Benjamin Chanakot![]() | Kornkanok Phoksawat*
| Kornkanok Phoksawat*![]()
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Consumer reviews represent customer sentiment. They provide valuable insights that businesses can use to improve product or service quality and meet customer needs. Therefore, this research presents an analysis of consumer sentiments towards online shopping using Context-Free Grammar and Deep Learning. It tested the effectiveness of classifying consumer sentiments from 3,600 product or service reviews. The dataset included three types of sentiment categories: Positive, Negative, and Neutral. Context-Free Grammar (CFG) was used to assign term functions as sentiment indicators, and Term Frequency-Inverse Document Frequency (TF-IDF) was used for feature selection. A threshold value was then assigned to each term that represented the sentiment categories. The dataset was divided into 15-fold cross-validation to test the effectiveness of the model before Deep Learning algorithm was used to classify the sentiments. Deep Learning algorithms have the capability to learn complex relationships between terms, allowing for precise sentiment classification. The evaluation showed that using CFG and TF-IDF for term weighting improved the selection of keyword features, leading to significantly more precise sentiment classification. The average Precision, Recall, and F-measure were higher than exclusively using TF-IDF. Moreover, the determination of an appropriate threshold value reduced data complexity without affecting the accuracy of sentiment classification.
natural language processing, sentiment analysis, TF-IDF, context-free grammar, deep learning
The advancement of information technology plays a significant role in our daily lives. It increasingly impacts our daily routines, particularly through the application of artificial intelligence and deep learning to aid in analysis, problem-solving, and decision-making. Examples include a social media content filtering, product recommendations, and the analysis of consumer behavior in online shopping. Currently, online shopping, in particular, has continued to grow exponentially and continuously [1]. This trend has been accelerated by the outbreak of the Covid-19 pandemic and the strict government measures to control the spread of Covid-19, which have made it impossible to engage in in-store shopping.
The outbreak of the Covid-19 pandemic has led consumers to increasingly rely on online shopping due to concerns about infection [2]. Even though the outbreak has been declining, consumers' positive attitude and preference for online shopping continue to persist and are expected to increase even further in the future. In comparison, in-store shopping has decreased proportionally to one-third to half of online shopping instances [3]. Nevertheless, it does not necessarily mean that all products available on online shopping platforms will be popular and produce massive sales. In fact, a key factor motivating consumer purchasing decisions are product or service reviews from other consumers who had purchasing experiences [4-6] since most consumers often learn from reviews before deciding to purchase a product [7]. Such reviews can be found directly on any online shopping platforms or from other online social networks. The opinions can vary, including positive, negative, and neutral [8, 9] which directly impact the product or service of the business mentioned in the review. If the customer's opinion goes in a positive direction, it can result in increasing product sales. However, if negative opinions are provided, even just a little, they can negatively impact the sale figures [10].
Consequently, businesses have become highly aware and given value to the customers’ sentiments towards their products or services due to the fact that they can also utilize such information for the purpose of analyzing consumer opinions towards their products or services, known as Sentiment Analysis. Therefore, they can plan and develop their strategies to present their products or services [11, 12] in a way that meets the customer's needs to ensure customer retention.
In the light of the phenomena mentioned above, this research reports an analysis of consumer sentiments towards online shopping using Deep Learning in categorizing the polarity of sentiments into 3 categories: Positive, Negative, and Neutral through Syntactic Analysis, which relies on the Context-Free Grammar (CFG) method is used to assign features to terms in a sentence and to select significant keywords based on their weight using the Term Frequency-Inverse Document Frequency (TF-IDF) method. TF-IDF is a popular approach in text classification that considers the frequency of terms appearing in the text, indicating sentiment. This process occurs before the sentiments are classified using a Deep Learning technique. Eventually, the performance of the model was evaluated of which the results can shed light on an analysis of customer sentiments towards products or services leading to improvement of the quality of products or services, and improvement of competitiveness in the market [13-15]. Furthermore, the data can be used to design products or develop other services to satisfy future consumers’ desires.
2.1 Steps for model development
This research employed Deep Learning to analyze consumer sentiments towards online shopping. It involves seven steps, including: 1) Data Collection, 2) Data Preprocessing, 3) Feature Selection, 4) Vector Space Model, 5) Cross-validation,6) Classification, and 7) Performance Evaluation.
