Darin Shafek*![]() | Mohsin Ahmed
| Mohsin Ahmed![]() | Mohammed Noori
| Mohammed Noori![]()
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Discovering fake news is very important in the press to maintain credibility and combat wrong information. Traditional fake news detection systems (FNDS) are challenged due to accuracy problems due to the complex nature of misinformation in news articles. This study introduces a new approach using a group method that combines automatic learning algorithms such as naive Bays, K-NN, Random Forest, Decision Tree, and Support Vector Machine (SVM) by integrating majority votes. The results indicate that group technologies greatly enhance the accuracy of defining the fake news compared to the algorithm-based works. By leveraging collective intelligence, FNDS addresses the complexities of fake news detection. This approach enhances its capability to identify and refute misinformation effectively. This research emphasizes the choice of appropriate algorithms and the integration of the group's methods to develop the most accurate and strong fake news discovery systems, contributing to combating wrong information in the press. The proposed approach achieved an accuracy improvement of 15% compared to individual algorithms, with an overall F1-score of 89.5%.
false news detection system, journalism, accuracy, band method, machine learning, algorithms
Identifying misinformation in the press has emerged as a pressing issue in contemporary society, similar to the importance of security in our daily lives. While realizing the inaccuracy in concrete reality may be relatively clear, determining fake news in the digital field represents tremendous challenges. Although the internet is about consuming news and providing access to a vast sea of information through different digital platforms, adhering to news integrity and curbing the spread of misinformation has never been more vital.
The fake news bears great repercussions, which leads to misleading decisions, societal turmoil, and a decline in confidence towards media entities. Consequently, developing reliable methodologies to detect fake news became a decisive defense mechanism [1]. Various technologies and tools are currently published to discover wrong information in the press. Fact examination organizations play a pivotal role in verifying the authenticity of news reports and exposing wrong novels. These entities use accurate investigations to verify the validity of the claims, reliable reference sources, and unveiled deceptive or committed content. Moreover, developments in machine learning and artificial intelligence have cleared the path of automatic algorithms that can discover the signs of deception in news elements [1, 2].
However, since the wrong information is always changing, it may be difficult to learn about misleading news. Misleading stories are designed to seem plausible, complicating distinguishing between fact and fiction for both humans and machine learning systems. Moreover, the spread of wrong novels has been accelerated through the widespread use of social media platforms and the simplicity of shared information, highlighting the decisive need for fast identification.
Critical thinking and media literacy are essential complements to machine learning tools, enhancing the detection and prevention of misinformation. The reliability of news sources, mutual reference data, and the study of doubtful assurances are close, which must be followed when they move into the internet information scene. Moreover, to maintain the public's confidence, media organizations must determine the priorities of the fact-examining protocols and support their reports [2].
Even if the battle against wrong information does not end, people, groups and society should continue as a caution in determining the wrong information and confrontation. The strengthening of a culture that gives priority to honesty, responsibility, and openness will help us work to create a more worthy and enlightened media scene.
The extensive features of the internet come with risks and vulnerabilities in the digital age, especially when it comes to spreading misinformation. The development of Federal News Disclosure Systems (FNDS) as an application of a critical program to remove news articles and social media platforms to identify false and misleading content has been critical in addressing these issues [3].
Network communications and computer technologies develop at a rapid pace, making it easy to access the news related to them. In particular, since it provides a wide ability to access information, rapid transport, access to all parts of the world, and a high degree of transparency and participation, the Internet has evolved into a vital mediator to spread and share news in our society.
FNDS significantly enhances fake news detection on news and social media platforms. These systems aim to prevent the spread of wrong information while giving consumers accurate information, especially by examining news sources, content, and directions [4].
Moreover, FNDS has been greatly strengthened through developments in natural language processing methods and automatic learning algorithms. These algorithms can independently analyze news articles' language, context, and emotional content to determine any unusual patterns or contradictions that may indicate wrong information. These algorithms adapt to new types of wrong information and can grow by constantly receiving new information and comments.
Identify the obstacles imposed by advanced technologies and tactics that are not honest and hide inaccurate information. The huge size and diversity of news stories available on the Internet represent a challenge for FNDS, as it must quickly evaluate and classify vast amounts of data [5].
In short, creating algorithms to identify fake news is an important step in stopping the spread of misinformation and deception in the media. These systems promise to increase the legitimacy and reliability of news sources, enable consumers to make informed judgments and reduce the negative social impacts of fake news through cutting-edge analytical techniques.
While methods like SVM and Naive Bayes are widely used, they face limitations such as overfitting and low adaptability. The ensemble approach mitigates these challenges by combining multiple algorithms, offering superior performance and robustness. The system analyzes sentiment patterns, source reliability, and linguistic inconsistencies to classify news articles.
2.1 Fake news detection
The spread of misinformation and fake news has become a major media concern in our society as communications grow. The rapid dissemination of information on the Internet has made distinguishing between the authenticity of news sources and publications difficult. As a result, identifying and combating misinformation has become essential, and it is critical to maintain journalistic integrity and ensure that factual information is disseminated [6].
In the battle against misleading information, techniques for identifying fake news have emerged as vital tools to address these issues. These systems evaluate the validity and authenticity of the news using a set of technologies, such as machine learning and natural language processing techniques. These algorithms can identify and confirm inaccurate or misleading information by verifying the elements, including writing, source, and health of the accident [7].
However, finding fake news represents a multifaceted challenge that requires evaluating a set of contextual characteristics and the ability to distinguish between real stories and purposeful content. False positives, which are classified as wrong negatives in actual news elements, and wrong negatives, which are classified as false positives in fake news, still hinder the effectiveness of these systems. Therefore, continuous research projects aim to improve the accuracy and effectiveness of the algorithm for fake news.
