Putta Durga![]() | Deepthi Godavarthi*
| Deepthi Godavarthi*![]()
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Sentiment analysis (SA), the process of determining the emotional tone behind a piece of text, has gained significant importance in various domains, including marketing, customer feedback analysis, and social media monitoring. Traditional SA models often face challenges handling diverse global datasets due to language variations, cultural nuances, and context differences. This paper proposes an Ensemble Recommendation System (ERS) approach to address these challenges and improve SA accuracy. The ERS combines Gated Attention-Based Recurrent Networks (GARNET) Steps with Transfer Learning. The ERS leverages the power of ensemble learning, combining multiple sentiment analysis models trained on global datasets from diverse linguistic backgrounds. The ERS can provide more robust and accurate sentiment classifications by aggregating predictions from these models. Additionally, the system utilizes a recommendation mechanism that dynamically selects the most suitable model based on the characteristics of the input text, such as language, tone, and context. In this paper, an advanced pre-trained model DistilBERT is used to train the selected datasets and apply transfer learning. Transfer learning is used to send the features extracted from training and sends them to the proposed approach ERS. Second, we design and train multiple state-of-the-art SA models integrated to handle specific linguistic attributes while also considering the cultural biases present in the datasets. Third, we introduce the ERS recommendation mechanism, which enhances the system's performance and optimizes computational resources. For the effectiveness of the proposed ERS, extensive experiments were conducted on benchmark datasets and comparing its performance with individual sentiment analysis models and conventional ensemble techniques. The performance of the proposed approach achieves superior sentiment classification accuracy, especially when dealing with challenging global datasets. Finally, ERS presents a promising solution for deep sentiment analysis over diverse global datasets. Finally, the ERS also focused on finding the popular items or products recommended by the proposed approach.
Ensemble Recommendation System (ERS), sentiment analysis, DistilBERT, deep learning
Sentiment analysis (SA), or opinion mining, is an exciting area of natural language processing (NLP) and machine learning. It entails applying computational techniques to ascertain the sentiment or emotion expressed in a text, such as a review, social media post, or customer feedback [1, 2]. The main goal of SA is to understand and interpret the writer's attitude or sentiment toward a particular topic, product, service, or event. With the rise of the internet and social media, textual data is exploding daily. Extracting valuable insights from this massive text can significantly benefit businesses, organizations, and individuals. Sentiment analysis is critical in this context, assisting companies in gauging the public's perception of their brand, products, or services and assisting in decision-making processes [3]. A text's sentiment can typically be divided into three categories: positive, negative, and neutral [4].
On the other hand, some more advanced sentiment analysis systems may include fine-grained sentiment analysis, which can differentiate between multiple levels of sentiment (e.g., very positive, somewhat positive, neutral, rather negative, very negative). Modern sentiment analysis systems are built on machine learning (ML) algorithms. These algorithms learn from labeled datasets in which each piece of text is assigned a sentiment label [5, 6]. The ML model can generalize and predict a new, unseen text by analyzing patterns and features in the text data [7].
Emotion detection, a subset of sentiment analysis, extends the analysis by attempting to recognize and categorize the specific emotions conveyed in the text and identifying the overall sentiment. This advanced level of analysis allows us to gain deeper insights into how people feel about a particular topic or product, providing valuable data for decision-making and improving user experiences. As social media platforms grew in popularity, sentiment analysis found widespread use in analyzing user sentiments on Twitter, Facebook, and other platforms. Because social media posts are short and informal, handling slang, abbreviations, and emoticons presented new challenges for SA [8]. DL revolutionized sentiment analysis in the 2010s. They demonstrated impressive results in various NLP tasks, including sentiment analysis, neural networks, particularly RNN, and later Transformer models like BERT. These models could capture context and long-term dependencies in text, resulting in more accurate sentiment classification. Sentiment analysis has expanded to include emotion analysis in text and multimodal sentiment analysis, combining information from textual and visual data (e.g., images and videos) as NLP and computer vision technologies have advanced [9, 10].
This paper is the combination of several models that help in finding the accurate sentiment analysis with the most popular products based on the overall positives for every product. The pre-trained model DistilBERT analyzes all the sentiments from the given datasets. Here, the transfer learning mainly extracts the significant patterns and sends those patterns to the proposed Gated Attention-Based Recurrent Networks (GARNET). ERS combines collaborative filtering (CF) and content-based filtering (CBF).
CF is based on user-item interactions and recommends items based on previous user behavior. Content-based filtering, on the other hand, suggests items based on their characteristics rather than user preferences. While both methods have advantages, they also have limitations. The ERS combines CF and CBF to address these limitations to provide more reliable and relevant recommendations. Combining the two approaches allows the system to compensate for the shortcomings of one method with the advantages of the other, resulting in a more robust and accurate recommendation process.
1.1 Contribution
(1) An advanced sentiment analysis is implemented with the GARNET model combined with the transfer learning that gets the significant patterns from the DistilBERT which is a pre-trained model.
(2) An ensemble pre-processing technique is used to remove the noise.
(3) A better feature extraction technique Continuous Bag of Words (CBOW) is used to extract the best features that show huge impact on final sentiment results.
(4) ERS represents a powerful and dynamic solution for finding popular products or items in the vast sea of online purchases. By amalgamating CF and CBF, the system can effectively cater to users' diverse preferences and provide them with meaningful and popular product recommendations, ultimately elevating their shopping experience.
Bengesi et al. [11] introduced a new sentiment approach based on disease prediction and prevention steps. This research mainly discussed several ML algorithms regarding the opinion, ideas, and views about the monkeypox disease. The proposed approach analyzes the 5 lacks tweets to know the emotions and views of various persons shared on Twitter. Among all the ML algorithms, the proposed approach achieved an immense accuracy of 0.9345. Liu et al. [12] proposed a new sentiment-based approach that solves issues in the ABSA model. The proposed model contains three methods: lexicon, ML, and DL. Also, this model shows the comparative performance with various metrics based on the sentiments. Gupta et al. [13] introduced a new sentiment analysis model that analyzes the tweets given by various users on Twitter social media. All these tweets were analyzed according to the sentiments. The proposed model's accuracy is about 84.5%, which is higher than existing models. Gao et al. [14] proposed the new dendritic neuron model (DNM) that is used to classify the effective prediction of the model that solves various issues in achieving accuracy. The DMM model performs a better classification to solve classification and prediction problems. Dragoni and Petrucci [15] introduced an advanced approach that develops better integration with DL and word embedding to get accurate sentiments. Singh et al. [16] proposed the SHE model that analyzes sentiments based on hashtags. The proposed model uses multitasking, such as sentiment analysis based on hashtag tweet-based classification, and extracts the semantic similar hashtags. The comparison between various models shows the performance of SHE is better in extracting the accuracy.
Kumar et al. [17] developed the IGCN model that measures the sentiments based on the context words over the given output, POS tags, and domain-particular word embeddings to predict the sentiments. The effectiveness of the proposed IGCN extracts better analysis from SemEval 2014 datasets. Zhang et al. [18] introduced a spectral clustering approach that clusters the sentiment words based on the relationship of the topic-specific sentiment lexicon, namely, the STCS lexicon. Based on the evaluation results, the proposed approach obtained high accuracy and solved various issues in concept-based sentiment words. Aslam et al. [19] introduced the advanced sentiment model that combined LSTM and GRU. The proposed Ensemble model integrates the word2vec and BoW combined with ML and DL models. The proposed ML model combined with BoW features such as LSTM-GRU obtains an accuracy of 99.8%, and emotion prediction accuracy is 92.34%. Wang et al. [20] proposed a multi-modal neural network that connects with multiple layers, which is used to convert the features into similar-model features. A better training model is used to train the dataset and extract the accurate features from the dataset. The proposed approach is combined with the Bidirectional (BI)-LSTM-CRF approach to achieve the word segmentation processing approach, which predicts a computation time of up to 1.94 times.
