Avaneesh Kumar Yadav* | Ashish Kumar Maurya | Ranvijay | Rama Shankar Yadav
© 2021 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
In this era of growing digital media, the volume of text data increases day by day from various sources and may contain entire documents, books, articles, etc. This amount of text is a source of information that may be insignificant, redundant, and sometimes may not carry any meaningful representation. Therefore, we require some techniques and tools that can automatically summarize the enormous amounts of text data and help us to decide whether they are useful or not. Text summarization is a process that generates a brief version of the document in the form of a meaningful summary. It can be classified into abstractive text summarization and extractive text summarization. Abstractive text summarization generates an abstract type of summary from the given document. In extractive text summarization, a summary is created from the given document that contains crucial sentences of the document. Many authors proposed various techniques for both types of text summarization. This paper presents a survey of extractive text summarization on graphical-based techniques. Specifically, it focuses on unsupervised and supervised techniques. This paper shows the recent works and advances on them and focuses on the strength and weaknesses of surveys of previous works in tabular form. At last, it concentrates on the evaluation measure techniques of summary.
text summarization, extractive text summarization, abstractive text summarization, supervised and unsupervised learning techniques
Text summarization is the process of extracting meaningful information from the document. It selects the sentences or paragraphs from the document and arranges them into sequential order. Nowadays, text summarization data is increasing exponentially as lots of data is generated through online and offline activities. The data may contain news articles, medical reports, the stock market data, abstract of scientific papers, news highlights (sport, event, meeting), summaries of the stories (digest), books, magazines, etc. Text summarization saves time to understand the document and requires less space to store the text data. In late 1958, a new tool for text summarization was developed. Since then, considerable growth has been observed in this area, and many techniques have been proposed for text summarization [1]. The text summarization generates a summary from the document, and it gives meaningful and relevant information needed in the future. It reduces the time to read the whole document and helps in the decision-making process using generated summary.
Generating a summary through automatic text summarization is a very challenging task. Performing summarization in multi-documents is complicated than single document as it involves various issues like compression ratio, maximum relevance, degree of redundancy, etc. [2, 3]. Recently, there are many overcome, such as resulting in common approaches to be identified relevant keyword or relevant content, the lack of coherence created by text summaries, and this type of summary come for the new part of the information. Several methods are available for evaluating automatic summaries, and it is good compared to the evaluation of human. However, it is also a major challenge because it may or may not be clear, which is generated by human beings. Then what type of content of the summary can be contained.
Text summarization is of two types: extractive text summarization and abstractive text summarization. Extractive text summarization extracts some important paragraphs and sentences from the document and place them into summary without any changes. It generates more relevant and meaningful information from the original document. It is easier and faster than abstractive text summarization. It uses many techniques such as Logistic Regression Model (LRM), Decision Trees, Hidden Markov Model (HMM), Binary classifier, Bayesian method, SVM, TextRank, LexRank, Deep learning techniques (Convolutional network, RNN, RBM, Autoencoder,), TF- IDF, maximal marginal relevance (MMR) algorithm, graphical methods, and clustering. Abstractive text summarization can produce meaningful summary, that may or may not be available in the given document since it focuses on a new summary. The abstractive text summarization gives better summary than the extractive text summarization because it creates a generalized summary. Also, it faces more difficulties during the computation than the extractive text summarization. It uses many techniques such as SVM, Neural Network, RNN, CNN, Singular Vector Decomposition (SVD), K-means algorithm, Naive Bayes decision theory, WordNet, Sequence-to-Sequence model, etc.
Based on the text languages of the system, summarization is of many types, such as monolingual, multi-lingual, and cross-lingual. In a monolingual system, the text language of the source document and its summary are the same. In a multi-lingual system, the source document contains more than one language like Punjabi, Telegu, Hindi, and English, and generates a summary in the different language. If the source document in one language and the system generates a summary in another language, it is called a cross-lingual system. For example, in a cross-lingual system, the summary may be generated in the English language if the source document is in the Hindi language.
Based on the number of input documents, the text summarization is of two types: (1) single document and (2) multiple documents. In a single document summarization, the summary is extracted only from a single document. In multiple documents summarization, the summary is extracted from more than one document, but all the documents have belonged to the same category/topic. Multiple document summarization may face some problems like sentence ordering, co-references, ambiguity, temporal dimension, etc. Also, this summarization builds a complex summary task compare to the single document summary task [4, 5]. A more distinguished issue is ambiguity/redundancy that is also presented with a multi-document summarization. This issue may be solved by choosing sentences from starting the passage or paragraphs in the original document and evaluating the similarities of many sentences. However, sentences are already selected, and the sentence is maintained and included in new related content. Some authors have given different type of methods to achieve the performance in multi-document text summarization [6, 7].
Based on the type of content in the document, the text summarization can be considered as Query, Generic, and Domain-based [8, 9]. In query-based summarization, a summary is generated by user queries. This summarization is also called user-focused or topic-focused summarization [10]. In generic-based summarization, selected relevant information is not user-specific [11]. In domain-based summarization, a summary is generated based on the sources of textual data such as Newspaper Articles (NA), Technical Report (TR), Web Pages (WP), Biomedical Domain (BD), Journal Articles (JA), Radio News (RN), Encyclopedia Articles (EA), Transcription Dialogues (TD), etc.
There are three main aspects that identify text summarization research through prior definition. First, the summary can be produced by single or multiple documents. Second, the summary may be identified as the most critical information from the main document(s), and last, the summary should be in short form. According to the overcome through linguistic and statistical techniques, some techniques include the sentences in the summary part containing nouns and pronouns.
Table 1. Frequently used words
|
TS |
Text Summarization |
Text summarization is a process to summarize the large text document into the smaller document and generates most relevant information of the document. |
|
ETS |
Extractive Text Summarization |
It extracts some important paragraphs and sentences from the document and place them into summary without any changes. |
|
ATS |
Abstractive Text Summarization |
It produces meaningful summary, that may or may not be available in the given document. |
|
SVM |
Support Vector Machine |
It is an algorithm of machine learning and used in regression analysis and classification of the data. |
|
LSTM |
Long-Short Term Memory |
LSTM is one type of RNN and used in text network for sentences sequencing problems. It is used to solve many problems in the areas like speech recognition, machine transition etc. |
|
CNN |
Convolution Neural Network |
CNN is used to train the text data in word vector classification of the sentence’s levels. |
|
TF-ISF |
Term Frequency - Inverse Sentence Frequency |
TF-ISF is calculated using the value of sentence from document with the help of TF and ISF. |
|
ROUGE |
Recall-Oriented Understudy for Gisting Evaluation |
Refer to section 5. |
|
NLP |
Natural Languages Processing |
NLP is a subfield of artificial intelligent (AI), linguistic, and computer science, and mostly used in speech and text summarization. |
|
SVD |
Singular Value Decomposition |
SVD is used in text summarization and semantically identifies the important part of the text document. |
|
RBM |
Restricted Boltzmann Machine |
RBM is one type of algorithm, which dimensionally reduces the text document of regression, and classification. It is used for feature extraction and feature selection. |
|
RNN |
Recurrent Neural Network |
RNN is used in sequence-to-sequence sentences. |
|
GRU |
Gated Recurrent Unit |
GRU is a part of RNN and works similar to LSTM. It is used in NLP, speech signal modelling, and polyphonic music modelling. |
|
DUC |
Document Understanding Conference |
DUC is a dataset for text summarization and used for the evaluation. Examples of DUC are DUC2000, DUC2001, DUC2002, DUC2003, DUC2004, etc. |
|
TAC |
Text Analysis Conferences |
TAC is a series of evaluation dataset, which encourages the research in NLP and used for common evaluation procedures, and large text collections. Examples of TAC are TAC2008, TAC2009, TAC2010, etc. |
|
LSA |
Latent Semantic Analysis |
LSA is an unsupervised learning, which is used in text summarization and extracts words or sentences from the documents. |
|
HITS |
Hyperlink-Induced Topic Search |
HITS algorithms are known as Link Analysis Algorithms (LAAs). It is used to find the scores of webpages using PageRank (PA) algorithm. |
|
HAN |
Hierarchical Attention Network |
HAN is a hierarchical structure of documents. It includes attention mechanism to be find most important words and sentences from a document. |
|
LCS |
Longest Common Subsequence |
Refer to section 5. |
1.1 Our contribution
In the literature, several research papers have been presented that discusses various approaches/techniques of extractive text summarization (ETS). In this paper, we have extended this area in novel ways and performed a survey. The contribution of our work can be summarized as follows:
We present a taxonomy for Extractive Text Summarization based on different existing approaches.
