Ratnakumari Challa* | VijayaKumari Gunta
© 2021 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Homomorphic encryption (HE) schemes became popular cryptographic primitives and very useful in variety of security applications. Homomorphic encryption based on coding theory have the advantages of faster computations due to the structural properties of the codes used. Several schemes are supporting unlimited $\operatorname{Mod} 2$ addition operations in literature. The present paper introduces Reed-Muller (RM) code based $\operatorname{Mod} 2$ multiplication operation thereby making RM code based HE scheme fully homomorphic. The representation of the codeword with necessary adaption to support unlimited number of $\operatorname{Mod} 2$ multiplication operations is presented along with the scheme first. The correctness proof of the homomorphic operations along with experimental evaluation is also presented to demonstrate the practical aspects of the proposal.
reed-muller code, coding theory, erroneous codewords, permutation, majority logic decoding
Homomorphic encryption is powerful cryptographic tool that enables secure computations on the private data. It evaluates any function for any operation securely on the encrypted data without knowing its corresponding plaintext. For original data p, c denotes the ciphertext of the original plaintext p, i.e., $c=E_{k}(p)$. The encryption scheme $E_{k}$ is said to be homomorphic with respect to some set of operations O, if, for any operation $o \in 0$ one can compute $E_{k}\left(p_{1}\right.$ o $\left.p_{2}\right)$ from $E_{k}\left(p_{1}\right)$ o $E_{k}\left(p_{2}\right)$.
In 1978, Rivest et al. investigated first design for homomorphic encryption scheme [1] and that was broken in 1987 [2]. Later research was carried on to determine the secure schemes which can perform homomorphic encryption operations efficiently. In 2009, Craig Gentry’s breakthrough work [3] has described theoretical construction of Fully Homomorphic encryption scheme. That scheme has become popular model as well as the root for other related developments of FHE schemes. Based on Gentry’s breakthrough work, a number of developments, variations and new FHE schemes were proposed. Few of such developments and variants are: the FHE scheme based on worst-case hardness on lattice problems [4]; Gentry’s scheme with reduced key and ciphertexts [5]; FHE scheme with practical implementation [6]; FHE based on Learning with Errors over Rings [7]; Ring-LWE based FHE [8]; Homomorphic encryption based on coding theory [9]; levelled FHE without bootstrapping [10]; FHE with fast implementation of operations [11]; and Reed-Muller based FHE using post processing [12]. Integer based HE scheme [13, 14] Homomorphic encryption schemes based on coding theory were developed, they support unlimited addition operations but multiplication operations with some specified depth [9].
Based on the standard theoretical schemes, several implementations of FHE are developed [15]. Few of them are PALISADE [16], HEAAN [17], FV-NFLib [18], NuFHE [19]. FHE with practical time complexities has shown to be very beneficial in secure cloud computing, as well as in a variety of other applications. Despite the fact that FHE can be useful for a wide range of applications, many of them are not currently practicable in terms of FHE due to the schemes' practical constraints in terms of computational complexity and space requirement [15].
In this work, an afford is made to develop FHE based on coding theory with practical time complexities. The operations involved in coding theory are quite simple and straightforward to execute, which make to build an efficient homomorphic system with low computing complexity and good security.
In this paper, we present the symmetric key construction of RM code based Fully Homomorphic Encryption (RMFHE). Reed-Muller codes are error correcting codes. We introduce set of artificial errors at certain positions specified by secret key to compute the ciphertext and use majority logic decoding to recover the message from erroneous codes using secret key. To achieve linear homomorphism, the additive and multiplicative property is preserved over the set.
In this section we have presented description of all symbols and notations used in RMFHE scheme. An integer will be expressed as lower case italic letters (for example: $n$ ), $\mathbb{F}$ be the arbitrary field. For an integer $n,[n]$ will be denoted as set of integers $[0,1,2, \ldots, n-1]$. Vector will be denoted as bold italic lower case letter $v \in \mathbb{F}_{2}^{n}$ and matrix will be expressed as sequence of vectors $\mathrm{V}=\left(v_{1}, v_{2}, \ldots, v_{k}\right) \in\left(\mathbb{F}_{2}^{n}\right)^{k}$ and it is denoted by uppercase letter. Upper case italic letters will represent the set of some elements $\mathrm{x}, \mathrm{y}$ and so on, i.e., $I=(\mathrm{x},$, $\mathrm{y}, \ldots) . \mathcal{F}_{e v}$ denotes any function that evaluates on given input to produce the output. For example, add function $\mathcal{F}_{a d d}$ : $(\mathrm{x}, \mathrm{y}) \rightarrow \mathrm{z}$, i.e., $\mathrm{z}=$ addition $(\mathrm{x}, \mathrm{y}) .|\boldsymbol{v}|$ denotes the Hamming weight of the vector $\boldsymbol{v}$, i.e., the number of nonzero elements in the vector, and $\sup p(\boldsymbol{v})$ denote the positions of the non-zero elements in the vector. The operator ' $+$ ' denote the addition $\operatorname{Mod} 2$ operator and $' .^{\prime}$ denote the multiplication Mod 2 operator.
