Shubhrata Kanungo*![]() | Suresh Jain
| Suresh Jain![]()
©2023 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
As it provides real-time insights into public opinion & emotional responses during disasters, social media sentiment analysis has gained in importance in disaster management. Twitter data can be used for sentiment analysis in the field of disaster management by employing G-LSTM, a hybrid deep neural network of Gated Recurrent Units (GRUs) and Long Short-Term Memory (LSTM) networks. Thanks to microblogging networks like Twitter, information pours in quickly after a calamity. Tweets are a good source of data. During a crisis, not all tweets are meant to help. Twitter updates on the death toll, property damage, and actions taken by civilised institutions are all welcome. A great deal of study has been devoted to the importance of rapidly disseminating disaster-related updates. Studying how people use Twitter during calamities like storms and floods could save needless loss of life. data from Twitter's API that has been processed using Natural Language Processing (NLP) in order to anticipate social media disasters Twitter conversations about recent calamities, both real and imagined. Pre-processing includes access to a database of 10,000 manually-classified tweets; N-gram analysis; removal of punctuation; removal of HTML tags; revision of spelling; and vectorization of data. Some of the deep learning algorithms proposed in this study are the Long Short-Term Memory (LSTM), the Gated Recurrent Unit (GRU), and the Hybrid LSTM-GRU. The measures utilised for assessment are accuracies, precisions, recall rates, and losses. The accuracy, precision, recall, and loss values of the hybrid GRU-LSTM were 0.9978, 0.9948, 0.9931, and 0.0060, respectively, when compared to those of the LSTM and the GRU Model.
disaster management, social media, deep learning, hybrid neural network
Social media sites, which may provide both real-time updates and user-generated content, have been increasingly important in recent years as information resources during crisis occurrences. Twitter, with its massive user base and simple interface, has attracted the most attention among these channels. The ability to track public opinion, feelings, and reactions in the wake of disasters has made social media sentiment analysis a crucial tool for emergency managers. This information can help emergency response teams, government agencies, and humanitarian organisations prioritise needs and allocate resources more efficiently [1].
However, it is extremely difficult to manually analyse and extract useful information from the large amount of user-generated content on social media due to the data's volume and velocity. When applied to the text data collected from social media platforms, traditional sentiment analysis approaches frequently fall short. This highlights the expanding want for cutting-edge computational methods that can automate sentiment analysis and supply real-time insights during crisis scenarios.For Twitter sentiment analysis in the field of disaster management, this research proposes the use of a hybrid deep neural network model called G-LSTM (Gated Long Short-Term Memory). Gated Recurrent Units (GRUs) and Long Short-Term Memory (LSTM) networks are both potent variations of recurrent neural networks (RNNs) noted for their capacity to capture sequential dependencies and handle long-term dependencies, respectively; both abilities are combined in the G-LSTM design. The G-LSTM model integrates the strengths of GRUs and LSTMs to enhance the precision and speed with which disaster-related Twitter data can be analysed for sentiment.
Objectives:
One goal was to create a G-LSTM model, a hybrid deep neural network, to analyse Twitter data for sentiment in the context of disaster management.
Second, want to see how well the G-LSTM model can predict emotion labels.
In order to (3) show how the G-LSTM model may be used in practise for real-time sentiment analysis during catastrophic events; and (4) get people talking about it.
This paper's remaining sections are structured as follows: The second section includes a survey of related research on the topic of catastrophe managementusing social media sentiment analysis.
The approach is laid out, which covers topics including data collecting, preprocessing methods, and the G-LSTM framework. Results and metrics for assessing the experiment's success. The results and potential uses of the proposed G-LSTM model.The report finishes with a review of the findings and recommendations for future study in Section 6.
In order to help emergency response and aid organisations make better decisions and allocate resources more efficiently during disasters, this study aims to contribute to the expanding field of social media analytics by developing an advanced sentiment analysis model tailored to Twitter data in the context of disaster management[2].
It's possible to send timely alerts and cautions, as well as helpful information and instructions, using social media. The increasing usage of social media could increase the number of people who hear warnings and notifications sent by emergency services [3]. This includes tornadoes and other forms of extreme weather. SM is the medium for the broader category of social interactions known as "extra-communicative." Everything from desktop computers to smartphones and tablets falls under this category of technology. With its help, users may create, share, and discuss content online, facilitating two-way communication between them and the wider world. The term "social media" (SM) is used to describe a group of online resources that build upon the ideas and architecture of Web 2.0 and enable users to create and share content collaboratively. Users of SM technologies should take an active role in content production, curation, and sharing. Word documents, audio files, video files, still photographs, electronic document files, PowerPoint presentations, and even GPS coordinates all count as forms of content. Sharing via social media makes it easier to talk to people on different platforms. It opens the door for people of both sexes to have a voice in shaping the future of social media. This technique allows for the rapid expansion of involvement through the production of real-time online events, the extension of online interactions offline, and the enhancement of live events via the Internet.
