect-based approaches, the proposed framework can leverage the strengths of each method, providing a more accurate and insightful sentiment analysis of the multimedia content. The lexicon-based approach captures general sentiment trends, while the aspect-based approach allows for a more detailed analysis of sentiments related to specific aspects or topics within the content. This combination enhances the overall sentiment analysis and provides a more comprehensive understanding of the sentiments expressed in the multimedia data.
3.1 Sentiment analysis based on text data
In today's digital landscape, there is an abundance of text-based information on the web. In light of this, sentiment analysis plays a crucial role in identifying and analyzing the sentiment expressed in the text, categorizing it as (positive, negative, neutral). The proposed framework for text-based sentiment analysis is illustrated in Figure 2.
Figure 1. LAMBDA approach for multimodal sentiment analysis
Figure 2. LAMBDA approach employed in text analysis
The process of text-based sentiment analysis encompasses several sequential steps. Initially, text is harvested from diverse sources, encompassing user-generated content across social media platforms, reviews, and textual commands. Following this, the collected text undergoes a series of pre-processing techniques designed to classify and identify pertinent keywords. Finally, sentiment analysis is conducted using a combination of lexicon-based and aspect-based approaches, leveraging the identified keywords. This analysis ultimately categorizes the sentiment of the text into one of three classes: (positive, negative, neutral). This multistep procedure is fundamental in gleaning insights from textual data, allowing for the assessment of public sentiment across a wide range of domains. The algorithm (2) illustrates text based approach.
Algorithm 2: Aspect-Based Sentiment Analysis (SA-ABSA)
Input: Text (T)
Output: Sentiment scores for each aspect (Positive, Neutral, Negative)
Representation: Sentiment Analysis, Aspect-Based-Sentiment-Analysis, Text-T, Pre-processing-P, Keywords-K, Word Count-N, Lexicon Approach-LA.
(1). Pre-process the text (T) using steps Tokenization, stop words, POS tagging, stemming and lemmatization.
(2). Processed text P={P1, P2, P3, P4} and extract the features from P1, P2, P3, P4 into P.
(3). Extract aspect keywords K from P.
(4). Calculate word count N for K.
(5). Initialize positive, neutral, and negative counters.
(6). For each aspect keyword K [i] in K:
a. Apply Lexicon Approach (LA) to calculate sentiment score for K [i].
b. Increment appropriate sentiment counter based on sentiment score.
(7). Calculate sentiment percentages for each aspect:
- Positive %= (Positive Count/N) *100
- Neutral %= (Neutral Count/N) *100
- Negative %= (Negative Count/N) *100
(8). Display sentiment scores for each aspect:
- Display Positive %, Neutral %, Negative % for each aspect.
This algorithm performs aspect-based sentiment analysis on the input text (T). It involves pre-processing the text by tokenizing, removing stop words, performing POS tagging, and applying stemming and lemmatization. The processed features are then used to extract aspect keywords. For each aspect keyword, the Lexicon Approach LA is applied to calculate the sentiment score, and sentiment counters are incremented accordingly. Finally, the algorithm calculates and displays the sentiment scores and percentages for each aspect.
3.2 Sentiment analysis based on audio data
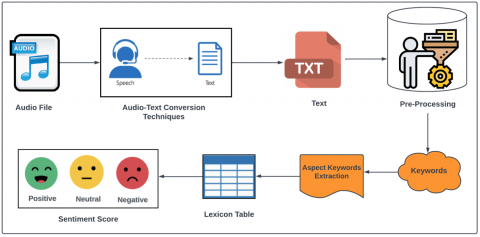
The next dimension of multimedia content is audio, which includes voice messages, voice notes, songs, and other forms commonly found online. In this context, sentiment analysis plays a pivotal role in detecting and evaluating the sentiment conveyed in audio content, classifying it into (positive, negative, neutral) categories. The framework introduced for analyzing sentiment in audio content is visually represented in Figure 3.