2.1 Expanded RM evaluation codes
In this work, our aim is to develop fully homomorphic encryption on the linear codes. The evaluation codes given in Frederik Scheme [9] supports unlimited addition operations over cipher texts but supports limited multiplication operations. To make the scheme fully homomorphic encryption scheme, the actual RM codes are represented in expanded form with slight modification to the codeword representation. Hence, it is called Expanded RM evaluation codes.
Definition 1. RM codeword matrix:
If there is a $k$ - dimensional linear subspace $\mathcal{C}$ of $\mathbb{F}_{2}^{n}$, which has a minimum hamming distance of $d$, then for $(k<n)$, $[n, k, d]$ represents a linear code. In the construction of RMFHE scheme, codeword and erroneous codewords are not exactly taken as given in def. 1 of Frederik's scheme [9]. RM code $\mathcal{C}$ is a set of codeword matrices $\left\{\mathrm{W}_{1}, \mathrm{~W}_{2}, \mathrm{~W}_{3}, \ldots\right\}$ where $\mathrm{W}_{i} \in\left(\mathbb{F}_{2}^{n}\right)^{k}$ is defined as $\boldsymbol{m}_{i} \times \mathrm{G}_{r m}$, where $\boldsymbol{m}_{i} \in \mathbb{F}_{2}^{k}$ is the message and $\mathrm{G}_{r m} \in\left(\mathbb{F}_{2}^{n}\right)^{k}$ is a generator matrix for given Reed-Muller input parameters $(r, m)$ for $i=1,2,3, \ldots .$
To hold true for additive property over $\mathcal{C}$, for codewords $\mathrm{W}_{1}, \mathrm{~W}_{2} \in \mathcal{C}, \mathrm{W}_{1}+\mathrm{W}_{2} \in \mathcal{C}$. We call the codeword matrix $\mathrm{W} \in$ $\mathcal{C}$ is an error free codeword and $W \in\left(\mathbb{F}_{2}^{n}\right)^{k} \backslash \mathcal{C}$ are erroneous codeword. Erroneous codewords are defined as $\mathrm{W}+\mathrm{E}$ where $\mathrm{E} \in\left(\mathbb{F}_{2}^{n}\right)^{k} \backslash 0$ called as error matrix. Error matrix $\mathrm{E} \in\left(\mathbb{F}_{2}^{n}\right)^{k}$ can be taken as set of error vectors $\left\{\boldsymbol{e}_{1}, \boldsymbol{e}_{2}, \ldots\right\}$ where $\boldsymbol{e}_{i} \in \mathbb{F}_{2}^{n}$ for all $i=1,2,3, \ldots .$ Each Erroneous codewords has some good locations and bad locations. The bad locations are the positions of error occurrences, and are specified by $\sup p(\boldsymbol{e})$ and remaining error free positions are known as good locations, i.e., $[n] \backslash \operatorname{supp}(\boldsymbol{e})$. For a subset $I \subset[n]$, we define $\mathcal{C}(I)=\{\mathrm{W}+$ $\mathrm{E} \mid \mathrm{W} \in \mathcal{C}$ and $\mathrm{E} \in\left(\mathbb{F}_{2}^{n}\right)^{k}$ for each vector $\boldsymbol{e} \in \mathrm{E}, \sup p(\boldsymbol{e}) \subseteq$ $[n] \backslash I\}$. This is called set of erroneous codeword matrices.
Definition 2. Computing original RM codeword from expanded codeword:
We define a step to compute the $\mathrm{RM}$ codeword $\boldsymbol{w} \in \mathbb{F}_{2}^{n}$ from the codeword matrix $W \in \mathcal{C}$. As $W$ is sequence of vectors $\boldsymbol{w}_{1}, \boldsymbol{w}_{2}, \boldsymbol{w}_{3}, \ldots, \boldsymbol{w}_{k} \quad ; \quad \mathrm{W}=\left(\boldsymbol{w}_{1}, \boldsymbol{w}_{2}, \boldsymbol{w}_{3}, \ldots, \boldsymbol{w}_{k}\right) \in$ $\left(\mathbb{F}_{2}^{n}\right)^{k}$ then adding of all vectors will result the $\mathrm{RM}$ codeword corresponding to RM codeword matrix i.e., $\boldsymbol{w}=\boldsymbol{w}_{1}+\boldsymbol{w}_{2}+$ $\boldsymbol{w}_{3}+\cdots+\boldsymbol{w}_{k}$. These codewords are now similar to the original RM codeword where we can directly apply the decoding algorithm to recover its original plaintext. Decoding of plaintext message from erroneous codewords using majority logic is now similar to the Frederik's scheme [9].
Definition 3: Permutation function:
We define a function $\sigma_{s}:\left(\mathbb{F}_{2}^{n}\right)^{k} \rightarrow\left(\mathbb{F}_{2}^{n}\right)^{k}$ for permuting the elements of matrix $V \in\left(\mathbb{F}_{2}^{n}\right)^{k}$ specified by the permutation key $S$ where $S \in\left(\mathbb{F}_{(x, y)}^{n}\right)^{k}$ is denoted as matrix of shuffled indices of $(x, y)$. For example, the permutation on vector $\mathrm{V}_{1}$ results to $\mathrm{V}_{2}$. That is given as $\mathrm{V}_{2} \leftarrow \sigma_{s}\left(\mathrm{~V}_{1}\right)$ where $\mathrm{V}_{1}, \mathrm{~V}_{2} \in$ $\left(\mathbb{F}_{2}^{n}\right)^{k} \quad$ and $\quad \mathrm{V}_{2}(i, j)=\mathrm{V}_{1}\left(i^{\prime}, j^{\prime}\right) \quad$ for all indices $i=$ $0,1,2, \ldots, k-1$ and $j=0,1,2, \ldots, n-1$ and $\left(i^{\prime}, j^{\prime}\right)=S[i, j]$.
