Zilong Li | Yong Zhou* | Rong Bao
© 2019 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
This paper proposes an image classification method based on fuzzy bag-of-words (FBoW) model and the fuzzy system with positive and negative rules. Firstly, the Gaussian membership function was adopted to construct multiple fuzzy membership histograms for image description, based on the distance between image features and multiple codebooks. Next, the fuzzy system with positive and negative rules was introduced to fuze the image description and image classification into a unified learning framework. After that, the precedent and antecedent parameters of the fuzzy system were learned by particle swarm optimization (PSO) and recursive least squares (RLS) algorithm, such that the parameters can be adjusted constantly in the learning process and that image description can fit in with the image classifier. Finally, the FBoW model was verified through experiment on the standard image dataset PASCAL Visual Object Classes Challenge 2007 (VOC2007). The results show that our method outperformed the classic FBoW model in image classification.
fuzzy bag-of-words (FBoW) model, image description, fuzzy system with positive and negative rules, particle swarm optimization (PSO), recursive least squares (RLS) algorithm
Image classification has long been a research hotspot of computer vision. The bag-of-words (BoW) model [1] is a popular method for image classification, thanks to its simplicity and efficiency. The BoW model lays the basis for many excellent image classification algorithms, such as spatial pyramid matching (PSM) [2], fuzzy bag-of-words (FBoW) [3], neural bag-of-features (NBoF) [4] and locality-constrained linear coding (LLC) [5]. In general, it takes three steps for the BoW model to classify images: First, the local features extracted from the target image, e.g. those extracted by scale-invariant feature transform (SIFT), are clustered, and the cluster centers are taken as the visual words in the codebooks. Next, the words in codebooks are assigned to the extracted image features by a certain strategy, and the image is represented by the number of features on the words. Finally, the image descriptions are classified by image classifiers like the k-nearest neighbors (kNN) algorithm and support vector machine (SVM).
Many scholars have attempted to improve the performance of the BoW model in image classification. For example, Ji et al. [6] quantifies the feature space with hidden Markov random field, aiming to generate codebooks by supervised learning. Wang et al. [5] proposes to obtain codebooks by learning the correlation between different classes on the hierarchy. Based on the BoW model, Cakir et al. [7] classifies different scenes with the metric function of the nearest neighbor classifier. Wang et al. [8] linearly codes the image-class distance and thus improves the image description ability. On this basis, Wang et al. [9] puts forward a cooperative linear coding method, which suppresses the effects of noise features on the coding process, making full use of the correlation between local features. Passalis and Tefas [10] sets up a BoW model under the learning framework of neural network (NN), and applies the model successfully in image retrieval [10]. Yang et al. [11] proposes a codebook generation method based on clustering and feature analysis; this method iteratively evaluates local features by k-means clustering (KMC) and similarity analysis, creating high-quality codebooks.
Despite the above attempts, the BoW model still has several defects. One of the defects is the fuzzy mapping between words and local features. The classical BoW model assigns local features via hard allocation. Each local feature is mapped to the nearest word in codebooks, that is, the local feature is quantified by the nearest neighbor classifier. This assignment approach causes a high quantification error [12, 13], especially when a local feature falls between codebooks. To solve the problem of hard allocation, many feature coding methods have emerged [14, 15].
To reduce the information loss in local feature coding, some scholars have developed coding methods based on soft allocation, such as kernel codebooks [16] and local coding [17]. The soft allocation methods can overcome some defects of hard allocation, but reduces the ability to identify image features. Wu et al. [18] presents a multi-sample, multi-tree method for computing codebooks, which lowers the information loss and produces more discriminative visual codebooks. To solve the defects of hard allocation, Van Gemert et al. [19] uses kernel function to estimate density and allocates local features to multiple words in codebooks. Altintakan and Yazici [20] both introduce the fuzzy set theory to solve the fuzziness and uncertainty of feature coding in the BoW model, that is, describe an image with a membership histogram based on the similarity membership function of the local feature and its nearest word. Zhao and Mao [21] replaces the hard mapping of the original codebook model with fuzzy mapping, and employs it for document representation. Altintakan and Yazici [22] further enhances the performance of the BoW model in two steps: setting up a membership function with the two words closest to image features, and introducing a new word weighting method to histogram.
