Deva Kumar Salluri* | Kalpana Bade | Gargi Madala
© 2020 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Natural disasters cause a great damage to human life. As these disasters occur naturally, no one can able to stop their occurrences. But for recovery there is a team named Disaster management or emergency management which helps in recovery of human loss. As recovering and analyzing the objects is not easy, it will be a tough challenge for Disaster management team to identify and process large amount of data in real-time. To make this simple and easy Convolutional Neural Networks (CNN) models are used for object detection of disaster’s aftermath. As there are various types of natural disasters such as hurricanes, tsunamis, floods, earthquakes etc., this study focuses on floods and earthquake images for object detection by using neural networks which has the ability to recognize objects easily. The network is processed on the DISASTER dataset which contains 2423 images out of which 1073 images belong to Flood and 1350 images belong to Earthquake. In this study ResNet50, VGG-16 and VGG-19 pre-trained models are used. These pre-trained models are CNN models which have been already trained on some sort of data. By using pre-trained models it will be more easy for object detection of flood and earthquake images. Among the three pre-trained models VGG-19 gets highest accuracy of 94.22%. As this study focused on floods and earthquake images for object detection. In future, by using different dataset and different images object detection will be done which will be helpful for recovery of human loss.
CNN, disaster, earthquake, floods, RESNET50, VGG-16, VGG-19
Catastrophe identification is the dynamic research zones in remote detecting, since sparing human lives is our need. With the evolving atmosphere, the recurrence and seriousness of cataclysmic events are additionally on the ascent requiring individuals and governments to be better arranged and furnished to adapt with the impacts of such calamities. Analysts have contemplated the impact of changes happened because of fiasco utilizing sensors and straightforward picture handling procedures, for example, picture variable based math. Convenient recovery and joining of debacle data are basic for viable calamity the executives. Past research discoveries show that fiasco recognition frameworks have a couple of serious issues, which remembers watching event of calamity for constrained range. Constant spatial data about debacle harm and hazard is of foremost significance to structuring suitable moderation techniques and reaction plans. It is vital in the coordination of quick reaction activities after a dangerous fiasco, for example, Flood and Earthquake.
As indicated by the United Nations Office for Disaster Risk Reduction (UNISDR), in the 10-year time frame finishing in 2014, cataclysmic events have influenced 1.7 billion individuals, asserted 700,000 lives, and cost 1.4 trillion Dollars in harms. On June 2013 Uttarakhand got substantial precipitation, enormous Landslides because of the huge flash floods, it endured most extreme harm of houses and structures, slaughtering in excess of 1000 individuals, sources asserted the loss of life could be ascend to 5000.
Earlier catastrophe discovery frameworks are for the most part concentrating on sensors, and they are unsophisticated. In this way, they experience a few noteworthy problems. This is because of constrained measure of catastrophe recognition sensor and gets data through verbal henceforth has low exactness. The DNN is the recent headway in the profound learning made errand straightforward for picture acknowledgment by as profoundly as conceivable learning. Profound learning is a subdivision of AI calculations, which are superb in recognizing designs, yet for the most part require more information. Article recognition has been a theme for challenge and numerous approaches are applied. Article discovery is identifying a particular item from a picture of different lines which are complex and structures. Article location which is utilized in face recognition, entity following, picture recovery, mechanized stopping frameworks. Papers in profound neural system are concentrated to comprehend the ideas of convNet system.
This paper objective is to assemble a programmed debacle discovery framework through investigating the event of a fiasco in a more extensive territory by means of satellite pictures and observing each and every catastrophe helped by profound learning methods, CNN.
As disasters occur naturally and for a successful disaster management, the key point is to have accurate data. In real-time as it is impossible to detect objects manually, Pi et al. [1] proposed an Unmanned Aerial Vehicle (UAV) using CNN model by deep learning which will be helpful for recognizing objects. As the vision of Digital Earth (DE) came into existence recently, Craglia et al. [2] developed a vision and report on large volumes of data that is available on social networks by which the information can be extracted and can be used for policy and science. However, as forest are present in remote areas and to monitor the ecosystems changes, Sulla-Menashe et al. [3] developed a 11-year time series of MODIS using temporal segmentation. By this the disturbance in forests can be identified perfectly regarding with their pixels, size and the timing of disturbance accurately.
