Mohamed Djerioui* | Youcef Brik | Mohamed Ladjal | Bilal Attallah
OPEN ACCESS
Nowadays, one of the main reasons for disability and mortality premature in the world is the heart disease, which make its prediction is a critical challenge in the area of healthcare systems. In this paper, we propose a heart disease prediction system based on Neighborhood Component Analysis (NCA) and Support Vector Machine (SVM). In fact, NCA is used for selecting the most relevant parameters to make a good decision. This can seriously reduce the time, materials, and labor to get the final decision while increasing the prediction performance. Besides, the binary SVM is used for predicting the selected parameters in order to identify the presence/absence of heart disease. The conducted experiments on real heart disease dataset show that the proposed system achieved 85.43% of prediction accuracy. This performance is 1.99% higher than the accuracy obtained with the whole parameters. Also, the proposed system outperforms the state-of-the-art heart disease prediction.
heart disease, prediction, neighborhood component analysis, support vector machines, feature selection
Heart disease is one of the main reasons for disability and premature death of people in the world. According to the World Health Organization an estimation of 17.9 million deaths have occurred worldwide due to Heart diseases in 2016 [1]. However, some key factors help us reduce the risk of heart disease as the blood pressure and cholesterol controlling [2]. In fact, heart disease should not be diagnosed when a heart attack, angina, stroke or heart failure occur. Therefore, the prediction of heart disease is a delicate, risky, and very important factor [3]. If done properly it can be used by the medical staff to save life. This process can be realized by exploring the registered patient data. Usually, the existing healthcare systems use electronic health records to store this data. Advances in computer and information technologies can deal with this routine data to make critical medical decisions [4].
Actually, machine learning techniques have been widely explored in healthcare systems to make decisions building on clinical data. In this context, many researchers have used these techniques on heart diseases prediction. Abushariah et al. [5] have developed two systems based on Artificial Neural Network (ANN) and Neuro-Fuzzy approaches in order to develop an automatic heart disease diagnosis system. According to Shafenoor et al. [3], a proper evaluation and comparison for testing different data mining techniques can improve the accuracy of predicting cardiovascular disease. Also, Deng et al. [4] have explored a dynamical ECG recognition framework for human identification and cardiovascular diseases classification based on radial basis function (RBF). Besides, Bouali and Akaichi [6] have used many machine learning techniques, such as: Baysian Network, Decision tree, Artificial Neural Network, Fuzzy pattern tree and Support Vector Machine (SVM), to classify the Cleavland heart disease dataset using 10-fold-cross validation. SVM achieved the highest prediction accuracy compared to other classifiers. Otoom et al. [7] have presented a system for Coronary artery disease detection and monitoring where three machine learning techniques are performed such as: Bayes Net, SVM, and Functional Trees. The authors have used WEKA tool for detection and by applying feature selection, SVM has provided the best technique with 85.1% of accuracy.
Practically, in heart disease prediction, there is a huge number of samples corresponding to several installed sensors and/or physico-chemical analysis to identify the presence or absence of the disease. Because of the increasing number of patients day after day, the preparation of these samples becomes very costly in time, materials, and labor. To address this problem, a selection of relevant parameters can efficiently reduce the data dimension and minimize the number of treatment conducted which minimize consequently the medical equipment and the corresponding health staff.
In this paper, we propose a heart disease prediction system based on Neighborhood Component Analysis (NCA) for selecting the most relevant parameters to make a good decision. In fact, the parameter selection in such a medical application can seriously reduce: (1) the number of medical equipments, (2) the labor required, and (3) the computing time to get the final decision while increasing the prediction performance. Besides, the binary support vector machine (SVM) is used for predicting the selected parameters in order to identify the presence/absence of heart disease. In fact, SVM can perfectly classify data in binary problem by finding the optimal hyper-plane that separates the data points of first class from those of second class. This makes it very adequate for heart disease prediction system which contains data of patient records with binary target, i.e. referring to the presence or absence of heart disease.
The rest of the paper is organized as follows: Section 2 presents an overview of the proposed system including data description, NCA, and SVM. In section 3, the experimental results are presented with details. In Section 4, a comparison of the state-of-the-art methods is given. Finally, the conclusions drawn from this work are in Section 5.
