Albertus Dwiyoga Widiantoro*![]() | Mustafid Mustafid
| Mustafid Mustafid![]() | Ridwan Sanjaya
| Ridwan Sanjaya![]()
© 2023 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
The burgeoning Financial Technology (FinTech) sector in Indonesia, while witnessing a surge in user base, contends with limitations in system functionalities and service offerings. The extraction of latent features from user comments is imperative for the identification of these inadequacies, serving as a catalyst for innovation and delivering advantages to both consumers and developers of FinTech applications. This study employs Latent Dirichlet Allocation (LDA) algorithm, an intelligent probabilistic model, to discern and extract underlying topics within narratives found in user comments on FinTech platforms. In this approach, words within each topic are ranked according to their respective probabilities. Through the LDA algorithm, ten salient topics, each comprising ten keywords, have been identified. These topics coalesce into three broad categories: system improvements in applications, services that are out of sync with the system, and service satisfaction. The coherence of the topics has been quantitatively assessed, with an average score of 0.564, indicative of substantial coherence. Findings from the LDA model are integrated into the User-Centered Design (UCeD) framework, wherein the algorithm streamlines the UCeD's evaluative and abstraction processes, as well as the grouping of user necessities. This integration aids FinTech management teams in pinpointing pertinent user feedback, thereby facilitating the refinement of application development.
Latent Dirichlet Allocation (LDA), feature extraction, Financial Technology (FinTech), User-Centered Design (UCeD), topic modelling
In the rapidly evolving sector of FinTech within Indonesia, significant strides have been witnessed, as evidenced by the proliferation of Android-based applications on the Play Store [1]. However, current FinTech services are fraught with challenges, notably highlighted by a substantial volume of user complaints, concerns over consumer protection [2], susceptibility to fraudulent activities, and illegal fundraising endeavours [3]. It has been empirically observed that user feedback frequently encompasses issues such as erroneous registration processes, verification failures, unjust loan rejections, unaddressed grievances, complications in data erasure, and failures in application upgrades. Matters pertaining to customer satisfaction, including restitution for monetary losses, deficient online support, and the absence of error detection mechanisms, are deemed crucial for the continuity of FinTech services [4].
Users, when encountering difficulties, are known to post reviews on various service platforms; these critiques serve as a rapid and cost-free feedback mechanism. It is postulated that such informative reviews provide insights into a multitude of issues that may escape the conventional development and testing phases, including but not limited to, device compatibility, screen resolutions, operating system variances, and network conditions [5]. It has been noted that Android applications fraught with errors or bugs gravely compromise the application's integrity [6], with tendencies for crashes being ascribed to factors such as complexity, temporal constraints, code anomalies, diffusion issues, and commit history [7]. Consequently, it can be inferred that the appearance, system functionality, and services, collectively referred to as 'features' within the realm of FinTech, are yet to reach an optimal state of reliability.
The term 'Financial Technology', or FinTech, encompasses an interdisciplinary nexus that amalgamates finance, technology management, and innovation management [8]. At its core, FinTech is predicated on the principle of deploying creative and technologically advanced solutions to enhance the efficiency and effectiveness of financial service processes within established commercial frameworks [9]. In technological parlance, FinTech is characterized by the employment of mobile devices, such as smartphones, digital assistants, radio frequency identification devices, and near-field communication tools, to facilitate transactions and the acquisition of goods and services [10]. The inclusivity of FinTech is particularly notable for its capacity to spur economic advancement, alleviate poverty, and buffer the volatility of the credit cycle during economic downturns [11].
Research conducted during the COVID-19 era has revealed that the adoption of FinTech is significantly influenced by customer perceptions of the benefits, societal implications, and trust associated with these technologies [12]. It has been established that trust in FinTech critically mediates the relationship between the perceived risk and the intent to utilize FinTech solutions. This indicates a higher propensity for customers to engage with FinTech services when they associate these platforms with substantial benefits, social value, and trust, while concurrently perceiving reduced risks.
From a corporate standpoint, the assimilation of FinTech is reported to have augmented profitability, catalyzed innovation, and strengthened risk management within the banking sector [13]. Adoption of FinTech enables financial management firms and commercial banks to refine their traditional business models, curtail operational costs, boost service efficiency, bolster risk management frameworks, and develop more customer-centric business models. This, in turn, has been shown to enhance their market competitiveness.
The concept of 'features' within FinTech is critically examined for its potential to advance the field. In the context of system development, 'features' are construed as a cohesive array of system functionalities that embody a segment of the system's requirements, implementation, and artifacts. A feature encapsulates a modularization of individual requirements within a specification, which collectively delineates the system's behavior. Within system implementations, 'features' pertain to a subset of modules associated with specific functionalities and span the entirety of the development life cycle, from requirements to code modules, test cases, and documentation [14]. In the domain of data analysis, 'features' refer to attributes or variables employed to describe and distinguish diverse groups of data objects, either explicitly or latently [15]. The extraction of features from user reviews facilitates the refinement of system functionalities and artifacts within applications. Additionally, 'features' are synonymous with 'dimensions,' conceptualized as latent constructs disseminated throughout the vocabulary used by consumers to articulate user experiences. These dimensions are probabilistically distributed across words or phrases and are interchangeably referred to as 'topics' [16]. An 'aspect' is defined as a semantic concept signifying the attributes of an item that users address in their reviews [17]. Each aspect is associated with a latent topic, a selection of words or phrases extracted from reviews. Aspects, or features, comprise predefined sets of words or phrases. When modeling aspects, several words or phrases extracted from textual reviews can express the properties of specific items [18]. In this study, aspects represent detailed concepts employed to describe items and are extensively utilized in recommendation systems to enhance interpretability [19].
In the domain of FinTech, machine learning has been harnessed to advance financial inclusion [20]. Recent studies have categorized the applications of contemporary data-based algorithmic approaches within this field into risk management, data privacy protection, portfolio management, and sentiment analysis. Such analysis has been exemplified by research utilizing data from Starbucks' Twitter feeds [21]. Given the voluminous nature of user comments, the necessity for service strategies informed by user preferences is paramount [22]. User reviews have been recognized as pivotal channels for uncovering a plethora of application issues [23], with reviews on FinTech features gaining prominence due to their substantial role in augmenting the propensity to adopt mobile banking [24].