Dragoni et al. [21] presented an approach that explores the semantic overlap among the domains to develop sentiment approaches that support polarity for the documents belonging to each field—word embeddings combined with the DL model implemented with the NeuroSent tool for developing the multi-domain sentiment model. The Dranziera protocol validates the proposed approach. The output shows improved performance, and the result is very effective. Du et al. [22] proposed a capsule-based integrated model that extracts semantic data effectively. BGRU combined with CNN gives better training that helps in reducing the computation time and achieving better performance. The experiments are evaluated on two text datasets, a movie dataset, with an accuracy of 83.23%, and NLPCC2014 Task II attained an accuracy of 85.67%. Du et al. [23] introduced a new network that combined RNN and CNN to increase sentiment classification. It shows the sentiment classification based on the sentence and document levels. Yuan et al. [24] proposed a novel approach that uses RBM to recognize the sentiments in the real-time dataset. RBMs are the GAN models that work on different labeled and unlabeled datasets. RBM model is used to train the data by using statistical distributions. The proposed RBM model recognizes the critical points in the real-time dataset. The experiment shows that the proposed model achieved effective performance in accuracy.
Zhao et al. [25] implemented a novel DL approach for reviewing sentiment classification products. It contains two steps: initializing the data with a high-level distribution stage based on rating information and then adding the classification layer to the embedding layer to obtain labeled sentences for the supervised fine-tuning approach. Finally, the proposed dataset includes 1.1 million weakly labeled review sentences and 11,754 text messages with labels obtained from Amazon. Kumar et al. [26] introduced a novel recommendation model for the analysis of movies based on the tweets given by Twitter users. The proposed method understands the tweets about the movies and analyzes the latest trends according to public sentiments. The proposed approach obtained a high accuracy compared with existing models. Rosa et al. [27] presented a new music recommendation system based on the intensity and enhanced sentiment metric connected with the lexicon-based sentiment metrics. The correct factor is identified based on the experiments conducted in the laboratory platform. All the user sentiments are extracted from the social networking sites and show the music recommendations. The proposed approach's performance recommended the latest music trends and achieved an accuracy of 65.7%. Zhang et al. [28] presented a new integrated sentiment analysis system called CMA-MemNet. The proposed approach mainly focused on solving several issues, such as mismatched classification, using advanced feature extraction. Ayyub et al. [29] proposed the sentiment qualification method that classifies the sentiment based on views, opinions, and blogs. The proposed approach mainly focused on extracting the features that show a significant impact on outcomes. Zhao and Gui [30] discussed various sentiment analyses from the Twitter datasets using text pre-processing techniques by combining two ML techniques that obtained better results. Table 1 explains the performances of various sentiment analyses with a recommendation system.
Table 1. Comparative performances of various sentiment analysis approaches
|
Reference |
Pre-trained Model |
Proposed Model |
Dataset |
Performance Metrics |
|
[30] |
CNN |
A Novel Hybrid DL model |
|
Acc-82.14, Pre-0.92, Recall-0.96 and F1-0.89 |
|
[31] |
Optimized BERT |
Hybrid DL model |
IMDB, Twitter US Airline Sentiment, Sentiment140 |
IMDB-Acc-92.6, Pre-0.93, Recall-0.93 and F1-0.93. Twitter US Airline Sentiment -Acc-91.37, Pre-0.91, Recall-0.91 and F1-0.91. Sentiment140- Acc-89.7, Pre-0.90, Recall-0.90 and F1-0.90. |
|
[32] |
Convolution Neural Network (CNN) |
ConvBiLSTM |
Tweets and SST-2 |
Twitter -Acc-94.37, Pre-95.49, Recall-89.67 and F1-91.86. SST-2- Acc-91.13, Pre-94.6, Recall-94.33 and F1-92.08. |
|
[33] |
SVM |
A Novel Hybrid Classification Approach |
COVID-19 and the Expo2020 |
COVID-19-Acc-82.6, Pre-86.8, Recall-82.6. Expo2020- Acc-90.84, Pre-91.22, Recall-90.08. |
|
[34] |
DL Models |
Hybrid Approach |
Twitter Dataset |
COVID-19-Acc-87.6, Pre-87.8, Recall-88.6. |
|
[35] |
DL Models |
Interactive-Attention networks |
SemEval-2014 |
Restaurants-Acc-0.786, Laptops-Acc-0.721 |
|
[36] |
Neural Networks |
Recurrent attention on memory |
SemEval-2014, Twitter, Chinese News Comment |
Laptop-Acc-0.744, Restaurant-Acc-0.80, Tweet-Acc-0.69, Comments-0.73 |
|
[37] |
BERT-large-case |
Decision-based RNN |
Twitter, Restaurants, Laptops |
Twitter-Acc-0.86, Restaurant-Acc-0.85, Laptops-Acc-0.95 |
Three datasets, namely Twitter, Restaurants, and Laptop-ACOS, were sourced from Kaggle, each comprising two folders for training and testing data. These datasets contain customer reviews intended for sentiment analysis. Specifically, Table 2 provides a comprehensive overview of the datasets. Preprocessing techniques were implemented on the data, involving the removal of stop-words, special characters, URLs, and punctuations.
Table 2. Training and testing of three datasets
|
|
$P_{ositive}$ |
$N_{egative}$ |
$N_{eutral}$ |
Total |
|
|
Laptop-ACOS |
Training |
986 |
567 |
447 |
2000 |
|
Testing |
867 |
534 |
675 |
2076 |
|
|
Restaurant |
Training |
789 |
345 |
366 |
1500 |
|
Testing |
698 |
369 |
433 |
1500 |
|
|
|
Training |
2698 |
1456 |
846 |
5000 |
|
Testing |
2589 |
1596 |
815 |
5000 |
|
3.1 Training on given sentiment datasets
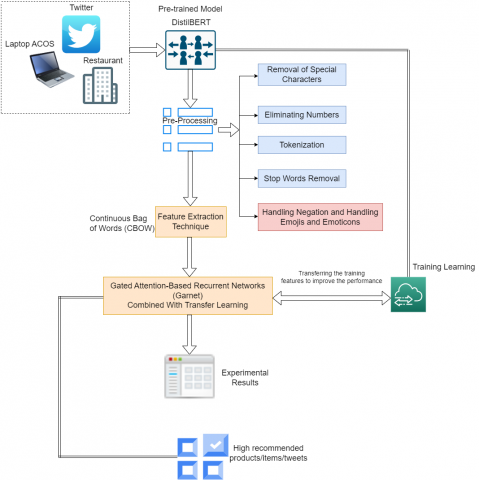
DistilBERT extends the well-known BERT (Bidirectional Encoder Representations from Transformers) model. The transmission-based model captures a massive corpus of text data to understand word context and meaning. DistilBERT is a smaller, faster version of BERT better suited for real-world applications with limited computational resources. CNNs, on the other hand, are DL models that have been widely applied to image processing tasks. However, their use in NLP, particularly for text classification tasks such as sentiment analysis, has yielded promising results. CNNs are particularly good at extracting local patterns and features from input data, which helps identify critical sentiment-bearing words and phrases in a given text. The proposed model's overall architecture is depicted in Figure 1.
Combining DistilBERT with CNN and leveraging transfer learning has proven to be an effective method for improving sentiment analysis performance. Transfer learning entails using pre-trained models, such as DistilBERT, and fine-tuning them for a specific task, such as sentiment analysis. It enables the model to benefit from pre-trained knowledge of language representations before focusing on learning sentiment-specific features from the target dataset. In this paper, a combined approach shows the strengths of DistilBERT and CNN and transfer learning. By combining DistilBERT's context-aware language understanding with CNNs' local feature extraction capabilities, our model can effectively capture the nuances and intricacies of sentiment expression in textual data. Transfer learning also allows us to save time and resources while training models, making it a practical and efficient solution for SA on large-scale datasets.
The following steps show the training on sentiment datasets.
Step 1: Preprocess the text data
Tokenize the input text into word pieces.
Add special tokens like [CLS] (start token) and [SEP] (end token) to mark the beginning and end of the text. Pad or truncate the sequences to ensure a fixed length.