The above literature shows that the fuzzy set theory has been recently applied and developed in the BoW model. The FBoW model, albeit its effectiveness, faces certain problems in local feature coding and classification strategy. Most scholars have treated feature coding and image classification independently, and only tackled one of the two issues. They have either tried to minimize the information loss in local feature coding, or strived to optimize the performance of the classifier. In fact, the two issues are closely intertwined and should be handled at once. If so, the reduction of information loss will bring more representative coding parameters and better classification effect.
Therefore, this paper designs a novel framework that supports simultaneous learning of image descriptions and classification models. Under this framework, the image descriptions being learned are closely related to classification problems, and thus able to represent images more discriminatively. In addition, the image presentation and classification were fused together by the fuzzy system with positive and negative rules [23]. This fuzzy system outperforms the traditional image classifiers, which often emphasize positive rule over negative rule. Next, the antecedent and consequent parameters of the fuzzy system were optimized by particle swarm optimization (PSO) and the recursive least squares (RLS) algorithm.
The remainder of this paper is organized as follows: Section 2 introduces the fuzzy system with positive and negative rules; Section 3 sets up the classification framework based on the fuzzy system and the BoW model, and describes the training process; Section 4 verifies our method through experiment and analyzes the experimental results; Section 5 draws the conclusions and looks forward to the future research.
The fuzzy system with positive and negative rules consists of a set of if-then fuzzy rules. The r-th fuzzy rule can be expressed as:
$R ^ { r } : I F x _ { k 1 }$ is $A _ { 1 } ^ { r } , \ldots , x _ { k M }$ is $A _ { M } ^ { r }$
THEN $y _ { k 1 }$ is $C _ { 1 }$ WITH $W _ { 1 } ^ { r } , \ldots , y _ { k N }$ is $C _ { N }$ WITH $W _ { N } ^ { r }$ (1)
where, xk=[xk1,…,xkM] (k=1,…,K) and yk=[yk1,…,ykN] are the inputs and outputs of the system; Ar m is the membership function of (m=1,…,M) in the r-th rule; Wr n((r=1,…,R) (n=1,…,N)) is the weight of xk belonging to class Cn (n=1,…,N); M, R, k and N are the dimensionality of input data, the total number of rules, the number of input sets, and the required number of classes, respectively. In this paper, the membership functions are Gaussian functions. Note that if the weight Wr n is positive, it means the weight of xk belonging to class Cn; if the weight Wr n is negative, then xk will be less likely to fall within class Cn.