The process of conducting sentiment analysis for audio content involves several sequential steps. Firstly, audio content is collected from various sources within the realm of social media, encompassing a wide range of materials such as user-generated voice recordings, voice notes, songs, and comparable forms of auditory data. Subsequently, this audio content is converted into a textual format that can be processed more effectively. Through the application of text pre-processing techniques, the extracted text is categorized, and pertinent keywords are identified to facilitate subsequent analysis. To determine the sentiment conveyed within the audio content, a combination of lexicon-based and aspect-based sentiment analysis approaches is employed. These methodologies leverage identified keywords to evaluate sentiment, classifying it as either (positive, negative, neutral) providing valuable insights into the emotional tone of the audio material. The algorithm (3) is LAMBDA Approach employed on Audio Data.
Algorithm 3: Aspect-Based Sentiment Analysis for Audio
Input: Audio File (AF)
Output: Sentiment scores for each aspect (Positive-pos, Neutral-neu, Negative-neg)
Representation: Sentiment Analysis, Aspect-Based-Sentiment-Analysis, Text-T, Pre-processing-P, Keywords-K, Word Count-N, Lexicon Approach-LA.
(1). Extract text T from audio file AF.
(2). Pre-process text T using steps Tokenization, stop words, POS tagging, stemming and lemmatization.
(3). Processed text P ={P1, P2, P3, P4} and extract the features from P1, P2, P3, P4 into P.
(4). Extract aspect keywords K from P.
(5). Calculate word count N for K.
(6). Initialize positive, neutral, and negative counters.
(7). For each aspect keyword K [i] in K:
a. Apply Lexicon Approach (LA) to calculate sentiment score for K [i].
b. Increment appropriate sentiment counter based on sentiment score.
(8). Calculate sentiment percentages for each aspect:
- Positive %= (Positive Count/N) *100
- Neutral %= (Neutral Count/N) *100
- Negative %= (Negative Count/N) *100
(9). Display sentiment scores for each aspect:
- Display Positive %, Neutral %, Negative % for each aspect.
(10). Stop
In this algorithm, we first extract the text from the audio file using speech recognition techniques such as Automatic Speech Recognition (ASR). Then, we perform pre-processing steps including “stop word removal”, “tokenization”, “stemming/lemmatization” & “POS tagging”. Next, we extract aspect keywords from the pre-processed text. For each aspect keyword, we apply the lexicon and aspect based approaches to calculate the sentiment score and increment the sentiment counters accordingly. Finally, we calculate and display the sentiment scores and percentages for each aspect.
Figure 3. LAMBDA approach employed on audio data
3.3 Sentiment analysis based on image data
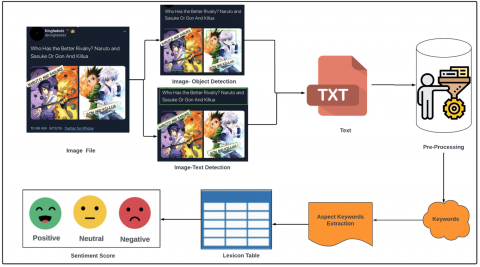
The image is the third significant component of multimedia content, and the web contains numerous images that are widely shared and used to convey information. Sentiment Analysis plays a crucial role in identifying and analyzing the sentiment expressed in these images, categorizing them as (positive, negative, neutral). The proposed framework for image-based-sentiment-analysis is illustrated in Figure 4.
The process of image-based-sentiment-analysis involves several stages. In the initial level, the process begins with the extraction of images from social media platforms. OCR techniques are then employed to extract text embedded within these images. The extracted text undergoes text pre-processing techniques to categorize and identify important keywords. Utilizing lexicon and aspect based approaches, the sentiment of the image content is determined based on these identified keywords, leading to a classification of sentiment as (positive, negative, neutral). Moving to Level 2, the process continues by capturing and converting objects present in the image into text using an OCR scanner. Similar to the previous level, the extracted text undergoes text pre-processing to identify relevant keywords. Lexicon-based methods are once again applied to determine sentiment based on these keywords, resulting in a sentiment classification of (positive, negative, neutral). This multilevel approach enables a comprehensive analysis of sentiment within image content.