Also, we give a taxonomy for evaluation measures and describe them in detail.
Further, we perform a relative comparison of existing approaches with their merits and demerits.
1.2 Organization structure
The rest of the paper is described as follows: In section 2, background of the extractive text summarization is discussed. Section 3 presents a literature review of extractive text summarization. Section 4 describes the existing techniques or methods of ETS. In section 5, the detailed discussion of the taxonomy of evaluation measures is performed. Section 6 includes challenges and future scope of the ETS and gives the conclusion of the work.
Table 1 describes frequently used words in this paper.
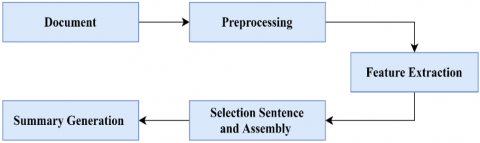
In extractive text summarization, summary is generated by selecting the most important sentences and paragraphs from the given document. In ETS, the summarization process consists of four steps: (i) Preprocessing (ii) Feature extraction (iii) Selection Sentence and Assembly (iv) Summary generation. These steps are shown in Figure 1.
All four steps have performed different tasks: The first step is prepossessing that consists of many operations such as
(a) Removing stopwords: The given input document has many stop-words that should not be included during the text summarization. Examples of stopwords include “a”, “an”, “is”, “am”, “has”, “have”, “they”, “it”, “could”, “may”, etc. Consider the following sentence: “he is playing football match in garden”. In this sentence, there are three stop-words such as “he”, “is”, and “in”. After removing stopwords, new sentence will be like “playing football match garden”.
(b) Segmentation: Segmentation divides the given input document into paragraphs, sentences, and words.
(c) Tokenization: Tokenization is similar to segmentation. It divides the words into unigram words, bigram words, trigram words, etc. Unigram has only single word tokenization, bigram words have combination of two words together. Similarly, trigram, and four-gram words can be defined. For example, consider the following sentence: “It cuts down the reaction time for edges”. In the given sentence, there are total eight unigram words such as “It”, “cuts”, “down”, “the”, “reactions”, “time”, “for”, and “edges”, there are total seven bigram words such as “It cuts”, “cuts down”, “down the”, “the reaction”, “reaction time”, “time for”, and “for edges” in the given sentence.
(d) Parts of Speech (POS) tagging: Large document have reduction during preprocessing efficient and fast. To the document reduction, first chosen the discourses most important POS like Verbs, Adverbs, Adjectives, Pronouns and Nouns. There are big challenges to extract important discourses term from the given documents. In English document, we can extract the POS with help of NLTK POS tagger easily.
(e) Word stemming: A word can be different forms in tenses, plural, singular and different POS tags. Example: goes, gone, going and went, this word has only one base root “go”. Word stemming is one type of process to be transfer each word into a root word.
In the second step, feature extractions: it is used to select text documents' features by acquiring sentences in documents to the important information. It gives value in terms of one (1) and zero (0). There are many common features of ETS are described in Table 2 such that are Sentence Length, Sentence Position, Similarity to Keywords, Title Similarity, Term Frequency (TF), Sentence to Centroid Similarity, Sentence to Sentence Similarity, Proper Noun, Cue Methods and many more.
The third step is sentence selection and assembly: It have first selected important sentences from the document with the help of techniques/methods. It is stored the sentences into decreasing rank of order. For summary of the important sentences to be collected few percentages of important sentences such as 20%, 25%, 30%, 35% etc., suppose it takes 25% of important sentence after arranging decreasing rank of sentences order from the document. 25% have topmost rank of sentences to be assemble the sentence as a summary.
The last step is the summary generation, which generates a summary and puts relevant information to the sentence's position from the main document.
Figure 1. Extractive text summarization process
Table 2. Common features of ETS
|
Features |
Description |
Remarks |
|
Sentence Length |
Any sentence has specific length which are considered as an important. |
In case of any sentences have longer or shorter but it is small values so that it cannot be suitable for summary. |
|
Sentence Position |
It is specified position of sentence means meaningful and important sentences should be placed in correct position such that first or last positions. |
In first or last position which has value is one. Then, it can be used to keep checking with others positions which has taken values in between zero and one. |
|
Similarity to Keywords |
It is computed by cosine similarity measure when similarity in between each keyword and sentence to be presents. |
This is generally used in query-based summarization. |
|
Title Similarity |
It focuses on title of the document when the sentence is an important then it is considered. This similarity calculated by cosine similarity. |
It cannot be used without title with document. |
|
Term Frequency (TF) |
In document, the number of times term of word occurred over in the total number of terms that is increase score of their sentences. So that it is focus on important word in document. |
The word term of term frequency which can consider many views that is unique word, n-gram (Such that n is 1, 2, 3 etc.) key. This is evaluated by number of occurrences for term. The largest TF for in evolution used are TF-ISF [12, 13] and TF-IDF [14].
|
|
Sentence to Centroid Similarity |
In this feature, there are calculated centroid sentence first. There are similarity in between centroid sentence and each sentence calculated [13]. |
Here, calculated centroid sentence through TF-ISF feature which sentence has TF-ISF highest value then it is decided to the centroid [13]. |
|
Sentence to Sentence Similarity |
It is one type of the complex phenomena which is not dependable on the words in it. But sentence can be equivalent in one and other one in opposite. |
It is the concept of text coherence [12]. |
|
Proper Noun |
In the document, many sentences belong in proper nouns and it is considered to be relevant sentences. |
Examples are places, organization, and name of person etc. |
|
Cue Methods |
In sentence, weight words have indicated negative or positive effect. |
It is involved in summary, and in conclusion. |
Many authors have proposed research work on ETS based on different techniques or methods, which helped in generating summaries of text document(s). There are many papers reviews summary mention below:
Mutlu et al. [15] focused on supervised learning that discusses the features, dataset, and methods applied for selecting sentences. Where there are two features syntactic and semantic uses in ETS. Syntactic feature space is generated using a dataset. From this feature; it is created informative, relevant summary and others (semantic) feature used in word2vec and Glove in embedding. When both features are working together, then it is worked based on the LSTM-NN model. It used dataset 41th International ACM Conference SIGIR 2018 corpus, which are summary measure by ROUGE metric.