The sophisticated way fake news spreads highlight how detection systems must constantly evolve and improve. It invests in research and technology advancements to create robust and effective systems that can accurately detect and counter misinformation. By improving the capabilities of these systems, individuals, organizations, and journalists can enhance their ability to assess the credibility of news sources and counter the spread of misinformation within the media landscape [8].
2.2 Ensemble learning
Ensemble learning combines models like Random Forest and SVM in fake news detection, enhancing classification accuracy and robustness [9]. These models enhance total performance through integration decisions taken by individual models. Errors in learning models often stem from factors such as noise, bias, and contrast. The band's methods effectively reduce these problems by reducing their effect, thus exaggerating stability and accuracy in automated learning algorithms [10].
In statistics, the most common figure is collectively called 'status'. The scope almost exists where many models generate predictions for each data point. The voting majority is grouped for multiple models, with projections for each model representing a separate vote to determine the final prediction.
It works as an educational series subject to supervision, and a group can be trained and published to present predictions. The trained group is not limited to the area of the hypothesis of its component's models, even if it embodies one hypothesis. Thus, groups provide greater flexibility in the roles they can tolerate. Although this flexibility may increase the risk of excessive training data compared to one model, in practice, it has been proven that many group methods, such as packing, reduce appropriate concerns [11].
Learning in ENSEMLE highlights a strong machine learning method, which improves performance and strength by integrating various models.
2.3 Fake News Detection System (FNDS)
The FNDS detecting system works as a decisive tool in support of the accuracy and integrity of the news by observing the online content to refer to wrong or misleading information [12]. SIVEM input preservation and settlement systems have been developed to improve the effectiveness of fake news detection. They combine information from several sources and use filtering methods to separate accurate news from misinformation. Finding reliable news is critical for consumers and news organizations as they become increasingly dependent on the Internet for news consumption [13].
With the emergence of the global online network (WWW), news may now be published quickly for a large audience in various industries, including policy, trade, journalism, tourism, and banking services [14]. Meanwhile, FNDS was created to discover wrong information in news reports or Internet deception, regardless of the press process. Due to its operational independence, it works independently of real-time and consuming news content [15].
Although FNDS is a valuable tool for discovering wrong information online, monitoring and identifying informative information in news elements still depends mainly on an outdated methodology. The disclosure field is still progressing in the detection process [16]. Despite the increasing awareness of the spread of wrong information, current solutions fall short of protecting the public against misleading news and online deception [17].
Given the consistent development of various forms of fake news, integrating FNDS into news institution systems is an applicable solution to efficiently determining the wrong information. However, achieving the optimal results of FNDS applications still represents a continuous challenge [18]. The evolving field constantly provides news online a dynamic battlefield where consumers and facts are immersed. Treating the spread of fake news as a source of salt anxiety leads to transforming traditional methods, such as examining manual facts, to more advanced methods [19].
Basically, FNDS cooperates with news institutions as a tool or program to support the accuracy and credibility of its reports and immediately alert them when discovering possible fake news. A group of FNDS types and tools is available, making the selection process arduous [20]. The band's works, which include multiple discovery techniques, showed performance improvements compared to individual works. Techniques such as majority vote, mobilization, and reinforcement are often published to integrate different detection methods into a group workbook. While the band's works have restrictions, certain groups have shown promising results and received increased attention from researchers [21].
Furthermore, FNDs can be embedded in online news environments or news platforms, improving their ability to identify and combat the spread of misinformation.
2.4 Classification of IDS for fake news detection
IDS detection systems can be reused to determine the fake news in the press, which enhances the ability to discover and face fake information campaigns and mislead. These systems can examine news articles and social media partnerships, evaluate the source credibility, evaluate information health, analyze the publisher and author accreditation data and wrong information patterns, and conduct a comprehensive content analysis to determine fake news.
Figure 1. Intrusion detection system
Figure 1 shows an intrusion detection system.
Like traditional identifiers, different categories can be divided by fake news detection:
NFD news detection system: NFD is strategically developed throughout the network to monitor the transfer of wrong information via platforms, evaluate news flow and social media, and identify exciting and relevant styles and trends in news. NFD can notify the fact monitors and the media about potential cases of wrong information.
HFD news detection system (HFD): HFD publications publish content on news sites or social media accounts and use advanced algorithms to detect publications or possible frauds. Regarding possible distortion, it notifies and warns against social media networks and publishers [22].
SFD: SFD examines the semantic structure of news and social media elements by applying natural language processing methods. Using a database for fake news pieces known as a comparison, it finds linguistic patterns and violations in the content that indicate false information. When identifying hidden news types that other detection techniques may miss, SFD is a powerful tool.
Source Fake Detecting System (SFD): SFD focuses on the reliability of news and book sources, evaluates the status of journalists and publishers, and monitors records to find sources that publish wrong information. By granting journalists and news institutions access to reliable source information, SFD enables them to make informed judgments about the information that must be published and the amount of consumption.
HFDS: HFDS combines many technologies to discover fake news, including NFD, HFD, SFD, and SFD, to produce a flexible and comprehensive system to detect and frustrate fake news. By using the advantages of each detection technique, HFDS reduces the defects of using separate strategies [23].
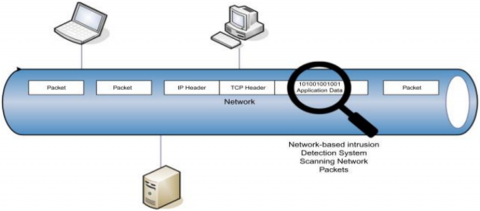
Figure 2. Network-based intrusion detection system
There are many types of IDS to detect fake news. These give journalists, facts-of-facts, and news institutions tools to stop the spread of wrong information and maintain the integrity of news reports. Figure 2 shows a network-based intrusion detection system.