The proposed framework and its procedures aim to effectively analyze the sentiment expressed in images and provide valuable insights into the emotional content conveyed through visual media.
Algorithm 4: Finding Sentiments using Aspect-Based Sentiment Analysis for Image (SA-ABSA)
Input: Image File (IF)
Output: Sentiment scores for each aspect (Positive-pos, Neutral-neu, Negative-neg)
Representation: Sentiment Analysis, Aspect-Based-Sentiment-Analysis, Text-T, Pre-processing-P, Keywords-K, Word Count-N, Lexicon Approach-LA.
(1). Start
(2). T1 = Extract text from the image file IF.
(3). P1-Tokenize T1
P2-Remove stop words from T1
P3-Perform POS tagging on T1
P4-Apply stemming and lemmatization to T1
(4). P= Process the features of {P1, P2, P3, P4}
(5). K1= Extract aspect keywords from P1
(6). N1= Word count of K1
(7). Initialize sentiment counters for each aspect: positive, negative, neutral.
(8). For each aspect keyword K1[i] in K1:
a. Check if the aspect keyword is present in the text.
b. If the aspect keyword is found:
i. Apply the Lexicon Approach LA to calculate the sentiment score for K1[i] using T1.
ii. If sentiment score is positive, increment the pos counter for the aspect.
iii. If sentiment score is negative, increment the neg counter for the aspect.
iv. If sentiment score is neutral, increment the neu counter for the aspect.
(9). End loop for aspect keywords.
(10). T1_Result = Sentiment scores obtained from T1 using the LA approach.
(11). IO= Extract image object from the image file IF.
(12). T2= Extract text from the image object IO.
(13). P2-Tokenize T2
P3-Remove stop words from T2
P4-Perform POS tagging on T2
P5-Apply stemming and lemmatization to T2
(14). P= Process the features of {P2, P3, P4, P5}
(15). K2= Extract aspect keywords from P2
(16). N2= Word count of K2
(17). Initialize sentiment counters for each aspect: positive, negative, neutral.
(18). For each aspect keyword K2[j] in K2:
a. Check if the aspect keyword is present in the text.
b. If the aspect keyword is found:
i. Apply the Lexicon Approach LA to calculate the sentiment score for K2[j] using T2.
ii. If sentiment score is positive, increment the pos counter for the aspect.
iii. If sentiment score is negative, increment the neg counter for the aspect.
iv. If sentiment score is neutral, increment the neu counter for the aspect.
(19). End loop for aspect keywords.
(20). T2_Result=Sentiment scores obtained from T2 using the LA approach.
(21). Display the sentiment scores for each aspect:
- Display the T1_Result.
- Display the T2_Result.
(22). Stop
Figure 4. LAMBDA approach employed on image data
Figure 5. LAMBDA approach employed on video data
In this algorithm 4, we first extract the text from the image file using OCR techniques. Then, we perform pre-processing steps such as “stop word removal”, “tokenization”, “stemming/lemmatization” & “POS tagging”. Next, we extract aspect keywords from the pre-processed text. For each aspect keyword, we apply the lexicon approach to calculate the sentiment score and increment the sentiment counters accordingly. Finally, we display the sentiment scores (positive, negative, neutral) for each aspect obtained from both the text extracted from the image file and the text extracted from the image object.
3.4 Sentiment analysis based on video data
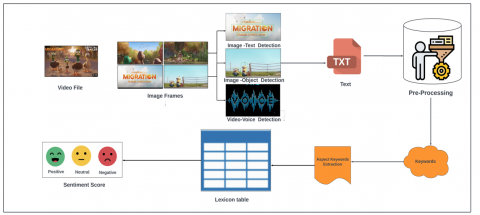
The video element represents the ultimate facet of multimedia content accessible on the internet, encompassing diverse video content used for conveying and expressing information. The provided framework for sentiment analysis in videos is depicted in Figure 5, employing sentiment analysis techniques.