Elbarougy et al. [16] proposed a graph-based system that used for Arabic text summarization. While the structure of Arabic languages of morphological is more complex, which for noun extraction very difficult so that this is used summarization process. Then, the document is converted into graphs where sentences represented vertices of the graph. There are applied modified PageRank algorithms; it is the initialized rank of each vertex because of many nouns available in sentences. More information is generated by nouns that are presented in given documents. The initial rank of sentences produced counts the number of nouns. Based on the number of nouns, the final summary of the given documents is more relevant and more information. Evolution of performance on the dataset EASC Corpus is used, and it is performed only on 10,000 iterations.
Cao and Zhuge [17] proposed a group-based text summarization. There are used linguistic or statistical techniques in ETS to extract important sentences from the document and concatenated these sentences for a summary. According to the group-based summarization, which is taken by clusters semantically sentences that are used in the group-based and into semantic link network. There are selected topmost rank from group-based summarization and concatenated into sequence order to be generated relevant summary. There are taken four types of semantic links for generating groups, such as cause-effect links, similar-to links, sequential links, and is-part-of link. Datasets are downloaded from ACL Anthology, which has contained a total of 173 ACL2014 conference papers.
Sanchez-Gomez et al. [18] discussed several criteria for ETS of the multi-document. It has considered only two ETS criteria: redundancy reduction and content coverage and any other coherence and relevance taken separately. These criteria are applied in generic extractive multi-document text summarization. There are used datasets from DUC and a combination of objective functions. Here, evaluation of the document by ROUGE metrics. The result was generated from redundancy reduction, relevance, and content coverage in terms of execution time and average ROUGE.
Al-sabahi et al. [19] proposed hierarchical structured self-attentive summarization (HSSAS) model, which is uses neural network architecture. It requires training algorithms to represent the effectiveness of learning and creates sentences and embedding. The given self-attention model provides extra information to guide the extraction process of summary. The given model is treated as a classification problem as a summarization task. This model calculates the probability of a summary sentence based on many features such as sentence position, saliences, and content information. Finally, the ROUGE metric is evaluated on two datasets such as DUC 2002 and CNN/Daily Mail.
Table 3. ETS: Discussed features, techniques/approaches, and performance of many papers
|
Title and year of paper |
Technique/ Evaluation |
Features |
Performance |
|
Candidate sentence selection for extractive text summarization, 2020 [15] |
Machine Learning (Supervised learning) Evaluation measure: ROUGE (ROUGE-1, ROUGE-2) |
Sentence Ranking, ensembled, syntactic, semantic |
In Summarization feature: ROUGE (ROUGE-1=0.65 in ensembled features) In Summarization methods: It is based on LSTM-NN using SummaRuNNe to improve to the ROUGE-1 by 3%. |
|
A Hierarchical Structured Self-Attentive Model for Extractive Document Summarization, 2018 [19] |
Linguistic approach Evaluation Metrics uses ROUGE for n-grams |
Information Content, Positional Representation, novelty, Salience |
Comparison of performance to other papers, Calculating through CNN/Daily Mail Datasets ROUGE-1=0.423, ROUGE-2=0.178 & ROUGE-L = 0.376, DUC 2002 Dataset ROUGE1=0.521, ROUGE-2=0.245 |
|
A Hybrid Approach to Single Document extractive summarization, 2018 [20] |
Hybrid Approach, Evaluation metric uses ROUGE measuring precision, recall and f-score. |
Unique-Terms, Title-Similarity, Numeric Token, Positive-Negative, keywords, Sentence length |
Performance measure to Page Rank Algorithms, MMR algorithms, Features based extraction approaches and Hybrid approaches. |
|
Integrating Extractive and Abstractive Models for Long Text Summarization, 2017 [21] |
Machine Learning Approach, Evaluation metric used ROUGE (R-N, R-L) |
Sentence extraction, Summary generation |
In this paper evaluated reference summary and system summary. |
|
SummaRuNNer: A Recurrent Neural Network Based Sequence Modelfor Extractive Summarization of Documents, 2017 [22] |
Machine Learning Approach Evaluation metric used ROUGE (R-N, R-L) |
Information Content, Salience, Novelty etc. |
Calculating results for SummaRuNNer on different dataset using ROUGE. |
|
Use of fuzzy logic and wordnet for improving performance of extractive automatic text summarization, 2016 [23] |
Linguistic approach Evaluation uses 95 documents and ROUGE metric on DUC 2002 datasets: R-1 and R-2 |
Title similarity, Sentence Centrality, Numerical Data, Sentence Scoring, Sentence length |
Performance evaluating for 95 documents through ROUGE-N (i.e., N= 1 and 2). Calculated precision, recall and f-measure. |
|
Extractive single-document summarization based on genetic operators and guided local search, 2014 [24] |
Machine Learning Evaluation Uses ROUGE metric: ROUGE-1, ROUGE-2 |
Title, Length, Position, Cohesion etc. |
Measuring performance of MA-SingleDocSum, DE and FEOM etc. through two Datasets DUC 2001 and 2002 etc. |
|
Combining Syntax and Semantics for Automatic Extractive Single-Document Summarization, 2012 [25] |
Statistical Approach Evaluation uses ROUGE metric for n-grams co-occurrence. |
TextRank Score, WordNet Score, Position Score |
Performance on ROUGE n-grams for MEAD and TextRank Sentence extraction for article YB and NB execution. |
|
Single document extractive text summarization using Genetic Algorithms, 2012 [26] |
Linguistic Approach, Machine Learning |
Cohesion Factor (CF), Readability Factor (RF), Topic Relation Factor (TRF) |
Calculating the recall, precision value of summary through DUC 2002. |
|
SumCR: A new subtopic-based extractive approach for text summarization 2012 [27] |
Machine Learning Evaluation uses ROUGE metric (ROUGE-2 and ROUGE-SU4) |
Keywords, title, sentence location, and cue words |
Performance measure for the SumCR-Q, SumCR-G, System-24 etc. |
|
Automated extractive single-document summarization: beating the baselines with a new approach, 2011 [28] |
Statistical Approach Evaluation uses ROUGE metric for compare SynSem. |
Total Sentence score, TextRank score, Position Score and WordNet Score |
Performance measure for SynSem and on the DUC 2002, first 100 words of each article. |
|
Integrating Prosodic Features in Extractive Meeting Summarization 2009, [29] |
Machine Learning (Semi-Supervised Learning) Evaluation uses ROUGE metric. |
Local context information, topic and speakers. |
Performance measuring for prosodic and non-prosodic information. |
|
A Probabilistic Generative Framework for Extractive Broadcast News Speech Summarization, 2008 [30] |
Machine learning Evaluation uses ROUGE metric. |