Cooperation between many organisations and sectors is essential for effective disaster risk management, regardless of the scale, severity, or scope of the disasters that must be mitigated [4, 5]. Some things you can do before a disaster strikes are more evident than others (like securing your home and storing up on non-perishable commodities like water and food), but you may also take some precautions online. Create your own 'group' on Facebook or any of the other many social media platforms out there. In case of an urgent situation, please share this link with your loved ones. Create a website where people can record their whereabouts and discuss their escape plans. Cities and towns provide PEP accounts for citizens to follow so that they are aware of emergency plans in their area. The locals should tune in to the reliable police, fire, and media outlets for updates [6]. There are a variety of apps for smartphones that can come in handy in a need. Having news and weather applications on your phone may help you keep informed and ready for any emergency circumstance, therefore they are a must-have. Disarray follows any major disaster. Having a plan in place beforehand might help you relax in tense situations. Social media allows for instantaneous communication between individuals, communities, and even governments [7]. Online users are recording and sharing images and videos of a disaster as it happens. Social media posts typically reach a wider audience than those made by mainstream media channels. In the case of a crisis, authorities will use social media to keep the public apprised of the whereabouts of aid and the anticipated arrival time of relief supplies. The magnitude of the damage can be documented and survivors can be located with the help of photos and videos published on social media. These images notify emergency personnel of the severity of the issue before they arrive. Connecting with the relevant groups and people ahead of time is advantageous because social media provides instant updates on road closures, evacuation routes, designated help spots, shelter places, and more in the event of a disaster [8]. You might utilise your social media accounts to inform those close to you of your current health situation. Update your Facebook, Twitter, and other social media profiles to let your friends and family know where you are and that you are safe. During a disaster, social media may be a great resource for finding out the latest information about road closures, evacuation routes, designated help zones, shelter places, and more. When disaster strikes, individuals use social media to coordinate efforts to find loved ones, animals, and misplaced items. There will be a great deal of people in need of medical care, food, and other basics, and this will assist get the word out about relief efforts and fundraising campaigns. Updates can be shared with clients, consumers, and vendors through a company's social media sites. The company's internet presence can be used to update clients on the status of the rebuilding, relocating, and reopening processes [9].
SM's widespread adoption in emergency management can be attributed to its widespread use, effectiveness, and simplicity. Notwithstanding potential disruptions to traditional means of communication, SM services & networking continue as usual. They aid and empower people and groups to work together for the greater good during all phases of emergency management, including prevention, preparedness, response, and cleanup. At times of natural disaster or other emergencies, it serves as the principal source of news. Via the Internet and text messages, it disseminates data on potential catastrophic outcomes. Awareness is raised within the impacted areas, which aids in recruiting emergency service volunteers and financial support. It serves as a vital link for those who have been separated from one another due to relocation. It details available humanitarian organizations and other resource hubs in the impacted region. The four most common uses of SM technologies among citizens identified in reviews of the literature are as follows: communication with family and friends; situation updates; situational/supplemental awareness; support in accessing resources. Social media aids communities before, during, and after disasters by reuniting and strengthening individuals and organizations for more effective response, recovery, and distribution of aid [10]. AI-Social Disaster is a software that collects and analyses social media conversations in real time during a disaster using AI services and algorithms [11].
Powers et al. [12] According to the literature study, Create neural & non-neural models using machine learning to autonomously classify tweets based on relevance & urgency. The deep convolutional neural network (CNN) & non-neural models are greatly outperformed by our best relevance classifiers, languages models BERT or XLNet, which also attain equivalent F1 scores. The study's development of techniques to automatically classify tweets that can alert first responders to people's demands for assistance in urgent, life-threatening situations advances machine learning & crisis communication research. Our research also identifies huge pretrained language models as viable for the future development of effective catastrophe tweet classifiers.
Zachlod et al. [13] used to address numerous research questions in various academic disciplines. Yet, the complexity of the study is because of the nature of social media information. The purpose of this study is to provide a complete overview of research that has looked at social media data since 2017. A comprehensive literature review of 94 investigations led to the conclusion that there's neither established nor frequently used unambiguous definitions. The primary fields of study are marketing, hospitality and tourism, disaster management, and disruptive technologies. Twitter is the primary source for the social media analysis. These days, we employ content and sentiment analysis. Half of the studies contain applications to real life. On the basis of the literature review, concise definitions are offered, and potential directions for top-notch future study are indicated.
Regarding, Yuan et al. [14] The goal of the investigation used social media to study how people responded to crises. These research, however, ignored the demographic component. This research suggests three goals to address this limitation: The goals of this study are threefold: 1) to better understand the social aspects of disaster resilience with both the help of response disparities; 2) to examine the concern themes in their expressions, including popularity of these themes & their sentiment towards them; and 3) to examine the differences in sentiment polarities between various ethnic and gender groups. The results showed that males and Latinos were more likely to have negative emotions. The black community seems to care more about the "pray/donate" option than the "storm warn" one. While the black community is unhappy with the "response," the white community is the most upbeat about the long-term results of extreme weather events like hurricanes and floods. The female group is less worried about the "hurricane warn" and more optimistic about the "hurricane/flood impact" and "response" than the male group. Our findings can aid crisis response managers in pinpointing the most at-risk individuals to which they should direct updates on the unfolding disaster and distributions of aid.