By fuzzy inference, the output of the n-th class in such a multi-input, multi-output fuzzy system can be defined as:
$y _ { k n } = \frac { \sum _ { r = 1 } ^ { R } \beta _ { r } \left( x _ { k } \right) W _ { n } ^ { r } } { \sum _ { r = 1 } ^ { R } \beta _ { r } \left( x _ { k } \right) } = \sum _ { r = 1 } ^ { R } \overline { \beta } _ { r } \left( x _ { k } \right) W _ { n } ^ { r }$ (2)
where, $\beta _ { r } \left( x _ { k } \right) = \prod _ { m = 1 } ^ { M } A _ { m } ^ { r } \left( x _ { k m } \right) , \quad A _ { m } ^ { r } \left( x _ { k m } \right) = \exp \left[ - \frac { \left( x _ { k m } - \mu _ { m } ^ { r } \right) ^ { 2 } } { 2 \left( \sigma _ { m } ^ { r } \right) ^ { 2 } } \right]$ and $\left\{ \mu _ { m } ^ { r } , \sigma _ { m } ^ { r } \right\}$ are parameters of the Gaussian function and the antecedent parameters to be learned by the fuzzy system. The output weight of class Cn under the r-th rule can be defined as:
$W _ { n } ^ { r } = w _ { n 0 } ^ { r } + w _ { n 1 } ^ { r } x _ { k 1 } + \ldots + w _ { n M } ^ { r } x _ { k M }$ (3)
where, $w _ { n } ^ { r } = \left( w _ { n 0 } ^ { r } , w _ { n 1 } ^ { r } , \dots , w _ { n M } ^ { r } \right)$ are the consequent parameters of the fuzzy system. Then, the class of input xk can be determined by the maximum membership principle:
$y _ { k } = C _ { n } \cdot \mathrm { n } ^ { \prime } = \underset { 1 \leq n \leq N } { \arg \max } \operatorname { ax } \left( y _ { k n } \right)$ (4)
Once the structure of the fuzzy system has been established, the next step is to determine the antecedent and consequent parameters of the system. Nguyen and Wu [23] said, the fuzzy system is trained by feedforward NN. However, the training proceeds slowly, and the learning process is easy to fall into the local optimum trap.
In the fuzzy system, the antecedent parameters are the two parameters of fuzzy membership, while the consequent parameters belong to the linear model. The former can be optimized through repeated iterations by the PSO, and the latter can be solved easily by the least squares (LS) method. In this paper, the PSO and the RLS are combined into a hybrid method to learn the parameters of the fuzzy system.
In the FBoW model [3], the fuzzy similarities between image features and visual words are measured by membership functions. Then, the lambda (λ) cut set of the fuzzy set is adopted to filter out the memberships with small fuzzy similarities. After that, the fuzzy membership histogram is constructed, forming a coded representation of the image. Finally, the SVM is introduced to judge the class of each input.
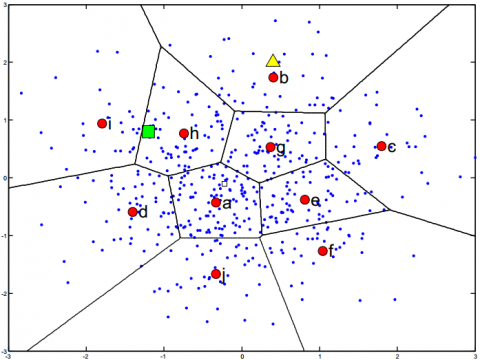
Based on the previous introduction, the fuzzy membership histogram of the FBoW model was taken as the input of the fuzzy system, aiming to fuse the FBoW model into the system. As mentioned by Li et al. [3], many image features are located at several neighboring visual words. As shown in Figure 1, the feature point in the green box is close to codebooks a, d, i and h. Thus, this feature point exhibits a certain fuzzy uncertainty in several visual words. Inspired by this rule, the author firstly constructed multiple fuzzy membership histograms based on R image features that have the highest fuzzy similarities with visual words. For each image Ik, a total of R fuzzy membership histograms was created. Next, a fuzzy rule was set up in the fuzzy system for each fuzzy membership histogram. The corresponding relationship between multiple rules and multiple histograms provides a unified framework for the coded representation and classification of images. Hence, our image classification method is denoted as the MFBoW.
