Nibras Z. Salih*![]() | Farah F. Alkhalid
| Farah F. Alkhalid![]()
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
The number of cars on the road has increased significantly as a result of the development of society, and this is one of the problems that traffic officials have focused on when diagnosing seat belts. With the increase in traffic accidents in recent years due to drivers not adhering to safety rules, it has become necessary to focus on this area. Seat belt diagnosis is an important rule that must be followed in the field of deep learning. In this paper, transfer learning is applied in seat belt diagnosis to reduce the number of risks and to protect passengers and drivers from traffic accidents when the seat belt is not used. The Xception model is proposed because this model has very deep hidden layers which leads to good metrics, the model is trained on the ImagNet dataset using fine-tuning learning. We find that previous training on ImageNet leads to a significant increase in the efficiency of the proposed architecture and extracts the important feature in a variety of situations to determine whether the driver has fastened his seat belt or not. The results show that the model can inspect seat belts with a high accuracy of 99.42% and a loss function of 8.15%.
transfer learning for traffic safety, automated surveillance, Xception model, ImageNet dataset
Automated surveillance has been attracting a lot of attention across a wide range of living fields, including monitoring traffic and self-driving cars. The policeman usually executes traffic rules manually on the roadways, which makes it complicated and inefficient because there aren't enough police officers to do it [1]. When the driver is not wearing a belt, they can easily be expelled and die, the studies show that wearing a belt can raise the chance of living.
To support law enforcement officials, the development of automated monitoring technologies has been necessary. Consequently, institutions dedicated to traffic safety are seeking automated methods for triggering the wearing of seat belts without putting detection devices within automobiles [2].
One of the key factors influencing the possibility of survival in road accidents is the usage of seatbelts. Despite the high level of protection offered in the event of an accident, seat belt resistance detection in cars is an essential component [1, 2]. In 1959, three-step security belts became public and were manufactured by Volvo company.
It was based on the basic safety concepts as stated by Nils Bohlin, a safety engineer at Volvo company. Over time, the safety belt has been improved with the addition of retractors, various pretensioner types, and loading constraints [3].
A collection of automated learning techniques known as deep learning that are built from several layers of artificial neural networks. Therefore, the most accurate learning models of deep learning techniques are automatic feature extraction [4, 5].
In several domains of study, deep learning algorithms have provided the most beneficial outcomes and solved several image detection issues. The algorithms used for deep learning take a lot of time to process the large number of parameters in the deep network and their different weights. Recently, deep learning algorithms have proven to be the most successful approach for producing the highest-quality results across multiple difficult domains [5-8].
In deep learning technology, transfer learning plays a crucial role when using several deep architectures for precise traffic monitoring and seat belt diagnosis. Due to this, it allows deep neural networks to learn extremely complex connections. Also, it is a well-established technique for proper diagnostics with fewer samples and it is one option that reduces the effort of the process [9, 10].
The primary goal of this study is to establish deep transfer learning to develop a seat belt classification. We have applied an Xception model as a deep transfer learning to analyze seatbelt monitoring by fine-tuning learning. To examine this model, we have compared the parameter value of the performance metrics with the models of other studies. To find the best solution for this model, accuracy, precision, and recall have computed. The efficiency of the proposed architecture increases significantly with previous training using ImageNet.
Other parts of this paper are organized as follows: Section 2 describes related works on seat belt diagnostics, Section 3 explains transfer learning and the dataset, Section 4 presents the methodology, Section 5 explains the experiment result and Section 6 discusses the conclusion.
In this section, relevant research on the problem of seat belt identification is described. A description of seatbelt infractions is still regarded as one of the most significant problems in the field of deep learning due to the recent increase in traffic accidents.
Yu et al. [11] presented an algorithm to identify seat belts on the road using a specific type of feature that utilizes gradient orientation. This feature is finally extracted in the selected area such as rear windshield location and detection of the human face. The author utilized two hundred and thirteen high-resolution photos of the traffic intersections. The accuracy depends to some extent on the result of the detection process the accuracy was 86% of not fastening the belts.