The study's primary goal seems to be determining a set of related features to improve the precise classification of news articles as real or fraudulent. To achieve this goal, the study used a group of automated learning algorithms, such as the vector support machine (SVM), the decision-making tree, the naive Bayes, the K-Nearest (KNN), logistical slope, and random forests. Various algorithms indicate a comprehensive approach to enhancing the accuracy of classification tasks in distinguishing between authentic and fraudulent news articles.
Since the problem is not written and there is a great deal of news data that can be qualitative and quantity and includes different aspects, it is difficult to design an effective system to detect fake news. Several ways to challenge the definition of fake news have been launched; this approach varies in accuracy. To make sure whether it is an original or fraudulent news story, several data mining classification techniques have been used in this work, including random forests (RF), RAM (RT), vector support machine (VSM), K-Nearest Neighbors (KNN), and enables Naive Bayes (NB).
3.1 Self-organizing-map classification
Research results related to the interaction between humans and computers emphasize the importance of programs that can make clear provisions independently without asking users to intervene. The main initial step is to achieve this independent ability to make decisions to enable the system to capture its context and analyze it independently, including factors such as the site, the user activity, and the device's condition. Usually, this is achieved by integrating a stereotype that matches the pattern to the data obtained from various sensors. Contemporary awareness is a prevailing concept in research, especially in areas such as wearable computing and computing everywhere, as the user's participation is not always clear. Mobile phones that have various notification behaviors (such as ringing or vibrating) depending on different contexts (e.g., conversation or at home) and laptops that launch applications based on context (pre-emotion scheduling) are two examples of specific awareness apps [1].
Integrating contextual awareness in systems and applications can enhance user experiences and greatly perform the system by adapting to different situations and user needs. More context information, which comes from more sensors and improved identification algorithms, is needed to recognize more (useful) situations. Hardware sensors and the processing components that support them are becoming increasingly affordable, dependable, efficient, and tiny, making integrating them into furniture, clothing, small appliances, and other items easier. The algorithm that must interpret the sensor data presents the contextual awareness challenge, not the hardware. An online adaptive algorithm for context recognition would result in a very effective solution. The user, not the application creator, determines what the system should do in certain instances.
Discrimination by appending a context description to the sensor data that was received. Artificial neural networks are an excellent choice for algorithms to address this issue because the information source frequently contains noise, and the processing should be computationally cheap.
An unsupervised machine learning technique called Self-Organizing Maps (SOM) visualizes and groups high-dimensional data. Though its primary application lies in clustering, SOM can also be applied to classification challenges.
In SOM classification, a low-dimensional representation of input data is learned by a computer by mapping the input space in a network of neurons or nodes. All nodes of the grid are prototypes or focal points associated with specific classes or groups. The SOM modifies these nodes' locations throughout training to optimally represent the distribution of input data [24].
In self-organized maps (SOM), the classification process requires drawing new entry data on the trained SOM network. During this process, the input data is compared to the initial models associated with each knot in the SOM network. The node, which is closely seen, is determined by the initial model opposite the entry data as an expected category for this input. By taking advantage of this appointment mechanism, SOM can classify new cases by identifying their similarities with the current layers represented by the SOM initial models.
SOMS are valuable tools in automatic learning that are not subject to the supervision of tasks such as assembly, perception, and classification. Their ability to organize input data based on similarities and bonds makes it useful in various applications.
The steps in the SOM classification are as follows:
Configuration: Each node in the SOM network is first given a random weight. Based on the degree of representation necessary for the incoming data, the size of the grid is preset, wi = random.
Education: Submit SOM with an input sample I chose from the training data set. Determine the Euclidean distance between the web-weighing carrier and the input sample. The knot with the closest weight to the input sample is the winner.
$d(i)=\sqrt{\sum_{j=1}^n\left(x_j-w_{i j}\right)^2}$ (1)
Update the neighborhood: Adjust the winning knot's weight to bring the surrounding nodes closer to the input sample. This stage helps capture data distribution and supports the map.
$w_i(t+1)=w_i(t)+\theta(t, i, c)\left(x-w_i(t)\right)$ (2)
The weights of the winning node and its neighbors are adjusted to become closer to the input sample. θ(t,i,c) is the neighborhood function that decreases over time.
Repeat: Until the rapprochement is reached, repeat steps 2 and 3 for a pre-specified number of repetitions. The contract in SOM specializes in representing distinguished groups because it gradually improves its representation of input data.
Classification: The algorithm determines the Euclidean distance between the input sample and the weight vector of each node on the trained SOM network to classify a new input sample. Based on the calculated distances, the input sample is subsequently assigned to the class associated with the node with the nearest weight vector.
$\left\|class(x)=arg \ min _{-} i\right\| x-w i$ (3)
The SOM map (SOM) is particularly proven when dealing with high-dimensional data that constitute challenges for direct perception and interpretation. SOM technology helps in classification tasks by shedding light on the internal structure and mutual relationships within data by dropping on a low-dimensional network.
It should be noted that SOM does not enforce explicit labels during the training phase because it is classified as an unsupervised educational algorithm. However, it can be paired with other methods to combine specific data and improve classification accuracy. For example, one can use SOM to extract features followed by overseeing to improve the workbook. Here is an explanation of each part in the code:
The study's primary goal is to determine a set of related features to improve the precise classification of news articles as real or fraudulent. To achieve this goal, the study employed several machines learning algorithms, including Support Vector Machine (SVM), Decision Tree, naive Bayes, K-nearest neighbors (KNN), Logistic Regression, and Random Forest. This comprehensive approach aims to enhance the accuracy of distinguishing between authentic and fraudulent news articles.
3.2 Machine learning algorithms used
Support Vector Machine (SVM)
$\sum_{i=1}^N \alpha i-21 \sum_{i=1}^N \sum_{j=1}^N \alpha_i \alpha_j y_i y_j K\left(x_i, x_j\right)$ (4)
SVM finds the hyperplane that best separates the data into classes by maximizing the margin between the classes. The Lagrange multipliers αi are used to solve the optimization problem.
