Mahraz Kabache* | Mhania Guerti
© 2021 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
A reliable perceptive analysis implying several sessions of listening turns out to be consuming in time and in human resources, and therefore not allowing a regular use in clinical practice. At the level of the Ear, Nose and Throat (ENT) services the rehabilitative speech therapist is in charge of estimating by listening to the quality of the voice, which entraines a non reliable perceptive evaluation compared with the one that will be proposed in this work. In this study, objective instrumental approaches based on physical measures has been proposed. These approaches allowing the analysis and estimation of the acoustic characteristics of the voice of the patients having a total laryngectomy. The results are compared with those obtained in a healthy vocal speaker. The outcomes indicate that objective evaluations can provide a homogeneous database for a better interpretation of articulators and vocal dysfunctions.
pathological voice, objective instrumental approaches, Algerian clinical environment, acoustic characteristics of the voice, total laryngectomy
The evaluation of the quality of pathological voice has always been the main clinical concern of speech pathologists. As in the other medical disciplines, they were attentive to all techniques which might give additional information to help diagnose and assess the effects of a surgical or a medical treatment or the progress of rehabilitation. For this purpose, a multiparametric acoustic analysis is conceived to qualify and quantify the vocal dysfunctions from acoustic, aerodynamic or electro-physiological measurements. These measurements are performed on the patient during vocal production by means of sensors designed to record and study multiple parameters of the speech production.
Makeieff et al. [1] have shown that after such surgery, voice is a significant quality of life factor. Fantini et al. [2] studied the rehabilitation of the substitution voice after open partial horizontal laryngectomy and identified the need for larger groups of patients to research voice discrepancy and rehabilitation. Schindler et al. [3] reported that the findings showed a highly dysphonic voice after laryngectomies. Their tested conducted after two years of rehabilitating the patients and depended on self-assessment long-term. Petrovic-Lazic et al. [4] concluded that acoustic and perceptual characteristic of voice in patients improved after phonomicrosurgical and voice treatment. Giovanni et al. [5] confirmed the importance of objective and subjective measurements in techniques aimed at improving voice quality after surgery. In same regard, Drugman et al. [6] proposed a dedicated scale for the objective Automatic Acoustic Assessment and showed the applicability.
In order to study the correlation of the Voice Handicap Index with the several objective parameters, Garcia et al. [7] performed a meta-analysis. The findings showed that the correlations were negligible or low. Allegra et al. [8] suggested that patients with laryngectomy be rehabilitated by a multidisciplinary team that addresses various patient problems in order to define and apply the most effective form of vocal rehabilitation. Coffey et al. [9] reported the need for further research to ascertain whether any effective methods of increasing reliability can be identified among parameters that have not reached good reliability.
Schindler et al. [10] indicated the importance of providing advice to the patient about the quality of life after surgery, based on the results of previous studies. Therefore, they implicitly indicated the need for more studies and conclusions in this regard.
According to the above survey, a lot of studies confirmed the need to more studies in regards of pathological voice after laryngectomee. Also, very little investigations employed Multi parametric method. Therefore, our work concerns the acoustic analysis and evaluation of pathological voice in subjects totally laryngectomee in an Algerian clinical environment by using Multi parametric method. The objective of this study is to show that the acoustic analysis can support; in this environment; the rehabilitation of a patient and to assess, in an objective way, the evolution of this rehabilitation over time.
The total or partial ablation of the larynx called laryngectomy is a surgical act resulting from a cancer. It may be limited to larynx cancer or a cancer of the larynx spread to the pharynx.
Cancers of the larynx or the pharynx are more common in men than in women (ten times more). They are mainly favored by the consumption of alcohol and tobacco use. Clinically, laryngeal cancer at its beginning occurs variably. It may be a gradual loss of vocal tone first, then gradually takes the aspect of both rough and dull [11]. It can result in a painful dysphagia (swallowing difficulty). The main character of these signs is their persistence and their progressive aggravation, hence the need for a laryngoscopy examination when these signs persist and in particular before any dysphonia or any swallowing gene that lasts more than three weeks.
