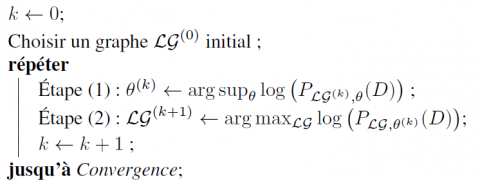OPEN ACCESS
Dynamic Bayesian Network (DBN) learning consists in learning both conditionnal independances and conditional probability tables between random variables evolving in time. In this article, we propose an approach to learn "labelled" DBNs. In this model, the graphical representation of the conditional independancies contains edges that are labeled amongst a small number of possible interactions. Conditional probabilities tables are defined by parameterized functions and parameters are shared between the functions. The proposed approach interleaves parameter improvement phases and structure improvement phases that locally improve the likelihood of the data. A labelled DBN model is proposed to represent the dynamic of species interacting whithin an ecological network. Experiments are performed, which demonstrate the feasibility and efficiency of the approach.
dynamic bayesian network, ecological network, ILP
L’apprentissage de la structure d’un réseau d’interactions entre entités est une question classique dans de nombreux domaines comme la bioinformatique (Yu et al., 2004), l’écologie (Milns et al., 2010) ou les sciences sociales (Liben-Nowell, Kleinberg, 2007). Les réseaux bayésiens ou BN (Bayesian Network), sont un cadre permettant de résoudre ce problème. Dans un réseau bayésien, les entités sont modélisées par des variables aléatoires et leurs indépendances conditionnelles sont modélisées par la structure du BN. Lorsque l’état des variables varie au cours du temps, le cadre des Réseaux Bayésiens Dynamiques (RBD) (Ghahramani, 1997 ; Dean, Kanazawa, 1989) permet alors de modéliser les dépendances temporelles. Le problème d’apprentissage de structure d’un réseau bayésien est bien défini, et plusieurs solutions existent. Il s’agit généralement d’apprendre à la fois la structure du réseau et les tables de probabilité conditionnelles associées. L’apprentissage de la structure d’un RBD (Murphy, 2002) est souvent un cas particulier des méthodes classiques d’apprentissage de réseaux bayésiens. L’idée est d’utiliser ces méthodes pour apprendre la structure de la distribution de probabilité sur l’état initial puis des probabilités de transitions. Plusieurs de ces approches utilisent une fonction de score qui mesure à quel point les observations sont compatibles avec la structure du graphe, et recherchent la structure optimisant ce score. Si la recherche d’un réseau bayésien optimal est un problème NP-difficile (Chickering, 1996), il est possible de réduire la complexité avec un apriori sur la structure du réseau considéré. Le cas d’un RBD sans arc synchrone, c’est à dire dont les transitions ne se font que d’un pas de temps au suivant, permet cette réduction de omplexité. En effet, un tel réseau est naturellement sans circuit, ce qui permet d’utiliser des méthodes maximisant des scores locaux en évitant une étape de vérification d’acyclicité. Un algorithme a été proposé pour résoudre en temps polynomial un problème d’apprentissage de RBD en optimisant des scores MDL (Minimum Description Length) ou BDe (Bayesian Dirichlet equivalence) (Dojer, 2006) et ces résultats ont été étendus (Vinh et al., 2011) afin de proposer un algorithme en temps polynomial pour un score MIT (Mutual Information Test).
Les approches mentionnées ci-dessus considèrent des RBD où chaque table de probabilité de transition est apprise indépendamment pour chaque individu et où l’on apprend chaque élément de la table. Si cela permet d’utiliser des modèles très flexibles, les approches mentionnées ne permettent pas d’inclure des connaissances expertes qui pourraient aider à l’apprentissage (par exemple : des égalités connues entre plusieurs tables), surtout lorsqu’il y a peu de réplicats. En utilisant des méthodes hybrides comme les MMHC dynamiques (Trabelsi, 2013), il est possible d’inclure des connaissances à priori sur la structure du graphe sous la forme d’arcs ou de groupes d’arcs interdits ou requis.
Il existe des cas où la connaissance experte permet de ne définir qu’un nombre limité et bien défini d’interactions possibles. Nous nous intéressons à des cas généraux de processus par contact, où des variables soumises à des influences similaires partagent une même table de probabilité conditionnelle. Il est alors possible d’étiqueter les arêtes du RBD selon le type d’interaction qu’elles représentent. Prendre en compte ces mécanismes d’interaction permet de réduire le nombre de paramètres à estimer.
Dans cet article, nous considérons le problème d’apprentissage d’un tel modèle de réseau bayésien dynamique étiqueté (RBD-E), où les arêtes sont étiquetées et les tables de probabilité de transition sont définies en fonction du nombre de parents associés à chaque étiquette d’arc et d’un nombre de paramètres limité et fixé. Ces paramètres sont partagés par toutes les tables de probabilité de transition. Les méthodes classiques d’apprentissage ne s’appliquent plus telles quelles. Ainsi, dans un cas classique, lorsque les paramètres sont directement les éléments des tables, des algorithmes incluant des contraintes d’égalité entre des éléments distincts des tables de probabilité de transition ont été étudiés (Niculescu et al., 2006). Cependant ces algorithmes ne sont pas applicables lorsque les probabilités de transitions sont représentées par une fonction paramétrée. Dans le cas non paramétré, lorsque la structure du RBD est connue, l’expression des estimateurs de maximum de vraisemblance de probabilité de transition depuis des données de comptage est analytique (Murphy, 2002). En revanche, la solution du maximum de vraisemblance n’a plus d’expression analytique dans le cadre des RBD étiquetés, les tables n’étant plus indépendantes.
L’apprentissage de structure pour un jeu de paramètres donné doit également être géré différemment. Tout d’abord, il faut apprendre l’étiquetage des arêtes en plus de leur présence. De plus, les fonctions de score qui combinent un terme de mesure de bonne modélisation des données par le réseau et un terme de pénalité de la complexité du modèle (comme le score BIC (Schwarz, 1978) par exemple), ne sont plus pertinentes dans un RBD-E où le nombre de paramètres est indépendant de la structure du graphe. Le score BDe (Heckerman et al., 1995) n’est pas plus pertinent car l’hypothèse d’indépendance entre les paramètres dans les différentes tables n’est pas vérifiée dans le cas d’un RBD-E.
Nous proposons ici une procédure générique pour apprendre la structure, les étiquettes des arcs et les paramètres d’un RBD-E. Cette approche améliore la vraisemblance du modèle de façon itérative en alternant l’apprentissage de la structure du réseau et l’estimation des paramètres définissant les probabilités de transition. Cette procédure est présentée en section 2. Ensuite, en section 3, nous modélisons dans le cadre des RBD-E un problème spécifique d’apprentissage d’un réseau d’interactions écologiques à partir de séries temporelles de présence ou d’absence d’espèces. Nous développons une version de notre procédure où la phase d’estimation des paramètres se fait par une méthode classique de maximisation de vraisemblance résolue numériquement, tandis que la phase d’apprentissage de la structure (et des étiquette des arcs) est modélisée comme un problème de programmation linéaire en nombre entiers 0-1(Korhonen, Parviainen, 2015). Cette procédure est présentée en section 4. Des résultats expérimentaux sont présentés en section 5.
2.1. Réseau Bayésien Dynamique
Considérons un ensemble de n processus aléatoires sur T pas de temps successifs $\left\{\left(X_{1}^{t}\right)_{t=1, \ldots T}, \ldots,\left(X_{n}^{t}\right)_{t=1, \ldots T}\right\}$. $X_{i}^{t}$ est une variable aléatoire prenant des valeurs binaires ($X_{i}^{t} \in\{0,1\}$ qui représente l’état du processus $X_{i}^{t}$ à l’instant t. Dans un modèle de RBD (Friedman et al., 1998), la dynamique de X est markovienne : l’état du système à un instant t +1 est indépendant de l’état du système à l’instant t − 1 conditionnellement à son état au temps t. Les RBD modélisent également un phénomène homogène sur le temps : la probabilité de transition du processus aléatoire est la même à chaque pas de temps. De plus, il existe des indépendances locales entre les variables qui sont exploitées dans l’expression de cette probabilité de transition.
Les indépendances locales entre les variables sont représentées par un graphe acyclique $\mathcal{G}=(V, E)$ entre deux ensembles de noeuds, tous deux indexés par {1, . . . , n} et représentant les variables $\left\{X_{1}^{t}, \ldots, X_{n}^{t}\right\}$ et $\left\{X_{1}^{t+1}, \ldots, X_{n}^{t+1}\right\}$. Dans G, les arêtes sont orientées des noeuds correspondant à l’instant t ou t + 1 vers les noeuds à l’instant t + 1. Toute variable $X_{i}^{t+1}$ est indépendante de l’ensemble des variables $\left\{X_{1}^{t-1}, \ldots, X_{n}^{t-1}\right\}$ sanchant les variables $\left\{X_{1}^{t}, \ldots, X_{n}^{t}\right\}$. Le processus étant markovien et homogène, les indépendances temporelles entre les variables ne dépendent pas de t. L’ensemble des parents d’une variable $X_{i}^{t+1}$ dans G est défini de la manière suivante : $\operatorname{Par}(i, \mathcal{G})=\{j,(j, i) \in E\}$. Il existe des RBD dans lequels aucun arc synchrone n’existe dans G, c’est à dire que $\forall i, j \in\{1, \ldots, n\}$, il n’existe aucun arc de $X_{j}^{t}$ vers $X_{i}^{t}$. Seuls des arcs de $X_{j}^{t+1}$ vers $X_{i}^{t+1}$ sont possibles. Cela rend ce type de RBD naturellement acyclique. Dans un tel RBD, la distribution des probabilités de transition est factorisée selon $\operatorname{Par}(i, \mathcal{G}) : P\left(X^{t+1} | X^{t}\right)=\prod_{i=1}^{n} P_{i}\left(X_{i}^{t+1} | X_{\operatorname{Par}(i, \mathcal{G})}^{t}\right)$. La figure 1 est une représentation graphique de G pour un exemple de RBD asynchrone avec n=4 noeuds pour 3 premiers pas de temps d’un phénomène.