Step 2: DistilBERT Embeddings
Pass the preprocessed tokens through the DistilBERT model to obtain word embeddings.
Step 3: Combine CNN with DistilBERT embeddings
For each layer of DistilBERT, extract the corresponding word embeddings.
Apply 1D convolutions with multiple filters (kernels) to the embeddings.
Apply ReLU to the convolution outputs.
Perform max-pooling over the temporal dimension (sequence length) to obtain a fixed-size representation.
The equations for the CNN layer can be described as follows:
Let E be the word embeddings obtained from the DistilBERT model for a single layer, where $\mathrm{E}=\left[\mathrm{e} \_1, \mathrm{e} \_2, \ldots, \text{e_n}\right]$, n being the sequence length (number of tokens).
Let K be the number of filters (kernels) used in the CNN layer, and f be the filter size (width of the filter). Typically, f is smaller than the sequence length.
The convolution operation for each filter k is defined as:
$\operatorname{conv}_{\mathrm{k}}=$ Conv1D(filter_size $=\mathrm{f}$, activation $=$ 'relu')(E)
The output of the convolution operation will have a shape of (n - f + 1, K).
Next, we apply max-pooling over the temporal dimension to get a fixed-size representation:
pooled $\mathrm{k}=$ MaxPooling1D(pool_size $=\mathrm{n}-\mathrm{f}+1)$ (conv_k)
This will result in pooled $_{\mathrm{k}}$ having a shape of (1, K).
Step 4: Sentiment Classification
Concatenate or average the $_{\mathrm{k}}$ representations from all the layers.
Feed the combined representation through a FCL.
The final layer's output will be passed through a softmax activation to obtain probabilities for different sentiment classes (e.g., positive, negative, neutral).
Figure 1. Overall architecture of ERS
3.2 Experimental evaluation based on training and testing accuracy with loss
In this section, three datasets such as Laptop-ACOS, Restaurant and Twitter were used to evaluate the training and testing loss with accuracy. The proposed pre-trained model design for training the sentiment analysis data; the training loss is typically lower than the testing loss. However, both metrics must monitor during model development to ensure that the model does not over fit the training data and performs well on unseen data. Over fitting may indicate a large gap between training and testing loss, which can be addressed using techniques such as regularization or adjusting the complexity of the model.
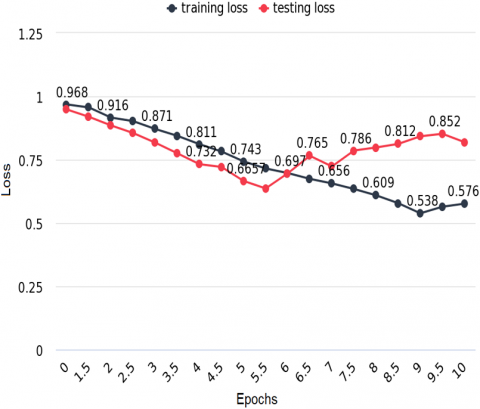
Figure 2. Training loss and testing loss for Laptop-ACOS
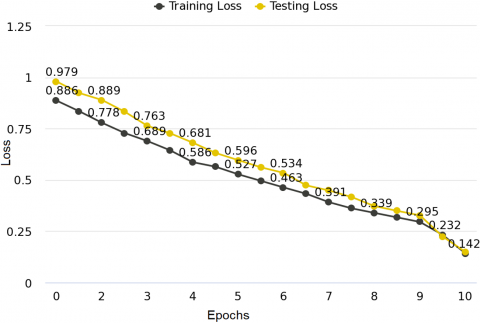
Figure 2 depicts the training and testing losses over ten epochs. The training and testing losses are the same at 0.968. The training loss is low when DistilBERT is used as the training model. The Laptop-ACOS dataset has a low testing loss. Low training loss indicates that the proposed approach honourably predicts the training data. An intense training loss suggests that DistilBERT captured the patterns and connections in the training dataset and can generalize well to the data seen during training.
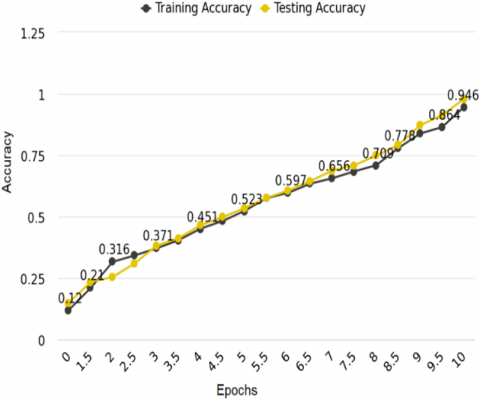
Figure 3. Training accuracy and testing accuracy Laptop-ACOS
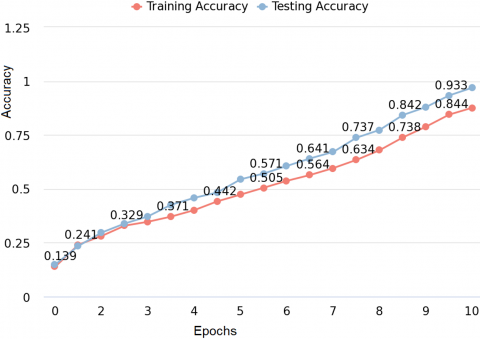
Figure 3 initializes the training and testing accuracy for the Laptop-ACOS dataset. The training accuracy is 0.864 and the testing accuracy is 0.946. The high training accuracy indicates that the model learned and remembered the patterns in the training data. It can accurately classify the sentiment of the examples on which it was trained. However, high training accuracy does not always imply that the model will perform well on unlabeled data.
Figure 4. The loss values for the training and testing phases were computed for the Restaurant dataset
Figure 5. The accuracy scores were measured for both the training and testing sets of the Restaurant dataset
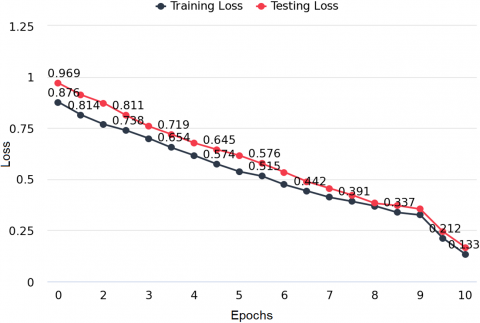
Figure 6. Training and testing loss for twitter dataset
Figure 7. Training and testing accuracy for twitter dataset
A high training loss suggests that the model struggles to effectively learn from the training data. This could indicate that the model requires assistance in discerning the underlying patterns within the data or that it may be overfitting to the training set. Overfitting arises when a model becomes excessively focused on capturing noise or specific examples within the training data, leading to diminished performance when applied to unseen data.
Figure 4 illustrates the training and testing loss for the Restaurant dataset, both of which are remarkably low and Figure 5 shows the high training and testing accuracy which represents the model fit for learning more significant factors from the dataset.
Figure 6 indicates the low training loss which is 0.142 and the testing loss is 0.142 for the Twitter dataset. These values represent the low training and testing loss. Figure 7 represents the high training and testing accuracy which indicates the better performance of the model.
3.3 Pre-processing technique
For sentiment analysis, effective pre-processing of the dataset is crucial to ensure accurate and meaningful results. Here are some advanced pre-processing techniques that can help improve the performance of SA models:
The following functions used to remove the punctuation marks, symbols, emojis, and any other non-alphanumeric characters.
def remove_special_characters(text):
# Define the pattern for identifying special characters and symbols
# The regular expression [^\w\s] matches any non-alphanumeric character (excluding whitespace)
pattern = r'[^\w\s]'
# Use the re.sub() function to replace all occurrences of the pattern with an empty string
clean_text = re.sub(pattern, '', text)
return clean_text
# Example usage:
cleaned_text = remove_special_characters(text_with_special_characters)
print(cleaned_text)
Output: Hello this is a sample text with special characters
In the preceding code, we use Python's re.sub() function to replace all occurrences of memorable characters and symbols in the input text with an empty string, effectively removing them. Remember that eliminating special characters may change the meaning of the text, mainly when dealing with emoticons, acronyms, or text-based communication such as social media posts. As a result, it's critical to think about the context and requirements of your specific sentiment analysis task. To further preprocess the data before performing sentiment analysis, you can convert all text to lowercase and remove extra whitespaces.