Laryngectomy may be classified as partial or total laryngectomy:
Partial laryngectomy preserves generally a sufficient portion of the larynx to allow the patient to speak properly after surgery. In some cases, the voice is a little hoarse or low, but the aero-digestive system is preserved.
The total laryngectomy requires the separation of the digestive and respiratory systems with final tracheal junction at the base of the neck. After total laryngectomy, the patient can no longer speak with the laryngeal voice using the pulmonary air. He can learn another technique to speak. Many methods of voice rehabilitation have developed since the appearance of total laryngectomy in the early of the nineteenth century [12]. Today, three methods of restoring the voice are the most used, the electrolarynx, the tracheoesophageal voice through removable prosthesis, and esophageal speech, which is the way of rehabilitation adopted in the ENT department and Neck Surgery of Center Hospito-University (CHU) Beni Messous, Algiers (Algeria).
The instrumental analysis (acoustic) of the parameters of the voice brings an objective dimension that allows to overcome partially the drawbacks of the subjective evaluation.
In general, the collected signals may be of several types and will or will not be subject of a data processing:
Acoustic: the signal is collected with to a microphone.
Aerodynamic: Record air pressures or flows (oral or nasal) and the time it takes to produce a voice signal (maximum phonation time (MTP).
Electroglottographic: with two electrodes put on each side of the larynx, the variation of the electrical signal is used to analyze the phase of abutment or separation of the vocal cords.
4.1 Population
The population selected for this study consists of nine male adult aged between 47 and 68 years, treated with ‘total laryngectomy’ for advanced laryngeal cancer, in the speech therapy unit of the ENT service of the hospital of Beni Messous (Algiers). Only patients who had followed a regular rehabilitation protocol were included in this study (one session per week). They received their complementary treatments (medical care), 8 weeks after the intervention. A period of vocal rehabilitation is carried out in 9 months. The technique for recovering the voice after chirugical operation is the esophageal voice. In this technique, a permanent opening, called "tracheostoma", is performed at the base of the neck. This opening allows the patient to breathe, thus generating this new voice, by storing air in the lower part of the esophagus (swallowing air) and then causing a voluntary eructation to give a semblance of voicing [8]. The rehabilitation protocol for patients began gradually in April 2008 until October 2011. All patients completed 9 months of rehabilitation.
For the reference voice (reference standard), the same corpus was pronounced by 5 Algerian male speakers, normal, aged between 40 and 58 years with no voice disorders.
4.2 Recording equipment
The corpus of the voice was recorded with an external sound card M-audio pro connected to a USB port, which gives a Signal to Noise Ratio (SNR) of 100 dB with 24-bit resolution, and sample rate up to 96 kHz. The sampling frequency chosen is 44100 Hz. This value of the sampling frequency gives a better sound quality to our audio recording. The recording is performed by a dynamic microphone of type Sennheiser's E815S, and a software of professional sound “Sound Forge version 10”. All Numerical data is stored in the hard disk of a laptop computer.
4.3 Recording protocol
The recording protocol had to meet several requirements. It had to be identical for all patients with the same tests in the same order for each record. Mouth distance – microphone must be respected for all patients. The patient should take a strong breath and hold the vowel [a] at comfortable height and intensity for as long as possible. We then chose a two-second duration corresponding to the most stable part of the signal. We also asked patients to say words and short sentences.
4.4 Recording conditions
It is always recommended to make voice recordings in a room as quiet as possible. This is particularly important for the objective analysis, as opposed to the human ear, the microphone used will not distinguish between the voice of the patient and external noise picked up by the microphone. In our study, the patients were recorded in a quiet room acoustically isolated, with the absence of sound echo, to minimize noise sound sources.
The patients were placed on a chair, before recording, we repeated once all the tests. During the recording of the tests, the distance between the microphone and the mouth of the patient was fixed to 5 cm. The microphone gain has been adjusted to avoid saturation and to ensure optimal recording quality.