Figure 1. Représentation des trois premiers pas de temps d’un phénomène modélisé par un réseau bayésien dynamique asynchrone avec 4 noeuds
Dans un problème dans lequel peu de données sont disponibles et des connaissances expertes sur le type d’interactions entre les variables permettent d’aider à la modélisation du problème de RBD, nous proposons un cas particulier de RBD avec un nombre réduit de paramètres.
2.2. Réseau bayésien dynamique étiqueté
Comme cela peut être le cas dans les processus de contact en épidémiologie (Franc, 2004), lorsque les connaissances expertes informent d’une influence similaire de certains liens d’interaction, il est possible de réduire le nombre de paramètres du modèle en décrivant les probabilités de transition individuelles comme des fonctions d’un nombre réduit et fixe de paramètres.
Un tel modèle est un réseau bayésien dynamique étiqueté, défini comme un réseau bayésien dynamique particulier tel que:
– Il n’existe aucun arc synchrone : tous les arcs du graphe associés vont de $X_{t}^{i}$ vers $X_{i}^{t+1}$.
– La représentation graphique des indépendances conditionnelles se fait sous la forme d’un graphe étiqueté noté $\mathcal{L} G$. Un graphe étiqueté est un graphe dans lequel chaque arc possède une étiquette parmi L étiquettes possibles à l’exception d’éventuels arcs de $X_{t}^{i}$ vers $X_{i}^{t+1}$. L’ensemble des parents d’un noeud i du graphe $\mathcal{L} \mathcal{G}$ connectés par des arcs d’une même étiquette l est noté $\operatorname{Par}^{l}(i, \mathcal{L} \mathcal{G})$.
– On suppose que deux noeuds parents de type l de i, c’est à dire appartenant à $\operatorname{Par}^{l}(i, \mathcal{L} \mathcal{G})$ ont une influence similaire sur i. De ce fait, la distribution de probabilité de l’état $X_{i}^{t+1}$ ne dépend que du nombre de parents de chaque étiquette de chaque état au temps t et de l’état de $X_{i}^{t}$ si un arc existe entre $X_{i}^{t}$ et $X_{i}^{t+1}$.
– Deux individus i et j ayant le même nombre de parents de chaque type, soit tels que $\operatorname{card}\left(\operatorname{Par}^{l}(i, \mathcal{L} \mathcal{G})\right)=\operatorname{card}\left(\operatorname{Par}^{l}(j, \mathcal{L} \mathcal{G})\right)$ pour tout l∈ L ont des tables de probabilité de transition identiques.
– La table de probabilités de transition d’un individu i peut être exprimée comme une fonction d’un ensemble de paramètres $\theta$ de taille restreinte. On comptera un paramètre par étiquette, ainsi qu’un éventuel paramètre supplémentaire modélisant des transitions indépendantes des états des parents.
Le cadre des RBD-E peut être utilisé pour tout phénomène que l’on peut modéliser par un réseau bayésien dynamique dont les liens entre les variables aléatoires sont étiquetées, de telle sorte que l’impact du lien d’une variable aléatoire sur une autre n’est dépendant que de l’étiquette de ce lien. C’est le cas par exemple dans des modèles d’épidémiologie par contact de type SIS, où la probabilité d’infection chez un individu n’est fonction que du nombre de voisins infecté. Il est possible de modéliser un tel phénomène comme un RBD-E à une seule étiquette.
Nous allons illustrer plus précisément le cas où seuls deux types d’interactions entre deux variables $X_{i}^{t}$ et $X_{j}^{t+1}$ sont possibles : les interactions positives +, qui augmentent les probabilité que $X_{j}^{t+1}=1$ et négatives − qui diminuent cette probabilité. Nous considérerons le graphe $\mathcal{L} \mathcal{G}=\left(V,\left(E_{+}, E_{-}\right)\right)$, une extension du graphe $\mathcal{G}$ où les arcs sont étiquetés. L’ensemble d’arcs E+ comprend ceux ayant l’étiquette + et qui décrivent une interaction positive et l’ensemble d’arcs E− comprend ceux ayant l’étiquette − et qui décrivent une interaction négative. À partir de $\mathcal{L} \mathcal{G}$, définissons l’ensemble des parents d’étiquette +, $\operatorname{Par}^{+}(i, \mathcal{L} \mathcal{G})$, et les parents d’étiquette −, $\operatorname{Par}^{-}(i, \mathcal{L} \mathcal{G})$ d’un noeud i. $\operatorname{Par}(i, \mathcal{L} \mathcal{G})$ est l’union de ces ensembles.
Les tables de probabilité de transition d’une variable $X_{i}^{t}$ prennent la forme : $P_{i, \theta}\left(X_{i}^{t+1} | X_{\operatorname{Par}(i, \mathcal{L} \mathcal{G})}^{t}\right)$ où $\theta$ est un vecteur de paramètres partagés par toutes les tables de probabilité de transition individuelles, comme décrit dans le cadre des RBD-E. On trouve dans $\theta$ un paramètre par type d’influence, positive et négative, ainsi qu’un paramètre de transition indépendant des parents.
Avec une telle représentation, les probabilités de transition de ce modèle peuvent être modélisées d’une manière très concise, par une fonction, en ne spécifiant que le graphe $\mathcal{L} \mathcal{G}$ (ou les ensembles $\operatorname{Par}^{+}(i, \mathcal{L} \mathcal{G})$ et $\operatorname{Par}^{-}(i, \mathcal{L} \mathcal{G})$, ainsi que le vecteur $\theta$ des paramètres. L’un des avantages d’utiliser cette représentation des probabilités est que l’on a moins de paramètres à apprendre à partir des données (c’est à dire l’observation des trajectoires des variables $\left(X_{i}^{t}\right)$) que dans un modèle de RBD classique ce qui est particulièrement intéressant lorsque peu de données sont disponibles.
2.3. Apprentissage dans un RBD-E
Apprendre un RBD-E consiste à apprendre à la fois sa structure $\mathcal{L} \mathcal{G}$ et ses paramètres $\theta$ à partir de donnéesD correspondant à l’ensemble des observations de chaque espèce à chaque pas de temps, $D=\left\{\left(x_{i}^{t}\right)\right\}_{i=1, \ldots, n ; t=1, \ldots, T}$. Nous considérons un apprentissage par maximum de vraisemblance non modifié plutôt qu’un score pénalisé, une pénalité sur la complexité du modèle n’ayant pas de sens avec un nombre fixe de paramètres. De ce fait, utiliser la vraisemblance non pénalisée ne risque pas de faire du surapprentissage. La vraisemblance $P_{\mathcal{L} \mathcal{G}, \theta}(D)$ des données D pour un graphe donné $\mathcal{L} G$ et un ensemble de valeurs de paramètres $\theta$ est défini comme:
$P_{\mathcal{L} \mathcal{G}, \theta}(D)=\prod_{t=1}^{T-1} \prod_{i=1}^{n} P_{\theta}\left(x_{i}^{t+1} | x_{\operatorname{Par}(i, \mathcal{L} \mathcal{G})}^{t}\right)$ (1)
Le problème d’apprentissage revient à trouver $\hat{\mathcal{L} \mathcal{G}}$ et $\hat{\theta}$ qui maximisent conjointement $\log \left(P_{\mathcal{L} \mathcal{G}, \theta}(D)\right)$.
Considérons une procédure itérative générale définie par l’algorithme 1 pour obtenir un maximum local de $\log \left(P_{\mathcal{L} \mathcal{G}, \theta}(D)\right)$.
Algorithme 1. Procédure d’apprentissage de RBD-E par fonction de score
Cet algorithme est très général, et peut être initialisé par un jeu de paramètres initiaux au lieu d’un graphe initial (les deux étapes sont alors inversées). Les deux étapes doivent être spécifiées pour un problème d’apprentissage de RBD-E donné pour pouvoir implémenter cet algorithme. Toutefois, pour n’importe quelle implémentation de cet algorithme, la proposition suivante est vérifiée:
PROPOSITION 1. — La procédure d’apprentissage d’un RBD-E converge vers un maximum local de la log-vraisemblance jointe, $\log \left(P_{\mathcal{L} \mathcal{G}, \theta}(D)\right)$.
Élément de preuve:
– Les étapes (1) et (2) augmentent conjointement la log-vraisemblance :
- L’étape (1) se construit de telle manière que les paramètres $\theta^{(k)}$ sont estimés pour maximiser $\log \left(P_{\mathcal{L} \mathcal{G}^{(k)}, \theta}(D)\right)$ pour un réseau $\mathcal{L} \mathcal{G}^{(k)}$. Il n’existe pas de jeu de paramètres $\theta^{(x)} \neq \theta^{(k)}$ tel que $\log \left(P_{\mathcal{L} \mathcal{G}, \theta^{(x)}}(D)\right)>\log \left(P_{\mathcal{L} \mathcal{G}, \theta^{(k)}}(D)\right)$.
- L’étape (2) se construit de telle manière qu’un graphe $\mathcal{L} \mathcal{G}^{(k+1)}$ ait une vraisemblance $\mathcal{L} \mathcal{G}^{(k+1)} \geq \log \left(P_{\mathcal{L} \mathcal{G}, \theta^{(k)}}(D)\right)$
- Ainsi, $\log \left(P_{\mathcal{L} \mathcal{G}^{(k+1)}, \theta^{(k+1)}}(D)\right) \geq \log \left(P_{\mathcal{L} \mathcal{G}^{(k)}, \theta^{(k)}}(D)\right), \forall k$
– Si il existe un k tel que $\mathcal{L} \mathcal{G}^{(k+1)}=\mathcal{L} \mathcal{G}^{(k)}$, alors $\theta^{(k+1)}=\theta^{(k)}$, dans ce cas, l’algorithme a convergé.
– Si $\mathcal{L} \mathcal{G}^{(k+1)} \neq \mathcal{L} \mathcal{G}^{(k)}, \mathcal{L} \mathcal{G}^{(k)}$ ne peut pas à nouveau être une solution d’un pas de temps suivant k′ > k.
– Puisque l’espace des graphes possibles est fini, il existe forcément un k tel que on a $\mathcal{L} \mathcal{G}^{(k+1)}=\mathcal{L} \mathcal{G}^{(k)}$.