2.2 Data collection
The data were totally 3,600 consumer opinions in Thai collected from www.shopee.co.th and www.lazada.co.th, the two most popular online shopping platforms in Thailand.
2.3 Data preprocessing
Data preparation refers to the step of preparing data for processing which included the following steps: Tokenization, Context-Free Grammar (CFG), Stop Word, and Word Stemming.
(1) Tokenization is the process of breaking down large texts into individual words or phrases [16, 17], using spaces to define the boundaries between morphemes [18]. It is a crucial step in Natural Language Processing performed before further processing. In this research, the Longest Word Pattern Matching Technique was employed as it uses a combination of word cutting and dictionary-based word segmentation which promotes accurate boundary definition.
(2) Functional Specification is a process in which the function of each term in a sentence is identified using Context-Free Grammar (CFG) in conjunction with a Lexicon-Based Process to assign roles to terms in the Thai language. This approach involves analyzing the sentence structure without considering the meaning [19], but aims to identify the parts of speech of each term i.e., nouns, adjectives, verbs, and adverbs, etc. through a Top-Down Parsing Approach which begins with analyzing the sentence string, then the nouns and verb phrases till the term string within the sentence.
Figure 1. An example of Thai language top-down parsing
As shown in Figure 1, an example of Thai language top-down parsing. The Thai language classifies words into seven categories as follows: 1) nouns, 2) pronouns, 3) verbs, 4) adjectives, 5) adverbs, 6) conjunctions, and 7) prepositions. Unlike other languages, the Thai language does not have specific adjectives to modify nouns. Instead, it relies on adverbs to extend the meanings of nouns, pronouns, and verbs.
(3) Stop Words involves the process of filtering the commonly used words out of a document, for example, exclamation words, pronouns, prepositions, conjunctions, including special characters and symbols when the removal doesn’t affect the overall message enough to lose meaning [20] [21]. This is because these stop words do not contribute to the document characteristics or represent the document.
(4) Stemming refers to the process of replacing morphological variants of a root word [22]. This process reduces redundancy and improves the accuracy of feature selection. In Thai, stemming is more challenging than in English because Thai lacks prefixes and suffixes. In this research, a lexicon was employed to compare a root word and select words with similar meanings.
2.4 Feature selection
Feature Selection, a process generally used in Machine Learning, occurs after the preprocessing step [23] targeting at reducing the dimensionality of data and decreasing processing time through the selection of effective and significant features for data classification [24, 25]. In this research, feature selection of terms was performed using the TF-IDF (Term Frequency-Inverse Document Frequency) method, an effective matric to reduce the dimensionality of data and select the best features.
2.5 Term frequency-inverse document frequency
Term Frequency-Inverse Document Frequency (TF-IDF) is a statistical technique used to determine the feature of keywords in a body of text [26]. The calculation involves multiplying two statistical values: the Term Frequency (TF), the frequency of an occurrence in the text, and the Inverse Document Frequency (IDF) [27, 28], measuring the feature of the term across all texts [29, 30]. TF-IDF can be calculated using the following equations.
$T F-I D F=T F_{i, j} \times \log \left(\frac{N}{D F_i}\right)$ (1)
where,
TFi,j is the frequency of term i appearing in text j
N is the frequency of term i appearing in text j
DFi is the number of term i appearing in all document.
2.6 Vector space model
Figure 2. Vector space model
The Vector Space Model is a linear mathematical model that converts texts into numbers [31]. This process transforms unstructured data into the structured set using the weights of terms as a feature of the text. The data is then represented in the form of a matrix [32], as shown in Figure 2.
Figure 2 shows the vector space model in a matrix with i rows and j columns, where W is the weight of term i in text j.
2.7 Cross-Validation
Cross-Validation is a technique used to evaluate the performance of a model by dividing the data into multiple parts. In this research, 15-fold cross- validation was employed. The method involves dividing the data into 15 equal parts. The model is then trained using data from parts 2-15, while the data from part 1 is used to test the performance of the model [33]. Eventually, this process is repeated until all the divided parts have been used for testing [34].
