Kanusu Srinivasa Rao*![]() | Ratnakumari Challa
| Ratnakumari Challa![]() | B.J.Job Karuna Sagar
| B.J.Job Karuna Sagar
© 2023 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
The spread of fake news on social media platforms can have serious consequences for society, especially in urgent situations such as crises. Despite efforts to combat it, fake news is still able to proliferate rapidly through social media, where users share and exchange a vast amount of information on a daily basis. This information, however, is not always accurate, making it difficult to distinguish real news from fake news. To address this problem, this research proposes additional characteristics based on social interactions and content to identify fake news on social media platforms. These characteristics are designed to work in conjunction with each other and are found to be more effective in identifying fake news compared to the current baseline criteria. In addition, a CNN-LSTM model is used to analyze the text and predict the veracity of news. Unlike early research that focuses on fake news that has been circulating for a long time, this study tests the identification of fake news on a real-world dataset. The proposed features and machine learning models outperformed the baseline in terms of accuracy, recall, and F1 metrics, which are standard measures of classification model performance.
fake news, convolution neural network, long short term memory network, deep learning
False news [1], also known as fake news, is a serious issue that can have significant consequences on individuals, communities, and even entire societies. It is now much simpler for incorrect information to be disseminated swiftly because to the growth of misleading facts pertaining to several social media sites and other kinds of media. This often results in confusion and misinformation. False news can have several negative impacts, including undermining trust in legitimate [2] news sources and institutions, sowing division and mistrust among communities, and even inciting violence and conflict. When misleading information is disseminated during elections, it is especially troubling since it may have a huge influence not only on the result of the election but also on the path that a nation will take in the future. Fact-checking is an important tool for combating false news, as it helps to identify and expose false information and provide accurate information to the public. It is essential for people to exercise healthy scepticism toward the information they take in and to independently confirm the veracity of the data before passing it on to others. It is necessary that social media platforms and other media sources take efforts with the purpose of preventing the dissemination of false information, such as by using fact-checking [3-5] algorithms and several other techniques. It is also crucial that these actions be taken. WhatsApp is the most used messaging app in the southern hemisphere, according to the report. WhatsApp, in contrast to popular social media programs such as Facebook, provides encrypted peer-to-peer communications that is difficult to monitor. Monitoring users' interactions infringes on their privacy [6]; however it is necessary for identifying false news and the source of the news stories.
The dissemination of misleading or incorrect information has been the focus of a number of recent initiatives, one of which being the passage of anti-manipulation law in France. It is against the law to make an effort to influence the result of an election, which is exactly what happened during the Brexit vote when newspapers [7-9] incited animosity against immigration and the EU. This behaviour is a violation of the law. The act limits the political influence that may be exerted by placing a transparency requirement on online platforms. These platforms are obliged to announce any sponsored content, which includes disclosing the author's name as well as the amount of money that was paid for the content. Platforms that get more than a certain number of visitors per day are obliged to create a legal presence to make their algorithms public. This requirement applies to platforms that receive more than a certain number of visits per day. In addition, according to the law, a judge is responsible for classifying false information based on three criteria: the false information must be manifest; the false information must be disseminated in a deliberate and widespread manner; and the false information must cause a compromise the outcome of an election or disturbance of the peace.
During election seasons, the legislation also calls for collaboration between the various digital platforms, which is required by the law. The French Broadcasting Authority oversees improving law enforcement in order to comply with this obligation. Aside from that, Emmanuel Hoog, who served as president of the French Press Agency in the past, has been given the responsibility of establishing an ethical council for the press. Finland, Malaysia, and Singapore have all taken steps to combat the spread of false information. Finland began implementing an anti-fake news effort in 2014, with the goal of teaching people how to recognize false information. The Anti-Fake News [11-13] Act was approved by the Malaysian government in 2018. But the Act has been accused of attempting to silence anyone who disagrees with the administration's policies. The Protection from Online Falsehoods and Manipulation Act, which was approved in Singapore in 2019, is yet another legislation aimed at combating false information. Some scholars claim that this legislation has been subjected to the same charges as Malaysia's law against false news.