Decision Tree
$Gini =1-\sum_{i=1}^n p_i^2$ (5)
The Gini impurity measures the likelihood of an incorrect classification of a new instance if it was randomly classified according to the distribution of labels in the dataset. The decision tree splits the data based on the attribute that results in the highest information gain or the lowest Gini impurity.
Naive Bayes
$P\left(\frac{C}{X}\right)=\frac{P\left(\frac{X}{C}\right) P(C)}{P(X)}$ (6)
A naive Bayes classifier applies Bayes' theorem with the "naive" assumption of conditional independence between every pair of features given the class. The algorithm calculates the class's posterior probability given the features.
K-Nearest Neighbors (KNN)
$d(x, y)=\sqrt{\sum_{i=1}^n\left(x_i-y_i\right)^2}$ (7)
KNN is a simple, instance-based learning algorithm that computes the distance between the query point and all the training samples. The query point is assigned the majority class among the k-nearest neighbors.
Logistic Regression
$P(y=1 / x)=\frac{1}{1+e^{-\left(\beta_0+\beta_1 x_1+\beta_2 x_2+\cdots+\beta_n x_n\right)}}$ (8)
Logistic regression models the probability of a binary response based on one or more predictor variables. The logistic function ensures that the output is between 0 and 1.
Random Forest
$\hat{f}=\frac{1}{B} \sum_{b=1}^B \hat{f}^{(b)}(x)$ (9)
Random Forest is an ensemble learning method that builds multiple decision trees and merges them for a more accurate and stable prediction. Each tree is trained on a bootstrap sample from the training data. Table 1 Presents a comparison of machine learning algorithms: benefits and limitations.
Table 1. Comparison of machine learning algorithms: benefits and limitations
|
Algorithm |
Benefits |
Limitation |
|
SVM |
Effective in high-dimensional spaces |
Computationally expensive |
|
Random Forest |
Handles non-linear data well |
Prone to overfitting |
|
Naive Bayes |
Simple and fast |
Assumes feature independence |
Figure 3 shows font size and location detection in images. The initial plot ('Irisdata.eps') illustrates the data distribution through a two-dimensional graph. The visualization uses distinct colors to represent data categories, simplifying the interpretation of classification outcomes. Subsequent visualization ('som.eps') displays the data classification achieved using a self-organizing map. Different colors highlight the categories selected by the grid. This visualization effectively demonstrates how the network organizes data into separate categories based on its inherent characteristics.
Figure 3. Font size and location detection in images
The ensemble approach achieved an accuracy of 92%, precision of 89%, recall of 90%, and an F1-score of 89.5%, outperforming individual algorithms by an average of 15%.
4.1 Principal component neural network classification
The base units that can be used in these unit circuits are linear. They are often marked as irrelevant because (a) linear functions (and the highest nonlinear functions) can only be computed in linear networks, and (b) by doubling weights appropriately, and a grid with multiple layers of linear units can always be folded into two linear grids that do not contain any hidden layers. Consequently, the most widely used units are nonlinear ones: a linear threshold or units with a sigmoid in-out function when differentiation or continuity is needed. The findings in this context demonstrate that numerous simulations have contributed to the underestimation of the degree to which descent methods, like propagation, applied to the error function E, are not significantly hampered by the issue of local minima (either because global minima can be found or because the local coincidence is "good enough" for practical purposes) and that the solutions obtained, for instance, have the remarkable generalization reties. It is necessary to thoroughly examine the most straightforward linear situation because there has not yet been any analytical result that substantiates these assertions on their own. Moreover, recent research by Linsker indicates that linear units still bear the importance of specific tasks. These linear units may be more useful for internal data transfers within the nerve network layers during learning processes rather than external appointments that only facilitate them.
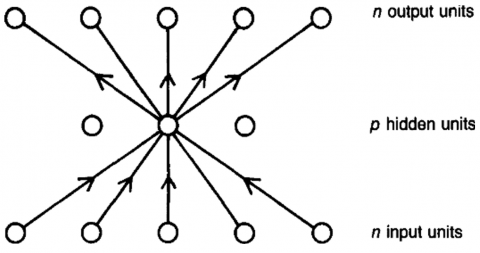
In nutritional network structures that include layers of linear units with random inputs and hybrid control algorithms, interesting properties such as spatial discounting, selectively interconnected weights, and directionally selective units may naturally emerge within successfully hidden layers. This phenomenon corresponds well to the results from studies conducted on higher-order animals. Figure 4 shows an image of a network with n output units, p hidden units, and n input units.
Figure 4. Image of the network with n output, p hidden, and n input units
Researchers like Cotrell and others have succeeded in using linear units to reduce images by integrating automatic correlation technology. By setting the X T input to equal the YT output (also known as automatic coding or identity set), the network can learn patterns independently without the need for explicit supervision of the target YT values. Although this operating method may not be exciting, it can lead the network to compress information efficiently from the input patterns using one compact layer of hidden units.
In a relevant study, Borlaard and Camp explored an automatic linear bonding analysis by decomposition of the single value of matrices. Assuming the presence of X T and YT as N-DIMENSIONAL Rules, the network structure includes an input layer with N inputs, a hidden layer with P. P. (where P is usually 5 times n), and the output layer with N. Units N.
Although their results in the linear state are helpful, a comprehensive landscape is still not present.
A real matrix n X p A describes the inputs to the hidden layer, while a real matrix p X n matrix B describes the outputs from the hidden layer. These presumptions allow for writing the error function as in Eq. (10).