Definition 4: Addition and multiplication operations:
We define the addition $(+)$ and multiplication (.) operations on the vector/matrix as the component wise $\operatorname{Mod} 2$ addition and $\operatorname{Mod} 2$ multiplication respectively over finite fields GF(2).
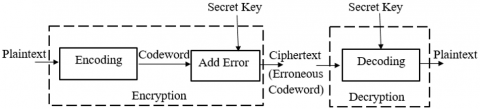
An abstract level description of the RMFHE scheme and the design principles of scheme are presented. The proposed scheme constructs Fully Homomorphic encryption scheme based on coding theory. Several works [20-24] have studied and presented on construction of encryption schemes based on coding theory. As depicted in the Figure 1, the basic idea is to get a codeword
The proposed scheme is an extension and variant of the scheme proposed by Kiayias et al. [20, 25, 26] and Armknecht et al. [9]. Encryption works in three steps: (i) at first, encoding over a plaintext produces a codeword (error-free) and (ii) then, some random errors at fixed positions, given by the secret key, are embedded in the codeword to get an erroneous codeword (iii) then, apply a fixed permutation on the erroneous codeword specified by a secret pattern to provide additional security. Similar to the scheme presented elsewhere [9], proposed scheme makes use of the concept of linear codes and it also maintains codeword synchronization.
Due to symmetric key, the erroneous positions as well as good positions repeat for each encryption, and component-wise operations over the ciphertexts also preserves the good positions and thus satisfies the homomorphic property.
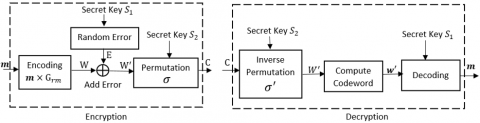
The proposed FHE scheme is designed based on the ReedMuller coding. Reed-Muller code (RM Code) is $[n, k, d]$ linear code and popular error correcting code. According to Reed-Muller coding [27-29], every message $\boldsymbol{m} \in \mathbb{F}_{2}^{k}$ is mapped to codeword $\boldsymbol{w} \in \mathbb{F}_{2}^{n}$ i.e. $\boldsymbol{w}=$ encode $(\boldsymbol{m})$ using $\boldsymbol{G}_{\boldsymbol{r m}} \in\left(\mathbb{F}_{2}^{n}\right)^{k}$, where $G_{r m}$ is a generator matrix of size $k \times n$. RM code has capability to auto correct the errors at the time of decoding when the number of errors in the received codeword is less than $d / 2$. Decoding using majority logic recover the message $\boldsymbol{m}$ from the received erroneous codeword $\boldsymbol{w}^{\prime}$ i.e., $\boldsymbol{m}$ $=\operatorname{decode}\left(\boldsymbol{w}^{\prime}\right)$ when number of errors in $\boldsymbol{w}^{\prime}$ is less than $d / 2$. Several researches $[26,30]$ stated that RM codes are best suitable as cryptographic primitives in security systems. The RMFHE scheme in principle follows the idea of adding artificial errors at the fixed position in the codeword specified by secret key (between $d / 2$ to $d$ positions) yield to give an erroneous codeword $\boldsymbol{w}^{\prime}$ as ciphertext. Decoding of this erroneous codeword using secret key permit to produce the plaintext message uniquely. When an addition operation is applied on two ciphertexts, decoding of the resultant ciphertext again permit to produce plaintext which is equal to the result of addition on the original plaintexts. That means it holds true for additively homomorphic property. But this approach does not necessarily satisfy multiplicatively homomorphic encryption. Hence, to get multiplicative homomorphic encryption, we consider the RM codeword in expanded form (matrix form) and is denoted as $\mathrm{W} \in\left(\mathbb{F}_{2}^{n}\right)^{k}$ instead of codeword vector $\boldsymbol{w} \in \mathbb{F}_{2}^{n}$. The proposed RMFHE with encryption and decryption is presented in the Figure 2 .
Figure 1. Basic idea of coding theory based encryption
Figure 2. Proposed RMFHE scheme
Present section provides a formal description of constructing the RMFHE scheme. The scheme is symmetric key fully homomorphic construction. This scheme is composed of four functions- Setup, Encryption, Decryption and Evaluation. Each function of the scheme is described is as follows:
Choose the initial RM parameters $r, m$ where $m \geq 2$ and $0<r \leq m$.
Setup: $K \leftarrow \operatorname{Setup}(r, m)$
Setup function take the initial RM parameters $(r, m)$ as input and compute the secretkey $K=\left(S_{1}, S_{2}\right)$ as an output. The setup algorithm chooses a key $S_{1}$ for representing the error positions in the codeword and another key $S_{2}$ as permutation key depending on the other parameters; length of the codeword $n$, dimension $k$ and hamming distance $d$ of RM code.