Features are Lexical, Prosodic, Confidence and Relevance. |
Here performing result on Chinese broadcast news on the different models. |
|
Summarizing Scientific Texts: Experiments with Extractive Summarizers, 2007 [31] |
Linguistic Approach Evaluation uses ROUGE metric: (R-1) |
Sentence order, Sentence position |
Evaluating precision, recall and f-measure through ROUGE metrics. |
|
Event-based Extractive Summarization using Event Semantic Relevance from External Linguistic Resource 2007, [32] |
Linguistic Approach Evaluation uses ROUGE metric: (ROUGE-1, ROUGE-2 and ROUGE-W) |
Semantic relation |
Performance measuring for semantic relation, normalization format of strength, bi-relation and parallel connection model. |
|
Sentence-extractive automatic speech summarization and evaluation techniques, 2006, [33] |
Linguistic Approach (F-measure, and 2 and 3-gram recall) |
Sentence Extraction (Confidence score, Linguistic score) etc. |
Evaluating to the performance of the sentence f-measure and N-gram recall and finding correlation analysis between subjective and objective scores. |
|
Intelligent Extractive Text Summarization Using Fuzzy Inference Systems, 2006, [34] |
Machine learning (Unsupervised Learning) |
Title, number of words, sentence selection etc. |
Summary evaluated by three parameters: Recall(R), Precision(P) and F (Overall Fitness) |
Table 4. ETS: Discussed about previous works to features, techniques / approaches and performance of each papers
|
S.N. |
Authors Name |
Document Type |
Types of Approaches (ToP) |
Domain Types |
Dataset |
||||||||||
|
SD |
MD |
SS |
L1 |
ML |
H1 |
RN |
NA |
JA |
TR |
TD |
EA |
WP |
|||
|
01 |
Al-Sabahi et al. [19] |
$\sqrt{ }$ |
× |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
× |
× |
× |
× |
C1 |
|
02 |
Chatterjee et al. [26] |
$\sqrt{ }$ |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
× |
× |
× |
× |
× |
D2 |
|
03 |
Wang et al. [21] |
× |
$\sqrt{ }$ |
× |
× |
$\sqrt{ }$ |
× |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
× |
|
04 |
Cao and Zhuge [17] |
× |
$\sqrt{ }$ |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
× |
× |
× |
× |
D1, D4, D5 |
|
05 |
Nallapati et al. [22] |
$\sqrt{ }$ |
× |
× |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
× |
× |
× |
D3 |
|
06 |
Filho et al. [31] |
$\sqrt{ }$ |
× |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
× |
× |
× |
× |
OT |
|
07 |
Mendoza et al. [24] |
$\sqrt{ }$ |
$\sqrt{ }$ |
× |
× |
$\sqrt{ }$ |
× |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
D2 D4 |
|
08 |
Hirohata et al. [33] |
× |
$\sqrt{ }$ |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
× |
× |
× |
× |
OT |
|
09 |
Mutlu et al. [15] |
$\sqrt{ }$ |
× |
× |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
× |
× |
× |
OT |
|
10 |
Barrera and Verma [25] |
$\sqrt{ }$ |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
D2 |
|
11 |
Abuobieda et al. [35] |
$\sqrt{ }$ |
$\sqrt{ }$ |
× |
× |
$\sqrt{ }$ |
× |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
D2 |
|
12 |
Yadav et al. [23] |
× |
$\sqrt{ }$ |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
× |
× |
× |
× |
D2 |
|
13 |
Barrera and Verma [28] |
× |
$\sqrt{ }$ |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
× |
× |
× |
× |
× |
D2 |
|
14 |
S.Gupta and S.K. Gupta [20] |
× |
$\sqrt{ }$ |
× |
× |
$\sqrt{ }$ |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
× |
× |
O1 |
|
15 |
Zhang et al. [36] |
× |
$\sqrt{ }$ |
× |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
× |
× |
× |
OT |
|
16 |
Jian-Ping and Lihui [27] |
× |
× |
× |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
× |
× |
× |
D1 |
|
17 |
Chen et al. [30] |
$\sqrt{ }$ |
× |
× |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
× |
× |
× |
OT |
|
18 |
Hernández and Ledeneva [37] |
× |
$\sqrt{ }$ |
× |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
× |
× |
× |
D2 |
|
19 |
Madhurima et al. [38] |
$\sqrt{ }$ |
× |
× |
$\sqrt{ }$ |
× |
× |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
× |
|
20 |
Liu et al. [32] |
$\sqrt{ }$ |
× |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
× |
× |
× |
× |
D4 |
|
21 |
Xie et al. [29] |
$\sqrt{ }$ |
× |
× |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
× |
× |
× |
OT |
|
22 |
Elbarougy et al. [16] |
$\sqrt{ }$ |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
× |
× |
× |
× |
× |
OT |
|
23 |
Kiani-B et al. [34] |
$\sqrt{ }$ |
× |
× |
× |
$\sqrt{ }$ |
× |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
× |
|
24 |
Van et a. [10] |
$\sqrt{ }$ |
× |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
× |
× |
× |
× |
OT |
|
25 |
Liu et al. [8] |
$\sqrt{ }$ |
× |
× |
× |
$\sqrt{ }$ |
× |
× |
× |
× |
× |
× |
× |
× |
OT |
Table 5. List of abbreviations used in Table 4
|
Document Type |
Dataset |
||
|
SD |
Single Document |
D1 |
DUC |
|
MD |
Multiple Document |
D2 |
DUC 2002 |
|
Type of approach |
D3 |
DUC 2002 and DailyMail |
|
|
SS |
Simple Statistical |
D4 |
DUC 2001 |
|
L1 |
Linguistics |
D5 |
DUC 2004 |
|
ML |
Machine Learning |
C1 |
CNN\DM |
|
H1 |
Hybrid |
O1 |
Opinions Opinion |
|
Domain Type |
OT |
Other datasets |
|
|
RN |
Radio News |
|
|
|
NA |
Newspaper Articles |
||
|
JA |
Journal Articles |
||
|
TR |
Technical Report |
||
|
TD |
Transcription Dialogues |
||
|
EA |
Encyclopedia Articles |
||
|
WP |
Web Pages |
||
Nallapati et al. [22] described extractive text summarization with the help of a neural network. The given method for text summarization is based on supervised learning approach of machine learning. It uses many features such as novelty, salience, and information content for training mechanisms. The features are needed to eliminate the extractive labels of data. It generates a meaningful, and relevant summary on two datasets such as DUC 2002 and CNN/Daily Mail corpus for ROUGE evaluation.
Mendoza et al. [24] discussed ETS for a single document, and given a method named MA-SingleDocSum that generates relevant summary of the document through local guided search and generic operators. According to the method, it first decides rank of each sentence in the document, which is stored into feature groups, and then selects the most relevant sentence from the features group based on sentences’ rank. The method uses different document features such as frequency of words, length of sentences, and title in the sentence. The performance of the given method has been evaluated on two datasets, DUC2001 and DUC 2002 for ROUGE measures.
Many researchers focused on extractive text summarization, which uses various techniques and evaluation, feature, and performance as discussed in Table 3. Table 4 describes the existing research work based on type of document, approaches of ETS, domain type, and datasets. Table 5 gives the abbreviations used in Table 4.
It is started in the late fifties now. There are many types of approaches used in previous research work in ETS and currently, use where ETS can be many taxonomies based on NLP summarization. One by one approach described, which is applicable in ETS summarization. Learning types of approaches are categorized into unsupervised, semi-supervised, and supervised learning. These approaches helpful for a relevant summary.