For every session of recording, we took five sound samples for the same patient and the same healthy subject, the purpose is to choose the slowest and the most stable sample.
4.5 Acoustic analysis of the pathological voice
The studied acoustic data have been manually extracted by using the PRAAT software, where each sound is introduced into the Praat software and analyze to extract the acoustic parameters [13]. The data was collected from a normalized window, lasting two seconds, placed in 200 ms after the vocalic attack to eliminate the phenomena associated to this one. The acoustic parameters selected for this study are: the fundamental frequency Fo (Pitch), jitter which evaluate short-term instability of Fo, the sound intensity, the shimmer which evaluate the short-term instability of the Fo amplitude, the signal to noise ratio HNR, the formants F1, F2 et F3 representing the resonance frequencies of the vocal duct, the percentage of voicing (Degree of Unvoiced Voice, DUV), For the aerodynamic parameters we used Maximum Phonation Time (MTP).
The acoustic measures used in this study were defined and calculated as follows:
The average fundamental frequency Fo is the first acoustic parameter used by the researchers as an indicator of the biomechanical characteristics of the vocal cords. The average F0 provides an overall measure of the pitch of the voice (high, low ...). To measure it, the PRAAT software proposes a default frequency range from 75 to 600 Hz. For a pathological voice, we have expanded this range to include low frequencies in the case of a man’s voice (for example 40 Hz). The average frequency can be calculated by the following equation:
F0 average $($ in $\mathrm{Hz})=\frac{1}{N} \sum_{i=1}^{N} F 0_{i}$ (1)
Short-term instability of F0 is the frequency variation between each oscillation cycle and is measured by the Jitter factor [14]. It consists of calculating the average of all the differences, in absolute value, between two consecutive periods of the signal, and dividing this average by the average length of the periods of the signal [15].
Jitter Ratio $=\frac{\sum_{i=1}^{n-1} \frac{\left|T_{i}-T_{i+1}\right|}{n-1}}{\sum_{i=1}^{n} \frac{T_{i}}{n}}$ (2)
Short-term instability of the Fo amplitude results in amplitude variations between each oscillation cycle. It is calculated by the Shimmer. The measure is based on exactly the same principle as the jitter ratio. We divide the average of the differences, in absolute value, between the maximum amplitude of two successive periods by the average of the maximum amplitudes of each period [16].
Shimmer $=\frac{\sum_{i=1}^{n-1} \frac{\left|A_{i}-A_{i+1}\right|}{n-1}}{\sum_{i=1}^{n} \frac{A_{i}}{n}}$ (3)
The percentage of voicing (Degree of Unvoiced Voice, DUV) represented by the rate of unvoiced windows (frame or portion of signal), which corresponds to the proportion of windows considered unvoiced on a portion of the speech signal. A window is considered as voiced if the voicing strength (score of the autocorrelation function) is lower than a certain threshold fixed under PRAAT to 0.45.
Measures of signal and noise explore the presence (or absence) of noise during phonation. This parameter is enhanced by the HNR. The HNR is calculated from a time method, this is the method adopted by PAAT [8]. Twenty-five consecutive cycles of voiced signal allow to establish an average wave form; subtracting the original signal and the average shape allows to obtain a residue considered as noise. This method consists of calculating the H/N ratio converted to dB from the energy of the H harmonies and the residual noise N.
As in the case of oral airflow, we can understand that the MTP depends both on lung capacity and a possible presence of a glottal leakage during phonation. Low lung capacity or glottal air leakage necessarily led to a reduction of MTP. We can measure the MTP using a stopwatch, which is plenty accurate. For reasons of convenience and speed, we measured it visually in the sound’s editor window of PRAAT.
The measures of the various acoustic parameters are presented in Table 1. For Every parameter, the validity is tested by comparison with the measurements obtained by the reference standard. The mentioned results obtained after acoustic analysis using PRAAT software. We have deliberately displayed for each acoustic parameter the minimum and maximum value of the patient’s pathological voice in order to show later the degree of discrepancy between the voices of patients who use esophageal speech after the step reeducation. We compared the mean value of each acoustic parameter with the mean value of the reference standard (healthy subject).