The proposed heart disease prediction system consists of several stages that work together to achieve the desired results. The first stage consists of dividing equally the used data into two subsets, one for training and the rest for testing. The second task consists in applying the NCA feature selection algorithm on the training subset in order to select the most relevant parameters. Then, SVM classifier performs the training phase with the best parameters. Finally, the trained SVM model can easily predict the testing samples. Figure 1 illustrates the overall flowchart of the proposed system.
Figure 1. The proposed system flowchart
2.1 Dataset description
The performance evaluation of this work is conducted on the famous cardiovascular dataset called the Heart UCI disease (University of California, Irvine, CA, USA). It has been collected from UCI machine learning repository [8]. This dataset contains in total 303 patient records with 76 attributes for each one, but only 14 of them are used for our evaluation to make our scores comparable to previous works. Table 1 provides a brief description about the selected attributes and their proprieties. The last attribute serves as the prediction target that indicates the absence or presence of heart disease in a patient (0 or 1 value, respectively). Of the 303 records, 165 records with Target 1 and the rest for patients with Target 0.
In this dataset, patients from age between 29 and 79 have been selected. Male patients are represented by 1 and female ones are represented by 0. Also, four types of chest pain ’Cp’ have been considered such as: typical type Angina, atypical type Angina, non-angina pain, and the Asymptomatic types. Each type of them is described by a value from 1 to 4, respectively. The next attribute ’trestbps’ is the resting blood pressure measured at the hospital admission. ’Chol’ is the blood cholesterol level. The parameter ’Fbs’ is the fasting blood sugar levels which is represented by 0 if the fasting blood sugar is less than 120 mg/dl and 1 if it is higher. ’Restecg’ is the resting electrocardiographic results classified in three levels 0, 1, and 2. Besides, the attribute ’thalach’ describes the maximum heart rate achieved. ’exang’ is the exercise induced angina which is recorded as 1 if there is pain and 0 else. The attribute ’oldpeak’ represents the ST depression induced by exercise relative to rest. Furthermore, the slope of the peak exercise ST segment has been recorded with the values 0, 1, and 2. The attribute ’ca’ is the number of major vessels colored by fluoroscopy varying from 0 to 4. Finally, the attribute ’thal’ represents the nature of defect which cantake an integer value from 0 to 3.
Table 1. Dataset parameter description
|
N°. |
Attributes |
Description |
values |
|
1 |
(age) |
patient age in years |
29 to 79 |
|
2 |
(sex) |
patient gender |
0=F,1=M |
|
3 |
(cp) |
Chest pain type |
1,2,3,4 |
|
4 |
(trestbps) |
Resting blood pressure (mm/Hg) |
94 to 200 |
|
5 |
(chol) |
Serum cholesterol (mg/dl) |
126 to 564 |
|
6 |
(fbs) |
fasting blood sugar (mg/dL) |
0,1 |
|
7 |
(restecg) |
resting Electrocardiograph results |
0,1,2 |
|
8 |
(thalach) |
Maximum Heart Rate Achieved |
71 to 202 |
|
9 |
(exang) |
Exercise induced angina |
0,1 |
|
10 |
(old peak) |
ST depression induced by resting exercise |
1 to 3 |
|
11 |
(slope) |
The slope of peak Exercise ST segment |
1,2,3 |
|
12 |
(ca) |
Major vessels colored by fluoroscopy |
0 to 3 |
|
13 |
(thal) |
Represents heart rate of the patient |
3,6,7 |
|
14 |
(num) |
Presence or absence of heart disease |
0,1 |
2.2 Atribute selection with NCA
NCA is a non-parametric and embedded method, based on the k-Nearest neighbor (KNN) algorithm [9], that handles the tasks of dimensionality reduction in a unified manner. NCA is used to learn feature weighting vector by maximizing the Leave-One-Out (LOO) accuracy of classification with an optimized regulation parameter [10, 11].