4.1 Fuzzy logic approach
Many researchers have used this approach in previous research. It is based on the proper noun, main concept, and several anaphors with binary values ranging from zero to one ([0-1]), but sometimes it is not exact. The fuzzy logic model has to add common sense reasoning to deals with uncertainty in an unsupervised manner. In fuzzy logic, the classification is appeared to text summarization [4, 7, 23]. In this approach, the sentence picks the highest-scoring based on relevance clustering. These sentences maintain relevant feature vectors such as semantic pattern, TF-ISF, length, and sentence position. Where FCM algorithms cluster the vector to be each sentence calculated relevance score. Finally, it is selected relevance sentence rank greater than 50 percent from the candidate sentences. From every cluster to be chosen highest ranked then it to be concatenated into a final summary.
4.2 Latent semantic analysis (LSA) approach
LAS is based on the contextual use of the word and fully-unsupervised learning techniques for learning. To semantic of word used for avoiding the problem of synonymy. It has three steps used for LSA composition: sentence selection, single value decomposition, and input creation matrix. Where input matrix creation is used in the input document. Sentence of the document to be represented column of matrix and word of the document represented into a row of the matrix. Each matrix cell is mapped into the words in a sentence. Weight functions are calculated from cell values using functions. There are many functions, such as entropy weight, IDF, TF-IDF, and Normal functions. In the year 2005, it is generated two new ideas for text summarization, which are LSA based on text relationship map (LSA+TRM) and Modified Corpus-Based Approach (MCBA). MCBA depends on the score function, which is solved by a trainable summarizer and generated summary through important features such as Centrality (Cen), negative keywords, positive keywords, Resemblance to the Title (R2T), and Position (Pos). LSA+TRM is used in semantic matrix documents to generated summaries using many functions.
4.3 Graphical based approach
In this approach, the graph has connected from the set of vertices and edges, which are generated from the document. The document's sentences represented vertices of the graph, and words of the document to be represented edges. Graph generated rank of each sentence, in the year 1998, Sergey and Page [39] developed Page-Ranking algorithms, then it used in sentence rank. There are edges represented similarities between nodes and nodes in weight graphs. In the graph approach, there are also used LexRank and TextRank. In the year 2004, LexRank, proposed by Erkan and Radev [40], is used in multiple document text summarization where the selection of sentences in the graph may produce a relevant sentence of the summary. In a single document task, there are uses keyword extraction and sentence extraction by TextRank. In the year 2013, proposed new techniques GRAPHSUM by Baralis et al. [41], it is applicable for discovering association rule in which represents correlations many terms based on graph models. LexRank and TextRank are both based on fully unsupervised algorithms. It is totally dependent on entire text-based but not training sets.
4.4 Discourse based approaches
This type of approach is used in the linguistic approach, which is used in ETS. There is a connection between many sentences, known as discourse relations. It is included many resources such as WordNet, POS pattern, n-grams, Tree Tagger, an e-dictionary, etc.; these are resources of lexical analysis [42]. In the year 1988, Mann and Thompson [43] developed a new technique for the computational linguistic domain that is Rhetorical Structure Theory (RST). In linguistics, there are two main challenges and issues present in text summarization: cohesion and coherence. Discourse approaches summarize the document in the easiest and generated meaningful, relevant summary.
4.5 Statistical based approaches
This approach is mostly used in text summarization to create in a sudden way relevant summary. Many researchers are focused on the statistical approach because it is mainly used centrality and frequency. Centrality and frequency are both also used in unsupervised approaches. This approach focused only on the non-linguistic feature of the document like word position, sentence position, and many more within a document to the tf-idf. Later it is developed keywords list. In the year 1995, [44] n-gram was used for statistical information because finding a keyword from the document. There are many more categories available for this approach, such as word co-occurrence, term-frequency [45], word frequency and term frequency-inverse document frequency [14], and any others. It is given the very trend and crude inappropriate quite results. Where this approach improvement by tf-idf means it is taken several occurrences of frequency word which are decided a keyword or not. This approach is applied to calculate the confidence of a word and the accuracy of a summary.
4.6 Machine learning approach (MLA)
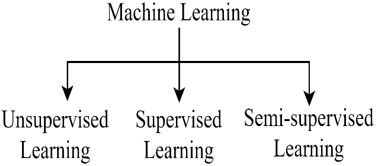
MLA is also classified into unsupervised, supervised, and semi-supervised approaches as shown in Figure 2. These approaches are also used in labeled data or training datasets. In an unsupervised learning technique, its summary is produced without the need for training data. There are many techniques uses in Deep learning techniques (Recurrent Neural Network (RNN), Convolutional Neural Network (CNN), RBM and Autoencoder, etc.). Supervised learning techniques are Naïve Bayes classifier, Genetic Algorithm, SVM, Regression, and Multilayer Neural Network. Semi-supervised learning techniques mixture of unlabeled and label data to the generated convenient classifier. It has many approaches, such as naïve Bayes classifier and SVM, and many more.
Figure 2. Classification of machine learning approach
Recently, MLA was used in Bayesian methods, binary classifier, and HMM. Bayes rule is applicable in the binary classifier, where the probability to be included in the summary is calculated by the given feature of sentences. Burges et al. [46] discussed the RankNet for gradient descent method using NN, which are learn about sentence ranking, then it helpful for sentence scores. Based on RankNet, Krysta et al. [47] developed NetSum. There are two-layer NN trained by RankNet. It is useful for the implementation of an enhanced algorithm known as LambdaRank, and this is put in the sentence in terms of scores [48]. Topmost rank selected for summary and calculated accuracy of summary. The SVM algorithm is used by Chali et al. [49] based on many features like name entities, word and phrase feature, sentence position, and semantic features trained by model for text sentence rank. In query-based summarization, there are also used SVM to be generated relevant summary [50].
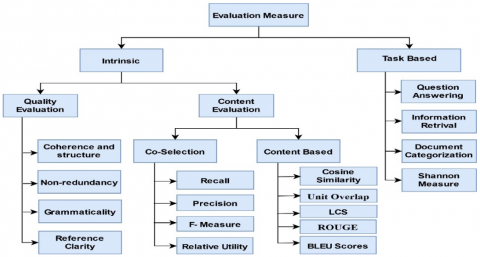
Evaluation measure is a difficult task for people or authors which type of information available in summary. According to the change, summary and collecting information randomly is not a very easy task. There is a described classification of summary evaluation measure shown in Figure 3.
Evaluation of summary determines into two types of performance of ETS. Task-based evaluation and intrinsic evaluation, which are shown in Figure 3.
5.1 Intrinsic evaluation
This is determined to the gathering the relevant information of summary in between human-made summary and machine-made summary, and it is categorized into two ways: Quality Evaluation and Content Evaluation and it is shown in Figure 3.
5.1.1 Quality evaluation
This is based on text quality measures, and it is also divided into several types:
Coherence and structure. When the sentence should be coherent, and the summary of a sentence should be well structured.
Non-redundancy. In summary, the text cannot include duplicate information from the document. Suppose the large document has many sentences or words repeated. There is a need to eliminate duplicate sentences or words from the document for measuring the performance of documents.
Grammatically. In case of, text cannot be included an item of non-textual or incorrect words or punctuation errors.
Reference clarity. In summary, there is always included clearly referred noun and pronoun.
Figure 3. Classification of summary evaluation measures
5.1.2 Content evaluation
Content evaluation summary further divided into two ways: Co-selection and Content-based. This is shown in Figure 3, co-selection and content types are divided into several types.
There are mention many conditions of co-selection and content-based measures in Table 6.
Co-selection. Co-selection is also divided into many types like (a) Recall (b) Precision (c) f-measures and (d) Relative utility. There are described one by one, and its mathematical condition are shown in Table 6.