Eliminating numbers: In many cases, numbers do not contribute to sentiment analysis, so removing them can simplify the data.
def remove_numbers_from_text(text):
# Use regex to replace any sequence of digits with an empty string
result = re.sub(r'\d+', '', text)
return result
# Example usage:
text_data = "This is an example text with 123 numbers 4567 scattered 89 throughout."
cleaned_text = remove_numbers_from_text(text_data)
print(cleaned_text)
This is an example text with numbers scattered throughout.
In this example, the function remove_numbers_from_text takes a text as input and uses the re.sub method from the re module to replace any sequence of digits (\d+) with an empty string. This effectively removes all numbers from the input text.
Tokenization:
Word Tokenization: The data split into words or tokens. It is mainly used to develop the word vocabulary for the model.
Sentence Tokenization: Divide the text into sentences, especially in cases where the sentiment analysis is at the sentence level.
Stopword Removal:
Remove common stopwords (e.g., "and," "the," "is") as they appear frequently in text but usually don't carry significant sentiment information.
Handling Negation:
Identify negation words like "not," "no," "never," etc., and modify the following words to represent negated sentiment properly (e.g., "good" becomes "not_good").
Handling Emojis and Emoticons:
Convert emojis and emoticons to textual representations to preserve their sentiment meaning.
N-grams and Feature Engineering:
The contextual data is created by n-grams which improve the performance in terms of text understanding.
Word2Vec is a word embedding method representing dense vectors in continuous vector space. This method introduces two types of techniques: Continuous Bag of Words (CBOW) and Skip-gram.
3.4 Feature extraction
3.4.1 Continuous Bag of Words (CBOW):
From the associated words the CBOW predicts the target word. The formula for CBOW can be explained as follows:
Let:
Vocab_size: Total number of unique words in the vocabulary
Word vector size: The dimensionality of the word embeddings (e.g., 100, 300)
Context window size: The number of words on both sides of the target word considered as context (e.g., 2, 5)
For each target word w(t) in the context window, the CBOW objective is to maximize the average log probability of predicting w(t) given its context words
$\mathrm{w}(\mathrm{t}-$ context_window $), \ldots, \mathrm{w}(\mathrm{t}-1), \mathrm{w}(\mathrm{t}+$ 1), $\ldots, w(t+$ context_window $)$ :
CBOW formula:
$\begin{aligned} & maximize \Sigma(\log \mathrm{P}(\mathrm{w}(\mathrm{t}) \mid \mathrm{w}(\mathrm{t}-\text { context_window }), \ldots, \mathrm{w}(\mathrm{t}-1), \mathrm{w}(\mathrm{t}+1), \ldots, \mathrm{w}(\mathrm{t}+ \text { context_window })))\end{aligned}$
Skip-gram:
In contrast, skip-gram attempts to predict context words given a target word. The formula for the Skip-gram is as follows:
For each target word w(t) in the context window, the Skip-gram objective is to maximize the average log probability of predicting the context words w(t-context_window), ..., w(t-1), w(t+1), ..., w(t+context_window) given the target word w(t):
Skip-gram formula:
$\operatorname{maximize} \Sigma(\log \mathrm{P}(\mathrm{w}(\mathrm{t}-$ context_window $), \ldots, \mathrm{w}(\mathrm{t}-$ 1), $\mathrm{w}(\mathrm{t}+1), \ldots, \mathrm{w}(\mathrm{t}+$ context_window $) \mid \mathrm{w}(\mathrm{t})))$
Word2Vec achieves this goal by iterative training on a large corpus of text data with neural networks, typically a shallow neural network with one hidden layer. The word vectors that result capture semantic relationships between terms, allowing for a variety of NLP tasks.
Figure 8 showcases how CBOW and Skip-gram methods are represented for feature extraction.
Figure 8. Architectures CBOW and Skip-gram
GARNet mainly used for sentiment analysis and other NLP tasks. It uses recurrent networks and attention processes to focus on essential parts of the input text to make estimates. Transfer learning can be used with GARNet by pre-training it on a large dataset and then fine-tuning it on the sentiment analysis task.
Transfer Learning for Sentiment Analysis
Prepare a sentiment analysis dataset with labeled text samples, where each sample is associated with a sentiment label (e.g., positive, negative, or neutral).
Step-1: Initialize the GARNet model with the weights learned from the pretraining step.
Step-2: Add a classification layer on top of the pre-trained GARNet model to predict sentiment labels.
Step-3: Freeze the parameters of the pretrained layers to preserve the learned representations, preventing them from being updated during fine-tuning.
Step-4: Use the sentiment analysis dataset to fine-tune the GARNet model using backpropagation and an appropriate loss function, such as cross-entropy loss.
Step-5: Train the model until convergence or based on early stopping criteria.
Step-6: GARNet combines recurrent layers, such as LSTM or GRU, with attention mechanisms. The calculations for LSTM and GRU are as follows:
LSTM:
$h_t c_t=\operatorname{LSTM}\left(x_t, h_{t-1}, c_{t-1}\right)$
where,
$\mathrm{x}_{\mathrm{t}}$: initialize time t,
$\mathrm{h}_{\mathrm{t}}$: hidden state,
$\mathrm{c}_{\mathrm{t}}$: cell state,
$\mathrm{h}_{\mathrm{t-1}}$: previous hidden state,
$\mathrm{c}_{\mathrm{t-1}}$: cell state, respectively.
4.1 GRU
The structure of the Gated Recurrent Unit is depicted in Figure 9.
Figure 9. Architecture diagram of GRU
$\mathrm{h}_{\mathrm{t}}=\operatorname{GRU}\left(\mathrm{x}_{\mathrm{t}}, \mathrm{h}_{\mathrm{t}-1}\right)$
where,
$\mathrm{x}_{\mathrm{t}}$: initialize time t,
$\mathrm{h}_{\mathrm{t}}$: Initialize hidden state at time t,
$\mathrm{h}_{\mathrm{t-1}}$: previous hidden state.
Attention mechanisms in GARNet aim to weigh the importance of different parts of the input sequence.
$\operatorname{Attention}(\mathrm{Q}, \mathrm{K}, \mathrm{V})=\operatorname{softmax}\left(\mathrm{Q} * \frac{\mathrm{K}^{\mathrm{T}}}{\operatorname{SQRT}\left(\mathrm{d}_{\mathrm{k}}\right)}\right) * \mathrm{~V}$
where,
Q, K, and V are the query, key, and value representations of the input sequence, respectively.
$\mathrm{d}_{\mathrm{k}}$ is the dimensionality of the key vectors.
The classification layer on top of the pre-trained GARNet can be a simple fully connected layer followed by a softmax activation function to predict the sentiment label probabilities.
Pseudo code for Sentiment Analysis
The Input dataset represents the following variables:
X: Input sentence (sequence of word embeddings),
W: Word embedding matrix,
$\mathrm{W}_{\mathrm{a}}$: Attention matrix,
$\mathrm{W}_{\mathrm{g}}$: Gating matrix.