Dou et al. [15] In order to calculate disaster losses using social media data, the majority of the literature developed a method that incorporates data preprocessing, fine-grained topic extraction, and quantitative damage estimation. The case of Typhoons Hato and Pakhar, which wreaked havoc in southern China from August 22nd through to the 30th, 2017, demonstrated the efficacy of the proposed approach. For instance, the catastrophe losses were substantially linked with subjects related to infrastructure destruction, demonstrating the promise of the proposed approach in exploiting granular themes to count disaster costs. The study's examination of social media's granular issues aided in the assessment of disaster damage.
Related to the preposition, Raza et al. [16] intended to restore communication in locations where it has been disrupted by a disaster or power loss. The suggested method uses ad hoc clusters to connect UE (user equipment) and end users in the event of an emergency. A new framework is suggested for cluster creation that allows for both direct and redirected communication between nodes. Using convex optimization, we are able to maximize throughput in the created clusters as a whole. The clusters and the areas around them will be classified as affected or unaffected by an intelligent system. As a proof of concept, we label a dataset of floods using a series of machine learning approaches that take into account data about specific regions in order to determine whether or not those regions were affected by the disaster. To help reestablish communication in disaster-stricken areas as well as classify the impact of disasters for different locations in disaster-prone regions, the good results of the proposed machine learning techniques can be employed in conjunction with the proposed clustering techniques.
Sentiment analysis of social media and Twitter is an expanding topic of study that seeks to make sense of the emotions expressed by online communities. In this critical analysis, will look at the available research in this field and analyse its merits, shortcomings, and potential future directions.
Strengths:
First, researchers have access to a wealth of real-time data thanks to social media sites like Twitter, enabling them to record and analyse emotions in the moment. This is a helpful way to gauge public opinion and observe developing situations.
Second, researchers have access to massive sample sizes for sentiment analysis because to the millions of active users on sites like Twitter. This gives the results greater statistical credibility and applicability.
Thirdly, the user-generated content found on social media platforms is a direct reflection of real people's views and feelings. As a result, unlike with traditional polls or questionnaires, the results of sentiment analysis conducted on these platforms are more genuine and indicative of public opinion.
Social media sentiment analysis has applications in public opinion research, brand management, political campaigning, and crisis management, all of which have the potential to have a significant impact on society at large. Research using sentiment analysis can add valuable insight to these types of decision-making processes.
Limitations:
Even if social media sites have a lot of users, they could not be a representative sample of the general public for a few reasons. Overrepresentation of some demographics or groups may introduce bias into the sample. Because of this, the results may not apply to the overall population.
Second, there is a lot of background noise and ambiguity in social media data due to the prevalence of typos, acronyms, slang, and sarcasm. Sentiment analysis algorithms may have difficulty correctly interpreting sentiment in certain circumstances due to the difficulties introduced by this.
Thirdly, there is a risk of missing important context when conducting sentiment analysis based just on 140-character tweets. The context of the chat, the user's past interactions, or external events are often necessary for a correct interpretation of the sentiment.
Most sentiment analysis methods try to figure out if a person feels positively, negatively, or neutrally about a topic. However, feelings tend to be nuanced and multifaceted, including a wide range of emotions and degrees of intensity. It's possible that simplifying the results of sentiment analysis by only looking at polarity.
Future research implications:
Future studies should concentrate on creating more advanced algorithms for sentiment analysis that can deal with the noise, ambiguity, and sarcasm found in social media data. Better sentiment classification is possible with the use of machine learning methods such as deep learning and natural language processing.
Better accuracy in interpreting sentiments is possible by improving sentiment analysis models to include contextual information. Topic modelling, discourse analysis, and named entity recognition are just some of the methods that can be used to better capture the context and enhance the findings of sentiment analysis.
Third, more nuanced sentiment analysis, which captures a broader range of emotions and intensities than polarity-based sentiment analysis, should be investigated in the future. This can help us get a fuller picture of the feelings people convey online.
The ethical issues of using sentiment analysis on social media should also be explored in this line of research. Priorities should be placed on protecting individuals' rights and preventing potential misuse by ensuring privacy, obtaining consent, and making responsible use of user data.
While real-time data and high sample sizes are two of the main benefits of social media and Twitter sentiment analysis, there are also drawbacks to keep in mind, such as sample bias and a lack of context. Improved sentiment analysis algorithms, contextual comprehension, exploration of fine-grained sentiment analysis, and consideration of ethical implications should be the focus of future study (Table 1).
Table 1. Related work summary
|
Author/ Year |
Dataset |
Method |
Parameter |
References |
|
Hao and Wang/2020 |
ILSVRC |
SVM,LR,ANN |
Accuracy=94.31% |
[17] |
|
Kavota et al./2020 |
-- |
PLS-SEM |
Mean=5.701 |
[18] |
|
Imran et al./2020 |
Twitter datasets |
CV,ML,AI |
-- |
[19] |
|
Liu et al./2020 |
-- |
Negative binomial regression |
-- |
[20] |
|
Li et al./2020 |
Typhoon Mangosteen dataset, |
SVM |
Accuracy=84% |
[21] |
2.1 Strengths
First, researchers have access to a wealth of real-time data thanks to social media sites like Twitter, enabling them to record and analyse emotions in the moment. This is a helpful way to gauge public opinion and observe developing situations.