User-Centered Design (UCeD), a method from the sphere of human-computer interaction, has been employed to incorporate end-users within the design process, ensuring the usability of the resultant systems [25]. The application development employing UCeD encompasses five principal design activities: scope, analysis, design, validation, and delivery [26]. Certain studies have delineated the UCeD process into stages: user evaluation, grouping user needs, classifying based on user experience, alongside the redesign and prototyping stages, with these phases often facilitated through interviews involving users and key stakeholders to garner insights [27].
UCeD has been implemented within decision support systems across various sectors, including health, where stakeholders' involvement is critical [28]. Its applications range from developing asthma health applications [29] to e-learning systems [30] and patient health reporting tools [31]. Integration of UCeD with agile methodologies, specifically feature-based development, has yielded a web-based information management system [32]. The evaluation of software applications typically involves two crucial quality attributes: usability and user experience. Usability, a task-centric attribute, gauges a system's capacity to enable users to achieve objectives efficiently and effectively [33]. User experience encompasses the entirety of a user's interaction with the system, influenced by their internal states and the system and contextual characteristics [34]. For the creation of intuitive and user-friendly digital services and products, UCeD integrates design elements such as information architecture, ergonomics, market acceptance, and user preferences with functionality/utility, coding, and aesthetics, encompassing the full spectrum of the design process [35]. UCeD methodologies adapt to specific environments, technological advancements, and design objectives, with continuous user testing forming an essential aspect of iterative design refinement [36].
This study introduces an algorithm based on topic modeling, which is posited as an alternative to traditional evaluation methodologies involving user stages, needs aggregation, and experience-based grouping. User review data is processed using a LDA algorithm to accurately ascertain pertinent topics. Topic models perform text extraction and apply probabilistic modeling to uncover latent structures within extensive document archives, identifying patterns of similar word usage. These models are adept at discerning the intrinsic topics within text documents, where a topic embodies a concept pervasive in a corpus and subject to temporal evolution [37]. This modeling approach has been applied to user-generated Amharic text [38], and investigations utilizing the LDA algorithm have spanned various domains. For instance, topic models coupled with time series analysis have been executed on datasets containing property and tax information, demonstrating a capability to generalize from unstructured textual data [39]. Furthermore, the integration of LDA with sentiment analysis has been shown to significantly enhance sentiment classification in transportation systems [40]. LDA’s predictive power extends to forecasting research trends, thereby facilitating future technology anticipation and innovation [41]. Its deployment in trust evaluation through label analysis has proven effective in identifying significant words and representing topics within data stacks [42]. In ecological disturbance research, the amalgamation of topic models with TFIDF and LDA analyses has elucidated association patterns, narrative groups, and trends from voluminous textual datasets [43].
LDA is recognized for its proficiency in handling multi-topic documents and unstructured data, not necessitating background knowledge for topic derivation. However, it is not without its limitations, including the challenge of determining the optimal number of topics and its reliance on word probability distributions to represent each topic. In practice, LDA requires the selection of a predetermined number of topics, thereafter allocating each word to a topic based on its probability—essentially, the word’s likelihood of belonging to a particular topic. This process involves parameter estimation within LDA to deduce the most probable topic distribution.
In this study, the enhancement of FinTech functionalities is pursued through the novel integration of the LDA algorithm and the UCeD model. High-probability words extracted via the LDA algorithm from user reviews are synthesized into topics indicative of system aspects necessitating augmentation or maintenance, as well as user services. These topics are subsequently utilized as inputs to the UCeD model, thus facilitating developers in pinpointing feature development or refinement priorities, thereby augmenting design efficacy in mapping out user requirements within the field of FinTech application development. The research harnesses user commentary data sourced from the Google Play Store, confined to the FinTech application domain and reflective of the user demographic in Indonesia. Through the analysis of user comments on FinTech platforms, application developers may acquire profound market insights prior to product launches or updates, and derive actionable intelligence for application enhancement.
Challenges have been identified in the analysis of user comments within Peer-to-Peer (P2P) Lending applications, increasingly adopting text mining approaches, coupled with the sluggish pace at which application proprietors analyze user feedback. This study aims to address these issues through the implementation of an intelligent methodology to analyze and distill latent topics utilizing LDA, and suggests the adaptation of the UCeD stages to include evaluations by user stages, categorized user requirements, and classification of user experiences via LDA, thereby streamlining the P2P Lending application development process.
The structure of this research is delineated as follows: the introductory segment outlines the context of Fintech in P2P lending, the LDA algorithm, the UCeD model, and the pertinence of this inquiry, concluding with a problem statement and delineation of research objectives. The methodology section details the LDA algorithm's application in topic determination, methodologies for data collection and processing, normalization procedures, and coherence testing. In the results and discussion section, a detailed analysis of the processed data is presented, examining the theoretical ramifications of the findings on the Fintech P2P lending domain, and proposing integration of LDA stages into UCeD. Managerial implications are also contemplated, providing guidance for Fintech application developers. The final section synthesizes the research conclusions and enumerates the study's limitations. This comprehensive compilation is anticipated to enrich the understanding of Fintech P2P lending user commentary, feature relevance, and potential contributions to Fintech management for the enhancement of quality and user experience.
2.1 LDA algorithm
The LDA algorithm was selected due to its capability as a generative probabilistic model to unearth latent semantic structures within a corpus of text. This algorithm is instrumental in categorizing the unstructured comments of P2P lending users into distinct topics, thereby revealing the intrinsic thematic content. The utility of LDA lies in its efficiency and effectiveness in parsing and analyzing voluminous user comments, a task that would otherwise be arduous and protracted if conducted manually.
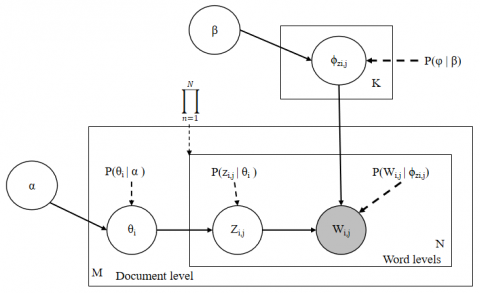
LDA operates as a computational technique that forecasts the assortment of words associated with individual topics and discerns the blend of topics that characterize each document. An illustrative overview of the topic modeling process utilizing LDA is depicted in Figure 1.