The process for conducting image-based sentiment analysis on video content involves several hierarchical levels of analysis. In Level 1, the audio of the video is extracted and converted into text format. This text is then subjected to text pre-processing techniques to identify keywords. Using Lexicon and aspect based approaches, the sentiment of the video content is determined. In Level 2, the video is segmented into frames, yielding multiple images. Text is extracted from these images using OCR, followed by text pre-processing techniques to classify the text into keywords. The sentiment of the image content is then established using Lexicon and aspect based approaches, considering the identified keywords. In Level 3, the objects within the images are captured and converted to text using an OCR Scanner. Similar text pre-processing techniques are applied to classify the text into keywords. The sentiment of the image content is determined using Lexicon and aspect based approaches based on these keywords, categorizing it as (positive, negative, neutral).This multi-level approach enables a comprehensive sentiment analysis of video content from various perspectives.
Algorithm 5: Finding Sentiments using Aspect-Based Sentiment Analysis for Video (SA-ABSA)
Input: Video File (VF)
Output: Sentiment scores for each aspect (Positive-pos, Neutral-neu, Negative-neg)
Representation: Sentiment Analysis, Aspect-Based-Sentiment-Analysis, Text-T, Pre-processing-P, Keywords-K, Word Count-N, Lexicon Approach-LA.
(1). Start
(2). A= Extract audio from the video file VF.
(3). T1= Extract text from A.
(4). P1- Tokenize T1
P2- Remove stop words from T1
P3- Perform POS tagging on T1
P4- Apply stemming and lemmatization to T1
(5). P= Process the features of {P1, P2, P3, P4}
(6). K1= Extract aspect keywords from P1
(7). N1= Word count of K1
(8). Initialize sentiment counters for each aspect: positive, negative, neutral.
(9). For each aspect keyword K1 [i] in K1:
a. Check if the aspect keyword is present in the text.
b. If the aspect keyword is found:
i. Apply the Lexicon Approach LA to calculate the sentiment score for K1[i] using T1.
ii. If sentiment score is positive, increment the pos counter for the aspect.
iii. If sentiment score is negative, increment the neg counter for the aspect.
iv. If sentiment score is neutral, increment the neu counter for the aspect.
(10). End loop for aspect keywords.
(11). T1_Result= Sentiment scores obtained from T1 using the LA approach.
(12). F= Extract image frame from VF.
(13). T2= Extract text from F.
(14). P2- Tokenize T2
P3- Remove stop words from T2
P4- Perform POS tagging on T2
P5- Apply stemming and lemmatization to T2
(15). P= Process the features of {P2, P3, P4, P5}
(16). K2= Extract aspect keywords from P2
(17). N2= Word count of K2
(18). Initialize sentiment counters for each aspect: positive, negative, neutral.
(19). For each aspect keyword K2[j] in K2:
a. Check if the aspect keyword is present in the text.
b. If the aspect keyword is found:
i. Apply the Lexicon Approach LA to calculate the sentiment score for K2[j] using T2.
ii. If sentiment score is positive, increment the pos counter for the aspect.
iii. If sentiment score is negative, increment the negcounter for the aspect.
iv. If sentiment score is neutral, increment the neu counter for the aspect.
(20). End loop for aspect keywords.
(21). T2_Result = Sentiment scores obtained from T2 using the LA approach.
(22). IO= Extract image object from F.
(23). T3= Extract text from IO.
(24). P3- Tokenize T3
P4- Remove stop words from T3
P5- Perform POS tagging on T3
P6- Apply stemming and lemmatization to T3
(25). P = Process the features of {P3, P4, P5, P6}
(26). K3 = Extract aspect keywords from P3
(27). N3 = Word count of K3
(28). Initialize sentiment counters for each aspect: positive, negative, neutral.
(29). For each aspect keyword K3[k] in K3:
a. Check if the aspect keyword is present in the text.
b. If the aspect keyword is found:
i. Apply the Lexicon Approach LA to calculate the sentiment score for K3[k] using T3.
ii. If sentiment score is positive, increment the pos counter for the aspect.
iii. If sentiment score is negative, increment the neg counter for the aspect.
iv. If sentiment score is neutral, increment the neu counter for the aspect.
(30). End loop for aspect keywords.