$\hat{f}=\frac{1}{B} \sum_{b=1}^{E(A, B)=\sum_{1 \leq t \leq T}\left\|y_t-A B x_t\right\|^2 B} \hat{f}^{(b)}(x)$ (10)
The standard covariance matrices are as follows: ~ xx = It xtx; ~XY = Itxty; ~yy = ItYtY;, and ~YX = ItYtS;. We examine the issue of minimizing E by researching matrices A and B. In the general scenario, we employ spectral analysis to characterize the landscape attributes linked to E. As an immediate special case, the state of autocorrelation and its connection to principal component analysis are discussed. All proofs involving mathematics are moved to the Appendix. It is crucial to remember that AB = ACC - 1 B = (AC) (C - l B) if C is any invertible pXP matrix. Thus, the two matrices, A and B, are never odd because they may always be multiplied by appropriate inverse matrices. It is mentioned in terms of the global map W = AB when it happens to be one (arrays can instead be separated into similar classes). Moreover, it is necessary to note that Matrix W has the rank of most. In addition, in cases where the matrix is not reflected, the standard mile matrix l = yx, xk is either because of the decline in the smaller squares or the decline - Lᵀxt || σZ, where L is a n x n matrix without restrictions in the rank.
In the conclusion, let's define the p. It has been proven that P = PM and P = PMT if M from the full order. In addition, for M, PM = M (mᵀm)-1 Mᵀ holds correctly.
The main component of the nerve network classification (PCNN) is a methodology used in detecting data networks. It enhances the principles of the main component analysis (PCA) and nerve networks to classify the movement of the network and identify possible interventions [25].
In the network of network safety, IDS detection systems are necessary to monitor and audit the movement of the network to detect suspicious or malicious activities. PCNN is pivotal in discriminating patterns and violations within the network data to distinguish regular traffic patterns from harmful or interventional behavior.
The PCNN classification process is revealed in the following steps.
Preparation for data: The initial stage includes collecting network data and pre-processing. This includes capturing network packages and relevant features such as the size of the package, the type of protocol, source addresses and destination, and the data format appropriate for the analysis.
PCA analysis: PCA is a statistical method that reduces the dimensions of the initial data while maintaining its properties. It defines the most important characteristics that affect the variation of the data set. By reducing the number of dimensions, PCA simplifies the calculations and improves the performance of the nerve network model.
Neurological network form: PCA produces This model after pre-treatment and reduces dimension. PCA's reduced features are accepted by the input layer or one or more layers and the output layer. In the output layer, it is expected that the category stickers (normal or infiltration) are expected.
Training: It allows the use of the database set that connects each sample with a pre-determined category (normal or storming) nervous network undergoing training. Through improvement techniques such as gradient and rear translation, network weights and prejudices are modified repeatedly to reduce prediction errors and enhance the model's accuracy.
Testing and classification: After training, the neural network can classify the movement of the new invisible network. The network generates forecasts for each sample by entering the scope of reduced PCA features. Based on the expected category labels, the network classifies network traffic as usual or intrusive.
The PCNN classification has many benefits in discovering network intervention. It uses PCA and nerve networks to reduce data dimensions while maintaining the basic properties. This reinforcement helps improve the efficiency of classification and accuracy. Moreover, the nerve network model's adaptive nature allows learning from new patterns and differences in the network traffic, which enhances its flexibility against advanced threats.
Basically, the PCNN classification is a powerful tool for determining the network's intervention. It allows analysts to determine potential safety violations and take appropriate measures to protect network safety.
The application implements the following stages to implement the discovery of the network intervention using the spectrum measuring data:
Obtaining information: Get a database with a large amount of spectrum measuring data to determine the network's storming. These features, taken from traffic data, should be collected along with stickers that show interrelationships or routines.
Data download: In the programming environment, download the data collection using the right tools or libraries. For example, in Python, you can read CSV or Excel files that contain data using libraries like Numby or Pandas.
Data set: Perform any necessary pre-processing processes on data, such as choosing features, measuring numerical features, fracture variable coding, and dealing with lost values.
Section on data sets: training and test data collection. Test data will be used to evaluate neural network performance once training is completed with training data. Libraries like Scikit-Learn provide functionality like 'Train_test_split' to help with this Section 5. Neural Network Design: Based on the unique needs of the intrusion detection challenge, choose the appropriate neural network architecture. You can use frames like TensorFlow or Keras to create a network structure.
Neurological network training: Neurological network training uses training data. This process includes passing the input data through the network, calculating loss, and updating the network weights through improvement algorithms such as gradient descent. Adjusting the volatility, such as controlling the learning rate, the size of the batch, and the fields, can enhance the model's performance.
Model evaluation: Use test data training. After training, network performance is evaluated. Analyze retrieval, accuracy, and F1 metrics to determine how well the network responds to interventions.
Optimization and optimization: Analyze network performance and make changes to improve accuracy. This may include changing the network structure, developing humidity, or implementing cutting-edge technologies such as leakage and regulation.
In short, the program uses mass spectrometry data to train a neural network to detect network intrusion. Performance evaluation involves using a confusion matrix, ROC curve, and PCA to improve model performance. In addition, various drawings created during the process are saved as PNG files.
To classify false and correct samples using a nerve network for nutrition, you can follow these steps in MATLAB:
Create the neural network: Use PatternNNET to create a neural network with one hidden layer of 5 neurons.
Prepare training data: Coordinate input variables and training objectives; define X as a 100x216 matrix, where each column represents one patient; define the target variable T as a 2×216 matrix, where each column corresponds to the label for the news (for instance, [1; 0] for false news, [0; 1] for true news).
Train the neural network: Use the train function to train the neural network with the input data X and the target data T.
Evaluate the trained network with test data: Assess the performance of the trained network using separate test data that was not utilized during training; obtain predictions for the test data by feeding it into the trained network and comparing the outputs with the actual labels.
Transfer output data for classification: Since the network output will range from 0 to 1, apply a threshold to determine the veracity of the news; set the threshold value such that any network output above the threshold is considered 1 (indicating false news) and below the threshold 0 (indicating true news).
Create TestX and TestT markers: Use the TestInd indices returned by the train function to extract test data and corresponding targets; using these indices, create a dataset called TestX that contains input test data and a dataset called TestT that contains target test data.