Figure 1. Different types of fake news
Legal position throughout the country: There is no specific regulation in India that prohibits the spreading of misleading information across the nation. The Constitution's Article 19, which protects an individual's right to freedom of speech, opens the way for an unrestricted flow of information, including the broadcast of news. Additionally, it has the jurisdiction to give a warning, reprimand, or punishment to the newspaper, the news agency, the editor, or the journalist in question. In addition, it has the authority to issue a warning, reprimand, or penalty to the newspaper [14-16] , news agency, editor, or journalist in question, depending on the severity of the violation. It is represented by the News Broadcasters Association, sometimes known as the NBA, is an organisation made up of independent news and current affairs broadcasters on television.
Complaints against electronic media are investigated by the self-regulatory organization. The Indian Broadcasting Foundation (IBF) is also responsible for investigating complaints about material broadcast by television broadcasters. The Broadcasting Programming Complaint Council (BCCC) investigates and adjudicates complaints against television broadcasters for inappropriate television content and false information. The Indian Penal Code (IPC) has a variety of sections that might be used to restrict the dissemination of false information, including the following ones: Both Section 153 (wantonly creating riot) and in the case of false news, the provisions of Section 295, which criminalises damaging or defiling a house of worship with the goal to offend the religious beliefs of any group, are relevant. and may be used to provide protection against it. Fake news can be protected against by using these sections of the law. The following is a copy of the text of Section 66 of the Information Technology Act of 2000: If a person engages in any of the activities listed in Section 43 (causing damage to a computer or computer system) with the intent to commit fraud or dishon People and companies that have lost money as a consequence of the spread of false information have the option of filing a defamation case against those who spread the false information, either in a civil or criminal court. The complaint may be filed in either kind of court. In the Indian Penal Code, a charge of defamation may be supported by either Section 499 (Defamation) or Section 500 (Civil Contempt), either of which may be cited.
Fake news has been a crucial factor in the development of the news industry as well as the general public's view of the news ever since the advent of the Internet. Journalists are coming to rely more and more discussion on the utilize of social platform of information since they are under increasing amounts of pressure to provide more material in a shorter amount of time. Figure 1 explains about different types of fake news. Confirming the veracity of the news that is disseminated via using various social media channels as a means of obtaining information may be very challenging for a number of reasons, including the pressure to produce more material. When journalists make mistakes in the verification of news sources, not only does it damage the image of their brand, but it also causes consumers to lose trust in the news media as a consequence of those journalists' activities.
It could take brand years to build a positive reputation, but it only takes a few seconds to ruin that reputation. The urge to provide content as quickly as possible results in less serious journalism. Fake news is a multifaceted and complicated problem. They may be disseminated to inflame conflict, achieve economic advantage, cause slander, or serve political objectives. Fake news is another factor that adds to the overall lack of awareness that exists among the general populace. According to the study, untrue rumours regarding the passing of a Chinese student named Alex Chow, who was 22 years old, spread about after his death. These rumours claimed that Chow had not committed suicide, but rather that members of the Hong Kong police force had pursued him or thrown him over a parking garage. In addition, the news reported that law enforcement officers had blocked the path of an ambulance that was headed for Chow. These fabricated news items were distributed in an effort to stoke support for protests against the government. A loss of a total of 130 billion US dollars in market value occurred in 2013 as a direct result of a decline of 143.5 points experienced by the Dow Jones Industrial Average. A piece of fabricated news claimed that two explosions that took place at the White House were intended for Barack Obama, who had previously served as President of the United States. Donald Trump referred to CNN and the Washington Post as "fake news" due to the fact that neither outlet was very supportive of him (they referred to his supporters as "a cult" and stated that he had "bewitched" the Republican Party on many occasions). Although it has been done in political settings for a long time, such as when the PRI (Institutional Revolutionary Party) in Mexico in 1988 used bogus poll numbers to discourage people from voting during political elections, this practice has never been done on the scale and to the extent that it is now possible thanks to advancements in technology. During the time leading up to the presidential election in the United States in 2016, there was an increase in the number of false news stories that were shared on social media platforms. This was one of the contributing factors that led to the election of Donald Trump as the 45th President of the United States of America. Platforms in the run-up to the United States presidential election in 2016 in the United States. Because of this, Donald Trump was victorious in his bid for the presidency of the United States. Several investigations that were carried out after the election of the president have proven that Russia was involved in the campaign in some way. In 2014, another instance of the use of fake news to exert political influence happened when ISIS started broadcasting propaganda on every social media platform known to humanity. This is an example of how false news may be used to influence politics. The public's capacity for logical communication is essential to the functioning of a democracy, and this capacity must be preserved. The public has had easier access to information as a consequence of the proliferation of digital technology; yet, at the same time as sophisticated forms of deep fake news are becoming more prevalent, the general population is growing less informed, which puts democracy at danger. As was said before, political influence, such as that wielded by the PRI, Russia, and Bolsonaro, constitutes a threat to democracy because it tends to centralise power and takes it away from the hands of the people.