(31). T3_Result = Sentiment scores obtained from T3 using the LA approach.
(32). Display the sentiment scores for each aspect:
- Display the T1_Result.
- Display the T2_Result.
- Display the T3_Result.
(33). Stop
In this algorithm 5, we first extract the audio from the video file using appropriate techniques. Then, we extract text from the audio using speech recognition techniques (e.g., Automatic Speech Recognition-ASR). After that, we perform pre-processing steps including, “POS tagging”, “stemming”, “stop word removal” & “lemmatization”, “tokenization” for each text obtained from audio, image frames, and image objects. Next, we extract aspect keywords from the pre-processed text for each part. For each aspect keyword, we apply the Lexicon Approach to calculate the sentiment score and increment the sentiment counters accordingly. Finally, we display the sentiment scores (positive, negative, neutral), for each aspect obtained from the audio, image frames, and image objects.
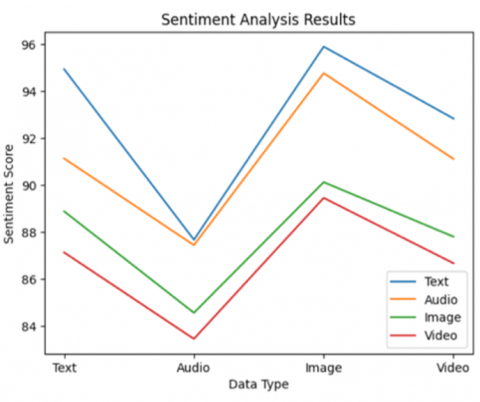
The provided framework assesses sentiments using text extracted from a multimedia Twitter dataset known as 'STS-Gold.'
Table 1. Sentiment score and accuracy of multimodal sentiment analysis
|
Type of Data |
Sentiment Score (Positive) |
Sentiment Score (Negative) |
Sentiment Score (Neutral) |
Accuracy |
|
Text |
94.93 |
87.67 |
95.89 |
92.83 |
|
Audio |
91.13 |
87.44 |
94.76 |
91.11 |
|
Image |
88.88 |
84.56 |
90.12 |
87.8 |
|
Video |
87.13 |
83.45 |
89.45 |
86.67 |
Table 2. Comparing the sentiment accuracy of tweets using textual data
|
Type of Data |
Existing Approaches |
Dataset Used |
Accuracy(%) |
|
Text |
[2] |
Twitter Dataset |
82.90 |
|
[31] |
Twitter Dataset |
85.40 |
|
|
[15] |
Twitter Dataset |
77.30 |
|
|
[17] |
Twitter Dataset |
84.62 |
|
|
[1] |
Twitter Dataset |
70.05 |
|
|
LAMBDA Approach |
Twitter Dataset |
92.83 |
|
|
Image |
[17] |
Twitter Dataset |
77.63 |
|
LAMBDA Approach |
Twitter Dataset |
87.80 |
|
|
Audio |
LAMBDA Approach |
Twitter Dataset |
91.11 |
|
Video |
LAMBDA Approach |
Twitter Dataset |
86.67 |
This dataset, obtained from the Twitter Streaming API, encompasses 10,000 labelled tweets, categorized into negative, positive, and neutral sentiments, and visually represented in Table 1 and Figure 6. This dataset forms the foundation for evaluating the proposed model's performance.
Table 2 Comparing the sentiment accuracy of tweets using textual data.
Figure 6. Sentiment analysis based on multimodal data
The Table 2 presents an analysis of existing approaches for sentiment analysis across different types of data, including Text, Image, Audio, and Video, along with their respective accuracy percentages. For Text-based sentiment analysis, various approaches have been explored. Approach [2] achieved an accuracy of 82.90%, while [26] achieved a higher accuracy of 85.40%. However, Poria et al. [15] lagged behind with an accuracy of 77.30%, and Jurek et al. [17] demonstrated an accuracy of 84.62%. Approach by Huddar et al. [1] had a lower accuracy of 70.05%. Interestingly, the LAMBDA Approach for Text analysis outperformed others with a significantly higher accuracy of 92.83%. Moving to Image-based sentiment analysis, Jurek et al. [17] achieved an accuracy of 77.63%, while the LAMBDA Approach showed a notable improvement with an accuracy of 87.80%. For Audio and Video-based sentiment analysis, the LAMBDA Approach excelled with an accuracy of 91.11% for Audio and 86.67% for Video. In summary, the LAMBDA Approach consistently performed well across different data types, particularly for Text, Audio, and Video sentiment analysis, achieving notably high accuracy percentages. These findings suggest the effectiveness of the LAMBDA Approach in sentiment analysis across various data modalities.
