Karim El Moutaouakil* | Abdellah Ahourag | Saliha Chellak | Hicham Baїzri | Mouna Cheggour
© 2022 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
The optimal regime models implement parameters presented by nominal values, intervals, fuzzy models, intuitionistic models. Unfortunately, these models are restrictive and ignore a significant portion of the knowledge contained in the specifications. To overcome this problem, we propose an optimal system that implements deep learning artificial neural networks and fuzzy genetic algorithms for the first time in the literature. The deep neural network extracts the information, the neural network units memorize this information, genetic algorithms select the best architecture of the auto-encoder basing on new regulation function, and fuzzy logic allows some flexibility for our system. First, we collect the expert's nutrients recommendations from different expert research papers. These recommendations are, then, represented in terms of trapezoidal numbers by adopting appropriate rules that encourage the consumption of the favorable nutrients and limit consumption of the unfavorable nutrients in daily diets. Then, we generate large data sets basing on the trapezoidal representation. To transform the expert's recommendations into significant crisp values, we call the auto-encoder neural network, and we propose an original regulation term that controls all the auto-encoder units. To select the best auto-encoder architecture, we use the fuzzy genetic algorithm basing on a simple fuzzy rule to determine the crossover percent, the mutation percent, and the population size at each iteration. Compared to the random systems, the proposed method has shown a great capacity to generalize its experience to unseen recommendations. In a clinical setting, our system can be used by a dietician to accurately determine the daily nutrient requirements of a given individual.
auto-encoder, fuzzy logic, genetic algorithm, deep learning, mixed-variable optimization
Mathematical programming plays an essential role in the field of nutrition, particularly in determining optimal diets for individuals suffering from chronic diseases [1, 2]. These Mathematical programming differ in the objective functions considered, the manner to consider favorable nutrients, unfavorable nutrients, and in the manner to estimate the requirements. Determining an optimal diet involves four steps: (a) definition of the target population, (b) quantification of the knowledge about the different nutrients, (c) mathematical modeling of the diet problem [1-3], and (d) solving the resulting problem by a suitable optimization method [3, 4]. As knowledge about nutrients is the basis of statistical studies, they are subject to uncertainty which makes phase two very difficult and strongly influences the quality of the resulting diet [3-5].
This article is in the context of artificial intelligence, particularly in the area of knowledge representation in the field of nutrition. In this regard, we propose a representation of nutrients expert knowledge based on an optimal auto-encoder based on a new regulation function for the first time in the literature [6]. Generally, in order to model the problem of optimal diet, one needs to know the individual's daily requirements of favorable and unfavorable nutrients. The representation by mean values is adopted in several works; it is very easy to treat especially in the phase of the resolution of the model but a single value does not allow to represent faithfully a vague information [7, 8]. The representation by a single interval considers a nominal value and the maximum deviation around this value [9]; this representation gives the same probability to different individuals without taking into account the age, gender, weight and height of the target individuals [10, 11]. The exhaustive representation takes into account all the details contained in the experts' knowledge; this results in giant tables that are difficult to manage in the model resolution phase [8, 10-12]. The representation based on fuzzy logic uses the knowledge of different experts to build membership functions reflecting the degree of trueness of such information [3]; this representation does not take into account the doubt that an expert can have on his decisions. Giving an estimate of daily nutrient requirement in terms of a single value for all ages and genders is a restrictive approach that is subject to over- or underestimation. In this article, we propose a personalized representation of nutrients expert knowledge based on trapezoidal numbers, an optimal auto-encoder based on a new regulation function [6], and on fuzzy genetic algorithm [7]. The trapezoidal numbers permit to generate a huge data set with labeled samples which permitted to set the parameters of the auto-encoder basing the new regulation function. This latter permitted the selection of optimal architecture for the auto-encoder with two hidden layers of only 5 units capable to predict the requirements of unseen individuals for all 14 favorable nutrients and 4 unfavorable nutrients. Compared to the fuzzy, means, worst, and the random auto-encoder, the proposed method has shown a great capacity to generalize its experience to unseen recommendations and produces requirements estimations appropriate to individuals given their characteristics.