2.8 Deep Learning
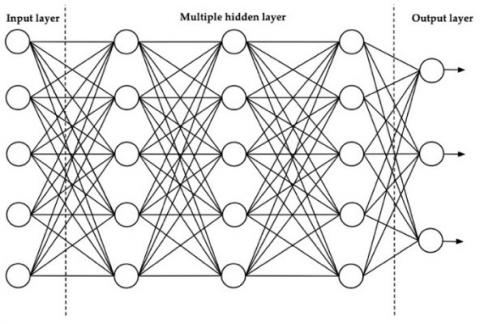
Deep Learning is a machine learning technique that mimics how human neurons work by stacking neural networks into Multi-Layers [35, 36]. Deep Learning is commonly used to address various problems in different areas such as Sentiment Analysis, Speech Recognition, and Image Classification, etc. This technique consists of three layers: Input Layer, Hidden Layer, and Output Layer [37].
Figure 3. Deep Learning network architecture
As shown in Figure 3, the architecture of a Deep Learning network consists of 3 different layers. Each layer consists of nodes which represent neurons, corresponding to synapses and connected by edge as a network imitating the way the human brain functions. Each layer performs the following tasks: 1) the Input Layer receives data, 2) the Hidden Layer is situated between the Input and Output Layers and performs processing, and 3) the Output Layer combines the results obtained from the Hidden Layer [37].
2.9 Performance evaluation
To evaluate the performance of the model, the following metrics were applied in this research: 1) Precision, 2) Recall, and 3) F-Measure Model. These metrics can be calculated through the following equations:
Precision $=\frac{\text { True Positive }}{\text { True Positive }+ \text { False Positive }}$ (2)
Recall $=\frac{\text { True Positive }}{\text { True Positive }+ \text { False Negative }}$ (3)
$F-$ measure $=\frac{2 \times \text { Precision } \times \text { Recall }}{\text { Precision }+ \text { Recall }}$ (4)
In which True Positive is the number of texts predicted correctly as Class C, False Positive is the number of texts predicted incorrectly as Class C, and False Negative is the number of texts predicted incorrectly as not Class C [34].
In this study, a Deep Learning model was created to classify customers’ sentiments towards online shopping in which Context-Free Grammar (CFG) is applied to assign functions to terms in a sentence, together with an application of Term Frequency-Inverse Document Frequency (TF-IDF) to select term features. A minimum threshold value was assigned to terms that represented clear sentiment categories. The dataset was then divided into 15-folds through cross-validation before Deep Learning algorithms were used to evaluate the performance of the model by calculating the Precision, Recall, and F-Measure. The results of the model performance evaluation are as follows:
Table 1. Results of performance evaluation of the model analyzing consumer sentiments towards online shopping using Context-Free Grammar and Deep Learning
|
Sentence (n) |
Class |
Performance of Model |
|||||
|
TF-IDF |
CFG & TF-IDF |
||||||
|
P |
R |
F |
P |
R |
F |
||
|
1,200 |
Positive |
89.00 |
80.00 |
84.00 |
94.00 |
81.00 |
87.00 |
|
Negative |
91.00 |
81.00 |
86.00 |
94.00 |
93.00 |
93.00 |
|
|
Neutral |
70.00 |
92.00 |
79.00 |
77.00 |
93.00 |
84.00 |
|
|
2,400 |
Positive |
93.00 |
82.00 |
87.00 |
96.00 |
88.00 |
92.00 |
|
Negative |
93.00 |
91.00 |
92.00 |
96.00 |
96.00 |
96.00 |
|
|
Neutral |
82.00 |
96.00 |
88.00 |
86.00 |
96.00 |
91.00 |
|
|
3,600 |
Positive |
95.00 |
88.00 |
92.00 |
96.00 |
96.00 |
96.00 |
|
Negative |
88.00 |
97.00 |
92.00 |
97.00 |
96.00 |
97.00 |
|
|
Neutral |
96.00 |
93.00 |
95.00 |
96.00 |
96.00 |
96.00 |
|
Table 2. Comparison of the Precision of the model analyzing consumer sentiments towards online shopping using Context-Free Grammar and Deep Learning