Figure 1. An example for the fuzzy uncertainty of a local feature in codebook model
In the FBoW, the fuzzy similarities between image features and visual words are computed by the fuzzy set theory, and used to draw the fuzzy membership histograms, thus completing the coded representation of the image. The fuzzy membership functions, which measure the fuzzy similarities, are exponential functions. This type of functions contains multiple parameters and consumes a long time. Therefore, this paper replaces exponential functions with Gaussian functions to measure the fuzzy similarities. Let fki be the i-th local feature extracted from the k-th image, and vm be the m-th visual word of codebook V=[v1,…,vM]. Then, the fuzzy membership function that measures the fuzzy similarities between image features and visual words can be expressed as:
$\mu \left( f _ { k i } \right) = \exp \left[ - \frac { \left( f _ { kj } - v _ { m } \right) ^ { 2 } } { 2 \left( \sigma _ { m } \right) ^ { 2 } } \right]$ (5)
where, μ(fki) is the fuzzy membership of fki; σm is the variance of the Gaussian model of visual word vm. After the set of fuzzy similarities had been obtained, the λ cut set of the fuzzy set was employed to filter out the memberships with small fuzzy similarities. After that, a fuzzy membership histogram was constructed, creating the vector representation of the image xk=[xk1,…,xkM]. In the FBoW, the suitable fuzzy similarities are selected by the global λ cut set. In this paper, the λm cut set focuses on specific words, and outshines the global cut set in the accuracy of image representation.
The optimal fuzzy membership histogram cannot be obtained without the optimization of σm and λm values and that of the antecedent and consequent parameters of the fuzzy system. To optimize these parameters, Nguyen and Wu [23] trains the fuzzy system with the feedforward NN, which is slow and prone to local optimum trap. To overcome these defects, this paper combines the PSO and the RLS to learn the fuzzy system.
Specifically, the antecedent parameters of the fuzzy system were learned by the PSO, in which the position of each particle is a parameter value, and the global optimal position of the population is the optimal parameter value. The consequent parameters of the fuzzy system were obtained through the RLS learning.
Let $\left\{ \left( I _ { k } , y _ { k } ^ { \prime } \right) , k = 1 , \ldots , K \right\}$ be the training set, where Ik is the k-th image and $y _ { k } ^ { \prime } = \left[ y _ { k 1 } ^ { \prime } , \cdots , y _ { k N } ^ { \prime } \right] ^ { T }$ are the desired classification results. The structure of the $y _ { k } ^ { \prime } = \left[ y _ { k 1 } ^ { \prime } , \cdots , y _ { k N } ^ { \prime } \right] ^ { T }$ can be described as:
$y _ { k } ^ { \prime } = \left[ y _ { k 1 } ^ { \prime } , \cdots , y _ { k v } ^ { \prime } \right] ^ { T } = \left\{ \begin{array} { l } { ( 1,0 , \cdots , 0 ) ^ { T } , \text { if } x _ { k } \in \text { class } C _ { 1 } } \\ { ( 0,1 , \cdots , 0 ) ^ { T } , \text { if } x _ { k } \in \text { class } C _ { 2 } } \\ {\cdots} \\ { ( 0,0 , \cdots , 1 ) ^ { T } , \text { if } x _ { k } \in \text { class } C _ { N } } \end{array} \right.$ (6)
If xk is inputted into the fuzzy system, then the output of class Cn can be described as:
$y _ { k n } =$
$\overline { \beta } _ { 1 } \left( x _ { k } \right) w _ { n 0 } ^ { 1 } + \overline { \beta } _ { 1 } \left( x _ { k } \right) w _ { n 1 } ^ { 1 } x _ { k 1 } + \cdots + \overline { \beta } _ { 1 } \left( x _ { k } \right) w _ { n M } ^ { 1 } x _ { k M } +$
$\overline { \beta } _ { 2 } \left( x _ { k } \right) w _ { n 0 } ^ { 2 } + \overline { \beta } _ { 2 } \left( x _ { k } \right) w _ { n 1 } ^ { 2 } x _ { k 1 } + \cdots + \overline { \beta } _ { 2 } \left( x _ { k } \right) w _ { n M } ^ { 2 } x _ { k M } +$