The rest of this article is organized as follows. In the second paragraph, we present the interest of mathematical programming to optimal diet and we point out the problem of requirements estimation. In the third section, we give our proposed process to transform expert nutrient recommendations into trapezoidal numbers. In the fourth paragraph, we present our control function to control the auto-encoder architecture. Towards the end, we use a fuzzy genetic algorithm to select an auto-encoder with an optimal architecture. We test the proposed system on large data sets that we generate based on trapezoidal numbers.
Over the years, the optimal regime problem has been the focus of many researchers whose contributions vary only in the objective functions considered. Stigler & Danzig introduced the first optimization model in which the objective function is the cost of the diet while the constraints represent the requirements on the good balance of the diet [13]. In the model proposed in Ref. [14], the objective function makes a trade-off between the different meals using the penalty technique. In this context, the authors consider the three usual meals, a snack and a portion of fruit. The proposal of Masset et al. [15] aims at controlling the difference between the actual and recommended intake according to the nutritional requirements. Additional investigations have proposed complementary diets and nutritional menus at minimal cost to children [16]. To control different objectives at the same time, other authors have used multi-objective mathematical models [16, 17]. Van Mierlo et al. [18] considered almost the same situation by substituting the cost of the diet with the minimization of fossil fuel depletion. Cholesterol intake and glycemic load are known to be the main factors contributing to childhood obesity and were the subject of the two objective functions of the multi-objective model proposed by Taniguchi [19].
Generally, in order to model the problem of optimal diet, one needs to know the individual's daily requirements of favorable and unfavorable nutrients. Several favorable and unfavorable nutrients exist but almost all research studies solve the optimal diet problem based on Calories (2000 kcal), Protein (91 g), Carbohydrate (271 g), Potassium (4044 mg), Magnesium (380 mg), Calcium (1316 mg), Iron (18 mg), Phosphorus (1740 mg), Zinc (14 mg), Vitamin b6 (2.4 mg), Vitamin b12 (8.3 µg), Vitamin C (155 mg), Vitamin A (1052 µg), Vitamin E (9.5 mg), Satured fat (17 g), Sodium (1779 mg), Total fat (65 g), and Cholesterol (230 mg) [5, 17, 19]. In parentheses, we give the estimates of favorable and unfavorable nutrient requirements adopted in Refs. [5-20].
To point out the daily nutrient’s requirements, consider, for example, the favorable nutrient Potassium. In 2019, the committee of the Academies of Science, Engineering, and Medicine (NASEM) updated the Dietary Reference Intakes (DRIs) for potassium (and sodium) [21]. The committee found the data insufficient to derive an estimated average requirement (EAR) for potassium. Therefore, it established AIs for all ages based on the highest median potassium intakes in healthy children and adults, and on estimates of potassium intakes from breast milk and complementary foods in infants. Table 1 presents the current potassium AIs for healthy individuals.
Table 1. Adequate Intakes (AIs) for Potassium
|
Age |
Male |
Female |
Pregnancy |
|
Birth to 6 months |
400 mg |
400 mg |
|
|
7–12 months |
860 mg |
860 mg |
|
|
1–3 years |
2000 mg |
2000 mg |
|
|
4–8 years |
2,300 mg |
2,300 mg |
|
|
9–13 years |
2,500 mg |
2,300 mg |
|
|
14–18 years |
3,000 mg |
2,300 mg |
2,600 mg |
|
19–50 years |
3,400 mg |
2,600 mg |
2,900 mg |
|
51+ years |
3,400 mg |
2,600 mg |
|
So, according to this table, the value 4044 mg [5] is a very exaggerated over-estimate and does not take into account the age, gender, pregency etc.
The idea proposed in this work is to generate a database on Table 1 and on the notion of triangular fuzzy numbers. A part of this database is used to educate an auto-encoder neural network. Then, given an individual (age, gender, ...), never seen before, our auto-encoder will give an adequate estimation of the needs of our individual in terms of Potassium. This process will be generalized to other nutrients (favorable or unfavorable), which will allow to automate and personalize the needs in a precise way.
It should be noted that the models proposed in the literature to solve the optimal diet problem are based on nominal (for example average) estimations of favorable and unfavorable nutrient requirements. In this sense, it is the first time in the literature that a technique based on auto-encoding is implemented to predict the requirements of different nutrients.
First, we collected the experts’ nutrients recommendations from different nutrient research papers [11, 12]. Then we transform these requirements intervals knowledge to trapezoidal numbers. Figure 1 presents the type of adopted trapezoidal function. The trapezoidal number (TN) associated with this function is denoted by <a,b,c,d>.