Second, researchers have access to massive sample sizes for sentiment analysis because to the millions of active users on sites like Twitter. This gives the results greater statistical credibility and applicability.
Thirdly, the user-generated content found on social media platforms is a direct reflection of real people's views and feelings. As a result, unlike with traditional polls or questionnaires, the results of sentiment analysis conducted on these platforms are more genuine and indicative of public opinion.
Social media sentiment analysis has applications in public opinion research, brand management, political campaigning, and crisis management, all of which have the potential to have a significant impact on society at large. Research using sentiment analysis can add valuable insight to these types of decision-making processes.
2.2 Limitations
Even if social media sites have a lot of users, they could not be a representative sample of the general public for a few reasons. Overrepresentation of some demographics or groups may introduce bias into the sample. Because of this, the results may not apply to the overall population.
Second, there is a lot of background noise and ambiguity in social media data due to the prevalence of typos, acronyms, slang, and sarcasm. Sentiment analysis algorithms may have difficulty correctly interpreting sentiment in certain circumstances due to the difficulties introduced by this.
Thirdly, there is a risk of missing important context when conducting sentiment analysis based just on 140-character tweets. The context of the chat, the user's past interactions, or external events are often necessary for a correct interpretation of the sentiment.
Most sentiment analysis methods try to figure out if a person feels positively, negatively, or neutrally about a topic. However, feelings tend to be nuanced and multifaceted, including a wide range of emotions and degrees of intensity. It's possible that simplifying the results of sentiment analysis by only looking at polarity.
2.3 Future research implications
Future studies should concentrate on creating more advanced algorithms for sentiment analysis that can deal with the noise, ambiguity, and sarcasm found in social media data. Better sentiment classification is possible with the use of machine learning methods such as deep learning and natural language processing.
Better accuracy in interpreting sentiments is possible by improving sentiment analysis models to include contextual information. Topic modelling, discourse analysis, and named entity recognition are just some of the methods that can be used to better capture the context and enhance the findings of sentiment analysis.
Third, more nuanced sentiment analysis, which captures a broader range of emotions and intensities than polarity-based sentiment analysis, should be investigated in the future. This can help us get a fuller picture of the feelings people convey online.
The ethical issues of using sentiment analysis on social media should also be explored in this line of research. Priorities should be placed on protecting individuals' rights and preventing potential misuse by ensuring privacy, obtaining consent, and making responsible use of user data.
While real-time data and high sample sizes are two of the main benefits of social media and Twitter sentiment analysis, there are also drawbacks to keep in mind, such as sample bias and a lack of context. Improved sentiment analysis algorithms, contextual comprehension, exploration of fine-grained sentiment analysis, and consideration of ethical implications should be the focus of future study.
This section discusses the suggested technique for predicting social media disasters based on Natural Language Processing (NLP) text data. Data from the Twitter API are first gathered, followed by EDA and preprocessing. The data is then split 85:15, with 85% used for training & 15% utilized for testing. Next, deep learning models for evaluation, including LSTM, GRU, as well as 1D Convolutional Neural Networks, will be used.
3.1 Data collection
Natural language processing (NLP) text data https://odsc.medium.com/20-open-datasets-for-natural-language-processing-538fbfaf8e38 from the Twitter API can be used to anticipate social media disasters, and includes both actual and fictitious disasters. use of a database containing 10,000 tweets with manually assigned categories. We also go over the NLP problem-solving basis. ID, keyword, location, text, and victim are only some of the categories found in the disaster dataset. There are more tweets that contain situational information than tweets that do not (a disparity that amounts to 5103 unique ids in the raw data).
In order to anticipate social media disasters using Natural Language Processing (NLP), various opportunities and considerations arise from the availability of a database consisting of 10,000 manually categorised tweets linked to both real and hypothetical disasters. One, it has a large database for training and assessing NLP models (10,000 manually categorised tweets). Due to the abundance of data, numerous facets of social media catastrophe prediction can be examined in depth. The manual labelling of the tweets' categories guarantees the presence of ground truth labels, which may be used as a trustworthy benchmark to measure the NLP models' results. This allows scientists to gauge how well their prediction models are doing.
3.1.1 Limitations
There is the potential for bias to be introduced by human annotators when tweets are manually categorised. Because of this inherent subjectivity, the accuracy and consistency of the labels in the dataset may be compromised.
It is important to assess the dataset's generalizability to other situations or languages, even though it may be a useful tool for analysing tweets about disasters.
It's possible that the dataset doesn't fully represent the intricacies and features of many crisis scenarios, reducing the generalizability of the results.
The time-sensitive nature of social media data, especially in the event of a natural disaster. Real-time social media disaster prediction may be hindered by the fact that the tweets in the database may only cover a certain time period.
Researchers should work on establishing and enhancing natural language processing (NLP) models that are optimised for social media catastrophe prediction. This can involve trying out new architectures, feature engineering methods, and cutting-edge methods like transfer learning and domain adaptability. To evaluate the models' robustness and generalizability, rigorous evaluation processes, such as cross-validation and testing on external datasets, should be implemented.