$\cdots$
$\overline { \beta } _ { R } \left( x _ { k } \right) w _ { n 0 } ^ { R } + \overline { \beta } _ { R } \left( x _ { k } \right) w _ { n 1 } ^ { R } x _ { k 1 } + \cdots + \overline { \beta } _ { R } \left( x _ { k } \right) w _ { n M } ^ { R } x _ { k M }$ (7)
For all training data, the weights Wn can be computed by the RLS algorithm by:
$W _ { n } = \left( B ^ { T } B \right) ^ { - 1 } B ^ { T } y _ { n } ^ { \prime }$ (8)
$W _ { n } = \left[ w _ { n 0 } ^ { 1 } , w _ { n 1 } ^ { 1 } , \ldots , w _ { n M } ^ { 1 } , \ldots , w _ { n 0 } ^ { R } , w _ { n 1 } ^ { R } , \ldots , w _ { n M } ^ { R } \right] ^ { T } , B$ and $y _ { n } ^ { \prime } = \left[ y _ { 1 n } ^ { \prime } , y _ { 2 n } ^ { \prime } , \ldots , y _ { k n } ^ { \prime } \right] ^ { T }$ are matrices of the size $( ( N + 1 ) \times R ) \times 1$ $K \times ( ( N + 1 ) \times R )$ and $K \times 1$ respectively. To reduce the computing load of matrix operations, the weights Wn can be optimized through RLS learning:
$P ( t + 1 ) = P ( t ) - \frac { P ( t ) b ( t + 1 ) b ^ { T } ( t + 1 ) P ( t ) } { 1 + b ^ { T } ( t + 1 ) P ( t ) b ( t + 1 ) }$ (9)
$W _ { n } ( t + 1 ) = W _ { n } ( t ) + P ( t + 1 ) b ( t + 1 ) \left( y _ { n } ^ { \prime } ( t + 1 ) - b ^ { T } ( t + 1 ) W _ { n } ( t ) \right)$ (10)
where $\left[ b ( t ) ^ { T } , y _ { n } ^ { \prime } ( t ) \right]$ is the t-th row of $\left[ B , y _ { n } ^ { \prime } \right]$ $( t = 0,1 , \ldots , ( K - 1 ) ) .$ In the RLS algorithm, $W _ { n } ( 0 )$ was initialized as the zero vector, and P0 was set as the product of a large positive number α and unit matrix I. Here, the value of α is set to 109.
During the fuzzy system learning based on the PSO and the RLS, the output of each iteration can be obtained by formula (2). Then, the error between the actual output and the desired output can be measured by the root-mean-square error (RMSE):
$R M S E = \sqrt { \frac { \sum _ { n = 1 } ^ { N } \sum _ { k = 1 } ^ { K } \left( y _ { b n } - y _ { k n } ^ { \prime } \right) ^ { 2 } } { N K } }$ (11)
The RMSE can evaluate the performance of system learning. Here, this index is taken as the particle fitness of the PSO. Below is the training process of the fuzzy system.
Step 1. Initialize the particle swarm of the antecedent parameters of the fuzzy system, and determine the input data and membership functions of the system.
Step 2. Compute the consequent parameters of the fuzzy system with the RLS algorithm, and set up multiple fuzzy rules for the fuzzy system.
Step 3. Compute the weight outputs for different classes, determine the RMSE between the actual output and the desired output, and use the RMSE to update the velocity and position of the particles in the swarm.
Step 4. If the RMSE satisfies the terminal condition, terminate the algorithm; otherwise, return to Step 2.
To verify its effectiveness, our method was tested on the standard image dataset PASCAL Visual Object Classes Challenge 2007 (VOC2007). The dataset contains 4,415 social images in 20 different classes. Every image is of the size 300×200 pixels.
The images were described separately by the BoW, the FBoW and the proposed MFBoW. Then, the image descriptions of the first two models were classified by the SVM [3]. Those of our algorithm were classified by the fuzzy system with positive and negative rules. The SVM classifier uses the parameters specified with Li et al. [3].
The same codebooks were prepared for the three models. There are three sizes of the codebooks: 1,000, 5,000 and 7,000. One third of the images in the dataset were randomly extracted to generate the codebooks, another one third to train the classifiers and the final one third to test the performance of the models.