Let $T=\left\{\left(x_{1}, y_{1}\right), \ldots\left(x_{i}, y_{i}\right), \ldots\left(x_{N}, y_{N}\right)\right\}$ the set of training samples, where $x_{i}$ is a feature vector of dimension d, y ∈ 1, ..., H is its corresponding class label and N is a number of samples. We denote the weighted distance between
two samples $x_{i}$ and $x_{j}$ by:
$d_{w}\left(x_{i}, x_{j}\right)=\sum_{r=1}^{d} w_{r}^{2} | x_{i r}-x_{j r}|$ (1)
where, $w_{r}$ is a weight associated with rth feature. However, due to the non differentiable of LOO function that identify a classification reference point by the nearest neighbor, the reference point can be determined by a probability of $x_{i}$ selects $x_{j}$ as its reference point as follows:
$p_{i j}=\left\{\begin{array}{cc}{\frac{k\left(D_{w}\left(x_{i} x_{j}\right)\right)}{\sum_{k \neq i} k\left(D_{w}\left(x_{i},x_{j}\right)\right)}} & {\text { if } i \neq j} \\ {0} & {\text { if } i=j}\end{array}\right.$ (2)
where, k(.) is a kernel function. Hence, the probability of $x_{i}$ being accurately classified in the correct label is given in Eqns. 3 and 4:
$p_{i}=\sum_{j} y_{i j} p_{i j}$ (3)
$H_{i}=\left\{j | y_{j}=y_{i}\right\}$ (4)
where, $y_{i j}=\left\{\begin{array}{l}{1, \text { if } y_{i}=y_{j}} \\ {0, \text { otherwise }}\end{array}\right.$
The final optimization criterion f(A) can then be defined by:
$f(\boldsymbol{A})=\sum_{i} p_{i}$ (5)
In order to optimize the matrix A, we use the gradient rule as follows:
$\frac{\partial f}{\partial w}=2 W \sum_{i}\left(p_{i} \sum_{k} p_{i k} x_{i k} x_{i k}^{T}-\sum_{j \in H_{i}} p_{i k} x_{i k} x_{i k}^{T}\right)$ (6)
where, $x_{i j}$ designs the short-hand for $x_{i}-x_{j}$. This function can be optimized using the gradient methods.
2.3 Prediction with SVM
The SVM technique, which was initially proposed by Vapnik [12], has been widely used for classification and prediction [13]. This technique is based on a set of powerful learning methods that perform statistical learning theory [12]. Firstly, SVMs were designed to solve binary classification. They can work for multiclass classification problem by combining several binary SVM classifiers for each pair of classes. Furthermore, SVM can be adapted to work as a nonlinear classifier by using nonlinear kernels. The SVM basic form which classifies an input vector $x \in \Re^{n}$ is defined as:
$f(x)=\omega \phi(x)+b$ (7)
where, w and b are two parameters that have to be estimated from inputs. $\emptyset(x)$ is the non-linear mapping function in the feature space. Unlike other classifiers which are based on the empirical error for minimizing the classification errors on training dataset, the SVM is based on the structural risk minimization for finding a compromise between the confidence measure corresponding to generalization and the empirical error. Consequently, the goal is to find the parameters w
and b such that $f(x)$ can be determined by optimizing the following constrained problem:$\min _{\omega, b, \xi_{i}} \frac{1}{2}\|\omega\|^{2}+C \frac{1}{N} \sum_{i=1}^{N} \xi_{i}$ (8)
subject to
$y_{i}\left(\omega . \phi\left(x_{i}\right)+b_{i}\right) \leq 1-\xi_{i}$ (9)
$\xi \geq 1,$ for $i=1, \dots, N$ (10)
where, $x \in \Re^{n}, i=1, \dots, N$, represents the training vectors with the corresponding class labels, and the parameter C controls the smoothness between the two measures. In our case, SVM output identify the presence/absence of the heart disease. The solution of the optimization problem can give the following:
$\omega=\sum_{i=1}^{N} \alpha_{i} y_{i} \emptyset\left(x_{i}\right)$ (11)
$b=\sum_{j=1}^{N} \alpha_{i} y_{i} \emptyset\left(x_{i}\right) \emptyset\left(x_{j}\right)+y_{i}, \forall i$ (12)