(a) Recall: This is also depended on the number of positive classes in prediction corresponding to the number of positive and number of negative class in the confusion table (Table 6).
(b) Precision: This is depended on the number of positive classes in prediction corresponding to the total positive class in the confusion table (Table 6).
(c) F – Measures: This is provided a unique score as well as the equivalent of both the concerns of recall and precision of a single figure.
(d) Relative Utility (RU): This method is permitted for Reference Summary (RS) that is extraction units of sentences, paragraphs, etc., which belong in the fuzzy membership in the reference summary. Where RS contains every sentence of the main document with the trustable number of values using to the addition in summary. The relative utility is useful for more than one document summarization and one-sentence constructing to the redundant, but this is automatically chastised the rank of evaluation. The system can be extracted more than two sentences equivalent chastise/penalized so that system has only one foregoing sentence is extracted, which means there are less informative sentences.
Content-based. It is divided into different types such as (a) Cosine Similarity (b) Unit Overlap (c) ROUGE (d) LCS and (e) BLEU Scores. Which are described one by one:
(a) Cosine Similarity: it is content-based similarity-based evaluation. There are dependent on the system summary and its reference document that contains vector space models. Its condition is shown in Table 6.
(b) Unit Overlap: This is another similarities evaluation based on sets of words.
(c) LCS: This is dependent on the sequence of words through two lengths of strings, which are the longest common subsequence uses edit of distances, i.e., the condition is mention in Table 6.
(d) ROUGE: This is also known as n-gram co-occurrence statistics that are used in automatic evaluation methods, and it is deepened on the similarity of n-grams means n-gram is subsequence is given main document text in term of n words, i.e., the condition is mentioned in Table 6.
(e) BLEU Scores: BLEU stand for Bilingual Evaluation Understudy evaluating the generated sentences to a reference sentence and prediction made by automatic machine translation systems. This is also supported by the language generation problem with deep learning approaches like Speech recognition, image caption generation, and text summarization. They cannot find more-perfect, but it offers few benefits for easy to understand, correlates highly with human evaluation, and is language independent to the widely adopted.
5.2 Task based evaluation
This is the determined quality of summary and how to decide the other tasks, i.e., question answering, document categorization, and information retrieval. When it is provided to help other tasks, then a summary is a good summary.
5.2.1 Question Answering (QA)
It is based on task-based evaluation and is an extrinsic evaluation. Here, it impacts the summarization in a task of QA carried out in. Suppose the authors picked three Graduate Aptitude Test in Engineering (GATE) reading comprehension exercises. In exercise, there is a multiple choice of QA present. However, only one answer is correct to be selected answers from each QA. Then, it is the measure. How many of QA is correct from different situations. According to the original passage of QA, it is an automatically generated summary.
Table 6. Taxonomy of content-based and frequency-based evaluation measures
|
Co-Selection Measures |
Precision, Recall, Accuracy and f-score |
Precision $($ Pr $)=\frac{\text { TP }}{T P+F P}$ $\operatorname{Recall}(\operatorname{Re})=\frac{\text { TP }}{\mathrm{TP}+\mathrm{FN}}$ $\mathrm{f}-$ score $=\frac{\left(\alpha^{2}+1\right) . \operatorname{Pr} . \operatorname{Re}}{\alpha^{2} . \operatorname{Pr}+\operatorname{Re}}$ when $\boldsymbol{\alpha}$=1 then $\mathrm{f}-$ score $=\frac{2 . \text { Pr. } \mathrm{Re}}{\operatorname{Pr}+\mathrm{Re}}$ |
P=Positive, N=Negative TP=True Positive, FN=False Negative
$\boldsymbol{\alpha}$= weighting factor If $\boldsymbol{\alpha}$>1 then favours precision If $\boldsymbol{\alpha}$ <1 then favours Recall |
|||||||||||||
|
Content-Based Measures |
Cosine Similarity |
$\cos (\mathrm{P}, \mathrm{Q})=\frac{\sum_{i} p_{i} . q_{i}}{\sqrt{\sum_{i} p_{i}^{2}} . \sqrt{\sum_{i} q_{i}^{2}}}$ |
Where P and Q: System summary and its reference document depends on vector space model. |
|||||||||||||
|
Unit Overlap |
$\operatorname{overlap}(P, Q)=\frac{\|P \cap Q\|}{\|P\|+\|Q\|-\|P \cap Q\|}$ |
Where P and Q denote lemma or set of words ‖P‖=size of set P and ‖Q‖=size of set Q. |
||||||||||||||
|
Longest Common Subsequence (LCS) |
$\operatorname{lcs}(P, Q)=\frac{\operatorname{len}(P)+\operatorname{len}(Q)-\operatorname{edit}_{d i}(P, Q)}{2}$ |
Where P and Q denote the sequence of a word, lcs (P, Q) = length of LCS in between P and Q, len(P) = length of string P, len(Q) = length of string Q, editdi(P, Q)= edit distance of P and Q. |
||||||||||||||
|
ROUGEs (N-gram Co-occurrence Statistics) |
ROUGE $-n=\frac{\sum_{C \in K} \sum_{M \in C} \text { COUNT }_{\text {match }}(M)}{\sum_{C \in K} \sum_{M \in C} \operatorname{COUN}(M)}$ |
K=reference summaries–reference summary set M=gramn COUN(M) = number of n-grams reference summary COUNTmatch (M) = maximum number of n-grams co-occurring in a candidate summary and a reference summary |
||||||||||||||
Table 7. Merits and demerits of ETS techniques
|
Approaches |
Merits |
Demerits |
|
Fuzzy-logic approaches [4, 7] |
Based on Unsupervised learning approaches |
|
|
LSA approach |
|
|
|
Graphical approaches [26] |
|
|
|
Discourses based approach |
|
|
|
Simple statistical approaches |
|
|
|
Machine Learning |
|
|
5.2.2 Information Retrieval (IR)
It is discarded redundancy and unimportant sentence or words from the document. IR is used in enhanced quality of summary, and it is helpful to selected documents from the database.
5.2.3 Document Categorization (DC)
It is based on text classification that is categorized into serval terms like intent detection, topic labeling, and sentiment analysis. The text is analyzed into different levels (i.e., document level, paragraph level, sentence level, and sub sentence level). Such that text process into paragraphs, sentence, and more depths. DC measures all different level points inaccurate summary from given documents.
5.2.4 Shannon Measure (SM)
Shannon measure is part of information theory (Shannon: developed in1948). SM aims to measure information content by focusing next tokens such as letters, words, etc., from the original text. The idea has been generated from SM in information theory. There is a focus on three groups like the important passage from the source document, no text at all, and generated summary.
Merits and demerits of the ETS approach, which are mention in Table 7. ETS approach supported in text summary in efficient ways. These approaches are helpful for document summarization with the help of recent techniques.
There are few approaches for ETS, facing problems from a few limitations. The Fuzzy-logic approach is improved sentence ranking issues, and it is a need for the fuzzy rule for human experts. LSA approach has a facing problem from polysemy, but it is provided semantic relations and the creation of better knowledge with minimal noise. Graph approaches can be summaries with the help of the ranking algorithm, and its accuracy depends on their using mathematical functions. Discourse approach generated summary with the help of languages, but it is needed domain-based dataset and suffer from cohesion and coherence. The statistical approach has no need for a training dataset, but it is processing in the easiest way and creates a summary without discourses or semantic knowledge. Machine learning approaches based on features and high number feature test for performance of the datasets and its use for the significantly larger dataset which has generated good summary of accuracy.