The algorithm for Setup is given as follows:
1. Given $r, m$, the RM code computes
$k=1+\left[\begin{array}{c}m \\ 1\end{array}\right]+\left[\begin{array}{c}m \\ 2\end{array}\right]+\left[\begin{array}{c}m \\ 3\end{array}\right]+\cdots+\left[\begin{array}{c}m \\ 3\end{array}\right]$
$n=2^{m}$ and $d=2^{m-1}$
2. Choose $S_{1} \subset[n]$, set of error locations of length between d/2 and d.
3. Choose the permutation key $S_{2}$ of $k \times n$ matrix.
4. Output the secretkey $K=\left(S_{1}, S_{2}\right)$.
Encryption: $\mathrm{C} \leftarrow \operatorname{Encrypt}(K, \boldsymbol{m})$
An encryption function $\mathcal{F}_{\text {Encrypt }}: \mathbb{F}_{2}^{k} \times K \rightarrow\left(\mathbb{F}_{2}^{n}\right)^{k}$ gets a plaintext $\boldsymbol{m} \in \mathbb{F}_{2}^{k}$ and a secretkey $K=\left(S_{1}, S_{2}\right)$ as inputs. Encryption function transforms the plaintext $\boldsymbol{m}$ into a ciphertext matrix $C \in\left(\mathbb{F}_{2}^{n}\right)^{k}$. First, it encodes the plaintext $\boldsymbol{m}$ into a codeword matrix $\mathrm{W} \in \mathcal{C}$ using generator matrix $\mathrm{G}_{r m}$. Then it samples a random error matrix $\mathrm{E}_{S_{1}} \in\left(\mathbb{F}_{2}^{n}\right)^{k} \backslash 0$ for each vector $\boldsymbol{e} \in \mathrm{E}_{S_{1}}, \operatorname{supp}(\boldsymbol{e}) \subseteq S_{1}$ to produce the erroneous codeword matrix $\mathrm{W}^{\prime}=\mathrm{W}+\mathrm{E}_{S_{1}}$ where $\mathrm{W}^{\prime} \in \mathcal{C}\left(S_{1}\right)$. Finally, the permutation function $\sigma_{S_{2}}$ is applied on $\mathrm{W}^{\prime}$ to get the ciphertext $\mathrm{C}$ using the permutation key $S_{2}$. The ciphertext matrix $C$ is the output of the encryption function. Given a message plaintext vector $\boldsymbol{m} \in \mathbb{F}_{2}^{k}$ as an input to encryption algorithm, it computes the ciphertext $C$ as follows:
$C=\sigma_{S_{2}}\left(\boldsymbol{m} \times G_{r m}+E_{S_{1}}\right)$
Decryption: $\boldsymbol{m} \leftarrow \operatorname{Decrypt}(K, \mathrm{C})$
The inputs to decryption function $\mathcal{F}_{\text {Decrypt }}:\left(\mathbb{F}_{2}^{n}\right)^{k} \times K \rightarrow$ $\mathbb{F}_{2}^{k}$ are ciphertext matrix $\mathrm{C} \in\left(\mathbb{F}_{2}^{n}\right)^{k}$ and secret key $K=$ $\left(S_{1}, S_{2}\right)$. Decryption function first computes the erroneous codeword matrix $\mathrm{W}^{\prime} \in\left(\mathbb{F}_{2}^{n}\right)^{k}$ using inverse permutation function $\sigma^{\prime}$ with permutation key $S_{2}$. Then, it computes the $R M$ codeword $\boldsymbol{w}^{\prime} \in \mathbb{F}_{2}^{n}$ from the erroneous codeword matrix W' by adding all its rows as given in Definition. 2 of Section 2. Since the codeword matrix is erroneous, the computed codeword is also erroneous. Then the erroneous codeword $\boldsymbol{w}^{\prime}$ can be decoded to recover the plaintext $\boldsymbol{m} \in \mathbb{F}_{2}^{k}$ by using majority logic decoding with known error positions specified by $S_{1}$. Given a ciphertext matrix $\mathrm{C}$ as an input to the decryption algorithm, it computes the plaintext vector $\boldsymbol{m}$ as follows:
1. Compute Codeword matrix $\mathrm{W}^{\prime}$ from $\mathrm{C}$ using inverse permutation function $\sigma_{S_{2}}^{\prime}$
$\mathrm{W}^{\prime}=\sigma_{S_{2}}^{\prime}(\mathrm{C})$
2. Compute the $\mathrm{RM}$ codeword $\boldsymbol{w}^{\prime} \in \mathbb{F}_{2}^{n}$ from codeword matrix W'
3. Extract the plaintext vector $\boldsymbol{m}$ from the codeword $\boldsymbol{w}^{\prime}$ using majority logic decoding function
$\boldsymbol{m}=\operatorname{Decode}\left(S_{1}, \boldsymbol{w}^{\prime}\right)$
Addition: $\mathrm{C}_{3} \leftarrow A d d\left(\mathrm{C}_{1}, \mathrm{C}_{2}\right)$
Addition function $\mathcal{F}_{\text {Add }}:\left(\mathbb{F}_{2}^{n}\right)^{k}+\left(\mathbb{F}_{2}^{n}\right)^{k} \rightarrow\left(\mathbb{F}_{2}^{n}\right)^{k}$ gets two ciphertexts $C_{1}, C_{2} \in\left(\mathbb{F}_{2}^{n}\right)^{k}$ as input where $C_{1}$ and $C_{2}$ are encryption of plaintext vectors $\boldsymbol{m}_{1}$ and $\boldsymbol{m}_{2}$. An encryption of sum of corresponding underlying plaintexts $\left(\boldsymbol{m}_{1}+\boldsymbol{m}_{2}\right)$, as a ciphertext $\mathrm{C}_{3} \in\left(\mathbb{F}_{2}^{n}\right)^{k}$ is generated. The addition operation on the two ciphertexts is given as follows:
$\mathrm{C}_{3}=\left\{\mathrm{C}_{1}+\mathrm{C}_{2} \mid \mathrm{C}_{1}(i, j)+\mathrm{C}_{2}(i, j) \forall i=0,1,2, \ldots, k-1\right.$
$\forall j=0,1,2, \ldots, n-1\}$
Multiplication: $\mathrm{C}_{3} \leftarrow \operatorname{Mul}\left(\mathrm{C}_{1}, \mathrm{C}_{2}\right)$
Multiplication function $\mathcal{F}_{M u l}:\left(\mathbb{F}_{2}^{n}\right)^{k} \cdot\left(\mathbb{F}_{2}^{n}\right)^{k} \rightarrow\left(\mathbb{F}_{2}^{n}\right)^{k}$ gets two ciphertexts $\mathrm{C}_{1}, \mathrm{C}_{2} \in\left(\mathbb{F}_{2}^{n}\right)^{k}$ as input and computes the product of corresponding underlying plaintexts as a ciphertext $\mathrm{C}_{3} \in\left(\mathbb{F}_{2}^{n}\right)^{k}$. The multiplication operation on the two ciphers texts is given as follows:
$\mathrm{C}_{3}=\left\{\mathrm{C}_{1} \cdot \mathrm{C}_{2} \mid \mathrm{C}_{1}(i, j) \cdot \mathrm{C}_{2}(i, j) \forall i=0,1,2, \ldots, k-1\right.$
$\forall j=0,1,2, \ldots, n-1\}$
Proposition 1:
The scheme is correct for encryption, decryption, addition and multiplication operations.
Theorem 1:
The scheme proposed above is correct with respect to fresh cipher text as well as homomorphic operations addition $\operatorname{Mod} 2$ and multiplication $\operatorname{Mod} 2$ over finite fields GF(2) as defined. (Bitwise AND and XOR Gentry circuit based unlimited operations supported).
Proof:
Decryption is implemented simply based on majority logic based RM decoder. When errors are within the limit between d/2 and d, decoding works correct only with the known error positions.
Let C be the ciphertext corresponding to the plaintext vector m. Decryption algorithm deciphers the plaintext m by using two step technique to eliminate the masks on the plaintext. In the first step, it removes the permutation mask using secretkey $S_{2}$. In the second step, it extracts the plaintext vector $m$ using RM error correction decoding with known error positions in the erroneous codeword specified by secretkey S1. Deciphering process by eliminating the masks is illustrated as follows
$\boldsymbol{m}=\operatorname{Decrypt}\left(S_{1}, \sigma_{S_{2}}^{\prime}(\mathrm{C})\right)$
$=>\operatorname{Decrypt}\left(S_{1}, \sigma_{S_{2}}^{\prime}\left(\sigma_{S_{2}}\left(\boldsymbol{m} \times \mathrm{G}_{r m}+\mathrm{E}_{S_{1}}\right)\right)\right)$
$\quad=>\operatorname{Decrypt}\left(S_{1}, \sigma_{S_{2}}^{\prime}\left(\sigma_{S_{2}}\left(\mathrm{~W}+\mathrm{E}_{S_{1}}\right)\right)\right)$ (1)
where, W=m×Grm.
Inverse permutation operation using key $S_{2}$ will remove the permutation mask and then Eq. (1) can now be
$=>\operatorname{Decrypt}\left(S_{1}, \mathrm{~W}+\mathrm{E}_{S_{1}}\right)$
The majority logic decoding of erroneous codeword using secret key $S_{1}$ will eliminate the error mask and extract the plaintext vector $\boldsymbol{m}$ as output. Hence, the correctness of decryption of fresh ciphertext is proved. Similarly, correctness of decryption can be proved for addition and multiplication operations over ciphertexts as given below:
Let $C_{1}$ and $C_{2}$ be the ciphertexts corresponding to two plaintexts $\boldsymbol{m}_{1}$ and $\boldsymbol{m}_{2}$. The homomorphic addition on $\mathrm{C}_{1}$ and $\mathrm{C}_{2}$ will produce $\mathrm{C}_{3}$ i.e., $\mathrm{C}_{3}=\mathrm{C}_{1}+\mathrm{C}_{2}$. The decryption of the resultant cipher deciphers the sum of two plaintext vectors. The correctness of homomorphic addition operation is proved as follows:
$\mathrm{C}_{3}=\mathrm{C}_{1}+\mathrm{C}_{2}$
$=>\sigma_{S_{2}}\left(\boldsymbol{m}_{1} \times \mathrm{G}_{r m}+\mathrm{E}_{S_{1}}\right)+\sigma_{S_{2}}\left(\boldsymbol{m}_{2} \times \mathrm{G}_{r m}+\mathrm{E}_{S_{1}}\right)$
$=>\sigma_{S_{2}}\left(\boldsymbol{m}_{1} \times \mathrm{G}_{r m}+\mathrm{E}_{S_{1}}+\boldsymbol{m}_{2} \times \mathrm{G}_{r m}+\mathrm{E}_{S_{1}}\right)$
$=>\sigma_{S_{2}}\left(\boldsymbol{m}_{1} \times \mathrm{G}_{r m}+\boldsymbol{m}_{2} \times \mathrm{G}_{r m}+\mathrm{E}_{S_{1}}+\mathrm{E}_{S_{1}}\right)$
Since $E_{S_{1}}+E_{S_{1}}$ will generate another error matrix $E_{S_{1}}^{\prime}$ with random bits at the positions specified by $S_{1}$ and remaining bits will become $0 \mathrm{~s}$.