Figure 1. Diagram of the LDA topic model
In this model, M signifies the total number of documents in the corpus, N represents the count of words within a specific document (the i-th document contains Ni words). Parameters α and β are the Dirichlet prior parameters influencing the topic distributions per document and word distributions per topic, respectively. θi denotes the distribution of topics for the i-th document, whereas φk encapsulates the word distribution for the k-th topic. The term zi,j corresponds to the topic assigned to the j-th word in the i-th document, and wi,j signifies the actual words in the j-th position within document i. The corpus encompasses a collection of M documents, D={w1, w2, …, wM).
The architecture of the LDA model is hierarchical, where the observable variables are represented by the shaded circles W, and the unshaded circles z and θ pertain to the latent variables. The plates-marked by squares-symbolize repetitions, with the outer plate corresponding to documents, and the inner plate indicating the repeated selection of topics and words within a document. Hyperparameters α and β are posited at the corpus level and presumed to be sampled singularly. The variable K stands for the number of topics, and φ1,…φk is a V-dimensional vector that harbors the parameter distribution of words across topics, given V as the vocabulary size. θ consists of rows defined by documents and columns defined by topics, φ consists of rows defined by topics and columns defined by words. Thus, φ1,…,φK{1-K} refers to a set of rows, or vectors, each of which is a distribution of words. θ1,…,θM{1-M} refers to a set of lines, each of which is a distribution of topics. Document probability distribution in a document and word probability distribution in a topic.
The initial procedure in LDA is the determination of the number of topics, iterations, and the parameters α and β. Subsequently, a random topic is assigned to each word, followed by the execution of the predetermined number of iterations. During each iteration, the probability distribution of topics within a document, and of words within a topic, is computed. From these distributions, the topic assignment for each word is iteratively updated until the prescribed iteration count is reached.
2.2 Research framework and methods
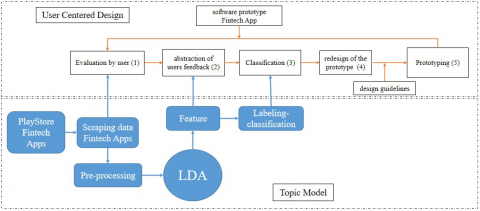
The research framework delineated in this study introduces a methodology for the development of Fintech features through the integration of topic modeling and UCeD, as illustrated in Figure 2. Traditionally, UCeD abstraction and classification involve Focus Group Discussions; however, in this schema, such discussions are supplanted by the application of the LDA model. The approach commences with the extraction of high-probability words from user reviews via the LDA algorithm, which collectively form distinct topics. These identified topics are then employed as inputs for the subsequent stages within the development process. Specifically, these inputs facilitate the developer's task in pinpointing features that necessitate creation or enhancement. Within the confines of UCeD, the methodology adopts topic modeling at various junctures: data collection, data cleansing, and topic derivation using LDA. These stages precede the discussion of feature implications, where the derived topics inform the input for stages one to three. Consequent steps encompass design formulation, prototyping, and iterative re-evaluation, culminating in the implementation of the system should no further modifications be requisite.
2.3 Data collection
Data for this research was obtained from user comments on P2P Lending applications hosted on the Google Play platform. The sample comprised comments from Indonesian users spanning 2020-2021, aggregating to 85,600 remarks prior to pre-processing. Post data deduplication, the corpus was reduced to 52,676 comments. The applications in focus - Investree, Pinjamindo, Banda, Finplus, and KreditPintar - were selected based on their substantial user base and the prevalence of consumer-related issues. The structure of the data encompassed various attributes: username, user image, content, score, thumbsUpCount, reviewCreatedVersion, at, replyContent, reviewAt, sortOrder, and appId. Only the content field, being textual, was extracted for analysis, with each comment being treated as an individual document.
The veracity and dependability of the data are noteworthy, given that it is derived from the Google Play Store, a source previously utilized in related scholarly inquiries into mobile banking, health and fitness applications, and the FinTech sector in Sri Lanka, as referenced in the study of Leem et al. [44-46] respectively. Furthermore, data cleaning protocols were rigorously applied to excise irrelevant and redundant content. To mitigate potential bias, the dataset encompassed a full year’s comments from a representative sample of five FinTech service providers on Google Play.
2.4 Data preprocessing
Data preprocessing was conducted through a structured five-step approach: (1) text normalization to lowercase, (2) special character removal, (3) stop word exclusion, (4) stemming, and (5) term-document matrix construction. Initially, uniformity was achieved by converting all text within the documents to lowercase. Special characters, such as punctuation and numerals, were then removed owing to their irrelevance in text mining analysis. This also included the conversion of the documents into a format amenable to term analysis. The third phase focused on the exclusion of stop words. It is acknowledged that commonly utilized words in any given language-here, Indonesian-do not contribute meaningfully to text analysis and thus were omitted. This process was executed in two distinct steps: the removal of generic stop words and the exclusion of domain-specific stop words. Following this, words were reduced to their base or stem forms to diminish the variation in text data. This process of stemming is a widely recognized practice in text mining, serving to refine the analysis by concentrating on core word forms. The final step entailed the generation of a term-document matrix, encapsulating the frequency of terms across documents. This matrix is critical as it constitutes the primary input for the LDA algorithm. Rigorous preprocessing is paramount, as it curtails the influence of data noise and redundancy on the LDA’s performance. Moreover, in this investigation, words within sentences comprising fewer than four words were omitted based on a manual review that identified such sentences as typically lacking substantive content.
Figure 4. Word cloud of preprocessed fata
Table 1. Lexical normalization in Indonesian text
|
Written Word |
Normalization |
|
bgus |
bagus |
|
bags |
bagus |
|
mdah |
mudah |
|
bngetttt |
banget |
|
kluar |
keluar |
|
pnjm |
pinjam |
|
dl |
download |
|
dlu |
download |
Subsequent to the preprocessing, a dimension reduction approach was applied to the FinTech user reviews, with the intent of isolating the dimensions that bear significantly on customer satisfaction. This is exemplified in the user comments which inherently emphasize areas of user focus or concern. The processed word distribution is depicted in Figure 3.
Preprocessing and normalization of the data, as presented in Figure 4, revealed that high-frequency words hold value in the feature extraction process. Patterns emerged when principal themes were isolated from the corpus. These topics are delineated in Table 1.
Data representation in a vector space model was adopted, denoting word occurrences in documents while disregarding sequence or semantics. A dictionary was formulated utilizing the 'corpora.Dictionary' module from the Gensim package, effectively mapping each word to a unique integer identifier. The construction of a bag-of-words model was then facilitated using the 'dictionary.doc2bow' method, wherein each document was transcribed into a list of (word ID, frequency) tuples.