These evaluation metrics help assess the performance of lexicon-based sentiment analysis approaches in terms of accuracy, precision, recall, and discrimination ability, providing insights into the model's effectiveness in predicting sentiment polarity. The Table 3 presents a comprehensive analysis of the performance metrics for various sentiment analysis approaches, including the LAMBDA Approach and several referenced methods labelled as [1, 2, 15, 17], and [26]. These metrics encompass True Positives (TP), True Negatives (TN), False Positives (FP), False Negatives (FN), Precision, F1 Score, Recall, and Accuracy, which collectively evaluate the efficacy of these approaches. The LAMBDA Approach, representing the method under investigation, delivers notably favourable results. It achieves a substantial number of True Positives and True Negatives, coupled with relatively low False Positives and False Negatives. Precision, a measure of accurate positive predictions, is impressively high at 90.71%, while the F1 Score, which balances Precision and Recall, reaches an outstanding 93.92%. Furthermore, the Recall, indicating the capacity to correctly identify actual positives, stands at 96.27%, ultimately leading to an impressive overall Accuracy score of 92.83%. In contrast, Huddar et al. [1] exhibits good True Positives and True Negatives but struggles with an elevated number of False Positives and an exceptionally high count of False Negatives, consequently resulting in a lower Accuracy of 70.05%. Another Approach demonstrates a balanced performance with a commendable Precision [2], F1 Score, Recall, and Accuracy. Conversely, the writers have used an Approach [15] experiences challenges with low True Positives and Precision, leading to diminished F1 Score, Recall, and Accuracy. The writes of [17] faces difficulties with low Precision, F1 Score, Recall, and relatively high False Positives. Lastly, An Approach [26] showcases robust performance with balanced Precision, F1 Score, Recall, and a solid Accuracy score. In summary, the LAMBDA Approach emerges as a strong contender, excelling in multiple performance metrics compared to the referenced approaches, signifying its effectiveness in sentiment analysis. Overall, the LAMBDA Approach appears to be the most effective model among the listed ones, offering a good balance of precision, recall, and F1-score, making it well-suited for sentiment analysis tasks. However, the other models exhibit relatively lower performance in terms of accuracy.
Table 3. Evaluating the outcomes of the STS-Gold Twitter dataset using various classifiers (text-based only)
|
References |
TP |
TN |
FP |
FN |
Precision |
F1_Score |
Recall |
Accuracy |
|
LAMBDA Approach |
4982 |
9964 |
512 |
163 |
90.71 |
93.92 |
96.27 |
92.83 |
|
[1] |
2856 |
3948 |
924 |
42210 |
80.6 |
83.7 |
88.2 |
70.05 |
|
[2] |
3844 |
4145 |
855 |
4456 |
81.8 |
79.3 |
76.9 |
82.90 |
|
[15] |
441 |
4573 |
427 |
4559 |
50.8 |
15.0 |
8.8 |
77.30 |
|
[17] |
617 |
1195 |
3805 |
4383 |
14.0 |
13.1 |
12.3 |
84.62 |
|
[31] |
4278 |
4121 |
879 |
722 |
83.0 |
84.2 |
85.6 |
85.40 |
In recent times, there's been a growing interest in opinion mining and sentiment analysis among a wider populace. However, the surge in online forums, where discussions unfold in an unstructured manner, poses significant challenges in this regard. To tackle these emerging issues, this study proposes and applies an innovative approach. The results of these experiments demonstrate that employing a lexicon and aspect-based text pre-processing strategy significantly enhances the management of social media text. In fact, in some cases, this extraction method outperforms state-of-the-art procedures when paired with the appropriate classifier. The primary objective of the study was to enhance performance, and this objective has been achieved. While there have been notable improvements in accuracy compared to previous methods, the practical application of sentiment analysis at this level of accuracy remains constrained by the potential for encountering false positives, ranging from 10% to 20%. Subsequent research endeavors will prioritize the exploration of deep learning techniques aimed at further enhancing the accuracy of sentiment analysis, particularly concerning multimedia information.