Balci et al. [12] proposed a mobile system of seat belt detection that could be operated in the police car. Actual images were taken throughout the night day via a camera system mounted a top of a car. They examined the dataset that contained 2600 actual images using a single-shot multi-box Detector (SSD) model and image classification algorithms such as CNN and Fisher Vector. The author concluded the SSD model was better than other algorithms with an accuracy of 83%.
Elihos et al. [13] investigated different techniques using deep learning for detecting seat belt violations in the head seat occupants that were based on a seatbelt SSD, image classification, and model of fisher vector classification. The model was trained using a near-infrared and color-camera monitoring system designed to monitor the front window of the cars. With a 91.9% accuracy rate, SSD is better for this issue according to the dataset that was used.
Zhang [14] identified appropriate position forms for drivers and passengers based on numerous types of noise such as light, weather, and crowds. The author has detected the behavior of wearing seatbelts with probability and statistical methods using the roadmap technique. The datasets were collected from traffic intersections in various methods. Zhang modeled vehicle objects into models and each partition of the model was used for the part division to enhance the result of the driver and seat belt detection.
Chun et al. [15] suggested a model using a convolution neural network to estimate the position of drivers and passengers. They analyzed working by a comprehensive analysis of gender, clothes, and environment. The Model was re-trained using the MS COCO dataset that was appropriate for user annotations. So, the algorithms' performance was examined under various image situations.
Kashevnik et al. [16] suggested using a camera located within the driver's cabin to identify the seat belt state. The model of seat belt stability was developed in the YOLO neural network design. Both the belt's corner and its main object were identified as two objects using Tiny YOLO.
Hosam [17] employed deep CNN to identify seatbelt infractions in every possible weather situation using a single model. The author utilized sensors based on the AlexNet approach to study the weather situation. Therefore, he concluded that applying a specific model for each weather condition is preferable to applying a general model that is compatible with all types of weather. The best approach was S-AlexNet with an accuracy higher than 90%.
On the other hand, Wang and Ma [18] utilized the traffic management system to identify seat belts and vehicles through smart Internet of Things Technology (IoT). They applied the YOLO video target algorithm to complete windshield identification. The authors implemented an efficient front-end feature extraction layout to detect the position of the driver's region. All previous studies used “detection”, but in this study “classification” was applied. As well, transfer learning has not been used to solve the seat belt identification problem before. In this research, transfer learning is applied to classify the driver's state using the Xception model to obtain high accuracy compared with previous related work that used other methods.
In neural networks, transfer learning is known as deep transfer learning, as it was first described in 1976 by Bozinovski and Fulgosi [19]. Recent use in deep learning tools has been established by frameworks such as TensorFlow and Keras. Transfer learning tasks are characterized to be similar in the original and desired domains, while the domains may differ. It enhances the accuracy of the deep learning model with minimal training samples and smaller processing resources. Furthermore, it is possible to train the desired model with the help of a previously original trained model. Transfer learning included two categories such as learning based on instances and features [20, 21].
1) Instance method, the knowledge is transmitted from the original domain to the desired domain by rescaling or adjusting the weight of the original instances. Thus, the instance method depends on two basic principles:
Principle 1: To enable utilized instances again, the specific number of instances method in the original domain is connected to the desired domain. Not all instances of the original data can be utilized again in the desired model.
Principle 2: Both domains have the same distributed conditions. But in many problems of the world, the basic requirements of instance learning algorithms are not always met.
2) Features are extracted from the model being trained on a huge dataset. The huge dataset trained the model that was previously trained on basic features. Moreover, this dataset allows the model to pick up most of the specific features. The adjustment of features is done to guarantee agreement between basic features and the data that are used for training [22].
In this work, the original domain is represented by the ImageNet dataset which has 1000 classes, while the desired domain is the Seatbelt vs no seatbelt dataset which has 2 classes.
3.1 Xception model
The architecture of the deep learning system has been enhanced to enable more accurate image classification methods. So, the Xception model is a transfer learning technique that may be applied to categorize datasets that developed from the Inception model and consist of seventy-one layers. François Chollet built the Xception model that was based on a robust hypothesis [23].
This approach is better during image recognition compared to both Inception and ResNet methods. Furthermore, compared to the other transfer learning approach, the network size of the Xception model is smaller [24].
The Xception model creates channel correlations and connections between pixels in fully separable CNN features [25].