Table 1. Results of the acoustic parameters analysis
|
|
Value |
Reference standard |
|||
|
Min |
Max |
Average |
|
||
|
Acoustic parameters |
F0 Average (Hz) |
62.80 |
110.3 |
80.4 |
121.53 |
|
F1 (Hz) |
685.2 |
854.3 |
781.4 |
564.11 |
|
|
F2 (Hz) |
1025.3 |
1331.2 |
1265.5 |
841.48 |
|
|
F3 (Hz) |
2757.9 |
2987.4 |
2883.2 |
2326.69 |
|
|
Jitter (%) |
0.12 |
3.04 |
2.07 |
0.70 |
|
|
Average intensity (dB) |
52.11 |
62.89 |
56.11 |
72.12 |
|
|
Shimmer (%) |
7.14 |
11.68 |
9.99 |
6.61 |
|
|
DUV (%) |
0.86 |
0.97 |
0.93 |
0 |
|
|
HNR (dB) |
7.27 |
14.33 |
11.31 |
19.14 |
|
|
MTP (s) |
2.35 |
6.65 |
4.45 |
8.02 |
|
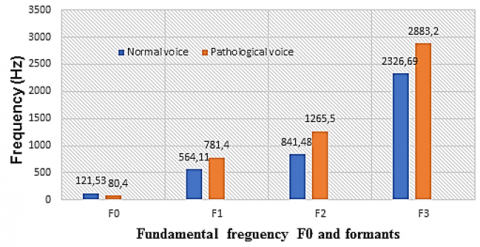
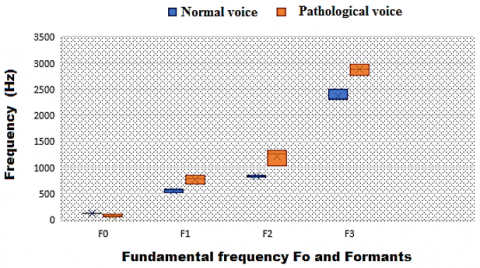
Figure 1. Comparison of the mean value of the fundamental frequency and the formants between the pathological voices of patients and the normal reference voice
Figure 2. Comparison of the average value of the different acoustic parameters of pathological voices with the reference voice (normal voice)
Figure 1 shows the comparison of basic tension (Pitch) and formants between normal and patient voice. We notice a low value of F0 compared to normal voice, and this explains that patient voice is distinguished by low tone sounds after the reeducation phase compared to normal people.
Figure 3. Comparison of acoustic parameters: Jitter, Shimmer and DUV of pathological voices with the reference voice (normal voice)
Figures 2 and 3 show a comparison of acoustics parameters between normal and patient voice. We have deliberately combined the acoustic elements that affect the amplitude and the frequency of the sound such as Jitter, Shimmer and DUV, and we have combined into the form 2 the tracer that affects the intensity of the sound such as intensity and HNR.
Figure 4. The difference between the minimum and maximum value of Fo and formants for a pathological voice and normal voice
Figure 5. The difference between the minimum and maximum value of the acoustic parameters for a pathological voice and normal voice
Figures 4 and 5 show the extent of the discrepancy in the values of the acoustic elements between normal and patient voices. This difference is due to a difference in the post-rehabilitation phase, the reeducation, whose results differ according to the degree of will of each patient.
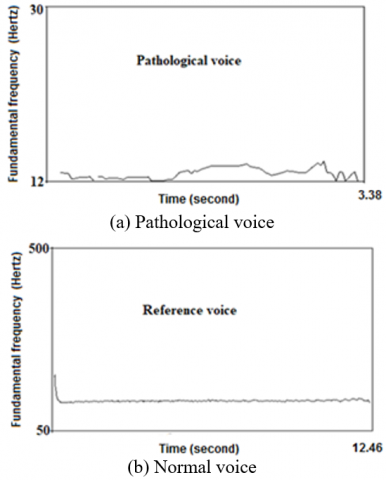
Figure 6 shows the change in the fundamental frequency (pitch) as a function of time between the normal voice and the pathological voice. We notice an instability in the pitch curve, this is due to compensating the vocal cords with a resonator, which becomes the source of vibration.