As previously stated, the fundamental objective of the research that will be carried out is to examine the problems that arise when many bogus breaking-news stories are shared on social media networks.
1. Assessing the Accuracy of Predictions Made by Various Methods Employed to Spot Fake News
There are currently some research projects that are being carried out with the intention of comprehending the phenomena of false news, as well as the identification of common patterns and traits, with the goal of developing automated solutions for the detection of fake news. Specifically, these research projects are aiming to:
2. Assessing the Accuracy of Predictions Made by Different Methods Employed to Identify Fake News
Second, we know very little about the level of discrimination afforded by the characteristics that are presented in the available research for the identification of false news, either on their own or in combination with other factors, especially when dealing with a wide variety of different circumstances. This is true whether we are talking about the features on their own or in combination with other factors. This is a pressing concern that will be addressed in the next part of the discussion.
Third, we investigate our results on automatically detecting fake news in order to build a new technique that will assist fact-checkers in determining which news items have a greater probability of being untrue. We have included our method into a platform that we refer to as the WhatsApp Monitor so that we can demonstrate its applicability in a situation that more closely resembles the real world.
The following organisational conventions have been applied to the remaining portions of the paper: The investigation is divided into the following sections:
In the most recent few years, rumor detection has become an important topic in embedding, and there are two ways that solutions may be proposed for this problem: model-based or feature-based. In some of the research articles, several characteristics, such as features pertaining to the content as well as characteristics pertaining to the social environment or network features, are presented. On the other hand, in some research papers, the most effective algorithms for discovering rumors are examined. In the essay [1], the authors addressed two fundamental issues. The first problem is that it might be difficult to track down rumor-related microblogs on the internet. Finding tweets that provide credibility to the rumour is the second difficult component of the situation. They investigated the effectiveness of three extracted characteristics, which were features based on the content, features based on the networks, and features based on the micro blogs. They relied on their particular memories in order to correctly categorize the rumors. They personally carried out ten thousand tests on the tweet, and they depicted on the map how their linked model obtains a score 0.95. which illustrates the data assemblage is the huge data-sets that may be used for the detection of rumours that are currently accessible. The authors [2] put up a fresh approach for the identification of rumors on Twitter in the year 2012. In that piece of written work, they examined how we might cope with rumors of this kind and detailed how rumors spread in the aftermath of a natural catastrophe such as an earthquake. They began by conducting an investigation into a real-world case of a rumor that had arisen in the aftermath of a catastrophe, and they made an effort to reveal the features of the rumor. On the basis of the results of the study, they developed a prototype for a system that is capable of identifying potential candidates for rumours that originate on Twitter. After extracting tweets from r1 and r2 data sets that included the phrases "server room", "geek", "how", and "come oil". After painstakingly looking through each tweet and deleting any tweets that were thought to be redundant, they were able to retrieve 1135 tweets from r1. The author of this study used the social spam analysis and detection framework known as (SPADE) [3] across many social networks in order to demonstrate the adaptability and effectiveness of the cross down classification. They exerted a considerable amount of effort and spent a considerable amount of time in order to produce the findings that were posted on the vast research web pages and in the email spam. The development of SPADE made use of many different models, and the web page model. All of these models are considered to be essential models. The first model is the profile-based model; the second and third models are both message-based models. Every one of the models is a representation of the most important thing on the social network. Because of the models' flexibility and scalability, all of the models' data are saved in XML instead of another format. In order to determine the outcome, they apply the F measure and accuracy assessment. The suggested classifier achieves an accuracy improvement of 7% and an FP rate that is more than 20%.