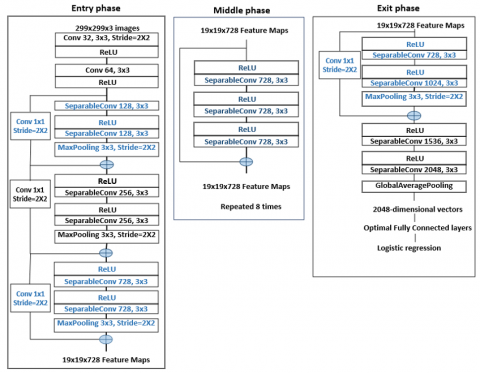
When entering data, the single convolutional dimension generates a distinct 3D convolution. These convolution volumes are later persisted into the non-conflicting portions of the channels that receive the output for collection as shown in Figure 1 [25, 26].
Figure 1. The Xception module divides the convolutions for each channel [25]
The architecture of the Xception model involves updating multiple units such as the convolution layer, depth-wise separable layer, and residual attachment. In the convolution layer, convolutional filters are created to compute new features from the original image. After that, the outcome is sent into the activation function and batch normalization at each layer for computation where the main activation function is Rectified Linear Unit (ReLU).
ReLU does not involve complex mathematics and its network has nonlinear behavior. Nonlinear behavior provides lower errors and more accurate predictions [26]. It's calculated by the following Eq. (1):
$\operatorname{ReLU}(m)=\max (m, 0)$ (1)
where, m represents the input value, which is linear for every positive number, and zero for every negative number. As for the depth-wise separable convolutions, it is one of the important parts of Xception due to its ability to reduce processing and model variables.
This layer is arranged according to channel color for spatial and depth attributes. It consists of two operations related to each other which are depthwise convolutions and pointwise convolutions. To achieve this operation, a deeper decoupling from the standard convolution process is performed to generate a kernel for each channel.
A filter is produced for every channel of the given input data set to $\mathrm{N}$ using a single filter from the source channel to calculate kernel size $R_F \times R_F \times N$. It's calculated by the following Eq. (2) [25-27].
$\widehat{D}_{a . b . n}=\sum_{i . j . n} \widehat{M}_{i . j . n} \times V_{a+i-1 . b+j-1 . n}$ (2)
where, the feature map input is represented by $V$ and the output of feature maps is produced by $\widehat{D}$, the depthwise convolution appears by $\widehat{M}$. To estimate the final result of the features, the $n$ filter in the $V$ is channeled using the $n$ filter in $\widehat{M}$ and convolution of the kernel for each pixel location imposed on $i$, $j$. Whereas the feature pixel locations determine $a, b$.
The following layers employ the max pooling layer to minimize the computational fees of the model as the following Eq. (3):
$P_m=\operatorname{MaxPooling}\left(P_i . n\right)$ (3)
The max-pooling filter is allocated by $n$ where $P_m$ is defined by the feature output and is organized into a dimensional model. Each $P_m$ holds the highest value of input features $P_j$. Thus, the fundamental component of feature extraction consists of 36 convolutional network layers.
Figure 2. The exception of architecture [23]
Xception generates fourteen units that are interrupted by the residual links except for the initial and final units. The required dimensions for the original image are 299 × 299 × 3 with three channels.
The information passes through an entry phase and utilizes two convolution layers with kernel 3x3 at the beginning. Then follows a middle phase that is executed eight times. After that, the information goes to the exit phase at the end [28, 29].
Figure 2 describes the Exception of architecture. The batch normalization layer is not shown in Figure 2 as it comes after each SeparableConvolution layer.
The deep hidden layers used in this model have made it suitable for the seatbelt versus no-seatbelt classification. Transfer learning can simply be done by making a train on the original dataset; this dataset should be huge to ensure good transfer learning, and then the four last layers are removed and chained to a new training with a seat belt dataset using previous knowledge.
3.2 ImageNet dataset
Based on the WordNet architecture, the ImageNet collection was constructed to facilitate research and development into visual object recognition [30].