3.1. Structure d’un réseau écologique
Un réseau écologique décrit les interactions entre les espèces vivantes d’un milieu donné. Ces interactions peuvent être de natures différentes : trophiques (proie/prédateur), parasitiques, de compétition... La dynamique des espèces résulte en grande partie de ces différentes interactions. On distinguera deux grands types d’interactions : les interactions positives qui facilitent la survie des espèces, et les interactions négatives qui la pénalisent. La structure d’un réseau écologique peut être représentée par un graphe orienté $\mathcal{E} \mathcal{G}$ avec n noeuds (un par espèce du système). Un arc d’une espèce i vers une espèce j représente l’influence de l’espèce i sur la dynamique de j. Un arc de i vers j est étiqueté afin de caractériser la nature de l’influence. Une étiquette "+" décrit une influence positive de l’espèce i sur la probabilité de survie de l’espèce j. Ainsi, i peut être une proie ou un facilitateur (par exemple, une espèce végétale qui abrite une espèce animale) de j. Une étiquette "−" décrit une influence négative de l’espèce i sur la probabilité de survie de l’espèce j. Ainsi, i peut être un prédateur, un parasite ou un compétiteur de j. Dans ce cas d’étude, nous faisons l’hypothèse qu’il existe au maximum un seul type d’interaction d’une espèce i vers une espèce j (une espèce ne peut pas avoir à la fois une influence positive et négative sur une autre). Des combinaisons de ces deux types d’interactions permettent de représenter des formes d’interactions plus complexes : une interaction positive i → j couplée à une interaction négative j → i peut représenter une relation trophique (proie/prédateur) ou parasitique ; une interaction négative i → j couplée à une autre interaction négative j → i peut représenter une compétition entre ces deux espèces.
La figure 2 (gauche) est un exemple de représentation d’un réseau écologique à 4 espèces dans lequel l’espèce 1 est une proie des espèces 2 et 4, l’espèce 2 est une proie de l’espèce 3 et l’espèce 1 un facilitateur de l’espèce 3.
Figure 2. Représentation d’un réseau écologique modélisé par un RBD. Gauche : Graphe $\mathcal{G}$ de la structure d’un réseau écologique où les arêtes colorés en vert correspondent à un influence positive et les arêtes colorés en rouge à une influence négative. Droite : Graphe $\mathcal{L} \mathcal{G}_{\rightarrow}$ de la structure de transition associé à ce réseau, dans lequel les arêtes colorés en noir décrivent la dynamique locale des espèces (survie, extinction ou recolonisation). Ces arêtes, directement déduites des données, ne sont pas estimées
Pour apprendre un réseau écologique, nous disposons d’observations d’absence $\left(x_{i}^{t}=0\right)$ ou de présence $\left(x_{i}^{t}=1\right)$ d’espèces $i \in\{1, \ldots, n\}$ au temps $t \in\{1, \ldots, T\}$. Nous disposons également d’informations sur le fait que la zone observée est protégée $\left(a^{t}=1\right)$ ou non $\left(a^{t}=0\right)$ à chaque instant. Cette information est un ajout par rapport au modèle de RBD-E décrit précédemment. at prend dans ce modèle la forme d’une observation non aléatoire et connue à l’avance pour chaque pas de temps. Cette information va modifier les probabilités de survie des espèces et son effet est le même sur toutes les espèces à un pas de temps donné.
Chaque observation $x_{i}^{t}$ est modélisée comme la réalisation d’une variable aléatoire $X_{i}^{t} \in\{0,1\}$. Pour cela, nous modélisons la dynamique des espèces dans le cadre des RBD-E. À partir d’un graphe $\mathcal{E} \mathcal{G}$ représentant le réseau écologique, nous définissons $\mathcal{L} \mathcal{G}$ : Lorsque $i \neq j$, il existe un arc de $X_{i}^{t}$ vers $X_{j}^{t+1}$ si et seulement si un arc de i vers j existe dans $\mathcal{E} \mathcal{G}$. La présence/absence d’une espèce i à l’instant t (représentée par la variable $X_{i}^{t}$) influence son état à l’instant t+1 (représenté par la variable $X_{i}^{t+1}$). Cette influence se décrit par l’existence d’un arc de $X_{i}^{t}$ vers $X_{i}^{t+1}$ pour tout i et tout instant t. Néanmoins, cet arc n’est pas labellisé, et n’est associé à aucun paramètre dans le modèle et est supposé connu (il n’a pas à être appris). Nous définissons alors respectivement $P a r^{+}(i, \mathcal{L} \mathcal{G}) \subset\{1, \ldots, n\}$ et $\operatorname{Par}^{-}(i, \mathcal{L} \mathcal{G}) \subset\{1, \ldots, n\}$ comme l’ensemble des espèces ayant une influence positive et négative sur i. $\operatorname{Par}(i, \mathcal{L} \mathcal{G})=$$\operatorname{Par}^{+}(i, \mathcal{L} \mathcal{G}) \cup \operatorname{Par}^{-}(i, \mathcal{L} \mathcal{G}) \cup\{i\}$. La Figure 2 montre un réseau écologique $\mathcal{E} \mathcal{G}$ et le graphe $\mathcal{L} G$ correspondant dans le modèle de RBD-E.
Chaque probabilité de transition individuelle dans le RBD est définie à partir d’une fonction d’un vecteur de paramètres $\theta=\left(\varepsilon, \rho^{+}, \rho^{-}, \mu\right)$ avec $\varepsilon$, la probabilité de recolonisation, $\rho^{+}, \rho^{-}$, les probabilités de succès des influences positives et négatives, et $\mu \in[0,1]$ un facteur de pénalité appliqué à la probabilité de recolonisation et à la probabilité de survie des espèces lorsque la zone observée n’est pas protégée. Dans ce modèle, nous supposons que (a) une espèce survit si et seulement si au moins l’une de ses influences positives réussit et toutes ses influences négatives échouent; (b) une espèce dont $\operatorname{Par}^{+}\left(i, \mathcal{L} \mathcal{G}_{\rightarrow}\right)$ est vide (une espèce en bas de la chaîne alimentaire par exemple) ne peut s’éteindre si la zone est protégée et aucune espèce dans $\operatorname{Par}^{-}\left(i, \mathcal{L} \mathcal{G}_{\rightarrow}\right)$ (aucune influence négative) n’est présente; et (c) une espèce dont l’ensemble $\operatorname{Par}^{+}\left(i, \mathcal{L} \mathcal{G}_{\rightarrow}\right)$ n'est pas vide ne peut pas survivre si aucune espèce dans $\operatorname{Par}^{+}\left(i, \mathcal{L} \mathcal{G}_{\rightarrow}\right)$ (l’ensemble de ses proies et de ses facilitateurs) n’est présente.
3.2. Probabilités de transition individuelles
Décrivons maintenant les probabilités de transition des espèces. Nous exprimons ici la probabilité présence $P\left(X_{i}^{t+1}=1 | x_{i}^{t}, a^{t}\right)$ d’une espèce i au temps t, sa probabilité d’absence se déduisant facilement : $P\left(X_{i}^{t+1}=0 | x_{i}^{t}, a^{t}\right)=1-P\left(X_{i}^{t+1}=1 | x_{i}^{t}, a^{t}\right)$. Considérons tout d’abord le cas où la zone observée est protégée (at= 1). Deux situations sont possibles:
(i) La probabilité pour une espèce absente au temps t de recoloniser la zone observée au temps t +1 est considérée dans ce modèle comme indépendante de la présence des autres espèces, et est définie comme:
$P\left(X_{i}^{t+1}=1 | X_{i}^{t}=0, a^{t}=1\right)=\varepsilon$ (2)
(ii) Soit $N_{i,+}^{t}=\left|\left\{j \in \operatorname{Par}^{+}\left(i, \mathcal{L} \mathcal{G}_{\rightarrow}\right), X_{j}^{t}=1\right\}\right|$ et $N_{i,-}^{t}=|\left\{j \in \operatorname{Par}^{-}\left(i, \mathcal{L} \mathcal{G}_{\rightarrow}\right)\right.$$\left.X_{j}^{t}=1\right\} |$, la probabilité pour une espèce présente à t de survivre à t + 1 correspond à la probabilité de succès d’au moins une influence positive (si besoin) et à l’échec de toutes les influences négatives. La probabilité de succès d’une influence positive est désignée comme $\rho^{+}$. Sur l’ensemble des parents à influence positive d’une espèce i à un instant t, la probabilité qu’au moins l’une d’entre elles réussissent est $1-\left(1-\rho^{+}\right)^{N_{i,+}^{t}}$ (exprimée comme l’inverse de l’échec de chaque influence positive). La probabilité de succès d’une influence négative est désignée comme $\rho^{-}$. Sur l’ensemble des parents à influence négative d’une espèce i à un instant t, la probabilité que toutes échouent est $\left(1-\rho^{-}\right)^{N_{i,-}^{t}}$. La probabilité de survie d’une espèce peut être exprimée par les équations (3) et (4). Lorsque la zone observée n’est pas protégée (at= 0), les probabilités de transitions 2), (3) et (4) sont multipliées par μ, qui décrit la baisse de probabilité de survie/recolonisation.
$P\left(X_{i}^{t+1}=1 | X_{i}^{t}=1, x_{P a r^{-}}^{t}-\left(i, \mathcal{G}_{\rightarrow}\right)^{, a^{t}}=1\right)=$$\left(1-\rho^{-}\right)^{N_{i,-}^{t}}-$ si $\operatorname{Par}^{+}\left(i, \mathcal{G}_{\rightarrow}\right)=\emptyset$ (3)
$P\left(X_{i}^{t+1}=1 | X_{i}^{t}=1, x_{\operatorname{Par}^{+}\left(i, \mathcal{G}_{-}\right)}^{t}, x_{\operatorname{Par}^{-}}^{t}\left(i, \mathcal{G}_{\rightarrow}\right), a^{t}=1\right)=$$\left(1-\left(1-\rho^{+}\right)^{N_{i,+}^{t}}\right)\left(1-\rho^{-}\right)^{N_{i}^{t}-} \operatorname{si} \operatorname{Par}^{+}\left(i, \mathcal{G}_{\rightarrow}\right) \neq \emptyset$ (4)
Un tel modèle est un cas particulier de modèle d’indépendance causale (Jurgelenaite, Lucas, 2005). En effet, comme dans un modèle de type Noisy-OR (Vomlel, 2015), la probabilité d’occurrence d’une variable $X_{i}$ est calculée à l’aide d’une fonction qui exploite l’indépendance causale entre les parents de $X_{i}$ pour diminuer le nombre de paramètres. Mais ce modèle va plus loin que le modèle Noisy-OR dans cette simplification en considérant qu’il n’existe qu’un nombre l de valeurs de probabilité conditionnelle $P\left(X_{i} | X_{j}\right), j \in \operatorname{Par}^{l}\left(j, \mathcal{L} \mathcal{G}_{\rightarrow}\right)$ possible. Dans le cas d’un modèle de réseau bayésien étiqueté avec une seule étiquette, $P\left(X_{i} | X_{j}\right)=P\left(X_{i} | X_{k}\right) \forall j, k \neq i$.