|
Sentence (n) |
Class |
Performance of Model |
|
|
TF-IDF |
CFG & TF-IDF |
||
|
Precision |
Precision |
||
|
1,200 |
Positive |
89.00 |
94.00 |
|
Negative |
91.00 |
94.00 |
|
|
Neutral |
70.00 |
77.00 |
|
|
Average |
83.33 |
88.33 |
|
|
2,400 |
Positive |
93.00 |
96.00 |
|
Negative |
93.00 |
96.00 |
|
|
Neutral |
82.00 |
86.00 |
|
|
Average |
89.33 |
92.67 |
|
|
3,600 |
Positive |
95.00 |
96.00 |
|
Negative |
88.00 |
97.00 |
|
|
Neutral |
96.00 |
96.00 |
|
|
Average |
93.00 |
96.33 |
|
Table 3. The Recall of the model analyzing consumer sentiments towards online shopping using Context-Free Grammar and Deep Learning
|
Sentence (n) |
Class |
Performance of Model |
|
|
TF-IDF |
CFG & TF-IDF |
||
|
Recall |
Recall |
||
|
1,200 |
Positive |
80.00 |
81.00 |
|
Negative |
81.00 |
93.00 |
|
|
Neutral |
92.00 |
93.00 |
|
|
Average |
84.33 |
89.00 |
|
|
2,400 |
Positive |
82.00 |
88.00 |
|
Negative |
91.00 |
96.00 |
|
|
Neutral |
96.00 |
96.00 |
|
|
Average |
89.67 |
93.33 |
|
|
3,600 |
Positive |
88.00 |
96.00 |
|
Negative |
97.00 |
96.00 |
|
|
Neutral |
93.00 |
96.00 |
|
|
Average |
92.67 |
96.00 |
|
Table 4. The F-Measure of the model analyzing consumer sentiments towards online shopping using Context-Free Grammar and Deep Learning
|
Sentence (n) |
Class |
Performance of Model |
|
|
TF-IDF |
CFG & TF-IDF |
||
|
F-Measure |
F-Measure |
||
|
1,200 |
Positive |
84.00 |
87.00 |
|
Negative |
86.00 |
93.00 |
|
|
Neutral |
79.00 |
84.00 |
|
|
Average |
83.00 |
88.00 |
|
|
2,400 |
Positive |
87.00 |
92.00 |
|
Negative |
92.00 |
96.00 |
|
|
Neutral |
88.00 |
91.00 |
|
|
Average |
89.00 |
93.00 |
|
|
3,600 |
Positive |
92.00 |
96.00 |
|
Negative |
92.00 |
97.00 |
|
|
Neutral |
95.00 |
96.00 |
|
|
Average |
93.00 |
96.33 |
|
Table 1 shows the results of a performance evaluation of a model that analyzes consumer sentiments toward online shopping using Context-Free Grammar and Deep Learning. The evaluation compares the efficiency of the model in analyzing the polarity of consumer sentiment by using Context-Free Grammar (CFG) with TF-IDF weighting compared to using TF-IDF weighting alone. The evaluation includes Precision (P), Recall (R), and F-measure (F).
Table 2 shows the results of the performance evaluation of the model using Context-Free Grammar (CFG) together with the calculation of the weight of terms using TF-IDF to select term features in a text with 1,200, 2,400, and 3,600 text samples revealed that the average Precision was 88.33%, 92.67%, and 96.33%, respectively. Furthermore, when considering the overall Precision, it was found to be higher than simply using TF-IDF to select term features alone. This means that using CFG together with the TF-IDF results in a better accuracy in identifying sentiments in text than exclusively using TF-IDF.
Table 3 shows the results from the evaluation of the model using Context-Free Grammar (CFG) combined with TF-IDF in selecting term features with 1,200, 2,400, and 3,600 text samples showed that the average Recall were 89.00%, 93.33%, and 96.00%, respectively. When considering the overall Recall value, it was found to be higher than just using the TF-IDF. This means that using CFG in conjunction with TF-IDF promotes accurate classification of sentiments, with a higher number of correctly classified texts than using just TF-IDF weighting alone.