It was suggested [4] that a model may be developed to automatically identify rumors on social media networks. The authors made use of a vast variety of implicit content-based and user-based characteristics, including a predisposition toward popularity, both extraneous and interior texture, emotional contradiction, and level, which communication fit the recipient's expectations. In addition, the authors considered the degree to which the message matched the recipient's expectations. In addition to this, the writers took into consideration the extent to which the message lived up to the anticipation of the receiver. The procedure for choosing the characteristics to investigate was the most significant aspect of this research. The cleaning of the data, the extraction of features, and the training of the model were the three components of their endeavour. During the process of cleaning up the data, they removed any communications that were considered to be spam as well as any obsolete features. Following the selection of the features, the classifier was applied using SVM in addition to the random forest classifier. In the end, they demonstrated their development in terms of accuracy and recall.
In the year 2016, a suggestion was made about the precise identification of rumours and the investigation of beliefs on social media networks such as Twitter [5]. This body of work makes an attempt to discover a solution to the problem of identifying rumours on the Twitter network, which is an issue that has not before been addressed. They extracted two new characteristics for the model that they offered: the first is a solution to the issue of missing words & postponement (TLV), and the next is the end-user trust in rumour. Both of these characteristics may be found in the model that they suggested. In order to determine whether or not they were true, the support vector machine. In order to investigate the proof provided by other classifiers. The purpose of the project was to build a system for the detection of rumours, and it did so by using the methodology of supervised machine learning to the data that was obtained from Twitter [6]. They employed a technique of machine learning that was supervised in two distinct ways in order to determine whether or not rumours were true. In order to achieve an accuracy of 81%, they used a number of models. In conclusion, rumours were discovered during the process of cleaning the content by assessing the qualities of the textual material.
The study that was written by the author and published in 2019 [7], they suggested a technique for detecting rumours that was built on SDSMOTE and feature selection. They utilised Sina microblogs to analyse the rumours around a certain subject, and they introduced six new features as part of their research report. They adopted the SMODE algorithm and utilised suspect, rating as their guide less words in order to decrease the influence that unbalanced data had. They were able to identify an appropriate degree of accuracy in ninety percent of the rumors. In the study [8], a unique strategy for rumor identification was provided. This strategy incorporates new elements, such as evaluating the properties of the network and accounting for bias potential. They validated their hypothesis by applying it to an actual data set including all tweets relating to health that were culled from the Twitter platform. The findings of the trials showed that making use of the extra features resulted in an acceptable degree of accuracy in the identification of 90% of the rumours. They also employed a number of different classifiers for the aim of picking a number of characteristics for rumour identification. This is helpful information for the future selection of the classifier that is the most successful and the features that it uses.