Item recognition is being utilized in different fields like resistance, design, and so on. Be that as it may, it is utilized for medicinal uses. Gada et al. [4] proposed one of the models which distinguishes tumor in the mind utilizing profound neural system. As occurrence of cyclones is also a natural disaster, to overcome the damage Kovordányi and Roy [5] presented a technique based on ANN. This technique is used for cyclone tracking using satellite images. For emergency responding and recovery Baker et al. [6] proposed coordination of multiple UAV’s to identify the disaster causalities as quickly as possible. To identify the earthquake damage and emergency response, Cooner et al. [7] evaluated a study on the effectiveness of damage caused by earthquake by using a remote sensing and machine learning algorithm.
CNNs are the best neural networks by which images classification done easily. Based on this, Krizhevskyet al. [8] proposed a deep neural network which is processed on ImageNet database which consists of 1000 of image categories. There are various applications of UAVs for object detection. To detect objects from aerial images Radovic et al. [9] utilized exchange learning dependent on You Only Look Once (YOLO) algorithm to recognize planes from ethereal views. Many UAVs have been used from recent years for knowing the damages caused by man-made or naturally, Bejiga et al. [10] proposed a study to support avalanche search and rescue (SAR) operation with UAVs which helps in detecting the damage occurrence in a reasonable time. As social media networks also play an important role for knowing the daily updates among them twitter is one. Van Quan et al. [11] proposed a CNN to detect the real-time earthquake which detects the level of occurrence. As landslide is also a common disaster, Ding et al. [12] proposed a novel method which recognizes landslides automatically using CNN. The results of their experiment achieved a low commission error. By using PASCAL Visual Object Classes (VOC) dataset, object detection is performed in the past few years. Girshick et al. [13] proposed a scalable detection algorithm which improves mean average precision (mAP) 30% than VOC.
Fast R-CNN and SPPnet have reduced the time for object detection based on location. Ren et al. [14] proposed a Region Proposal Network (RPN) which is a fully connected network which is used for predicting the object bounds and scores at each position. Everingham et al. [15] described a dataset which analyse the methods to overcome the VOC challenge. Potter et al. [16] provided an outline to the Canterbury earthquakes, ongoing effects and their local environments. Toshev and Szegedy [17] proposed a method for human pose estimation based on DNN. This method is based on body joints. As CNNs have great performance in object detection, Guirado et al. [18] proposed a robust and generalizable CNN system for detecting of whales. Farabet et al. [19] proposed a method which uses CNN trained from raw pixels which extracts dense features.
To find out the large-scale image recognition, Simonyan and Zisserman [20] presented a work which investigates the effect of CNN based on its accuracy. Szegedy et al. [21] proposed a method which detects objects using DNN. It discretizes the output into a default boxes over different scales and ratios. Satellite imagery provides valuable information based on any calamities such as earthquakes, floods etc. Gueguen and Hamid [22] presented a semi-supervised learning framework which detects the damage in satellite imagery. Appleby-Arnold et al. [23] presented a project which describes about the relationship between the man- made and natural disaster. Their study focussed on attitudes, feelings and perceptions.