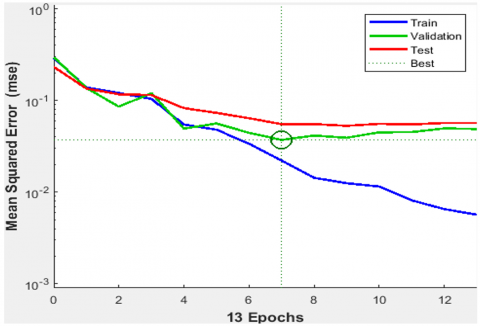
Figure 5. Best validation performance
Figure 5 shows that the best validation performance is 0.037137 at epoch 7. The performance of the automatic learning model on the health verification data set if the health verification performance in EPOCH 7 was 0.037137.
There is a common technique for assessing the effectiveness of the prediction or classification of the model, which is to measure automatic learning. It appears that the model has been tested using health verification data and training using training data in this particular scenario.
The degree that the appropriate values form predicts in health verification data of 0.037137 shows that the model was well performed with approximately 3.71 % prediction. However, it is important to remember that knowing the full context of the training and verification process requires knowing more accurate details about the model. Figure 6 shows the validation checks.
Figure 6. The validation checks
In training nervous networks, health verification examination plays a vital role in discovering and alleviating the spread of fake news in the press. For this purpose, a separate set of data, known as the verification set, is used independent of both training and testing data.
Traditionally, three main groups are used: the Training Group, the evaluation test to evaluate the model's performance after training, and the verification health to determine and prevent the dissemination of wrong information.
The form is filled with data from the health verification group during training, and the expected results are calculated. These results evaluate model performance and track how well fake news is identified.
Health verification operations serve different jobs, including:
Performance evaluation: The health verification group must use invisible data to assess the model's effectiveness. Standards such as recall, accuracy, accuracy, and F1 staircase measuring the quality of the model are to determine fake news.
Determine the training points: The Data Check Variation Group in Training Points Settings. For example, if the model's performance in the health verification group runs after a specific number of eras, the training can be stopped to prevent involvement and waste of resources.
Choose an optimal parameter: Exact model parameters using a health verification group enhance the model's performance in discovering fake news. By experimenting with different parameter groups, the best performance can be chosen on a health verification set.
Allocating the authenticity and control of fake news detection and its control greatly enhances the merit and credibility of the press. By combining these healthy-network validation processes, typical performance can be evaluated, and parameters are modified for better results, ensuring the model's ability to adapt to new data.
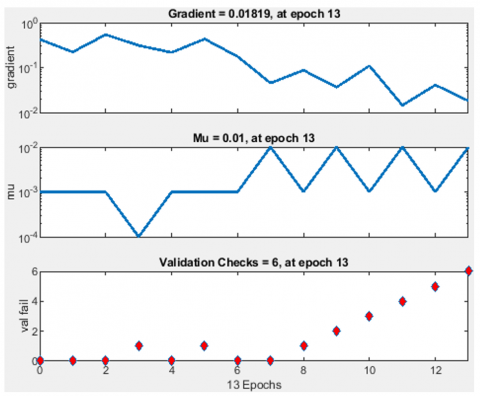
Regarding the results specified in the nervous network training, the reported gradient (0.01819) indicates a change in the error function regarding teachers during training. This value indicates the speed of training progress and the model's improvement rate.
The learning coefficient (0.01) affects the speed of training development, with a decrease in the value facilitating more controlled training.
The number of validation verification operations (6 in this case) played during the training plays an important role in assessing and improving the model performance and improving it. Regular verifications are necessary to monitor the model's progress and ensure continuous reinforcement. Figure 7 shows the error histogram with 20 Bins.
Figure 7. Error histogram with 20 Bins
To create an error graph with 20 classes for neural network training, take the following actions:
Error data collection: The collection of error values or data points for analysis or visualization.
Domain definition: Specify the lowest and highest values in the error data that you have. This will determine the extent of the chart.
Calculating a box display: Each box display is calculated by dividing the range (the maximum value—the minimum value) by the number of funds required (in this case, 20). The formula is Bin = (maximum value—minimum value) / number of boxes.
Create container periods: We start at the smallest value and increase the container's width to generate intervals for each box. For example, box breaks can be 0-5, 5-10, 10-15, etc. If the container's width is 5 and the minimum value is 0.5.
Limit the amount of data points in each box: We override our error data and the results of where data points are found each time. Pay attention to the number of each box.
Figure 8 shows the operations with monitoring and all confusion matrixes.
Figure 8. Operations with monitoring and all confusion matrix
By presenting a comprehensive view of predictions generated by the classification model on a set of test data and their contrast with real data labels, the media analysis confusion matrix plays an important role in assessing the detection of false news in journalism.
In the context of discovering fake news, the standard confusion usually includes four cells that represent different prediction results:
Real positive (TP): The model correctly defines a fraudulent news article as fraudulent.
Real negative (TN): The model predicts accurately with a real news article.
Positive error (FP): The model accidentally describes a real news article as fraudulent.
Palm false (FN): The model incorrectly describes a fraudulent news article as real.
The group analyzed these results, and analysts were able to assess the effectiveness of the classification model in successfully discriminating between fake news using the confusion matrix. Researchers and journalists can use this evaluation to measure how much their tactics work to refute the wrong information and improve the caliber of news reports.
Analysts can assess how classification models work well in determining false news articles by modifying the confusion matrix to suit the specified task of finding fake news in the press. Since the classrooms are now the actual advantages and topics of a news article, the matrix continues to show the results of the model classification. The columns show the model's predictions, and the rows show the actual article classifications.