Figure 6. Variations of the fundamental frequency:
(a) Pathological voice, (b) Reference voice
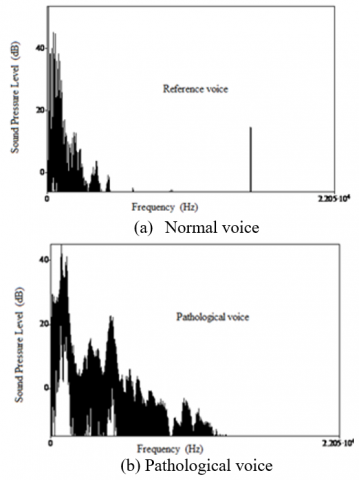
Figure 7. Average spectrum of narrowband over the same duration for the sound pressure in decibels as a function of frequency: (a) Normal reference voice. (b) Pathological voice
Figure 7 shows the comparison of the degree of air leakage between normal voice and speech after total laryngectomy. The value of the air escaped can be expressed by the HNR. The breath of the voice is considered a noise superimposed on the vocal signal (the new voice). Spectral analysis shows a well-defined line spectrum for a good quality normal voice signal and a massive continuous spectrum for a pathological voice signal, due to air leakage (Figure 7). The voice in this case is blown and the timbre is altered.
The aim of this study was to evaluate the results of voice rehabilitation of the voice after total laryngectomy with an objective method, based on acoustic analysis. The aim is to clarify the contribution of this analysis on the therapeutic management of this type of pathology.
After a duration of therapy average of 9 months, we notice values of pitch a little weak and unstable compared to the normal state. The pitch value and the percentage of voicing DUV show that voicing acquired thanks to the neoglottis is noticeable but is still far from the normal voicing of vocal cords. The results for these two parameters can be explained by the shape, volume and elasticity of the neoglottis which is totally different from those of the vocal cords.
The measured values for the jitter show a constant evolution of this parameter towards the normal. This is explained by the improvement of the vibrational properties of the neoglottis, and it shows that the rehabilitation technique used gives significant results. This technique of reeducation is based on the esophageal speech which consists of storing air in the lower part of the esophagus (swallowing air) and then causing a voluntary eructation to give a semblance of voicing. The othophonist work on certain parameters such as: breath independence exercises, intensity, the sound regularity of all sylabes, repetition of words containing injecting phonemes, eructation, ... It remains nevertheless to make a more sustained effort towards the improvement of this parameter.
The value of 56 dB of the average intensity is considered acceptable because, usually the sound level of an esophageal voice is between 55 and 65 dB [17]. This interval is lower than that in the laryngeal voice because the neovibrator is fed by the esophageal air.
The intensity requires the control of the neovibrator voltage and the increase of the volume of air in its rise with the support of the abdominal muscles. In esophageal voice, the intensity is strongly correlated with its frequency. The patient cannot vary the intensity without varying the frequency. The fundamental frequency and the intensity often worked jointly.
The results obtained for the shimmer must be interpreted with precaution since the esophageal speech signal is a random realization, thus the hypothesis of stationarity which guarantees the reliability of the results is not fulfilled. The shimmer measurement concluded that the frequency of the esophageal voice is not as obvious and that this one is characterized by large fluctuations in both the amplitude and the period.
The HNR function is to estimate the emergence of harmonics of a signal with regard to the noise. The time analysis of the samples of the laryngectomy voice revealed the existence of a noise preceding the beginning of the pronunciation, due to the intense breathing effort of the patient to produce the esophageal speech. Noise corresponds to one or several short-term impulses relative to the frame of speech. Furthermore, a noise of permanent breath is present because of the explosions of lips and of the irregular vibrations of the oesophagus.