where, $\alpha_{i}, i=1, \ldots, N$ are the multipliers of Lagrange corresponding to the training input $x_{i}$. Here, the support vectors are the training vectors with non-zero coefficients $\alpha_{i}$ which they contribute to determine the parameter $\omega$ . The computation in input space can be mapped in another feature space using kernel function as follows:
$K\left(x_{i}, x_{j}\right)=\emptyset\left(x_{i}\right) \emptyset\left(x_{j}\right)$ (13)
It is worth noticing that any function that satisfies Mercer’s theorem [14] can be used as a kernel function. Finally, the estimating function can be expressed as:
$f(x)=\sum_{j=1}^{N} \alpha_{j} y_{j} K\left(x_{i}, x_{j}\right)+b$ (14)
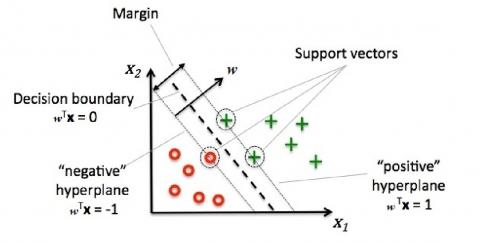
Figure 2. The SVM principle
Table 2. Kernel functions used in SVM training
|
Kernel name |
Mathematical function |
|
Linear |
$K\left(x_{i}, x_{j}\right)=x(i) x(j)$ |
|
Polynomial |
$K\left(x_{i}, x_{j}\right)=(\gamma x(i) x(j)+C)^{d}$ |
|
RBF |
$K\left(x_{i}, x_{j}\right)=\exp \left(-\gamma|x(i) x(j)|^{2}\right)$ |
|
Sigmoid |
$K\left(x_{i}, x_{j}\right)=\tanh (\gamma x(i) x(j)+C)$ |
The SVM classifier can use some kernel functions to mapping an original input space into a higher dimensional feature space, where the optimal hyperplane is determined to maximize the generalization ability of the classifier through some mapping functions chosen a priori. Table 2 presents four types of SVM kernels that we use in this work including: linear, polynomial, radial basis function (RBF), and sigmoid kernel.
In this section, we carried out several experiments to show the effectiveness of the proposed method. Firstly, SVM classifier is evaluated with four different kernels above-mentioned in Table 2 for selecting the best one among them. Then, we perform NCA algorithm on the training subset in order to reduce the number of parameters required for the treatment. It should be noted that the material used to perform our experiments is Intel Core TM i5-4300U cores of 1.9-GHz CPU processor with 8-GB RAM of memory.
3.1 Features selection results
The parameter selection consists in reordering them according to theirs weights $W_{i}$ obtained from NCA algorithm. This order describes the feature importance to the heart disease, such that the most relevant parameter takes the higher weight. Figure 3 shows the weight computed by NCA for each parameter and Table 3 reports the new order of parameters according to their relevance.
Figure 3. Parameter weighting using NCA
Table 3. Parameter ordering before and after NCA application
|
Parameter order before NCA |
Parameter order after NCA |
|
1: age |
12: ca |
|
2: sex |
3: cp |
|
3: cp |
13: thal |
|
4: trestbps |
9: exang |
|
5: chol |
2: sex |
|
6: fbs |
10: old peak |
|
7: restecg |
11: slope |
|
8: thalach |
6: fbs |
|
9: exang |
7: restecg |
|
10: old peak |
8: thalach |
|
11: slope |
1: age |
|
12: ca |
4: trestbps |
|
13: thal |
5: chol |
As we can see in Figure 3, the parameter ’ca’ has the higher weight value compared to others. It’s worth saying that this parameter is the most representative in heart disease diagnosis. Also, the parameters ’cp’, ’thal’, and ’exang’ have a considerable importance for the treatment.
3.2 Prediction results
Now, to check how many parameters can be involved in the disease prediction while keeping a higher performance, we evaluated the SVM classifier with different input combinations according to the NCA ordering. We recall that our evaluation scenario consists of adding at each experiment a parameter from the higher weight to the least. Finally, the considered parameter combination is one that provides a performance greater than or equal to prediction system accuracy with all parameters. Table 4 reports the obtained performance with different experiments.