The authors used long short-term memory, also known as LSTM, in order to recognise urban legends that have been propagated over the internet [9]. Using a neural network that they created, they were able to determine whether or not a piece of information included a forwarding, spreader, or diffusion structure. This allowed them to recognise rumours. Because of this, they were able to access their long-term as well as their short-term memories (LSTM). In order to make the material more readily available to those who need it, can use an embedding model system for the encoding. found that forward-looking information was appealing, and they included this discovery into the content of their flyer [10]. They recommended to change the pattern of diffusion functionality, as well as reflects the interaction between the multiple diffusion layers [11], in order to improve the diffusion process. This would include the process of moving particles from one layer to another. There are 1623 rumours and 1756 things that are not rumours included in the whole collection of data. The results of the experiment were compared to the article that served as the baseline, and accuracy and the F1 measure were the criteria that were utilised for the assessment. This inquiry [12] revealed and talk-about of two classification of rumours, which can open-out via social platforms [13]. The first kind of rumor is one that has been going about for a significant amount of time, while the second type is one that has just begun circulating and is the result of rapid-fire events, such as breaking news, in which stories are passed around without being verified. They provided an overview of a technique for categorising rumours, which is comprised of the following four steps: the first step is rumour detection; the second step is rumour monitoring; the third step is rumour stance classification; and the fourth and final step is rumour veracity classification.
A classification model that might be used to predict false news was built by Girgis et al. [14] using vanilla Recurrent Neural Network (RNN) [15, 16] related models such as Gated Recurrent Unit (GRU) models and LSTMs. This approach has the potential to be used in the categorization of inaccurate information (long short-term memories). Their research made use of LIAR dataset, which includes 12,836 condensed statements that have been organised in accordance with a variety of criteria. During the process of creating the dataset, they isolated each sentence and eliminated any unnecessary terms. In the end, they conducted three separate tests using Vanilla, GRU, and LSTM and compared the results to see which one generated the most accurate results. The results obtained with GRU were superior to those obtained with Vanilla and LSTM.
When it comes to spotting false news, there are several obstacles to overcome. Fake news sites, in both design and content, are often imitative of legitimate news platforms. It is possible that some accurate things are blended in with misleading ones in fake news pieces, which is why they are not always 100 percent phony. The ability to create photographs and videos is conceivable with today's technology, making it hard to instantaneously check the validity of news reports. It is equally simple to construct fictitious companies for the purpose of disseminating false information. This may be accomplished with the use of free web tools, and existing photographs can be utilized for the purpose of face swapping. [Polyakov (2018)]. As a result of the fact that real news articles typically include either original or dramatic content, and that they typically contain more superlatives and loaded phrases (in order to play on emotions), natural language processing (NLP) should be feasible for distinguishing between fake news and real news. However, it is a challenging and time-consuming procedure because recognises the fact that words may have diverse meanings depending on the context in which they are spoken and because a new version of NLP has to be constructed for each language and dialect. The amount of material that can be accessed is limited, but there is a higher quantity of legitimate news than there is of fake news. As a consequence of this, the process of training models to categorise data is impeded. Classification and regression models, using either the content of articles or rumour transmission routes as input, have historically been used for the purpose of detecting fake news, with the latter method being the more prevalent of the two. RNN is the method that we will use for the time being to figure out if a certain claim is correct or not. In this particular scenario, it will only take the assertions one at a time and will be unable to process large volumes of temporal information. A model of a deep neural network that is presented in this study is one that is constructed on bidirectional Long Short-Term Memory (LSTM). The model receives its input in the form of article content, rumour propagation channels represented as time series, and metadata.
Figure 2. CNN-LSTM architecture
The content of the article is word embedded. It consists of a variety of descriptive criteria for both the articles and their corresponding tweets and retweets, including the article ID, tweet and retweet identification, tweet and retweet content, and the number of followers for each of the articles. Description parameters in metadata are continuous numerical characteristics that are both normalized and discrete. The pathways of rumor spread are used to generate time series data sets. Last but not least, the word embedded article content, the discretized continuous characteristics, and the time series are concatenated and input into the bidirectional LSTM-CNN network, which categorizes news articles from the PolitiFact dataset as either genuine or fictitious.
|
Algorithm-1: CNN-LSTM for fake news classification |
train_x, train_y = normalize (train_x, train_y).