Figure 1. Trapezoidal function of the support [a b]
To construct the trapezoidal numbers from the requirements intervals, we adopt the following rules:
(rule 1) IF the nutrient is favorable, THEN we favor the upper bound by weighted it with .8 and lower bound by .2 (this will encourage the consumption of the favorable nutrients). Example: iron is a favorable nutrient and individual (whose age is great than 9 years) minimum needs is given by the interval 10-18 mg. We favor the upper bounds, a=10, d=18, b=.8*18+.2*10=16.4, and c=.2*16.4+.8*18=17.68. Iron is represented by <10,16.4,17.78,18>;
(rule 2) IF the nutrient is unfavorable, THEN we favor the lower bound by weighted it with .8 and lower bound by .2 (this will limit the consumption of the favorable nutrients). Example: cholesterol is an unfavorable nutrient and individual (whose the age is great than 9 years) maximum needs is given by the interval 200-230 mg. We favor the lower bounds, a=200, d=230, b=0.8*200+0.2*230=206, and c=0.8*206+0.2*230=210.8. cholesterol is represented by <200,206,210.8,230>.
Generally, the favorite bound is multiplied by a large α (very close to 1) and the other bound is multiplied by 1- α.
In this work, we consider 14 favorable nutrients (calories, protein, carbohydrate, potassium, magnesium, calcium, iron, phosphorus, zinc, vitamins b6, b12, c, a, and e, and 4 unfavorable nutrients sutured fat, sodium, cholesterol, and total fat. When applying the proposed rules to the potassium, magnesium, and calcium requirements, we obtain the trapezoidal numbers presented in the Table 2, Table 3 and Table 4.
Table 2. Potassium trapezoidal number daily requirements
|
Gender |
Potassium TN (mg/day) |
|
Male (M) |
<3000,3800,3960,4000> |
|
Female (F) |
<2500,2900,2980,3000> |
Table 3. Calcium trapezoidal number daily requirements
|
Age (gender) |
Calcium TN (mg/day) |
|
19-50 (F) OR 19-70 (M) OR 9-11 (M/F) |
<800,830.72,836.86,838.4> |
|
>70(M) OR >51(F) OR 12-18 (M/F) |
<1050, 1250,1290,1300> |
Table 4. Phosphorus trapezoidal daily requirements
|
Age (gender) |
Phosphorus TN (mg/day) |
|
9-18yr |
<1055,1211,1142.2,1250> |
|
>19yr |
<600,920,984,1000> |
Basing on the TN tables of different nutrients, we generate the expert's knowledge data sets. We find more details in the experimentation paragraph.
The auto-encoder is widely used to compress data [6]. We use this multilayers neural network to transform different TN to crisp values. First, we start with an auto-encoder with random architecture (random number of layers and number of units in each layer) (Figure 2). In this figure, the auto-encoder is a deep neural network that contains two principles parts encoder and decoder, the middle layer is formed by a single neuron that produces the coded information or that produces the crisp value which represents the nutrient prediction. The encoder contains three layers: one output layer of six neurons whom 4 represent the TN components and 2 for gender and age, two hidden layers or treatment layers. The decoder contains three layers: the output layer that will produce the coded information from the crisp value and the treatment layers. At the biggening we don’t know the optimal architecture of the auto-encoder that permit to produce predictions of the nutrient with minimum loss of information. To solve this problem, we propose a new regulation function and we use fuzzy genetic algorithm to select the optimal auto-encoder architecture problem basing on the generated data.
Figure 2. Auto-encoder with random architecture; the middle layer produces crisp values
Fitting the auto-encoder parameters Ω consists of minimizing some cost function E(Ω) whose principal terms are the mean square error, the regulation term, and the sparsity term.
$E(\Omega)=M S E(\Omega)+\sigma * \Lambda(\Omega)+\mu * \phi(\Omega)$ (1)
The first term is the global reconstruction error, the second term is the regulation function (norm of the matrix formed by the auto-encoder parameters) [22], and the last term is the sparsity term [23]. When training a sparse autoencoder, it is possible to make the sparsity regulariser small by increasing the values of the weights and decreasing the values of the compression obtained by the auto-encoder. Adding a regularization term on the weights to the cost function prevents it from happening. This term is called the regularization term and is defined by $\sum_{i}\left\|\Omega_{i}\right\|^{2}$ where $\left(\Omega_{i}\right)$ are the parameters of the auto-encoder. Unfortunately, this formulation doesn't distinguish between different units and doesn't control the number of neurons. In this work, we introduce an original regulation term given by the Eqns. (2), (3), and (4).