Data normalization was particularly tailored to account for the use of colloquial and non-standard Indonesian in user comments. This normalization was indispensable to ensure coherence and correct interpretation of the text data.
2.5 Using Sastrawi
For the stemming of Indonesian text, Sastrawi, a specialized algorithmic tool, was employed. This tool is designed for the task of reducing Indonesian words to their root forms, as well as for tokenization, which is the process of splitting text into individual terms.
2.6 Probability distribution of topics in a document
The estimation of topic probabilities within documents is encapsulated by assigning a probabilistic value to each topic's presence. For exemplification, a document denoted as 'I' may present Topic A with a probability of 'X', and Topic B with a probability of 'Y', reflecting the diversity of topics contained within. This value can be derived from the topic probability formula in a document (k, d, alpha=0.1), the number of k topics in document d+aplha divided by the length of the document d+number of topics * alpha. With: K is the Topic index and D is the Document index and alpha is the directlect parameter. The α parameter is used to determine the distribution of topics in a document, the greater the alpha value in a document, indicating the more mix of topics discussed in the document.
The evaluation of LDA incorporates methods predicated on human judgment. The topic model identifies clusters of words, designated as 'topics', from the document's textual content without the prerequisite of semantic annotation. Given the absence of semantic anchoring, these topics may not be intrinsically interpretable. Consequently, coherence measures are employed to discern the distinction between them. A cohort of ten topics will undergo a coherence evaluation, with expertise in information systems and linguistics being pivotal for the interpretation of the lexical items. The quality of topics extrapolated from the models is measured by a specific metric known as 'topic coherence'. This metric is pivotal in gauging human comprehension of the latent topics. A significant attribute of this metric is the assessment of its value against the original corpus that served to train the topic model, rather than any external corpus. The calculation of the topic coherence score is conducted by applying the prescribed equation.
2.7 Coherence
In the context of LDA analysis, the coherence score is employed as an indicator to evaluate the integrity of topics deduced from the model. This coherence refers to the degree to which a set of topics or facts substantiates one another, thereby facilitating a comprehensive and coherent interpretation pertinent to the context. Within a document, coherence implies that the extracted topics encapsulate the core message or the underlying thematic essence.
To ascertain the ideal quantity of topics within an LDA framework, the coherence score is deemed critical. It underpins the profundity of comprehension regarding the subject matter at hand. The current analysis adopts the C_V coherence measure, which involves a methodical sliding window technique, segmentation of prominent keywords, and an indirect validation approach employing pointwise mutual information (NPMI) along with cosine similarity to appraise the degree of coherence.
$C_{-} V=\sum i<j \operatorname{score}\left(w_i, w_j\right)$ (1)
In the Eq. (1), for a topic, the words i, j are scored ∑i<j score (wi, wj) has the highest probability of occurrence for that topic. It’s assumed that the number of words in a topic of 10 words is considered a score.
Here, the sigma notation (∑) signifies the aggregation of elements within the series. Indices i and j denote the positions of words within the topic, and the score (wi, wj) is a metric that quantifies the semantic interrelation between word pairs wi and wj. The frequency of concurrent appearance within the corpus texts or semantic similarity, as assessed by metrics such as NPMI or Cosine Similarity, underlies this scoring. The calculation encompasses all unique word pairs in a topic where i<j, circumventing redundant recalculations, parallel pairings, and self-pairings. The cumulative outcome of these scores is the coherence value for the topic, reflecting the semantic congruency among the constituent words. A higher coherence value (C_V) signifies a topic characterized by greater semantic cohesion, thereby serving as a robust indicator of the topic model's quality.
3.1 Coherence testing results
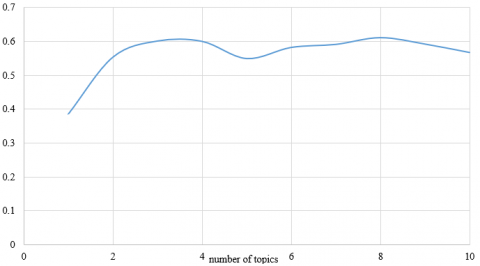
An examination of coherence scores derived from P2P lending user commentary yielded encouraging results. Elevated coherence scores are indicative of the topic modeling framework's efficacy in generating topics with substantial relatedness. The objective resides in striking a delicate equilibrium between a comprehensive array of topics to encapsulate the data's variability and the achievement of topics marked by high coherence. As depicted in Table 2, varying the number of topics within the P2P dataset elicited fluctuating coherence outcomes, as visually represented in Figure 5. An analysis of the C_V coherence values assigned to individual topics, along with the frequency of each word within these topics, revealed a spectrum of coherence. Notably, a set of eight topics emerged with the pinnacle coherence value of 0.612, whereas the solitary topic configuration presented the nadir value of 0.385. The coherence values oscillated between 0.385 and 0.612. With a threshold coherence value set at 0.50, the model identified ten topics, each comprising ten words, surpassing this benchmark. The mean coherence value across all topics stood at 0.564, thus all topics were adjudged to exceed the stipulated average coherence criterion of 0.50. This outcome was instrumental in the identification of FinTech-related thematic features, leading to the selection of these ten topics. This constellation of topics demonstrated sufficient word occurrences to divulge pertinent information while maintaining readability.
Table 2. Topic coherence
|
Number of Topics |
Coherence Score |
|
1 |
0.385 |
|
2 |
0.554 |
|
3 |
0.602 |
|
4 |
0.601 |
|
5 |
0.550 |
|
6 |
0.583 |
|
7 |
0.592 |
|
8 |
0.612 |
|
9 |
0.593 |
|
10 |
0.568 |
Figure 5. Coherence graph
3.2 Processing results using LDA
The LDA algorithm yielded topics φzi,j, document-specific topic assignments Zi,j, and topic proportions θi as outcomes. The distribution of words within the topics is illustrated in Table 2, where for each topic, the ten most probable words from the posterior distribution are listed. Such distributions offer a granular view of the topics' composition.
Given that topics are distributions of words, to facilitate a more accessible interpretation, topics were assigned labels post-analysis rather than being presented merely as word amalgamations. The derivation of topics through unsupervised learning precludes the automation of topic labeling, necessitating human judgment to evaluate coherence and meaningfulness and to apply labels [44, 47]. Consequently, subsequent to topic extraction via LDA, the results were scrutinized and labeled during a focused group discussion (FGD). The FGD encompassed an Expert in Information Systems, three Information Systems candidates, and a Language expert, culminating in the categorization of topics into three primary groups.