|
It is essential to collect data about the news in order to produce a dataset that is factual and fair. It is also vital to supply data for training that is of a high quality and to provide outstanding results despite the fact that there is a substantial quantity of datasets that may be accessible for the purpose of researching false news. The body of research presented clear evidence of substantial limitations with regard to scale, classification, and bias. After doing an exhaustive examination, we came up with a WELFake that was more comprehensive. the outcome of integrating four datasets, namely those from Reuters, Kaggle, McIntire, as well as BuzzFeed, for a number of very specific reasons. To begin, they have a comparable appearance and texture to one another. an organizational framework with two distinct categories (that is, true news as well as phoney news). Second, combining the datasets may reduce the amount of restriction placed on the analysis while also improving its precision. free dataset including 72,134 news items that have been categorized into 35,028 different groups. There are 37,106 different misleading items of news. The collection includes three different recordings in total.
There will be a binary label next to each column, indicating whether the column includes bogus news or the true deal (i.e., title, text, and label).
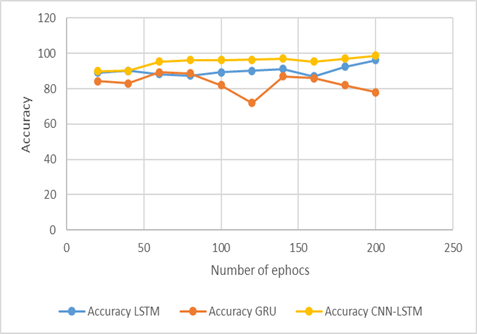
Figure 3. Accuracy
The degree to which samples may be correctly identified as false or authentic can be seen in Figure 3, which is shown here. In addition, the graph contrasts the already implemented LSTM and GRU models with the proposed CNN-LSTM model. The LSTM model is not successful in performing the categorization of fraudulent and authentic samples. The reason why LSTM and GRU are unable to extract better features and the connection between various text sequences is because false data is extremely closely connected to real data. However, the CNN-LSTM model that has been suggested has superior feature extraction processes in addition to a memory unit that has the potential to deliver greater accuracy as the number of epochs increases. While this is going on, other models don't seem to be able to offer any more accurate results no matter how many epochs are added.
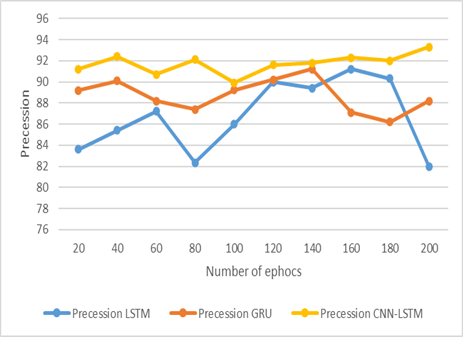
Figure 4. Precession
Figure 4 represents the precession the graph compares the LSTM and GRU models that have previously been implemented with the CNN-LSTM model that has been suggested. The LSTM model does not succeed in executing the classification of real and counterfeit samples successfully. Because fake data is tightly intertwined with actual data, LSTM and GRU are unable to successfully extract superior features and the link between multiple text sequences. This is the primary explanation for this failure. On the other side, there is a model known as CNN-LSTM that has been proposed has improved feature extraction procedures in addition to a memory unit that possesses the ability to give more precession as the number of epochs grows. While this is taking place, it seems that alternative models cannot provide any more accurate findings, regardless of the number of epochs that are added to the analysis.