The Xception model has the high accuracy of ImageNet with 1000 actual labeled images making it one of the most accurate models among traditional deep neural models. ImageNet relied on academic developers from Stanford and Princeton universities. Therefore, the basic principle of ImageNet’s ontology is the assumption that the visual world is globally organized to draw a comprehensible schema. The ImageNet dataset contains over a million tagged images that have been used for training several different models [31].
In this research, the Xception model was pre-trained on ImageNet using a large dataset that was used to classify seat belts to obtain the best results. Table 1 below summarizes the details of the ImageNet dataset.
Table 1. ImageNet details
|
Dataset [30] |
Classes |
Training Image |
Validation Image |
Testing Image |
|
1000 |
1,281,167 |
50,000 |
100,000 |
3.3 Seatbelt dataset
We have used a sufficient dataset with labels that can be implemented and modified. This dataset is obtained from Robflow [32], this dataset is modified to fit the proposed model, hence, the original dataset had two classes (Seatbelt and no seatbelt).
Table 2 below summarizes the details of the modified dataset and Figure 3 below shows samples of the seatbelt dataset.
Table 2. Seatbelt dataset details
|
Dataset |
Classes |
Positive |
Negative |
Total |
|
2 |
4118 images |
4500 images |
8618 images |
Figure 3. Samples of seatbelts dataset
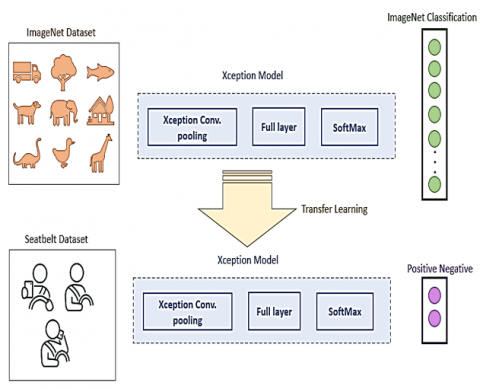
First of all, the pre-trained weights of ImageNet dataset training are transferred to be reused in a new model training using the new Seatbelt dataset.
Figure 4. The proposed model diagram
The model Xception was used after removing the last four fully connected layers by freezing these layers, while the input images were fed by seatbelt images.
The dataset is divided into two parts, the training dataset “80%” and the validation dataset “20%” of this model. The proposed model is evaluated using the validation dataset after completion of the training. With 10 epochs for the training and processing time for an epoch of 535 sec, Adam optimizer and Softmax activation function are applied.
Figure 4 shows the diagram of the proposed model and Table 3 below denotes a summary description of the proposed model.
The model is modeled using Python-based Jupyter Notebook using MSI laptop, 11th Gen Intel (R) Core (TM) i7-11800H@2.30GHz, RAM 16.0 GB. (Note that, the software and hardware used in this work are available, and it is not compulsory to use them).
Table 3. Proposed model description
|
Feature |
Value |
|
Model |
Xception |
|
Pretrained Dataset |
Imagenet |
|
Input shape |
299, 299, 3 |
|
Ephocs |
10 |
|
Steps |
238 |
|
Epoch processing time |
535 s |
|
Step processing time |
2 s |
|
Optimizer |
Adam |
|
Activation |
Softmax |
|
Validation_split |
0.2 |
|
Dataset |
Seatbelt |
|
Classes |
2 |
4.1 Summary of model parameters
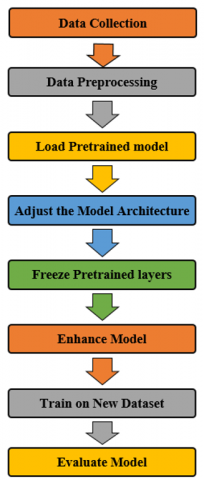
We have summarized the steps of the proposed model, which includes eight fundamental points
1. Data Collection: Gather a dataset that achieves the target of this work (Seatbelt, No Seatbelt), and ensure the data are labeled correctly.
2. Data Preprocessing: Raw data needs to be processed like resized and normalized, especially the Xception model treated with size (299 X 299).
3. Load Pretrained model: The Xception model is pre-trained on an ImageNet dataset with predefined weights. In this work, the model is imported from a TensorFlow source.
4. Adjust the Model Architecture: Modify the model by removing the top fully connected layers used for ImageNet classification (in this work, the four last layers), then insert new fully connected layers to match the binary classification (seatbelt and no seatbelt).