Disasters affects millions of people, and for their recovery there are only few tools and very limited information. To overcome this, Barnes et al. [24] analysed a technique which combines quantitative and statistical methods to identify the quality and the measure development. Their study focussed on “disaster management”, “natural hazards” and “simulation”. As the disasters cause great human loss, Bronfman et al. [25] presented a study which reports the levels of the preparedness of the community when exposed to the natural hazards. Redmon et al. [26] presented YOLO, which is a new approach for object detection using a single neural network. Raikes et al. [27] prepared a systematic review on 147 articles which are based on pre-disaster planning and their preparedness. To make a strategy of how to overcome the natural disasters risks, Richard Eiser et al. [28] developed a conceptual framework which guides about how to overcome the risks, self-protection etc. Galbusera and Giannopoulos [29] produced a theory, in which the economic loss and ripple effects are discussed that are caused when a disaster occurs. Becker et al. [30] explores the experiences on preparedness of earthquakes.
As Natural disaster causes loss of lives, in order to identify the data, we had introduced an automated object detection using deep neural networks for natural disaster recovery. The objective of this methodology is to identify the objects during natural disasters. To identify the objects manually is a big risk and it’s impossible to be sure about the object which was found after disaster occurrence. To make this process easy this study uses CNN model which is trained on pre-trained models for classifying the images which are taken from DISASTER dataset. Let’s have a brief description about the methodology of this study. Section 3.1 gives a brief description about neural networks. Section 3.2 describes about the architecture on which dataset is processed.
3.1 Artificial Neural Network
Counterfeit Artificial Neural Networks (ANN) depends on Biological Neural Networks. In ANN each associated hub is referred as a Neuron. Here the ANN works same as a natural mind, it gets the sign, process it and can flag a neuron associated with it.
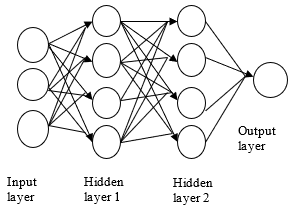
As shown in the Figure 1, if you send an image as input it will undergo many steps and then send an output. Between input and output layers there are some other layers which are referred as hidden layers. Among all these Convolutional Neural Network (CNN) is the best algorithm used for implementing deep learning techniques. CNN is also a kind of ANN. CNN is also known as ConvNet, consisting several layers named as convolutional layers, ReLu layer, pooling layer, and fully-connected layer. The basic deep neural network is shown in Figure 1.
Figure 1. Basic deep neural network
3.2 Methodology
A pre-trained model contains Convolutional layers and fully connected layers. Image features are extracted in Convolution layer and classifying those features extracted images is done in fully connected layers.
When we train a CNN on image data, it is seen that top layers of the network learn to extract general features from images such as edges, distribution of colors, etc. As we keep going deep in the network, the layers tend to extract more specific features.
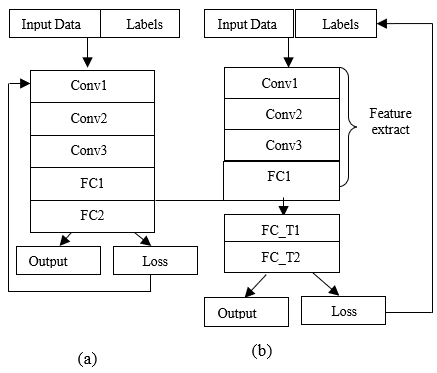
Now, we can use these pre-trained models which already know how to extract features and avoid the training from scratch. This concept is known as Transfer learning. The following figure is taken from towards data science website.
Figure 2. (a). Basic structure of pre-trained model; (b). Modified pre-trained model
From the above, Figure 2 (a) represents the basic pre-trained model which undergoes Convolution, ReLu, Pooling and Fully Connected layers for classifying the images. Whereas, Figure 2 (b) represents the modified pre-trained model. In Figure 2 (a) all layers are frozen whereas in Figure 2 (b) the layers upto FC1 are frozen and last layer is modified with FC_T1 and FC_T2. FC_T1 and FC_T2 are nothing but Fully Connected layers which are our own fully connected layers that are added in the place of FC2 for task-specific classification. Weights of the pre-trained model are used as feature extractor. While training the weights are not updated as they are frozen. Compared to Figure 2 (a) the computational time of Figure 2 (b) is less because training a neural network takes more time than compared to a pre-trained model. Pre-trained models are already trained on some sort of data by which the process will not begin from scratch. FC_T1 and FC_T2 are our own predicting layers on which the pre-trained model will work further and process the output. By this model, there will be less usage of time and result will be gained accurately.