L’utilisation d’interactions négatives ajoute une particularité au modèle de RBD-E décrit en section 2.2. En effet, si les interactions positives se comportent de la même manière qu’un modèle Noisy-OR pour représenter les probabilités conditionnelles des variables du graphe, les interactions négatives agissent sur les probabilités conditionnelles comme un modèle Noisy-AND. Le problème de caractérisation des arcs en interactions positives ou négatives existe dans le cadre des réseaux bayésiens qualitatifs (Wellman, 1990), mais une telle structure étiquetée est utilisée pour apprendre les paramètres d’un réseau bayésien en contraignant les tables de probabilités conditionnelles apprises (Feelders, Gaag, 2006).
3.3. Discussion sur les hypothèses du modèle
Le modèle utilisé pour représenter un réseau écologique est basé sur plusieurs hypothèses écologiques. Ces hypothèses peuvent s’éloigner de la réalité écologique, mais restent raisonnables au regard des informations contenues dans les données d’entrée que l’on souhaite traiter, et permettent de décrire la dynamique des espèces du réseau par un modèle de réseau bayésien étiqueté. Certaines peuvent être assouplies si nécessaire, nécessitant un ajustement du modèle.
Dynamique temporelle : la dynamique des espèces s’observe sous la forme de séries temporelles de présence ou d’absence des espèces au cours du temps. Lever cette contrainte nécessite de définir un modèle de réseau bayésien étiqueté non-dynamique, qui n’est pas décrit dans ce papier.
Uniformité de l’impact de la protection : l’impact de la protection de la zone observée est le même pour toutes les espèces. Cette hypothèse est valide pour notre application, où l’on souhaite un effet global de la protection de la zone, mais il est parfaitement possible d’associer l’information de protection à une espèce, ce qui ne modifiera les probabilités de recolonisation et de survie que pour cette espèce.
Modèle à deux étiquettes : un réseau écologique représente deux types d’interactions : des interactions positives, facilitant la survie des espèces et des interactions négatives, qui la pénalise. L’intensité d’une relation écologique n’est indiquée que par son type. Une interaction positive ou négative a le même effet que n’importe quelle autre du même type, quelles que soient les espèces en interaction. Il est possible d’affiner le modèle en intégrant d’autres interaction, avec différentes forces, ce qui se traduira par plus d’étiquettes dans le modèle de RBD-E. Nous avons choisi dans notre modèle de ne retenir que deux étiquettes afin de garder une complexité algorithmique peu élevée.
Indépendance causale : la probabilité de survie d’une espèce à un instant donné dépend uniquement du nombre d’influences positives et négatives reçues par cette espèce à cet instant. Cette hypothèse est inhérente à notre modèle de RBD-E. Elle reste interprétable écologiquement. Par exemple, une espèce ayant beaucoup d’influences positives dans le réseau écologique est une espèce "généraliste", tandis qu’une espèce ayant peu d’influences positives est une espèce "spécialiste". Une espèce généraliste n’a pas besoin de la présence de toutes les espèces ayant une influence positive pour survivre, tant qu’elle arrive à se nourrir sur l’une de ses proies présentes (si ses influences positives représentent des proies).
Modèle asynchrone : l’état d’une espèce à un instant donné ne dépend que de l’état de cette espèce et de ses parents à l’instant précédent. Nous négligeons les interactions synchrones entre espèces. Cela permet de simplifier grandement l’algorithme d’apprentissage, notamment en évitant une phase de vérification d’acyclicité nécessaire à l’apprentissage de réseaux bayésiens.
Pas d’arc étiqueté intra-espèce : aucune espèce n’a d’interaction écologique avec elle-même. En pratique, les interactions d’une espèce vers elle-même sont souvent décrit entre différent stades de développement d’une espèce (il peut exister du cannibalisme entre une espèce au stade adulte et une espèce au stade larvaire ou juvénile). Dans ce cas, on préférera considérer des noeuds distincts pour chaque stade de ces espèces. La prise en compte d’arcs d’une espèce vers elle-même complique l’interprétation du modèle et l’algorithme d’apprentissage. Nous avons donc choisi de ne pas les inclure.
Décrivons maintenant comment construire un algorithme itératif pour l’apprentissage de la structure d’un réseau écologique et des paramètres de la dynamique des espèces à partir de la procédure d’apprentissage générique de la section 2.2. L’algorithme d’apprentissage de structure de RBD-E proposé alterne deux étapes. L’étape de maximisation de la vraisemblance des paramètres pour une structure de graphe donnée utilise la méthode des points intérieurs dans le cadre de la programmation non linéaire (Byrd et al., 1999). Pour la deuxième étape, nous formulons la maximisation de la vraisemblance du graphe comme un problème de programmation linéaire en nombres entiers en introduisant des variables supplémentaires servant à décrire le réseau et à faire le lien entre le réseau et les données. Avant de détailler cette deuxième étape, décrivons l’expression de la log-vraisemblance du modèle.
4.1. Vraisemblance du modèle
Pour exprimer la vraisemblance du modèle, nous distinguons les espèces dont l’ensemble $\operatorname{Par}^{+}(i, \mathcal{L} \mathcal{G})$ n’est pas vide (les espèces non basales nb) des autres (les espèces basales b, soit celles sans parents à influence positive). Nous définissons également la quantité $R_{i, V}^{t, d^{+}, d^{-}}$, une variable binaire modélisant le fait que l’espèce i de type V a exactement d+ proies (ou autre influence positive) et d− prédateurs (ou autre influence négative) présents à l’instant t. $R_{i, V}^{t, d^{+}, d^{-}}$ est égal à 1 si et seulement si l’espèce i est de type $V \in\{n b, b\}$ et que au temps t, $N_{i,+}^{t}=d^{+}, N_{i,-}^{t}=d^{-} ; R_{i, V}^{t, d^{+}, d^{-}}$ est égal à 0 sinon. Par convention, pour une espèce basale, nous définissons $N_{i,+}^{t}=0$. Nous admettons également que le nombre maximum d’arêtes vers un noeud i est fixé à une quantité k. La log-vraisemblance d’un jeu de données $D=\left\{x^{1}, \ldots, x^{T}\right\}$ peut être décomposée en une somme de scores locaux ($P_{\mathcal{L} \mathcal{G}, \theta}\left(x^{1}\right)$ n’est pas estimé.): $\log P_{\mathcal{L} \mathcal{G}, \theta}\left(x^{2}, \ldots, x^{T} | x^{1}, a\right)=$$\sum_{i=1}^{n} \operatorname{score}(i)$.
La fonction score(i) est la contribution d’une espèce i à la log-vraisemblance. L’expression du score d’une espèce i est donnée par l’équation (5).
$\operatorname{score}(i)=\sum_{t=1}^{T-1}$$\left(\begin{array}{c}{\left(1-x_{i}^{t}\right) \cdot \log \left(P_{0}^{t}\left(x_{i}^{t+1}\right)\right)} \\ {+x_{i}^{t} \cdot \sum_{d^{+}}^{k}=0 \sum_{d^{-}=0}^{k-d^{+}}\left(\begin{array}{c}{\log \left(P_{1,+}^{t, d^{+}}, d^{-}\left(x_{i}^{t+1}\right)\right) \cdot R_{i, n b}^{t, d^{+}, d^{-}}} \\ {+\log \left(P_{1, b}^{t, 0, d^{-}}\left(x_{i}^{t+1}\right)\right) \cdot R_{i, b}^{t, 0, d^{-}}}\end{array}\right)}\end{array}\right)$ (5)
Ce score est une somme d’éléments décrivant la dynamique de l’espèce i à un temps t et la probabilité associée à ces dynamiques. À un instant t donnée, un seul élément de la dynamique de i n’est pas nul parmi ceux décrits ci-dessous :
1. Si l’élément $\left(1-x_{i}^{t}\right)$ n’est pas nul (l’espèce i est présente au temps t), seule la probabilité de recolonisation de cette espèce sera exprimée au temps t + 1, les autres étant multipliées par 0.
2. Pour tout d+, d−, un élément $R_{i, n b}^{t, d^{+}, d^{-}}$ n’est pas nul si et seulement si l’espèce i est présente au temps t et n’est pas basale. Si cet élément n’est pas nul, seule la probabilité de survie de l’espèce non basale i sera exprimée au temps t + 1, les autres étant multipliées par 0.
3. Pour tout d−, un élément $R_{i, b}^{t, 0, d^{-}}$ n’est pas nul si l’espèce i est présente au temps t et est basale. Dans le cas contraire, tous ces éléments valent 0 quel que soit d+, d−. Si cet élément n’est pas nul, seule la probabilité de survie de l’espèce basale i sera exprimée au temps t + 1, les autres étant multipliées par 0.
Les probabilités associées aux termes $R_{i, n b}^{t, d^{+}, d^{-}}$ et $R_{i, b}^{t, 0, d^{-}}$ sont données par les équations 6 et 7.