Important insights into model accuracy in classifying articles as true or false can be obtained by carefully examining the confusion matrix in identifying fake news. The main measures such as accuracy (comprehensive right to classify models), accuracy (percentage of real news stories classified with precision from all real articles), calling (the percentage of real news stories that were correctly identified from all actual real news elements), and F1 The result (a balanced scale that combines accuracy and summons) provides a complete understanding of both the positive and real positives and negatives. Figure 9 shows all ROC results.
Ultimately, taking advantage of the confusion matrix in the world of fake news allows a comprehensive assessment of typical performance and enhances the improvement of classification models to combat wrong information in the press effectively.
Figure 9. All ROC results
ROC is a scale widely used in data analysis to assess the effectiveness of dual classification models. Although it is not used directly during the training of nerve networks, ROC is an important tool for assessing their performance after training.
Based on the results of the bilateral prediction of the nerve network model, ROC can be a useful tool to assess the quality of the distinction between wrong and accurate information regarding incorrect information discovered in the media. The two main standards of ROC are the actual negative average (privacy) and the real positive rate (allergies). Allergies measure the actual positive cases the model has discovered properly, while privacy measures the effective negative cases correctly classified.
When evaluating fake news in the media, dual-direction predictions can be used for the neural network model to determine the extent of the distinction between actual information and approval. This is where ROC comes. The basic ROC criteria for privacy (negative average) and allergies (actual positive average) must be found for this evaluation. Privacy determines the percentage of the actual negative cases correctly classified. At the same time, the sensitivity appears to the actual positive cases described properly based on the model's expectations.
Using ROC analysis to identify fake news, analysts can assess how well a neural network model distinguishes between fraudulent and real material. A common understanding of privacy and sensitivity measures obtained from the ROC curve helps to thoroughly assess the discriminatory capabilities of the model and see how well they are in countering erroneous material in the media.
By comparing the model's performance in this study with relevant studies, we found that the model achieved a good performance with an approximate error rate of 3.71% (the best achievement of 0.037137). This indicates a relatively high accuracy in distinguishing between real and fake news. Compared to previous studies, for example, Vaca Torres and Gomez Rodriguez [26]. A higher F1 score is about 0.82 using Naive Bayes, equivalent to less accuracy than the model within the study.
Regarding automated learning techniques, this study used nerve networks, while previous studies focused on algorithms such as SVM, Naive Bayes, Random Forest, and KNN. Our study agreed with Wang et al. [27] in the use of nerve network models, where they used LSTM-CNN to extract features.
With regard to verification and training, this study focused heavily on the verification process, with 6 verifications and details about the learning rate and the value of graduation. While previous studies have not provided similar details about the process of training and verification of health, this makes our approach more transparent and repetitive.
Regarding the use of multiple models, this study proposed the use of self-regulatory maps (SOMS) in addition to traditional methods, which corresponds to the combined model's curriculum in some previous studies, such as Popovic [28] and Vaca Torres and Gómez Rodríguez [26].
As for the extraction of features, this study did not provide specific details about the features of extracting the features used, while previous studies focused on techniques such as the word bag, TF-IDF, and feelings analysis.
Regarding the circular, this study emphasized the importance of continuous verification and improving performance, which may indicate a greater focus on generalizing new data. Previous studies, such as Vaca Torres and Gómez Rodríguez [26], also focus on the performance of invisible data models.
Finally, machine learning techniques have been applied in further applications, including governing modern cyber-attacks in computer networks [29], detecting cyberattacks in underwater wireless sensor networks [30], and enhancing cloud security through block chain [31].
The study highlights the importance of identifying wrong information in the media to maintain credibility and address misconceptions. The complex nature of wrong information in news articles is an accurate problem for traditional counter-news detection systems (FNDS). By combining many Sayyive, K -NN, Random Forest, Discography Tree, and Support Agect Machine (SVM) - for the majority, this study introduces a new approach in this field.
The study results show that compared with the curricula based on individual algorithms, the integration of collective technologies significantly enhances the accuracy of defining fake news. FNDS effectively addresses the challenges of defining fake news by taking advantage of the common intelligence of many algorithms, which improves their ability to identify and refute trusted materials. The study highlights the importance of choosing the right algorithms and using frequency range techniques to create systems that define strong news, which helps combat wrong information in the media.
In short, combining FNDS into news institution systems provides a useful way to effectively describe inaccurate materials. But maintaining the best possible results with FNDS applications requires continuous work and improvement. The battlefield against fake news is an advanced online news scene that provides a dynamic environment. Fake news detection systems may significantly contribute to pressure on integrity and confronting wrong information by setting accuracy and reliability priorities. This makes the ecosystem of the media safer and enlightening for everyone.
[1] Ahmadi S.S. (2019). Machine learning models for network intrusion detection and authentication of smart phone users. Master thesis, Morehead State University.
[2] Abirami, M.S., Pandita, S., Rustagi, T. (2019). Improving intrusion detection system using an extreme learning machine algorithm. International Journal of Recent Technology and Engineering, 8(2S4): 234-127. https://doi.org/10.35940/ijrte.B1043.0782S419
[3] Divyasree, T.H., Sherly, K.K. (2018). A network intrusion detection system based on ensemble CVM using efficient feature selection approach. Procedia Computer Science, 143: 442-449. https://doi.org/10.1016/j.procs.2018.10.416
[4] Divekar A., Parekh M., Savla V., Mishra R., Shirole M. (2018). Benchmarking datasets for Anomaly-based Network Intrusion Detection: KDD CUP 99 alternatives. In 2018 IEEE 3rd International Conference on Computing, Communication and Security (ICCCS), Kathmandu, Nepal, pp. 1-8. https://doi.org/10.1109/CCCS.2018.8586840
[5] Altwaijry, H. (2013). Bayesian based intrusion detection system. In IAENG Transactions on Engineering Technologies, pp. 29-44. https://doi.org/10.1007/978-94-007-4786-9_3
[6] Cannady, J. (1998). Artificial neural networks for misuse detection. In Proceedings of the 1998 National Information Systems Security Conference, NISSC'98, pp. 443-456.