5. Freeze Pretrained layers: In this step, the pre-trained feature’s weights are kept from updating during the new dataset's (seatbelt and no seatbelt) training.
6. Enhance Model: Specify the model parameters to enhance it, using the activation function “Softmax” and optimizer “Adam”.
7. Train on New Dataset: train the model on (seatbelt and no seatbelt) dataset, then regularly fine-tune the pre-trained layers by unfreezing them with a lower learning rate, in this step, the model utilizes the previous knowledge.
8. Evaluate the model: choose metrics to evaluate the model like accuracy, loss function, valid precision, and recall. Figure 5 below denotes the flow process of the proposed model.
Figure 5. Flowchart of the proposed model
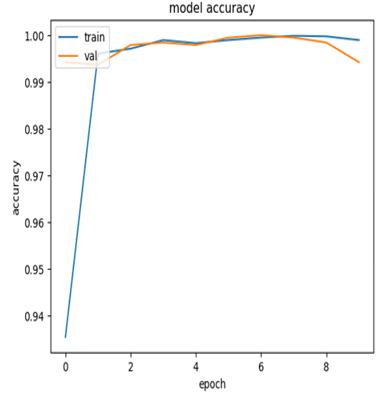
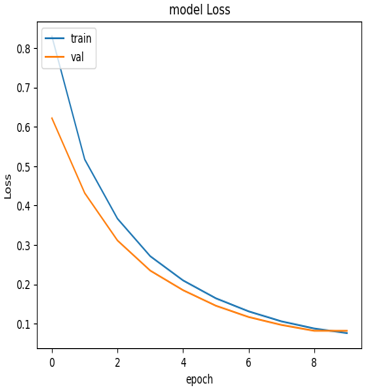
Transfer learning based on the Xception model is applied in the proposed approach. The output result of accuracy is 99.42% and validation accuracy is 99.42%, which are considered very satisfactory, and the loss function is 0.815 for both training and validation datasets referring to Figures 6 and 7 below show the accuracy and the loss function of this model. The training accuracy is raised to 99% from the first epoch, as well as the validation value, the precision is 0.9986, recall is 0.9979, valid precision is 0.9995, and valid recall is 0.9995. The high performance from the first epoch is achieved because of the use of transfer learning in the right case; however, the original domain matches the target domain.
The proposed model has approved the best metrics by comparing the proposed model with other previous works.
The state of the art of this work is used a classification approach to classify the seat belt dataset while all previous works and studies used detection approaches. Therefore, transfer learning achieves good metrics and a fast process.
Table 4 below shows the comparison between Xception model and other studies.
Figure 6. Accuracy
Figure 7. Loss function
Table 4. Comparison with other works
|
Ref. |
Method |
Accuracy |
Val Accuracy |
Loss |
Val Loss |
|
[13] |
Gradient Orientation |
86% |
- |
- |
- |
|
[14] |
SSD |
83% |
- |
- |
- |
|
[15] |
SSD |
91.9% |
- |
- |
- |
|
[18] |
Tiny YOLO |
95% |
- |
- |
- |
|
[19] |
Alexnet |
90% |
90% |
0.7 |
0.7 |
|
Proposed Model |
Transfer learning |
99.42% |
99.42% |
0.815 |
0.815 |
The interest in human safety has gotten high priority, seatbelt is one of the most important ways of human protection. Therefore, many works are focused on this field and proposed many studies to achieve this protection.
In this work, a new model is proposed, this model is based on using the transfer learning technique. The Xception model is applied to learn new features for the Seatbelt dataset and to enhance the driver classification.
Furthermore, it is utilized to accelerate the training by using previous knowledge of training the model using the Imagenet dataset which is a huge dataset with millions of images belonging to 1000 classes. We have found that previous training on ImageNet leads to a significant increase in the efficiency of the proposed model. This dataset contains 8,618 actual images from Robflow and is modified to correspond with the applied model.
The proposed Xception model achieved very satisfied metrics (Accuracy = 99.42%, Validation Accuracy = 99.42%, loss = 0.815, Validation loss = 0.815, precision = 0.9986, recall = 0.9979, Valid precision = 0.9995 and Valid recall = 0.9995).