Step-1: Initialize hidden state:
$\mathrm{h}_{\text {prev }}=0$
For each word embedding $x_t$ in X:
Step-2: Input gate calculation:
$\mathrm{i}_{\mathrm{t}}=\operatorname{sigmoid}\left(\mathrm{W}_{\mathrm{g}} *\left[\mathrm{~h}_{\mathrm{prev}}, \mathrm{x}_{\mathrm{t}}\right]\right)$
Step-3: Forget gate calculation:
$\mathrm{f}_{\mathrm{t}}=\operatorname{sigmoid}\left(\mathrm{W}_{\mathrm{g}} *\left[\mathrm{~h}_{\mathrm{prev}}, \mathrm{x}_{\mathrm{t}}\right]\right)$
Step-4: Candidate hidden state calculation:
$\mathrm{C}_{\mathrm{t}}=\tanh \left(\mathrm{W} * \mathrm{x}_{\mathrm{t}}+\mathrm{W}_{\mathrm{a}} *\left(\mathrm{~h}_{\mathrm{prev}}, \mathrm{x}_{\mathrm{t}}\right)\right)$
Step-5: Cell state update:
$\mathrm{C}_{\mathrm{t}}$ new $=\mathrm{i}_{\mathrm{t}} * \mathrm{C}_{\mathrm{t}}+\mathrm{f}_{\mathrm{t}} * \mathrm{C}_{\mathrm{t}}$ prev
Step-6: Output gate calculation:
$\mathrm{o}_{\mathrm{t}}=\operatorname{sigmoid}\left(\mathrm{W}_{\mathrm{g}} *\left[\mathrm{~h}_{\mathrm{prev}}, \mathrm{x}_{\mathrm{t}}\right]\right)$
Step-7: Hidden state update:
$\mathrm{h}_{\mathrm{t}}=\mathrm{o}_{\mathrm{t}} * \tanh \left(\mathrm{C}_{\mathrm{t}}\right. new)$
Step-8: Update previous cell state and hidden state for the next iteration:
$\begin{gathered}\mathrm{C}_{\mathrm{t}} \text { prev }=\mathrm{C}_{\mathrm{t}} \text { new } \\ \mathrm{h}_{\text {prev }}=\mathrm{h}_{\mathrm{t}}\end{gathered}$
Output: The final hidden state $\mathrm{h}_{\mathrm{t}}$ indicates the sentiments for every input sentence X.
Note: In the pseudo code above, '$\mathrm{h}_{\text {prev }}$' represents previous hidden state, $\mathrm{C}_{\mathrm{t}} \mathrm{prev}$ represents previous cell state, $\mathrm{x}_{\mathrm{t}}$ is the word embedding at time step $\mathrm{t}$, and ' '*' represents matrix multiplication. The sigmoid function squashes value between 0 and 1 , while the tanh function squashes values between -1 and 1. Hidden state at time $\mathrm{t}$. The $\mathrm{W}, \mathrm{W}_{\mathrm{a}}$, and $\mathrm{W}_{\mathrm{g}}$ matrices are the learnable weight parameters of the model.
4.2 Product/item/service recommendation system
Personalized product recommendations are critical in today's e-commerce world for improving user experiences and increasing customer satisfaction. CF and CBF are two popular techniques for developing recommendation systems. These approaches to understanding user preferences and delivering relevant laptop or product recommendations are distinct. CF is a user-centric recommendation technique that generates personalized suggestions by leveraging the collective behavior of users. It assumed that users who have previously expressed similar preferences will continue to do so. CF identifies users with comparable purchase or rating histories and recommends products that one user has liked to another with similar tastes in the context of a laptop or product recommender system.
CBF mainly focused on the characteristics and attributes of the products/items themselves. It creates user and product profiles based on relevant features such as specifications, descriptions, or product categories. The system then recommends products that match the user's preferences based on the content of the items. The clod-start problems mainly occurred with the CBF approach. These drawbacks, overcome by an Ensemble Recommender system, are introduced to measure top trending products from the following datasets: laptop-ACOS, Restaurant, and Twitter.
Pseudo code for combination of CF and CBF
# Step 1: Load the data and preprocess if necessary
# data = LoadData()
# Step 2: Train individual recommendation algorithms
# CF = TrainAlgorithm1(data)
# CBF = TrainAlgorithm2(data)
# Step 3: Make predictions using individual algorithms
# predictions1 = CF.Predict(data)
# predictions2 = CBF.Predict(data)
# Step 4: Define weights for each individual algorithm
# weight1 = 0.4
# weight2 = 0.3
# Step 5: Combine predictions using weighted average or other methods
def ensemble_recommendations(predictions1, predictions2, weight1, weight2):
ensemble_predictions = {}
for user in predictions1.keys():
recommendations = {}
for item in predictions1[user].keys():
# Weighted average of the predictions from individual algorithms
final_score = (weight1 * predictions1[user][item]) + (weight2 * predictions2[user][item]))
recommendations[item] = final_score
# Sort and recommend top N items for each user
sorted_recommendations = {k: v for k, v in sorted(recommendations.items(), key=lambda item: item[1], reverse=True)}
top_N_recommendations = list(sorted_recommendations.keys())[:N]
ensemble_predictions[user] = top_N_recommendations
return ensemble_predictions
# Step 6: Get the final ensemble recommendations
# final_recommendations = ensemble_recommendations(predictions1, predictions2, weight1, weight2)
# Step 7: Present the recommendations to the user
# PresentRecommendations(final_recommendations)
4.3 Performance metrics
$\begin{gathered}\text { Accuracy }(\mathrm{Acc})=\frac{\mathrm{TP}+\mathrm{TN}}{\mathrm{TP}+\mathrm{TN}+\mathrm{FP}+\mathrm{FN}} \\ \text { Precision }(\text { Pre })=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FP}} \\ \text { Recall (RE) }=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FN}} \\ \text { F1 Score (F1S) }=\frac{2 * \text { Precision } * \text { Recall }}{\text { Precision }+ \text { Recall }} \\ \text { Error Rate (ER) }=1-\text { Accuracy }\end{gathered}$
This section outperforms individual classifiers and traditional single-model approaches for sentiment analysis. We ran a series of experiments on a diverse and representative dataset that shows the performance of ERS for sentiment analysis. The three datasets comprise user-generated content from social media, product reviews, and online forums, and the sentiments are labeled as positives, negatives, and neutrals.