This architecture is implemented on three different pre-trained models like ResNet50, VGG-16 and VGG-19.
3.2.1 VGG-19
VGG represents visual Geometry Group. VGG-19 is a convolutional system in which millions of images will be processed and it has the capability to identify the class of the image to which it belongs. It consists of 19 layers. This model is processed on DISASTER dataset which consists of 2423 images in which training set contains 1938 images and testing set contains 485 images. These images will undergo the first basic step called convolution. In this the features are extracted from the input image which is termed as filter. This filter is scrolled all over the image and the dot product operation is performed. The result is stored in a feature map. Later this is forwarded to ReLu layer which is an activation function, in which the negative values are replaced by zero and the positive values remain same. Later in pooling layer, there are three types of pooling: Min. Pooling, Max. Pooling and Avg. Pooling. To perform any of these pooling techniques first a stride is selected. Next, this stride will be scrolled all over the filtered image. If Max. Pooling is being performed the Max. Value will be selected and placed in the feature map. Pooling is done to reduce the size of the image. Next, flattening of the image will be done. Here, the data is converted into one-dimensional array and then a dropout of (0.5) is done by which accuracy increases and loss decreases. Dropout is used to ignore the neurons which are of no use. This is performed to overcome the over fitting of neural networks. Later this result will be forwarded to fully connected layer where classification of the image is done and the output is produced.
The same procedure is done with the remaining two models VGG-16 and ResNet50.
The network was pre-trained on the Natural Disaster dataset which is available from pyimage search sources which contains four classes namely earthquake, flood, cyclone and wildfire. In this paper we took two classes i.e. earthquake and flood, it consists of 2423 images for classification out of which 1073 images belong to Flood and 1350 images belong to Earthquake. Here the training set consists of 1938 images and testing set consists of 485 images. This network was implemented by Anaconda framework. The inputs of the network are the disaster images and the output indicate the category of the input image. We processed our dataset on other pre-trained models like VGG-16, VGG-19 and ResNet50 for comparing the accuracy among them as shown in the Table 1.
4.1 Performance evaluation
TP = True Positive
FN = False Negative
TN = True Negative
FP = False Positive
Accuracy test is used to differentiate the proportions of the affected cases and the un-affected cases in all cases.
$\text { Accuracy }=\frac{\mathrm{TP}+\mathrm{TN}}{\mathrm{TP}+\mathrm{TN}+\mathrm{FP}+\mathrm{FN}}$ (1)
Table 1. Accuracy of pre-trained models
|
Model |
Accuracy |
|
VGG-19 |
94.22% |
|
VGG-16 |
93.81% |
|
RESNET50 |
93.57% |
4.2 Results and discussions
As dataset is tested on different pre-trained models, we get different accuracies. Now, Let’s have a brief description about the dataset accuracy which we had processed on pre-trained models.
4.2.1 VGG-19
When we processed our dataset on VGG-19, we got an accuracy of 94.22%. This model consists of 19 layers (16 convolution layers followed by Max. Pool and 3 fully connected layers) and finally a softmax classifier. As our model contains only flood and earthquake class categories, modification of the pre-trained model is done by adding own predictive layers in place of softmax classifier as we require only 2 class classification. This model has an input size of 224×224. Here we had taken 2423 images of DISASTER dataset, in which training set contains 1938 images and testing set contains 485 images. Adam optimizer is used for computing the learning rates. Here we had taken 5 epochs to classify the images and run the process on a single CPU system.