Table 4 shows the results of the performance evaluation of the model using Context-Free Grammar (CFG) combined with applying TF-IDF in assigning term features with the following numbers of test samples: 1,200, 2,400, and 3,600, showed that the average F-Measure was 88.00%, 93.00%, and 96.33%, respectively. Moreover, overall, the F-Measure was found to be higher than exclusively using the TF-IDF method for feature selection. This means that using CFG with TF-IDF weighting allows more accurate classification of sentiment compared to the use of only the TF-IDF method.
This research aims to evaluate the effectiveness of a model used for analyzing the sentiments of online shoppers. The model categorizes sentiment polarities into three categories: Positive, Negative, and Neutral. It uses the technique of Context-Free Grammar (CFG) to assign functions of terms in a sentence and term weighting through the Term Frequency-Inverse Document Frequency (TF-IDF) method to determine threshold values for keywords that represent clear sentiment categories. The data is then divided into 15-fold cross-validation before a Deep Learning algorithm is used to evaluate the model performance. The results showed that sentiment classification accuracy depends on Context-Free Grammar (CFG) accurately assigning term roles in the sentence, resulting in increased accuracy in the selection of keywords representing the text. Therefore, when the assignment of term roles is precise, it improves the accuracy of sentiment classification. Additionally, it was found that selecting good features can also reduce the size of the data without affecting the performance of sentiment classification, thereby reducing processing time.
This research has been supported by the Faculty of Management Technology, Rajamangala University of Technology Srivijaya.
[1] Munna, M.H., Rifat, M.R.I., Badrudduza, A.S.M. (2020). Sentiment analysis and product review classification in e-commerce platform. In 2020 23rd International Conference on Computer and Information Technology (ICCIT), DHAKA, Bangladesh, pp. 1-6. https://doi.org/10.1109/ICCIT51783.2020.9392710
[2] Aulawi, H., Karundeng, E., Kurniawan, W.A., Septiana, Y., Latifah, A. (2021). Consumer sentiment analysis to e-commerce in the Covid-19 pandemic era. In 2021 International Conference on ICT for Smart Society (ICISS), Bandung, Indonesia, pp. 1-5. https://doi.org/10.1109/ICISS53185.2021.9533261
[3] Diaz-Gutierrez, J.M., Mohammadi-Mavi, H., Ranjbari, A. (2023). COVID-19 impacts on online and in-store shopping behaviors: Why they happened and whether they will last post pandemic. Transportation Research Record, 03611981231155169. https://doi.org/10.1177/03611981231155169
[4] Smetanin, S., Komarov, M. (2019). Sentiment analysis of product reviews in Russian using convolutional neural networks. In 2019 IEEE 21st Conference on Business Informatics (CBI), 1: 482-486. https://doi.org/10.1109/CBI.2019.00062
[5] Kothalawala, M., Thelijjagoda, S. (2020). Aspect-based sentiment analysis on hair care product reviews. In 2020 International Research Conference on Smart Computing and Systems Engineering (SCSE), Colombo, Sri Lanka, pp. 228-233. https://doi.org/10.1109/SCSE49731.2020.9313040
[6] Rahardja, U., Hariguna, T., Baihaqi, W.M. (2019). Opinion mining on e-commerce data using sentiment analysis and k-medoid clustering. In 2019 Twelfth International Conference on Ubi-Media Computing (Ubi-Media), Bali, Indonesia, pp. 168-170. https://doi.org/10.1109/Ubi-Media.2019.00040
[7] Noor, A., Islam, M. (2019). Sentiment analysis for women's e-commerce reviews using machine learning algorithms. In 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kanpur, India, pp. 1-6. https://doi.org/10.1109/ICCCNT45670.2019.8944436
[8] Porntrakoon, P., Moemeng, C. (2018). Thai sentiment analysis for consumer’s review in multiple dimensions using sentiment compensation technique (SenSecomp). In 2018 15th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Chiang Rai, Thailand, pp. 25-28. https://doi.org/10.1109/ECTICon.2018.8619892