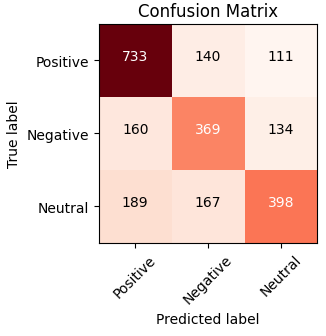
Table 3. Confusion matrix for Laptop-ACOS dataset
|
Models |
TP |
TN |
FP |
FN |
|
IAN |
867 |
666 |
169 |
290 |
|
RAM |
801 |
541 |
159 |
189 |
|
IGCN |
789 |
446 |
201 |
225 |
|
DSA |
1110 |
880 |
46 |
38 |
|
ERS (Proposed) |
1115 |
901 |
40 |
19 |
Table 4. Assessing the performance disparity between established and proposed algorithms on the Laptop-ACOS dataset
|
Model |
Acc |
Pre |
RE |
F1S |
ER |
|
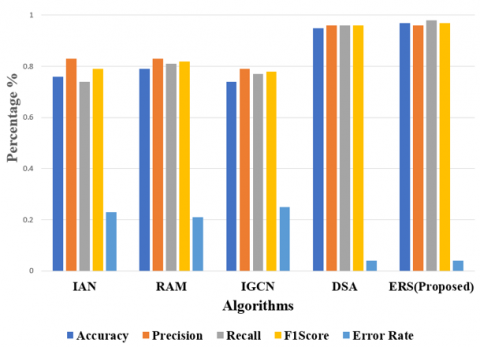
IAN |
0.769 |
0.836 |
0.749 |
0.7907 |
0.231 |
|
RAM |
0.794 |
0.8344 |
0.8091 |
0.8215 |
0.206 |
|
IGCN |
0.7435 |
0.7970 |
0.7781 |
0.7874 |
0.2565 |
|
DSA |
0.9595 |
0.9602 |
0.9669 |
0.9635 |
0.0405 |
|
ERS (Proposed) |
0.9716 |
0.9654 |
0.9832 |
0.9742 |
0.041 |
Table 5. Confusion matrix for Restaurant dataset
|
Models |
TP |
TN |
FP |
FN |
|
IAN |
654 |
510 |
210 |
126 |
|
RAM |
610 |
530 |
221 |
139 |
|
IGCN |
670 |
480 |
240 |
110 |
|
DSA |
945 |
365 |
110 |
80 |
|
ERS (Proposed) |
1145 |
210 |
98 |
47 |
Figure 10. Count values for the Laptop-ACOS dataset
Figure 11. Comparative evaluation of various DL models alongside the proposed model on the Laptop-ACOS dataset
Figure 12. Confusion matrix count values for Restaurant dataset
Figure 13. Performances of the Restaurant dataset in terms of metrics
Table 6. Performance of models based on the count values
|
Model |
Acc |
Pre |
RE |
F1S |
ER |
|
IAN |
0.776 |
0.7569 |
0.8385 |
0.7956 |
0.224 |
|
RAM |
0.76 |
0.7341 |
0.8144 |
0.7722 |
0.24 |
|
IGCN |
0.766 |
0.7363 |
0.8590 |
0.7929 |
0.234 |
|
DSA |
0.8733 |
0.8957 |
0.9220 |
0.9087 |
0.1267 |
|
ERS (Proposed) |
0.9033 |
0.9212 |
0.928 |
0.9606 |
0.0967 |
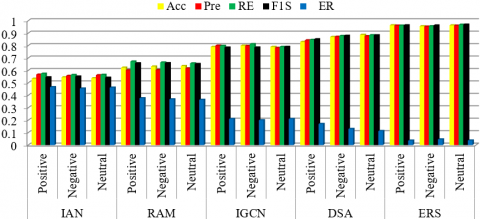
Table 3 shows the count values obtained from the confusion matrix that shows the comparison between list of DL algorithms. Compared with all the algorithms, the TP values are 1115, which is high for ERS, and the other values are TN obtained at 901, FP received at 40, and FN received at 19. IAN got a low performance in terms of count values. Figure 10 shows the performance using the visualization of count values - all these values obtained for the Laptop-ACOS dataset. The performance analysis from these count values with the parameters is shown in Table 4. Among all the algorithms, the version of the ERS shows high accuracy with 0.9716. The ERS offers a low error rate compared with the IAN model. High accuracy is obtained based on the overall positives by calculating actual and predicted values that are the same. High accuracy represents the strength of the proposed model, and low accuracy represents the drawback of the model. Figure 11 shows the comparative performances obtained from Table 4.
Table 5 shows the count values of the Restaurant dataset based on the confusion matrix. Figure 12, comparative count values among the list of DL algorithms. Table 6 and Figure 13 indicate the comparison between the list of models based on obtained results from the confusion matrix. ERS shows high for the Restaurant dataset with the accuracy of 0.9033 which is high among all the other models, and a low error rate of 0.0967.
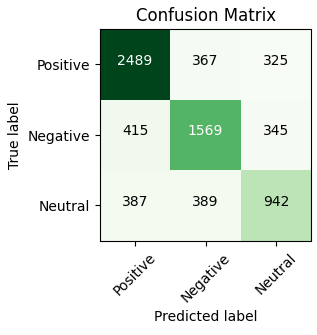
Table 7 and Figure 14 show the count values of overall performances that are obtained from confusion matrix. Table 8 and Figure 15 represent the performances of list of algorithms based on parameters given in Table 8. Among all the results the proposed approach obtained the high results compare with the existing models. The accuracy is 0.911 which is high compare with existing algorithms.
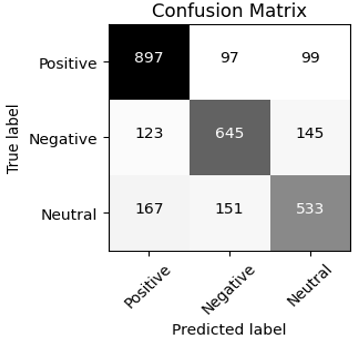
Table 7. Count values obtained from the twitter dataset for list of algorithms
|
Algorithms |
TP |
TN |
FP |
FN |
|
IAN |
1741 |
1729 |
650 |
880 |
|
RAM |
1812 |
1659 |
759 |
770 |
|
IGCN |
1920 |
1732 |
880 |
468 |
|
DSA |
3081 |
1341 |
189 |
389 |
|
ERS (Proposed) |
3145 |
1410 |
331 |
114 |
Table 8. Performances of algorithms based on the given parameters for Twitter dataset
|
Model |
Acc |
Pre |
RE |
F1S |
ER |
|
IAN |
0.694 |
0.7281 |
0.6643 |
0.6947 |
0.306 |
|
RAM |
0.6942 |
0.7048 |
0.7018 |
0.7033 |
0.306 |
|
IGCN |
0.7304 |
0.6857 |
0.8040 |
0.7402 |
0.2696 |
|
DSA |
0.8844 |
0.9422 |
0.8879 |
0.9142 |
0.1156 |
|
ERS (Proposed) |
0.911 |
0.9048 |
0.9650 |
0.9339 |
0.089 |
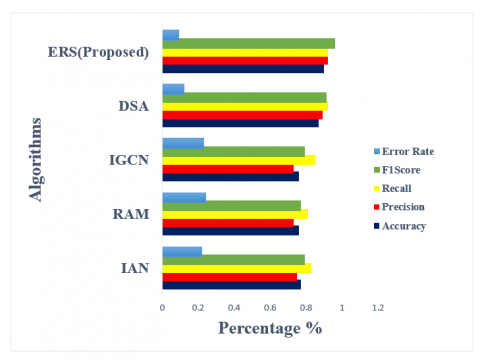
Table 9. Overall performances of sentiment analysis for list of algorithms in terms of positive, negative and neutral for Laptop-ACOS
|
Algorithms |
|
Acc |
Pre |
RE |
F1S |
ER |
|
IAN |
Positive |
0.761 |
0.834 |
0.736 |
0.791 |
0.212 |
|
Negative |
0.745 |
0.812 |
0.745 |
0.786 |
0.255 |
|
|
Neutral |
0.712 |
0.825 |
0.739 |
0.794 |
0.234 |
|
|
RAM |
Positive |
0.798 |
0.834 |
0.809 |
0.832 |
0.207 |
|
Negative |
0.801 |
0.841 |
0.819 |
0.827 |
0.203 |
|
|
Neutral |
0.783 |
0.836 |
0.807 |
0.818 |
0.201 |
|
|
IGCN |
Positive |
0.756 |
0.8 |
0.798 |
0.784 |
0.254 |
|
Negative |
0.81 |
0.798 |
0.812 |
0.785 |
0.21 |
|
|
Neutral |
0.79 |
0.782 |
0.79 |
0.79 |
0.21 |
|
|
DSA |
Positive |
0.95 |
0.923 |
0.945 |
0.958 |
0.17 |
|
Negative |
0.942 |
0.947 |
0.878 |
0.879 |
0.13 |
|
|
Neutral |
0.946 |
0.956 |
0.884 |
0.883 |
0.113 |
|
|
ERS (Proposed) |
Positive |
0.978 |
0.981 |
0.986 |
0.971 |
0.036 |
|
Negative |
0.981 |
0.971 |
0.976 |
0.972 |
0.046 |
|
|
Neutral |
0.984 |
0.976 |
0.978 |
0.989 |
0.037 |
Figure 14. Confusion matrix for Twitter dataset
Figure 15. Performance in terms of parameters
Figure 16. Comparative assessment of the overall performance of DL models on the Laptop-ACOS
Figure 17. Overall comparative performances of DL Algorithms for Restaurant dataset
Figure 18. Overall comparative performances of DL algorithms for the twitter dataset
Table 9 shows the overall performances of the list of algorithms by showing the sentiments like positive, negative and neutral. Among all these algorithms the high sentiments are obtained by the proposed ERS algorithm. Figure 16 shows the comparative performances in terms of sentiments with performance metrics. All these are applied to the Laptop-ACOS dataset.
Table 10 and Figure 17 show the performances in terms of positive, negative and neutral values obtained from the proposed approach.