$=>\sigma_{S_{2}}\left(\left(\boldsymbol{m}_{\mathbf{1}}+\boldsymbol{m}_{\mathbf{2}}\right) \times \mathrm{G}_{r m}+\mathrm{E}_{S_{1}}^{\prime}\right)$
$\mathrm{C}_{3}=\sigma_{S_{2}}\left(\left(\boldsymbol{m}_{\mathbf{1}}+\boldsymbol{m}_{\mathbf{2}}\right) \times \mathrm{G}_{r m}+\mathrm{E}_{S_{1}}^{\prime}\right.$
Decryption of the result cipher $\mathrm{C}_{3}$ will result $\boldsymbol{m}_{3}=\boldsymbol{m}_{1}+$ $\boldsymbol{m}_{2}$. Hence, homomorphic addition operation is proved.
Finally, for homomorphic multiplication operation.
Let $C_{1}$ and $C_{2}$ be the ciphertexts corresponding to two plaintexts $\boldsymbol{m}_{1}$ and $\boldsymbol{m}_{2}$. The homomorphic multiplication on $\mathrm{C}_{1}$ and $\mathrm{C}_{2}$ will produce $\mathrm{C}_{3}$ i.e., $\mathrm{C}_{3}=\mathrm{C}_{1} . \mathrm{C}_{2}$. The decryption of the resultant cipher deciphers the product of two plaintext vectors. The correctness of homomorphic multiplication operation is proved as follows:
$\mathrm{C}_{3}=\mathrm{C}_{1} \cdot \mathrm{C}_{2}$
$=>\sigma_{S_{2}}\left(\boldsymbol{m}_{1} \times \mathrm{G}_{r m}+\mathrm{E}_{S_{1}}\right) \cdot \sigma_{S_{2}}\left(\boldsymbol{m}_{2} \times \mathrm{G}_{r m}+\mathrm{E}_{S_{1}}\right)$
$=>\sigma_{S_{2}}\left(\mathrm{~W}_{1}+\mathrm{E}_{S_{1}}\right) \cdot \sigma_{S_{2}}\left(\mathrm{~W}_{2}+\mathrm{E}_{S_{1}}\right)$
$=>\sigma_{S_{2}}\left(\left(\mathrm{~W}_{1}+\mathrm{E}_{S_{1}}\right) \cdot\left(\mathrm{W}_{2}+\mathrm{E}_{S_{1}}\right)\right)$
$=>\sigma_{S_{2}}\left(\mathrm{~W}_{1} \cdot \mathrm{W}_{2}+\mathrm{W}_{1} \cdot \mathrm{E}_{S_{1}}+\mathrm{W}_{2} \cdot \mathrm{E}_{S_{1}}+\mathrm{E}_{S_{1}} \cdot \mathrm{E}_{S_{1}}\right)$
$=>\sigma_{S_{2}}\left(\mathrm{~W}_{1} \cdot \mathrm{W}_{2}+\mathrm{E}_{S_{1}}^{\prime}\right)$
Since $W_{1} \cdot E_{S_{1}}+W_{2} \cdot E_{S_{1}}+E_{S_{1}} \cdot E_{S_{1}}$ will generate another error matrix $E_{S_{1}}^{\prime}$ with random bits at the positions specified by $S_{1}$ and remaining bits will become $0 \mathrm{~s}$.
$=>\sigma_{S_{2}}\left(\left(\boldsymbol{m}_{1} \cdot \boldsymbol{m}_{2}\right) \times \mathrm{G}_{r m}+\mathrm{E}_{S_{1}}^{\prime}\right)$
$\mathrm{C}_{3}=\sigma_{S_{2}}\left(\left(\boldsymbol{m}_{1} \cdot \boldsymbol{m}_{2}\right) \times \mathrm{G}_{r m}+\mathrm{E}_{S_{1}}^{\prime}\right)$
Decryption of the result cipher $\mathrm{C}_{3}$ will result $\boldsymbol{m}_{3}=\boldsymbol{m}_{1} \cdot \boldsymbol{m}_{2}$. Hence, homomorphic multiplication operation is proved.
The proposed RM FHE scheme is implemented in JAVA platform to execute all the functions of the scheme: Encryption, Decryption, Homomorphic operations. The program was run on the system with basic configurations: Intel(R) Core(TM) i5-3230M CPU 2.60 GHz and 4GB RAM, in Windows 10 Professional 64-bit Operating system environment. The experimental evaluation is conducted to measure the practical time required for every function of the proposed scheme for different parameter values. The implementation of the scheme for various levels of security is obtained. The values of the various parameters corresponding to the different security levels (Toy, small, Medium and Large) is explored and presented in the Table 1. The time required for the functions and operations at different security levels is also obtained and presented in Table 2. The space required to store the secret key (key1 and key2) and ciphertext is presented in Table 3.