$\Lambda(\Omega)=\Lambda 1(\Omega)+\Lambda 2(\Omega)$ (2)
where,
$\Lambda 1(\Omega)=\sum_{l, i} P_{E n c, l, i}\left\|\Omega_{E n c, l, i}\right\|^{2}$ (3)
$\Lambda 2(\Omega)=\sum_{l, i} P_{\text {Dec }, l, i}\left\|\Omega_{\text {Dec }, l, i}\right\|^{2}$ (4)
We comment the Eq. (3) and the equation (4) is obtained by analogies. $P_{D e c, l, i}$ is the penalty coefficient that permits to control the weighted term. Here, we penalize each of the parameter’s neuron with specific penalty coefficients:
If the neurons $i$ and $j$ are in the same hidden layer 1 , and if $\mathrm{i}<\mathrm{j}$, then $P_{E n c, l, i}<P_{E n c, l, j}$ ; compared to the neuron $\mathrm{j}$, the neuron i has a very high chance of remaining in the layer 1 .
For two given hidden layers 1 and $\mathrm{k}$, if $1<\mathrm{k}$, then $\max _{i} P_{E n c, l, i}<\min _{j} P_{E n c, k, j}$;compared to the layer $\mathrm{k}$, the layer 1 has high chance of remaining in the auto-encoder.
To find a local minimum for the function E, one can use a recurrent network called continuous Hopfield network [24] and [25]. As we can use an evolutionary heuristic method such as: firefly optimization based [26], genetic algorithm [27], particle swarm algorithm, stochastic fractal search, and moth swarm algorithm with specific operators [20].
To benefit from the evolutionary strategy of producing good quality solutions from the current solutions thanks to the operators of crossing and mutation and the ability of fuzzy logic of reason in stochastic environments, we use, in this work, fuzzy genetic algorithm to minimize the function E to obtain an auto-encoder with optimal architecture.
In this part, we generate the data sets of different nutrients requirements basing on the TN representations. Then, we use the fuzzy genetic algorithm to minimize the function E to select an optimal auto-encoder. Then, we test the proposed system on unseen TN samples.
The Table 5, Table 6, and Table 7 illustrate the data generation process on potassium, phosphorus, and calcium requirements from different TNs.
Table 5. Potassium TN daily requirements data set
|
Gender |
Age |
Potassium TN (mg/day) |
|
G=1 |
9<A=rand (1000) |
(3000,3800,3960,4000,1,.A) |
|
G=0 |
(2500,2900,2980,3000,0,.A) |
Table 6. Phosphorus TN daily requirements data set
|
Gender |
Age |
Phosphorus TN (mg/day) |
|
G=rand (100) from {0,1} |
9≤A=rand (1000) ≤18 19≤A=rand (1000) |
(1055,1211,1142.2,1250,.G,.A) |
|
G=0 |
(600,920,984,1000,.G,.A) |
Table 7. Calcium TN daily requirements data set
|
Gender |
Age |
Calcium TN (mg/day) |
|
G=0 |
19≤A=rand (1000) ≤50 |
(800,830.72,836.86,838.4,0,.A) |
|
G=1 |
19≤A=rand (1000) ≤70 |
(800,830.72,836.86,838.4,1,.A) |
|
G=rand (100) from {0,1} |
9≤A=rand (1000) ≤11 |
(800,830.72,836.86,838.4,G,.A) |
|
G=1 |
70≤A=rand (1000) |
(1050,1250,1290,1300,1,.A) |
|
G=0 |
51≤A=rand (1000) |
(1050, 1250,1290,1300,0,.A) |
|
G=rand (100) from {0,1} |
12≤A=rand (1000) ≤18 |
(1050, 1250,1290,1300,.G,.A) |
To illustrate clearly the procedure of generation of the data and the example of type of obtained data, we consider at present the favorable nutrient the Phosphorus.