Further results from the LDA included assignments of topics to each document (Zi,j), and the proportional representation of topics (θi). Within the corpus of FinTech user comments, it proved insightful to portray the topics pertinent to each comment, including their proportional significance. The topics were visually differentiated in the text, with relevant words for each topic highlighted accordingly.
Table 3 showcases the output of Topic 1 from the LDA processing, displaying a set of ten words alongside their respective probability values-0.254, 0.100, 0.065, etc.-indicative of their prevalence within the topic. Accompanying these quantitative data, a descriptive column presents interpretations derived from a focused group discussion, underscoring the human element in the analytical process. Analysis of the P2P lending data yielded ten distinct topics, each distinguished by a significant degree of coherence. The thematic range is broad, encompassing various user experiences: Topic 1 relates to challenges encountered in data deletion; Topic 2 identifies issues with updating procedures and borrowing; Topic 3 corresponds to the rejection of loan applications; Topic 4 discusses the anomalies in credit settlement; Topic 5 captures the complications in application login and subsequent customer service interactions, leading to application un-installation; Topic 6 reflects the expediency of the loan approval process; Topic 7 praises the efficacy and comprehensiveness of certain applications in facilitating loans; Topic 8 pertains to the adaptability of functions for business capital and transactions; Topic 9 touches on the automatism in loan deductions; while Topic 10 delves into the unsuccessful acquisition of promotional vouchers. The human-augmented evaluation of these ten topics has ensured that each term can be seamlessly integrated within the Fintech discourse, in alignment with the assertions by Chang et al. [48] regarding the necessity of human verification for the word probabilities within each topic model.
Table 3. Description of the topic processing results
|
Topic |
Processing Results with 10 Words |
Description |
|
Topic 1 |
0.254 data, 0.108 help, 0.100 delete, 0.065 wrong, 0.064 name, 0.056 borrow, 0.036 responsible, 0.033 accept, 0.032 charge, 0.031 report |
Borrowing data errors and difficulties in deleting data |
|
Topic 2 |
0.182 liquid, 0.144 funds, 0.103 Download, 0.086 update, 0.083 Difficult, 0.052 change, 0.047 customer, 0.044 Borrow, 0.035 difficult, 0.029 Plus |
Difficulty/difficulty in updating and borrowing and disbursing funds |
|
Topic 3 |
0.333 proposals, 0.227 decline, 0.181 borrow, 0.061 acc, 0.054 person, 0.025 personal, 0.023cancel, 0.019 trick, 0.016 turn, 0.010steal |
Refusal/disapproval of loan applications, danger of data theft |
|
Topic 4 |
0.205 accounts, 0.201 pay, 0.085 credit, 0.070 admin, 0.050 paid, 0.046 tempo, 0.039 fall, 0.039 bill, 0.039 borrow, 0.030 success |
Redemption detection error: Credit was repaid even though it was deemed due |
|
Topic 5 |
0.167login, 0.150times, 0.083email, 0.070cs, 0.066destination, 0.060arrived, 0.060send, 0.040uninstall, 0.035help, 0.032clear |
Difficulty entering the application and contacting CS, finally uninstalled it |
|
Topic 6 |
0.184acc, 0.079 easy, 0.070 borrow, 0.070 fast, 0.053 need, 0.051 hope, 0.048 process, 0.041 interest, 0.038 register, 0.036 late |
The hope is that the loan process will be quickly approved |
|
Topic 7 |
0.398 good, 0.200 help, 0.106 limit, 0.070 good, 0.065 complicated, 0.045 complete, 0.027 got, 0.024 only, 0.015 not bad, 0.011 suggestions |
Good and complete application, can help with loans, so that the limits and completeness are not complicated |
|
Topic 8 |
0.124 money, 0.120 use, 0.115 balance, 0.090 content, 0.074 service, 0.065 order, 0.059 buy, 0.047 capital, 0.045 credit, 0.039 business |
Use of loans for business capital, buy credit to confirm to the system |
|
Topic 9 |
0.189 direct, 0.146 system, 0.132 reason, 0.114 transfer, 0.088 conform, 0.082 return, 0.056 cut, 0.049 borrow, 0.031 yesterday, 0.020 price |
Complaints about automation in loan deductions, which are transferred not according to deductions |
|
Topic 10 |
0.083 disappointed, 0.071 failed, 0.068 expired, 0.066 ktp, 0.055 promo, 0.048 true, 0.046 bank, 0.044 voucher, 0.034 completed, 0.030 now |
Disappointed because I failed to get a promo voucher |
Table 4. System topics that must be repaired from the system and service side
|
Topic |
Description |
|
Topic 1 |
Borrowing data errors and difficulties in deleting data |
|
Topic 2 |
Difficulty/difficulty in updating and borrowing and disbursing funds |
|
Topic 4 |
Redemption detection error: Credit was repaid even though it was deemed due |
|
Topic 5 |
difficulty entering the application and contacting CS, finally uninstalled it |
Table 5. Service topics that are out of sync with the system
|
Topic |
Description |
|
Topic 3 |
Refusal/disapproval of loan applications, danger of data theft |
|
Topic 8 |
Use of loans for business capital, buy credit to confirm to the system |
|
Topic 10 |
Disappointed because I failed to get a promo voucher |
Table 6. Service topics that must be maintained (user satisfaction)
|
Topic |
Description |
|
Topic 6 |
The hope is that the loan process will be quickly approved |
|
Topic 7 |
Good and complete application, can help with loans, so that the limits and completeness are not complicated |
|
Topic 9 |
Complaints about automation in loan deductions, which are transferred not according to deductions |
The analytic outcome delineates three principal clusters derived from the data: Group 1 encompasses aspects linked to the application system (Table 4), Group 2 pertains to service-related topics (Table 5), and Group 3 corresponds to service satisfaction (Table 6). Group 1 comprises four distinct topics-1, 2, 4, and 5-each bearing relevance to the application system's functionality. As detailed in Table 4, these topics address several user challenges: the intricacies of erasing personal data, hurdles in updating processes, errors in payment recognition, and obstacles faced when accessing the application. Group 2, as presented in Table 5, includes three topics-3, 8, and 10-that revolve around the realm of application services. This cluster captures the nuances of loan application rejections, potential threats of data breaches, the strategic utilization of loans for business capital, and the frustration stemming from unattained promotional benefits. Lastly, Group 3, demonstrated in Table 6, consists of three topics-6, 7, and 9-which are indicative of customer satisfaction levels. The subjects covered here range from the efficiency of the loan approval process and the effectiveness of applications facilitating loan procurement to the systematic procedures of loan deductions.