The model has proposed the best results by comparing with other interesting works on the seatbelt, as denoted above, the proposed model presents the best accuracy and loss function.
[1] Abdelwahab, H.T., Abdel-Aty, M.A. (2001). Development of artificial neural network models to predict driver injury severity in traffic accidents at signalized intersections. Transportation Research Record, 1746(1): 6-13. https://doi.org/10.3141/1746-02
[2] Itu, C., Toderita, A., Melnic, L.V., Vlase, S. (2022). Effects of seat belts and shock absorbers on the safety of racing car drivers. Mathematics, 10(19): 3593. https://doi.org/10.3390/math10193593
[3] Bohlin, N.I. (1968). A statistical analysis of 28,000 accident cases with emphasis on occupant restraint value. SAE Transactions, 2981-2994.
[4] Coulibaly, S., Kamsu-Foguem, B., Kamissoko, D., Traore, D. (2019). Deep neural networks with transfer learning in millet crop images. Computers in Industry, 108: 115-120. https://doi.org/10.1016/j.compind.2019.02.003
[5] Abou Baker, N., Zengeler, N., Handmann, U. (2022). A Transfer learning evaluation of deep neural networks for image classification. Machine Learning and Knowledge Extraction, 4: 22-41. https://doi.org/10.3390/make4010002
[6] Alkhalid, F.F., Albayati, A.Q., Alhammad, A.A. (2022). Expansion dataset COVID-19 chest X-ray using data augmentation and histogram equalization. International Journal of Electrical and Computer Engineering, 12(2): 1904-1909. http://doi.org/10.11591/ijece.v12i2
[7] Muhsin, M.A., Alkhalid, F.F., Oleiwi, B.K. (2019). Surveillance system based motion detection using the image sequence difference algorithm. Journal of Engineering and Applied Science, 14(2): 5490-5494. http://doi.org/10.36478/jeasci
[8] Oleiwi, B.K., Alkhalid, F.F. (2018). Smart E-attendance system utilizing eigenfaces algorithm. Iraqi Journal of Computer Communication of Control and System Engineering, 18(1): 56-63. https://doi.org/10.33103/uot.ijccce.18.1.6
[9] Shao, S.Y., McAleer, S., Yan, R.Q., Baldi, P. (2018). Highly accurate machine fault diagnosis using deep transfer learning. IEEE Transactions on Industrial Informatics, 15(4): 2446-2455. https://doi.org/10.1109/TII.2018.2864759
[10] Qian, W.W., Li, S.M., Wang, J.R. (2018). A new transfer learning method and its application on rotating machine fault diagnosis under variant working conditions. IEEE Access, 6: 69907-69917. https://doi.org/10.1109/ACCESS.2018.2880770
[11] Yu, D., Zheng, H., Liu, C. (2013). Driver's seat belt detection in crossroad based on gradient orientation. In 2013 International Conference on Information Science and Cloud Computing Companion, Guangzhou, China, pp. 618-622. https://doi.org/10.1109/ISCC-C.2013.65
[12] Balci, B., Alkan, B., Elihos, A., Artan, Y. (2018). NIR camera based mobile seat belt enforcement system using deep learning techniques. In 2018 14th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Las Palmas de Gran Canaria, Spain, pp. 247-252. https://doi.org/10.1109/SITIS.2018.00045
[13] Elihos, A., Alkan, B., Balci, B. and Artan, Y. (2018). Comparison of image classification and object detection for passenger seat belt violation detection using NIR & RGB surveillance camera images. In 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, pp. 1-6. https://doi.org/10.1109/AVSS.2018.8639447
[14] Zhang, D.B. (2019). Analysis and research on the images of drivers and passengers wearing seat belt in traffic inspection. Cluster Computing, 2(4): 9089-9095. https://doi.org/10.1007/s10586-018-2070-x
[15] Chun, S., Hamidi Ghalehjegh, N., Choi, J., Schwarz, C., Gaspar, J., McGehee, D., Baek, S. (2019). NADS-Net: A nimble architecture for driver and seat belt detection via convolutional neural networks. In 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea (South), pp. 2413-2421. https://doi.org/10.1109/ICCVW.2019.00295
[16] Kashevnik, A., Ali, A., Lashkov, I., Shilov, N. (2020). Seat belt fastness detection based on image analysis from vehicle in-abin camera. In 2020 26th Conference of Open Innovations Association (FRUCT), Yaroslavl, Russia, pp. 143-150. https://doi.org/10.23919/FRUCT48808.2020.9087474
[17] Hosam, O. (2020). Deep learning-based car seatbelt classifier resilient to weather conditions. International Journal of Engineering & Technology, 9(1): 229-237. https://doi.org/10.14419/ijet.v9i1.30050
[18] Wang, Z.Y., Ma, Y.J. (2022). Detection and recognition of stationary vehicles and seat belts in intelligent Internet of Things traffic management system. Neural Computing and Applications, 34(5): 3513-3522. https://doi.org/10.1007/s00521-021-05870-6
[19] Bozinovski, S., Fulgosi, A. (1976). The influence of pattern similarity and transfer learning upon training of a base perceptron b2. Proceedings of Symposium Informatica, 3: 121-126.