[1] Huddar, M.G., Sannakki, S.S., Rajpurohit, V.S. (2019). A survey of computational approaches and challenges in multimodal sentiment analysis. International Journal of Computer Sciences and Engineering, 7(1): 876-883.
[2] Xu, N., Mao, W. (2017). Multisentinet: A deep semantic network for multimodal sentiment analysis. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, pp. 2399-2402. https://doi.org/10.1145/3132847.3133142
[3] Kaur, R., Kautish, S. (2022). Multimodal sentiment analysis: A survey and comparison. Research anthology on implementing sentiment analysis across multiple disciplines, 1846-1870. https://doi.org/10.4018/978-1-6684-6303-1.ch098
[4] Gandhi, A., Adhvaryu, K., Poria, S., Cambria, E., Hussain, A. (2023). Multimodal sentiment analysis: A systematic review of history, datasets, multimodal fusion methods, applications, challenges and future directions. Information Fusion, 91: 424-444. https://doi.org/10.1016/j.inffus.2022.09.025
[5] Ainapure, B.S., Pise, R.N., Reddy, P., Appasani, B., Srinivasulu, A., Khan, M.S., Bizon, N. (2023). Sentiment analysis of COVID-19 tweets using deep learning and lexicon-based approaches. Sustainability, 15(3): 2573. https://doi.org/10.3390/su15032573
[6] Sirisha, U., Bolem, S.C. (2022). Aspect based sentiment & emotion analysis with ROBERTa, LSTM. International Journal of Advanced Computer Science and Applications, 13(11): 766-774. https://doi.org/10.14569/IJACSA.2022.0131189
[7] Sirisha, U., Chandana, B.S., Harikiran, J. (2023). NAM-YOLOV7: An improved YOLOv7 based on attention model for animal death detection. Traitement du Signal, 40(2). https://doi.org/10.18280/ts.400239
[8] Vu, L., Le, T. (2017). A lexicon-based method for sentiment analysis using social network data. In Proceedings of the International Conference on Information and Knowledge Engineering (IKE). The Steering Committee of The World Congress in Computer Science, Computer Engineering and Applied Computing (WorldComp), pp. 10-16.
[9] Abirami, A.M., Gayathri, V. (2017). A survey on sentiment analysis methods and approach. In 2016 Eighth International Conference on Advanced Computing (ICoAC), Chennai, India, pp. 72-76. https://doi.org/10.1109/ICoAC.2017. 7951748
[10] Pamungkas, E.W., Putri, D.G.P. (2016). An experimental study of lexicon-based sentiment analysis on Bahasa Indonesia. In 2016 6th International Annual Engineering Seminar (InAES), Yogyakarta, Indonesia, pp. 28-31. https://doi.org/10.1109/ INAES.2016.7821901
[11] Agarwal, A., Toshniwal, D. (2018). Application of lexicon based approach in sentiment analysis for short tweets. In 2018 International Conference on Advances in Computing and Communication Engineering (ICACCE), Paris, France, pp. 189-19. https://doi.org/10.1109/ICACCE.2018.8441696
[12] Alessia, D., Ferri, F., Grifoni, P., Guzzo, T. (2015). Approaches, tools and applications for sentiment analysis implementation. International Journal of Computer Applications, 125(3): 26-33.