[7] Li, L., Yu, Y., Bai, S., Hou, Y., Chen, X. (2017). An effective two-step intrusion detection approach based on binary classification and KNN. IEEE Access, 6: 12060-12073. https://doi.org/10.1109/ACCESS.2017.2787719
[8] Lutins E. (2017). Ensemble methods in machine learning: what are they and why use them? Towards Data Science.
[9] Ramzai J. (2019). Simple guide for ensemble learning methods. Towards Data Science.
[10] Bonab, H., Can, F. (2019). Less is more: A comprehensive framework for the number of components of ensemble classifiers. IEEE Transactions on Neural Networks and Learning Systems, 30(9): 2735-2745. https://doi.org/10.1109/TNNLS.2018.2886341
[11] Salim, R., Rao, G.R.K. (2007). Intrusion detection system: A brief study. In Web Services Security and E-Business, pp. 129-141. https://doi.org/10.4018/978-1-59904-168-1.ch007
[12] Zhang, J., Zulkernine, M. (2006). Anomaly based network intrusion detection with unsupervised outlier detection. In 2006 IEEE International Conference on Communications, Istanbul, Turkey, 2388-2393. https://doi.org/10.1109/ICC.2006.255127
[13] Kukiełka, P., Kotulski, Z. (2010). Analysis of neural networks usage for detection of a new attack in IDS. Annales UMCS Informatica Lublin-Polonia Sectio AI, 10(1): 51-59. https://doi.org/10.2478/v10065-010-0035-7
[14] Liu, H., Lang, B. (2019). Machine learning and deep learning methods for intrusion detection systems: A survey. Applied Sciences, 9(20): 4396. https://doi.org/10.3390/app9204396
[15] Bahl, S., Dahiya, D. (2017). Features contribution for detecting attacks of an intrusion detection system. Global Journal of Pure and Applied Mathematics, 13(9): 5635-5653.
[16] Madhavi, B.K., Mohan, V., Ghodki, V.M. (2016). An enhanced genetic algorithm based intrusion detection system for detection of denial–of-service attacks. International Journal of Computer Science Trends and Technolog, 4(5): 214-219
[17] Agarwal, N., Hussain, S.Z. (2018). A closer look at intrusion detection system for web applications. Security and Communication Networks, 2018(1): 9601357. https://doi.org/10.1155/2018/9601357
[18] Singh, P., Tiwari, A. (2014). A review intrusion detection system using KDD’99 dataset. International Journal of Engineering Research & Technology, 3(11): 1103-1108.
[19] Hasan, M.A.M., Nasser, M., Pal, B., Ahmad, S. (2013). Haq, N.F., Onik, A.R., Hridoy, M.A.K., Rafni, M., Shah, F.M., Farid, D.M. (2015). Application of machine learning approaches in intrusion detection system: A survey. IJARAI-International Journal of Advanced Research in Artificial Intelligence, 4(3): 9-18. https://doi.org/10.14569/IJARAI.2015.040302
[20] Intrusion detection using combination of various kernels based support vector machine. International Journal of Scientific & Engineering Research, 4(9): 1454-1463.
[21] Rais, H.M., Mehmood, T. (2016). Feature selection in intrusion detection, state of the art: A review. Journal of Theoretical and Applied Information Technology, 94(1): 30-43.
[22] Intrusion Detection System (IDS). https://www.geeksforgeeks.org/intrusion-detection-system-ids.
[23] Hasan, M.A.M., Nasser, M., Ahmad, S., Molla, K.I. (2016). Feature selection for intrusion detection using random forest. Journal of Information Security, 7(3): 129-140. https://doi.org/10.4236/jis.2016.73009
[24] Tchakoucht, T.A., Ezziyyani, M. (2018). Building a fast intrusion detection system for high-speed-networks: Probe and dos attacks detection. Procedia Computer Science, 127: 521-530. https://doi.org/10.1016/j.procs.2018.01.151
[25] Ambusaidi, M.A., He, X., Nanda, P., Tan, Z. (2016). Building an intrusion detection system using a filter-based feature selection algorithm. IEEE Transactions on Computers, 65(10): 2986-2998. https://doi.org/10.1109/TC.2016.2519914
[26] Vaca Torres, A.M., Gómez Rodríguez, L.F. (2017). Increasing EFL Learners’ Oral Production at a Public School through Project-Based Learning. Profile Issues in Teachers’ Professional Development, 19: 57-71. https://doi.org/10.15446/profile.v19n2.59889
[27] Wang, H., Feng, J., Zhang, H. and Li, X. (2020). The effect of digital transformation strategy on performance: The moderating role of cognitive conflict. International Journal of Conflict Management, 31(3): 41-462. https://doi.org/10.1108/IJCMA-09-2019-0166
[28] Popovic, M. (2018) Error classification and analysis for machine translation quality assessment. In: Translation Quality Assessment, Springer, Cham, 129-158. https://doi.org/10.1007/978-3-319-91241-7_7
[29] Raghavendra, G.S., Yesaswini, A.M. (2024). Design and implementation of Internet of Things (IoT) framework for governing modern cyber attacks in computer network. International Journal of Safety and Security Engineering, 14(5): 1385-1390. https://doi.org/10.18280/ijsse.140505
[30] Altameemi, A.I., Mohammed, S.J., Mohammed, Z.Q., Kadhim, Q.K., Ahmed, S.T. (2024). Enhanced SVM and RNN classifier for cyberattacks detection in Underwater Wireless Sensor Networks. International Journal of Safety and Security Engineering, 14(5): 1409-1417. https://doi.org/10.18280/ijsse.140508
[31] Tanam, A., Raja, G. (2024). Enhancing cloud security through block chain: A data integrity and trust approach. International Journal of Safety and Security Engineering, 14(5): 1455-1464. https://doi.org/10.18280/ijsse.140513