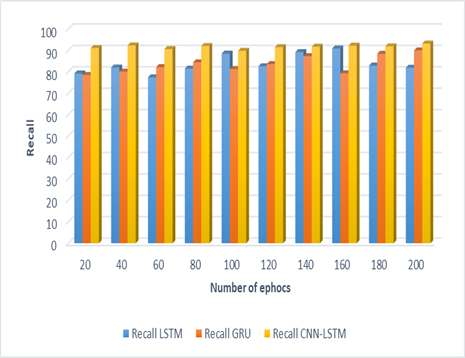
Figure 5. Recall
Figure 6. F-score
Figure 5 depicts recall for the categorization of data pertaining to fraudulent and legitimate news sources. On the graph, the recall is represented along the Y-axis, while the number of epochs is shown along the X-axis. The LSTM model is unable to correctly execute the categorization of actual and counterfeit samples into their respective categories. Both LSTM and GRU fail to properly extract better characteristics and the connection between numerous text sequences when presented with data that is intricately intermingled with false data. This is due to the fact that fake data is strongly intertwined with genuine data. This is the most important factor contributing to this failure. On the other hand, the CNN-LSTM model that has been proposed has improved feature extraction procedures in addition to a memory unit that is able to provide increased recall as the number of epochs in the model rises. Both of these features have been included into the model. During this time, it would seem that alternative models are unable to provide any conclusions that are any more accurate, regardless of the number of epochs that are added to the study.
In this instance, Figure 6 displays the classification of actual news samples and fake news samples based on their respective F-scores. The recall is indicated along the Y-axis of the graph, while the number of epochs is shown along the X-axis of the graph. The LSTM model is unable to correctly execute the categorization of actual and counterfeit samples into their respective categories. Both LSTM and GRU fail to properly extract better characteristics and the connection between numerous text sequences when presented with data that is intricately intermingled with false data. This is due to the fact that fake data is strongly intertwined with genuine data. This is the most important factor contributing to this failure. On the other side, there is a model known as CNN-LSTM that has been suggested includes enhanced feature extraction processes in addition to a memory unit that is able to deliver greater recall as the number of epochs increases. Both of these features have been included into the model. During this time, it would seem that alternative models are unable to provide any conclusions that are any more F-score, regardless of the number of epochs that are added to the study.
In order to resist elevate tendency utilising social platform as a significant origin for bulletin, it is necessary to discern between information that can be verified and falsehoods that have no basis in reality. In recent years, this activity has become not only more challenging but also more important. It is made much easier for users of social media platforms to publish content whose truth values are unknown, and for users to quickly disseminate such knowledge among themselves situated in various regions of the world, thanks to a number of the features of social media platforms. If they are not debunked as quickly as is physically feasible, false breaking news reports might have extremely serious consequences. The vast bulk of the research that is presently available on recognising bogus news derived manually pulling characteristics from social networking sites is the only viable option or using algorithms. The authors of this study propose a new set of characteristics for the identification of fake news on Twitter by making use of a framework for deep learning. This research was carried out by Twitter. Our approach is able to learn by monitoring the manner in which the compiled data shifts throughout a variety of time intervals in connection with each event. This allows our technique to acquire new knowledge. CNN-LSTM models Our CNN-LSTM-based technique is shown to be better when evaluated in comparison to baseline models. This helps us determine whether or not our product is superior than the product in question. The strategy that is being adopted has promise that has not yet been realised. In the future, more stringent testing will be needed in order to get a deeper knowledge of how deep learning may assist in the identification of rumours. This understanding will be necessary in order to develop more effective countermeasures. This is due to the fact that there is a chance that deep learning might assist in the identification of rumours. It is feasible that we will also be able to develop models without supervision if we make advantage of the vast amounts of unlabeled data that are readily accessible on social media sites.
The author Dr. Kanusu Srinivasa Rao, thanks to the authories of Yogi Vemana University, Kadapa, India for sanction of the seed money research grant funded project through “No. YVU/SMRG/Dr. KSR/CST/Administrative Sanction /2022” to carry out the present research work.
[1] Alkhodair, S.A., Ding, S.H., Fung, B.C., Liu, J. (2020). Detecting breaking news rumors of emerging topics in social media. Information Processing & Management, 57(2): 102018. https://doi.org/10.1016/j.ipm.2019.02.016
[2] Qazvinian, V., Rosengren, E., Radev, D., Mei, Q. (2011). Rumor has it: Identifying misinformation in microblogs. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, pp. 1589-1599.