As mentioned before, the fuzzy system consists of multiple fuzzy rules. The system output hinges on the number of rules. In addition, the classification effect partially depends on the size of codebooks. For example, Li et al. [3] compares the image classification effects with different codebook sizes. Thus, the number of rules and codebook size were both considered. During the experiments on VOC2007, the author observed how classification accuracy is correlated with the two factors.
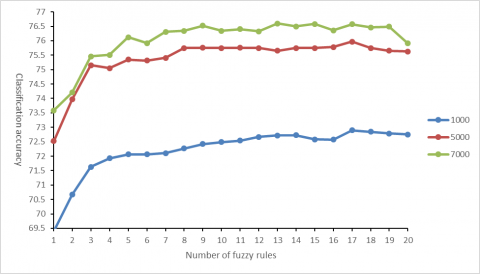
Figure 2. Relationship between the number of fuzzy rules, codebook size and classification accuracy
The observed results (Figure 2) show that, with the growth in the number of fuzzy rules, the classification accuracy improved at different codebook sizes. However, a high number of fuzzy rules did not always lead to a good classification effect. When there were 17 fuzzy rules, the fuzzy system achieved good classification accuracy at different codebook sizes. Therefore, the number of fuzzy rules was set to 17 in the subsequent experiments.
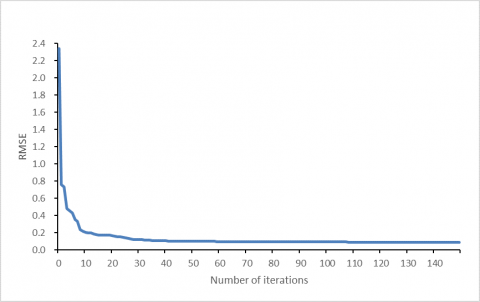
To further verify the effectiveness of our method, the relationship between the RMSE and the number of iterations was plotted for the codebook size of 1,000. As shown in Figure 3, the RMSE remained at about 0.1 and tended to be stable after the 37th iteration. Hence, the termination condition of the algorithm was set as the RMSE=0.1.
Figure 3. Relationship between the number of iterations and the RMSE
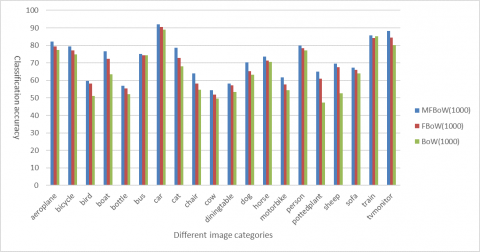
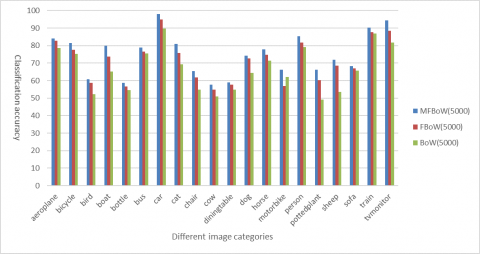
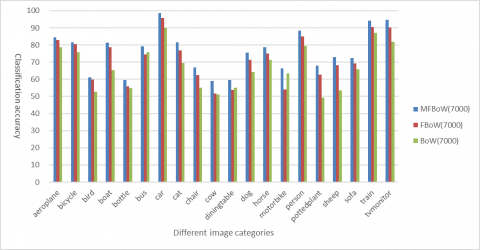
Next, the image classification effects of our method, the FBoW and the BoW were compared at three different codebook sizes. According to the comparative results in Figures 4~6, our method achieved a much higher classification accuracy than the two contrastive models.