[13] Mudinas, A., Zhang, D., Levene, M. (2012). Combining lexicon and learning based approaches for concept-level sentiment analysis. In Proceedings of The First International Workshop on Issues of Sentiment Discovery and Opinion Mining, pp. 1-8. https://doi.org/10.1145/2346676.2346681
[14] Dedeepya, P., Sowmya, P., Saketh, T.D., Sruthi, P., Abhijit, P., Praveen, S.P. (2023). Detecting cyber bullying on twitter using support vector machine. In 2023 Third International Conference on Artificial Intelligence and Smart Energy (ICAIS), Coimbatore, India, pp. 817-822. https://doi.org/10.1109/ICAIS56108.2023.10073658
[15] Poria, S., Cambria, E., Howard, N., Huang, G.B., Hussain, A. (2016). Fusing audio, visual and textual clues for sentiment analysis from multimodal content. Neurocomputing, 174: 50-59. https://doi.org/10.1016/j. neucom.2015.01.095
[16] Ahmad, M., Aftab, S., Ali, I., Hameed, N.J.I.J.M.S.E. (2017). Hybrid tools and techniques for sentiment analysis: A review. International Journal of Multidisciplinary Sciences and Engineering, 8(3): 29-33.
[17] Jurek, A., Mulvenna, M.D., Bi, Y. (2015). Improved lexicon-based sentiment analysis for social media analytics. Security Informatics, 4: 1-13. https://doi.org/10.1186/s13388-015-0024-x
[18] Nigam, N., Yadav, D. (2018). Lexicon-based approach to sentiment analysis of tweets using R language. In Advances in Computing and Data Sciences: Second International Conference, ICACDS 2018, Dehradun, India, Revised Selected Papers, Part I 2. Springer Singapore, pp. 154-164. https://doi.org/10.1007/978-981-13-1810-8_16
[19] Taboada, M., Brooke, J., Tofiloski, M., Voll, K., Stede, M. (2011). Lexicon-based methods for sentiment analysis. Computational Linguistics, 37(2): 267-307. https://doi.org/10.1162/COLI_a_00049
[20] Maynard, D., Dupplaw, D., Hare, J. (2013). Multimodal sentiment analysis of social media. BCS SGAI Workshop on Social Media Analysis. University of Southampton Institutional Repository. http://eprints.soton.ac.uk/id/eprint/360546
[21] Arava, K., Chaitanya, R.S.K., Sikindar, S., Praveen, S.P., Swapna, D. (2022). Sentiment analysis using deep learning for use in recommendation systems of various public media applications. In 2022 3rd International Conference on Electronics and Sustainable Communication Systems. ICESC, Coimbatore, India, pp. 739-744. https://doi.org/10.1109/ICESC54411.2022.9885648
[22] Kumar A, Garg G (2019) Sentiment analysis of multimodal twitter data. Multimed Tools Appl, 78(17): 24103-24119. https://doi.org/10.1007/s11042-019-7390-1
[23] Marrapu, B.V., Raju, K.Y.N., Chowdary, M.J., Vempati, H., Praveen, S.P. (2022). Automating the creation of machine learning algorithms using basic math. In 2022 4th International Conference on Smart Systems and Inventive Technology (ICSSIT), IEEE, Tirunelveli, India, pp. 866-871. https://doi.org/10.1109/ICSSIT53264.2022.9716270
[24] Ahmed, S., Jaidka, K., Skoric, M. (2016). Tweets and votes: A four-country comparison of volumetric and sentiment analysis approaches. In Proceedings of the International AAAI Conference on Web and Social Media, 10(1): 507-510. https://doi.org/10.1609/icwsm.v10i1.14773
[25] Madhuri, A., Jyothi, V.E., Praveen, S.P., Altaee, M., Abdullah, I.N. (2023). Granulation-Based data fusion approach for a critical thinking worldview information processing. Journal of Intelligent Systems and Internet of Things, 9(1): 49-68. https://doi.org/10.54216/JISIoT.090104
[26] JayaLakshmi, G., Madhuri, A., Vasudevan, D., Thati, B., Sirisha, U., Praveen, S.P. (2023). Effective disaster management through transformer-based multimodal tweet classification. Revue d'Intelligence Artificielle, 37(5): 1263-1272. https://doi.org/10.18280/ria.370519