[9] Jabbar, J., Urooj, I., JunSheng, W., Azeem, N. (2019). Real-time sentiment analysis on E-commerce application. In 2019 IEEE 16th International Conference on Networking, Sensing and Control (ICNSC), Banff, AB, Canada, pp. 391-396. https://doi.org/10.1109/ICNSC.2019.8743331
[10] Hossain, M.J., Joy, D. D., Das, S., Mustafa, R. (2022). Sentiment analysis on reviews of e-commerce sites using machine learning algorithms. In 2022 International Conference on Innovations in Science, Engineering and Technology (ICISET), Chittagong, Bangladesh, pp. 522-527. https://doi.org/10.1109/ICISET54810.2022.9775846
[11] Zhang, Y., Sun, J., Meng, L., Liu, Y. (2020). Sentiment analysis of E-commerce text reviews based on sentiment dictionary. In 2020 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, pp. 1346-1350. https://doi.org/10.1109/ICAICA50127.2020.9182441
[12] Zhang, M. (2020). E-commerce comment sentiment classification based on deep learning. In 2020 IEEE 5th International Conference on Cloud Computing and Big Data Analytics (ICCCBDA), Chengdu, China, pp. 184-187. https://doi.org/10.1109/ICCCBDA49378.2020.9095734
[13] Shuai, Q., Huang, Y., Jin, L., Pang, L. (2018). Sentiment analysis on Chinese hotel reviews with Doc2Vec and classifiers. In 2018 IEEE 3rd Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, pp. 1171-1174. https://doi.org/10.1109/IAEAC.2018.8577581
[14] Lu, Z., Chen, Y. (2022). User evaluation sentiment analysis model based on machine learning. In 2022 2nd International Conference on Consumer Electronics and Computer Engineering (ICCECE), Guangzhou, China, pp. 461-464. https://doi.org/10.1109/ICCECE54139.2022.9712835
[15] He, H., Zhou, G., Zhao, S. (2022). Exploring e-commerce product experience based on fusion sentiment analysis method. IEEE Access, 10: 110248-110260. https://doi.org/10.1109/ACCESS.2022.3214752
[16] Abualigah, L.M., Khader, A.T. (2017). Unsupervised text feature selection technique based on hybrid particle swarm optimization algorithm with genetic operators for the text clustering. The Journal of Supercomputing, 73: 4773-4795. https://doi.org/10.1007/s11227-017-2046-2
[17] Manjari, K.U., Rousha, S., Sumanth, D., Devi, J.S. (2020). Extractive Text Summarization from Web pages using Selenium and TF-IDF algorithm. In 2020 4th International Conference on Trends in Electronics and Informatics (ICOEI), pp. 648-652. https://doi.org/10.1109/ICOEI48184.2020.9142938
[18] Ahirrao, M., Joshi, Y., Gandhe, A., Kotgire, S., Deshmukh, R.G. (2021). Phrase composing tool using natural language processing. In 2021 International Conference on Intelligent Technologies (CONIT), Hubli, India, pp. 1-4. https://doi.org/10.1109/CONIT51480.2021.9498546
[19] Dorđević, T., Stojković, S. (2020). Syntax analysis of serbian language using context-free grammars. In 2020 55th International Scientific Conference on Information, Communication and Energy Systems and Technologies (ICEST), Serbia, pp. 50-53. https://doi.org/10.1109/ICEST49890.2020.9232872
[20] Hasan, M.M., Dip, S.T., Kamruzzaman, T.M., Akter, S., Salehin, I. (2021). Movie subtitle document classification using unsupervised machine learning approach. In 2021 IEEE 6th International Conference on Computing, Communication and Automation (ICCCA), Arad, Romania, pp. 219-224. https://doi.org/10.1109/ICCCA52192.2021.9666391
[21] Li, M., Wu, K., Chen, L. (2022). An analysis on the weibo topic detection based on k-means algorithm. In 2022 IEEE International Conference on Electrical Engineering, Big Data and Algorithms (EEBDA), Changchun, China, pp. 1328-1331. https://doi.org/10.1109/EEBDA53927.2022.9744787
[22] Bhopale, A.P., Kamath, S.S. (2017). Novel hybrid feature selection models for unsupervised document categorization. In 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Udupi, India, pp. 1471-1477. https://doi.org/10.1109/ICACCI.2017.8126048