We throw a coin in the air to generate the gender, let's say we get 1. Then, we go on to generate the age which is an arbitrary positive real between 9 and 18 years, let's say we get 10 years. In this case we get the sample (1055,1211,1142.2,1250,1,10). The experts confirm that the daily phosphorus requirement is approximatively 1250 mg. Thus, the output associated with the sample is 1250. Let's repeat this procedure 100 times for the gender and 1000 times for the age, we get 100*1000 samples that encodes the need for 100000 artificial individuals.
This process permits the generation of a data set of 406000 samples. 80% of this data set is used to fit and to select optimal auto-encoder.
We use a genetic algorithm to minimize the function E based on the following operators:
- Random convex-combination crossover operator;
- Random multi chromosomes mutation operator;
- Random permutation selection operator.
Mutation percent, crossover percent, and population size are chosen based on a fuzzy strategy, where the inputs are iteration fitness, best fitness, variation cost, and mean cost. In this context, we adopt nine simple fuzzy rules. The Figure 3 presents the fuzzy genetic system. There are four inputs and three outputs and nine rules [28].
Figure 3. Fuzzy genetic system
Figure 4 shows how to estimate mutation percent from best fitness and iteration membership.
Figure 4. Estimation of the mutation percent from best fitness and iteration
Figure 5 implements the performance curve of the fuzzy genetic algorithm on the loss function E. This figure gives the best and the mean fitness of each generation. The average change in the penalty fitness value becomes stable very early (from generation 10). The number of optimal hidden units is 5. To permit FGA to find a good local minimum, we can increase the mutation rate or the size of the population when minimizing the function E.
Figure 5. The genetic strategy performance curve
Figure 6 presents the optimal auto-encoder. The optimal auto-encoder has symmetric architecture. Two hidden layers (of 5 units) are sufficient to reproduce the trapezoidal numbers presenting the individual requirements.
Figure 6. The optimal auto-encoder
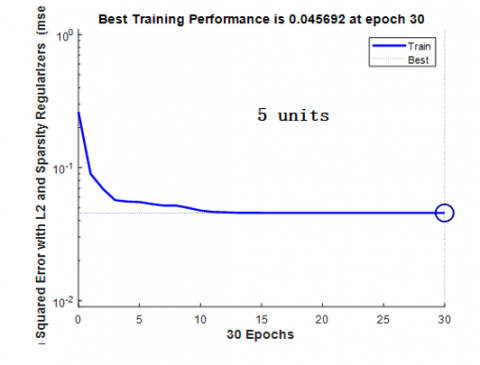
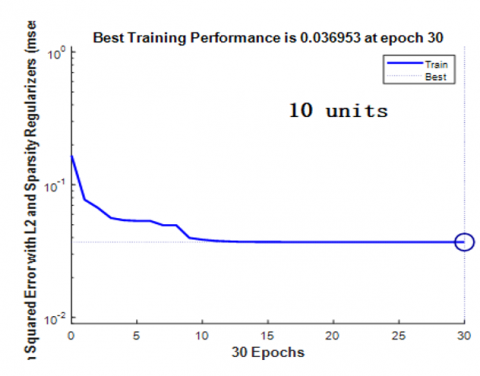
Figure 7 and Figure 8 represent the performance curve of the optimal auto-encoder and an auto-encoder with random architecture (10 hidden units), respectively.
Compared to the random auto-encoder, the optimal auto-encoder has a large learning error; in fact, EOPT (training set)=0.045692>ER and (training set)=0.036953. But, the optimal auto-encoder is better than the random one on the test data set; in fact, EOPT (test data set)=0.0016<ER and (test data set)=0.0135. Consequently, the optimal auto-encoder is capable to extend its experience to unseen data. The proposed system is capable to predict appropriate daily nutrients requirements given the individual characteristics such as age, gender etc.
Figure 7. Performance curve of the optimal auto-encoder on training dataset
Figure 8. Performance of random auto-encoder with 10 units in the hidden layer
To determine a personalized optimal diet basing on mathematical modeling, one needs to know the individual's daily requirements of favorable and unfavorable nutrients. giving an estimate of daily nutrient requirement in terms of a single value for all ages and genders is a restrictive approach that is subject to over- or underestimation. In this paper, we propose a personalized representation of nutrients expert knowledge based on fuzzy trapezoidal numbers, an optimal auto-encoder based on a new regulation function, and on fuzzy genetic algorithm. Thanks to our regulation function and the deep learning of the optimal architecture auto-encoder educated on the basis of intelligently generated data set, the proposed system is able to predict the positive and negative nutrient requirements of each individual once the age and gender of that individual is provided. In a practical setting, our system can be used by a dietician to accurately determine the daily nutrient requirements of a given individual. In addition, the different mathematical models can use the different predictions to automatically solve the optimal diet problem. The resulted system can be used by a dietician to select a set of foods from a predetermined set of foods that meet the daily nutrient requirements while setting an economic function that depends on the targeted disease.