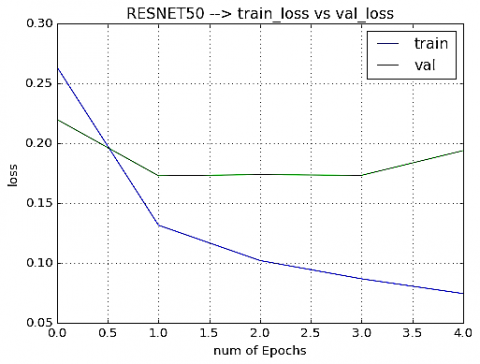
Training loss is the error on training data and validation loss is the error that occurred after running the neural network. As training loss is lower than validation loss to overcome overfitting problem a dropout of 0.5 is taken as shown in Figure 3.
Figure 3. train_loss vs val_loss
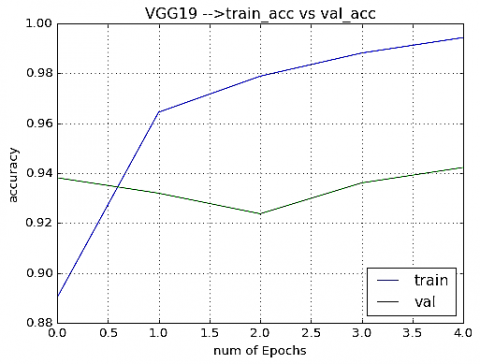
Figure 4. train_acc vs val_acc
Table 2. Accuracy levels of VGG-19 for flood and earthquake
|
|
Precision |
Recall |
F1-score |
Support |
|
Flood |
0.92 |
0.95 |
0.94 |
218 |
|
Earthquake |
0.96 |
0.94 |
0.95 |
267 |
|
Accuracy |
|
0.94 |
485 |
|
|
macro avg |
0.94 |
0.94 |
0.94 |
485 |
|
weighted avg |
0.94 |
0.94 |
0.94 |
485 |
Training accuracy is the accuracy we gain when the model is trained on the training data and validation accuracy is the accuracy we gain after validating the neural network as shown in Figure 4 above.
Here, precision means the correct positive values divided with all positive values given by the classifier. Recall means the correct positive values divided with all the relevant positive samples. F1-score means test’s accuracy which consider both precision and recall. Support means number of positive samples lie in that class as shown in Table 2.
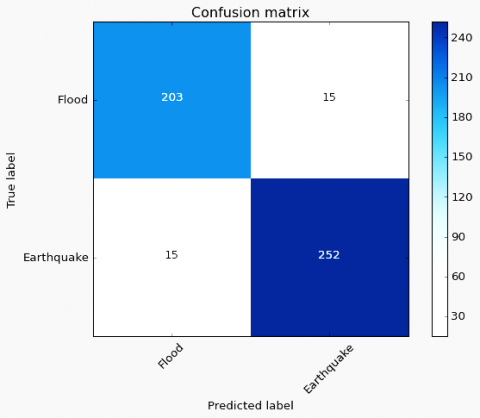
Figure 5. VGG-19 confusion matrix
Confusion matrix is used to describe the performance of the classification model as shown in Figure 5.
4.2.2 VGG-16
When we processed our dataset on VGG-16, we got an accuracy of 93.81%, this model is also referred as OxfordNet and consists of 16 layers (12 convolution layers followed by Max. Pooling layers and 4 fully connected layers) and finally 1000-way softmax classifier. But as our model contains only flood and earthquake class categories, modification of the pre-trained model is done by adding own predictive layers in place of the 1000-way softmax classifier as we require only 2 class classification. This model has an input size of 224×224. Here we had taken 2423 images of DISASTER dataset, in which training set contains 1938 images and testing set contains 485 images. Adam optimizer is used for computing the learning rates. Here we had taken 5 epochs to classify the images and run the process on a single CPU system. Like VGG-19, model VGG-16 generates the loss between training and testing as shown in Figure 6, accuracy between training and testing as shown in Figure 7, different measurement metrics as shown in Table 3 and confusion matrix shown in Figure 8.