For the MTP we notice a time lower than 5 seconds, which is short compared to the reference. Several factors may influence on the value of the MTP. Logically, it may decrease if the vocal intensity is high, because maintaining this intensity requires significant subglottic pressure. As a result, the speaker uses a large amount of air in a short time.
The formant structure is not altered. This is normal because the cavities of the vocal tract resonances were not altered. On the other hand, we found a significant increase in formant values after ablation of the larynx. This can be explained by the fact that the distance between the neoglottis and the first cavity is modified (shortening of the vocal system).
We have noted beyond our objective of this study of the real difficulties for the patients to pronounce certain consonants specific to Arabic, and also, the patient pronounces other deaf consonants accompanied by a voicing. This may explain that the patient, does not control the vibration of the neoglottis or perhaps a poor distribution of the ejected air or a poor knowledge of the exact modes and locations of the articulation of consonants. We propose future studies that will address this confusion in detail and analyze the acoustic parameters of the Arabic-specific consonants to confirm whether ablation of larynx may influence the pronunciation of these consonants because of the distance between the neoglottis and the first cavity (pharyngeal cavity) or there is another reason.
The evaluation of the quality of voice was always the main clinical concern of phonates and speech therapists in the hospital centers. The first acoustic evaluation tool is the human ear, yet the hearing is insufficient because it treats the acoustic signal in its entirety. The ear can be thus deceived. Acoustic analysis will not replace the perceptive assessment used by orthophonist, but it will be able to help him in the improvement of his rehabilitation technique and especially the periodic and objective evaluation of the pathological voice. We noticed in this study, absence of formation of orthophonist in the manipulation of acoustic analysis software. Based on the results found, it is important to reinforce the competencies and knowledge of the speech language pathologist, this allows him to adapt his rehabilitation technique by giving importance to physical interpretations of perceptive pathological voices.
Objective evaluations can provide a database to speech-language pathologists through the parameters of acoustic analysis, therefore a better interpretation of vocal dysfunctions. Also, this allowing to put in relation the measurements and the physiopathological phenomena by defining more precise and consensual evaluation standards.
We propose at the end of this study to install a coordination cell between the researcher in the research laboratory, the teacher in the university environment and the speech-language pathologist re-educator in the hospital environment, to give a better effectiveness to the rehabilitation, in an Algerian clinical setting.
[1] Makeieff, M., Barbotte, E., Giovanni, A., Guerrier, B. (2005). Acoustic and aerodynamic measurement of speech production after supracricoid partial laryngectomy. The Laryngoscope, 115(3): 546-551. https://doi.org/10.1097/01.mlg.0000157848.78530.ee
[2] Fantini, M., Gallia, M., Borrelli, G., Pizzorni, N., Maccarini, A.R., Torre, A.B., Schindlerm A., Succo, G., Crosetti, E. (2020). Substitution Voice rehabilitation after open partial horizontal laryngectomy through the proprioceptive elastic method (PROEL): A preliminary study. Journal of Voice. https://doi.org/10.1016/j.jvoice.2020.04.025