Figure 4. Image classification results (codebook size: 1,000)
Figure 5. Image classification results (codebook size: 5,000)
Figure 6. Image classification results (codebook size: 7,000)
Further, the following three tables respectively list the mean classification effects of the three models. It can be seen that, the MFBoW surpassed the FBoW by 3.12 %, 3.92 % and 4.11 % in mean classification accuracy, when the codebook size was 1,000, 5,000 and 7,000, respectively. In addition, the standard deviation of the MFBoW was always smaller than that of the FBoW and that of the BoW, whichever the codebook size. To sum up, our method can achieve better effect than the other two models in image classification.
Table 1. Image classification effects (codebook size: 1,000)
|
Codebook Size |
MFBoW(%) |
FBoW(%) |
BoW(%) |
|
1,000 |
72.24 ± 10.07 |
69.12 ± 11.08 |
65.05 ± 12.91 |
|
Codebook Size |
MFBoW(%) |
FBoW(%) |
BoW(%) |
|
5,000 |
75.37 ± 11.93 |
71.45 ±12.03 |
66.73 ± 12.64 |
|
Codebook Size |
MFBoW(%) |
FBoW(%) |
BoW(%) |
|
7,000 |
76.03 ± 12.36 |
71.92 ±13.27 |
66.95 ± 12.59 |
This paper mainly improves the BoW-based classification method. The classic FBoW model treats feature coding and image classification as separate processes, failing to ensure the fitness between the encoded representation of the image and the classification model. In this paper, the fuzzy system with positive and negative rules is adopted to fuse the coded representation and classification of images into the same learning framework, such that the image descriptions are suitable for the classification model. The experimental results show that our model (MFBoW) achieved better classification effect than the classic FBoW model. The future research will further improve the image classification effect with deep learning.
This work is supported by the National Natural Science Foundation of China (60273064), the Project of Jiangsu Province Construction System (2018ZD077), the Open Foundation of Key Laboratory of Intelligent Industrial Control Technology of Jiangsu Province in Xuzhou Institute of Technology (JSKLIIC201705, JSKLII201802).
[1] Li, F.F., Perona, P. (2005). A bayesian hierarchical model for learning natural scene categories. 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2(2): 524-531. https://doi.org/10.1109/CVPR.2005.16
[2] Xie, L., Lee, F.F., Liu, L., Yin, Z., Yan, Y., Wang, W.D., Zhao, J.J., Chen, Q. (2018). Improved spatial pyramid matching for scene recognition. Pattern Recognition, 82: 118-129. https://doi.org/10.1016/j.patcog.2018.04.025
[3] Li, Y., Liu, W., Huang, Q., Li, X. (2016). Fuzzy bag of words for social image description. Multimedia Tools and Applications, 75(3): 1371-1390. https://doi.org/10.1007/s11042-014-2138-4
[4] Passalis, N., Tefas, A. (2017). Neural bag-of-features learning. Pattern Recognition, 64: 277-294. https://doi.org/10.1016/j.patcog.2016.11.014
[5] Wang, J., Yang, J., Yu, K., Lv, F., Huang, T.S., Gong, Y.H. (2010). Locality-constrained linear coding for image classification. 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pp. 3360-3367. https://doi.org/10.1109/CVPR.2010.5540018
[6] Ji, R., Yao, H., Sun, X., Zhong, B., Gao, W. (2010). Towards semantic embedding in visual vocabulary. 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pp. 918-925. https://doi.org/10.1109/CVPR.2010.5540118
[7] Cakir, F., Güdükbay, U., Ulusoy, Ö. (2011). Nearest-neighbor based metric functions for indoor scene recognition. Computer Vision and Image Understanding, 115(11): 1483-1492. https://doi.org/10.1016/j.cviu.2011.07.007