$\log \left(P_{0}^{t}\left(x_{i}^{t+1}\right)\right)=\begin{array}{l}{x_{i}^{t+1} \cdot a^{t} \cdot \log \varepsilon+\left(1-x_{i}^{t+1}\right) \cdot a^{t} \cdot \log (1-\varepsilon)} \\ {+x_{i}^{t+1} \cdot\left(1-a^{t}\right) \cdot \log (\mu \varepsilon)+\left(1-x_{i}^{t+1}\right) \cdot\left(1-a^{t}\right) \cdot \log (1-\mu \varepsilon)}\end{array}$ (6)
$\begin{aligned} & x_{i}^{t+1} \cdot a^{t} \cdot \log \left(P_{1}^{1} V_{1}\left(d^{+}, d^{-}\right)\right) \\ \log \left(P_{1, V}^{t, d^{+}}, d^{-}\left(x_{i}^{t+1}\right)\right)=&+\left(1-x_{i}^{t+1}\right) \cdot a^{t} \cdot \log \left(P_{1 \rightarrow 0}^{1 V}\left(d^{+}, d^{-}\right)\right) \\ &+x_{i}^{t+1} \cdot\left(1-a^{t}\right) \cdot \log \left(P_{1 \rightarrow 1}^{0}\left(d^{+}, d^{-}\right)\right) \\ &+\left(1-x_{i}^{t+1}\right) \cdot\left(1-a^{t}\right) \cdot \log \left(P_{1 \rightarrow 0}^{0 V}\left(d^{+}, d^{-}\right)\right) \end{aligned}$ (7)
où $P_{1 \rightarrow x_{i}^{t+1}}^{a^{t} V}\left(d^{+}, d^{-}\right)$ est la probabilité de transition de $x_{i}^{t}=1$ vers $x_{i}^{t+1}$ pour l’espèce i de type V sous l’action de protection at, lorsque d+ de ses influences positives et d− de ses influences négatives sont présentes. Ces probabilités sont décrites par les équations (3) et (4). L’intérêt de cette expression de la log-vraisemblance est qu’il s’agit d’une fonction linéaire des variables $\left\{R_{i, V}^{t, d^{+}, d^{-}}\right\}$ étant donné les données $\left\{x_{i}^{t}\right\}$, {at} et les paramètres $\left(\varepsilon, \rho^{+}, \rho^{-}, \mu\right)$ du modèle. Nous exploitons cela dans la section 4.2, pour construire la fonction objectif du PLNE-0/1. Avec une structure de réseau fixée, la vraisemblance est une fonction continue des paramètres $\theta$. L’estimation de ces paramètres peut être résolue par une méthode d’optimisation classique.
4.2. Apprentissage de la structure du graphe à paramètres connus
Cette étape consiste à apprendre la structure d’un réseau qui maximise la logvraisemblance à paramètres fixés. Décrivons un réseau par deux ensembles de variables binaires : $\left\{g_{i j}^{+}\right\}_{1 \leq i, j \leq n}$ et $\left\{g_{i j}^{-}\right\}_{1 \leq i, j \leq n}$, tels que $g_{i j}^{l}=1$ si et seulement si $j \in$$\operatorname{Par}^{l}(i, \mathcal{L} \mathcal{G})$, pour $l \in\{+,-\}$. Ainsi, le problème d’optimisation consiste à optimiser la vraisemblance sur les variables $\left\{g_{i j}^{+}\right\}_{1 \leq i, j \leq n}$ et $\left\{g_{i j}^{-}\right\}_{1 \leq i, j \leq n}$.
Toutefois, l’expression de la log-vraisemblance à partir de l’expression (5) ne dépend pas explicitement de ces variables. En effet, elle est exprimée à partir des variables $\left\{R_{i, V}^{t, d^{+}, d^{-}}\right\}$, elles-mêmes fonction des variables $g_{i j}^{l}$ ainsi que des données observées D. Nous montrons ici une manière de définir les variables $\left\{R_{i, V}^{t, d^{+}, d^{-}}\right\}$ à partir de contraintes linéaires impliquant les variables binaires $\left\{g_{i j}^{l}\right\}$, des variables binaires intermédiaires ainsi que les données observées D. Pour cela, nous définissons un problème de programmation linéaire que l’on peut résoudre par des solveurs classiques. Puisque la log-vraisemblance se décompose en scores indépendants, le problème de programmation linéaire est décomposable en sous-problèmes par espèce, permettant de paralléliser la résolution du problème global. Un problème de programmation linéaire pour une espèce i décrit les arêtes pointant vers i qui maximisent la quantité score(i). Nous décrivons ci-dessous des variables binaires intermédiaires qu’il est nécessaire d’introduire afin d’exprimer $\left\{R_{i, V}^{t, d^{+}, d^{-}}\right\}$ pour une espèce i donnée.
Test de basalité : cette première variable auxiliaire binaire (0-1) est ajoutée pour identifier si l’espèce i est basale ou non. Elle est définie de la façon suivante : hi=1 ssi $\operatorname{Par}^{+}(i, \mathcal{L} \mathcal{G}) \neq \emptyset, \forall i=1, \ldots, n$. Cette variable est définie pour tout $i \in\{1, \ldots, n\}$ par les contraintes linéaires définies en (8).
Borne inférieure du nombre de parents présents : l’ensemble de variables $\left\{M_{i, l}^{t, d}\right\}$ est défini pour $l \in\{+,-\}, i=\{1 . . n\}, t=\{1 . . T\}, d=\{0 . . k\}$, où k est le nombre de parents maximum autorisé (sans tenir compte des étiquettes), comme suit : $M_{i, l}^{t, d}=1$ ssi $N_{i, l}^{t} \geq d$. $M_{i, l}^{t, d}$ vérifie si l’espèce i a au moins d parents étiquetés de type l présents au temps t. Ces variables binaires sont définies par les contraintes linéaires définies en (9).
Borne supérieure du nombre de parents présents : de la même façon, l’ensemble de variables binaires $\left\{\nu_{i, l}^{t, d}\right\}$ se définit pour $l \in\{+,-\}, i=\{1 . . n\}, t=$$\{1 . . T\}, d=\{0 . . k\}$ comme suit : $\nu_{i, l}^{t, d}=1$ ssi $N_{i, l}^{t} \leq d$. $N_{i, l}^{t}$ vérifie si l’espèce i a au plus d parents étiqueté de type l présents au temps t. Ces variables binaires sont définies par les contraintes linéaires définies en (10).
Test du nombre de parents présents : l’ensemble des variables binaires 0-1 $\left\{\Lambda_{i, l}^{t, d}\right\}$ se définit pour $l \in\{+,-\}, i=\{1 . . n\}, t=\{1 . . T\}, d=\{0 . . k\}$ comme suit: $\Lambda_{i, l}^{t, d}=1$ ssi $N_{i, l}^{t}=d$. $\Lambda_{i, l}^{t, d}$ vérifie si l’espèce i a exactement d parents étiqueté de type l au temps t. Ces variables binaires sont définies par les contraintes linéaires définies en (11).
Test du nombre de parents présents selon la basalité : pour rappel, nous avons défini $R_{i, V}^{t, d^{+}}, d^{-}=1$ si et seulement si l’espèce i est de type $V \in\{n b, b\}$ et a exactement d+ parents de type + et d− parents de type − présents au temps t. Ainsi, $R_{i, n b}^{t, d^{+}, d^{-}}=1$ ssi hi=1, $\Lambda_{i,+}^{t, d^{+}}=1, \Lambda_{i,-}^{t, d^{-}}=1$, et $R_{i, b}^{t, d^{+}, d^{-}}=1$ ssi $h_{i}=0, \Lambda_{i,+}^{t, d^{+}}=1, \Lambda_{i,-}^{t, d^{-}}=1$. On remarque que dans la seconde série d’équations, $\Lambda_{i,+}^{t, d^{+}}=1 \Rightarrow d^{+}=0$. Enfin, ces variables sont définies pour tout $i \in\{1, \ldots, n\}, t \in\{1, \ldots, T\}, d^{+} \in\{0, \ldots, k\}, d^{-} \in\left\{0, \ldots, k-d^{+}\right\}$ par l’ensemble des contraintes linéaires dans (12) pour celles associées aux espèces basales et dans (13) pour les autres espèces.
$h_{i} \leq \sum_{j=1}^{n} g_{j i}^{+}$
$h_{i} \geq g_{j i}^{+}, \forall i, j \in\{1, \ldots, n\}$ (8)
$M_{i, l}^{t, d} \cdot(d+1)-\sum_{j=1}^{n}\left(g_{j i}^{l} \cdot x_{j}^{t}\right) \leq 1$
$M_{i, l}^{t, d} \cdot(k+1-d)-\sum_{j=1}^{n}\left(g_{j i}^{l} \cdot x_{j}^{t}\right)>-d$ (9)
$\nu_{i, l, l}^{t, d} \cdot(k+1-d)+\sum_{j=1}^{n}\left(g_{j i}^{l} \cdot x_{j}^{t}\right) \leq k+1$
$\nu_{i, l}^{t, d} \cdot(d+1)+\sum_{j=1}^{n}\left(g_{j i}^{l} \cdot x_{j}^{t}\right)>d$ (10)
$\Lambda_{i, l}^{t, d}-M_{i, l}^{t, d} \leq 0$
$\Lambda_{i, l}^{t, d}-\nu_{i, l}^{t, d} \leq 0$
$\Lambda_{i, l}^{t, d}-M_{i, l}^{t, d}-\nu_{i, l}^{t, d} \geq-1$ (11)
$R_{i, b}^{t, d^{-}} \leq \Lambda_{i, l}^{t, d^{-}}$
$R_{i, b}^{t, d^{-}} \leq 1-h_{i}$
$R_{i, b}^{t, d^{-}} \geq-h_{i}+\Lambda_{i,-}^{t, d^{-}}$ (12)
$R_{i, n b}^{t, d^{+}, d^{-}} \leq \Lambda_{i, l}^{t, d^{+}}$
$R_{i, n b}^{t, d^{+}, d^{-}} \leq \Lambda_{i, l}^{t, d^{-}}$
$R_{i, n b}^{t, d^{+}, d^{-}} \leq h_{i}$
$R_{i, n b}^{t, d^{+}, d^{-}} \geq h_{i}+\Lambda_{i,+}^{t, d^{+}}+\Lambda_{i,-}^{t, d^{-}}-2$ (13)
Nous avons ainsi modélisé le problème d’apprentissage de la structure d’un réseau écologique qui optimise la vraisemblance par un problème de programmation linéaire en nombres entiers binaires avec les variables $\left\{g_{i j}^{l}, M_{i, l}^{t, d}, \nu_{i, l}^{t, d}, \Lambda_{i, l}^{t, d}, R_{i, V}^{t, d^{+}, d^{-}}\right\}$ et les contraintes (8–18). Le nombre de variables de ce problème pour une espèce donnée est : $\left(3 \cdot n+1+T \cdot\left(\frac{k^{2}}{2}+\frac{3 \cdot k}{2}+8\right)\right)$. Pour une espèce donnée, le nombre de contraintes de ce problème est : $\left(1+T \cdot\left(2 \cdot k^{2}+6 \cdot k+19\right)\right)$. Pour apprendre la structure complète d’un graphe, il faut résoudre n problèmes de ce type (un par espèce). Ce nombre de variables donne une idée de la complexité de l’algorithme, l’apprentissage de la structure du graphe par programmation linéaire étant l’étape la plus complexe. Il est à noter que dans un cas général, avec un nombre supplémentaire d’étiquettes, le nombre de variables et de contraintes du problème de programmation linéaire augmenterait. Le nombre de variables pour L étiquettes différentes serait de l’ordre de $n+T+k^{L}$ par espèce, car nous avons besoin des variables notées R pour l’intégralité des combinaisons possibles de $d^{1}, \ldots, d^{L}$ tels que $d^{1}+\ldots+d^{L}<k$.