It is worth noticing that the training accuracy (atr), training time (ttr), testing accuracy (ats), and testing time (tts) have been considered as performance assessment criteria. Besides, the parameter adjustments of SVM and its kernels are set by trial and error.
For the prediction results without feature selection, we found that the best training accuracy is achieved by SVM-RBF with 97,35 %. While the SVM-linear provides the best testing accuracy with 84.10%. Concerning the execution time, SVM-RBF is the fastest classifier in the training and testing phases compared to other SVM variants.
Table 4. The obtained performance with and without feature selection
|
Method |
# of attributes |
atr (%) |
ttr (ms) |
ats (%) |
Tts (ms) |
|
SVM-Linear |
13 |
88.07 |
15 |
84.1 |
1.3 |
|
NCA-SVM-Linear |
11 |
86.09 |
4 |
84.76 |
0.1 |
|
SVM-Polynomial |
13 |
86.75 |
27 |
83.44 |
5 |
|
NCA-SVM-Poly |
10 |
86.09 |
9 |
85.43 |
2 |
|
SVM-RBF |
13 |
97.35 |
7 |
75.49 |
2 |
|
NCA-SVM-RBF |
5 |
92.05 |
3 |
79.47 |
0.1 |
|
SVM-Sigmoid |
13 |
53.64 |
23 |
55.62 |
3 |
|
NCA-SVM-Sigmoid |
2 |
72.84 |
3 |
77.48 |
0.1 |
Now, by applying the NCA feature selection, we note that the prediction performance has been significantly improved with all SVM variants. For example, NCA-SVM-RBF achieved 79.74% in term of testing accuracy using only the first five parameters the most relevant. This performance is 3.98% higher than the accuracy obtained with the whole parameters. However, the best performance is obtained with the combination NCA-SVM-Polynomial by reducing three parameters, namely ’trestbps’, ’chol’, and ’age’. This combination obviously outperforms SVM-Polynomial without feature selection by 1.99% testing accuracy margin and more than two times fast.
In order to give an idea on where our heart disease prediction system ranks performance-wise, we compare with works that used the same experimental protocol, the same performance measures, and the same datasets. Also, we note that the execution time don’t be considered in the comparison due to the lack of this information in the works that we compare with. The heart disease prediction accuracy computed in our proposed system as well as in other similar works have been reported in Table 5.
From Table 5, it is clear that the NCA-SVM-based heart disease prediction outperforms the similar state-of-the-art systems. The advantages of our proposed system can be summarized as follows: (1) it reduces significantly the number of required parameters by increasing the importance of parameter that help in heart disease prediction and reducing the weight of those which do not. (2) Our proposed system can reduce the decision-making time by eliminating the irrelevant samples as well as the material required. (3) SVM can perfectly classify the heart disease data by finding the optimal hyper-plane that separates the first class from those of second class. This makes it very adequate for heart disease prediction system which contains data of patient records with binary target.
Table 5. Comparison of state-of-the-art methods
|
Authors |
Method |
Accuracy (%) |
|
Shouman et al. [15] |
Decision tree |
81.4 |
|
Peter et al. [16] |
Multilayer perceptron |
82.22 |
|
Nahar et al. [17] |
Naive Bayes |
69.11 |
|
Ismaeel et al. [18] |
Extreme learning machine |
80 |
|
Amin et al. [3] |
Logistic regression |
78.03 |
|
Our work |
NCA-SVM |
85.43 |
In this work, the combination of NCA and SVM is used to predict heart disease from real datasets provided by the UCI machine learning repository. The NCA feature selection can effectively select the most relevant parameters to make a good decision. Thus, the parameter selection in such a clinical application can seriously reduce the number of medical equipment as well as the labor and the time required to get the final decision while increasing the prediction performance. However, SVM was used for predicting the selected parameters in order to identify the presence/absence of heart disease. The obtained results showed that the NCA-SVM improve considerably the prediction system performance. Applying this model can have a direct impact and economic savings on the design and development of heart disease prediction systems in healthcare.