Figure 6. train_loss vs val_loss
Figure 7. train_acc vs val_acc
Table 3. Accuracy levels of VGG-16 for flood and earthquake
|
|
Precision |
Recall |
F1-score |
Support |
|
Flood |
0.93 |
0.93 |
0.93 |
218 |
|
Earthquake |
0.94 |
0.94 |
0.94 |
267 |
|
Accuracy |
|
0.94 |
485 |
|
|
macro avg |
0.94 |
0.94 |
0.94 |
485 |
|
weighted avg |
0.94 |
0.94 |
0.94 |
485 |
Figure 8. VGG-16 confusion matrix
4.2.3 ResNet50
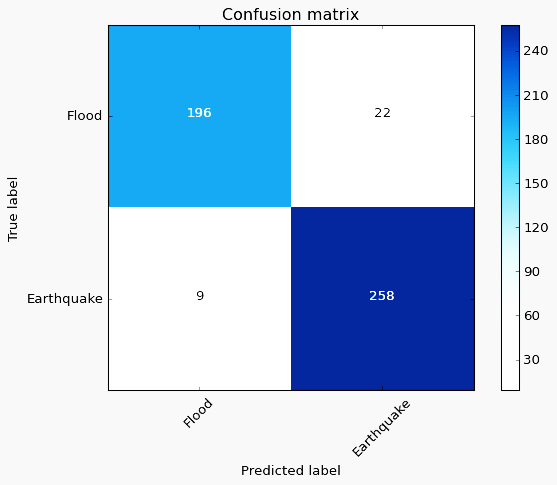
When we processed our dataset on ResNet50, we got an accuracy of 93.57%. It consists of 50 layers (48 convolution layers, 1 Max. Pool layer and 1 Avg. Pool layer). As our model contains only flood and earthquake class categories, modification of the pre-trained model is done by adding own predictive layers in place of softmax classifier as we require only 2 class classification. This model has an input size of 224×224. Here we had taken 2423 images of DISASTER dataset, in which training set contains 1938 images and testing set contains 485 images. Adam optimizer is used for computing the learning rates. Here we had taken 5 epochs to classify the images and run the process on a single CPU system. Like VGG-19, model ResNet50 generates the loss between training and testing as shown in Figure 9, accuracy between training and testing as shown in Figure 10, different measurement metrics as shown in Table 4 and confusion matrix shown in Figure 11.
Figure 9. train_loss vs val_loss
Table 4. Accuracy levels of RESNET50 for flood and earthquake
|
|
Precision |
Recall |
F1-score |
Support |
|
Flood |
0.96 |
0.90 |
0.93 |
218 |
|
Earthquake |
0.92 |
0.97 |
0.94 |
267 |
|
Accuracy |
|
0.94 |
485 |
|
|
macro avg |
0.94 |
0.93 |
0.94 |
485 |
|
weighted avg |
0.94 |
0.94 |
0.94 |
485 |
Figure 10. train_acc vs val_acc
Figure 11. ResNet50 Confusion matrix
As we trained the dataset on different pre-trained models, the main aim of this study is to identify the disaster images accurately by which it will be helpful for disaster management sources. Based on all the models performance VGG-19 gets highest accuracy compared to other models. The advantage of VGG-19 is it takes a very less time for computation when compared to VGG-16 and ResNet50. As the accuracies of three models are very close but the computational time is different and among these three models VGG-19 takes very less time and gets an accuracy of 94.22%.
As one cannot stop the occurrence of Natural Disasters, but as the disaster takes place there will a huge loss in human life. A disaster management will help in recovery, but as manual identification of large amount of data is not possible, in this study with the help of CNN along with pre-trained models the data is identified. Here, data is processed on three different pre-trained models among which VGG-19 gets highest accuracy of 94.22% compared to other models. In this study DISASTER dataset contains only Earthquake and flood images. The main advantage of using this model is large amount of data can be processed within a less span of time as pre-trained models was used in this study. Objects can be identified accurately and easily by which there will be no wastage of time. In future, we will run our model on different dataset and different images which contains thousands of images to improve the accuracy.