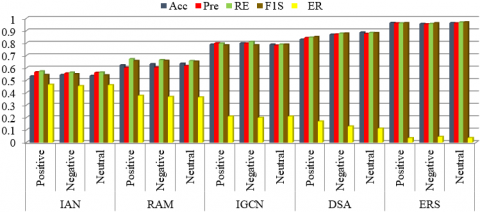
Table 11 and Figure 18 show the overall performances of the sentiments based on the obtained results. The sentiments are obtained based on the positive, negative and neutral values measured by using the count values.
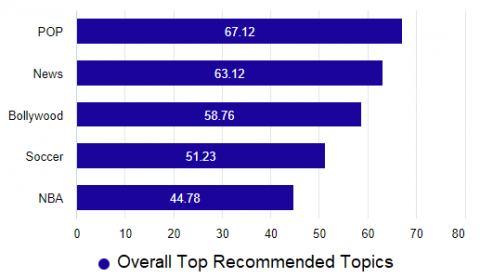
Figures 19-21 show the top recommended laptops, Restaurant-ACOS and Twitter data analysis is given in this section.
Table 10. Overall performances of list of algorithms in terms of positive, negative and neutral for Restaurant dataset
|
Algorithms |
|
Acc |
Pre |
RE |
F1S |
ER |
|
IAN |
Positive |
0.771 |
0.745 |
0.845 |
0.793 |
0.229 |
|
Negative |
0.772 |
0.751 |
0.832 |
0.7834 |
0.228 |
|
|
Neutral |
0.765 |
0.763 |
0.842 |
0.799 |
0.235 |
|
|
RAM |
Positive |
0.768 |
0.734 |
0.819 |
0.772 |
0.207 |
|
Negative |
0.776 |
0.743 |
0.821 |
0.786 |
0.203 |
|
|
Neutral |
0.783 |
0.745 |
0.823 |
0.798 |
0.201 |
|
|
IGCN |
Positive |
0.771 |
0.743 |
0.8576 |
0.7956 |
0.254 |
|
Negative |
0.786 |
0.787 |
0.834 |
0.785 |
0.21 |
|
|
Neutral |
0.79 |
0.782 |
0.79 |
0.79 |
0.21 |
|
|
DSA |
Positive |
0.901 |
0.923 |
0.915 |
0.918 |
0.17 |
|
Negative |
0.912 |
0.917 |
0.878 |
0.949 |
0.13 |
|
|
Neutral |
0.916 |
0.926 |
0.884 |
0.933 |
0.113 |
|
|
ERS (Proposed) |
Positive |
0.986 |
0.981 |
0.956 |
0.971 |
0.036 |
|
Negative |
0.978 |
0.971 |
0.976 |
0.972 |
0.046 |
|
|
Neutral |
0.991 |
0.926 |
0.938 |
0.989 |
0.037 |
Table 11. Overall performances of list of algorithms in terms of positive, negative and neutral sentiments for Twitter
|
Algorithms |
|
Acc |
Pre |
RE |
F1S |
ER |
|
IAN |
Positive |
0.698 |
0.721 |
0.667 |
0.691 |
0.229 |
|
Negative |
0.712 |
0.724 |
0.669 |
0.702 |
0.228 |
|
|
Neutral |
0.693 |
0.713 |
0.671 |
0.701 |
0.235 |
|
|
RAM |
Positive |
0.697 |
0.704 |
0.719 |
0.703 |
0.207 |
|
Negative |
0.693 |
0.703 |
0.701 |
0.706 |
0.203 |
|
|
Neutral |
0.694 |
0.705 |
0.803 |
0.708 |
0.201 |
|
|
IGCN |
Positive |
0.734 |
0.681 |
0.807 |
0.741 |
0.254 |
|
Negative |
0.739 |
0.691 |
0.802 |
0.752 |
0.21 |
|
|
Neutral |
0.74 |
0.693 |
0.810 |
0.745 |
0.21 |
|
|
DSA |
Positive |
0.8834 |
0.9412 |
0.8867 |
0.918 |
0.17 |
|
Negative |
0.882 |
0.937 |
0.888 |
0.929 |
0.13 |
|
|
Neutral |
0.886 |
0.946 |
0.884 |
0.933 |
0.113 |
|
|
ERS (Proposed) |
Positive |
0.931 |
0.965 |
0.936 |
0.941 |
0.036 |
|
Negative |
0.943 |
0.947 |
0.946 |
0.932 |
0.046 |
|
|
Neutral |
0.954 |
0.965 |
0.938 |
0.959 |
0.037 |
Figure 19. Overall percentage of Top-5 laptops based on SA
Figure 20. Overall percentage of Top-5 Restaurants based on SA
Figure 21. Overall percentage of top recommended topics in twitter data
In this paper, an Ensemble Recommendation System (ERS) is implemented by using Python language. The main aim was to enhance the accuracy and robustness of SA by combining the strengths of multiple SA models. The first step explored and selected a diverse set of state-of-the-art SA models, including RNN, CNN, and Transformer-based models. Each model had its strengths and weaknesses, and by combining them, we sought to mitigate individual model biases and errors. The ERS makes predictions based on the collective decisions of the constituent models. We achieved a more comprehensive and balanced sentiment analysis outcome by doing so.
To assess the performance of our approach, a wide range of benchmark datasets from various domains and languages were used. The proposed ERS outperformed the individual models in terms of accuracy (Acc), precision (Pre), recall (RE), F1S, and ER. This improvement showcased the effectiveness of our approach in handling various sentiment analysis tasks. Moreover, the proposed ERS exhibited robustness against noise and adversarial attacks, crucial for real-world applications where data can be noisy and unreliable. However, it is acknowledged that our study also had some limitations.
The choice of models and fusion techniques could be further optimized, and the computational cost of running an ensemble of models may be higher than using a single model. Therefore, future research could focus on developing more efficient fusion strategies and exploring lightweight models that maintain comparable performance. Finally, the proposed ERS for deep sentiment analysis has shown promising results, surpassing individual models' accuracy and robustness.
Combining multiple models has demonstrated the potential for creating more reliable and accurate sentiment analysis systems. This research opens avenues for further investigations and applications in various domains, such as social media monitoring, market analysis, and customer feedback processing.