3.3 The topic's relationship with FinTech
The topics elicited via LDA highlight critical areas in FinTech application development necessitating attention. It is discerned that a subset of system-related topics, as enumerated in Table 4, demands immediate rectification and enhancement. This includes Topic 1, which deals with the complications encountered in borrowing data and the challenges in data deletion; Topic 2, which delves into the issues with updates, borrowing, and the disbursement of funds; Topic 4, which reveals discrepancies in repayment detection, specifically instances where credits were erroneously marked as repaid; and Topic 5, which encompasses difficulties in application access and the consequent necessity to contact customer support, often culminating in the application's uninstallation.
Such findings underscore an imperative for augmentative measures in financial technology application features, signified by the preponderance of user-centered topics (four topics) necessitating managerial heed for the betterment of services. Concurrently, certain aspects receive affirmative user feedback, notably the expedited loan approval processes, the utility of applications in loan facilitation, and the automated deduction features within the system. These positive domains, identified by user commendation, should not only be preserved but potentially highlighted as core competencies.
This analysis, transcending beyond the attribute-level sentiment identification as observed by Han and Moghaddam [49], leverages LDA to pinpoint critical themes integral to the evolution of FinTech offerings. The derived topics outline several dimensions: Table 3 delineates four system and service topics requiring urgent attention; Table 4 presents three topics reflecting consumer service issues that impart insights into customer service challenges; and Table 5 spotlights three topics associated with customer satisfaction, services that are endorsed by users and should be upheld or even showcased as exemplary.
The aggregate of discerned topics furnishes substantive insights into user encounters with FinTech products and services. Such analytics are instrumental for developers to identify and prioritize system enhancements. The utility of topic modeling in parsing user commentary is thus validated, with the application of LDA producing semantically cohesive and interpretable clusters that not only condense voluminous documents but also illuminate patterns within user feedback for streamlined analysis.
3.4 The topic of models on UCeD
The UCeD model encompasses several phases, including user evaluation, the categorization of user requirements based on user experiences, and iterative redesign culminating in prototyping [26]. This methodology aligns with the approach adopted by Cen et al. [50], wherein the LDA algorithm is employed to discern latent thematic structures within user comments, thereby eliciting significant lexical features that can be construed into evaluative statements, experiential accounts, and user necessities in the context of UCeD. LDA facilitates the UCeD process by assimilating three core steps: evaluation, abstraction, and classification of user requirements. Specifically, in the LDA phase, the initial data scraping yields user comments which supplant the evaluation phase; subsequent clustering generates topics which surrogate the abstraction process; and the final adjustment and thematic grouping supersedes the user needs grouping stage.
The topical modeling yields ten distinct topics, which are categorized into three principal segments: system-related topics necessitating rectification from both system and service perspectives, services exhibiting misalignment with system capabilities, and services meriting preservation. This is congruent with the assertion by Tian et al. [18] that UCeD orchestrates the evaluation phase by the user, consolidates user needs, and organizes these based on user experiences to inform redesign and prototyping activities. Employing the LDA stage within UCeD offers the potential to enhance the efficiency and velocity of the FinTech application improvement process. At this juncture, it suffices to extract features from FinTech user commentary, which can be managed by the system, allowing for data retrieval, processing, and interpretation to occur seamlessly and in real-time.
In this study, latent dimensions within comments by Indonesian Fintech service users were investigated through the application of LDA. It was demonstrated that LDA can uncover significant dimensions within user comments, dimensions which may remain obscured by traditional analytical approaches. The heterogeneity and intensity intrinsic to these user comments necessitate extraction and identification for a nuanced understanding of user sentiment.
The managerial implications of this research are manifold. Primarily, it equips managers in the Fintech sector with the capability to discern the importance and diversity of topics within user-generated data. Additionally, by harnessing customer discourse, P2P Fintech perceptions are mapped, uniquely highlighting features that necessitate enhancement, and those that should be preserved, advancing beyond the scope of consumer satisfaction dimensions as explored by previous studies [41]. Three distinct categories emerged from the analysis: topics related to system improvements, topics indicating a dissonance between service expectations and system performance, and topics associated with service aspects that warrant maintenance. These categories suggest that P2P lending applications demand managerial attention to address shortcomings and to sustain commendable features.
The efficacy of the proposed approach, in distilling meaningful topics from P2P lending user comments, was substantiated through the research findings. For instance, the prevalence of the topic concerning 'data and account access difficulties' signalled a pronounced consumer concern for security in their financial dealings. Such insights are imperative for the progression of financial technologies, signalling a requisite for heightened security protocols.
This research offers a window into the challenges faced by consumers in the realm of Fintech P2P lending, aiding financial institutions and policy-makers in pinpointing areas ripe for enhancement. The utilization of LDA in elucidating latent topics from user grievances permits stakeholders a more profound comprehension of consumer necessities and apprehensions, paving the way for improved product and service development.
The outcomes derived from the LDA serve as inputs in the implementation phase of the UCeD model. It was observed that LDA encapsulates and streamlines the UCeD's tripartite process, encompassing evaluation, abstraction, and the categorization of user needs. Such facilitation is poised to assist management in the development of Fintech applications adhering to the UCeD paradigm.
Further research is envisaged to integrate deep learning methodologies with sentiment analysis, aiming to enhance the efficiency of the proposed approach when applied to extensive data sets. Such integration is anticipated to yield a more profound understanding of the underlying data. Moreover, the versatility of the method will be explored through its application in domains beyond the financial markets, thereby evaluating its broader applicability and utility.