L’ordre de grandeur du nombre de contraintes est du même ordre. Notons qu’il n’existe pas qu’une seule façon d’étendre le modèle de dynamique écologique au cas de L étiquettes car il y a plusieurs façons de combiner les effets des différents types d’influence. Néanmoins, quel que soit le modèle, la vraisemblance s’écrit comme une fonction de ces quantités R.
4.3. Ajout de connaissances expertes
Nous avons toutes les variables nécessaires pour calculer la vraisemblance. Nous pouvons exploiter davantage la formulation du problème de programmation linéaire afin d’inclure des connaissances expertes sur les réseaux écologiques sous la forme de contraintes linéaires supplémentaires. Dans notre problème, nous avons défini des contraintes qui décrivent les hypothèses inhérentes au modèle :
– L’espèce i a au plus k parents, contrainte décrite dans l’équation (14).
– Il ne peut exister qu’un seul arc d’une espèce i vers une espèce j. Cette contrainte est décrite dans l’équation (15).
– Il n’y a jamais d’arc labellisé d’une espèce i vers elle-même. Cette contrainte est décrite dans l’équation (16). L’arc entre $X_{i}^{t}$ et $X_{i}^{t+1}$ i est décrit par les expressions des probabilités de transition individuelles et n’a pas à être appris. Il n’apparaît donc pas dans le problème de programmation linéaire.
– Si l’espèce i n’est pas basale, elle ne peut pas survivre au temps t + 1 si aucune de ses influences positives n’est présente au temps t. Cette contrainte est décrite dans l’équation (17).
– Si l’espèce i est basale, elle survivra nécessairement au temps t + 1 si aucune de ses influences négatives n’est présente au temps t. Cette contrainte est décrite dans l’équation (18).
$\sum_{j=1}^{n} \sum_{l \in\{+,-\}} g_{j i}^{l} \leq k, \forall i=1, \ldots, n$ (14)
$g_{j i}^{+}+g_{j i}^{-} \leq 1, \forall i=1, \ldots, n ; j=1, \ldots, n$ (15)
$g_{i i}^{+} \leq 0, \forall i=1, \dots, n$ (16)
$R_{i, n b}^{t, d^{+}}=0, d^{-} \cdot x_{i}^{t+1}=0, \forall i, t, d^{-}$ (17)
$R_{i, b}^{t, d^{+}, d^{-}}=0, x_{i}^{t} \cdot\left(1-x_{i}^{t+1}\right) \cdot a^{t}=0, \forall i, t, d^{+}$ (18)
Nous avons testé la performance des deux étapes de l’algorithme (estimation des paramètres et apprentissage de structure de réseau ) ainsi que l’algorithme d’apprentissage de RBD-E complet sur des exemples de réseaux écologiques. Les graphes $\mathcal{G}$ utilisés sont des sous-graphes d’un réseau écologique réel connu (Beas-Luna et al., 2014) dans lequel nous avons extrait des espèces de telle sorte qu’aucune d’entre elles n’a plus d’un nombre k fixé de parents. Un tel réseau sera désigné comme un k-graphe. Les données sont simulées pour une observation d’une zone sur T = 30 pas de temps non protégée pendant les 12 premiers pas de temps et protégée pendant les 18 derniers pas de temps. Différentes configurations sont testées pour $\theta=\left\{\varepsilon, \rho^{+}, \rho^{-}, \mu\right\}$: haque paramètre prend la valeur 0,2 (influence faible) ou 0,8 (influence forte) pour un total de 24 configurations possibles. Chaque configuration de $\left(\varepsilon, \rho^{+}, \rho^{-}, \mu\right)$ est indexée comme dans le tableau 1.
Tableau 1. Description des différentes configurations de paramètres
|
cfg. |
$\varepsilon$ |
ρ+ |
ρ− |
μ |
cgf. |
$\varepsilon$ |
ρ+ |
ρ− |
μ |
|
1 |
0.2 |
0.2 |
0.2 |
0.2 |
9 |
0.8 |
0.2 |
0.2 |
0.2 |
|
2 |
0.2 |
0.2 |
0.2 |
0.8 |
10 |
0.8 |
0.2 |
0.2 |
0.8 |
|
3 |
0.2 |
0.2 |
0.8 |
0.2 |
11 |
0.8 |
0.2 |
0.8 |
0.2 |
|
4 |
0.2 |
0.2 |
0.8 |
0.8 |
12 |
0.8 |
0.2 |
0.8 |
0.8 |
|
5 |
0.2 |
0.8 |
0.2 |
0.2 |
13 |
0.8 |
0.8 |
0.2 |
0.2 |
|
6 |
0.2 |
0.8 |
0.2 |
0.8 |
14 |
0.8 |
0.8 |
0.2 |
0.8 |
|
7 |
0.2 |
0.8 |
0.8 |
0.2 |
15 |
0.8 |
0.8 |
0.8 |
0.2 |
|
8 |
0.2 |
0.8 |
0.8 |
0.8 |
16 |
0.8 |
0.8 |
0.8 |
0.8 |
5.1. Performance de l’étape d’estimation des paramètres du RBD-E
L’estimation des paramètres est testée sur des données simulées à partir d’un 2-graphe à 18 espèces. Pour chacune des 16 configurations de paramètres, nous réalisons 150 simulations de dynamique d’espèces et les paramètres sont estimés par maximisation de la vraisemblance sachant le graphe utilisé pour la génération des données à l’aide de la fonction fmincon de Matlab. Des indicateurs de performance (moyenne et écart-type des estimateurs) sur les 150 simulations de chaque configuration de paramètres sont représentées en figure 3. En moyenne, la différence (en valeur absolue) entre la valeur des paramètres estimés et celle des paramètres réels est faible.
Figure 3. Diagramme des valeurs moyennes des paramètres estimés pour 150 observations simulées pour les 16 configurations de paramètres. Les cercles représentent la valeur réelle des paramètres, et l’intervalle tracé entre deux croix représentent la différence entre la valeur moyenne des paramètres estimés et leur écart-type
5.2. Performance de l’étape d’apprentissage de structure d’un RBD-E
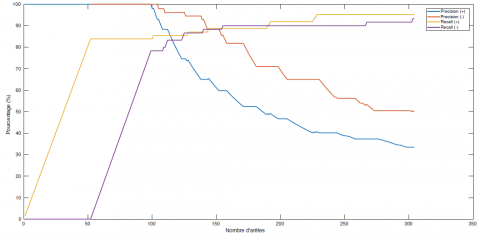
Le réseau utilisé pour la simulation des données est le même que celui représenté en figure 2 avec 4 espèces. Pour chacune des 16 configurations de paramètres, nous avons lancé 150 simulations de dynamique d’espèces. L’optimisation de la structure du graphe par programmation linéaire 0-1 est résolu à l’aide du logiciel cplex. Pour une configuration donnée de $\theta_{\rightarrow}$, nous utilisons différents indicateurs de performance. Nous relevons la précision et le rappel moyen pour chaque étiquette d’arcs. Ces indicateurs sont calculés à partir de la matrice de confusion entre $\mathcal{L} \mathcal{G}$ et $\hat{\mathcal{L} \mathcal{G}}$. La précision pour une étiquette d’arc (un type d’intéraction, + ou -) correspond à la quantité $\frac{\text { arcs correctement appris }}{\text { arcs appris }}$. Le rappel pour une étiquette d’arc correspond à la quantité $\frac{\text { arcs correctement appris }}{\text { arcs présents dans le graphe original }}$. Pour un graphe de cette taille, il faut environ 35.6 secondes pour apprendre la structure d’un graphe à paramètres $\theta_{\rightarrow}$ fixé. La précision et le rappel sont représentés en figure 4.
Figure 4. Précision et rappel moyen (à partir de 150 données simulées) pour un graphe à 4 espèces pour l’étape d’apprentissage de structure pour chaque configuration de paramètres
Pour ce problème de petite taille, les résultats dépendent de la configuration des paramètres. La qualité de l’apprentissage, mesurée par la précision ou le rappel, est bien meilleure lorsque les paramètres $\rho^{+}$et $\varepsilon$ augmentent, et est légèrement meilleure lorsque les paramètres $\rho^{-}$ et μ augmentent. Les meilleures performances sur des jeux de paramètres à valeur élevé s’explique vraisemblablement par le fait que les interactions sont plus marquées avec une valeur de paramètre élevée. De ce fait, la distinction entre une interaction existante et une absence d’interaction est plus facile à faire, car il existe moins de graphes vraisemblable pour les données générés avec ces valeurs de paramètre.
5.3. Performance de l’algorithme complet d’apprentissage de RBD-E
Pour l’apprentissage de la structure du graphe conjointement à l’estimation des paramètres, nous considérons un 4-graph avec 45 espèces et la configuration 16 pour les paramètres $\theta_{\rightarrow}$. 40 simulations de dynamique d’espèces sont réalisés avec ce graphe, et pour chacune de ces simulations, l’algorithme d’apprentissage de RBD-E complet est appliqué.