[1] Chakraborty, K., Bhattacharyya, S., Bag, R. (2020). A survey of sentiment analysis from social media data. IEEE Transactions on Computational Social Systems, 7(2): 450-464. https://doi.org/10.1109/TCSS.2019.2956957
[2] Huang, F., Li, X., Yuan, C., Zhang, S., Zhang, J., Qiao, S. (2021). Attention-emotion-enhanced convolutional LSTM for sentiment analysis. IEEE transactions on neural networks and learning systems, 33(9): 4332-4345. https://doi.org/10.1109/TNNLS.2021.3056664
[3] Nandwani, P., Verma, R. (2021). A review on sentiment analysis and emotion detection from text. Social Network Analysis and Mining, 11(1): 81. https://doi.org/10.1007/s13278-021-00776-6
[4] Schouten, K., Frasincar, F. (2015). Survey on aspect-level sentiment analysis. IEEE Transactions on Knowledge and Data Engineering, 28(3): 813-830. https://doi.org/10.1109/TKDE.2015.2485209
[5] Munezero, M., Montero, C.S., Sutinen, E., Pajunen, J. (2014). Are they different? Affect, feeling, emotion, sentiment, and opinion detection in text. IEEE Transactions on Affective Computing, 5(2): 101-111. https://doi.org/10.1109/TAFFC.2014.2317187
[6] Babu, N.V., Kanaga, E.G.M. (2022). Sentiment analysis in social media data for depression detection using artificial intelligence: A review. SN Computer Science, 3(1): 74. https://doi.org/10.1007/s42979-021-00958-1
[7] Yadav, A., Vishwakarma, D.K. (2020). Sentiment analysis using deep learning architectures: A review. Artificial Intelligence Review, 53(6): 4335-4385. https://doi.org/10.1007/s10462-019-09794-5
[8] Cambria, E. (2016) Affective computing and sentiment analysis. IEEE Intelligent Systems, 31(2): 102-107. https://doi.org/10.1109/MIS.2016.31
[9] Chen, B., Hao, Z., Cai, X., Cai, R., Wen, W., Zhu, J., Xie, G. (2019). Embedding logic rules into recurrent neural networks. IEEE Access, 7: 14938-14946. https://doi.org/10.1109/ACCESS.2019.2892140
[10] Thakkar, A., Mungra, D., Agrawal, A., Chaudhari, K. (2022). Improving the performance of sentiment analysis using enhanced preprocessing technique and Artificial Neural Network. IEEE Transactions on Affective Computing, 13(4): 1771-1782. https://doi.org/10.1109/TAFFC.2022.3206891
[11] Bengesi, S., Oladunni, T., Olusegun, R., Audu, H. (2023). A machine learning-sentiment analysis on Monkeypox outbreak: An extensive dataset to show the polarity of public opinion from twitter tweets. IEEE Access, 11: 11811-11826. https://doi.org/10.1109/ACCESS.2023.3242290
[12] Liu, H., Chatterjee, I., Zhou, M., Lu, X. S., Abusorrah, A. (2020). Aspect-based sentiment analysis: A survey of deep learning methods. IEEE Transactions on Computational Social Systems, 7(6): 1358-1375. https://doi.org/10.1109/TCSS.2020.3033302
[13] Gupta, P., Kumar, S., Suman, R.R., Kumar, V. (2020). Sentiment analysis of lockdown in India during covid-19: A case study on twitter. IEEE Transactions on Computational Social Systems, 8(4): 992-1002. https://doi.org/10.1109/TCSS.2020.3042446
[14] Gao, S., Zhou, M., Wang, Y., Cheng, J., Yachi, H., Wang, J. (2018). Dendritic neuron model with effective learning algorithms for classification, approximation, and prediction. IEEE Transactions on Neural Networks and Learning Systems, 30(2): 601-614. https://doi.org/10.1109/TNNLS.2018.2846646
[15] Dragoni, M., Petrucci, G. (2017). A neural word embeddings approach for multi-domain sentiment analysis. IEEE Transactions on Affective Computing, 8(4): 457-470. https://doi.org/10.1109/TAFFC.2017.2717879
[16] Singh, L.G., Anil, A., Singh, S.R. (2020). SHE: Sentiment hashtag embedding through multitask learning. IEEE Transactions on Computational Social Systems, 7(2): 417-424. https://doi.org/10.1109/TCSS.2019.2962718
[17] Kumar, A., Narapareddy, V.T., Srikanth, V.A., Neti, L. B.M., Malapati, A. (2020). Aspect-based sentiment classification using interactive gated convolutional network. IEEE Access, 8: 22445-22453. https://doi.org/10.1109/ACCESS.2020.2970030
[18] Zhang, B., Xu, D., Zhang, H., Li, M. (2019). STCS lexicon: Spectral-clustering-based topic-specific Chinese sentiment lexicon construction for social networks. IEEE Transactions on Computational Social Systems, 6(6): 1180-1189. https://doi.org/10.1109/TCSS.2019.2941344
[19] Aslam, N., Rustam, F., Lee, E., Washington, P.B., Ashraf, I. (2022). Sentiment analysis and emotion detection on cryptocurrency related tweets using ensemble LSTM-GRU model. IEEE Access, 10: 39313-39324. https://doi.org/10.1109/ACCESS.2022.3165621
[20] Wang, D., Su, J., Yu, H. (2020). Feature extraction and analysis of natural language processing for deep learning English language. IEEE Access, 8: 46335-46345. https://doi.org/10.1109/ACCESS.2020.2974101
[21] Du, Y., Zhao, X., He, M., Guo, W. (2019). A novel capsule based hybrid neural network for sentiment classification. IEEE Access, 7: 39321-39328. https://doi.org/10.1109/ACCESS.2019.2906398
[22] Du, J., Gui, L., He, Y., Xu, R., Wang, X. (2019). Convolution-based neural attention with applications to sentiment classification. IEEE Access, 7: 27983-27992. https://doi.org/10.1109/ACCESS.2019.2900335
[23] Yuan, M., Tang, H., Li, H. (2014). Real-time keypoint recognition using restricted Boltzmann machine. IEEE Transactions on Neural Networks and Learning Systems, 25(11): 2119-2126. https://doi.org/10.1109/TNNLS.2014.2303478
[24] Zhao, W., Guan, Z., Chen, L., He, X., Cai, D., Wang, B., Wang, Q. (2017). Weakly-supervised deep embedding for product review sentiment analysis. IEEE Transactions on Knowledge and Data Engineering, 30(1): 185-197. https://doi.org/10.1109/TKDE.2017.2756658
[25] Kumar, S., De, K., Roy, P.P. (2020). Movie recommendation system using sentiment analysis from microblogging data. IEEE Transactions on Computational Social Systems, 7(4): 915-923. https://doi.org/10.1109/TCSS.2020.2993585
[26] Rosa, R.L., Rodriguez, D.Z., Bressan, G. (2015). Music recommendation system based on user's sentiments extracted from social networks. IEEE Transactions on Consumer Electronics, 61(3): 359-367. https://doi.org/10.1109/TCE.2015.7298296
[27] Zhang, Y., Xu, B., Zhao, T. (2020). Convolutional multi-head self-attention on memory for aspect sentiment classification. IEEE/CAA Journal of Automatica Sinica, 7(4): 1038-1044. https://doi.org/10.1109/JAS.2020.1003243
[28] Ayyub, K., Iqbal, S., Munir, E.U., Nisar, M.W., Abbasi, M. (2020). Exploring diverse features for sentiment quantification using machine learning algorithms. IEEE Access, 8: 142819-142831. https://doi.org/10.1109/ACCESS.2020.3011202
[29] Zhao, J., Gui, X. (2017). Comparison research on text pre-processing methods on twitter sentiment analysis. IEEE Access, 5:2870-2879. https://doi.org/10.1109/ACCESS.2017.2672677
[30] Salur, M.U., Aydin, I. (2020). A novel hybrid deep learning model for sentiment classification. IEEE Access, 8: 58080-58093. https://doi.org/10.1109/ACCESS.2020.2982538
[31] Tan, K.L., Lee, C.P., Anbananthen, K.S.M., Lim, K.M. (2022). RoBERTa-LSTM: a hybrid model for sentiment analysis with transformer and recurrent neural network. IEEE Access, 10: 517-21525. https://doi.org/10.1109/ACCESS.2022.3152828
[32] Tam, S., Said, R.B., Tanriöver, Ö.Ö. (2021). A ConvBiLSTM deep learning model-based approach for Twitter sentiment classification. IEEE Access, 9: 41283-41293. https://doi.org/10.1109/ACCESS.2021.3064830
[33] Alhashmi, S.M., Khedr, A.M., Arif, I., El Bannany, M. (2021). Using a hybrid-classification method to analyze Twitter data during critical events. IEEE Access, 9: 141023-141035. https://doi.org/10.1109/ACCESS.2021.3119063
[34] Bakar, M.F.R.A., Idris, N., Shuib, L., Khamis, N. (2020). Sentiment analysis of noisy Malay text: State of art, challenges and future work. IEEE Access, 8: 24687-24696. https://doi.org/10.1109/ACCESS.2020.2968955
[35] Ma, D., Li, S., Zhang, X., Wang, H. (2017). Interactive attention networks for aspect-level sentiment classification. arXiv preprint arXiv: 1709.00893. https://doi.org/10.48550/arXiv.1709.00893
[36] Chen, P., Sun, Z., Bing, L., Yang, W. (2017). Recurrent attention network on memory for aspect sentiment analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, pp. 452-461. https://doi.org/10.18653/v1/D17-1047
[37] Durga, P., Godavarthi, D. (2023). Deep-Sentiment: An effective deep sentiment analysis using a Decision-based Recurrent Neural Network (D-RNN). IEEE Access, 11: 108433-108447. https://doi.org/10.1109/ACCESS.2023.3320738