[1] World health organization report on cardiovascular diseases. https://www.who.int/health-topics/cardiovascular-diseases/#tab=tab_1, accessed on Sep. 02, 2019.
[2] Raza, K. (2019). Improving the prediction accuracy of heart disease with ensemble learning and majority voting rule. U-Healthcare Monitoring Systems, 1: 179-196. https://doi.org/10.1016/B978-0-12-815370-3.00008-6
[3] Amin, M.S., Chiam, Y.K., Varathan, K.D. (2019). Identification of significant features and data mining techniques in predicting heart disease. Telematics and Informatics, 36: 82-93. https://doi.org/10.1016/j.tele.2018.11.007
[4] Deng, M., Wang, C., Tang, M., Zheng, T. (2018). Extracting cardiac dynamics within ECG signal for human identification and cardiovascular diseases classification. Neural Networks, 100: 70-83. https://doi.org/10.1016/j.neunet.2018.01.009
[5] Abushariah, M.A., Alqudah, A.A., Adwan, O.Y., Yousef, R.M. (2014). Automatic heart disease diagnosis system based on artificial neural network (ANN) and adaptive neuro-fuzzy inference systems (ANFIS) approaches. Journal of Software Engineering and Applications, 7(12): 1055. https://doi.org/10.4236/jsea.2014.712093.
[6] Bouali, H., Akaichi, J. (2014). Comparative study of different classification techniques: Heart disease use case. In: 2014 13th International Conference on Machine Learning and Applications, Detroit, MI, USA, pp. 482-486. https://doi.org/10.1109/ICMLA.2014.84
[7] Otoom, A.F., Abdallah, E.E., Kilani, Y., Kefaye, A., Ashour, M. (2015). Effective diagnosis and monitoring of heart disease. International Journal of Software Engineering and Its Applications, 9(1): 143-156. https://doi.org/10.14257/ijseia.2015.9.1.12
[8] Heart disease dataset of University of California at Irvine (UCI). https://archive.ics.uci.edu/ml/datasets/Heart+Disease. accessed on Sept. 02, 2019.
[9] Goldberger, J., Hinton, G.E., Roweis, S.T., Salakhutdinov, R.R. (2005). Neighbourhood components analysis. Advances in Neural Information Processing Systems, pp. 513-520.
[10] Singh-Miller, N., Collins, M., Hazen, T.J. (2007). Dimensionality reduction for speech recognition using neighborhood components analysis. In: 8th International Conference of Inter Speech, pp. 1158-1161.
[11] Yang, W., Wang, K., Zuo, W. (2012). Neighborhood component feature selection for high-dimensional data. Journal of Computers, 7(1): 161-168. https://doi:10.4304/jcp.7.1.161-168
[12] Vapnik, V. (1995). The Nature of Statistical Learning Theory. Springer Verlag, Berlin.
[13] Scholkopf, B., Smola, A.J. (2001). Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond. MIT Press.
[14] Radhika, Y., Shashi, M. (2009). Atmospheric temperature prediction using support vector machines. International Journal of Computer Theory and Engineering, 1(1): 55. https://doi.org/10.7763/IJCTE.2009.V1.9
[15] Shouman, M., Turner, T., Stocker, R. (2011). Using decision tree for diagnosing heart disease patients. In: 9th Australasian Data Mining Conference, pp. 23-30.
[16] Peter, T.J., Somasundaram, K. (2012). An empirical study on prediction of heart disease using classification data mining techniques. In: International Conference on Advances in Engineering, Science and Management (ICAESM-2012), pp. 514-518.
[17] Nahar, J., Imam, T., Tickle, K.S., Chen, Y.P.P. (2013). Computational intelligence for heart disease diagnosis: A medical knowledge driven approach. Expert Systems with Applications, 40(1): 96-104. https://doi.org/10.1016/j.eswa.2012.07.032
[18] Ismaeel, S., Miri, A., Chourishi, D. (2015). Using the extreme learning machine technique for heart disease diagnosis. In: International Humanitarian Technology Conference (IHTC2015), Ottawa, ON, Canada, pp. 1-3. https://doi.org/10.1109/IHTC.2015.7238043