Regardless of the contributions of the model and the good results obtained in this work, the proposed system and its application have some limitations. The proposed system uses the same autoencoder to predict the requirements of the 18 nutrients, which may lead to erroneous predictions in some borderline cases. For example, vitamin requirements are very low while calorie requirements are very high. In addition, positive nutrients should not be treated in the same way as negative nutrients. At least three auto-encoders should be considered: one for unfavorable nutrients, one for small favorable nutrients and large favorable nutrients.
We will use our system to dress optimal diets for different patients that suffer from chronic diseases. And to take into account of the falsity, one can use intuitionist logic in genetic algorithm instead of classical logic that considers the trueness only.
This work was supported by Ministry of National Education, Professional Training, Higher Education and Scientific Research (MENFPESRS) and the Digital Development Agency (DDA) and CNRST of Morocco (Nos. Alkhawarizmi/2020/23).
[1] Bello, P., Gallardo, P., Pradenas, L., Ferland, J.A., Parada, V. (2020). Best compromise nutritional menus for childhood obesity. Plos One, 15(1): e0216516. https://doi.org/10.1371/journal.pone.0216516
[2] Ivy, J.S. (2009). Can we do better? Optimization models for breast cancer screening. In Handbook of Optimization in Medicine, 1-28. https://doi.org/10.1007/978-0-387-09770-1_2
[3] Cadenas, J.M., Pelta, D.A., Pelta, H.R., Verdegay, J.L. (2004). Application of fuzzy optimization to diet problems in Argentinean farms. European Journal of Operational Research, 158(1): 218-228. https://doi.org/218-228. 10.1016/s0377-2217(03)00356-4
[4] Dantzig, G.B. (1990). The diet problem. Interfaces, 20(4): 43-47. https://doi.org/10.1287/inte.20.4.43
[5] Bas, E. (2014). A robust optimization approach to diet problem with overall glycemic load as objective function. Applied Mathematical Modelling, 38(19-20): 4926-4940. https://doi.org/10.1016/j.apm.2014.03.049
[6] Yang, Y., Feng, C., Shen, Y., Tian, D. (2018). Foldingnet: Point cloud auto-encoder via deep grid deformation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 206-215
[7] Carlsson, C., Fullér, R. (1996). Fuzzy multiple criteria decision making: Recent developments. Fuzzy Sets and Systems, 78(2): 139-153. https://doi.org/10.1016/0165-0114(95)00165-4
[8] Specker, B.L., Beck, A., Kalkwarf, H., Ho, M. (1997). Randomized trial of varying mineral intake on total body bone mineral accretion during the first year of life. Pediatrics, 99(6): e12. https://doi.org/10.1542/peds.99.6.e12
[9] Donati, M., Menozzi, D., Zighetti, C., Rosi, A., Zinetti, A., Scazzina, F. (2016). Towards a sustainable diet combining economic, environmental and nutritional objectives. Appetite, 106: 48-57. https://doi.org/10.1016/j.appet.2016.02.151
[10] Hurrell, R., Ranum, P., de Pee, S., Biebinger, R., Hulthen, L., Johnson, Q., Lynch, S. (2010). Revised recommendations for iron fortification of wheat flour and an evaluation of the expected impact of current national wheat flour fortification programs. Food and Nutrition Bulletin, 31(1_suppl1): 7-21. https://doi.org/10.1177/15648265100311S102
[11] Morris Jr, R.C., Sebastian, A., Forman, A., Tanaka, M., Schmidlin, O. (1999). Normotensive salt sensitivity: effects of race and dietary potassium. Hypertension, 33(1): 18-23. https://doi.org/10.1161/01.HYP.33.1.18
[12] Lind, T., Lönnerdal, B., Stenlund, H., Ismail, D., Seswandhana, R., Ekström, E.C., Persson, L.Å. (2003). A community-based randomized controlled trial of iron and zinc supplementation in Indonesian infants: Interactions between iron and zinc. The American Journal of Clinical Nutrition, 77(4): 883-890. https://doi.org/10.1093/ajcn/77.4.883