There are the following Challenges and Issues that arise in the course of ETS implementation.
Challenges in ETS:
Find the good quality of summary from the original document through effective keywords.
Assemble keywords in proper order for generating meaningful sentence to convert into a summary.
Multi-lingual ETS is also a task challenge.
Difficulties in ETS which approaches are better uses than ATS.
Issues in ETS:
Multi-document ETS, various issues frequently arise while assessment of summaries like a temporal dimension, redundancy, co-reference or sentence ordering, etc. that assembles very hard to attain the quality of the relevant summary. However, few other issues arise, like coherence, cohesion, and damage for the summary.
In ETS, few people are focusing, few sets of sentences are key for the summary.
ETS has an interesting topic of the research field in natural language processing and elaborate study of several approaches that produce non-redundant, concise, coherent, sentence ordering problems, and relevant information summary. Moreover, it is described as an explanation of the ETS approach and measure the evaluation task. ETS has many types of approaches. Several authors are focusing based on learning and graphical-based approach. Evaluation measure is classified in more depth with explanations and their conditions. This helps to summary in the easiest ways. Few researchers move toward unsupervised learning in the ETS summary. Along with these have mention issues and challenges of ETS. In the ETS summarization evaluation measure, there are huge challenges in this area.
In future, we will consider abstractive text summarization approaches and give their taxonomy, merits and demerits. Further, we will find out research challenges and issues in abstractive text summarization.
We thank innominate reviewers for helpful advices. This research was partially supported by Ministry of Human Resource Development (MHRD), Government of India (GoI). We thank our Student Research Committee (SRC) members at Motilal Nehru National Institute of Technology Allahabad, Prayagraj, India, who supported directly or indirectly for this research paper.
[1] Jones, K.S. (2007). Automatic summarising: The state of the art. Inf. Process. Manag., 43(6): 1449-1481. https://doi.org/10.1016/j.ipm.2007.03.009
[2] Zajic, D.M., Dorr, B.J., Lin, J., (2008). Singledocument and multi-document summarization techniques for email threads using sentence compression. Inf. Process. Manag., 44(4): 1600-1610. https://doi.org/10.1016/j.ipm.2007.09.007
[3] Barzilay, R., McKeown, K.R. (2005). Sentence fusion for multi document news summarization. Comput. Linguist., 31(3): 297-328. https://doi.org/10.1162/089120105774321091
[4] Goularte, F.B., Nassar, S.M., Fileto, R., Saggion, H. (2019). A text summarization method based on fuzzy rules and applicable to automated assessment. Expert Systems with Applications, 115: 264-275. https://doi.org/10.1016/j.eswa.2018.07.047
[5] Tao, Y., Zhou, S., Lam, W., Guan, J. (2008). Towards more effective text summarization based on textual association networks. In Semantics, Knowledge and Grid, 2008. SKG’08. Fourth International Conference on, pp. 235-240. https://doi.org/10.1109/SKG.2008.17
[6] Wang, D., Zhu, S., Li, T., Chi, Y., Gong, Y. (2011). Integrating document clustering and multi document summarization. ACM Trans. Knowl. Discov. from Data, 5(3): 14. https://doi.org/10.1145/1993077.1993078
[7] Darshna, P., Shah, S., Chhinkaniwala, H. (2019). Fuzzy logic based multi document summarization with improved sentence scoring and redundancy removal technique. Expert Systems with Applications, 134: 167-177. https://doi.org/10.1016/j.eswa.2019.05.045
[8] Liu, B. (2012). Sentiment analysis and opinion mining. Synth. Lect. Hum. Lang. Technol., 5(1): 1-167. https://doi.org/10.2200/S00416ED1V01Y201204HLT016
[9] Gong, Y., Liu, X. (2001). Generic text summarization using relevance measure and latent semantic analysis. In Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 19-25. https://doi.org/10.1145/383952.383955
[10] Van Lierde, H., Chow, T.W.S. (2019). Query-oriented text summarization based on hypergraph transversals. Information Processing & Management, 56(4): 1317-1338. https://doi.org/10.1016/j.ipm.2019.03.003
[11] Aliguliyev, RM. (2006). A novel partitioning-based clustering method and generic document summarization. In Proceedings of the 2006 IEEE/WIC/ACM international conference on Web Intelligence and Intelligent Agent Technology, pp. 626-629. IEEE Computer Society. https://doi.org/10.1109/WI-IATW.2006.16
[12] Neto, J.L., Freitas, A.A., Kaestner, C.A.A. (2002). Automatic text summarization using a machine learning approach. In Brazilian Symposium on Artificial Intelligence, pp. 205-215. https://doi.org/10.1007/3-540-36127-8_20
[13] Singh, S.P., Kumar, A., Mangal, A., Singhal, S. (2016). Bilingual automatic text summarization using unsupervised deep learning. In Electrical, Electronics, and Optimization Techniques (ICEEOT), International Conference on, pp. 1195-1200. https://doi.org/10.1109/ICEEOT.2016.7754874
[14] Salton, G., Buckley, C. (1988). Term-weighting approaches in automatic text retrieval. Inf. Process. Manag., 24(5): 513-523. https://doi.org/10.1016/0306-4573(88)90021-0
[15] Begum, M., Sezer, E.A., Akcayol, M.A. (2020). Candidate sentence selection for extractive text summarization. Information Processing & Management, 57(6): 102359. https://doi.org/10.1016/j.ipm.2020.102359
[16] Elbarougy, R., Behery, G., El Khatib, A. (2020). Extractive Arabic text summarization using modified PageRank algorithm. Egyptian Informatics Journal, 21(2): 73-81. https://doi.org/10.1016/j.eij.2019.11.001
[17] Cao, M.Y., Hai, Z.G. (2020). Grouping sentences as a better language unit for extractive text summarization. Future Generation Computer Systems. https://doi.org/10.1016/j.future.2020.03.046
[18] Sanchez-Gomez, J.M., Vega-Rodríguez, M.A., Perez, C.J. (2020). Experimental analysis of multiple criteria for extractive multi-document text summarization. Expert Systems with Applications, 140: 112904. https://doi.org/10.1016/j.eswa.2019.112904
[19] Al-Sabahi, K., Zhang, Z.P., Nadher, M. (2018). A hierarchical structured self-attentive model for extractive document summarization (hssas). IEEE Access, 6: 24205-24212. https://doi.org/10.1109/ACCESS.2018.2829199
[20] Gupta, S., Gupta, S.K. (2018). Abstractive summarization: an overview of the state of the art. Expert Systems with Applications. https://doi.org/10.1016/j.eswa.2018.12.011
[21] Wang, S., Zhao, X., Li, B., Ge, B., Tang, D.Q. (2017). Integrating extractive and abstractive models for long text summarization. In 2017 IEEE International Congress on Big Data (BigData Congress), pp. 305-312. https://doi.org/10.1109/BigDataCongress.2017.46