[3] Takahashi, T., Igata, N. (2012). Rumor detection on twitter. In The 6th International Conference on Soft Computing and Intelligent Systems, and the 13th International Symposium on Advanced Intelligence Systems, Kobe, Japan, pp. 452-457. https://doi.org/10.1109/SCIS-ISIS.2012.6505254
[4] Wang, D., Irani, D., Pu, C. (2011). A social-spam detection framework. In Proceedings of the 8th annual Collaboration, Electronic Messaging, Anti-Abuse and Spam Conference, pp. 46-54. https://doi.org/10.1145/2030376.2030382
[5] Zhang, Q., Zhang, S., Dong, J., Xiong, J., Cheng, X. (2015). Automatic detection of rumor on social network. In: Li, J., Ji, H., Zhao, D., Feng, Y. (eds), Natural Language Processing and Chinese Computing. NLPCC 2015. Lecture Notes in Computer Science, 9362. Springer, Cham. https://doi.org/10.1007/978-3-319-25207-0_10
[6] Hamidian, S., Diab, M. (2016). Rumor identification and belief investigation on twitter. In Proceedings of the 7th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, pp. 3-8.
[7] Thakur, H.K., Gupta, A., Bhardwaj, A., Verma, D. (2018). Rumor detection on Twitter using a supervised machine learning framework. International Journal of Information Retrieval Research (IJIRR), 8(3): 1-13. https://doi.org/10.4018/IJIRR.2018070101
[8] Geng, Y., Sui, J., Zhu, Q. (2019). Rumor detection of Sina Weibo based on SDSMOTE and feature selection. In 2019 IEEE 4th International Conference on Cloud Computing and Big Data Analysis (ICCCBDA), Chengdu, China, pp. 120-125. https://doi.org/10.1109/ICCCBDA.2019.8725715
[9] Gopi, A.P., Naik, K.J. (2022). An IoT model for Fish breeding analysis with water quality data of pond using Modified Multilayer Perceptron model. In 2022 International Conference on Data Analytics for Business and Industry (ICDABI), Sakhir, Bahrain, pp. 1-6. https://doi.org/10.1109/ICDABI56818.2022.10041617
[10] Sicilia, R., Giudice, S.L., Pei, Y., Pechenizkiy, M., Soda, P. (2018). Twitter rumour detection in the health domain. Expert Systems with Applications, 110: 33-40. https://doi.org/10.1016/j.eswa.2018.05.019
[11] Liu, Y., Jin, X., Shen, H. (2019). Towards early identification of online rumors based on long short-term memory networks. Information Processing & Management, 56(4): 1457-1467. https://doi.org/10.1016/j.ipm.2018.11.003
[12] Riquelme, F., González-Cantergiani, P. (2016). Measuring user influence on Twitter: A survey. Information processing & management, 52(5): 949-975. https://doi.org/10.1016/j.ipm.2016.04.003
[13] Ma, J., Gao, W., Mitra, P., Kwon, S., Jansen, B.J., Wong, K.F., Cha, M. (2016). Detecting rumors from microblogs with recurrent neural networks. Proceedings of the 25th International Joint Conference on Artificial Intelligence (IJCAI 2016), pp. 3818-3824.
[14] Girgis, S., Amer, E., Gadallah, M. (2018). Deep learning algorithms for detecting fake news in online text. In 2018 13th International Conference on Computer Engineering and Systems (ICCES), Cairo, Egypt, pp. 93-97. https://doi.org/10.1109/ICCES.2018.8639198
[15] Gopi, A.P., Naik, K.J. (2021). A model for analysis of IoT based aquarium water quality data using CNN model. In 2021 International Conference on Decision Aid Sciences and Application (DASA), Sakheer, Bahrain, pp. 976-980. https://doi.org/10.1109/DASA53625.2021.9682251
[16] Gopi, A.P., Jyothi, R.N.S., Narayana, V.L., Sandeep, K.S. (2023). Classification of tweets data based on polarity using improved RBF kernel of SVM. International Journal of Information Technology, 15(2): 965-980. https://doi.org/10.1007/s41870-019-00409-4