[1] Phan, D.H.B., Narayan, P.K., Rahman, R.E., Hutabarat, A.R. (2020). Do financial technology firms influence bank performance? Pacific-Basin Finance Journal, 62: 101210. https://doi.org/10.1016/j.pacfin.2019.101210
[2] Davis, K., Maddock, R., Foo, M. (2017). Catching up with Indonesia’s fintech industry. Law and Financial Markets Review, 11(1): 33-40. https://doi.org/10.1080/17521440.2017.1336398
[3] Agarwal, S., Chua, Y.H. (2020). FinTech and household finance: A review of the empirical literature. China Finance Review International, 10(4): 361-376. https://doi.org/10.1108/CFRI-03-2020-0024
[4] Jerene, W., Sharma, D. (2020). The effect of e-finance service quality on bank customers' fintech e-loyalty: Evidence from Ethiopia. International Journal of E-Business Research (IJEBR), 16(2): 69-83. https://doi.org/10.4018/IJEBR.2020040105
[5] Palomba, F., Linares-Vásquez, M., Bavota, G., Oliveto, R., Di Penta, M., Poshyvanyk, D., De Lucia, A. (2018). Crowdsourcing user reviews to support the evolution of mobile apps. Journal of Systems and Software, 137: 143-162. https://doi.org/10.1016/j.jss.2017.11.043
[6] Su, T., Fan, L., Chen, S., Liu, Y., Xu, L., Pu, G., Su, Z. (2020). Why my app crashes? understanding and benchmarking framework-specific exceptions of android apps. IEEE Transactions on Software Engineering, 48(4): 1115-1137. https://doi.org/10.1109/TSE.2020.3013438
[7] Xia, X., Shihab, E., Kamei, Y., Lo, D., Wang, X. (2016). Predicting crashing releases of mobile applications. In Proceedings of the 10th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, Ciudad Real Spain, pp. 1-10. https://doi.org/10.1145/2961111.2962606
[8] Milian, E.Z., Spinola, M.D.M., de Carvalho, M.M. (2019). Fintechs: A literature review and research agenda. Electronic Commerce Research and Applications, 34: 100833. https://doi.org/10.1016/j.elerap.2019.100833
[9] Leong, K., Sung, A. (2018). FinTech (Financial Technology): What is it and how to use technologies to create business value in fintech way? International Journal of Innovation, Management and Technology, 9(2): 74-78. https://doi.org/10.18178/ijimt.2018.9.2.791
[10] Alkhowaiter, W.A. (2020). Digital payment and banking adoption research in Gulf countries: A systematic literature review. International Journal of Information Management, 53: 102102. https://doi.org/10.1016/j.ijinfomgt.2020.102102
[11] López, T., Winkler, A. (2019). Does financial inclusion mitigate credit boom-bust cycles? Journal of Financial Stability, 43: 116-129. https://doi.org/10.1016/j.jfs.2019.06.001
[12] Al Nawayseh, M.K. (2020). Fintech in COVID-19 and beyond: what factors are affecting customers’ choice of fintech applications? Journal of Open Innovation: Technology, Market, and Complexity, 6(4): 153.
[13] Wang, Y., Xiuping, S., Zhang, Q. (2021). Can fintech improve the efficiency of commercial banks? An analysis based on big data. Research in International Business and Finance, 55: 101338. https://doi.org/10.1016/j.ribaf.2020.101338
[14] Turner, C.R., Fuggetta, A., Lavazza, L., Wolf, A.L. (1999). A conceptual basis for feature engineering. Journal of Systems and Software, 49(1): 3-15. https://doi.org/10.1016/S0164-1212(99)00062-X
[15] Dong, G., Liu, H. (2018). Feature engineering for machine learning and data analytics. CRC press.
[16] Tirunillai, S., Tellis, G.J. (2014). Mining marketing meaning from online chatter: Strategic brand analysis of big data using latent dirichlet allocation. Journal of Marketing Research, 51(4): 463-479. https://doi.org/10.1509/jmr.12.0106
[17] Banna, H., Hassan, M.K., Rashid, M. (2021). Fintech-based financial inclusion and bank risk-taking: Evidence from OIC countries. Journal of International Financial Markets, Institutions and Money, 75: 101447. https://doi.org/10.1016/j.intfin.2021.101447
[18] Tian, X., He, J.S., Han, M. (2021). Data-driven approaches in FinTech: a survey. Information Discovery and Delivery, 49(2): 123-135. https://doi.org/10.1108/IDD-06-2020-0062
[19] Hu, Z., Ding, S., Li, S., Chen, L., Yang, S. (2019). Adoption intention of fintech services for bank users: An empirical examination with an extended technology acceptance model. Symmetry, 11(3): 340. https://doi.org/10.3390/sym11030340
[20] Tao, C., Guo, H., Huang, Z. (2020). Identifying security issues for mobile applications based on user review summarization. Information and Software Technology, 122: 106290. https://doi.org/10.1016/j.infsof.2020.106290
[21] Pandey, N., Pal, A. (2020). Impact of digital surge during Covid-19 pandemic: A viewpoint on research and practice. International Journal of Information Management, 55: 102171. https://doi.org/10.1016/j.ijinfomgt.2020.102171
[22] Kopf, L. M., & Huh-Yoo, J. (2023). A user-centered design approach to developing a voice monitoring system for disorder prevention. Journal of Voice, 37(1): 48-59. https://doi.org/10.1016/j.jvoice.2020.10.015
[23] Maedche, A., Botzenhardt, A., Neer, L. (2012). Software for people: Fundamentals, trends and best practices. Springer Science & Business Media. https://doi.org/10.1007/978-3-642-31371-4
[24] Burkhardt, D., Stab, C., Steiger, M., Breyer, M., Nazemi, K. (2012). Interactive exploration system: A user-centered interaction approach in semantics visualizations. In 2012 International Conference on Cyberworlds, Darmstadt, Germany, pp. 261-267. https://doi.org/10.1109/CW.2012.45
[25] Tucker Edmonds, B., Hoffman, S.M., Lynch, D., Jeffries, E., Jenkins, K., Wiehe, S., Kuppermann, M. (2019). Creation of a decision support tool for expectant parents facing threatened periviable delivery: Application of a user-centered design approach. The Patient-Patient-Centered Outcomes Research, 12: 327-337. https://doi.org/10.1007/s40271-018-0348-y