The execution results shown that the scheme is quite simple for implementation. Given novelty of the scheme, we consider the results are quite promising at the different security levels. Comparative to the other coding theory based homomorphic schemes (Fredrik’s Scheme [9]), the scheme supports unlimited addition and multiplication operations over ciphertext with reasonable time effort. The time for decryption and size of the ciphertext is high compared to other similar schemes. However, it is considered that the decryption is required only at the end when the user decrypt ciphertext after performing all required homomorphic operations by the third party. Hence, there is no much effect of the decryption time on the efficiency of the scheme. Over all the practical implementation of our scheme is possible for FHE with high efficiency, compared to the other schemes based on Lattice cryptography [16], CKKS [17]. RLWE [18].
Table 1. Parameter values at different levels
|
Level of Security |
(r,m) |
Codeword length n |
Codeword dimension k |
Minimum distance d |
Auto error correcting capability dmin |
|
Toy |
(1,3) |
8 |
4 |
4 |
1 |
|
Small |
(1,5) |
32 |
6 |
16 |
7 |
|
Medium |
(1,8) |
256 |
8 |
128 |
63 |
|
Large |
(1,11) |
2048 |
12 |
1024 |
511 |
|
Very Large |
(1,15) |
32768 |
16 |
16384 |
8191 |
Table 2. Practical performance of the scheme at different security levels
|
|
Encryption (in Sec) |
Decryption (in Sec) |
Addition (in Sec) |
Multiplication (in Sec) |
|
Toy |
0.000019110 |
0.00010892 |
0.00000382 |
0.00000299 |
|
Small |
0.00016293 |
0.00203898 |
0.00001671 |
0.00001939 |
|
Medium |
0.000204300 |
0.26720770 |
0.000216690 |
0.000172310 |
|
Large |
0.010767670 |
4.822113740 |
0.000069260 |
0.000147250 |
|
Very Large |
6.046015519 |
36879 |
0.000889150 |
0.003025590 |
Table 3. Space requirement of Key and Ciphertext at different security level
|
|
Size of $S_{1}$ (in KBytes) |
Size of $S_{2}$(in KBytes) |
Length of C (in bits) |
Size of C (in KBytes) |
|
Toy |
$<1$ |
$<1$ |
32 |
$<1$ |
|
Small |
$<1$ |
$<1$ |
192 |
$<1$ |
|
Medium |
$<1$ |
17 |
2304 |
$<1$ |
|
Large |
14 |
75 |
24576 |
16 |
|
Very Large |
34 |
1662 |
5,24,288 |
98 |
In this paper an efficient variation of Fredrik’s scheme [9] is presented with correctness proof and experimental evaluation. To achieve multiplicative homomorphism, Reed-Muller code has been represented and considered in an expanded form (matrix form), i.e., $\left(\mathbb{F}_{2}^{n}\right)^{k}$ instead of $\mathbb{F}_{2}^{n}$. The scheme supports unlimited $\operatorname{Mod} 2$ addition and multiplication operations over ciphertexts without refreshing operation. The experimental evaluation of the scheme is performed at different levels of security and the results shown that implementation of our scheme is really practical with high efficiency as compared to other practical implementations of FHE schemes such as schemes based on RLWE, Lattice cryptography, CKKS, in terms of simple and easy operations involved in the scheme.
[1] Rivest, R., Adleman, L., Dertouzos, M. (1978). On data banks and privacy homomorphisms. Foundations of Secure Communication, pp. 169-177.