[22] Nallapati, R., Zhai, F.F., Zhou, B.W. (2017). Summarunner: A recurrent neural network-based sequence model for extractive summarization of documents. In Thirty-First AAAI Conference on Artificial Intelligence. https://arxiv.org/abs/1611.04230
[23] 2Yadav, J., Meena, Y.K. (2016). Use of fuzzy logic and wordnet for improving performance of extractive automatic text summarization. In 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI), pp. 2071-2077. https://doi.org/ 10.1109/ICACCI.2016.7732356
[24] Mendoza, M., Bonilla, S., Noguera, C., Cobos, C., León, E. (2014). Extractive single-document summarization based on genetic operators and guided local search. Expert Systems with Applications, 41(9): 4158-4169, 2014. https://doi.org/10.1016/j.eswa.2013.12.042
[25] Araly, B., Verma, R. (2012). Combining syntax and semantics for automatic extractive single-document summarization. In International Conference on Intelligent Text Processing and Computational Linguistics, pp. 366-377. https://doi.org/10.1007/978-3-642-28601-8_31
[26] Chatterjee, N., Mittal, A., Goyal, S. (2012). Single document extractive text summarization using genetic algorithms. In 2012 Third International Conference on Emerging Applications of Information Technology, pp. 19-23. https://doi.org/10.1109/EAIT.2012.6407852
[27] Mei, J.P., Chen, L.H. (2012). SumCR: A new subtopic-based extractive approach for text summarization. Knowledge and Information Systems, 31(3): 527-545. https://doi.org/10.1007/s10115-011-0437-x
[28] Araly, B., Verma, R. (2011). Automated extractive single-document summarization: Beating the baselines with a new approach. In Proceedings of the 2011 ACM Symposium on Applied Computing, pp. 268-269. https://doi.org/10.1145/1982185.1982247
[29] Xie, S.S., Hakkani-Tür, D., Favre, B., Liu, Y. (2009). Integrating prosodic features in extractive meeting summarization. In 2009 IEEE Workshop on Automatic Speech Recognition & Understanding, pp. 387-391. https://doi.org/10.1109/ASRU.2009.5373302
[30] Chen, Y.T., Chen, B.L., Wang, H.M. (2008). A probabilistic generative framework for extractive broadcast news speech summarization. IEEE Transactions on Audio, Speech, and Language Processing, 17(1): 95-106. https://doi.org/10.1109/TASL.2008.2005031
[31] Filho, B., Paulo, P., Salgueiro Pardo, T.A., das Gracas Volpe Nunes, M. (2007). Summarizing scientific texts: Experiments with extractive summarizers. In Seventh International Conference on Intelligent Systems Design and Applications (ISDA 2007), pp. 520-524. https://doi.org/10.1109/ISDA.2007.92
[32] Liu, M.F., Li, W.J., Wu, M.L., Hu, H.J. (2007). Event-based extractive summarization using event semantic relevance from external linguistic resource. In Sixth International Conference on Advanced Language Processing and Web Information Technology (ALPIT 2007), pp. 117-122. https://doi.org/10.1109/ALPIT.2007.9
[33] Makoto, H., Shinnaka, Y., Iwano, K., Furui, S. (2006). Sentence-extractive automatic speech summarization and evaluation techniques. Speech Communication, 48(9): 1151-1161. https://doi.org/10.1016/j.specom.2006.04.005
[34] Arman, K.B., Akbarzadeh, M.R., Moeinzadeh, M.H. (2006). Intelligent extractive text summarization using fuzzy inference systems. In 2006 IEEE International Conference on Engineering of Intelligent Systems, pp. 1-4. https://doi.org/10.1109/ICEIS.2006.1703156
[35] Albaraa, A., Salim, N., Kumar, Y.J., Osman, A.H. (2013). An improved evolutionary algorithm for extractive text summarization. In Asian Conference on Intelligent Information and Database Systems, pp. 78-89. https://doi.org/10.1007/978-3-642-36543-0_9
[36] Zhang, J.J., Chan, R.H.Y., Fung, P. (2009). Extractive speech summarization using shallow rhetorical structure modeling. IEEE Transactions on Audio, Speech, and Language Processing, 18(6): 1147-1157. https://doi.org/10.1109/TASL.2009.2030951
[37] García-Hernández, R.A., Ledeneva, Y. (2013). Single extractive text summarization based on a genetic algorithm. In Mexican Conference on Pattern Recognition, pp. 374-383. https://doi.org/10.1007/978-3-642-38989-4_38
[38] Madhurima, D., Kumar Das, A., Mallick, C., Sarkar, A., Das, A.K. (2019). A graph based approach on extractive summarization. In Emerging Technologies in Data Mining and Information Security, 179-187. https://doi.org/10.1007/978-981-13-1498-8_16
[39] Sergey, B., Page, L. (1998). The anatomy of a large-scale hypertextual web search engine. Computer Networks and ISDN Systems, 30(1): 107-117. https://doi.org/10.1016/S0169-7552(98)00110-X
[40] Günes, E., Radev, D.R. (2004). Lexrank: Graph-based lexical centrality as salience in text summarization. Journal of Artificial Intelligence Research, 22: 457-479. https://doi.org/10.1613/jair.1523
[41] Baralis, E., Cagliero, L., Mahoto, N., Fiori, A. (2013). "GraphSum: Discovering correlations among multiple terms for graph-based summarization. Information Sciences, 249: 96-109. https://doi.org/10.1016/j.ins.2013.06.046
[42] Mahak, G., Gupta, V. (2017). Recent automatic text summarization techniques: a survey. Artificial Intelligence Review, 47(1): 1-66. https://doi.org/10.1007/s10462-016-9475-9
[43] Mann, W.C., Thompson, SA. (1988). Rhetorical structure theory: Toward a functional theory of text organization. Text, 8(3): 243-281. http://dx.doi.org/10.1515/text.1.1988.8.3.243
[44] Cohen, J.D. (1995). Highlights: Language‐and domain‐independent automatic indexing terms for abstracting. Journal of the American Society for Information Science, 46(3): 162-174. https://doi.org/10.1002/(SICI)1097-4571
[45] Naik, S.S., Gaonkar, M.N. (2017). Extractive text summarization by feature-based sentence extraction using rule-based concept. In 2017 2nd IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), pp. 1364-1368. https://doi.org/10.1109/RTEICT.2017.8256821
[46] Burges, C., Shaked, T., Renshaw, E., Lazier, A., Deeds, M., Hamilton, N., Hullender, G. (2005). Learning to rank using gradient descent. In Proceedings of the 22nd International Conference on Machine Learning, pp. 89-96. https://doi.org/10.1145/1102351.1102363
[47] Svore, K., Vanderwende, L., Burges, C. (2007). Enhancing single-document summarization by combining RankNet and third-party sources. In Proceedings of the 2007 joint conference on empirical methods in natural language processing and computational natural language learning (EMNLP-CoNLL), pp. 448-457. https://www.aclweb.org/anthology/D07-1047
[48] Yadav, M.P., Raj, G., Akarte, H.A., Yadav, D.K. (2020). Horizontal scaling for containerized application using hybrid approach. Ingénierie des Systèmes d’Information, 25(6): 709-718. https://doi.org/10.18280/isi.250601
[49] Yllias, C., Hasan, S.A., Joty, S.R. (2009). A SVM-based ensemble approach to multi-document summarization. In Canadian Conference on Artificial Intelligence, pp. 199-202. https://doi.org/10.1007/978-3-642-01818-3_23
[50] Kleinberg, J.M. (1999). Authoritative sources in a hyperlinked environment. Journal of the ACM (JACM), 46(5): 604-632. https://doi.org/10.1145/324133.324140