Cet algorithme demande soit une structure de graphe initiale soit un jeu de paramètres initial. Pour cet application, nous choisissons d’initialiser l’algorithme d’apprentissage par un graphe initial. De par la nature du modèle et des hypothèses écologiques induites, il existe de nombreux graphes pour lesquels la vraisemblance associée n’est pas finie, car leur structure induit des interactions interdites par le modèle. Un graphe vide, par exemple, a peu de chances de permettre une vraisemblance finie du modèle de RBD-E car dans un tel graphe, toutes les espèces sont basales et n’ont aucune influence négative. Selon le modèle, elles ne peuvent jamais s’éteindre. Le graphe initial est un graphe construit à l’aide de l’algorithme 2 pour lequel la vraisemblance du modèle de RBD-E associé aux données de présence/absence est finie. Il existe deux situations où la vraisemblance n’est pas finie : si une espèce survit alors qu’aucune de ses influences positives n’est présente, ou si une espèce basale ne survit pas alors qu’aucune de ses influences négatives n’est présente. Le principe de ce graphe est d’attribuer à chaque espèce des parents tels qu’au moins un parent d’influence positive est présent à chaque survie de l’espèce, ou qu’au moins un parent d’influence négative est présent à chaque extinction de l’espèce basale. Cela permet de s’assurer d’avoir un graphe initial ne respectant pas les conditions nécessaires au bon fonctionnement de l’algorithme. Si aucun graphe n’est trouvé pour la valeur de k donné, il faudra augmenter cette valeur afin de trouver un graphe permettant d’avoir une vraisemblance finie.
Résultats : l’algorithme complet itère en moyenne 6,4 fois. La précision moyenne est de moins de 20 % pour les deux étiquettes d’arcs, et le rappel moyen est inférieur à 30 %, ce qui n’est pas un résultat satisfaisant. Toutefois, si l’on considère un graphe "consensus" composé des x arcs les plus souvent apprises parmi les 40 graphes appris, et que l’on compare ce graphe avec l’original (utilisé pour la simulation des données), il est possible de contrôler un niveau de précision et de rappel en sélectionnant une valeur raisonnable pour x. La figure 5 illustre la manière de construire ces graphes consensus.
Figure 5. Illustration de la construction d’un graphe consensus. En haut sont représentés 4 graphes appris avec 4 différents jeux de données. En bas sont représentés les graphes consensus des x arcs les plus souvent appris. La largeur de chaque arc est proportionnelle au nombre de fois où il a été appris
Le rappel augmente nécessairement avec x alors que la précision peut baisser avec x, comme représenté en figure 6. Par exemple, si l’on considère le graphe des 100 arcs les plus souvent représentés, la précision est de 65,67 % pour les arcs étiquetés + et de 93,94 % pour les arcs étiquetés −, tandis que le rappel moyen est de 83,02 % pour les arcs étiquetés + et de 59,62 % pour les arcs étiquetés −. Peu importe la valeur de x, le rappel et la précision sont bien meilleurs sur un graphe consensus appris avec notre méthode d’apprentissage que sur un graphe généré aléatoirement arc par arc (voir figure 6).
5.4. Performance de l’algorithme d’apprentissage avec ajout de connaissances
Dans la pratique, on dispose de connaissances expertes que l’on souhaite inclure afin de guider l’apprentissage. Pour tester la faisabilité et l’intérêt de cet ajout de connaissances, 20 jeux de données ont été simulés avec un 8-graph avec 38 espèces contenant 62 interactions positives et 60 interactions négatives. La configuration 16 a été utilisée pour les paramètres $\theta_{\rightarrow}$. L’algorithme d’apprentissage de RBD-E a été appliqué sur ces données simulées. Lors de la phase d’amélioration de la structure, une partie des interactions du graphe réel a été ajoutée comme connaissance supplémentaire.
Algorithme 2 . Recherche d’un graphe minimal permettant une vraisemblance finie
Figure 6. Évolution de la précision et du rappel pour l’algorithme d’apprentissage complet de la structure d’un RBD-E pour un graphe à 42 espèces. L’axe x représente le nombre d’arcs dans le graphe consensus construit à partir de 40 jeux de données
La qualité de l’algorithme va donc être mesurée en comparant les interactions non sélectionnées comme interactions connues. On considère comme connues 70 % des paires d’espèces sans interaction dans le graphe réel, et 70 % des paires d’espèces avec une interaction (positive ou négative) sélectionnées au hasard. La figure 7 présente l’évolution de la précision et du rappel du graphe modal des x espèces les plus souvent apprises parmi les paires d’espèces dont les interactions n’ont pas été ajoutées comme connaissances à priori. Il existe des valeurs de x tels que on peut arriver à une très bonne précision et à un très bon rappel. Il semble que connaître une partie de la structure permette de mieux apprendre le reste. En effet, la précision baisse moins tôt avec x et le rappel atteint son plateau plus vite. Ces bons résultats peuvent également s’expliquer par le fait que l’évaluation se fait sur moins d’interactions que précédemment (donc moins d’erreurs possibles).
5.5. Performance de l’algorithme d’apprentissage pour des données générées à partir d’un modèle différent
Nous avons également testé l’efficacité de l’algorithme lorsque le modèle générant les données est différent du modèle d’apprentissage. Les données utilisées ont été générées à partir du même graphe étiqueté que celui utilisé en 5.4. À chacun des arcs de ce graphe est associé une valeur $\rho_{i, j}^{+}$ ou $\rho_{i, j}^{-}$ comprise entre 0 et 1, correspondant à une force d’interaction spécifique à cet arc. Ces valeurs sont attribuées aléatoirement, sous la forme d’un nombre généré par une loi uniforme continue pour chaque arc du graphe.
Figure 7. Évolution de la précision et du rappel pour l’algorithme d’apprentissage complet de la structure d’un RBD-E pour un graphe à 42 espèces où 70 % des interactions sont connues. L’évaluation ne se fait que sur les interactions inconnues
Le nombre de paramètres de ce modèle est alors le nombre d’arcs du graphe, auquel on ajoute les paramètres " et μ. Les formules de probabilité de transition restent les mêmes que celles du RBD-E de la section 3 mais les parents peuvent maintenant être distingués. Les paramètres ρ+ et ρ− sont remplacés par des valeurs d’interactions $\rho_{i, j}^{+}$ et $\rho_{i, j}^{-}$. L’apprentissage de la structure du réseau associé, lui, se fait sous l’hypothèse que $\rho_{i, j}^{+}=\rho^{+}$ et $\rho_{i, j}^{-}=\rho^{-} \forall i, j$. Les paramètres utilisés dans cet algorithme restent $\theta=\left\{\varepsilon, \rho^{+}, \rho^{-}, \mu\right\}$. La précision moyenne de ces apprentissages de structure est de 28,9 % pour les arcs positifs, et de 20 % pour les arcs négatifs, et le rappel moyen est de 17 % pour les arcs positifs et de 10,8 % pour les arcs négatifs. Ces résultats sont assez proches de ceux obtenus pour l’apprentissage sur des données simulées avec le modèle de RBD-E à 4 paramètres. Il est également possible d’évaluer la qualité de l’apprentissage à l’aide d’un graphe consensus. La figure 8 montre l’évolution de la précision et du rappel en fonction du nombre d’arcs dans le graphe consensus. La qualité globale de l’apprentissage a baissé par rapport au cas présenté en 5.3. Il est en effet difficile de trouver un graphe consensus ayant à la fois une bonne précision et un bon rappel. Les courbes de ces deux indicateurs se croisent en dessous de 50 %.
Cependant, la qualité de l’estimation dépend également de la valeur des forces d’interaction $\rho_{i, j}^{+}$ et $\rho_{i, j}^{-}$. Ainsi, la figure 9 montre la précision et le rappel calculés uniquement sur le sous-graphe du graphe réel composé uniquement des arcs tels que $\rho_{i, j}^{+}$ et $\rho_{i, j}^{-}$ sont inférieurs à un seuil donné. On remarque une augmentation globale de la qualité avec l’augmentation de ce seuil. Par exemple, la précision et le rappel du graphe contenant uniquement des forces d’interaction supérieurs à 0,8 se croisent alors que leur valeur est de 70%, et un graphe consensus à moins de 100 arcs suffit pour obtenir ces valeurs.
Figure 8. Évolution de la précision et du rappel pour l’algorithme d’apprentissage complet de la structure d’un RBD-E pour un graphe à 38 espèces. Les données de dynamique d’espèces ont été simulées à partir d’un modèle considérant une valeur d’interaction différente pour chaque arc du graphe associé alors que l’apprentissage se fait par un modèle à 4 paramètres
5.6. Choisir un nombre d’arcs dans le graphe consensus
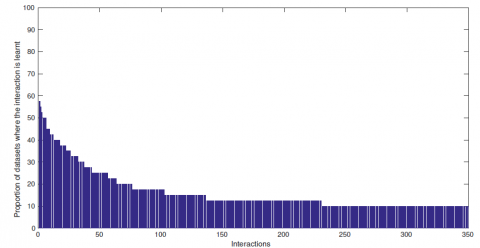
Dans la pratique, nous ne connaissons pas le réseau réel. Il est difficile d’évaluer directement la qualité du graphe appris, et donc d’en définir un nombre d’arcs à retenir dans le graphe consensus. Pour obtenir un graphe unique après une série d’apprentissages sur plusieurs jeux de données, plusieurs solutions sont possibles. Une première est de considérer directement un graphe dans lequel chaque arc est pondéré par le nombre de fois où il a été appris sur l’ensemble des jeux de données considérés. La valeur appliquée à chaque arc peut être interprétée comme la probabilité que l’interaction associée fasse partie du réseau écologique. Si l’on préfère considérer un réseau écologique dans lequel les arcs ne sont pas pondérés, on peut établir un seuil tel que les arcs retenus dans le graphe consensus soient appris dans au moins x% des jeux de données considérés. La figure 10 ordonne chaque arc selon le pourcentage de fois où il a été appris sur les 40 simulations de la section 5.3. Cette figure peut aider à choisir un nombre d’arcs x. Cependant, la justification de ce graphe consensus n’a pas de base théorique très forte. Il semble être une évaluation satisfaisante de notre méthode d’apprentissage, qui rassure sur le fait que les interactions les plus souvent apprises par cet algorithme sont des interactions appartenant au graphe recherché, même si beaucoup de bruit est appris.