[3] Schindler, A., Favero, E., Nudo, S., Albera, R., Schindler, O., Cavalot, A.L. (2006). Long-term voice and swallowing modifications after supracricoid laryngectomy: objective, subjective, and self-assessment data. American Journal of Otolaryngology, 27(6): 378-383. https://doi.org/10.1016/j.amjoto.2006.01.010
[4] Petrovic-Lazic, M., Jovanovic, N., Kulic, M., Babac, S., Jurisic, V. (2015). Acoustic and perceptual characteristics of the voice in patients with vocal polyps after surgery and voice therapy. Journal of Voice, 29(2): 241-246. https://doi.org/10.1016/j.jvoice.2014.07.009
[5] Giovanni, A., Guelfucci, B., Yu, P., Robert, D., Zanaret, M. (2002). Acoustic and aerodynamic measurements of voice production after near-total laryngectomy with epiglottoplasty. Folia Phoniatrica et logopaedica, 54(6): 304-311. https://doi.org/10.1159/000066152
[6] Drugman, T., Rijckaert, M., Janssens, C., Remacle, M. (2015). Tracheoesophageal speech: A dedicated objective acoustic assessment. Computer Speech & Language, 30(1): 16-31. https://doi.org/10.1016/j.csl.2014.07.003
[7] Garcia, A., Dias, F., Gonçalves, A., Claudio, R., Freitas. E., Menezes, M., Kulcsar, M. (2020). Supratracheal laryngectomy: a multi-institutional stady. Brazilian Journal of Otorhinolaryngology, 86(5): 609-616. https://doi.org/10.1016/j.bjorl.2019.04.004
[8] Allegra, E., La Mantia, I., Bianco, M.R., Drago, G.D., Le Fosse, M.C., Azzolina, A., Grillo, C., Saita, V. (2019). Verbal performance of total laryngectomized patients rehabilitated with esophageal speech and tracheoesophageal speech: impacts on patient quality of life. Psychology Research and Behavior Management, 12: 675. https://doi.org/10.2147/PRBM.S212793
[9] Coffey, M.M., Tolley, N., Howard, D., Hickson, M. (2019). An investigation of reliability of the Sunderland tracheosophageal voice perceptual scale. Folia Phoniatrica et Logopaedica, 71(1): 16-23. https://doi.org/10.1159/000493751
[10] Schindler, A., Mozzanica, F., Ginocchio, D., Invernizzi, A., Peri, A., Ottaviani, F. (2012). Voice-related quality of life in patients after total and partial laryngectomy. Auris Nasus Larynx, 39(1): 77-83. https://doi.org/10.1016/j.anl.2011.03.009
[11] Makeieff, M., Giovanni, A., Guerrier, B. (2007). Laryngostroboscopic evaluation after supracricoid partial laryngectomy. Journal of Voice, 21(4): 508-515. https://doi.org/10.1016/j.jvoice.2006.03.001
[12] Jiang, J.J., Zhang, Y., MacCallum, J., Sprecher, A., Zhou, L. (2009). Objective acoustic analysis of pathological voices from patients with vocal nodules and polyps. Folia Phoniatrica et Logopaedica, 61(6): 342-349. https://doi.org/10.1159/000252851
[13] Kreiman, J., Gerratt, B.R. (2005). Perception of aperiodicity in pathological voice. The Journal of the Acoustical Society of America, 117(4): 2201-2211. https://doi.org/10.1121/1.1858351
[14] Yu, P., Ouaknine, M., Revis, J., Giovanni, A. (2001). Objective voice analysis for dysphonic patients: A multiparametric protocol including acoustic and aerodynamic measurements. Journal of Voice, 15(4): 529-542. https://doi.org/10.1016/S0892-1997(01)00053-4
[15] Yu, P.,Garrel, R., Nicollas, R., Maurice Ouaknine, M., Giovanni, A. (2007). Objective voice analysis in dysphonic patients: New data including nonlinear measurements. Folia Phoniatrica et logopaedica, 59(1): 20-30. https://doi.org/10.1159/000096547
[16] Crevier-Buchman, L., Laccourreye, O, Wuyts, FL., Monfrais-Pfauwadel, M.C., Pillot, C., Brasnu, D. (1998). Comparison and evolution of perceptual and acoustic characteristics of voice after supracricoid partial laryngectomy with cricohyoidoepiglottopexy. Acta Otolaryngol, 118(4): 594-599. https://doi.org/10.1080/00016489850154784
[17] Finger, L.S., Cielo, C.A., Schwarz, K. (2009). Acoustic vocal measures in women without voice complaints and with normal larynxes. Brazilian Journal of Otorhinolaryngology, 75(3): 432-440. https://doi.org/10.1016/S1808-8694(15)30663-7