[13] Dantzig, G. (2016). Linear Programming and Extensions. Princeton University Press. https://doi.org/10.1515/9781400884179
[14] Orešković, P., Kljusurić, J.G., Šatalić, Z. (2015). Computer-generated vegan menus: The importance of food composition database choice. Journal of Food Composition and Analysis, 37: 112-118. https://doi.org/10.1016/j.jfca.2014.07.002
[15] Masset, G., Monsivais, P., Maillot, M., Darmon, N., Drewnowski, A. (2009). Diet optimization methods can help translate dietary guidelines into a cancer prevention food plan. The Journal of Nutrition, 139(8): 1541-1548. https://doi.org/10.3945/jn.109.104398
[16] Donati, M., Menozzi, D., Zighetti, C., Rosi, A., Zinetti, A., Scazzina, F. (2016). Towards a sustainable diet combining economic, environmental and nutritional objectives. Appetite, 106: 48-57. https://doi.org/10.1016/j.appet.2016.02.151
[17] Fister, I., Fister Jr, I., Fister, D. (2019). Computational intelligence in sports. Berlin: Springer. https://doi.org/10.1007/978-3-030-03490-0
[18] Van Mierlo, K., Rohmer, S., Gerdessen, J.C. (2017). A model for composing meat replacers: Reducing the environmental impact of our food consumption pattern while retaining its nutritional value. Journal of Cleaner Production, 165: 930-950. https://doi.org/10.1016/j.jclepro.2017.07.098
[19] Taniguchi, E. (2014). Concepts of city logistics for sustainable and liveable cities. Procedia-social and Behavioral Sciences, 151: 310-317. https://doi.org/10.1016/j.sbspro.2014.10.029
[20] El Moutaouakil, K., Cheggour, M., Chellak, S., Baïzri, H. (2021, July). Metaheuristics optimization algorithm to an optimal Moroccan diet. In 2021 7th Annual International Conference on Network and Information Systems for Computers (ICNISC), pp. 364-368. https://doi.org/10.1109/ICNISC54316.2021.00072
[21] National Academies of Sciences, Engineering, and Medicine. (2019). Dietary reference intakes for sodium and potassium.
[22] Moller, M.F. (1993). A scaled conjugate gradient algorithm for fast supervised learning. Neural Networks, 6(4): 525-533. https://doi.org/10.1016/S0893-6080(05)80056-5
[23] Olshausen, B.A., Field, D.J. (1997). Sparse coding with an overcomplete basis set: A strategy employed by V1. Vision Research, 37(23): 3311-3325. https://doi.org/10.1016/S0042-6989(97)00169-7
[24] El Moutaouakil, K., Touhafi, A. (2020). A new recurrent neural network fuzzy mean square clustering method. In 2020 5th International Conference on Cloud Computing and Artificial Intelligence: Technologies and Applications (CloudTech), pp. 1-5. https://doi.org/10.1109/CloudTech49835.2020.9365873
[25] Haddouch, K., El Moutaouakil, K. (2018). New starting point of the continuous Hopfield network. In International Conference on Big Data, Cloud and Applications, pp. 379-389. https://doi.org/10.1007/978-3-319-96292-4_30
[26] Kaur, P.K., Attwal, K.P.S., Singh, H. (2021). Firefly optimization based noise additive privacy-preserving data classification technique to predict chronic kidney disease. Revue d'Intelligence Artificielle, 35(6): 447-456. https://doi.org/10.18280/ria.350602
[27] Yadav, A., Prasad, B.B.V.S.V., Mojjada, R.K., Kothamasu, K.K., Joshi, D. (2020). Application of artificial neural network and genetic algorithm based artificial neural network models for river flow prediction. Revue d'Intelligence Artificielle, 34(6): 745-751. https://doi.org/10.18280/ria.340608
[28] Jang, J.S.R., Sun, C.T., Mizutani, E. (1997). Neuro-fuzzy and soft computing-a computational approach to learning and machine intelligence [Book Review]. IEEE Transactions on Automatic Control, 42(10): 1482-1484. https://doi.org/10.1109/TAC.1997.633847