[1] Pi, Y., Nath, N.D., Behzadan, A.H. (2020). Convolutional neural networks for object detection in aerial imagery for disaster response and recovery. Advanced Engineering Informatics, 43: 101009. https://doi.org/10.1016/j.aei.2019.101009
[2] Craglia, M., Ostermann, F., Spinsanti, L. (2012). Digital Earth from vision to practice: Making sense of citizen-generated content. Intternational Journal of Digitl Earth, 5(5): 398-416. http://dx.doi.org/10.1080/17538947.2012.712273
[3] Sulla-Menashe, D., Kennedy, R.E., Yang, Z., Braaten, J., Krankina, O.N., Friedl, M.A. (2014). Detecting forest disturbance in the Pacific Northwest from MODIS time series using temporal segmentation. Remote Sensing of Environment, 151: 114-123. http://dx.doi.org/10.1016/j.rse.2013.07.042
[4] Gada, J., Savla, A., Chheda, S., Bhogale, P. (2016). Brain tumor segmentation. International Journal of Computer Applications, 138(13): 6-8. https://doi.org/10.5120/ijca2016908975
[5] Kovordányi, R., Roy, C. (2009). Cyclone track forecasting based on satellite images using artificial neural networks. ISPRS Journal of Photogrammetry and Remote Sensing, 64(6): 513-521. https://doi.org/10.1016/j.isprsjprs.2009.03.002
[6] Baker, C.A.B., Ramchurn, S., Teacy, W.T.L., Jennings, N.R. (2016). Planning search and rescue missions for UAV teams. Frontiers in Artificial Intelligence and Applications, 285: 1777-1782. https://doi.org/10.3233/978-1-61499-672-9-1777
[7] Cooner, A.J., Shao, Y., Campbell, J.B. (2016). Detection of urban damage using remote sensing and machine learning algorithms: Revisiting the 2010 Haiti earthquake. Remote Sens., 8(10): 868. https://doi.org/10.3390/rs8100868
[8] Krizhevsky, A., Sutskever, I., Hinton, G.E. (2017). ImageNet classification with deep convolutional neural networks. Communications of the ACM, 60(6): 84-90. https://doi.org/10.1145/3065386
[9] Radovic, M., Adarkwa, O., Wang, Q. (2017). Object recognition in aerial images using convolutional neural networks. J. Imaging, 3(2): 21. https://doi.org/10.3390/jimaging3020021
[10] Bejiga, M.B., Zeggada, A., Melgani, F. (2016). Convolutional neural networks for near real-time object detection from UAV imagery in avalanche search and rescue operations. 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, pp. 693-696. https://doi.org/10.1109/IGARSS.2016.7729174
[11] Van Quan, N., Yang, H.J., Kim, K., Oh, A. (2017). Real-time earthquake detection using convolutional neural network and social data. 2017 IEEE Third International Conference on Multimedia Big Data (BigMM), Laguna Hills, CA, pp. 154-157. https://doi.org/10.1109/BigMM.2017.58
[12] Ding, A., Zhang, Q., Zhou, X., Dai, B. (2017). Automatic recognition of landslide based on CNN and texture change detection. 2016 31st Youth Academic Annual Conference of Chinese Association of Automation (YAC), Wuhan, pp. 444-448. https://doi.org/10.1109/YAC.2016.7804935
[13] Girshick, R., Donahue, J., Darrell, T., Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., pp. 580-587. arXiv:1311.2524v5 [cs.CV].
[14] Ren, S., He, K., Girshick, R., Sun, J. (2017). Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell., 39(6): 1137-1149. arXiv:1506.01497v3 [cs.CV].