[26] Lewis, E., Martin, N., Koeppen, K., Uriarte, A., Poirier, L., Trujillo, A., Gittelsohn, J. (2022). User-centered design of a mobile application to improve healthy food availability in under-resourced urban settings. Current Developments in Nutrition, 6(S1): 134-134. https://doi.org/10.1093/cdn/nzac051.050
[27] Banimahendra, R.D., Santoso, H.B. (2018). Implementation and evaluation of LMS mobile application: scele mobile based on user-centered design. In Journal of Physics: Conference Series, 978(1): 012024. https://doi.org/10.1088/1742-6596/978/1/012024
[28] Gracey, L.E., Zan, S., Gracz, J., Miner, J.J., Moreau, J.F., Sperber, J., Kvedar, J.C. (2018). Use of user-centered design to create a smartphone application for patient-reported outcomes in atopic dermatitis. NPJ Digital Medicine, 1(1): 33. https://doi.org/10.1038/s41746-018-0042-4
[29] Krohn, T., Kindsmüller, M.C., Herczeg, M. (2009). User-centered design meets feature-driven development: An integrating approach for developing the web application myPIM. In Human Centered Design: First International Conference, HCD 2009, Held as Part of HCI International 2009, San Diego, CA, USA, pp. 739-748. https://doi.org/10.1007/978-3-642-02806-9_86
[30] Nakamura, W.T., de Oliveira, E.C., de Oliveira, E.H., Redmiles, D., Conte, T. (2022). What factors affect the UX in mobile apps? A systematic mapping study on the analysis of app store reviews. Journal of Systems and Software, 193: 111462. https://doi.org/10.1016/j.jss.2022.111462
[31] Law, E.L.C., Van Schaik, P. (2010). Modelling user experience–An agenda for research and practice. Interacting with Computers, 22(5): 313-322. https://doi.org/10.1016/j.intcom.2010.04.006
[32] Sánchez, E., Macías, J.A. (2019). A set of prescribed activities for enhancing requirements engineering in the development of usable e-Government applications. Requirements Engineering, 24: 181-203. https://doi.org/10.1007/s00766-017-0282-x
[33] Trilar, J., Sobočan, T., Stojmenova Duh, E. (2021). Family-centered design: Interactive performance testing and user interface evaluation of the Slovenian eDavki public tax portal. Sensors, 21(15): 5161. https://doi.org/10.3390/s21155161
[34] Lamba, M., Madhusudhan, M. (2019). Author-topic modeling of DESIDOC journal of library and information technology (2008-2017), India. Library Philosophy and Practice, 1-15.
[35] Cheng, Z., Ding, Y., Zhu, L., Kankanhalli, M. (2018). Aspect-aware latent factor model: Rating prediction with ratings and reviews. In Proceedings of the 2018 world wide web conference, pp. 639-648. https://doi.org/10.1145/3178876.3186145
[36] Guan, X., Cheng, Z., He, X., Zhang, Y., Zhu, Z., Peng, Q., Chua, T.S. (2019). Attentive aspect modeling for review-aware recommendation. ACM Transactions on Information Systems (TOIS), 37(3): 1-27. https://doi.org/10.1145/3309546
[37] Zeng, Z., Shi, Y., Pieptea, L.F., Ding, J. (2021). Using latent features for building an interpretable recommendation system. The Electronic Library, 39(2): 281-295. https://doi.org/10.1108/EL-06-2020-0154
[38] Fang, X., Zhan, J. (2015). Sentiment analysis using product review data. Journal of Big Data, 2(1): 1-14. https://doi.org/10.1186/s40537-015-0015-2
[39] Lai, Y., Kontokosta, C.E. (2019). Topic modeling to discover the thematic structure and spatial-temporal patterns of building renovation and adaptive reuse in cities. Computers, Environment and Urban Systems, 78: 101383. https://doi.org/10.1016/j.compenvurbsys.2019.101383
[40] Ali, F., Kwak, D., Khan, P., El-Sappagh, S., Ali, A., Ullah, S., Kwak, K.S. (2019). Transportation sentiment analysis using word embedding and ontology-based topic modeling. Knowledge-Based Systems, 174: 27-42. https://doi.org/10.1016/j.knosys.2019.02.033
[41] Gupta, R.K., Agarwalla, R., Naik, B.H., Evuri, J.R., Thapa, A., Singh, T.D. (2022). Prediction of research trends using LDA based topic modeling. Global Transitions Proceedings, 3(1): 298-304. https://doi.org/10.1016/j.gltp.2022.03.015
[42] Chen, X., Yuan, Y., Orgun, M.A., Lu, L. (2020). A topic-sensitive trust evaluation approach for users in online communities. Knowledge-Based Systems, 194: 105546. https://doi.org/10.1016/j.knosys.2020.105546
[43] Altaweel, M., Bone, C., Abrams, J. (2019). Documents as data: a content analysis and topic modeling approach for analyzing responses to ecological disturbances. Ecological Informatics, 51: 82-95. https://doi.org/10.1016/j.ecoinf.2019.02.014
[44] Leem, B.H., Eum, S.W. (2021). Using text mining to measure mobile banking service quality. Industrial Management & Data Systems, 121(5): 993-1007. https://doi.org/10.1108/IMDS-09-2020-0545
[45] Guo, L., Sharma, R., Yin, L., Lu, R., Rong, K. (2017). Automated competitor analysis using big data analytics: Evidence from the fitness mobile app business. Business Process Management Journal, 23(3): 735-762. https://doi.org/10.1108/BPMJ-05-2015-0065
[46] Sally, M.S. (2023). Why are consumers dissatisfied? A text mining approach on Sri Lankan mobile banking apps. International Journal of Intelligent Computing and Cybernetics, 16(4): 727-744. https://doi.org/10.1108/IJICC-02-2023-0027
[47] Bastani, K., Namavari, H., Shaffer, J. (2019). Latent Dirichlet allocation (LDA) for topic modeling of the CFPB consumer complaints. Expert Systems with Applications, 127: 256-271. https://doi.org/10.1016/j.eswa.2019.03.001
[48] Chang, J., Gerrish, S., Wang, C., Boyd-Graber, J., Blei, D. (2009). Reading tea leaves: How humans interpret topic models. Advances in Neural Information Processing Systems, 22: 288-296.
[49] Han, Y., Moghaddam, M. (2021). Analysis of sentiment expressions for user-centered design. Expert Systems with Applications, 171: 114604. https://doi.org/10.1016/j.eswa.2021.114604
[50] Cen, C., Luo, G., Li, L., Liang, Y., Li, K., Jiang, T., Xiong, Q. (2023). User-centered software design: user interface redesign for Blockly–electron, artificial intelligence educational software for primary and secondary schools. Sustainability, 15(6): 5232. https://doi.org/10.3390/su15065232