[20] Prajapati, S.A., Nagaraj, R., Mitra, S. (2017). Classification of dental diseases using CNN and transfer learning. In 2017 5th International Symposium on Computational and Business Intelligence (ISCBI), Dubai, United Arab Emirates, pp. 70-74. https://doi.org/10.1109/ISCBI.2017.8053547
[21] Niu, S.T., Liu, Y.X., Wang, J. and Song, H.B. (2020). A decade survey of transfer learning (2010-2020). IEEE Transactions on Artificial Intelligence, 1(2): 151-166. https://doi.org/10.1109/TAI.2021.3054609
[22] Hassan, S.M., Maji, A.K., Jasiński, M., Leonowicz, Z., Jasińska, E. (2021). Identification of plant-leaf diseases using CNN and transfer-learning approach. Electronics, 10(12): 1388. https://doi.org/10.3390/electronics10121388
[23] Chollet, F. (2017). Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1251-1258.
[24] Abunasser, B.S., AL-Hiealy, M.R.J., Zaqout, I.S., Abu-Naser, S.S. (2022). Breast cancer detection and classification using deep learning Xception algorithm. International Journal of Advanced Computer Science and Applications, 13(7): 223-228, https://doi.org/10.14569/IJACSA.2022.0130729
[25] Jinsakul, N., Tsai, C.F., Tsai, C.E., Wu, P. (2019). Enhancement of deep learning in image classification performance using Xception with the swish activation function for colorectal polyp preliminary screening. Mathematics, 7(12): 1170. https://doi.org/10.3390/math7121170
[26] Salim, F., Saeed, F., Basurra, S., Qasem, S.N., Al-Hadhrami, T. (2023). DenseNet-201 and Xception pre-trained deep learning models for fruit recognition. electronics, 12(14): 3132. https://doi.org/10.3390/electronics12143132
[27] Gülmez, B. (2023). A novel deep neural network model based Xception and genetic algorithm for detection of COVID-19 from X-ray images. Annals of Operations Research, 328: 617-641. https://doi.org/10.1007/s10479-022-05151-y
[28] Endah, S.N., Shiddiq, I.N. (2020). Xception architecture transfer learning for garbage classification. In 2020 4th International Conference on Informatics and Computational Sciences (ICICoS), Semarang, Indonesia, pp. 1-4. https://doi.org/10.1109/ICICoS51170.2020.9299017
[29] Adityatama, R., Putra, A. (2023). Image classification of human face shapes using convolutional neural network Xception architecture with transfer learning. Recursive. Journal of Informatics, 1(2): 102-109. https://doi.org/10.15294/rji.v1i2.70774
[30] Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L. (2009). Imagenet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, pp. 248-255. https://doi.org/10.1109/CVPR.2009.5206848
[31] Denton, E., Hanna, A., Amironesei, R., Smart, A., Nicole, H. (2021). On the genealogy of machine learning datasets: A critical history of ImageNet. Big Data and Society, 8(2). https://doi.org/10.1177/20539517211035955
[32] Dataset. (2022). Seatbelt dataset. Roboflow Universe. https://universe.roboflow.com/dataset-9xayt/seatbelt-0lhjh