[2] Brickell, E.F., Yacobi, Y. (1987). On privacy homomorphisms. Advances in Cryptology – Proceedings of EUROCRYPT'87, the Netherlands, pp. 117-125. https://doi.org/10.1007/3-540-39118-5_12
[3] Gentry, C. (2009). Fully homomorphic encryption using ideal lattices. Proceedings of the 41st Annual ACM Symposium on Theory of Computing (STOC’09), New York, NY, USA, pp. 169-178. https://doi.org/10.1145/1536414.1536440
[4] Gentry, C. (2010). Toward basing fully homomorphic encryption on worst-case hardness. Advances in Cryptology- Proceedings of CRYPTO’10, Santa Barbara, CA, USA, pp. 116-137. https://doi.org/10.1007/978-3-642-14623-7_7
[5] Smart, N.P., Vercauteren, F. (2010). Fully homomorphic encryption with relatively small key and ciphertext sizes. Public Key Cryptography (PKC’10), Paris, France, pp. 420-443. https://doi.org/10.1007/978-3-642-13013-7_25
[6] Gentry, C., Halevi, S. (2011). Implementing gentry’s fully-homomorphic encryption scheme. Advances in Cryptology – EUROCRYPT 2011, Tallinn, Estonia, pp. 129-148. https://doi.org/10.1007/978-3-642-20465-4_9
[7] Lyubashevsky, V., Peikert, C., Regev, O. (2010). On ideal lattices and learning with errors over rings. Advances in Cryptology – EUROCRYPT 2010, French Riviera, pp. 1-23. https://doi.org/10.1007/978-3-642-13190-5_1
[8] Brakerski, Z., Vaikuntanathan, V. (2011). Fully homomorphic encryption from ring-LWE and security for key dependent messages. Advances in Cryptology-CRYPTO’11, Santa Barbara, CA, USA, pp. 505-524. https://doi.org/10.1007/978-3-642-22792-9_29
[9] Armknecht, F., Augot, D., Perret, L., Sadeghi, A.R. (2011). On constructing homomorphic encryption schemes from coding theory. Cryptography and Coding, Oxford, UK, pp. 23-40. https://doi.org/10.1007/978-3-642-25516-8_3
[10] Brakerski, Z., Gentry, C., Vaikuntanathan, V. (2014). (Leveled) fully homomorphic encryption without bootstrapping. Proceedings of the 3rd Innovations in Theoretical Computer Science Conference, New York, USA, pp. 309-325. https://doi.org/10.1145/2633600
[11] Ducas, L., Micciancio, D. (2015). FHEW: Bootstrapping homomorphic encryption in less than a second. Advances in Cryptology -- EUROCRYPT 2015, Sofia, Bulgaria, pp. 617-640. https://doi.org/10.1007/978-3-662-46800-5_24
[12] Challa R., Gunta V. (2016). Reed-muller code based symmetric key fully homomorphic encryption scheme. Information Systems Security. Information Systems Security, Jaipur, India, 499-508. https://doi.org/10.1007/978-3-319-49806-5_29
[13] Van Dijk, M., Gentry, C., Halevi, S., Vaikuntanathan, V. (2010). Fully homomorphic encryption over the integers. Advances in Cryptology – EUROCRYPT 2010, French Riviera, pp. 24-43. https://doi.org/10.1007/978-3-642-13190-5_2
[14] Ramaiah, Y.G., Kumari, G.V. (2012). Towards practical homomorphic encryption with efficient public key generation. International Journal on Network Security, 3(4): 10.
[15] Viand, A., Patrick, J., Anwar, H. (2021). SoK: Fully homomorphic encryption compilers. arXiv preprint arXiv:2101.07078.
[16] Polyakov, Y., Rohloff, K., Ryan, G.W. (2019). PALISADE Lattice Cryptography Library User Manual (v1.6.0), Tech. Rep., Sep. 2019. Available: https://palisade-crypto.org/documentation.
[17] Cheon, J.H., Kim, A., Kim, M., Song, Y. (2017). Homomorphic encryption for arithmetic of approximate numbers. Advances in Cryptology-ASIACRYPT 2017, Hong Kong, China, pp. 409-437. https://doi.org/10.1007/978-3-319-70694-8_15
[18] Crypto Experts. (2019). FV-NFLlib. GitHub. https://github.com/CryptoExperts/FV-NFLlib, accessed on 1 November 2021.
[19] NuCypher. (2019). A GPU implementation of fully homomorphic encryption on torus. GitHub. https://github.com/nucypher/nufhe, accessed on 1 November 2021.
[20] Kiayias, A., Yung, M. (2007). Cryptographic hardness based on the decoding of Reed-Solomon codes. Cryptology ePrint Archive, Report 2007/153, 2007. https://eprint.iacr.org/2007/153.pdf.
[21] McEliece, R.J. (1978). A public-key system based on algebraic coding theory. The Deep Space Network Progress Report, 114-116.
[22] Niederreiter, H. (1985). A public-key cryptosystem based on shift register sequences. Advances in Cryptology - EUROCRYPT’85, Linz, Austria, pp. 35-39. https://doi.org/10.1007/3-540-39805-8_4
[23] Courtois, N.T., Finiasz, M., Sendrier, N. (2001). How to achieve a McEliece-based digital signature scheme. Advances in Cryptology - ASIACRYPT 2001, Australia, pp. 157-174. https://doi.org/10.1007/3-540-45682-1_10
[24] Baldi, M., Bodrato, M., Chiaraluce, G.F. (2008). A new analysis of the McEliece cryptosystem based on QC-LDPC codes. Security and Cryptography for Networks, Amalfi, Italy, pp. 246-262. https://doi.org/10.1007/978-3-540-85855-3_17
[25] Kiayias, A., Yung, M. (2002). Cryptographic hardness based on the decoding of Reed-Solomon codes. Automata, Languages and Programming, Málaga, Spain, pp. 232-243. https://doi.org/10.1007/3-540-45465-9_21
[26] Katz, J., Lindell, Y. (2007). Introduction to Modern Cryptography, 1st edition, CRC Press.
[27] Macwilliams F.J., Sloane, N.J.A. (1983). The Theory of Error-Correcting Codes. North-Holland Mathematical Library. North Holland.
[28] Abbe, E., Shpilka, A., Wigderson, A. (2015). Reed-Muller codes for random erasures and errors. IEEE Transactions on Information Theory, 61(10): 5229-5252. https://doi.org/10.1109/TIT.2015.2462817
[29] Høholdt, T., Van Lint, J.H., Pellikaan, R. (1998). Algebraic geometry codes. Handbook of Coding Theory, 1(Part 1): 871-961.
[30] Gueye, C.T., Mboup, E.H.M. (2013). Secure cryptographic scheme based on modified Reed Muller codes. International Journal of Security and Its Applications, 7(3): 55-64.