[23] Jamalludin, M.D., Shidik, G.F., Fanani, A.Z., Al Zami, F. (2021). Implementation of feature selection using gain ratio towards improved accuracy of support vector machine (SVM) on Youtube Comment Classification. In 2021 International Seminar on Application for Technology of Information and Communication (iSemantic), Semarangin, Indonesia, pp. 28-31. https://doi.org/10.1109/iSemantic52711.2021.9573191
[24] Ratmana, D.O., Shidik, G.F., Fanani, A.Z., Pramunendar, R.A. (2020). Evaluation of feature selections on movie reviews sentiment. In 2020 International Seminar on Application for Technology of Information and Communication (iSemantic), Semarang, Indonesia, pp. 567-571. https://doi.org/10.1109/iSemantic50169.2020.9234287
[25] Chidambaram, S., Srinivasagan, K.G. (2019). Performance evaluation of support vector machine classification approaches in data mining. Cluster Computing, 22: 189-196. https://doi.org/10.1007/s10586-018-2036-z
[26] Mishra, R.K., Urolagin, S. (2019). A Sentiment analysis-based hotel recommendation using TF-IDF Approach. In 2019 International Conference on Computational Intelligence and Knowledge Economy (ICCIKE), Dubai, United Arab Emirates, pp. 811-815. https://doi.org/10.1109/ICCIKE47802.2019.9004385
[27] Patil, R.S., Kolhe, S.R. (2022). Supervised classifiers with TF-IDF features for sentiment analysis of Marathi tweets. Social Network Analysis and Mining, 12(1): 51. https://doi.org/10.1007/s13278-022-00877-w
[28] Rahman, S., Talukder, K.H., Mithila, S.K. (2021). An empirical study to detect cyberbullying with TF-IDF and machine learning algorithms. In 2021 International Conference on Electronics, Communications and Information Technology (ICECIT), Khulna, Bangladesh, pp. 1-4. https://doi.org/https://doi.org/10.1109/ICECIT54077.2021.9641251
[29] Zheng, Y. (2019). An exploration on text classification with classical machine learning algorithm. In 2019 International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Taiyuan, China, pp. 81-85. https://doi.org/10.1109/MLBDBI48998.2019.00023
[30] Liu, C.Z., Sheng, Y.X., Wei, Z.Q., Yang, Y.Q. (2018). Research of text classification based on improved TF-IDF algorithm. In 2018 IEEE International Conference of Intelligent Robotic and Control Engineering (IRCE), Lanzhou, China, pp. 218-222. https://doi.org/10.1109/IRCE.2018.8492945
[31] Parida, U., Nayak, M., Nayak, A.K. (2019). Ranking of Odia text document relevant to user query using vector space model. In 2019 International Conference on Applied Machine Learning (ICAML), Bhubaneswar, India, pp. 165-169. https://doi.org/10.1109/ICAML48257.2019.00039
[32] Roy, T. D., Khatun, S., Begum, R. (2018). Vector space model based topic retrieval from Bengali documents. In 2018 International Conference on Innovations in Science, Engineering and Technology (ICISET), Chittagong, Bangladesh, pp. 60-63. https://doi.org/10.1109/ICISET.2018.8745587
[33] Prexawanprasut, T., Chaipornkaew, P. (2019). An analytical study on email classification using 10-fold cross-validation. In 2019 5th International Conference on Science in Information Technology (ICSITech) Yogyakarta, Indonesia, pp. 38-43. https://doi.org/10.1109/ICSITech46713.2019.8987571
[34] Chanakot, B., Sanrach, C. (2023). Classifying thai news headlines using an artificial neural network. Bulletin of Electrical Engineering and Informatics, 12(1): 395-402. https://doi.org/10.11591/eei.v12i1.4228
[35] Habimana, O., Li, Y., Li, R., Gu, X., Yu, G. (2020). Sentiment analysis using deep learning approaches: An overview. Science China Information Sciences, 63: 1-36. https://doi.org/10.1007/s11432-018-9941-6
[36] Kaur, H., Ahsaan, S.U., Alankar, B., Chang, V. (2021). A proposed sentiment analysis deep learning algorithm for analyzing COVID-19 tweets. Information Systems Frontiers, 1-13. https://doi.org/10.1007/s10796-021-10135-7
[37] Alharbi, A., Kalkatawi, M., Taileb, M. (2021). Arabic sentiment analysis using deep learning and ensemble methods. Arabian Journal for Science and Engineering, 46: 8913-8923. https://doi.org/10.1007/s13369-021-05475-0