Due to the urgency of social media data during disasters, it is important that future studies focus on creating real-time prediction algorithms that can continually monitor and analyse incoming tweets. This would make it possible to respond and intervene in urgent circumstances more quickly. Overall, the availability of a database with 10,000 carefully categorised tweets connected to social media disasters gives tremendous prospects for NLP-based prediction models. Researchers, however, need to keep in mind the caveats of bias, generalizability, and temporal sensitivity. To improve the efficacy of social media disaster prediction, more work needs to be done in the future to address these limitations through data augmentation, model development, real-time analysis, and multilingual techniques
3.2 Pre-processing
N-gram analysis, punctuation removal, HTML tag removal, spelling revision, and vectorization for data cleaning are all steps in the pre-processing process. A text document that contains n consecutive objects, including words, numbers, symbols, and punctuation, is said to contain an n-gram. In many text analytics applications where word sequences are important, such as mood analysis, text classification, and text generation, N-gram models are helpful. The Python clean-text library comes with an inbuilt function called remove emoji.
3.3 Data splitting
Before developing the classification scheme, the data will be divided 85:15 between training and testing phases. Training data, not validation or testing data, is used when a deep learning tool is being taught to spot patterns or fulfill predefined criteria.
3.4 EDA
In addition to the traditional modeling & hypothesis testing effort, EDA is used to gain a deeper knowledge of the variables inside the data collection & their interrelationships. The appropriateness of the statistical methods you were planning to use for data analysis can also be determined with its aid. An outlier is a data point that deviates notably from both its immediate surroundings and the rest of the dataset by being noticeably higher or lower.
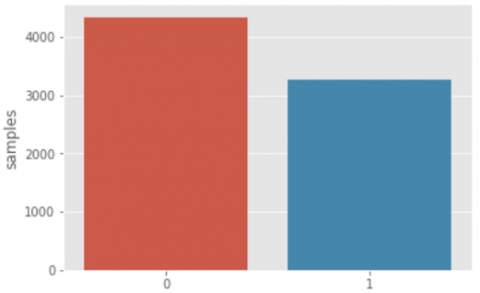
The distribution of tweets about disasters and tweets about no disaster is shown in Figure 1. Class 0 tweets (No catastrophe) outnumber class 1 tweets in terms of frequency. (disaster tweets).
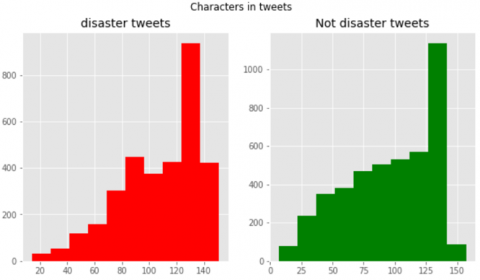
The characters in tweets are depicted in Figure 2. The distribution of both appears to be nearly identical. Red is considered to be a disaster color, while green is considered to be a non-disaster color. The most popular character limit for tweets is between 120 and 140.
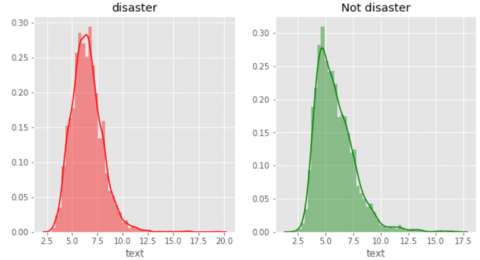
Figure 3 shows the words found in tweets. Both look to have nearly identical distributions. Green is regarded as a color that is not associated with disasters, whereas crimson is. The most common Twitter word count is between 15 and 20.
Figure 1. Class distribution
Figure 2. Characters in tweets
Figure 3. Words in tweets
Figure 4. Average word length in each tweet
Figure 5. Analysing stop words
Red indicates a disaster and green indicates a situation that is not a disaster, with the average word length of each tweet shown in Figure 4 falling between 2.5 and 12.5 characters.
Following analysis, Figure 5 displays the frequently used stop words, including "the," "a," "to," "and," "of," and others. most common stop word is they have more than 1400 values.
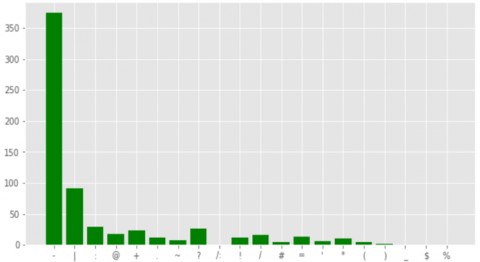
After research, Figure 6 shows the most common punctuation marks, such as "-" "!" ":" "@" "+" and others. The most common puntuation is "-" which has a value of more than 350.
Figure 6. Analyzing punctuations
3.5 Deep learning models
Disaster response using deep learning models such as 1D Convolutional neural network (CNN), Long Short Term Memory, and Recurrent Neural Networks (LSTM), and Gated Recurrent Unit (GRU) with attention mechanisms are used to identify situational tweets that comprise both situational and non-situational information.