Figure 9. Évolutions de la précision et du rappel pour l’algorithme d’apprentissage complet de la structure d’un RBD-E pour un graphe à 38 espèces. Les données de dynamique d’espèces ont été simulées à partir d’un modèle considérant une valeur d’interaction différente pour chaque arc du graphe associé alors que l’apprentissage se fait par un modèle à 4 paramètres. L’évaluation se fait uniquement sur des graphes contenant des interactions dont le paramètre associé est supérieur à 4 différents seuils
Figure 10. Diagramme représentant le pourcentage de fois où chaque arc a été appris sur les 40 jeux de données utilisés l’expérimentation de la section 5.3
Nous avons proposé un cadre particulier de réseau bayésien dynamique et un algorithme permettant d’apprendre sa structure. Cette approche permet de répondre efficacement au cas où le type d’interactions possibles est petit, en se servant de cette connaissance pour construire des probabilités de transition dépendant d’un petit nombre de paramètres partagés. L’algorithme fonctionne de façon gloutonne en itérant deux étapes, dont une étape d’amélioration de structure modélisée par n problèmes de programmation linéaire en nombres entiers 0-1 : un par variable du réseau bayésien dynamique. Lorsque plusieurs jeux de données sont disponibles, nous avons suggéré une méthode naïve d’agrégation des graphes appris : un graphe "consensus" qui réunit les arêtes les plus souvent apprises. Malgré sa nature très empirique, un tel graphe donne de bons résultats.
Cette procédure est générique puisque la log-vraisemblance d’un RBD peut toujours être décomposée comme une fonction linéaire de variables décrivant la structure du graphe (Cussens, 2011), et tant que les contraintes supplémentaires sur ces variables sont linéaires, la programmation linéaire en nombres entiers peut être appliquée. D’un RBD-E spécifique peut découler un modèle de programmation linéaire en nombres entiers. Nous considérons en particulier un problème d’apprentissage de la structure d’un réseau écologique à partir de données temporelles de présence/absence d’espèces. Dans ce cas, il y a un nombre limité de types d’interactions possibles entre les espèces, et le P-BDN modélisant la dynamique de ces espèces n’a que peu de paramètres. Cela nous permet de construire un problème de programmation linéaire spécifique avec moins de variables que dans le cas général. Nous avons appliqué l’algorithme d’apprentissage sur des données simulées à partir de réseaux avec différents ensembles de paramètres. L’étape d’estimation des paramètres est satisfaisante, d’autant plus que les interactions sont marquées. Cette conclusion vaut également pour l’étape d’apprentissage de structure.
Apprendre un problème de programmation linéaire en nombre entiers 0-1 peut rapidement devenir difficile lorsque le nombre de variables du réseau d’interaction augmente. Une solution classique dans ce cas est l’utilisation d’une relaxation continue du problème de programmation linéaire afin de le résoudre plus facilement, et d’arrondir la solution afin d’obtenir une étape d’amélioration de la structure du réseau approchée. Il est par ailleurs possible d’utiliser directement les solutions continues du problème de programmation linéaire relâchée pour l’étape d’estimation des paramètres. Ces solutions peuvent alors être interprétées comme des "probabilités de présence" des interactions, dans l’esprit d’un algorithme de type EM.
À court terme, nous cherchons à comparer cette méthode d’apprentissage par réseau bayésien dynamique paramétré à d’autres méthodes présentes dans l’état de l’art. Le modèle de RBD-E à deux étiquettes, présenté plus particulièrement dans cet article est généralisable. Cette généralisation permettrait de décrire un grand nombre de problèmes, notamment les phénomènes de type "Processus de contact" sur graphe faisant intervenir un nombre d’interactions fixé, ainsi que des informations complémentaires modifiant la probabilité de certaines variables aléatoires (de la même manière que l’on modélise dans le cas des réseaux écologiques la protection de la zone observée). Le cas d’un réseau bayésien étiqueté non dynamique fera parti de cette généralisation.
L’ajout de connaissances expertes semble être efficace pour apprendre un réseau plus proche de la réalité. Mais ces connaissances portent rarement directement sur les arêtes du graphe. Cette connaissance peut porter sur des communautés au comportement spécifique au sein du réseau. Pour cela, nous avons proposé d’intégrer un modèle à priori sur la structure sous forme de modèle à blocs stochastiques. Cela permet d’introduire des probabilités de présence des arêtes dépendantes des communautés. Dans le cas des réseaux écologiques, il est possible de prendre en compte les niveaux trophiques de chaque espèce lorsqu’ils sont connus (Auclair et al., 2017). La connaissance des niveaux trophiques des espèces permet de contraindre la forme du graphe en augmentant la probabilité qu’une espèce ait des interactions avec les niveaux trophiques les plus proches. Cette forme de connaissance s’avère aussi efficace que la connaissance brute de plusieurs arêtes.
L’un des principaux problèmes de l’algorithme d’apprentissage est qu’il est peu efficace sur un seul jeu de données. Dans cet article, ce problème a été contourné en étudiant un graphe consensus, issu de l’apprentissage de plusieurs jeux de données. Si les résultats sont satisfaisants pour évaluer notre méthode, et rassure sur le fait que l’algorithme apprend, dans l’ensemble, des interactions cohérentes, cette méthode est très empirique et sa justification théorique n’est pas bien établie. Une justification théorique ou une autre méthode pour regrouper les résultats ou les données est nécessaire pour l’utilisation de cet algorithme d’apprentissage à des cas plus généraux.
Le problème d’apprentissage de la structure d’un réseau écologique présent dans cet article est la première étape de résolution d’un problème plus complexe dans lequel l’apprentissage de structure est combiné avec l’élaboration d’une stratégie de conservation d’un écosystème. Dans ce problème d’apprentissage combiné à de la gestion (ou gestion adaptative (Williams, Brown, 2016)), le but est d’élaborer une stratégie qui partage le budget alloué aux ressources entre des actions d’apprentissage (comme des observations de contenus d’estomacs) et des actions de gestion (comme la protection d’un petit nombre d’espèces à protéger, ou l’éradication d’espèces invasives), afin d’atteindre un compromis entre le bon apprentissage et la conservation des espèces. Ces problèmes de gestion adaptative sont également rencontrés dans la gestion des maladies ou le contrôle des espèces invasives.
Auclair E., Peyrard N., Sabbadin R. (2017). Labeled dbn learning with community structure knowledge. In Joint european conference on machine learning and knowledge discovery in databases, p. 158–174.
Beas-Luna R., Novak M., Carr M. H., Tinker M. T., Black A., Caselle J. E. et al. (2014, 10). An online database for informing ecological network models. PLoS ONE, vol. 9, p. 1-9.
Byrd R. H., Hribar M. E., Nocedal J. (1999). An interior point algorithm for large-scale nonlinear programming. SIAM Journal on Optimization, vol. 9, no 4, p. 877–900.
Chickering D. M. (1996). Learning Bayesian networks is NP-complete. In Learning from data, p. 121–130.
Cussens J. (2011). Bayesian network learning with cutting planes. In UAI 2011, proceedings of the 27th conference on uncertainty in artificial intelligence, Barcelona, Spain, july 14-17, 2011, p. 153–160.
Dean T., Kanazawa K. (1989). A model for reasoning about persistence and causation. Computational intelligence, vol. 5, no 2, p. 142–150.
Dojer N. (2006). Learning bayesian networks does not have to be np-hard. In Mfcs, p. 305–314.
Feelders A., Gaag L. C. Van der. (2006). Learning bayesian network parameters under order constraints. International Journal of Approximate Reasoning, vol. 42, no 1-2, p. 37–53.
Franc A. (2004). Metapopulation dynamics as a contact process on a graph. Ecological Complexity, vol. 1, no 1, p. 49–63.
Friedman N., Murphy K., Russell S. (1998). Learning the structure of Dynamic Probabilistic networks. In Proc. of the 14th conference on uncertainty in artificial intelligence (uai’98).
Ghahramani Z. (1997). Learning Dynamic Bayesian networks. Lecture Notes in Computer Science, vol. 1387, p. 168–197.
Heckerman D., Geiger D., Chickering D. M. (1995). Learning Bayesian networks: The combination of knowledge and statistical data. Machine learning, vol. 20, no 3, p. 197–243.
Jurgelenaite R., Lucas P. J. (2005). Exploiting causal independence in large bayesian networks. Knowledge-Based Systems, vol. 18, no 4, p. 153–162.
Korhonen J. H., Parviainen P. (2015). Tractable Bayesian network structure learning with bounded vertex cover number. In C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, R. Garnett (Eds.), Advances in Neural Information Processing Systems 28, p. 622–630. Curran Associates, Inc.
Liben-Nowell D., Kleinberg J. (2007). The link-prediction problem for social networks. Journal of the American society for information science and technology, vol. 58, no 7, p. 1019–1031.
Milns I., Beale C. M., Smith V. A. (2010). Revealing ecological networks using Bayesian network inference algorithms. Ecology, vol. 91, no 7, p. 1892–1899.
Murphy K. (2002). Dynamic Bayesian networks: representation, inference and learning. Thèse de doctorat non publiée, University of California.
Niculescu R. S., Mitchell T. M., Rao R. B. (2006). Bayesian network learning with parameter constraints. Journal of Machine Learning Research, vol. 7, no Jul, p. 1357–1383.
Schwarz G. (1978). Estimating the dimension of a model. The Annals of Statistics, vol. 6, no 2, p. 461–464.
Trabelsi G. (2013). New structure learning algorithms and evaluation methods for large dynamic bayesian networks. Thèse de doctorat non publiée, Université de Nantes; Ecole Nationale d’Ingénieurs de Sfax.
Vinh M., Chetty M., Coppel R., Wangikar P. (2011). Polynomial time algorithm for learning optimal Dynamic Bayesian networks. In Neural information processing, p. 719-729.
Vomlel J. (2015). Generalizations of the noisy-or model. Kybernetika, vol. 51, no 3, p. 508–524.
Wellman M. P. (1990). Fundamental concepts of qualitative probabilistic networks. Artificial intelligence, vol. 44, no 3, p. 257–303.
Williams B. K., Brown E. D. (2016). Technical challenges in the application of adaptive management. Biological Conservation, vol. 195, p. 255–263.
Yu J., Smith V. A., Wang P. P., Hartemink A. J., Jarvis E. D. (2004). Advances to Bayesian network inference for generating causal networks from observational biological data. Bioinformatics, vol. 20, no 18, p. 3594–3603.