[8] Wang, Z., Feng, J., Yan, S., Xi, H. (2018). Linear distance coding for image classification. IEEE Transactions on Image Processing, 22(2): 537-548. https://doi.org/10.1109/TIP.2012.2218826
[9] Wang, Z., Feng, J., Yan, S. (2015). Collaborative linear coding for robust image classification. International Journal of Computer Vision, 114(2-3): 322-333. https://doi.org/10.1007/s11263-014-0739-z
[10] Passalis, N., Tefas, A. (2017). Learning neural bag-of-features for large-scale image retrieval. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 47(10): 2641-2652. https://doi.org/10.1109/TSMC.2017.2680404
[11] Yang, F., Ma, Z., Xie, M. (2017). Codebook learning for image recognition based on parallel key SIFT analysis. IEICE Transactions on Information and Systems, 100(4): 927-930. https://doi.org/10.1587/transinf.2016EDL8167
[12] Philbin, J., Chum, O., Isard, M., Sivic, J., Zisserman, A. (2008). Lost in quantization: Improving particular object retrieval in large scale image databases. 2008 IEEE Conference on Computer Vision and Pattern Recognition, pp. 1-8. https://doi.org/10.1109/CVPR.2008.4587635
[13] Zhang, C., Xiao, X., Pang, J., Liang, C., Zhang, Y., Huang, Q. (2014). Beyond visual word ambiguity: Weighted local feature encoding with governing region. Journal of Visual Communication and Image Representation, 25(6): 1387-1398. https://doi.org/10.1016/j.jvcir.2014.05.010
[14] Chatfield, K., Lempitsky, V., Vedaldi, A., Zisserman, A. (2011). The devil is in the details: an evaluation of recent feature encoding methods. BMVC, 2(4): 1-8.
[15] Huang, Y., Wu, Z., Wang, L., Tan, T. (2013). Feature coding in image classification: A comprehensive study. IEEE Transactions on Pattern Analysis and Machine Intelligence, 36(3): 493-506. https://doi.org/10.1109/TPAMI.2013.113
[16] Van Gemert, J.C., Veenman, C.J., Smeulders, A.W.M., Geusebroek, J.M. (2009). Visual word ambiguity. IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(7): 1271-1283. https://doi.org/10.1109/TPAMI.2009.132
[17] Liu, L., Wang, L., Liu, X. (2011). In defense of soft-assignment coding. 2011 International Conference on Computer Vision, pp. 2486-2493. https://doi.org/10.1109/ICCV.2011.6126534
[18] Wu, Z., Ke, Q., Sun, J., Shun, H. (2009). A multi-sample, multi-tree approach to bag-of-words image representation for image retrieval. 2009 IEEE 12th International Conference on Computer Vision, pp. 1992-1999. https://doi.org/10.1109/ICCV.2009.5459439
[19] Van Gemert, J.C., Geusebroek, J.M., Veenman, C.J., Smeulders, A.W.M. (2008). Kernel codebooks for scene categorization. European Conference on Computer Vision. Springer, Berlin, Heidelberg, pp. 696-709. https://doi.org/10.1007/978-3-540-88690-7_52
[20] Altintakan, U.L., Yazici, A. (2016). A novel fuzzy feature encoding approach for image classification. 2016 IEEE International Conference on Fuzzy Systems, pp. 1134-1139. https://doi.org/10.1109/FUZZ-IEEE.2016.7737815
[21] Zhao, R., Mao, K. (2018). Fuzzy bag-of-words model for document representation. IEEE Transactions on Fuzzy Systems, 26(2): 794-804. https://doi.org/10.1109/TFUZZ.2017.2690222
[22] Altintakan, U.L., Yazici, A. (2015). An improved BOW approach using fuzzy feature encoding and visual-word weighting. 2015 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), pp. 1-5. https://doi.org/10.1109/FUZZ-IEEE.2015.7338108
[23] Nguyen, T.M., Wu, Q.M.J. (2008). A combination of positive and negative fuzzy rules for image classification problem. 2008 Seventh International Conference on Machine Learning and Applications, pp. 741-746. https://doi.org/10.1109/ICMLA.2008.14