3.5.1 Long Short-Term Memory (LSTM)
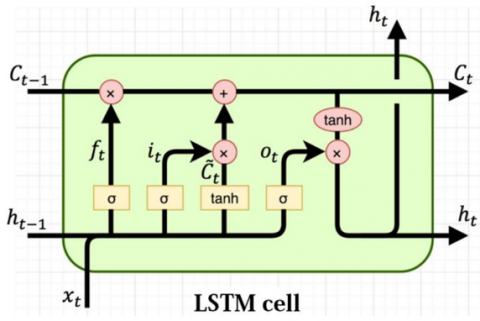
Long short-term memory networks, or LSTM, are a key component of deep learning. Specifically in sequence prediction problems, some varieties of neural networks with recurrent neurons (RNNs) can develop long-term dependencies. LSTM contains feedback connections and it can process the entire sequence of data, unlike single data points like pictures. Used in areas such as voice recognition and machine translation. The LSTM variation of RNNs excels in solving a wide variety of problems. Model architecture of LSTM is shown in Figure 7.
Figure 7. LSTM model
$i_t=\sigma\left(x_t U^I+h_{t-1} W^i\right)$ (1)
$f_t=\sigma\left(x_t U^f+h_{t-1} W^f\right)$ (2)
$o_t=\sigma\left(x_t U^o+h_{t-1} W^o\right)$ (3)
$\tilde{C}_t=\tanh \left(x_t U^g+h_{t-1} W^g\right)$ (4)
$C_t=\sigma\left({f_t}^* C_{t-1}+{i_t}^* \tilde{C}_t\right)$ (5)
$h_t=\tanh \left(C_t\right) * o_t$ (6)
3.5.2 Gated Recurrent Unit (GRU)
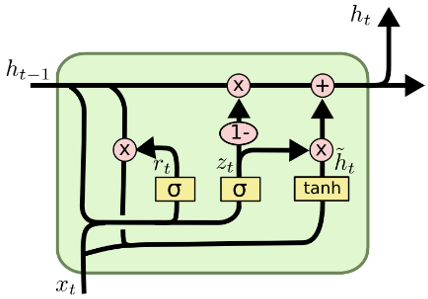
Recurrent neural networks can be classified as gated recurrent units or GRUs. It resembles an LSTM but only has two gates: a restart gate and an update gate. Also missing is an output gate. Since GRUs have fewer parameters, they are often easier and faster to train than LSTMs. Each Gated Recurrent Unit (GRU) in a Gated Recurrent Network (RNN) follows the same procedure as an RNN but employs a unique set of operations and gates. To solve the problem that traditional RNNs have, GRU employs two gates, the Update gate or the Reset gate. The Gated recurrent unit Model is depicted in Figure 8.
$z_t=\sigma\left(W_z \cdot\left[h_{t-1}, x_t\right]\right)$ (7)
$r_t=\sigma\left(W_r \cdot\left[h_{t-1}, x_t\right]\right)$ (8)
$\tilde{h}_t=\tanh \left(W \cdot\left[{r_t }^* h_{t-1}, x_t\right]\right)$ (9)
$h_t=\left(1-z_t\right)^* h_{t-1}+{z_t}^* \tilde{h}_t$ (10)
Figure 8. GRU Model
4.1 Performance evaluation
Data is first gathered from the Twitter API, and then it goes through a preprocessing procedure that includes Ngram analysis, punctuation removal, HTML tag removal, spelling revision, and vectorization to clean up the data. When data is split into an 85:15 training:testing ratio and used to train the suggested model, a text document is said to contain an n-gram if there are n consecutive items, such as words, numbers, symbols, and punctuation. Below are the metrics used for the assessment.
$ Accuracy =\frac{(T P+T N)}{(T P+F P+T N+F N)}$ (12)
$ Precision =\frac{T P}{T P+F P}$ (13)
$ Recall =\frac{T P}{T P+F N}$ (14)
$Loss =-\frac{1}{m} \sum_{i=1}^m \mathcal{Y}_i \cdot \log \left(\widehat{\mathcal{Y}}_i\right)$ (15)
Natural language processing (NLP) activities like sentiment analysis and disaster prediction make extensive use of recurrent neural network (RNN) designs like LSTM (Long Short-Term Memory) and GRU (Gated Recurrent Unit). Both LSTM and GRU have proven useful in dealing with sequential data, but their performance in actual catastrophe prediction tasks may be hindered by their lack of robustness to foreseeable difficulties like noisy or incomplete data.
First, there's "noisy data," which is information marred by the kinds of typos, misspellings, slang, abbreviations, and grammatical inconsistencies that are all too typical in online social interactions. The following are some of the ways in which LSTMs and GRUs are impacted by noisy data:
Noise in the data can introduce inconsistent word embeddings due to differences in word usage. The accuracy with which LSTM and GRU models can "get" the meaning and context of the words being captured can be impacted by this.
Noisy input can disturb the temporal dependencies on which LSTMs and GRUs rely, making it more difficult to capture dependencies. When the noise produces erratic patterns or breaks the sequence structure, these designs may have trouble modelling long-term interdependence.
Although LSTM and GRU models have shown promising performance in NLP tasks such as disaster prediction, they can face difficulties because to their lack of tolerance to noisy or missing input. By addressing the problems caused by noisy and incomplete data, mitigation measures like data pretreatment, data augmentation, contextual enrichment, and attention mechanisms might aid in improving their performance in real-world disaster prediction tasks. It's worth noting, though, that the features of the dataset and the type of noise or incompleteness in the data can affect how well these tactics work.