[15] Everingham, M., Van Gool, L. Williams, C.K.I., Winn, J., Zisserman, A. (2010). The pascal visual object classes (VOC) challenge. International Journal of Computer Vision, 88(2): 303-338. https://doi.org/10.1007/s11263-009-0275-4
[16] Potter, S.H., Becker, J.S., Johnston, D.M., Rossiter, K.P. (2015). An overview of the impacts of the 2010-2011 Canterbury earthquakes. International Journal of Disaster Risk Reduction, 14(Part 1): 6-14. http://dx.doi.org/10.1016/j.ijdrr.2015.01.014
[17] Toshev, A., Szegedy, C. (2014). DeepPose: Human pose estimation via deep neural networks. 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, pp. 1653-1660. https://doi.org/10.1109/CVPR.2014.214
[18] Guirado, E., Tabik, S., Rivas, M.L., Alcaraz-Segura, D., Herrera, F. (2019). Whale counting in satellite and aerial images with deep learning. Sci. Rep., 9(1). https://doi.org/10.1101/443671
[19] Farabet, C., Couprie, C., Najman, L., Lecun, Y. (2013). Learning hierarchical features for scene labeling. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8): 1915-1929. https://doi.org/10.1109/TPAMI.2012.231
[20] Simonyan, K., Zisserman, A. (2015). Very deep convolutional networks for large-scale image recognition. 3rd Int. Conf. Learn. Represent. ICLR 2015 - Conf. Track Proc., pp. 1-14. arXiv:1409.1556[cs.CV]
[21] Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A. (2015). Going deeper with convolutions. 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, pp. 1-9. https://doi.org/10.1109/CVPR.2015.7298594
[22] Gueguen, L., Hamid, R. (2015). Large-scale damage detection using satellite imagery. 015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, pp. 1321-1328. https://doi.org/10.1109/CVPR.2015.7298737
[23] Appleby-Arnold, S., Brockdorff, N., Jakovljev, I., Zdravković, S. (2018). Applying cultural values to encourage disaster preparedness: Lessons from a low-hazard country. International Journal of Disaster Risk Reduction, 31: 37-44. https://doi.org/10.1016/j.ijdrr.2018.04.015
[24] Barnes, B., Dunn, S., Wilkinson, S. (2019). Natural hazards, disaster management and simulation: A bibliometric analysis of keyword searches. Natural Hazards, 97(2): 813-840. https://doi.org/10.1007/s11069-019-03677-2
[25] Bronfman, N.C., Cisternas, P.C., Repetto, P.B., Castañeda, J.V. (2019). Natural disaster preparedness in a multi-hazard environment: Characterizing the sociodemographic profile of those better (worse) prepared. PLoS One, 14(4): 1-18. https://doi.org/10.1371/journal.pone.0214249
[26] Redmon, J., Divvala, S.,Girshick, R., Farhadi, A. (2016). You only look once: Unified, real-time object detection. Proc. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, pp. 779-788. https://doi.org/10.1109/CVPR.2016.91
[27] Raikes, J., Smith, T.F., Jacobson, C., Baldwin, C. (2019). Pre-disaster planning and preparedness for floods and droughts: A systematic review. Internaltional Journal of Disaster Risk Reduction, 38: 101207. https://doi.org/10.1016/j.ijdrr.2019.101207
[28] Richard Eiser, J., Bostrom, A., Burton, I., Johnston, D.M., McClure, J., Paton, D., der Pligt, J., White, M.P. (2012). Risk interpretation and action: A conceptual framework for responses to natural hazards. International Journal of Disaster Risk Reduction, 1: 5-16. http://dx.doi.org/10.1016/j.ijdrr.2012.05.002
[29] Galbusera, L., Giannopoulos, G. (2018). On input-output economic models in disaster impact assessment. International Journal of Disaster Risk Reduction, 30: 186-198. https://doi.org/10.1016/j.ijdrr.2018.04.030
[30] Becker, J.S., Paton, D., Johnston, D.M., Ronan, K.R., McClure, J. (2017). The role of prior experience in informing and motivating earthquake preparedness. International Journal of Disaster Risk Reduction, 22: 179-193. http://dx.doi.org/10.1016/j.ijdrr.2017.03.006