Table 2. Hyper parameter used for evaluation
|
Dropout |
0.5 |
|
Activation |
Relu |
|
Padding |
same |
|
Epochs |
100 |
|
Metrices |
Accuracy, Precision, Recall and Loss |
|
Layers |
Max pooling |
Table 3. Performance evaluation of LSTM GRU and hybrid bidirectional and LSTM
|
Models |
Accuracy |
Precision |
Recall |
Loss |
|
LSTM |
0.9954 |
0.9907 |
0.9848 |
0.0131 |
|
GRU |
0.9956 |
0.9898 |
0.9865 |
0.0104 |
|
Hybrid GRU-LSTM |
0.9978 |
0.9948 |
0.9931 |
0.0060 |
Performance comparison between LSTM GRU & Hybrid GRU-LSTM is displayed in Table 2, with the highest Accuracy, Precision, Recall, and least loss values obtained by Hybrid GRU-LSTM in comparison to LSTM and GRU Model, GRU-LSTM hybrid received values of 0.9978, 0.9948, 0.9931, & 0.0060, respectively.
The specific hyperparameters that were used in the modeling procedure are detailed in Table 2, which may be seen below. After that, the results of the performance evaluation for the LSTM models, the GRU models, and the hybrid bidirectional LSTM models are presented in Table 3.
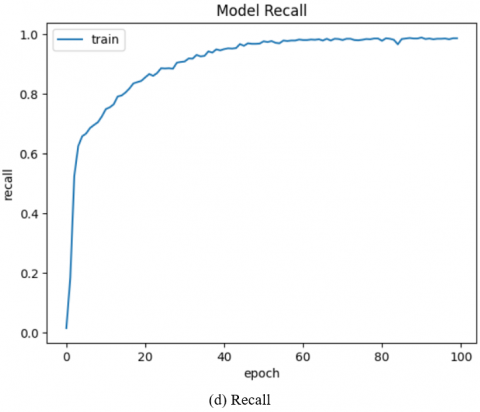
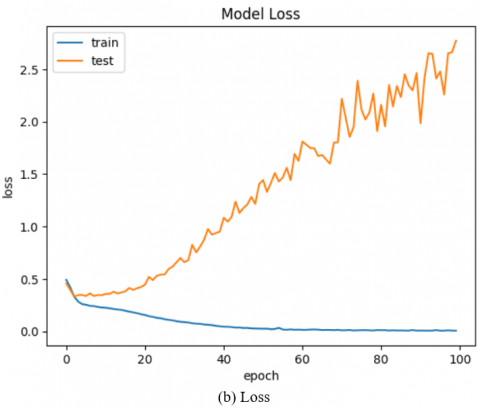
In Figures 9 to 11, the Accuracy, Precision, Recall with Loss curve of the LSTM, GRU, & Hybrid GRU-LSTM Model is displayed, with the Training displayed in Blue and the Testing displayed in Orange.
It is essential to take into account the interpretability of the predictions made by models with Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) in order to comprehend how these models get to their conclusions and derive new understandings from their internal representations. In spite of the fact that LSTM and GRU models are well-known for their capacity to efficiently describe sequential data and to capture long-term dependencies, the interpretability of these models might be difficult to achieve due to their complicated architecture and large dimensionality.
Figure 9. LSTM model performance
Figure 10. GRU model evaluation
Figure 11. Hybrid GRU-LSTM Model Metrics
Sentiment analysis of social media in real time is essential for crisis management. Twitter sentiment during crisis management can be analysed by G-LSTM, a hybrid deep neural network that combines GRUs and LSTM networks. Twitter expedites the spread of disaster reports. Information gathered via Twitter. Certain tweets sent during a crisis prove useful. Twitter users applaud violence, death, and the destruction of property and civilization. Recent disaster updates have been extensively researched. Studying how people use Twitter during natural disasters could save lives. Data from Twitter's API that has been subjected to natural language processing can foretell social media crises. The worst of Twitter Pre-vectorization processing includes N-gramme analysis, removing punctuation and HTML elements, correcting spelling, and proofreading. In this paper, LSTM deep learning is proposed. To comprehend how LSTM and GRU models arrive at conclusions and learn from internal representations, their predictions must be interpretable. While LSTM and GRU models are able to represent sequential data and capture long-term dependencies, they are difficult to interpret due to their complexity and high dimensionality. LSTM, GRU, and LSTM-GRU are some of the deep learning algorithms proposed by this study. Precision, recall, accuracy, and loss are measured. When compared to both LSTM and GRU Models, the hybrid's 0.9978, 0.9948, 0.9931, and 0.0060 accuracy, precision, recall, and loss scores are superior.
[1] Bhavaraju, S.K.T., Beyney, C., Nicholson, C. (2019). Quantitative analysis of social media sensitivity to natural disasters. International Journal of Disaster Risk Reduction, 39: 101251. https://doi.org/10.1016/j.ijdrr.2019.101251
[2] Murthy, D., Gross, A.J. (2017). Social media processes in disasters: Implications of emergent technology use. Social Science Research, 63: 356-370. https://doi.org/10.1016/j.ssresearch.2016.09.015
[3] Zhang, C., Fan, C., Yao, W., Hu, X., Mostafavi, A. (2019). Social media for intelligent public information and warning in disasters: An interdisciplinary review. International Journal of Information Management, 49: 190-207. https://doi.org/10.1016/j.ijinfomgt.2019.04.004
[4] Ogie, R.I., Clarke, R.J., Forehead, H., Perez, P. (2019). Crowdsourced social media data for disaster management: Lessons from the Peta Jakarta. org project. Computers, Environment and Urban Systems, 73: 108-117. https://doi.org/10.1016/j.compenvurbsys.2018.09.002.
[5] Zaw, T.N., Lim, S. (2017). The military's role in disaster management and response during the 2015 Myanmar floods: A social network approach. International Journal of Disaster Risk Reduction, 25: 1-21. https://doi.org/10.1016/j.ijdrr.2017.06.023.
[6] Teodorescu, H.N. (2015). Using analytics and social media for monitoring and mitigation of social disasters. Procedia Engineering, 107: 325-334. https://doi.org/10.1016/j.proeng.2015.06.088
[7] Chair, S., Charrad, M., Saoud, N.B.B. (2019). Towards a social media-based framework for disaster communication. Procedia Computer Science, 164: 271-278. https://doi.org/10.1016/j.procs.2019.12.183
[8] Eismann, K., Posegga, O., Fischbach, K. (2021). Opening organizational learning in crisis management: On the affordances of social media. The Journal of Strategic Information Systems, 30(4): 101692. https://doi.org/10.1016/j.jsis.2021.101692
[9] Gangadhari, R.K., Khanzode, V., Murthy, S. (2021). Disaster impacts analysis using social media data. In 2021 International Conference on Maintenance and Intelligent Asset Management (ICMIAM), IEEE Ballarat, Australia, pp. 1-6. https://doi.org/10.1109/ICMIAM54662.2021.9715186.
[10] Joseph, J.K., Dev, K.A., Pradeepkumar, A.P., Mohan, M. (2018). Big data analytics and social media in disaster management. Integrating Disaster Science and Management, 287-294. https://doi.org/10.1016/B978-0-12-812056-9.00016-6
[11] Sufi, F.K. (2022). AI-SocialDisaster: An AI-based software for identifying and analyzing natural disasters from social media. Software Impacts, 13: 100319. https://doi.org/10.1016/j.simpa.2022.100319
[12] Powers, C.J., Devaraj, A., Ashqeen, K., Dontula, A., Joshi, A., Shenoy, J., Murthy, D. (2023). Using artificial intelligence to identify emergency messages on social media during a natural disaster: A deep learning approach. International Journal of Information Management Data Insights, 3(1): 100164. https://doi.org/10.1016/j.jjimei.2023.100164
[13] Zachlod, C., Samuel, O., Ochsner, A., Werthmüller, S. (2022). Analytics of social media data–State of characteristics and application. Journal of Business Research, 144: 1064-1076. https://doi.org/10.1016/j.jbusres.2022.02.016
[14] Yuan, F., Li, M., Liu, R., Zhai, W., Qi, B. (2021). Social media for enhanced understanding of disaster resilience during Hurricane Florence. International Journal of Information Management, 57: 102289. https://doi.org/10.1016/j.ijinfomgt.2020.102289
[15] Dou, M., Wang, Y., Gu, Y., Dong, S., Qiao, M., Deng, Y. (2021). Disaster damage assessment based on fine-grained topics in social media. Computers & Geosciences, 156: 104893. https://doi.org/10.1016/j.cageo.2021.104893
[16] Raza, M., Awais, M., Ali, K., Aslam, N., Paranthaman, V.V., Imran, M., Ali, F. (2020). Establishing effective communications in disaster affected areas and artificial intelligence based detection using social media platform. Future Generation Computer Systems, 112: 1057-1069. https://doi.org/10.1016/j.future.2020.06.040
[17] Hao, H., Wang, Y. (2020). Leveraging multimodal social media data for rapid disaster damage assessment. International Journal of Disaster Risk Reduction, 51: 101760. https://doi.org/101760. 10.1016/j.ijdrr.2020.101760
[18] Kavota, J.K., Kamdjoug, J.R.K., Wamba, S.F. (2020). Social media and disaster management: Case of the north and south Kivu regions in the Democratic Republic of the Congo. International Journal of Information Management, 52: 102068. https://doi.org/10.1016/j.ijinfomgt.2020.102068
[19] Imran, M., Ofli, F., Caragea, D., Torralba, A. (2020). Using AI and social media multimodal content for disaster response and management: Opportunities, challenges, and future directions. Information Processing & Management, 57(5): 102261. https://doi.org/10.1016/j.ipm.2020.102261
[20] Liu, W., Xu, W.W., Tsai, J.Y.J. (2020). Developing a multi-level organization-public dialogic communication framework to assess social media-mediated disaster communication and engagement outcomes. Public Relations Review, 46(4): 101949. https://doi.org/10.1016/j.pubrev.2020.101949
[21] Li, L.F., Wang, Z.Q., Zhang, Q.P., Wen, H. (2020). Effect of anger, anxiety, and sadness on the propagation scale of social media posts after natural disasters. Information Processing & Management, 57(6): 102313. https://doi.org/10.1016/j.ipm.2020.102313